1. Introduction
We examine how to approach bad data in the classical multiple regression setting. We are given a section of
n vectors,
. We have
p predictors; hence,
. The random variable model we consider is
where
represents the (random) unexplained portion of the response. In vector form we have
where
is the
vector of responses.
is the
matrix whose
n rows contain the predictor vectors, and
is the vector of random errors. Minimizing the sum of squared errors leads to the well-known formula
Since
is a linear combination of the responses, any outliers will result in corresponding influence in the parameter estimates. Alternatively, outliers in the predictor vectors can exert a strong influence on the estimated parameter vector. With modern gigabit datasets, both outliers may be expected. Outliers in the predictor space may or may not be viewed as errors. In either case, they may result in high leverage, as any prediction errors there that are very large would result in a large fraction of the SSE; thus, we would expect
to pay attention and try to rotate to minimize that effect. In practice, it is more common to assume the features are measured accurately and without error and to focus on outliers in the response space. We will adopt this framework initially.
2. Strategies for Handling Outliers in the Response Space
Denote the multivariate normal PDF by
. Although it is not required, if we assume the distribution of the error vector
is multivariate normal with zero mean and covariance matrix
, maximizing the likelihood
may be shown to be equivalent to minimizing the residual sum of squares
over
, leading to the least squares estimator given in Equation (
1), where
is the predicted response. Again we remark that the least squares criterion in Equation (
3) is often invoked without assuming the errors are independent and normally distributed.
Robust estimation for the parameters of the normal distribution as in Equation (
2) is a well-studied topic. In particular, the likelihood is modified so as to avoid the use of the non-robust squared errors found in Equation (
3). For example,
may be modified to be bounded from above, or may even take a more extreme modification to have redescending shape (to zero); see [
1,
2,
3]. Either approach requires the specification of meta-parameters that explicitly control the shape of the resulting influence function. Typically, this is done by an iterative process where the residuals are computed and a robust estimate of their scale is obtained. For example, the median of the absolute median residuals.
As an alternative, we advocate making an assumption about the explicit shape of the residuals, for example, . With such an assumption, it is possible to replace likelihood and influence function approaches with a minimum distance criterion. As we shall show, the advantage of doing so is that an explicit estimate of the fraction of contaminated data may be obtained. In the next section, we briefly describe this approach and the estimation equations.
3. Minimum Distance Estimation
We follow the derivation of the
algorithm described by Scott [
4]. Suppose we have a random sample
from an unknown density function
, which we propose to model with the parametric density
. Either
x or
may be multivariate in the following. Then as an alternative to evaluating potential parameter values of
with respect to the likelihood, we consider instead estimates of how close the two densities are in the integrated squared or
sense:
Notes: In Equation (
4), the hat on the integral sign indicates we are seeking a data-based estimator for that integral; in Equation (
5), we have simply expanded the integrand into three individual integrals, the first of which can be calculated explicitly for any posited value of
and need not be estimated; in Equation (
6), we have omitted the hat on the first integral and eliminated entirely the third integral since it is a constant with respect to
, and we have observed that the middle integral is (by definition) the expectation of our density model at a random point
; and finally, in Equation (
7), we have substituted an unbiased estimate of that expectation. Note that the quantity in brackets in Equation (
7) is fully data-based, assuming the first integral exists for all values of
. Scott calls the resulting estimator
as it minimizes an
criterion.
We illustrate this estimator with the 2-parameter
model. Then the criterion in Equation (
7) becomes
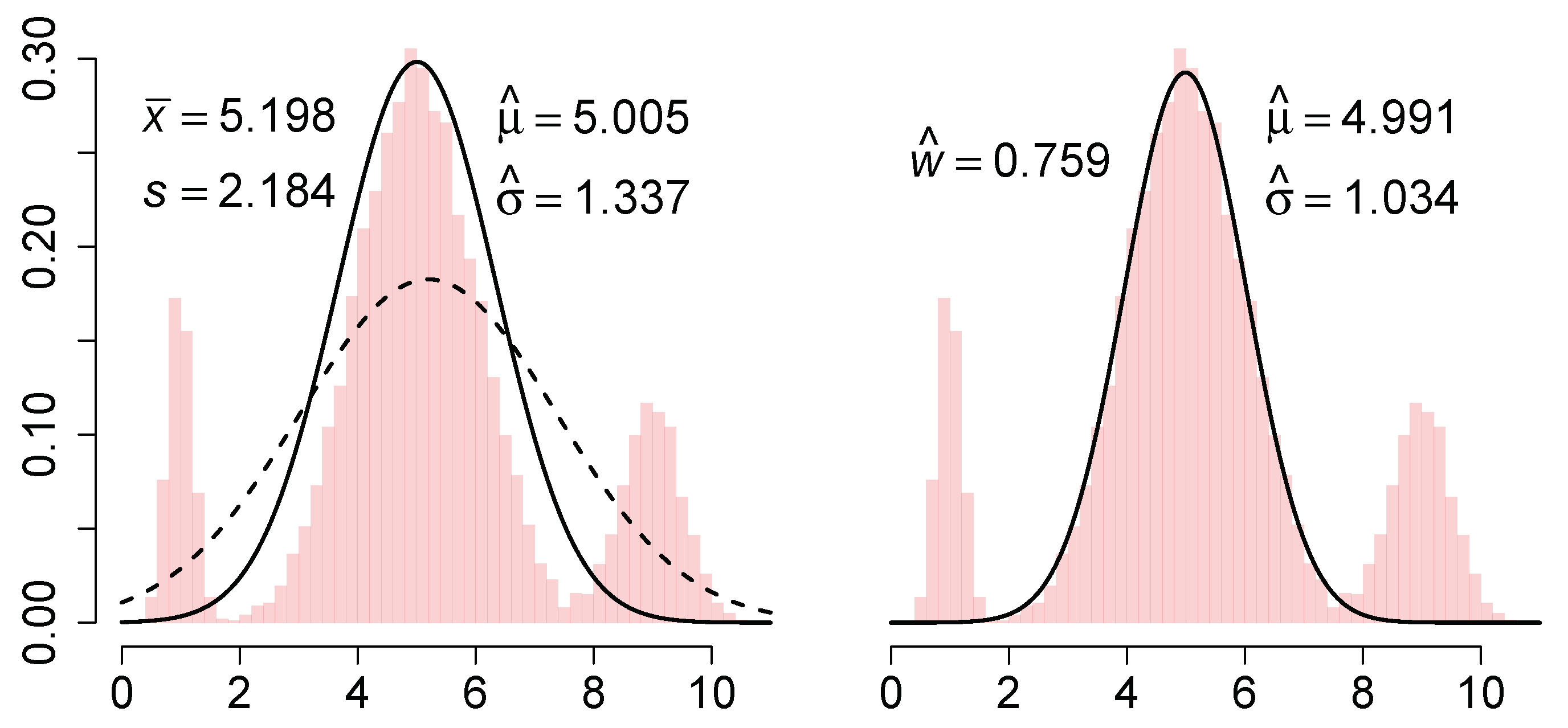
We illustrate this estimator on a sample of
points from the normal mixture
. The L2E and MLE curves are shown in the left frame of
Figure 1.
A careful examination of the L2E derivation in Equation (
4) shows that we crucially used the fact that
was a density function, but nowhere did we require the model
to also be a bona fide density function. Scott proposed fitting a partial mixture model, namely
which he called a partial density component. (Here, the L2E criterion could be applied to a full 3-component normal mixture density.) When applied to the previous data, the fitted curve is shown in the right frame of
Figure 1.
We discuss these 3 estimators briefly. The MLE is simply , and the nonrobustness of both parameters is clearly illustrated. Next, the L2E estimate of the mean is clearly robust, but the scale estimate is also inflated compared to the true value . After reflection, this is the result of the fitted model having an area equal to 1. The closest normal curve is close to the central portion of the mixture, but with standard deviation inflated by a third. Note that the fitted curve completely ignores the outer mixture components. However, when the 3-parameter partial density component model is fitted, , which suggests that some 24% of the data are not captured by the minimum distance fit. Thus the estimation step itself conveys important information about the adequacy of the fit. By way of contrast, a graphical diagnosis of the MLE fit such as a q–q plot would show the fit is also inadequate, but give no explicit guidance as to how much data are outliers and what the correct parameters might be. Note that the parameter estimates of the mean and standard deviation by partial L2E are both robust, although the estimate of is inflated by 3%, reflecting some overlap of the third mixture component with the central component. Thus, we should not assume is an unbiased estimate of the fraction of “good data”, but rather an upper bound on it.
With the insight gained by this example, we shift now to the problem at hand, namely, multiple regression. We will use the partial L2E formulation in order to gain insight into the portion of data not adequately modeled by the linear model.
4. Minimum Distance Estimation for Multiple Regression
If we are willing to make the (perhaps rather strong but explicit) assumption that the error random variables follow a normal distribution, the appropriate model is
Given initial estimates for
,
, and
w, we use any nonlinear optimization routine (for example,
nlminb in the R language) to minimize Equation (
7)
over the
parameters
. In practice, the intercept may be coded as another parameter, or a column of 1s may be included in the design matrix,
. Notice that the residuals are assumed to be normal (at least partially) and centered at 0. It is convenient to use the least-squares estimates to initialize the L2E algorithm. In some cases, there may be more than one solution to Equation (
9), especially if using the partial component model. In every case, the fitted value of
w should offer clear guidance.
6. Discussion
Maximum likelihood or entropy or Kullbach–Liebler estimators are examples of divergence criteria rather than being distance-based. It is well-known these are not robust in their native form. Donoho and Liu argued that all minimum distance estimators are inherently robust [
9]. Other minimum distance criteria (L1 or Hellinger, e.g.) exist with some properties superior to L2E such as being dimensionless. However, none are fully data-based and unbiased. Often a kernel density estimate is placed in the role of
, which introduces an auxiliary parameter that is problematic to calibrate. Furthermore, numerical integration is almost always necessary. Numerical optimization of a criterion involving numerical integration severely limits the number of parameters and the dimension that can be considered.
The L2E approach with multivariate normal mixture models benefits greatly from the following closed form integral:
whose proof follows from the Fourier transform of normal convolutions; see the appendix of Wand and Jones [
10]. Thus the robust multiple regression problem could be approached by fitting the parameter vector
to the random variable vector
and then computing the conditional expectation. In two dimensions, the number of parameters is
compared to the multiple regression parameter vector
, which has 2 + 1 + 1 parameters (including the intercept). The advantage is much greater as
p increases, as the full covariance matrix requires
parameters alone.
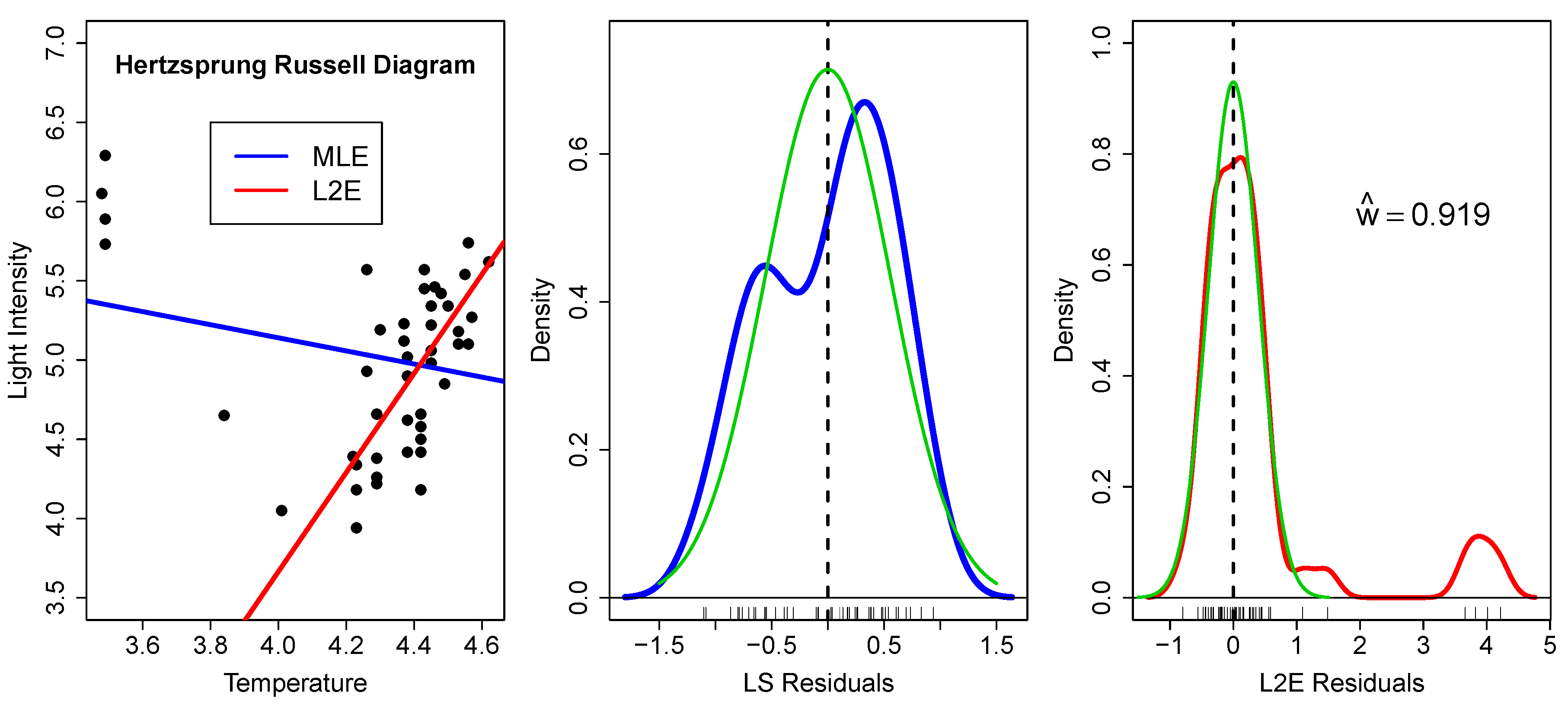
To illustrate this approach, we computed the MLE and L2E parameters estimates for the Hertzsprung–Russell data [
11]. The solutions are depicted in
Figure 10 by three level sets corresponding to 1-, 2-, and 3-
contours. These data are not perfectly modeled by the bivariate normal PDF; however, the direct regression solutions shown in the left frame of
Figure 2 are immediately evident. The estimate of
here was 0.937, which is slightly larger than the estimate shown in the right frame of
Figure 2.
If the full correlation structure is of interest, then the extra work required to robustly estimate the parameters may be warranted. For
, this requires estimation of
or
parameters. In
this means estimating 66 parameters, which is on the edge of optimization feasibility currently. Many simulated bivariate examples of partial mixture fits with 1–3 normal components are given in Scott [
11]. When the number of fitted components is less than the true number, initialization can result in alternative solutions. Some correctly isolate components, others combine them in interesting ways. Software to fit such mixtures and multiple regression models may be found at
http://www.stat.rice.edu/~scottdw/ under the
Download software and papers tab.
We have not focused on the theoretical properties of L2E in this article. However, given the simple summation form of the L2E criterion in Equation (
7), the asymptotic normality of the estimated parameters may be shown. Such general results are to be found in Basu, et al. [
12], for example. Regularization of L2E regression, such as the
penalty in LASSO, has been considered by Ma, et al. [
13]. LASSO can aid in the selection of variables in a regression setting.
7. Conclusions
The ubiquitousness of massive datasets has only increased the need for robust methods. In this article, we advocate application of numerous robust procedures, including L2E, in order to find similarities and differences among their results. Many robust procedures focus on high-breakdown as a figure of merit; however, even those algorithms may falter in the regression setting; see Hawkins and Olive [
14]. Manual inspection of such high-dimensional data is not feasible. Similarly, graphical tools for inspection of residuals also are of limited utility; however, see Olive [
15] for a specific idea for multivariate regression. The partial L2E procedure described in this article puts the burden of interpretation where it can more reasonably be expected to succeed, namely, in the estimation phase. Points tentatively tagged as outliers may still be inspected in aggregate for underlying cause. Such points may have residuals greater than some multiple of the estimated residual standard deviation,
, or simply be the largest
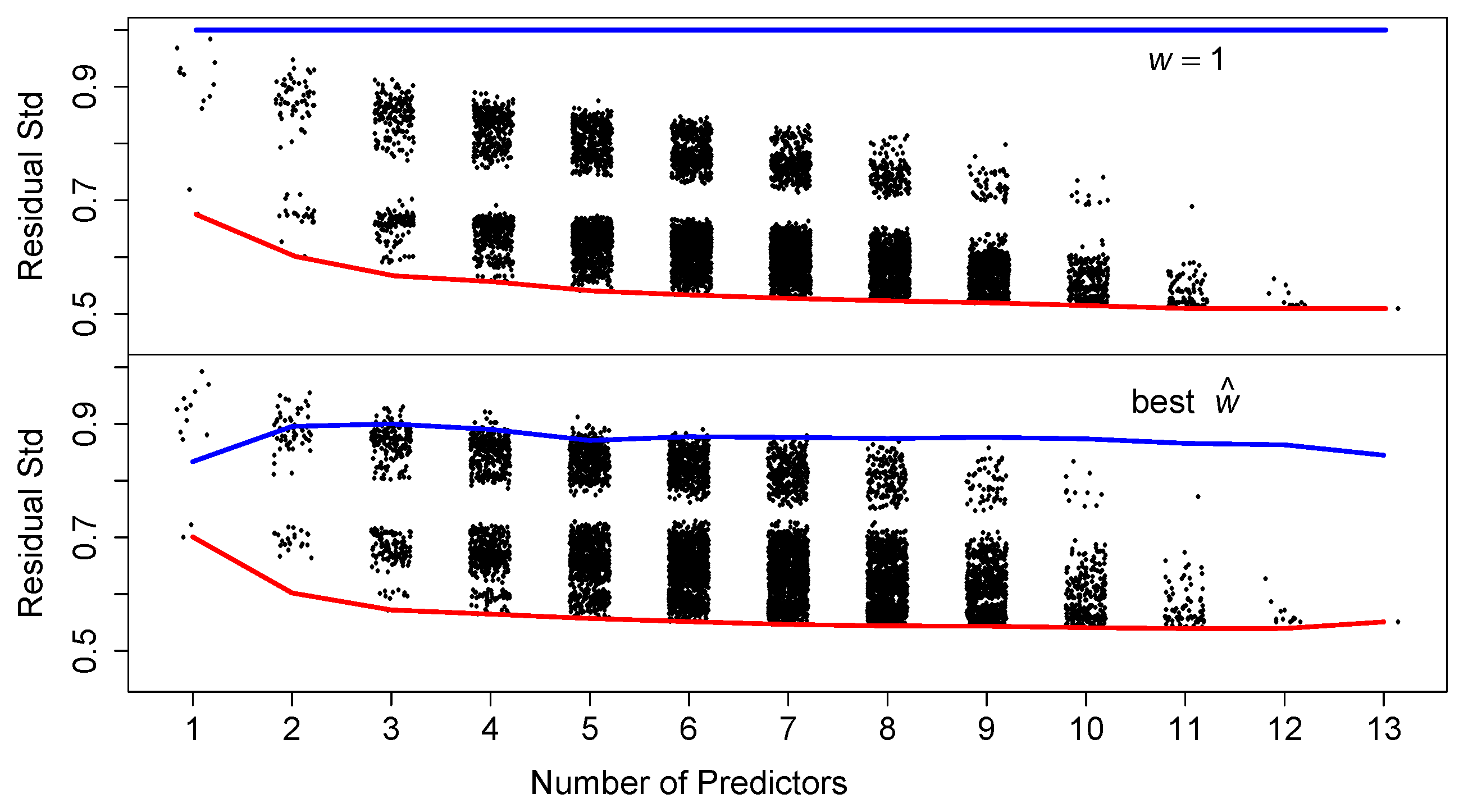
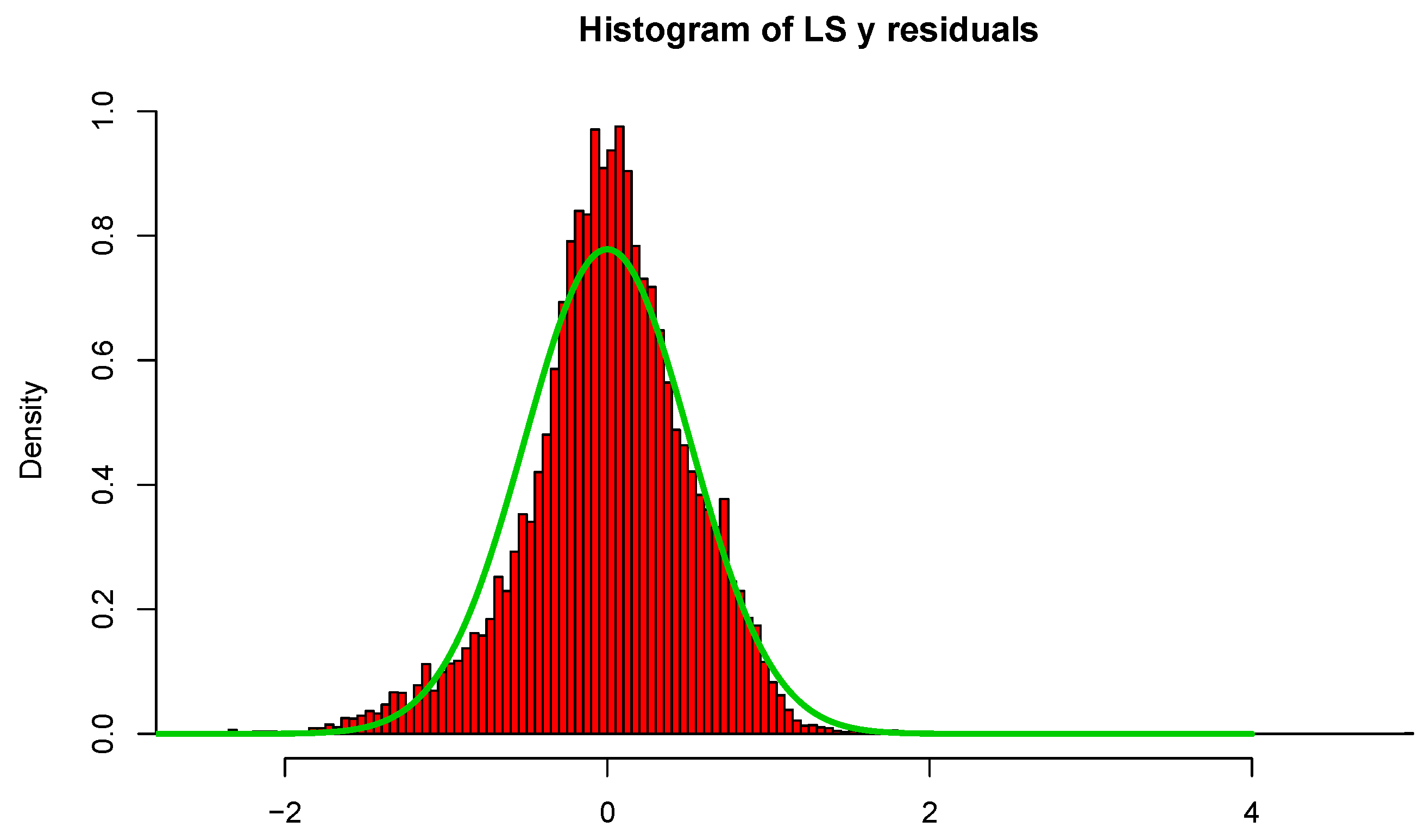
of the residuals in magnitude. In either case, the understanding of the data is much greater than least-squares in the high-dimensional case.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}