1. Introduction
Turbo codes were proposed in 1993, and have been widely used in 3G and 4G wireless communication systems due to their good error correction [
1]. Yang et al. proposed new, partially information-coupled (PIC) turbo codes in 2018 [
2], which can improve decoding performance without changing the decoder. The Log-MAP algorithm was often used in decoding turbo codes. In order to reduce logic resource consumption with the Log-MAP algorithm, Martina et al. proposed a turbo decoder with low complexity based on an approximated Log-MAP algorithm in 2014 [
3]. Compared with the Log-MAP algorithm, the approximate Log-MAP algorithm can save nearly 30% of logic resources by linear approximation of the function max*. In 2015, Ivanov et al. summarized the common approximation methods of the max* function [
4,
5]. In 2018, Liu et al. proposed an improved turbo decoder that approximates the function max* with a Taylor series [
6]. The idea of normalized approximation mainly comes from the low-density parity check (LDPC) decoder based on the normalized min-sum (NMS) algorithm, as proposed by Wu et al. in 2010 [
7], and we use this method to approximate the function max*. In 2011, Sun et al. proposed a dynamic interleaving structure based on a quadratic permutation polynomial (QPP) interleaver that performs real-time interleaving address output and reduces storage unit consumption [
8,
9]. Sun et al. also proposed a flexible functional unit (FFU) for a soft-input soft-output (SISO) decoder, while a turbo decoder achieves a throughput of 1280 Mbit/s with a clock frequency of 400 MHz under 3GPP-LTE and LTE-advanced standards [
9,
10]. Rohit et al. put forward an idea for a hybrid algorithm in 2013, and its decoding performance is better than a Log-MAP algorithm after combining a LUT-Log-MAP algorithm and Linear-Log-MAP algorithm in every state metric calculation [
11], although this implementation results in a large consumption of logic resources. In 2017, Zhen et al. proposed a calculation method of the function max* that can be applied for reverse calculation in engineering implementation [
12].
In this paper, we propose a Nor-Log-MAP algorithm that uses a fixed normalized factor to approximate the function max*. According to the idea of a hybrid algorithm [
11], we also propose a LUT-Nor-Log-MAP algorithm that uses different algorithms in different metric calculation states so as to reduce the number of lookup tables and consumption of logical resources. LUT-Nor-Log-MAP is a new kind of algorithm that combines Nor-Log-MAP with LUT-Log-MAP. The LUT-Log-MAP algorithm is used to calculate forward-state and backward-state metrics, and the Nor-Log-MAP algorithm is used to compute external information and posteriori information. Based on the LUT-Nor-Log-MAP algorithm, we incorporated an FFU and a normalization functional unit (NFU) into the design of the SISO unit.
The rest of this paper is organized as follows.
Section 2 reviews turbo decoding principles and the Log-MAP algorithm.
Section 3 presents the Nor-Log-MAP algorithm.
Section 4 introduces the LUT-Nor-Log-MAP algorithm and the structure of the SISO unit.
Section 5 analyzes the proposed algorithm.
Section 6 presents the synthesis results and comparisons.
Section 7 concludes the paper.
3. The Normalized Log-MAP Algorithm
The function
is a nonlinear calculation in Equation (8) that will consume lots of logic resources in decoder design, so we need to simplify the function
in max*. In [
4,
5], two commonly used algorithms for approximating the nonlinear function
are as follows:
(a) The
approximation method of the Max-Log-MAP algorithm is shown in Equation (10).
(b) The max* approximation method of the LUT-Log-MAP algorithm is shown in
Table 1 [
9].
The Max-Log-MAP algorithm consumes fewer logic resources, but has a poor decoding performance. The LUT-Log-MAP algorithm has a better decoding performance, but consumes a large amount of logic resources. The LUT-Log-MAP algorithm reduces the complexity of the Log-MAP algorithm in hardware implementation with only 0.1 dB decoding performance loss, so it can be said that the performance of the LUT-Log-MAP algorithm is better. However, the LUT-Log-MAP algorithm involves a large number of lookup table operations in hardware implementation, as well as having a large consumption of logical resources. So finding a max* approximation method becomes the key point in obtaining considerable decoding performance and reducing logic resource consumption.
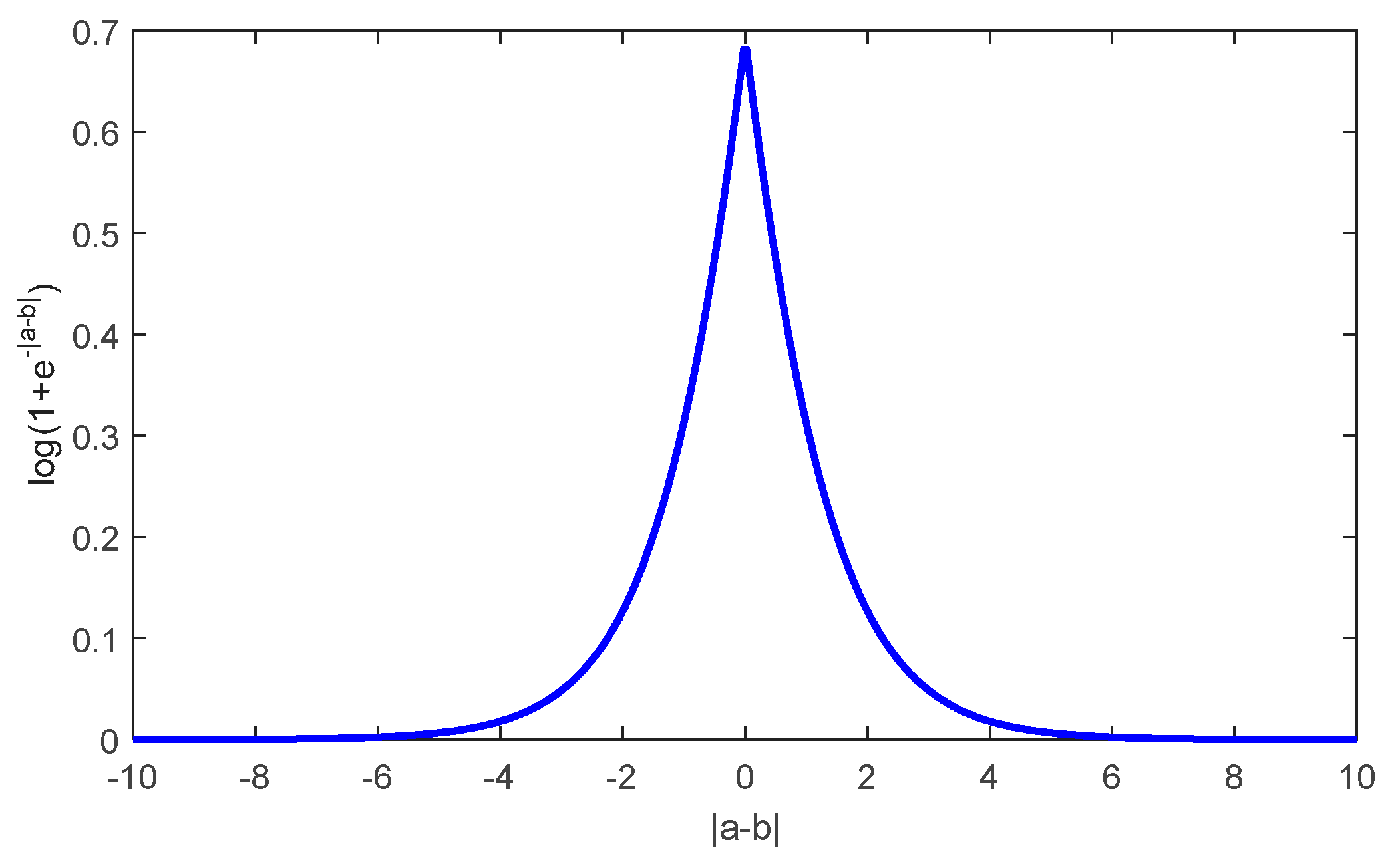
It can be seen from
Figure 2 that function
has a small range of
with arbitrary real numbers
and
Therefore, we try to establish Equation (11) by finding a fixed normalization factor
.
From the approximation method of the LUT-Log-MAP algorithm [
6], when
, the value of function
approaches zero and becomes the Max-Log-MAP algorithm [
7]. A lookup table is used to facilitate the algorithm in hardware implementation. Combining this idea, the proposed Nor-Log-MAP algorithm will determine the value of
under condition
, and the value of
in
will be equal to 1. Then, the optimal range
can be verified under this fixed
. The Nor-Log-MAP algorithm based on the above concept is shown in Equation (12).
Turbo codes with a 1/2 code rate and 192 code length are used in a MATLAB simulation. As the final result needs to support hardware implementation, all the variables’ values in the algorithm will go through Q2 quantization (Q total bits with 2 fractional bits) [
8]. The Q2 quantization involves a decimal number with two fractional bits going through binary conversion, followed by the removal of the fractional bits and converting into a decimal number. Therefore, in the process of simulation,
will be
by Q2 quantization. We can achieve the lookup table method based on Q2 quantization, as shown in
Table 2 [
8], and this method is also used in normalized quantization.
In order to make
Figure 3,
Figure 4 and
Figure 5 clearer, we omit other poor performance curves.
Figure 3 shows the effect of decoding performance with different normalization factors
under the range of
with a step size of
= 0.05.
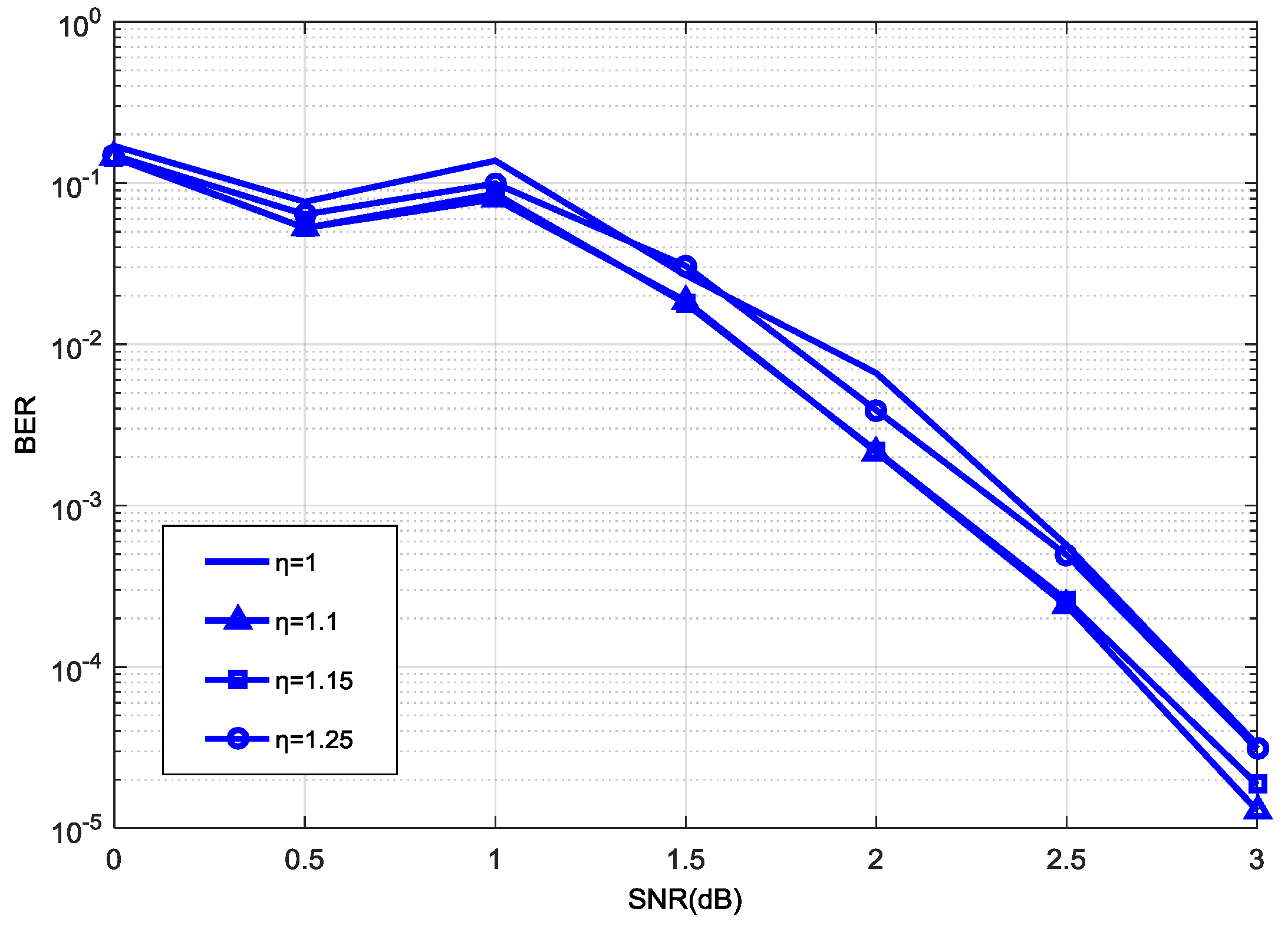
Figure 3 shows that we can achieve the best decoding performance when
= 1.1, and the decoding performance was low when
was between 1 and 1.25. We set
= 1.1 as the center to find a more accurate
. In
Figure 4, we achieved the best decoding performance when
was between 1.11 and 1.14. Considering that addition will reduce more logic resource consumption than multiplication in a hardware simulation, we can change the multiplication of
and the function max* into an addition of the max and its shift value. But addition can only be performed when the fractional part of the normalization factor
η is
(
). Since the fractional part of the normalization factor
is constrained as the form of
(
) (e.g., 1.5, 1.25, 1.125, etc.), there are not many legal options for this factor. In our work, the value of normalization factor
is taken as 1.125.
In addition, our experiments illustrate that these legal options result in very slight performance differences, as shown in
Figure 3 and
Figure 4. The optimal factor can be discovered from the experiments that used a 192 code length, as described in this study. However, the greatest advantage of the proposed normalization factor lies in greatly reducing the logic resources in the hardware implementation, while maintaining a similar performance or having a negligible loss of performance. In this view, the factor is independent of code length or code rate to some extent.
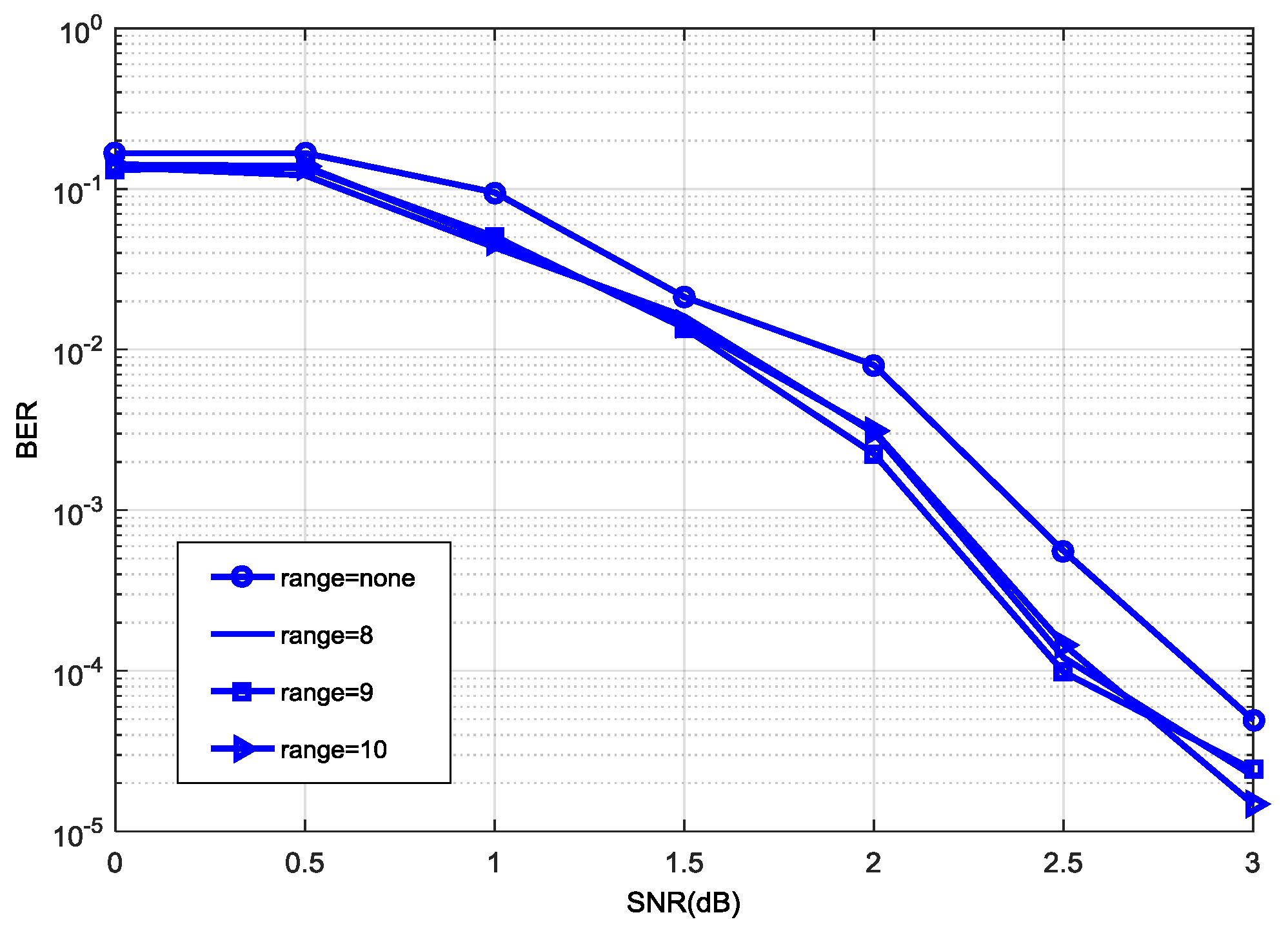
Figure 5 shows the effect of decoding performance under the normalization factor
with different
ranges, where we define
. In
Figure 5, the decoding performance is better when
and
, and the decoding performance with
is better than that
with a signal noise ratio (SNR) from 1.5 to 2.8 dB. Considering decoding performance with a medium to high SNR, the range
can be determined as
. Therefore, the Nor-Log-MAP algorithm can be rewritten as Equation (13). In the hardware simulation, Equation (13) can be realized by Equation (14) after binary conversion, where
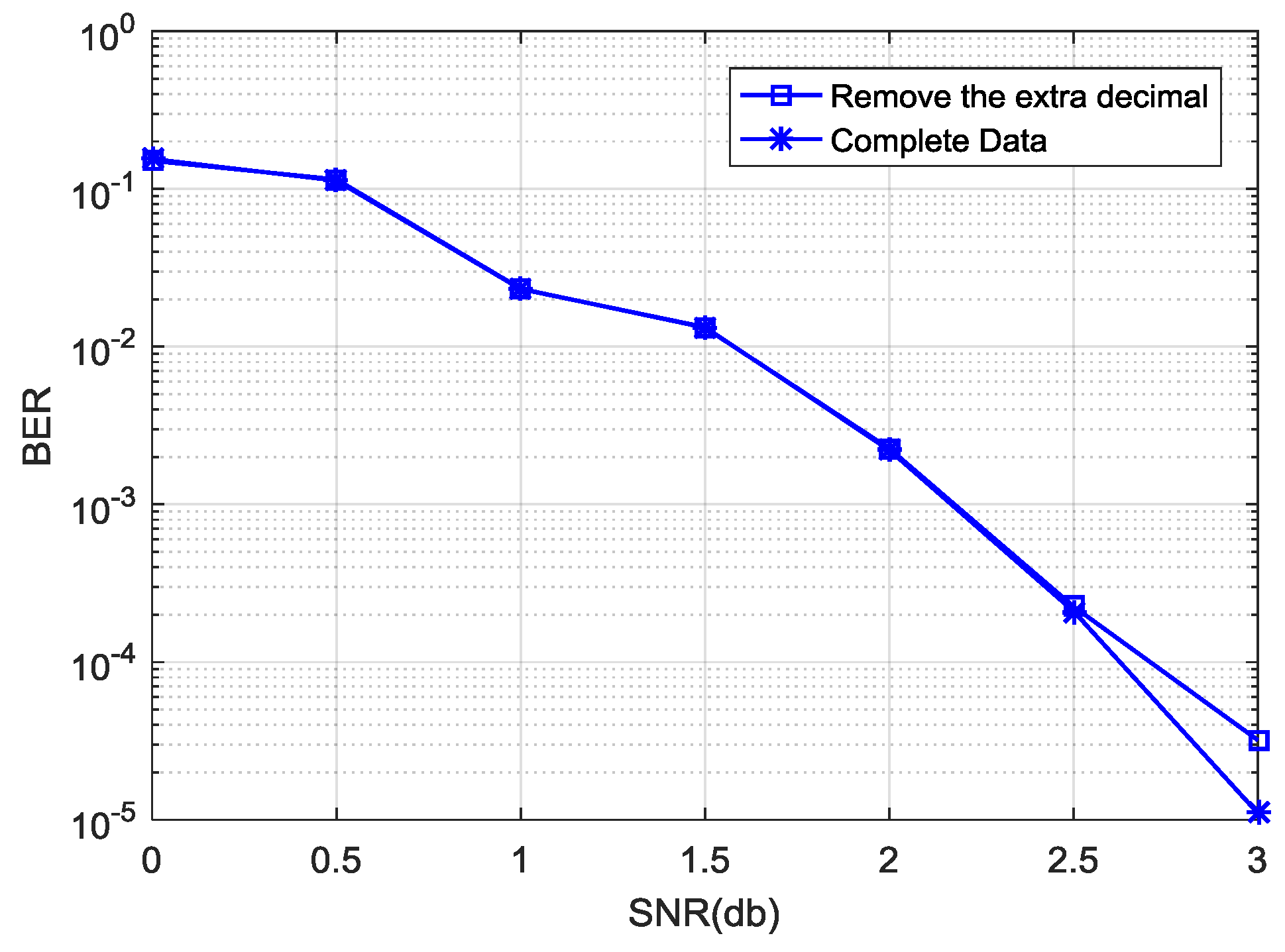
can be computed by intercepting the corresponding data based on selected bit width and the number of decimal digits. During the hardware simulation, 7-bit channel information is used, where 5 bits are integers and 2 bits are decimals. When computing, the data part that exceeds two decimal places is removed, however this results in performance loss. As can be seen from
Figure 6, there is a little gap between the removed extra decimal places and the complete data in decoding performance. We also know that hard decision in turbo decoding relates to the sign bit of information directly rather than the absolute value of the data. In this way, the algorithm can replace multiplication with an addition operation, and will reduce some logic resource consumption compared with the lookup table method.
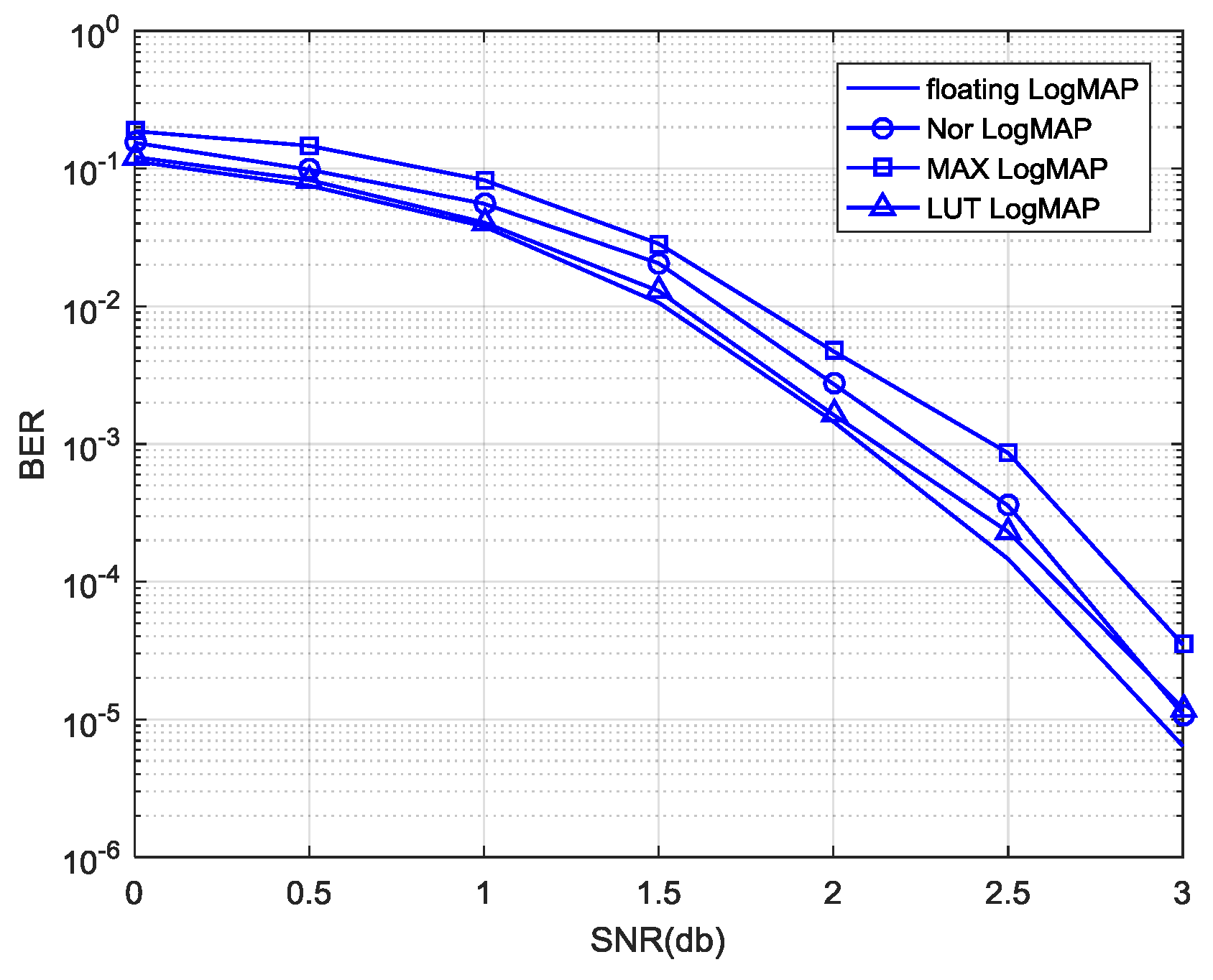
The comparison between the proposed Nor-Log-MAP algorithm and other approximate algorithms in decoding performance is shown in
Figure 7. As can be seen, the decoding performance of the proposed Nor-Log-MAP algorithm is superior to the Max-Log-MAP algorithm, and has a maximum gain of 0.25 dB in decoding performance. Compared with the Log-MAP algorithm and LUT-Log-MAP algorithm, the Nor-Log-MAP algorithm has some disadvantages, but the decoding performance of the Nor-Log-MAP algorithm is close to (or even surpasses) the LUT-Log-MAP algorithm with a high SNR. Considering that the logic complexity of the Nor-Log-MAP algorithm is close to that of the Max-Log-MAP algorithm theoretically, it can be concluded that the Nor-Log-MAP algorithm has a considerable decoding performance and less logic complexity.
4. The SISO Design of the Turbo Decoder
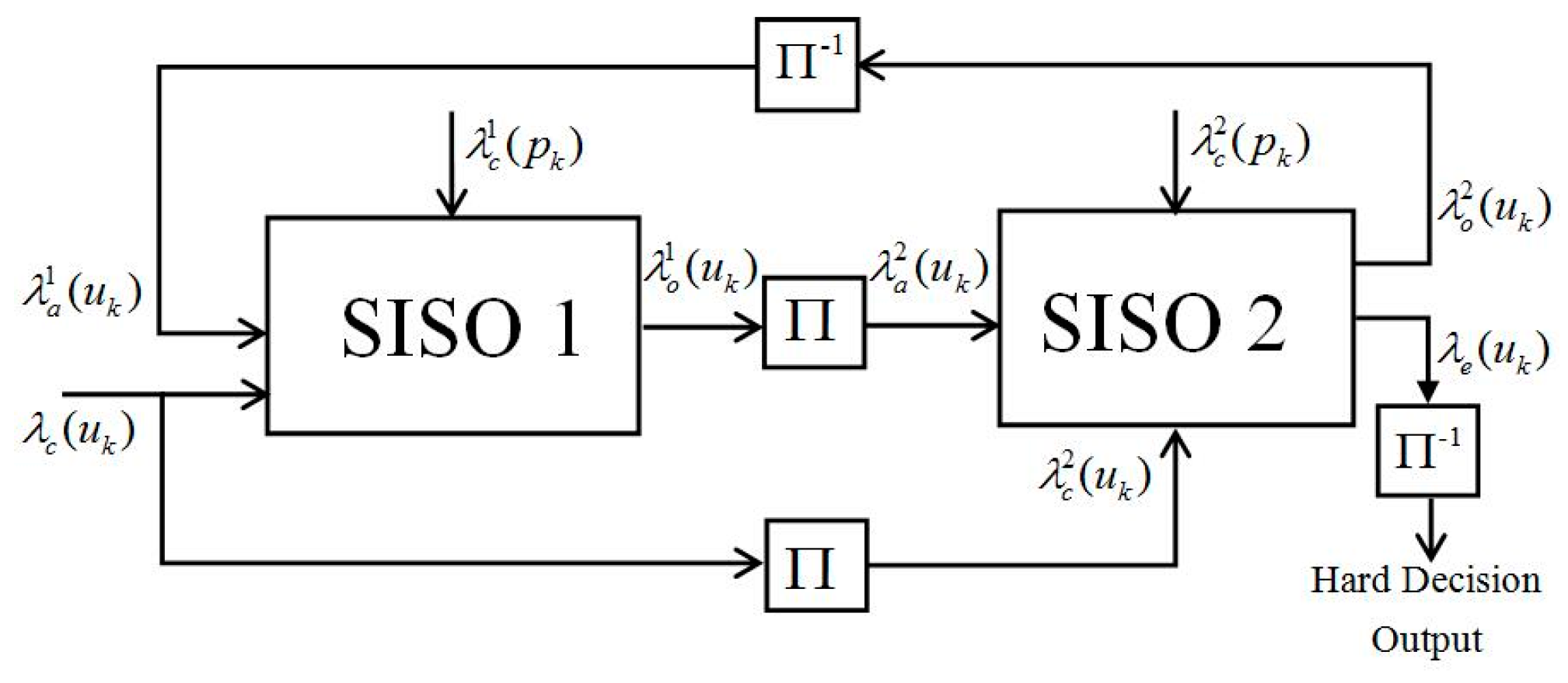
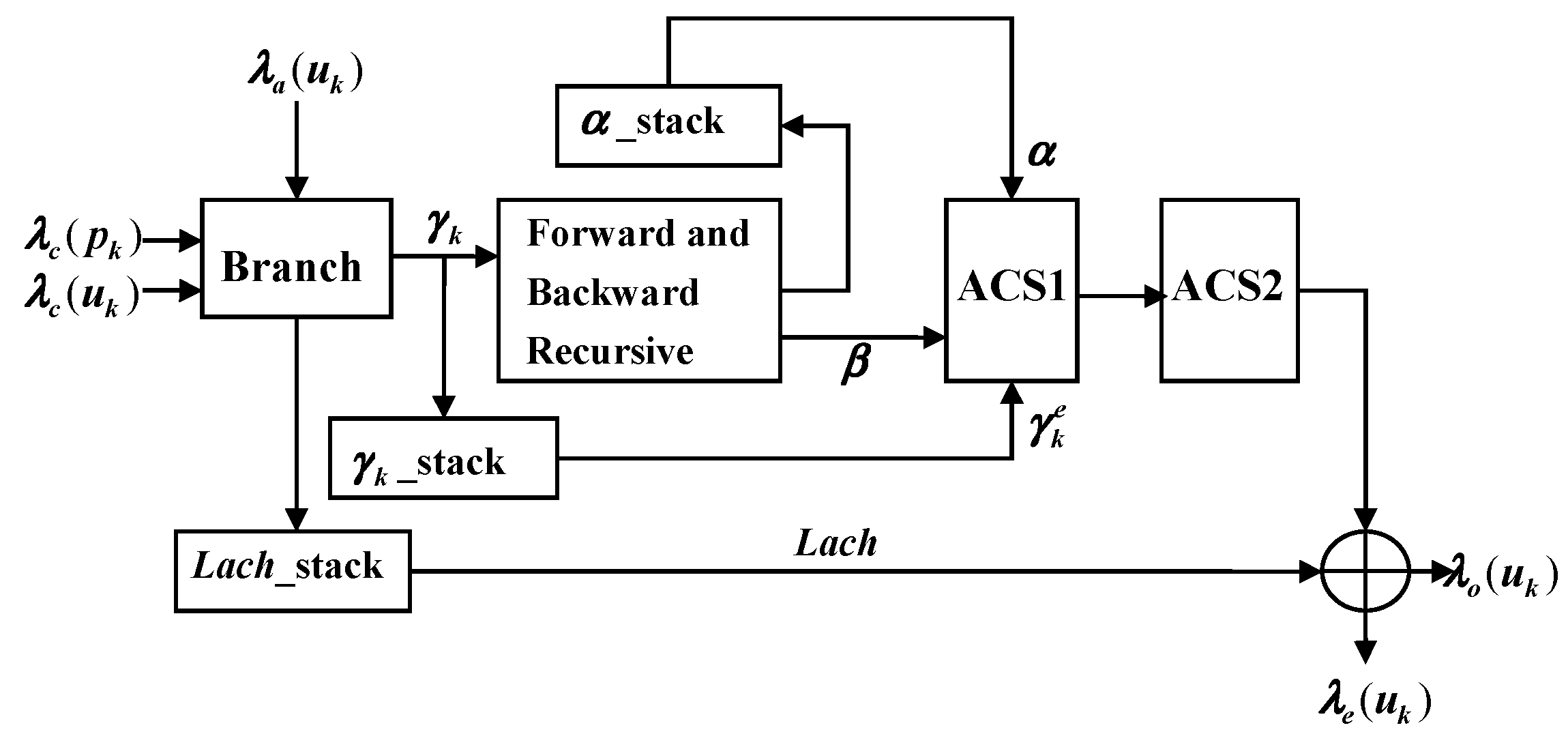
The decoding process of turbo codes in SISO is shown in
Figure 8 [
14,
15]. Firstly, received system information
, check information
and priori information
are used to compute
,
, and
Lach in the branch unit. Then, we use a generated branch metric and initialized value
and to compute the new
and
through a forward and backward recursive (FBR) unit. Finally, add compare select 1 (ACS1) and ACS2 are used to compute posteriori information
and external information
[
16,
17].
In
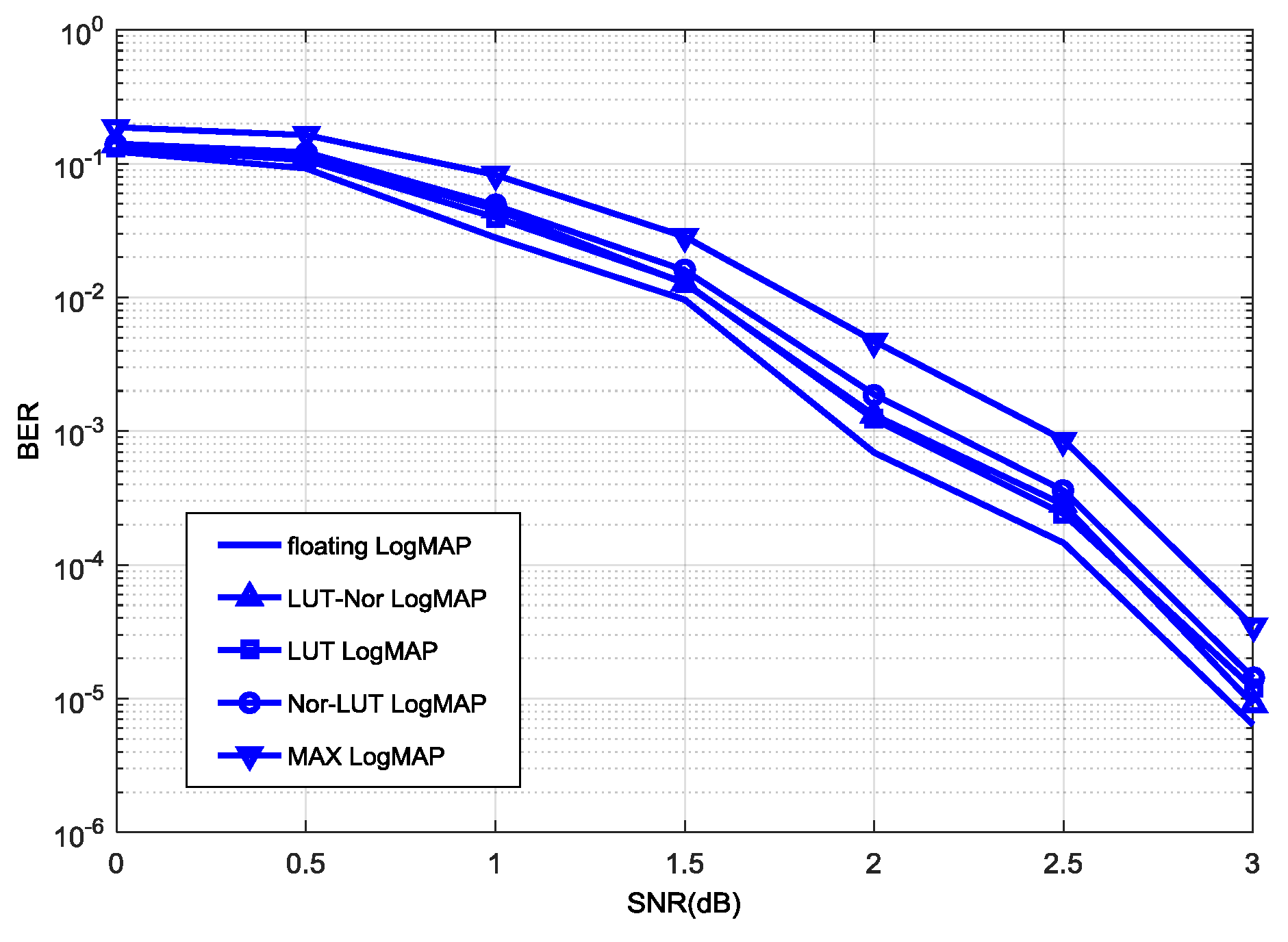
Figure 7, the LUT-Log-MAP algorithm is demonstrated to be superior to the Nor-Log-MAP algorithm in decoding performance, so we tried to employ these two algorithms using a turbo decoder for better decoding performance. In the simulation, the LUT-Log-MAP algorithm is adopted in computing forward-state and backward-state metrics, while posteriori information and external information are computed by the Nor-Log-MAP algorithm. The decoding performance of this hybrid algorithm is shown in
Figure 9. As can be seen, the LUT-Nor-Log-MAP algorithm not only compensates for the decoding performance of the Nor-Log-MAP algorithm with a low SNR, but also maintains the advantages of the Nor-Log-MAP algorithm with a high SNR. Furthermore, compared to the Max-Log-MAP algorithm, it has maximum of a 0.5 dB increase in decoding performance.
At the same time, we also propose the Nor-LUT-Log-MAP algorithm, which uses the Nor-Log-MAP algorithm to calculate forward-state and backward-state metrics as well as the LUT-Log-MAP algorithm to compute external information and posteriori information. As shown in
Figure 9, the decoding performance of the Nor-LUT-Log-MAP algorithm is less than that of the LUT-Nor-Log-MAP algorithm, and it can be concluded that the forward-state and backward-state metric computation requires a better algorithm in the turbo decoding process [
18].
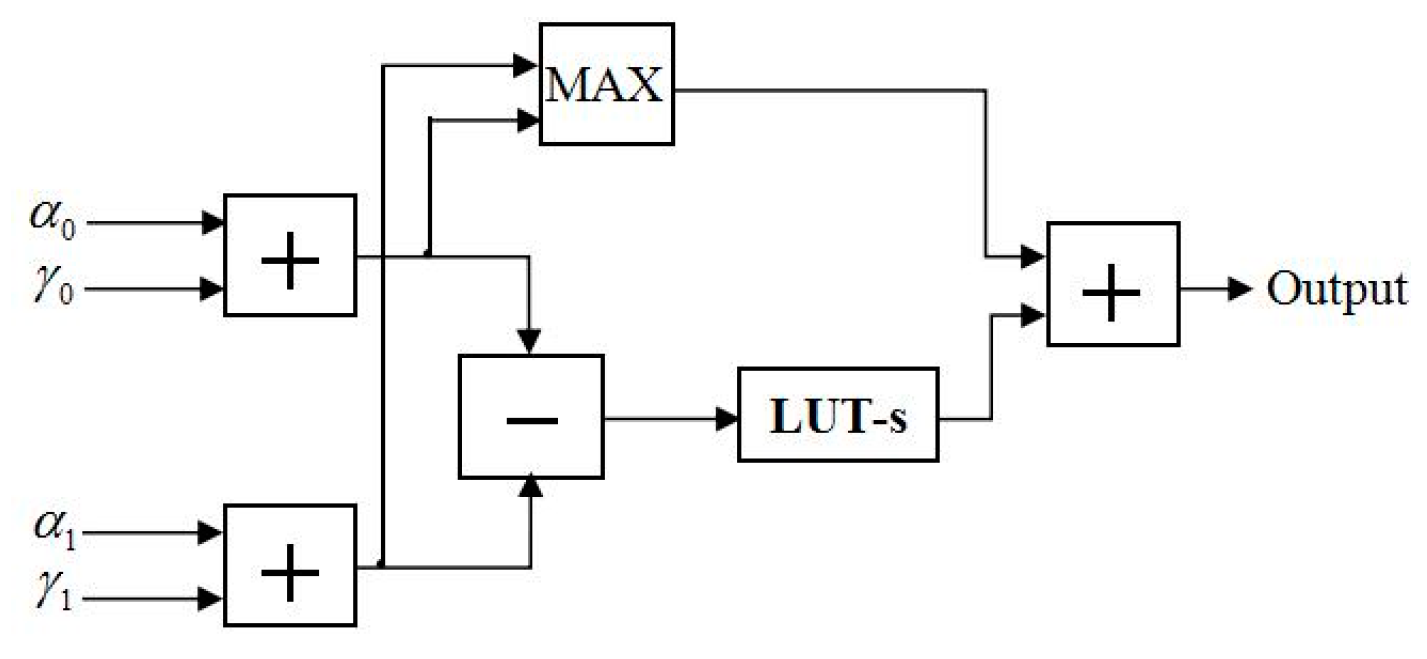
In [
10], Sun et al. proposed FFU to compute the metrics of every state. The structure of the FFU is shown in
Figure 10, where the input signals of the module are
and
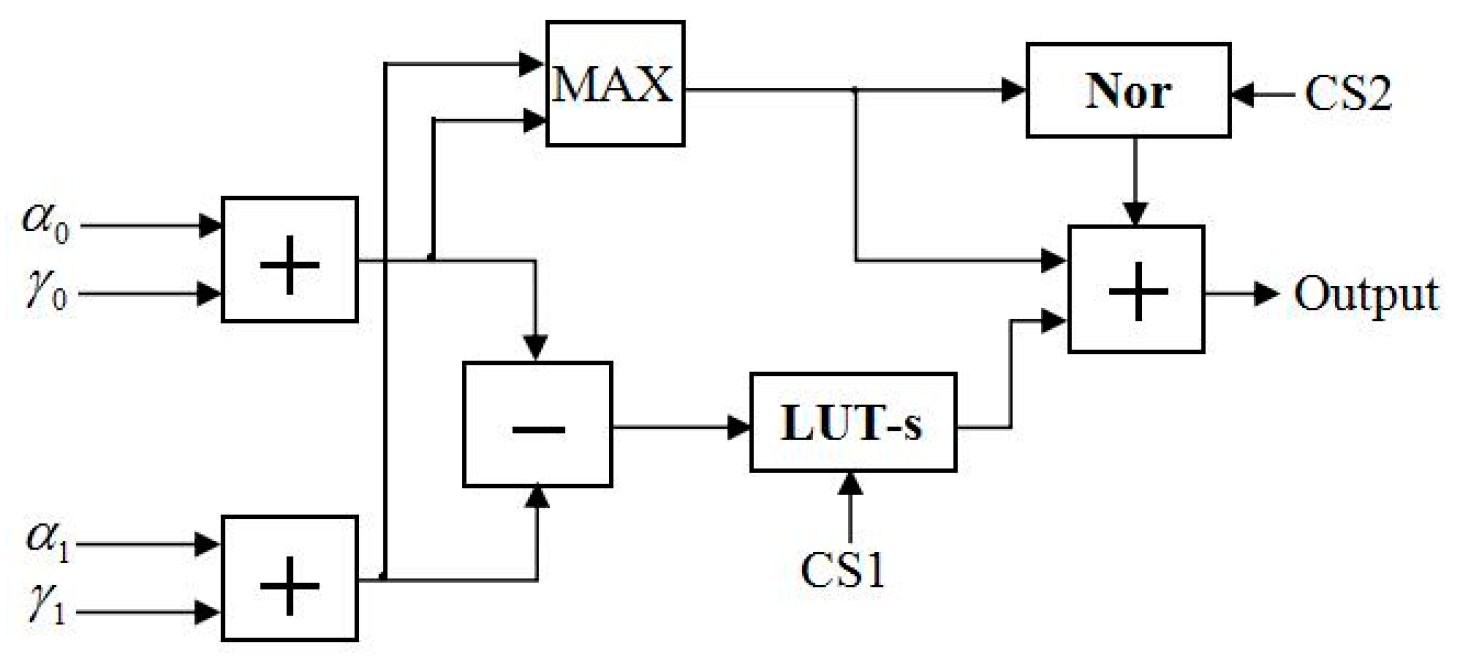
during the forward-state metric computation. In order to satisfy the proposed LUT-Nor-Log-MAP algorithm, we designed an NFU based on the FFU, which is applicable to all state metric calculation at the same time. The structure of the NFU is shown in
Figure 11. The operation of the lookup table unit and the normalization unit are controlled by control signals (CSs). LUT-s and
Nor represent lookup table approximation and the normalized approximation for function
, respectively. Hence, it is possible to adopt different approximation methods for satisfying the forward-state and backward-state metrics, as well as posteriori information and external information computation.
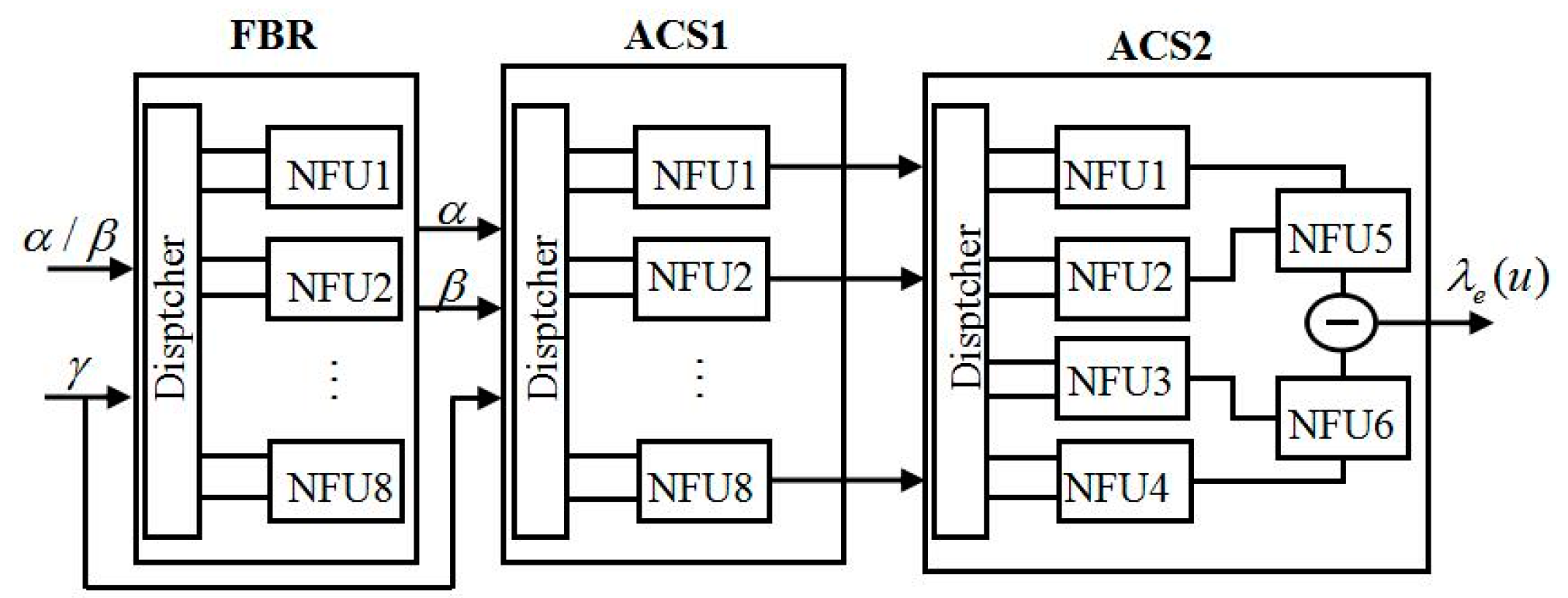
Figure 12 shows the rule of the state trellis transition of the turbo decoder under the time division long term evolution (TD-LTE) standard. In order to satisfy the eight-state transition rule of the turbo trellis network in the decoding process [
19,
20], the FBR unit calls eight NFUs, and the ACS1 and ACS2 units call eight and six NFUs, respectively. The structure of the modified SISO unit is shown in
Figure 13. Each NFU will complete the calculation of max* one at a time. As can be seen from
Figure 11 and
Figure 13, for the eight-state turbo code with TD-LTE standard, a codeword for each turbo code needs at least 16 LUTs for the calculation of forward-state and backward-state metrics [
21], and an external or posteriori information bit requires 14 LUTs for max* operation. As the degree of parallelism increases, the number of LUTs increase with the same multiple. Therefore, in hardware implementation, the proposed LUT-Nor-Log-MAP algorithm can transform the required 14 LUTs operation per bit into addition operations during turbo code decoding, and thus reduce logic resource consumption.
Table 3 shows the logic resource consumption of the turbo decoder and its SISO under different algorithms. Simulation results show that decoder logic resource consumption based on the LUT-Nor-Log-MAP algorithm is 74.5 K. Compared with the Max-Log-MAP algorithm, our design consumes more about 8.4% logic resources, but our design has advantages in decoding performance. Compared with the LUT-Log-MAP algorithm, our design saves about 2.1% of logic resources with a similar decoding performance.
5. Complexity Analysis of the Proposed Algorithm
In the improved Log-MAP algorithm, the main part of improvement is the
of the function max*, so that different algorithms have different complexities of the max* function. The complexity analysis of this section starts with one decoded bit (or a trellis transition), then we calculate the complexity of the Log-MAP algorithm and the complexity of the function max* using different approximation algorithms [
22,
23].
First of all, for the rule of an eight-state trellis transition of the TD-LTE turbo codes, there are 16 branch metrics, which means that there are 16 message transmission paths. The complexity calculation of the Log-MAP algorithm is as follows:
Step 1: The calculation of the branch metric by Equation (2) requires a total of 8 × 2 × n addition operations and 8 × 2 × n multiplication operations.
Step 2: In Equation (4), the calculation of forward-state metrics requires a total of eight additions, which correspond to the forward-state metrics of the eight sides in
Figure 12, and this requires eight max* calculations.
Step 3: Calculation of backward-state metrics using Equation (5) is the same as in Step 2.
Step 4: In Equation (6), the calculation of external information needs 8 × 4 additions and one subtraction operation; it also requires a total of 8 + 4 + 2 max* calculations in hardware implementation. The logic addition is same as subtraction.
Step 5: The calculation of posteriori information only requires 8 × 2 additions in Equation (7).
The complexity analysis of the Log-MAP algorithm is summarized in
Table 4. As can be seen, the total complexity of the Log-MAP algorithm is 95 + 32 × n, which consists of 65 + 16 × n additions or subtractions, 16 × n multiplications, and 30 max* operations.
Next, the different complexities of approximation algorithms of the function max* are analyzed as follows. As can be seen in
Figure 10, only two additions and one comparison are performed for Max-Log-MAP algorithm, due to the omission of the
of the function max*. For the LUT-Log-MAP algorithm, two additions are made at first, followed by a comparison and a subtraction, then the LUT equivalent to four comparators. Finally, the results of the lookup table make an addition with the comparison results of the function max. As can be seen in
Figure 11, for the Nor-Log-MAP algorithm, two additions are performed at first, then the results go through a normalization operation after the function max comparison; for the selected normalized factor in Equation (14), every datum needs to be shifted three times. Finally, an addition operation is used to sum. In addition to considering the complexity of the LUT-Log-MAP and Nor-Log-MAP algorithms, the LUT-Nor-Log-MAP algorithm requires a mode comparison to choose between LUT-Log-MAP decoding and Nor-Log-MAP decoding. The synthesis results of the complexity for different Log-MAP approximation algorithms are shown in
Table 5.
We can see from
Table 5 that the Max-Log-MAP algorithm only needs two additions and one comparison in the max* function, but its decoding performance is the worst. Compared with the LUT-Log-MAP algorithm, the Nor-Log-MAP algorithm reduces a subtraction and four comparisons in the max* function, but increases three shifts. According to
Table 3, it can be seen that Nor approximation reduces consumption of logic resources compared with LUT approximation. By adding a mode comparison, the LUT-Nor-Log-MAP algorithm can be switched between LUT and Nor approximation in function max* processing. The simulation results of
Table 3 show that the LUT-Nor-Log-MAP algorithm consumes more logic resources than the Nor-Log-MAP algorithm, which is in line with expectations. However, compared to the LUT-Log-MAP algorithm, the proposed algorithm still reduces logic resource consumption considerably.
6. Synthesis Results and Comparisons
In this paper, a turbo decoder was designed using the Cyclone IV series FPGA EP4CE115F29C7 chip as the target device, and the QPP interleaver was used for interleaving and de-interleaving. In simulation, we adopted turbo codes with a 3072 information block size and 1/2 code rate, and allocated 12 SISO decoders to work in parallel with a maximum clock frequency
M of 44 MHz. Through Equation (15), we can see that the throughput of the proposed decoder is 36 Mbit/s when the clock cycle of each iteration is 1502 and the maximum number
N of iterations is 5.
The comparisons with other literatures are presented in
Table 6. As can be seen, the LUT-Nor-Log-MAP algorithm achieved a decoding throughput of 36 Mbit/s in five iterations. Compared with [
24], we had advantages in decoding performance and logic resource consumption, and under the same clock frequency our design was able to achieve a higher throughput. Compared with [
25], our algorithm had obvious advantages in throughput. Although the throughput of our design was close to [
26] and less than [
27], the proposed LUT-Nor-Log-MAP algorithm had better decoding performance than the Max-Log-MAP algorithm [
26]. Compared with [
27], the logic resource consumption in our design was greatly reduced.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}