1. Introduction
Geometric method plays an important role in Bayesian statistics. At present, there are two main ways to study Bayesian inference through geometric methods. An idea is to regard the prior distribution, the probability distribution of the statistical model and the posterior distribution as the vectors in Hilbert space
. The research is then carried out through the geometric properties of Hilbert space. M. de Carvalho [
1] used the cosine of the angle between vectors to study their relationship with each other, where the cosine of priors represents coherency of opinions of experts, the cosine of prior and probability density represents prior-data agreement and the cosine of prior and posterior represents sensitivity of the posterior to the prior specification. Furthermore, M. de Carvalho used Monte Carlo Markov Chain to give an estimation of the cosine value for further analysis. R. Kulhavy [
2] viewed statistical inference as an approximation of the empirical density rather than an estimation of a true density, and built a model by analyzing the trace of orthogonal projection of conditional empirical distributions onto the model manifold. He also used Kerridge inaccuracy as a generalized empirical error. Kerridge inaccuracy is a generalization of Shannon entropy. It is used to measure the difference between observed distribution
and true distribution
, which is defined by
. The advantage of this idea is providing a unified treatment to all pieces of Bayesian theorem. However, the finite parameter space measure is required.
Another idea is to give the statistical manifolds Riemannian metrics. J.A. Hartigan [
3,
4,
5] proposed a reparametrization invariance prior-
-parallel prior and later J. Takeuchi and S. Amari [
6,
7] clarified an interesting connection between the information geometrical properties of the statistical model and the existence of the
-parallel prior.
-parallel prior, as an uninformed prior, is invariant under the coordinate transformation and can well reflect the intrinsic properties of the model. It is worth noting that the general
-parallel prior does not always exist, but 0-parallel prior, Jeffreys prior, always exists. After obtaining the corresponding prior, subsequent Bayesian inference and prediction can be carried out. J. Takeuchi and S. Amari studied the asymptotic properties of minimum description length (MDL) estimation and projected Bayesian estimation of general exponential families, and extended it to curve exponential families. The differential geometry of curved exponential families are given by S. Amari and M. Kumon [
8,
9].
In many confidential fields, historical data is difficult to obtain. Hence one of the advantages of the above idea is giving prior a good theoretical basis. Besides, this idea can illustrate the geometric meaning of the common Bayesian estimations and provide an estimation in the sense of minimal mean geodesic distance. In the application of target detection, maritime radar performance is often seriously interfered and suppressed by sea clutter, especially for the detection of weak targets on the sea. Therefore, whether sea clutter can be effectively suppressed is the key factor to improve the performance of maritime radar systems. Thus the study of sea clutter is of vital importance [
10]. With the development of radar hardware technology, the statistical distribution histogram of radar sea clutter appears long “trailing tail”, which is manifested as frequent sea peak phenomenon, and the amplitude distribution of clutter seriously deviates from the Rayleigh distribution proposed before. In order to solve this problem, an improved Rayleigh model-compound Gaussian model is proposed [
11]. The compound Gaussian model successfully illustrates the formation mechanism of sea clutter, and is more successful than the single point probability distribution model in terms of data fitting. In the compound Gaussian model,
K distribution and Pareto distribution are two typical representatives. When the structural component is Gamma distribution, the compound Gaussian model is
K distribution. When the structural component is inverse Gamma distribution, the compound Gaussian model is Pareto distribution. In 2010, M. Farshchian and F.L. Posner [
12] analyzed the sea clutter data in X-band, and used Pareto distribution to fit data. They found that the fitting effect of the tail was better than
K distribution.
The paper is organized as follows—
Section 2 introduces the preliminary including some geometric structure of statistical manifolds and some concepts of Bayesian inference. In
Section 3, we introduce the geometric approaches for Bayesian inference by using
-parallel connection, and propose a geometric loss function based on geodesic distance. In
Section 4, we prove that Pareto two-parameter model does not have general
-parallel prior. Then we adopt Jeffreys prior to provide the explicit expressions of estimations in the sense of minimal mean geodesic distance. Furthermore, we come up with theorems under Al-Bayyati’s loss function to obtain a new class of Bayesian estimations. The bounds of certain expressions without closed forms are given. Besides, we show the existence of the best parameter in Al-Bayyati’s loss function. In
Section 5, we show the advantages of the proposed Bayesian estimations and the posterior prediction distributions.
3. The Geometric Approaches for Bayesian Inference
In this section, we introduce the basic methods of Bayesian inference with geometric means. The idea of geometry is embodied in the selection of priors and loss functions.
3.1. The Geometric Prior
The idea of geometric methods is to extend the uniform distribution naturally and construct geometric priors suitable for multidimensional and measure infinite-dimensional parameter space according to the idea that probability measure is proportional to volume element. The studied probability distribution family can be regarded as a statistical manifold with Riemannian metrics.
Fisher information matrix is the most widely used Riemannian metric on statistical manifolds, and the prior generated by its corresponding volume element is Jeffreys prior. -connection is a natural extension of the Levi-Civita connection corresponding to Fisher information matrix. Its corresponding volume element is -parallel volume element, and the generated prior is called -parallel prior. In particular, the 0-parallel prior is the Jeffreys prior.
-parallel prior reflects the intrinsic property of the model and does not depend on the selection of parameters. Although Jeffreys prior must exist, general
-parallel prior does not necessarily exist. (
1) gives the necessary and sufficient conditions for the existence of general
-parallel prior.
Therefore, when one deals with Bayesian inference by geometric methods, the first step is to select the appropriate geometric priors, that is, to verify the existence of -parallel prior in a specific statistical manifold.
With Riemannian metric, we can acquire geometric information of the statistical manifold, such as connection, curvature, geodesic and geodesic distance [
14,
15]. Through geometric priors, the joint posterior density of the parameters can be obtained, and then the corresponding Bayesian estimation and Bayesian posterior prediction are carried out [
16].
3.2. The Geometric Loss Functions
In this subsection, we show the geometric meaning of the common Bayesian estimations and propose a new geometric approach of choosing loss functions.
Proposition 2. Suppose that . Let be the joint posterior distribution and be the estimation of θ. For the loss function , the corresponding estimation is . For the loss function , the corresponding estimation is .
Proof. Denote . Let be the marginal posterior density and be its cumulative distribution. Assume that and , where and they may be infinite.
For the loss function
, we define
Then we get
Let
, we have
.
For the loss function
, we define
Then we obtain
Hence,
implies that
. □
If the loss function is the distance induced by , then by Proposition 2 we see that the corresponding risk function represents the average distance between the estimated value and the true value. Besides, the posterior median estimation of parameters minimizes risk function, which means that this estimation has the minimum mean distance from the posterior density.
If the loss function is the distance induced by , then the corresponding risk function represents the average value of the square of the distance between the estimated value and the true value. The obtained estimation is the posterior expectation of parameters, which has the minimum mean square error from the posterior density.
These two kinds of loss functions above are distances or increasing functions of distances in . However, in the parameter space endowed with corresponding Riemannian metric, the distance between two points is geodesic distance instead of Euclidean distance.
Hence, in order to make the estimation more accurate, we take the geodesic distance or its increasing function as a loss function, the corresponding risk function represents the geodesic distance between the estimated value and the true value. Before that, we need the following definition.
Definition 4. (Mean Geodesic Estimation) Assume that the statistical manifold is equipped with Fisher Riemannian metric . Let be the joint posterior distribution and be the geodesic distance between θ and , where is the estimation of θ. Let F: be an increasing function. Denote . The risk function with the loss function is The estimation minimizing is called mean geodesic estimation (MGE) and denoted by .
The geometric priors, the corresponding geodesic distance and the corresponding Bayesian inference depend on the choice of the Riemannian metric. Hence choosing a proper Riemannian metric is of great importance to Bayesian inference.
4. Bayesian Inference on Pareto Model
4.1. The Geometric Structure of Pareto Two-Parameter Model
The probability density function of Pareto two-parameter distribution satisfies
where
is called the scale parameter and
is called the shape parameter.
Its logarithmic likelihood function is
Noting that the Pareto distribution family does not meet the common regularity condition, hence the Fisher-Rao metric on the Pareto distribution family is not equal to the negative Hessian matrix.
Furthermore, from References [
17,
18] we can get the geometric structure of Pareto model. On Pareto two-parameter distribution family, the tensor form of Fisher-Rao metric satisfies
which is isometric to the upper half of the Poincar
plane. Hence, Pareto two-parameter model
is a Riemannian manifold endowed with Riemannian metric
g. The volume form, the connection form, the curvature form, the Christoffel symbols and the geodesic distance formula on
are given as follows
4.2. The Existence of α-Parallel Prior on Pareto Two-Parameter Model
Theorem 1. When , Pareto two-parameter model does not have any α-parallel prior.
Proof. Denote
. Then by calculation, we can obtain
Hence, we get
and
It is obvious that means . Therefore, according to Proposition 1, we find that Pareto two-parameter model does not have any -parallel prior when . □
From Theorem 1, we see that Pareto two-parameter model only has the 0-parallel prior (Jeffreys prior). Its Jeffreys prior satisfies , which is a generalized prior density whose integral is infinite. We assume that .
4.3. Bayesian Estimations of Pareto Model
Before we proceed, we state necessary results from Reference [
17].
The joint probability density of a simple random sample on Pareto model is
The posterior distribution of Pareto model under Jeffreys prior is obtained by Bayesian formula
where
. Furthermore, by calculation we can see that the maximum likelihood estimation and the maximum posterior estimation of
are given as
The marginal posterior density of
determined by the joint posterior density
is
and its cumulative distribution function is
The marginal posterior density of
determined by the joint posterior density
is
Under posterior distribution (
13), when
is known, the conditional posterior density of
is
and its cumulative distribution function is
When
is known, the conditional posterior density of
is
4.3.1. Mean Geodesic Estimation
The geodesic distance between
and
is expressed as
Hence, the distance function is a monotone function of
We denote (
22) as
By the discussion in the
Section 3, when
and
are unknown,
can be taken as the loss funtion, and the estimations
and
in the sense of minimum mean geodesic distance can be obtained. When
or
,
or
can be taken as the loss function respectively, and we can get the mean geodesic estimation
or
.
Theorem 2. When α and β are unknown, we have Proof. Denote
, then have
Let
, then we have
Denote
, then
Denote
, then have
Firstly, we show that
. Since
when
, we have
Combining
with
we get
Secondly, we will show that
. In fact, from
we see that when
, we have
Noting that
and
we have
As a result, we obtain . □
Theorem 3. When β is known, we have . And when α is known, we have .
Proof. When
is known, the risk function is
Since
when
, we have
Hence
When
α is known, the risk function is
Since
when
, we have
Noting that
hence we have
. □
4.3.2. Bayesian Estimations under Al-Bayyati’s Loss Function
The Al-Bayyati’s loss function was stated by Reference [
19] as
where
c is a real number. Next, we use Al-Bayyati’s loss function to derive the Bayesian estimation of Pareto model.
Proposition 3. Assume that . Under Al-Bayyati’s loss function, the Bayesian estimation of parameter θ is given by Proof. Since the risk function
we have
Then we have
by letting
. □
Using Al-Bayyati’s loss function, lacks the simple display expression. Thus we give the upper and lower bound estimations.
Theorem 4. Using Al-Bayyati’s loss function and assuming , we find that when β is unknown, then satisfiesAnd when α is unknown, thenFurthermore, there exists such that , where is the real value of shape parameter β. Proof. When
is unknown, we have
Noting that
and that
we have
Similarly, we can get
Furthermore, by Proposition 3, we have
and
When
α is unknown, we have
Thus, by Proposition 3, we have
And when
, we have
. □
Remark 1. When β is unknown, we haveIn particular, when , we get From (27), we know that . By analyzing (26), when gradually increases, will increase firstly and then decrease, and finally will converge to . Let be the real value of scale parameter α, then when , there exists such that , When , is the closest estimation among all . When , there exists such that is the closest estimation among all . Theorem 5. Using Al-Bayyati’s loss function, we find that when β is known, . When α is known, . In both cases, there exist and such that and , where and are the real value of scale and shape parameter respectively.
Proof. When
β is known, we have
and
Then by Proposition 3, we have
When
α is known, we get
Thus by Proposition 3, we get
When
, we have
Noting that if
, then
, where
Hence either
or
is the true value of
.
When
, we have
Hence we can take
such that
is the true value of
β. □
4.4. Bayesian Posterior Prediction
Let
be the value that needs to be observed from Pareto distribution. In the sense of posterior distribution (
13), if the sample X is given, we can make relevant posterior prediction of
. The discussion will be divided into the following three cases.
When neither
nor
are unknown, then we have
where
When
α is known and
is unknown, we have
When
is known and
is unknown, we have
For the above posterior prediction distribution, given the prediction credibility k, we can make Bayesian prediction inference in practical applications. The specific process is as follows. From , multiple sets of , can be got. By choosing appropriately the upper and lower bounds for such that is smaller, then we can obtain higher prediction accuracy.
5. Simulation
In real life, the proposed algorithm for target detection of maritime radar needs to be tested and verified on sea clutter data. In order to determine the sea clutter better, it is often necessary to estimate the parameters of sea clutter model.
Therefore, in this section, we will use the conclusion of
Section 4 to estimate the parameters of Pareto model of sea clutter and show the simulation results.
5.1. The Influence of Parameters on Sea Clutter
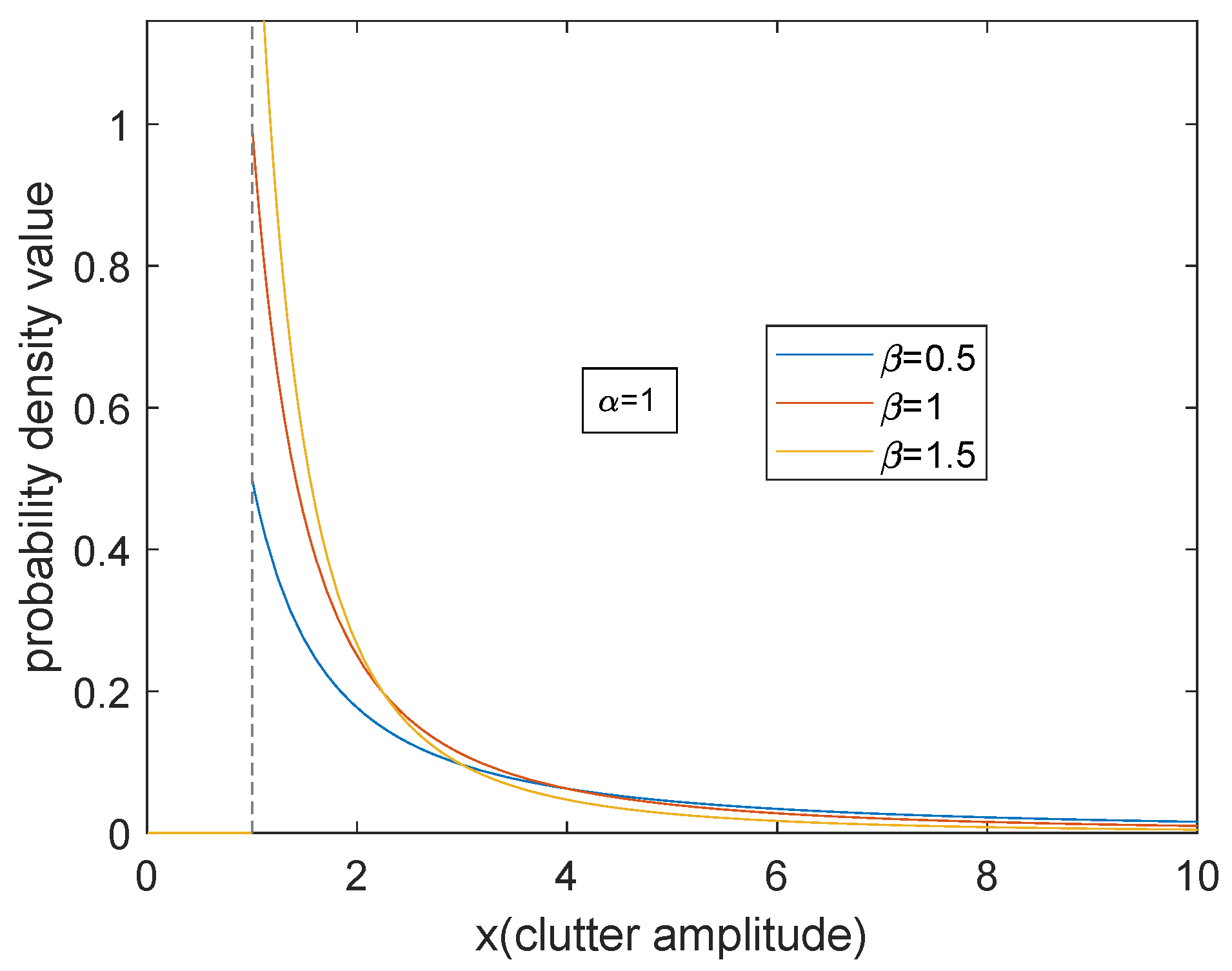
In this subsection, we show the effect of scale parameter α and shape parameter β on sea clutter.
Figure 1 and
Figure 2 show the probability density curve of Pareto distribution with respect to two parameters. It can be seen from the figures that when the scale parameter
α is larger, the density curve is even. The proportion of small clutter amplitude increases, and the decline of the whole curve is gentle. As the shape parameter
β becomes larger, the proportion of small clutter amplitude increases significantly and becomes more concentrated, and the tail descends faster. On the whole, for Pareto model, the energy is concentrated on the small clutter. The trailing phenomenon is apparent. The essential reason is that when the radar is grazing incident, the overall backscatter echo is relatively weak.
5.2. Various Types of Bayesian Estimation on Sea Clutter Models
In this subsection, we show the aforementioned Bayesian estimations of sea clutter.
In order to generate random samples of Pareto distribution with parameters
and
, we use the inverse distribution function and take the inverse transformation method to extract Pareto samples:
, where
U is the uniformly distributed random variable on
. We carry out numerical simulations where
and
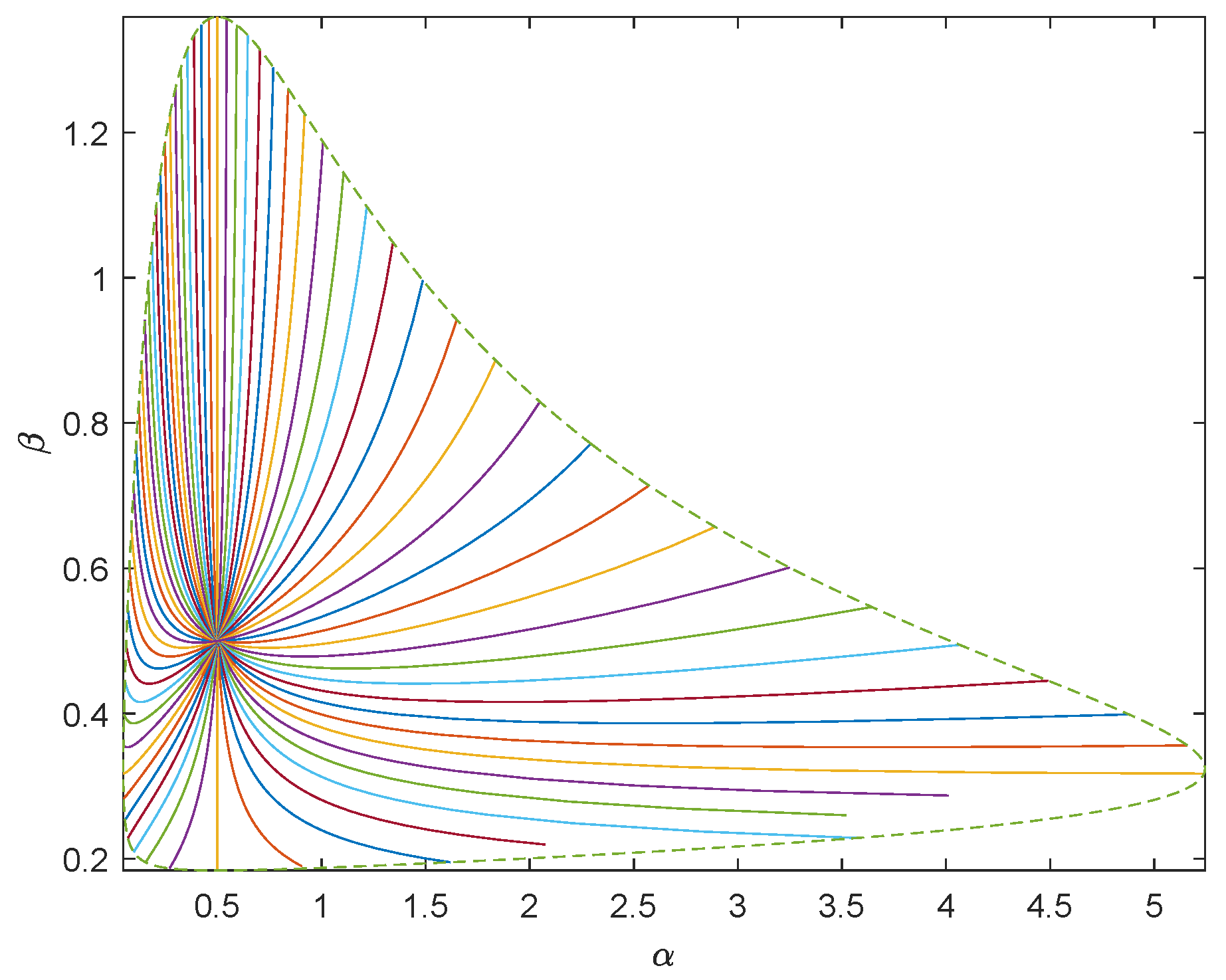
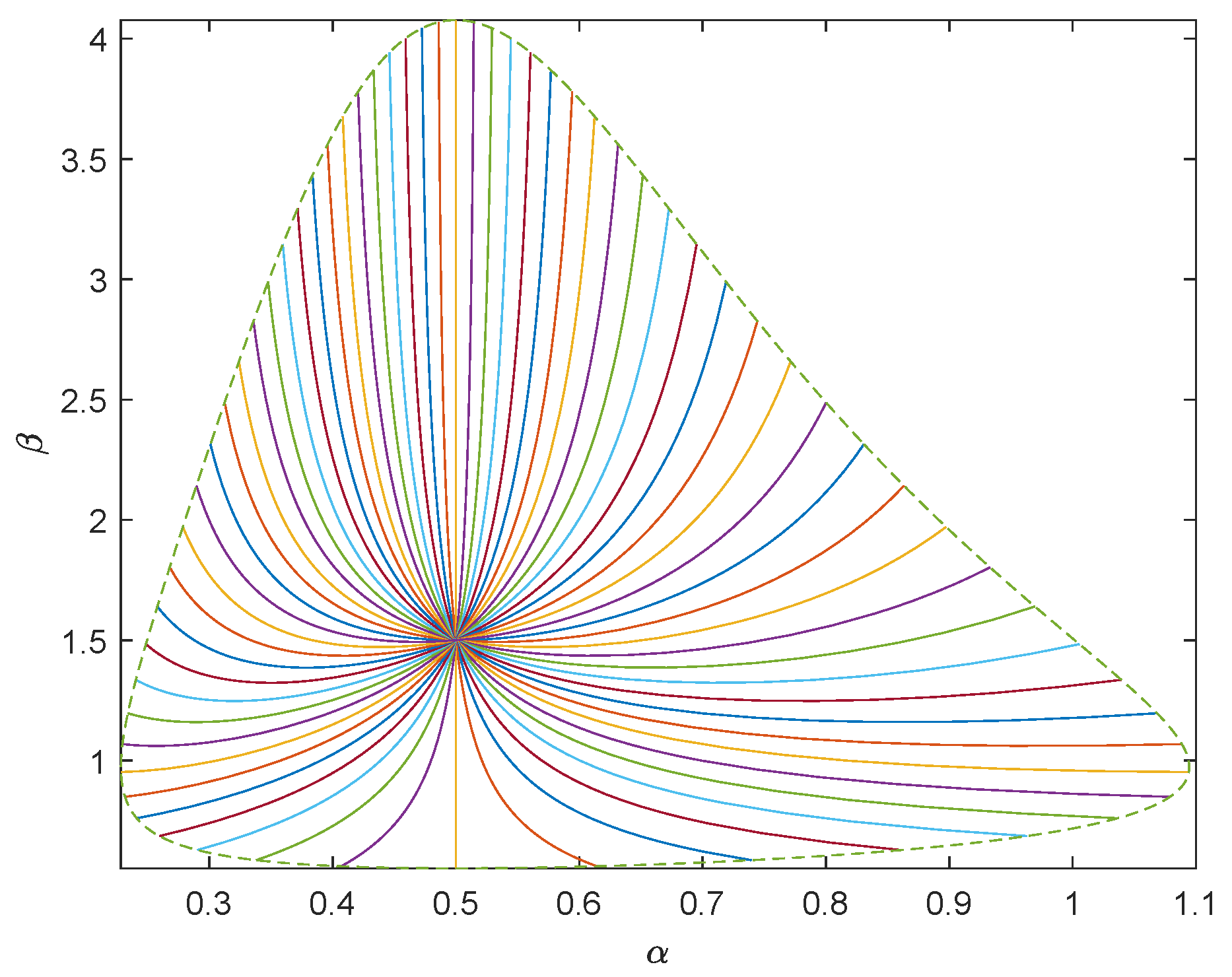
, respectively. Using the inverse transformation method, we generate 1000 random samples subject to Pareto distribution. To show the geometry of Pareto model of sea clutter, we take
as the center and draw the unit geodesic circumference with dotted line. We draw 64 uniformly distributed geodesics with directions
with solid line. See
Figure 3 and
Figure 4.
To describe the proximity between the estimated values of each group and the predetermined parameter value
, we need to calculate the geodesic distance
. If the distance between the estimated value and the predetermined parameter value is close, we believe that the estimation is accurate. By (
22),
. Hence the smaller
and
are, the more accurate the estimation is.
Next we will make a comparative analysis of various types of Bayesian estimations.
5.2.1. Mean Geodesic Estimation and the Common Bayesian Estimations
Case 1. Both scale parameter and shape parameter are unknown.
From
Table 1 we know that
and
are less than
, hence
and
are almost equal. Since
does not have explicit expression,
can take the place of
and it also has more precise geometric explanation.
In most simulation tests, is more accurate than and . Hence, in general the estimation MGE that we proposed is better than the common Baysesian estimations.
Case 2. Either shape parameter or scale parameter is known.
When one parameter is known, the statistical manifold is degenerated. Hence taking the Euclidean distance or the geodesic distance does not make much difference. This can be seen in
Table 2 and
Table 3.
Comparing
Table 2 and
Table 3, when
is known, the accuracy of the estimations is
and when
is known, the accuracy of all kinds of estimations is
. Therefore, the accuracy of various types of estimations will improve if
is known. This indicates that scale parameter
is more easily obtained from samples in the sea clutter model and has strong robustness. Shape parameter
is more sensitive than scale parameter
.
5.2.2. The Estimations under Al-Bayyati’s Loss Function
In this subsection, we give the simulation of various types of Bayesian estimations when .
Case 1. Both scale parameter and shape parameter are unknown.
When
α and
β are unknown, the variation trend of Bayesian estimation of the two parameters under Al-Bayyati’s loss function with parameter
c is shown in
Figure 5 and
Figure 6, respectively. When
β is unknown, by (
26)
Figure 5 shows the case when
. Hence from the discussion in Remark 1,
is the closest estimate among all
with the increasing of positive
c.
When
is unknown, by Theorem 4
When
,
and when
,
. As shown in
Figure 6, there always exists infinitely many
c such that
is closer than the common Bayesian estimations. And
is nothing but the real value of parameter
. These two figures also show that MGE are better than the common Bayesian estimations when both of the parameters are unknown. Therefore, when
and
are unknown, to obtain closer estimations, we are able to change
and
to make
and
smaller and even obtain the minimum value. Through the previous discussions, the choice of the best
depends on the inequality among real parameter
,
and
. The best
is
.
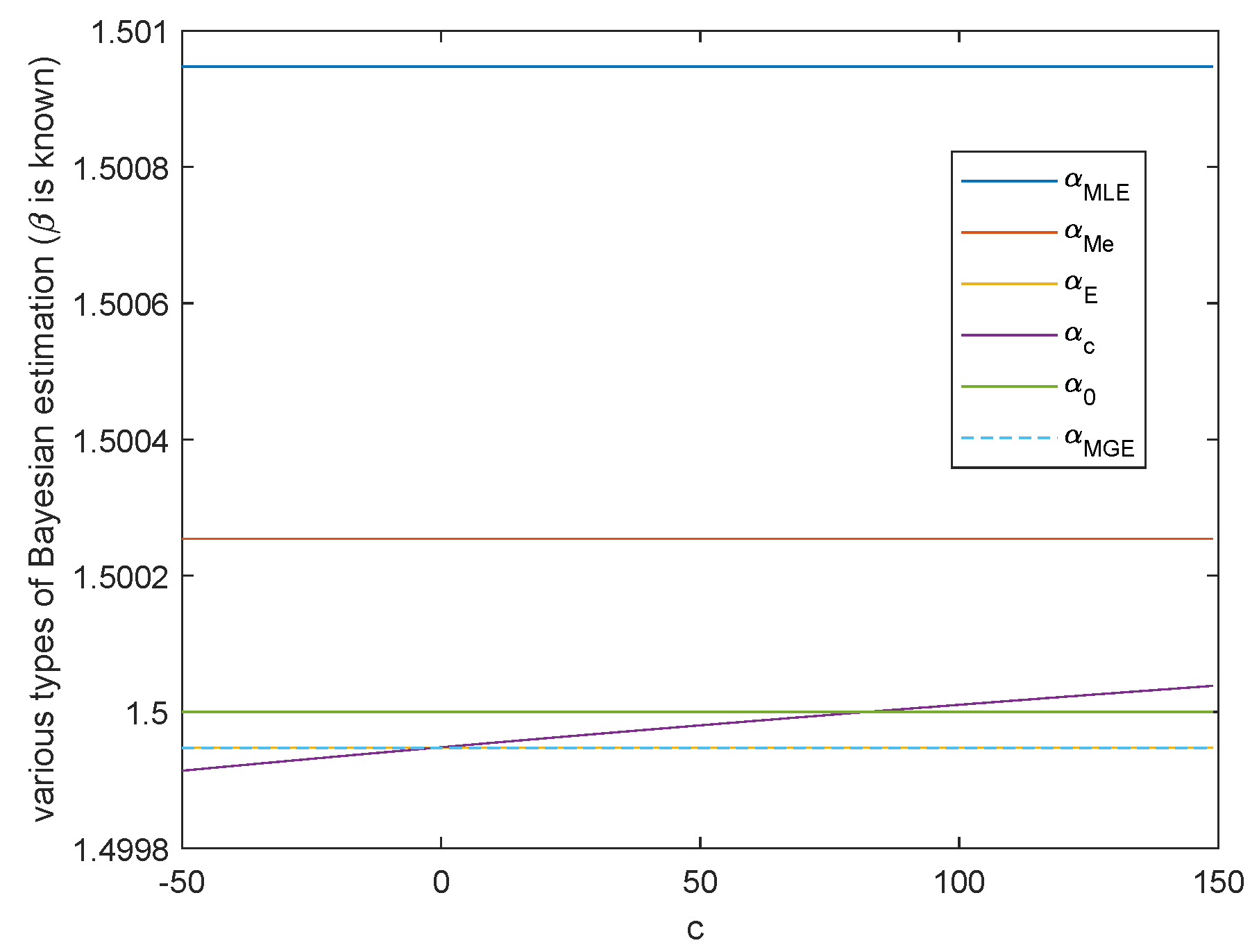
Case 2. Either shape parameter β or scale parameter α is known.
When
or
is known, the variation trend of various Bayesian estimation of parameter
or parameter
in Al-Bayyati’s loss function with parameter
c is shown in
Figure 7 or
Figure 8, respectively. When
, by Theorem 5, we get
If
, we have
when
. Hence either
is the true value of
, or we can take
such that
, which is the true value of
. This is shown in
Figure 7.
When
, by Theorem 5, we get
If
, then
. Hence we can take
such that
is the true value of
. This is shown in
Figure 8.
In above two cases, there are infinitely many c such that or is closer than the common Bayesian estimations.
5.3. Simulation of Posterior Predictive Distribution
In order to observe the simulation effect of the posterior prediction distribution, according to the samples generated in
Section 5.2, we drew the posterior prediction distribution of sea clutter and the real Pareto distribution
of sea clutter where
for comparative analysis. See
Figure 9,
Figure 10 and
Figure 11.
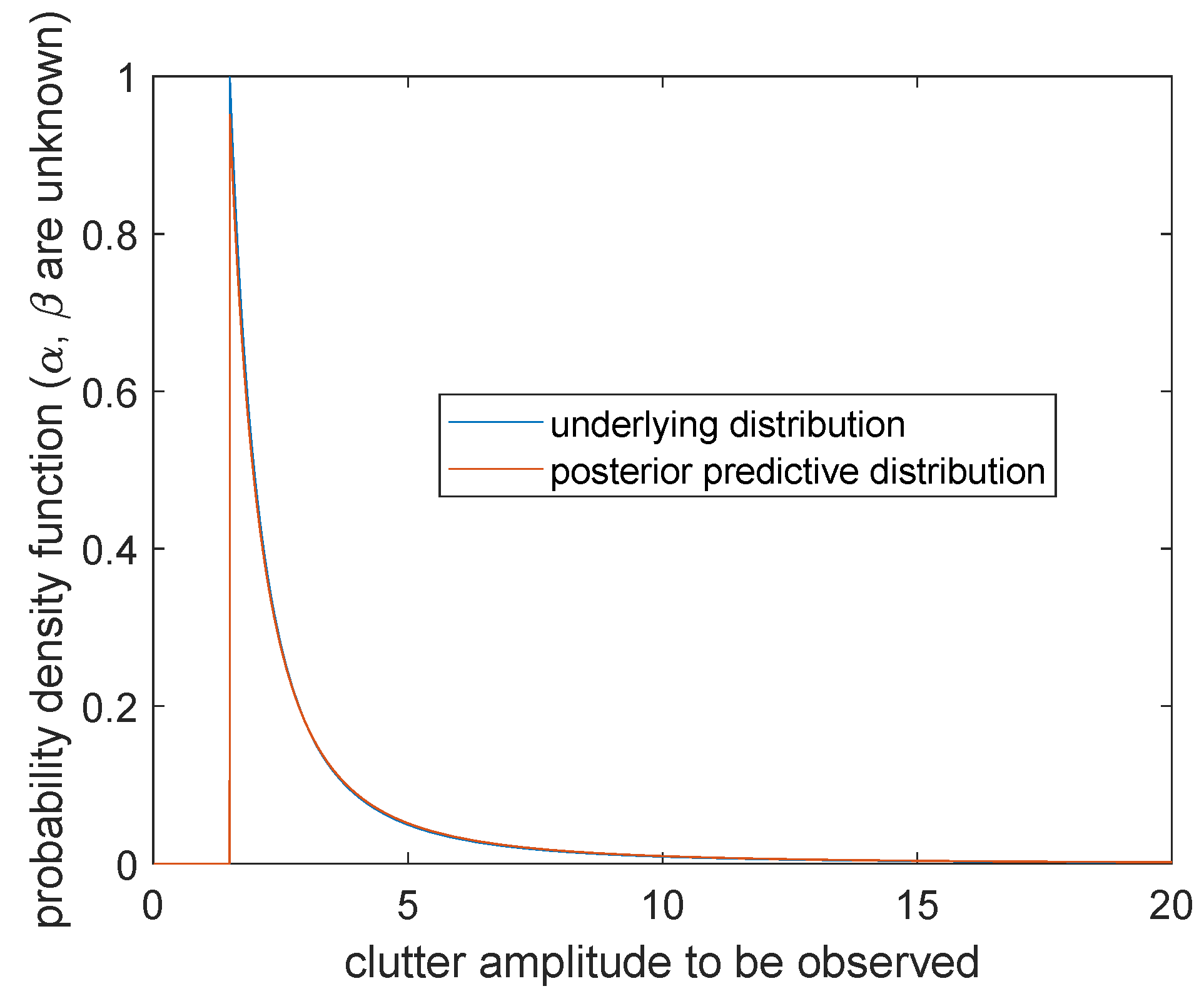
Case 1. Scale parameter α and shape parameter β are unknown
The posterior prediction distribution of sea clutter is
where
The image is shown in
Figure 9. The blue curve represents the probability distribution of sea clutter
, which gives positive values at the right side of the boundary point
. The orange curve represents the posterior prediction distribution of sea clutter
, which changes continuously when
, but forms a cusp at
. Compared with the two curves, the curve of the predicted distribution of sea clutter is connected by a continuous curve and shifts slightly to the left. It is worth noting that although
tends to infinity as
, it is not reflected in the image and can be ignored in the actual calculation of the probability.
Case 2.α is known and β is unknown
The posterior prediction distribution of sea clutter is
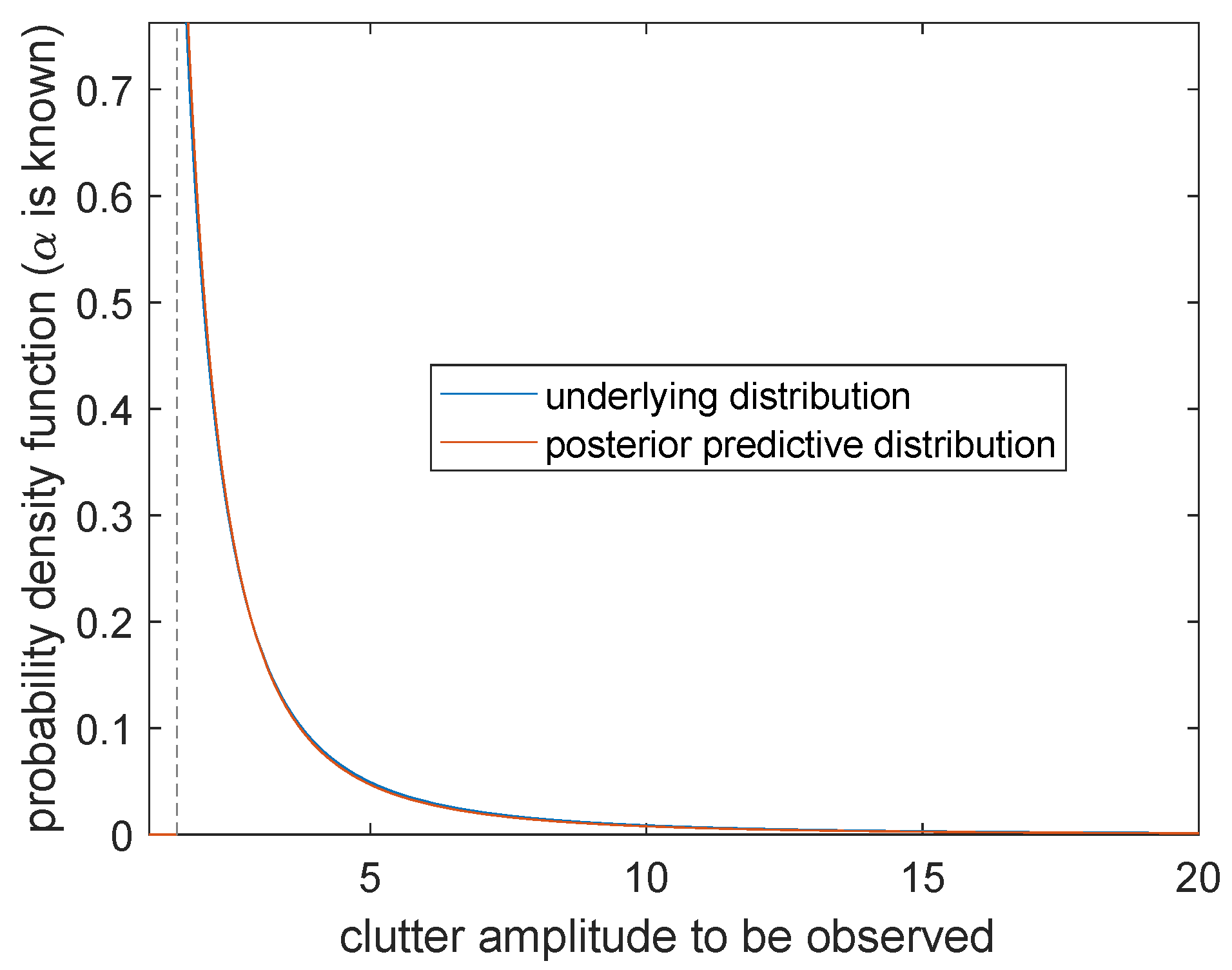
It can be seen from
Figure 10 that the probability distribution
(the blue curve) and the posterior prediction distribution
(the orange curve) can only obtain positive values at the right side of the boundary point
. There is a very high degree of overlap, which means that when
is known, the prediction is going to be very accurate. We come to the conclusion that more effective information can be obtained for parameter
than
.
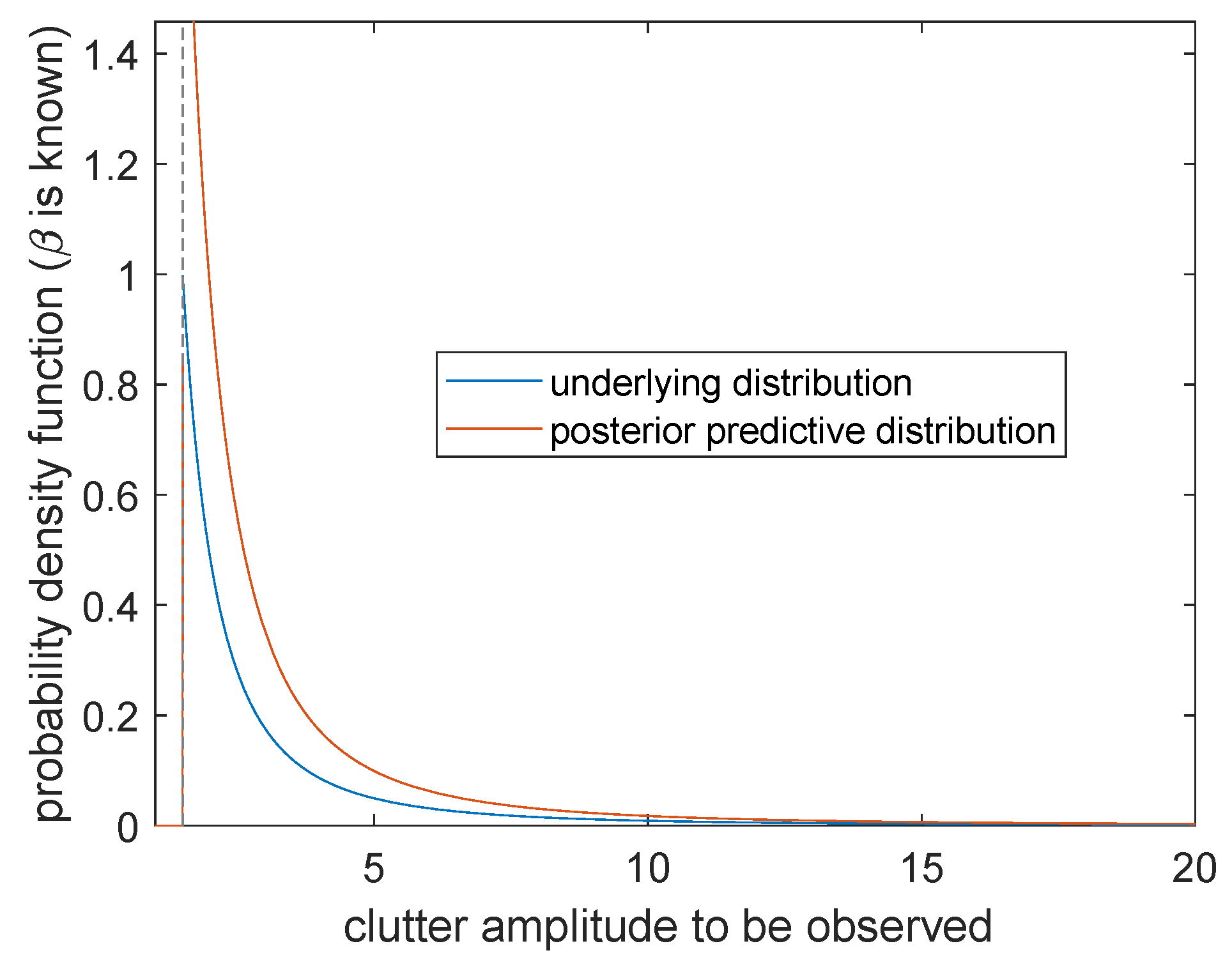
Case 3.β is known and α is unknown
The posterior prediction distribution of sea clutter is
The probability distribution (the blue curve) obtains a positive value at the right side of boundary point . The posterior prediction distribution (the orange curve) changes continuously at and forms a cusp at . By comparing these two curves, the posterior prediction distribution shows a significant right shift, and the simulation effect is not ideal near . However, with the continuous increasing of , the two curves gradually coincide and the prediction accuracy becomes higher. Therefore, when is known and is unknown, the larger the clutter amplitude is to be observed, the higher the prediction accuracy will be.
To sum up, for the sea clutter model, the Bayesian posterior prediction results under the above three conditions are ideal, and the prediction model can well reflect the characteristics of sea clutter towing.
6. Conclusions and Future Work
In this paper, we presented systematic methods for Bayesian inference from geometric viewpoints and applied it to Pareto model. We carried out simulations on sea clutter to show the effectiveness.
For Pareto model, there does not exist general α-parallel prior. Using the Jeffreys prior and by using geodesic distance and Al-Bayyati’s loss function, we obtain two new classes of Bayesian estimations. We call the estimation in the sense of mean geodesic distance MGE and it is proved that MGE has following advantages: it has the explicit expression, and is more accurate than the common Bayesian estimations which has shown in our simulation. We also prove that the estimations under the Al-Bayyati’s loss function are more accurate than the common Bayesian estimations. Actually, there are infinitely many c such that the new estimations are better. These results are important for the estimation of parameters when studying sea clutter model. Finally we show that the Bayesian posterior prediction results can well reflect the characteristics of sea clutter towing in any case.
In the future, more in-depth researches are worth discussing. From statistical viewpoints, we can apply Bayesian inference for the Pareto model to non-linear regression models [
20]. From geometrical viewpoints, we expect to generalize our framework and combine more tools from information geometry. We want to carry out more experiments and applications in different fields.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
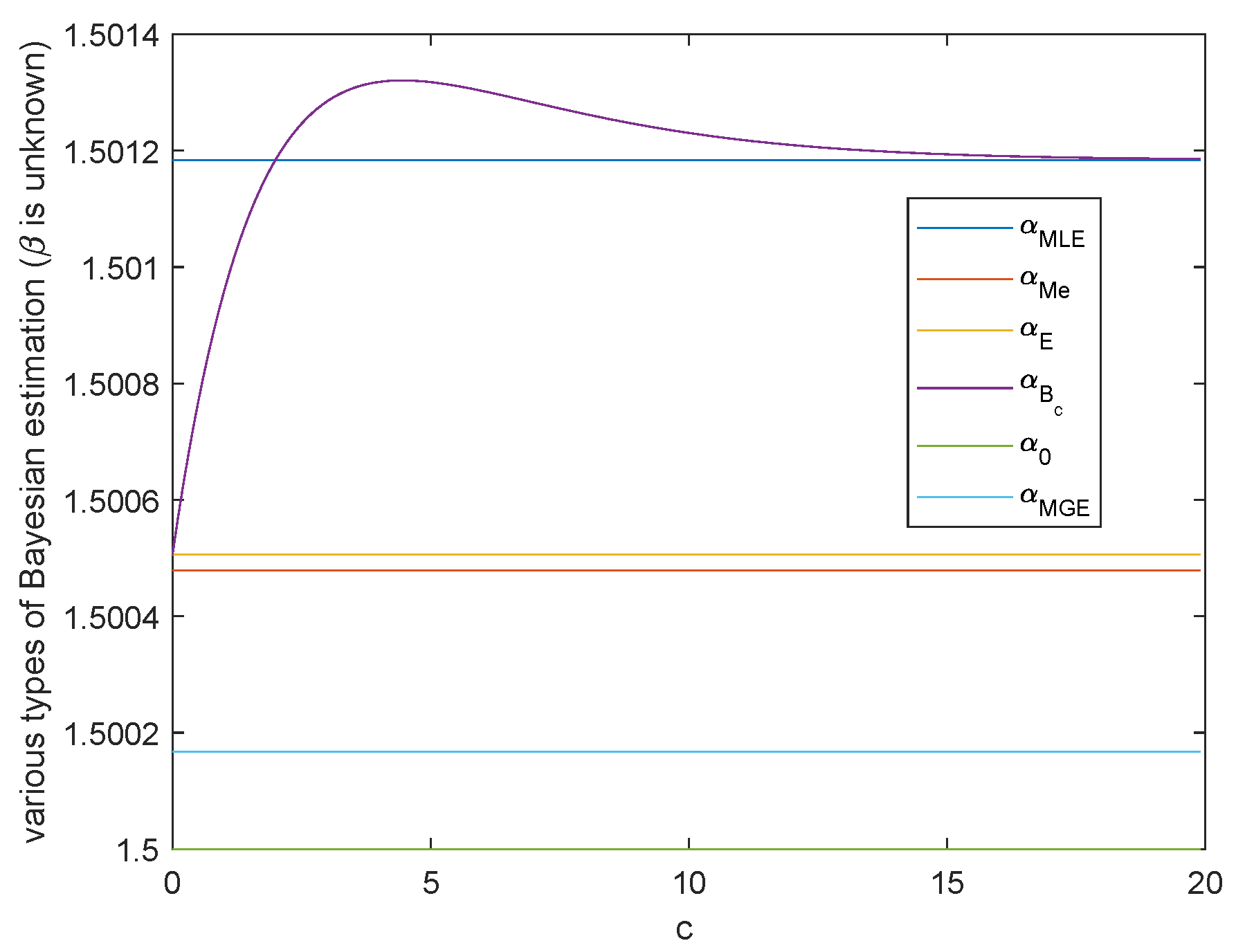{kind=link}
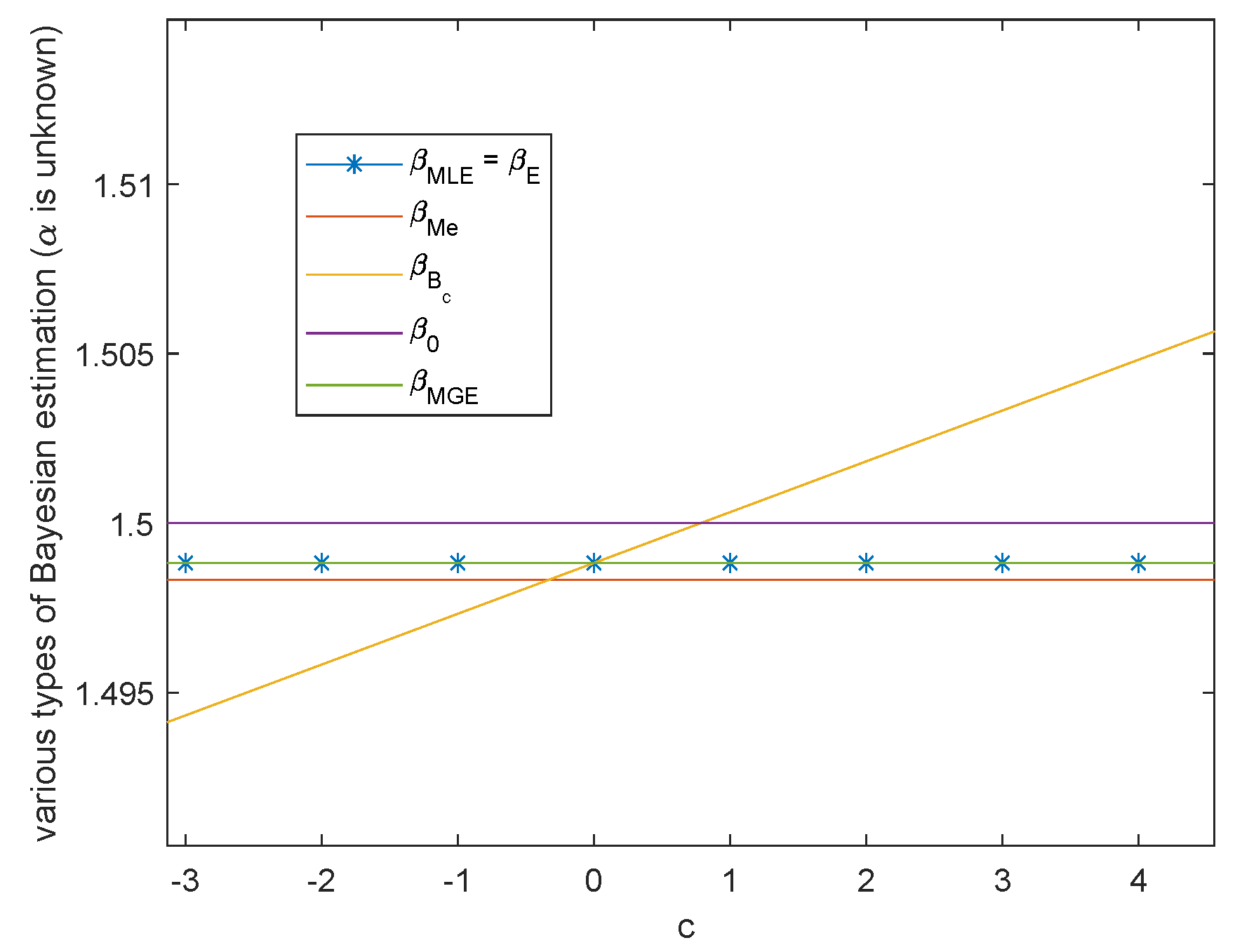{kind=link}
{kind=link}
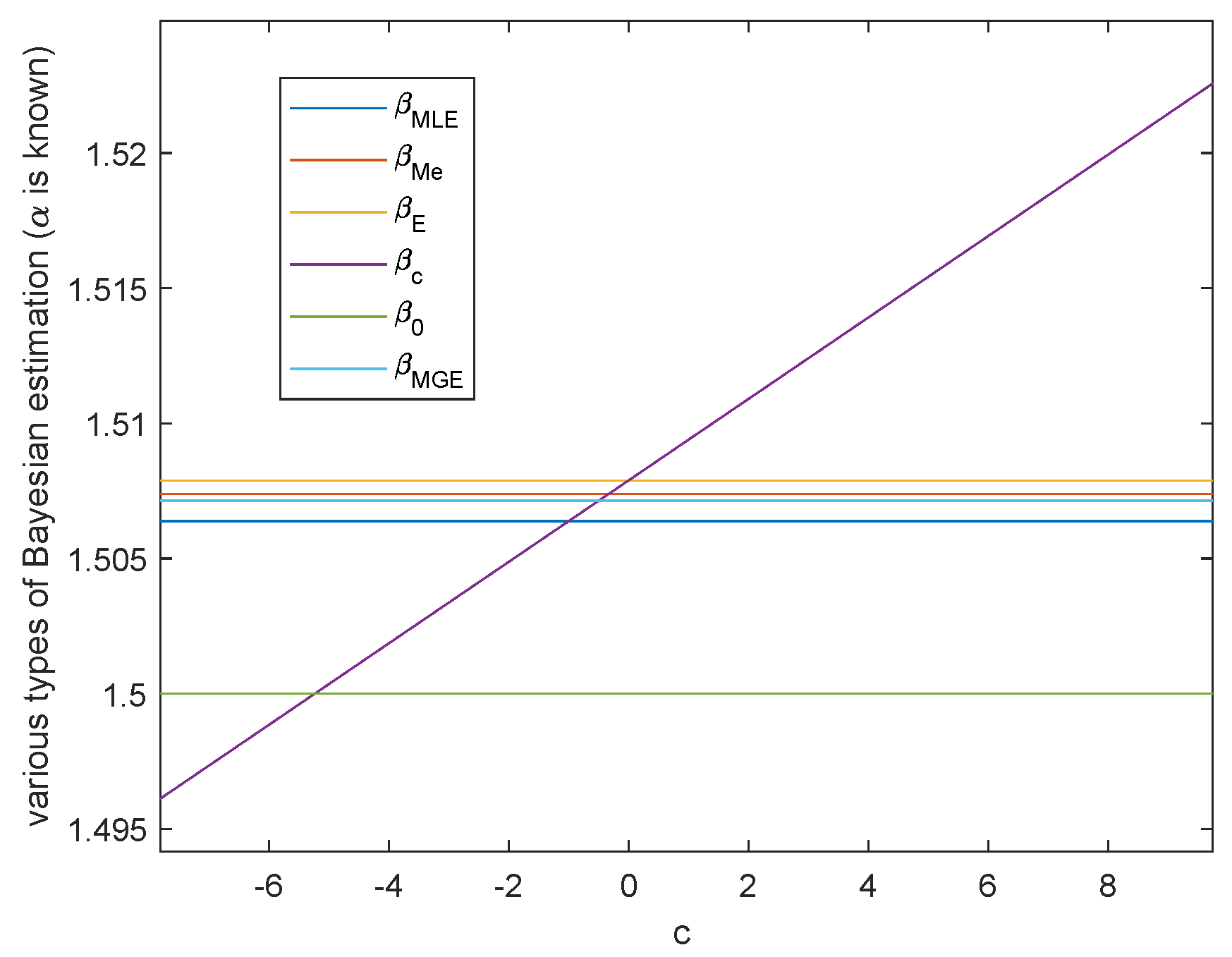{kind=link}
{kind=link}
{kind=link}
{kind=link}