1. Introduction
For any pair of random variables
X and
Y, the entropy
H satisfies the inequality
From this inequality, it is easy to see that the conditional entropies and mutual information are non-negative,
For any pair of sets
A and
B, a measure
satisfies the inequality
which follows from the non-negativity of measure on the relative complements and the intersection,
Although the entropy is not itself a measure, several authors have noted the entropy is analogous to measure in this regard [
1,
2,
3,
4,
5,
6,
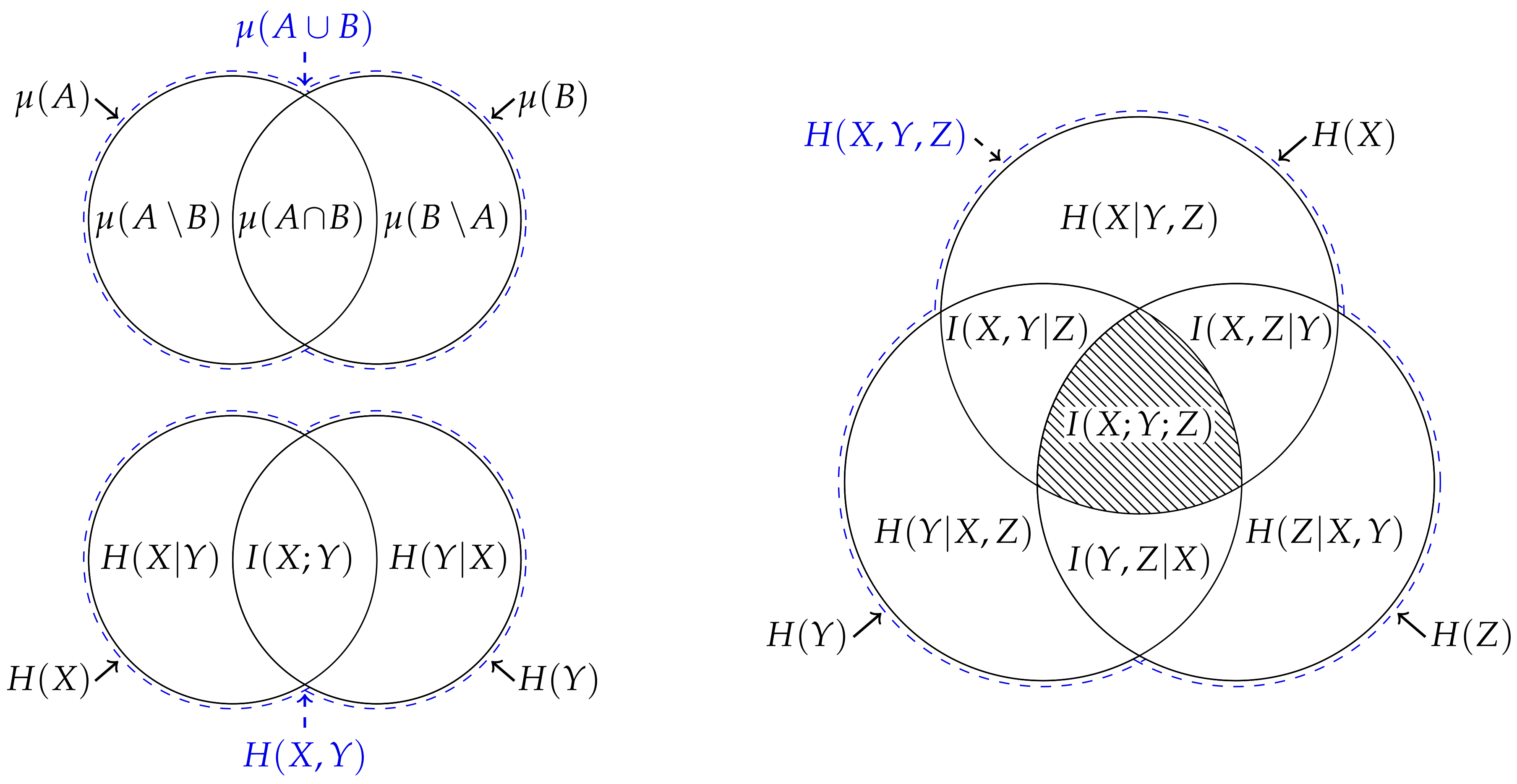
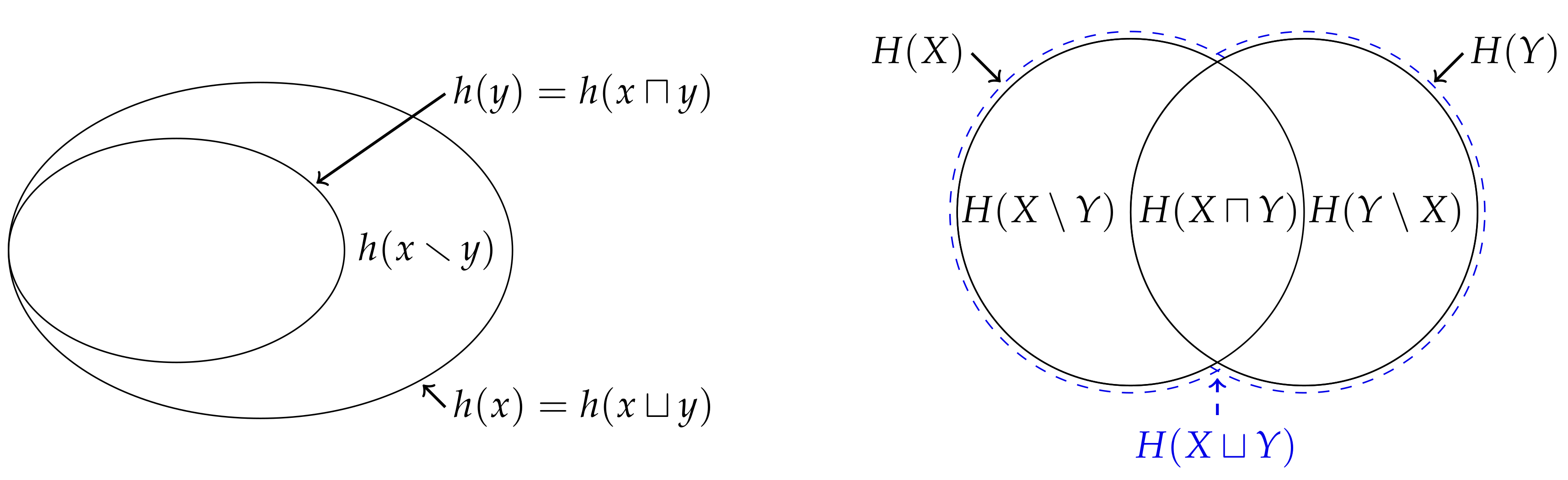
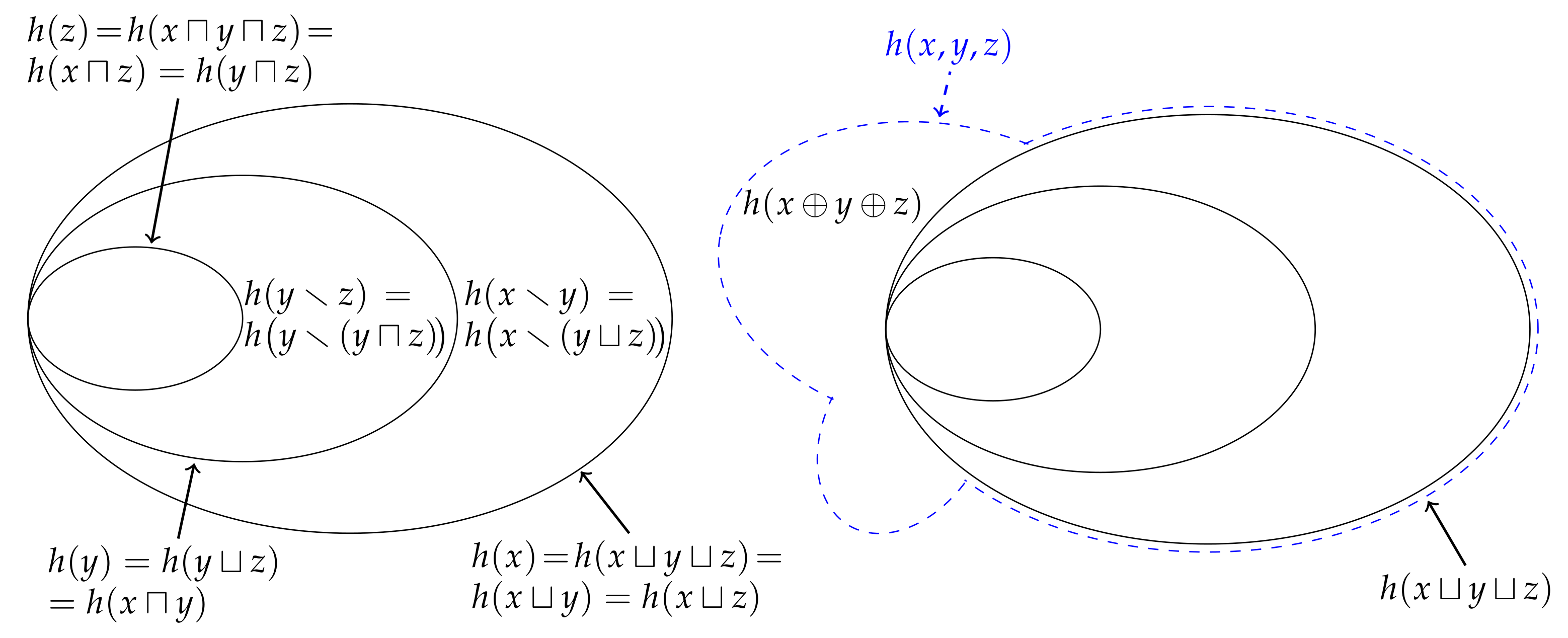
7]. Indeed, it is this analogy which provides the justification for the typical depiction of a pair of entropies using Venn diagrams, i.e.,
Figure 1. Nevertheless, MacKay [
8] noted that this representation is misleading for at least two reasons: Firstly, since the measure on the intersection
is a measure on a set, it gives the false impression that the mutual information
is the entropy of some intersection between the random variables. Secondly, it might lead one to believe that this analogy can be generalised beyond two variables. However, the analogy does not generalise beyond two variables since the multivariate mutual information [
9] between three random variables (which is also known as the interaction information [
10], amount of information [
2] or co-information [
11]),
is not non-negative [
3,
9,
12], and hence is not analogous to measure on the triple intersection
[
3]. Indeed, this “unfortunate” property led Cover and Thomas to conclude that “there isn’t really a notion of mutual information common to three random variables” (p. 49 [
13]). Consequently, MacKay [
8] recommended against depicting the entropy of three or more variables using a Venn diagram, i.e.,
Figure 1, unless one is aware of these issues with this representation.
However, Yeung [
6,
7] showed that there is an analogy between entropy and
signed measure that is valid for an arbitrary number of random variables. To do this, Yeung defined a signed measure on a suitably constructed
-algebra that is uniquely determined by the joint entropies of the random variables involved. This correspondence enables one to establish information-theoretic identities from measure-theoretic identities and hence Venn diagrams can be used to represent the entropy of three or more variables provided one is aware that the certain overlapping areas may correspond to negative quantities. Moreover, the multivariate mutual information is useful both as summary quantity and for manipulating information-theoretic identities provided one is mindful it may have “no intuitive meaning” [
5,
6].
In this paper, we introduce new measures of multivariate information that are analogous to measures upon sets and maintain their operational meaning when considering an arbitrary number of variables. These new measures complement the existing measures of multivariate mutual information, and will be constructed by considering the distinct ways in which a set of marginal observers might share their information with a non-observing third party. In
Section 2, we discuss the existing measures of information content in terms of a set of individuals who each have different knowledge about a joint realisation from a pair of random variables. Then, in
Section 3, we discuss how these individuals can share their information with a non-observing third party, and derive the functional form of this individual’s information. In
Section 4, we relate this new measure of information content back to the mutual information.
Section 5,
Section 6 and
Section 7 then generalise the arguments of
Section 3 and
Section 4 to consider an arbitrary number of observers. Finally, in
Section 8, we discuss how these new measures can be combined to define new measures of mutual information.
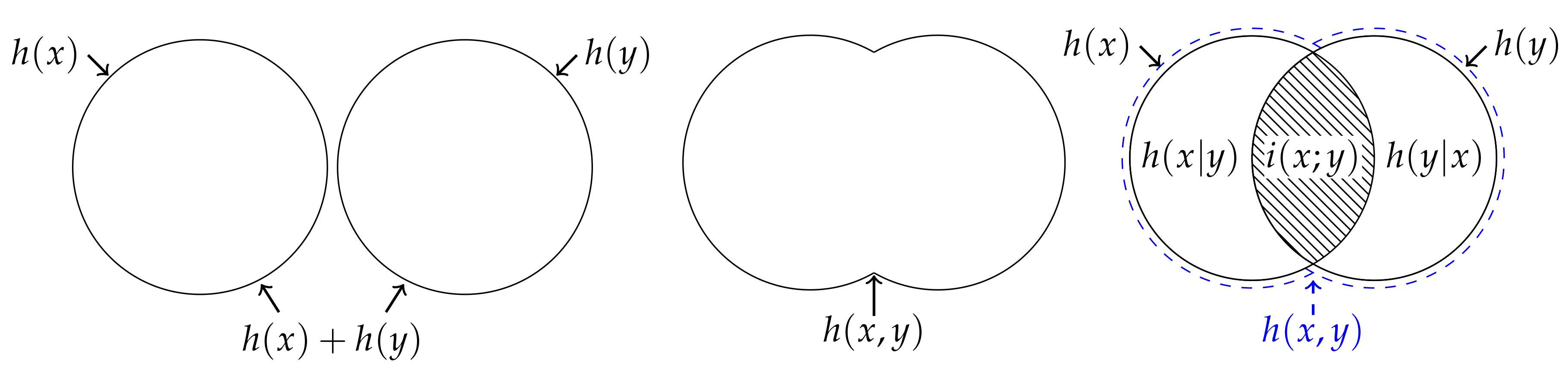
2. Mutual Information Content
Suppose that Alice and Bob are separately observing some process and let the discrete random variables
X and
Y represent their respective observations. Say that Johnny is a third individual who can simultaneously make the same observations as Alice and Bob such that his observations are given by the joint variable
. When a realisation
occurs, Alice’s information is given by the information content [
8],
where
is the probability mass of the realisation
x of variable
X computed from the probability distribution
. Likewise, Bob’s information is given by the information content
, while Johnny’s information is by the joint information content
. The information that Alice can expect to gain from an observation is given by the entropy,
where
represents an expectation value over realisations of the variable
X. Similarly, Bob’s expected information gain is given by the entropy
and Johnny’s expected information is given by the joint entropy
. Clearly, for any realisation, Johnny has at least as much information as either Alice or Bob,
The conditional information content can be used to quantify how much more information Johnny has relative to either Alice or Bob, respectively,
Similarly, we can quantify how much more information Johnny expects to get compared to either Alice or Bob via the conditional entropies,
Now, consider a fourth individual who does not directly observe the process, but with whom Alice and Bob share their knowledge. To be explicit, we are considering the situation whereby this individual knows that the joint realisation
has occurred and knows the marginal distributions
and
, but does not know the joint distribution
. How much information does this individual obtain from the shared marginal knowledge provided by Alice and Bob? The answer to this question is provided in
Section 3, but for now let us consider a simplified version of this problem. Suppose that such an individual, whom we call Indiana (or Indy for short), assumes that Alice’s observations are independent of Bob’s observations. In terms of the probabilities, this means that Indy believes that the joint probability
is equal to the product probability
, while, in terms of information, this assumption leads Indiana to believe that her information is given by the independent information content
. Moreover, the information that Indiana expects to gain from any one realisation is given by
.
Let us now compare how much information Indiana believes that she has compared to our other observers. For every realisation, Indiana believes that she has at least as much information as either Alice or Bob,
Since Indy knows what both Alice and Bob know individually, it is hardly surprising that she always has at least as much information as either Alice or Bob. The comparison between Indiana and Johnny, however, is not so straightforward—there is no inequality that requires the information content of the joint realisation to be less than the information content of the independent realisations, or vice versa. Consequently, the difference between the information that Indiana thinks she has and Johnny’s information, i.e., the mutual information content between a pair of realisations,
is not non-negative [
14]. (This function goes by several different names including the pointwise mutual information, the information density [
15] or simply the mutual information [
9].) Thus, similar to how it is potentially misleading to depict the entropy of three of more variables using a Venn diagram, representing the information content of two variables using a Venn diagram is somewhat dubious (see
Figure 2).
Since Johnny knows the joint distribution
, while Indiana only knows the marginal distributions
and
, we might expect that Indiana should never have more information than Johnny. However, Indiana’s assumed information is based upon the belief that Alice’s observations
X are independent of Bob’s observations
Y, which leads Indiana to overestimate her information on average. Indeed, Indiana is so optimistic that the information she expects to get upper bounds the information that Johnny can expect to get,
Thus, despite the fact that Indiana can have less information than Johnny for certain realisations—i.e., despite the fact that the mutual information content is not non-negative—the mutual information in expectation is non-negative,
Crucially, and in contrast to the information content (
10) and entropy (
11), the non-negativity of the mutual information does not follow directly from the non-negativity of the mutual information content (
18), but rather must be proved separately. (Typically, this is done by showing that the mutual information can be written as a Kullback–Leibler divergence which is non-negative by Jensen’s inequality, e.g., see Cover and Thomas [
13].) Thus, not only does Indiana potentially have more information than Johnny for certain realisations, but on average we expect Indiana to have more information than Johnny. Of course, by assuming Alice’s observations are independent of Bob’s observations, Indiana is overestimating her information. Thus, in the next section, we consider the situation whereby one does not make this assumption.
3. Marginal Information Sharing
Suppose that Eve is another individual who, similar to Indiana, does not make any direct observations, but with whom both Alice and Bob share their knowledge; i.e., Eve knows the joint realisation has occurred and knows the marginal distributions and , but does not know the joint distribution . Furthermore, suppose that Eve is more conservative than Indiana and does not assume that Alice’s observations are independent of Bob’s observations—how much information does Eve have for any one realisation?
It seems clear that Eve’s information should always satisfy the following two requirements. Firstly, since Alice and Bob both share their knowledge with Eve, she should have at least as much information as either of them have individually. Secondly, since Eve has less knowledge than Johnny, she should have no more information than Johnny; i.e., in contrast to Indy, Eve should never have more information than Johnny. As the following theorem shows, these two requirements uniquely determine the functional form of Eve’s information:
Theorem 1. The unique function of and that satisfies for all is Proof. Clearly, the function is lower bounded by . The upper bound is given by the minimum possible , which corresponds to the maximum allowed . For any and , the maximum allowed is , which corresponds to .□
Eve’s information is given by the maximum of Alice’s and Bob’s information, or the information content of the most surprising marginal realisation. Although we have defined Eve’s information by requiring it to be no greater than Johnny’s information, it is also clear that Eve also has no more information than Indiana. As such, Eve’s information satisfies the inequality
which is analogous to the inequality (
5) satisfied by measure. Hence, as pre-empted by the notation (and as further justified in
Section 6), Eve’s information is referred to as the
union information content. The union information content is the maximum possible information that Eve can get from knowing what Alice and Bob know—it quantifies the information provided by a joint event
when one knows the marginal distributions
and
, but does not know nor make any assumptions about the joint distribution
.
Similar to how the conditional information contents (
15) and (
16) enable us to quantify how much more information Johnny has relative to either Alice or Bob, the inequality (
22) enables us to quantify how much information Eve gets from Alice relative to Bob and vice versa, respectively,
These non-negative functions are analogous to measure on the relative complements of a pair of sets and are called the
unique information content from x relative to y, and vice versa, respectively. It is easy to see that, since Eve’s information is either equal to Alice’s or Bob’s information (or both), at least one of these two functions must be equal to zero.
The inequality (
22) also enables us to quantify how much more information Indiana has relative to Eve. Since Indiana’s assumed information is given by the sum of Alice’s and Bob’s information while Eve’s information is given by the maximum of Alice’s and Bob’s information, the difference between the two is given by the minimum of Alice’s and Bob’s information,
In contrast to the comparison between Indiana and Johnny, i.e., the mutual information content (
18), the comparison between Indiana and Eve is non-negative. As such, this function is analogous to measure on the intersection of two sets and hence will be referred to as the
intersection information content. The intersection information content is the minimum possible information that Eve could have gotten from knowing either what Alice or Bob know, and is given by the information content of the least surprising marginal realisation.
Finally, from (
21) and (
23)–(
25), it is not difficult to see that Eve’s information can be decomposed into the information that could have been obtained from either Alice or Bob, the unique information from Alice relative to Bob and the unique information from Bob relative to Alice,
Of course, as already discussed, at least one of these unique information contents must be zero.
Figure 3 depicts this decomposition for some realisation whereby Alice’s information
is greater than Bob’s information
.
To summarise thus far, both Alice and Bob share their information with Indiana and Eve, who then each interpret this information in a different way. By comparing
Figure 2 and
Figure 3, we can easily contrast their distinct perspectives. Eve is more conservative than Indiana and assumes that she has gotten as little information as she could possibly have gotten from knowing what Alice and Bob know; this is given by the maximum from Alice’s and Bob’s information, or is the information content associated with the most surprising marginal realisation observed by Alice and Bob. In effect, Eve’s conservative approach means that she pessimistically assumes that the information provided by the least surprising marginal realisation was already provided by the most surprising marginal realisation. In contrast, Indiana optimistically assumes that the information provided by the least surprising marginal realisation is independent of the information provided by the most surprising marginal realisation.
Let us now consider the information that Eve expects to get from a single realisation,
This function is called the union entropy, and quantifies the expected surprise of the most surprising realisation from either
X or
Y. Similar to how the non-negativity of the entropy (
11) follows from the non-negativity of the information content (
10), the non-negativity of the union entropy (
27) follows directly from the non-negativity of the union information content (
21)—i.e., we do not need to invoke Jensen’s inequality. Indeed, the union entropy cannot be written as a Kullback–Leibler divergence.
Since the expectation value is monotonic, and since the union information content satisfies the inequality (
22), we get that the union entropy satisfies
and hence is also analogous to measure on the union of two sets. Using this inequality, we can quantify how much more information Eve expects to get from Alice relative to Bob, or vice versa, respectively,
These functions are also analogous to measure on the relative complements of a pair of sets and hence will be called the unique entropy from
X relative to
Y, and vice versa, respectively. Crucially, and in contrast to (
23) and (
24), both of these quantities can be simultaneously non-zero; although Alice might observe the most surprising event in one joint realisation, Bob might observe the most surprising event in another and hence both functions can be simultaneously non-zero.
Now, consider how much more information Indiana expects to get relative to Eve,
This function is also analogous to measure on the intersection of two sets function will be called the intersection entropy. In contrast to the mutual information (
20), since the intersection information content (
25) is non-negative, we do not require an additional proof to show that the intersection entropy is non-negative. Moreover, the intersection entropy cannot be written as a Kullback–Leibler divergence.
Finally, similar to (
26), we can decompose Eve’s expected information into the following components,
It is important to reiterate that, in contrast to (
26), there is nothing which requires either of the two unique entropies to be zero. Thus, as shown in
Figure 3, the Venn diagram which represents the union and intersection entropy differs from that which represents the union information content.
4. Synergistic Information Content
As discussed at the beginning of the previous section, and as required in Theorem 1, one of the defining features of Eve’s information is that it is never greater than Johnny’s information,
Thus, we can compare how much more information Johnny has relative to Eve,
This non-negative function is called the
synergistic information content, and it quantifies how much more information one gets from knowing the joint probability
relative to merely knowing the marginal probabilities
and
.
Figure 4 shows how this relationship can represented using a Venn diagram. Of course, by this definition, Johnny’s information is equal to the union information content plus the synergistic information content, and hence, by using (
26), we can decompose Johnny’s information into the intersection information content, the unique information contents and the synergistic information contents,
This decomposition can be seen in
Figure 4, although it is important to recall that at least one of
and
must be equal to zero. In a similar manner, the extra information that Johnny has relative to Bob (
13) can be decomposed into the unique information content from Alice and the synergistic information content, and vice versa for the extra information that Johnny has relative to Alice (
14),
Now, recall that the mutual information content (
18) is given by Indiana’s information minus Johnny’s information. By replacing Johnny’s information with the union information content plus the synergistic information content via (
34) and rearranging using (
25), we get that the mutual information content is equal to the intersection information content minus the synergistic information content,
Indeed, this relationship can be identified in
Figure 4. Clearly, the mutual information content is negative whenever the synergistic information content is greater than the intersection information content. From this perspective, the mutual information content can be negative because there is nothing to suggest that the synergistic information content should be no greater than the intersection information content. In other words, the additional surprise associated with knowing
relative to merely knowing
and
can exceed the surprise of the least surprising marginal realisation.
Let us now quantify how much more information Johnny expects to get relative to Eve,
which we call the synergistic entropy. Crucially, although the synergistic information content is given by the minimum of the two conditional information contents, the synergistic entropy does not in general equal one of the two the conditional entropies. This is because, although Alice might observe the most surprising event in one joint realisation such that the synergistic information content is equal to Bob’s information given Alice’s information, Bob might observe the most surprising event in another realisation such that the synergistic information content is equal to Alice’s information given Bob’s information for that particular realisation. Thus, the synergistic entropy does not equal the conditional entropy for the same reason that unique entropies (
29) and (
30) can be simultaneously non-zero.
With the definition of synergistic entropy, it is not difficult to show that, similar to (
35), the joint entropy can be decomposed into the following components,
Figure 5 depicts this decomposition using a Venn diagram, and shows how the union entropy from
Figure 3 is related to the joint entropy
. Likewise, similar to (
36) and (
37), it is easy to see that conditional entropies can be decomposed as follows,
Finally, as with (
38), we can also show that the mutual information is equal to the intersection entropy minus the synergistic entropy,
Although there is nothing to suggest that the synergistic information content must be no greater than the intersection information content, we know that the synergistic entropy must be no greater than the intersection entropy because
. In other words, the expected difference between the surprise of the joint realisation and the most surprising marginal realisation cannot exceed the expected surprise of the least surprising realisation.
5. Properties of the Union and Intersection Information Content
Theorem 1 determined the function form of Eve’s information when Alice and Bob share their knowledge with her. We now wish to generalise this result to consider the situation whereby an arbitrary number of marginal observers share their information with Eve. Rather than try to directly determine the functional form, however, we proceed by considering the algebraic structure of shared marginal information.
If Alice and Bob observe the same realisation x such that they have the same information , then upon sharing we would intuitively expect Eve to have the same information . Similarly, the minimum information that Eve could have received from either Alice or Bob should be the same information . Since the maximum and minimum operators are idempotent, the union and intersection information content both align with this intuition.
Property 1 (Idempotence)
. The union and intersection information content are idempotent, It also seems reasonable to expect that Eve’s information should not depend on the order in which Alice and Bob share their information, nor should the minimum information that Eve could have received from either individual. Again, since the maximum and minimum operators are commutative, the union and intersection information content both align with our intuition.
Property 2 (Commutativity)
. The union and intersection information content are commutative, Now, suppose that Charlie is another individual who, similar to Alice and Bob, is separately observing some process, and let the random variable Z represent her observations. Say that Dan is yet another individual with whom, similar to Eve, our observers can share their information. Intuitively, it should not matter whether Alice, Bob and Charlie share their information directly with Eve, or whether they share their information through Dan. To be specific, Alice and Bob could share their information with Dan such that his information is given by , and then Charlie and Dan could subsequently share their information with Eve such that her information is given by . Similarly, Bob and Charlie could share their information with Dan such that his information is given by , and then Alice and Dan could subsequently share their information with Eve such that her information is given by . Alternatively, Alice, Bob and Charlie could entirely bypass Dan and share their information directly with Eve such that her information is given by . Since the maximum operator is associative, the union information content is the same in all three cases and hence aligns with our intuition. A similar argument can be made to show that the intersection information content is also associative.
Property 3 (Associative)
. The union and intersection information content are associative, Suppose now that Alice and Bob share their information with Dan such the information that he could have gotten from either Alice or Bob is given by
. If Alice and Dan both share their information with Eve, then Eve’s information is given by
and hence Bob’s information has been absorbed by Alice’s information. Now, suppose that Alice and Bob share their information with Dan such his information is given by
. If Alice and Dan both share their information with Eve, then the information that Eve could have gotten from either Alice or Dan is given by
Again, Bob’s information has been absorbed by Alice’s information. Both of these results are a consequence of the fact that the maximum and minimum operators are connected to each other by the absorption identity.
Property 4 (Absorption)
. The union and intersection information content are connected by absorption, Now, say that Daniella is, similar to Eve or Dan, an individual with whom our observers can share their information. Consider the following two cases: Firstly, suppose that Bob and Charlie share their information with Dan such that the information that Dan could have gotten from either Bob or Charlie is given by
. If both Alice and Dan share their information with Eve, then her information is given by
. In the second case, suppose that Alice and Bob share their information with Dan such that his information is given by
, while Alice and Charlie simultaneously share their information with Daniella such that her information is given by
. If Dan and Daniella both share their information with Eve, then the information that she could have gotten from either Dan or Daniella is then given by
. In both cases, Eve has the same information since the maximum operator is distributive,
Since the maximum and minimum operators are distributive over each other, regardless of whether Eve gets Alice’s information and Bob’s or Charlie’s information, or if Eve gets Alice’s and Bob’s information or Alice’s and Charlie’s information, Eve has the same information. The same reasoning can be applied to show that, regardless of whether Eve gets Alice’s information or Bob’s and Charlie’s information, or if Eve gets Alice’s or Bob’s information and Alice’s or Charlie’s information, Eve has the same information.
Property 5 (Distributivity)
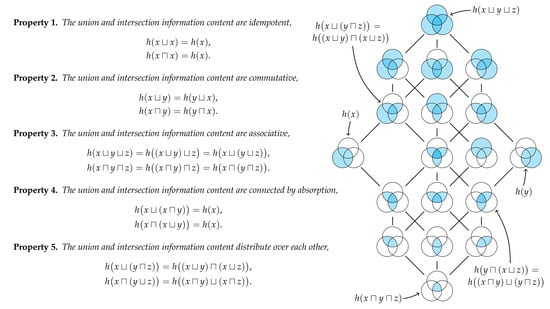
. The union and intersection information content are distribute over each other, Now, consider a set of
n individuals and let
be the joint random variable that represents their observations. Suppose that these individuals together observe the joint realisation
from
. By Property 3 and the general associativity theorem, it is clear that Eve’s information is given by
while the minimum information that Eve could have gotten from any individual observer is given by
This accounts for the situation whereby
n marginal observers directly share their information with Eve, and could clearly be considered for any subset
of the observers
. We now wish to consider all of the distinct ways that these marginal observers can share their information indirectly with Eve. As the following theorem shows, Properties 1–5 completely characterise the unique methods of marginal information sharing.
Theorem 2. The marginal information contents form a join semi-lattices under the max operator. Separately, the marginal information contents form a meet semi-lattice under the min operator.
Proof. Properties 1–3 completely characterise semi-lattices [
16,
17]. □
Theorem 3. The marginal information contents form a distributive lattice under the max and min operators.
Proof. From Property 4, we have that the semi-lattices
and
are connected by absorption and hence form a lattice
. By Property 5, this is a distributive lattice [
16,
17].□
Each way that a set of
n observers can share their information with Eve such that she has distinct information corresponds to an element in partially ordered set, or more specifically the free distributive lattice on
n generators [
16].
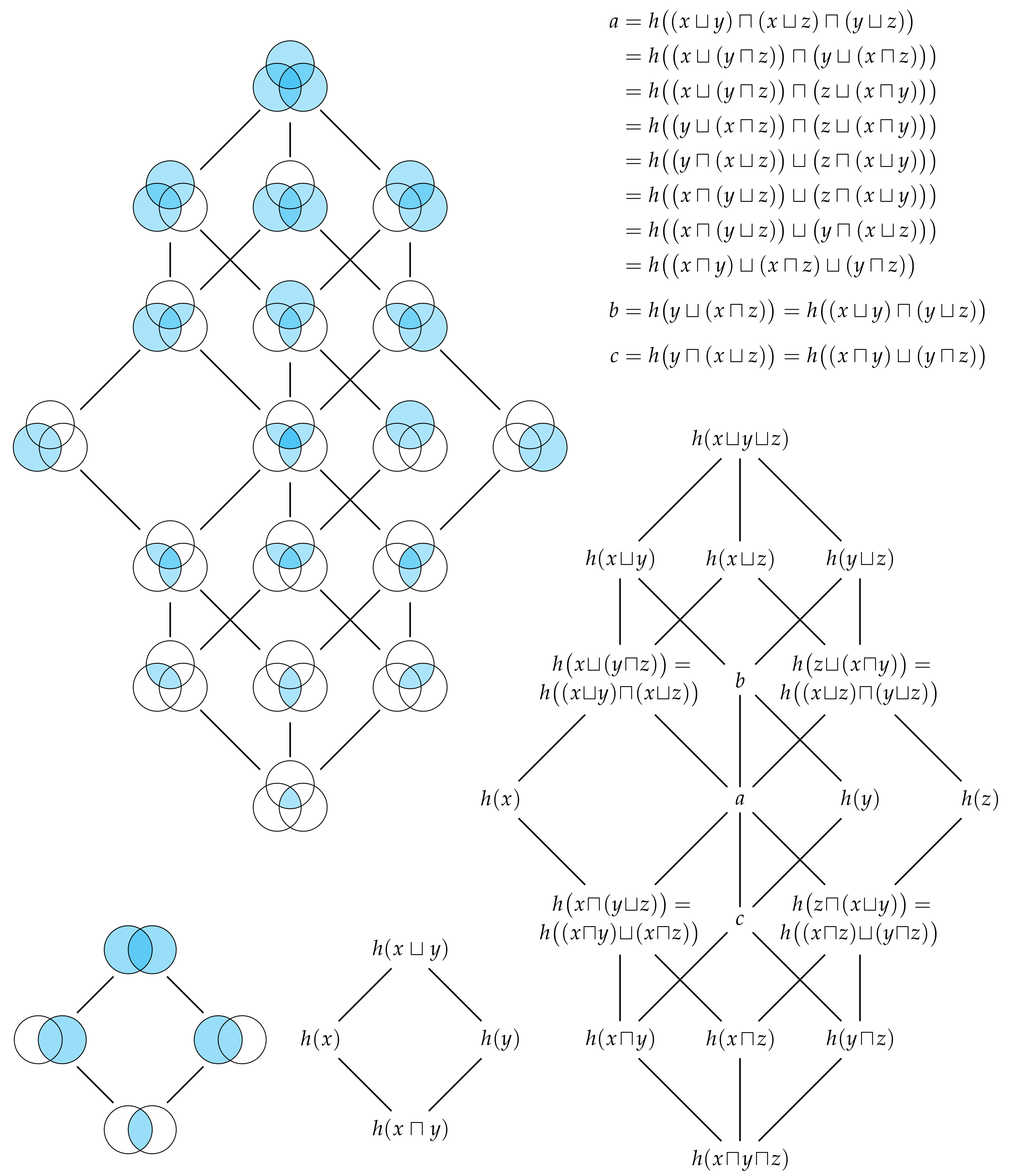
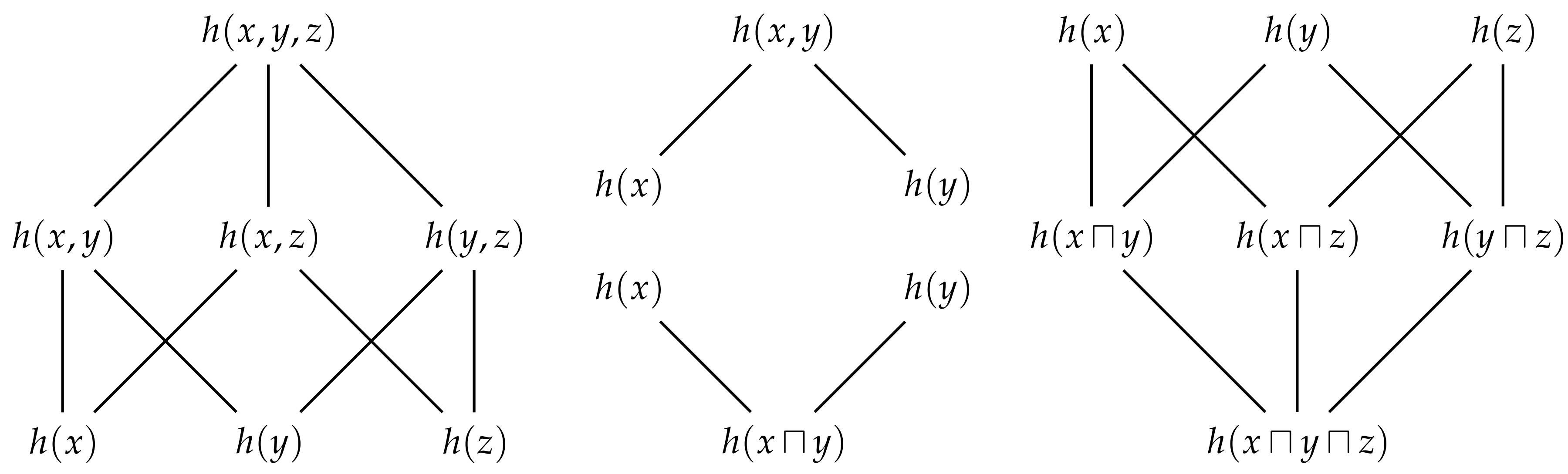
Figure 6 shows the free distributive lattices generated by
and
observers. The number of elements in this lattice is given by the (
n)th Dedekind number (p. 273 [
18]) (see also [
19]). By the fundamental theorem of distributive lattices (or Birkhoff’s representation theory), there is isomorphism between the union information content and set union, and between the intersection information content and set intersection [
16,
17,
20,
21]. It is this one-to-one correspondence that justifies our use of the terms union and intersection information content for
n variables in general. Every identity that holds in a lattice of sets will have a corresponding identity in this distributive lattice of information contents.
Figure 6 also depicts the sets which correspond to each term in the lattice of information contents. Just as the cardinality of sets is non-decreasing as we consider moving up through the various terms in a lattice of sets, Eve’s information is non-decreasing as we moving up through the various terms in the corresponding lattice of information contents. In particular, we can quantify the unique information content that Eve gets from one method of information sharing relative to any other method that is lower in the lattice.
Every property of the union and intersection information content that we have considered thus far has been directly inherited by the union and intersection entropy. However, there is one final property is not inherited by the entropies. If Alice and Bob share their information with Eve, then Eve’s information is given by either Alice’s or Bob’s information, and similar for the information that Eve could have gotten from either Alice or Bob. As the subsequent theorem shows, this property enables us to greatly reduce the number of distinct terms in the distributive lattice for information content since any partially ordered set with a connex relation forms a total order.
Property 6 (Connexity)
. The union and intersection information content are given by at least one of 7. Multivariate Information Decomposition
In
Section 4, we use the shared marginal information from
Section 3 to decompose the joint information content into four distinct components. Our aim now is to use the generalised notion of shared information from the previous section to produce a generalised decomposition of the joint information content. To begin, suppose that Johnny observes the joint realisation
while Alice, Bob and Charlie observe the marginal realisations
x,
y and
z, respectively, and say that Alice, Bob and Charlie share their information with Eve such that her information is given by
. Clearly, Johnny has at least as much information as Eve,
Thus, we can compare how much more information Johnny has relative to Eve,
This non-negative function generalises the earlier definition of the synergistic information content (
34) such that it now quantifies how much information one gets from knowing the joint probability
relative to merely knowing the three marginal probabilities
,
and
.
Figure 8 shows how this relationship can be represented using a Venn diagram.
Now, consider three more observers, Joan, Jonas, and Joanna, who observe the joint marginal realisations
,
and
, respectively. Clearly, these additional observers greatly increase the number of distinct ways in which marginal information might be shared with Eve. For example, if Alice and Joanna share their information, then Eve’s information is given by
. Alternatively, if Joan and Jonas share their information, then Eve’s information is given by
. Perhaps most interestingly, if Joan, Jonas and Joanna share their information, then Eve’s information is given by
. Moreover, we know that Johnny has at least as much information as Eve has in this situation,
Thus, by comparing how much more information Johnny has relative to Eve in this situation, we can define a new type of synergistic information content that quantifies how much information one gets from knowing the full joint realisation to merely knowing all of the pairwise marginal realisations,
Of course, these new ways to share joint information are not just restricted to the union information. If Alice and Joanna share their information, then the information that Eve could have gotten from either is given by
. It is also worthwhile noting that this quantity is not less than the information that Eve could have gotten from either Alice’s information or Bob’s and Charlie’s information,
Thus, we can also consider defining new types of synergistic information content associated with these this mixed type comparisons,
However, it is important to note that this quantity does not equal
.
With all of these new ways to share joint marginal information, it is not immediately clear how we should decompose Johnny’s information. Nevertheless, let us begin by considering the algebraic structure of joint information content. From the inequality (
12), we know that any pair of marginal information contents
and
are upper-bounded by the joint information content
. It is also easy to see that the joint information content is idempotent, commutative and associative. Together, these properties are sufficient for establishing that the algebraic structure of joint information content is that of a join semi-lattice [
16] which we denote by
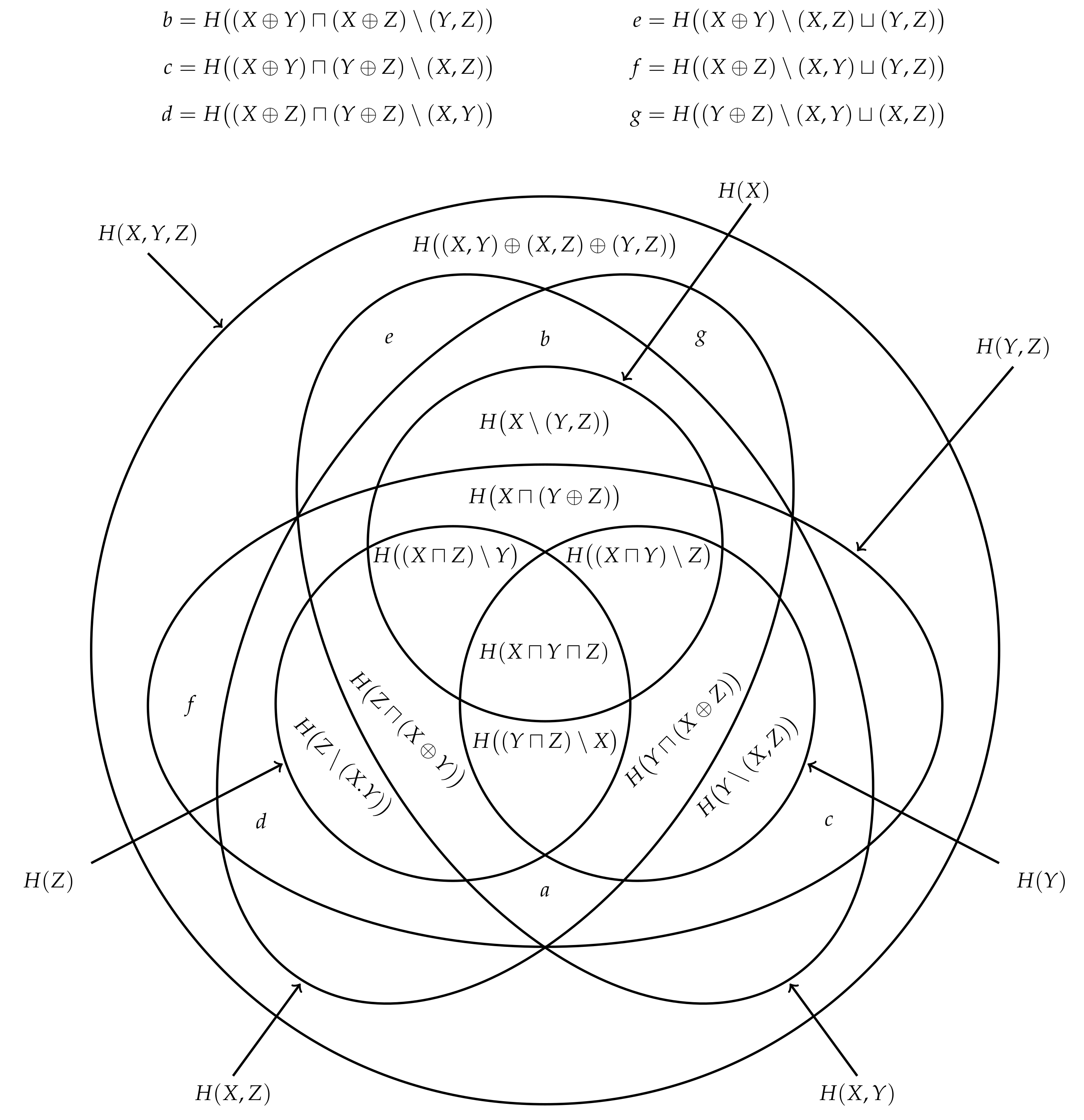
.
Figure 9 shows the semi-lattices generated by
and
observers.
We now wish to establish the relationship between this semi-lattice of joint information content
and the distributive lattice of shared marginal information
. In particular, since our aim is to decompose Johnny’s information, consider the relationship between the join semi-lattice
and the meet semi-lattice
, which is also depicted in
Figure 9. In contrast to the semi-lattice of union information content
, the semi-lattice
is not connected to the semi-lattice
. Although the intersection information content absorbs the joint information content, since
for all
and
, the joint information content does not absorb the intersection information content since
is equal to
for
, i.e., is not equal to
as required for absorption. Since the the join semi-lattice
is not connected to the meet semi-lattice
by absorption, their combined algebraic structure is not a lattice.
Despite the fact that the overall algebraic structure is not a lattice, there is a lattice sub-structure
within the general structure. This substructure is isomorphic to the redundancy lattice from the partial information decomposition [
23] (see also [
24]), and its existence is a consequence of the fact that the intersection information content absorbs the joint information content in (
68). To identify this lattice, we must first determine the reduced set of elements
upon which it is defined. We begin by considering the set of all possible joint realisations which is given by
where
. Elements of this set
correspond to the elements from the join semi-lattice
, e.g., the elements
and
correspond to
and
, respectively. In alignment with Williams and Beer [
23], we call the elements of
sources and denote them by
. Next, we consider set of all possible
collections of sources which are given by the set
. Each collection of sources corresponds to an element of the meet semi-lattice
, or a particular way in which we can evaluate the intersection information content of a group of joint information contents. For example, the collections of sources
and
correspond to the
and
, respectively. Not all of these collections of sources are distinct, however. Since the intersection information content absorbs the joint information content, we can remove the element
corresponding to
as this information is already captured by the element
corresponding to
. In general, we can remove any collection of sources that corresponds to the intersection information content between a source
and any source
that is in the down-set
with respect to the join semi-lattice
. (A definition of the down-set can be found in [
17]. Informally, the down-set
is the set of all elements that precede
.) By removing all such collections of sources, we get the following reduced set of collections of sources,
Formally, this set corresponds to the set of antichains on the lattice
, excluding the empty set [
23].
Now that we have determined the elements upon which the lattice sub-structure is defined, we must show that they indeed form a lattice. Recall that when constructing the set
, we first considered the ordered elements of the semi-lattice
and then subsequently consider the ordered elements of the semi-lattice
. Thus, we need to show that these two orders can be combined together into one new ordering relation over the set
. This can be done by extending the approach underlying the construction of the set
to consider any pair of collections of sets
and
from
. In particular, the collection of sets
precedes the collection of sets
if and only if for every source
from
, there exists a source
from
such that
is in the down-set
with respect to the join-semi-lattice
, or formally,
The fact that
forms a lattice was proved by Crampton and Loizou [
25,
26] where the corresponding lattice is denoted
in their notation. Furthermore, they showed that this lattice is isomorphic to the distributive lattices, and hence the number of elements in the set
for
n marginal observers is also given by the (
n)th Dedekind number (p. 273 [
18]) (see also [
19]). Crampton and Loizou [
26] also provided the meet ∧ and join ∨ operations for this lattice, which are given by
where
denotes the set of minimal elements of
with respect to the semi-lattice
. (A definition of the set of minimal elements can be found in [
17]. Informally,
is the set of sources of
that are not preceded by any other sources from
with respect to the semi-lattice
.) This lattice
is the aforementioned sub-structure that is isomorphic to the
redundancy lattice from Williams and Beer [
23]. However, as it is a lattice over information contents, it is actually equivalent to the specificity lattice from [
27].
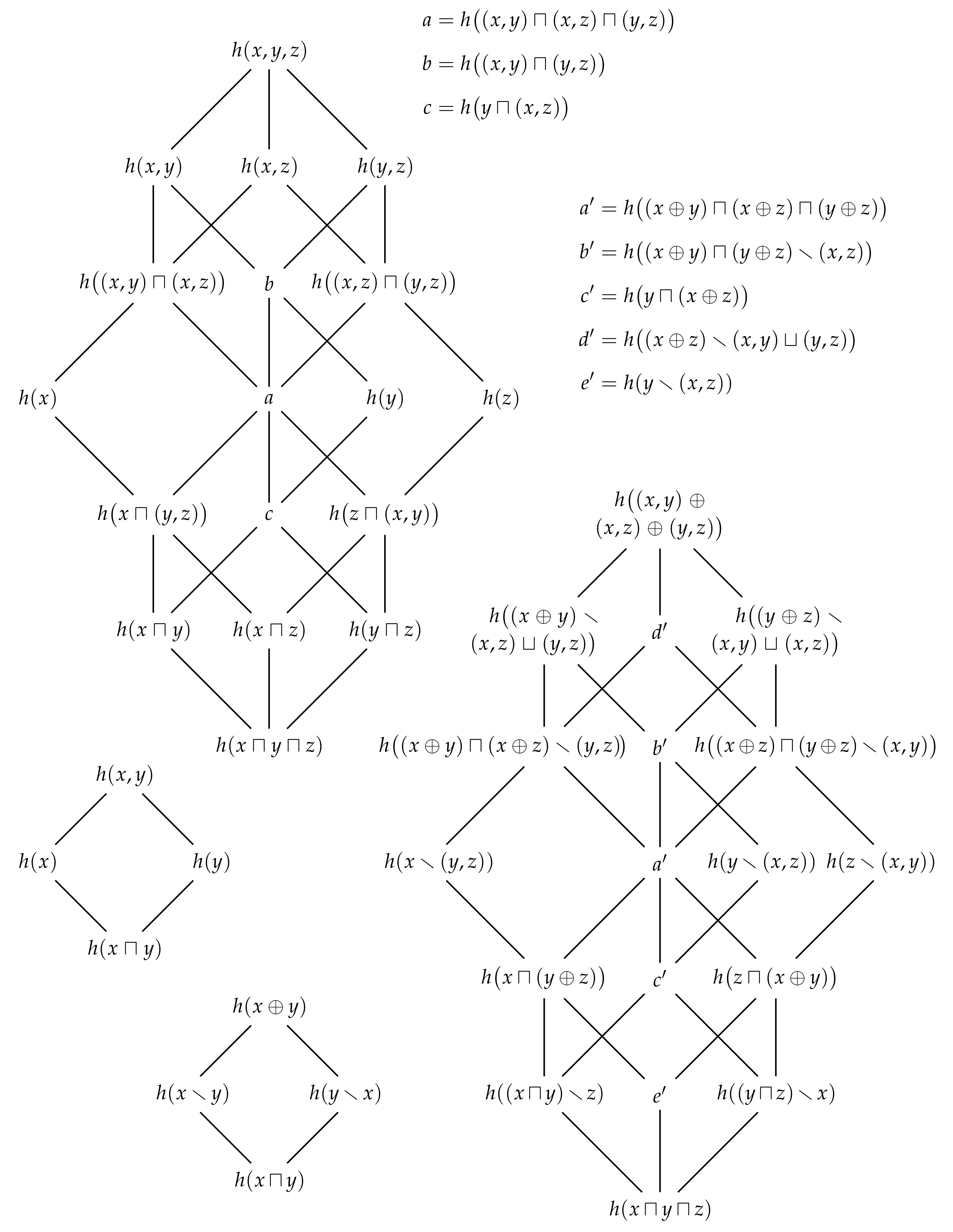
Figure 10 depicts the redundancy lattice of information contents for
and
marginal observers.
Similar to how Eve’s information is non-decreasing as we move up through the terms of the distributive lattice of shared information, the redundancy lattice of information contents enables to see that, for example, the information that Eve could have gotten from either Alice or Joanna
is no less than the information that Eve could have gotten from Alice or Bob
. Thus, by taking the information
associated with the collection of sources
from
and subtracting from it the information
associated with any collection of sources
from the down-set
, we can evaluate the unique information
provided by
relative to
. Moreover, as per Williams and Beer [
23], we can derive a function that quantifies the
partial information content associated with the collection of sources
that is not available in any of the collections of sources that are covered by
. (The set of collections of sources that are covered by
is denoted
. A definition of the covering relation is provided in [
17]. Informally,
is the set collections of sources that immediately precede
.) Formally, this function corresponds to the Möbius inverse of
h on the redundancy lattice
, and can be defined implicitly by
By subtracting away the partial information terms that strictly precede
from both sides, it is easy to see that the partial information content
can be calculated recursively from the bottom of the redundancy lattice of information contents,
As the following theorem shows, the partial information content can be written in closed-form.
Theorem 5. The partial information content is given by where each is a collection of sets from .
Proof. For
, define the set-additive function
From (
73), we have that
. The partial information can then by subtracting the set additive on the down-set
from the set additive function on the strict down-set
,
By applying the principle of inclusion-exclusion [
21], we get that
For any lattice
L and
, we have that
is equal to
(p. 57 [
17]), and since the meet operation is given by the intersection information content, we have that
where the final step has been made using (
61) and (
76).□
The closed-form solution (
75) from Theorem 5 is the same as the closed-form solution presented in Theorem A2 from Finn and Lizier [
27]. This, together with the aforementioned fact that the lattice
is equivalent to the specificity lattice, means that each partial information content
is equal to the partial specificity
from (A22) of [
27]. As such, the partial information decomposition present in this paper is equivalent to the pointwise partial information decomposition presented in [
27].
Let us now use the closed-form solution (
75) from Theorem 5 to evaluate the partial information contents for the
redundancy lattice of information contents. Starting from the bottom, we get the intersection information content,
followed by the unique information contents,
and, finally, the synergistic information content,
It is clear that these partial information contents recover the intersection, unique and synergistic information contents from
Section 3 and
Section 4. Moreover, by inserting these partial terms back into (
73) for
, we recover the earlier decomposition (
35) of Johnny’s information,
Of course, our aim is to generalise this result such that we can decompose the joint information content for an arbitrary number of marginal realisations. This can be done by first evaluating the partial information contents over the redundancy lattice corresponding to
n marginal realisations, and then subsequently inserting the results back into (
73) for
. For example, we can invert the
redundancy lattice of information contents which yields the partial information contents shown in
Figure 10. (The inversion is evaluated in the
Appendix A.) When inserted back into (
73), we get the following decomposition for Johnny’s information,
Finally, we can also consider taking the expectation value of each term in the redundancy lattice of information contents. Since the expectation is a linear and monotonic operator, the resulting expectation values will inherit the structure of the redundancy lattice of information contents and so form a redundancy lattice of entropies, i.e.,
Figure 10 with
x,
y,
z and
h replaced by
X,
Y,
Z and
H, respectively. By inverting the
redundancy lattice of entropies, we can recover the decomposition (
40) from
Figure 5. Furthermore, inverting the
lattice generalises this result and is depicted in
Figure 11.
8. Union and Intersection Mutual Information
Suppose that Alice, Bob and Johnny are now additionally and commonly observing the variable
Z. When a realisation
occurs, Alice’s information for
z is given by the conditional information content
, while Bob’s conditional information is given by
and Johnny’s conditional information is given by
. By using the same argument as in
Section 3, it is easy to see that Eve’s conditional information given
z is given by the conditional union information content,
Likewise, we can define the conditional unique information contents and conditional intersection information content, respectively,
Furthermore, since Johnny’s conditional information
is no less than Eve’s conditional information content
, we can also define the conditional synergistic information content,
Similar to (
35), we can decompose Johnny’s conditional information
into the following components,
Moreover, similar to (
38), the conditional mutual information content is equal to the difference between the conditional intersection information content and the conditional synergistic information content,
Notice that all of the above definitions directly correspond to the definitions of the unconditioned quantities, with all probability distributions conditioned on
z here.
Let us now consider how much information each of our observers have about the commonly observed realisation
z. The information that Alice has about
z from observing
x is given by the mutual information content,
Similarly, Bob’s information about
z is given by
, while Johnny’s information is given by the joint mutual information content
. Thus, the question naturally arises—are we able to quantify how much information Eve has about the realisation
z from knowing Alice’s and Bob’s shared information?
Clearly, we could consider defining the union mutual information content,
It is important to note that, while the mutual information can be defined in three different ways
, there is only one way in which one can define this function. (Indeed, this point aligns well with our argument based on exclusions presented in [
28].) Similar to (
94), we could consider respectively defining the unique mutual information contents, the intersection mutual information content and synergistic mutual information content,
As with the mutual information content (
18), there is nothing to suggest that these quantities are non-negative. Of course, the mutual information or expected mutual information content (
20) is non-negative. Thus, with this in mind, consider defining the union mutual information
However, there is nothing to suggest that this function is non-negative. Consequently, it is dubious to claim that this function represents Eve’s expected information about
Z, and is similarly fallacious to say that Eve’s information about
z is given by the union mutual information content (
94). Indeed, by inserting the definitions (
21) and (
86) into (
94), it is easy to see why it is difficult to interpret these functions,
That is, the union mutual information content can mix the information content provided by one realisation with the conditional information content provided by another. Thus, there is no guarantee that this function’s expected value will be non-negative. It is perhaps best to interpret this function as being a difference between two surprisals, rather than a function which represent information. Of course, similar to the multivariate mutual information (
9), the union mutual information can be used a summary quantity provided one is careful not to misinterpret its meaning. The same is true for the unique mutual informations, intersection mutual information and synergistic mutual information, which we can similarly define,
Despite lacking the clear interpretation that we had for the information contents, these functions share a similar algebraic structure. For example, by using (
35) and (
91), we can decompose the mutual information content into the following components,
which is similar to the earlier decomposition of the joint entropy (
35). Moreover, similar to (
38), by using (
38) and (
92), we get that the multivariate mutual information content is given by the difference between the intersection mutual information content and the synergistic mutual information content,
Of course, since the expectation value is a linear operator, both of these results can be carried over to the joint mutual information. Hence, the mutual information can be decomposed into the following components,
while the the multivariate mutual information is equal to the intersection mutual information minus the synergistic mutual information,
This latter result aligns with Williams and Beer’s prior result that the multivariate mutual information conflates redundant and synergistic information (Equation (
14) [
23]).
9. Conclusions
The main aim of this paper has been to understand and quantify the distinct ways that a set of marginal observers can share their information with some non-observing third party. To accomplish this objective, we examined the distinct ways in which two marginal observers, Alice and Bob, can share their information with the non-observing individual, Eve, and introduced several novel information-theoretic quantities: the union information content, which quantifies how much information Eve gets from the Alice and Bob; the intersection information content, which quantifies how much information Eve could have gotten from either Alice or Bob; and the unique information content, which quantifies how much information Eve gets from Alice relative to Bob, and vice versa. We then investigated the algebraic structure of these new measures of shared marginal information and showed that the structure of shared marginal information is that of a distributive lattice. Next, by using the fundamental theorem of distributive lattices, we showed that these new measures are isomorphic to the various unions and intersections of sets. This isomorphism is similar to Yeung’s correspondence between multivariate mutual information and signed measure [
6,
7]. However, in contrast to Yeung’s correspondence, the measures of information content presented in this paper are non-negative and maintain a clear operational meaning regardless of the number of realisations or variables involved. (This is, of course, excepting the mutual information contents presented in
Section 8, which are not non-negative.)
The appearance of a lattice structure within the context of information theory is by no means novel. Han [
12] developed a lattice-theoretic description of the entropy over a Boolean lattice generated by a set of random variables. This lattice encapsulates all linear sums and differences of the basic information-theoretic quantities, i.e., entropy, conditional entropy, mutual information and conditional mutual information. Moreover, this lattice structure captures several of the existing multivariate generalisations of mutual information [
29], including the aforementioned multivariate mutual information (
9) (which is also known as the interaction information [
10], amount of information [
2] or co-information [
11]), the total correlation [
30] (which is also known as the multivariate constraint [
31], multi-information [
32] or integration [
33]), the dual total correlation [
12] (which is also known as binding information [
34]) and the novel measure of multivariate mutual information defined by Chan et al. [
29] (see Han [
12] and Chan et al. [
29] for further details). Similar to the lattice of shared marginal information content, Han’s lattice is distributive—indeed, on a fundamental level, it is this algebraic structure that enables Yeung [
6,
7] to establish a correspondence with signed measure. Nevertheless, there two important differences to note between Han’s information lattice and the lattice of shared marginal information content: Firstly, Han’s lattice is based upon the entropies of random variables rather than the information content of realisations. In principle, there is no reason why one could not consider the information content of a Boolean lattice generated by a set of realisations (although the mutual information content would not be non-negative). Secondly, the Möbius inverse on Han’s information lattice yields the multivariate mutual information (
9), which is not non-negative. In contrast, the partial information contents (
75) that result from the Möbius inversion of the lattice of shared marginal information content are non-negative. Thus, in contrast to the multivariate mutual information, the new measures of multivariate information presented in this paper maintain their operational meaning for any number of random variables.
Similar to Han, Shannon [
35] introduced his own information lattice, although it is based upon the notion of common information. In comparison to Shannon’s other work, this paper is not well recognised. Indeed, this common information was later independently proposed and studied by Gács and Körner [
36]. Shannon’s original paper is relatively brief; however, Li and Chong [
37] expanded upon Shannon’s discussion by formalising his argument in terms of
-algebras and sample space partitions (see also [
38]). To be specific, they described a random variable
X as “being-richer-than” another random variable
Y if the former’s sample space partition is finer than the latter’s sample space partition. Moreover, if their
-algebras coincide, then two random variables are said to be informationally equivalent. This relation naturally forms a partial order over a set of random variables. For all
X and
Y, the joint variable
is the poorest amongst all of the variables that are richer than both
X and
Y. Conversely, one can define a random variable
Z that is the richest amongst all of the variables that are poorer than both
X and
Y. The entropy of this common variable
Z defines the aforementioned common information. In contrast to the joint variable
, it is relatively difficult to characterise the common variable
Z [
36,
37,
39]. Nevertheless, its existence is sufficient for the definition of Shannon’s information lattice [
35,
37]. There are several features that distinguish this lattice from the lattice of shared marginal information. Firstly, similar to Han’s information lattice, the joint entropy and common information are defined in terms of entire random variables, rather than the information content of realisations. Secondly, even if we were to restrict ourselves to the comparing Shannon’s information lattice to the lattice of shared marginal entropy, the meet and join operations for these lattices are fundamentally different. We have already discussed the between their respective join operations, i.e., the joint entropy and union entropy, in
Section 3 and
Section 4. If we consider their respective meet operations, we get the common information is relatively restrictive compared to the intersection entropy, due to the fact that the common information requires one to identify the common random variable
Z. This follows from the fact that the intersection information is greater than or equal the mutual information (
43), which is in turn greater than or equal to the common information [
36]. Finally, in general, Shannon’s information lattice is not distributive, nor is it even modular [
35,
37]. Thus, unlike the lattice of share marginal information or Han’s information lattice, the fundamental theorem of distributive lattice is not applicable, and hence Shannon’s information lattice does inherit any set-like identities.
The secondary objective of this paper has been to understand and demonstrate how we can use the measures of shared information content to decompose multivariate information. We began by comparing the union information content to the joint information content and used this comparison to define a measure of synergistic information content that captures how much more information a full joint observer, Johnny, has relative to an individual, Eve, who knows which joint realisation has occurred, but only knows the marginal distributions. We showed how one can use this measure, together with the measures of shared information content, to decompose the joint information content. We then compared the algebraic structure of joint information to the lattice structure of shared information, and showed how one can find the redundancy lattice from the partial information decomposition [
23] embedded within this larger algebraic structure. More specifically, since this paper considers information contents, this redundancy lattice is actually same as the specificity lattice from pointwise partial information decomposition [
27,
28]. This observation connects the work presented in this paper to the existing body of theoretical literature on information decomposition [
23,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62], and its applications [
63,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75,
76,
77,
78,
79,
80,
81,
82,
83,
84,
85,
86]. (For a brief summary of this literature, see [
24].) Nevertheless, in contrast to the pointwise partial information decomposition [
27,
28], most of these approaches aim to decompose the average mutual information rather than the information content. The ability to decompose information content, and pointwise mutual information, provides a unique perspective on multivariate dependency.
To our knowledge, the only other approach that attempts to provide this pointwise perspective is due to Ince [
87]. Ince’s approach proposes a method of information decomposition based upon the entropy, but can be applied to the information content (or in Ince’s terminology, the local entropy). Of particular relevance to this paper, Ince obtains a result that is equivalent to (
38) whereby the mutual information content is equal to the redundant information content minus the synergistic information content (Equation (
5) [
87]). However, Ince’s definition of redundant information content differs from that of the intersection information content in (
38). To be specific, it is based upon the sign of the multivariate mutual information content (or pointwise co-information), which is interpreted as a measure of “the set-theoretic overlap” of multiple information contents (or local entropies) (p. 7 [
87]). However, as discussed in
Section 1, this set-theoretic interpretation of the multivariate mutual information (co-information) is problematic. To account for these difficulties, Ince disregards the negative values, defining the redundant information content to equal to the multivariate mutual information when it is positive, and to be zero otherwise.
There are several avenues of inquiry for which this research will yield new insights, particularly in complex systems, neuroscience and communications theory. For instance, these measures might be used to better understand and quantify distributed intrinsic computation [
66,
79]. It is well known that that dynamics of individual regions in the brain depend synergistically on multiple other regions; synergistic information content might provide a means to quantify such dependencies in neural data [
69,
77,
88,
89,
90]. Furthermore, these measures might be helpful for quantifying the synergistic encodings used in network coding [
7]. Finally, it is well-known that many biological traits are not dependent on any one gene, but rather are synergistically dependent on two or more genes, and the decomposed information provides a means to quantify the unique, redundant and synergistic dependencies between a trait and a set of genes [
91,
92,
93,
94].



{kind=link}
{kind=link}
{kind=link}
{kind=link}
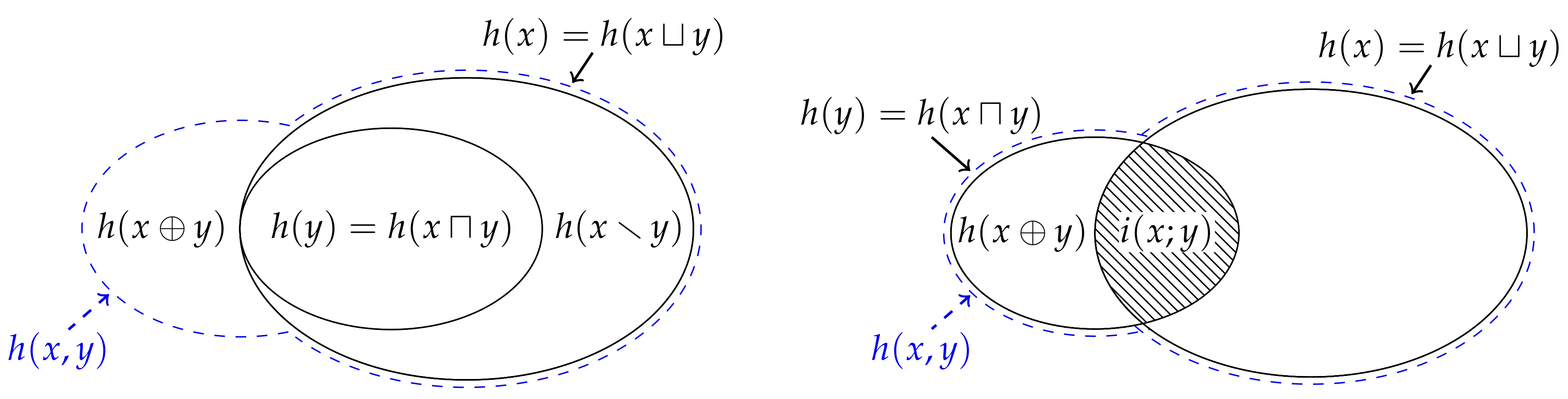{kind=link}
{kind=link}
{kind=link}
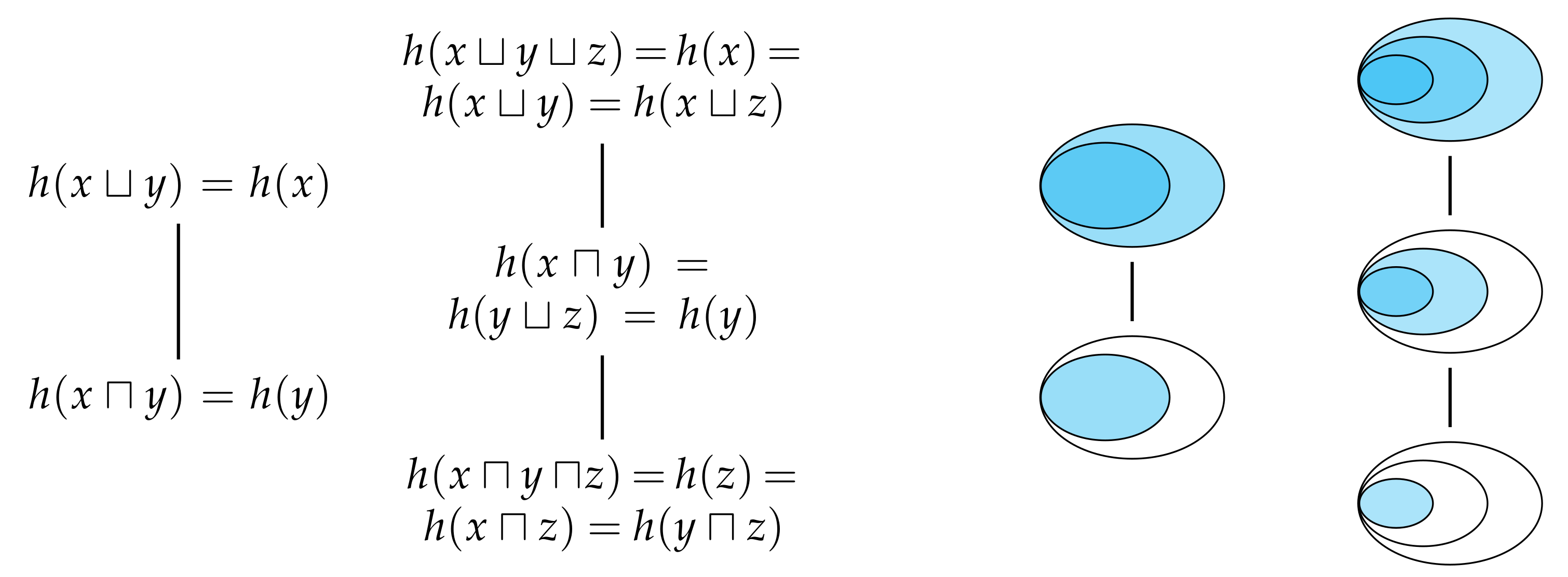{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










