PGNet: Pipeline Guidance for Human Key-Point Detection

 , and
, and 
Abstract
1. Introduction
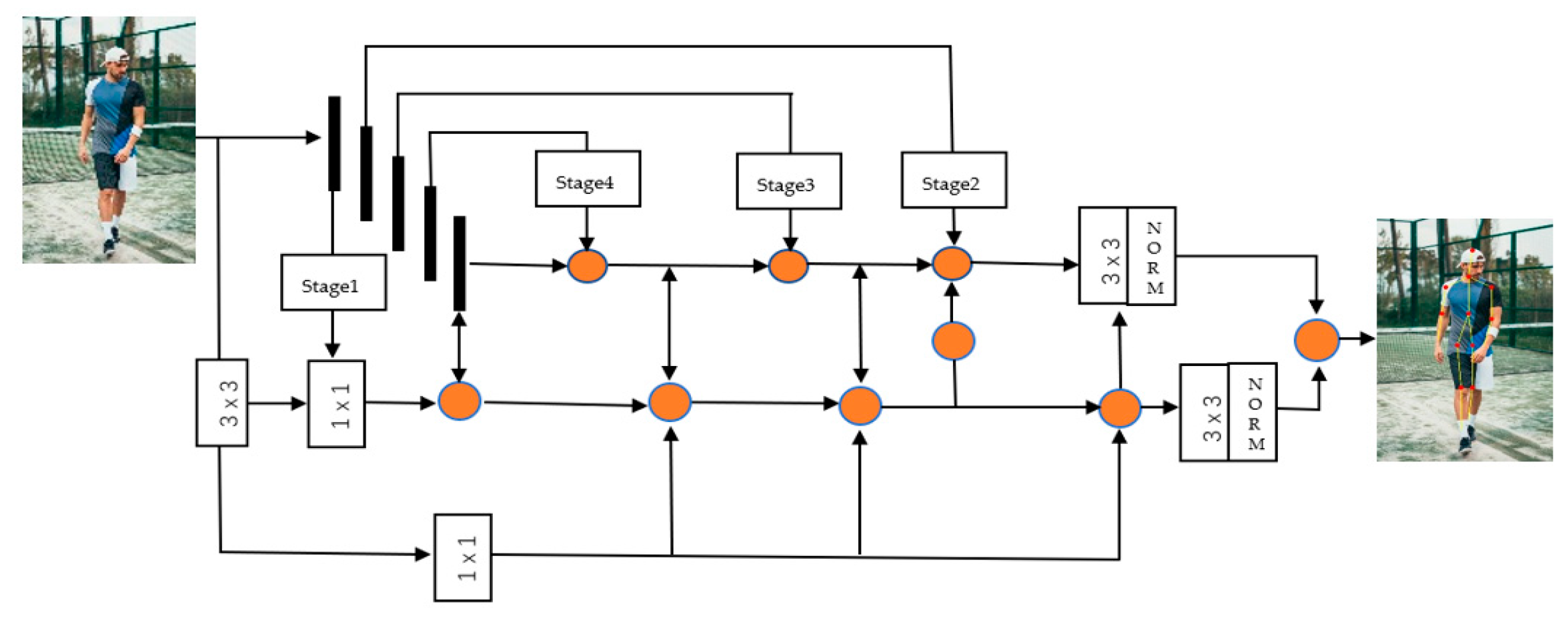
- We introduce a kind of pipeline guiding strategy (PGS) to share the extracted features to all layers (shallow layers and deep layers) in the form of a pipeline. This allows each layer to better separate the background noise, and at the same time share the weight of the opposite transfer between each other.
- We propose a cross-fusion feature extraction mode. Combining this model with PGS enables shallow spatial information and deep semantic information to be combined through a pipelined bus strategy, so that the computational efficiency and the network’s separation of foreground and background can effectively remove the foreground noise and the background effective information at the edges is fully considered.
- We developed a crossed Distance-IoU loss function. To obtain the region of interest, we calculated the convergence and speed of the border regression. The Cross-Distance-IoU loss function used is based on the distance between the center points and the overlap area, and shows excellent results in the rectangular anchor border regression. The pipeline is used to guide the network to use the Distance-IoU loss function and the backbone network uses the GIoU loss function.
2. Materials and Methods
2.1. Key-Point Detection Method
2.2. Pipeline Guidance Strategy
2.3. IoU Loss
3. Results
3.1. Cascaded Fusion Feature Model
3.2. Pipeline Guidance Strategies
4. Discussion
4.1. Datasets and Evaluation Metrics
4.2. Ablation Studies
5. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
References
- Liu, S.; Li, Y.; Hua, G. Human Pose Estimation in Video via Structured Space Learning and Halfway Temporal Evaluation. IEEE Trans. Circuits Syst. Video Technol. 2019, 29, 2029–2038. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Y.; Lin, Z.; Yuille, A.L. Robust 3D Human Pose Estimation from Single Images or Video Sequences. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1227–1241. [Google Scholar] [CrossRef]
- Yunqing, Z.; Fok, W.W.T.; Chan, C.W. Video-Based Violence Detection by Human Action Analysis with Neural Network. Proc. SPIE 2019, 11321, 113218. [Google Scholar] [CrossRef]
- Gouiaa, R.; Meunier, J. Learning Cast Shadow Appearance for Human Posture Recognition. Pattern Recognit. Lett. 2017, 97, 54–60. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, Z.; Tao, D. Towards High Performance Human Keypoint Detection. arXiv 2020, arXiv:2002.00537. [Google Scholar]
- Ke, S.; Bin, X.; Dong, L.; Jingdong, W. Deep High-Resolution Representation Learning for Human Pose Estimation. arXiv 2019, arXiv:1902.09212. [Google Scholar]
- He, S. A Sitting Posture Surveillance System Based on Kinect. In Proceedings of the 2018 International Conference on Electronics, Communications and Control Engineering, Avid College, Maldives, 6–8 March 2018; Kettani, H., Sivakumar, R., Song, I., Eds.; Volume 1026. [Google Scholar]
- Liang, G.; Lan, X.; Chen, X.; Zheng, K.; Wang, S.; Zheng, N. Cross-View Person Identification Based on Confidence-Weighted Human Pose Matching. IEEE Trans. Image Process. 2019, 28, 3821–3835. [Google Scholar] [CrossRef]
- Patel, P.; Bhatt, B.; Patel, B. Human Body Posture Recognition A Survey. In Proceedings of the 2017 International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 21–23 February 2017; pp. 473–477. [Google Scholar]
- Raja, M.; Hughes, A.; Xu, Y.; Zarei, P.; Michelson, D.G.; Sigg, S. Wireless Multifrequency Feature Set to Simplify Human 3-D Pose Estimation. IEEE Antennas Wirel. Propag. Lett. 2019, 18, 876–880. [Google Scholar] [CrossRef]
- Rasouli, M.S.D.; Payandeh, S. A Novel Depth Image Analysis for Sleep Posture Estimation. J. Ambient Intell. Humaniz. Comput. 2019, 10, 1999–2014. [Google Scholar] [CrossRef]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. LCR-Net++: Multi-Person 2D and 3D Pose Detection in Natural Images. IEEE Trans. Pattern Anal. Mach. Intell. 2019. [Google Scholar] [CrossRef]
- Chenchen, Z.; Yihui, H.; Savvides, M. Feature Selective Anchor-Free Module for Single-Shot Object Detection. arXiv 2019, arXiv:1903.00621, 10. [Google Scholar]
- Han, G.; Du, H.; Liu, J.; Sun, N.; Li, X. Fully Conventional Anchor-Free Siamese Networks for Object Tracking. IEEE Access 2019, 7, 123934–123943. [Google Scholar] [CrossRef]
- Zhen, H.; Jian, L.; Daxue, L.; Hangen, H.; Barber, D. Tracking by Animation: Unsupervised Learning of Multi-Object Attentive Trackers. arXiv 2019, arXiv:1809.03137. [Google Scholar]
- Wang, J.; Ding, J.; Guo, H.; Cheng, W.; Pan, T.; Yang, W. Mask OBB: A Semantic Attention-Based Mask Oriented Bounding Box Representation for Multi-Category Object Detection in Aerial Images. Remote Sens. 2019, 11. [Google Scholar] [CrossRef]
- Bao, W.; Xu, B.; Chen, Z. MonoFENet: Monocular 3D Object Detection with Feature Enhancement Networks. IEEE Trans. Image Process. Publ. IEEE Signal Process. Soc. 2019. [Google Scholar] [CrossRef]
- Chan-Tong, L.; Ng, B.; Chi-Wang, C. Real-Time Traffic Status Detection from on-line Images Using Generic Object Detection System with Deep Learning. In Proceedings of the 2019 IEEE 19th International Conference on Communication Technology (ICCT), Xi’an, China, 16–19 October 2019; 2019; pp. 1506–1510. [Google Scholar] [CrossRef]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.-H. Combining Faster R-CNN and Model-Driven Clustering for Elongated Object Detection. IEEE Trans. Image Process. 2020, 29, 2052–2065. [Google Scholar] [CrossRef]
- Gong, T.; Liu, B.; Chu, Q.; Yu, N. Using Multi-Label Classification to Improve Object Detection. Neurocomputing 2019, 370, 174–185. [Google Scholar] [CrossRef]
- Dingfu, Z.; Jin, F.; Xibin, S.; Chenye, G.; Junbo, Y.; Yuchao, D.; Ruigang, Y. IoU loss for 2D/3D Object Detection. arXiv 2019, arXiv:1908.03851. [Google Scholar]
- Fagui, L.; Dian, G.; Cheng, C. IoU-Related Arbitrary Shape Text Scoring Detector. IEEE Access 2019, 7, 180428–180437. [Google Scholar] [CrossRef]
- Yan, J.; Wang, H.; Yan, M.; Diao, W.; Sun, X.; Li, H. IoU-Adaptive Deformable R-CNN: Make Full Use of IoU for Multi-Class Object Detection in Remote Sensing Imagery. Remote Sens. 2019, 11, 286. [Google Scholar] [CrossRef]
- Zhao, T.; Wu, X. Pyramid Feature Attention Network for Saliency detection. arXiv 2019, arXiv:1903.00179. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Int. Conf. Comput. Vis. 2017, 2980–2988. [Google Scholar] [CrossRef]
- Bin, X.; Haiping, W.; Yichen, W. Simple Baselines for Human Pose Estimation and Tracking. arXiv 2018, arXiv:1804.06208. [Google Scholar]
- Zhe, C.; Simon, T.; Shih-En, W.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv 2016, arXiv:1611.08050. [Google Scholar]
- Zhang, H.; Ouyang, H.; Liu, S.; Qi, X.; Shen, X.; Yang, R.; Jia, J. Human Pose Estimation with Spatial Contextual Information. arXiv 2019, arXiv:1901.01760. [Google Scholar]
- Zeming, L.; Chao, P.; Gang, Y.; Xiangyu, Z.; Yangdong, D.; Jian, S. DetNet: Design Backbone for Object Detection. arXiv 2018, arXiv:1804.06215. [Google Scholar]
- Huang, G.; Liu, Z.; Pleiss, G.; van der Maaten, L.; Weinberger, K.Q. Convolutional Networks with Dense Connectivity. arXiv 2020, arXiv:2001.02394. [Google Scholar] [CrossRef]
- Alyafeai, Z.; Ghouti, L. A Fully-Automated Deep Learning Pipeline for Cervical Cancer Classification. Expert Syst. Appl. 2020, 141. [Google Scholar] [CrossRef]
- Hsu, Y.S. Finite Element Approach of the Buried Pipeline on Tensionless Foundation under Random Ground Excitation. Math. Comput. Simul. 2020, 169, 149–165. [Google Scholar] [CrossRef]
- Qiu, R.; Zhang, H.; Zhou, X.; Guo, Z.; Wang, G.; Yin, L.; Liang, Y. A multi-objective and multi-scenario optimization model for operation control of CO2-flooding pipeline network system. J. Clean. Prod. 2020, 247. [Google Scholar] [CrossRef]
- Zhang, Y.; Lobo-Mueller, E.M.; Karanicolas, P.; Gallinger, S.; Haider, M.A.; Khalvati, F. CNN-based survival model for pancreatic ductal adenocarcinoma in medical imaging. BMC Med. Imaging 2020, 20, 11. [Google Scholar] [CrossRef] [PubMed]
- Shengkai, W.; Xiaoping, L. IoU-balanced Loss Functions for Single-stage Object Detection. arXiv 2019, arXiv:1908.05641, 8. [Google Scholar]
- Ruiqi, L.; Huimin, M. Occluded Pedestrian Detection with Visible IOU and Box Sign Predictor. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1640–1644. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression. arXiv 2019, arXiv:1911.08287. [Google Scholar]
- Jiang, B.; Luo, R.; Mao, J.; Xiao, T.; Jiang, Y. Acquisition of Localization Confidence for Accurate Object Detection. Springer Int. Publ. 2018, 816–832. [Google Scholar] [CrossRef]
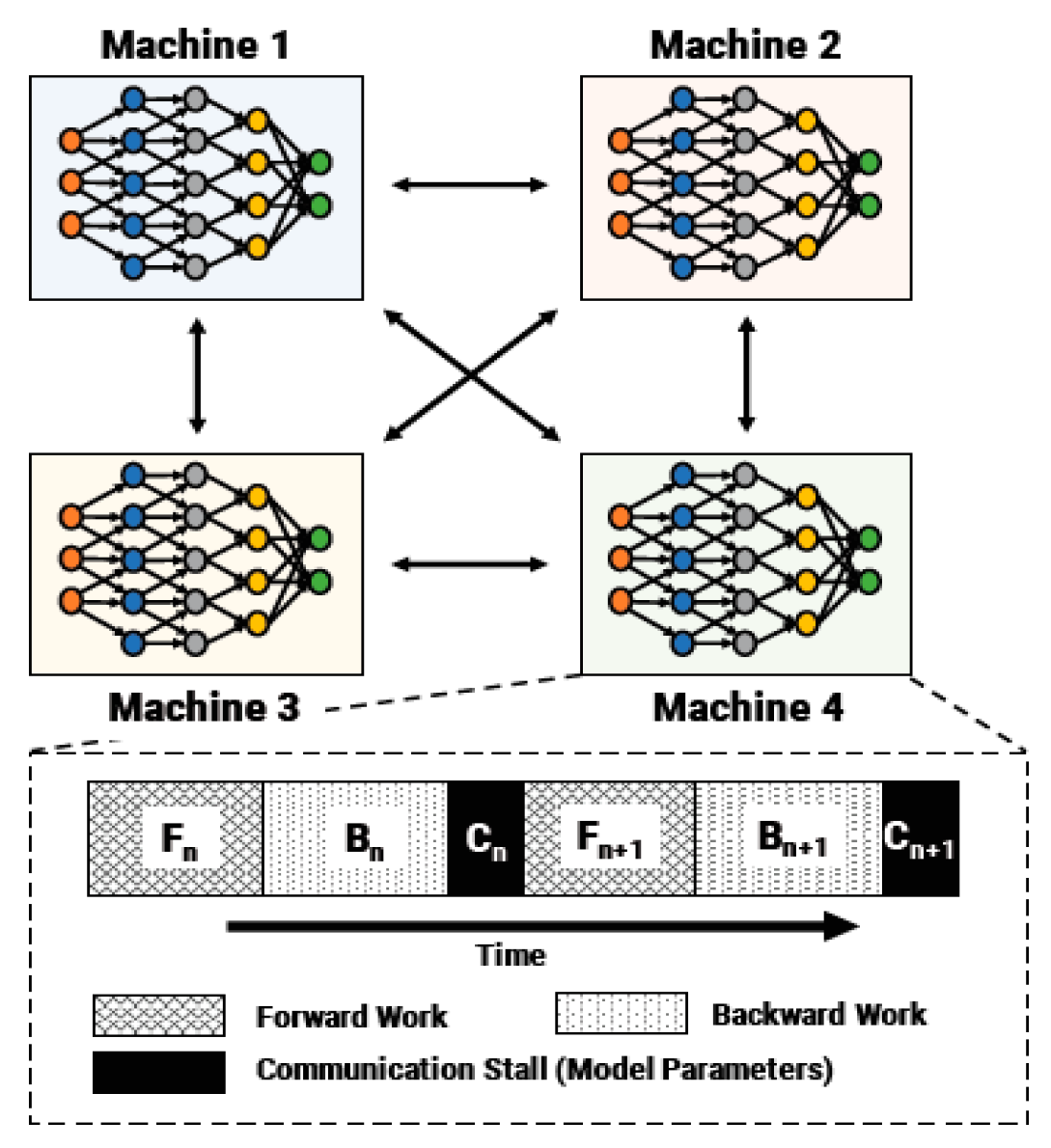
- Harlap, A.; Narayanan, D.; Phanishayee, A.; Seshadri, V.; Devanur, N.; Ganger, G.; Gibbons, P. PipeDream: Fast and Efficient Pipeline Parallel DNN Training. arXiv 2018, arXiv:1806.03377. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; JunYoung, G.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection Over Union: A Metric and a Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
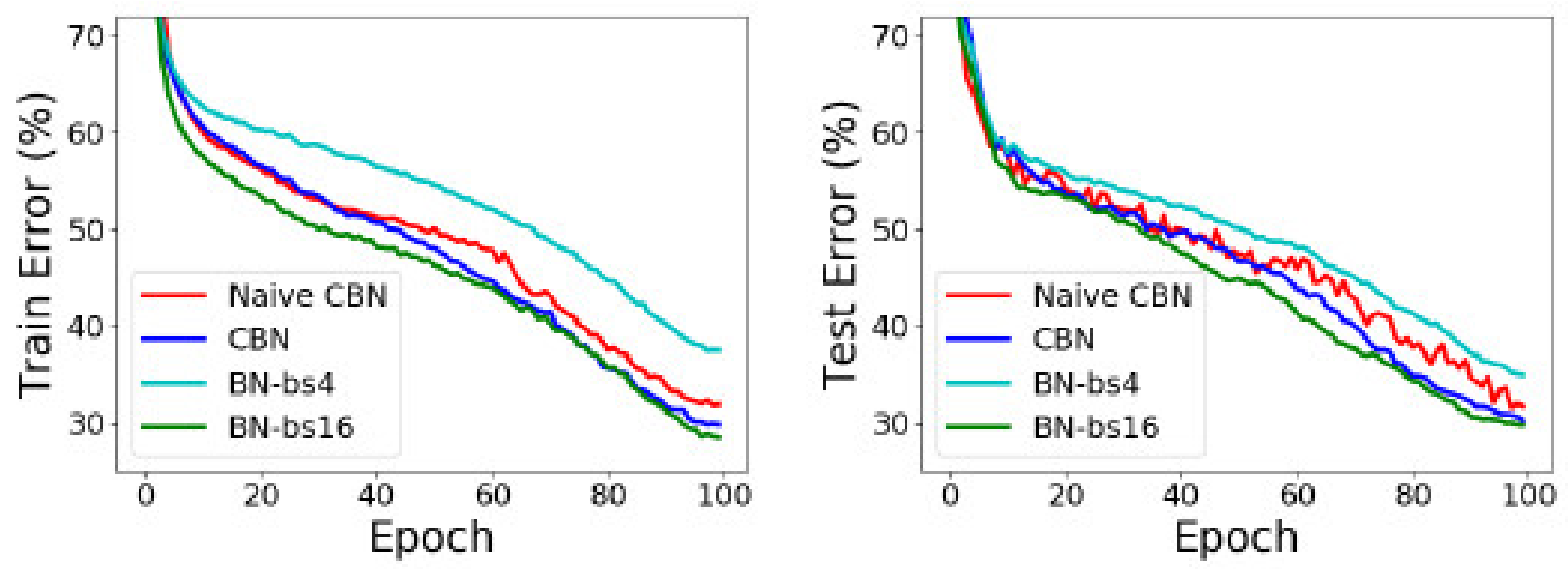
- Yao, Z.; Cao, Y.; Zheng, S.; Huang, G.; Lin, S. Cross-Iteration Batch Normalization. arXiv 2020, arXiv:2002.05712. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Decoder | Postprocessing | Performance |
|---|---|---|---|---|
| Mask-R-CNN [25] | ResNet-50-FPN | conv+deconv | offset regression | 63.1AP@COCO |
| DHN [26] | ResNet-152 | deconv | Flip/sub-pixel shift | 73.7 AP@COCO |
| CNN [27] | VGG-19 | conv | Flip/sub-pixel shift | 61.8 AP@COCO |
| PGNN [28] | ResNet-50 | GlobalNet | Flip/sub-pixel shift | 68.7 AP@COCO |
| DetNet [29] | ResNet-50 | deconv | Flip/sub-pixel shift | 69.7 AP@COCO |
| DENSENETS [30] | ResNet-50 | deconv | - | 61.8AP@COCO |
| LCR-Net++ [12] | ResNet-50 | deconv | Flip/sub-pixel shift | 73.2AP@COCO |
| HRNet [6] | HRNet-152 | 1×1conv | Flip/sub-pixel shift | 77.0AP@COCO |
| [5] | ResNet-101 | deconv | Flip/sub-pixel shift | 69.9 AP@COCO |
| PFAN [24] | VGG-19 | multi-stage CNN | Flip/sub-pixel shift | 70.2 AP@COCO |
| Proposed method | ResNet-50-Pipeline | Deconv+1×1conv | offset regression | 77.2AP@COCO |
| Alogrithm1 IoU for two axis-Aligned BBox. |
| Require: -Corners of the bounding boxes: |
| (,),(,),(,),(,), |
| (,),(,),(,),(,), |
| Where ≤,≤,and , |
| Ensure: - IoU value; |
| 1:▲The area of |
| 2:▲The area of |
| 3:▲The area of overlap: |
| min()); |
| 4:▲; |
| Backbone | Norm | APbbox | AP50bbox | AP75bbox | APSbbox | APMbbox | APLbbox |
|---|---|---|---|---|---|---|---|
| ResNet50+FPN | GN | 37.8 | 59.0 | 40.8 | 22.3 | 41.2 | 48.4 |
| syncGN | 37.7 | 58.5 | 41.1 | 22.3 | 40.2 | 48.9 | |
| CBN | 37.8 | 59.8 | 40.3 | 22.5 | 40.5 | 49.1 | |
| ResNet101+FPN | GN | 39.3 | 60.6 | 42.7 | 22.5 | 42.5 | 48.8 |
| syncGN | 39.3 | 59.8 | 43.0 | 22.3 | 42.9 | 51.6 | |
| CBN | 39.2 | 60.0 | 42.2 | 22.3 | 42.6 | 51.8 | |
| ResNet50+proposed | GN | 39.3 | 60.7 | 42.6 | 22.5 | 43.2 | 48.1 |
| syncGN | 39.3 | 59.8 | 43.5 | 23.4 | 43.7 | 51.9 | |
| CBN | 39.4 | 59.8 | 43.2 | 23.1 | 42.9 | 52.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hong, F.; Lu, C.; Liu, C.; Liu, R.; Jiang, W.; Ju, W.; Wang, T. PGNet: Pipeline Guidance for Human Key-Point Detection. Entropy 2020, 22, 369. https://doi.org/10.3390/e22030369
Hong F, Lu C, Liu C, Liu R, Jiang W, Ju W, Wang T. PGNet: Pipeline Guidance for Human Key-Point Detection. Entropy. 2020; 22(3):369. https://doi.org/10.3390/e22030369
Chicago/Turabian StyleHong, Feng, Changhua Lu, Chun Liu, Ruru Liu, Weiwei Jiang, Wei Ju, and Tao Wang. 2020. "PGNet: Pipeline Guidance for Human Key-Point Detection" Entropy 22, no. 3: 369. https://doi.org/10.3390/e22030369
APA StyleHong, F., Lu, C., Liu, C., Liu, R., Jiang, W., Ju, W., & Wang, T. (2020). PGNet: Pipeline Guidance for Human Key-Point Detection. Entropy, 22(3), 369. https://doi.org/10.3390/e22030369