The Arbitrarily Varying Relay Channel †


{kind=link}
{kind=link}
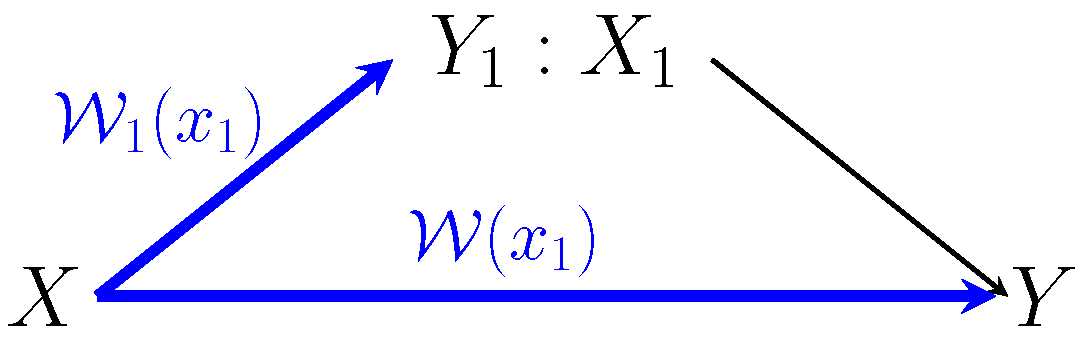{kind=link}
{kind=link}
{kind=link}
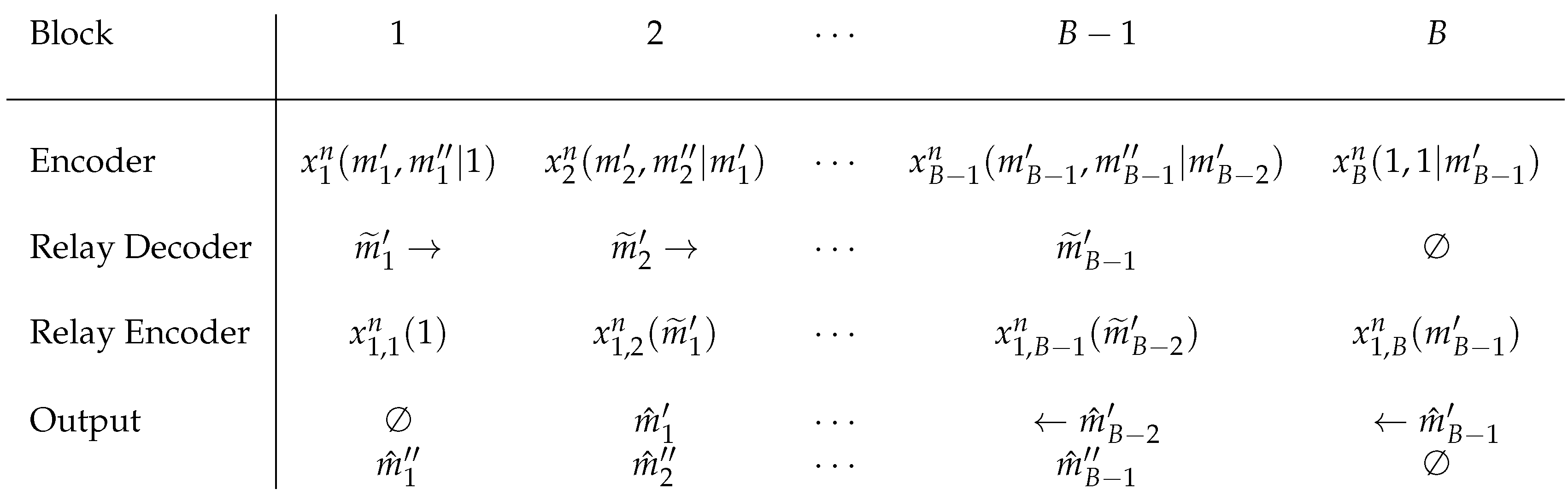{kind=link}
Abstract
1. Introduction
2. Definitions
2.1. Notation
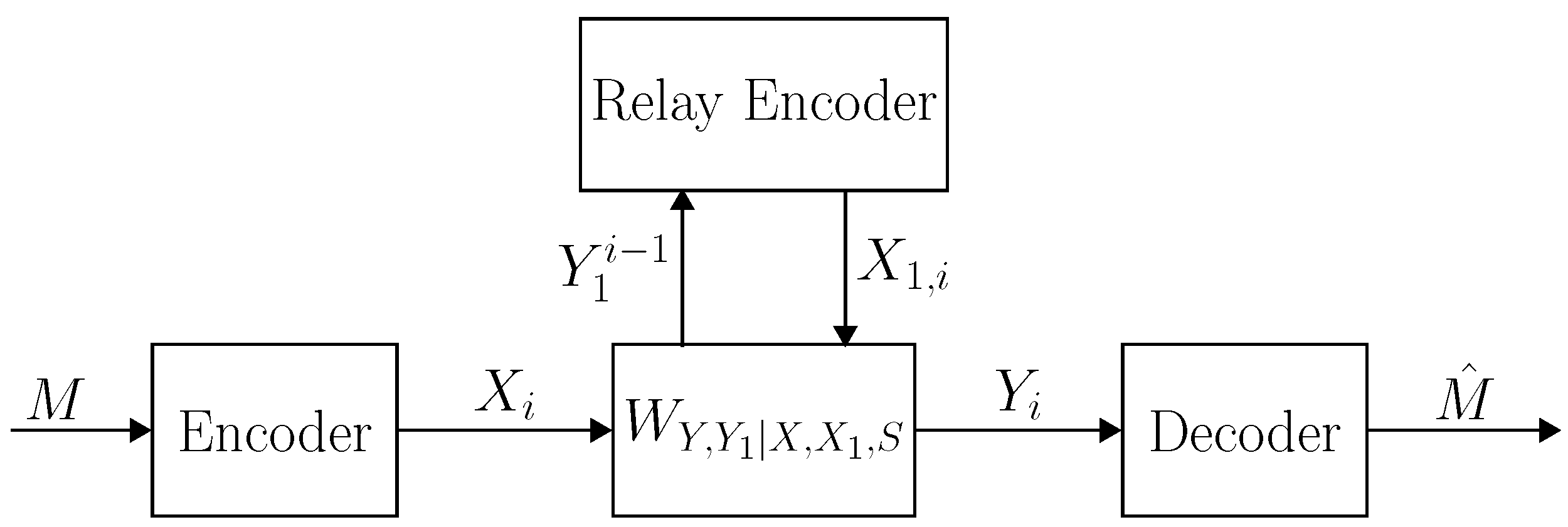
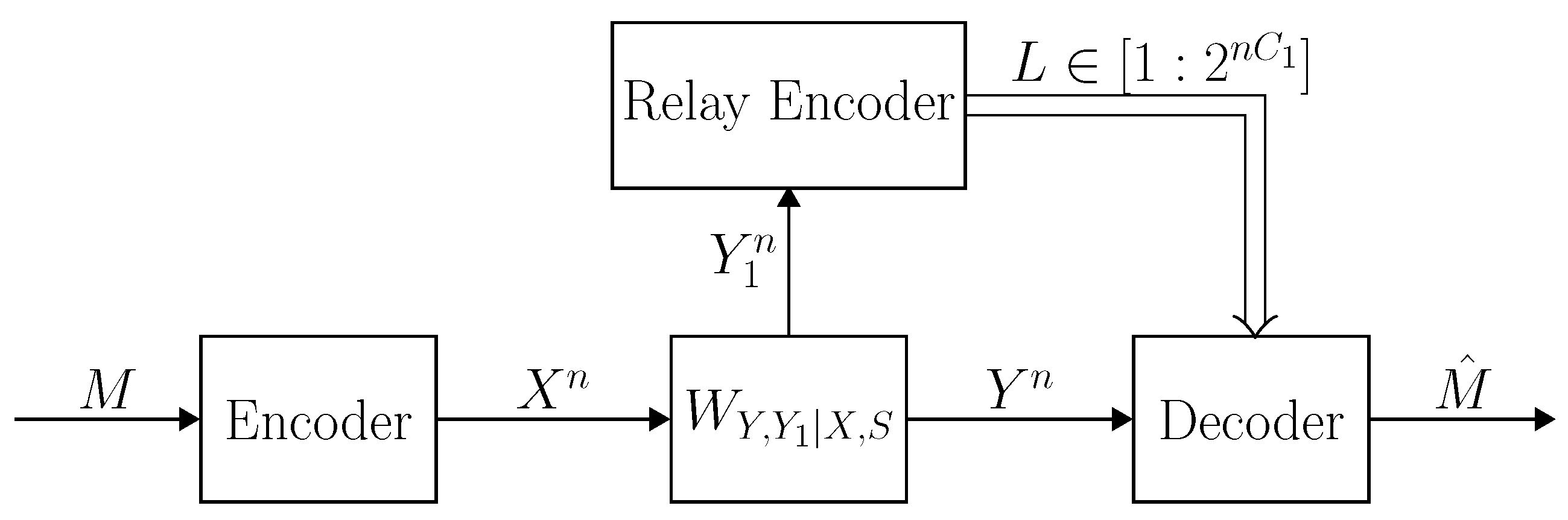
2.2. Channel Description
2.3. Coding
3. Main Results—General AVRC
3.1. The Compound Relay Channel
- 1.
- If is strongly reversely degraded, then
- 2.
- If is strongly degraded, then
3.2. The AVRC
3.2.1. Random Code Lower and Upper Bounds
- 1.
- If is strongly reversely degraded,
- 2.
- If is strongly degraded,
3.2.2. Deterministic Code Lower and Upper Bounds
- 1.
- If and are non-symmetrizable-, then . In this case,
- 2.
- If is strongly reversely degraded, where is non-symmetrizable-, then
- 3.
- If is strongly degraded, where is non-symmetrizable- and for some , and , then
3.3. AVRC with Orthogonal Sender Components
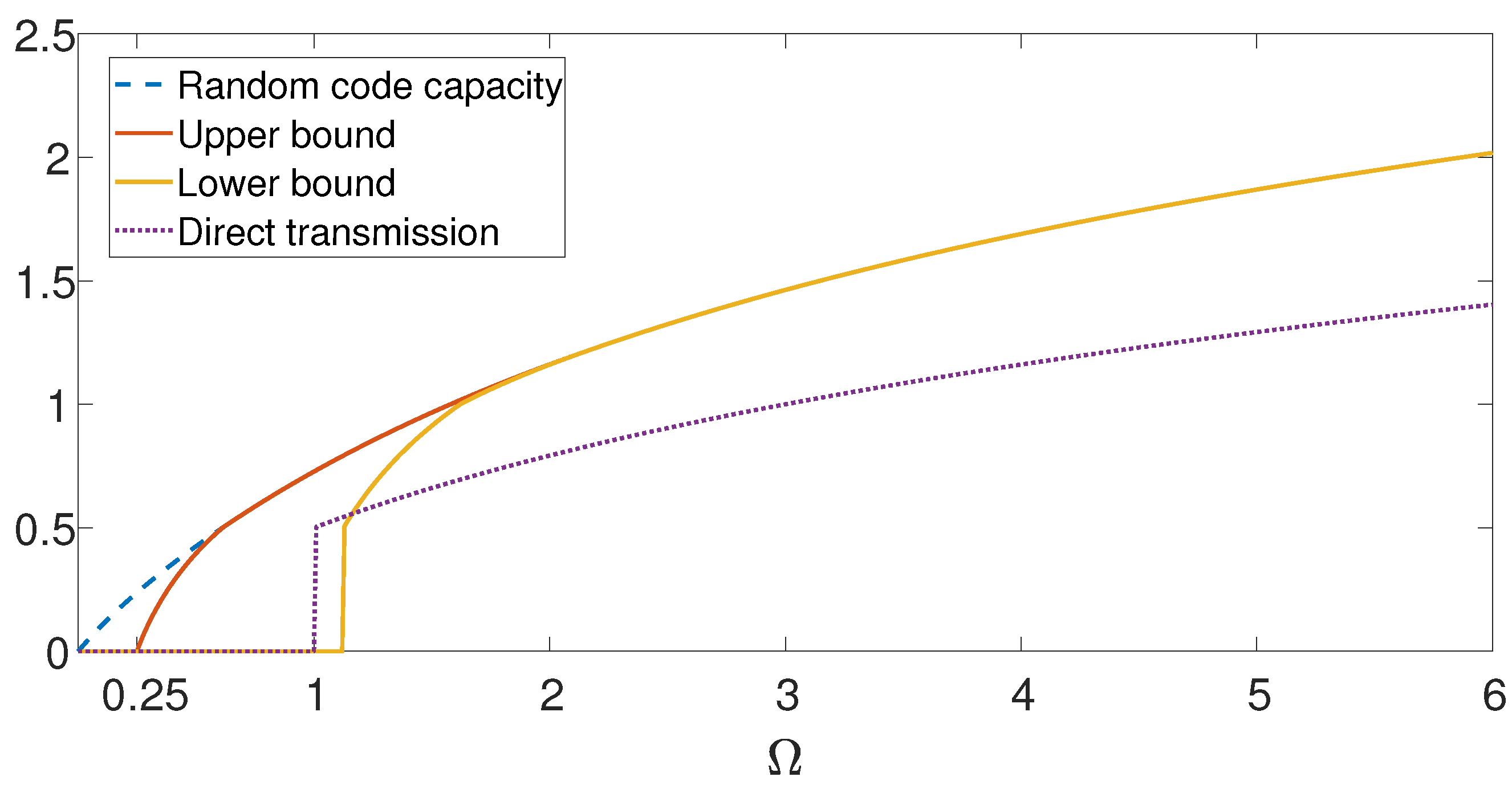
4. Gaussian AVRC with Sender Frequency Division
5. Main Results—Gaussian AVRC with SFD
5.1. Gaussian Compound Relay Channel
5.2. Gaussian AVRC
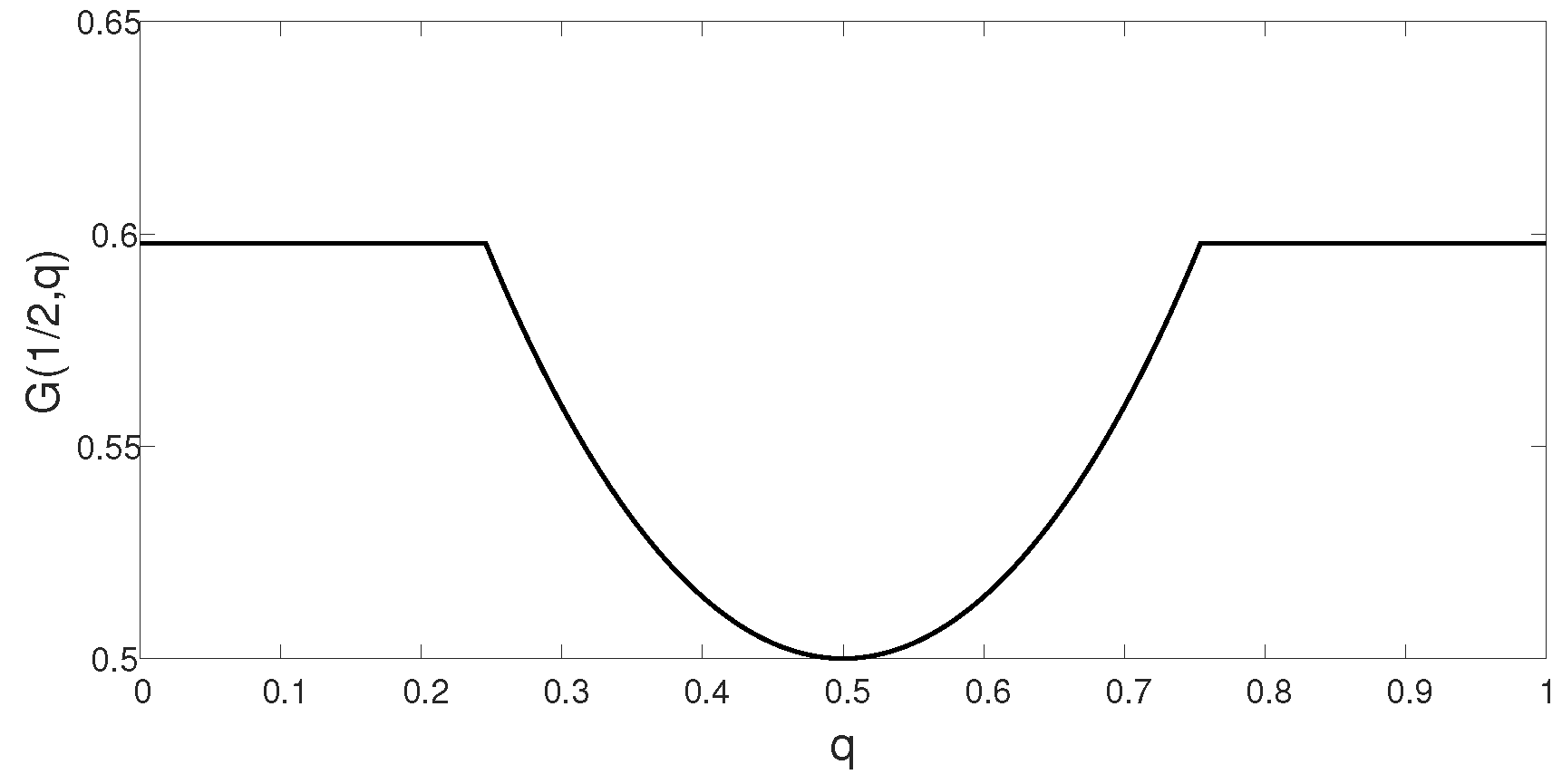
6. The Primitive AVRC
6.1. Definitions and Notation
6.2. Main Results—Primitive AVRC
- 1.
- If is strongly reversely degraded, i.e., , then
- 2.
- If is strongly degraded, i.e., , then
- 1.
- If is non-symmetrizable, then . In this case,
- 2.
- If is strongly reversely degraded, where is non-symmetrizable, then
- 3.
- If is strongly degraded, such that for some , , then
- 4.
- If is symmetrizable, where , then .
6.3. Primitive Gaussian AVRC
7. Discussion
Author Contributions
Conflicts of Interest
Abbreviations
| AVC | Arbitrarily varying channel |
| AVRC | Arbitrarily varying relay channel |
| DMC | Discrete memoryless channel |
| pmf | probability mass function |
| RT | Robustification technique |
| SFD | Sender frequency division |
| Eq. | Equation |
| RHS | Right hand side |
| LHS | Left hand side |
Appendix A. Proof of Lemma 1
Appendix A.1. Partial Decode-Forward Lower Bound

Appendix A.2. Cutset Upper Bound
Appendix B. Proof of Corollary 1
Appendix C. Proof of Corollary 2
Appendix D. Proof of Theorem 1
Appendix D.1. Partial Decode-Forward Lower Bound
Appendix D.2. Cutset Upper Bound
Appendix E. Proof of Lemma 2
Appendix F. Proof of Corollary 4
Appendix G. Proof of Lemma 3
Appendix H. Proof of Lemma 4
Appendix I. Analysis of Example 1
Appendix J. Proof of Lemma 5
Appendix J.1. Achievability Proof
Appendix J.2. Converse Proof
Appendix K. Proof of Lemma 6
Appendix K.1. Achievability Proof
Appendix K.2. Converse Proof
Appendix L. Proof of Theorem 2
Appendix L.1. Achievability Proof
Appendix L.2. Converse Proof
Appendix M. Proof of Theorem 3
Appendix M.1. Lower Bound
- 1.
- there exist unit vectors,such that for every unit vector and ,and if and , then
- 2.
- Furthermore, for every , there exist unit vectors,such that for every unit vector and ,and if and , then
Appendix M.2. Upper Bound
References
- Van der Meulen, E.C. Three-terminal communication channels. Adv. Appl. Probab. 1971, 3, 120–154. [Google Scholar] [CrossRef]
- Kim, Y.H. Coding techniques for primitive relay channels. In Proceedings of the Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 26–28 September 2007; pp. 129–135. [Google Scholar]
- El Gamal, A.; Kim, Y. Network Information Theory; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Cover, T.; Gamal, A.E. Capacity theorems for the relay channel. IEEE Trans. Inf. Theory 1979, 25, 572–584. [Google Scholar] [CrossRef]
- Gamal, A.E.; Zahedi, S. Capacity of a class of relay channels with orthogonal components. IEEE Trans. Inf. Theory 2005, 51, 1815–1817. [Google Scholar]
- Xue, F. A New Upper Bound on the Capacity of a Primitive Relay Channel Based on Channel Simulation. IEEE Trans. Inf. Theory 2014, 60, 4786–4798. [Google Scholar] [CrossRef]
- Wu, X.; Özgür, A. Cut-set bound is loose for Gaussian relay networks. In Proceedings of the Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 29 September–2 October 2015; pp. 1135–1142. [Google Scholar]
- Chen, Y.; Devroye, N. Zero-Error Relaying for Primitive Relay Channels. IEEE Trans. Inf. Theory 2017, 63, 7708–7715. [Google Scholar] [CrossRef]
- Wu, X.; Özgür, A. Cut-set bound is loose for Gaussian relay networks. IEEE Trans. Inf. Theory 2018, 64, 1023–1037. [Google Scholar] [CrossRef]
- Wu, X.; Barnes, L.P.; Özgür, A. “The Capacity of the Relay Channel”: Solution to Cover’s Problem in the Gaussian Case. IEEE Trans. Inf. Theory 2019, 65, 255–275. [Google Scholar] [CrossRef]
- Mondelli, M.; Hassani, S.H.; Urbanke, R. A New Coding Paradigm for the Primitive Relay Channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2018), Talisa Hotel in Vail, CO, USA, 17–22 June 2018; pp. 351–355. [Google Scholar]
- Ramachandran, V. Gaussian degraded relay channel with lossy state reconstruction. AEU Int. J. Electr. Commun. 2018, 93, 348–353. [Google Scholar] [CrossRef]
- Chen, Z.; Fan, P.; Wu, D.; Xiong, K.; Letaief, K.B. On the achievable rates of full-duplex Gaussian relay channel. In Proceedings of the Global Communication Conference (GLOBECOM’2014), Austin, TX, USA, 8–12 December 2014; pp. 4342–4346. [Google Scholar]
- Kolte, R.; Özgür, A.; Gamal, A.E. Capacity Approximations for Gaussian Relay Networks. IEEE Trans. Inf. Theory 2015, 61, 4721–4734. [Google Scholar] [CrossRef]
- Jin, X.; Kim, Y. The Approximate Capacity of the MIMO Relay Channel. IEEE Trans. Inf. Theory 2017, 63, 1167–1176. [Google Scholar] [CrossRef]
- Wu, X.; Barnes, L.P.; Özgür, A. The geometry of the relay channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2017), Aachen, Germany, 25–30 June 2017; pp. 2233–2237. [Google Scholar]
- Lai, L.; El Gamal, H. The relay–eavesdropper channel: Cooperation for secrecy. IEEE Trans. Inf. Theory 2008, 54, 4005–4019. [Google Scholar] [CrossRef]
- Yeoh, P.L.; Yang, N.; Kim, K.J. Secrecy outage probability of selective relaying wiretap channels with collaborative eavesdropping. In Proceedings of the Global Communication Conference (GLOBECOM’2015), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Kramer, G.; van Wijngaarden, A.J. On the white Gaussian multiple-access relay channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2000), Sorrento, Italy, 25–30 June 2000; p. 40. [Google Scholar]
- Schein, B.E. Distributed Coordination in Network Information Theory. Ph.D. Thesis, Massachusetts Institute of Technology, Cambridge, MA, USA, 2001. [Google Scholar]
- Rankov, B.; Wittneben, A. Achievable Rate Regions for the Two-way Relay Channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2006), Seattle, WA, USA, 9–14 July 2006; pp. 1668–1672. [Google Scholar]
- Gunduz, D.; Yener, A.; Goldsmith, A.; Poor, H.V. The Multiway Relay Channel. IEEE Trans. Inf. Theory 2013, 59, 51–63. [Google Scholar] [CrossRef]
- Maric, I.; Yates, R.D. Forwarding strategies for Gaussian parallel-relay networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2004), Chicago, IL, USA, 27 June–2 July 2004; p. 269. [Google Scholar]
- Kochman, Y.; Khina, A.; Erez, U.; Zamir, R. Rematch and forward for parallel relay networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2008), Toronto, ON, Canada, 6–11 July 2008; pp. 767–771. [Google Scholar]
- Awan, Z.H.; Zaidi, A.; Vandendorpe, L. Secure communication over parallel relay channel. arXiv 2010, arXiv:1011.2115. [Google Scholar] [CrossRef]
- Xue, F.; Sandhu, S. Cooperation in a Half-Duplex Gaussian Diamond Relay Channel. IEEE Trans. Inf. Theory 2007, 53, 3806–3814. [Google Scholar]
- Kang, W.; Ulukus, S. Capacity of a class of diamond channels. In Proceedings of the Allerton Conference on Communication, Control and Computing, Urbana-Champaign, IL, USA, 23–26 September 2008; pp. 1426–1431. [Google Scholar]
- Chern, B.; Özgür, A. Achieving the Capacity of the N-Relay Gaussian Diamond Network Within logN Bits. IEEE Trans. Inf. Theory 2014, 60, 7708–7718. [Google Scholar] [CrossRef]
- Sigurjónsson, S.; Kim, Y.H. On multiple user channels with state information at the transmitters. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2005), Adelaide, Australia, 4–9 September 2005; pp. 72–76. [Google Scholar]
- Simeone, O.; Gündüz, D.; Shamai, S. Compound relay channel with informed relay and destination. In Proceedings of the Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 30 September–2 October 2009; pp. 692–699. [Google Scholar]
- Zaidi, A.; Vandendorpe, L. Lower bounds on the capacity of the relay channel with states at the source. EURASIP J. Wirel. Commun. Netw. 2009, 2009, 1–22. [Google Scholar] [CrossRef]
- Zaidi, A.; Kotagiri, S.P.; Laneman, J.N.; Vandendorpe, L. Cooperative Relaying With State Available Noncausally at the Relay. IEEE Trans. Inf. Theory 2010, 56, 2272–2298. [Google Scholar] [CrossRef]
- Zaidi, A.; Shamai, S.; Piantanida, P.; Vandendorpe, L. Bounds on the capacity of the relay channel with noncausal state at the source. IEEE Trans. Inf. Theory 2013, 59, 2639–2672. [Google Scholar] [CrossRef]
- Blackwell, D.; Breiman, L.; Thomasian, A.J. The capacities of certain channel classes under random coding. Ann. Math. Stat. 1960, 31, 558–567. [Google Scholar] [CrossRef]
- Simon, M.K.; Alouini, M.S. Digital Communication over Fading Channels; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 95. [Google Scholar]
- Shamai, S.; Steiner, A. A broadcast approach for a single-user slowly fading MIMO channel. IEEE Trans. Inf. Theory 2003, 49, 2617–2635. [Google Scholar] [CrossRef]
- Abdul Salam, A.; Sheriff, R.; Al-Araji, S.; Mezher, K.; Nasir, Q. Novel Approach for Modeling Wireless Fading Channels Using a Finite State Markov Chain. ETRI J. 2017, 39, 718–728. [Google Scholar] [CrossRef][Green Version]
- Ozarow, L.H.; Shamai, S.; Wyner, A.D. Information theoretic considerations for cellular mobile radio. IEEE Trans. Veh. Tech. 1994, 43, 359–378. [Google Scholar] [CrossRef]
- Goldsmith, A.J.; Varaiya, P.P. Capacity of fading channels with channel side information. IEEE Trans. Inf. Theory 1997, 43, 1986–1992. [Google Scholar] [CrossRef]
- Caire, G.; Shamai, S. On the capacity of some channels with channel state information. IEEE Trans. Inf. Theory 1999, 45, 2007–2019. [Google Scholar] [CrossRef]
- Zhou, S.; Zhao, M.; Xu, X.; Wang, J.; Yao, Y. Distributed wireless communication system: A new architecture for future public wireless access. IEEE Commun. Mag. 2003, 41, 108–113. [Google Scholar] [CrossRef]
- Xu, Y.; Lu, R.; Shi, P.; Li, H.; Xie, S. Finite-time distributed state estimation over sensor networks with round-robin protocol and fading channels. IEEE Trans. Cybern. 2018, 48, 336–345. [Google Scholar] [CrossRef]
- Kuznetsov, A.V.; Tsybakov, B.S. Coding in a memory with defective cells. Probl. Peredachi Inf. 1974, 10, 52–60. [Google Scholar]
- Heegard, C.; Gamal, A.E. On the capacity of computer memory with defects. IEEE Trans. Inf. Theory 1983, 29, 731–739. [Google Scholar] [CrossRef]
- Kuzntsov, A.V.; Vinck, A.J.H. On the general defective channel with informed encoder and capacities of some constrained memories. IEEE Trans. Inf. Theory 1994, 40, 1866–1871. [Google Scholar] [CrossRef]
- Kim, Y.; Kumar, B.V.K.V. Writing on dirty flash memory. In Proceedings of the Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 30 September–3 October 2014; pp. 513–520. [Google Scholar]
- Bunin, A.; Goldfeld, Z.; Permuter, H.H.; Shamai, S.; Cuff, P.; Piantanida, P. Key and message semantic-security over state-dependent channels. IEEE Trans. Inf. Forensic Secur. 2018. [Google Scholar] [CrossRef]
- Gungor, O.; Koksal, C.E.; Gamal, H.E. An information theoretic approach to RF fingerprinting. In Proceedings of the Asilomar Conference on Signals, Systems and Computers (ACSSC’2013), Pacific Grove, CA, USA, 3–6 November 2013; pp. 61–65. [Google Scholar]
- Ignatenko, T.; Willems, F.M.J. Biometric security from an information-theoretical perspective. Found. Trends® Commun. Inf. Theory 2012, 7, 135–316. [Google Scholar] [CrossRef]
- Han, G.; Xiao, L.; Poor, H.V. Two-dimensional anti-jamming communication based on deep reinforcement learning. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Xu, W.; Trappe, W.; Zhang, Y.; Wood, T. The feasibility of launching and detecting jamming attacks in wireless networks. In Proceedings of the ACM International Symposium on Mobile Ad Hoc Networking and Computing, Urbana-Champaign, IL, USA, 25–27 May 2005; pp. 46–57. [Google Scholar]
- Alnifie, G.; Simon, R. A multi-channel defense against jamming attacks in wireless sensor networks. In Proceedings of the ACM Workshop on QoS Security Wireless Mobile Networks, Crete Island, Greece, 22 October 2007; pp. 95–104. [Google Scholar]
- Padmavathi, G.; Shanmugapriya, D. A survey of attacks, security mechanisms and challenges in wireless sensor networks. arXiv 2009, arXiv:0909.0576. [Google Scholar]
- Wang, T.; Liang, T.; Wei, X.; Fan, J. Localization of Directional Jammer in Wireless Sensor Networks. In Proceedings of the 2018 International Conference on Robots & Intelligent System (ICRIS) (ICRIS’2018), Changsha, China, 26–27 May 2018; pp. 198–202. [Google Scholar]
- Ahlswede, R. Elimination of correlation in random codes for arbitrarily varying channels. Z. Wahrscheinlichkeitstheorie Verw. Gebiete 1978, 44, 159–175. [Google Scholar] [CrossRef]
- Ericson, T. Exponential error bounds for random codes in the arbitrarily varying channel. IEEE Trans. Inf. Theory 1985, 31, 42–48. [Google Scholar] [CrossRef]
- Csiszár, I.; Narayan, P. The capacity of the arbitrarily varying channel revisited: Positivity, constraints. IEEE Trans. Inf. Theory 1988, 34, 181–193. [Google Scholar] [CrossRef]
- Ahlswede, R. Coloring hypergraphs: A new approach to multi-user source coding, Part 2. J. Comb. 1980, 5, 220–268. [Google Scholar]
- Ahlswede, R. Arbitrarily varying channels with states sequence known to the sender. IEEE Trans. Inf. Theory 1986, 32, 621–629. [Google Scholar] [CrossRef]
- Jahn, J.H. Coding of arbitrarily varying multiuser channels. IEEE Trans. Inf. Theory 1981, 27, 212–226. [Google Scholar] [CrossRef]
- Hof, E.; Bross, S.I. On the deterministic-code capacity of the two-user discrete memoryless Arbitrarily Varying General Broadcast channel with degraded message sets. IEEE Trans. Inf. Theory 2006, 52, 5023–5044. [Google Scholar] [CrossRef]
- Winshtok, A.; Steinberg, Y. The arbitrarily varying degraded broadcast channel with states known at the encoder. In Proceedings of the 2006 IEEE International Symposium on Information Theory, Seattle, WA, USA, 9–14 July 2006; pp. 2156–2160. [Google Scholar]
- He, X.; Khisti, A.; Yener, A. MIMO Multiple Access Channel With an Arbitrarily Varying Eavesdropper: Secrecy Degrees of Freedom. IEEE Trans. Inf. Theory 2013, 59, 4733–4745. [Google Scholar]
- Pereg, U.; Steinberg, Y. The arbitrarily varying degraded broadcast channel with causal side information at the encoder. In Proceedings of the 2018 International Zurich Seminar Information Communication (IZS’2018), Aachen, Germany, 25–30 June 2018; pp. 20–24. [Google Scholar]
- Keresztfalvi, T.; Lapidoth, A. Partially-robust communications over a noisy channel. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2018), Vail, CO, USA, 17–22 June 2018; pp. 2003–2006. [Google Scholar]
- Gubner, J.A. Deterministic Codes for Arbitrarily Varying Multiple-Access Channels. Ph.D. Dissertation, University of Maryland, College Park, MD, USA, 1988. [Google Scholar]
- Gubner, J.A. On the deterministic-code capacity of the multiple-access arbitrarily varying channel. IEEE Trans. Inf. Theory 1990, 36, 262–275. [Google Scholar] [CrossRef]
- Gubner, J.A. State constraints for the multiple-access arbitrarily varying channel. IEEE Trans. Inf. Theory 1991, 37, 27–35. [Google Scholar] [CrossRef]
- Gubner, J.A. On the capacity region of the discrete additive multiple-access arbitrarily varying channel. IEEE Trans. Inf. Theory 1992, 38, 1344–1347. [Google Scholar] [CrossRef]
- Gubner, J.A.; Hughes, B.L. Nonconvexity of the capacity region of the multiple-access arbitrarily varying channel subject to constraints. IEEE Trans. Inf. Theory 1995, 41, 3–13. [Google Scholar] [CrossRef]
- Ahlswede, R.; Cai, N. Arbitrarily Varying Multiple-Access Channels; Universität Bielefeld: Bielefeld, Germany, 1996. [Google Scholar]
- Ahlswede, R.; Cai, N. Arbitrarily varying multiple-access channels. I. Ericson’s symmetrizability is adequate, Gubner’s conjecture is true. IEEE Trans. Inf. Theory 1999, 45, 742–749. [Google Scholar] [CrossRef]
- He, X.; Khisti, A.; Yener, A. MIMO multiple access channel with an arbitrarily varying eavesdropper. In Proceedings of the Allerton Conference on Communication, Control and Computing (Allerton’2011), Monticello, IL, USA, 28–30 September 2011; pp. 1182–1189. [Google Scholar]
- Wiese, M.; Boche, H. The arbitrarily varying multiple-access channel with conferencing encoders. IEEE Trans. Inf. Theory 2013, 59, 1405–1416. [Google Scholar] [CrossRef]
- Nitinawarat, S. On the Deterministic Code Capacity Region of an Arbitrarily Varying Multiple-Access Channel Under List Decoding. IEEE Trans. Inf. Theory 2013, 59, 2683–2693. [Google Scholar] [CrossRef][Green Version]
- MolavianJazi, E.; Bloch, M.; Laneman, J.N. Arbitrary jamming can preclude secure communication. In Proceedings of the Allerton Conference on Communication, Control and Computing, Monticello, IL, USA, 30 September–2 October 2009; pp. 1069–1075. [Google Scholar]
- Boche, H.; Schaefer, R.F. Capacity results and super-activation for wiretap channels with active wiretappers. IEEE Trans. Inf. Theory 2013, 8, 1482–1496. [Google Scholar] [CrossRef]
- Aydinian, H.; Cicalese, F.; Deppe, C. Information Theory, Combinatorics, and Search Theory; Springer: Berlin/Heidelberg, Germany, 2013; Chapter 5. [Google Scholar]
- Boche, H.; Schaefer, R.F.; Poor, H.V. On arbitrarily varying wiretap channels for different classes of secrecy measures. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2014), Honolulu, HI, USA, 29 June–4 July 2014; pp. 2376–2380. [Google Scholar]
- Boche, H.; Schaefer, R.F.; Poor, H.V. On the continuity of the secrecy capacity of compound and arbitrarily varying wiretap channels. IEEE Trans. Inf. Forensic Secur. 2015, 10, 2531–2546. [Google Scholar] [CrossRef]
- Nötzel, J.; Wiese, M.; Boche, H. The arbitrarily varying wiretap channel—Secret randomness, stability, and super-activation. IEEE Trans. Inf. Theory 2016, 62, 3504–3531. [Google Scholar] [CrossRef]
- Goldfeld, Z.; Cuff, P.; Permuter, H.H. Arbitrarily Varying Wiretap Channels with Type Constrained States. IEEE Trans. Inf. Theory 2016, 62, 7216–7244. [Google Scholar] [CrossRef]
- He, D.; Luo, Y. Arbitrarily varying wiretap channel with state sequence known or unknown at the receiver. arXiv 2017, arXiv:1701.02043. [Google Scholar]
- Boche, H.; Deppe, C. Secure identification for wiretap channels; Robustness, super-additivity and continuity. IEEE Trans. Inf. Forensic Secur. 2018, 13, 1641–1655. [Google Scholar] [CrossRef]
- Pereg, U.; Steinberg, Y. The Arbitrarily Varying Channel Under Constraints with Side Information at the Encoder. IEEE Trans. Inf. Theory 2019, 65, 861–887. [Google Scholar] [CrossRef]
- Pereg, U.; Steinberg, Y. The arbitrarily varying channel under constraints with causal side information at the encoder. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2017), Aachen, Germany, 25–30 June 2017; pp. 2805–2809. [Google Scholar]
- Csiszár, I.; Narayan, P. Capacity of the Gaussian arbitrarily varying channel. IEEE Trans. Inf. Theory 1991, 37, 18–26. [Google Scholar] [CrossRef]
- Behboodi, A.; Piantanida, P. On the simultaneous relay channel with informed receivers. In Proceedings of the IEEE International Symposium on Information Theory (ISIT’2009), Seoul, Korea, 28 June–3 July 2009; pp. 1179–1183. [Google Scholar]
- Bjelaković, I.; Boche, H.; Sommerfeld, J. Capacity results for arbitrarily varying wiretap channels. In Information Theory, Combinatorics, and Search Theory; Springer: Berlin/Heidelberg, Germany, 2013; pp. 123–144. [Google Scholar]
- Sion, M. On General Minimax Theorems. Pac. J. Math. 1958, 8, 171–176. [Google Scholar] [CrossRef]
- Pereg, U.; Steinberg, Y. The arbitrarily varying gaussian relay channel with sender frequency division. arXiv 2018, arXiv:1805.12595. [Google Scholar]
- Hughes, B.; Narayan, P. Gaussian arbitrarily varying channels. IEEE Trans. Inf. Theory 1987, 33, 267–284. [Google Scholar] [CrossRef]
- Csiszár, I.; Körner, J. Information Theory: Coding Theorems for Discrete Memoryless Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2011. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Blackwell, D.; Breiman, L.; Thomasian, A.J. The capacity of a class of channels. Ann. Math. Stat. 1959, 30, 1229–1241. [Google Scholar] [CrossRef]
- Diggavi, S.N.; Cover, T.M. The worst additive noise under a covariance constraint. IEEE Trans. Inf. Theory 2001, 47, 3072–3081. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423, 623–656. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]





© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereg, U.; Steinberg, Y. The Arbitrarily Varying Relay Channel. Entropy 2019, 21, 516. https://doi.org/10.3390/e21050516
Pereg U, Steinberg Y. The Arbitrarily Varying Relay Channel. Entropy. 2019; 21(5):516. https://doi.org/10.3390/e21050516
Chicago/Turabian StylePereg, Uzi, and Yossef Steinberg. 2019. "The Arbitrarily Varying Relay Channel" Entropy 21, no. 5: 516. https://doi.org/10.3390/e21050516
APA StylePereg, U., & Steinberg, Y. (2019). The Arbitrarily Varying Relay Channel. Entropy, 21(5), 516. https://doi.org/10.3390/e21050516