A Graph-Based Author Name Disambiguation Method and Analysis via Information Theory



Abstract
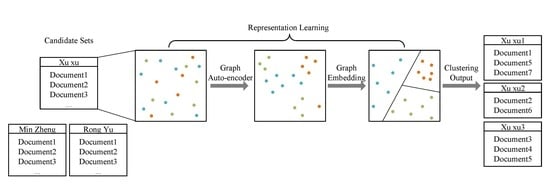
1. Introduction
- Should we use labeled data? The disambiguation performance of supervised methods is generally better than unsupervised methods because of utilizing labeled data. But the size of datasets is usually large and manually labeling all tags will consume a lot of manpower and time. Solving this problem by semi-supervised methods has become a more practical solution to this problem.
- How do we make the best of information and present a comprehensive model that could fit most datasets? Most existing methods are usually based on either feature extraction or on paper relationship and author relationship. Feature extraction methods adopt a large number of attributes and formulate many rules to measure the similarity between documents. When some attributes are missing, the rules will be invalidated. Research based on relationship graphs ignores some basic attributes of documents and reduces the performance of name disambiguation. It is necessary to design a basic method to deal with all kinds of datasets with different attributes.
- Does the proposed method work well on larger datasets? Many state-of-art methods dealing with author name disambiguation are evaluated on relatively small document sets, associated with no more than twenty author name references. When the dataset becomes larger, the performance may drop a lot.
- Why does the proposed method work well? Graph-based name disambiguation approaches can be interpreted as introducing relationship. We wish to know what role the training process plays and why some approaches lacking interpretability perform well.
2. Related Work
2.1. Name Disambiguation
2.2. Information Plane
3. Preliminaries
3.1. Problem Formulation
3.2. Mutual Information and Information Bottleneck
4. Framework
4.1. Feature Embedding
4.2. Variational Graph Auto-Encoder
4.3. Graph Embedding
4.4. Clustering
5. Calculating Mutual Information
6. Experiments
6.1. Datasets
6.2. Competing Method
6.3. Experimental Results
6.4. Component Analysis
6.5. Evaluating by Information Theory
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, J.; Berzins, K.; Hicks, D.; Melkers, J.; Xiao, F.; Pinheiro, D. A boosted-trees method for name disambiguation. Scientometrics 2012, 93, 391–411. [Google Scholar] [CrossRef]
- Tran, H.N.; Huynh, T.; Do, T. Author name disambiguation by using deep neural network. In Asian Conference on Intelligent Information and Database Systems; Springer: Berlin/Heidelberg, Germany, 2014; pp. 123–132. [Google Scholar]
- Tang, J.; Zhang, J.; Yao, L.; Li, J.; Zhang, L.; Su, Z. Arnetminer: Extraction and mining of academic social networks. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 990–998. [Google Scholar]
- Zhang, Y.; Zhang, F.; Yao, P.; Tang, J. Name Disambiguation in AMiner: Clustering, Maintenance, and Human in the Loop. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, London, UK, 19–23 August 2018; pp. 1002–1011. [Google Scholar]
- Zhang, B.; Al Hasan, M. Name disambiguation in anonymized graphs using network embedding. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 1239–1248. [Google Scholar]
- Fan, X.; Wang, J.; Pu, X.; Zhou, L.; Lv, B. On graph-based name disambiguation. J. Data Inf. Qual. (Jdiq) 2011, 2, 10. [Google Scholar] [CrossRef]
- Cetoli, A.; Akbari, M.; Bragaglia, S.; O’Harney, A.D.; Sloan, M. Named Entity Disambiguation using Deep Learning on Graphs. arXiv 2018, arXiv:1810.09164. [Google Scholar]
- Kim, K.; Rohatgi, S.; Giles, C.L. Hybrid Deep Pairwise Classification for Author Name Disambiguation. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2369–2372. [Google Scholar]
- Bunescu, R.; Paşca, M. Using encyclopedic knowledge for named entity disambiguation. In Proceedings of the 11th conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 4 April 2006. [Google Scholar]
- Han, H.; Giles, L.; Zha, H.; Li, C.; Tsioutsiouliklis, K. Two supervised learning approaches for name disambiguation in author citations. In Proceedings of the 2004 Joint ACM/IEEE Conference on Digital Libraries, Tucson, AZ, USA, 7–11 June 2004; pp. 296–305. [Google Scholar]
- Delgado, A.D.; Martínez, R.; Montalvo, S.; Fresno, V. Person name disambiguation on the web in a multilingual context. Inf. Sci. 2018, 465, 373–387. [Google Scholar] [CrossRef]
- Emami, H. A graph-based approach to person name disambiguation in Web. Acm Trans. Manag. Inf. Syst. (Tmis) 2019, 10, 1–25. [Google Scholar] [CrossRef]
- Cen, L.; Dragut, E.C.; Si, L.; Ouzzani, M. Author disambiguation by hierarchical agglomerative clustering with adaptive stopping criterion. In Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval, Dublin, Ireland, 28 July–1 August 2013; pp. 741–744. [Google Scholar]
- Wu, H.; Li, B.; Pei, Y.; He, J. Unsupervised author disambiguation using Dempster–Shafer theory. Scientometrics 2014, 101, 1955–1972. [Google Scholar] [CrossRef]
- Song, Y.; Huang, J.; Councill, I.G.; Li, J.; Giles, C.L. Efficient topic-based unsupervised name disambiguation. In Proceedings of the 7th ACM/IEEE-CS Joint Conference on Digital Libraries, Vancouver, BC, Canada, 18–23 June 2007; pp. 342–351. [Google Scholar]
- Tang, J.; Fong, A.C.; Wang, B.; Zhang, J. A unified probabilistic framework for name disambiguation in digital library. IEEE Trans. Knowl. Data Eng. 2011, 24, 975–987. [Google Scholar] [CrossRef]
- Tang, J.; Qu, M.; Mei, Q. Pte: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar]
- Levin, M.; Krawczyk, S.; Bethard, S.; Jurafsky, D. Citation-based bootstrapping for large-scale author disambiguation. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 1030–1047. [Google Scholar] [CrossRef]
- Louppe, G.; Al-Natsheh, H.T.; Susik, M.; Maguire, E.J. Ethnicity sensitive author disambiguation using semi-supervised learning. In Proceedings of the International Conference on Knowledge Engineering and the Semantic Web, Prague, Czech Republic, 21–23 September 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 272–287. [Google Scholar]
- Giles, C.L.; Zha, H.; Han, H. Name disambiguation in author citations using a k-way spectral clustering method. In Proceedings of the 5th ACM/IEEE-CS Joint Conference on Digital Libraries (JCDL’05), Denver, CO, USA, 7–11 June 2005; pp. 334–343. [Google Scholar]
- Hussain, I.; Asghar, S. DISC: Disambiguating homonyms using graph structural clustering. J. Inf. Sci. 2018, 44, 830–847. [Google Scholar] [CrossRef]
- Km, P.; Mondal, S.; Chandra, J. A Graph Combination With Edge Pruning-Based Approach for Author Name Disambiguation. J. Assoc. Inf. Sci. Technol. 2020, 71, 69–83. [Google Scholar] [CrossRef]
- Zhang, W.; Yan, Z.; Zheng, Y. Author Name Disambiguation Using Graph Node Embedding Method. In Proceedings of the 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design (CSCWD), Porto, Portugal, 6–8 May 2019; pp. 410–415. [Google Scholar]
- Wang, X.; Tang, J.; Cheng, H.; Philip, S.Y. Adana: Active name disambiguation. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 794–803. [Google Scholar]
- Shin, D.; Kim, T.; Choi, J.; Kim, J. Author name disambiguation using a graph model with node splitting and merging based on bibliographic information. Scientometrics 2014, 100, 15–50. [Google Scholar] [CrossRef]
- Delgado, A.D.; Martínez, R.; Fresno, V.; Montalvo, S. A data driven approach for person name disambiguation in web search results. In Proceedings of the COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, Dublin, Ireland, 23–29 August 2014; pp. 301–310. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the black box of deep neural networks via information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Cheng, H.; Lian, D.; Gao, S.; Geng, Y. Utilizing Information Bottleneck to Evaluate the Capability of Deep Neural Networks for Image Classification. Entropy 2019, 21, 456. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. Deepwalk: Online learning of social representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 701–710. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Ward, J.H., Jr. Hierarchical grouping to optimize an objective function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Description |
|---|---|
| the set of all documents included in the database | |
| the number of documents in the database | |
| i | author name i |
| the document set associated with the author name i | |
| document n associated with the author name i | |
| f | a stemmed word of an attribute |
| p | real-life person p |
| the set of all collaborators of author i | |
| clusters for author i |
| Document 1: Author: Yanjun Zhang, Jun Shan, Zhanjun Liu, Fanqin Li Orgnization: College of Chemical Engineering, Department of Applied Chemistry, |
| Document 2: Author: Yanjun Zhang, Guanghan Zuo, Jun Ji Orgnization: College of Chemical Engineering Ctr. For Element and Strct. Anal. |
| Document 3: Author: Jun Shan, Zhanjun Liu, Guanghan Zuo, Jun Ji Orgnization: Department of Applied Chemistry, Ctr. For Element and Strct. Anal. |
| Name | Our Approach | Zhang and Yao | Zhang et al. | GHOST | Union Finding | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | Prec | Rec | F1 | |
| Xu Xu | 70.73 | 70.06 | 70.39 | 74.18 | 45.86 | 56.68 | 47.73 | 39.98 | 43.51 | 61.34 | 21.79 | 32.15 | 7.22 | 66.29 | 13.02 |
| Rong Yu | 73.07 | 42.81 | 53.99 | 89.13 | 46.51 | 61.12 | 66.53 | 36.9 | 47.47 | 92.00 | 36.41 | 52.17 | 16.00 | 41.22 | 23.05 |
| Yong Tian | 78.12 | 61.03 | 68.53 | 76.32 | 51.95 | 61.82 | 73.18 | 56.34 | 63.66 | 86.94 | 54.58 | 67.06 | 10.78 | 94.50 | 19.36 |
| Lu Han | 60.02 | 35.29 | 44.45 | 51.78 | 28.05 | 36.39 | 46.05 | 17.95 | 25.83 | 69.72 | 17.39 | 27.84 | 15.10 | 96.30 | 26.10 |
| Lin Huang | 74.72 | 50.43 | 60.21 | 77.10 | 32.87 | 46.09 | 69.43 | 33.13 | 44.86 | 86.15 | 17.25 | 28.74 | 5.91 | 33.76 | 10.06 |
| Kexin Xu | 91.09 | 89.65 | 90.37 | 91.37 | 98.64 | 94.87 | 85.74 | 44.13 | 58.27 | 92.90 | 28.52 | 43.64 | 77.63 | 83.62 | 80.51 |
| Wei Quan | 77.23 | 48.86 | 59.85 | 53.88 | 39.02 | 45.26 | 74.41 | 33.94 | 46.62 | 86.42 | 27.80 | 42.07 | 37.16 | 96.57 | 53.67 |
| Tao Deng | 76.38 | 53.82 | 63.15 | 81.63 | 43.62 | 56.86 | 55.25 | 27.93 | 37.11 | 73.33 | 24.50 | 36.73 | 12.55 | 64.76 | 21.03 |
| Hongbin Li | 70.09 | 78.48 | 74.05 | 77.20 | 69.21 | 72.99 | 65.79 | 52.86 | 58.62 | 56.29 | 29.12 | 38.39 | 12.92 | 94.59 | 22.73 |
| Hua Bai | 65.86 | 41.94 | 51.25 | 71.49 | 39.73 | 51.08 | 54.93 | 35.97 | 43.47 | 83.06 | 29.54 | 43.58 | 22.08 | 93.23 | 35.71 |
| Meiling Chen | 79.60 | 47.84 | 59.76 | 74.93 | 44.70 | 55.99 | 79.22 | 25.15 | 38.18 | 86.11 | 23.85 | 37.35 | 24.83 | 66.92 | 36.22 |
| Yanqing Wang | 49.00 | 66.49 | 56.42 | 71.52 | 75.33 | 73.37 | 72.73 | 42.62 | 53.74 | 80.79 | 40.39 | 53.86 | 24.12 | 66.95 | 35.46 |
| Xudong Zhang | 74.55 | 22.24 | 34.26 | 62.40 | 22.54 | 33.12 | 55.63 | 8.11 | 14.16 | 85.75 | 7.23 | 13.34 | 65.12 | 47.36 | 54.84 |
| Qiang Shi | 53.38 | 50.36 | 51.83 | 52.20 | 36.15 | 42.72 | 43.33 | 37.99 | 40.49 | 53.72 | 26.80 | 35.76 | 18.11 | 86.37 | 29.94 |
| Min Zheng | 59.85 | 20.76 | 30.82 | 57.65 | 22.35 | 32.21 | 53.62 | 17.63 | 26.54 | 80.50 | 15.21 | 25.58 | 11.95 | 74.48 | 20.60 |
| Average | 78.10 | 67.47 | 72.40 | 77.96 | 63.03 | 69.70 | 70.22 | 48.72 | 57.53 | 81.72 | 40.43 | 54.09 | 40.78 | 76.52 | 53.20 |
| Prec | Rec | F1 | |
|---|---|---|---|
| Feature Embedding | 72.29 | 50.14 | 59.21 |
| Graphh Auto-Encoder | 75.53 | 58.01 | 65.62 |
| Graph Embedding | 77.71 | 54.46 | 64.04 |
| Overall | 78.10 | 67.47 | 72.40 |
| F1 | |||
|---|---|---|---|
| Feature Embedding | 5.3230 | 2.0379 | 0.6209 |
| Graph Auto-Encoder (after one epoch training) | 3.8771 | 2.2304 | 0.7834 |
| Graph Auto-Encoder (after training) | 4.5186 | 2.2781 | 0.7939 |
| Graph Embedding (after one epoch training) | 4.3635 | 2.2659 | 0.7918 |
| Graph Embedding (after training) | 1.5175 | 2.2801 | 0.8155 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Wu, Y.; Lu, C. A Graph-Based Author Name Disambiguation Method and Analysis via Information Theory. Entropy 2020, 22, 416. https://doi.org/10.3390/e22040416
Ma Y, Wu Y, Lu C. A Graph-Based Author Name Disambiguation Method and Analysis via Information Theory. Entropy. 2020; 22(4):416. https://doi.org/10.3390/e22040416
Chicago/Turabian StyleMa, Yingying, Youlong Wu, and Chengqiang Lu. 2020. "A Graph-Based Author Name Disambiguation Method and Analysis via Information Theory" Entropy 22, no. 4: 416. https://doi.org/10.3390/e22040416
APA StyleMa, Y., Wu, Y., & Lu, C. (2020). A Graph-Based Author Name Disambiguation Method and Analysis via Information Theory. Entropy, 22(4), 416. https://doi.org/10.3390/e22040416