Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning


Abstract
:1. Introduction
2. Kernel Risk-Sensitive Mean p-Power Error
2.1. Definition
2.2. Properties
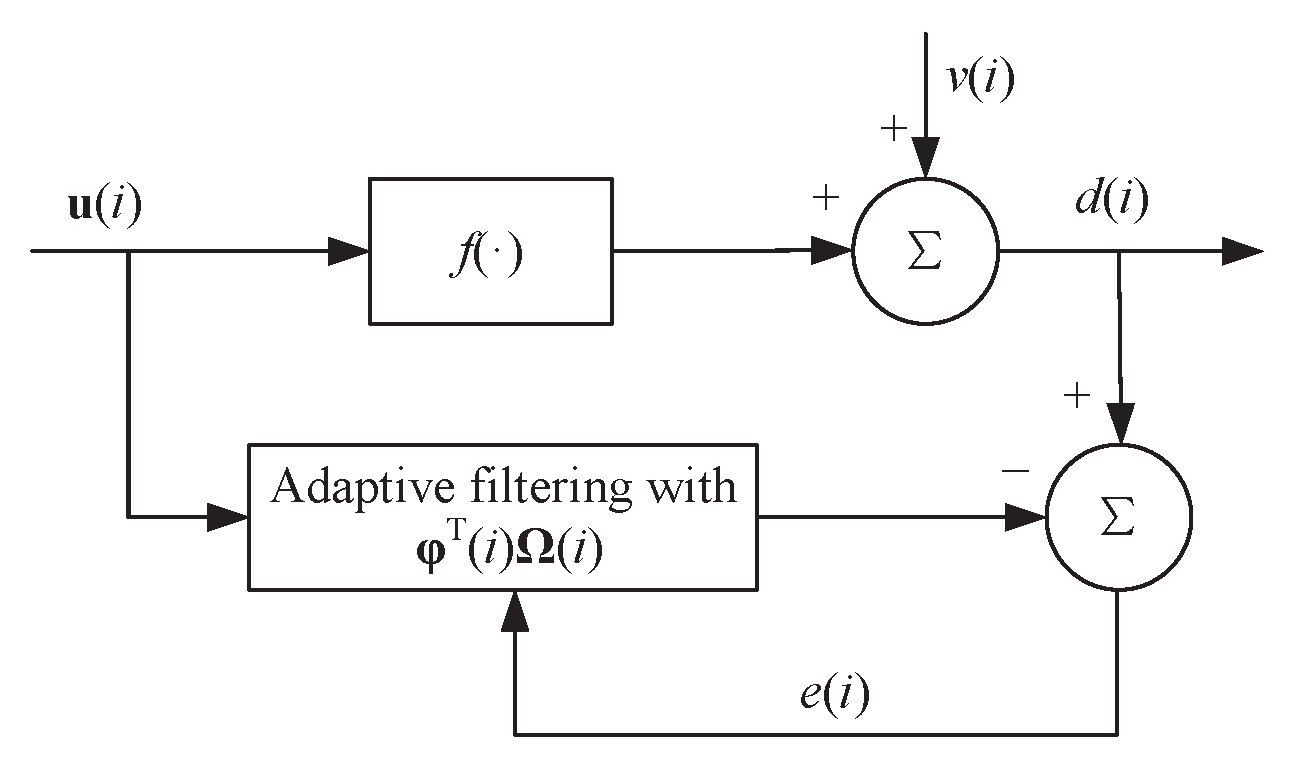
3. Application to Adaptive Filtering
3.1. RMKRP
| Algorithm 1: The RMKRP Algorithm. |
| Initialization: . . . Computation: While { available do 1) 2) 3) 4) 5) 6) 7) 8) end while |
3.2. QRMKRP
| Algorithm 2: The QRMKRP algorithm. |
| Initialization: , , . , . Computation: While { available do 1) Compute the distance between and : dis, where = . 2) If dis: Keep the dictionary unchanged: , Update by (32), by (33), by (34). 3) Otherwise: The dictionary changes: , Update by (35), by (36), by (38). end while |
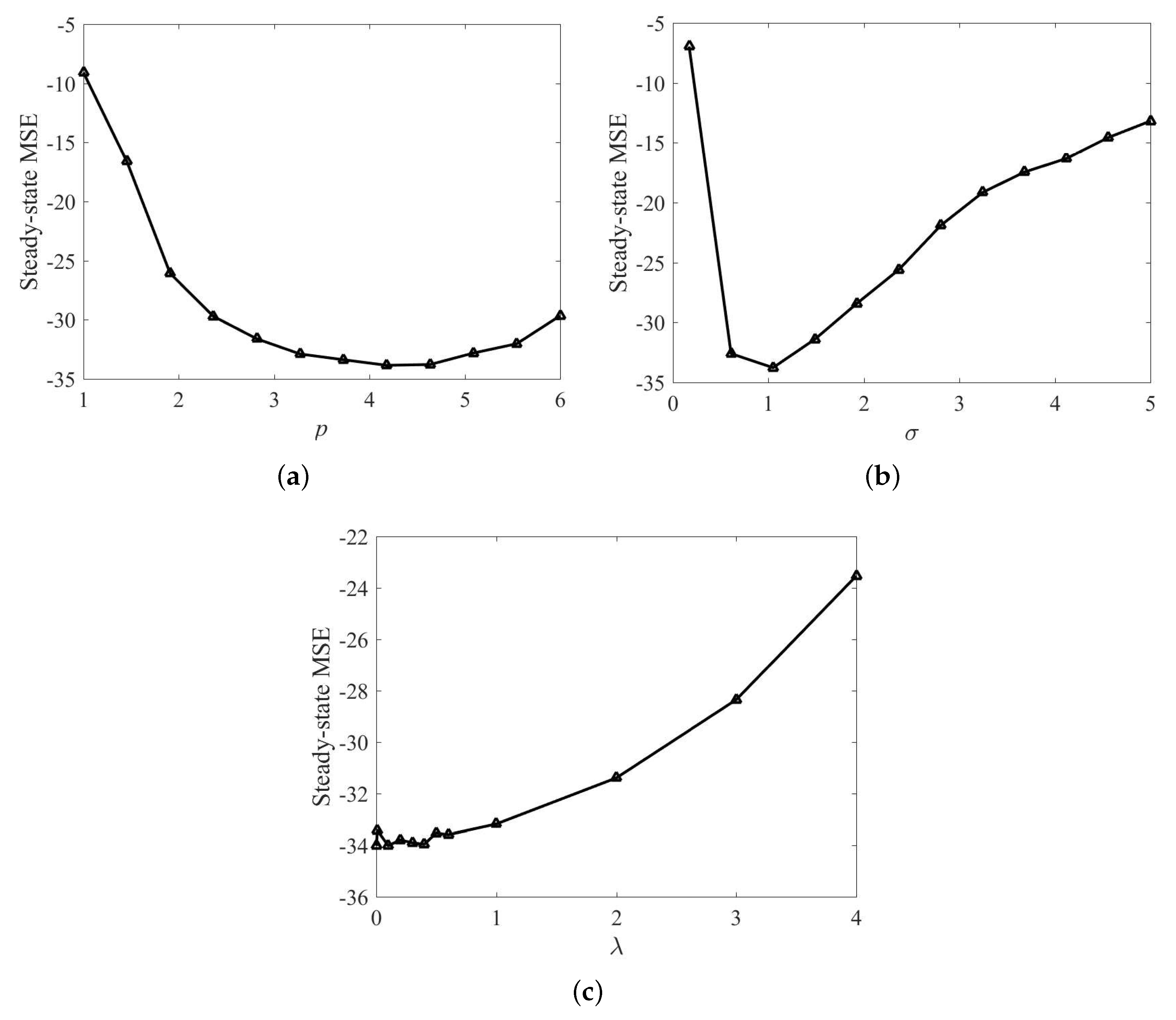
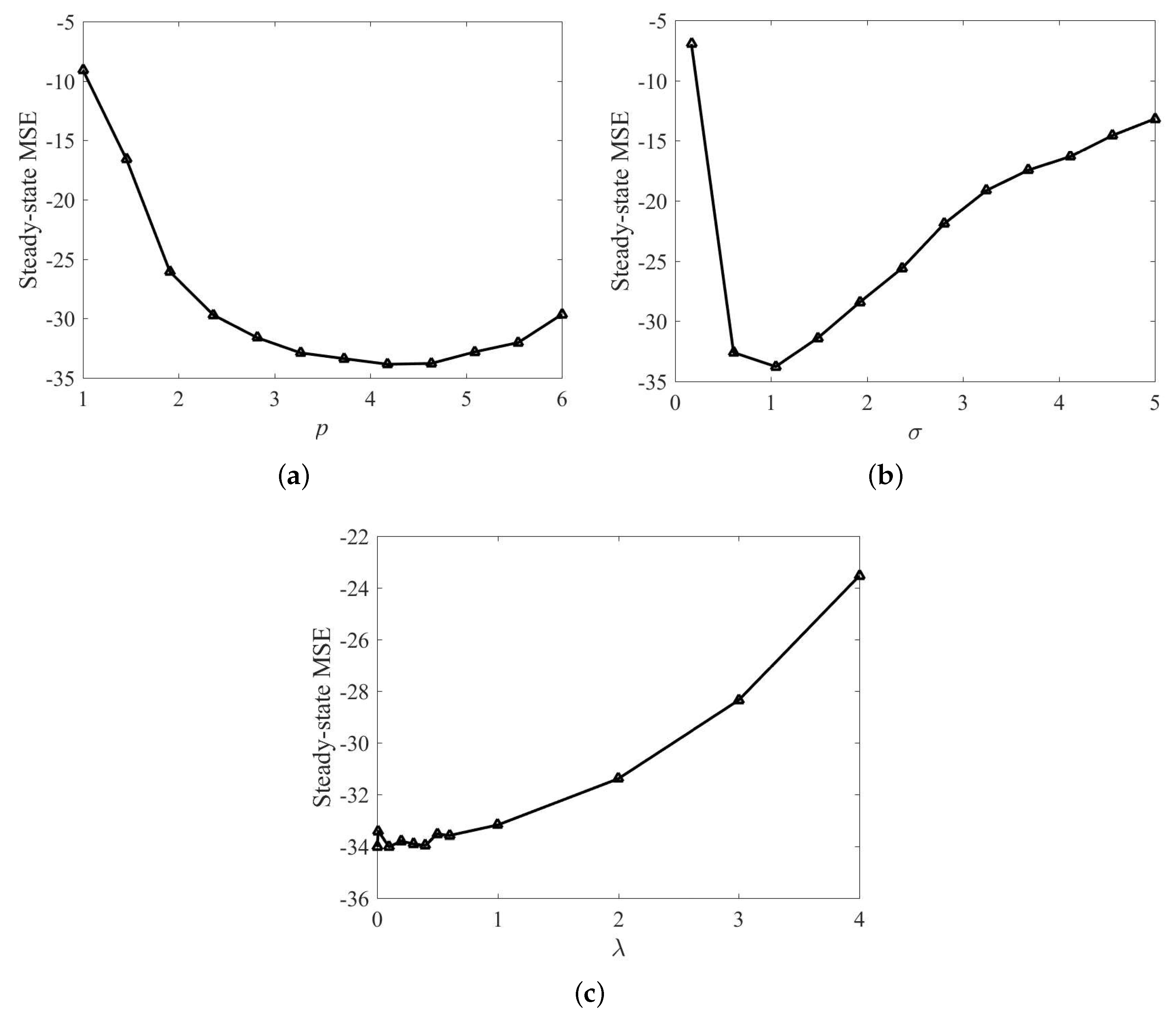
4. Simulation
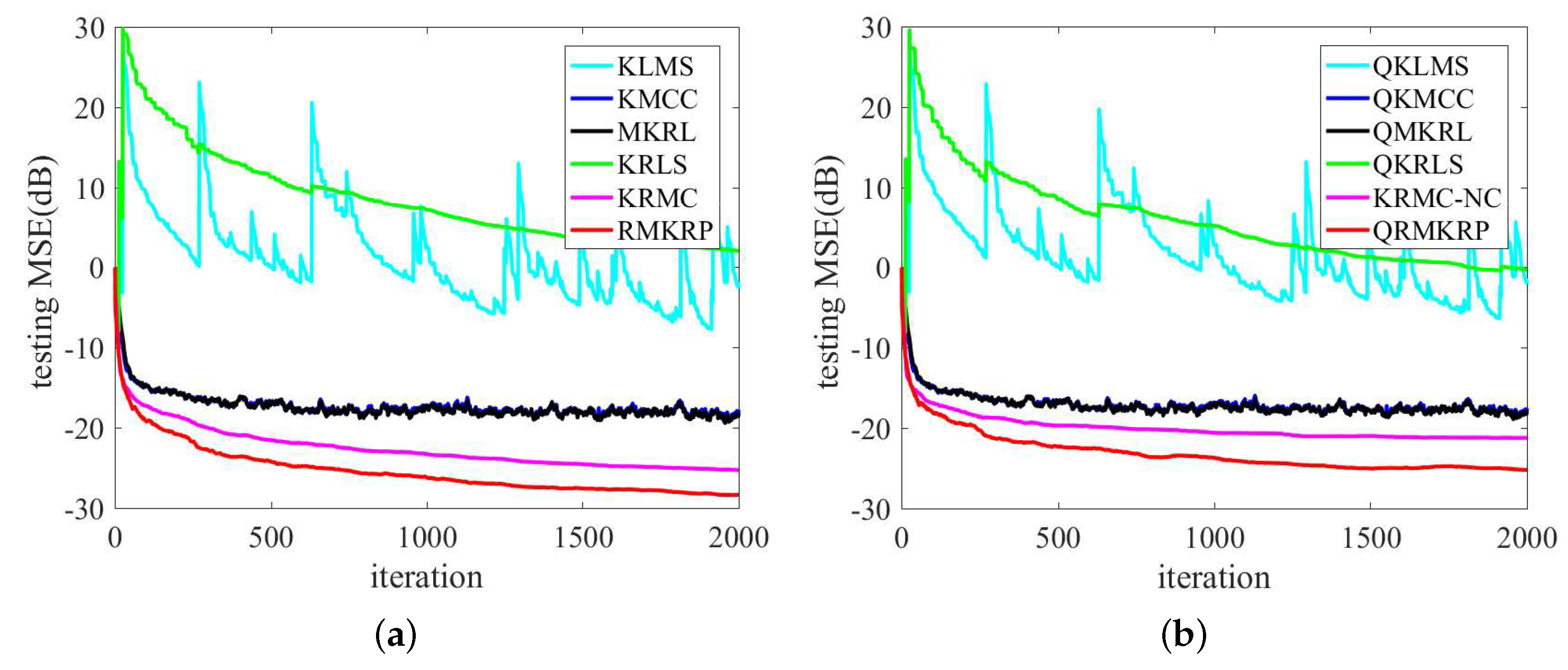
4.1. Chaotic Time Series Prediction
4.2. Nonlinear System Identification
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Kivinen, J.; Smola, A.J.; Williamson, R.C. Online learning with kernels. IEEE Trans. Signal Process. 2004, 52, 1540–1547. [Google Scholar] [CrossRef]
- Chen, B.; Li, L.; Liu, W.; Príncipe, J.C. Nonlinear adaptive filtering in kernel spaces. In Springer Handbook of Bio-/Neuroinformatics; Springer: Berlin, Germany, 2014; pp. 715–734. [Google Scholar]
- Nakajima, Y.; Yukawa, M. Nonlinear channel equalization by multi-kernel adaptive filter. In Proceedings of the IEEE 13th International Workshop on Signal Processing Advances in Wireless Communications, Cesme, Turkey, 17–20 June 2012; pp. 384–388. [Google Scholar]
- Jiang, S.; Gu, Y. Block-sparsity-induced adaptive filter for multi-clustering system identification. IEEE Trans. Signal Process. 2015, 63, 5318–5330. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Feng, J.; Tse, C.K. A modified quantized kernel least mean square algorithm for prediction of chaotic time series. Digital Signal Process. 2016, 48, 130–136. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, P.P.; Príncipe, J.C. The kernel least mean square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, J.C. Kernel affine projection algorithms. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar]
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least-squares algorithm. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar] [CrossRef]
- Liu, W.; Park, I.; Príncipe, J.C. An information theoretic approach of designing sparse kernel adaptive filters. IEEE Trans. Neural Netw. 2009, 20, 1950–1961. [Google Scholar] [CrossRef]
- Platt, J. A resource-allocating network for function interpolation. Neural Comput. 1991, 3, 213–225. [Google Scholar] [CrossRef]
- Richard, C.; Bermudez, J.C.M.; Honeine, P. Online prediction of time series data with kernels. IEEE Trans. Signal Process. 2009, 57, 1058–1067. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, S.; Zhu, P.; Príncipe, J.C. Quantized kernel least mean square algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 22–32. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, S.; Zhu, P.; Príncipe, J.C. Quantized kernel recursive least squares algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1484–1491. [Google Scholar] [CrossRef] [PubMed]
- Príncipe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Pei, S.-C.; Tseng, C.-C. Least mean p-power error criterion for adaptive FIR filter. IEEE J. Sel. Areas Commun. 1994, 12, 1540–1547. [Google Scholar]
- Boel, R.K.; James, M.R.; Petersen, I.R. Robustness and risk sensitive filtering. IEEE Trans. Autom. Control 2002, 47, 451–461. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Zheng, N.; Príncipe, J.C. Kernel risk-sensitive loss: Definition, properties and application to robust adaptive filtering. IEEE Trans. Signal Process. 2017, 65, 2888–2901. [Google Scholar] [CrossRef]
- Ma, W.; Duan, J.; Man, W.; Zhao, H.; Chen, B. Robust kernel adaptive filters based on mean p-power error for noisy chaotic time series prediction. Eng. Appl. Artif. Intell. 2017, 58, 101–110. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and applications in non-gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Príncipe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 2014, 21, 880–884. [Google Scholar]
- Wu, Z.; Shi, J.; Zhang, X.; Ma, W.; Chen, B. Kernel recursive maximum correntropy. Signal Process. 2015, 117, 11–16. [Google Scholar] [CrossRef]
- Zhao, S.; Chen, B.; Príncipe, J.C. Kernel adaptive filtering with maximum correntropy criterion. In Proceedings of the International Joint Conference on Neural Network, San Jose, CA, USA, 31 July–5 August 2011; Volume 31, pp. 2012–2017. [Google Scholar]
- He, R.; Hu, B.; Zheng, W.; Kong, X. Robust principal component analysis based on maximum correntropy criterion. IEEE Trans. Image Process. 2011, 20, 1485–1494. [Google Scholar]
- He, R.; Zheng, W.; Hu, B. Maximum correntropy criterion for robust face recognition. IEEE Trans. Patt. Anal. Mach. Intell. 2011, 33, 1561–1576. [Google Scholar]
- Santamaría, I.; Pokharel, P.P.; Príncipe, J.C. Generalized correlation function: Definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 2006, 54, 2187–2197. [Google Scholar] [CrossRef]
- Luo, X.; Deng, J.; Wang, W.; Wang, J.-H.; Zhao, W. A Quantized Kernel Learning Algorithm Using a Minimum Kernel Risk-Sensitive Loss Criterion and Bilateral Gradient Technique. Entropy 2017, 19, 365. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Wang, X.; Qin, J.; Zheng, N. Robust learning with kernel mean p-power error loss. IEEE Trans. Cybern. 2017, 48, 2101–2113. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Príncipe, J.C.; Haykin, S. Kernel Adaptive Filtering: A Comprehensive Introduction; Wiley: New York, NY, USA, 2010. [Google Scholar]
- Weng, B.; Barner, K.E. Nonlinear system identification in impulsive environments. IEEE Trans. Signal Process. 2005, 53, 2588–2594. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, Y.; Duan, S.; Wang, L.; Tan, H. Quantized kernel maximum correntropy and its mean square convergence analysis. Dig. Signal Process. 2017, 63, 164–176. [Google Scholar] [CrossRef]
- Fan, H.; Song, Q. A linear recurrent kernel online learning algorithm with sparse updates. Neural Netw. 2014, 50, 142–153. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
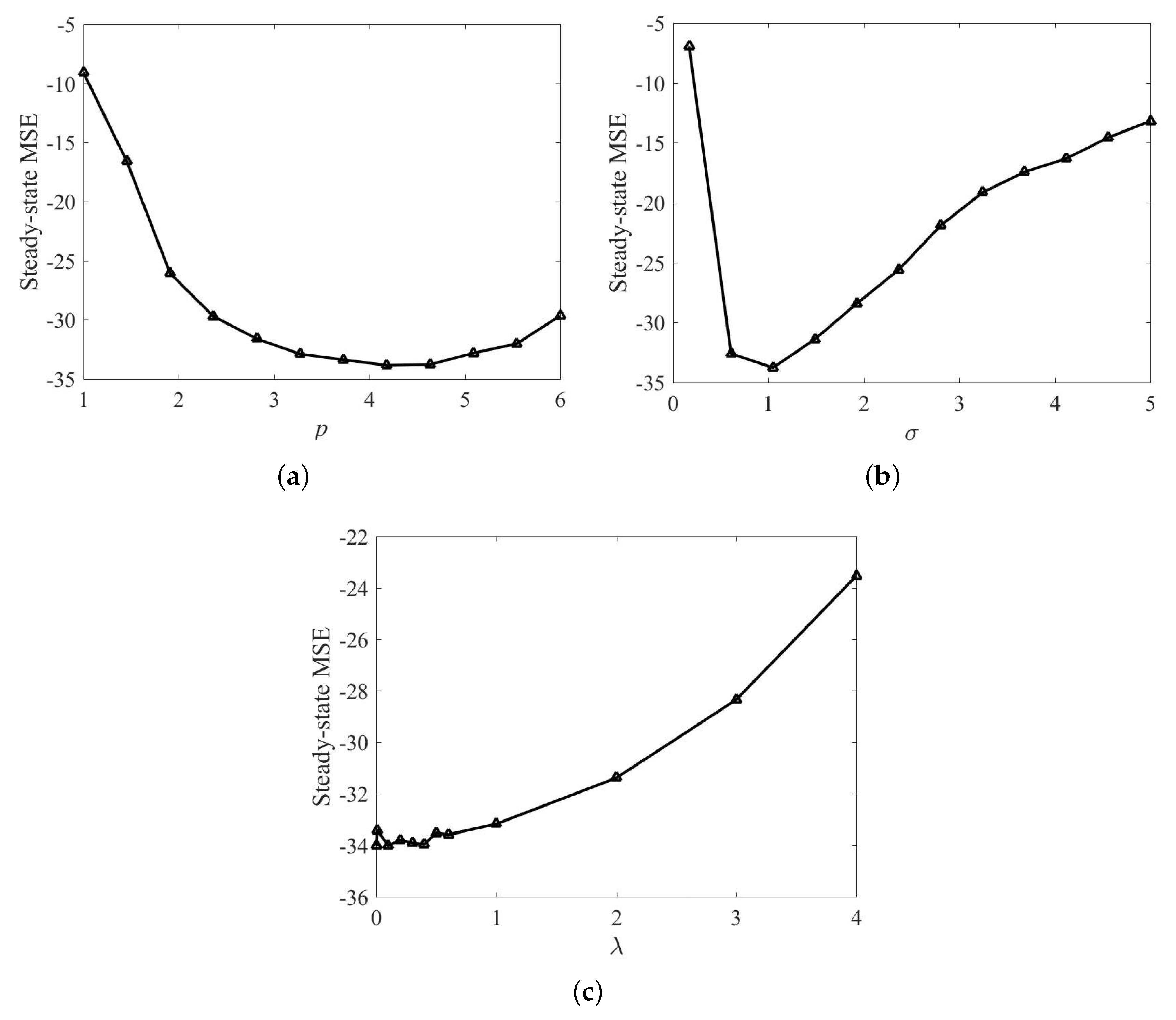{kind=link}
{kind=link}
{kind=link}
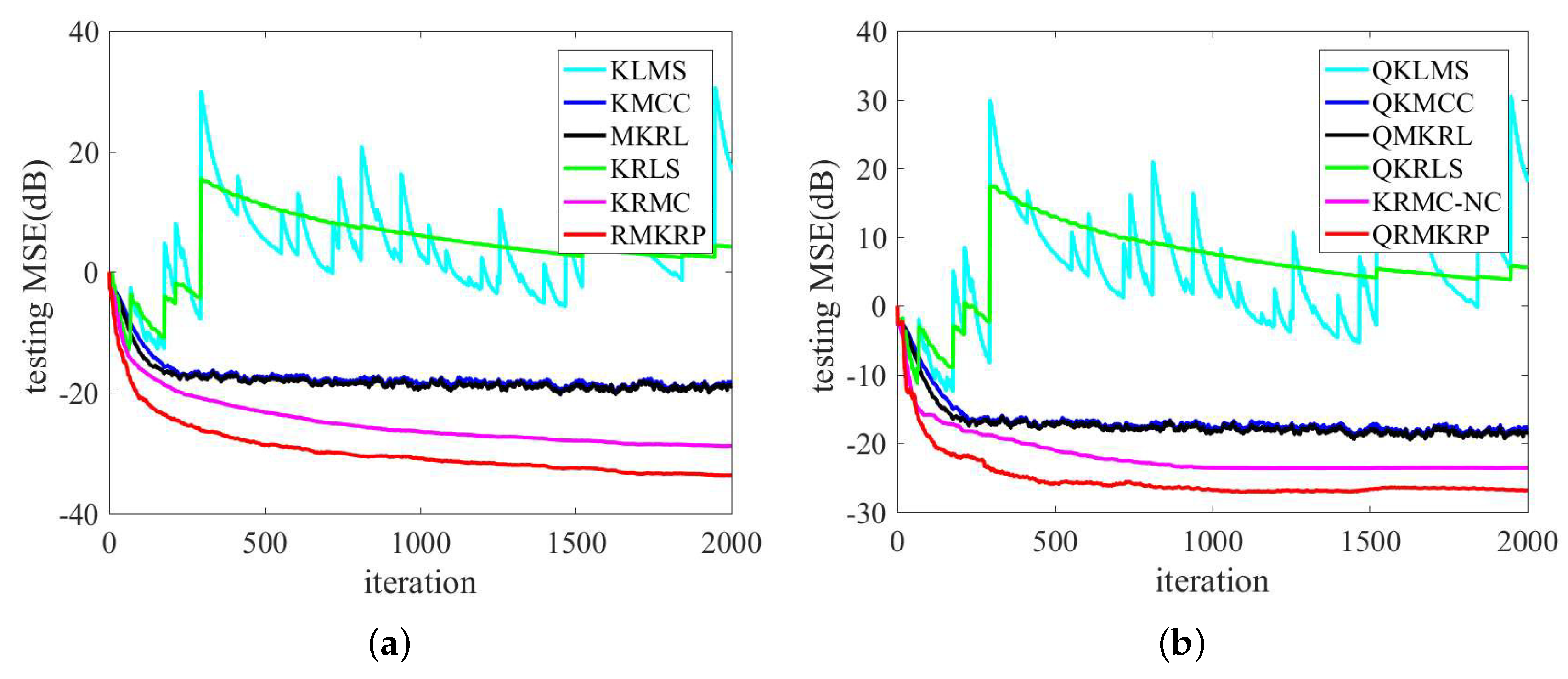{kind=link}
| Algorithms | Size | Time (s) | MSE (dB) |
|---|---|---|---|
| KLMS [6] | 2000 | 30.9501 s | N/A |
| QKLMS [12] | 28 | 2.1011 s | N/A |
| KRLS [8] | 2000 | 58.5358 s | N/A |
| QKRLS [13] | 28 | 2.3374 s | N/A |
| KMCC [22] | 2000 | 30.8285 s | −18.5063 |
| QKMCC [30] | 28 | 2.0995 s | −17.8707 |
| MKRL [26] | 2000 | 30.9117 s | −18.7312 |
| QMKRL [26] | 28 | 2.1063 s | −18.1037 |
| KRMC [21] | 2000 | 58.1229 s | −25.1618 |
| KRMC-NC [21] | 462 | 2.8045 s | −21.5183 |
| QRMKRP | 28 | 2.3443 s | −24.9326 |
| RMKRP | 2000 | 58.2196 s | −28.1802 |
| Algorithms | Size | Time (s) | MSE (dB) |
|---|---|---|---|
| KLMS [6] | 2000 | 21.2447 s | N/A |
| QKLMS [12] | 14 | 1.7284 s | N/A |
| KRLS [8] | 2000 | 48.6055 s | N/A |
| QKRLS [13] | 14 | 1.9643 s | N/A |
| KMCC [22] | 2000 | 21.1328 s | −19.233 |
| QKMCC [30] | 14 | 1.763 s | −17.9723 |
| MKRL [26] | 2000 | 21.0313 s | −19.5390 |
| QMKRL [26] | 14 | 1.7243 s | −18.5748 |
| KRMC [21] | 2000 | 48.7601 s | −28.7583 |
| KRMC-NC [21] | 496 | 2.6874 s | −23.671 |
| QRMKRP | 14 | 1.9681 s | −27.3128 |
| RMKRP | 2000 | 48.6101 s | −34.0790 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, T.; Wang, S.; Zhang, H.; Xiong, K.; Wang, L. Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning. Entropy 2019, 21, 588. https://doi.org/10.3390/e21060588
Zhang T, Wang S, Zhang H, Xiong K, Wang L. Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning. Entropy. 2019; 21(6):588. https://doi.org/10.3390/e21060588
Chicago/Turabian StyleZhang, Tao, Shiyuan Wang, Haonan Zhang, Kui Xiong, and Lin Wang. 2019. "Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning" Entropy 21, no. 6: 588. https://doi.org/10.3390/e21060588
APA StyleZhang, T., Wang, S., Zhang, H., Xiong, K., & Wang, L. (2019). Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning. Entropy, 21(6), 588. https://doi.org/10.3390/e21060588