Abstract
The goal of continuous variable quantum key distribution (CVQKD) is to be diffusely used and adopted in diverse scenarios, so the adhibition of atmospheric channel will play a crucial part in constituting global secure quantum communications. Atmospheric channel transmittance is affected by many factors and does not vary linearly, leading to great changes in signal-to-noise ratio. It is crucial to choose the appropriate modulation variance under different turbulence intensities to acquire the optimal secret key rate. In this paper, the four-state protocol, back-propagation neural network (BPNN) algorithm was discussed in the proposed scheme. We employ BPNN to CVQKD, which could adjust the modulation variance to an optimum value for ensuring the system security and making the system performance optimal. The numerical results show that the proposed scheme is equipped to improve the secret key rate efficiently.
1. Introduction
The flying start of quantum communication makes secure communication conceivable in practice [1,2,3]. As an important applicatory adhibition in the quantum communications, quantum key distribution (QKD) permits communication objects to generate a public secret key at the existence of eavesdropping, and this approach implements secure key interchange that does not rely on computational complexity [4,5,6,7,8,9]. Discrete-variable quantum key distribution (DVQKD) as well as continuous-variable quantum key distribution (CVQKD) are two primary ways to implement QKD. DVQKD protocol demands greatly faint light pulses in the process of generation and detection [5,6]. Another method of protocol, CVQKD, can utilize standard components of fiber optic communication without the need for a single photon detector [7,8,9,10].
Nowadays, QKD has entered a new stage of development with the goal of widespread application and adoption under a variety of environmental conditions. Long distance QKD in the atmospheric turbulence channel has been realized [11,12,13]. Experimental advances in this field have enabled the transmission of quantum light over horizontal communication links to be shown to be successful [14,15,16,17,18,19], and the satellite-to-ground DVQKD has been confirmed to exceed 1200 km [20]. Schemes employing single-photon detectors are influenced by background noise [21]; at the same time, coherent detection uses a bright local oscillator (LO) operating as a filter to decrease the background noise [22].
In the process of atmospheric propagation, the beam as a whole experiences random broadening, deformation and random deflection. The main influence comes from the turbulence fluctuation of a refractive index. In addition, the beam can be weaken by backward scattering and absorption. For weak turbulence, the atmosphere mainly causes beam wandering, and this case may be well depicted by the log-negative Weibull distribution [23], while, for moderate and strong turbulence, the beam will be stretched and deformed to form a smooth probability distribution of the transmittance (PDT). In addition, the elliptic-beam model gives consistent results with this situation [24]. Furthermore, this model can also be employed to analyze atmospheric quantum channels under different weather circumstances [25].
The secure key rate depends on the modulation variance, transmittance and excess noise. Unlike optical fiber channels, atmospheric channel transmittance is affected by many factors and does not vary linearly. Therefore, it is crucial to select a suitable modulation variance for different turbulence intensities. This is a kind of a parameter optimization that could guarantee the system security and make the system performance optimal. Previously, to obtain the optimal parameters, it always recurred to simulation and iteration. With enough time and iteration in advance, the approach is mature and accurate [26,27]. Nevertheless, emulators often consume a large amount of time, notably when running optimizers, which must be repeated many times. Parameter optimization becomes more complex when we extend point-to-point communication to communication networks.
Machine learning provides formidable implements for settling matters in many fields, such as estimating parameters, output forecast on the basis of previous input data, data sorting, and pattern identification [28,29]. In recent years, machine learning technology has been diffusely used both in coherent optical communication [30,31,32,33,34] and QKD systems [35,36,37,38,39]. The support vector regression (SVR) is applied to predict the time-along intensity evolutions of the laser light and the LO pulse to improve system performance [35]. In addition, for parameter optimization, this has been done with machine learning in measurement-device-independent (MDI) DVQKD [38,39]. Hence, the above-mentioned methods provide an idea for parameter optimization in CVQKD at the atmospheric turbulence channel.
In this paper, we propose an approach that employs a back propagation artificial neural network (BPNN), which is one of the most popular machine learning tools. The theory of BPNN is described in detail, and parameter optimization on atmospheric channels is proposed. In parameter optimization, BPNN is mainly used to predict, rather than search, the optimized parameter. We employ BPNN to CVQKD, which could adjust the modulation variance to an optimal value to ensure the system security and make the system performance optimal. The numerical results show that the proposed scheme is equipped to improve the secret key rate efficiently.
The structure of the paper is listed next. In Section 2, we briefly introduce the transmission models under different intensities of turbulence and the security analysis—whereafter, the Monte Carlo method is employed to estimate transmittance distribution of the atmospheric turbulence channel. In Section 3, we propose the BPNN-based CVQKD scheme. Section 4 verifies the performance improvement and security analysis of the CVQKD system with numerical simulations. In the end, the conclusions are drawn in Section 5.
2. Transmittance and Security Analysis
In this section, the main purpose is to analyze the security of the atmospheric channel. Due to the fluctuating of the atmospheric channel, we first analyze the transmittance of the channel according to different turbulence intensity. In addition, we then apply the transmittance analyzed above to the calculation of the secret key rate, in order to obtain the CVQKD security analysis under the atmospheric channel.
The Rytov variance is used for depicting the turbulence intensity, and its expression is [40,41]
where is the refraction index structure parameter, k denotes the optical wave number, and L represents the horizontal propagation distance. In the case of horizontal propagation, can be seen as a constant. As shown in Table 1, the value of we used is on the basis of long-term radiosonde measurements in Hefei, Anhui, China [42].

Table 1.
The values (median) of in four seasons.
2.1. Transmittance Analysis
In a weak turbulent atmosphere, beam-wandering plays a primary role. Generally, they are induced by unstable adjustment of a radiation source and aperture truncation of the light at the receiving end [43]. The characterization of the beam wandering mechanism and channel models of fluctuation are demonstrated in [23].
Under the circumstance of beam wandering (see Figure 1a), an approximate analytical representative of transmission efficiency can be expressed as
where r denotes the distance of beam-deflection. denotes the transmission coefficient maximum for the specified beam-spot radius value W, R and are scale and shape parameters. The above parameters will be explained in detail in “Appendix A”.
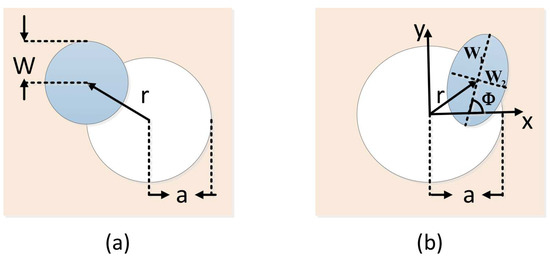
Figure 1.
(a) in the beam wandering case, the fluctuation of transmittance results from the variation of the beam-deflection distance r; (b) the elliptical beam profile is characterized with the half axis and , where rotates on the angle relating to the x-axis. Beam wandering is characterized by parameter r, which represents the beam-centroid position with respect to the center of the aperture.
Designed for simplicity, the aperture radius a is normalized, so that the distribution of is acquired. As shown in Figure A1, decreases with the increase of beam deflection distance, while the maximum increases with the falling of beam spot radius W. On the basic of Ref. [44], the fluctuation of beam-deflection distance r is subject to the Rice distribution [45] with the variance and the distant d from the center of the aperture. Under the circumstance of , this distribution is simplified to the log-negative Weibull distribution,
for and , otherwise. Then, the mean of the fading probability distribution can be calculated from and .
As for strong turbulence, the elliptic-beam model can well describe its characteristics. For now, the probability distribution for free space transmittance could be obtained by using the Glauber–Sudarshan P function on the basic of elliptic beam approximation [24,46]. Compared with the log-normal model [23], the elliptic-beam model is more consistent with the experimental data [47]. Similarly, this model can also be employed to analyze atmospheric quantum channels under different weather circumstances [25].
As depicted in Figure 1b, the elliptic-beam model can describe any spot at the receiving aperture with five parameters, and . Here, represents the position of the beam centroid and reflects the degree of beam wandering, while denotes the half axis of elliptical beam section, and is the angle between the half axis and the x-axis. The above three parameters are used to describe the characteristic of beam broadening and distortion, and give a definition of all possible directions. With this ellipse hypothesis, the transmittance can be approximated as
where a denotes the aperture radius, represents the effective point radius, denotes the transmission coefficient maximum for the centered beam, and and are scale and shape functions, respectively. The above parameters will be explained in detail in “Appendix A”.
On the basic of the above equations, the probability distribution of atmospheric transmittance can be calculated by the Monte Carlo method. It is evident that the transmittance T is at rest with five parameters , where . Parameter is uniformly distributed and irrelevant to the other parameters. The vector is a Gaussian random vector. The above-mentioned parameters are elaborated in “Appendix A”. The density distribution of the horizontal link transmittance is simulated by the Monte Carlo method, which is shown in Figure 2. It is obvious that the distance and refraction index structure parameter affect the transmittance. With the increase of distance and , the transmittance declines.
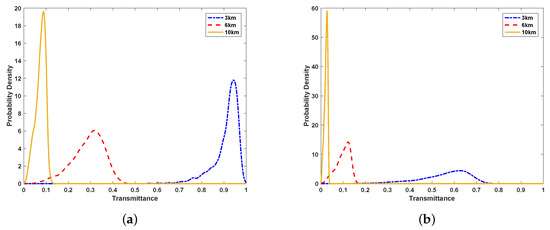
Figure 2.
(a) the probability density function of transmittance at a distance of 3 km, 6 km, and 10 km for the case of ; (b) the probability density function of transmittance at a distance of 3 km, 6 km, and 10 km for the case of . The initial beam-spot radius mm, and the receiving aperture radius mm.
The average value of the PDT could be represented by the simulated transmission value [25]
where is acquired from Equation (4), and the absorption and scattering losses describe with extinction factor which is a stochastic variable [25]. Hence, the fading transmittance’s average value has access to acquire
2.2. Secret Key Rate in the Atmosphere Turbulence Channel
For the sake of the CVQKD investigation in the atmospheric channel, we firstly make analysis centering around the key rate through the fading channel. The schematic diagram of discrete modulated CVQKD in the atmosphere turbulence channel is shown in Figure 3. First, Alice discretely modulates the quantum signal and then dispatches it to Bob via a fading channel whose feature is transmittance distribution T. After taking over the quantum signal, Bob conducts the coherent detection on the received signals and acquires the raw key data. A practical detector is featured by an efficiency and a noise on account of detector electronics.
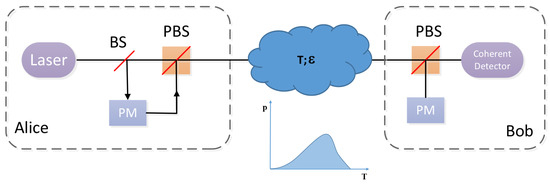
Figure 3.
Schematic diagram of prepare-and-measure discrete modulated continuous variable quantum key distribution (CVQKD) in the atmosphere turbulence channel. Alice discretely modulates the quantum signal, and Bob performs the coherent detection on the received states. PM, phase modulator, BS, beamsplitter, and PBS, polarization beamsplitter.
Here, the reachable secret key rate of atmospheric discrete modulation coherent state CVQKD is presented on the basis of the calculation results of the above sections. In the case of collective attack, assume that Alice and Bob apply the reverse reconciliation with reconciliation efficiency ; the key rate can be given by [48]
With the assumption of channel’s transmittance and excess noise , the covariance matrix of is shown as [49]
where , with
According to covariance matrix, , : and : can be acquired (see Appendix B). Figure 4 shows the secret key rate versus the transmittance and modulation variance. The results indicate that the maximum key rate can be obtained by adjusting the modulation variance. Therefore, the optimal modulation variance can be derived by maximizing the key rate under diverse system conditions. The system conditions include the transmission distance L, the Rytov variance , the detector efficiency , and the electrical noise .
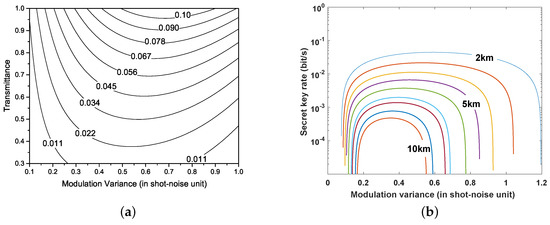
Figure 4.
(a) key rate as a function of modulation variance and transmittance; (b) key rate as a function of modulation variance for various distances. From top to bottom, the distance increases by 1 km. The excess noise is set as 0.01, detector efficiency , electrical noise .
In this section, we have analyzed the transmittance of the atmospheric channel under different turbulence intensity and calculate the secret key rate of discrete modulated CVQKD in the atmospheric channel. Through the above analysis, we conclude that adjusting the modulation variance can increase the secret key rate of the system.
3. BPNN-Based CVQKD Scheme
Different from optical fiber channel, the transmittance of the atmospheric channel is nonlinear. Factors affecting transmittance include not only distance but also climatic conditions. In order to achieve the maximum secret key rate transmission, it is very important to choose an appropriate modulation variance at Alice end. BPNN can be applied to the system to predict the most suitable modulation variance quickly and accurately. For simplicity, we convert the above relationship into the mathematical formula as follows:
The secret key rate K is the function of , which is . Modulation variance optimization could be regarded as searching for to maximize K, as indicated
At the beginning, we invent an input layer that contains three neurons. They receive distance L, Rytov parameter and transmittance as the input, respectively. For input parameters, L is the distance between Alice and Bob, and Rytov parameter is mainly dependent on refraction index structure parameter . Transmittance is relevant to atmosphere turbulence. Then, a hidden layer comprised of eight neurons is enhanced to connect the input layer. In the end, an output layer of only one neuron is installed, which will output the modulation variance .
Here, we prepare the training data for BPNN. First, a program was written to randomly sample the input data space, randomly select the combination of (for which we generate 1000 sets of data from , , ), and calculate the corresponding optimal parameters and the secret key rate by using the local search algorithm (LSA).
The next step is to train BPNN. We record all the above-mentioned and as the training dataset U and V. Then, we introduce the BPNN that is applied to predict . First, we extract from and make a label dataset . Then, we put the dataset U into BPNN and adjust the network connection weights with the back propagation algorithm (BPA) according to the difference between the output of the BPNN and label dataset . The working principle of BPNN is described in detail in Appendix C. Once trained, the neural network can find the optimal parameters and key rate directly according to any input, which greatly speeds up the parameter optimization process.
After the training is achieved, three groups of data are randomly selected using the training network, and the outcomes are recorded in Table 2. The table indicates that the predicted parameters and the matching key rate are very familiar with the optimal values acquired by LSA, for the parameters predicted by BPNN reaching of the optimal key rate. As depicted in Figure 5, we compared the BPNN-predicted and optimized parameters by scanning the distance from 0 to 11 km. Compared with the traditional LSA, the BPNN performs very well in predicting optimal values for modulation variance and attains a very similar key rate level.
Table 2.
Optimal vs. back-propagation neural network (BPNN)-predicted parameters. The modulation variance is the BPNN-predicted parameter, and key rate K is generated by applying the BPNN predicted . The parameters L, , and are the systems conditions. Moreover, and can be converted by the formula , hence the input dimension is 3 instead of 4.
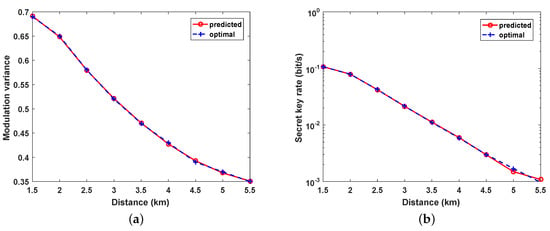
Figure 5.
(a) comparison of BPNN-predicted and optimized modulation variance ; (b) comparison of the key rate generated using the BPNN predicted parameter and optimized key rate. The excess noise is set as 0.01, detector efficiency , and electrical noise .
4. Performance Analysis
In this part, we analyze the key rate that can be realized according to the consequences of Section 2 and Section 3. The secret key rate is evaluated by the Monte Carlo method. The excess noise induced by the phase fluctuation is incapable of compensating precisely yet, and after adopting diverse valid compensation approaches, it is tough to evaluate the actual excess noise [50]. Therefore, we ignore the change of phase excess noise free space situations temporarily. However, we still study the key rates that can be achieved at different fixed excess noise levels: and .
The secret key rate with excess noise is illustrated in Figure 6a. As Figure 6a shows, the secret key rate of the system employing BPNN is higher than LSA, a little higher but not much. Then, the excess noise is set as , and the performance is as portrayed in Figure 6b. In comparison with Figure 6a, the realized transmission distance is significantly shortened.
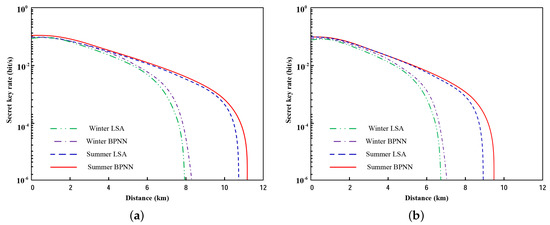
Figure 6.
The secret key rate as a function of distance for local search algorithm (LSA) and BPNN in the summer and winter. (a) ; (b) .
The performance profiling in this section points out a few of pivotal cores. Above all, the BPNN based CVQKD system furnishes a higher achievable key rate and more efficient parameter optimization. Secondly, we find that transmittance fluctuations are negative to key rates. Therefore, the effect of beam wandering, broadening and deformation should be emphasized in practical experiments. Third, due to the considerable influence of excess noise, the phase excess noise will be much larger than ; valid approaches to possess the phase excess noise are required to improve the key rate.
5. Conclusions
In this work, considering that the fluctuating of the atmospheric turbulence channel has significant influences on the performance and practical security of CVQKD system, we put forward a method to optimize the relevant system. Here, we employ machine learning to CVQKD, which could adjust the modulation variance to an optimal value to ensure the system security and make the system performance optimal. The transmittance is simulated in consideration of not only the atmospheric turbulence, but also the absorption and scattering losses. The LSA algorithm is adopted to generate optimal data as training data of BPNN. Meanwhile, by comparing the two algorithms, we get that a BPNN based CVQKD system furnishes a higher achievable key rate and more efficient parameter optimization. In particular, this approach can be applied to any measurable physical parameter of signals in atmospheric turbulence or fiber channel [35,39].
Author Contributions
Conceptualization, Y.S., Y.G. and D.H.; software, Y.S.; validation, D.H.; Writing—Original draft preparation, Y.S.; Writing—Review and editing, D.H.
Funding
This work was supported by the Fundamental Research Funds for the Central Universities of Central South University (Grant No. 2019zzts580) and the National Natural Science Foundation of China (Grant Nos. 61572529, 61871407, 61872390, and 61801522).
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. The Atmospheric Transmittance Analysis

Figure A1.
Transmission efficiency as a function of the beam deflection distance r for different values of the beam-spot radius W. The aperture radius a is normalized.
Figure A1.
Transmission efficiency as a function of the beam deflection distance r for different values of the beam-spot radius W. The aperture radius a is normalized.

In this appendix, we will demonstrate the formulas for the aforementioned parameters in Section 2.1. Under the circumstance of beam wandering (see Figure 1a), an approximate analytical representative of transmission efficiency can be expressed as
where r denotes the distance of beam-deflection, and R are the shape and scale parameter, respectively, which can be derived
and denotes the transmission coefficient maximum for the specified beam-spot radius value W; one can be given by
where a denotes the aperture radius. Obviously, the transmittance efficiency is dominated by the ratio and reduced at . Designed for simplicity, the aperture radius a is normalized, so that the distribution of is acquired.
For strong turbulence, the maximal transmittance for a centered beam can be given by
which is a function of the two eigenvalues . The shape and scale R functions are given by
In the case of , the effective squared spot radius is expressed as
On the basic of the above equations, the probability distribution of atmospheric transmittance can be calculated by the Monte Carlo method. It is evident that the transmittance T is decided by five parameters , where is log-normally distributed and it can be acquired by . Parameter is uniformly distributed and irrelevant to the other parameters. The relevance of is represented by covariance matrix [24,25]
For weak turbulence, the elements of the covariance matrix can be given by [24]
with
In the case of strong turbulence, these elements are expressed by [24]
with
The weak turbulence results can be applied, e.g., for short propagation distances with . In near-to-ground propagation, the latter condition is fulfilled for optical frequencies for night-time communication. The strong turbulence results are applied for short distance communication, . For a near-to-ground communication scenario, this corresponds to the day-time operation on clear sunny days.
Appendix B. Secret Key Rate
With the assumption of channel’s transmittance and excess noise , the covariance matrix of is shown as [49]
According to , the mutual information of Alice and Bob for homodyne detection is
where .
The maximum information that Eve can be accessed is expressed by
where , and the formulas to calculate are derived from
with
where ,
Appendix C. Back-Propagation Neural Network

Figure A2.
The basic structure of BPNN. It contains three layers, namely the input layer, the hidden layer and the output layer.
Figure A2.
The basic structure of BPNN. It contains three layers, namely the input layer, the hidden layer and the output layer.

The back-propagation neural network (BPNN) is the most elementary and widely used neural network. Its output result adopts forward propagation while the error takes in back propagation. The feedforward neural network refers to the hierarchical arrangement of neurons, which is made up of input layer, hidden layer and output layer. Neurons in each layer of this neural network only receive input from neurons in the previous layer, and the latter layer has no signal feedback to the former layer. Each layer converts the input data to some extent, and then utilizes the outcome as the input of the following layer up to the eventual outcome. The back propagation is used to adjust the network weights and thresholds during training, which needs to be supervised. When your network is not well trained, the output must be different from what you think; then, we will get a deviation, and the deviation of one level forward, layer by layer to get the error . This is the feedback. The feedback is used to find the partial derivative, which is typically used for gradient descent. Then, the gradient descent is applied to acquire the minimum value of the cost function, so that the error between the expectation and the output can be reduced as much as possible.
Table A1.
Parameter definition.
Table A1.
Parameter definition.
| Parameter | Definition |
|---|---|
| Threshold of the k-th neuron in output layer | |
| Threshold of the j-th neuron in hidder layer | |
| The weight between the i-th node in the input layer and the j-th node in the hidden layer | |
| The weight between the j-th node in the hidden layer and the k-th node in the output layer | |
| The input value that the j-th neuron received in the hidden layer | |
| The input value that the k-th neuron received in the output layer | |
| Activation function. | |
| Learning rate |
The flow diagram of the back-propagation neural network algorithm is shown in Figure A3, it can be roughly divided into five steps:
Step 1: Initialize network weights and offsets. We know that, after training, the connection weight (network weight) between different neurons is diverse. Therefore, in the initialization stage, we give each network connection weight a small random number (generally −1.0~1.0 or −0.5~0.5), and each neuron has a bias (bias can be regarded as the weight of each neuron), which will also be initialized to a random number.
Step 2: Forward propagation. Enter a training pattern and figure out the output result of each and every neuron. Each neuron works out a linear combination of its inputs. The calculation formula of the activation value of each neuron in the hidden layer is indicated as
Then, the output value of the j-th neuron in the hidden layer is , where . The input value that the k-th neuron received in the output layer is
In the end, the final output of the k-th neuron in the output layer is
Step 3: Calculation error and back propagation. This stage is the learning process of the algorithm. In the learning process, we hope that the output of the algorithm can be consistent with our real value to the greatest extent. When the output value and real value is different, there will ineluctably be an error. The lesser the error, the better the prediction effect of the algorithm. Obviously, the input data are known, and the variables are only those connection weights that will affect the output.

Figure A3.
The flow diagram of the back-propagation neural network algorithm.
Figure A3.
The flow diagram of the back-propagation neural network algorithm.

For training example , suppose the output of the neural network is . Therefore, the mean square error in the training example is expressed as
Based on the gradient descent strategy, the BP algorithm adjusts the parameters in the direction of the negative gradient of the target. In the case of learning rate , for the error in the formula Equation (A25), there is the following formula:
where
Similarly, , and can be derived
with
Step 4: Adjust connection weights and thresholds. At this stage, the connection weight and threshold are adjusted in accordance with the error of hidden layer neurons.
Step 5: End of the training. For each sample, if its error is less than the set threshold or the number of iterations has been reached, then the training is over. Otherwise, the training is resumed at the second step.
References
- Weedbrook, C.; Pirandola, S.; García-Patrón, R.; Cerf, N.J.; Ralph, C.T.; Shapiro, J.H. Gaussian quantum information. Rev. Mod. Phys. 2012, 84, 621. [Google Scholar] [CrossRef]
- Gisin, N.; Thew, R. Quantum communication. Nat. Photonics 2011, 55, 298. [Google Scholar]
- Pirandola, S.; Mancini, S.; Lloyd, S.; Braunstein, S.L. Continuous variable quantum cryptography using two-way quantum communication. Nat. Phys. 2006, 5, 726–730. [Google Scholar] [CrossRef]
- Huang, D.; Huang, P.; Lin, D.K.; Zeng, G.H. Supplementary Material for: Long-distance continuous-variable quantum key distribution by controlling excess noise. Sci. Rep. 2015, 6, 19201. [Google Scholar] [CrossRef] [PubMed]
- Shor, P.W.; Preskill, J. Simple Proof of Security of the BB84 Quantum Key Distribution Protocol. Phys. Rev. Lett. 2000, 85, 441–444. [Google Scholar] [CrossRef] [PubMed]
- Pomerene, A.; Starbuck, A.L.; Lentine, A.L.; Long, C.M.; Derose, C.T.; Trotter, D.C. Silicon photonic transceiver circuit for high-speed polarization-based discrete variable quantum key distribution. Opt. Express 2017, 25, 12282–12294. [Google Scholar]
- Huang, P.; He, G.Q.; Fang, J.; Zeng, G.H. Performance improvement of continuous-variable quantum key distribution via photon subtraction. Phys. Rev. A 2013, 87, 530–537. [Google Scholar] [CrossRef]
- Fang, J.; Huang, P.; Zeng, G.H. Multichannel parallel continuous-variable quantum key distribution with Gaussian modulation. Phys. Rev. A 2014, 89, 022315. [Google Scholar] [CrossRef]
- Liao, Q.; Guo, Y.; Huang, D.; Huang, P.; Zeng, G.H. Long-distance continuous-variable quantum key distribution using non-Gaussian state-discrimination detection. New J. Phys. 2017, 20, 023015. [Google Scholar] [CrossRef]
- Su, Y.; Guo, Y.; Huang, D. Kalman filter-based phase estimation of continuous-variable quantum key distribution without sending local oscillator. Phys. Let. A 2019, 383, 2394–2399. [Google Scholar] [CrossRef]
- Tunick, A.; Moore, T.; Deacon, K.; Meyers, R. Quantum Communications and Quantum Imaging VIII. Int. Soc. Opt. Photonics 2010, 7815, 781512. [Google Scholar]
- Fedrizzi, A.; Ursin, R.; Herbst, T.; Nespoli, M.; Prevedel, R.; Scheisl, T.; Tiefenbacher, F.; Jennewein, T.; Zeilinger, A. High-fidelity transmission of entanglement over a high-loss free-space channel. Nat. Phys. 2009, 5, 389–392. [Google Scholar] [CrossRef]
- Liao, S.K.; Yong, H.L.; Liu, C.; Shentu, G.L.; Li, D.D.; Lin, J.; Dai, H.; Zhao, S.Q.; Li, B.; Guan, J.Y.; et al. Long-distance free-space quantum key distribution in daylight towards inter-satellite communication. Nat. Photonics 2017, 11, 509–513. [Google Scholar] [CrossRef]
- Ursin, R.; Tiefenbacher, F.; Schmitt-Manderbach, T.; Weier, H.; Scheidl, T.; Lindenthal, M.; Blauensteiner, B.; Jennewein, T.; Perdigues, J.; Trojek, P.; et al. Entanglement-based quantum communication over 144 km. Nat. Phys. 2007, 3, 481–486. [Google Scholar] [CrossRef]
- Scheidl, T.; Ursin, R.; Fedrizzi, A.; Ramelow, S.; Ma, X.S.; Herbst, T.; Prevedel, R.; Ratschbacher, L.; Kofler, J.; Jennewein, T.; et al. Feasibility of 300 km Quantum Key Distribution with Entangled States. New J. Phys. 2009, 11, 085002. [Google Scholar] [CrossRef]
- Capraro, I.; Tomaello, A.; Dall’Arche, A.; Gerlin, F.; Ursin, R.; Vallone, G.; Villoresi, P. Impact of turbulence in long range quantum and classical communications. Phys. Rev. Lett. 2012, 109, 200502. [Google Scholar] [CrossRef] [PubMed]
- Yin, J.; Ren, J.G.; Lu, H.; Cao, Y.; Yong, H.L.; Wu, Y.P.; Liu, C.; Liao, S.K.; Zhou, F.; Jiang, Y.; et al. Quantum teleportation and entanglement distribution over 100-kilometre free-space channels. Nature (London) 2012, 488, 185–188. [Google Scholar] [CrossRef] [PubMed]
- Ma, X.S.; Herbst, T.; Scheidl, T.; Wang, D.; Kropatschek, S.; Naylor, W.; Wittmann, B.; Mech, A.; Kofler, J.; Anisimova, E.; et al. Quantum teleportation over 143 kilometres using active feed-forward. Nature (London) 2012, 489, 269–273. [Google Scholar] [CrossRef] [PubMed]
- Peuntinger, C.; Heim, B.; Müller, C.R.; Gabriel, C.; Marquardt, C.; Leuchs, G. Distribution of Squeezed States through an Atmospheric Channel. Phys. Rev. Lett. 2014, 113, 060502. [Google Scholar] [CrossRef]
- Liao, S.K.; Cai, W.Q.; Liu, W.Y.; Zhang, L.; Li, Y.; Ren, J.G.; Yin, J.; Shen, Q.; Cao, Y.; Li, Z.P.; et al. Satellite-to-ground quantum key distribution. Nature 2017, 549, 43–47. [Google Scholar] [CrossRef]
- Miao, E.L.; Han, Z.F.; Gong, S.S.; Zhang, T.; Diao, D.S.; Guo, G.C. Background noise of satellite-to-ground quantum key distribution. New J. Phys. 2005, 7, 215. [Google Scholar]
- Heim, B.; Peuntinger, C.; Wittmann, C.; Marquardt, C.; Leuchs, G. Free Space Quantum Communication using Continuous Polarization Variables. In Applications of Lasers for Sensing & Free Space Communications; Optical Society of America: Washington, DC, USA, 2011. [Google Scholar]
- Vasylyev, D.Y.; Semenov, A.A.; Vogel, W. Toward Global Quantum Communication: BeamWandering Preserves Nonclassicality. Phys. Rev. Lett. 2012, 108, 220501. [Google Scholar] [CrossRef]
- Vasylyev, D.; Semenov, A.A.; Vogel, W. Atmospheric quantum channels with weak and strong turbulence. Phys. Rev. Lett. 2016, 117, 090501. [Google Scholar] [CrossRef] [PubMed]
- Vasylyev, D.; Semenov, A.A.; Vogel, W. Free-space quantum links under diverse weather conditions. Phys. Rev. A 2017, 96, 043856. [Google Scholar] [CrossRef]
- Wang, W.; Xu, F.; Lo, H.-K. Enabling a scalable high-rate measurement-device-independent quantum key distribution network. arXiv 2018, arXiv:1807.03466. [Google Scholar]
- Xu, F.; Xu, H.; Lo, H.-K. Protocol choice and parameter optimization in decoy-state measurement-device-independent quantum key distribution. Phys. Rev. A 2014, 89, 052333. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Harrington, P. Machine Learning in Action; Manning Co.: New York, NY, USA, 2012. [Google Scholar]
- Zibar, D.; Winther, O.; Franceschi, N.; Borkowski, R.; Caballero, A.; Arlunno, V.; Schmidt, M.N.; Gonzales, N.G.; Mao, B.; Ye, Y.; et al. Nonlinear impairment compensation using expectation maximization for dispersion managed and unmanaged PDM 16-QAM transmission. Opt. Express 2012, 20, B181–B196. [Google Scholar] [CrossRef]
- Jarajreh, M.A.; Giacoumidis, E.; Aldaya, I.; Le, S.T.; Tsokanos, A.; Ghassemlooy, Z.; Doran, N.J. Artificial Neural Network Nonlinear Equalizer for Coherent Optical OFDM. Photonics Technol. Lett. 2015, 27, 387–390. [Google Scholar] [CrossRef]
- Zibar, D.; Piels, M.; Jones, R.; Schäeffer, C.G. Machine learning techniques in optical communication. J. Lightwave Technol. 2016, 34, 1442–1452. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, M.; Li, Z.; Song, C.; Fu, M.; Li, J.; Chen, X. System impairment compensation in coherent optical communications by using a bio-inspired detector based on artificial neural network and genetic algorithm. Opt. Commun. 2017, 399, 1–12. [Google Scholar] [CrossRef]
- Yuan, Y.; Zhang, M.; Luo, P.F.; Ghassemlooy, Z.; Wang, D.S.; Tang, X.Y.; Han, D.H. SVM detection for superposed pulse amplitude modulation in visible light communications. In Proceedings of the 2016 10th International Symposium on Communication Systems, Networks and Digital Signal Processing (CSNDSP), Prague, Czech Republic, 20–22 July 2016; pp. 1–5. [Google Scholar]
- Liu, W.; Huang, P.; Peng, J.; Fan, J.; Zeng, G. Integrating machine learning to achieve an automatic parameter prediction for practical continuous-variable quantum key distribution. Phys. Rev. A 2018, 97, 022316. [Google Scholar] [CrossRef]
- Li, J.W.; Guo, Y.; Wang, X.D.; Xie, C.L.; Zhang, L.; Huang, D. Discrete-modulated continuous variable quantum key distribution with a machine-learning-based detector. Opt. Eng. 2018, 57, 066109. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, P.; Guo, Y.; Zhang, L.; Huang, D. Blind modulation format identification based on machine learning algorithm for continuous variable quantum key distribution. J. Opt. Soc. Am. B 2019, 36, 51–58. [Google Scholar] [CrossRef]
- Liu, H.; Wang, W.; Wei, K.; Fang, X.-T.; Li, L.; Liu, N.-L.; Liang, H.; Zhang, S.-J.; Zhang, W.; Li, H.; et al. Experimental demonstration of high-rate measurement-device-independent quantum key distribution over asymmetric channels. arXiv 2018, arXiv:1808.08584. [Google Scholar] [CrossRef] [PubMed]
- Lu, F.Y.; Yin, Z.Q.; Wang, C.; Cui, C.H.; Teng, J.; Wang, S.; Chen, W.; Huang, W.; Xu, B.J.; Guo, G.C.; et al. Parameter optimization and real-time calibration of a measurement-device-independent quantum key distribution network based on a back propagation artificial neural network. J. Opt. Soc. Am. B 2019, 36, 92–98. [Google Scholar] [CrossRef]
- Ishimaru, A. Wave Propagation and Scattering in Random Media; Oxford University Press: Oxford, UK, 1997. [Google Scholar]
- Fante, R.L. Electromagnetic beam propagation in turbulent media. Proc. IEEE 1975, 63, 1669–1692. [Google Scholar] [CrossRef]
- Wang, Y.; Fan, C.; Wei, H. Laser Beam Propagation and Applications through the Atmosphere and Sea Water; National Defense Industry Press: Beijing, China, 2015. [Google Scholar]
- Zunino, L.; Gulich, D.; Funes, G.; Perez, D.G. Turbulence-induced persistence in laser beam wandering. Opt. Lett. 2015, 40, 3145–3148. [Google Scholar] [CrossRef] [PubMed]
- Berman, G.P.; Chumak, A.A.; Gorshkov, V.N. Beam wandering in the atmosphere: The effect of partial coherence. Phys. Rev. E 2007, 76, 056606. [Google Scholar] [CrossRef]
- Jakeman, E.; Ridley, K.D. A Review of Modeling Fluctuations in Scattered Waves. Waves Random Complex Media 2007, 17, 405. [Google Scholar] [CrossRef]
- Glauber, R.J. Coherent and incoherent states of the radiation field. Phys. Rev. 1963, 131, 2766. [Google Scholar] [CrossRef]
- Usenko, V.C.; Heim, B.; Peuntinger, C.; Wittmann, C.; Marquardt, C.; Leuchs, G.; Filip, R. Entanglement of Gaussian states and the applicability to quantum key distribution over fading channels. New J. Phys. 2012, 14, 093048. [Google Scholar] [CrossRef]
- Leverrier, A.; Grangier, P. Unconditional Security Proof of Long-Distance Continuous-Variable Quantum Key Distribution with Discrete Modulation. Phys. Rev. Lett. 2009, 102, 180504. [Google Scholar] [CrossRef] [PubMed]
- Shen, Y.; Zou, H.X.; Tian, L.; Chen, P.X.; Yuan, J.M. Experimental study on discretely modulated continuous-variable quantum key distribution. Phys. Rev. A 2010, 82, 022317. [Google Scholar] [CrossRef]
- Wang, S.Y.; Huang, P.; Wang, T.; Zeng, G.H. Atmospheric effects on continuous-variable quantum key distribution. New J. Phys. 2018, 20, 083037. [Google Scholar] [CrossRef]






© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).