Abstract
Dempster–Shafer (DS) evidence theory is widely applied in multi-source data fusion technology. However, classical DS combination rule fails to deal with the situation when evidence is highly in conflict. To address this problem, a novel multi-source data fusion method is proposed in this paper. The main steps of the proposed method are presented as follows. Firstly, the credibility weight of each piece of evidence is obtained after transforming the belief Jenson–Shannon divergence into belief similarities. Next, the belief entropy of each piece of evidence is calculated and the information volume weights of evidence are generated. Then, both credibility weights and information volume weights of evidence are unified to generate the final weight of each piece of evidence before the weighted average evidence is calculated. Then, the classical DS combination rule is used multiple times on the modified evidence to generate the fusing results. A numerical example compares the fusing result of the proposed method with that of other existing combination rules. Further, a practical application of fault diagnosis is presented to illustrate the plausibility and efficiency of the proposed method. The experimental result shows that the targeted type of fault is recognized most accurately by the proposed method in comparing with other combination rules.
1. Introduction
Multi-source data fusion is the process of combining data obtained from different sources to make robust and complete evaluation on the certain system. As is known, single data source cannot provide sufficient information to detect a complex system in a full scale. By contrast, multi-source data fusion presents comprehensive and credible results after integrating groups of data that reflect various features of the system [1,2]. Therefore, multi-source data fusion technology is widely applied in many real applications, such as energy management strategy [3,4], health prognosis [5,6,7], suppliers selection [8,9,10,11], decision making [12,13,14], evaluation [15,16,17], etc. However, since the single data source is easily disturbed by environmental factors, it is unavoidable to meet the situation when the data collected from different sources are inconsistent, irrelevant or even conflicted [18]. How to fuse these groups of data from different sources correctly has received much attention but is still an open problem [19,20]. Thus far, many theories and methods have been proposed to solve the uncertain problem, which were extended from Z-numbers [21,22], D-numbers [23,24,25,26,27], R-numbers [28], fuzzy sets [29,30,31,32], rough sets [33], evidence theory [34], entropy [35,36], quantum [37], and so on.
Dempster–Shafer evidence theory (DS evidence theory), firstly proposed by Dempster [38] and later developed by Shafer [39], is a general framework for reasoning with uncertainty. As a generalization of Bayesian theory, DS evidence theory can express uncertain and imprecise data more explicitly by using mass function, which can assign the probability to the union of single elements [40,41]. Besides, DS evidence theory provides a combination rule to fuse pieces of evidence. Due to its flexibility and effectiveness on handling uncertainty, DS evidence theory is widely applied in information fusion technology [42,43,44]. However, the combination rule in DS evidence theory presents counter-intuitive results when evidence is highly in conflict [45,46]. To address this problem, many modified combination methods have been proposed, which derive from two basic strategies. One is to modify classical DS combination formula. Based on this strategy, Yager [47] believed that little about conflicting evidence can be understood and reassigned the conflict constant to the unknown space. In [48], Smets thought that the conflict is attributed to the incompleteness of the frame of discernment and proposed unnormalized combination rule. In [49], Lefevre et al. proposed a general framework to unify the general combination rules. In [50], Sun et al. believed that the availability of conflicting evidence is associated with their credibilities. In [51], Li et al. reallocated the conflict constant based on the weighted average support degree to each piece of evidence. However, the main shortcoming of these methods is the loss of associative properties, which greatly increases the computational complex degree especially when fusing thousands of pieces of evidence simultaneously. Another strategy is to pre-process the original evidence and apply the classical DS evidence theory on the adjusted evidence multiple times. Many combination methods have been proposed on the basis of this strategy. In [52], Murphy generated the modified evidence by simply averaging the original evidence. In [53], Deng et al. took the distance between pieces of evidence into consideration and reallocated the weight on the evidence. In [54], Jiang et al. proposed a new combination rule based on information volume calculated by belief entropy. In [55], Zhang et al. applied cosine theorem to calculate the support degree of evidence. In [56], Lin et al. generated a similarity vector by measuring Euclidean distances between pieces of evidence before generating the weighted average evidence. Although these combination methods presented quite reasonable fusing results, there is still some room for further improvement. In this paper, therefore, a novel multi-source data combination method is proposed to handle the problem of highly-conflicted evidence fusion.
In particular, by taking advantage of the belief entropy to quantify the information volume of the system and belief divergence to measure the difference among multi-source data, the credibility and the information volume, as two important factors of evidence are integrated to allocate the weight on the original evidence. In this way, the weight of untrustworthy evidence is declined, so that the influence of conflicted evidence is controlled more strictly. The main steps of the proposed procedure are concluded as follows. Firstly, the credibility of evidence is calculated according to their similarity with the average evidence. Besides, the belief entropy is applied to calculate the information volume of each piece of evidence. After that, the weight is allocated on the evidence based on their credibility and information volume before the weighted average evidence is generated. Finally, classical DS evidence is used to fuse the modified evidence multiple times and the final result is obtained. A practical application of fault diagnosis is given to prove the efficiency of the proposed method.
The following parts of this paper are organized as follows. In Section 2, some basic concepts and definitions of DS evidence theory, belief entropy and Belief Jenson–Shannon divergence are concisely introduced. In Section 3, a novel multi-source data fusion method is presented. In Section 4, a numerical example is used to compare the fusing results with other existing combination rules. In Section 5, the proposed combination method is applied in a practical example of fault diagnosis. Finally, the conclusion of this paper is discussed in Section 6.
2. Preliminaries
In this section, several preliminary theories are briefly introduced, including DS evidence theory, belief entropy and Belief Jenson–Shannon divergence.
2.1. Dempster–Shafer Evidence Theory
Dempster–Shafer evidence theory is an extension of the Bayes probability theory. Comparing with probability theory, DS evidence theory can not only assign the probability on one single element, but also on the subset of the universal set [57,58]. Besides, DS evidence theory can handle uncertainty and imprecision without prior probability is given [59,60,61,62]. When the probability is only allocated on several single elements, DS evidence theory degenerates into Bayes probability theory [63,64]. Some basic concepts of Dempster–Shafer theory are introduced as follows.
Definition 1 (Frame of discernment).
Assume Θ is an exhaustive and finite set of all possible, independent and exclusive values of variable x, indicated by:
where Θ is denoted as a frame of discernment. The power set of Θ is . If , then A is called a proposition [65,66,67,68].
Definition 2 (Basic probability assignment).
On the frame of discernment Θ, assume a mapping m: -> [0,1], which satisfies:
then function m is called mass function or basic probability assignment (BPA).
In DS evidence theory, represents how strongly the evidence supports hypothesis A [69,70,71]. If , A is called a focal element of m [72,73].
Definition 3 (Belief function).
The belief function is a mapping : -> , defined as:
which represents the total belief on A [74,75]. Belief function is the lower limit function of A.
Definition 4 (Plausibility function).
The plausibility function is a mapping : -> [0,1], defined as:
which represents the undeniable degree on A [76,77]. Plausibility function is the upper limit function of A.
Definition 5 (DS combination rule).
Assume and are two independent BPAs on . In DS evidence theory, their orthogonal sum is defined as:
where
The orthogonal sum in Equation (5) can be extended to the condition when n pieces of BPAs are fused simultaneously, which satisfies the mathematical communication law and the associative law. In Equation (5), the constant k measures the conflict degree of BPAs [78,79,80]. If k is higher, the conflict between BPAs is more serious [81,82,83].
2.2. Belief Entropy
In [84], Deng proposed belief entropy. As a generalization of Shannon entropy [85], Deng’s belief entropy can be used to measure the information volume of BPAs. When the belief is only assigned to the single element, Deng’s belief entropy degenerates into Shannon entropy. Many applications have proved the efficiency of Deng entropy [86]. Deng’s belief entropy is defined as follows:
where m is a BPA defined on the frame of discernment , and A is a focal element of m. indicates the cardinality of A. When the belief is only assigned to single elements of , Deng’s belief entropy degenerates into Shannon entropy, which is shown as:
However, Deng’s belief entropy has some limitations when the propositions are of intersections. To address this shortcoming, Cui et al. [87] improved Deng ’s belief entropy, which takes out the redundant volume created by intersections. Cui et al.’s belief entropy is defined as follows:
where denotes the cardinality of proposition A. Here, a numerical example in [87] is used to demonstrate that Cui et al.’s belief entropy is more efficient in measuring the information volume of evidence that contains intersecting propositions.
Example 1.
Assume the frame of discernment is . The values of two BPAs is presented as follows:
According to the data above, both and have the same scale of focal elements and the same function values. However, the propositions of are of intersections, which only contain three elements a, b and c. Therefore, has greater information volume than that of . Next, Deng’s belief entropy and Cui et al.’s belief entropy of two pieces of evidence are calculated as follows.
Deng’s belief entropy:
Cui et al.’s belief entropy:
As shown in Example 1, Deng’s belief entropy ignores the influence of intersections and presents the same uncertain degree of two pieces of evidence. Comparatively, Cui et al.’s belief entropy takes the redundant space of intersections out from their information volume. Therefore, if the evidence has many intersecting propositions, it would be better to use Cui et al.’s belief entropy to measure their information volume more accurately. Besides, if the evidence has greater belief entropy, it contains more information and there fewer less conflicts between this subset and the frame of discernment. Therefore, the evidence that has greater belief entropy should be assigned more weights in the fusing procedure.
2.3. Belief Jenson–Shannon Divergence
In [88], Xiao proposed Belief Jensen–Shannon (BJS) divergence by integrating DS evidence theory and Jenson–Shannon divergence. Suppose and are two BPAs on the same frame of discernment that contains n elements; the BJS divergence between and is defined as:
where
The main contribution of the belief Jenson–Shannon divergence is that it replaces the probabilities distributions in JS divergence with BPAs, so that BJS divergence can be applied in DS evidence theory to measure the difference between BPAs.
3. The Proposed Method
To address the problem of fusing highly-conflicted evidence, a new combination method is proposed in this section. To allocate the weight on evidence more properly, not only credibility of the evidence but also its information volume is taken into consideration. The procedure is divided into three parts. Firstly, the credibility weight of evidence is obtained after transforming BJS divergence into similarities. Secondly, the information volume weight of evidence is obtained by calculating the belief entropy. Thirdly, the weighted average BPA is generated before fusing it by DS combination rule. The flowchart of the method is shown in Figure 1. More details and explanations about each step of the method are described as follows.
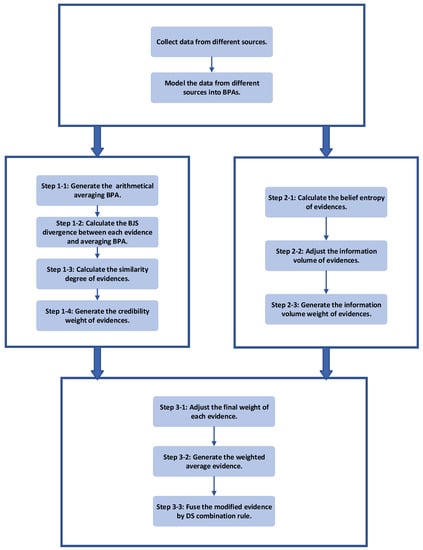
Figure 1.
The flowchart of the proposed method.
3.1. Calculate the Credibility Weight of Evidences
Step 1-1. Suppose is a set of n independent BPAs on the same frame of discernment that contains N elements: . The arithmetical average BPA is defined as:
Step 1-3. Since the similarities of the pieces of evidence are negatively correlated with their divergences, if the divergence between two pieces of evidence is higher, they have lower similarity. The divergence between and is converted into their similarity as follows:
Step 1-4. If a piece of evidence is highly similar to the average BPA, it means that the evidence is supported by most of the other pieces of evidence and it is more reliable, thus it gains high credibility. Thus, the credibility weight of the pieces of evidence is determined by normalizing their similarity with the arithmetical average BPA. The credibility weight () of each piece of evidence is defined as follows:
3.2. Calculate Information Volume Weight of Evidence
Step 2-1. Calculate the belief entropy of () according to Equation (8).
Step 2-2. To avoid assigning zero weight to the evidence whose belief entropy is zero, the information volume in Step 2-1 is modified as follows:
where represents the belief entropy of .
Step 2-3. Calculate the information volume weight () of each piece of evidence by normalizing , which is defined as:
3.3. Generate the Modified Evidence and Fuse
Step 3-1. Based on the credibility weight and information volume weight of evidence, the weight of each piece of evidence is adjusted as follows:
Step 3-2. Normalize the modified weight as follows:
Step 3-3. Generate the modified evidence by calculating the weighted average sum of BPAs, which is defined as:
Step 3-4. DS combination rule is used times on the modified evidence based on [52], then the final combination result is obtained:
4. Numerical Example
In this section, the proposed method is compared with other existing combination rules by a numerical example in [55] and the effectiveness of the proposed method is illustrated.
4.1. Example Presentation
Assume the frame of discernment . There are five pieces of evidence denoted as , , , , and and their mass functions are listed in Table 1. Here, evidence is not credible as other pieces of evidence since the sensor which is modeled into is disturbed by some unknown environmental factors.

Table 1.
A numerical example in [55].
4.2. Combination by the Proposed Method
Step 1-1. Calculate the arithmetical average BPA.
Step 1-2. Calculate the BJS divergence between each piece of evidence and .
Step 1-3. Calculate the similarity degree of each piece of evidence.
Step 1-4. Calculate the weight of credibility.
Step 2-1. Calculate the belief entropy of each piece of evidence.
Step 2-2. Adjust the information volume of each piece of evidence.
Step 2-3. Calculate the weight of information volume.
Step 3-1. Adjust the weight of each piece of evidence.
Step 3-2. Normalize the modified weight of each piece of evidence.
Step 3-3. Generate the modified evidence.
Step 3-4. Use the classical DS combination rule to fuse the modified evidence four times, and the result is shown in Table 2.
Table 2.
Fusing results by different methods in the example.
4.3. Analysis
According to Table 1, shows great conflict with the four other pieces of evidence, which assigns most of the belief on B, while the remaining four pieces of evidence all support A. In this case, the major belief after fusing should be allocated on A since the is modeled from an abnormal sensor. The fusing results of the proposed method and other existing combination rules are presented in Table 2 and Figure 2.
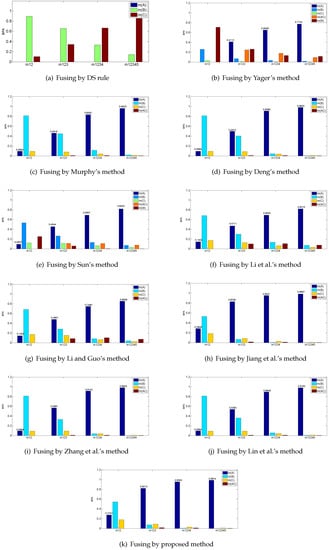
Figure 2.
Fusing results by different combination methods in the example.
As shown in Table 2, classical DS combination rule is disturbed by the abnormal evidence and assigns most of its belief on C wrongly. The remaining combination rules all present the reasonable results and majorly support A. The incredible evidence appears on the first time fusion and misguides the fusing process to recognize C, but as the later credible pieces of evidence join the fusion process, these combination methods all turn to assign their beliefs mainly on A. However, in the real situation, a slight increase of accuracy is significant to improve the performance of the system [54,55,56]. Comparatively, the proposed method achieves the highest accuracy of 0.9874 for identifying A among these combination rules. Therefore, the proposed method is relatively effective because it takes two important factors of evidence—the credibility and information volume—into consideration, so that the weight of the incredible evidence is controlled more strictly.
5. Application
5.1. Problem Statement
An automobile system was excessively used and it caused shortage of power. According to the records in the database, there were three possible faults that may lead to this problem: low oil pressure, air leakage in the intake system and a stuck solenoid valve, which are denoted as and , respectively. Five sensors, denoted as and , were placed at different positions to measure the parameters including the air displacement, maximum power, maximum torsion, compression ratio and maximum rotation speed of the power system. After all the sensors finished measuring, the central controlling system then modeled the parameters detected from sensors to BPAs, which are presented in Table 3, where is the frame of discernment and is the evidence modeling from (). In this application, was broken because the engine speed accidentally exceeded its upper limitation and could not function normally as the four other sensors. The objective is to judge which type of fault has occurred in the automobile system according to these pieces of evidence.
Table 3.
BPAs after modeling from sensors.
5.2. Fuse Evidences by the Proposed Method
Step 1-1. Calculate the arithmetical average BPA.
Step 1-2. Calculate the BJS divergence between each piece of evidence and .
Step 1-3. Calculate the similarity degree of each piece of evidence.
Step 1-4. Calculate the weight of credibility.
Step 2-1. Calculate the belief entropy of each piece of evidence.
Step 2-2. Adjust the information volume of each piece of evidence.
Step 2-3. Calculate the weight of information volume.
Step 3-1. Adjust the weight of each piece of evidence.
Step 3-2. Normalize the modified weight of each piece of evidence.
Step 3-3. Generate the modified evidence.
Step 3-4. Use the classical DS combination rule to fuse the modified evidence four times, and the result is shown in Table 4.
Table 4.
Fusing results of the application.
5.3. Discussion
Table 4 and Figure 3 show the results of fusing five BPAs by applying the proposed method, together with the other existing combination rules. Here, a threshold is set based on [54]. After fusing by the combination method, if , it means that the method recognizes fault successfully; otherwise, this combination rule cannot identify what kind of fault and “unknown” is marked in Table 4.
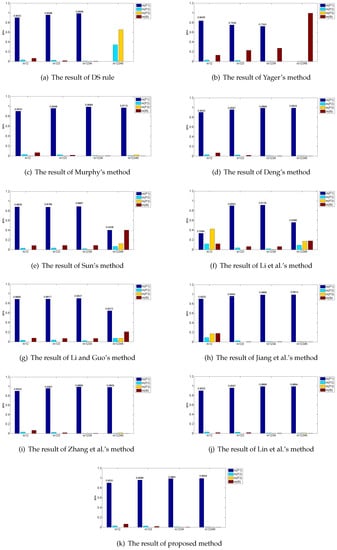
Figure 3.
Fusing results by different combination methods in the application.
In this application, , , , and all work well, and the pieces of evidence after transforming their detected data are greatly consistent, which all assign most of their beliefs to according to Table 3. However, is broken and the evidence after modeling the data collected from intensively conflicts with the other four pieces of evidence, which assigns most of the belief to wrongly. Based on these considerations, is judged as the fault in the automobile system. The ideal result after fusing by these combination methods is to recognize fault accurately, ignoring the disturbing effect of .
As shown in Table 4, the classical DS combination rule successfully recognizes fault after fusing the first four pieces of evidence, but, when the incredible evidence joins, it drastically reassigns most of the beliefs to the fault wrongly. Therefore, classical DS combination rule fails to fuse the highly conflicting evidence. Yager’s method reallocates the conflicting degree to the unknown space and it cannot identify which type of fault. Sun et al.’s method, Li and Guo’s method and Li et al.’s method do not reach the threshold . As a result, they cannot distinguish the targeted type of fault. Deng’s method, Jiang’s method, Zhang’s method, Lin et al.’s method and the proposed method all recognize the fault successfully. Deng introduced a combination method based on the distances among evidences and it presents 99.33% recognition accuracy comparing with 99.34% of the proposed method, which indicates that Deng’s method can deal with the conflicting evidence. However, in Deng’s method, the sizes of its distance matrix and similarity matrix are both , while the sizes of divergence vector and information volume vector are both in the proposed method. Therefore, the proposed method presents better accuracy of targeted type of fault with a lower computational complexity algorithm comparing with Deng’s method. It is worth noting that a slight increase of accuracy is significant to improve the performance of the system in the real application [54,55,56]. When the conflicting evidence joins the fusion, Lin et al.’s method shows a slight decrease from 98.99% to 98.94% and Jiang et al.’s method climbs from 98.95% to 99.14%, while the proposed method increases from 98.91% to 99.34%. This means that the proposed method can overcome the influence of incredible evidence better and maintain the degree of increase as more pieces of evidence join. Overall, the proposed method can diagnosis the targeted type of fault more accurately than other combination rules as it assigns the highest belief of 0.9934 to the fault . The reason is that the proposed method not only makes use of Belief Jenson–Shannon function to measure the credibility of the evidence, but also considers their information volume by applying belief entropy before allocating the final weight to each piece of evidence. Since the conflicted evidence has not only low credibility but small information volume, its weight is declined, so that the influence of fault evidence is controlled more strictly in comparison with the other proposed combination rules.
6. Conclusions
Dempster–Shafer evidence theory is widely used in information fusion field due to its efficiency in handling uncertainty and imprecision. However, some counter-intuitive results occur when the evidence is highly in conflict. To address this shortcoming, a novel multi-source combination method is proposed in this paper based on BJS divergence measure and the improved Deng entropy. Not only the credibility but also the information volume of the evidence is taken into consideration to allocate the weight on the original evidence before fusing the modified evidence, so that the influence of untruthful evidence is controlled more seriously, resulting in the higher attention on the credible evidence when fusing. Next, the proposed method is compared with other existing combination rules in a numerical example. The result shows that the proposed method achieves the highest accuracy of 99.74% among these combination rules. Furthermore, the proposed method is applied in an application of fault diagnosis to identify the type of fault in an automobile system. Among the combination rules which successfully recognized the correct type of fault, the proposed method shows the highest degree of accuracy of 99.34% with lower computational complexity since the sizes of two vectors are both rather than . In summary, this study provides a promising way to deal with the multi-source data fusion problems. In the near future, to make the proposed method more applicable in the real environment, how to generate BPAs more properly from different sources will be further considered.
Author Contributions
Z.W. designed and performed the experiments and wrote the paper. F.X. developed the method, conceived the experiments and revised the paper.
Acknowledgments
The authors greatly appreciate the reviews’ suggestions and the editor’s encouragement. This research was supported by the Fundamental Research Funds for the Central Universities (No. XDJK2019C085) and Chongqing Overseas Scholars Innovation Program (No. cx2018077).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Alam, F.; Mehmood, R.; Katib, I.; Albogami, N.N.; Albeshri, A. Data Fusion and IoT for Smart Ubiquitous Environments: A Survey. IEEE Access 2017, 5, 9533–9554. [Google Scholar] [CrossRef]
- Knuth, K.H.; Shah, A.S.; Truccolo, W.A.; Mingzhou, D.; Bressler, S.L.; Schroeder, C.E. Differentially variable component analysis: Identifying multiple evoked components using trial-to-trial variability. J. Neurophysiol. 2013, 95, 3257–3276. [Google Scholar] [CrossRef] [PubMed]
- Zhou, D.; Al-Durra, A.; Gao, F.; Ravey, A.; Matraji, I.; Simoes, M.G. Online energy management strategy of fuel cell hybrid electric vehicles based on data fusion approach. J. Power Sources 2017, 366, 278–291. [Google Scholar] [CrossRef]
- Zhou, D.; Al-Durra, A.; Zhang, K.; Ravey, A.; Gao, F. A Robust Prognostic Indicator for Renewable Energy Technologies: A Novel Error Correction Grey Prediction Model. IEEE Trans. Ind. Electron. 2019. [Google Scholar] [CrossRef]
- Cao, Z.; Lai, K.L.; Lin, C.T.; Chuang, C.H.; Chou, C.C.; Wang, S.J. Exploring resting-state EEG complexity before migraine attacks. Cephalalgia 2017, 38, 1296–1306. [Google Scholar] [CrossRef] [PubMed]
- Dobell, E.; Herold, S.; Buckley, J. Spreadsheet Error Types and Their Prevalence in a Healthcare Context. J. Organ. End User Comput. (JOEUC) 2018, 30, 20–42. [Google Scholar] [CrossRef]
- Xiao, F.; Ding, W. Divergence measure of Pythagorean fuzzy sets and its application in medical diagnosis. Appl. Soft Comput. 2019, 79, 254–267. [Google Scholar] [CrossRef]
- Chatterjee, K.; Pamucar, D.; Zavadskas, E.K. Evaluating the performance of suppliers based on using the R’AMATEL-MAIRCA method for green supply chain implementation in electronics industry. J. Clean. Prod. 2018, 184, 101–129. [Google Scholar] [CrossRef]
- Keshavarz Ghorabaee, M.; Amiri, M.; Zavadskas, E.K.; Antucheviciene, J. Supplier evaluation and selection in fuzzy environments: A review of MADM approaches. Econ. Res.-Ekon. Istraživanja 2017, 30, 1073–1118. [Google Scholar] [CrossRef]
- Khatwani, G.; Srivastava, P.R. Impact of Information Technology on Information Search Channel Selection for Consumers. J. Organ. End User Comput. (JOEUC) 2018, 30, 63–80. [Google Scholar] [CrossRef]
- Strang, K.D.; Vajjhala, N.R. Student resistance to a mandatory learning management system in online supply chain courses. J. Organ. End User Comput. (JOEUC) 2017, 29, 49–67. [Google Scholar] [CrossRef]
- He, Z.; Jiang, W. An evidential dynamical model to predict the interference effect of categorization on decision making. Knowl.-Based Syst. 2018, 150, 139–149. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. D number theory based game-theoretic framework in adversarial decision making under a fuzzy environment. Int. J. Approx. Reason. 2019, 106, 194–213. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Martínez, L. R-numbers, a new risk modeling associated with fuzzy numbers and its application to decision making. Inf. Sci. 2019, 483, 206–231. [Google Scholar] [CrossRef]
- Liu, Z.; Pan, Q.; Dezert, J.; Han, J.; He, Y. Classifier Fusion With Contextual Reliability Evaluation. IEEE Trans. Cybern. 2018, 48, 1605–1618. [Google Scholar] [CrossRef] [PubMed]
- Kang, B.; Zhang, P.; Gao, Z.; Chhipi-Shrestha, G.; Hewage, K.; Sadiq, R. Environmental assessment under uncertainty using Dempster–Shafer theory and Z-numbers. J. Ambient Intell. Hum. Comput. 2019. [Google Scholar] [CrossRef]
- Dahooie, J.H.; Zavadskas, E.K.; Abolhasani, M.; Vanaki, A.; Turskis, Z. A Novel Approach for Evaluation of Projects Using an Interval–Valued Fuzzy Additive Ratio Assessment ARAS Method: A Case Study of Oil and Gas Well Drilling Projects. Symmetry 2018, 10, 45. [Google Scholar] [CrossRef]
- Wang, X.; Song, Y. Uncertainty measure in evidence theory with its applications. Applied Intelligence 2018, 48, 1672–1688. [Google Scholar] [CrossRef]
- Fu, C.; Liu, W.; Chang, W. Data-driven multiple criteria decision making for diagnosis of thyroid cancer. In Annals of Operations Research; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Yazidi, A.; Herrera-Viedma, E. A new methodology for identifying unreliable sensors in data fusion. Knowl.-Based Syst. 2017, 136, 85–96. [Google Scholar] [CrossRef]
- Kang, B.; Chhipi-Shrestha, G.; Deng, Y.; Hewage, K.; Sadiq, R. Stable strategies analysis based on the utility of Z-number in the evolutionary games. Appl. Math. Comput. 2018, 324, 202–217. [Google Scholar] [CrossRef]
- Kang, B.; Deng, Y.; Hewage, K.; Sadiq, R. A Method of Measuring Uncertainty for Z-Number. IEEE Trans. Fuzzy Syst. 2019, 27, 731–738. [Google Scholar] [CrossRef]
- Deng, X.; Deng, Y. D-AHP method with different credibility of information. Soft Comput. 2019, 23, 683–691. [Google Scholar] [CrossRef]
- Xiao, F. A multiple criteria decision-making method based on D numbers and belief entropy. Int. J. Fuzzy Syst. 2019, 21, 1144–1153. [Google Scholar] [CrossRef]
- Mo, H.; Deng, Y. An evaluation for sustainable mobility extended by D numbers. Technol. Econ. Dev. Econ. 2019. accepted. [Google Scholar] [CrossRef]
- Xiao, F. A novel multi-criteria decision making method for assessing health-care waste treatment technologies based on D numbers. Eng. Appl. Artif. Intell. 2018, 71, 216–225. [Google Scholar] [CrossRef]
- Mo, H.; Deng, Y. A New MADA Methodology Based on D Numbers. Int. J. Fuzzy Syst. 2018, 20, 2458–2469. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A. Developing the R-TOPSIS methodology for risk-based preventive maintenance planning: A case study in rolling mill company. Comput. Ind. Eng. 2019, 128. [Google Scholar] [CrossRef]
- Fan, C.; Song, Y.; Fu, Q.; Lei, L.; Wang, X. New Operators for Aggregating Intuitionistic Fuzzy Information With Their Application in Decision Making. IEEE Access 2018, 6, 27214–27238. [Google Scholar] [CrossRef]
- Herrera, F.; Herrera-Viedma, E.; Alonso, S.; Chiclana, F. Computing with words and decision making. Fuzzy Optim. Decis. Mak. 2009, 8, 323–324. [Google Scholar] [CrossRef]
- Xiao, F. A Hybrid Fuzzy Soft Sets Decision Making Method in Medical Diagnosis. IEEE Access 2018, 6, 25300–25312. [Google Scholar] [CrossRef]
- Mardani, A.; Nilashi, M.; Zavadskas, E.K.; Awang, S.R.; Zare, H.; Jamal, N.M. Decision Making Methods Based on Fuzzy Aggregation Operators: Three Decades Review from 1986 to 2017. Int. J. Inf. Technol. Decis. Mak. 2018, 17, 391–466. [Google Scholar] [CrossRef]
- Ding, W.; Lin, C.T.; Prasad, M. Hierarchical co-evolutionary clustering tree-based rough feature game equilibrium selection and its application in neonatal cerebral cortex MRI. Expert Syst. Appl. 2018, 101, 243–257. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W.; Wang, Z. Zero-sum polymatrix games with link uncertainty: A Dempster-Shafer theory solution. Appl. Math. Comput. 2019, 340, 101–112. [Google Scholar] [CrossRef]
- Cao, Z.; Lin, C.T. Inherent Fuzzy Entropy for the Improvement of EEG Complexity Evaluation. IEEE Trans. Fuzzy Syst. 2018, 26, 1032–1035. [Google Scholar] [CrossRef]
- Dong, Y.; Zhang, J.; Li, Z.; Hu, Y.; Deng, Y. Combination of Evidential Sensor Reports with Distance Function and Belief Entropy in Fault Diagnosis. Int. J. Comput. Commun. Control 2019, 14, 329–343. [Google Scholar] [CrossRef]
- Ding, W.; Lin, C.T.; Chen, S.; Zhang, X.; Hu, B. Multiagent-consensus-MapReduce-based attribute reduction using co-evolutionary quantum PSO for big data applications. Neurocomputing 2018, 272, 136–153. [Google Scholar] [CrossRef]
- Dempster, A.P. Upper and Lower Probabilities Induced by a Multivalued Mapping. In Classic Works of the Dempster–Shafer Theory of Belief Functions; Springer: Berlin/Heidelberg, Germany, 2008; pp. 57–72. [Google Scholar]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976; Volume 42. [Google Scholar]
- Su, X.; Li, L.; Qian, H.; Sankaran, M.; Deng, Y. A new rule to combine dependent bodies of evidence. In Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Gong, Y.; Su, X.; Qian, H.; Yang, N. Research on fault diagnosis methods for the reactor coolant system of nuclear power plant based on D-S evidence theory. Ann. Nucl. Energy 2018, 112, 395–399. [Google Scholar] [CrossRef]
- Yin, L.; Deng, Y. Measuring transferring similarity via local information. Phys. A Stat. Mech. Appl. 2018, 498, 102–115. [Google Scholar] [CrossRef]
- Fei, L.; Deng, Y.; Hu, Y. DS-VIKOR: A New Multi-criteria Decision-Making Method for Supplier Selection. Int. J. Fuzzy Syst. 2018, 21, 157–175. [Google Scholar] [CrossRef]
- Sun, R.; Deng, Y. A new method to identify incomplete frame of discernment in evidence theory. IEEE Access 2019, 7, 15547–15555. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, C.; Deng, X. A new probability transformation method based on a correlation coefficient of belief functions. Int. J. Intell. Syst. 2019. [Google Scholar] [CrossRef]
- Su, X.; Li, L.; Shi, F.; Qian, H. Research on the Fusion of Dependent Evidence Based on Mutual Information. IEEE Access 2018, 6, 71839–71845. [Google Scholar] [CrossRef]
- Yager, R.R. On the Dempster–Shafer framework and new combination rules. Inf. Sci. 1987, 41, 93–137. [Google Scholar] [CrossRef]
- Smets, P. The Combination of Evidence in the Transferable Belief Model. IEEE Trans 1990, 12, 447–458. [Google Scholar] [CrossRef]
- Lefevre, E.; Colot, O.; Vannoorenberghe, P. Belief function combination and conflict management. Inf. Fusion 2002, 3, 149–162. [Google Scholar] [CrossRef]
- Sun, Q.; Ye, X.; Gu, W. A New Combination Rules of Evidence Theory. Acta Electron. Sin. 2000, 28, 117–119. [Google Scholar]
- Li, B.; Bo, W.; Wei, J.; Huang, Y.; Guo, Z. Efficient combination rule of evidence theory. In Object Detection, Classification, & Tracking Technologies; International Society for Optics and Photonics: Bellingham, WA, USA, 2001. [Google Scholar]
- Murphy, C.K. Combining belief functions when evidence conflicts. Decis. Support Syst. 2000, 29, 1–9. [Google Scholar] [CrossRef]
- Deng, Y.; Shi, W.; Zhu, Z.; Liu, Q. Combining belief functions based on distance of evidence. Decis. Support Syst. 2005, 38, 489–493. [Google Scholar]
- Jiang, W.; Wei, B.; Xie, C.; Zhou, D. An evidential sensor fusion method in fault diagnosis. Adv. Mech. Eng. 2016, 8. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, T.; Chen, D.; Zhang, W. Novel Algorithm for Identifying and Fusing Conflicting Data in Wireless Sensor Networks. Sensors 2014, 14, 9562–9581. [Google Scholar] [CrossRef]
- Yun, L.; Li, Y.; Yin, X.; Zheng, D. Multisensor Fault Diagnosis Modeling Based on the Evidence Theory. IEEE Trans. Reliab. 2018, 67, 513–521. [Google Scholar]
- Song, Y.; Deng, Y. A new method to measure the divergence in evidential sensor data fusion. Int. J. Distrib. Sens. Netw. 2019, 15. [Google Scholar] [CrossRef]
- Yin, L.; Deng, X.; Deng, Y. The negation of a basic probability assignment. IEEE Trans. Fuzzy Syst. 2019, 27, 135–143. [Google Scholar] [CrossRef]
- Deng, X.; Jiang, W. Dependence assessment in human reliability analysis using an evidential network approach extended by belief rules and uncertainty measures. Ann. Nucl. Energy 2018, 117, 183–193. [Google Scholar] [CrossRef]
- Yager, R.R.; Elmore, P.; Petry, F. Soft likelihood functions in combining evidence. Inf. Fusion 2017, 36, 185–190. [Google Scholar] [CrossRef]
- Zhang, W.; Deng, Y. Combining conflicting evidence using the DEMATEL method. Soft Comput. 2018. [Google Scholar] [CrossRef]
- Jiang, W.; Hu, W. An improved soft likelihood function for Dempster-Shafer belief structures. Int. J. Intell. Syst. 2018, 33, 1264–1282. [Google Scholar] [CrossRef]
- Knuth, K.H.; Habeck, M.; Malakar, N.K.; Mubeen, A.M.; Placek, B. Bayesian evidence and model selection. Digit. Signal Process. 2015, 47, 50–67. [Google Scholar] [CrossRef]
- Knuth, K.; Placek, B.; Angerhausen, D.; Carter, J.; D’Angelo, B.; Gai, A.; Carado, B. EXONEST: The Bayesian Exoplanetary Explorer. Entropy 2017, 19, 559. [Google Scholar] [CrossRef]
- Yang, J.; Xu, D. Evidential reasoning rule for evidence combination. Artif. Intell. 2013, 205, 1–29. [Google Scholar] [CrossRef]
- Chatterjee, K.; Zavadskas, E.K.; Tamosaitiene, J.; Adhikary, K.; Kar, S. A Hybrid MCDM Technique for Risk Management in Construction Projects. Symmetry 2018, 10, 46. [Google Scholar] [CrossRef]
- Han, Y.; Deng, Y. A hybrid intelligent model for Assessment of critical success factors in high risk emergency system. J. Ambient Intell. Humaniz. Comput. 2018, 9, 1933–1953. [Google Scholar] [CrossRef]
- Xu, H.; Deng, Y. Dependent Evidence Combination Based on DEMATEL Method. Int. J. Intell. Syst. 2019, 34, 1555–1571. [Google Scholar] [CrossRef]
- Song, Y.; Wang, X.; Zhu, J.; Lei, L. Sensor dynamic reliability evaluation based on evidence theory and intuitionistic fuzzy sets. Appl. Intell. 2018, 48, 3950–3962. [Google Scholar] [CrossRef]
- Fei, L.; Deng, Y. A new divergence measure for basic probability assignment and its applications in extremely uncertain environments. Int. J. Intell. Syst. 2019, 34, 584–600. [Google Scholar] [CrossRef]
- Han, Y.; Deng, Y. A novel matrix game with payoffs of Maxitive Belief Structure. Int. J. Intell. Syst. 2019, 34, 690–706. [Google Scholar] [CrossRef]
- He, Z.; Jiang, W. An evidential Markov decision making model. Inf. Sci. 2018, 467, 357–372. [Google Scholar] [CrossRef]
- Han, Y.; Deng, Y. An Evidential Fractal AHP target recognition method. Def. Sci. J. 2018, 68, 367–373. [Google Scholar] [CrossRef]
- Li, Z.; Chen, L. A novel evidential FMEA method by integrating fuzzy belief structure and grey relational projection method. Eng. Appl. Artif. Intell. 2019, 77, 136–147. [Google Scholar] [CrossRef]
- Chen, L.; Yu, H. Emergency Alternative Selection Based on an E-IFWA Approach. IEEE Access 2019, 7, 44431–44440. [Google Scholar] [CrossRef]
- Chen, L.; Deng, Y. A new failure mode and effects analysis model using Dempster–Shafer evidence theory and grey relational projection method. Eng. Appl. Artif. Intell. 2018, 76, 13–20. [Google Scholar] [CrossRef]
- Chen, L.; Deng, X. A Modified Method for Evaluating Sustainable Transport Solutions Based on AHP and Dempster–Shafer Evidence Theory. Appl. Sci. 2018, 8, 563. [Google Scholar] [CrossRef]
- Jiang, W. A correlation coefficient for belief functions. Int. J. Approx. Reason. 2018, 103, 94–106. [Google Scholar] [CrossRef]
- Deng, X. Analyzing the monotonicity of belief interval based uncertainty measures in belief function theory. Int. J. Intell. Syst. 2017, 33, 1869–1879. [Google Scholar] [CrossRef]
- Zhu, J.; Wang, X.; Song, Y. Evaluating the Reliability Coefficient of a Sensor Based on the Training Data Within the Framework of Evidence Theory. IEEE Access 2018, 6, 30592–30601. [Google Scholar] [CrossRef]
- Fu, C.; Chang, W.; Xue, M.; Yang, S. Multiple criteria group decision making with belief distributions and distributed preference relations. Eur. J. Oper. Res. 2019, 273, 623–633. [Google Scholar] [CrossRef]
- Seiti, H.; Hafezalkotob, A.; Naja, S.; Khalaj, M. A risk-based fuzzy evidential framework for FMEA analysis under uncertainty: An interval-valued DS approach. J. Intell. Fuzzy Syst. 2018, 35, 1419–1430. [Google Scholar] [CrossRef]
- Zhang, H.; Deng, Y. Engine fault diagnosis based on sensor data fusion considering information quality and evidence theory. Adv. Mech. Eng. 2018, 10. [Google Scholar] [CrossRef]
- Deng, Y. Deng entropy. Chaos Solitons Fractals 2016, 91, 549–553. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. SIGMOBILE Mob. Comput. Commun. Rev. 2001, 5, 3–55. [Google Scholar] [CrossRef]
- Li, Y.; Deng, Y. Generalized Ordered Propositions Fusion Based on Belief Entropy. Int. J. Comput. Commun. Control 2018, 13, 792–807. [Google Scholar] [CrossRef]
- Cui, H.; Liu, Q.; Zhang, J.; Kang, B. An improved Deng entropy and its application in pattern recognition. IEEE Access 2019, 7, 18284–18292. [Google Scholar] [CrossRef]
- Xiao, F. Multi-sensor data fusion based on the belief divergence measure of evidence and the belief entropy. Inf. Fusion 2019, 46, 23–32. [Google Scholar] [CrossRef]
- Li, W.; Guo, K. Combination rules of D-S evidence theory and conflict problem. Syst. Eng. Theory Pract. 2010, 30, 1422. [Google Scholar]



© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).