Straggler-Aware Distributed Learning: Communication–Computation Latency Trade-Off


Abstract
1. Introduction
2. An Overview of Existing Straggler Avoidance Techniques
2.1. Coded Computation Schemes
2.2. Coded Transmission Schemes
2.3. Uncoded Computation Schemes
3. Coded Computation with MMC
3.1. Lagrange Coded Computation (LCC)
3.2. LCC with MMC
4. GC with MMC
4.1. Correlated Code Design
| Algorithm 1 GC with MMC (correlated design) |
|
4.2. Uncorrelated Code Design
| Algorithm 2 GC with MMC (uncorrelated design) |
|
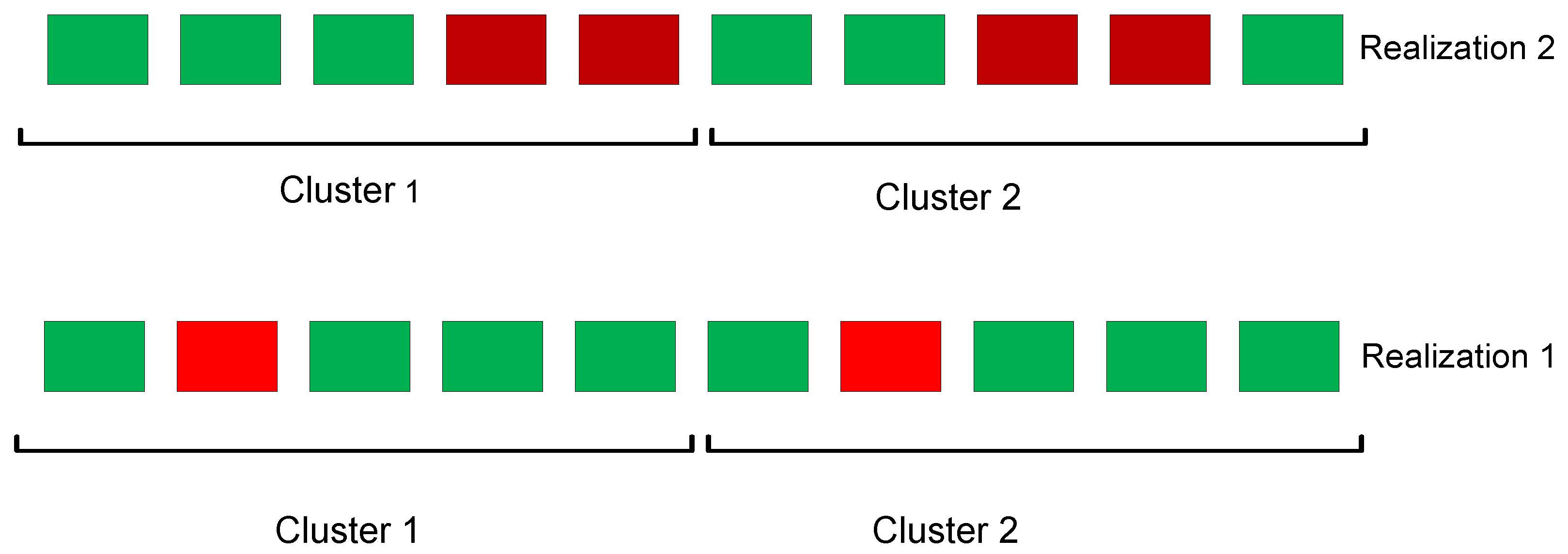
4.3. Clustering
4.4. Hybrid Implementation
5. Uncoded Computation with MMC
6. Per-Iteration Completion Time Statistics
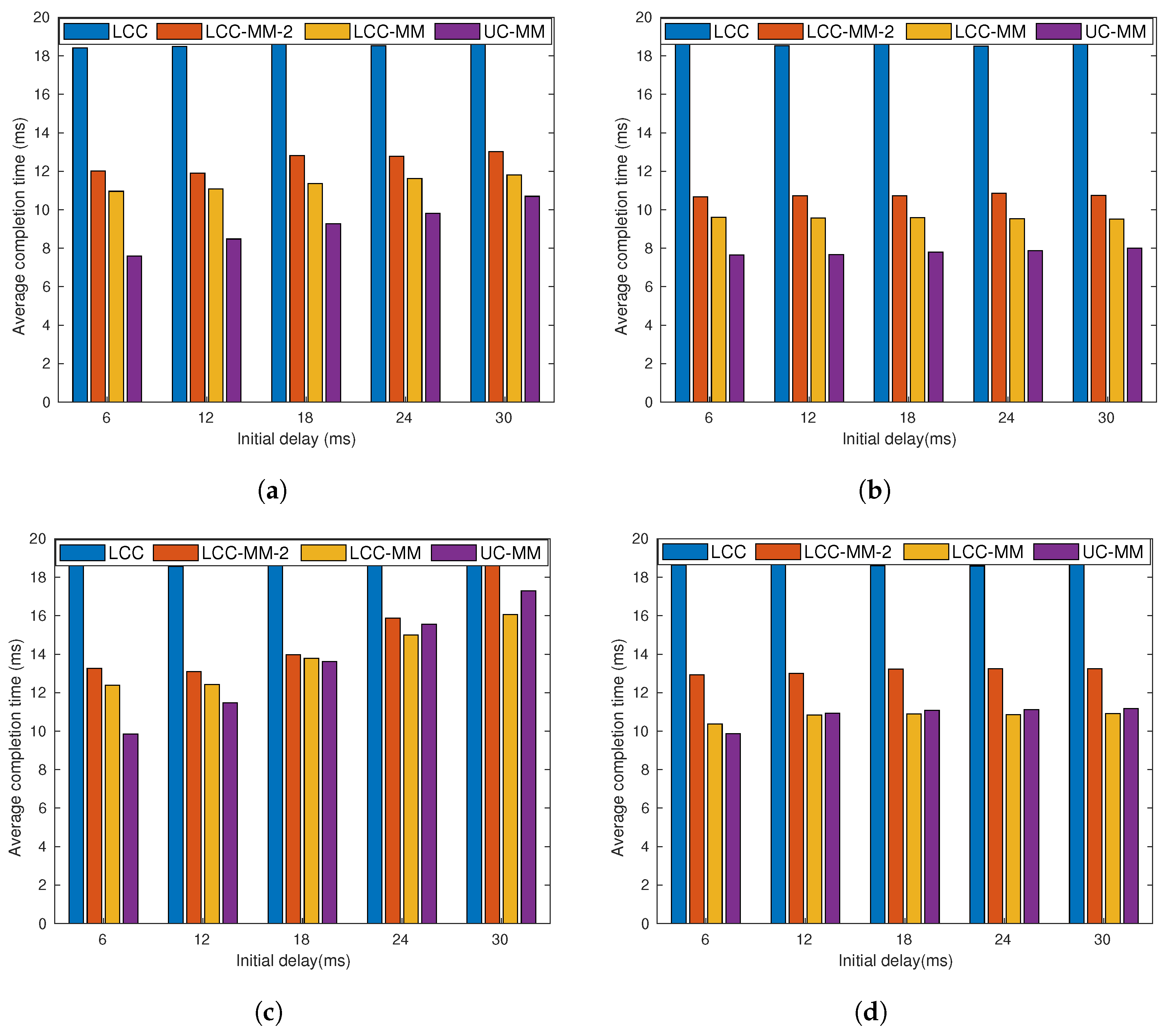
7. Numerical Results and Discussions
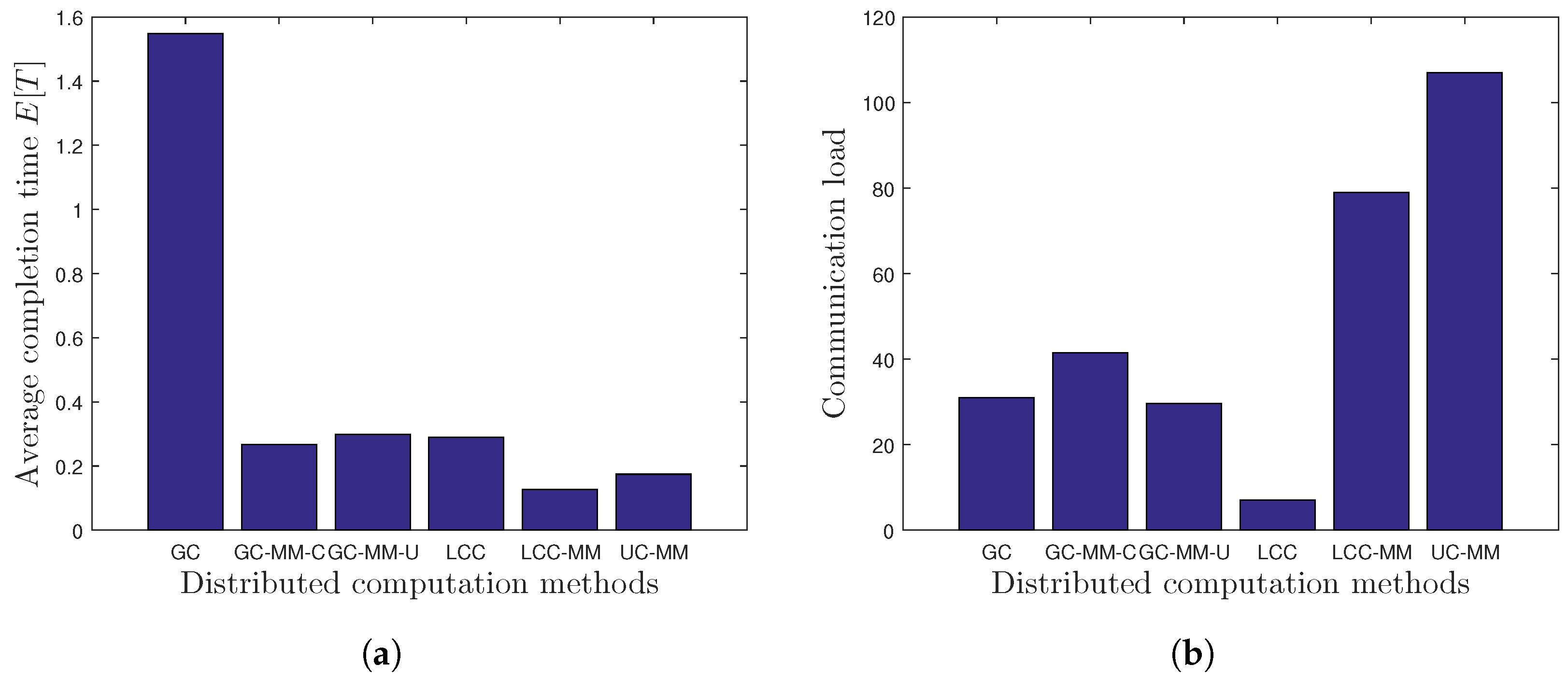
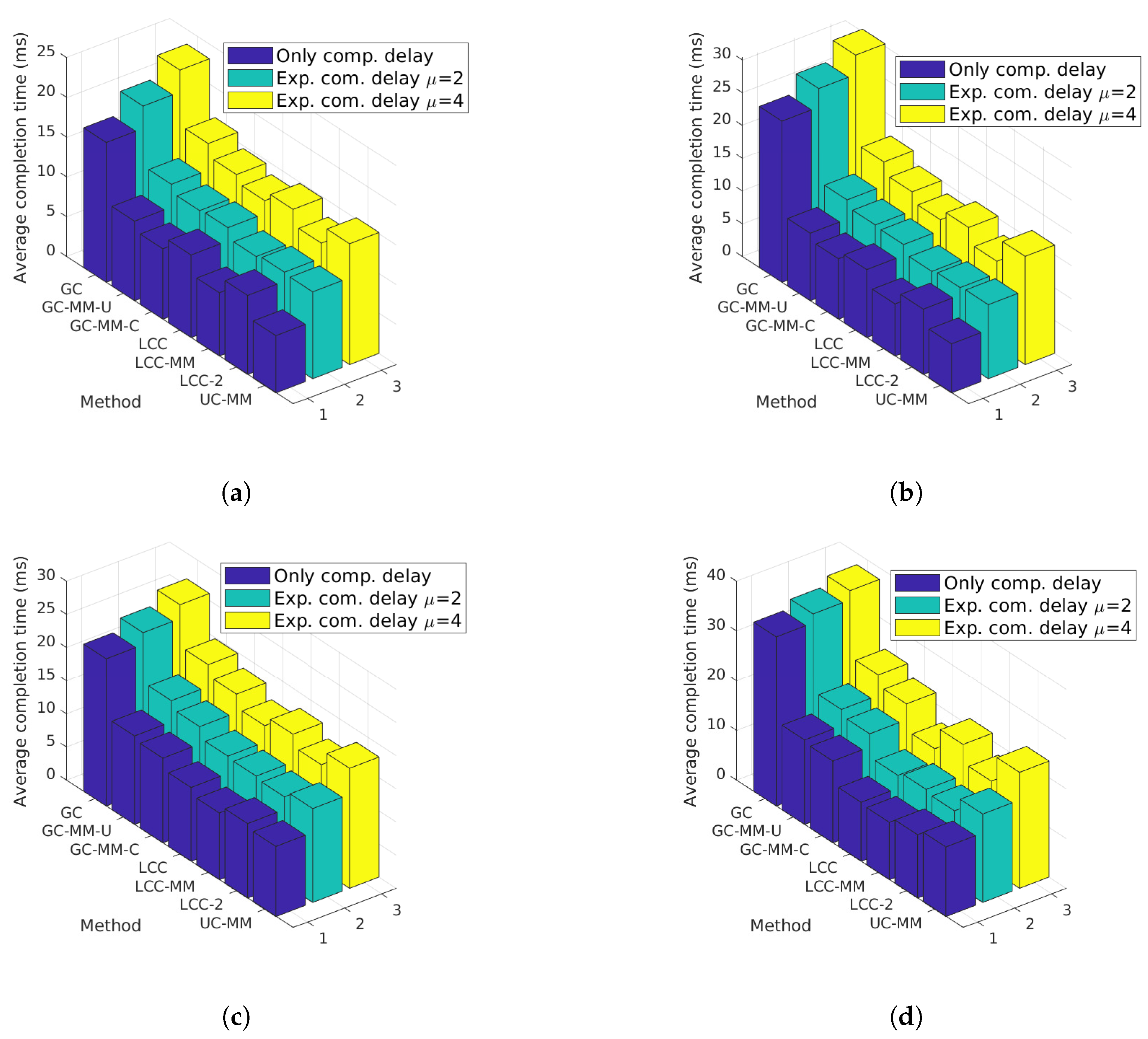
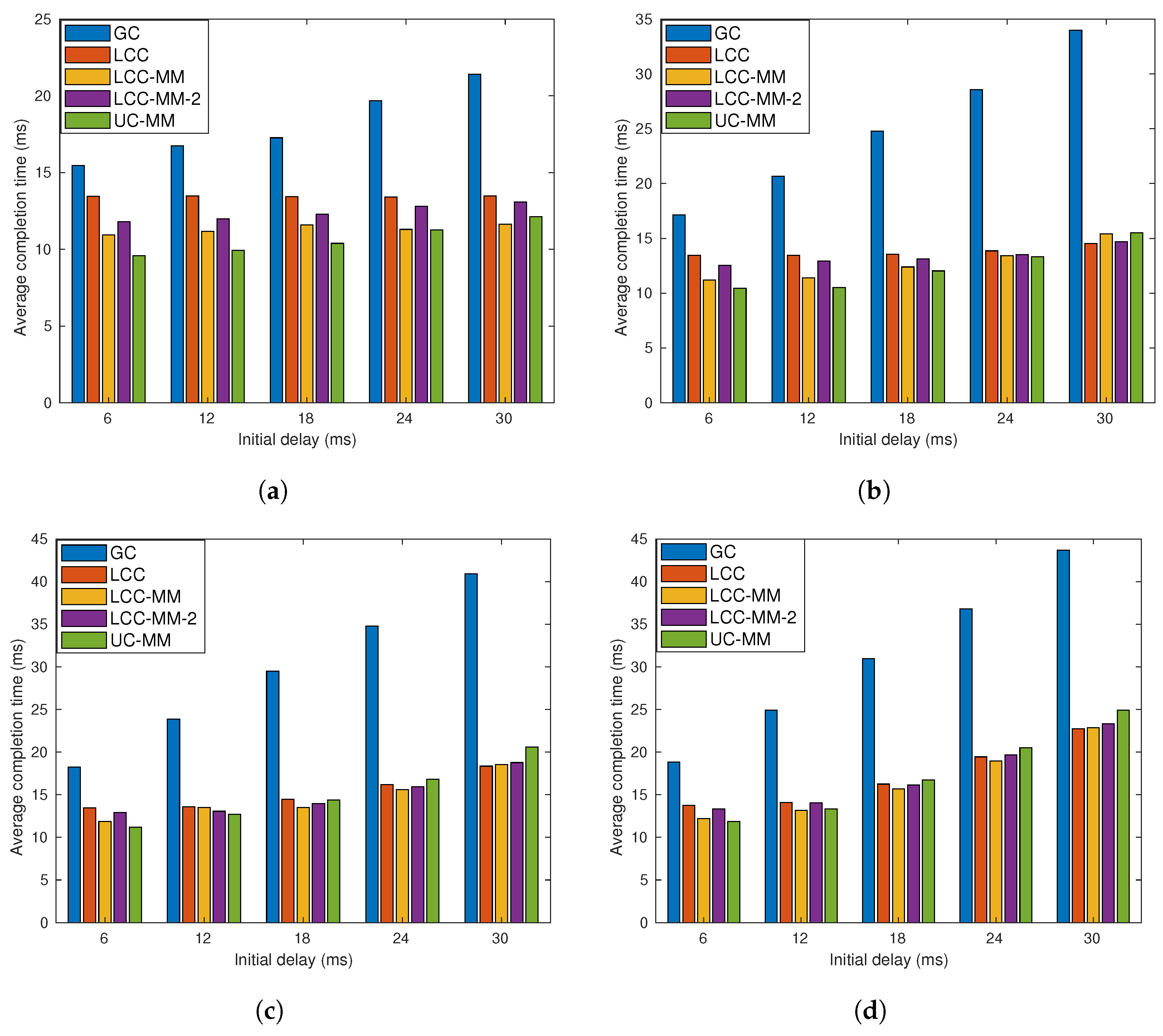
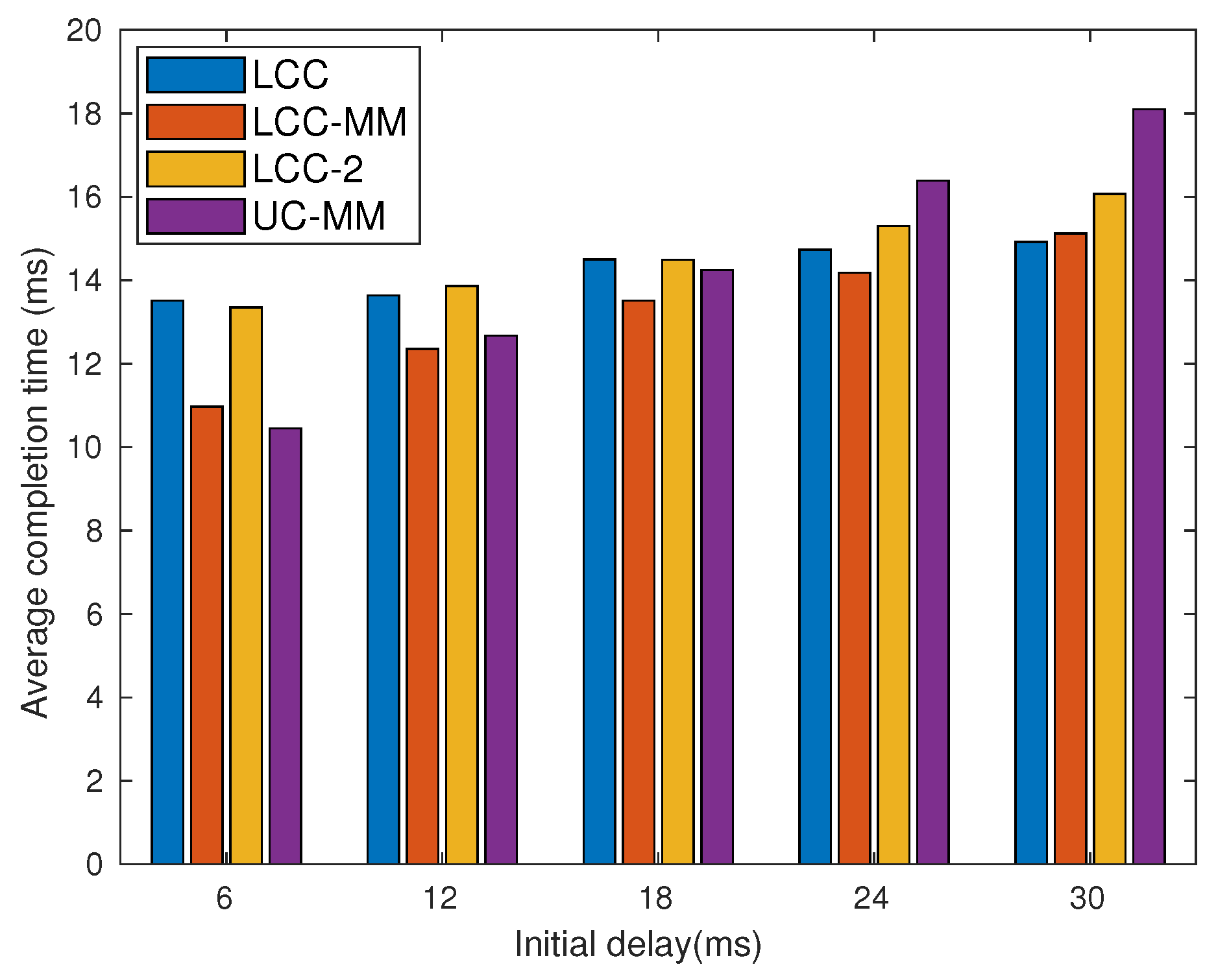
7.1. Model-Based Analysis
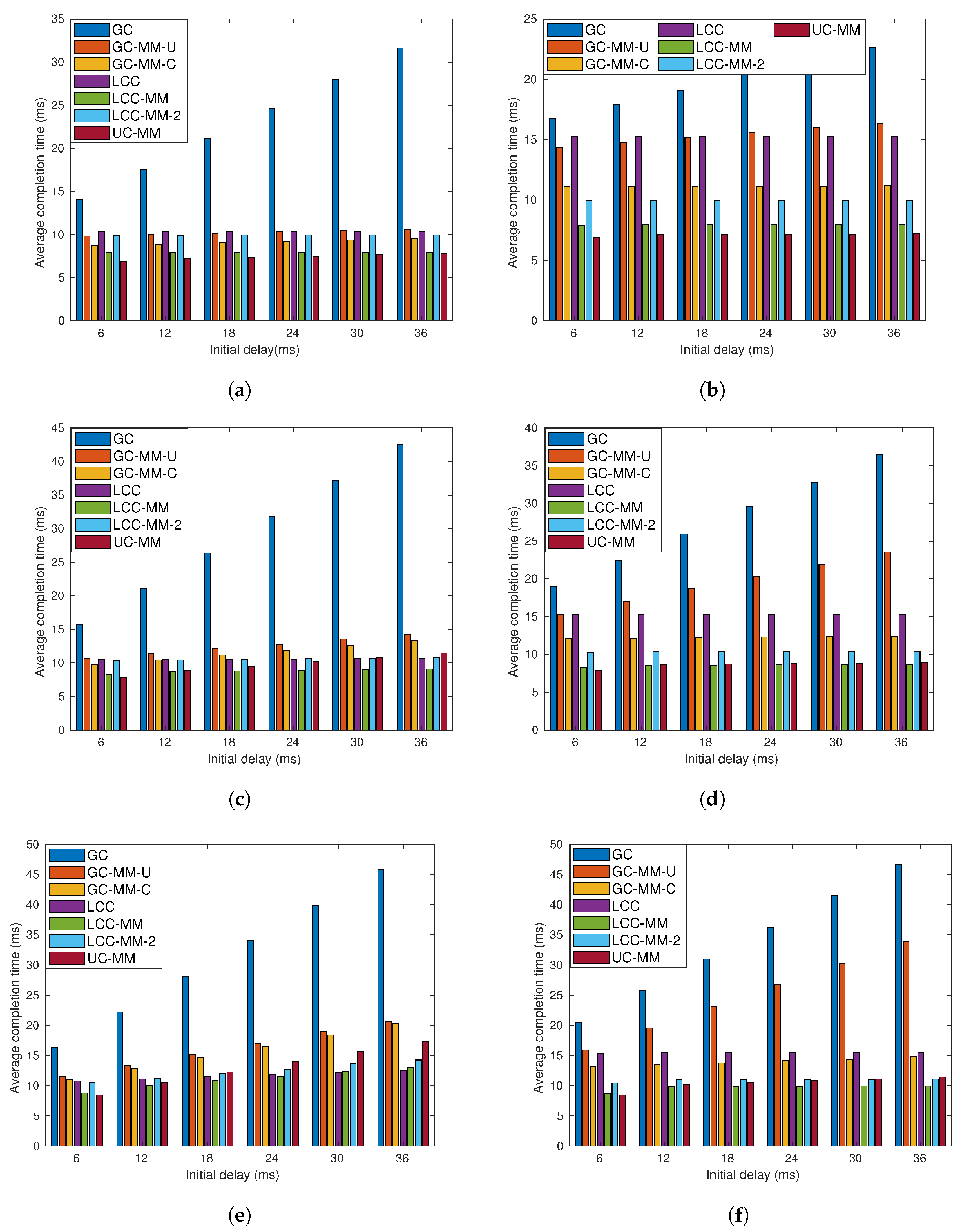
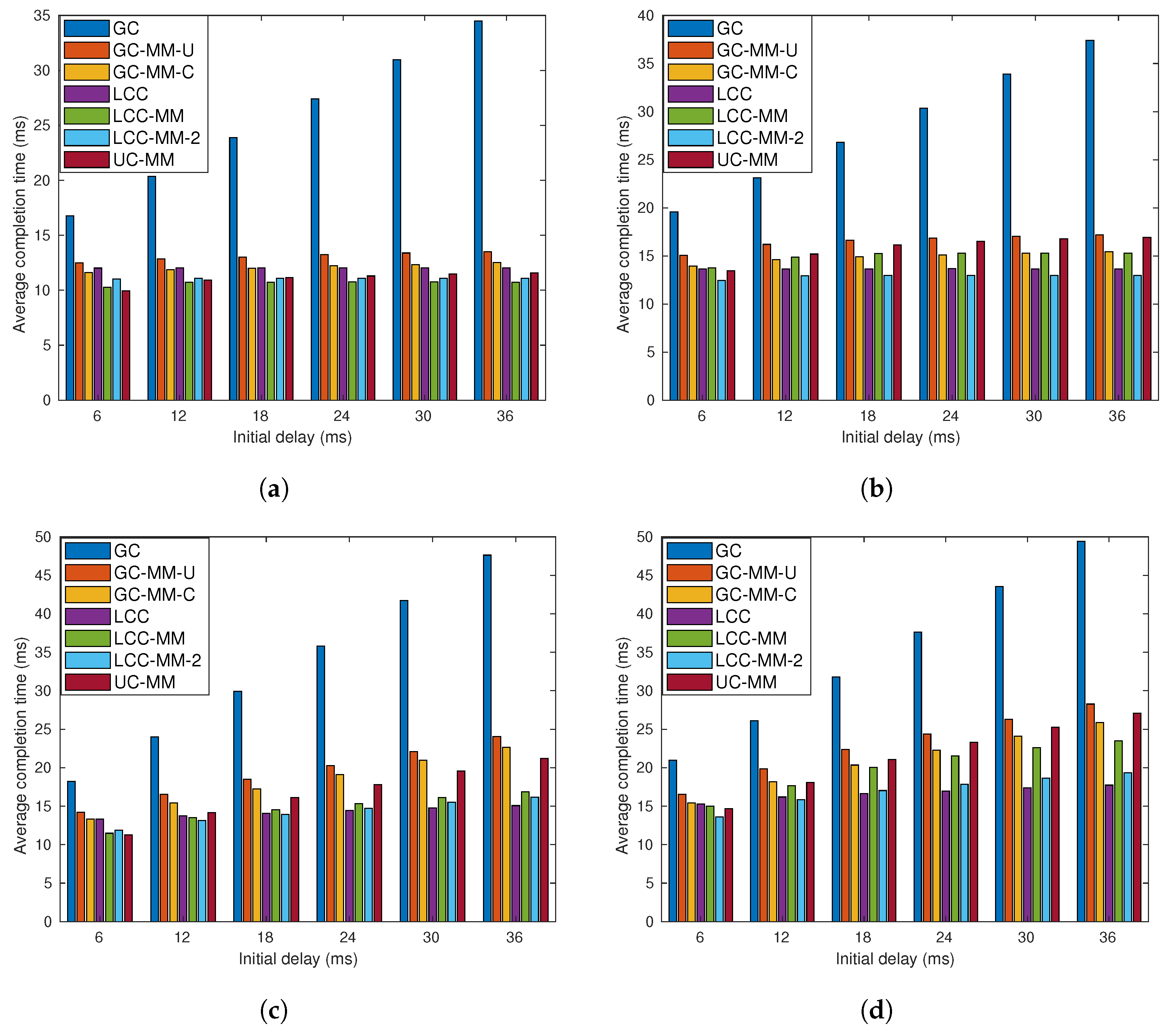
7.2. Data Driven Simulations
7.2.1. Scenario 1
7.2.2. Scenario 2
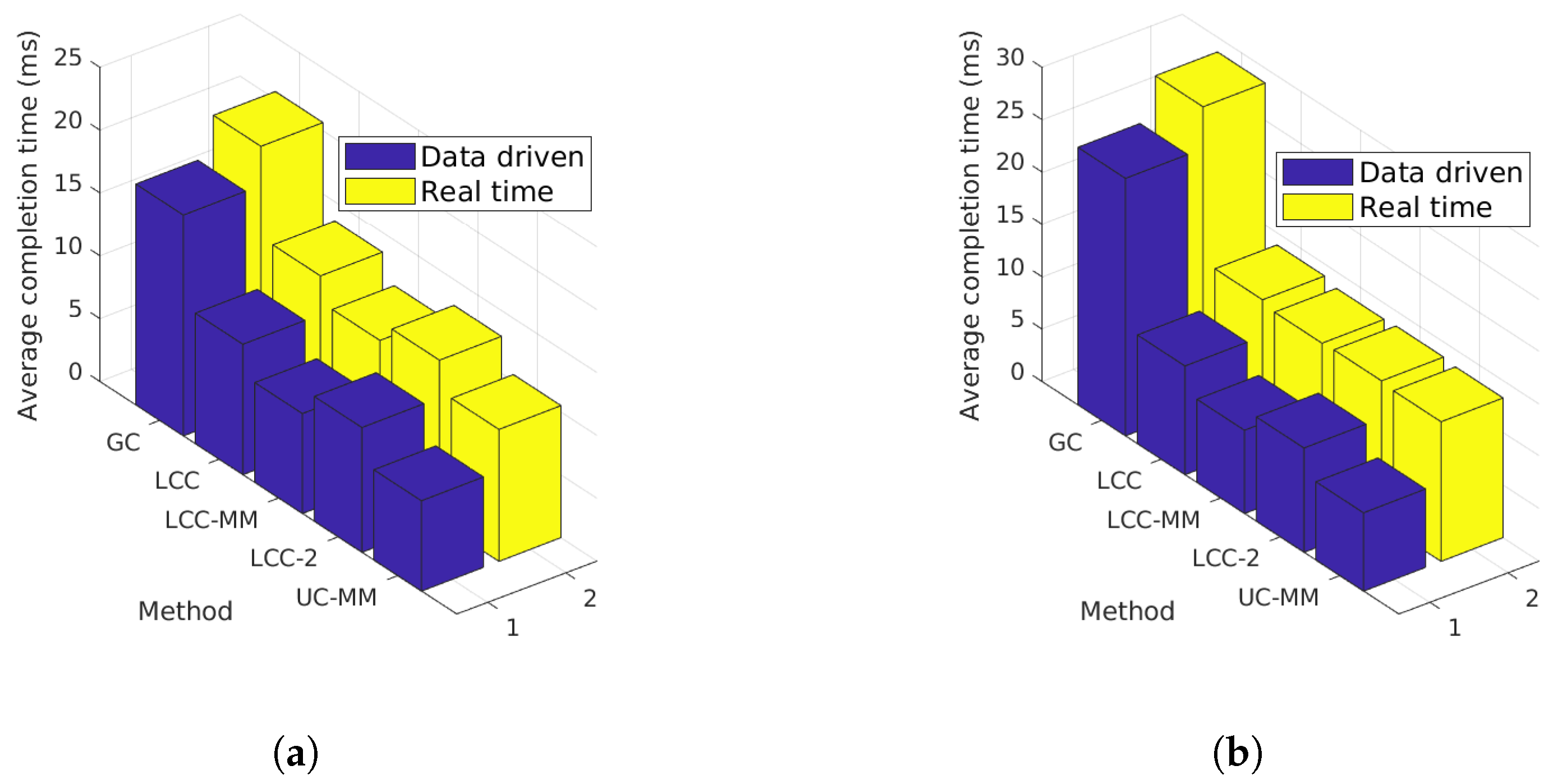
7.3. Real Time Simulations
7.4. Discussions
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Dean, J.; Corrado, G.S.; Monga, R.; Chen, K.; Devin, M.; Le, Q.V.; Mao, M.Z.; Ranzato, M.; Senior, A.; Tucker, P.; et al. Large Scale Distributed Deep Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2012; Volume 1, pp. 1223–1231. [Google Scholar]
- Dekel, O.; Gilad-Bachrach, R.; Shamir, O.; Xiao, L. Optimal Distributed Online Prediction Using Mini-batches. J. Mach. Learn. Res. 2012, 13, 165–202. [Google Scholar]
- Zinkevich, M.A.; Weimer, M.; Smola, A.; Li, L. Parallelized Stochastic Gradient Descent. In Proceedings of the 23rd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2010; Volume 2, pp. 2595–2603. [Google Scholar]
- Li, M.; Andersen, D.G.; Park, J.W.; Smola, A.J.; Ahmed, A.; Josifovski, V.; Long, J.; Shekita, E.J.; Su, B.Y. Scaling Distributed Machine Learning with the Parameter Server. In Proceedings of the 11th USENIX Conference on Operating Systems Design and Implementation; USENIX Association: Berkeley, CA, USA, 2014; pp. 583–598. [Google Scholar]
- Li, S.; Kalan, S.M.M.; Avestimehr, A.S.; Soltanolkotabi, M. Near-Optimal Straggler Mitigation for Distributed Gradient Methods. In Proceedings of the 2018 IEEE International Parallel and Distributed Processing Symposium Workshops, Vancouver, BC, Canada, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 857–866. [Google Scholar]
- Ferdinand, N.; Draper, S.C. Anytime Stochastic Gradient Descent: A Time to Hear from all the Workers. In Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 552–559. [Google Scholar] [CrossRef]
- Mohammadi Amiri, M.; Gündüz, D. Computation Scheduling for Distributed Machine Learning with Straggling Workers. IEEE Trans. Signal Process. 2019, 67, 6270–6284. [Google Scholar] [CrossRef]
- Behrouzi-Far, A.; Soljanin, E. On the Effect of Task-to-Worker Assignment in Distributed Computing Systems with Stragglers. In Proceedings of the 2018 56th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 2–5 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 560–566. [Google Scholar] [CrossRef]
- Chen, J.; Monga, R.; Bengio, S.; Józefowicz, R. Revisiting Distributed Synchronous SGD. arXiv 2016, arXiv:1604.00981. [Google Scholar]
- Aktas, M.F.; Soljanin, E. Straggler Mitigation at Scale. arXiv 2019, arXiv:1906.10664. [Google Scholar] [CrossRef]
- Wang, D.; Joshi, G.; Wornell, G.W. Efficient Straggler Replication in Large-Scale Parallel Computing. ACM Trans. Model. Perform. Eval. Comput. Syst. 2019, 4, 2376–3639. [Google Scholar] [CrossRef]
- Tandon, R.; Lei, Q.; Dimakis, A.G.; Karampatziakis, N. Gradient Coding: Avoiding Stragglers in Distributed Learning. In Proceedings of the 34th International Conference on Machine Learning; Precup, D., Teh, Y.W., Eds.; PMLR International Convention Centre: Sydney, Australia, 2017; Volume 70, pp. 3368–3376. [Google Scholar]
- Ye, M.; Abbe, E. Communication-Computation Efficient Gradient Coding. In Proceedings of the 35th International Conference on Machine Learning; Dy, J., Krause, A., Eds.; PMLR: Stockholmsmässan, Stockholm, Sweden, 2018; Volume 80, pp. 5610–5619. [Google Scholar]
- Halbawi, W.; Azizan, N.; Salehi, F.; Hassibi, B. Improving Distributed Gradient Descent Using Reed-Solomon Codes. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2027–2031. [Google Scholar] [CrossRef]
- Ozfatura, E.; Gündüz, D.; Ulukus, S. Gradient Coding with Clustering and Multi-Message Communication. In 2019 IEEE Data Science Workshop (DSW); IEEE: Piscataway, NJ, USA, 2019; pp. 42–46. [Google Scholar] [CrossRef][Green Version]
- Sasi, S.; Lalitha, V.; Aggarwal, V.; Rajan, B.S. Straggler Mitigation with Tiered Gradient Codes. arXiv 2019, arXiv:1909.02516. [Google Scholar] [CrossRef]
- Lee, K.; Lam, M.; Pedarsani, R.; Papailiopoulos, D.; Ramchandran, K. Speeding Up Distributed Machine Learning Using Codes. IEEE Trans. Inf. Theory 2018, 64, 1514–1529. [Google Scholar] [CrossRef]
- Ferdinand, N.; Draper, S.C. Hierarchical Coded Computation. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1620–1624. [Google Scholar]
- Maity, R.K.; Singh Rawa, A.; Mazumdar, A. Robust Gradient Descent via Moment Encoding and LDPC Codes. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2734–2738. [Google Scholar] [CrossRef]
- Li, S.; Kalan, S.M.M.; Yu, Q.; Soltanolkotabi, M.; Avestimehr, A.S. Polynomially Coded Regression: Optimal Straggler Mitigation via Data Encoding. arXiv 2018, arXiv:1805.09934. [Google Scholar]
- Ozfatura, E.; Gündüz, D.; Ulukus, S. Speeding Up Distributed Gradient Descent by Utilizing Non-persistent Stragglers. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2729–2733. [Google Scholar] [CrossRef]
- Dutta, S.; Fahim, M.; Haddadpour, F.; Jeong, H.; Cadambe, V.; Grover, P. On the Optimal Recovery Threshold of Coded Matrix Multiplication. IEEE Trans. Inf. Theory 2019, 66, 278–301. [Google Scholar] [CrossRef]
- Yu, Q.; Maddah-Ali, M.; Avestimehr, S. Polynomial Codes: An Optimal Design for High-Dimensional Coded Matrix Multiplication. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 4403–4413. [Google Scholar]
- Park, H.; Lee, K.; Sohn, J.; Suh, C.; Moon, J. Hierarchical Coding for Distributed Computing. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1630–1634. [Google Scholar]
- Mallick, A.; Chaudhari, M.; Joshi, G. Fast and Efficient Distributed Matrix-vector Multiplication Using Rateless Fountain Codes. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8192–8196. [Google Scholar]
- Karakus, C.; Sun, Y.; Diggavi, S.; Yin, W. Straggler Mitigation in Distributed Optimization Through Data Encoding. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; pp. 5434–5442. [Google Scholar]
- Kiani, S.; Ferdinand, N.; Draper, S.C. Exploitation of Stragglers in Coded Computation. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1988–1992. [Google Scholar]
- Das, A.B.; Tang, L.; Ramamoorthy, A. C3LES: Codes for Coded Computation that Leverage Stragglers. In Proceedings of the 2018 IEEE Information Theory Workshop (ITW), Guangzhou, China, 25–29 November 2018; pp. 1–5. [Google Scholar]
- Ozfatura, E.; Ulukus, S.; Gündüz, D. Distributed Gradient Descent with Coded Partial Gradient Computations. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3492–3496. [Google Scholar]
- Haddadpour, F.; Yang, Y.; Chaudhari, M.; Cadambe, V.R.; Grover, P. Straggler-Resilient and Communication-Efficient Distributed Iterative Linear Solver. arXiv 2018, arXiv:1806.06140. [Google Scholar]
- Wang, H.; Guo, S.; Tang, B.; Li, R.; Li, C. Heterogeneity-aware Gradient Coding for Straggler Tolerance. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 555–564. [Google Scholar]
- Kim, M.; Sohn, J.; Moon, J. Coded Matrix Multiplication on a Group-Based Model. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 722–726. [Google Scholar] [CrossRef]
- Yang, Y.; Interlandi, M.; Grover, P.; Kar, S.; Amizadeh, S.; Weimer, M. Coded Elastic Computing. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2654–2658. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. Straggler Mitigation in Distributed Matrix Multiplication: Fundamental Limits and Optimal Coding. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 2022–2026. [Google Scholar]
- Dutta, S.; Bai, Z.; Jeong, H.; Low, T.M.; Grover, P. A Unified Coded Deep Neural Network Training Strategy based on Generalized PolyDot codes. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1585–1589. [Google Scholar]
- Soto, P.; Li, J.; Fan, X. Dual Entangled Polynomial Code: Three-Dimensional Coding for Distributed Matrix Multiplication. In Proceedings of the 36th International Conference on Machine Learning; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 5937–5945. [Google Scholar]
- Park, H.; Moon, J. Irregular Product Coded Computation for High-Dimensional Matrix Multiplication. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1782–1786. [Google Scholar]
- Das, A.B.; Ramamoorthy, A. Distributed Matrix-Vector Multiplication: A Convolutional Coding Approach. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 3022–3026. [Google Scholar]
- Mallick, A.; Joshi, G. Rateless Codes for Distributed Computations with Sparse Compressed Matrices. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 2793–2797. [Google Scholar]
- Yu, Q.; Maddah-Ali, M.A.; Avestimehr, A.S. Coded Fourier Transform. In Proceedings of the 2017 55th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 3–6 October 2017. [Google Scholar]
- Reisizadeh, A.; Prakash, S.; Pedarsani, R.; Avestimehr, A.S. CodedReduce: A Fast and Robust Framework for Gradient Aggregation in Distributed Learning. arXiv 2019, arXiv:1902.01981. [Google Scholar]
- Buyukates, B.; Ulukus, S. Timely Distributed Computation with Stragglers. arXiv 2019, arXiv:1910.03564. [Google Scholar]
- Hasircioglu, B.; Gomez-Vilardebo, J.; Gunduz, D. Bivariate Polynomial Coding for Exploiting Stragglers in Heterogeneous Coded Computing Systems. arXiv 2020, arXiv:2001.07227. [Google Scholar]
- Severinson, A.; i Amat, A.G.; Rosnes, E.; Lázaro, F.; Liva, G. A Droplet Approach Based on Raptor Codes for Distributed Computing with Straggling Servers. In Proceedings of the 2018 IEEE 10th International Symposium on Turbo Codes Iterative Information Processing (ISTC), Hong Kong, China, 3–7 December 2018; pp. 1–5. [Google Scholar]
- Severinson, A.; Graell i Amat, A.; Rosnes, E. Block-Diagonal and LT Codes for Distributed Computing with Straggling Servers. IEEE Trans. Commun. 2019, 67, 1739–1753. [Google Scholar] [CrossRef]
- Zhang, J.; Simeone, O. Improved Latency-communication Trade-off for Map-shuffle-reduce Systems with Stragglers. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 8172–8176. [Google Scholar]
- Li, S.; Maddah-Ali, M.A.; Avestimehr, A.S. Coded Distributed Computing: Straggling Servers and Multistage Dataflows. In Proceedings of the 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 27–30 September 2016; pp. 164–171. [Google Scholar]
- Konstantinidis, K.; Ramamoorthy, A. CAMR: Coded Aggregated MapReduce. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1427–1431. [Google Scholar]
- Dutta, S.; Joshi, G.; Ghosh, S.; Dube, P.; Nagpurkar, P. Slow and Stale Gradients Can Win the Race: Error-Runtime Trade-offs in Distributed SGD. In Proceedings of the 21st International Conference on Artificial Intelligence and Statistics (AISTATS), Playa Blanca, Spain, 9–11 April 2018. [Google Scholar]
- Bitar, R.; Wootters, M.; Rouayheb, S.E. Stochastic Gradient Coding for Straggler Mitigation in Distributed Learning. arXiv 2019, arXiv:1905.05383. [Google Scholar]
- Wang, H.; Charles, Z.B.; Papailiopoulos, D.S. ErasureHead: Distributed Gradient Descent without Delays Using Approximate Gradient Coding. arXiv 2019, arXiv:1901.09671. [Google Scholar]
- Wang, S.; Liu, J.; Shroff, N.B. Fundamental Limits of Approximate Gradient Coding. arXiv 2019, arXiv:1901.08166. [Google Scholar] [CrossRef]
- Horii, S.; Yoshida, T.; Kobayashi, M.; Matsushima, T. Distributed Stochastic Gradient Descent Using LDGM Codes. In Proceedings of the 2019 IEEE International Symposium on Information Theory (ISIT), Paris, France, 7–12 July 2019; pp. 1417–1421. [Google Scholar]
- Zhang, J.; Simeone, O. LAGC: Lazily Aggregated Gradient Coding for Straggler-Tolerant and Communication-Efficient Distributed Learning. arXiv 2019, arXiv:1905.09148. [Google Scholar]
- Chen, T.; Giannakis, G.B.; Sun, T.; Yin, W. LAG: Lazily Aggregated Gradient for Communication-efficient Distributed Learning. In Proceedings of the 32nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: Red Hook, NY, USA, 2018; pp. 5055–5065. [Google Scholar]
- New York University. Python MPI. 2017. Available online: https://nyu-cds.github.io/python-mpi/ (accessed on 11 May 2020).
- Bottou, L.; Curtis, F.; Nocedal, J. Optimization Methods for Large-Scale Machine Learning. SIAM Rev. 2018, 60, 223–311. [Google Scholar] [CrossRef]
- Shallue, C.J.; Lee, J.; Antognini, J.; Sohl-Dickstein, J.; Frostig, R.; Dahl, G.E. Measuring the Effects of Data Parallelism on Neural Network Training. J. Mach. Learn. Res. 2019, 20, 1–49. [Google Scholar]
- Goyal, P.; Dollár, P.; Girshick, R.B.; Noordhuis, P.; Wesolowski, L.; Kyrola, A.; Tulloch, A.; Jia, Y.; He, K. Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour. arXiv 2017, arXiv:1706.02677. [Google Scholar]
- You, Y.; Zhang, Z.; Hsieh, C.J.; Demmel, J.; Keutzer, K. ImageNet Training in Minutes. In Proceedings of the 47th International Conference on Parallel Processing; ACM: New York, NY, USA, 2018; pp. 1–10. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ozfatura, E.; Ulukus, S.; Gündüz, D. Straggler-Aware Distributed Learning: Communication–Computation Latency Trade-Off. Entropy 2020, 22, 544. https://doi.org/10.3390/e22050544
Ozfatura E, Ulukus S, Gündüz D. Straggler-Aware Distributed Learning: Communication–Computation Latency Trade-Off. Entropy. 2020; 22(5):544. https://doi.org/10.3390/e22050544
Chicago/Turabian StyleOzfatura, Emre, Sennur Ulukus, and Deniz Gündüz. 2020. "Straggler-Aware Distributed Learning: Communication–Computation Latency Trade-Off" Entropy 22, no. 5: 544. https://doi.org/10.3390/e22050544
APA StyleOzfatura, E., Ulukus, S., & Gündüz, D. (2020). Straggler-Aware Distributed Learning: Communication–Computation Latency Trade-Off. Entropy, 22(5), 544. https://doi.org/10.3390/e22050544