1. Introduction
The terms of edge and contour are often used interchangeably in the field of image processing. Still, the term “edge” is mostly used to denote image points where intensity difference between pixels is significant. On the other hand, the term “contour” is used to denote connected object boundaries. The goal of edge detection is to identify pixels at which the intensity or brightness changes sharply. Ideally, edge detection should generate a set of straight or curved line segments for defining some closed object boundaries, thus benefiting diverse research areas such as image segmentation [
1], pattern recognition [
2], and motion tracking [
3,
4]. Traditional edge detectors like Roberts [
5] can hardly produce a set of connected lines and curves that correspond to object boundaries. Using low level edge detectors often yields redundant details and even false contours. These undesirable effects are particularly unacceptable wherein gestalt edges are required and grouped for constructing boundaries of objects as perceived by the human eyes [
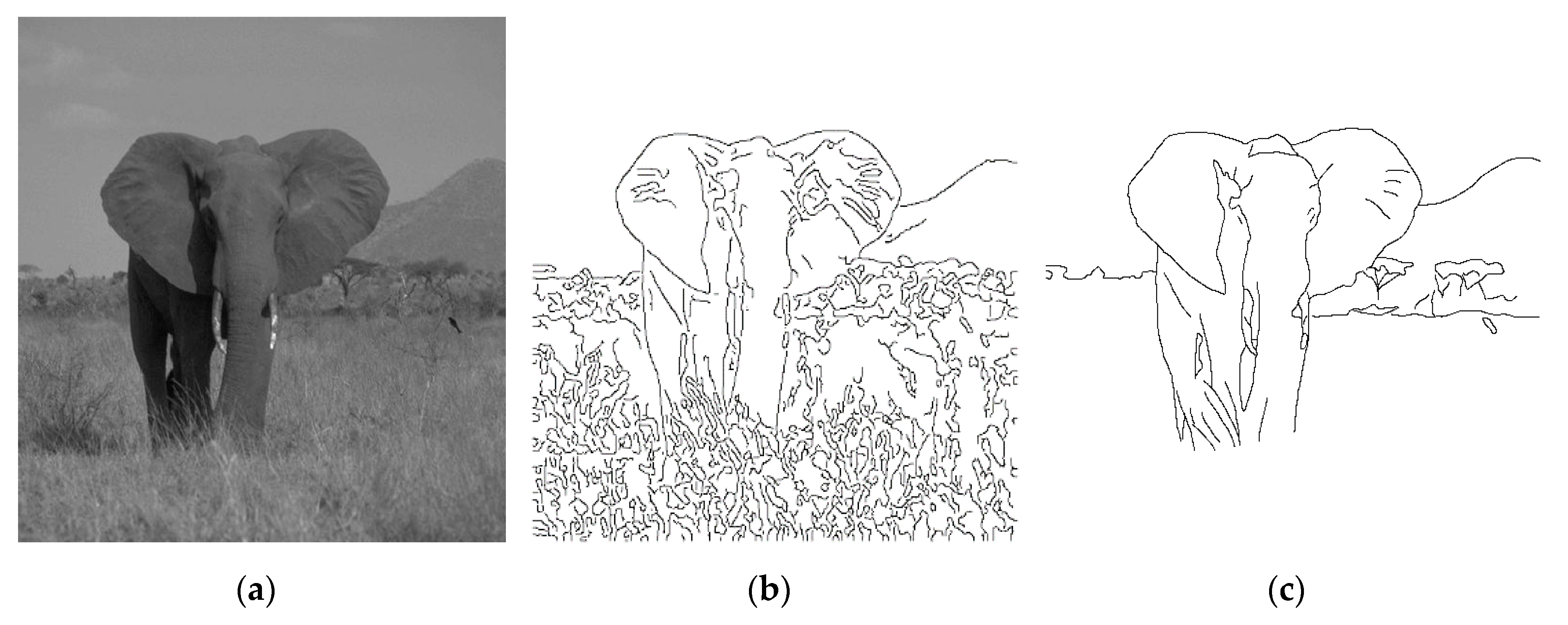
6], as the elephant, tress, and mountain in
Figure 1c. Although Laplacian [
7] and Canny [
8] can be used to detect most edges by proper parameters adjustment, it is rather difficult (if not impossible) to produce gestalt edges, as they are based on differential calculation or criterion-based optimization.
Figure 1b shows that too many fine edges or redundant details are extracted by the well-known Canny detector, particularly for the complex nature image of
Figure 1a. The human visual system can quickly compile complex scenes into simple object contours for survival or even art creation; this observation should allow us to conjecture that successful detection of gestalt edges is not only useful for simplifying the low-level tasks of edge linking in forming closed contours, but also beneficial for the high-level operations of image analysis and even artwork creation.
The word “gestalt” is German for “unified whole”. Historically, the first gestalt principles were devised in the 1920s by psychologists Wertheimer, Koffka, and Kohler, who aimed to understand how humans typically gain meaningful perceptions from the chaotic stimuli around them. They identified a set of laws which address the natural compulsion to find order in disorder. The gestalt laws are a set of principles [
9] to account for the observation that humans naturally perceive objects as organized patterns and objects. Gestalt psychologists argued that the human mind innately tends to perceive patterns in the stimulus based on certain rules. Normally, gestalt principles are organized into five categories: proximity, similarity, continuity, closure, and connectedness. The principle of similarity says that elements that are similar are perceived to be more related than elements that are dissimilar. Similarity helps us organize objects by their relatedness to other objects within a group and can be affected by the attributes of color, size, shape, and orientation. The law of proximity states that items that are close together tend to be perceived as a unified group. Namely, items close to each other tend to be grouped together, whereas items farther apart are less likely to be grouped together.
This paper associates gestalt theory, in particular the laws of proximity and similarity, together with the Expectation-Minimization (EM) algorithm and the Bayesian decision to achieve the extraction of gestalt edges for an input image. We present a novel method called
GestEdge, in which the directivity of a target pixel is iteratively evaluated with a sampling window of which the shape is deformable by the EM algorithm. Upon convergence, the final directivity value should reflect the likelihood of pointing to the similar direction among the neighboring pixels within the converged window, and can be plugged into a Bayesian decision formula to determine whether the target pixel is qualified to be a gestalt edge point. In view of entropy as an inverse indicator of direction uniformity, plus the observation that the gradient always points in the direction of largest possible intensity increase and the length of the gradient vector corresponds to the rate of change in that direction, the deformable window enables
GestEdge to exploit the proximity and similarity for each target pixel points. By sliding the detection window, left-to-right and top-to-bottom, through the entire input image,
GestEdge can effectively detect gestalt edges essential for constructing contours consistent with human perception. The proposed method mainly comprises the following steps: (i) First, a subset of pixels is selected from the input image as POI (pixels of interest); (ii) then we take each pixel of the POI as a target pixel and iteratively update the shape of a detection window center at the target pixel; when convergence is reached, a directivity value representing the likelihood of perceiving the target pixel as edge point is obtained; (iii) then we invoke the Bayesian process [
10], to determine whether the target pixel is a gestalt edge, and if it is not, the target pixel is eliminated; (iv) we then slide the window to the next pixel in POI and go to Step (ii), until all pixels in POI are processed; and, finally, (v) the remaining candidate pixels are outputted as the gestalt edge pixels.
4. Directivity-Aware Directivity Evaluation
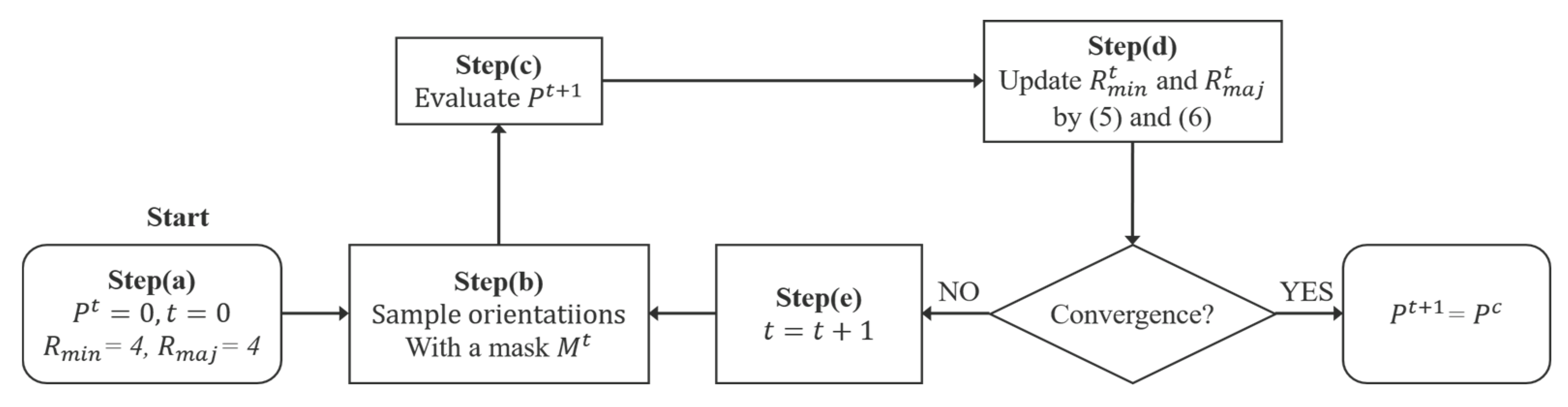
The flowchart of
GestEdge is shown in
Figure 2, mainly comprising five steps.
Step (a): Quantize , using the formula , where Bn is the user-specified total number of bins in the histogram of quantized θ, and denotes the integer nearest to . Next, define a circular mask with an area of r2 × π as the sampling window centered at a target pixel picked from POI and let the initial directivity be . Heuristically, setting r to 4 (pixels) and, hence, Bn to 51 is sufficient for dealing with various types of images. The initial sampling window has a semimajor axis of 4 and a semiminor axis of 4. During the iteration, will rotate to align the semiminor axis with the quantized . Namely, the sampling window is set in parallel with the direction + 90°.
Step (b): This step, along with Step (c), corresponds to the E-step in the EM algorithm. Elements of
covered by
act as the observable data and are used for computing a histogram of gradient orientation, in which the height of a bin is written as
. In particular,
denotes the
highest bin among all bins
,
i = 1, 2…
Bn. In a sense,
corresponds to the principal orientation in Reference [
16]. Specifically, denote
as the bin associated with the target pixel.
Step (c): The directivity of the target pixel is updated as follows:
In Equation (3), the parameter
α is defined as
and
measures the difference in the occurrence frequency between the gradient direction of the target pixel and the principal orientation. The term
interestingly has special implications for human visual perception, and we later elaborate on this further. Moreover,
denotes the local maximum entropy:
and the global maximum entropy,
, is obtained when
=
Bn, which occurs when each pixel in
by itself is a separate nonzero bin.
Step (d): This step corresponds to the M-step in the EM algorithm for updating the latent parameters (i.e., convergent semimajor and semiminor axes of
). The original circle,
, might deform to an ellipse, and the semiminor and semimajor axes are updated by using the following equation:
Step (e):; iterate Steps (b)–(d) until convergence. The converged directivity is noted as .
To facilitate understanding the flowchart of
Figure 2, we use
Figure 3 to schematically illustrate the deformation of sampling window
as the directivity-aware scheme iterates Steps (b)–(d) until convergence.
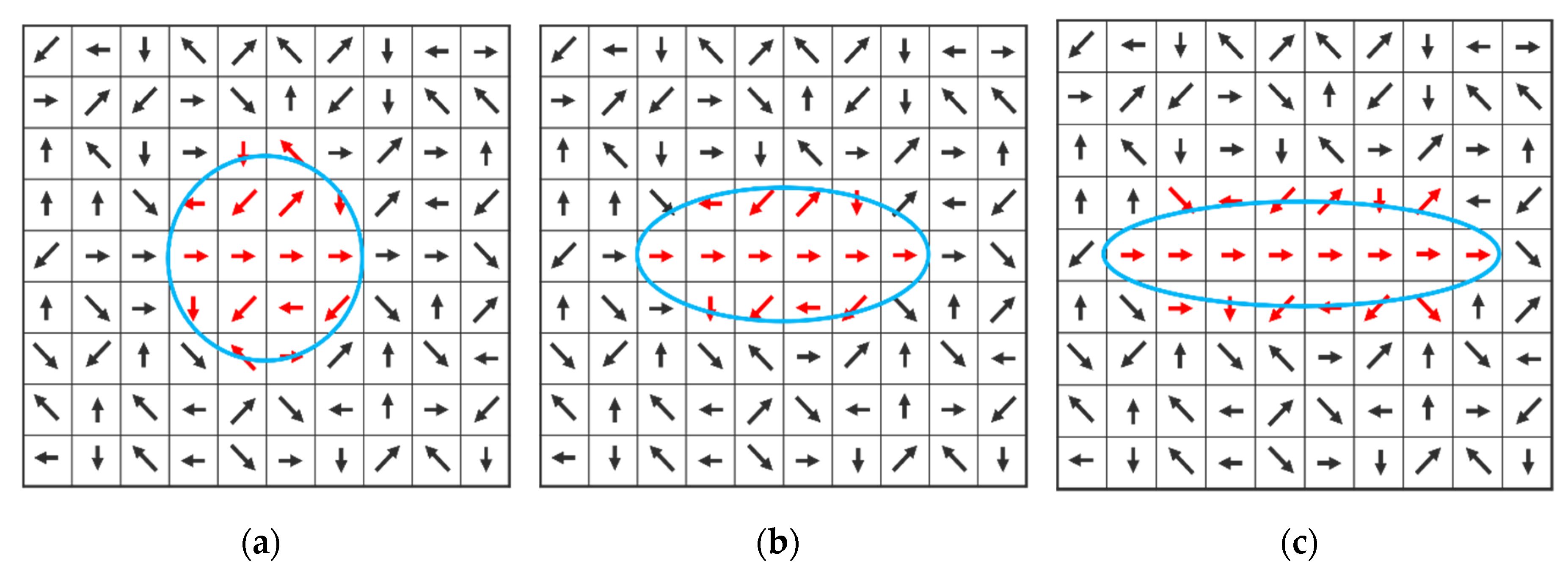
Figure 3a shows the initial
. After the first iteration of Steps (b)–(d), the sampling window is forced to deform by the zero-degree directivity evaluated at the center pixel in the first iteration.
Figure 3c shows that the window shape is further elongated after the second iteration, to reflect the actual situation in which the target pixel is at, that is, more neighboring pixels are found to be in line with the target pixel (i.e., obeying laws of proximity and similarity), making it possess a high directivity when reaching convergence at the third iteration. Note that the entropy
for each window is calculated by using Equation (2), and, without the deformable window design, it would merely account for pixel intensity entropy. The parameter
(<
Bn) denotes the total number of nonzero bins.
inversely stands for the orientation resemblance between the pixels covered by
. In other words, a larger
indicates a weaker directivity because of the more uniform distribution of
, and vice versa. Thus, using
to compute
enables the orientation resemblance within
to be evaluated conveniently, which simulates the similarity law of gestalt theory [
17] stating the tendency to group items (e.g., pixels and edges) into meaningful contours, if they are similar in terms of shape, color, or texture. Despite these good properties, human perception is quite a complex task from the perspective of information theory, which could render
inadequate for accurately measuring the directivity of a target pixel in some special cases. To see this, assume
, and then Equation (1) is readily reduced to the following:
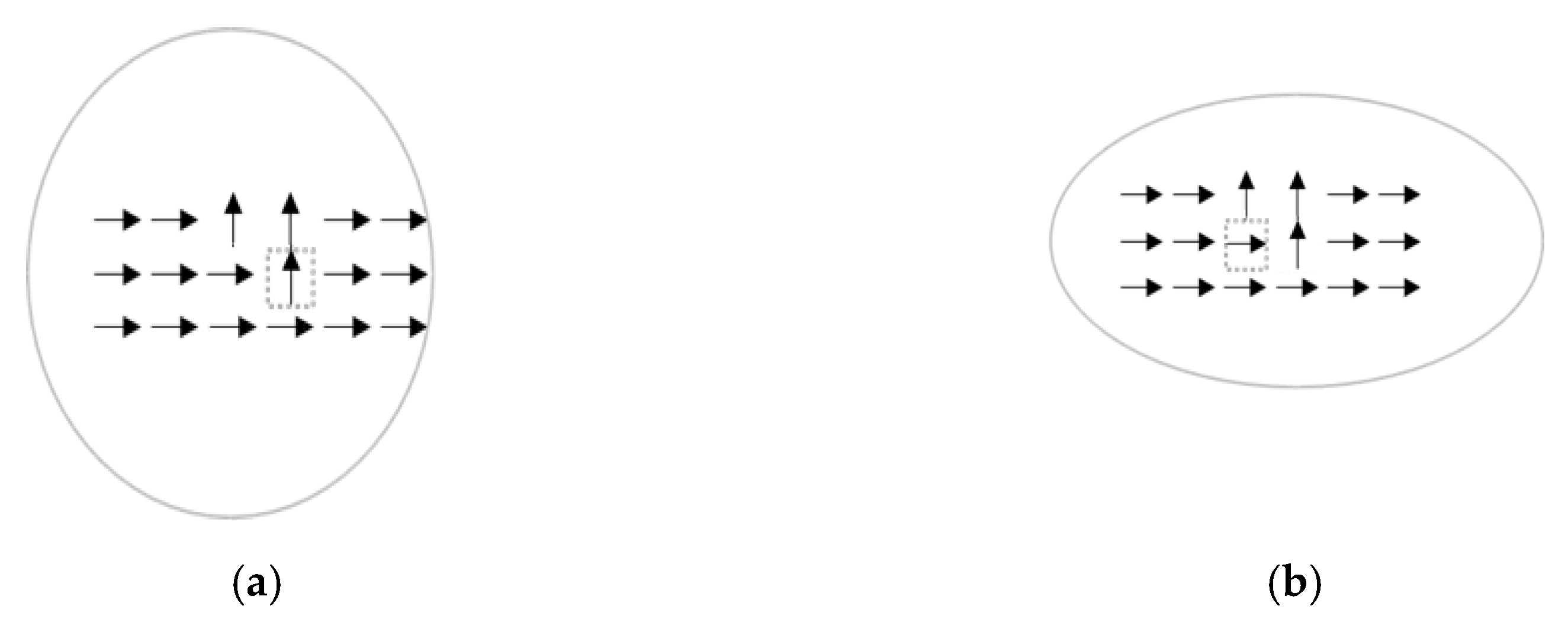
Figure 4 shows two examples with an infinitely large receptive field. The target pixels are enclosed by dashed squares, with symbols → and ↑ representing orientations 0° and 90°, respectively.
Figure 4a can be easily perceived as separate lines broken at the target pixel, whereas
Figure 4b will be perceived as straight lines.
Figure 4a,b are perceived differently, yet both cases have
, using (2), because
. That is, the normalized occurrence frequencies of → in
Figure 4a,b are calculated as
and
, respectively. Moreover,
(i.e., the normalized occurrence frequencies of ↑ in
Figure 4a,b are calculated as
and
, respectively. Using Equation (7), the directivity value for both target pixels in
Figure 4a,b is 1, which is contradictory to human perception. To address this issue, we first note that the target pixel ↑ in
Figure 4a should possess a directivity much smaller than that in
Figure 4b. Clearly, a compensation term is required in Equation (7). In this study, the compensation term
is given as in Equation (3). In particular,
is defined as conflict index and has two implications: (i)
is regulated by
if
or even if
equals approximately one. (ii) If
equals or is close to
, then
, and
is unnecessary.
For the first implication, we assume
and
, which corresponds to
Figure 4a, where many sampled pixels share the same orientation (i.e., 0°). In other words, a nearly zero entropy
indicates the existence of a dominant mode. For a large conflict index (
a large value of
is required to get rid of the adverse effect. From Equation (3),
, because
, and a small directivity value can be correctly obtained by using Equation (1). Thus, the problem in
Figure 4a is solved. Note that, as the number of ↑ increases in
Figure 4a, the value of
decreases, and as the number of ↑ goes to infinite, the conflict effect goes away, which is precisely the situation in
Figure 4b. Clearly,
can appropriately offset the conflict effect. That is, a larger value of
can be obtained by using Equation (3) for offsetting a stronger conflict effect. The second implication simply states that either
itself is the dominant mode (e.g., 0° in
Figure 4b) or at least two major modes coexist (i.e.,
). In both cases,
is nearly zero, and the conflict effect is insignificant, making Equation (7) essentially identical to Equation (1).
Recall that
is rotated to align with
under the iterative EM algorithm. The window shape will become narrower (wider) for a larger (smaller)
value. Specifically, the window shape is allowed to deform iteratively, until it covers pixels from which a directivity value that best characterizes the target pixel can be evaluated. Doing so can simultaneously support the proximity and similarity laws, meaning that the EM-driven deformation not only enables as many pixels (with orientations similar to that of the target pixel) as possible to be covered by
, but also allows the target pixel to
spatially depart from pixels that are dissimilar in gradient orientation.
Figure 5a shows an example of a converged window centered at a target pixel of 90° (↑) when
= 0.2 (three pixels of ↑ and fifteen pixels of →; i.e.,
= 3 and
= 15). In contrast,
Figure 5b shows an example of a converged window centered at a target pixel of 0° (→) when
(i.e.,
). From Equation (1), the directivity value of the target pixel (enclosed by a square) in
Figure 5a is 0.05, which is smaller than the directivity value (0.36, using Equation (7)) of the target pixel in
Figure 5b.
It is interesting to note that depictions in
Figure 5a,b actually share the same histogram distribution, yet their converged window shapes are quite different. The high directivity possessed by the target pixel in
Figure 5b indicates that if the target pixel is a gestalt pixel, the likelihood of observing such a histogram should be high; conversely, if a target pixel possesses a low directivity value, as in
Figure 5a, then it should be very unlikely to observe such a histogram associated with a gestalt pixel. Therefore, a window deformed according to Equations (5) and (6) indeed is effective in measuring the likelihood of observing a gestalt pixel. In the context of directivity-awareness, although the target pixel in
Figure 5a satisfies the proximity law that describes the gestalt tendency to group items into meaningful configurations [
17], it does not meet the similarity law, and, hence, results in a low directivity value. In contrast, because the target pixel in
Figure 5b satisfies both the proximity law and similarity law, it has a high directivity value and the converged window shape is much more elongated than that in
Figure 5a. Comparison of
Figure 5a,b justifies that our sampling window is directivity-aware in the sense that its deformation implicitly accounts for spatial occupation entropy and indeed can support both laws of proximity and similarity.
To prove the stability of the iterative directivity-aware scheme, an energy function is defined as follows:
The first derivative of
Et with respect to
Pt can be written as
where
. According to Equation (5), the term
in Equation (9) is always smaller than zero if
, and it will be always greater than zero if
. Namely,
is always negative. Therefore,
in Equation (8) is guaranteed to converge at least to a local minimum when
is iteratively updated. An analogy of this convergent process can be found in the well-known Hopfield Network [
18] in updating the connection weights between neurons.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}













