1. Introduction
Being the brain one of the most complex systems within the observable universe, it is not surprising that there is still a large number of unanswered questions related to its structure and functions. With the aim of developing new ways of addressing such questions, there is an increasing consensus among neuroscientists in that interdisciplinary approaches are promising. As a prominent example of this, computational neuroscience has been greatly enriched during the last decades by tools, ideas and methods coming from statistical physics [
1,
2]. Moreover, these methods are recently being revisited with renewed interest due to the arrival of experimental techniques that generate huge volumes of data. In particular, neuroscientists have become progressively aware of the powerful computational techniques used by statistical physicists to analyze experimental data and large scale simulations.
When studying the firing patterns of collections of neurons, one of the most popular principles from statistical mechanics is the
maximum entropy principle (MEP), which builds the least structured model that is consistent with average values measured from experimental data. These average values are usually restricted to firing rates and synchronous pairwise correlations, which gives rise to models composed by time independent and identically distributed (i.i.d) random variables, i.e., stochastic processes without temporal structure [
3,
4,
5]. Needless to say, there exists strong evidence in favour of memory effects playing a major role in spike train statistics, and biological process in general [
6,
7,
8,
9]. Following this evidence, over the last years the study of complex biological systems has started to consider time-dependent processes where the past has an influence on future behavior [
10,
11,
12]. The corresponding asymmetry between past and future is called the “arrow of time”, which is the unique direction associated with the irreversible flow of time that is noticeable in most biological systems.
Interestingly, the statistical physics literature has a fertile toolkit for studying time asymmetric processes [
13]. First, one introduces the distinction between steady states that imply thermal equilibrium, and steady states that still carry fluxes—being called non-equilibrium steady states (NESS). Additionally, the extent to which a steady-state is not in equilibrium (i.e., the strength of its associated currents) can be quantified by the
entropy-production rate [
14], which is associated with the degree of time-irreversibility in the corresponding process [
14]. Several studies have pointed out that being out-of-equilibrium is an important characteristic of biological systems [
15,
16,
17]. Therefore, statistical characterizations consistent with the out-of-equilibrium condition should reproduce some degree of time irreversibility. One popular method that is suitable for studying these issues is Markov chain modeling [
11,
18,
19,
20,
21,
22].
Despite the potential of interdisciplinary pollination related to these fascinating issues, many scientists find it hard to explore these topics because of the major entry barriers, including differences in jargon, conventions, and notations across the various fields. To bridge this gap, this tutorial intends to provide an accessible introduction to the non-equilibrium properties of maximum entropy Markov chains, with an emphasis in spike train statistics. While not introducing novel material, the main added value of this tutorial is to present results of the field of non-equilibrium statistical mechanics in a pedagogical manner based on examples. These results have direct application to maximum entropy Markov chains, and may shed new light on the study of spike train statistics. This tutorial is suitable for researchers in the fields of physics or mathematics who are curious about the interesting questions and possibilities that computational neurosciences offers. The focus on this community is motivated by the growing community of mathematical physicists interested in computational neuroscience.
The rest of this tutorial is structured as follows. First,
Section 2 introduces basic concepts of neural spike trains and Markov processes. Then,
Section 3 introduces the notion of observable, and explores their fundamental properties.
Section 4 introduces the core ideas of MEP, proposing the formal question and exploring methods for solving it.
Section 5 studies various properties of interest of MEP models, including fluctuation-dissipation relationships, and their entropy production. Finally,
Section 6 summarizes our conclusions.
2. Preliminary Considerations
This section introduces definitions, notations, and conventions that are used throughout the tutorial in order to give the necessary toolkit of ideas and notions to the unfamiliar reader.
2.1. Binning and Spike Trains
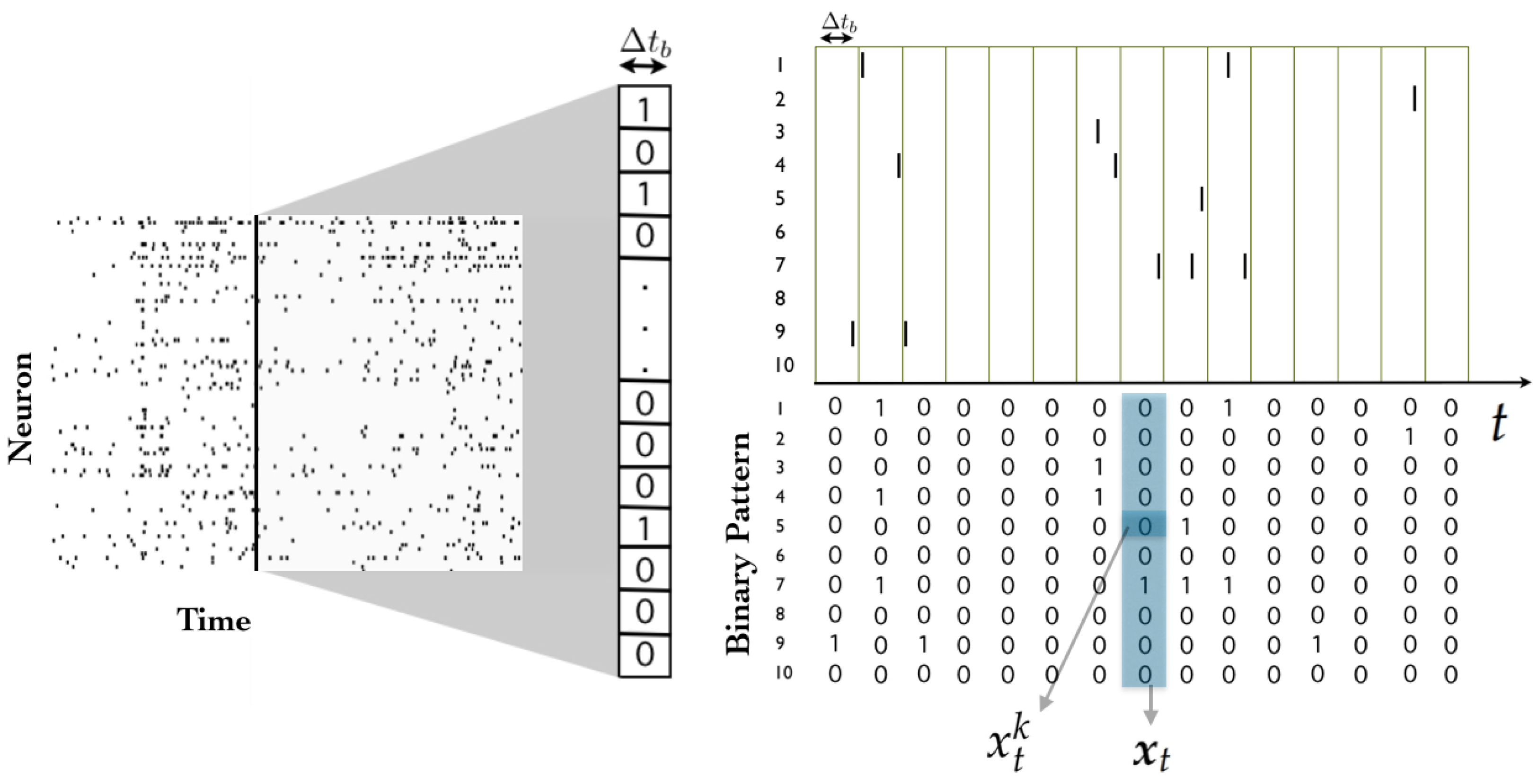
Consider a network of N spiking neurons, where time has been binned (i.e., discretized) in such a way that each neuron can exhibit no more than one action potential within one time bin . Action potentials, or “spikes”, are “all-or-none” events, and hence, spike data can be encoded using sequences of zeros and ones. A spiking state is denoted by , and corresponds to the event in which the k-th neuron spikes during the t-th time bin, while implies that it remains silent.
A
spike pattern is defined as the spike-state of all neurons at time bin
t, and is denoted by
. A
spike block is a consecutive sequence of spike patterns, denoted by
(see
Figure 1). While the length of the spike block
is
, it is useful to consider spike blocks of infinite length starting from time
, which are denoted by
. Finally, in this tutorial we consider that a
spike train is an infinite sequence of spiking patterns. This assumption turns out to be useful because it allows us to put our analysis in the framework of stochastic processes, and because it also allows us to characterize asymptotic statistical properties.
The set of all possible spike patters (or state space) in a network of N neurons is denoted by , and the set of all spike blocks of length R in a network of N neurons is denoted by .
Even at a single neuron level, for repetitions of the same stimulus, neurons respond randomly, but with a certain statistical structure. This is the main reason to look for statistical characterizations of spike trains. When trying to find a statistical representation considering a whole population of neurons responding simultaneously to a given stimulus, the problem is the following. Consider an experimental spike train from a network of
N neurons where sequences of spike patterns are considered time-independent. The spike patterns can take
values (state space). For
is not possible to observe all possible states in real experimental data nor computer simulations (2 h of recordings binned at 20 ms produce less than
spike patterns). For
the state space is
, therefore the frequentist approach is useless to estimate the invariant measure. Can we learn something about the statistics of spike patterns from data having access only to a very small fraction of the state space? The maximum entropy principle provides an answer to this question. This principle has been used in the context of spike train statistics mainly considering firing rates and synchronous pairwise correlations, which gives rise to trivial stochastic processes composed by (i.i.d) random variables [
3,
4,
5]. However, as mentioned in the introduction, there exists strong evidence in favour of past events playing a role in spike train statistics, and the biological process in general [
6,
7,
8,
9,
11]. This principle can be generalized considering non-synchronous correlations, affording to build Markov chains from data. This approach opens the way to a richer modeling framework that can afford to model time irreversibility (highly expected in biological systems) and to a remarkable mathematical machinery based on non-equilibrium statistical mechanics which can be used to characterize collective behavior and to explore the capabilities of the system. We focus our tutorial on non-equilibrium steady states in the context of maximum entropy spike trains. In the next section of this tutorial we present the elementary properties of Markov chains (our main object of analysis) which will be used in the next chapters to extract relevant information about the underlying neuronal network generating the data.
2.2. Elementary Properties of Markov Chains
A stochastic process is a collection of random variables
indexed by
that often refers to time. The set
represents the phase-space of the process; in the case of stochastic processes representing spike trains, one usually takes
. Moreover, considering the temporal binning discussed in
Section 2.1, usually
(the set of natural numbers) corresponds to the so-called discrete-parameter stochastic processes.
While spike trains can be characterized by stochastic processes dependent on an infinite past [
23,
24], Markov chains are particularly well-suited for modeling data sequences with finite temporal dependencies. In the next paragraphs we give the precise definition of a Markov process.
A stochastic process
defined on a measure space
is said to be a
–Markov chain if it satisfies the
Markov property (with respect to the probability measure
): if, for every
and for each sequence of states
, the following relationship holds:
This property is usually paraphrased as: the conditional distribution of the future given the current state and all past events depends exclusively on the current state of the process. It is direct to show that the Markov property is equivalent to the following condition: for every increasing sequence of indices
in
, and for arbitrary states
in
, we have:
To characterize the transition probabilities, define a -indexed stochastic matrix to be a doubly indexed array of non-negative real numbers such that for every . It can be shown that a Markov chain is well-defined if the following is provided:
- (i)
An initial probability distribution, encoded by a vector .
- (ii)
A collection of -indexed stochastic matrices .
Using these two elements, one can build probability measures
on
as follows,
Furthermore, the Kolmogorov extension theorem [
25] guarantees the existence of a unique probability measure
on
such that the coordinate process satisfies:
and with respect to which
is a Markov chain. In this case
is said to be the probability law of the Markov chain
. This notation also remarks that
is the law with initial distribution
.
2.3. Homogeneity, Ergodicity and Stationarity
A Markov chain is said to be
homogeneous if the transition matrices do not depend on the time parameter
t, i.e., if there exists a
-indexed stochastic matrix
P such that
for every
. Note that if
is a
–homogeneous Markov chain, then for every
:
In the rest of this paper we focus exclusively on homogeneous Markov chains, since this is the model assumed in the maximum entropy framework.
Consider now a homogeneous Markov chain
with initial distribution
and transition matrix
P. Moreover, consider
to be the
-th entry of the product matrix
. These quantities correspond to the
m–steps transition probabilities. Equation (
2) can be generalized to
A stochastic matrix P is said to be ergodic if there exists such that all the k–step transition probabilities are positive—i.e., there is a non-zero probability to go between any two states in k steps. A homogeneous Markov chain is ergodic if it can be defined by an initial distribution and an ergodic matrix.
Finally, a probability distribution
on
is called a
stationary distribution for the Markov chain specified by
P if
Equivalently,
is stationary for
P if
is a left eigenvector of the transition matrix corresponding to the eigenvalue
, and is a probability distribution on
. While it is true that 1 is always an eigenvalue of
P, it may be the case that no eigenvector associated to it can be normalized to a probability distribution. Further conditions for existence and uniqueness will be given in the next paragraph. Finally, if a
–indexed stochastic matrix
P admits a stationary probability distribution
and
is a Markov chain with initial distribution
and transition matrix
P, then for every
and
:
In this case
is said to be a stationary Markov chain, or that the Markov chain is started from stationarity.
The notion of homogeneous ergodic Markov chains is relevant in the context of spike train statistics because of the Ergodic Theorem for finite-state Markov Chains, which state that for all finite-state, homogeneous, ergodic Markov chains with transition matrix P the following hold:
- (a)
There exists a unique stationary distribution for P that satisfies that for every .
- (b)
Equivalently, for every distribution , This property guarantees the uniqueness of the maximum entropy Markov chain.
2.4. The Reversed Markov Chain
Given a discrete ergodic Markov chain, it is mathematically possible to define its associated time reversed Markov chain. Some Markov chains in the steady-state yield the same Markov chain (in distribution) if the time course is inverted and others do not. It has been argued multiple times that those Markov chains that are different from their time inverted version are better suited to represent biological stochastic processes [
6,
7,
9,
11,
12].
Let
be a stochastic matrix, and assume that it admits a stationary probability measure
. Assume too that
for every
(according to (a) in the Ergodic Theorem from the previous section, this is the case when
is ergodic). Define the
–indexed matrix
with entries:
A direct calculation shows that is also a stochastic matrix. Moreover, if is stationary for , then it is for as well.
Using the above facts, let
and
be the laws of two stationary Markov chains, denoted by
and
, whose stationary distribution is
and transition probabilities are
and
, respectively. The following holds
By virtue of this result, it is natural to call the chain the reversed chain associated to .
2.5. Reversibility and Detailed Balance
A transition matrix
P is
reversible with respect to
if the associated Markov chain started from
has the same law as the reversed chain started from the same distribution. The reversibility of
P with respect to
is equivalent to the condition of
detailed balance, given by
Note that any probability measure
that satisfies detailed balance with respect to
P is necessarily stationary, since
The converse is, however, not true in general: a stationary distribution may not satisfy Equation (
4).
Intuitively, Equation (
4) states that, in the stationary state, the fluxes between each pair of states balance each other. In contrast, detailed balance is broken when there is a cycle of three or more states in the state space supporting a net probability current—even in the steady state. Detailed balance is also interpreted as “time reversibility”, as one could not distinguish the steady state dynamics of the system when going forward or backward in time. Certainly, this property is not expected in stochastic processes generated by biological systems. Several disciplines use the term “equilibrium” to refer to long-term behaviour, i.e., what is not transient. In this tutorial we use the term
equilibrium state exclusively to refer to probability vectors that satisfy the detailed balance conditions—given in Equation (
4). Markov chains that satisfy the detailed balance condition are referred as equilibrium steady states, and conversely, steady states that do not satisfy the detailed balance conditions are called
Non-Equilibrium Steady States (NESS).
How to characterize (finite state, homogeneous) reversible Markov chains? Following [
26], consider any finite graph
, with vertex set
and with the edge between vertices
i and
j labelled by the non-negative edge
. The graph can be visualized as a system of points labelled by
, and with a line segment between points whenever the corresponding conductance is positive. Define
and the
–indexed stochastic matrix given by
Now define
. It is straightforward to prove that
P is reversible with respect to the probability measure given by
and thus it is stationary for
P. The unique Markov chain started from
and transition matrix
P is called the stationary random walk on the network
. Conversely, any reversible
–valued Markov chain can be identified with the random walk on the graph with vertex set
and edges given by
.
2.6. Law of Large Numbers for Ergodic Markov Chains
The Law of Large Numbers (LLN) that applies to independent and identically distributed random variables (i.i.d.) can be extended to the realm of ergodic Markov chains. In effect, for a given ergodic Markov chain
with stationary distribution
and transition matrix
P, define the random variables
equal to the number of occurrences of the state
i up to time
, i.e.,
where
is an indicator function. Similarly, define the random variables
as the number of occurrences of the consecutive pair of states
—in that order—up to time
, i.e.,
With this, the
Strong Law of Large Numbers for Markov chains can be stated as follows: if
is ergodic and
is its unique stationary distribution, then
holds for any initial distribution
. The result, in turn, implies the
Weak Law of Large Numbers for Markov chains, which state that, following the above notation, for every
and for every starting distribution
:
Let’s denote by
the space of real-valued functions on
. Clearly, any function of
can be written as
for certain constants
,
. Then, the above result generalizes as: for every
, ergodic chain
, and probability distribution
, the following holds:
This corresponds to a particular form of the Birkhoff Ergodic Theorem, which is briefly outlined in the next section and is relevant to characterize spike trains of observables as from data it is possible to accurately measure average values of firing rates and correlations. For an ergodic stationary Markov chain with a state space relatively small with respect to the sample size, this theorem guarantees that from a large sample the transition probabilities and the invariant measure can be recovered. This is not the case in spike train statistics at the population level as only a very small fraction of the state space is sampled in experimental spike trains. However, some features of the spike trains can be sampled very accurately from experimental data. In the next section, we present the basic elements to build from these characteristics a statistical model of the entire population.
3. Observables of Markov Chains and Their Properties
The notion of observable plays a central role in the study of maximum entropy spike trains. This section discusses their nature and fundamental properties.
3.1. Observables and Their Empirical Averages
Suppose a spiking neuronal network of N neurons is provided. Suppose too that measurements of spike patterns for T time bins have been performed. The observables are real-valued functions over the possible spike blocks, denoted here by . Let be the space of such observables, i.e., the linear space of real-valued functions . Recall the space of observables of range 1, discussed at the end of the above section. This space can be naturally embedded into ; thus, it can be considered as a linear subspace of the latter. More generally, the space of observables of range R for , denoted , is just the space of real-valued functions on , that we identify with its image through the natural embedding into .
We are interested in the average of observables with respect to several probability measures. If
is a probability measure on
(i.e.,
and
) and
f an observable of range
i.e.,
, we define its expectation with respect to
as
Since the space of blocks of length T is finite, the above sum is always finite, and thus our definition makes sense for every probability measure on .
In the context of spike-trains, an important class of observable is made up of
-valued functions. It can be proved that any finite-range binary observable can be written as a finite sum of finite products of functions of the form
that represents the event that the
j-th neuron fires during the
i-th bin. The average value if this observable is known as the firing rate of neuron
j. This quantity has been proposed as one of the major neural coding strategies used by the brain [
27].
Consider a spike block
, where
T is the sample length. Although in most cases the probability measure
that characterizes the spiking activity is not known, it is meaningful to use the experimental data to estimate the mean values of specific observables. The range of the validity of this procedure is usually based on prior assumptions about the nature of the source that originates the sample. For example, it can be assumed that the sample is a short piece of an infinite path that comes running from the far past, and so it can be assumed that this piece exhibits a behavior that is close to the stationary distribution. In this case, one can consider for any number
the quantity:
that counts the number of appearances of the sequence
as a consecutive sub-sequence of
. Now, for any set
, define:
When the empirical distribution is not explicitly stated, it is customary to write to denote the average of the observable f with respect to this probability measure.
3.2. Moments and Cumulants
Observables are random variables whose average values can be determined from experimental data or from the explicit representation of the underlying measure characterizing the stochastic process generating the data. Important statistical properties of random variables are encoded in the
cumulants. We will use the cumulants in
Section 5 of this tutorial to characterize and infer properties of maximum entropy Markov chains. Let us now introduce them.
The moment of order
r of a real-valued random variable
X is given by
, for
(here we freely use the notation
to denote the expectation with respect to a probability measure that should be inferred from the context). The moment generating function (or Laplace transform) of a random variable is defined by:
and provided it is a function of
t with continuous derivatives of arbitrary order at 0, we have that:
The cumulants
are the coefficients in the Taylor expansion of the cumulant generating function. The cumulants are defined as the logarithm of the moment generating function, namely,
The relation between the moments and cumulants is obtained extracting coefficients from the Taylor expansion, i.e.,
which yields the first values:
and so on. In particular, the first four cumulants are the mean, the variance, the skewness and the kurtosis.
3.3. Observables and Ergodicity
Let
be the shift operator that acts on a sequence
as:
i.e.,
shifts the sequence one position to the left. Now, assume that the Markov chain
is ergodic. Let
be its unique stationary probability distribution. The Birkhoff Ergodic Theorem states that under the above assumptions, for every
:
for every initial measure
. This equation means that under the ergodic hypothesis, the temporal averages converge to the spatial averages. The importance of this fundamental result should not be underestimated since this result supports the practice of regarding averages of (hopefully) large samples of experimental data as faithful approximations of the
true values of the expectations of the observables.
3.4. Central Limit Theorem for Observables
Consider an arbitrarily large sequence of spike patterns of
N neurons. Consider
and let
be the spike-block of length
t. Also, let
f be an arbitrary observable of fixed range
R. The asymptotic properties of
are established in the following context: the finite sample is drawn from an ergodic Markov chain, i.e.,
, where
is the Markov probability measure of an ergodic chain
started from an arbitrary initial distribution. Let
be the unique stationary measure for the Markov chain. Observe that by virtue of the ergodic assumption, the empirical averages of observables become more accurate as the sampling size grows, i.e.,
for any starting condition
. However, the above result does not clarify the rate at which the accuracy improves. The central limit theorem (CLT) for ergodic Markov chains provides a result to approach this issue (for datails see [
28]).
Theorem 1 (Central limit theorem for ergodic Markov chains). Under the above assumptions, and keeping notation, define:Let be the law of the random variable under the measure of an ergodic Markov chain started from an arbitrary distribution. Let L be the law of a standard normal random variable. Then in the sense of weak convergence of convergence in distribution. This is usually written as: This theorem implies that “typical” fluctuations of around its long term average are of the order of . For spike trains, this theorem quantifies the expected Gaussian fluctuations of observables in terms of the sample size of the experimental data.
3.5. Large Deviations of Average Values of Observables
Although the CLT for ergodic Markov chains is precise in describing the typical fluctuations around the mean, it does not characterize the probabilities of large fluctuations. While it is clear that the probability of large fluctuations of average values vanish as the sample size increases, it is sometimes relevant to characterize the decrease rate of this probability. That is what the large deviation principle (LDP) does.
Let
f be a function of finite range defined on the space of sequences. In many situations,
f will be a
–valued function. Let
be the probability measure on the space of sequences induced by an ergodic Markov chain with stationary probability
. The empirical average
satisfies a large deviation principle (LDP) with rate function
, defined as
if the above limit exists. The above condition implies for large
t that
. In particular, if
the Law of Large Numbers (LLN) ensure that
goes to zero as
t increases, but the rate function quantifies the speed at which this occurs.
Calculating
using the definition (Equation (
6)), is usually impractical. However, the Gärtner-Ellis theorem provides a clever alternative to circumvent this problem [
29]. Let us introduce the
scaled cumulant generating function (SCGF) associated to the random variable
f by
when the limit exists (details about cumulant generating functions are found in [
30]). While the empirical average
is taken over a sample (empirical measure), the expectation in (
7) is computed over the probability distribution given by
.
Theorem 2 (Gärtner-Ellis theorem). If is differentiable, then the average satisfies a LDP with rate function given by the Legendre transform of , that is Therefore, the large deviations of empirical averages can be characterized by first computing their SCGF and then finding their Legendre transform.
A useful application of the LDP is to estimate the likelihood that the empirical average
takes a value far from its expected value. Let us assume that
is a positive differentiable convex function. Then,
is also differentiable [
31] (for a comprehensive discussion about the differentiability of
see [
30].) Then, as
is convex it has a unique global minimum. Denoting this minimum by
, from the differentiability of
it follows that
. Additionally, it follows from properties of the Legendre transform that
, which is the LLN that says that
concentrates around
. Consider
and that
admits a Taylor expansion around
As
is zero and a minimum of
, the first two terms of this expansion are zero, and as
is convex
. For large
t, it follows from (
6) that
so the “small deviations” (we are using Taylor expansion) of
around
are Gaussian (in Equation (
9)
). In this sense, the LDP can be considered as an extension of the CLT as it goes beyond the small deviations around
(Gaussian), but additionally the large deviations (not Gaussian) of
.
4. Building Maximum Entropy Temporal Models
This section presents the main concepts behind the construction of maximum entropy models for temporal data. The next
Section 4.1, introduces the concept of entropy, and then
Section 4.2 formulates the problem of maximizing the entropy rate. Methods for solving this problem are discussed in
Section 4.3, which are then illustrated in an example presented in
Section 4.4.
4.1. The Entropy Rate of a Temporal Model
4.1.1. Basic Definitions
In order to give mathematical meaning to the rather vague notion of uncertainty, a natural approach is to employ the well-established notion of
Shannon entropy. For any probability measure
p defined over the state space
E (not necessarily
), the Shannon entropy of
p is given by
Note that this definition can be used for measures on the spaces of infinite sequences . However, as in most cases of interest, the value saturates in infinite. A better suited notion in this context is given by the entropy rate, which plays a crucial role in the rest of this tutorial.
Definition 1 (entropy rate). Let μ be a probability measure on the space of sequences . For let be the probability measure induced by μ on the initial n coordinates, i.e., is the probability distribution on given by:The entropy rate of the measure μ is defined by: The above definition applies to any probability distribution on the space of sequences. Intuitively, the entropy rate correspond to the entropy per time unit, and represents how much “uncertainty” is created by the process as time moves forward.
4.1.2. The Entropy Rate of I.I.D. and Markov Models
Let us consider first a null model of spike activity, where there is complete statistical independence between two consecutive spike patters. For this, first recall that
, where
N is the fixed number of neurons. Without loss of generality, we can enumerate the elements of
as
. Let
be a probability measure on
such that:
For a
T–block
and for every
, we set:
On the space of infinite spike trains
we consider the probability
, i.e., the product measure on the space of spike trains. Observe that the induced measure is given by:
With this, a straightforward calculation shows that
and in this case we observe that the entropy rate is equal to the entropy of the probability distribution induced by each coordinate map.
A reasonable next step in the hierarchy of models is to weaken the independence hypothesis and assume instead that the spike activity keeps some bounded memory of the past. For this, following the considerations of
Section 2, let us consider an ergodic discrete Markov chain with transition matrix
P and invariant distribution
taking values in
. Let
be the measure induced by this chain on the space
. Observe that, with the above notation:
A direct computation shows that
and induction shows that:
Thus dividing by
n and taking the limit in Equation (
10), one finds that
4.2. Entropy Rate Maximization under Constraints
Now we introduce the central problem of this tutorial. Assume we have empirical data from spiking activity. Consider the empirical averages of
K observables,
, for
. We need to characterize the Markov chains that are consistent with these average values. Except for trivial and uninteresting situations, there is no finite set of empirical averages that uniquely determines a distribution
on
that fits the averages, in the sense that
Consequently, we need to impose further restrictions in order to guarantee uniqueness. A useful and meaningful approach is the so-called Maximum Entropy Markov Chain model (MEMC), which fit the unique probability measure
among all the stationary Markov measures
on
that match the expected values of a given set of observables and that maximizes the entropy rate. Mathematically, it is written in the following form:
where
is a shorthand for the sets of stationary Markov measures on
. Formally:
It is to be noted that the maximum entropy principle can be derived in some scenarios from more general principles based on large deviation theory [
30]. In this framework, entropy maximization corresponds to Kullback-Leiber divergence minimization. This approach can be useful for accounting additional information that is not in the form of functional constraints, but as a Bayesian prior. A major drawback of this approach to be applied to spike trains, is that it assumes stationarity in the data. While this condition is not to be naturally expected in biological systems, controlled experiments can be carried out in the context of spike train analysis in order to maintain these conditions [
3,
8,
32,
33]. The maximum entropy principle as presented here is useful only in the stationary case. However, some extensions have been proposed [
34,
35]. Note also that there are alternative variational principles which can be used to find distributions that extremize the value of quantities such as the maximum entropy production principle [
36,
37,
38], or the Prigogine minimum entropy production principle [
39,
40]. To the best of our knowledge, these alternatives have not yet been explored in the context of spike train statistics.
4.3. Solving the Optimization Problem
We now discuss techniques for finding models that maximize the entropy rate.
4.3.1. Lagrange Multipliers and the Variational Principle
To solve the above optimization problem, let us introduce the set of Lagrange multipliers
and an
energy function
, which is a linear combination of observables. Consider the following unconstrained optimization problem, which can be framed in the context of the
variational principle of the thermodynamic formalism [
41]:
where
is called the
free energy and
is the average value of
with respect to the measure
. The following holds:
where
is the average of
with respect to
p (maximum entropy measure), which is equal (by restriction) to the average value of
with respect to the empirical measure from the data.
The maximum-entropy (ME) principle [
42] has been successfully applied to spike data from the cortex and the retina [
3,
8,
9,
11,
12,
43]. The approach starts by fixing the set of constraints determined by the empirical average of observables measured from spiking data. Maximizing the entropy (concave functional) under constraints, gives a unique distribution. The choice of observables to measure in the empirical data (constraints) determines the statistical model. The approach of Lagrange multipliers may not be practical when trying to fit a MEMC. In the next section we introduce an alternative optimization based on spectral properties.
4.3.2. Transfer Matrix Method
In order to illustrate the transfer matrix method, we start with a classical example that allow us to introduce a fundamental definition. Let
A be a adjacency matrix i.e., a
-valued square matrix with rows and columns indexed by the elements of
. If there exists an
such that
for every
, we say that
A is
primitive. The next well-known theorem of Linear Algebra is crucial [
44] for the uniqueness of the MEMC.
Theorem 3 (Perron-Frobenius theorem). Let A be a primitive matrix. Then,
There is a positive maximal eigenvalue ρ > 0 such that all other eigenvalues satisfy . Moreover ρ is simple;
There are positive left- and right-eigenvectors s.t.
Apply the above theorem to a primitive matrix
A, and define:
where
is the standard inner product in
(we refer the reader to [
44] for details). The matrix
P built above is stochastic. Moreover,
is its unique stationary measure. Define the Parry measure to be the Markov measure:
It is well known that the Parry measure is the unique measure of maximal entropy consistent with the adjacency matrix
A [
45,
46].
Inspired by this result, we consider now the general case. Consider constraints given by a set of empirical averages of observables, as explained in the previous section. The above example certainly fits this setting: just consider binary observables associated to each pair of states
that evaluates to 1 when a transition from state
i to state
j has been observed in the data. In our general setting, we assume that the chosen observables have a finite maximum range
R. From these observables the energy function
of finite range
R is built as a linear combination of these observables. Using this energy function we build a matrix denoted by
, so that for every
its entries are given as follows:
where
is the concatenated block built from
and
. For observables of range one, the matrix above is defined as
. Assuming
, the elements of the matrix
are non-negative. Furthermore, in every non trivial case, the matrix is primitive and satisfies the Perron-Frobenius theorem [
44]. Denote by
the unique largest eigenvalue of
. Just as above, we denote by
and
the left and right eigenvectors of
associated to
. Notice that
and
, for all
. The
free energy associated to a transfer matrix is the logarithm of the unique maximum eigenvalue.
The matrix
can be turned into a Markov matrix of maximum entropy. For a primitive matrix
M with spectral radius
, and positive right eigenvector
associated to
, the stochastic matrix built from
M is computed as follows:
where
D is the diagonal matrix with entries
. The MEMC transition matrix
P and unique stationary probability measure
are explicitly given by
Note that when
, the MEMC is characterized by the Markov transition matrix with components [
47]:
where
A is the adjacency matrix.
4.3.3. Finite Range Gibbs Measures
For a fixed energy function
of range
, there is a unique stationary Markov measure
for which there exist a constant
such that [
46],
that attains the supremum (
11). The measure
, as defined by (
14), is known in the symbolic dynamics literature as
Gibbs measure in the sense of Bowen [
48]. All MEMCs belong to this class of measures. Moreover, the classical Gibbs measures in statistical mechanics are particular cases of (
14), when
,
and
is an energy function of range one, leading to an i.i.d stochastic process characterized by the product measure
. In this case the following holds:
The free energy that is defined here has a deep relationship with the free energy in thermodynamics. Consider a thermodynamic system in equilibrium. The Helmholtz free energy derived from the partition function as follows:
where
and
k is Boltzmann’s constant and
T is the temperature.
This quantity is related to the cumulant generating function for the energy. In the context of the maximum entropy principle, the physical temperature and the Boltzmann’s constant play no role, so usually both are considered equal to 1. From the free energy, all of the thermodynamic properties of the system can be obtained via its derivatives, examples are the internal energy, specific heat, and entropy. It is to be noted that the definition used in this tutorial for the free energy (
11) follows from the conventions used in the field of thermodynamic formalism [
41,
45,
46] and changes its sign with the usual convention in the field of statistical mechanics.
4.4. Example
We present here the toy example that we will use to explore statistical properties of spike trains using the non-equilibrium statistical physics approach. We present the transfer matrix technique to compute the Markov transition matrix, its invariant measure and free energy from a potential .
Consider a range-2 potential with two neurons (
). We use the notation introduced in
Section 2.1:
The state space of this problem is given by:
The transfer matrix (
12) associated to
is, in this case, a
matrix
This matrix satisfies the hypothesis of the Perron-Frobenius theorem. The maximum eigenvalue is
and the free energy
5. Statistical Properties of Markov Maximum Entropy Measures
The procedure of finding a maximum entropy model gives us a full statistical model of the system of interest. In this section we discuss the added value that having such a model can provide.
5.1. Cumulants from Free Energy
All the statistical properties of the observables and their correlations can be obtained by taking the successive derivatives of the free energy with respect to the Lagrange Multipliers. This property explains the important role played by the free energy in the framework of MEMC. In general,
where
is the cumulant of order
n (Equation (
5)). In particular, taking the first derivative:
where
is the average with respect to the maximum entropy distribution
p, which is equal to the average value of
with respect to the empirical measure. With Equation (
16) the parameters of the MEMC can be fitted to be consistent with fixed average values of observables.
Suppose that we compute from data the average values of the following observables
and
. We solve (
16) (two equations and two unknowns) and obtain
and
. With these parameters, the following Markov transition matrix and invariant measure are obtained from (
13):
5.2. Fluctuation-Dissipation Relations
For a first-order stationary Markov chain, since each
depends on its predecessor, this induces a non-zero time-correlation between
and
, even when the distance
r is greater than 1. This correlation, and more generally, time correlations between observables can be directly derived from the free energy. This relationship is usually referred to as Fluctuation-dissipation, and is also related to the linear response function that is presented in
Section 5.7.
Let
P be an ergodic matrix and indexed by the states in some finite set
E, and
be its unique stationary measure. In this general context, for two real-valued functions that depend on a fixed finite number of components, we define the
n–step correlation as
In the particular case of MEMC with potentials of range
there is a positive time correlation between pairs of observables
and
. Suppose the correlations decay fast enough so that (at least)
Then the following sum (known as the Green-Kubo formula [
49]) converges and is non-negative:
Additionally, it can be shown that the energy function and the free energy depends smoothly upon maximum entropy parameters. Moreover, the correlations between observables can be obtained from the free energy through:
The relationship between a correlation and a derivative of the free energy is called the fluctuation-dissipation theorem [
50]. For a MEMC characterized by
, the fluctuation-dissipation relationships can be obtained explicitly:
For MEMC built from
K observables, the correlations can be conveniently arranged in a
symmetric matrix denoted by
(the symmetry refers to the Onsager reciprocity relations [
51]).
For the example
Section 4.4, we obtain the matrix
by taking the second derivatives of (
15) and evaluate at the parameters found previously,
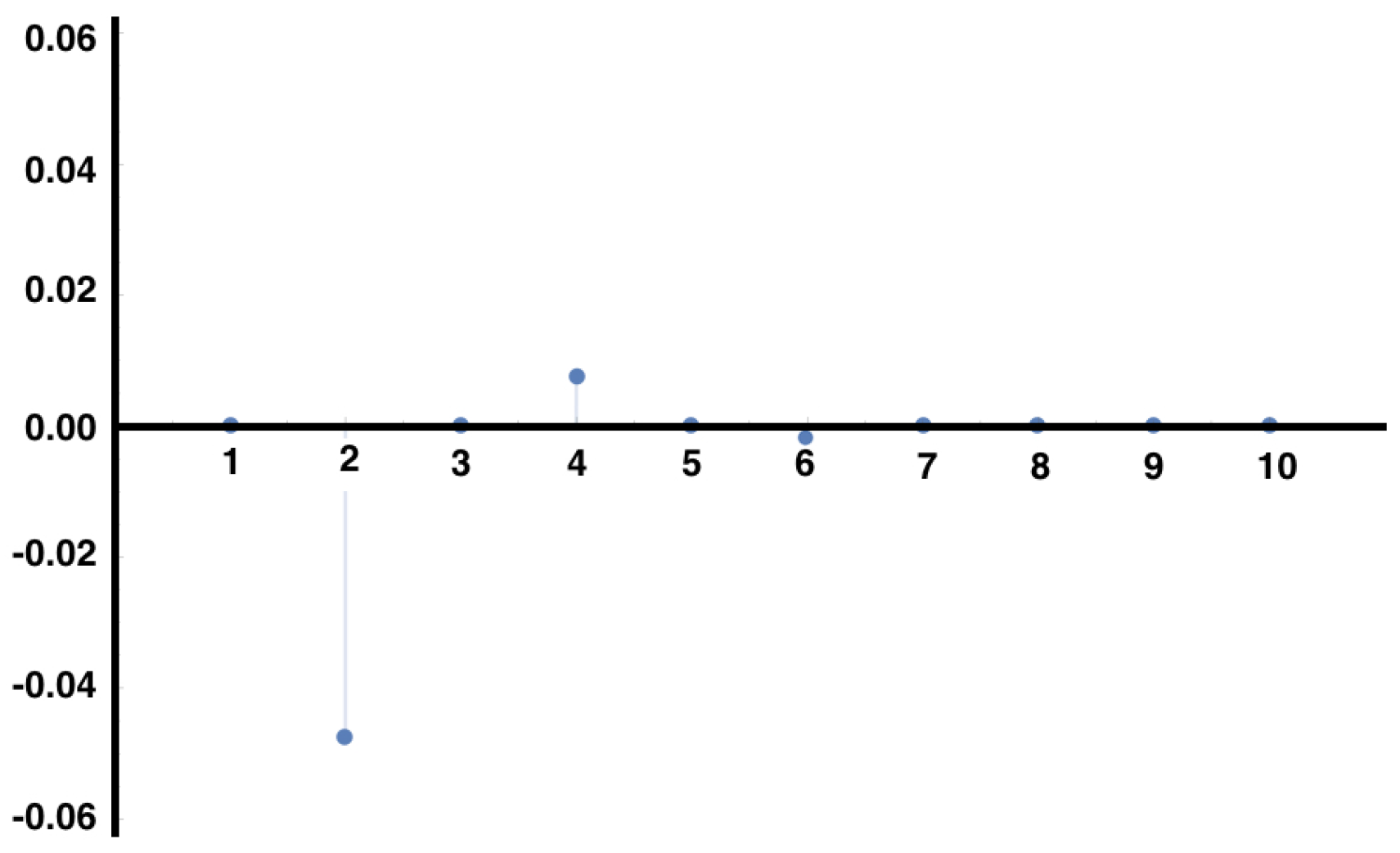
In
Figure 2, we plot the right hand side of Equation (
18) for the MEMC built from the example
Section 4.4 consistent with constraints considered in the example of
Section 5.1, for the auto-correlation of the observable
.
5.3. Resonances and Decay of Correlations
We now turn back to the general setting of an arbitrary ergodic matrix
P with stationary measure
associated to a Markov chain taking values on a finite state space (not necessarily the space of spike-patterns). Without loss of generality, assume that
P is indexed by the states in
. It can be proved that in this case there exists
and
, sets of left and right eigenvectors respectively, associated to the eigenvalues
. We can assume that the eigenvectors and left and right eigenvalues have been sorted and normalized in such a way that
,
is the unique
P–stationary probability vector
,
, and
where
is the Kronecker delta, and
corresponds to the Dirac’s bra-ket,
. With the same notation, the spectral decomposition of
P is written:
Given two functions
and
the following holds,
Recall the discussion in previous sections regarding the reverse chain
Section 2.4. Writing
for the expectation operator associated to the reverse Markov measure, i.e., to the measure
, one can see that
and hence (
21) becomes
From (
20)
and thus (
21) becomes
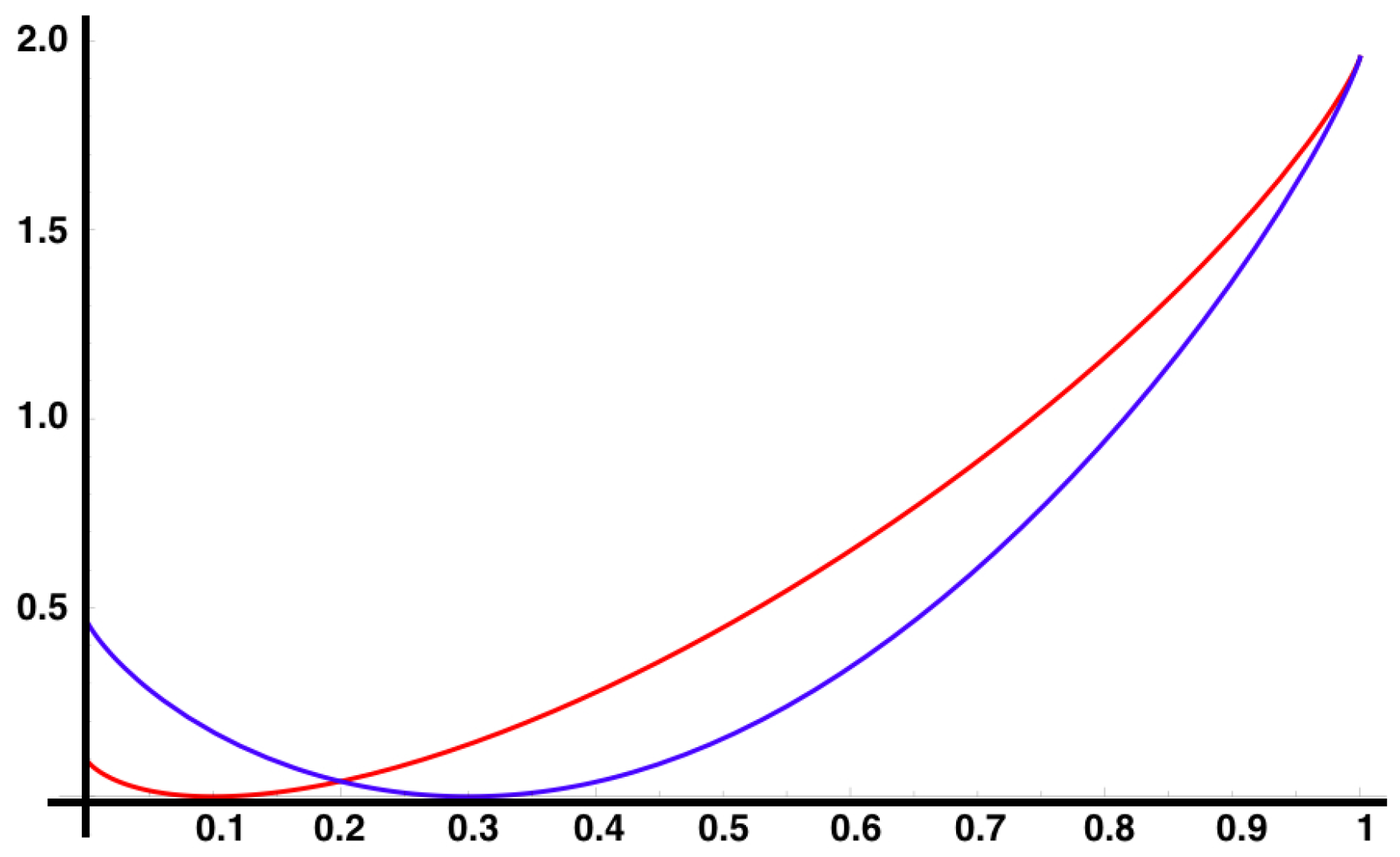
In
Figure 3, we show the auto-correlations of the same observable considered in
Figure 1, for the same MEMC. We observe modulations in the decay of the auto-correlations due to the complex eigenvalues in Equation (
22), which arise in the non-symmetric transition matrix induced by the irreversibility of the MEMC.
We have found in Equation (
22) an explicit expression for the decay of correlation for observables from the set of eigenvalues and eigenvectors of the transition matrix
P. This is relevant in the context of spike train statistics because as the matrix
P characterizing the spike trains is not expected to be symmetric, its eigenvalues are not necessarily real and modulations in the decay of correlations are expected (resonances). When measuring correlations between observables from data, one may observe this oscillatory situation that resembles resonances. This may be a symptom of a non-equilibrium situation.
5.4. Large Deviations for Average Values of Observables in MEMC
Obtaining the probability of “rare” average values of firing rates, pairwise correlations, triplets or non-synchronous observables is relevant in spike train statistics as these observables are likely to play an important role in neuronal information processing, and rare values may convey crucial information or be a symptom that the system in not working properly.
Here, we build from a previous article [
52] where it is shown that the SCGF (
7) can be obtained directly from the inferred Markov transition matrix
P through the Gärtner-Ellis theorem (
8). Consider a MEMC with transition matrix
P. Let
f be an observable of finite range and
. We introduce the
tilted transition matrix by f of
P, parametrized by
k and denoted by
[
53] as follows:
The tilted transition matrix can be directly obtained from the spectral properties of the transfer matrix (
12),
Recall that is the right eigenvector associated to its maximum eigenvalue of the transfer matrix . Here we use the notation to specify that the energy function is built from the elements of the state space i and j. Remarkably, this result is valid not only for the observables in the energy function, i.e., from here the LDP of more general observables can be computed.
To obtain an explicit expressions for the SCGF
, it is possible to take advantage of the structure of the underlying stochastic process. For instance, for i.i.d. random process
where
from Definition
7, one can obtain that
which is the case of range one observables. Using the Equation (
23), we obtain that the maximum eigenvalue of the tilted matrix
is,
As is a primitive matrix, the uniqueness of is ensured from the Perron-Frobenius theorem.
For additive observables of ergodic Markov chains, a direct calculation (see [
54]) leads us to
It can also be proved that
, in this case, is differentiable [
54], setting up the scene to use the Gärtner-Ellis theorem to obtain
as shown in
Figure 4.
5.5. Information Entropy Production
Given a Markov chain
on a general finite state space
E with transition matrix
P started from the distribution
, denoted
the distribution of
, namely, for
:
Obviously,
, and
The information-theoretic entropy of the probability distribution
at time
n is given by
and the
change of entropy over one time step is defined as
The first term on the right hand side above is called
information entropy flow and the second term
information entropy production [
12].
In the stationary case, i.e., when
P admits a stationary measure
and the chain is started from that distribution, one has that
for every
; thus, in this case, the change of entropy rate is zero, i.e., for stationary chains, the information entropy flow equals (minus) information entropy production. This case is the focus of this work. The chain is associated to spike train activity for transitions between
L–blocks. Starting from stationarity the entropy production rate is explicitly given by
The non-negativity implies that information entropy is positive as long as the process violates the detailed balance conditions (
4). This is analogous to the second law of thermodynamics [
55]. From this equation it is easy to realize that if the Markov chain satisfies the detailed balance condition, the information entropy production is zero.
In
Figure 5, we compute the information entropy production from Equation (
24), for the MEMC of the example (
Section 4.4) for different values of the parameters
.
It may seem contradictory that in stationary state the entropy is constant, while there is a positive “production” of entropy. The information entropy production in stationary state always compensate the information entropy flow, which leaves the information entropy rate constant. In this case we refer to non-equilibrium steady states (NESS).
5.6. Gallavotti-Cohen Fluctuation Theorem
To characterize the fluctuations of the IEP, consider the MEMC
and the following observable:
It can be shown that
. The Gallavotti-Cohen fluctuation theorem is as a statement about properties of the SCGF and rate function of the IEP [
14].
This symmetry holds for a general class of stochastic processes including NESS from Markov chains [
56], and is a
universal property of the IEP, i.e., it is independent of the parameters of the MEMC. To compute
and
, define
. If
is the largest eigenvalue of
, then
.
In
Figure 6, we illustrate the Gallavotti-Cohen symmetry property of the large deviation functions associated to the IEP (Equation (
25)).
These properties are relevant to the large deviations of the averaged entropy production denoted
over a trajectory
of the Markov chain
. The following relationship holds,
This means that the positive fluctuations of are exponentially more probable than negative fluctuations of equal magnitude.
5.7. Linear Response
The linear response serves to quantify how a small perturbation
of a set of the maximum entropy parameters affects the average values of observables in terms of the unperturbed measure. This is relevant in the context of spike trains statistics to identify stiff and sloppy directions in the space of parameters. A small change in a sloppy parameter produces very little impact in the statistical model. In contrast, a small change in a stiff parameter produces a significant change. For a MEMC characterized by
corresponding to an energy function with fixed parameters
denoted by
, one can obtain the average value of a given observable
from (
16).
Now, consider a perturbed energy denoted by
. Using a Taylor expansion, the average value of an arbitrary observable
with respect to the MEMC can be obtained
associated to the perturbed energy. Considering the Taylor expansion of
about
We use (
16) to go from (26) to (27). Observe from (27) that a small perturbation of a parameter
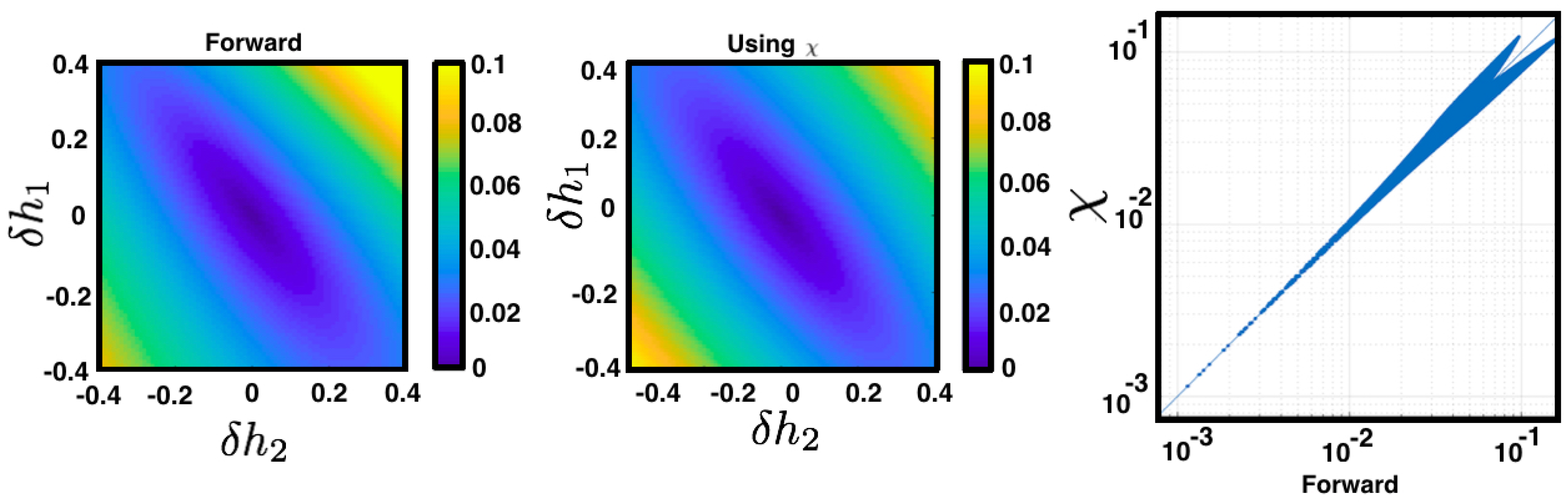
influences the average value of all other observables in the energy function (as
is arbitrary). The perturbation is modulated by the second derivatives of the free energy corresponding to the unperturbed regime
(see
Figure 7).
6. Discussion and Future Work
This tutorial explores how one can use maximum entropy methods to capture asymmetric temporal aspects of spike trains from experimental data. In particular, we showed how spatio-temporal constraints can produce homogeneous irreducible Markov chains whose unique steady state is, in general, non-equilibrium (NESS)—thus, detailed balance condition is not satisfied causing strictly positive entropy production. This fact highlights that only non-synchronous maximum entropy models induce time irreversible processes, which is one of the key hallmarks of biological systems.
We have presented a survey of diverse techniques from mathematics and statistical mechanics to study these NESS, which correspond to a rich toolkit that can be employed to study unexplored aspects of spike train statistics. We emphasise that many of these concepts, including entropy production and fluctuation-dissipation relationships, have not been explored much in the context of spike train analysis. However, the fact that time irreversibility is such an important feature of living systems suggest that these notions might play an important role in neural dynamics.
Possible extensions include measuring the entropy production for different choices of spatio-temporal constraints using the maximum entropy method on biological spike train recordings. A more ambitious extension is to explore the relationship between entropy production computed from experimental data obtained from different physiological processes and relate them to features such as adaptation or learning. Concerning time-dependent neuronal network models, future studies might lead to a better understanding of the impact of particular synaptic topologies of neuronal network models on the corresponding entropy production, decay of correlations, resonances and other sophisticated statistical properties.
Other possible extensions are related to the drawbacks of current approaches. This can include limitations of the maximum entropy method related to the requirement of stationarity in the data, which is not a natural condition for some biological scenarios. However, several of the techniques presented in this tutorial naturally extend to the non-stationary case, including the information entropy production, which can still be defined along non-stationary trajectories [
14]. Related to this issue is that the approach presented in this tutorial does not make any reference to the stimulus. While this issue has been addressed in the synchronous framework [
34], there is still an open field to explore the Markovian extension of these ideas. Another interesting topic to explore in future studies is the inclusion of the non-stationary approach such as the state space analysis proposed in [
35]. Also, another open problem is related to the efficient implementation of the transfer matrix technique, which currently requires an important computational effort in the case of large neural networks. Recently, some improvements of this approach have been proposed based in Monte Carlo methods [
57].
In summary, we believe that these topics are fertile ground for multi-disciplinary exploration by teams composed of mathematicians, physicists, and neuroscientists. It is our hope that this work may foster future collaborative research among disciplines, which might bring new breakthroughs to advance our fundamental understanding of how the brain works.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
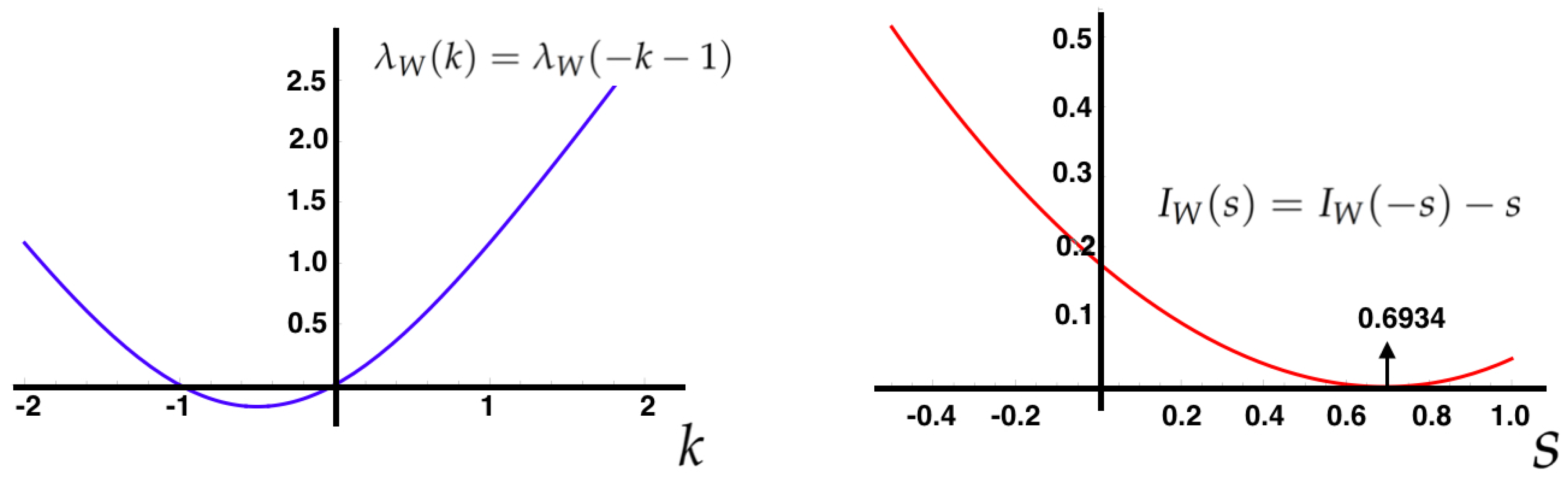{kind=link}
{kind=link}






