1. Introduction
The list of publications devoted to the study of sampling-recovery algorithms (SRA) for realization of random processes is huge and difficult to read. The problem, formulated in the title of the article, covers issues related to multidimensional SRA. Let us note two of the standard and most important of them: (1) In accordance with the selected criterion, it is necessary to determine the optimal structure of the device for restoring realizations of the selected random process for a given set of samples and (2) to assess the quality of restoration realizations. These two problems must be studied for many types of stochastic processes and for different types of sampling realizations. In the general case, the set of samples of realizations can be random and described by a stream of random points. Deterministic sampling can be periodic or non-periodic. When random jitter or gaps are present in the samples, the determinism of the samples disappears. In addition, the number of samples involved in recovery in all these cases can be arbitrary.
For each of the options mentioned, specific bibliographic lists of published works can be found. Here we will indicate only a few typical publications [
1,
2,
3,
4,
5,
6,
7,
8,
9], in which SRAs of multidimensional stochastic processes are discussed (the list of works does not claim to be complete). A similar situation is due to the fact that in this article: (1) The study is carried out using the conditional mean method (CMM), which has not been used by other authors when solving such problems; (2) the problem of restoring the realizations for individual components of a multidimensional Gaussian process based on given samples of all components, has not been investigated. The conducted bibliographic search for the problem “Theory of sampling” did not reveal sources with the indicated characteristics, with the exception the author’s publications.
The application of the CMM (see, for example, [
10,
11,
12]) to the study of SRA of realizations of random processes has a number of advantages (see [
13,
14,
15,
16,
17] and references therein) in comparison with the well-known Balakrishnan theorem (TB) [
18] and many of its generalizations. Indeed, SRA based on CMM are distinguished by such positive qualities as: (1) Restoration of a sampled realization of a random process according to the CMM automatically provides a minimum of the root-mean-square error of restoration; (2) the restoring function, like the restoring error function in the general case, takes into account the main statistical characteristics of a random process: Probability density, covariance, and cumulant functions; spectrum (a process with a limited spectrum is a special case); (3) the considered algorithms are optimal for any number and location of samples (the variant of periodic samples is a special case); (4) general analytical expressions for the considered SRA cover stationary and non-stationary variants of stochastic processes; (5) sampled stochastic processes can be Gaussian and non-Gaussian, continuous and discontinuous, etc. Moreover, the CMM has been productively applied to study the SRA of random fields, both Gaussian [
19,
20] and fields with jumps [
17,
21]. Of course, the version of a multidimensional Gaussian process turns out to be more convenient for analysis since there are simple analytical relations for it.
Note, the application of CMM to the study of SRA-realizations of multidimensional random processes has not been sufficiently discussed in the literature. The work is intended to partially fill this gap. The aim of the article is to study SRA for message models that are described by two-dimensional Gaussian random processes. However, the dimension of the problem is not limited by the presence of two random processes at the input and output of the linear system, since in addition to them, the problem includes two sets of samples fixed in the realizations of these processes. These fixed sets are made up of an arbitrary number of samples that are randomly located on the time axis. The number of samples involved in reconstruction significantly increases the dimension of the problem. CMM expressions for a multidimensional random Gaussian variable [
22,
23] are generalized in relation to the problem formulated in the title of the article. The use of CMM allows us to overcome the difficulties that arise and obtain general expressions for describing the optimal structures and assessing the quality of the restoration.
In practice, the option under discussion arises, for example, in telemetry systems, when messages with statistical dependence are transmitted over separate channels. The most suitable and convenient model for this kind of messages is a set of Gaussian random processes at the input and output of an arbitrary linear system described by an impulse response . By changing the type of the function , you can change the type of statistical relationship between the two processes. In this case, the message is a two-dimensional Gaussian process . The realizations of both components are sampled and transmitted to the receiving side. Sets of samples and realizations of components and are arbitrary both in quantity and location on the time axis.
The matrix description of the recovery procedure allows one to obtain general optimal recovery algorithms for both input and output realizations using both sets of samples and . In addition, you can evaluate the quality of restoration of the realizations of both components. In this case, the recovery of each of the realizations by the proposed method turns out to be higher than with the usual recovery algorithm only from its own samples. The study of this general case allows us to consider two particular options, each of which consists in the fact that on the basis of both sets of samples and it is necessary to restore only one of the transmitted messages. For example, the algorithm for restoring the realization of the output process must use not only a set of its own samples , but also a set of samples to implement an auxiliary input process . The examples below also consider the opposite case, when the realization of the input process is restored, and the samples of the realization of the output process play an auxiliary role. The positive effect of this operation is due to the fact both processes are statistically related, and therefore the role of the cross-covariance function between output and input is significant.
The aim of the study is to provide an analytical description of the proposed algorithm for recovering realizations of a two-dimensional Gaussian process and to assess the quality of its functioning, taking into account the sets of samples of realizations of both processes. It should be emphasized that instead of analyzing reconstruction functions that depend on a set of sample values, we will study basic functions, which are the impulse responses of the shaping filters for each sample. Reconstruction functions are created by multiplying each sample by its own basic function and then adding them. It is clear the basic functions are independent of the sampled values.
The scientific novelty of the article is as follows: (1) The sampling—restoration algorithms (SRA) of realizations of the components of a two-dimensional Gaussian process are studied, taking into account the fact that the restoration is carried out not only on the basis of a set of their own samples of the realization of the selected component, but also taking into account the set of samples of the realization of another component, statistically related to the first. Owing to the use of CMM, general variants of SRAs with an arbitrary number and location of samples in both realizations are investigated. (2) As a result, a general scheme of the restorer of both realizations was obtained, which provides minimal restoration errors. In addition, general relations are found to estimate the minimum recovery errors for each of the sampled realizations. (3) For several typical models of linear systems with different input processes, the cross-covariance functions between input and output are determined. These functions play a major role in studying the influence of the set of samples of the realization of the auxiliary component on the structure and quality of restoration of the realization of the selected component. (4) Variants of SRA have been studied when the restoration of the realization of the selected component occurs at one or several sampling intervals for various cross-covariance functions of the processes. Several examples investigate non-trivial cases when the sampling intervals of the realizations of both components are different. (5) In all the options considered, the optimal forms of the basic functions are determined, and the functions of recovery errors are calculated. The latter show the advantages of the proposed method in improving the quality of restoration in comparison with the classical method when restoration is carried out only according to own samples of realization.
The article consists of the following sections.
Section 2 presents general formulas for the vector of conditional mathematical expectations and the matrix of conditional covariances in relation to the here considered.
Section 3 discusses the models of the Gaussian processes used.
Section 4 is devoted to the description of the optimal structure of the reductant of realizations of both components of a two-dimensional Gaussian process based on a set of samples of the input and output processes of an arbitrary linear system.
Section 5 discusses examples describing SRP in a single recovery interval.
Section 6 is devoted to examining SRP at multiple recovery intervals. There is one
Appendix A.
2. General Formulas for the Statistical Characteristics of the Two-Dimensional Conditional Gaussian Process
In the mathematical literature, there is a result that is closely related to the problem formulated in here. Namely, in [
22] (see also [
23]), matrix expressions were obtained for the conditional mean vector and for the conditional covariance matrix of one vector for a fixed other vector. These relations have been derived for multidimensional Gaussian random variables. These formulas are given in the
Appendix A and are designated by the letter “A”. They cannot be used directly to solve the problem posed in the article. We generalize them to the case when two components are Gaussian processes with continuous time, and the other components (sets of samples) are random Gaussian variables with discrete time.
For our purpose, we use different designations than those used in the
Appendix A. Consider a column vector
that is analogous to the vector
z (see Formula (A1)):
where
where
are the numbers of samples in both sets.
The vector
is described by the mathematical expectation vector (see analogue the Formula (A2)):
and covariance matrix
where
are the covariance matrices of vectors
and
, respectively;
—matrices of cross covariance between vectors
and
. Expression (9) is an analog of the matrix (A3) written in the new notation. We fix the vector
, and the vector
remains random with its components conditional with respect to the vector
. Then, the vector
is described by a Gaussian two-dimensional conditional probability density, which is characterized by a column vector of conditional mathematical expectations and a matrix of conditional covariances. The vector of conditional mathematical expectations instead of (A4) is written in the form:
As in the one-dimensional case [
13,
14,
15,
16], based on (10), we introduce the definition of a multidimensional basic function
Relation (10) determines the optimal recovery structure for the sampled realizations of the two-dimensional process (see the
Section 4). Recovery should be carried out sequentially at sampling intervals.
The matrix of conditional covariance
of the vector function
, when the vector
is fixed, based on (A5), (9) takes the form:
Equating in (12) times , it is possible to obtain relations that determine the functions of conditional variance, which characterize the quality of restoration of realizations of each component.
Let us describe the general form of the submatrices included in expression (9). The two-dimensional Gaussian process
is described by the mathematical expectation vector (7) and the covariance matrix
In (13), functions
are covariance functions of processes
and
, accordingly. The degree of statistical dependence between the processes is determined by the functions of cross covariance
. The remaining three sub-matrices are written this way:
Here and below, the dots above the letters indicate centered random variables.
Using Formulas (13)—(16), we can specify the relations (10) and (12), which should be calculated sequentially in the intervals for interpolation and for extrapolation at . There is a retropolation option, when . Here, the superscripts and are omitted.
3. Models of Used Gaussian Processes
Below, the use of the above general algorithm is illustrated with a series of examples in which two statistically related Gaussian processes appear. Covariance and cross-covariance functions of processes vary within wide limits. As indicated in
Section 1, these processes are most simply described using a linear system with a given impulse response
. When the covariance function
of the input process
and characteristics
change, the output process
is described by various covariance functions. In this case, of course, the cross-covariance function between the input and output is also changed. There are general formulas [
23], which can be used to determine the desired covariance functions for given
and
. Let us write them out in relation to the stationary case, setting
:
There are two cross-covariance functions
, that have the property
:
For our purposes, when choosing linear systems, it is advisable to choose the simplest in structure and description. In this case, it can easily be demonstrated how the auto- and cross-covariance functions of the input and output processes of linear systems affect the main characteristics of the SRP: The structure of recovery devices (or basic functions) and the functions of recovery errors. As linear systems, it is appropriate to choose low-pass filters, consisting of series-connected integrating RC circuits, at the input of which there is white Gaussian noise. Such systems can have one or more connected integrating RC circuits separated by buffer cascades [
23]. At the outputs of such systems, Gaussian processes with various statistical characteristics are formed. Below, this method will be used to describe both input and output processes.
The simplest linear system is a single integrating RC circuit, at the input of which there is white noise. At the output of such a system, a Markov Gaussian process with an exponential covariance function is formed. At the outputs of two, three, and further circuits, the output processes will not be Markov.
Formulas (17) and (18) will be used below when considering examples.
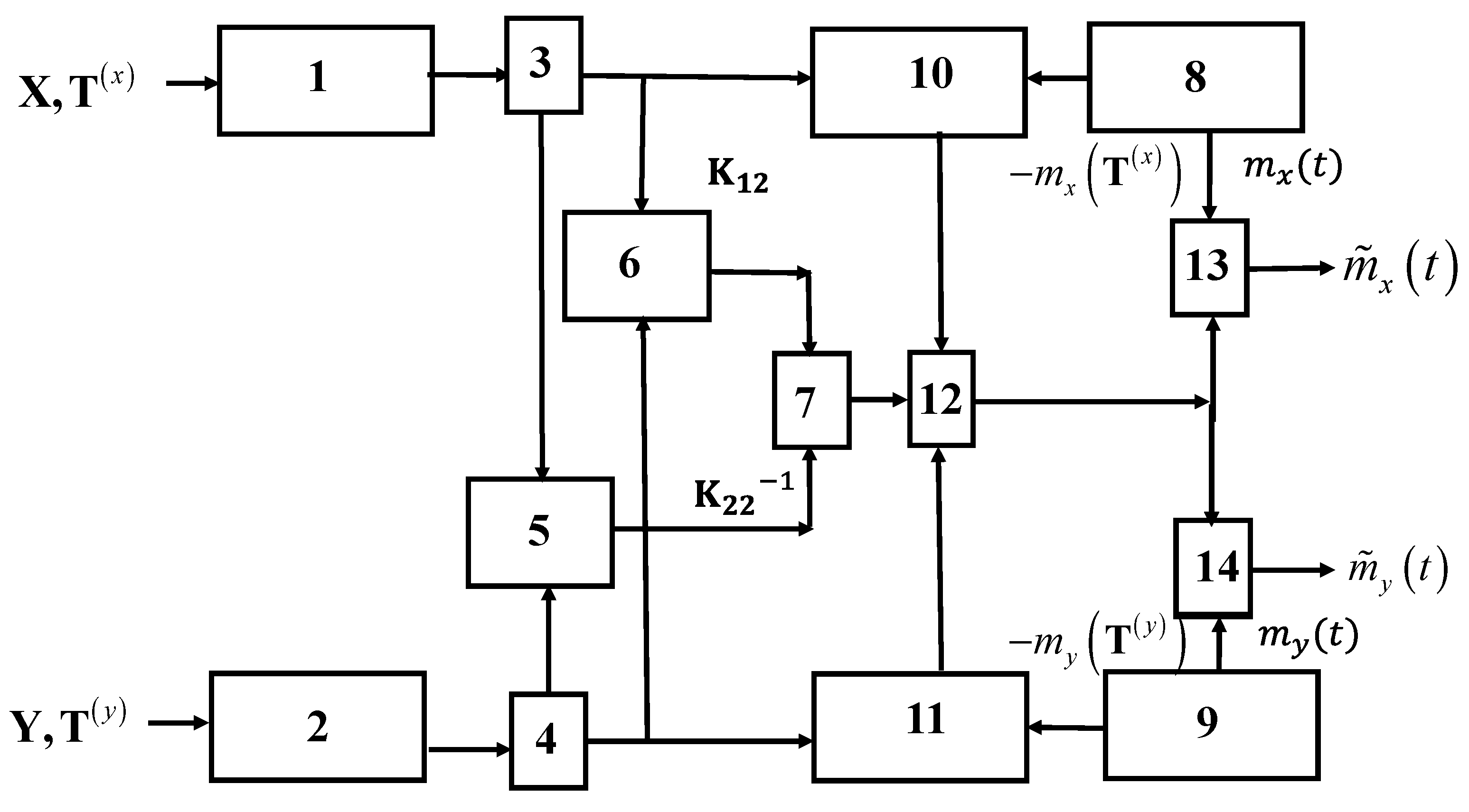
4. General Optimal Structure of Restoration of Realizations of the Two-Dimensional Gaussian Process
Optimal recovery is understood to mean an algorithm that uses both sets of samples
in the recovery of each of the components of a two-dimensional process
. The structure of the optimal recovery device is determined by Formula (10) and is given in
Figure 1.
Both inputs of the device receive sets of samples , which are stored in memory registers 1 and 2. The sets of samples are shifted in blocks 3 and 4 to obtain the best restoration quality (see, for example, Example 3). Then, information about the location of the samples along with the characteristics of the linear system is used to calculate the matrix elements in blocks 5 and 6. In block 7, these matrices are multiplied. A priori information about the mathematical expectation functions (7) and (8) is stored in blocks 8, 9, and is used when subtracting average values at the reference points in blocks 10, 11, and also when summing the functions in blocks 13, 14 In block 12, matrix multiplication is performed from the output of block 7 and elements of a centered a column vector of input samples. Recovered realizations are formed at outputs of blocks 13, 14.
We draw attention to the fact that the matrix of basic functions
in the diagram in
Figure 1 is not indicated. However, in accordance with (11), it is formed at the output of block 7. The elements of the matrix
represent a set of an orthonormal system of functions. It means that
superscripts are omitted here.
The number of basic functions is the same as the total number of samples. To clarify the physical meaning of the elements of the matrix
, consider a special case when
. This option is explored in the Examples 1 and 2 in the next section. Let us concretize the matrices included in relation (11):
As a result of multiplying (20) and (21), we obtain the matrix of basic functions
whose elements are written in the form (we give only two of them):
Let us change the notation:
Using relations (22)–(25), we write expressions for basic functions in the form:
Formulas (26) and (27) allow us to give a physical interpretation: (1) As in the one-dimensional case, the basic function for each sample
or
in the general case is determined by the sum of a product of the autocovariance function with arguments
(superscripts are omitted here) and elements of inverse covariance matrix. The difference is that in the case under consideration, we mean not only autocovariance functions
, but also cross-covariance functions
. (2) It is clear for independent components, the sums with cross-covariances in (26) and (27) disappear. Then, formulas for the basic functions coincide with the expressions for the one-dimensional version, and the diagram in
Figure 1 is split into two independent channels.
Each example presented in the article is illustrated not only by the type of basic functions, but also by the corresponding graphs of recovery errors. Moreover, in the latter case, among many curves, a curve corresponding to the reconstruction algorithm is necessarily shown, in which only the own samples of the reconstructed realization are used. Comparison of the quality of restoration is performed for the same process models and selected parameters. Note that the always-proposed algorithm is characterized by an improvement in the quality of functioning.
5. Study Cases: Reconstruction of Realizations on One Sampling Interval
Shown in
Figure 1, the general recovery scheme includes the option under consideration (one sampling interval) as a special case; therefore, a somewhat simplified scheme will not be discussed. Two of the most important characteristics of the SRA are detailed below: The basic functions for each sample involved in recovery and the error recovery functions. The purpose of considering a set of examples is to find out how the following parameters affect the specified characteristics: (1) The number and location of samples of input and output realizations, (2) input and output covariance functions, (3) their cross-covariance functions, and (4) the type of recovery procedure—on one interval or multiple intervals.
Further research requires specification of data on the number and location of samples. We note one important feature of the discussed algorithm, which will be considered when calculating the recovery errors in all the examples considered below. Formulas (10) and (12) are of a general nature, and their application for a large set of samples is associated with the complication of the device. Theoretically, each sample should participate in the formation of the output processes of the system shown in
Figure 1. Actually, the samples of the realization of one component (say
) affect the formation and the error of recovery of the other component
only when the localization of samples of the first component is located near or inside the sampling interval of the recovered realization of the second component. The reason for this effect is that it is realized through the cross-covariance function: When the argument of this function is less than the covariance time
of the output process
, then the value of the function
is close to the maximum and the influence of the corresponding sample on the quality of recovery is significant. In addition to the position of the maximum of the function
, the discrepancy between the samples of the auxiliary and recovered realizations also affect the reduction of the recovery error. Such an effect occurs, for example, with unequal sampling periods
(see Examples 5 and 6). In this case, the minimum of the recovery error will be in the interval close to the point
(here
is location of the point at which the function
reaches its maximum within the sampling interval
). The main characteristics of the SRA are also influenced by the elements of the inverse covariance matrix. However, it is difficult to establish at least some patterns of such influence.
In
Section 5.1 Example 1 and
Section 5.2 Example 2, the numbers of samples are equal to two and the samples of both realizations are located at the same points. In
Section 5.3 Example 3, the auxiliary sample is one, but its location varies within the sampling interval
.
5.1. Example 1. System from One RC Chain with Markov Input Process
A Markov Gaussian process is formed at the output of an integrating RC circuit that is under the influence of white noise. Its normalized covariance function
in the stationary mode is determined by the formula
where
is the constant parameter.
We put
. The linear system is also an integrating RC circuit with an impulse response
Using expressions (18), (28) and (29) we determine the normalized covariance function of the output process
:
as well as normalized cross-covariance functions (17) between the processes
and
:
where
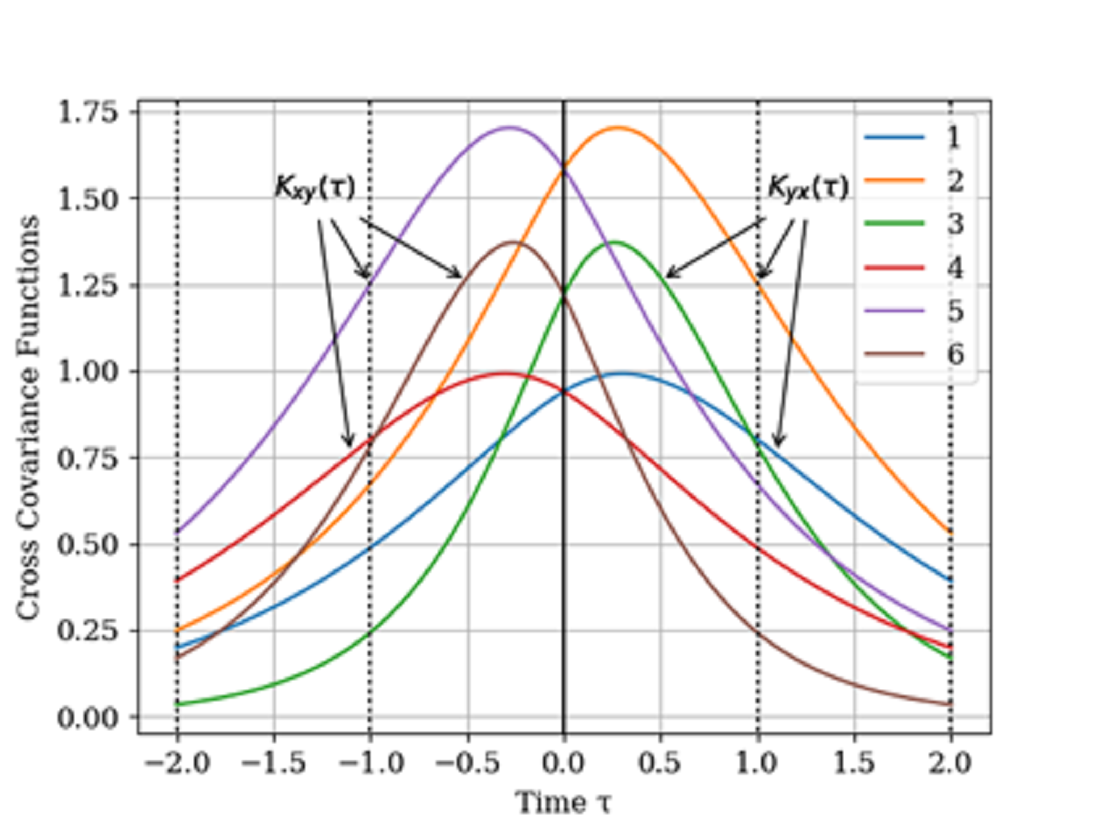
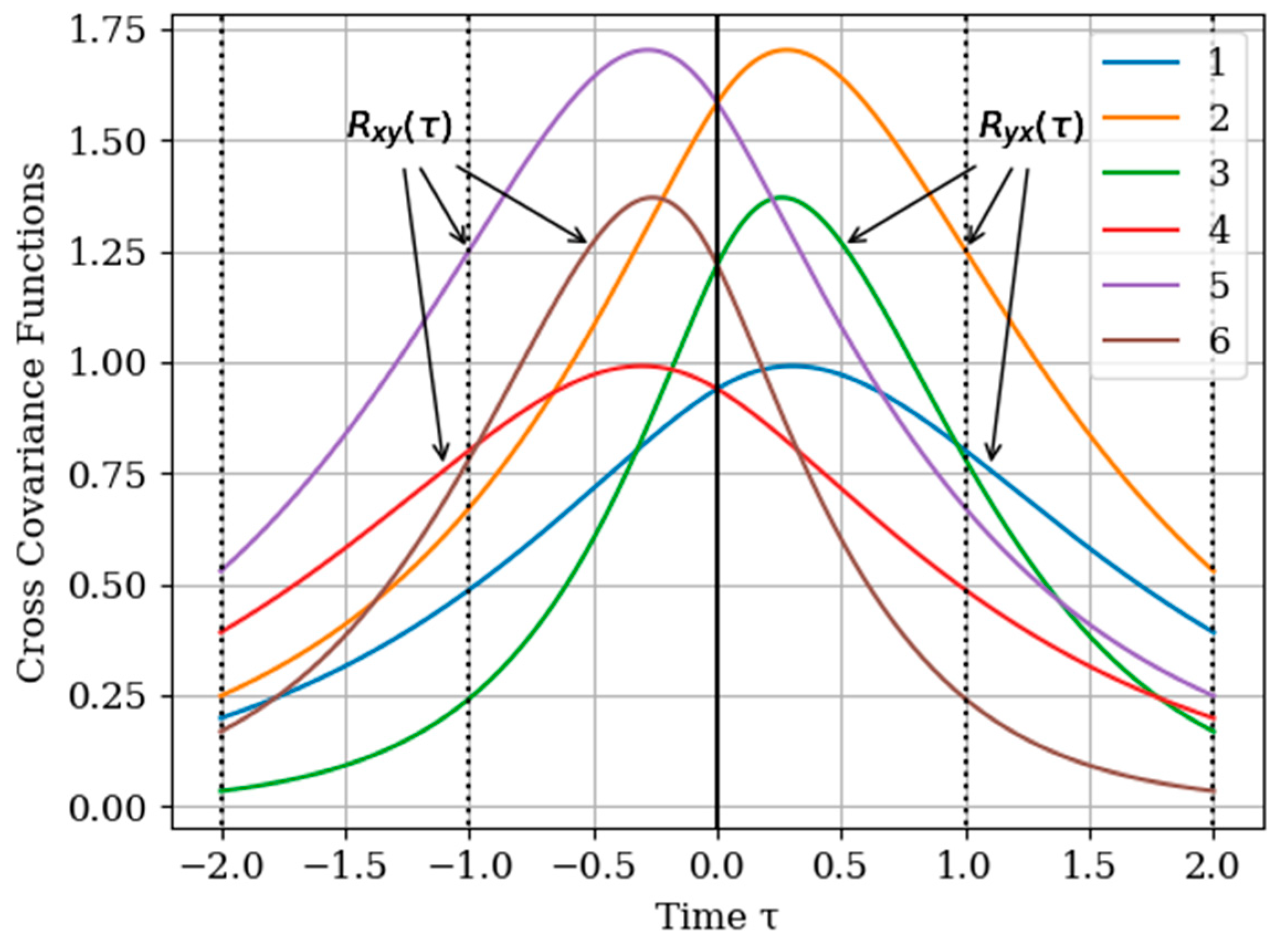
. In
Figure 2 shows the graphs of the cross covariance function
and
for various values of the parameters
and
. The curves are calculated for the following parameters: Curve 1—
; curve 2—
; curve 3—
for
and curve 4—
; curve 5—
; curve 6—
for
. As can be seen, the cross-covariance functions are odd, and their maxima are shifted of the point
. Especially we note the curves 3 and 4 with their maxima in points
and
for
and
, respectively. In general, when the value of parameters
of cross covariance functions
increase, their maxima values decrease. This is explained, because the realizations of the input and output process are more chaotic when the bandwidth is increased, which is described by the value of parameters
.
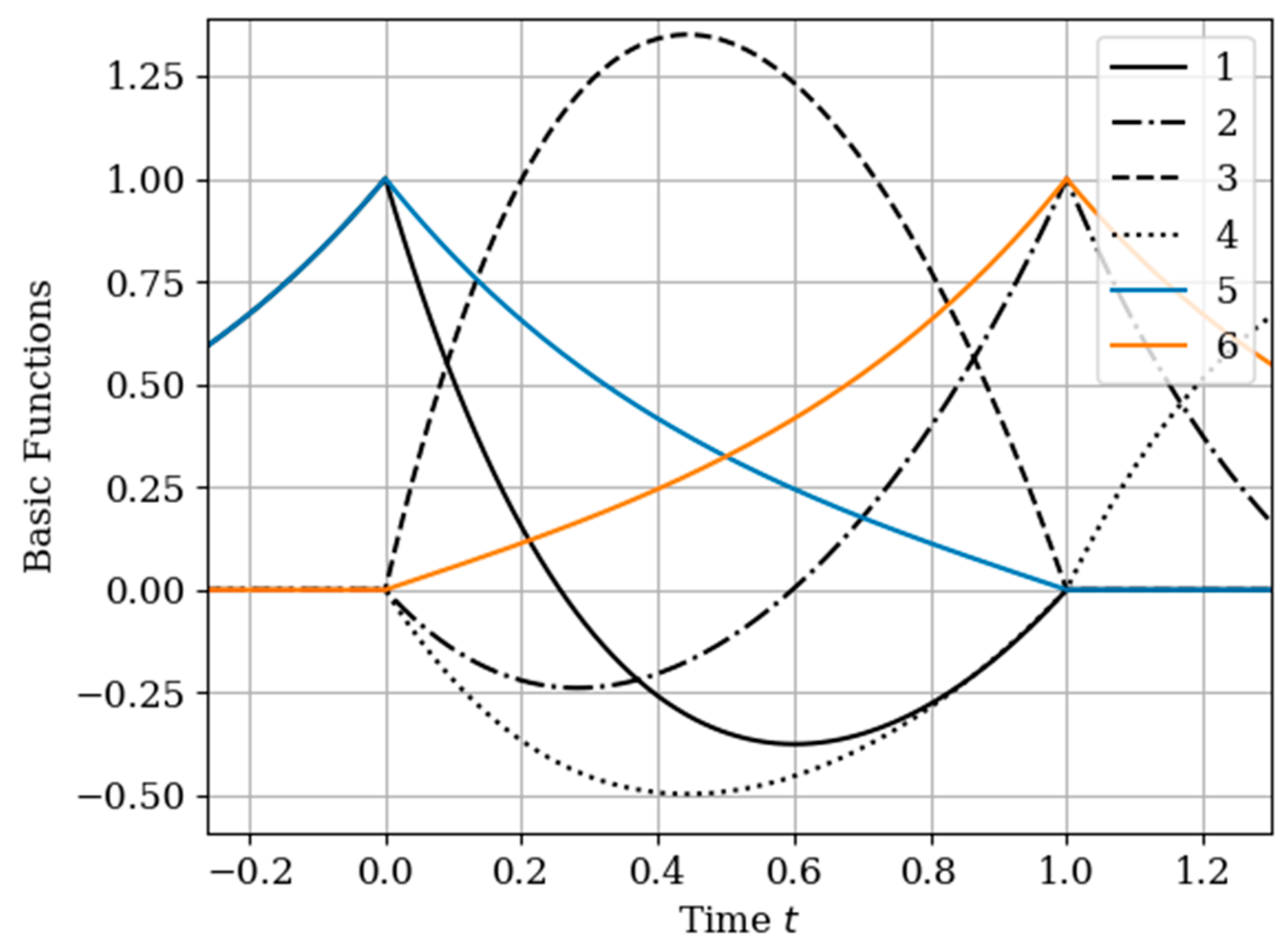
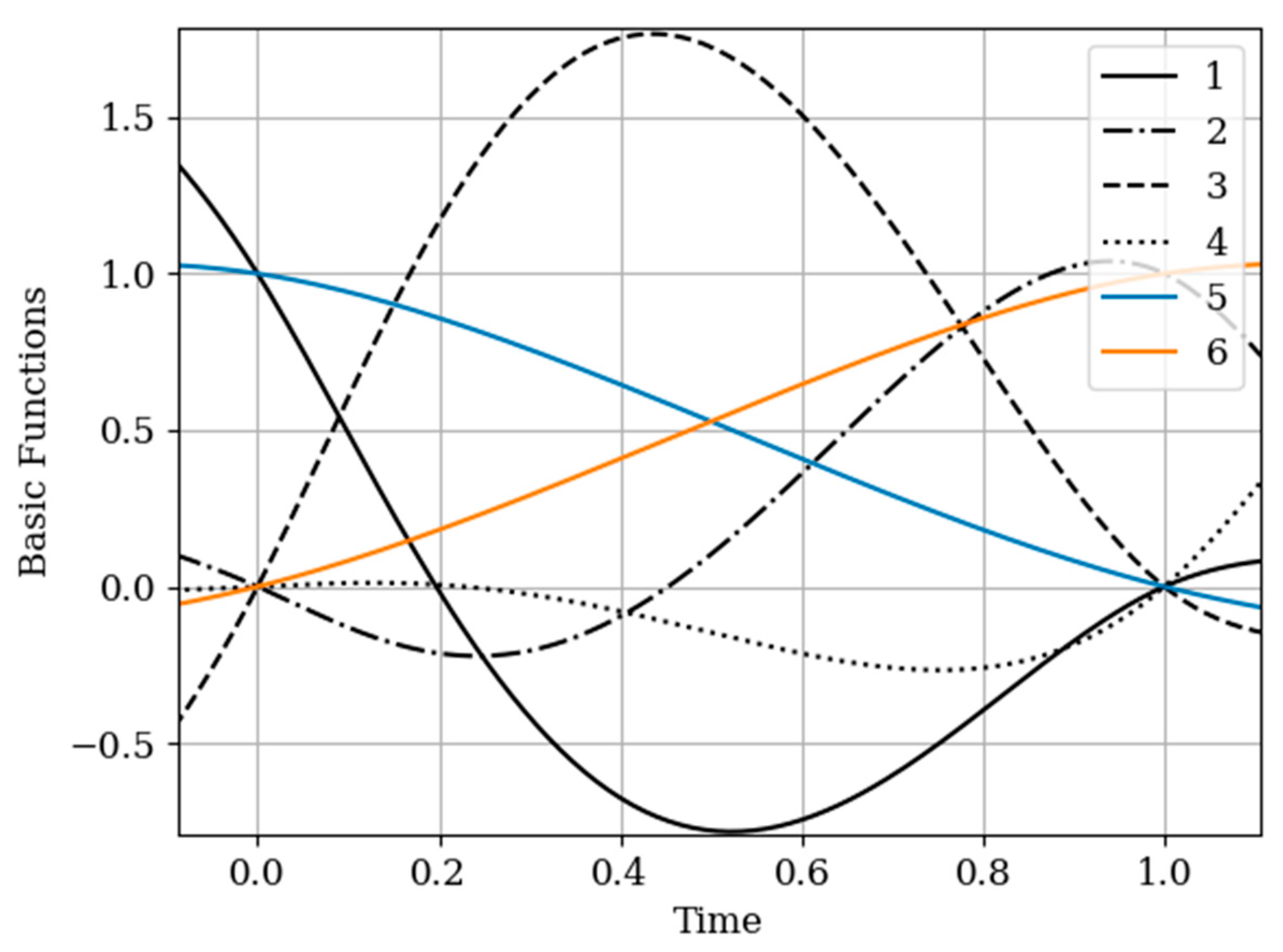
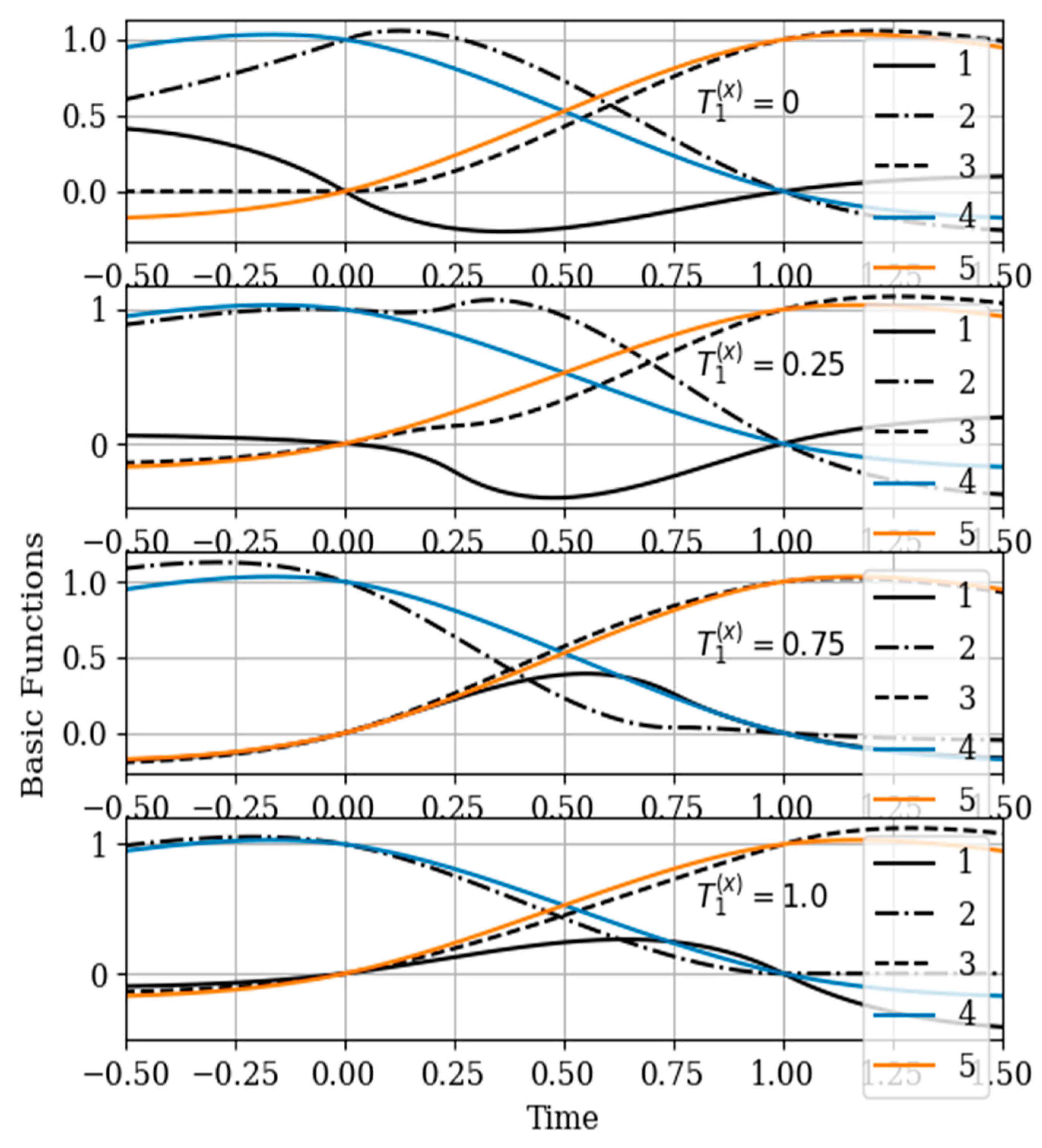
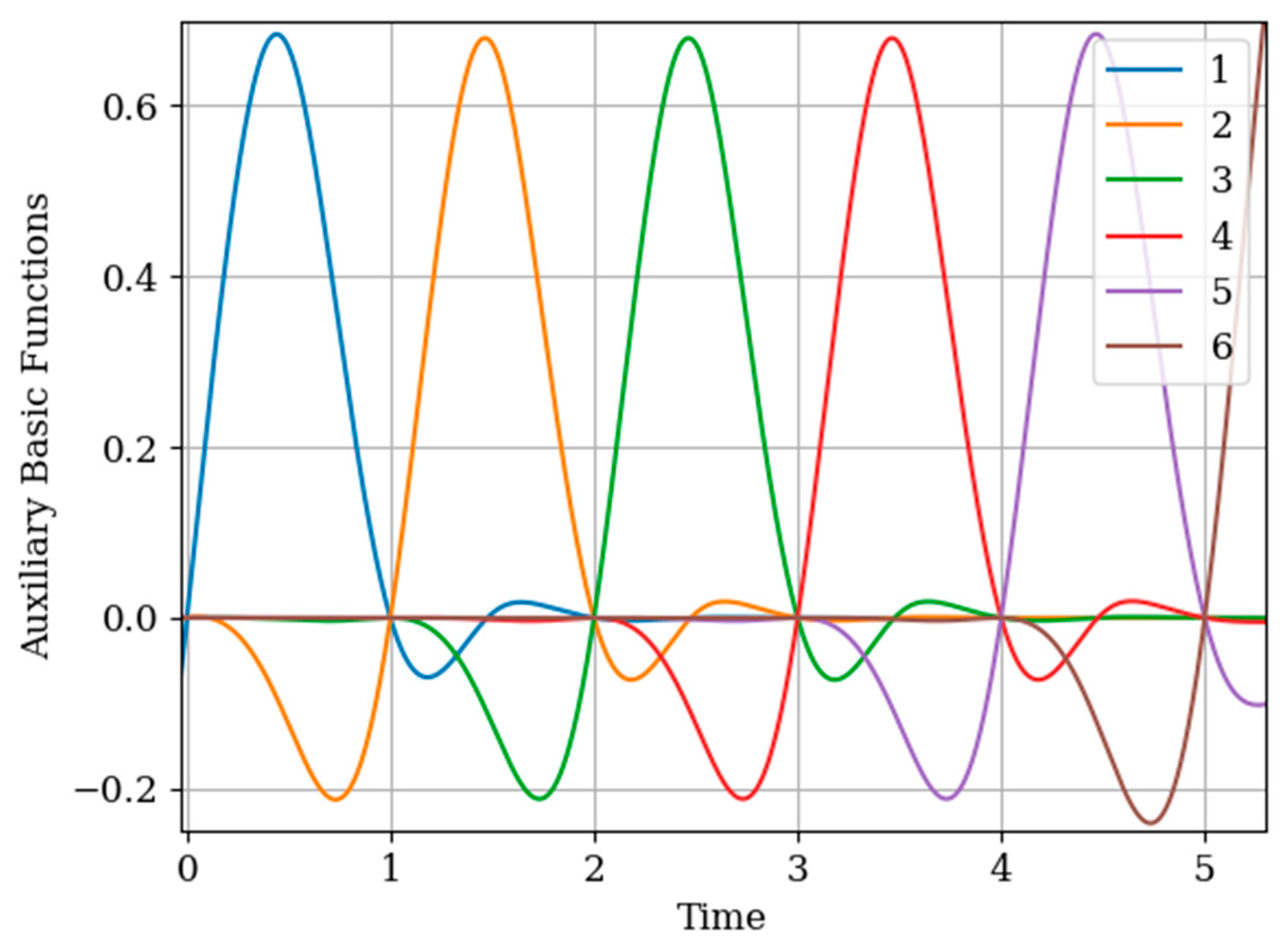
The results of calculations of basic functions carried out according to formula (11) are shown in
Figure 3. The values of the selected parameters are as follows:
the number of samples involved in the recovery of realizations is the same: The samples are located at the same points:
. In
Figure 3 shows the basic functions of the multidimensional algorithm
(curves 1–4) and the one-dimensional algorithm
(curves 5 and 6). These basic functions correspond to the restoration of realization of process
at the input of the system. The samples of the realization of the output process
are auxiliary samples here. The multivariate algorithm has four basic functions (for own and for auxiliary samples), while the unidimensional algorithm has two basic functions.
Curves 5 and 6 in
Figure 3 refer to a one-dimensional algorithm. They are described by the first term in (26) and the covariance function (28). In accordance with (26), the multidimensional algorithm includes four basic functions, including two of them formed on the basis cross covariance functions (32). Moreover, these functions, elements of the inverse matrix, influence the calculation of the basic functions. It is obvious that the form of the multidimensional basic function changes radically in relation to the main functions in a one-dimensional algorithm.
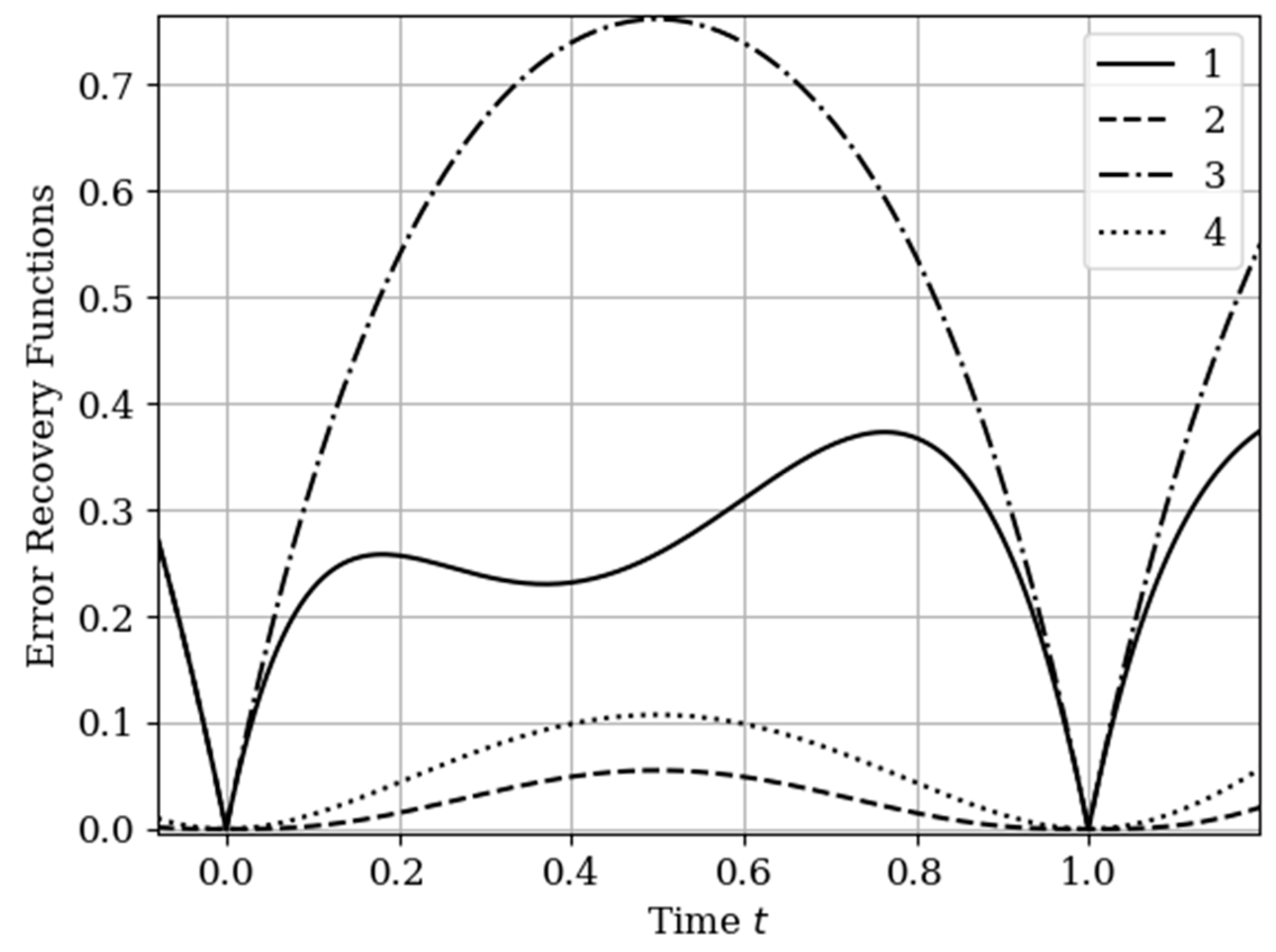
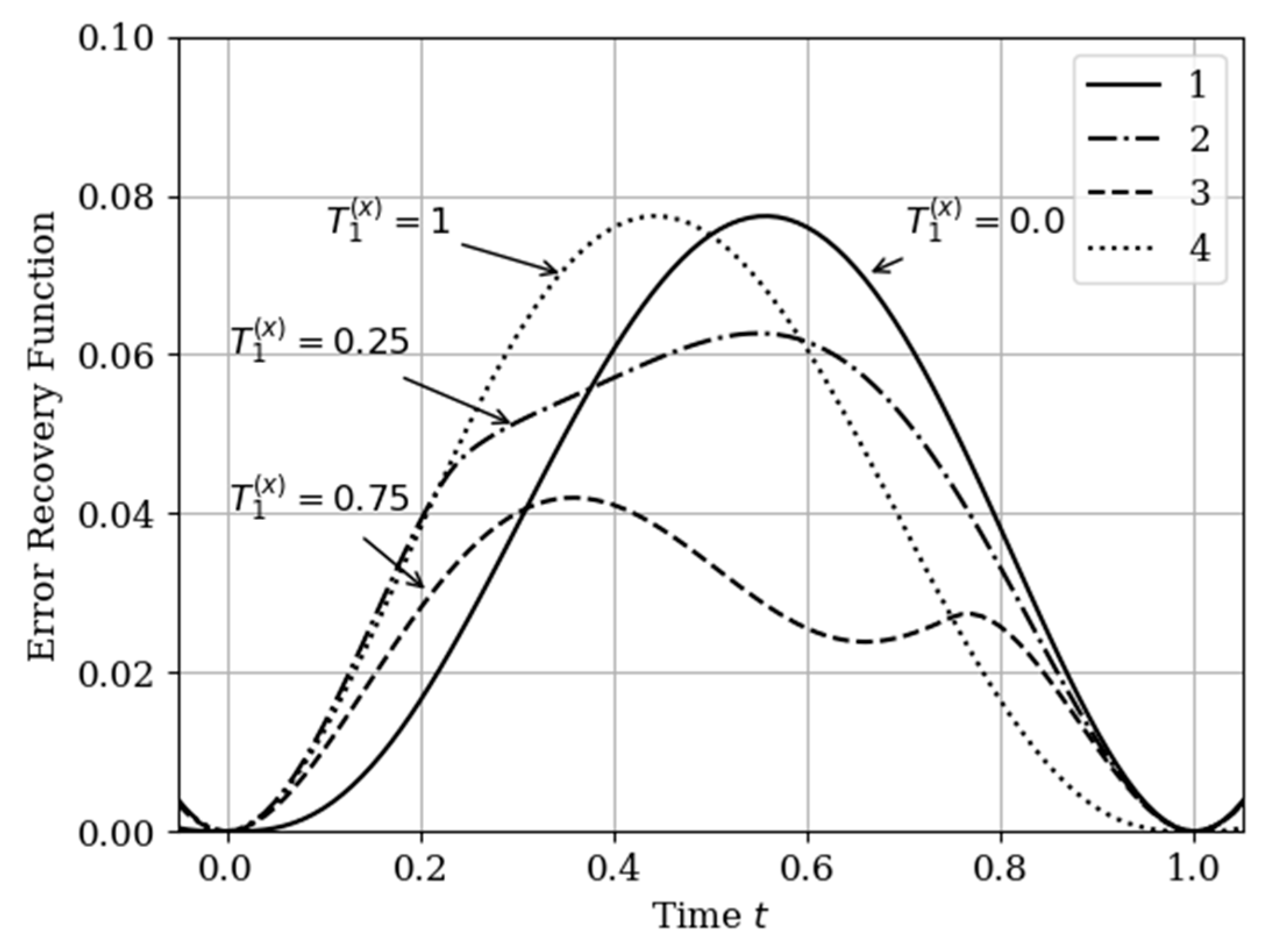
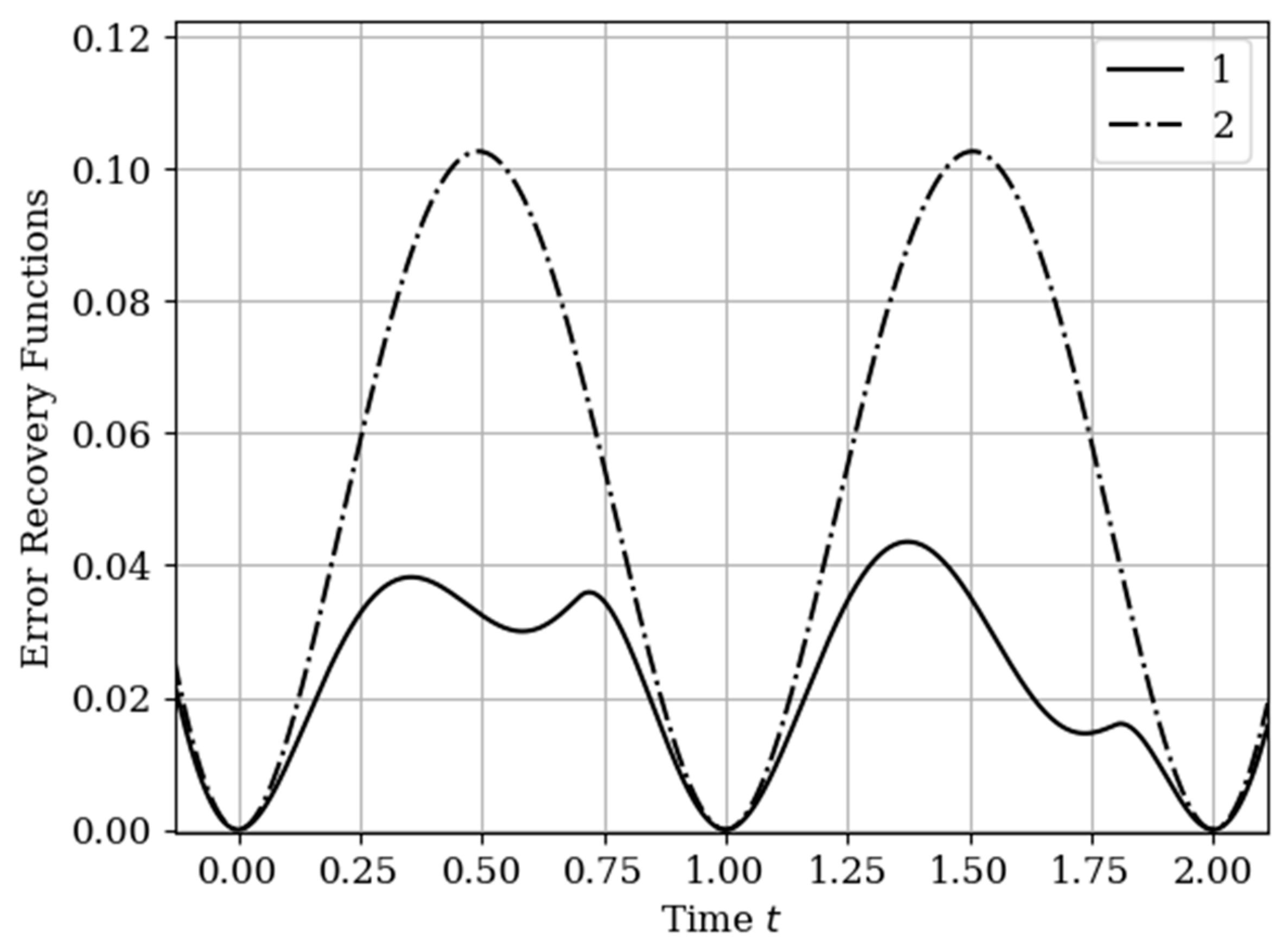
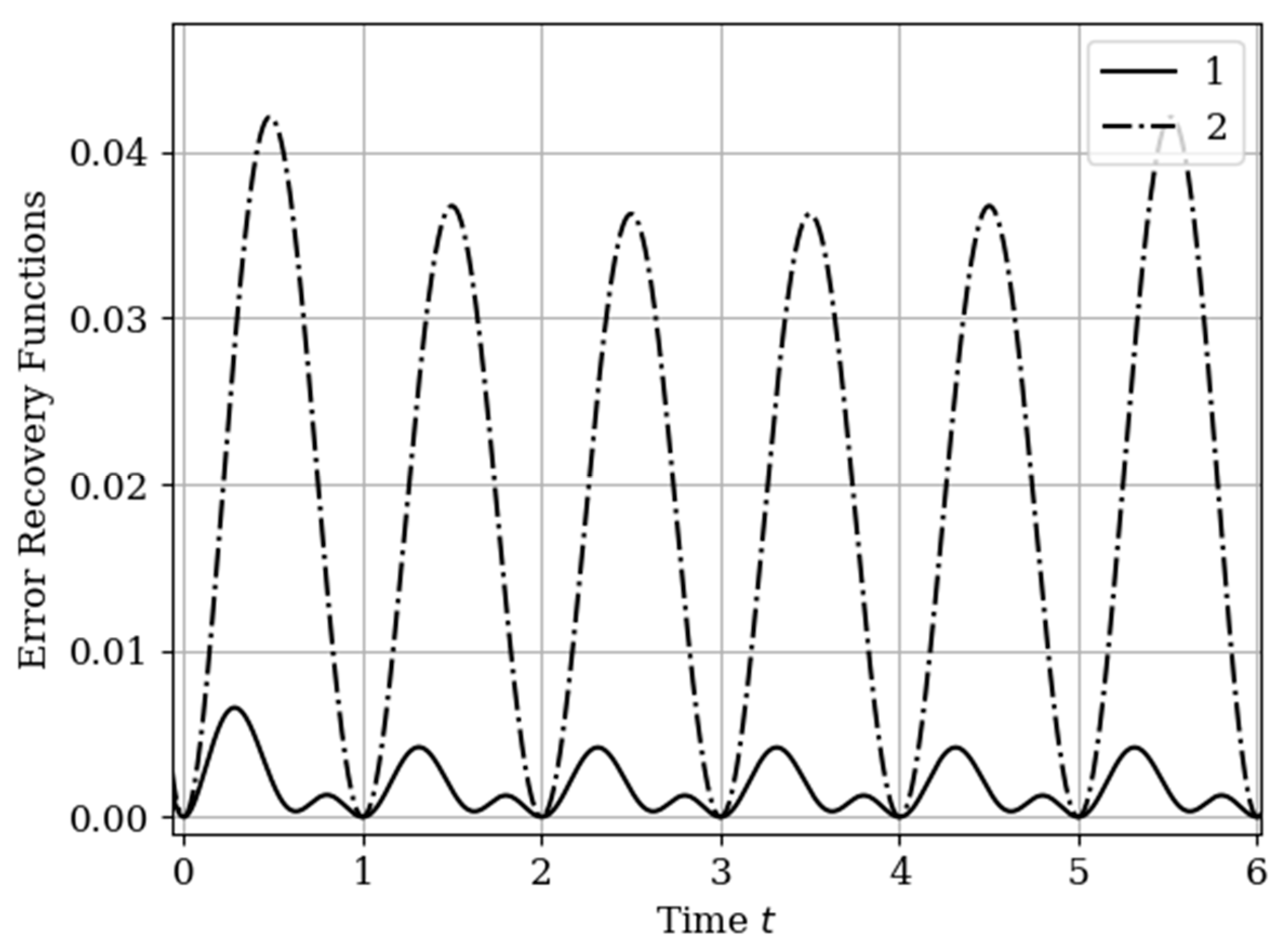
The results of calculations of recovery errors carried out according to formula (12) are shown in
Figure 4. The values of the selected parameters are the same as in the comments to
Figure 3. Curve 1 describes the recovery error of realization of
with multidimensional algorithm. It has a smoothed minimum close to the point
, because the function
has maximum at this point. The smoothness of the discussed extremum is influenced by the proximity of the control point, where the error is zero by the definition.
Curves 3 and 4 describe the recovery errors for the one-dimensional algorithm, when the recovery is performed only on their own samples. The difference in the values of the curve maxima is explained by the difference in the time structure of the processes: The output process is smoother than the input process . Curves 1 and 2 are obtained by a multidimensional algorithm, when both sets of samples participate in the restoration of each realization. The even form of curve 3 is explained, because this form is determined by the covariance functions . According to formula (27), the influential of these functions are weighed by the elements of the inverse matrix. A comparison of pairs of curves 2, 4, and 1, 3 indicates that the restoration using the multidimensional algorithm provides a higher quality of recovery than the similar procedure according to the one-dimensional algorithm.
5.2. Example 2. The Input Is Non-Markovian Process Formed by Two Sequential RC Chains. System Is One RC Chain
There is one difference between Example 1 and Example 2: Here, the input process is not Markovian. This circumstance changes all the covariance functions included in the expressions for the analysis of the studied algorithm.
The covariance function of the input process is determined by relation (30) with the change of index.
The linear system under study is described by the function
and the process at its output is characterized by the covariance function (18)
The cross-covariance functions between the input and output are determined by the following expressions (17)
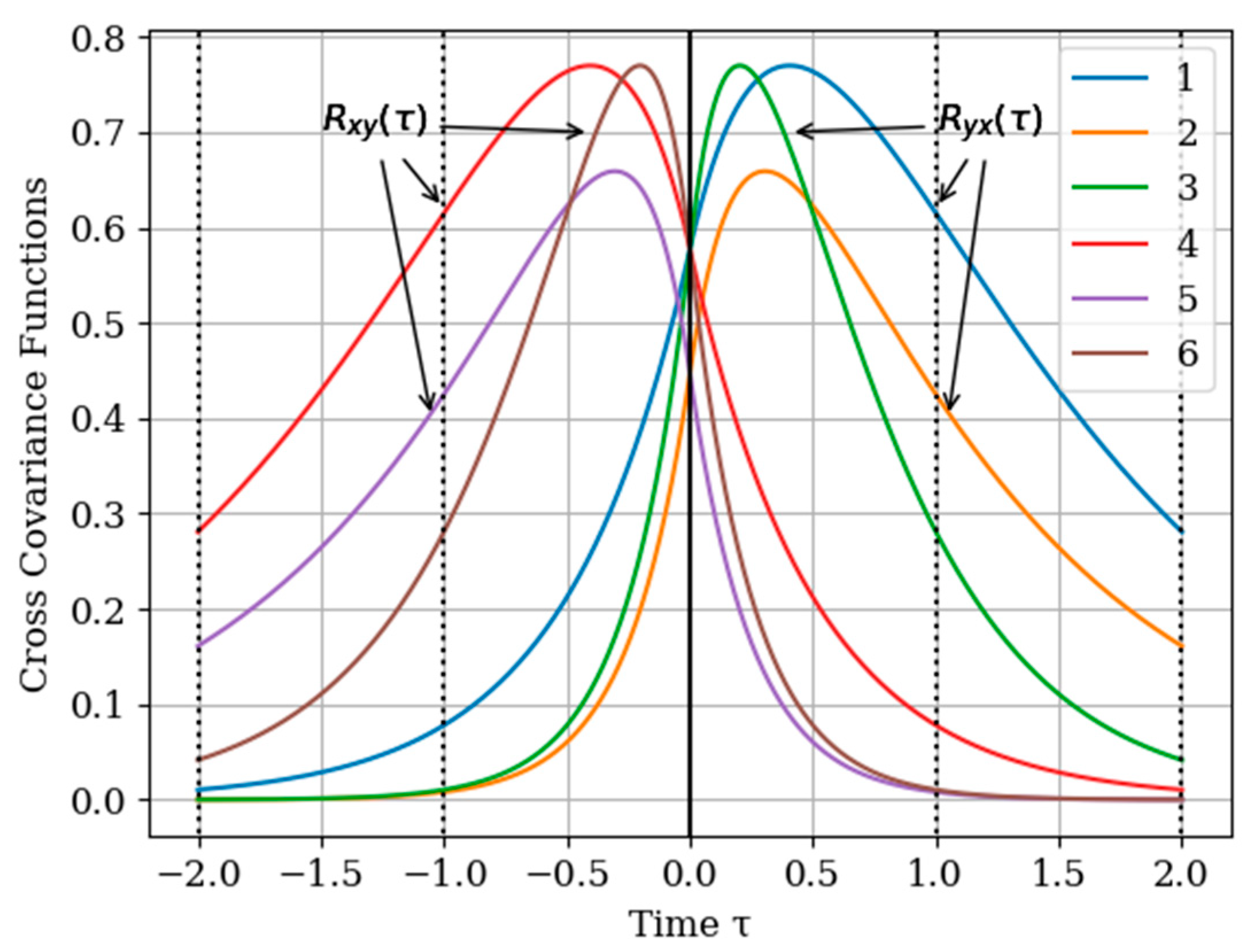
Figure 5 shows the graphs of the cross covariance function
and
following (35) and (36) for various values of the parameters
and
. The curves are calculated for the parameters: curve 1—
; curve 2—
; curve 3—
for
and curve 4—
; curve 5—
; curve 6—
for
.
As can be seen, the cross -covariance functions are odd, and their maxima are shifted to the points
and
for
and
, respectively. In general, when the value of parameters
of cross-covariance functions
increase, their maxima are decreasing. This is due to the fact that the realizations of the input and output processes have wider spectrums Note that all the curves are smoother than those in
Figure 2. This is explained by the fact that both processes
are non-Markovian.
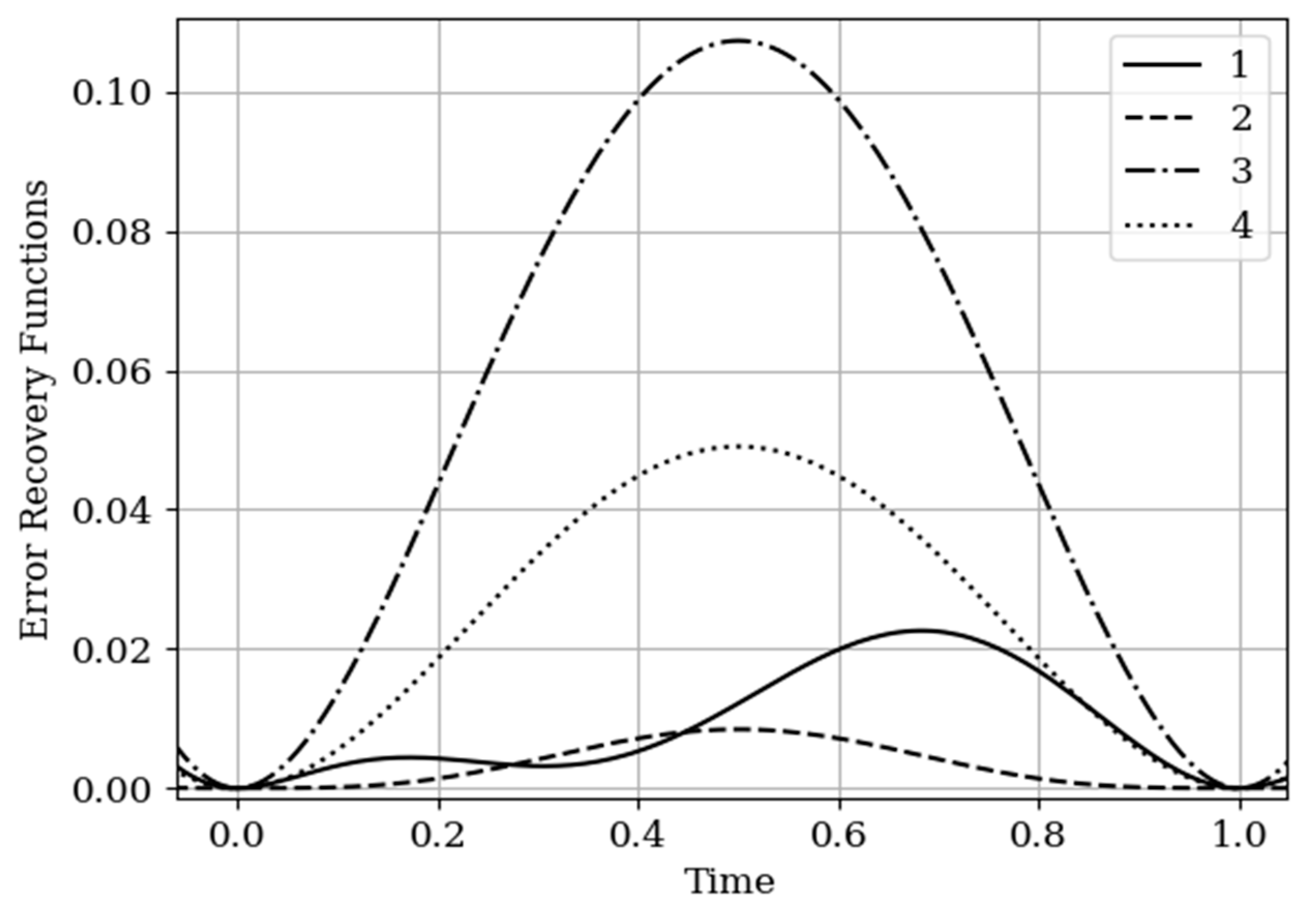
The results of calculations of basic functions and recovery errors are shown in
Figure 6 and
Figure 7. The values of the selected parameters are as follows: The number of samples involved in the recovery of realizations is the same:
the samples are located at the same points:
.
In
Figure 6, the basic functions of the multidimensional algorithm (curves 1–4) and one-dimensional algorithm (curves 5 and 6) are observed.
As in the previous example, covariance functions and elements of the inverse matrix influence the basic functions. The difference is explained by non-Markovian characteristics of the output process.
The results of calculations of recovery errors are shown in
Figure 7. The Curves 1–4 are characterized by the same parameters as in
Figure 6. When the basic functions change, the error recovery functions must also change. Comparison of the curves in
Figure 4 and
Figure 7 shows that the maximum error values differ significantly. This fact is explained by the greater smoothness of the studied processes in this example compared to the processes in
Section 5.1 Example 1 (see more about this effect in [
13,
14,
16]). In addition, note that the curve 1 is asymmetric compared to curve 3. This is explained because the influence of the output process determines the reconstruction of the process at the input by means of the cross-covariance function. Meanwhile, curve 2 is a symmetric function, because the cross-covariance function
influences the reconstruction to a lesser extent.
In
Section 5.1 Example 1 and
Section 5.2 Example 2, the processes at the input and output of the linear system are different in the time structure: The process
is more smoothed compared to the process
. The results of restoration errors calculations in
Section 5.1 Example 1 and
Section 5.2 Example 2 show that the degree of influence of additional samples of one process on the restoration quality of another process is different. Specifically, when the process is more smoothed, then its positive influence on the restoration quality of another process is significantly higher than in the other situation. (see differences between curves 1 and 3, 2 and 4 in
Figure 4 and
Figure 7).
The option considered in the first two examples of
Section 5, in addition to theoretical, is of practical interest. We repeat that the proposed method refers to the case when the transmitted messages must have a statistical relationship. In telemetry systems, such messages are transmitted over different channels. It is quite possible that a message described by the simplest covariance function (in our model this is an input process) must be reconstructed with greater accuracy. Then, naturally, the message samples with a more complex covariance function (this is an output process) will play an auxiliary role.
5.3. Example 3. Displacement of the Auxiliary Sample within the Sampling Interval of the Main Component
Again, consider the system studied in
Section 5.1 Example 1. That means there is a system of one RC circuit with a parameter
. A Markov process
with a parameter
acts at its input. There are three important differences: (1) The input
is an auxiliary process, (2) the set of samples
consists of one sample
, and (3) the location of this sample is changed within sampling interval
of the main restored component
. The output process still has two samples
. All characteristics of this example are described by the formulas (28)–(32). For this simple variant, we specify the relations (14)–(16):
Elements of matrices (37) and (38) show that cross-covariance functions have an important role in calculating reconstruction error.
In this example, the auxiliary sample
is located at five time points:
. These different points affect the shape of the basic functions as well as the course of the reconstruction error curves. The results of calculating these dependences are shown in
Figure 8 and
Figure 9.
It should be noted again that a realization to be restored belongs to the output process, which is characterized by the cross-covariance function in
Figure 1, curve 4 in contrast to
Section 5.1 Example 1 and
Section 5.2 Example 2.
In
Figure 8, the basic functions of the multidimensional algorithm
are designated by the numbers 1, 2, 3, meanwhile the basic functions of the one-dimensional algorithm
are denoted by the numbers 4 and 5.
The influence of the auxiliary sampling moments
on the reconstruction depends on the location of the maximum of the cross- covariance function
in the interpolation region. It should be noted that the maximum of the
covariance function (
Figure 2 curve 4) is located at
; that is, the maximum of the cross covariance function is located at
. As a consequence,
this, the lobe of the basic function of the auxiliary sampling instant
, is negative. This corresponds to the sampling moments
. On the other hand, the maximum of the cross-covariance function
is in the interpolation region, that is, in the interval
. This occurs when the auxiliary sample instant is located at
. The lobe of the basic function
has positive values in this region. Finally, the auxiliary sampling instant
is located with the second own sample, that is
. The influence of the mutual covariance function is located the interpolation region, that is
. As a result, the basic functions
have the same shape as the basic functions of the one-dimensional algorithm
.
In the proposed method, with a limited number of counts, each of the counts has its own basic function. This is true even for a one-dimensional algorithm. In the multidimensional version, the situation is more complicated, since the form of the basic function is influenced by both its own samples and the samples of the auxiliary realization. Moreover, the first of them affect the form of the basic function through their own covariance function, and the second through the cross-covariance function. In addition, in both cases, the elements of the inverse covariance matrix and the temporal position of the entire set of samples play a role. The variety of these factors makes it difficult to comment on the form of basic functions (see curves in
Figure 8). One can only assert the following: The article contains an analytical expression that defines the form of basic functions in general; the specified types of basic functions in all cases provide a minimum of recovery errors.
In
Figure 9, there are four error recovery curves when the auxiliary sample
is located at four different instants: Curve 1—
curve 2—
curve 3—
curve 4—
.
In
Figure 9 shows the influence of the auxiliary sampling moments on the reconstruction quality
. When the auxiliary sample
is located at some point in the own samples
, the error recovery is quantitatively equal
, as can be seen in curves 1 and 4. When the auxiliary sample is displaced
(curve 4), the effect of the cross-covariance function
is zero, because the influence of the auxiliary sample goes to the extrapolation interval. The different locations of the maximum error (curves 1 and 4) is explained by locating the maximum of the cross-covariance function
at the instants
(
Figure 9). For example, when the cross-covariance function
is at
, curve 1 is tilted to the right (
Figure 9). This is explained by the influence of the maximum of the cross-covariance function
manifesting itself in the region close to the sampling instant
. On the other hand, when the sampling moments are located in the interpolation region, the error reconstruction is reduced according to the fact that the maximum of the cross-covariance function is shifted towards the sampling moment
, as observed in curve 2 and 3.
6. Study Cases: Reconstruction of Realizations on Several Sampling Intervals
There are three examples here with multiple sampling intervals SRA. The input process realizations are auxiliar. The realization of the output process should be restored. Each example has its own peculiarity.
Section 6.1 Example 4 and
Section 6.2 Example 5 are described by the same input process and system as in
Section 5.1 Example 1.
Section 6.1 Example 4 differs in sampling procedures: The sampling of the input realization is non-periodic; the sample of the output realization is periodic. The number of samples is equal
. In
Section 6.2 Example 5, the sampling of the realizations of both processes is periodic, but the instance points are offsets. The number of samples is equal
.
Section 6.3 Example 6 examines the SRA when the input process is not Markov. The number of samples is equal
.
6.1. Example 4. SRA Algorithm with Non-Periodic Sampling of Auxiliary Input Process
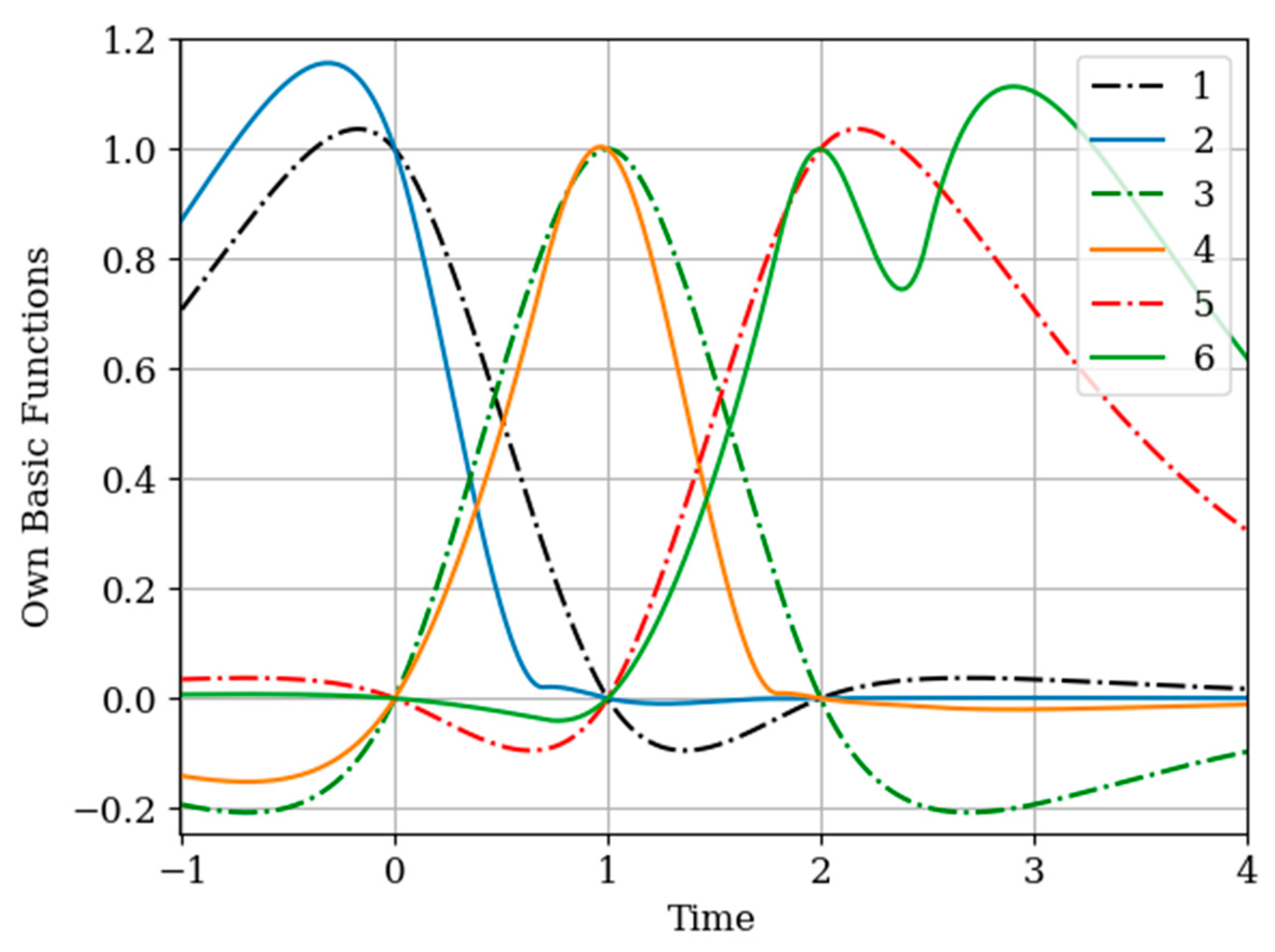
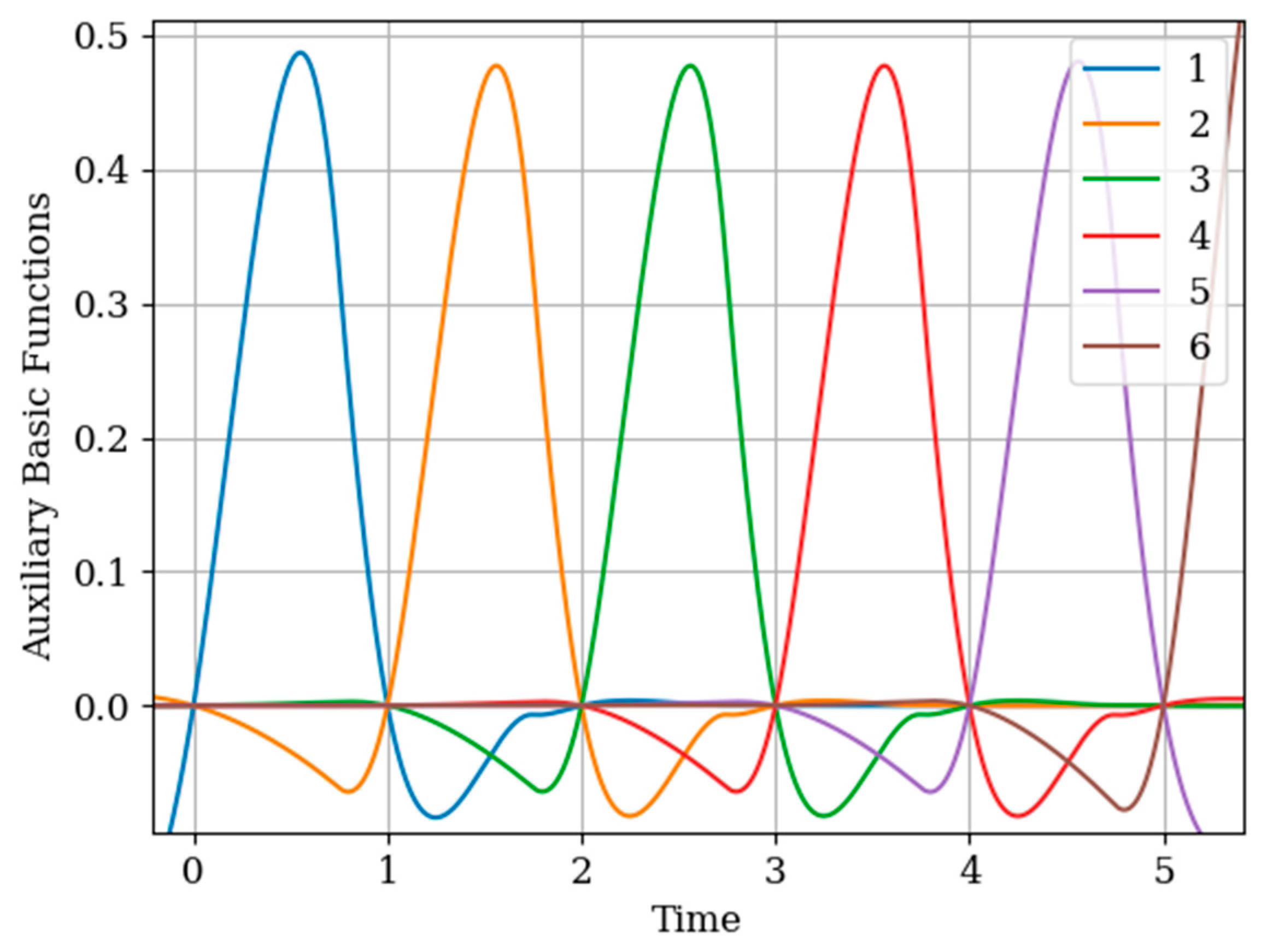
There is a system of one RC circuit with a parameter . A Markov process with a parameter acts at its input. The option of recovering the output process at several intervals, when the procedures for sampling the processes and are different, is considered. The numbers of samples are the same, i.e., . Sampling intervals of the process are periodic: . Samples of the realization of the process are non-periodic: . This is a non-trivial case, which, however, is easily studied by the applied methodology.
Note that the basic functions of the multidimensional algorithm
(even number curves) are narrower than the basic one-dimensional functions
(odd number curves). This is explained by the influence of the displaced cross covariance function
at the sampling instants
(
Figure 10). This influence is weighted by the elements
of the inverse covariance matrix. This influence is most clearly seen in the basic function
(curve 6) in the extrapolation region, where there is an approximate fluctuation. This is explained by the presence of the sampling instant
.
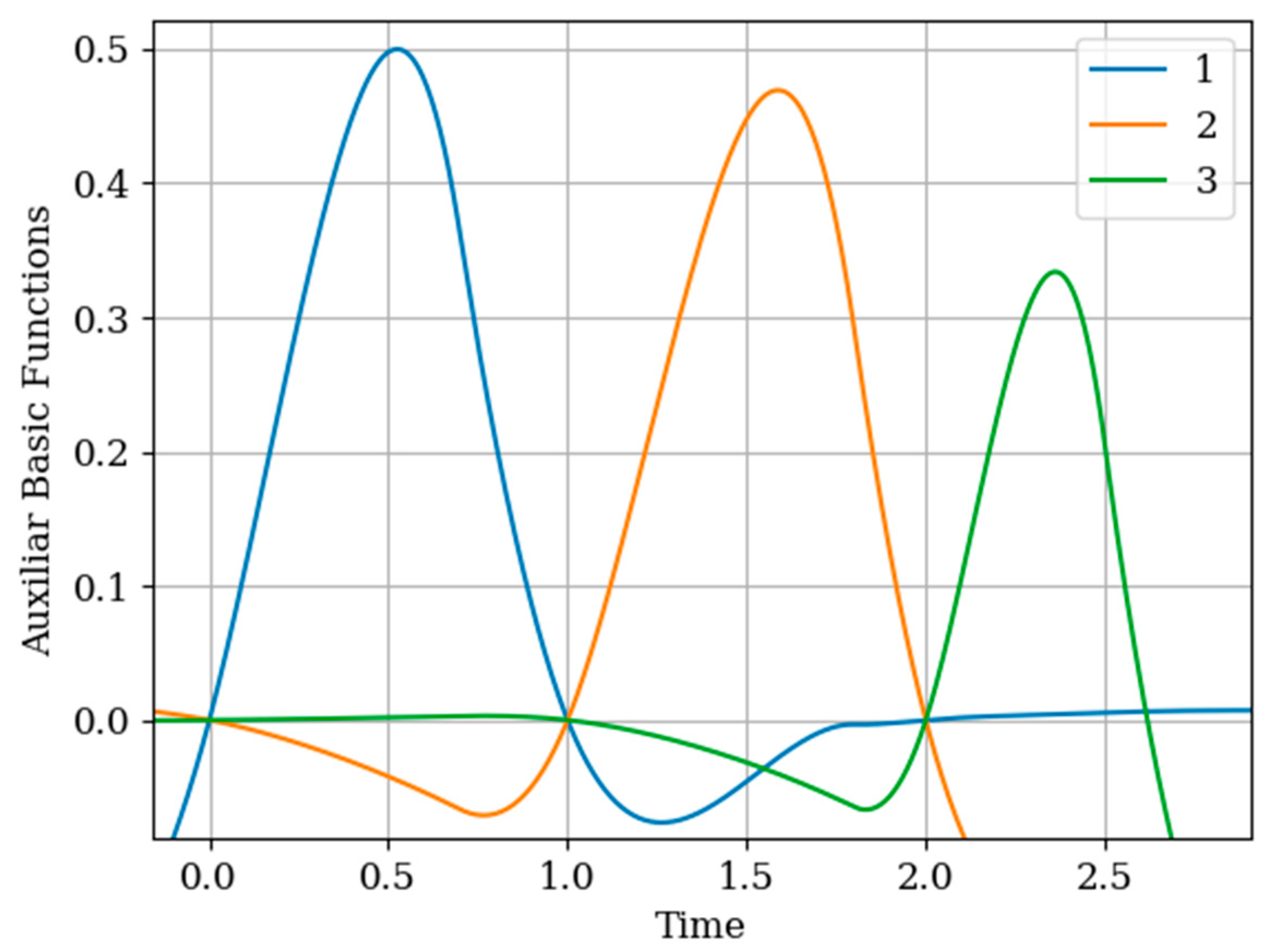
Attention should be paid to
Figure 11 that shows the auxiliary main functions (curves 1–3) have a variable shape. This is explained because the sampling intervals
between the sampling instants
are arbitrary. The amplitude of each basic function
decreases with increasing sampling interval. This means that, as the sampling interval
increases, the influence between the mutual covariance functions
decreases; this is manifested in the coefficients
in the inverse covariance matrix.
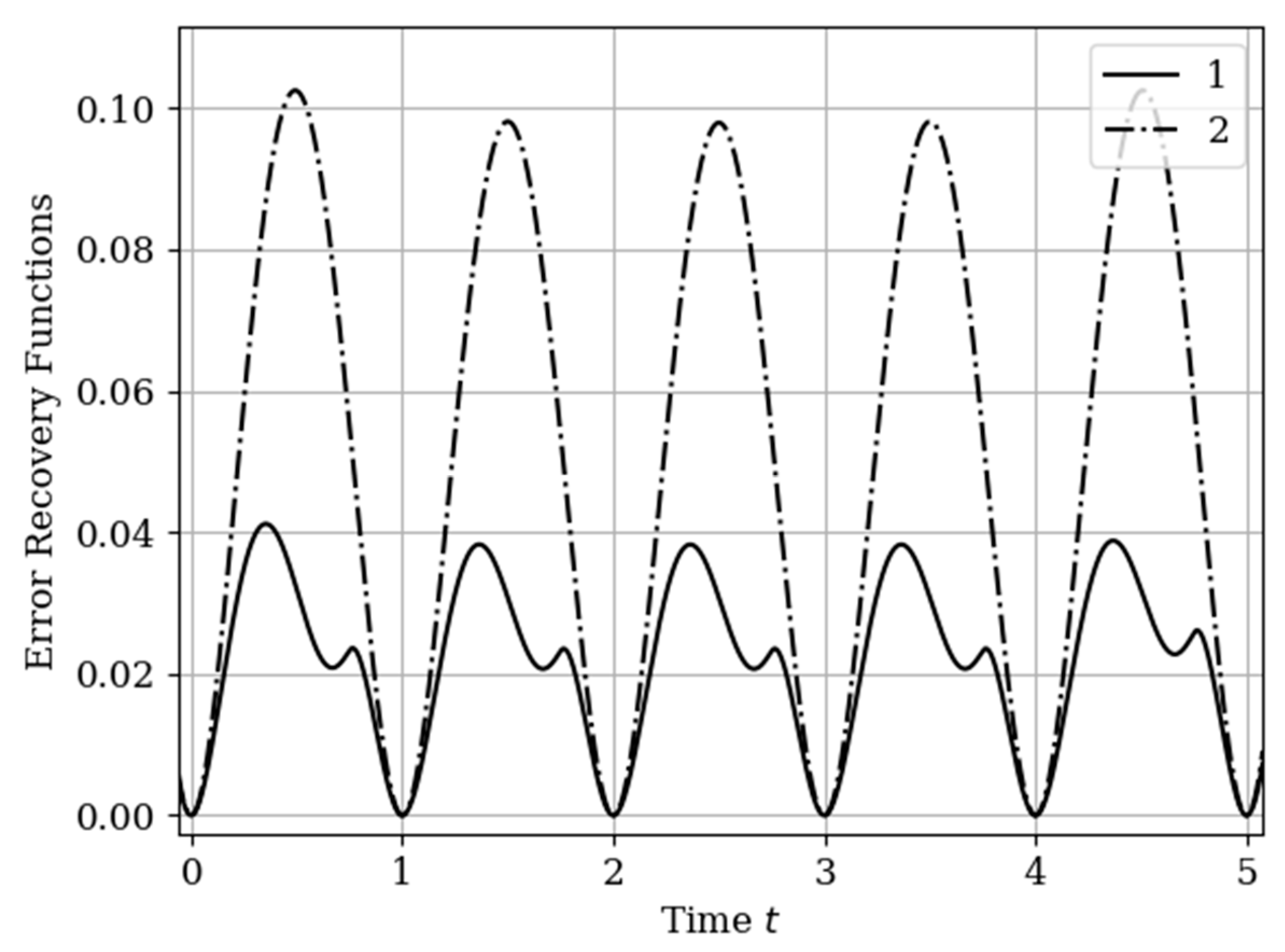
The results of calculations of recovery errors are presented in
Figure 12. Curve 1 describes the recovery error using the multidimensional algorithm, and curve 2 refers to the one-dimensional version. As you can see, the character of curve 1 is different on both sampling intervals due to non-periodicity of auxiliary samples.
6.2. Example 5. SRA of the Realizations of Both Processes Is Periodic, but the Instance Points of the Input Are Offsets
In this example, the question of using the proposed algorithm when restoring the realization of the output process at sampling intervals 5 and 6 is considered.
The description of the system and the input process coincides with the data of
Section 5.1 Example 1. All covariance functions are characterized by expressions (28), (30)–(32). The example is considered when the numbers of samples are equal
, and the sampling of the input
and output
processes occurs with different periods. So, the set of input and output processes is described by such data:
Sample sets are used to reconstruct the realization of the output process .
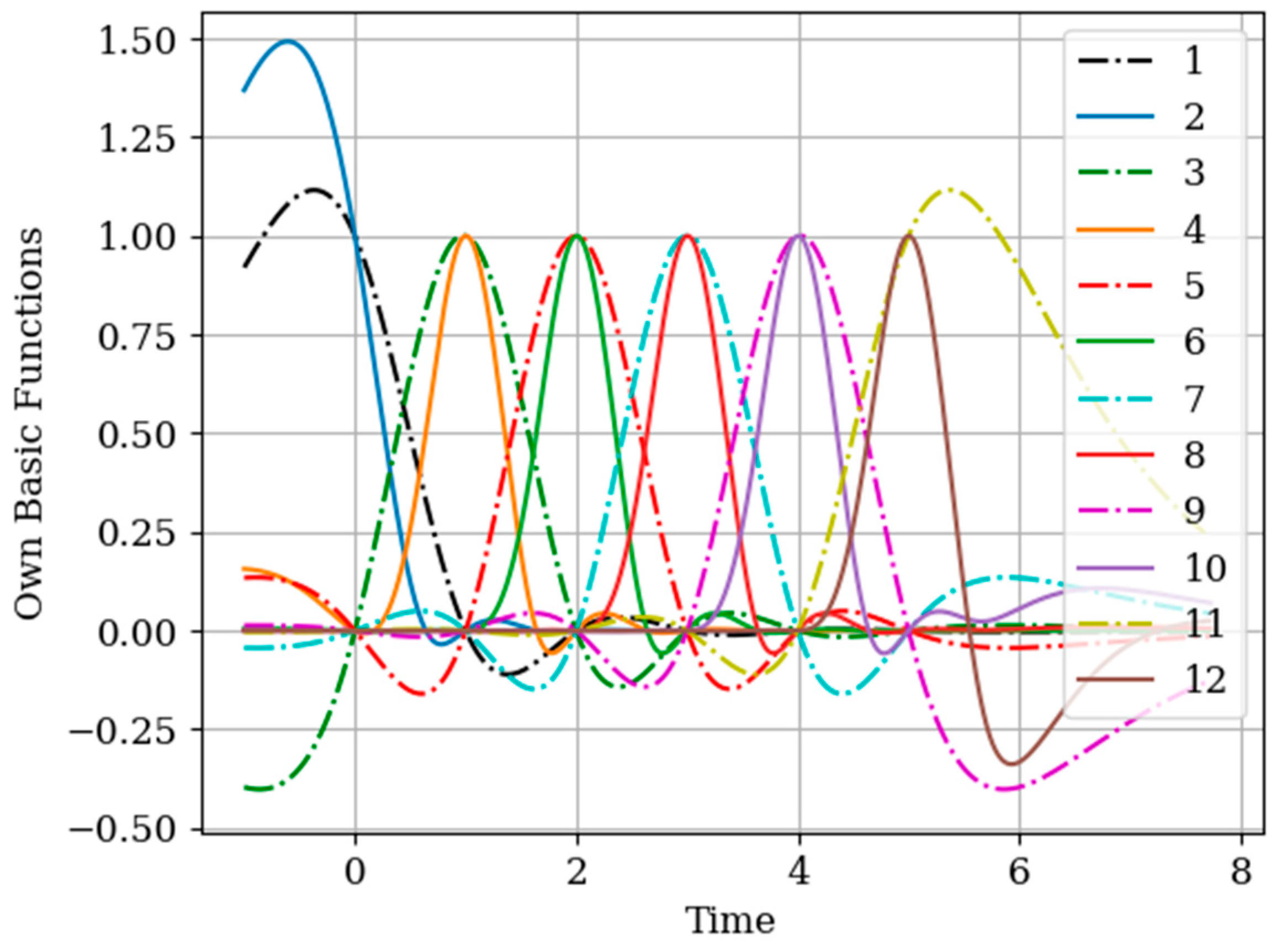
The basic functions of the multidimensional algorithm
(odd curves) and basic functions of the one-dimensional algorithm
(even curves) are shown in
Figure 13. Note that the shape of the basic functions of the multidimensional algorithm differs from the functions of the one-dimensional algorithm close to the moments of the auxiliary samples
. This means that this difference is caused by the functions of cross-covariance
in the instants
(as one can see in
Figure 2).
As can be seen in
Figure 14, the form in the interpolation region of the auxiliary basic function
is determined primarily from the cross-covariance function
that determines the
, as appropriate. Note that the auxiliary basic functions
have a smaller amplitude than the own
and one-dimensional
basic functions. This is explained by the elements of the inverse matrix
. The auxiliary basic function
has a different form than the basic functions
. The reason for this is that all coefficients are positive for the auxiliary sample
. That means covariance functions and cross-covariance functions are summed.
The recovery error of the output process
by multidimensional and one-dimensional algorithms is illustrated in
Figure 15. Curve 1 characterizes the recovery using a multidimensional algorithm. Curve 2 relates to a one-dimensional algorithm. The influence of the displacement of the auxiliary samples with respect to the own samples
is observed. This means that the maximums of the cross-covariance functions are located the interpolation region. This location corresponds to the minimum of the reconstruction error function, that is
. There is a small smoothed minimum at the highs of curve 2 in the middle of the total interval. This effect for non-Markov processes is described in the analysis of a one-dimensional algorithm [
13,
14,
16]. In this example, the difference in the maxima of the one-dimensional curves is insignificant. On curve 1, this effect is seen by the dependence among their samples.
6.3. Example 6. SRA When the Input Process Is Non–Markovian
Consider another example, which is an analogue of
Section 5.2 Example 2. Here, the system is an RC circuit with a parameter
, and the input process is formed from white noise by two consecutive RC circuits with parameters
. Covariance functions are defined by expressions (34)–(36). The input process
here is non-Markovian. Input and output processes are sampled as follows:
As can be seen, the number of samples is different and equal to 7. Input samples are delayed for a while . A realization of the output process is reconstructed.
In
Figure 16, the basic functions of the multidimensional
(odd curves) and one-dimensional algorithm
(even curves) are compared. Note that the maximum of the basic functions of the multidimensional and one-dimensional algorithm corresponds to the sampling instant
. This means that there is a greater of the covariance functions
, which are weighted by the elements of the inverse covariance matrix
, as observed in Formula (27). Another feature to note is that the basic functions of the multidimensional algorithm
are narrower than the functions of the one-dimensional algorithm
. This is because all the cross-covariance functions
influence the recovery of the samples
.
In
Figure 17, the auxiliary basic functions
of the multidimensional algorithm are observed. Comparing the results with
Figure 15, the amplitude of the functions
in
Figure 17 is greater. This is related to the cross-covariance function
, which is manifested in the elements of the inverse covariance matrix
. To explain the last basic function
of the last instant of the auxiliary sample
concentrates the influence in an additive form (that is, the coefficients of the inverse matrix
are positive in this last auxiliary sampling instant) of the covariance function
and the mutual covariance function
.
The form in
Figure 18 of the curves shows an analogy with
Figure 15 in
Section 6.2 Example 5. The main differences in (18) (with a comparison of
Figure 15) are associated with a significant decrease in the values of the errors n and the asymmetric nature of the curves related to multivariate recovery. The reasons are obvious: (1) The output process
is smoother and (2) the shift of the samples of the set
as compared with the samples of the set
, and with the size of the sampling interval, is insignificant (0.15). Curve 1 shows the effect of reducing the error in the center between the extreme samples. Obviously, this is a reflection the greater statistical relationship between samples in the considered non-Markov process.
The increase in the quality of restoration (in
Figure 18) is physically explained by the fact that in the known method when restoring realizations, only its own samples are used. In the proposed method, the number of samples participating in the reconstruction is increased due to samples from another, statistically related realization. Moreover, the number of additional samples can be arbitrary. It is obvious that the restoration of realizations from a larger number of samples leads to an increase in the quality of restoration.
7. Conclusions
The problem investigated in the article work to the problem of sampling—recovery of two-dimensional Gaussian processes. The dimensionality of the problem is not limited by the presence of two random processes at the input and output of the linear system, since, in addition to them, the problem includes two sets of samples fixed in the realizations of these processes. The algorithm developed differs in that the reconstruction of the realizations of both components, or one of them, is carried out on the basis of two sets of samples. This means that the recovery occurs not only with the participation of its own realization samples, but with the realization samples of another component. The considered examples illustrate some applications of the proposed algorithm. They studied the options when the following changes: (1) The type and input of the system, (2) the number of intervals on which the restoration is performed, (3) as well as the number of auxiliary samples involved in the functioning of the multidimensional algorithm.
In all cases, there are basic functions and error recovery functions. These functions are optimal and characterize the estimation of yields using the recovery algorithm studied. These reconstruction characteristics allow us to demonstrate the advantage of using the algorithm based on the quality of the reconstruction. This result will be used as long as the random processes have a statistical dependency.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}

















