Towards a Unified Theory of Learning and Information

Abstract
{kind=link}
{kind=link}
1. Introduction
1.1. Generalization Risk
1.2. Types of Generalization
1.3. Paper Outline
2. Notation
3. Related Work
4. Uniform Generalization
4.1. Preliminary Definitions
4.2. Variational Information
4.3. Equivalence Result
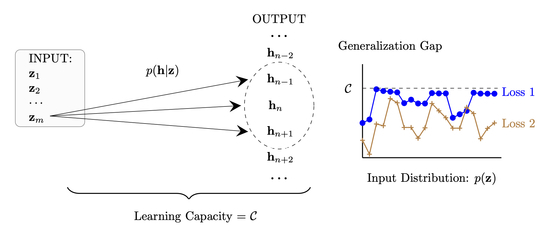
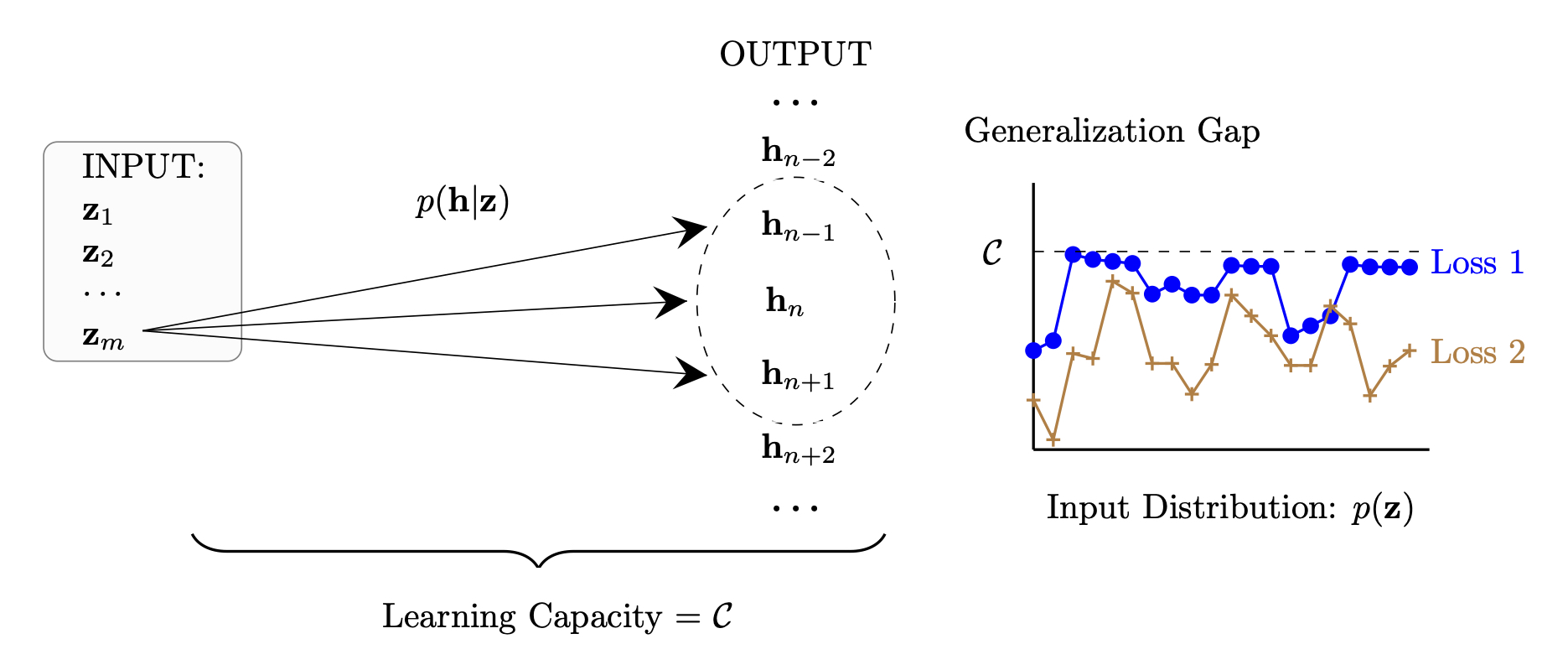
4.4. Learning Capacity
- Statistical: The learning capacity is equal to the supremum of the expected generalization risk across all input distributions and all bounded parametric losses. This holds by Theorem 2 and Definition 6.
- Information-Theoretic: The learning capacity is equal to the amount of information contained in the hypothesis about the training examples. This holds because .
- Algorithmic: The learning capacity measures the influence of a single training example on the distribution of the final hypothesis . As such, a learning algorithm has a small learning capacity if and only if it is algorithmically stable. This follows from the fact that .
4.5. The Definition of Hypothesis
4.6. Concentration
5. Properties of the Learning Capacity
5.1. Data Processing
5.2. Effective Domain Size
5.3. Finite Hypothesis Space
5.4. Differential Privacy
5.5. Empirical Risk Minimization of 0–1 Loss Classes
- If is an empirical risk minimizer, then set
- Otherwise, set .
- admits an ERM learning rulewhose learning capacitysatisfiesas.
- has a finite VC dimension.
6. Concluding Remarks
7. Further Research Directions
7.1. Induced VC Dimension
7.2. Unsupervised Model Selection
7.3. Effective Domain Size
Funding
Conflicts of Interest
Appendix A. Proof of Lemma 2
Appendix B. Proof of Theorem 1
Appendix C. Proof of Proposition 1
Appendix D. Proof of Theorem 3
Appendix E. Proof of Proposition 3
Appendix F. Proof of Proposition 4
- If , then as proved in Lemma 1. This happens with probability by design.
- Otherwise, . Thus: .
Appendix G. Proof of Theorem 5
Appendix H. Proof of Proposition 5
Appendix I. Proof of Theorem 8
Appendix J. Proof of Theorem 9
References
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Stochastic Convex Optimization. In Proceedings of the Annual Conference on Learning Theory, Montreal, QC, Canada, 18–21 June 2009. [Google Scholar]
- Bartlett, P.L.; Jordan, M.I.; McAuliffe, J.D. Convexity, classification, and risk bounds. J. Am. Stat. Assoc. 2006, 101, 138–156. [Google Scholar] [CrossRef]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Blumer, A.; Ehrenfeucht, A.; Haussler, D.; Warmuth, M.K. Learnability and the Vapnik-Chervonenkis dimension. JACM 1989, 36, 929–965. [Google Scholar] [CrossRef]
- McAllester, D. PAC-Bayesian stochastic model selection. Mach. Learn. 2003, 51, 5–21. [Google Scholar] [CrossRef]
- Bousquet, O.; Elisseeff, A. Stability and generalization. JMLR 2002, 2, 499–526. [Google Scholar]
- Bartlett, P.L.; Mendelson, S. Rademacher and Gaussian complexities: Risk bounds and structural results. JMLR 2002, 3, 463–482. [Google Scholar]
- Kutin, S.; Niyogi, P. Almost-everywhere algorithmic stability and generalization error. In Proceedings of the Eighteenth conference on Uncertainty in Artificial Intelligence (UAI), Edmonton, AB, Canada, 1–4 August 2002. [Google Scholar]
- Poggio, T.; Rifkin, R.; Mukherjee, S.; Niyogi, P. General conditions for predictivity in learning theory. Nature 2004, 428, 419–422. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley & Sons: New York, NY, USA, 1991. [Google Scholar]
- Hardt, M.; Recht, B.; Singer, Y. Train faster, generalize better: Stability of stochastic gradient descent. arXiv 2015, arXiv:1509.01240. [Google Scholar]
- Dwork, C.; Feldman, V.; Hardt, M.; Pitassi, T.; Reingold, O.; Roth, A. Preserving Statistical Validity in Adaptive Data Analysis. In Proceedings of the Forty-Seventh Annual ACM on Symposium on Theory of Computing (STOC), Portland, OR, USA, 14–17 June 2015; pp. 117–126. [Google Scholar]
- Shalev-Shwartz, S.; Ben-David, S. Understanding Machine Learning: From Theory to Algorithms; Cambridge University Press: New York, NY, USA, 2014. [Google Scholar]
- Raginsky, M.; Rakhlin, A.; Tsao, M.; Wu, Y.; Xu, A. Information-theoretic analysis of stability and bias of learning algorithms. In Proceedings of the 2016 IEEE Information Theory Workshop (ITW), Cambridge, UK, 11–14 September 2016; pp. 26–30. [Google Scholar]
- Janson, S. Probability asymptotics: Notes on notation. arXiv 2011, arXiv:1108.3924. [Google Scholar]
- Tao, T. Topics in Random Matrix Theory; American Mathematical Society: Providence, RI, USA, 2012. [Google Scholar]
- Shalev-Shwartz, S.; Shamir, O.; Srebro, N.; Sridharan, K. Learnability, stability and uniform convergence. JMLR 2010, 11, 2635–2670. [Google Scholar]
- Talagrand, M. Majorizing measures: The generic chaining. Ann. Probab. 1996, 24, 1049–1103. [Google Scholar] [CrossRef]
- Audibert, J.Y.; Bousquet, O. Combining PAC-Bayesian and generic chaining bounds. JMLR 2007, 8, 863–889. [Google Scholar]
- Xu, H.; Mannor, S. Robustness and generalization. Mach. Learn. 2012, 86, 391–423. [Google Scholar] [CrossRef]
- Csiszár, I. A Class of Measures of Informativity of Observation Channels. Period. Math. Hung. 1972, 2, 191–213. [Google Scholar] [CrossRef]
- Csiszár, I. Axiomatic Characterizations of Information Measures. Entropy 2008, 10, 261–273. [Google Scholar] [CrossRef]
- Russo, D.; Zou, J. Controlling Bias in Adaptive Data Analysis Using Information Theory. In Proceedings of the 19th International Conference on Artificial Intelligence and Statistics (AISTATS), Cadiz, Spain, 9–11 May 2016. [Google Scholar]
- Bassily, R.; Moran, S.; Nachum, I.; Shafer, J.; Yehudayoff, A. Learners that Use Little Information. PMLR 2018, 83, 25–55. [Google Scholar]
- Elkan, C. The foundations of cost-sensitive learning. In Proceedings of the IJCAI, Seattle, WA, USA, 4–10 August 2011. [Google Scholar]
- Kull, M.; Flach, P. Novel decompositions of proper scoring rules for classification: Score adjustment as precursor to calibration. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases; Springer: Cham, Switzerland, 2015; pp. 68–85. [Google Scholar]
- Robbins, H. A remark on Stirling’s formula. Am. Math. Mon. 1955, 62, 26–29. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support vector machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Q.; Chen, Y. RBF kernel based support vector machine with universal approximation and its application. ISNN 2004, 3173, 512–517. [Google Scholar]
- Downs, T.; Gates, K.E.; Masters, A. Exact simplification of support vector solutions. JMLR 2002, 2, 293–297. [Google Scholar]
- Stigler, S.M. The History of Statistics: The Measurement of Uncertainty before 1900; Harvard University Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Third Theory of Cryptography Conference (TCC 2006), New York, NY, USA, 4–7 March 2006; pp. 265–284. [Google Scholar]
- Dwork, C.; Roth, A. The algorithmic foundations of differential privacy. Theor. Comput. Sci. 2013, 9, 211–407. [Google Scholar]
- Koren, T.; Levy, K. Fast rates for exp-concave empirical risk minimization. In Proceedings of the NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 1477–1485. [Google Scholar]
- Kolmogorov, A.N.; Fomin, S.V. Introductory Real Analysis; Dover Publication, Inc.: New York, NY, USA, 1970. [Google Scholar]
- Alabdulmohsin, I.M. An information theoretic route from generalization in expectation to generalization in probability. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics (AISTATS 2017), Fort Lauderdale, FL, USA, 20–22 April 2017. [Google Scholar]
- Alabdulmohsin, I. Information Theoretic Guarantees for Empirical Risk Minimization with Applications to Model Selection and Large-Scale Optimization. In Proceedings of the International Conference on Machine Learning (ICML 2018), Stockholm, Sweden, 10–15 July 2018; pp. 149–158. [Google Scholar]
- Pavlovski, M.; Zhou, F.; Arsov, N.; Kocarev, L.; Obradovic, Z. Generalization-Aware Structured Regression towards Balancing Bias and Variance. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 13–19 July 2018; pp. 2616–2622. [Google Scholar]
- Alabdulmohsin, I.M. Algorithmic Stability and Uniform Generalization. In Proceedings of the NIPS 2015, Montreal, QC, Canada, 7–12 December 2015; pp. 19–27. [Google Scholar]
- Pelleg, D.; Moore, A.W. X-means: Extending k-means with efficient estimation of the number of clusters. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 727–734. [Google Scholar]
- Bardenet, R.; Maillard, O.A. Concentration inequalities for sampling without replacement. Bernoulli 2015, 21, 1361–1385. [Google Scholar] [CrossRef]

© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alabdulmohsin, I. Towards a Unified Theory of Learning and Information. Entropy 2020, 22, 438. https://doi.org/10.3390/e22040438
Alabdulmohsin I. Towards a Unified Theory of Learning and Information. Entropy. 2020; 22(4):438. https://doi.org/10.3390/e22040438
Chicago/Turabian StyleAlabdulmohsin, Ibrahim. 2020. "Towards a Unified Theory of Learning and Information" Entropy 22, no. 4: 438. https://doi.org/10.3390/e22040438
APA StyleAlabdulmohsin, I. (2020). Towards a Unified Theory of Learning and Information. Entropy, 22(4), 438. https://doi.org/10.3390/e22040438