1. Introduction
Predicting the future from past observations is a key problem across science. Constructing models that predict future observations is a fundamental method of making and testing scientific discoveries. Understanding and predicting dynamics has been a fundamental goal of physics for centuries. In engineering, devices often have to predict the future of their environment to perform efficiently. Living organisms need to make inferences about their environment and its future for survival.
Real-world systems often generate complex dynamics that can be hard to compute. A biological organism typically will not have the computational capacity to perfectly represent the environment. In science, measurements have limited precision, limiting the precision with which one can hope to make predictions. In these settings, the main goal will typically be to get good prediction at low computational cost.
This motivates the study of models that try to extract those key features of past observations that are most relevant to predicting the future. A general information-theoretic framework for this problem is provided by Predictive Rate–Distortion [
1,
2], also known as the past-future information bottleneck [
3]. The Predictive Rate–Distortion trade-off seeks to find an encoding of past observations that is maximally informative about future observations, while satisfying a bound on the amount of information that has to be stored. More formally, this framework trades off prediction loss in the future, formalized as cross-entropy, with the cost of representing the past, formalized as the mutual information between the past observations and the compressed representations of the past. Due to its information-theoretic nature, this framework is extremely general and applies to processes across vastly different domains. It has been applied to linear dynamical systems [
3,
4], but is equally meaningful for discrete dynamical systems [
2]. For biological systems that make predictions about their environment, this corresponds to placing an information-theoretic constraint on the computational cost used for conditioning actions on past observations [
5].
The problem of determining encodings that optimize the Predictive Rate–Distortion trade-off has been solved for certain specific kinds of dynamics, namely for linear dynamic systems [
3] and for processes whose predictive dynamic is represented exactly by a known, finite Hidden Markov Model [
2]. However, real-world processes are often more complicated. When the dynamics are known, a representing Hidden Markov Model may still be extremely large or even infinite, making general-purpose automated computation difficult. Even more importantly, the underlying dynamics are often not known exactly. An organism typically does not have access to the exact dynamics of its surroundings. Similarly, the exact distribution of sentences in a natural language is not known exactly, precluding the application of methods that require an exact model. Such processes are typically only available implicitly, through a finite sample of trajectories.
Optimal Causal Filtering (OCF, Still et al. [
6]) addresses the problem of estimating Predictive Rate–Distortion from a finite sample of observation trajectories. It does so by constructing a matrix of observed frequencies of different pairs of past and future observations. However, such a method faces a series of challenges [
2]. One is the curse of dimensionality: Modeling long dependencies requires storing an exponential number of observations, which quickly becomes intractable for current computation methods. This exponential growth is particularly problematic when dealing with processes with a large state space. For instance, the number of distinct words in a human language as found in large-scale text data easily exceeds 1×
, making storing and manipulating counts of longer word sequences very challenging. A second challenge is that of overfitting: When deploying a predictive model constructed via OCF on new data to predict upcoming observations, such a model can only succeed when the past sequences occurred in the sample to which OCF was applied. This is because OCF relies on counts of full past and future observation sequences; it does not generalize to unseen past sequences.
Extrapolating to unseen past sequences is possible in traditional time series models representing processes that take continuous values; however, such methods are less easily applied to discrete sequences such as natural language. Recent research has seen a flurry of interest in using flexible nonlinear function approximators, and in particular recurrent neural networks, which can handle sequences with discrete observations. Such machine learning methods provide generic models of sequence data. They are the basis of the state of the art by a clear and significant margin for prediction in natural language [
7,
8,
9,
10]. They also have been successfully applied to modeling many other kinds of time series found across disciplines [
11,
12,
13,
14,
15,
16,
17,
18].
We propose Neural Predictive Rate–Distortion (NPRD) to estimate Predictive Rate–Distortion when only a finite set of sample trajectories is given. We use neural networks both to encode past observations into a summary code, and to predict future observations from it. The universal function approximation capabilities of neural networks enable such networks to capture complex dynamics, with computational cost scaling only linearly with the length of observed trajectories, compared to the exponential cost of OCF. When deploying on new data, such a neural model can generalize seamlessly to unseen sequences, and generate appropriate novel summary encodings on the fly. Recent advances in neural variational inference [
19,
20] allow us to construct predictive models that provide almost optimal predictive performance at a given rate, and to estimate the Predictive Rate–Distortion trade-off from such networks. Our method can be applied to sample trajectories in an off-the-shelf manner, without prior knowledge of the underlying process.
In
Section 2, we formally introduce Predictive Rate–Distortion, and discuss related notions of predictive complexity. In
Section 3, we describe the prior method of Optimal Causal Filtering (OCF). In
Section 4, we describe our method NPRD. In
Section 5, we validate NPRD on processes whose Predictive Rate–Distortion is analytically known, showing that it finds essentially optimal predictive models. In
Section 6, we apply NPRD to data from five natural languages, providing the first estimates of Predictive Rate–Distortion of natural language.
2. Predictive Rate–Distortion
We consider stationary discrete-time stochastic processes
, taking values in a state space
S. Given a reference point in time, say
, we are interested in the problem of predicting the future of
from the past
. In general—unless the observations
are independent—predicting the future of the process accurately will require taking into account the past observations. There is a trade-off between the accuracy of prediction, and how much information about the past is being taken into account. On one extreme, not taking the past into account at all, one will not be able to take advantage of the dependencies between past and future observations. On the other extreme, considering the entirety of the past observations
can require storing large and potentially unbounded amounts of information. This trade-off between information storage and prediction accuracy is referred to as Predictive Rate–Distortion (PRD) [
2]. The term rate refers to the amount of past information being taken into account, while distortion refers to the degradation in prediction compared to optimal prediction from the full past.
The problem of Predictive Rate–Distortion has been formalized by a range of studies. A principled and general formalization is provided by applying the Information Bottleneck idea [
2,
6,
21]: We will write
for the past
, and
for the future
, following [
2]. We consider random variables
Z, called codes, that summarize the past and are used by the observer to predict the future. Formally,
Z needs to be independent from the future
conditional on the past
: in other words,
Z does not provide any information about the future except what is contained in the past. Symbolically:
This is equivalent to the requirement that be a Markov chain. This formalizes the idea that the code is computed by an observer from the past, without having access to the future. Predictions are then made based only on Z, without additional access to the past .
The rate of the code Z is the mutual information between Z and the past: . By the Channel Coding Theorem, this describes the channel capacity that the observer requires in order to transform past observations into the code Z.
The distortion is the loss in predictive accuracy when predicting from
Z, relative to optimal prediction from the full past
. In the Information Bottleneck formalization, this is equivalent to the amount of mutual information between past and future that is
not captured by
Z [
22]:
Due to the Markov condition, the distortion measure satisfies the relation
i.e., it captures how much less information
Z carries about the future
compared to the full past
. For a fixed process
, choosing
Z to minimize the distortion is equivalent to maximizing the mutual information between the code and the future:
We will refer to (
4) as the predictiveness of the code
Z.
The rate–distortion trade-off then chooses
Z to minimize distortion at bounded rate:
or—equivalently—maximize predictiveness at bounded rate:
Equivalently, for each
, we study the problem
where the scope of the maximization is the class of all random variables
Z such that
is a Markov chain.
The objective (
7) is equivalent to the Information Bottleneck [
21], applied to the past and future of a stochastic process. The coefficient
indicates how strongly a high rate
is penalized; higher values of
result in lower rates and thus lower values of predictiveness.
The largest achievable predictiveness
is equal to
, which is known as the excess entropy of the process [
23]. Due to the Markov condition (
1) and the Data Processing Inequality, predictiveness of a code
Z is always upper-bounded by the rate:
As a consequence, when
, then (
7) is always optimized by a trivial
Z with zero rate and zero predictiveness. When
, any lossless code optimizes the problem. Therefore, we will be concerned with the situation where
.
2.1. Relation to Statistical Complexity
Predictive Rate–Distortion is closely related to Statistical Complexity and the
-machine [
24,
25]. Given a stationary process
, its causal states are the equivalence classes of semi-infinite pasts
that induce the same conditional probability over semi-infinite futures
: Two pasts
belong to the same causal state if and only if
holds for all finite sequences
(
). Note that this definition is not measure-theoretically rigorous; such a treatment is provided by Löhr [
26].
The causal states constitute the state set of a a Hidden Markov Model (HMM) for the process, referred to as the
-machine [
24]. The statistical complexity of a process is the state entropy of the
-machine. Statistical complexity can be computed easily if the
-machine is analytically known, but estimating statistical complexity empirically from time series data are very challenging and seems to at least require additional assumptions about the process [
27].
Marzen and Crutchfield [
2] show that Predictive Rate–Distortion can be computed when the
-machine is analytically known, by proving that it is equivalent to the problem of compressing causal states, i.e., equivalence classes of pasts, to predict causal states of the backwards process, i.e., equivalence classes of futures. Furthermore, [
6] show that, in the limit of
, the code
Z that optimizes Predictive Rate–Distortion (
7) turns into the causal states.
2.2. Related Work
There are related models that represent past observations by extracting those features that are relevant for prediction. Predictive State Representations [
28,
29] and Observable Operator Models [
30] encode past observations as sets of predictions about future observations. Rubin et al. [
31] study agents that trade the cost of representing information about the environment against the reward they can obtain by choosing actions based on the representation. Relatedly, Still [
1] introduces a Recursive Past Future Information Bottleneck where past information is compressed repeatedly, not just at one reference point in time.
As discussed in
Section 2.1, estimating Predictive Rate–Distortion is related to the problem of estimating statistical complexity. Clarke et al. [
27] and Still et al. [
6] consider the problem of estimating statistical complexity from finite data. While statistical complexity is hard to identify from finite data in general, Clarke et al. [
27] introduces certain restrictions on the underlying process that make this more feasible.
3. Prior Work: Optimal Causal Filtering
The main prior method for estimating Predictive Rate–Distortion from data are Optimal Causal Filtering (OCF, Still et al. [
6]). This method approximates Predictive Rate–Distortion using two approximations: first, it replaces semi-infinite pasts and futures with bounded-length contexts, i.e., pairs of finite past contexts
and future contexts
of some finite length
M.(It is not crucial that past and future contexts have the same lengths, and indeed Still et al. [
6] do not assume this). (We do assume equal length throughout this paper for simplicity of our experiments, though nothing depends on this). The PRD objective (
7) then becomes (
9), aiming to predict length-
M finite futures from summary codes
Z of length-
M finite pasts:
Second, OCF estimates information measures directly from the observed counts of
using the plug-in estimator of mutual information. With such an estimator, the problem in (
9) can be solved using a variant of the Blahut–Arimoto algorithm [
21], obtaining an encoder
that maps each observed past sequence
to a distribution over a (finite) set of code words
Z.
Two main challenges have been noted in prior work: first, solving the problem for a finite empirical sample leads to overfitting, overestimating the amount of structure in the process. Still et al. [
6] address this by subtracting an asymptotic correction term that becomes valid in the limit of large
M and
, when the codebook
becomes deterministic, and which allows them to select a deterministic codebook of an appropriate complexity. This leaves open how to obtain estimates outside of this regime, when the codebook can be far from deterministic.
The second challenge is that OCF requires the construction of a matrix whose rows and columns are indexed by the observed past and future sequences [
2]. Depending on the topological entropy of the process, the number of such sequences can grow as
, where
A is the set of observed symbols, and processes of interest often do show this exponential growth [
2]. Drastically, in the case of natural language,
A contains thousands of words.
A further challenge is that OCF is infeasible if the number of required codewords is too large, again because it requires constructing a matrix whose rows and columns are indexed by the codewords and observed sequences. Given that storing and manipulating matrices greater than is currently not feasible, a setting where cannot be captured with OCF.
4. Neural Estimation via Variational Upper Bound
We now introduce our method, Neural Predictive Rate–Distortion (NPRD), to address the limitations of OCF, by using parametric function approximation: whereas OCF constructs a codebook mapping between observed sequences and codes, we use general-purpose function approximation estimation methods to compute the representation Z from the past and to estimate a distribution over future sequences from Z. In particular, we will use recurrent neural networks, which are known to provide good models of sequences from a wide range of domains; our method will also be applicable to other types of function approximators.
This will have two main advantages, addressing the limitations of OCF: first, unlike OCF, function approximators can discover generalizations across similar sequences, enabling the method to calculate good codes Z even for past sequences that were not seen previously. This is of paramount importance in settings where the state space is large, such as the set of words of a natural language. Second, the cost of storing and evaluating the function approximators will scale linearly with the length of observed sequences both in space and in time, as opposed to the exponential memory demand of OCF. This is crucial for modeling long dependencies.
4.1. Main Result: Variational Bound on Predictive Rate–Distortion
We will first describe the general method, without committing to a specific framework for function approximation yet. We will construct a bound on Predictive Rate–Distortion and optimize this bound in a parametric family of function approximators to obtain an encoding
Z that is close to optimal for the nonparametric objective (
7).
As in OCF (
Section 3), we assume that a set of finite sample trajectories
is available, and we aim to compress pasts of length
M to predict futures of length
M. To carry this out, we restrict the PRD objective (
7) to such finite-length pasts and futures:
It will be convenient to equivalently rewrite (
10) as
where
is the prediction loss. Note that minimizing prediction loss is equivalent to maximizing predictiveness
.
When deploying such a predictive code Z, two components have to be computed: a distribution that encodes past observations into a code Z, and a distribution that decodes the code Z into predictions about the future.
Let us assume that we already have some encoding distribution
where
is the encoder, expressed in some family of function approximators. The encoder transduces an observation sequence
into the parameters of the distribution
. From this encoding distribution, one can obtain the optimal decoding distribution over future observations via Bayes’ rule:
where
uses the Markov condition
. However, neither of the two expectations in the last expression of (
13) is tractable, as they require summation over exponentially many sequences, and algorithms (e.g., dynamic programming) to compute this sum efficiently are not available in general. For a similar reason, the rate
of the code
is also generally intractable.
Our method will be to introduce additional functions, also expressed using function approximators that approximate some of these intractable quantities: first, we will use a parameterized probability distribution
q as an approximation to the intractable marginal
:
Second, to approximate the decoding distribution
, we introduce a parameterized decoder
that maps points
into probability distributions
over future observations
:
for each code
. Crucially,
will be easy to compute efficiently, unlike the exact decoding distribution
.
If we fix a stochastic process and an encoder , then the following two bounds hold for any choice of the decoder and the distribution q:
Proposition 1. The loss incurred when predicting the future from Z via ψ upper-bounds the true conditional entropy of the future given Z, when predicting using the exact decoding distribution (13): Furthermore, equality is attained if and only if .
Proposition 2. The KL Divergence between and , averaged over pasts , upper-bounds the rate of Z: Equality is attained if and only if is equal to the true marginal .
Proof. The two equalities follow from the definition of KL Divergence and Mutual Information. To show the inequality, we again use Gibbs’ inequality:
Here, equality holds if and only if , proving the second assertion. □
We now use the two propositions to rewrite the Predictive Rate–Distortion objective (
18) in a way amenable to using function approximators, which is our main theoretical result, and the foundation of our proposed estimation method:
Corollary 1 (Main Result)
. The Predictive Rate–Distortion objective (18)is equivalent towhere range over all triples of the appropriate types described above. From a solution to (19), one obtains a solution to (18) by setting . The rate of this code is given as follows:and the prediction loss is given by Proof. By the two propositions, the term inside the minimization in (
19) is an upper bound on (
18), and takes on that value if and only if
equals the distribution of the
Z optimizing (
18), and
are as described in those propositions. □
Note that the right-hand sides of (
20) and (
21) can both be estimated efficiently using Monte Carlo samples from
.
If
are not exact solutions to (
19), the two propositions guarantee that we still have bounds on rate and prediction loss for the code
Z generated by
:
To carry out the optimization (
19), we will restrict
to a powerful family of parametric families of function approximators, within which we will optimize the objective with gradient descent. While the solutions may not be exact solutions to the nonparametric objective (
19), they will still satisfy the bounds (
22) and (
23), and—if the family of approximators is sufficiently rich—can come close to turning these into the equalities (
20) and (
21).
4.2. Choosing Approximating Families
For our method of Neural Predictive Rate–Distortion (NPRD), we choose the approximating families for the encoder , the decoder , and the distribution q to be certain types of neural networks that are known to provide strong and general models of sequences and distributions.
For
and
, we use recurrent neural networks with Long Short Term Memory (LSTM) cells [
32], widely used for modeling sequential data across different domains. We parameterize the distribution
as a Gaussian whose mean and variance are computed from the past
: We use an LSTM network to compute a vector
from the past observations
, and then compute
where
are parameters. While we found Gaussians sufficiently flexible for
, more powerful encoders could be constructed using more flexible parametric families, such as normalizing flows [
19,
33].
For the decoder
, we use a second LSTM network to compute a sequence of vector representations
(
) for
. We compute predictions using the softmax rule
for each element
of the state space
, and
is a parameter matrix to be optimized together with the parameters of the LSTM networks.
For
q, we choose the family of Neural Autoregressive Flows [
20]. This is a parametric family of distributions that allows efficient estimation of the probability density and its gradients. This method widely generalizes a family of prior methods [
19,
33,
34], offering efficient estimation while surpassing prior methods in expressivity.
4.3. Parameter Estimation and Evaluation
We optimize the parameters of the neural networks expressing
for the objective (
19) using Backpropagation and Adam [
35], a standard and widely used gradient descent-based method for optimizing neural networks. During optimization, we approximate the gradient by taking a single sample from
Z (
24) per sample trajectory
and use the reparametrized gradient estimator introduced by Kingma and Welling [
36]. This results in an unbiased estimator of the gradient of (
19) w.r.t. the parameters of
.
Following standard practice in machine learning, we split the data set of sample time series into three partitions (training set, validation set, and test set). We use the training set for optimizing the parameters as described above. After every pass through the training set, the objective (
19) is evaluated on the validation set using a Monte Carlo estimate with one sample
Z per trajectory; optimization terminates once the value on the validation set does not decrease any more.
After optimizing the parameters on a set of observed trajectories, we estimate rate and prediction loss on the test set. Given parameters for
, we evaluate the PRD objective (
19), rate (
22), and the prediction loss (
23) on the test set by taking, for each time series
from the test set, a single sample
and computing Monte Carlo estimates for rate
where
is the Gaussian density with
computed from
as in (
24), and prediction loss
Thanks to (
22) and (
23), these estimates are guaranteed to be
upper bounds on the true rate and prediction loss achieved by the code
, up to sampling error introduced into the Monte Carlo estimation by sampling
z and the finite size of the test set.
It is important to note that this sampling error is different from the overfitting issue affecting OCF: Our Equations (
26) and (
27) provide
unbiased estimators of upper bounds, whereas overfitting
biases the values obtained by OCF. Given that Neural Predictive Rate–Distortion provably provide upper bounds on rate and prediction loss (up to sampling error), one can objectively compare the quality of different estimation methods: among methods that provide upper bounds, the one that provides the lowest such bound for a given problem is the one giving results closest to the true curve.
Estimating Predictiveness
Given the estimate for prediction loss, we estimate predictiveness
with the following method. We use the encoder network that computes the code vector
h (
24) to also estimate the marginal probability of the past observation sequence,
.
has support over sequences of length
M. Similar to the decoder
, we use the vector representations
computed by the LSTM encoder after processing
for
, and then compute predictions using the softmax rule
where
is another parameter matrix.
Because we consider stationary processes, we have that the cross-entropy under
of
is equal to the cross-entropy of
under the same encoding distribution:
. Using this observation, we estimate the predictiveness
by the difference between the corresponding cross-entropies on the test set [
37]:
which we approximate using Monte Carlo sampling on the test set as in (
26) and (
27).
In order to optimize parameters for estimation of
, we add the cross-entropy term
to the PRD objective (
19) during optimization, so that the full training objective comes out to:
Again, by Gibbs’ inequality and Propositions 1 and 2, this is minimized when
represents the true distribution over length-
M blocks
,
describes an optimal code for the given
,
q is its marginal distribution, and
is the Bayes-optimal decoder. For approximate solutions to this augmented objective, the inequalities (
22) and (
23) will also remain true due to Propositions 1 and 2.
4.4. Related Work
In (
19), we derived a variational formulation of Predictive Rate–Distortion. This is formally related to a variational formulation of the Information Bottleneck that was introduced by [
38], who applied it to neural-network based image recognition. Unlike our approach, they used a fixed diagonal Gaussian instead of a flexible parametrized distribution for
q. Some recent work has applied similar approaches to the modeling of sequences, employing models corresponding to the objective (
19) with
[
39,
40,
41,
42].
In the neural networks literature, the most commonly used method using variational bounds similar to Equation (
19) is the Variational Autoencoder [
36,
43], which corresponds to the setting where
and the predicted output is equal to the observed input. The
-VAE [
44], a variant of the Variational Autoencoder, uses
(whereas the Predictive Rate–Distortion objective (
7) uses
), and has been linked to the Information Bottleneck by [
45].
6. Estimating Predictive Rate–Distortion for Natural Language
We consider the problem of estimating rate–distortion for natural language. Natural language has been a testing ground for information-theoretic ideas since Shannon’s work. Much interest has been devoted to estimating the entropy rate of natural language [
10,
47,
48,
49]. Indeed, the information density of language has been linked to human processing effort and to language structure. The word-by-word information content has been shown to impact human processing effort as measured both by per-word reading times [
50,
51,
52] and by brain signals measured through EEG [
53,
54]. Consequently, prediction is a fundamental component across theories of human language processing [
54]. Relatedly, the Uniform Information Density and Constant Entropy Rate hypotheses [
55,
56,
57] state that languages order information in sentences and discourse so that the entropy rate stays approximately constant.
The relevance of prediction to human language processing makes the difficulty of prediction another interesting aspect of language complexity: Predictive Rate–Distortion describes how much memory of the past humans need to maintain to predict future words accurately. Beyond the entropy rate, it thus forms another important aspect of linguistic complexity.
Understanding the complexity of prediction in language holds promise for enabling a deeper understanding of the nature of language as a stochastic process, and to human language processing. Long-range correlations in text have been a subject of study for a while [
58,
59,
60,
61,
62,
63]. Recently, Dębowski [
64] has studied the excess entropy of language across long-range discourses, aiming to better understand the nature of the stochastic processes underlying language. Koplenig et al. [
65] shows a link between traditional linguistic notions of grammatical structure and the information contained in word forms and word order. The idea that predicting future words creates a need to represent the past well also forms a cornerstone of theories of how humans process sentences [
66,
67].
We study prediction in the range of the words in individual sentences. As in the previous experiments, we limit our computations to sequences of length 30, already improving over OCF by an order of magnitude. One motivation is that, when directly estimating PRD, computational cost has to increase with the length of sequences considered, making the consideration of sequences of hundreds or thousands of words computationally infeasible. Another motivation for this is that we are ultimately interested in Predictive Rate–Distortion as a model of memory in human processing of grammatical structure, formalizing psycholinguistic models of how humans process individual sentences [
66,
67], and linking to studies of the relation between information theory and grammar [
65].
6.1. Part-of-Speech-Level Language Modeling
We first consider the problem of predicting English on the level of Part-of-Speech (POS) tags, using the Universal POS tagset [
68]. This is a simplified setting where the vocabulary is small (20 word types), and one can hope that OCF will produce reasonable results. We use the English portions of the Universal Dependencies Project [
69] tagged with Universal POS Tags [
68], consisting of approximately 586 K words. We used the training portions to estimate NPRD and OCF, and the validation portions to estimate the rate–distortion curve. We used NPRD to generate 350 codebooks for values of
sampled from [0, 0.4]. We were only able to run OCF for
, as the number of sequences exceeds
already at
.
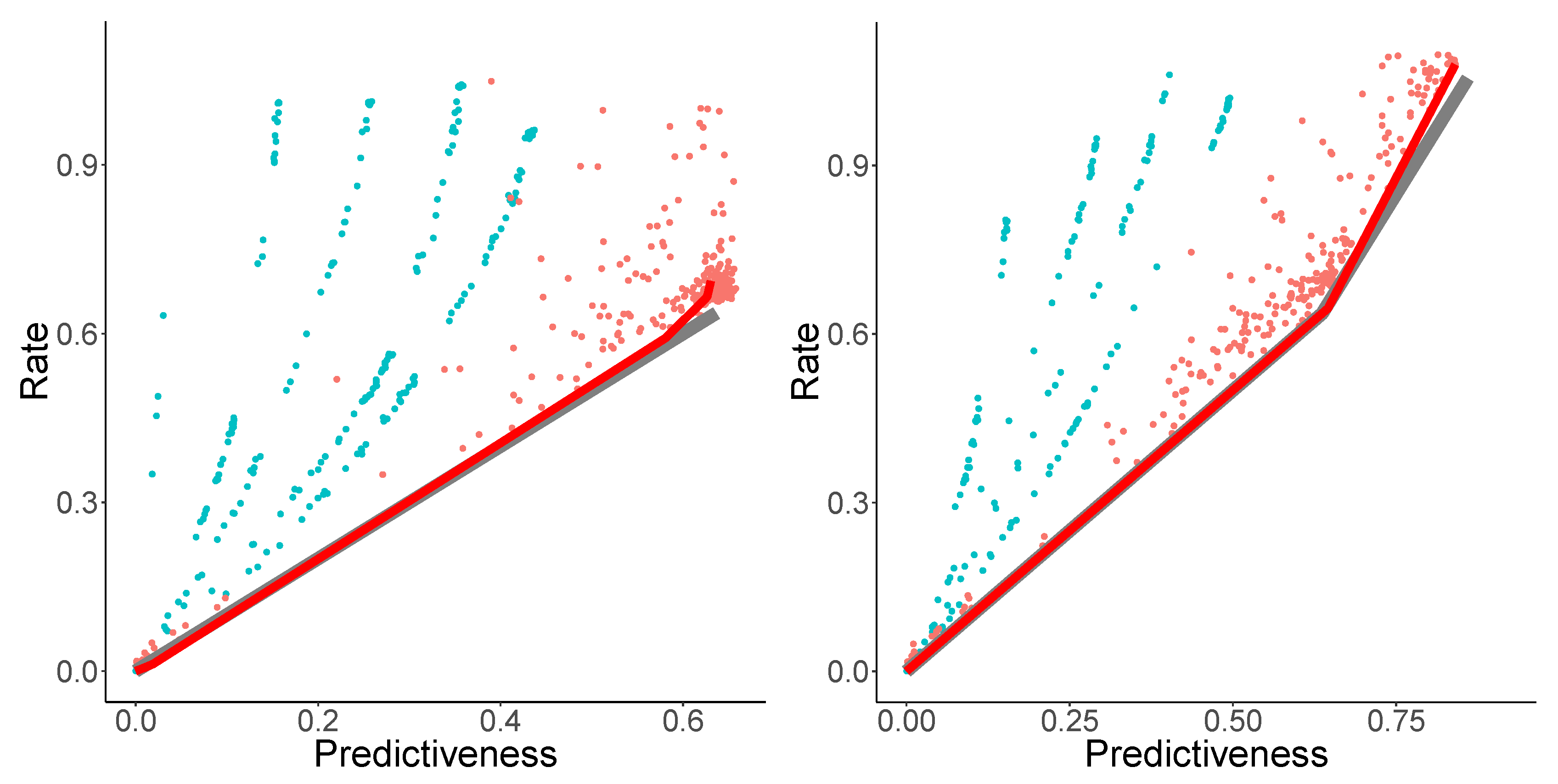
The PRD curve is shown in
Figure 5 (left). In the setting of low rate and high distortion, NPRD and OCF (blue,
) show essentially identical results. This holds true until
, at which point the bounds provided by OCF deteriorate, showing the effects of overfitting. NPRD continues to provide estimates at greater rates.
Figure 5 (center) shows rate as a function of
. Recall that
is the trade-off-parameter from the objective function (
7). In
Figure 5 (right), we show rate and the mutual information with the future, as a function of
. As
, NPRD (red,
) continues to discover structure, while OCF (blue, plotted for
) exhausts its capacity.
Note that NPRD reports rates of 15 nats and more when modeling with very low distortion. A discrete codebook would need over 3 million distinct codewords for a code of such a rate, exceeding the size of the training corpus (about 500 K words), replicating what we found for the Copy3 process: Neural encoders and decoders can use the geometric structure of the code space to encode generalizations across different dimensions, supporting a very large effective number of distinct possible codes. Unlike discrete codebooks, the geometric structure makes it possible for neural encoders to construct appropriate codes ’on the fly’ on new input.
6.2. Discussion
Let us now consider the curves in
Figure 5 in more detail. Fitting parametric curves to the empirical PRD curves in
Figure 5, we find a surprising result that the statistical complexity of English sentences at the POS level appears to be unbounded.
The rate-predictiveness curve (left) shows that, at low rates, predictiveness is approximately proportional to the rate. At greater degrees of predictiveness, the rate grows faster and faster, whereas predictiveness seems to asymptote to nats. The asymptote of predictiveness can be identified with the mutual information between past and future observations, , which is a lower bound on the excess entropy. The rate should asymptote to the statistical complexity. Judging by the curve, natural language—at the time scale we are measuring in this experiment—has a statistical complexity much higher than its excess entropy: at the highest rate measured by NPRD in our experiment, rate is about 20 nats, whereas predictiveness is about 1.1 nats. If these values are correct, then—due to the convexity of the rate-predictivity curve—statistical complexity exceeds the excess entropy by a factor of at least . Note that this picture agrees qualitatively with the OCF results, which suggest a lower-bound on the ratio of at least .
Now, turning to the other plots in
Figure 5, we observe that rate increases at least linearly with
, whereas predictiveness again asymptotes. This is in qualitative agreement with the picture gained from the rate-predictiveness curve.
Let us consider this more quantitatively. Based on
Figure 5 (center), we make the ansatz that the map from
to the rate
is superlinear:
with
. We fitted
(
,
). Equivalently,
From this, we can derive expressions for rate
and predictiveness
as follows. For the solution of Predictive Rate–Distortion (
10), we have
where
is the codebook defining the encoding distribution
, and thus
Our ansatz therefore leads to the equation
Qualitatively, this says that predictiveness P asymptotes to a finite value, whereas rate R—which should asymptote to the statistical complexity—is unbounded.
Equation (
37) has the solution
where
is the incomplete Gamma function. Since
, the constant
C has to equal the maximally possible predictiveness
.
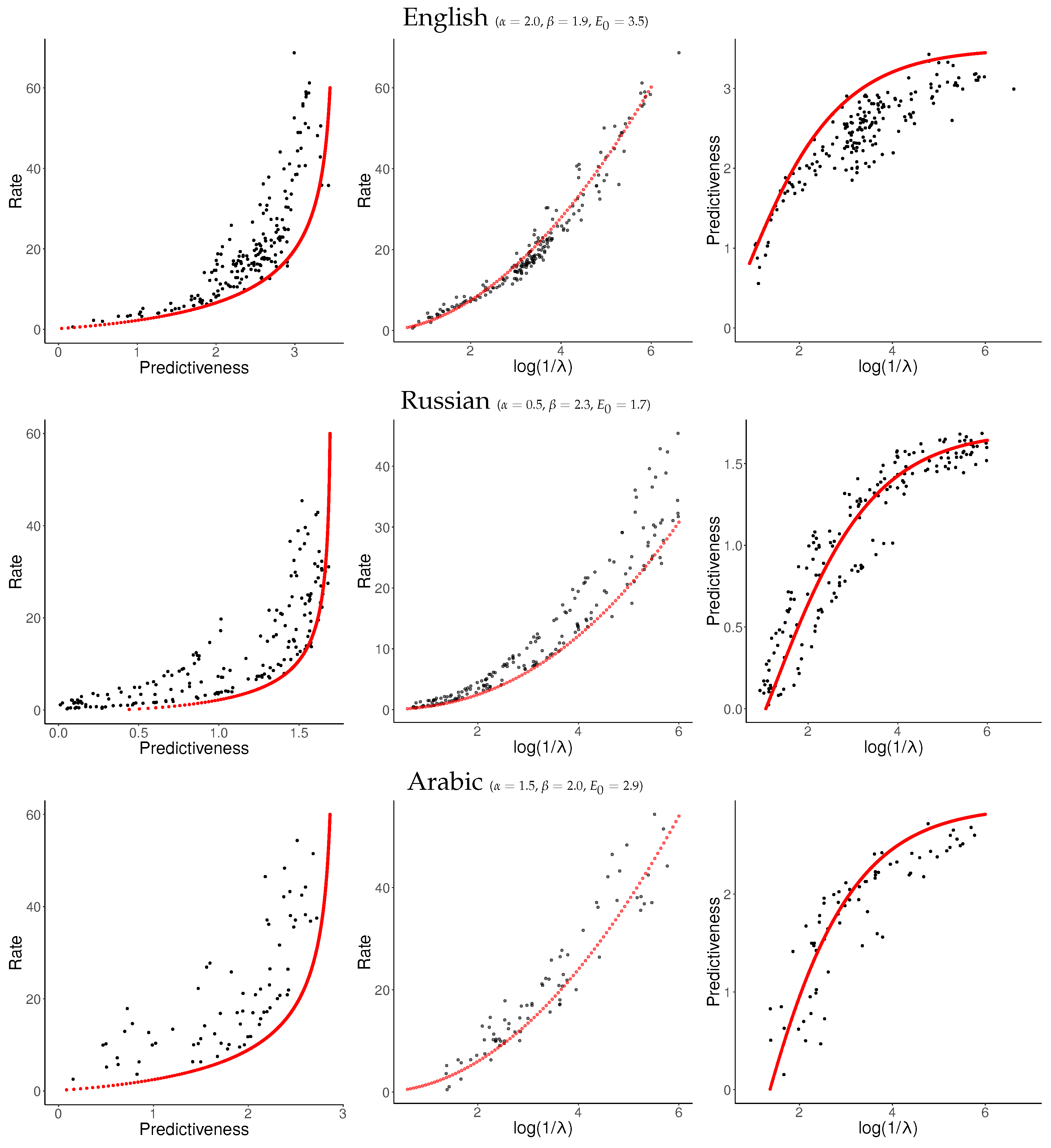
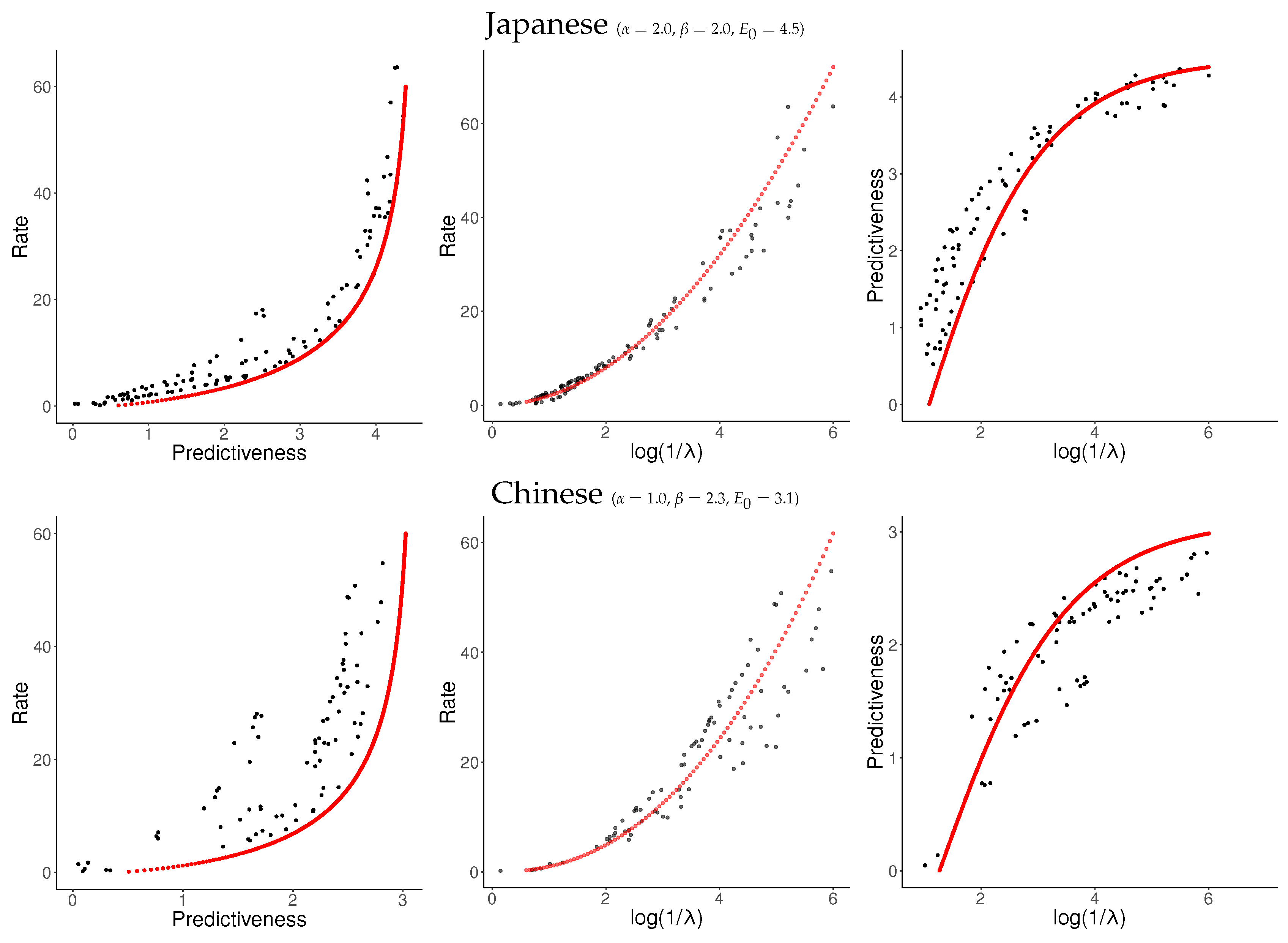
Given the values fitted above (
,
), we found that
yielded a good fit. Using (
33), this can be extended without further parameters to the third curve in
Figure 5. Resulting fits are shown in
Figure 6.
Note that there are other possible ways of fitting these curves; we have described a simple one that requires only two parameters , , in addition to a guess for the maximal predictiveness . In any case, the results show that natural language shows an approximately linear growth of predictiveness with a rate at small rates, and exploding rates at diminishing returns in predictiveness later.
6.3. Word-Level Language Modeling
We applied NPRD to the problem of predicting English on the level of part-of-speech tags in
Section 6.1. We found that the resulting curves were described well by Equation (
37). We now consider the more realistic problem of prediction at the level of words, using data from multiple languages. This problem is much closer to the task faced by a human in the process of comprehending text, having to encode prior observations so as to minimize prediction loss on the upcoming words. We will examine whether Equation (
37) describes the resulting trade-off in this more realistic setting, and whether it holds across languages.
For the setup, we followed a standard setup for recurrent neural language modeling. The hyperparameters are shown in
Table A1. Following standard practice in neural language modeling, we restrict the observation space to the most frequent
words; other words are replaced by their part-of-speech tag. We do this for simplicity and to stay close to standard practice in natural language processing; NPRD could deal with unbounded state spaces through a range of more sophisticated techniques such as subword modeling and character-level prediction [
70,
71].
We used data from five diverse languages. For English, we turn to the Wall Street Journal portion of the Penn Treebank [
72], a standard benchmark for language modeling, containing about 1.2 million tokens. For Arabic, we pooled all relevant portions of the Universal Dependencies treebanks [
73,
74,
75]. We obtained 1 million tokens. We applied the same method to construct a Russian corpus [
76], obtaining 1.2 million tokens. For Chinese, we use the Chinese Dependency Treebank [
77], containing 0.9 million tokens. For Japanese, we use the first 2 million words from a large processed corpus of Japanese business text [
78]. For all these languages, we used the predefined splits into training, validation, and test sets.
For each language, we sampled about 120 values of
uniformly from
and applied NPRD to these. The resulting curves are shown in
Figure 7 and
Figure 8, together with fitted curves resulting from Equation (
37). As can be seen, the curves are qualitatively very similar across languages to what we observed in
Figure 6: In all languages, rate initially scales linearly with predictiveness, but diverges as the predictiveness approaches its supremum
. As a function of
, rate grows at a slightly superlinear speed, confirming our ansatz (
33).
These results confirm our results from
Section 6.1. At the time scale of individual sentences, Predictive Rate–Distortion of natural language appears to quantitatively follow Equation (
37). NPRD reports rates up to
nats, more than ten times the largest values of predictiveness. On the other hand, the growth of rate with predictiveness is relatively gentle in the low-rate regime. We conclude that predicting words in natural language can be approximated with small memory capacity, but more accurate prediction requires very fine-grained memory representations.
6.4. General Discussion
Our analysis of PRD curves for natural language suggests that human language is characterized by very high and perhaps infinite statistical complexity, beyond its excess entropy. In a similar vein, Dębowski [
64] has argued that the excess entropy of connected texts in natural language is infinite (in contrast, our result is for isolated sentences). If the statistical complexity of natural language is indeed infinite, then statistical complexity is not sufficiently fine-grained as a complexity metric for characterizing natural language.
We suggest that the PRD curve may form a more natural complexity metric for highly complex processes such as language. Among those processes with infinite statistical complexity, some will have a gentle PRD curve—meaning that they can be well-approximated at low rates—while others will have a steep curve, meaning they cannot be well-approximated at low rates. We conjecture that, although natural language may have infinite statistical complexity, it has a gentler PRD curve than other processes with this property, meaning that achieving a reasonable approximation of the predictive distribution does not require inordinate memory resources.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}










