Biometric Identification Method for Heart Sound Based on Multimodal Multiscale Dispersion Entropy


Abstract
:1. Introduction
2. Materials and Methods
2.1. Mathematical Model of Heart Sound
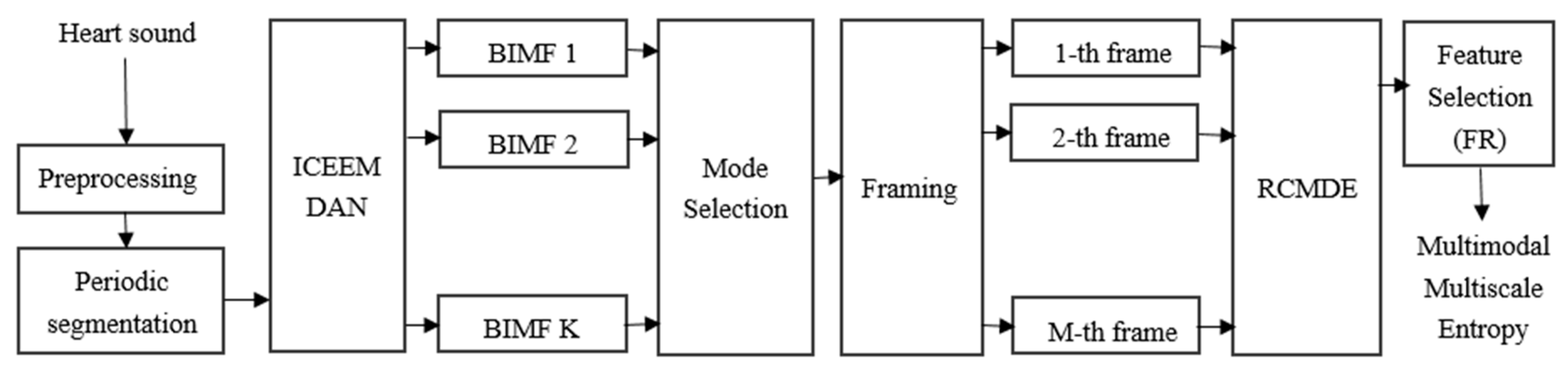
2.2. ICEEMDAN Method
- (1)
- Set and find all extremums of .
- (2)
- Interpolate between the minimum value (the maximum value) of to obtain the lower (upper) envelope ().
- (3)
- Calculate the average envelope: .
- (4)
- Calculate the candidate IMF: .
- (5)
- Is an IMF?Yes, save d_(k+1), calculate the residual , make , and put as input data in step (2).No, is taken as input data in step (2).
- (6)
- Continue to cycle until the final residual meets some predefined stopping criteria.
- (1)
- Calculate the local mean of the signal by I-times realization of EMD: , get the first residual , where represents the average operator.
- (2)
- The first modal is calculated from the residual obtained in the step (1): .
- (3)
- The second residual is calculated by , and defines the second mode: .
- (4)
- For , calculate the kth residual: .
- (5)
- Calculate the kth modal: .
- (6)
- Go to the next of step (4) until all modes are obtained.
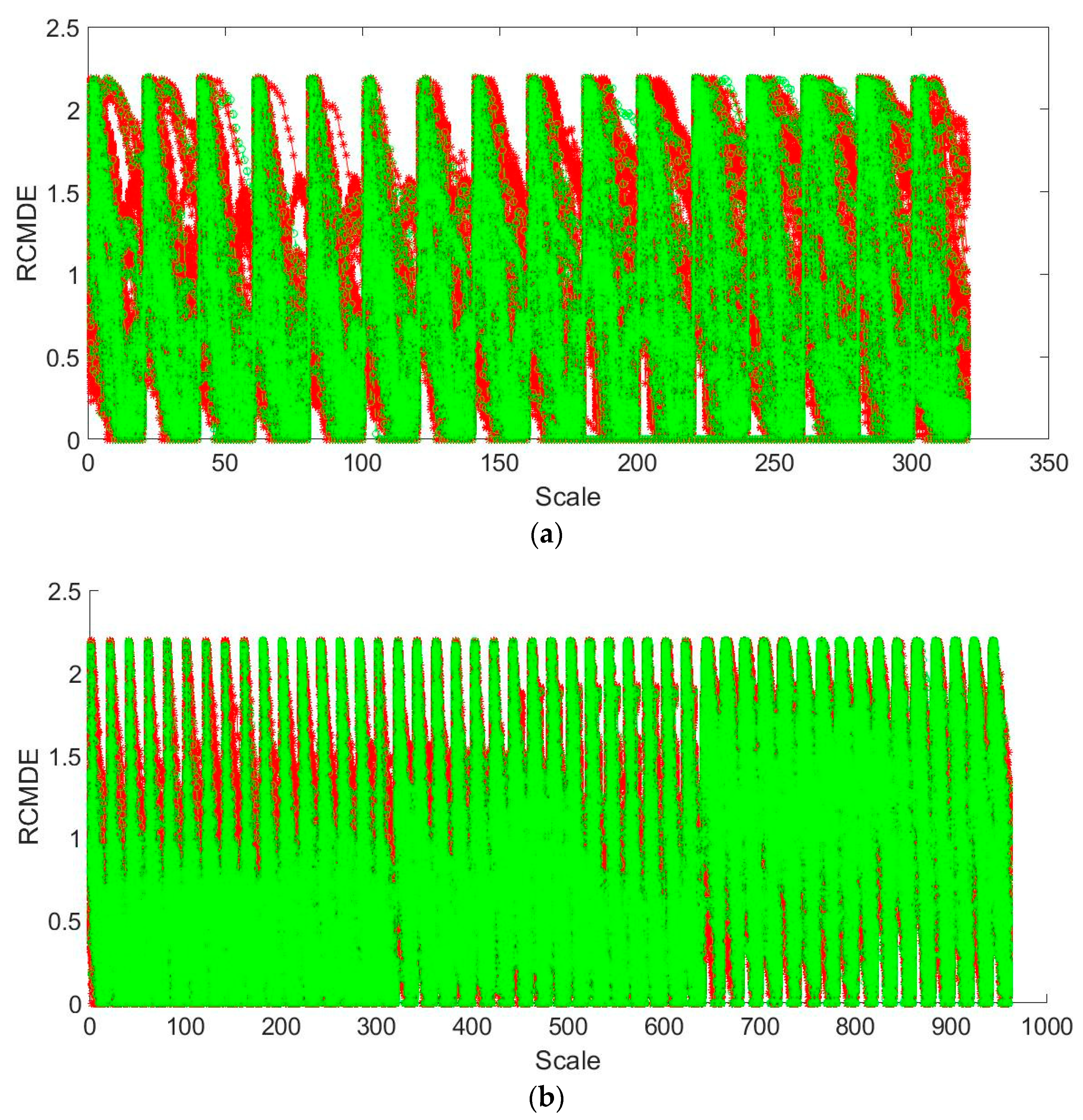
2.3. RCMDE Method
2.4. Feature Selection
2.5. Matching Recognition
2.6. Evaluation Methods
3. Results and Discussion
3.1. Data Sources
3.2. Feature Extraction and Recognition
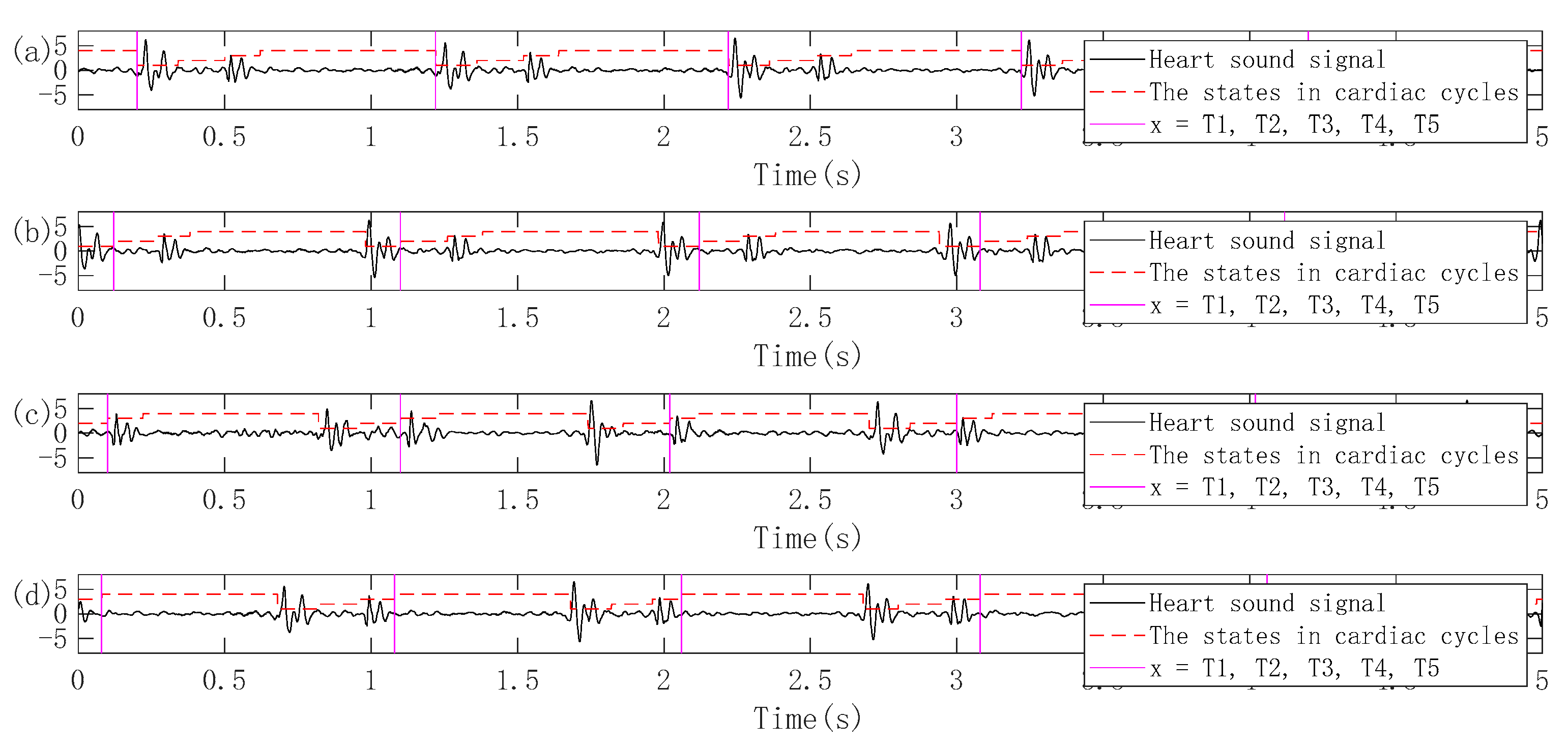
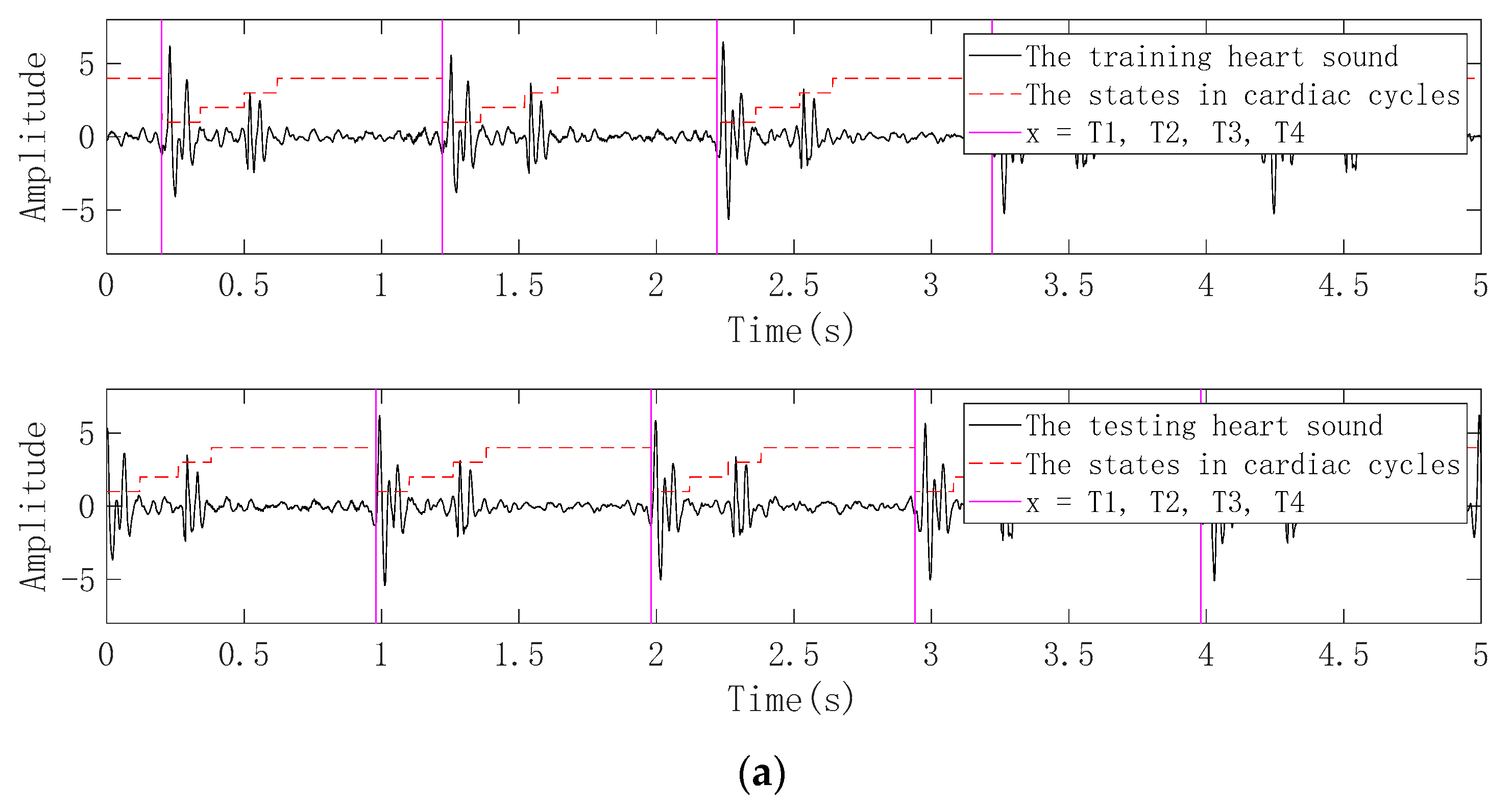
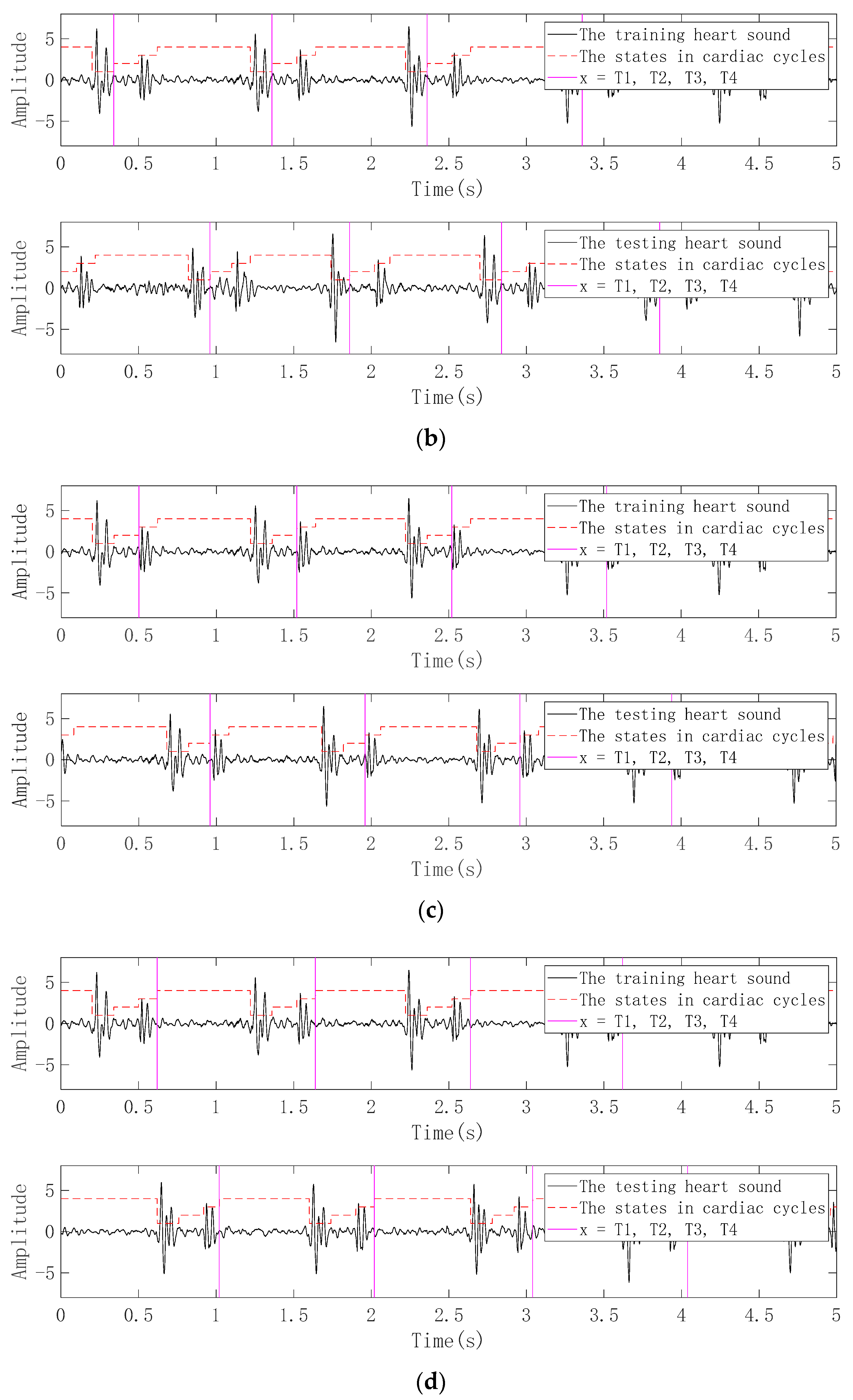
3.2.1. Pretreatment
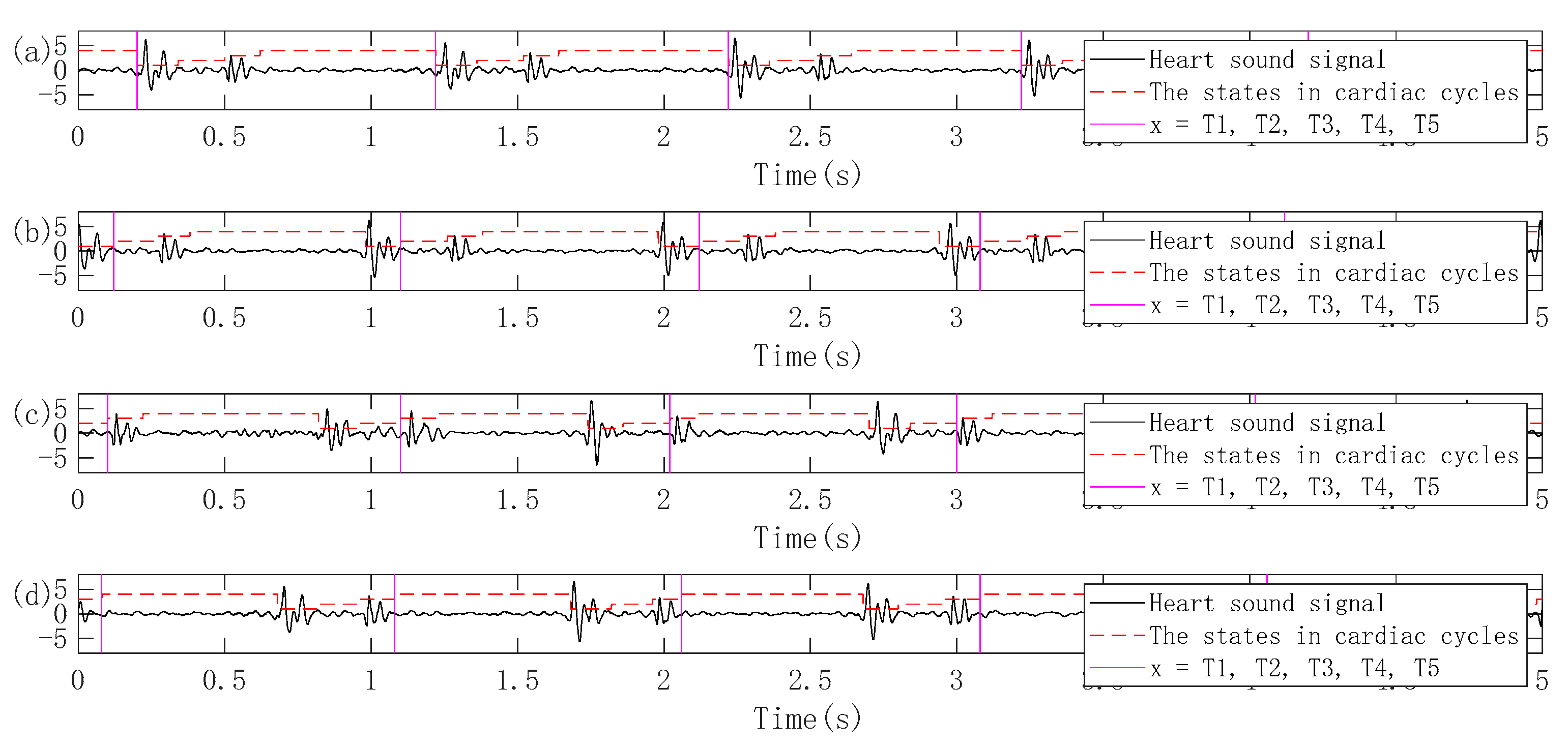
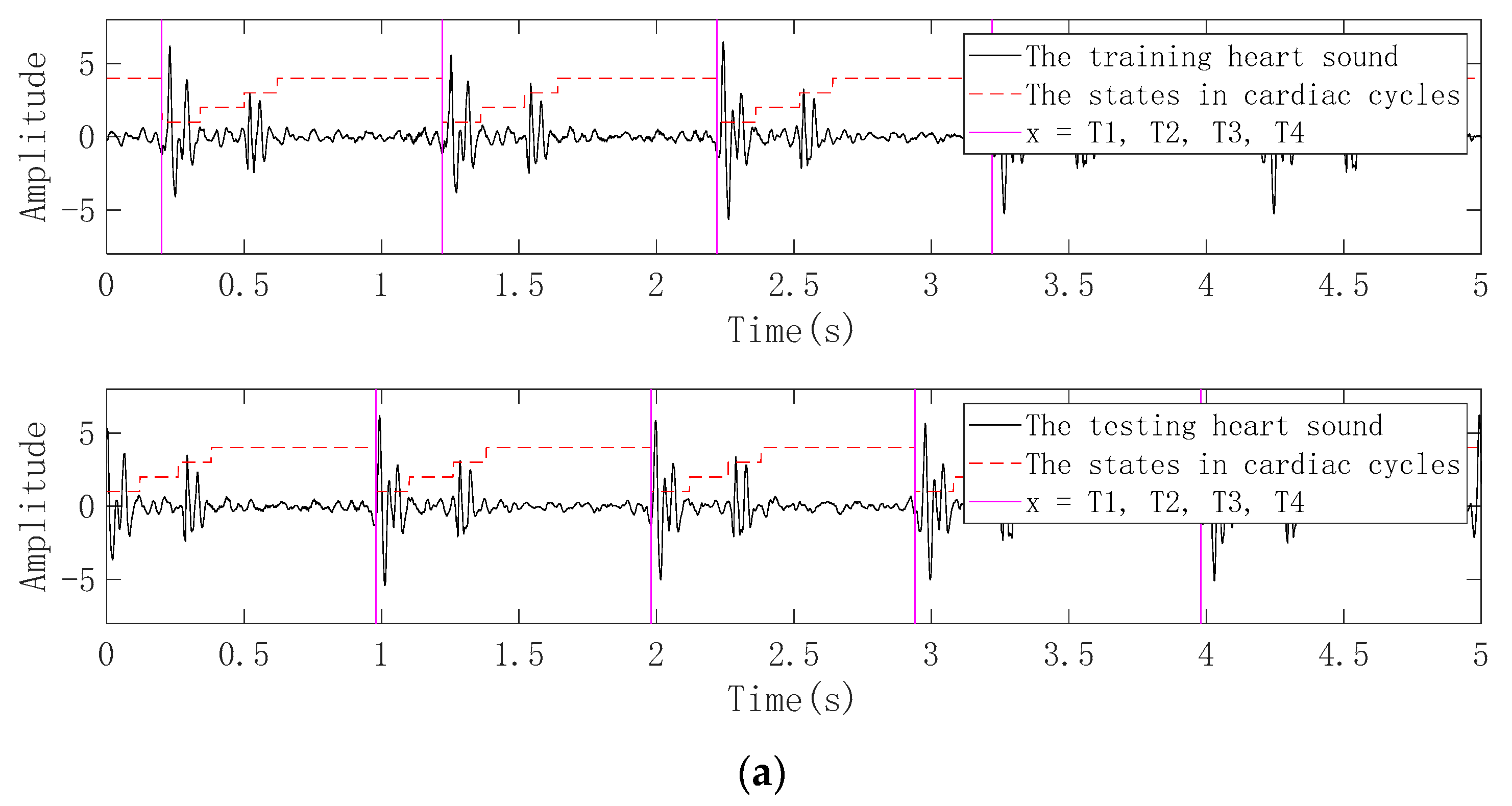
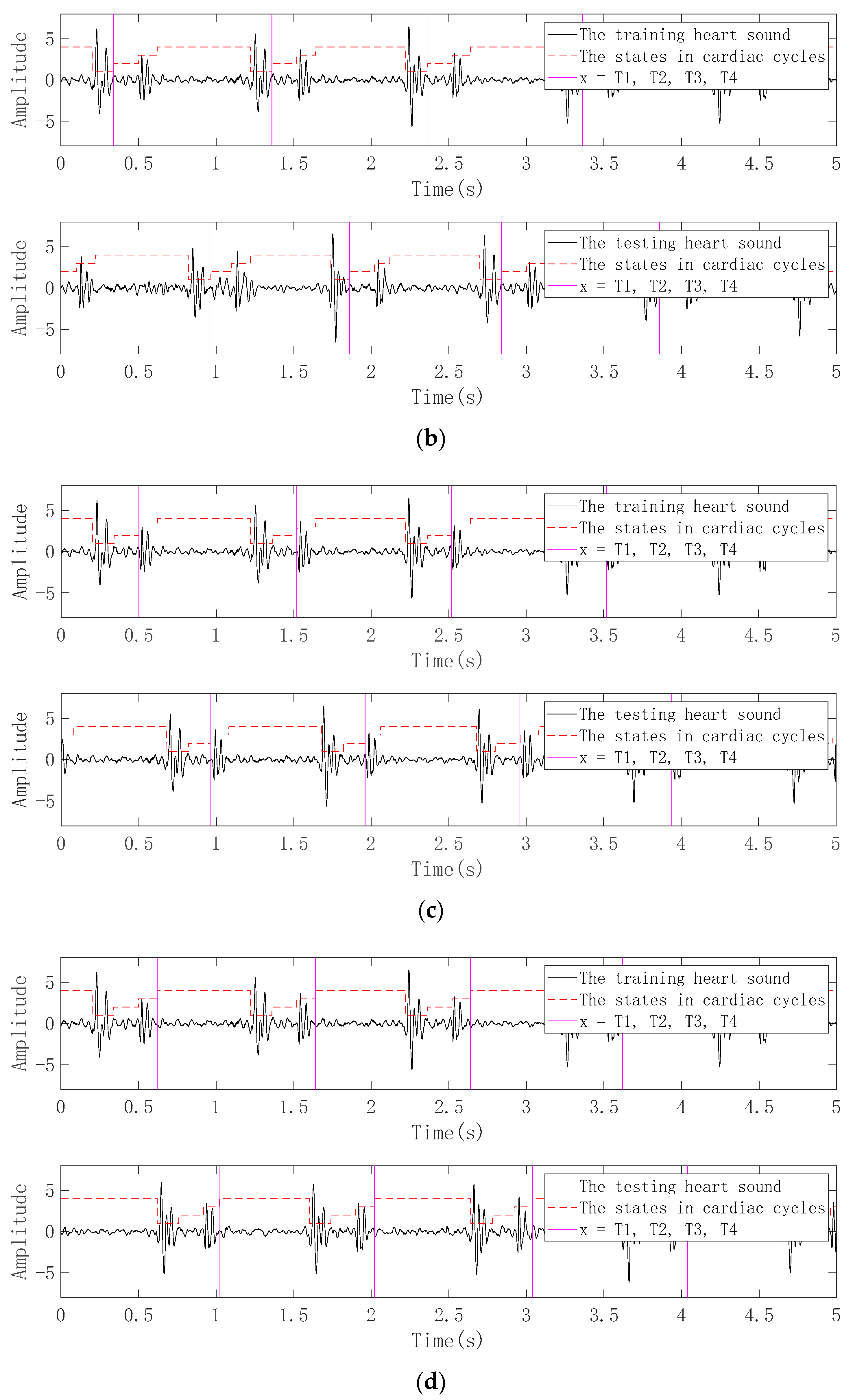
3.2.2. Periodic Segmentation
3.2.3. Framing and Windowing
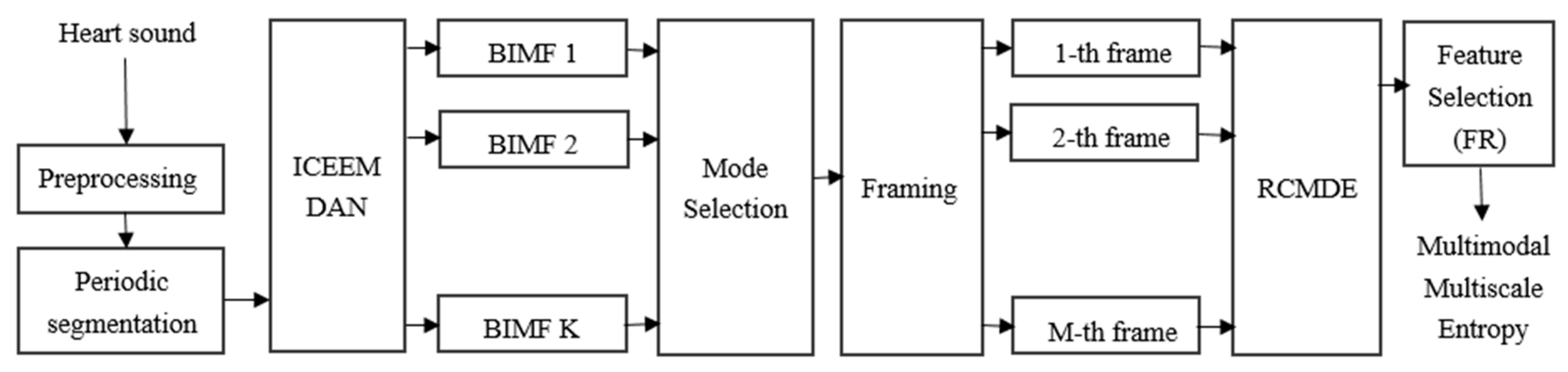
3.2.4. ICEEMDAN-RCMDE-FR-ED Algorithm
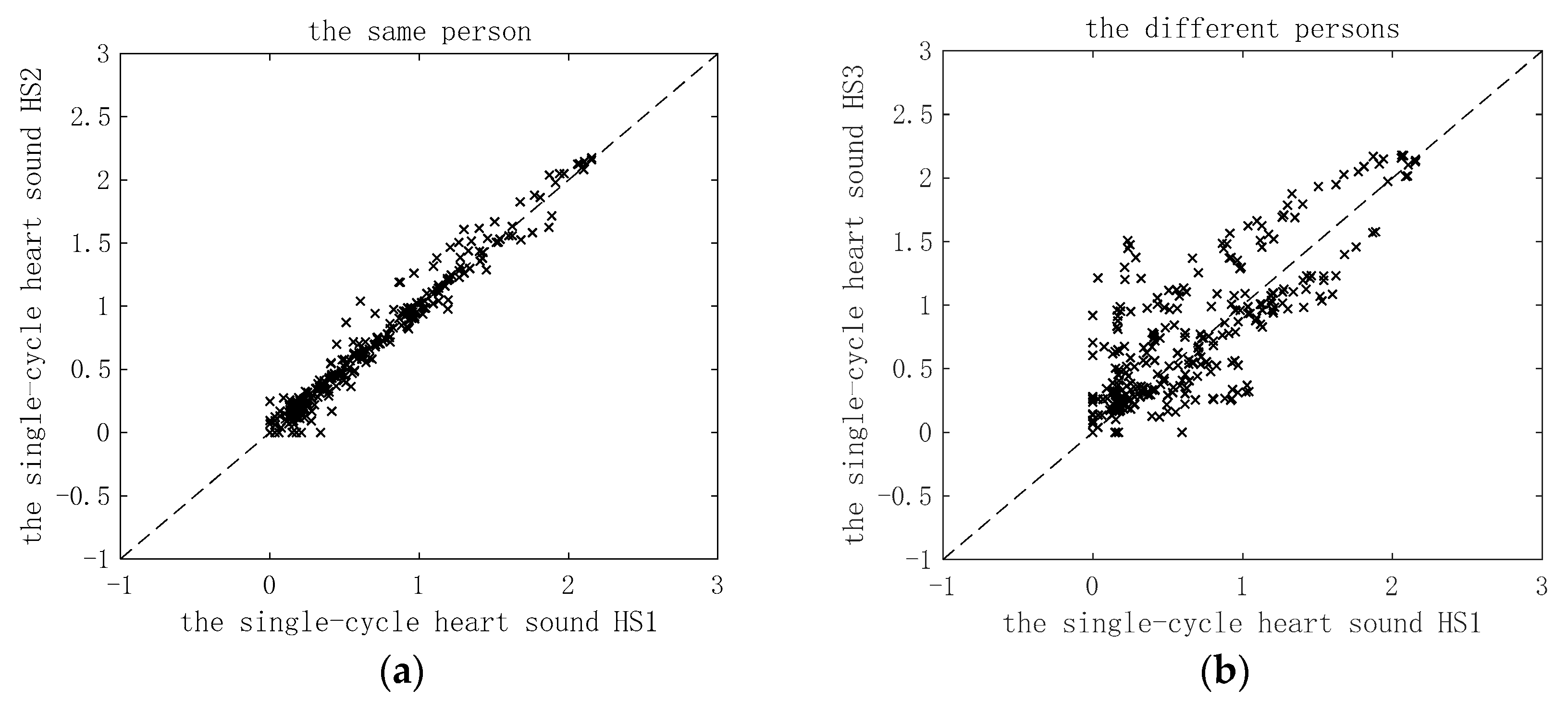
3.3. Practical Application of ICEEMDAN-RCMDE-FR-ED Algorithm
3.4. Comparison with Related Literature
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Cheng, X.F.; Ma, Y.; Liu, C.; Zhang, X.J.; Guo, Y.F. An introduction to heart sounds identification technology. Sci. China-Inf. Sci. 2012, 42, 237–251. [Google Scholar]
- Beritelli, F.; Serrano, S. Biometric identification based on frequency analysis of cardiac sounds. IEEE Trans. Inf. Forensics Secur. 2007, 2, 596–604. [Google Scholar] [CrossRef]
- Phua, K.; Chen, J.F.; Dat, T.H.; Shue, L. Heart sound as a biometric. Pattern Recognit. 2008, 41, 906–919. [Google Scholar] [CrossRef]
- Beritelli, F.; Spadaccini, A. Human identity verification based on mel frequency analysis of digital heart sounds. In Proceedings of the 16th International Conference on Digital Signal Processing, Santorini, Greece, 5–7 July 2009. [Google Scholar]
- Beritelli, F.; Spadaccini, A. An improved biometric identification system based on heart sound and gaussian mixture models. In Proceedings of the 2010 IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications, Taranto, Italy, 9 September 2010. [Google Scholar]
- Fatemian, S.Z.; Agrafioti, F.; Hatzinakos, D. Heartid: Cardiac biometric recognition. In Proceedings of the Fourth IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS), Washington, DC, USA, 27–29 September 2010. [Google Scholar]
- Tran, D.H.; Leng, Y.R.; Li, H. Feature integration for heart sound biometrics. International Conference on Acoustics Speech Signal Processing. In Proceedings of the 2010 IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 1714–1717. [Google Scholar]
- Cheng, X.F.; Tao, Y.W.; Huang, Z.J. Cardiac sound recognition—A prospective candidate for biometric identification. Adv. Mater. Res. 2011, 225, 433–436. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, Y.; Lei, S.; Zhao, Z.; Pan, M. Study of biometric identification of Cardiac sound base on Mel-Frequency cepstrum coefficient. J. Biomed. Eng. 2012, 29, 1015–1020. [Google Scholar]
- Zhong, L.; Wan, J.; Huang, Z.; Guo, X.; Duan, Y. Research on biometric method of Cardiac sound signal based on GMM. Chin. J. Med. Instrum. 2013, 37, 92–99. [Google Scholar]
- Zhao, Z.D.; Shen, Q.Q.; Ren, F.Q. Heart sound biometric system based on marginal spectrum analysis. Sensors 2013, 13, 2530–2551. [Google Scholar] [CrossRef]
- Babiker, A.; Hassan, A.; Mustafwa, H. Cardiac sounds biometric system. J. Biomed. Eng. Med. Device 2017, 2, 2–15. [Google Scholar] [CrossRef]
- Akhter, N.; Tharewal, S.; Kale, V.; Bhalerao, A.; Kale, K.V. Heart-Based Biometrics and Possible Use of Heart Rate Variability in Biometric Recognition Systems. In Proceedings of the 2nd International Doctoral Symposium on Applied Computation and Security Systems (ACSS), Kolkata, India, 23–25 May 2015. [Google Scholar]
- Bao, S.; Poon, C.C.Y.; Zhang, Y.; Shen, L. Using the Timing Information of Heartbeats as an Entity Identifier to Secure Body Sensor Network. IEEE Trans. Inf. Technol. Biomed. 2008, 12, 772–779. [Google Scholar]
- Palaniappan, R. Two-stage biometric authentication method using thought activity brain waves. In Proceedings of the 7th International Conference on Intelligent Data Engineering and Automated Learning (IDEAL 2006), Burgos, Spain, 20–23 September 2006. [Google Scholar]
- Mu, Z.; Hu, J.; Min, J. EEG-Based Person Authentication Using a Fuzzy Entropy-Related Approach with Two Electrodes. Entropy 2016, 18, 432. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. A 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Colominas, M.A.; Schlotthauer, G.; Torres, M.E. Improve complete ensemble EMD: A suitable tool for biomedical signal processing. Biomed. Signal Process. Control 2014, 14, 19–29. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A Complete Ensemble Empirical Mode Decomposition with Adaptive Noise. In Proceedings of the 36th IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- Rostaghi, M.; Azami, H. Dispersion Entropy: A Measure for Time-Series Analysis. IEEE Signal Process. Lett. 2016, 23, 610–614. [Google Scholar] [CrossRef]
- Azami, H.; Rostaghi, M.; Abasolo, D.; Escudero, J. Refined Composite Multiscale Dispersion Entropy and its Application to Biomedical Signals. IEEE Trans. Biomed. Eng. 2017, 64, 2872–2879. [Google Scholar]
- Matlab Codes for Refined Composite Multiscale Dispersion Entropy and Its Application to Biomedical Signals. Available online: https://datashare.is.ed.ac.uk/handle/10283/2637 (accessed on 7 November 2019).
- Pruzansky, S.; Mathews, M.V. Talker-Recognition Procedure Based on Analysis of Variance. J. Acoust. Soc. Am. 1964, 36, 2021–2026. [Google Scholar] [CrossRef]
- Zhou, Z.H. Machine Learning, 3rd ed.; Tsinghua University Press: Beijing, China, 2016; pp. 24–47. [Google Scholar]
- University of Michigan Department of Medicine. Michigan Heart Sound and Murmur Library. Available online: http://www.med.umich.edu/lrc/psb/heartsounds/ (accessed on 7 November 2019).
- Washington Heart Sounds & Murmurs Library. Available online: https://depts.washington.edu/physdx/heart/tech5.html (accessed on 7 November 2019).
- Littmann Heart and Lung Sounds Library. Available online: http://www.3m.com/healthcare/littmann/mmm-library.html (accessed on 7 November 2019).
- Cheng, X.F.; Zhang, Z. A construction method of biorthogonal heart sound wavelet. Acta Phys. Sin. 2013, 62, 168701. [Google Scholar]
- Gupta, C.N.; Palaniappan, R.; Swaminathan, S.; Krishnan, S.M. Neural network classification of homomorphic segmented heart sounds. Appl. Soft Comput. 2007, 7, 286–297. [Google Scholar] [CrossRef]
- Liu, C.; Springer, D.; Li, Q.; Moody, B.; Juan, R.A.; Chorro, F.J.; Castells, F.; Roig, J.M.; Silva, I.; Johnson, A.E.; et al. An open access database for the evaluation of heart sound algorithms. Physiol. Meas. 2016, 37, 2181–2213. [Google Scholar] [CrossRef]
- Springer, D.B.; Tarassenko, L.; Clifford, G.D. Logistic Regression-HSMM-Based Heart Sound Segmentation. IEEE Trans. Biomed. Eng. 2016, 63, 822–832. [Google Scholar] [CrossRef]
- Jasper, J.; Othman, K.R. Feature extraction for human identification based on envelogram signal analysis of cardiac sounds in time-frequency domain. Electron. Inf. Eng. 2010, 2, 228–233. [Google Scholar]
- Gautam, G.; Deepesh, K. Biometric system from Cardiac sound using wavelet based feature set. In Proceedings of the 2013 International Conference on Communication and Signal Processing, Melmaruvathur, India, 3–5 April 2013. [Google Scholar]
- Tan, W.; Yeap, H.; Chee, K.; Ramli, D. Towards real time implementation of sparse representation classifier (SRC) based heartbeat biometric system. Comput. Probl. Eng. 2014, 307, 189–202. [Google Scholar]
- Verma, S.; Tanuja, K. Analysis of Cardiac sound as biometric using mfcc and linear svm classifier. IJAREEIE 2014, 3, 6626–6633. [Google Scholar]
- Abo-Zahhad, M.; Ahmed, S.M.; Abbas, S.N. PCG biometric identification system based on feature level fusion using canonical correlation analysis. In Proceedings of the 27th Canadian Conference on Electrical and Computer Engineering, Toronto, ON, Canada, 4–7 May 2014. [Google Scholar]
- Abo-Zahhad, M.; Farrag, M.; Abbas, S.N.; Ahmed, S.M. A comparative approach between cepstral features for human authentication using heart sounds. Signal Image Video Process. 2016, 10, 843–851. [Google Scholar] [CrossRef]
- Abo-Zahhad, M.; Ahmed, S.M.; Abbas, S.N. Biometric authentication based on PCG and ECG signals: Present status and future directions. Signal Image Video Process. 2014, 8, 739–751. [Google Scholar] [CrossRef]
- Bugdol, M.D.; Mitas, A.W. Multimodal biometric system combining ECG and sound signals. Pattern Recognit. Lett. 2014, 38, 107–112. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Heart Sound Database | Including 2005 Single-Cycle Heart Sounds from the Open Database Michigan, Washington, and Littman | ||
|---|---|---|---|
| Algorithm | RCMDE-ED | ||
| win (inc = win) | inc (win = T/4) | ||
| T | 45.16% | win | 84.55% |
| T/2 | 78.71% | win/2 | 84.82% |
| T/3 | 82.52% | win/3 | 88.88% |
| T/4 | 84.55% | win/4 | 87.11% |
| T/5 | 81.09% | win/5 | 90.08% |
| T/6 | 82.83% | win/6 | 88.68% |
| T/7 | 81.56% | win/7 | 88.20% |
| T/8 | 76.77% | win/8 | 88.64% |
| T/9 | 75.13% | win/9 | 89.66% |
| T/10 | 65.40% | win/10 | 89.47% |
| Heart Sound Database | Including 2005 Single-Cycle Heart Sounds from the Open Database Michigan, Washington, and Littman | ||
|---|---|---|---|
| Algorithm | ICEEMDAN-RCMDE-ED | ||
| Input | Input | ||
| IMF 1 | 90.04% | IMF 5 | 41.08% |
| IMF 2 | 88.96% | IMF 6 | 24.28% |
| IMF 3 | 82.68% | IMF 7 | 14.94% |
| IMF 4 | 59.58% | IMF 8 | 12.15% |
| Heart Sound Database | Including 2005 Single-Cycle Heart Sounds from the Open Database Michigan, Washington, and Littman | ||
|---|---|---|---|
| Feature Extraction | Numbers of Feature | Kappa Coefficients | |
| RCMDE | 320 | 90.08% | 0.8994 |
| ICEEMDAN-RCMDE-FR | 300 | 96.08% | 0.9602 |
| n Random Trials | The Average Test Accuracy | Standard Deviation | t Value | The Critical Value Range | The Degree of Confidence |
|---|---|---|---|---|---|
| n = 10 | 0.9681 | 0.0147 | 1.570 | [−2.262, 2.262] | 0.95 |
| n = 20 | 0.9653 | 0.0146 | 1.378 | [−2.093, 2.093] | 0.95 |
| n = 30 | 0.9634 | 0.0144 | 0.989 | [−2.045, 2.045] | 0.95 |
| n = 50 | 0.9639 | 0.0161 | 1.362 | [−2.010, 2.010] | 0.95 |
| n = 100 | 0.9603 | 0.0162 | −0.309 | [−1.984, 1.984] | 0.95 |
| n = 200 | 0.9608 | 0.0162 | 0 | [−1.972, 1.972] | 0.95 |
| n = 300 | 0.9606 | 0.0162 | −0.214 | [−1.968, 1.968] | 0.95 |
| n = 400 | 0.9608 | 0.0162 | 0 | [−1.966, 1.966] | 0.95 |
| n = 500 | 0.9607 | 0.0162 | −0.138 | [−1.965, 1.965] | 0.95 |
| n = 600 | 0.9608 | 0.0162 | 0 | [−1.964, 1.964] | 0.95 |
| Heart Sound Database | Including 2005 Single-Cycle Heart Sounds from the Open Database Michigan, Washington, and Littman | |||
|---|---|---|---|---|
| Feature Extraction | ICEEMDAN-RCMDE-FR | |||
| Classifier | Classifier Parameter | Speed | Kappa Coefficients | |
| SVM | c = 64, g = 0.001 | Slowest | 95.91% | 0.9585 |
| KNN | k = 5 | Medium | 73.14% | 0.7276 |
| k = 3 | 84.83% | 0.8462 | ||
| k = 2 | 95.97% | 0.9591 | ||
| ED and the close principle | None | Fastest | 96.08% | 0.9602 |
| Heart Sound Database | Including the 80 Heart Sound Recordings from the Self-Built Heart Sound Database | |
|---|---|---|
| Algorithm | ICEEMDAN-RCMDE-FR-ED | |
| The Starting and Ending Position of the Input Single-Cycle Heart Sound | CRR | Kappa Coefficients |
| the starting position of S1—the starting position of next S1 | 97.5% | 0.9744 |
| the starting position of systole—the starting position of next systole | 92.5% | 0.9231 |
| the starting position of S2—the starting position of next S2 | 95.0% | 0.9487 |
| the starting position of diastole—the starting position of next diastole | 95.0% | 0.9487 |
| Comparative Literature | Heart Sound Database | Feature Extraction | Classifier | Accuracy |
|---|---|---|---|---|
| Phua et al. [3] | 10 people | LFBC | VQ | CRR = 94% |
| GMM | CRR = 96% | |||
| Fatemian et al. [6] | 21 subjects | STFT | LDA and ED | CRR = 100% EER = 33% |
| Tran et al. [7] | 52 users | temporal shape, spectral shape, MFCC, LFCC, harmonic feature, rhythmic feature, cardiac feature and GMM-super vector | RFE-SVM | CRR = 80% CRR = 90% |
| Jasper and Othman [32] | 10 people | WT-SSE | Template matching | CRR = 98.67% |
| Cheng et al. [1] | 12 people 300 HS | HS-LBFC | similar distances | CRR = 99% |
| Cheng et al. [8] | 10 people | ICC-ISF | similar distances | CRR = 85.7% |
| Zhao et al. [11] | 40 participants 280 samples | MS | VQ and ED | CRR = 94.16% |
| HSCT-11 80 subjects | CRR = 92% | |||
| Gautam and Deepesh [33] | 10 subjects | segment S1 and S2 by windowing and thresholding +WT | BP-MLP-ANN | CRR = 90.52% EER = 9.48% |
| Tan et al. [34] | 52 users | extract S1 and S2 by ZCR and STA techniques + MFCC | SRC | CRR = 85.45% |
| Verma and Tanuja [35] | 30 people | MFCC | SVM | CRR = 96% |
| Abo Zahhad et al. [36] | 17 subjects | MFCC, LFCC, BFCC and DWT+ CCA | GMM and Bayesian rules | CRR = 99% |
| Abo Zahhad et al. [37] | HSCT-11 206 subjects | WPCC | LDA and Bayesian Decision Rules | CRR = 90.26% |
| NLFCC | CRR = 92.94% | |||
| BioSec. 21 subjects | WPCC | CRR = 97.02% | ||
| NLFCC | CRR = 98.1% | |||
| The proposed method | Michigan, Washington, and Littman 72 subjects | segment cardiac cycle by LR-HSMM + framing and windowing + ICEEMDAN-RCMDE-FR | SVM | CRR = 95.91% |
| KNN | CRR = 95.97% | |||
| ED and the close principle | CRR = 96.08% | |||
| 40 users 80 HS | ED and the close principle | CRR = 97.5% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, X.; Wang, P.; She, C. Biometric Identification Method for Heart Sound Based on Multimodal Multiscale Dispersion Entropy. Entropy 2020, 22, 238. https://doi.org/10.3390/e22020238
Cheng X, Wang P, She C. Biometric Identification Method for Heart Sound Based on Multimodal Multiscale Dispersion Entropy. Entropy. 2020; 22(2):238. https://doi.org/10.3390/e22020238
Chicago/Turabian StyleCheng, Xiefeng, Pengfei Wang, and Chenjun She. 2020. "Biometric Identification Method for Heart Sound Based on Multimodal Multiscale Dispersion Entropy" Entropy 22, no. 2: 238. https://doi.org/10.3390/e22020238
APA StyleCheng, X., Wang, P., & She, C. (2020). Biometric Identification Method for Heart Sound Based on Multimodal Multiscale Dispersion Entropy. Entropy, 22(2), 238. https://doi.org/10.3390/e22020238