Here, I consider yet another strategy of solving the problem of which of the two numbers is larger by formulating it as a database classification. Problems of database classification are quite general because many algorithms can be re-formulated as database classifications. Let us consider an algorithm
A that returns a discrete output on an input in the form of
N real numbers belonging to the algorithm domain
. Moreover, we assume that the number of possible answers is finite. Let
describe the number of answers. Formally, we describe such an algorithm as a map:
where
. If we consider an element
, then:
Each record of
contains
N predictors
and the record type
. The classifier of the database
is supposed to return the correct record type if the predictor values are used as the input. A classifier that correctly classifies any dataset
can be seen as a program that executes the algorithm
A. For example, the XOR operation
can be completely described by the classification of database:
Therefore, the chemistry based classifier of
is a chemical realization of the XOR gate. The same approach applies to any logical operations involving those of multivariable ones.
2.1. The Time Evolution Model of an Oscillator Network
In this section, I briefly introduce oscillator networks, discuss the specific properties of the Belousov–Zhabotinsky reaction that can be useful for construction of classifiers and introduce a simple model of network time evolution. The detailed information can be found in [
28].
The networks of chemical oscillators can be formed in different ways. One can use individual continuously stirred chemical reactors (CSTRs) and link them by pumps ensuring the flow of reagents [
29,
30]. Alternatively, networks of oscillators can be formed by touching droplets containing a water solution of reagents of an oscillatory BZ reaction stabilized by lipids dissolved in the surrounding oil phase. If phospholipids (asolectin) are used, then BZ droplets communicate mainly via an exchange of the reaction activator (
molecules) that can diffuse through the lipid bilayers and transmits excitation between droplets [
31]. A high uniformity of droplets that form the network can be achieved if droplets are generated in a microfluidic device [
32]. One can also use DOVEX beads or silica balls [
33] to immobilize the catalyst and inhibit oscillations by illumination or electric potential [
34].
The simplest mathematical model of a BZ-reaction describes the process as an interplay between two reagents: the activator and the inhibitor (the oxidized form of the catalyst). Two variable models, such as the Oregonator [
35] or Rovinsky–Zhabotinsky model [
36], give a pretty realistic description of simple oscillations, excitability and the simplest spatio-temporal phenomena. However, the numerical complexity of models based on kinetic equations is still substantial, and they are too slow for large scale evolutionary optimization of a classifier made as a network of oscillators. Here, following [
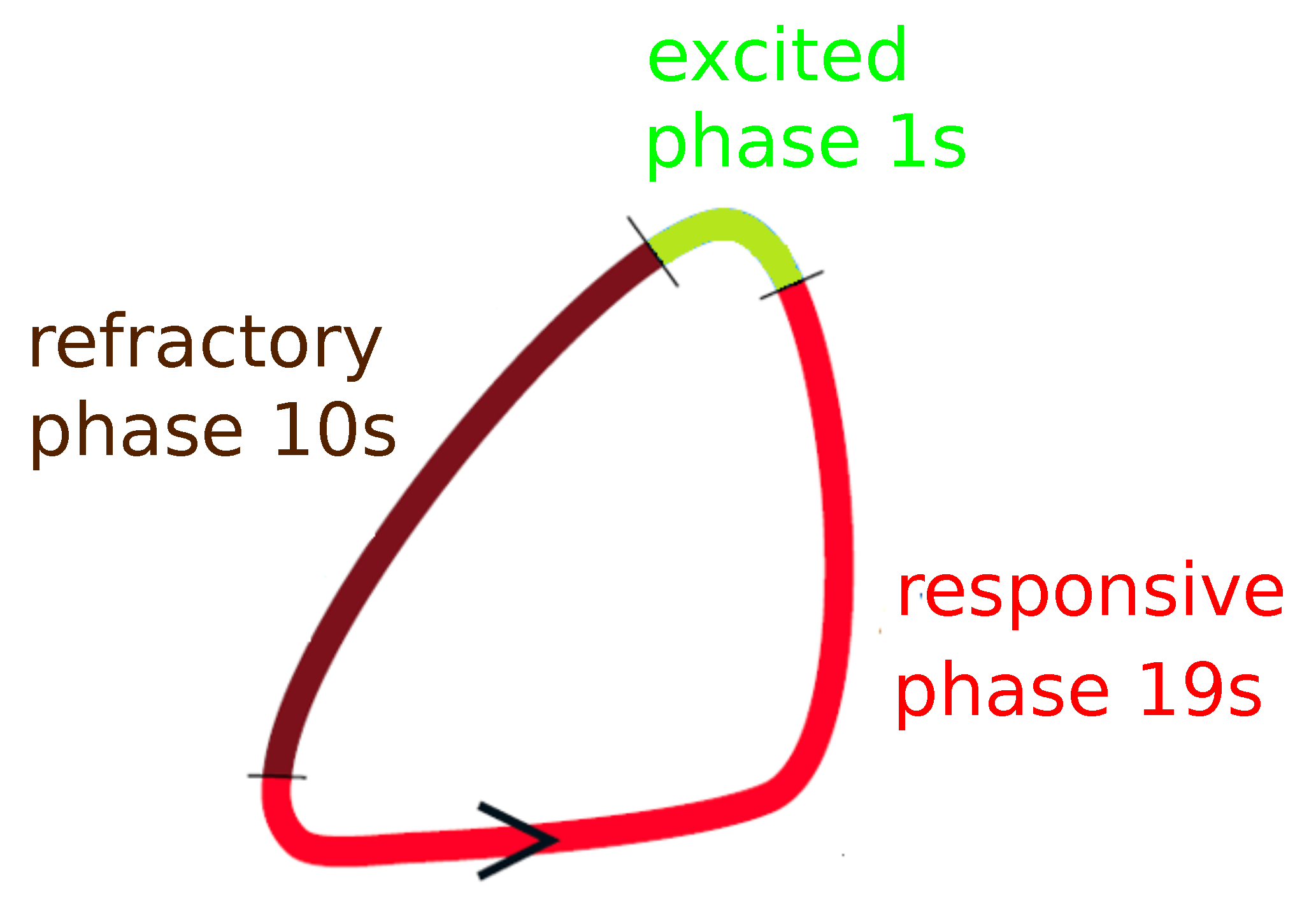
28], I use the event based model. I assume that three different phases: excited, refractive and responsive can be identified during a single oscillation cycle of a typical chemical oscillator [
21,
22,
28]. The excited phase denotes the peak of activator concentration. A chemical oscillator in the excited phase is able to spread out the activator molecules and trigger excitations in the medium around. In the refractory phase, the concentration of the inhibitor is high, and an oscillator in this phase does not respond to an activator transported from oscillators around. In the responsive phase, the inhibitor concentration decreases. An oscillator in the response phase can get excited by interactions with an oscillator in the excited phase. Following the previous papers [
28], the oscillation cycle combines the excitation phase lasting 1 s, the refractive phase, lasting 10 s and the responsive phase that is 19 s long (cf.
Figure 2). For an isolated oscillator, the excitation phase appears again after the responsive phase ends and the cycle repeats. Thus, the period of the cycle is 30 s. Oscillations with such a period have been observed in experiments with BZ-medium [
20]. The separation of oscillation cycle into phases allows introducing a simple model for interactions between individual oscillators. An oscillator in the refractory phase does not respond to the excitations of its nearest neighbors. An oscillator in the responsive phase can be activated by an excited neighbor. I also assume that if an oscillator is in the excitation phase, then 1 s later, all oscillators coupled with it, that are in the responsive phase, switch into the excitation phase. It is also assumed that after illumination is switched on, the phase changes into the refractory one. When the illumination is switched off, the excited phase starts immediately. The model defined above is much faster than models based on the kinetic equations.
2.2. The Computing Medium Made of Interacting Oscillators and Its Evolutionary Optimization
In this section, I introduce the parameters needed for numerical simulations of a chemical classifier. In order to use a network of coupled oscillators for information processing, we have to specify the time interval within which the time evolution of the network is observed. This is an important assumption because it reflects the fact that the information processing is a transient phenomenon. I assume that output information can be extracted by observing the system within the time interval , and it is not important if the network reaches a steady state before or not.
It is assumed that the state of each oscillator in the network can be controlled by an external factor (illumination). There are two types of oscillators in the network: the normal ones and the input ones. For a normal oscillator k, its activity is inhibited within the time interval (). After the time the oscillation cycle starts from the excited phase. For a given classification problem the set of times defining the inhibition of normal oscillators is the same for all processed records. This set of times defines the “program” executed by the network to solve the problem. If an oscillator is considered as an input for the j-th predictor and if the predictor value is , then such oscillator is inhibited (illuminated) within the time interval , where the values of (both ) are the same for all predictors. The network geometry (i.e., locations of input and normal oscillators and the geometry of interactions between oscillators) together with illuminations of normal oscillators and times , fully define the network and allow for simulations of its time evolution after the predictor values are selected. In the following, I will assume that the classifier output is represented by the number of excitations observed on oscillators within the time interval .
To verify if the network performs its classification function correctly, I introduce the testing database composed of records of the form where are uniformly distributed random numbers from . The classifier accuracy is calculated as the fraction of correct answers for records from . As the zero-th order approximation, one can neglect observation of the classifier evolution and say that x is always larger than y. If is selected without bias, then such classifier should show accuracy.
In order to increase the accuracy, we have to optimize the classifier parameters. In the optimization discussed below, they included the maximum time within which the system evolution is observed (
), the locations of input oscillators and the oscillators characterized by fixed illuminations (the normal ones), the times defining the introduction of input values (
and
) and the illuminations of normal oscillators
. Moreover, defining the classifier, we should decide how the output is extracted from the evolution. I select two strategies. I postulate that the classifier output can be read out from the number of excitations on a selected oscillator or as a pair of numbers of excitations observed on two selected oscillators. The quality of a classifier
corresponding to the algorithm
A can be estimated if one decides how to read the output information but without interpreting if the obtained result corresponds to the case
or
. To do it, we can use the mutual information between the set of record types and the set of classifier outputs. Let us consider a set of arguments
(Equation (
3)) and the related database
(Equation (
4)) of the algorithm
A. Let us assume that the classifier
produces the output string
on the record
:
Now let us consider three lists:
and
The mutual information between
B and
O defined as [
37]:
where
is the Shannon information entropy of the strings that belong to the list
X. If this list contains
k different strings then:
where
is the probability of finding the string #k in the list.
In order to calculate , one needs to specify how the output is read out of the network evolution. For example, if the number of excitations observed on a single oscillator within the time interval is used as the output string, then we should consider all oscillators as potential candidates for the output one. The oscillator, for which the maximum is achieved, is selected as the output one. In the case of the output coded in a pair of excitation numbers observed on two selected oscillators, one should consider all pairs of oscillators as candidates for the output oscillators. Like in the case of a single oscillator, the pair that produces that maximum is considered as the output. The maximum value of obtained within a given method of extracting the output string is considered as the quality (fitness) of the classifier .
Let us notice that when , so the classifier works without errors, then and . On the other hand, if the answers are not correlated with the record types then and . In general, is an average number of bits of the information about the string we get if we know the string . Therefore, we can expect that an increase in does reflect the rise in classifier accuracy.
To define a classifier, we need to specify:
—the network geometry and interactions between oscillators,
—location of the input oscillators,
,
,
and
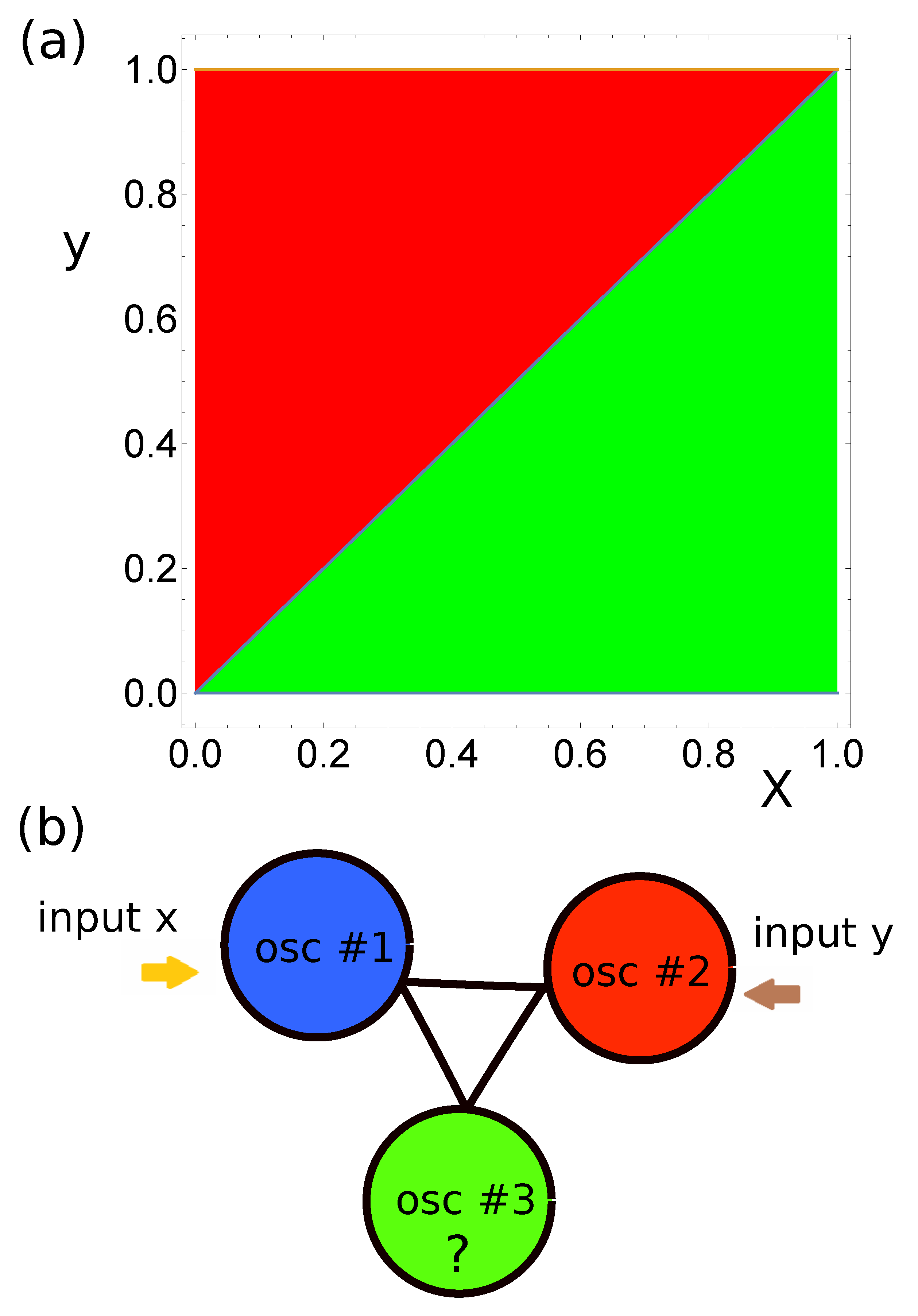
. In the considered problem of verification of which of the two numbers is larger, I assumed that the classifier had a triangular geometry, as illustrated in
Figure 1b, and that all oscillators were interconnected. In such a geometry, all oscillators are equivalent. Therefore, we can assume that oscillator #1 is the input of the first predictor. Moreover, the system symmetry allows us to assume that oscillator #2 is the input of the second predictor. Therefore, the only missing element of the classifier structure is the type of oscillator #3 (
) and it is a subject of optimization. I did not introduce any constraints on the type of this oscillator. It could be an input oscillator or the normal one.
The optimization of all parameters of the classifier (
) was done using the evolutionary algorithm. The technique has been described in detail in [
28]. At the beginning, 1000 classifiers with randomly initialized parameters were generated. Of course, it would be naive to believe that a randomly selected network of oscillators performs an accurate classification of the selected database. The generated networks made the initial population for evolutionary optimization. Next, the fitness (Equation (
5)) of each classifier was evaluated. In order to speed up the algorithm, the fitness was calculated using the database
where predictors were
randomly generated pairs
. The database
was 10 times smaller than
used to estimate the accuracy of the optimized classifier. However,
is still large enough to contain a representative number of records characterizing the problem. The upper
of the most fitting classifiers were copied to the next generation. The remaining
of classifiers of the next generation were generated by recombination and mutation processes applied to pairs of classifiers randomly selected from the upper
of the most fitting ones. At the beginning, recombination of two parent classifiers produces a single offspring by combining randomly selected parts of their parameters. Next, the mutation operations were applied to the offspring. It was assumed that oscillator #3 can change its type with the probability
. Moreover, random changes of
,
,
and
were also allowed. The evolutionary procedure was repeated more than 500 times. A typical progress of optimization is illustrated in
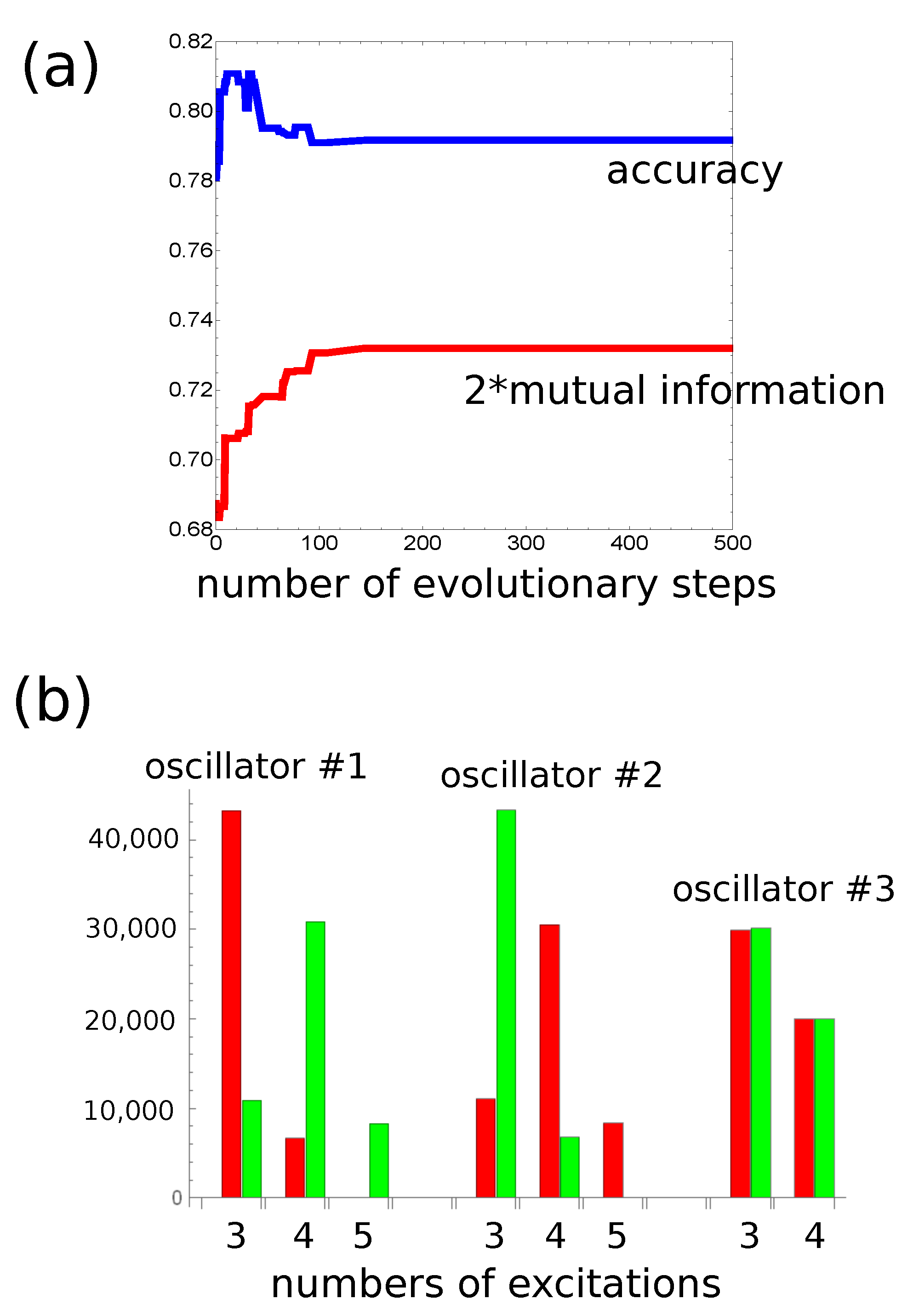
Figure 3a and Figure 5a.
2.3. Chemical Algorithms for Verification of Which of the Two Numbers Is Larger
In this section, I discuss the optimized networks that verify which of the two real numbers x and y from [0,1] is larger.
At the beginning, let us consider the network that produces the output as a number of excitations observed at a selected node. The progress of optimization on a small database with 1000 records is illustrated in
Figure 3a. The optimization continued for 500 evolutionary steps. For the optimized network
s. As it has been assumed, oscillators #1 and #2 correspond to inputs of x and y, respectively. The values of
and
are
and
s, respectively. The highest mutual information was obtained if oscillator #3 was the normal one and
s.
Figure 3b illustrates the numbers of cases corresponding to different numbers of excitations and the relationship between
x and
y for records from
. The red and green bars correspond to
and
, respectively.
Figure 3b compares the number of cases observed on different oscillators of the network. It is clear that oscillator #3 is useless as the output because it has excited the same number of time by inputs with
and by inputs with
. On the other hand, for oscillators #1 and #2, the situation is very different. For example, three excitations are observed mainly for
, whereas four or five excitations are dominant for
. Therefore, we can define the classifier output as the number of excitations on oscillator #1 such that three excitations correspond to
and four or five excitations to
. The accuracy of such a classifier is
.
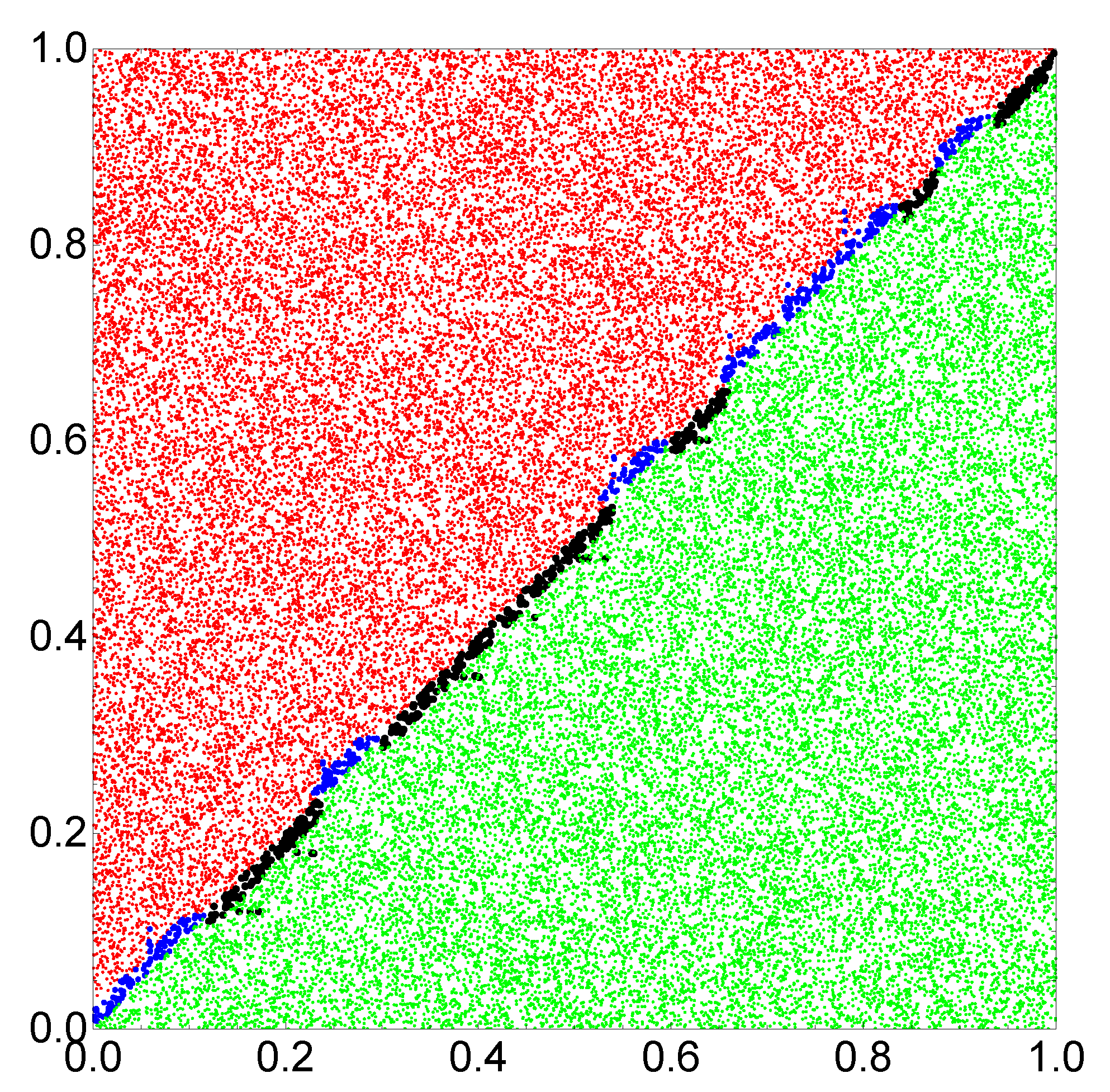
Figure 4 illustrates the location of correctly and incorrectly classified pairs
if the output reading rule defined above is used. The correctly classified pairs in which
and
are marked by red and green points, respectively. Incorrectly classified pairs in which
and
are marked by blue and black points, respectively. Similar results are obtained when oscillator #2 is used as the output (
Figure 3b), but the accuracy is
. I believe the small difference between using oscillators #1 and #2 as the output is related to randomness in the generated database.
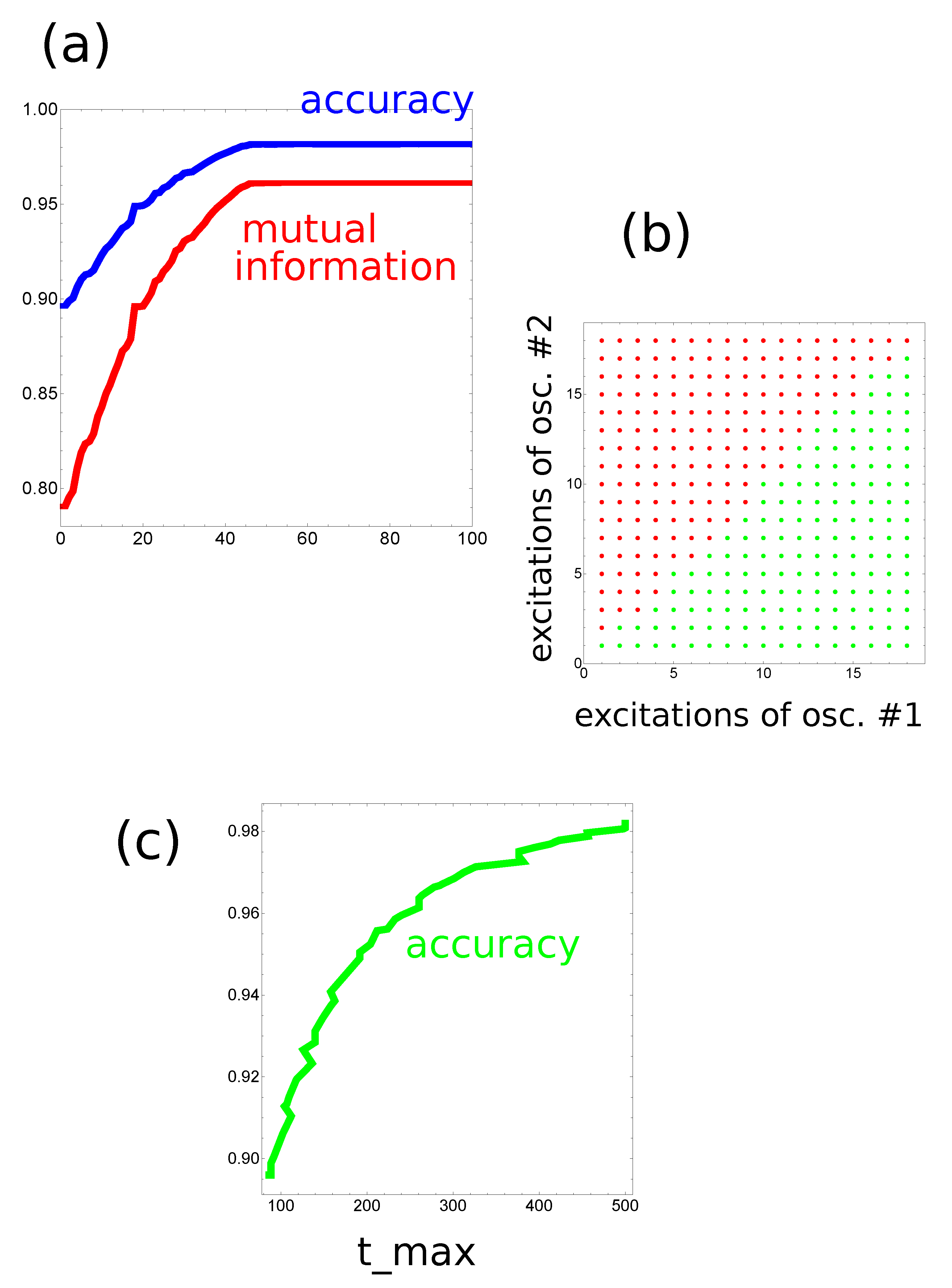
In order to increase the classification accuracy, I considered the same network but another rule of reading out the information. I assumed that the output is coded in a pair of excitation numbers observed on two oscillators. The initial progress of optimization with
is illustrated in
Figure 5a. The optimization procedure was continued for 1000 generations. The classifier structure was the same as in the previous case; oscillator #3 was the normal one. The optimized classifier is characterized by
s,
s,
s and
s. The numbers of excitations observed on oscillators #1 and #2 were used as the classifier answer. The translation of the observed number of excitations into the classifier answer is illustrated in
Figure 5b. The mutual information between the classifier outputs and the record types in
is
and the classification accuracy is
. Both numbers are remarkably high, especially having in mind that the computing medium is formed by three oscillators only. The optimization procedure has shown that the classifier accuracy strongly depends on
, as illustrated in
Figure 5c. In the optimization procedure, the value of
was limited at 500s.
Figure 6 illustrates the location of correctly and incorrectly classified pairs
if the output reading rule defined in
Figure 5b is used.
2.4. Shadows on Optimization Towards the Maximum Mutual Information
As in the previous papers [
21,
22,
23,
28], I assumed that the increase in mutual information means that the classifier accuracy increases, so one can use easy-to-calculate mutual information to estimate the quality of a classifier. But does the increase in the mutual information really mean that the classifier accuracy is higher? The example given below illustrates that it is not.
Let us consider the following example. Assume a database with
records corresponding to two types
v and
w of the form:
Therefore, the list of record types contains N elements v and N elements w and the Shannon information entropy .
Let us also assume that there is a classifier
C of the database
F that produces two outputs
and
in the following way: If the record type is
v, then for
L records, the classifier output is
, and for
records, the classifier output is
. Let us redistribute these database records such that:
if
and
if
. Moreover, if the record type is
w, then for
M records, the classifier output is
, and for
records, the classifier output is
. Yet again let us redistribute these database records such that:
if
and
if
. Therefore, it is more likely to get the
answer if the record type is
v and the
answer if the record type is
w. The interpretation: the record type is
v if the classifier produces
, and the record type is
w if the classifier produces
leads to the highest accuracy equal to:
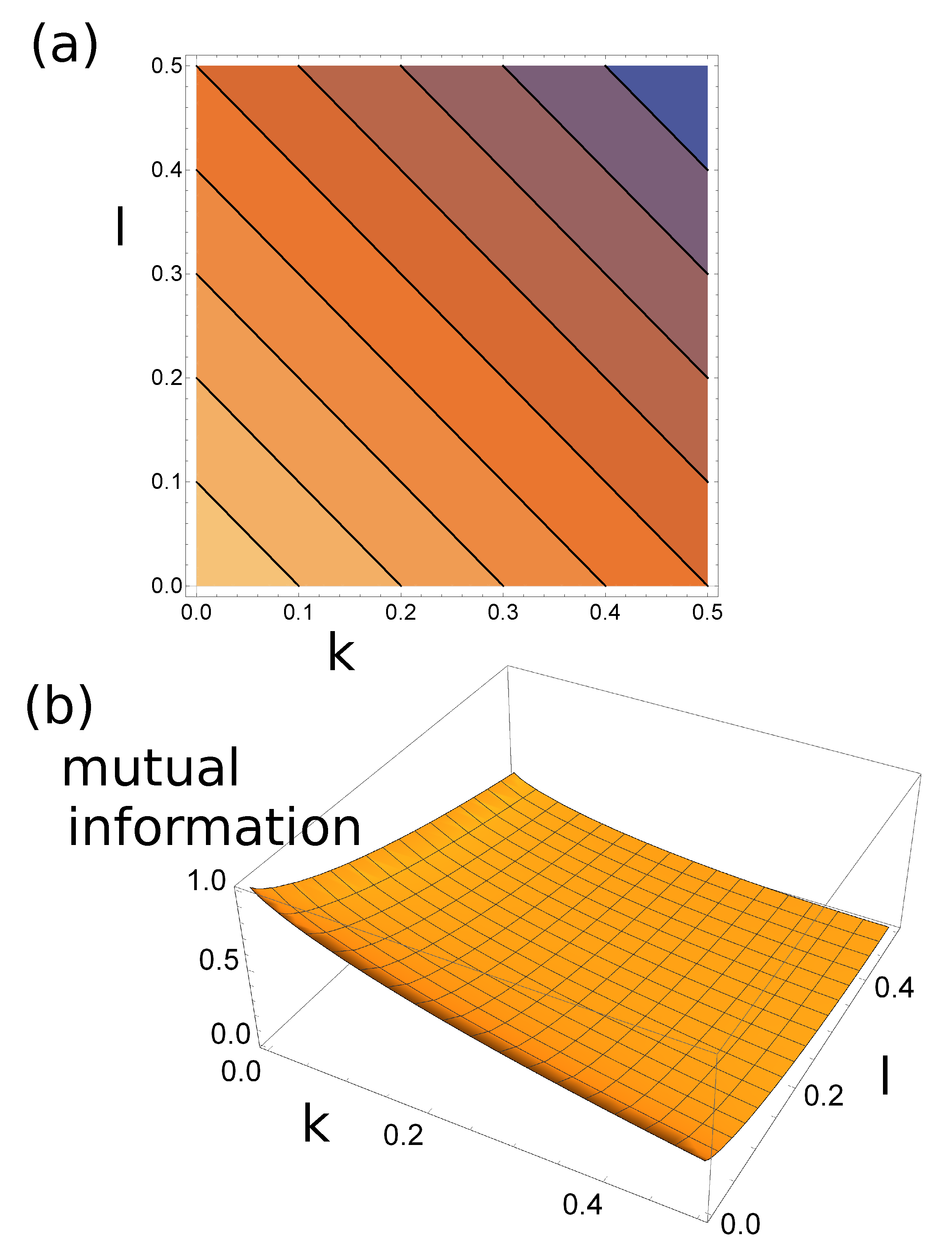
where
and
. The contour plot of
is shown in
Figure 7a.
The list of classifier answers
B on the database
F is made of
symbols
and
symbols
. Therefore;
For the considered classifier, the list
is formed of
L strings
,
strings
,
K strings
and
strings
. The Shannon information entropy
equals:
and the mutual information between record types and answers of the classifier is:
The function
is illustrated in
Figure 7b.
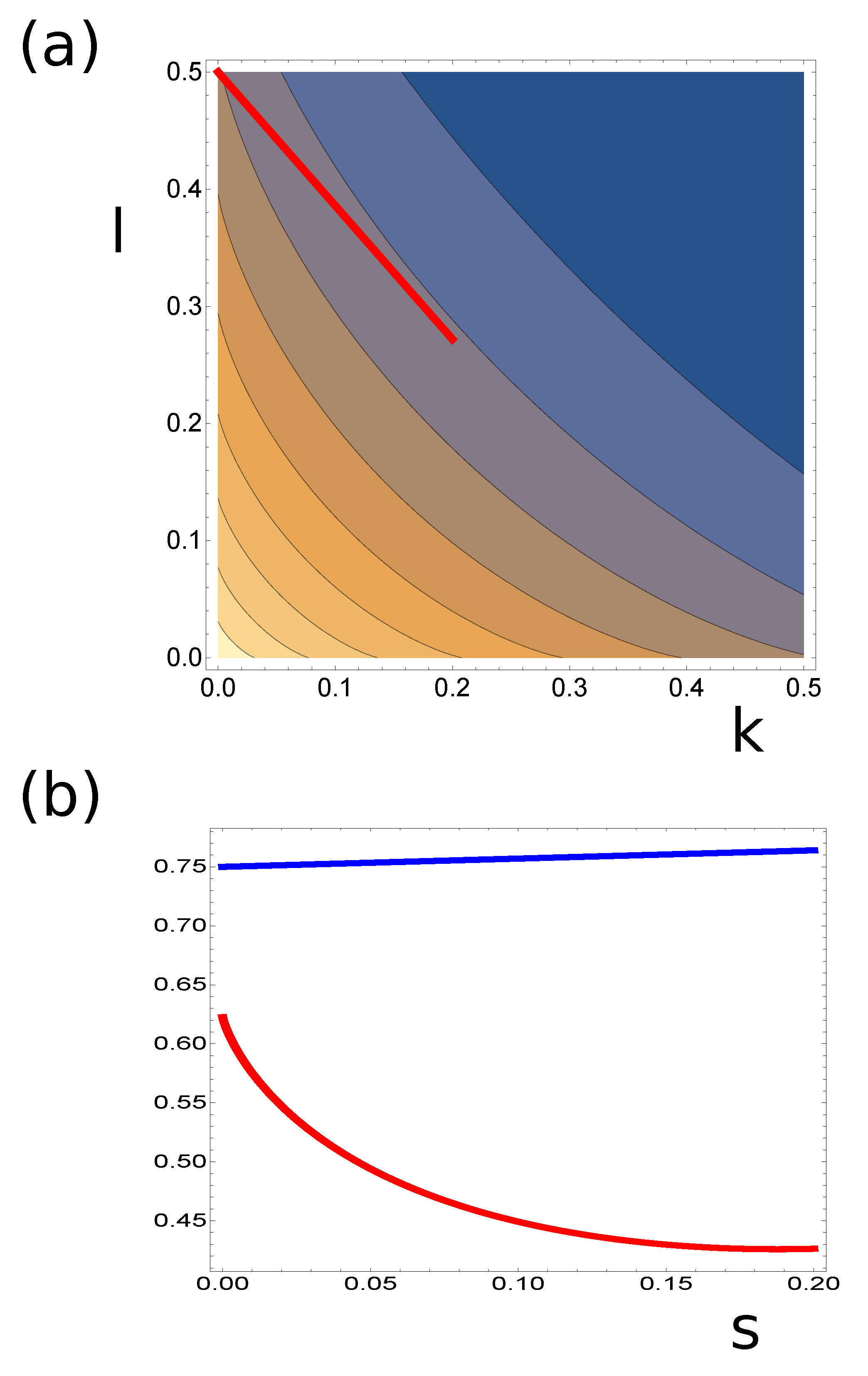
Comparing the dependence of
with
, we can identify a path in
space along which one of the functions increases and the other decreases. An example of such a path is marked by the red line in
Figure 8a. The values of
and
along this path are shown in
Figure 8b. As seen, the increase in
can slightly decrease
.
Having this result in mind, we can say that although optimization based on the mutual information is attractive because it can be easily applied in an optimization program and does not involve direct translation of the evolution into the classification result, a better classifier can still be evolved if its accuracy is used to estimate the classifier fitness.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







