Bayesian Uncertainty Quantification with Multi-Fidelity Data and Gaussian Processes for Impedance Cardiography of Aortic Dissection

 ,
,  , , ,
, , , 
Abstract
1. Introduction
2. Bayesian Multi-Fidelity Scheme
2.1. Statistical Model
2.2. Prediction and Its Uncertainty
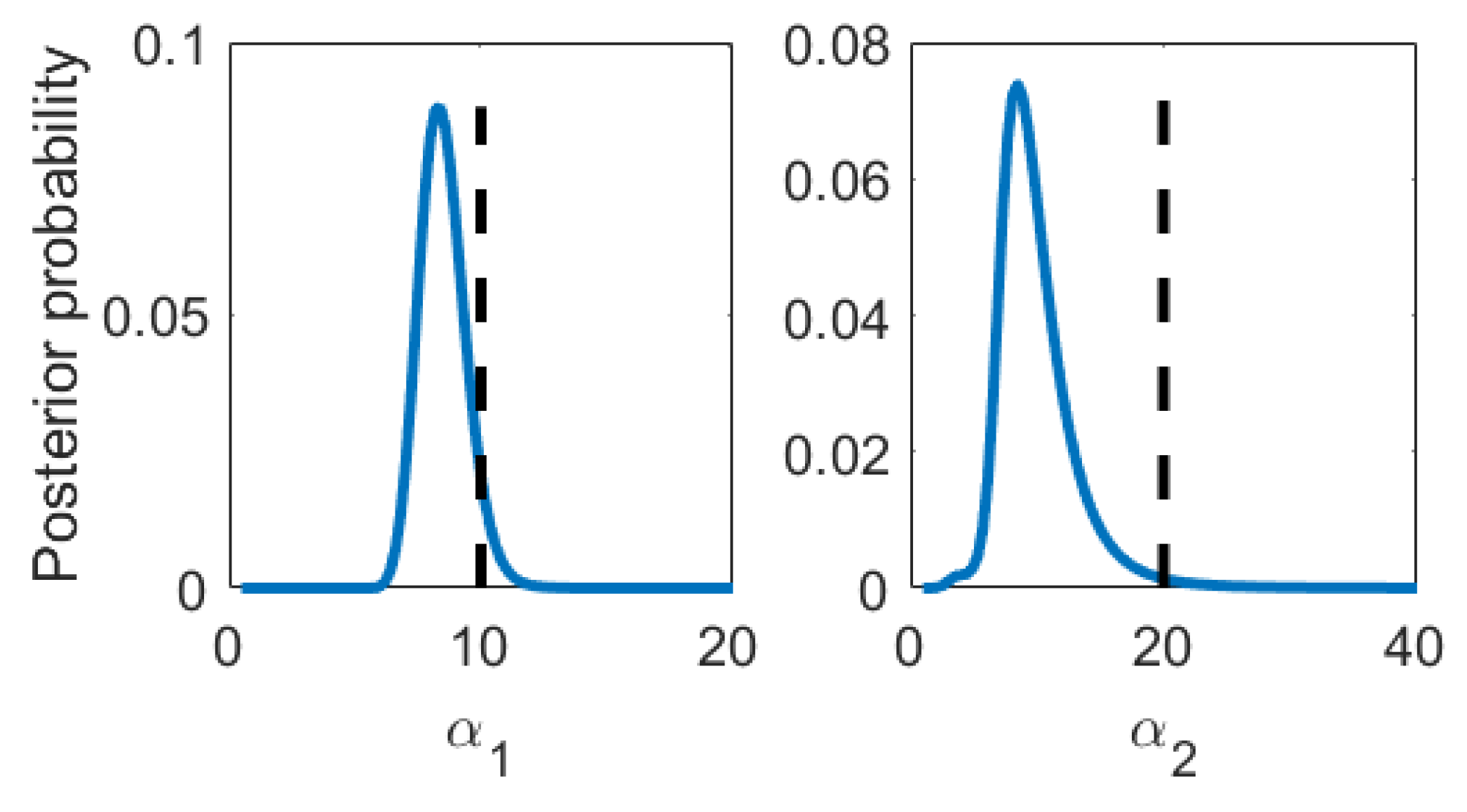
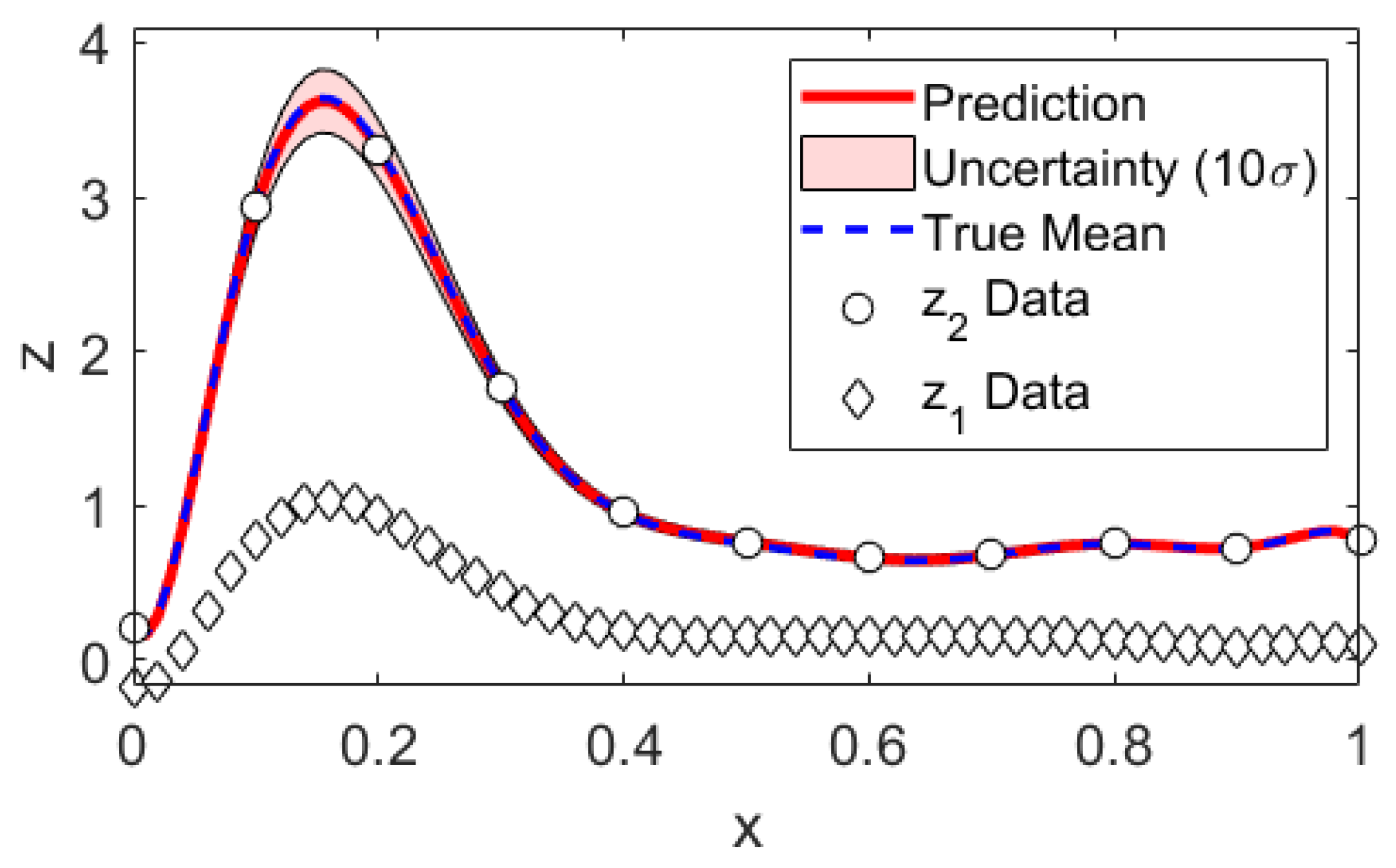
3. Algorithm and Mock Data Scrutiny
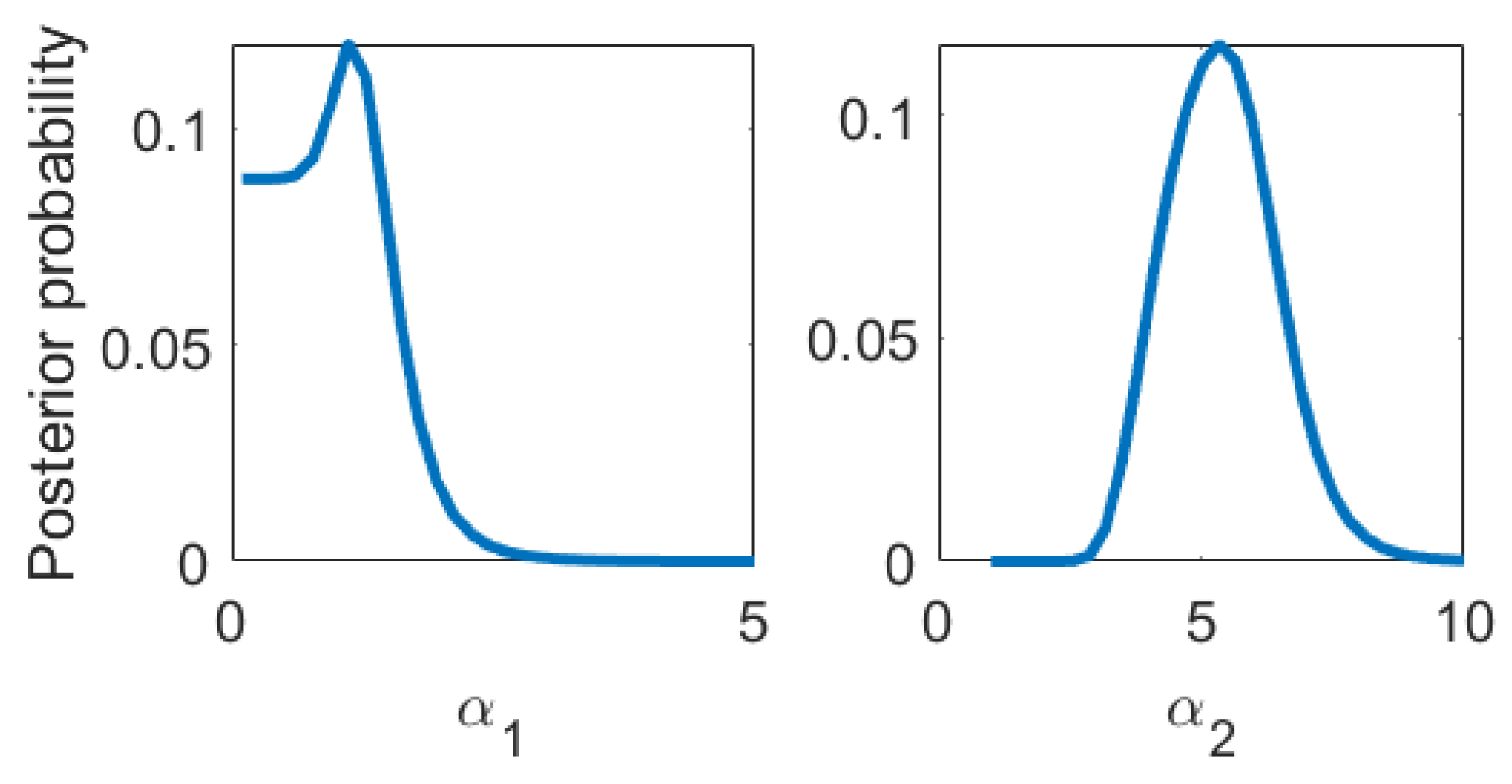
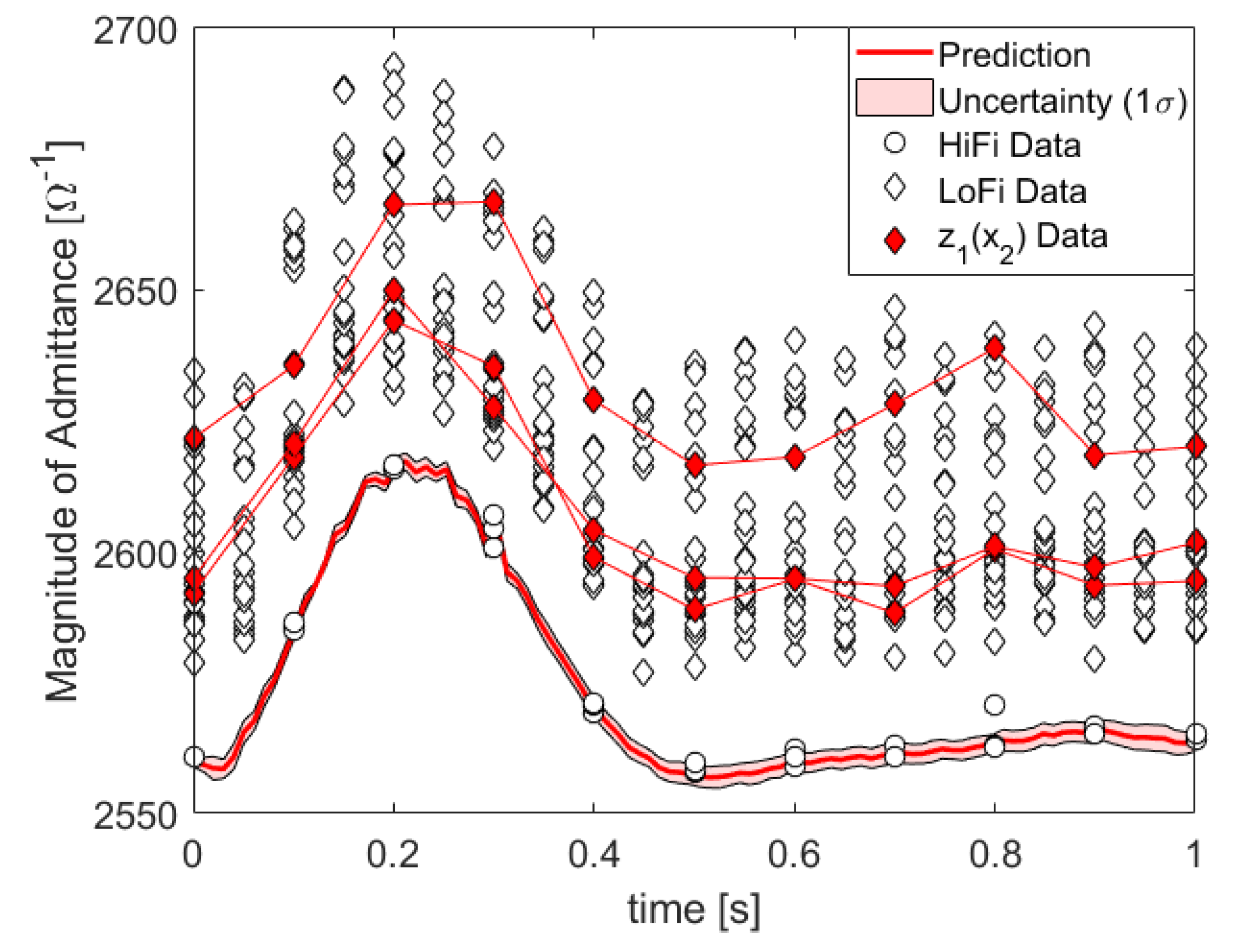
4. Application to Finite Element Simulations of Impedance Cardiography of Aortic Dissection
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Sample Availability
Appendix A. Mathematical Proofs
Appendix A.1. Parameter Posterior and Parameter Estimates
Appendix A.2. Predictive Mean
Appendix A.3. Predictive Covariance
References
- Ghanem, R.G.; Owhadi, H.; Higdon, D. Handbook of Uncertainty Quantification; Springer: Basel, Switzerland, 2017. [Google Scholar]
- Haylock, R. Bayesian Inference about Outputs of Computationally Expensive Algorithms with Uncertainty on the Inputs. Ph.D. Thesis, Universtity of Nottingham, Nottingham, UK, May 1997. [Google Scholar]
- O’Hagan, A.; Kennedy, M.C.; Oakley, J.E. Uncertainty Analysis and Other Inference Tools for Complex Computer Codes. 1999. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.51.446&rep=rep1&type=pdf (accessed on 26 December 2019).
- O’Hagan, A. Bayesian analysis of computer code outputs: A tutorial. Reliab. Eng. Syst. Saf. 2006, 91, 1290–1300. [Google Scholar] [CrossRef]
- Wiener, N. The Homogeneous Chaos. Am. J. Math. 1938, 60, 897–936. [Google Scholar] [CrossRef]
- Ghanem, R.G.; Spanos, P.D. Stochastic Finite Elements: A Spectral Approach; Springer: Basel, Switzerland, 1991. [Google Scholar]
- Xiu, D.; Karniadakis, G.E. The Wiener-Askey polynomial chaos for stochastic differential equations. SIAM J. Sci. Comput. 2005, 27, 1118–1139. [Google Scholar] [CrossRef]
- O’Hagan, A. Polynomial Chaos: A Tutorial and Critique from a Statistician’s Perspective. Available online: http://tonyohagan.co.uk/academic/pdf/Polynomial-chaos.pdf (accessed on 25 June 2019).
- O’Hagan, A. Curve Fitting and Optimal Design for Prediction. J. R. Stat. Soc. Ser. B Methodol. 1978, 40, 1–42. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Bishop, C. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1996. [Google Scholar]
- MacKay, D.J. Information Theory, Inference, and Learning Algorithms; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kennedy, M.C.; O’Hagan, A. Predicting the output from a complex computer code when fast approximations are available. Biometrika 2000, 87, 1–13. [Google Scholar] [CrossRef]
- Koutsourelakis, P.S. Accurate Uncertainty Quantification using inaccurate Computational Models. SIAM J. Sci. Comput. 2009, 31, 3274–3300. [Google Scholar] [CrossRef]
- Perdikaris, P.; Raissi, M.; Damianou, A.; Lawrence, N.D.; Karniadakis, G.E. Nonlinear information fusion algorithms for data-efficient multi-fidelity modelling. Proc. R. Soc. A Math. Phys. Eng. Sci. 2017, 473, 20160751. [Google Scholar] [CrossRef] [PubMed]
- Eck, V.G.; Donders, W.P.; Sturdy, J.; Feinberg, J.; Delhaas, T.; Hellevik, L.R.; Huberts, W. A guide to uncertainty quantification and sensitivity analysis for cardiovascular applications. Int. J. Numer. Methods Biomed. Eng. 2016, 32, e02755. [Google Scholar] [CrossRef] [PubMed]
- Biehler, J.; Gee, M.W.; Wall, W.A. Towards efficient uncertainty quantification in complex and large-scale biomechanical problems based on a Bayesian multi-fidelity scheme. Biomech. Model. Mechanobiol. 2015, 14, 489–513. [Google Scholar] [CrossRef] [PubMed]
- Zienkiewicz, O.C.; Taylor, R.L.; Zhu, J.Z. The Finite Element Method: Its Basis and Fundamentals; Elsevier: Amsterdam, The Netherlands, 1967. [Google Scholar]
- Miller, J.C.; Horvath, S.M. Impedance Cardiography. Psychophysiology 1978, 15, 80–91. [Google Scholar] [CrossRef] [PubMed]
- Reinbacher-Köstinger, A.; Badeli, V.; Biro, O.; Magele, C. Numerical Simulation of Conductivity Changes in the Human Thorax Caused by Aortic Dissection. IEEE Trans. Magn. 2019, 55, 1–4. [Google Scholar] [CrossRef]
- Humphrey, J.D. Cardiovascular Solid Mechanics; Springer: Basel, Switzerland, 2002; p. 758. [Google Scholar]
- Khan, I.A.; Nair, C.K. Clinical, diagnostic, and management perspectives of aortic dissection. Chest 2002, 122, 311–328. [Google Scholar] [CrossRef] [PubMed]
- Gabriel, C.; Gabriel, S.; Corthout, E.C. The dielectric properties of biological tissues: I. Literature survey. Phys. Med. Biol. 1996, 41, 2231–2249. [Google Scholar] [CrossRef] [PubMed]
- Sivia, D.; Skilling, J. Data Analysis: A Bayesian Tutorial; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Le Gratiet, L.; Garnier, J. Recursive Co-Kriging Model for Design of Computer Experiments With Multiple Levels of Fidelity. Int. J. Uncertain. Quantif. 2014, 4, 365–386. [Google Scholar] [CrossRef]
- Ranftl, S.; Melito, G.M.; Badeli, V.; Reinbacher-Köstinger, A.; Ellermann, K.; von der Linden, W. On the Diagnosis of Aortic Dissection with Impedance Cardiography: A Bayesian Feasibility Study Framework with Multi-Fidelity Simulation Data. Proceedings 2019, 33, 24. [Google Scholar] [CrossRef]
- Alastruey, J.; Xiao, N.; Fok, H.; Schaeffter, T.; Figueroa, C.A. On the impact of modelling assumptions in multi-scale, subject-specific models of aortic haemodynamics. J. R. Soc. Interface 2016, 13. [Google Scholar] [CrossRef] [PubMed]
- Comsol, A.B.; Stockholm, S. Comsol Multiphysics Version 5.4. Available online: http://www.comsol.com (accessed on 4 June 2019).
- Raissi, M.; Perdikaris, P.; Karniadakis, G.E. Inferring solutions of differential equations using noisy multi-fidelity data. J. Comput. Phys. 2017, 335, 736–746. [Google Scholar] [CrossRef]
- Albert, C.G. Gaussian processes for data fulfilling linear differential equations. Proceedings 2019, 33, 5. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Estimate (Multi-Fidelity) | Truth |
|---|---|---|
| 0 | ||
| 3 | ||
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ranftl, S.; Melito, G.M.; Badeli, V.; Reinbacher-Köstinger, A.; Ellermann, K.; von der Linden, W. Bayesian Uncertainty Quantification with Multi-Fidelity Data and Gaussian Processes for Impedance Cardiography of Aortic Dissection. Entropy 2020, 22, 58. https://doi.org/10.3390/e22010058
Ranftl S, Melito GM, Badeli V, Reinbacher-Köstinger A, Ellermann K, von der Linden W. Bayesian Uncertainty Quantification with Multi-Fidelity Data and Gaussian Processes for Impedance Cardiography of Aortic Dissection. Entropy. 2020; 22(1):58. https://doi.org/10.3390/e22010058
Chicago/Turabian StyleRanftl, Sascha, Gian Marco Melito, Vahid Badeli, Alice Reinbacher-Köstinger, Katrin Ellermann, and Wolfgang von der Linden. 2020. "Bayesian Uncertainty Quantification with Multi-Fidelity Data and Gaussian Processes for Impedance Cardiography of Aortic Dissection" Entropy 22, no. 1: 58. https://doi.org/10.3390/e22010058
APA StyleRanftl, S., Melito, G. M., Badeli, V., Reinbacher-Köstinger, A., Ellermann, K., & von der Linden, W. (2020). Bayesian Uncertainty Quantification with Multi-Fidelity Data and Gaussian Processes for Impedance Cardiography of Aortic Dissection. Entropy, 22(1), 58. https://doi.org/10.3390/e22010058