In 1995, Kennedy and Eberhart proposed a population-based metaheuristic algorithm known as Particle Swarm Optimization (PSO), where each individual in the population, called particle, carries out its adaptation based on three essential factors:
In these types of techniques, each individual in the population represents a potential solution to the problem being solved, and moves constantly within the search space trying to evolve the population to improve the solutions. Algorithm 1 describes the search and optimization process carried out by the basic PSO method.
Since its creation, different versions of this well-known optimization technique have been developed. Originally, it was defined to work in continuous spaces, so there were spatial considerations that had to be taken into account to work in discrete spaces. For this reason, ref. [
24] defined a new binary version of the
PSO method. One of the key problems of this new method is its difficulty to change from 0 to 1 and from 1 to 0 once it has stabilized. This drove the development of different versions of binary
PSO that sought to improve its exploratory capacity.
4.1. Optimization Algorithm
To move in an n-dimensional space, each particle in the population is formed by:
- (a)
a binary individual and its best individual , both with the format ;
- (b)
a continuous individual and its corresponding best individual , both with the format ;
- (c)
the fitness value corresponding to the individual and that of its best individual ; and
- (d)
three speed vectors, , and , all with format .
As it can be seen, the particle has both a binary and a continuous part. Speeds
and
are combined to determine the direction in which the particle will move on the discrete space, and
is used to move the particle on the continuous space.
stores the discrete location of the particle, and
stores the location of the best solution found so far by it.
and
contain the location of the particle and that of the best solution found, the same as
and
, but they do so in the continuous space.
is the fitness value of the individual, and
is the value corresponding to the best solution found by it. In
Section 4.4, the process used to calculate the fitness of a particle from its two positions (one in each space) will be described.
Then, each time the ith particle moves, its current position changes as follows:
Binary part
where
represents the inertia factor,
and
are random values with uniform distribution in
,
and
are constant values that indicate the significance assigned to the respective solutions found before,
and
correspond to the
jth digit in binary vectors
and
of the
ith particle, and
represents the binary position of the particle with the best fitness within the environment of particle
(local) or the entire swarm (global). As shown in Equation (
1), in addition to considering the best solution found by the particle, the position of the best neighboring particle is also taken into account. Therefore, the value
corresponds to the
jth value of vector
of particle
with a fitness value
higher than its fitness (
).
It should be noted that, as discussed in [
26] and unlike the Binary
PSO method described in [
24], the movement of vector
in the directions corresponding to the best solution found by the particle and the best value in the neighborhood do not depend on the current position of the particle. Then, each element in speed vector
is calculated using Equation (
1) and controlled using Equation (
2):
where
because of the limits that keep variable values within the set range. Then, vector
is used to update the values of speed vector
, as shown in Equation (
4):
Vector
is controlled in a similar way as vector
by changing
and
by
and
, respectively. This will yield
which will be used as in Equation (
2) to limit the values of
. Then, the sigmoid function is applied and the new position of the particle is calculated using Equations (
5) and (
6):
where
is a random number with uniform distribution in
. Adding the sigmoid function in Equation (
5) radically changes how the speed vector is used to update the position of the particle.
Continuous part
and then,
where, once again,
represents the inertia factor,
and
are random values with uniform distribution in
, and
and
are constant values that indicate the significance assigned to the respective solutions previously found. In this case,
corresponds to vector
from the same particle from which vector
was taken to adjust
with vector
in Equation (
2). Both
and
are controlled by
,
,
and
, similar to how speed vectors
and
in the binary part were controlled.
Note that, even though the procedure followed to update vectors
and
is the same (Equations (
4) and (
8)), the values of
are used as argument in the sigmoid function (Equation (
5)) to obtain a value within
that is equivalent to the likelihood that the position of the particle takes a value of 1. Thus, probabilities within interval
can be obtained. Extreme values, when mapped by the sigmoid function, produce very similar probability values, close to 0 or 1, reducing the chance of change in particle values and stabilizing it.
4.2. Representation of Individuals and Documents
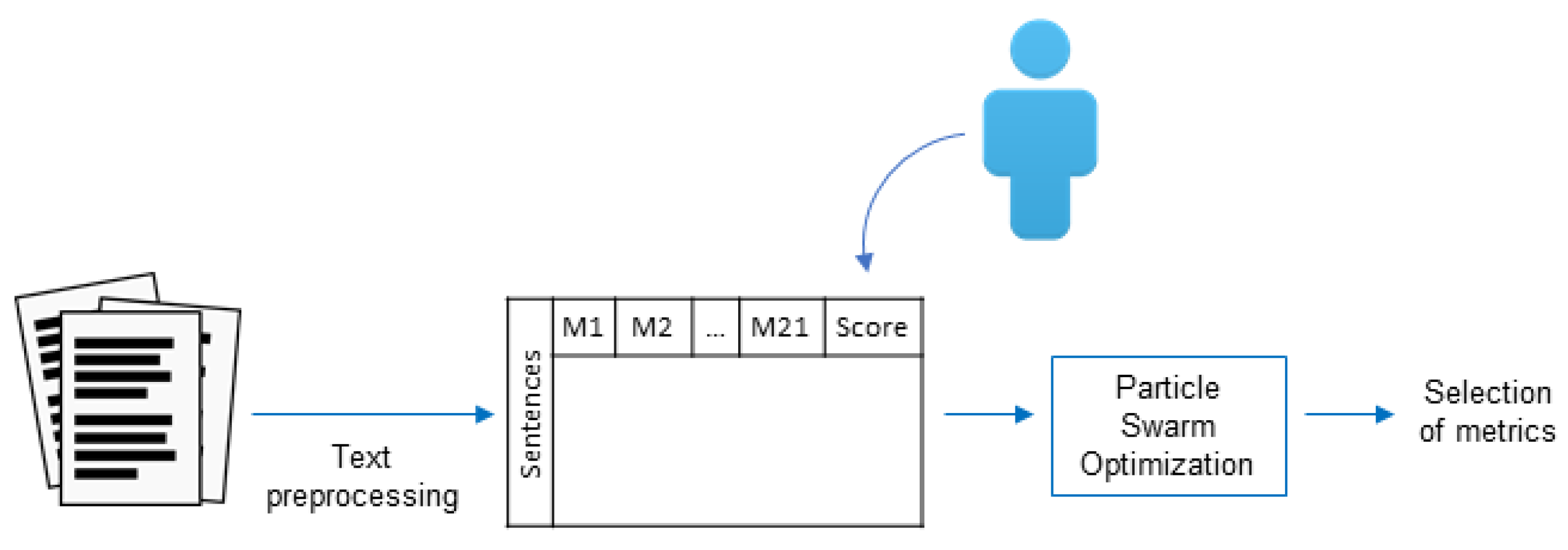
For this article, 16 metrics described in the literature were selected. They are based on sentence location and length on the one hand, and on word frequency and word matching on the other. Then, each sentence in each document was converted to a numeric vector whose dimension is given by the number of metrics to be used, in this case, 16. Therefore, each document will be represented by a set of these vectors whose cardinality matches the number of sentences in it.
Using PSO to solve a specific problem requires making two important decisions. The first decision involves the information included in the particle, and the second one is about how to calculate the particle’s fitness value.
In the case of document summarization, particles compete with each other searching for the best solution. This solution consists of finding the coefficients that, when applied to each sentence metrics, have a ranking that is similar to the one established by the user. Then, following the indications detailed in the previous section, each particle is formed by five vectors and two scalar values. The dimension of the vectors will be determined by the number of metrics to use. The binary vector will determine if the metric is considered or not depending on its value—1 means it will be considered, 0 means it will not. Vector will include the coefficients that will weight the participation of each metric in calculating the score. The three remaining vectors are speed vectors and operate as described in the previous section.
4.3. Fundamental Aspects of Method
The method proposed here starts with a population of N individuals randomly located within the search space based on preset boundaries. However, the binary part is not initialized the same as was the continuous one. The reason for this difference will be discussed below.
During the evolutionary process, individuals move through the discrete and the continuous spaces according to the equations detailed in
Section 4.1. Something that should be taken into account is how to modify speed vector when the sigmoid function (Equation (
5)) is used. In the continuous version of
PSO, the speed vector initially has higher values to facilitate the exploration of the solution space, but these are later reduced (typically, proportionally to the number of maximum iterations to perform) to allow the particle to become stable by searching in a specific area identified as promising. In this case, the speed vector represents the inertia of the particle and it is the only factor that prevents it from being strongly attracted, whether by its previous experiences, or by the best solution found by the swarm. On the other hand, when the particle’s binary representation is used, even though movement is still real, the result identifying the new position of the particle is binarized by the sigmoid function instead. In this case, to be able to explore, the sigmoid function must start by evaluating values close to zero, where there is a higher likelihood of change. In the case of the sigmoid function expressed in Equation (
5), when
x is 0, it returns a result of
. This is the greatest state of uncertainty when the expected response is 0 or 1. Then, as it moves away from 0, either in the positive or negative direction, its value becomes stable. Therefore, unlike the work done on the continuous part, when working with binary
PSO, the opposing procedure must be applied, i.e., starting with a speed close to 0 and then increasing or decreasing its value.
As already seen in Equation (
1), and because of the reasons explained above, an inertia factor
is used to update speed vector
, similar to the use of
for
in (
7). Each factor
w (
and
) is dynamically updated based on Equation (
9):
where
is the initial value of
w and
its end value,
is the current iteration, and
is the total number of iterations. Using a variable inertia factor facilitates population adaptation. A higher value of
w at evolution start allows particles to make large movements and reach different positions in the search space. As the number of iterations progresses, the value of
w decreases, allowing them to perform finer tuning.
The proposed algorithm uses the concept of elitism, which preserves the best individual from each iteration. This is done by replacing the particle with lowest fitness by that with the best fitness from the previous iteration.
As regards the end criterion for the adaptive process, the algorithm ends when the maximum number of iterations (indicated before starting the process) is reached, or when the best fitness does not change (or only slightly changes) during a given percentage of the total number of iterations.
4.4. Fitness Function Design
Learning the criterion used by a person when summarizing a text requires having a set of documents previously summarized by that person. Typically, a person highlights those portions of the text considered to be important; in a computer, this is equivalent to assigning internal labels to the corresponding sentences. Thus, each sentence in a document is classified as one of two types–“positive,” if it is found in the summary, or “negative,” if it is not.
Regardless of the problem to be solved, one of the most important aspects of an optimization technique is its fitness function. Since the summarization task presented in this work involves solving a classification problem through supervised learning, the confusion matrix will be used to measure the performance of the solution found by each particle. Among the most popular metrics used for this type of tasks, the one known as Matthews Correlation Coefficient (MCC) was selected.
Due to the type of problem to be solved, the sum of
True Positives and
False Negatives is equal to the sum of
True Positives and
False Positives. For this reason, by not including
True Negatives in its calculation,
Recall,
Precision and
F-measure have the same value and are not useful to differentiate the quality of the different solutions. On the other hand,
MCC does consider all cells in the confusion matrix and, therefore, it maximizes the global accuracy of the classification model. As a result, no average has to be calculated for the confusion matrices corresponding to every training document.
MCC’s values range between
, where 1 corresponds to the perfect model and
to the worst one. Finally, the fitness corresponding to any given individual is calculated as follows:
where
indicates the number of sentences. As it can be seen in Equation (
10), the confusion matrix used to calculate the value of
MCC must be built for each particle and each document. Building this matrix involves re-building the solution represented by the particle based on its
and
vectors. The first vector will allow for identifying the most representative characteristics of the criterion applied by the user, and the second one will allow weighting each of them. Even though they both represent the position of the particle in each space, the binary location is considered, since this is the one controlling the remaining fitness calculation. From the continuous vector, only the positions indicated by the binary one are used.
Since several metrics are calculated for each sentence in each document, it is expected that a linear combination of these, as expressed in Equation (
11), will represent the criterion applied by the user:
where
,
being the coefficient that individual
i will use to weight the value of metric
j in sentence
k, indicated as
.
score() is a positive integer number proportional to the estimated significance of the sentence. Since each coefficient corresponds to the
value for the individual and is within interval
,
, before using it for calculations, it must be scaled to
using such limits so that metric values are not subtracted to adjust the score. However, even though using negative coefficients for calculations is pointless,
PSO requires both positive and negative values to move particles within the search space. Adding up a metric more than once is also pointless. For this reason, once the values have been scaled, they are divided by the cumulative total to establish their individual significance in relation to the total and thus identify the metrics that have a greater influence on score calculations. As the coefficient increases, so does the significance of the metric when summarizing.
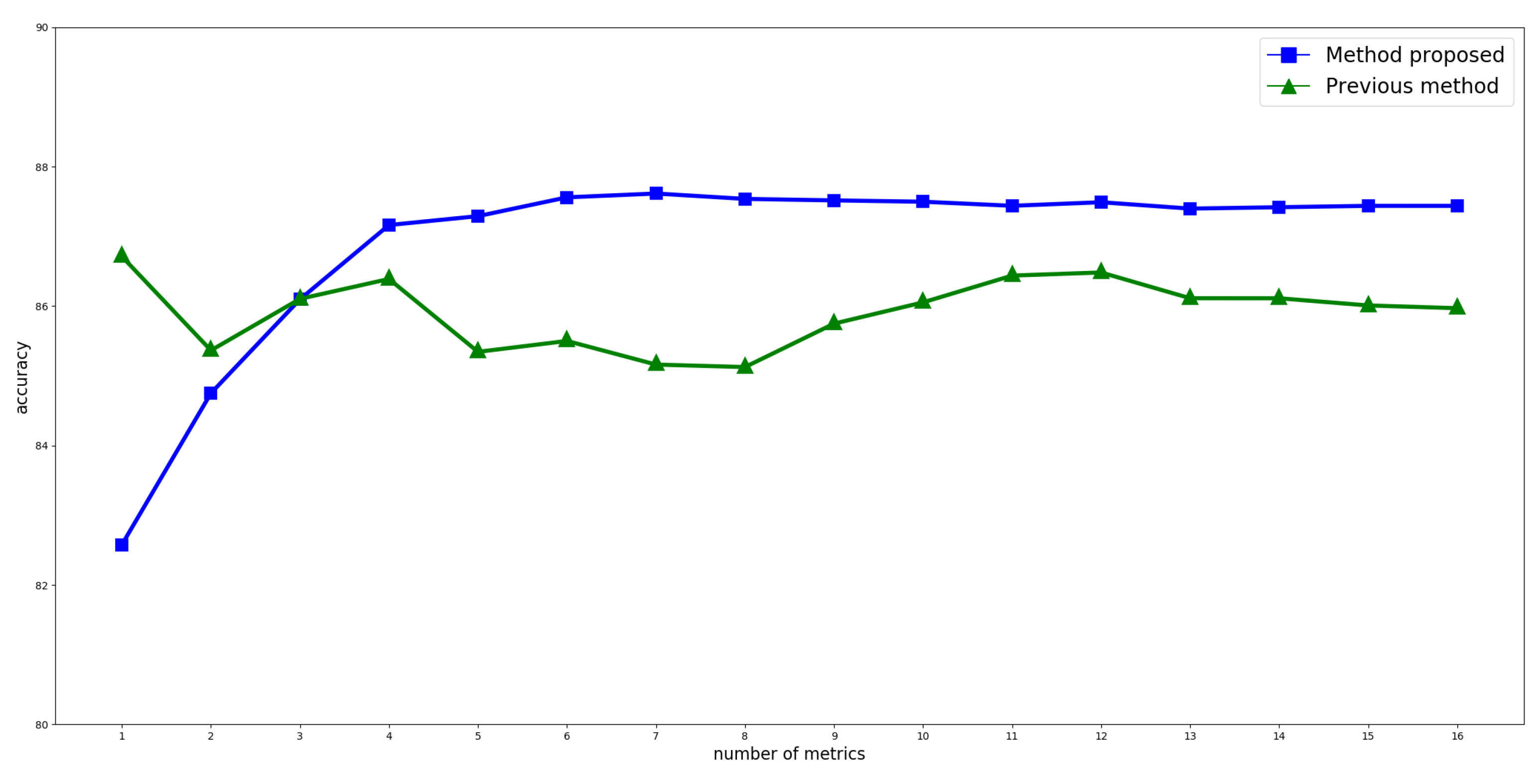
Each particle evolves to find coefficients such that, when multiplied by the values of each metric for all sentences, they allow for approximating the summary produced by the user. Once the score of all sentences in the document has been calculated, they can be sorted from highest to lowest. Those sentences that are assigned a score of 0 will be interpreted as irrelevant, while those that receive higher values will be more significant. User preference for a given sentence in the document is determined by the score assigned to it by the linear combination. Then, the automatic summary of the document will be obtained by considering the best t sentences, t being a threshold defined a priori.
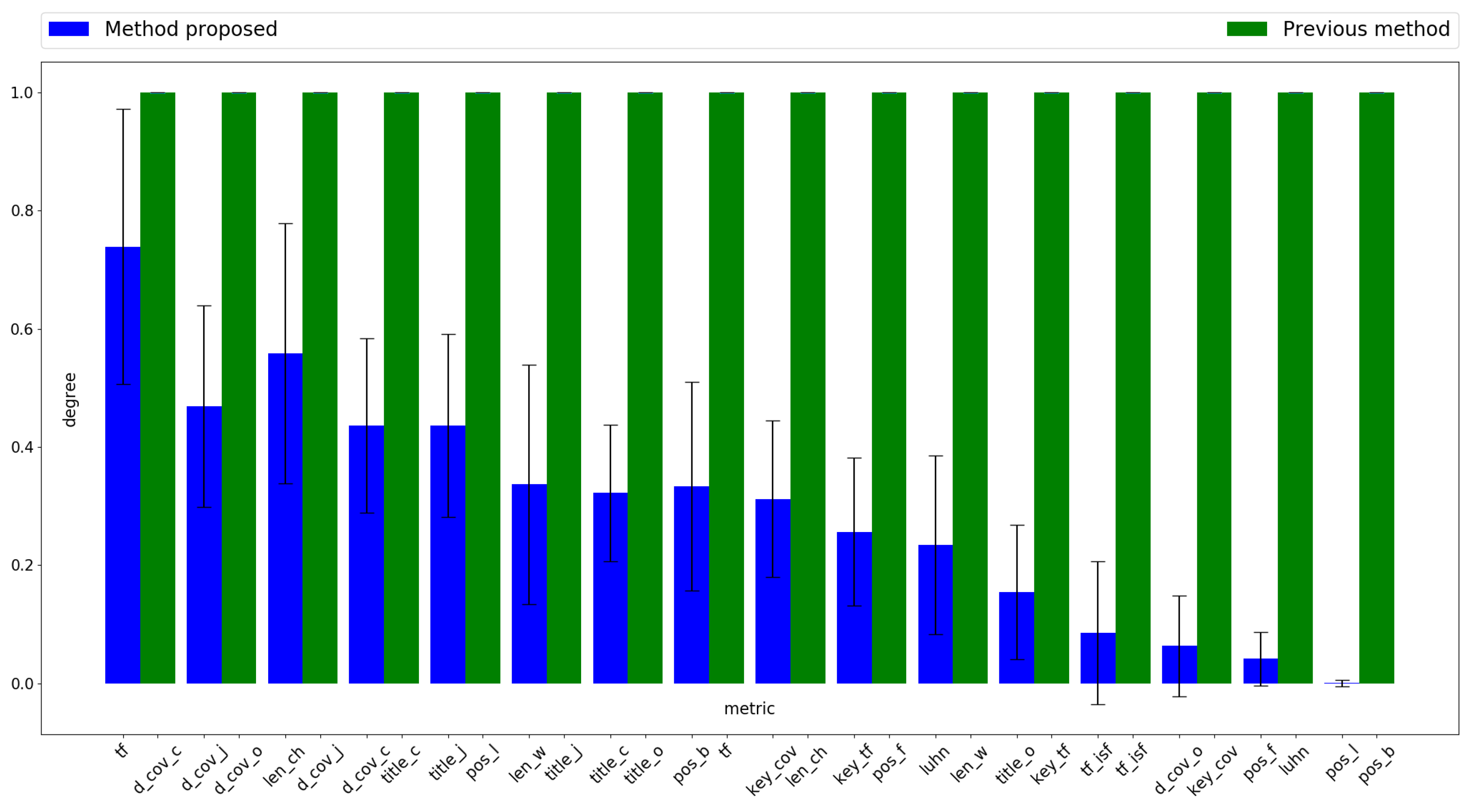
It should be noted that the assessment of individual performance is not limited to all components of vector whose value is 1, but that the binary individual is used to generate combinations. All possible combinations are generated by selecting a metric for each type. The only case when no metric is used is when all positions are at 0. When there is a single 1 among its dimensions, the metric corresponding to that dimension is the only one of that type that participates in combinations. This procedure not only allows for reducing the dimensionality, but it also helps prevent inconsistencies and redundancies among metrics included in the summarization criterion. For instance, there would be no point in simultaneously using two position metrics, one that assigns a higher weight to sentences found at the end of the document and another one that does exactly the same with sentences at the beginning of the document. In this case, the method should select the position metric that assigns high values to sentences located on either end of the document. After evaluating all combinations, that with the highest fitness value is selected. As a result, vector becomes vector and keeps the value indicated in only for relevant characteristics; all others are set to 0. To avoid excessively affecting how the optimization technique operates, each element that participates in the winning combination (each k in that was canceled when storing the final combination in ) will receive a reduction in and a reduction in . Thus, the possibility that discarded dimensions are selected in the next move of the particle is reduced, but not completely voided, which allows PSO to explore near the solution that is currently being proposed by the particle.
Finally, after evaluating each particle’s fitness value, the will show the metrics to use and the weights included in the criterion applied by the user that effectively represent the particle whose fitness value is in . Even though the fitness value of the particle matches the values indicated by , the particle is still moving in the conventional manner using the three speed vectors.
Algorithm 2 shows the proposed PSO method described previously.
| Algorithm 2: Proposed PSO algorithm |
Input: popSize, maxIte
- 1:
initialize , , and - 2:
initialize , , and - 3:
initialize , , , - 4:
create swarm population with size maxIte - 5:
repeat - 6:
adjust inertia factor value according to Equation ( 9) - 7:
for all do - 8:
calculate particle fitness according to Equation ( 10) - 9:
if then - 10:
- 11:
end if - 12:
end for - 13:
for all do - 14:
retrieve best particle from neighborhood - 15:
update speed according to Equations ( 1)–( 4) and ( 7) to binary and continuous part respectively - 16:
modify particle position according to Equations ( 6) and ( 8) - 17:
end for - 18:
until reaching iterations - 19:
return solution of best particle in population
|
| Output: The particle with the last best fitness value |







{kind=link}
{kind=link}
{kind=link}