Visual Analysis of Research Paper Collections Using Normalized Relative Compression

Abstract
1. Introduction
- A method for comparing the relative difference of a paper with respect to another.
- A fully automatic pipeline to process and evaluate PDF files of research articles.
- A series of visualizations intended to illustrate conference or author profile evolution.
2. Previous Work
2.1. Text Analysis
2.2. Visualization of Research Papers
3. Initial Analysis
3.1. Data Selection
3.2. Word Frequency Analysis
4. Similarity Measurement Using NRC
4.1. Requirements
- Indicates the degree of novelty of a certain paper.
- Can be used to classify papers by research areas.
- Is able to further separate within papers of the same area.
4.2. Data Preparation
- Text extraction.
- Data cleaning.
- Word stemming.
- Stopword removal.
- Removing spaces and changing text to lowercase.
- Erasing non-printable characters.
- Removing extraneous characters.
4.3. Similarity Measures
- iff string x can be built efficiently from (is very similar to) y;
- iff ;
4.4. Validation
4.4.1. Accuracy Test
4.4.2. Author Style vs. Contents
4.4.3. Containment
4.4.4. Validation Results
5. Results
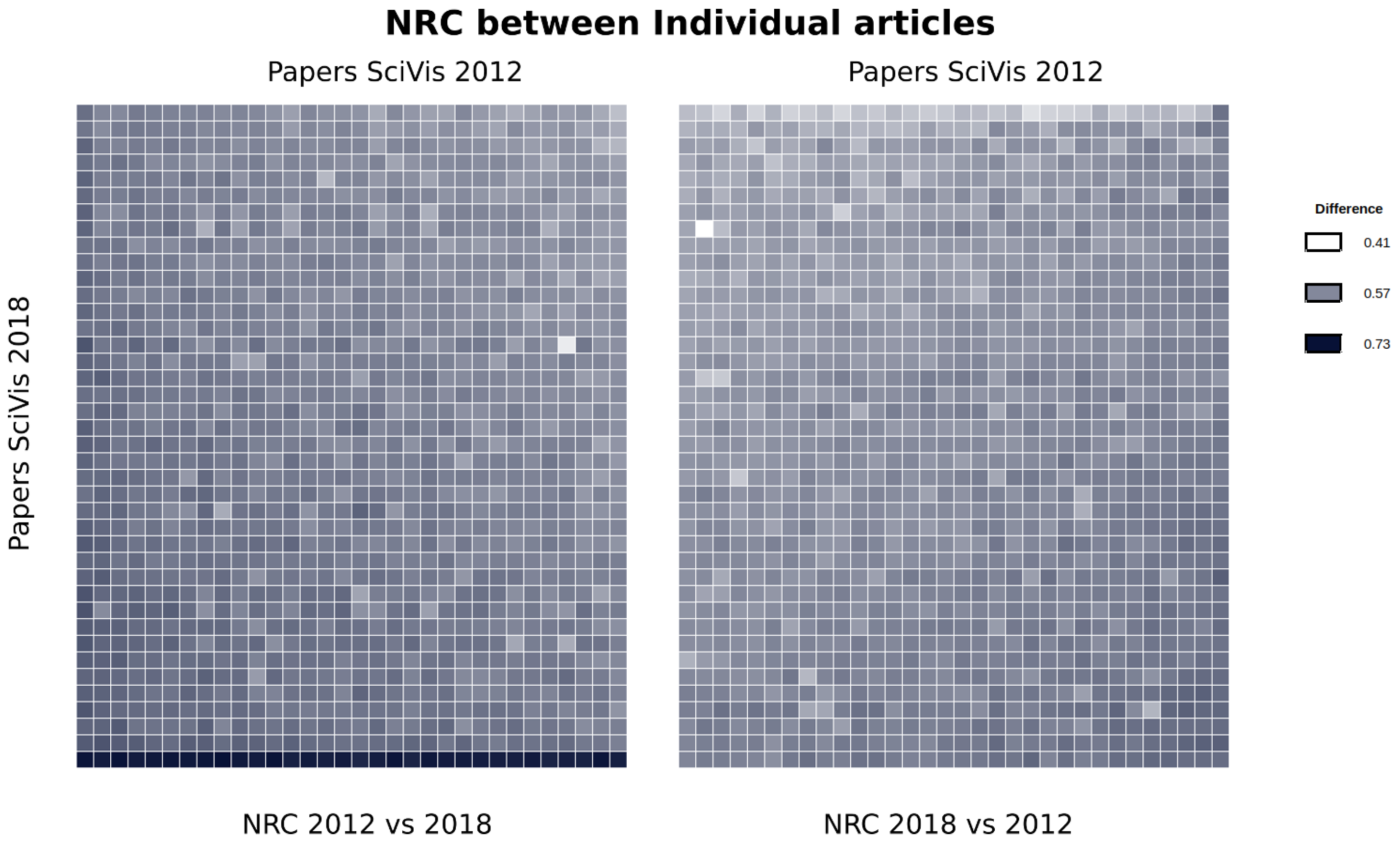
5.1. Evaluating Conference Evolution
5.2. Author Profile Analysis
5.3. Details and Performance
6. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Documents Used in the Experiments
Appendix A.1. Paper Classification Experiment
- IV1
- Viola, I., Kanitsar, A., & Groller, M. E. (2005). Importance-driven feature enhancement in volume visualization. IEEE Transactions on Visualization and Computer Graphics, 11(4), 408–418.
- IV2
- Viola, I., Kanitsar, A., & Gröller, M. E. (2004, April). GPU-based frequency domain volume rendering. In Proceedings of the 20th spring conference on Computer graphics (pp. 55–64). ACM.
- IV3
- Viola, I., Kanitsar, A., & Groller, M. E. (2003, October). Hardware-based nonlinear filtering and segmentation using high-level shading languages. In Proceedings of the 14th IEEE Visualization 2003 (VIS’03) (p. 41). IEEE Computer Society.
- IV4
- Viola, I., Kanitsar, A., & Groller, M. E. (2004, October). Importance-driven volume rendering. In Proceedings of the conference on Visualization’04 (pp. 139–146). IEEE Computer Society.
- IV5
- Viola, I., & Gröller, M. E. (2005, May). Smart visibility in visualization. In Computational Aesthetics (pp. 209–216).
- SB1
- Bruckner, S., & Groller, M. E. (2006). Exploded views for volume data. IEEE Transactions on Visualization and Computer Graphics, 12(5), 1077–1084.
- SB2
- Bruckner, S., & Gröller, E. (2007). Enhancing depth-perception with flexible volumetric halos. IEEE Transactions on Visualization and Computer Graphics, 13(6), 1344–1351.
- SB3
- Bruckner, S., & Gröller, M. E. (2007, September). Style transfer functions for illustrative volume rendering. In Computer Graphics Forum (Vol. 26, No. 3, pp. 715–724). Oxford, UK: Blackwell Publishing Ltd.
- SB4
- Bruckner, S., & Groller, M. E. (2005). Volumeshop: An interactive system for direct volume illustration (pp. 671–678). IEEE.
- SB5
- Grimm, S., Bruckner, S., Kanitsar, A., & Gröller, E. (2004). Flexible direct multi-volume rendering in dynamic scenes. In VMV (pp. 379–386).
- SB6
- Rautek, P., Csébfalvi, B., Grimm, S., Bruckner, S., & Gröller, M. E. (2006, May). D 2 VR: high-quality volume rendering of projection-based volumetric data. In Proceedings of the Eighth Joint Eurographics/IEEE VGTC conference on Visualization (pp. 211–218). Eurographics Association.
- TR1
- Ropinski, T., Steinicke, F., & Hinrichs, K. (2006, July). Visually supporting depth perception in angiography imaging. In International Symposium on Smart Graphics (pp. 93–104). Springer, Berlin, Heidelberg.
- TR2
- Ropinski, T., Steinicke, F., & Hinrichs, K. H. (2005). Interactive importance-driven visualization techniques for medical volume data. In Proceedings of the 10th International Fall Workshop on Vision, Modeling, and Visualization (VMV05) (pp. 273–280).
- TR3
- Ropinski, T., Steinicke, F., & Hinrichs, K. (2005). An Efficient Approach for Emphasizing Regions of Interest in Ray-Casting-based Volume Rendering.
- TR4
- Ropinski, T., Steinicke, F., & Hinrichs, K. (2006). Visual exploration of seismic volume datasets.
- TR5
- Ropinski, T., Specht, M., Meyer-Spradow, J., Hinrichs, K. H., & Preim, B. (2007, November). Surface glyphs for visualizing multimodal volume data. In VMV (pp. 3–12).
- NO_VIS1
- Deshpande, A., & Ouldridge, T. E. (2019). Optimizing enzymatic catalysts for rapid turnover of substrates with low enzyme sequestration. arXiv preprint arXiv:1905.00555.
- NO_VIS2
- Morrill, G., Kuznetsov, S., Kanovich, M., & Scedrov, A. (2018, August). Bracket induction for Lambek calculus with bracket modalities. In International Conference on Formal Grammar (pp. 84–101). Springer, Berlin, Heidelberg.
- NO_VIS3
- Liu, S. (2019). Compactification of Extensive Forms and Belief in the Opponents’ Future Rationality. arXiv preprint arXiv:1905.00355.
- NO_VIS4
- Liu, B., Lai, D., & Wang, Y. H. (2019). Black Hole and Neutron Star Binary Mergers in Triple Systems: II. Merger Eccentricity and Spin-Orbit Misalignment. arXiv preprint arXiv:1905.00427.
- VIS1
- Xu, K., Xia, M., Mu, X., Wang, Y., & Cao, N. (2019). EnsembleLens: Ensemble-based Visual Exploration of Anomaly Detection Algorithms with Multidimensional Data. IEEE transactions on visualization and computer graphics, 25(1), 109–119.
- VIS2
- Chen, W., Guo, F., Han, D., Pan, J., Nie, X., Xia, J., & Zhang, X. (2019). Structure-Based Suggestive Exploration: A New Approach for Effective Exploration of Large Networks. IEEE transactions on visualization and computer graphics, 25(1), 555–565.
- VIS3
- Ament, M., Weiskopf, D., & Carr, H. (2010). Direct interval volume visualization. IEEE transactions on visualization and computer graphics, 16(6), 1505–1514.
- VIS4
- Ankele, M., & Schultz, T. (2019). DT-MRI streamsurfaces revisited. IEEE transactions on visualization and computer graphics, 25(1), 1112–1121.
- VIS5
- Lee, B., Yun, J., Seo, J., Shim, B., Shin, Y. G., & Kim, B. (2010). Fast high-quality volume ray casting with virtual samplings. IEEE Transactions on visualization and computer graphics, 16(6), 1525–1532.
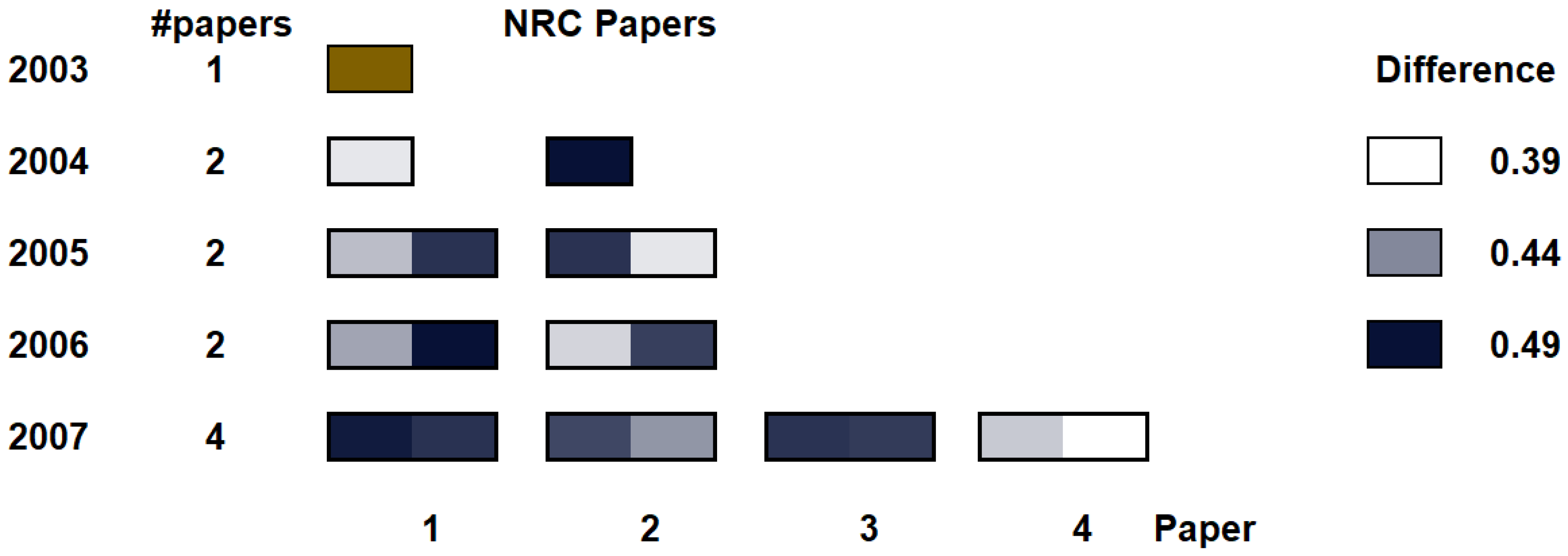
Appendix A.2. Author Profile Evolution Test
- 2003
- Viola, I., Kanitsar, A., & Groller, M. E. (2003, October). Hardware-based nonlinear filtering and segmentation using high-level shading languages. In Proceedings of the 14th IEEE Visualization 2003 (VIS’03) (p. 41). IEEE Computer Society.
- 2004,1
- Viola, I., Kanitsar, A., & Gröller, M. E. (2004, April). GPU-based frequency domain volume rendering. In Proceedings of the 20th spring conference on Computer graphics (pp. 55–64). ACM.
- 2004,2
- Viola, I., Kanitsar, A., & Groller, M. E. (2004, October). Importance-driven volume rendering. In Proceedings of the conference on Visualization’04 (pp. 139–146). IEEE Computer Society.
- 2005,1
- Artner, M., Möller, T., Viola, I., & Gröller, M. E. (2005, June). High-quality volume rendering with resampling in the frequency domain. In EuroVis (pp. 85–92).
- 2005,2
- Viola, I., & Gröller, M. E. (2005, May). Smart visibility in visualization. In Computational Aesthetics (pp. 209–216).
- 2006,1
- Rautek, P., Viola, I., & Groller, M. E. (2006). Caricaturistic visualization. IEEE Transactions on Visualization and Computer Graphics, 12(5), 1085–1092.
- 2006,2
- Viola, I., Feixas, M., Sbert, M., & Groller, M. E. (2006). Importance-driven focus of attention. IEEE Transactions on Visualization and Computer Graphics, 12(5), 933–940.
- 2007,1
- Balabanian, J. P., Viola, I., Ona, E., Patel, R., & Gröller, M. E. (2007, May). Sonar Explorer: A New Tool for Visualization of Fish Schools from 3D Sonar Data. In EuroVis (pp. 155–162).
- 2007,2
- Burns, M., Haidacher, M., Wein, W., Viola, I., & Gröller, M. E. (2007, May). Feature emphasis and contextual cutaways for multimodal medical visualization. In EuroVis (Vol. 7, pp. 275–282).
- 2007,3
- Tóth, Z., Viola, I., Ferko, A., & Gröller, E. (2007). N-dimensional Data-Dependent Reconstruction Using Topological Changes. In Topology-based Methods in Visualization (pp. 183–198). Springer, Berlin, Heidelberg.
- 2007,4
- Viola, I., & Gröller, E. (2007). On the role of topology in focus+ context visualization. In Topology-based Methods in Visualization (pp. 171–181). Springer, Berlin, Heidelberg.
Appendix A.3. Containment Experiments
- STAR
- Kozlikova, B., Krone, M., Falk, M., Lindow, N., Baaden, M., Baum, D., Viola, I., Parulek, J. & Hege, H. C. (2015). Visualization of biomolecular structures: State of the art.
- P1
- Kottravel, S., Falk, M., Sundén, E., & Ropinski, T. (2015, April). Coverage-based opacity estimation for interactive depth of field in molecular visualization. In 2015 IEEE Pacific Visualization Symposium (PacificVis) (pp. 255–262). IEEE.
- P2
- Grottel, S., Krone, M., Scharnowski, K., & Ertl, T. (2012, February). Object-space ambient occlusion for molecular dynamics. In 2012 IEEE Pacific Visualization Symposium (pp. 209–216). IEEE.
- P3
- Tarini, M., Cignoni, P., & Montani, C. (2006). Ambient occlusion and edge cueing for enhancing real time molecular visualization. IEEE transactions on visualization and computer graphics, 12(5), 1237–1244.
- P4
- Duran, D., Hermosilla, P., Ropinski, T., Kozlikova, B., Vinacua, A., & Vázquez, P. P. (2019). Visualization of large molecular trajectories. IEEE transactions on visualization and computer graphics, 25(1), 987–996.
- P5
- Lindow, N., Baum, D., & Hege, H. C. (2018). Atomic accessibility radii for molecular dynamics analysis.
- Initial
- Vázquez, P. P., Feixas, M., Sbert, M., & Heidrich, W. (2001, November). Viewpoint selection using viewpoint entropy. In VMV (Vol. 1, pp. 273–280).
- Follow-up
- Vázquez, P. P., Feixas, M., Sbert, M., & Llobet, A. (2002, May). Viewpoint entropy: a new tool for obtaining good views of molecules. In ACM International Conference Proceeding Series (Vol. 22, pp. 183–188).
Appendix B. Acronyms
- EMD:
- Earth Mover’s Distance. A distance metric between two probability distributions. In mathematics it is known as the Wasserstein metric.
- InfoVis:
- IEEE Information Visualization, the international conference on information visualization, organized yearly by IEEE in the so-called VisWeek, along with SciVis and VAST.
- NCCD:
- Normalized Conditional Compression Distance.
- NCD:
- Normalized Compression Distance.
- NRC:
- Normalized Relative Compression.
- TVCG:
- IEEE Transactions on Visualization and Computer Graphics, the IEEE journal on visualization.
- SciVis:
- IEEE Scientific Visualization, the international conference on scientific visualization, organized yearly by IEEE in the so-called VisWeek, along with InfoVis and VAST.
- VAST:
- IEEE Visualization Analytics Science and Technology, the international conference on visual analytics, organized yearly by IEEE in the so-called VisWeek, along with InfoVis and SciVis.
- WMD:
- Word Mover’s Distance. A distance metric based on deep learning.
References
- Isenberg, P.; Isenberg, T.; Sedlmair, M.; Chen, J.; Möller, T. Visualization as seen through its research paper keywords. IEEE Trans. V. Computer Gr. 2017, 23, 771–780. [Google Scholar] [CrossRef] [PubMed]
- Gomaa, W.H.; Fahmy, A.A. A survey of text similarity approaches. Int. J. Computer Appl. 2013, 68, 13–18. [Google Scholar]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef] [PubMed]
- Kusner, M.; Sun, Y.; Kolkin, N.; Weinberger, K. From Word Embeddings to Document Distances. Available online: http://proceedings.mlr.press/v37/kusnerb15.pdf (accessed on 15 May 2019).
- Zhao, R.; Mao, K. Fuzzy Bag-of-Words Model for Document Representation. IEEE Trans. Fuzzy Syst. 2017, 26, 794–804. [Google Scholar] [CrossRef]
- Wu, L.; Yen, I.E.; Xu, K.; Xu, F.; Balakrishnan, A.; Chen, P.Y.; Ravikumar, P.; Witbrock, M.J. Word Mover’s Embedding: From Word2Vec to Document Embedding. arXiv 2018, arXiv:1811.01713. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. A metric for distributions with applications to image databases. In Proceedings of the Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271), Bombay, India, 4–7 January 1998; pp. 59–66. [Google Scholar]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The earth mover’s distance as a metric for image retrieval. Int. J. Computer Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C. The Earth Mover’s Distance. In Perceptual Metrics for Image Database Navigation; Springer: Boston, MA, USA, 2001; pp. 13–28. [Google Scholar]
- Pinho, A.J.; Pratas, D.; Ferreira, P.J. Authorship attribution using relative compression. In Proceedings of the 2016 Data Compression Conference (DCC), Snowbird, UT, USA, 30 March–1 April 2016; pp. 329–338. [Google Scholar]
- Cilibrasi, R.; Vitanyi, P.M. Clustering by Compression. IEEE Trans. Inf. Theor. 2005, 51, 1523–1545. [Google Scholar] [CrossRef]
- Cerra, D.; Datcu, M. Expanding the algorithmic information theory frame for applications to earth observation. Entropy 2013, 15, 407–415. [Google Scholar] [CrossRef]
- Oliveira, W., Jr.; Justino, E.; Oliveira, L.S. Comparing compression models for authorship attribution. Forensic Sci. Int. 2013, 228, 100–104. [Google Scholar] [CrossRef] [PubMed]
- Helmer, S.; Augsten, N.; Böhlen, M. Measuring structural similarity of semistructured data based on information-theoretic approaches. Int. J. Very Large Data Bases 2012, 21, 677–702. [Google Scholar] [CrossRef]
- Coutinho, D.P.; Figueiredo, M.A. An Information Theoretic Approach to Text Sentiment Analysis. Available online: https://scitepress.org/papers/2013/42690/42690.pdf (accessed on 5 June 2019).
- Coutinho, D.P.; Figueiredo, M.A. Text classification using compression-based dissimilarity measures. Int. J. Pattern Recognit. Artif. Intell. 2015, 29, 1553004. [Google Scholar] [CrossRef]
- Pratas, D.; Silva, R.; Pinho, A. Comparison of Compression-Based Measures with Application to the Evolution of Primate Genomes. Entropy 2018, 20, 393. [Google Scholar] [CrossRef]
- Pratas, D.; Pinho, A.J. Metagenomic composition analysis of sedimentary ancient DNA from the Isle of Wight. In Proceedings of the 2018 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1177–1181. [Google Scholar]
- Carvalho, J.M.; Brás, S.; Pinho, A.J. Compression-Based Classification of ECG Using First-Order Derivatives. In Proceedings of the International Conference on Intelligent Technologies for Interactive Entertainment (INTETAIN 2018), Guimarães, Portugal, 21–23 November 2018; pp. 27–36. [Google Scholar]
- Isenberg, P.; Heimerl, F.; Koch, S.; Isenberg, T.; Xu, P.; Stolper, C.; Sedlmair, M.; Chen, J.; Möller, T.; Stasko, J. vispubdata. org: A metadata collection about ieee visualization (vis) publications. IEEE Trans. V. Computer Gr. 2017, 23, 2199–2206. [Google Scholar] [CrossRef]
- Isenberg, P.; Isenberg, T.; Sedlmair, M.; Chen, J.; Möller, T. Online Database. 2014. Available online: http://keyvis.org/ (accessed on 5 May 2019).
- Coulter, N.; Monarch, I.; Konda, S. Software engineering as seen through its research literature: A study in co-word analysis. J. Am. Soc. Inf. Sci. 1998, 49, 1206–1223. [Google Scholar] [CrossRef]
- De la Hoz-Correa, A.; Muñoz-Leiva, F.; Bakucz, M. Past themes and future trends in medical tourism research: A co-word analysis. Tour. Manag. 2018, 65, 200–211. [Google Scholar] [CrossRef]
- Corrales-Garay, D.; Ortiz-de Urbina-Criado, M.; Mora-Valentín, E.M. Knowledge areas, themes and future research on open data: A co-word analysis. Gov. Inf. Q. 2018, 36, 77–87. [Google Scholar] [CrossRef]
- Callon, M.; Courtial, J.P.; Laville, F. Co-word analysis as a tool for describing the network of interactions between basic and technological research: The case of polymer chemsitry. Scientometrics 1991, 22, 155–205. [Google Scholar] [CrossRef]
- Liu, Y.; Goncalves, J.; Ferreira, D.; Xiao, B.; Hosio, S.; Kostakos, V. CHI 1994–2013: Mapping Two Decades of Intellectual Progress Through Co-word Analysis. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Toronto, ON, Canada, 26 April–1 May 2014; pp. 3553–3562. [Google Scholar] [CrossRef]
- Ponsard, A.; Escalona, F.; Munzner, T. PaperQuest: A visualization tool to support literature review. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, San Jose, CA, USA, 7–12 May 2016; pp. 2264–2271. [Google Scholar]
- Nikhil, N.; Srivastava, M.M. Content based document recommender using deep learning. In Proceedings of the Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017; pp. 486–489. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Shen, Y.; He, X.; Gao, J.; Deng, L.; Mesnil, G. A Latent Semantic Model with Convolutional-Pooling Structure for Information Retrieval. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 101–110. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.; Robertson, S.; Porter, M. New Models in Probabilistic Information Retrieval; University of Cambridge: Cambridge, UK, 1980. [Google Scholar]
- Tran, N. The normalized compression distance and image distinguishability. In Proceedings of the Human Vision and Electronic Imaging XII, San Jose, CA, USA, 29 January–1 February 2007. [Google Scholar]
- Vázquez, P.P.; Marco, J. Using normalized compression distance for image similarity measurement: An experimental study. Vis. Comput. 2012, 28, 1063–1084. [Google Scholar] [CrossRef]
- Axelsson, S. Using normalized compression distance for classifying file fragments. In Proceedings of the 2010 International Conference on Availability, Reliability and Security, Krakow, Poland, 15–18 February 2010; pp. 641–646. [Google Scholar]
- Li, M.; Vitányi, P. An introduction to Kolmogorov Complexity and Its Applications; Springer: Berlin, Germany, 2013. [Google Scholar]
- Nikvand, N.; Wang, Z. Image distortion analysis based on normalized perceptual information distance. Signal Image Video Process. 2013, 7, 403–410. [Google Scholar] [CrossRef]
- Sculley, D.; Brodley, C.E. Compression and machine learning: A new perspective on feature space vectors. In Proceedings of the Data Compression Conference (DCC’06), Snowbird, UT, USA, 28–30 March 2006; pp. 332–341. [Google Scholar]
- Cilibrasi, R.; Cruz, A.L.; de Rooij, S.; Keijzer, M. CompLearn. Available online: https://complearn.org/ (accessed on 10 June 2019).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Paper | Follow-up | |
|---|---|---|
| Initial paper | 0.439 | |
| Follow-up | 0.408 |
| Technique | Accuracy Test | Separates Research Areas | Contents over Style | Containment |
|---|---|---|---|---|
| NRC | ✓ | ✓ | ✓ | ✓ |
| NCC | ✓ | (✓) | (✓) | ✓ |
| NCCD | ✓ | ✗ | ✗ | N/A |
| NCD | ✓ | ✗ | ✗ | N/A |
| WMD | ✗ | (✓) | (✓) | N/A |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vázquez, P.-P. Visual Analysis of Research Paper Collections Using Normalized Relative Compression. Entropy 2019, 21, 612. https://doi.org/10.3390/e21060612
Vázquez P-P. Visual Analysis of Research Paper Collections Using Normalized Relative Compression. Entropy. 2019; 21(6):612. https://doi.org/10.3390/e21060612
Chicago/Turabian StyleVázquez, Pere-Pau. 2019. "Visual Analysis of Research Paper Collections Using Normalized Relative Compression" Entropy 21, no. 6: 612. https://doi.org/10.3390/e21060612
APA StyleVázquez, P.-P. (2019). Visual Analysis of Research Paper Collections Using Normalized Relative Compression. Entropy, 21(6), 612. https://doi.org/10.3390/e21060612