1. Introduction
Bipolar Disorder (BD) is a chronic mental illness with a prevalence of approximately 1–2% [
1,
2]. It has high heritability rate and equal distribution across both genders [
3]. The main symptom is the recurrent changing of symptomatic episodes of depression or of elevated mood (mania) with non-symptomatic (remission) periods [
4]. The factors contributing to relapse in BD are not yet clearly understood, but it has been suggested that there is an association with the dysregulation of circadian rhythm and sleep [
5,
6].
There have been many attempts to rate or quantify the level of depression or mania [
7]. The ultimate goal is to evaluate the effects of treatment. Most of these approaches are based on a set of psychiatric symptoms, as those described in the comprehensive study [
8]. In this work, the 17 most commonly found symptoms in depression were first identified. Subsequently, a depression scale was created using 10 out of these 17 symptoms, those that exhibited the largest variation with treatment, and the highest correlation with changes. A similar rating approach could be applied to BD, but, in the case of BD, it is more important at first to distinguish between the three mood states. Such technical approach could be more convenient in this case than a classical psychiatric approach.
The three possible episodes: depression (dep), mania (man), and remission (rem) are hypothesized to be linked to different degrees and patterns of physical activity [
9]. Taking advantage of all the disparity of wearables available nowadays, with actigraphy monitoring and recording capabilities, it is reasonable to assume that a suitable analysis of the resulting actigraphy time series could become a reliable tool for diagnosis and assessment in BD.
An actigraph is a wrist-worn device used for inexpensive evaluation of sleep and circadian rhythms [
10,
11,
12] in common conditions (ambulatory patients mainly). In general, motor activity measurement or actigraphy can be used for a disparity of clinical purposes: to quantify physical activity, in chronobiology applications, to detect sleep patterns and stages, and many more that are related to health and diseases [
10]. For example, and specifically in the case of BD, the dysregulation of rhythmicity that is connected to BD and the Krane–Gartiser actigraphy study described in [
9] suggested that the complexity of activity differs among mood episodes. However, the short duration of the actigraphy follow-up period in most of these studies poses the main challenge in comparing data from symptomatic periods, since they occur quite rarely [
2] (once in every two years).
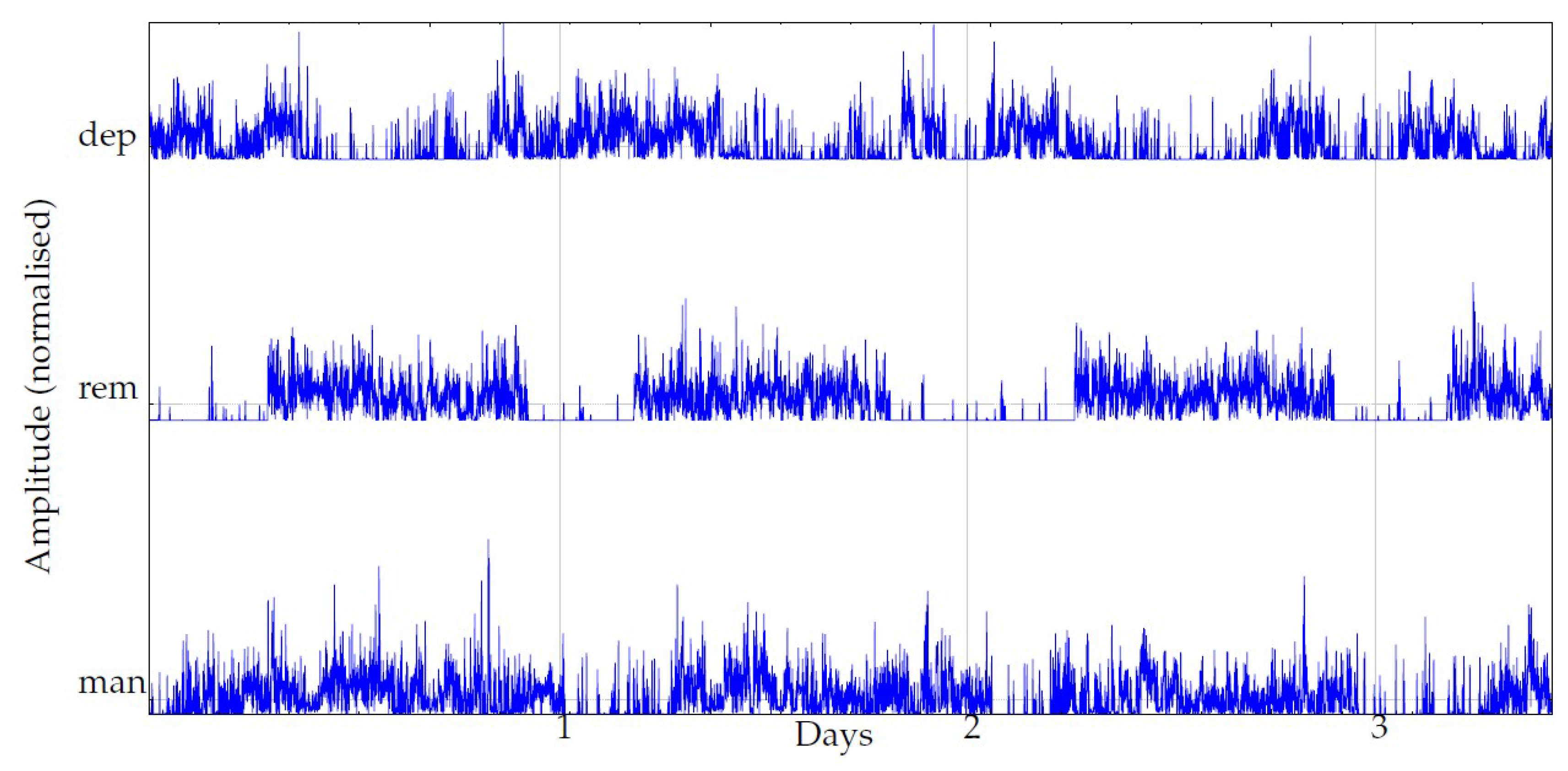
We devised a study to compare actigraphy recordings from in vivo symptomatic mood episodes of outpatients with a long follow-up period (up to two years). Using this new scheme, we were able to explore actigraphy data from remission periods as well as relapse episodes of mania and depression, gaining new insight into disease progression and outcome.
However, manual inspection of these long-term records is cumbersome and error prone. The time series are very noisy and the important information might be scarce and blurred by artifacts or other activity aspects independent of the disease state. Because the use of non-linear methods to expose hidden characteristics of time series has proven to be a very powerful tool in similar frameworks, we studied the feasibility of such methods in this new signal classification task at hand. Recent works have already pointed in that same direction, such as [
13]. In this work, 106 bipolar I type patients, 73 unaffected siblings, and 76 control subjects with valid actigraphy and sleep diary data for at least eight days were included in the analysis. This analysis was based on Detrended Fluctuation Analysis [
14], using six time windows. The results gave evidence of significant differences between control and bipolar patients, but no differences between depressive or manic symptoms were found in the patients group.
There are many more non-linear signal analysis methods described in the scientific literature. We first explored the most promising methods: Sample Entropy (SampEn) [
15], Permutation Entropy (PE) [
16], and a few derived methods that apparently yield a better classification performance [
17], quantified in terms of accuracy. Some of these methods are Weighted PE (WPE) [
18], Bubble Entropy (BE) [
19] and Slope Entropy (SlopEn) [
20], and they have the theoretical advantage of using more than a single source of information, mainly amplitude and ordinal information. From this exploratory analysis, we chose the final method according to the highest classification performance achieved, in this case SlopEn. This performance has been recently confirmed in another classification study [
21].
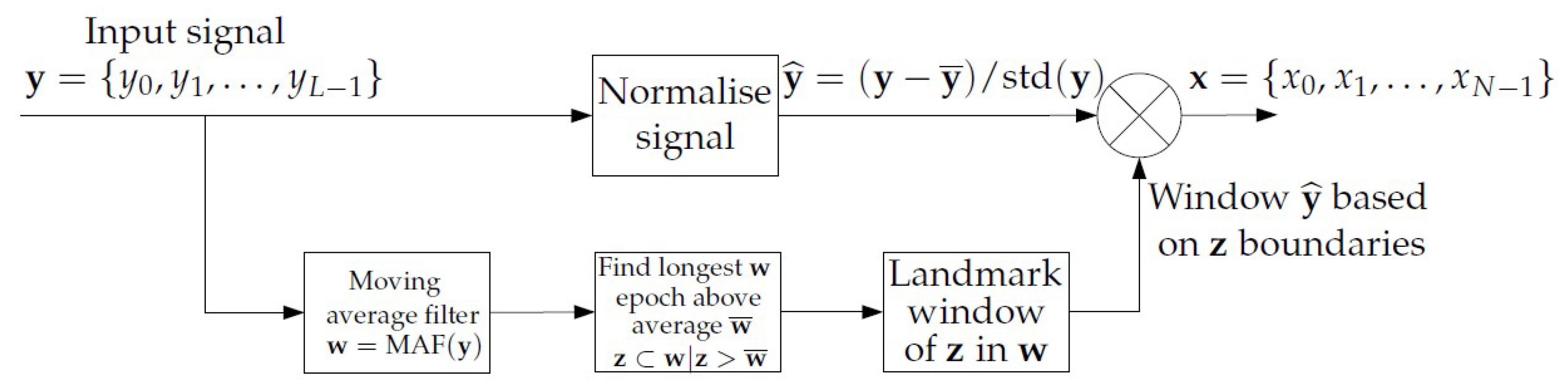
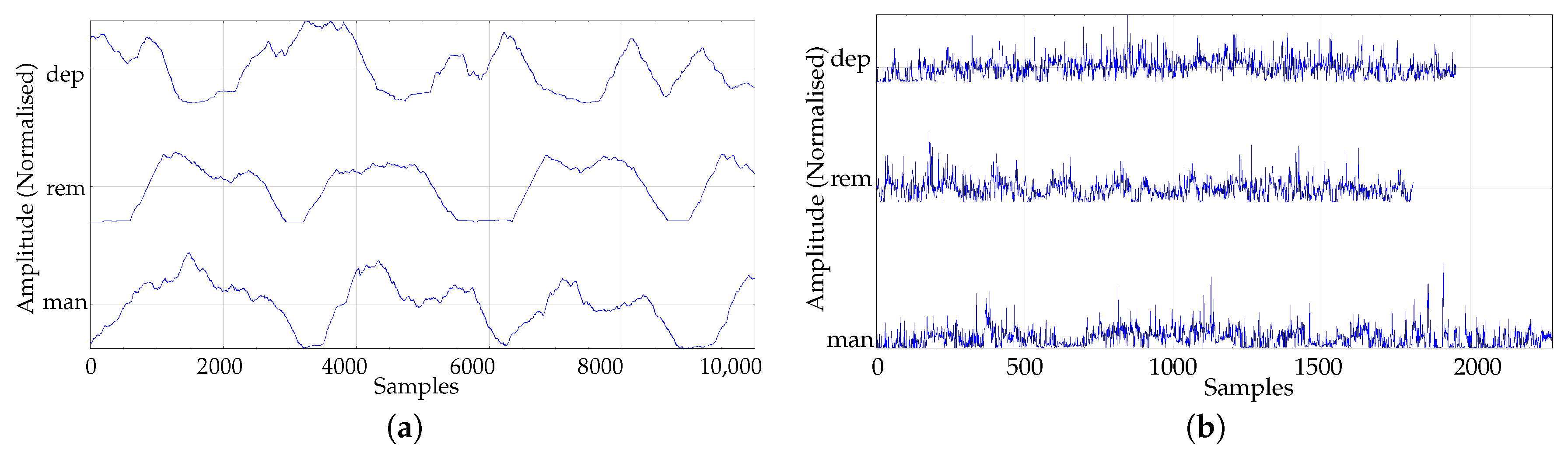
A preprocessing stage was also included in order to improve the quality of the data to be analysed. This preprocessing isolated the epochs of greatest activity and used them for classification purposes based on SlopEn, omitting periods of no-activity (sleep mainly) or with too short activity.
Figure 1 shows a general diagram of the proposed method.
According to the achieved results, the method can robustly distinguish between dep and man records, with an accuracy higher than 70% in most cases and, less robustly, yet still statistically significant, for dep–rem and man–rem (61% and 63%, respectively). These promising results arguably entail a new line of research worth exploring, with a lot of room for improvement both in terms of signal acquisition (more stable and longer periods of activity, better separation of activity, and no-activity epochs), and signal processing (more optimised entropy measures, better input parameter settings).
3. Experiments and Results
The first stage of the experiments was an exploratory analysis using several entropy calculation methods in order to choose the approach most likely to be successful in the difficult task of finding significant differences among the three classes available (grid search parameter values), analysed on a two by two basis.
Table 1 shows the classification accuracy results of this exploratory analysis.
Because the best performance was achieved using SlopEn, this was the method finally configured for a general classification analysis (statistically significant differences in all comparisons), although, on a single case-by-case basis, there were specific higher accuracies. In order to keep the computational burden of this configuration within reasonable limits, parameters
m and
were kept constant, and only
was varied, from 0.10 up to 0.90, in 0.10 steps.
Table 2 depicts the performance achieved, omitting the intermediate
values that did not provide significant results, until
.
Table 3 shows a finer tuning of the SlopEn parameters. Once the region 0.80–0.90 was considered to be the optimal region, since it was the only region with statistically significant results in all cases,
was varied in 0.01 steps between 0.80 and 0.95 for further optimisation. All of the additional values tested also yielded significant results for the three classification problems addressed. However, the results for
seemed to slightly be above the others, and this was the parameter value finally chosen for the later experiments. For this configuration, and after normalising the SlopEn results by the maximum SlopEn value obtained in all the time series (to keep the values within the 0–1 range [
39]), the entropy values for each class were
for rem,
for dep, and
for man. Anyway, any other configuration would have been equally acceptable.
As stated in
Section 2.1, the experimental dataset contained, in some cases, more than a single episode per subject and per state, or a subject had episodes in more than a single state. We devoted more experiments to assess the possible influence of these many-to-one and one-to-many correspondences. First, the classification analysis was repeated removing any episode duplication per subject. In this case, the number of objects per class was reduced to 35 for dep, 15 for man, and 77 for rem.
Table 4 shows the results.
Subsequently, the classification analysis was repeated removing any subject from the original dataset that only had data in one state (except for man class, due to its small size). In this case, the number of objects per class was reduced to 34 for dep, 16 for man, and 49 for rem.
Table 5 shows the results.
For comparative purposes, if this processing was applied using another popular metric in actigraphy records classification tasks [
40], the signal mean (before normalisation), the achieved results were 0.74 and 0.75 for Se and Sp, respectively, with
when comparing dep and man records, 0.72 and 0.51, with
, for dep and rem, and 0.58 and 0.68, with
, for man and rem.
Because the actigraphy records were relatively long, with 40,320 samples, additional experiments were conducted while using more than a single best representative epoch for time series. In the previous results, only the longest epoch was used, which was assumed to feature the most stable and longer activity period of each subject. In order to use more data from the available records, all epochs longer than a predefined
N threshold were included in the analysis, the same as in
Table 3. The tested signals were of lengths
to 2000, with a 250 step. As a consequence, the number of records finally processed,
n, also varied.
Table 6 shows these results.
Given that most entropy quantification methods are length–sensitive, a specific test was devised to find out whether record length played a significant role in the classification performance results. Instead of using the longest epoch available (
Table 3), or as many records of a specific length available, as in the previous case (
Table 6), in this experiment maximum length records extracted were cut short to 1000 samples in all cases. In other words, a time series of 1000 points was the single representative from each record.
Table 7 shows the corresponding results.
Finally, the results of the LOO analysis are shown in
Table 8, where, in each experiment realisation, an epoch is randomly left out. These results are more representative of the possible classification performance achievable in a real application using the method proposed.
4. Discussion
The initial exploratory analysis was devoted to select the most suited method to the classification of actigraphy records. The candidates corresponded to some of the most widely used entropy methods in similar tasks, whose performance has been assessed in multiple studies. As expected, all of them yielded reasonably good results, after a limited grid search for optimal parameter configuration and avoid over-fitting.
According to the values presented in
Table 1, the classification results were the highest for classes (dep,man) using any of the tested methods. Specifically, SampEn achieved the highest performance, with a classification accuracy of 0.80, and the lowest was achieved using WPE, 0.70, but did not reach statistical significance (
). The other methods yielded significant results, with a performance of 0.73 for PE, and 0.77 for both BE and SlopEn. It is important to note that, although only the best results were reported in
Table 1, these results were very robust in terms of parameter values, with very similar performances for a wide range of input parameters. Therefore, this case, classes (dep,man), can be considered easy to classify while using a diverse set of entropy methods with a small parameter configuration effort.
The classification of classes (dep,rem) was more difficult, although all of the methods exhibited significance in their classifications. The accuracy was lower, 0.67 at most, again for SampEn, but also for PE, with BE and SlopEn slightly behind with 0.65. WPE was again the worst performing method, with only 0.61. It is important to note that input parameters for the methods were, in general, different to those that were used in the previous case.
The last case, the discrimination between classes man and rem, was, by far, the most difficult case. Despite a relatively extensive grid search for parameter values (m from 3 to 8, and for SampEn, with r from 0.15 up to 0.30), only SlopEn was capable of finding statistically significant results, although with PE that is relatively close (). This is the case that made the difference, with a parameter configuration for SlopEn of , and .
Once SlopEn was considered to be the best choice, a finer parameter tuning process was conducted in order to find out if the performance could be improved further. In order to keep the complexity of the process within reasonable limits, tuning was only applied to parameter
. The main goal of this process was to find a single parameter configuration that could significantly find differences for all the cases studied simultaneously, since that is more practical for real applications. This analysis is summarised in
Table 2. It can be observed that, for
, the highest significant accuracy corresponds to the region above 0.80.
The final stage of this SlopEn parameter customisation scheme is shown in
Table 3. Although the classification results for
remained quite stable in terms of significance and accuracy, the specific value
was taken as the optimal value to use in subsequent experiments. It is important to be aware of the fact that the grid search was not exhaustive,
was varied, keeping
m and
constant, and that could entail that other better configurations were overlooked. However, from all the parameter regions explored, it can arguably be concluded that no great difference was likely to be found. Moreover, a combination of parameter values, from the best case for each pair of classes, could yield even higher classification results. For example,
yielded an accuracy of 0.77 for classes (dep,man), whereas the chosen value, 0.94, achieved 0.75. Anyway, such an approach would overcomplicate things and it would be more likely to result in data over-fitting. As a consequence,
was the chosen value, keeping in mind that other values could provide slightly better performances. With a different optimal parameter configuration, the results in
Table 7 confirmed that time series length did not play a significant role in classification performance.
The results presented in
Table 4 and
Table 5 were obtained removing duplicities, or subjects featured by a single state. Using the same input parameters as for the entire dataset, the results were reasonably stable. However, statistical significance was not achieved for the classification of man and rem classes. This is the case most difficult to classify, and it seems that a reduction in class objects has a detrimental impact on significance, despite achieving a similar overall classification accuracy. On the other hand, the separation of dep and man classes is fairly robust, with a high accuracy.
The results using more than one epoch per time series exhibited a similar behaviour (
Table 6). For relatively few samples (250 samples correspond to 125 min), the number of epochs processed grew significantly (3198 and 2853 respectively), but the performance was poor. It can be hypothesised that few samples do not suffice to reflect the status of the subject in terms of entropy computation. On the other end, if the length of activity required is too large in the preprocessing stage, many records are not represented in the final experimental set, since they do not contain epochs of stable activity (no inactivity periods interspersed) of such length, and therefore the classes become more unbalanced. The length zone around 1000 samples is probably the best one, since at least all of the time series are still represented, and many of them with more than a record. In fact, these are the results closer to those that were achieved using the longest epoch as in
Table 3.
The LOO analysis yielded a slightly lower accuracy than the classification using the entire dataset, as expected, since the thresholds were computed with some instances, and applied to the removed instances that did not have anything to do with that computation in order to assess genericity. Despite this reduction in accuracy, the LOO results were arguably very close to their counterparts using all of the records, 0.75 vs. 0.77, 0.58 vs. 0.61, and 0.62 vs. 0.63, for pairs (dep,man), (dep,rem), and (man,rem), respectively. Once more, it is apparent that dep and man records can be easily distinguished, whereas the other two cases will probably need further studies in order to achieve a higher performance.
5. Conclusions
Actigraphy is a promising tool for assessing the differences among the episodes that can be found in BD patients. Long term monitoring enabled by advanced wearables pave the way for better analysis, but manual inspection of the resulting records can be difficult and time consuming. Entropy related methods can be successfully introduced in this context to aid in this regard, as the results of this paper have demonstrated.
All of the classification analyses carried out in the present study have demonstrated that it is feasible to discriminate between dep and man episodes fairly easily, with accuracies in the vicinity of 0.75, balanced sensitivity and specificity, and good statistical significance. The other two comparisons, dep–rem and man–rem, are more difficult, with borderline classification results that would need additional classification features, or a finer input parameter tuning.
From a practical perspective, and keeping in mind that further studies are still necessary, the proposed method could be implemented by detecting activity periods of at least 1000 samples (movement above certain predefined threshold), and applying the SlopEn configuration of
Table 7, among others, to the data. The resulting value could then be classified as dep, rem, or man, also using a set of predefined thresholds or any other kind of classifier.
The results achieved in the present study could also be further improved while using recent straightforward approaches described in the scientific literature. For example, it can be hypothesised that there is some synergy between methods that could be exploited. This synergy could be exploited when considering each method as a feature of a multidimensional vector, and apply a clustering algorithm to find differences between classes, as in [
37], or use each method as the independent variable of a model that assigns a probability to each class [
41], among many other pattern recognition methods.
Another possibility is to avoid the information reduction that mapping relative frequencies of SlopEn patterns using Shannon entropy entails. Relevance feature analyses have demonstrated that not all relative frequencies account equally for class differences [
42], and that was practically demonstrated in [
43]. Future studies should assess the role of each symbolic pattern for SlopEn, or even other similar measures, such as PE, on the differences found among actigraphy records.
Finally, SlopEn still has a long way to go in terms of performance optimisation. The SlopEn configuration used in the present paper is the baseline configuration described in the seminal paper [
20]; the only difference is that records were normalised in this case. In addition to the grid search conducted, another optimisation could be to use a non-symmetric approach (use different thresholds for rising and falling slopes), vary also parameter
, and use a different number of slope thresholds, instead of only two.

 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}