This section is structured as follows: In
Section 3.1, we explore the relationship among the model accuracy,
, and
; in
Section 3.2, we introduce our information plane-based framework and utilize this framework to compare the differences between FCs and CNNs in the information plane; in
Section 3.3, we compare the evaluation framework with loss curves and state that our framework is more informative when evaluating neural networks; in
Section 3.4, we evaluate modern popular CNNs in the information plane; in
Section 3.5, we show that the information plane can be used to evaluate DNNs, not only on a dataset, but also on each single class of the dataset in image classification tasks; in
Section 3.6, we use IB to evaluate DNNs for image classification problems with an unbalanced data distribution; in
Section 3.7, we analyze the efficiency of transfer learning in the information plane; in
Section 3.8, we compare different optimization algorithms of neural networks in the information plane.
3.1. Relationship among Model Accuracy, I(X;T), and I(T;Y)
Accuracy is a common “indicator” to reflect the model’s quality. Since we are to use mutual information to evaluate neural networks, it is necessary to investigate the relationship among
,
, and the accuracy. The work in [
22] studied the relationship between mutual information and accuracy and stated that
explains the training accuracy,
serves as a regularization term that controls the generalization; while from our experiments, we found that in deep neural networks, when
is fixed, there is also a correlation between
and the training accuracy, where
X represents the training data. Furthermore, the correlation grew stronger as the network got deeper.
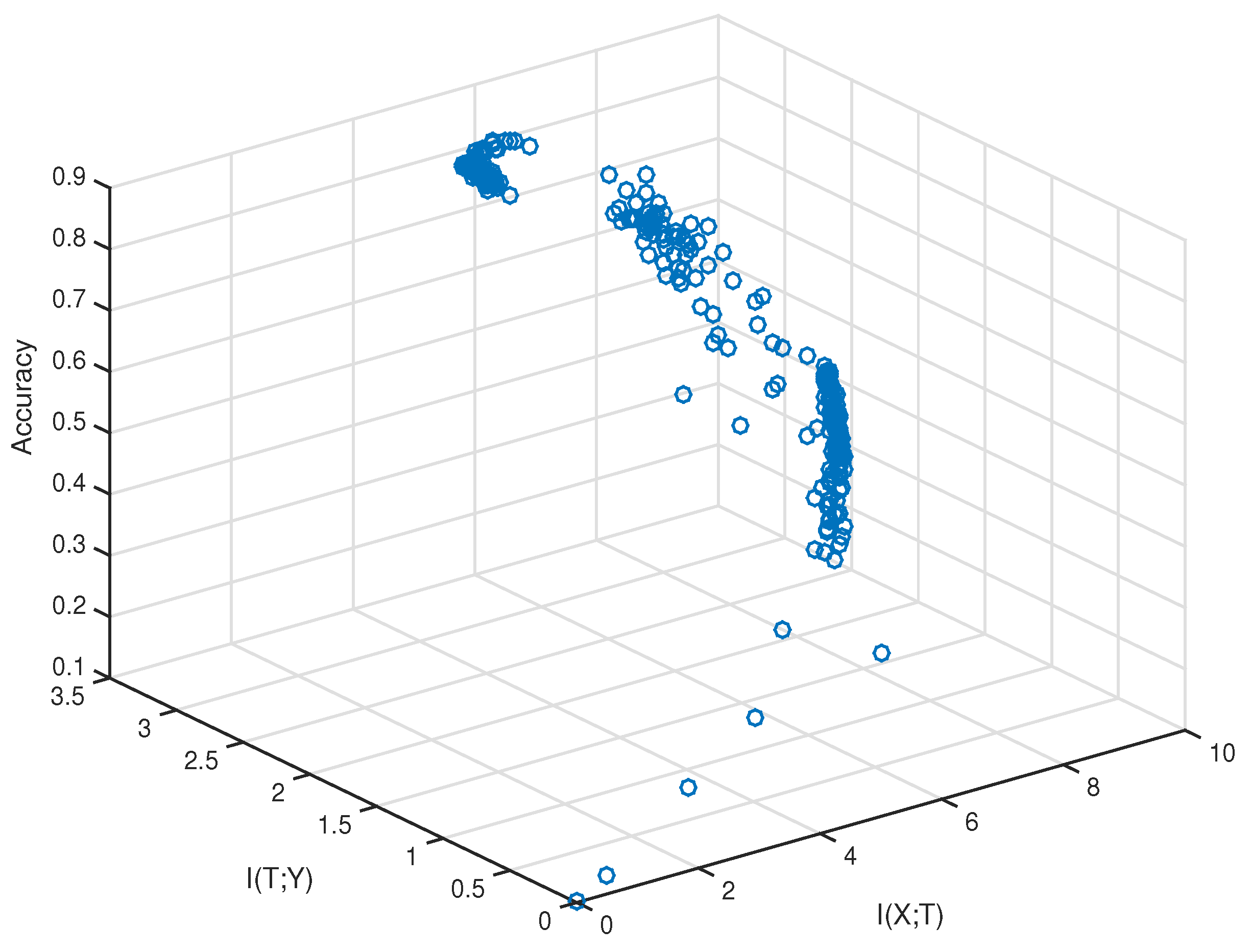
To validate the hypothesis experimentally, we need to sample the values of the training accuracy,
, and
. The method of estimating mutual information has been discussed in
Section 2.3. The network and dataset we chose were VGG-16 and CIFAR-10, respectively. The sampling was performed after every fixed iteration steps during the training. We first plotted
,
, and the training accuracy of sampled data in 3D space, which is shown in
Figure 3.
From
Figure 3, we can see the data did not fully fill the whole space. They came from a narrow area out of the whole 3D space. Furthermore, there existed two points that had similar
, but the point with smaller
had a higher training accuracy. To verify the correlation between
and the training accuracy quantitatively, we used the method of “checking inversion”.
First, we used
,
, and
to denote the values of the
ith sampling result, which corresponds to a blue circle in
Figure 3. Suppose there exists a sample pair
such that
, then we can directly check the relationship between
and the training accuracy to find how they are related. However, each
is a real number, and it is difficult to find samples that have the same value of
. Thus, we verify the hypothesis by checking inversions. An inversion is defined as a pair of samples
that satisfies
and
. A “satisfied inversion” is defined as an inversion for which
and
. The “percentage”, defined as follows:
is a proper indicator to reflect the rightness of our hypothesis that low
also contributes to the training accuracy. Consider two cases:
The percentage is near 0.5. This means that almost half of the inversion pairs satisfy and , and the other inversion pairs satisfy and . Thus, almost has no relation to the training accuracy.
The percentage is high. This means that a large number of inversion pairs satisfy and . Thus, low also contributes to the training accuracy.
We performed experiments under different training conditions to train the neural networks.
Table 1, from [
15], records percentages with different training conditions.
Table 1 shows that in various condition settings, the percentages were all over 0.5, which indicates that
also contributed to the training accuracy. Furthermore, different training schemes (SGD, batch gradient descent (BGD)) and network structures (FC, CNN) may lead to different percentages. We explain these phenomenons as follows:
Even though
represents the correlation between the model output and label,
is not a monotonic function of the training accuracy. Suppose there are
C classes in the image dataset, and let
be the
ith class. Consider two cases: In the first case,
where
is an identity mapping, which indicates that the model output
T always equals the true class. For another case,
where
is a shift mapping, which indicates that if the true class is
, the prediction of
T is
. In both cases, since
and
are invertible functions, from (
4), we have
. However, in the first case, the training accuracy was one, whereas in the other case it was zero.
The activation function of the linear network was identity mapping. Thus, the loss function of the linear network was a convex function; whereas the loss function of convolutional neural networks is highly non-convex. By using BGD to optimize a convex function with a proper learning rate, the training loss with respect to all the training data always decreased (the model was stablest in this case), which indicated that T was gradually closer to Y during training. Thus, can fully explain the training accuracy and may not have contributed to the training accuracy greatly; however, when the loss function was a non-convex function, or the training scheme was SGD. The loss with respect to all the training data did not decrease all the time (the network was sometimes learning in the wrong direction). Thus, cannot fully explain the training accuracy for SGD and convolutional neural networks.
The work in [
29] used
to represent the stability of the learning algorithm. The model with low
tended to be more stable on the training data. Thus, when
and
are equal, the model with low
may lead to a high training accuracy.
Another interesting phenomenon is that we found that there was a correlation between percentage and the number of layers of convolutional neural networks.
Table 2, from [
15], shows that percentage rose as we increased the number of layers of convolutional neural networks. This result may relate to some inherent properties of CNNs, which is worth investigating for future work.
Compared to the training accuracy, we were more interested in validation accuracy. Thus, we also validated our hypothesis on the validation data where
X represents the validation input.
Table 3, from [
15], shows that low
also contributed to the validation accuracy. This observation will form the basis of our evaluation framework proposed in the next section.
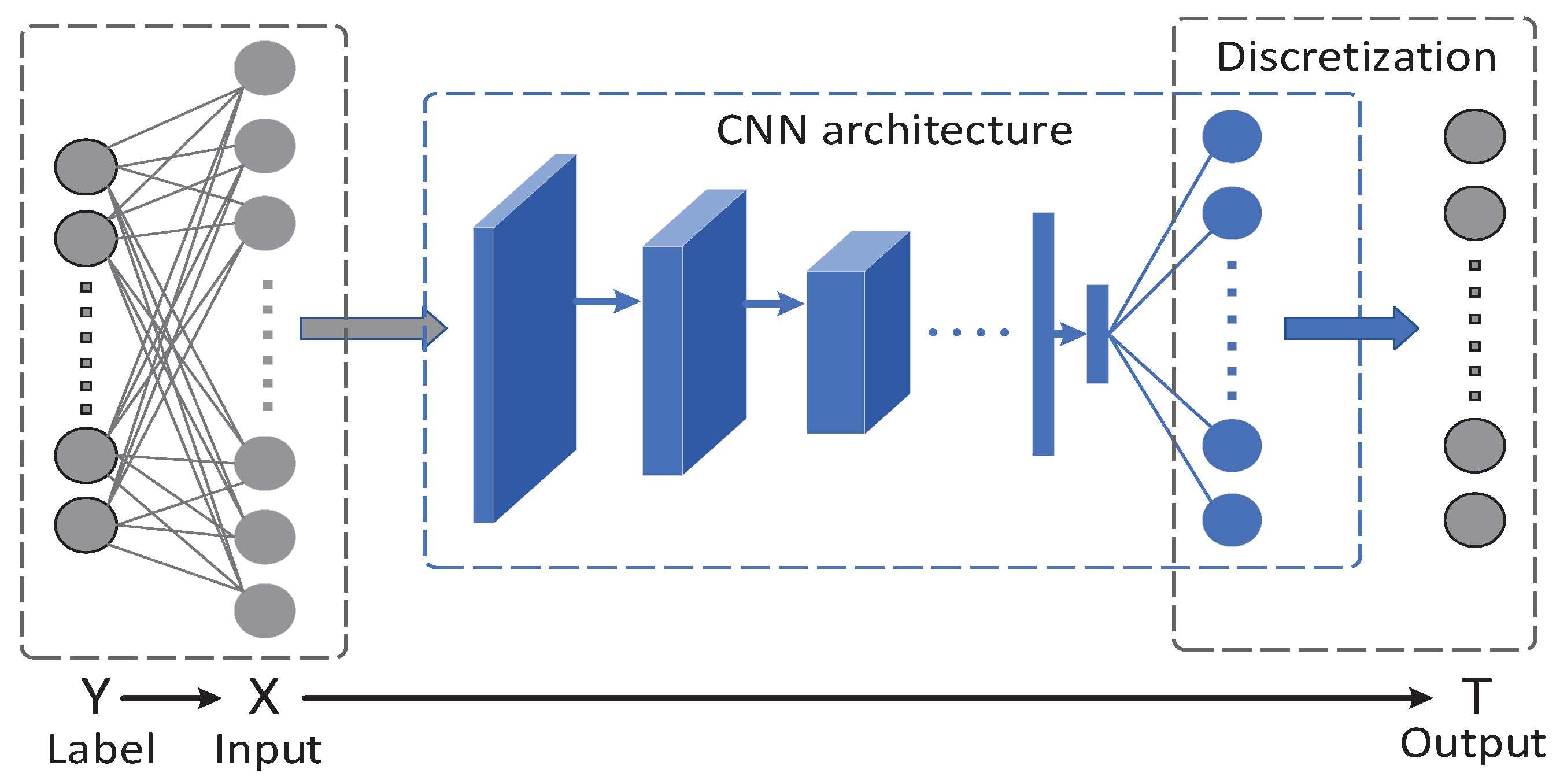
3.2. Evaluating DNNs in the Information Plane
In
Section 2.2, we explain that
and
are essential for analyzing neural networks. The neural network training process can be regarded as finding a trade-off between
and
. Furthermore, in
Section 3.1, the experiments showed that not only high
, but also low
contributed to the validation accuracy, where
X represents validation input. Since
and
are both indicators to reflect the model’s accuracy, we used
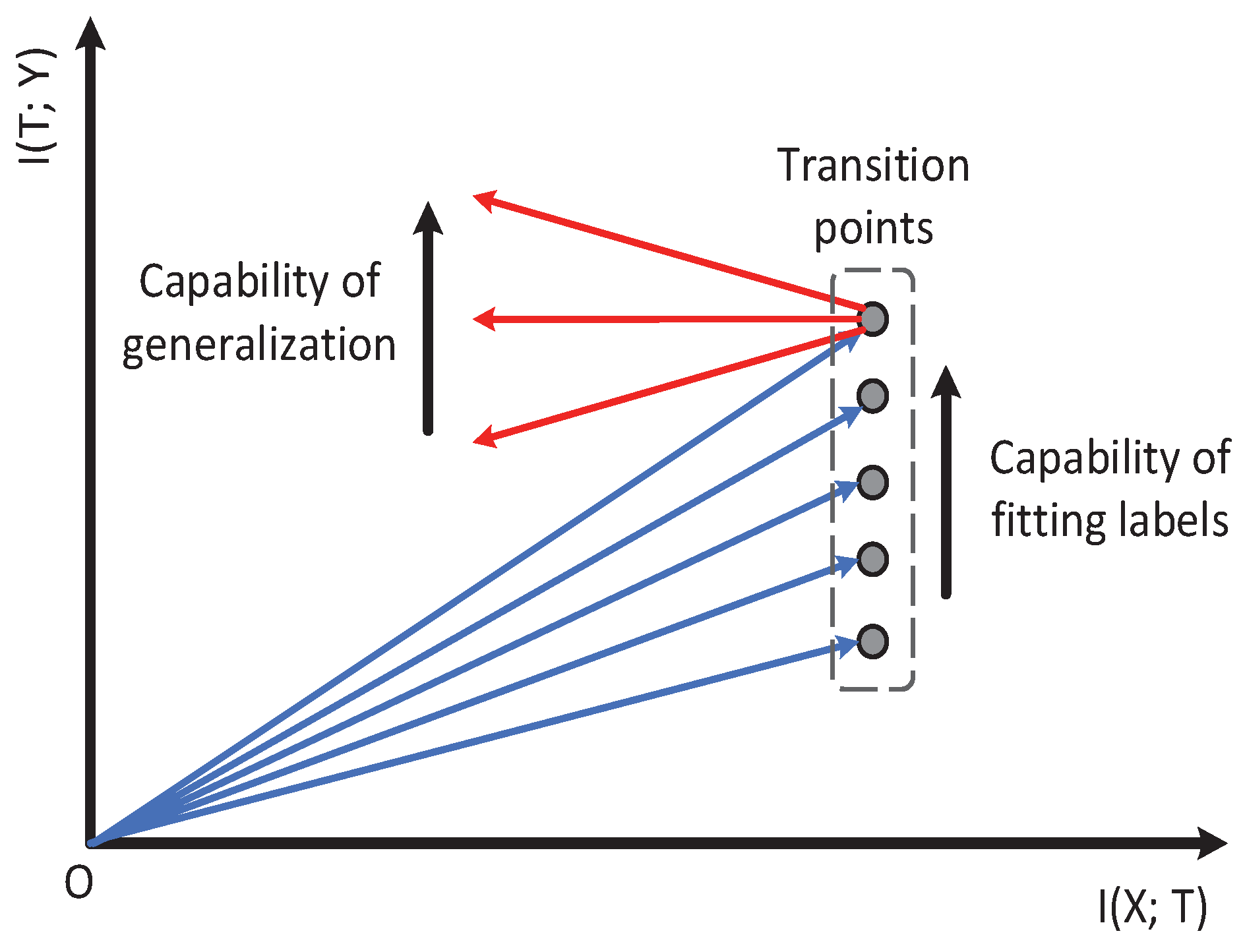
to represent the model’s learning capability in the information plane. Notice that
is exactly the slope of the mutual information curve. Thus, it represents the model’s learning capability at each moment.
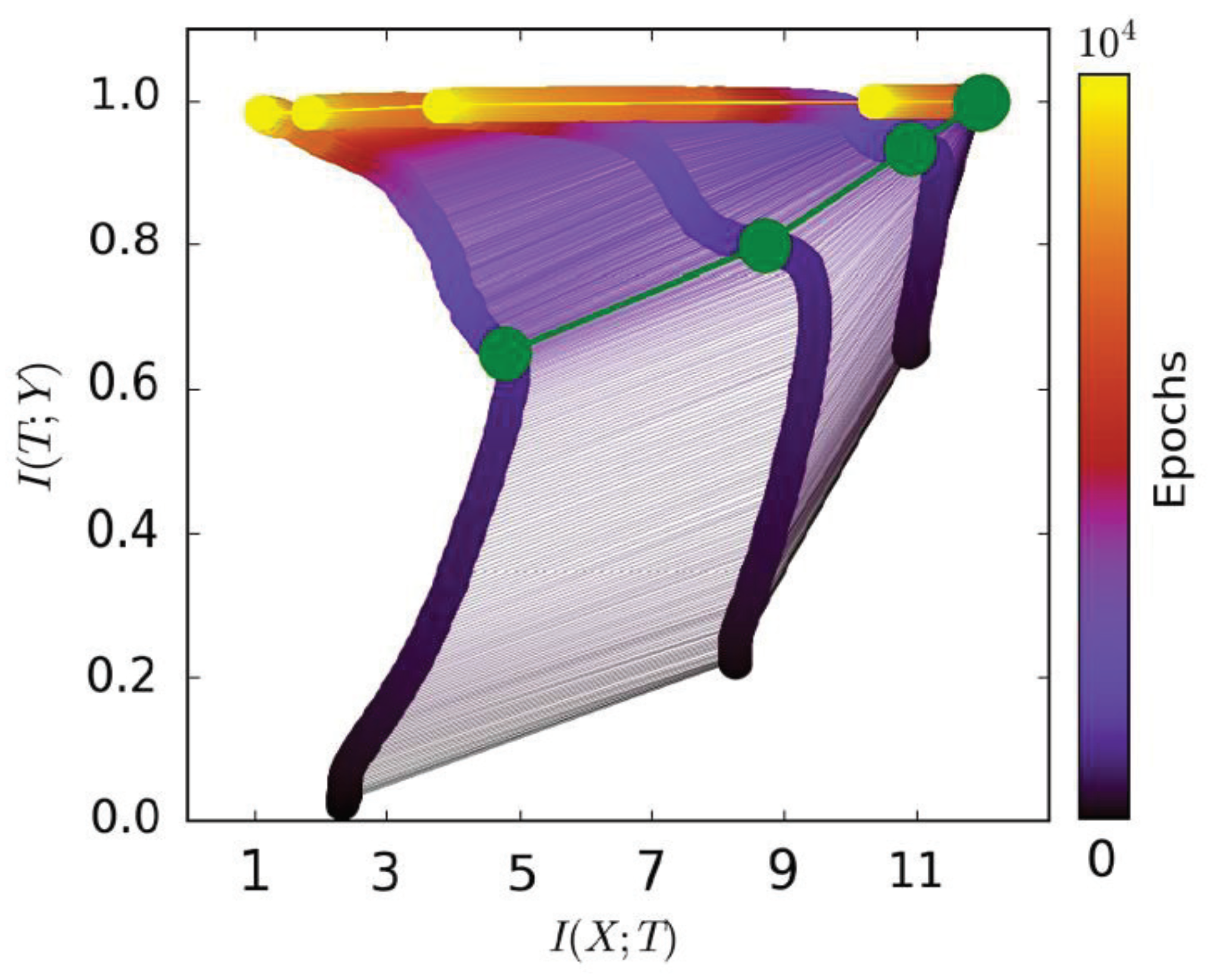
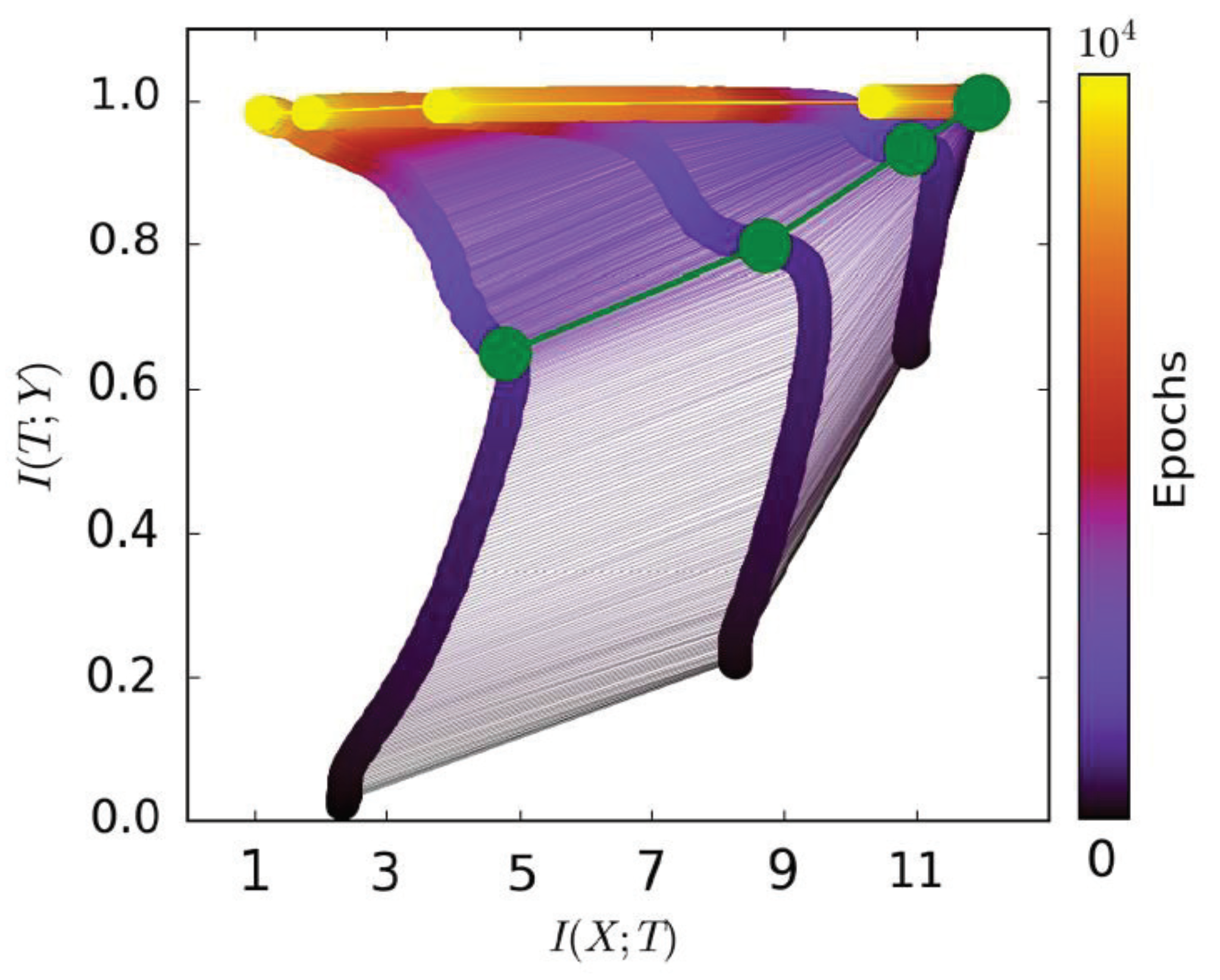
Figure 1, from [
15], shows that a mutual information path contains two learning stages. The first fitting phase only took very little time compared to the whole learning process. The model began to generalize at the second compression phase. Thus, we only used
to represent the model’s learning capability in the second phase. A better model is expected to have smaller (negative)
in the second phase; while for the first fitting phase,
of the model increased (the model needed to remember the training data for fitting the label). Thus, we only used
to represent the model’s capability of fitting the label. Based on our analysis above, we propose our information plane-based framework in
Figure 4.
To further explore how different datasets or network structures influence the mutual information curves in the information plane, we performed an experiment on two datasets: MNISTand CIFAR-10. The network structure contained fully-connected neural networks and convolutional neural networks with various numbers of layers. Notice for subsequent experiments,
X in
represents the validation input, since we cared about the validation accuracy rather than training accuracy. Furthermore, we smoothed the mutual information curves in the information plane for simplicity and better visualization.
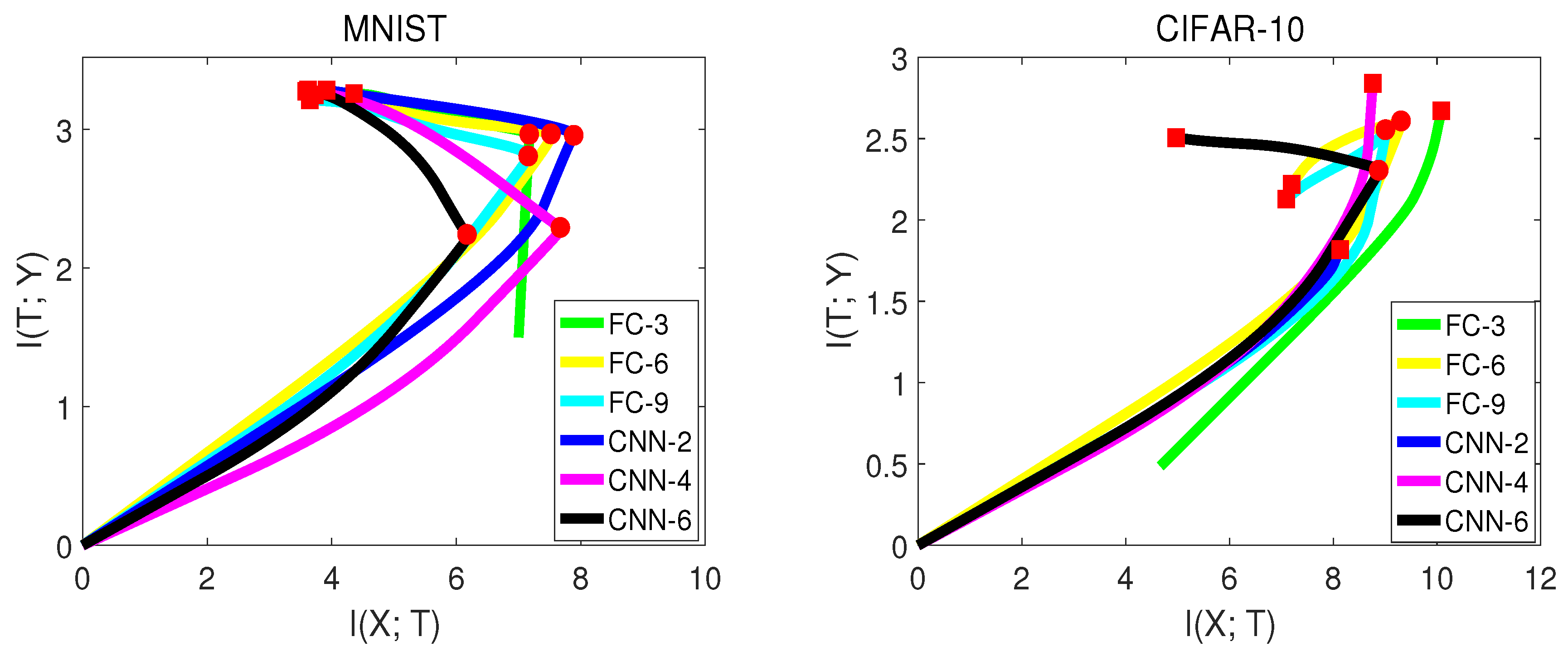
Table 4 and
Figure 5, from [
15] show the experiment results.
There are some interesting observations from
Figure 5:
Not all networks had exactly the second compression phase. For the MNIST experiment, all networks had two learning stages. However, for CIFAR-10, the networks with fewer hidden layers (FC-3, CNN-2, CNN-4) did not show the second phase. The reason is that CIFAR-10 is a more difficult dataset for the network to classify. The network with fewer hidden layers may not have enough generalization capability.
Convolutional neural networks had better generalization capability than fully-connected neural networks by observing in the second phase. This led to higher validation accuracy. However, of convolutional neural networks was sometimes lower than fully-connected neural networks by comparing at the transition point, which indicates that fully-connected networks may have a better capability of fitting the labels than convolutional neural networks in the first phase. The fact that fully-connected neural networks have a large number of weights may contribute to this.
Not all networks have increasing in the second phase. For CIFAR-10, of FC-6 and FC-9 dropped down in the second phase. One possible reason is that FC with more layers may over-fit the training data.
3.3. Informativeness and Guidance of the Information Plane
There does not exist a network that is optimal for all problems (datasets). Usually, researchers have to test many neural network structures on a specific dataset. The network is chosen by comparing the final validation accuracy of each network. This process is time consuming since we have to train each network until convergence. In this section, we will show that the information plane could ease this searching process and facilitate a quick model selection of neural networks.
In
Section 3.2, we show that
can represent the capability of generalization at each moment in the second compression phase. Thus, a direct way to select the model is to compare each model’s
at the beginning of the compression phase. Since the first compression phase only takes a little time, we can select a better model in a short time.
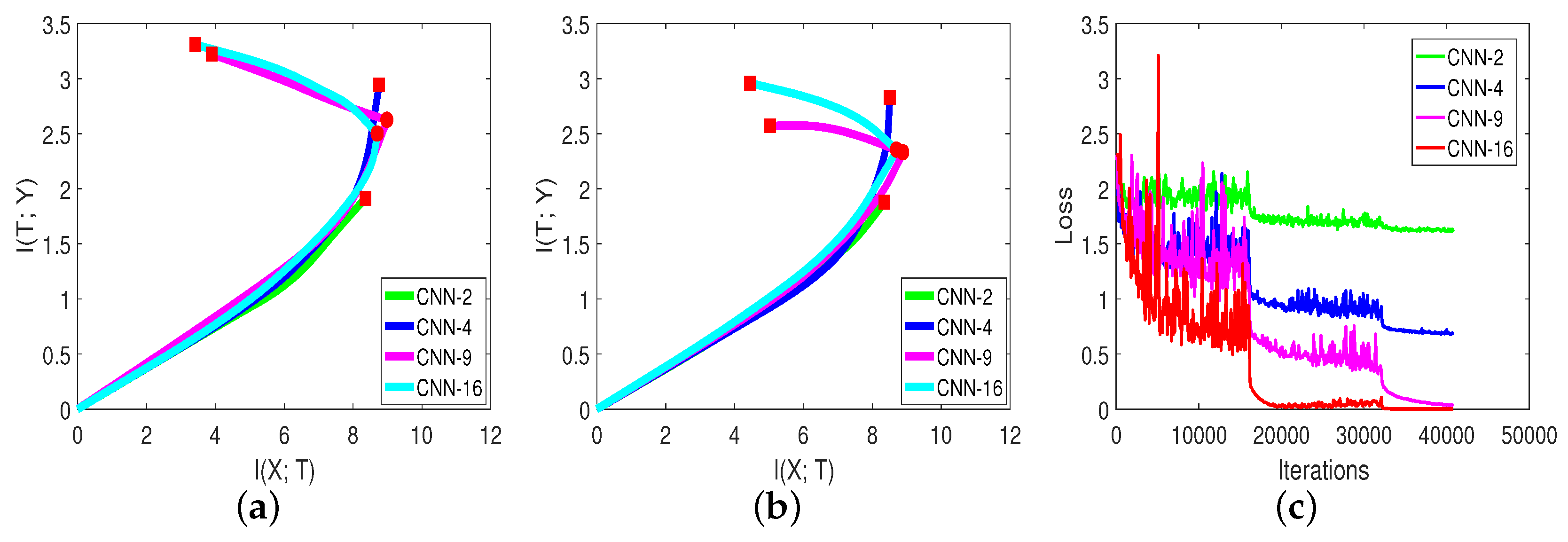
Figure 6 and
Table 5, from [
15], show the mutual information paths and validation accuracies of different networks on the CIFAR-10 dataset.
can be used to select a better network. We can compare CNN-9 and CNN-16 in
Figure 6b. The slope of the mutual information curve of CNN-16 was smaller (negative) than CNN-9, which represents a better generalization capability. The final validation accuracy in
Table 5 is consistent with our analysis. Thus, for a specific problem, we can visualize each model’s mutual information curve on the validation data to select a better model quickly.
The information plane is more informative than the loss curve. By comparing
Figure 6c with
Figure 6a,b, we can see that the training loss of each model continued to decrease with training steps. However, the mutual information curves behaved differently. The model with fewer layers did not clearly show the second compression phase. Thus, the information plane could reveal more information about the network.
mostly contributed to the accuracy in the second phase. We record the percentage of each network in
Table 5. From
Table 5, when the network had fewer layers, the mutual information path did not clearly show the second phase, and the percentage was low; whereas for the network that had the compression phase, the percentage was high. One possible reason is that in the second phase, the model learned to generalize (extract common features from each mini-batch). The value of percentages indicates that the compression happened even when
’s remained the same.
We can view and as: determines how much the knowledge T has about the label Y, and determines how easy this knowledge can be learned by the network.
3.4. Evaluating Popular CNNs in the Information Plane
The architecture of neural networks has undergone substantial development. From AlexNet [
1], VGG [
7] to ResNet [
9] and DenseNet [
30], researchers have made great efforts in searching for efficient networks. In this section, we visualize these popular networks in the information plane.
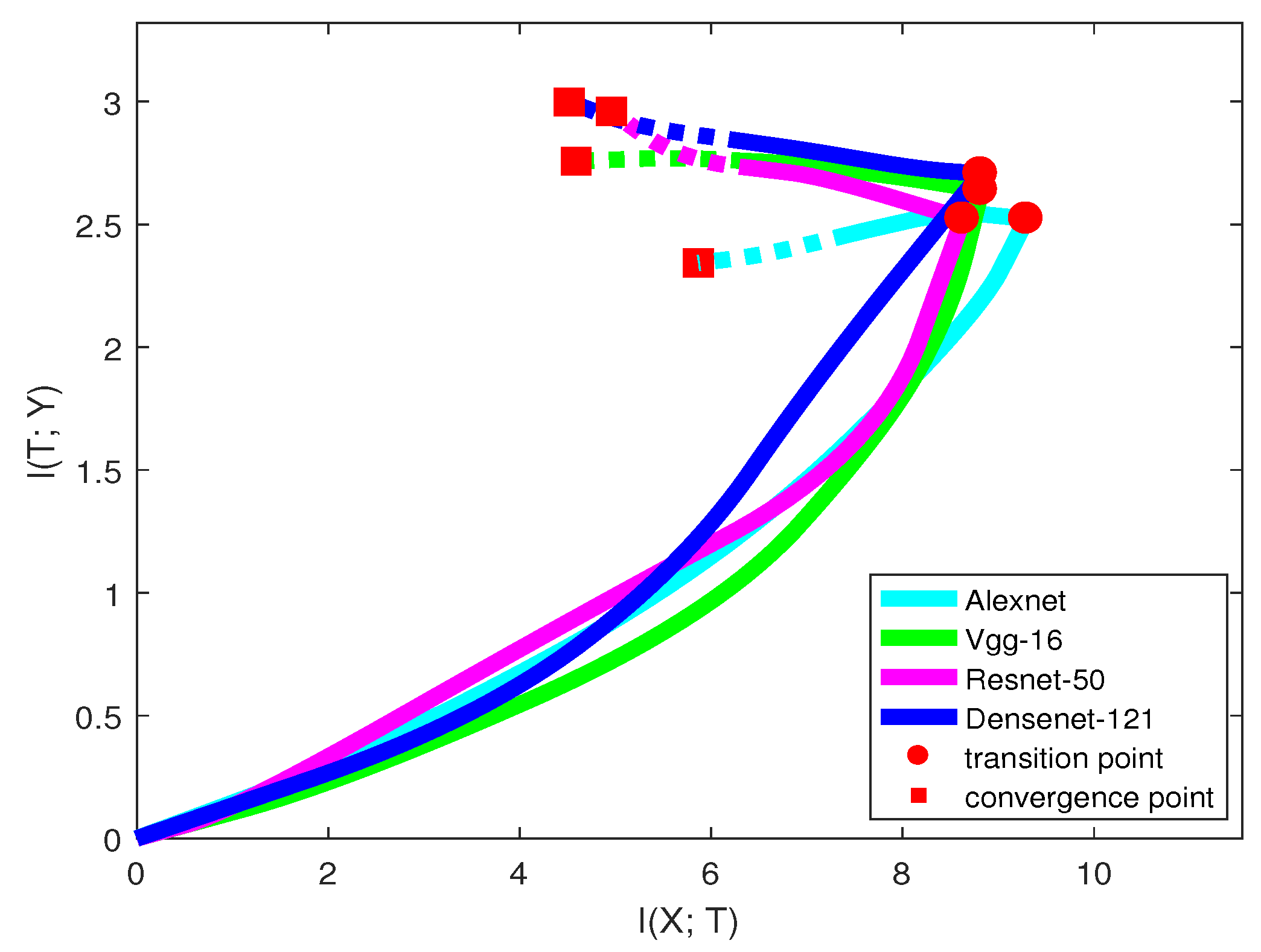
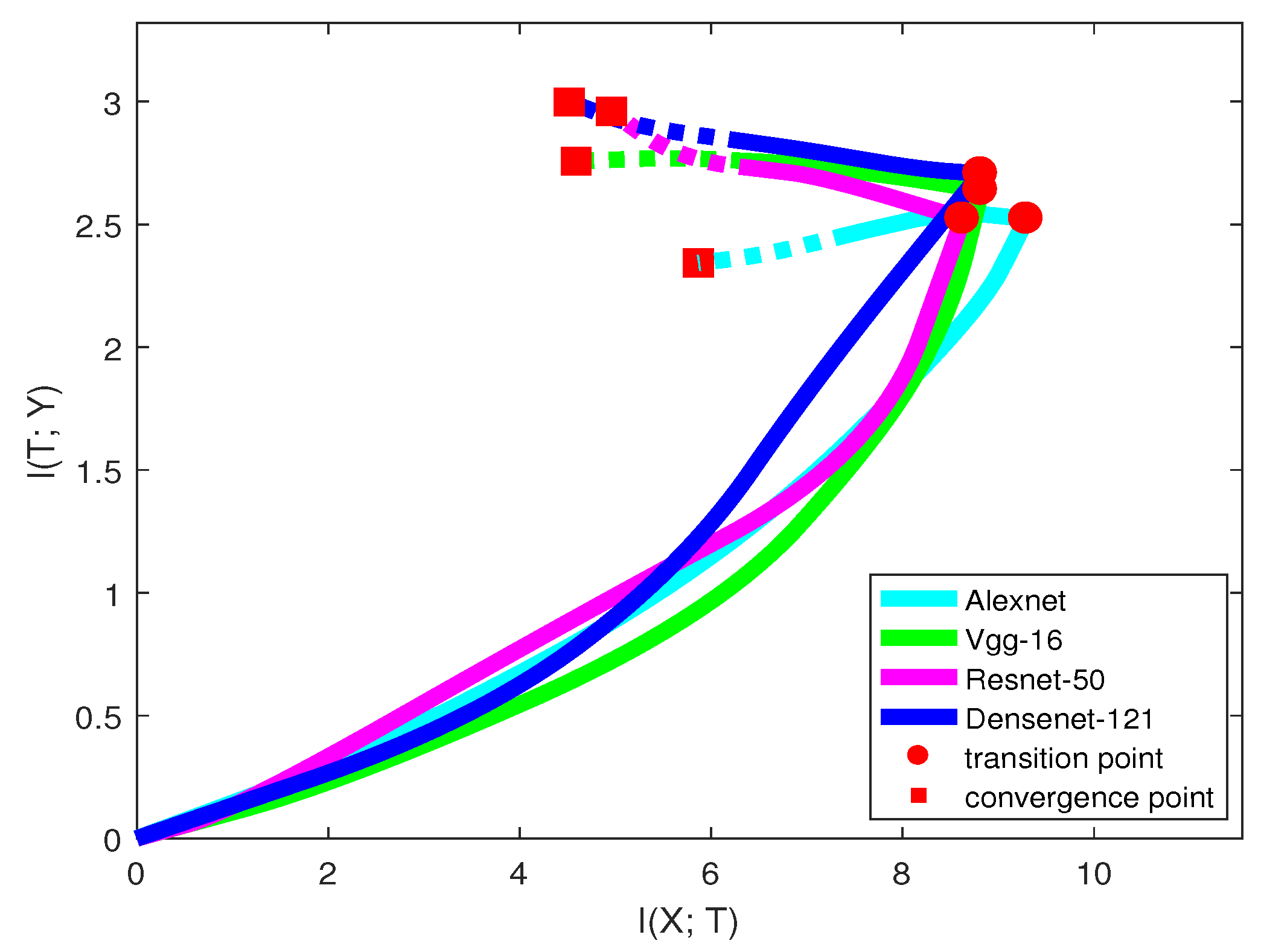
Figure 7 and
Table 6 show the information curve, training epochs, and accuracy of each network structure on the CIFAR-10 dataset.
Only looking at the solid line in
Figure 7, we may infer that when classifying the CIFAR-10 dataset, AlexNet was the worst neural network among all the models. AlexNet has a low capability of fitting the labels, and after the transition point,
of the model even dropped down, indicating losing information on labels. VGG had a stronger capability of fitting labels than ResNet, but the generalization capability was relatively lower. From the trend of the curves,
of ResNet may be larger than VGG in the future. DenseNet was better than all the other models in both two learning phases. The model accuracies in
Table 6 are consistent with our analysis.
Here, we emphasize that our prediction may not always be true, since the mutual information path may have a larger slope change in the future. See ResNet in
Figure 7. Thus, there existed a trade-off between the training time and confidence of our prediction. We can make a more confident prediction by training the network with a longer time. However, it is still an efficient way for guiding us on choosing a better network that leads to a high validation accuracy.
Table 6 also shows that with more convolutional layers, the model can reach the transition point more quickly. This means that for many deep networks, we can predict the networks’ quality and choose a better model in a short time.
3.5. Evaluating DNN’s Capability of Recognizing Objects from Different Classes
The previous sections evaluated neural networks on a whole dataset. However, this evaluation can only test the performance of the network on all the classes. In this section, we will show how to evaluate DNNs on a single class in the information plane when performing image classification tasks.
Suppose there are
C classes in the dataset and
denotes the
ith class. To evaluate networks on the
ith class, we labeled other classes as one class. Thus, the dimension of label
Y changes from
C to two. We also made label
Y balanced when calculating mutual information so that
is equal to one. This process is similar to one-vs.-all classifications [
31]. However, instead of concentrating on the accuracy, we paid attention to the mutual information. Furthermore, notice that we did not change the network structure; we only performed pre-processing on the validation data. The training scheme and other conditions did not change during this process. We selected three classes (airplane, automobile, bird) on CIFAR-10 to perform the experiment.
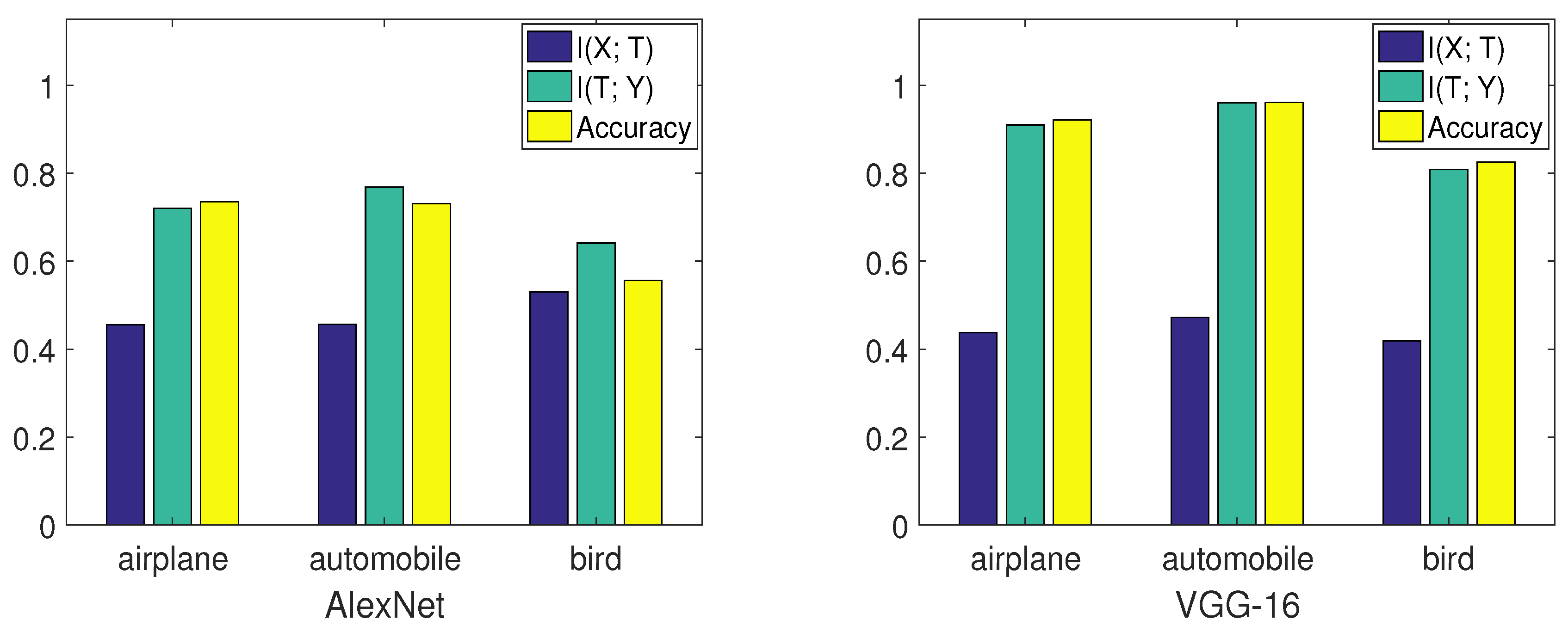
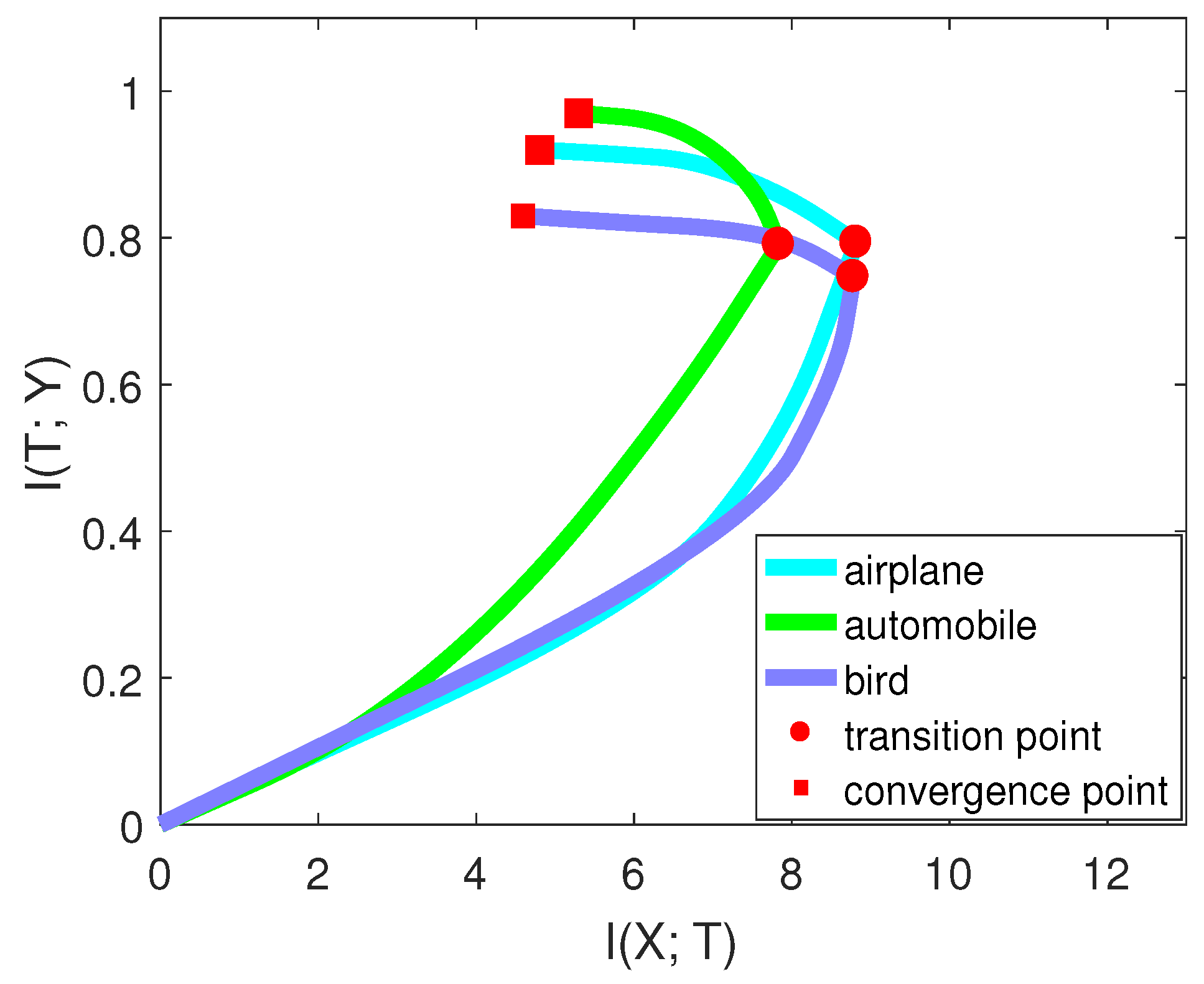
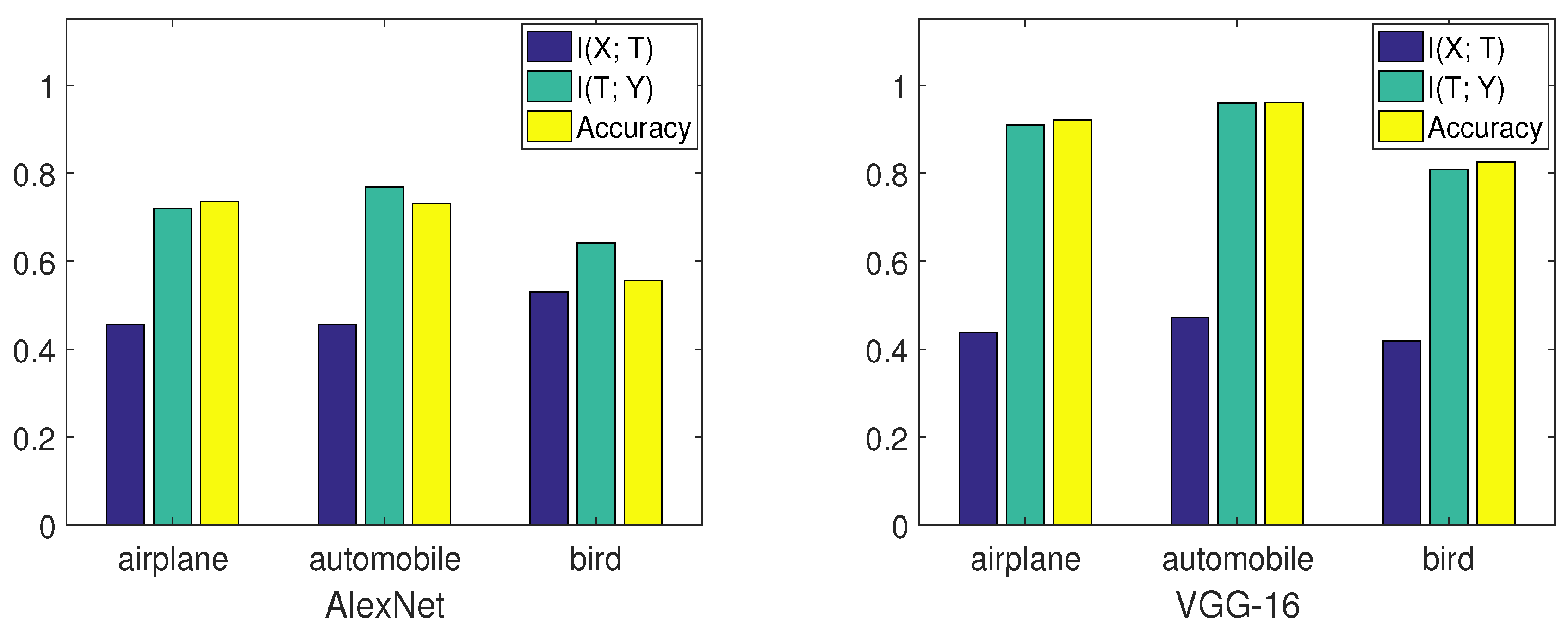
Figure 8, from [
15], compares the performance of two networks on these three classes.
Figure 9, from [
15], shows the mutual information curve on each class in the information plane.
By comparing the mutual information curves of automobile and airplane, we can find that they had almost the same value of at the transition point. However, the slope of automobile was smaller than airplane. Thus, the final validation accuracy of automobile may be higher than airplane. By comparing the mutual information curves of airplane and bird, we can find that they almost had the same slope of mutual information curves in the second phase. However, of airplane was higher than that of bird. Thus, the final validation accuracy of airplane may be higher than bird. The true validation accuracies were 0.921 (airplane), 0.961 (automobile), and 0.825 (bird), which are consistent with our analysis.
Furthermore, we examined two models on the same classes. From
Figure 8, VGG-16 had better performance than AlexNet on each class by comparing
,
, and validation accuracies. Thus, the information plane also provided a way to analyze the performance of the network on each class in the image classification task.
3.6. Evaluating DNNs for Image Classification with an Unbalanced Data Distribution
In a multi-class classification problem, each class may have different numbers of samples. Suppose we want our model to have a balanced classification capability: we need to control the number of training samples for each class. We suggest that the information plane could help in a quick way.
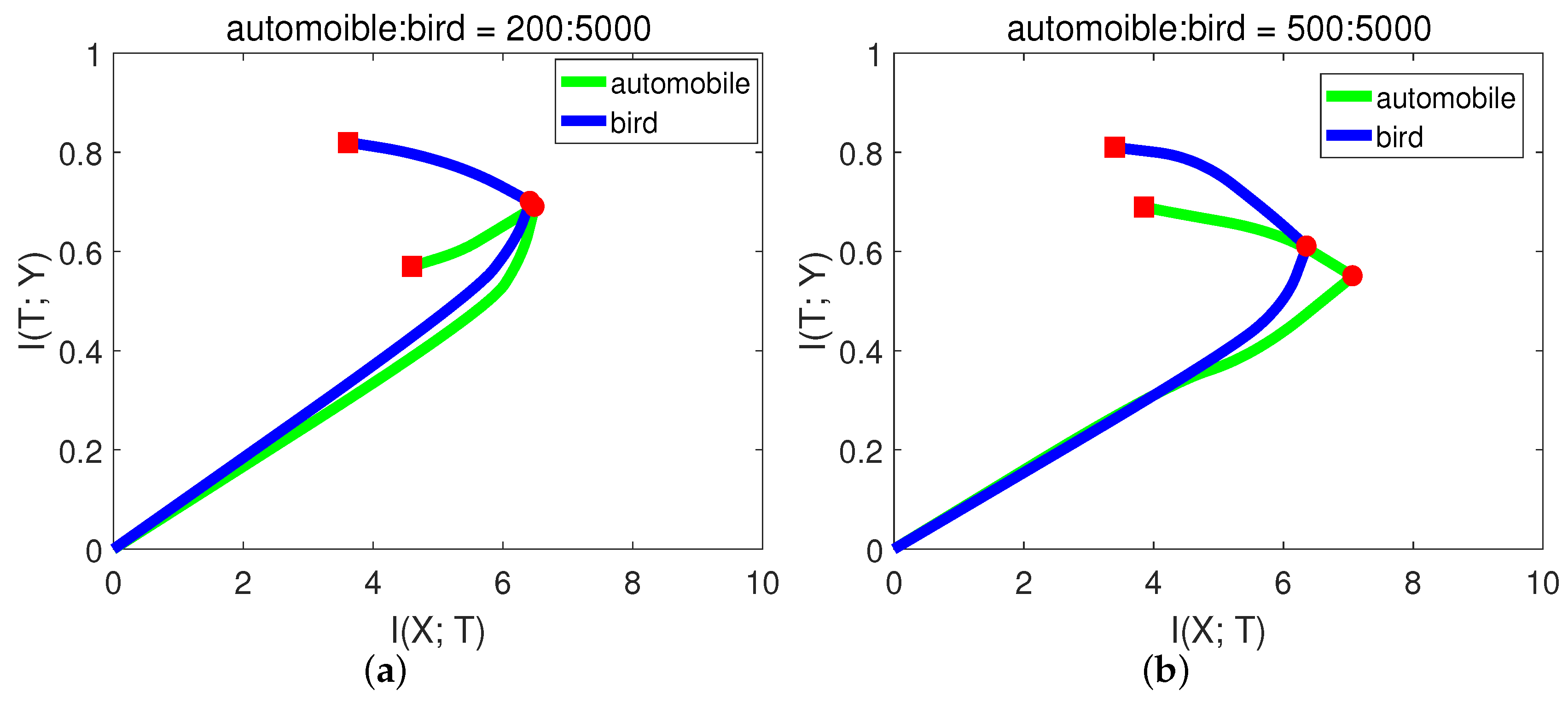
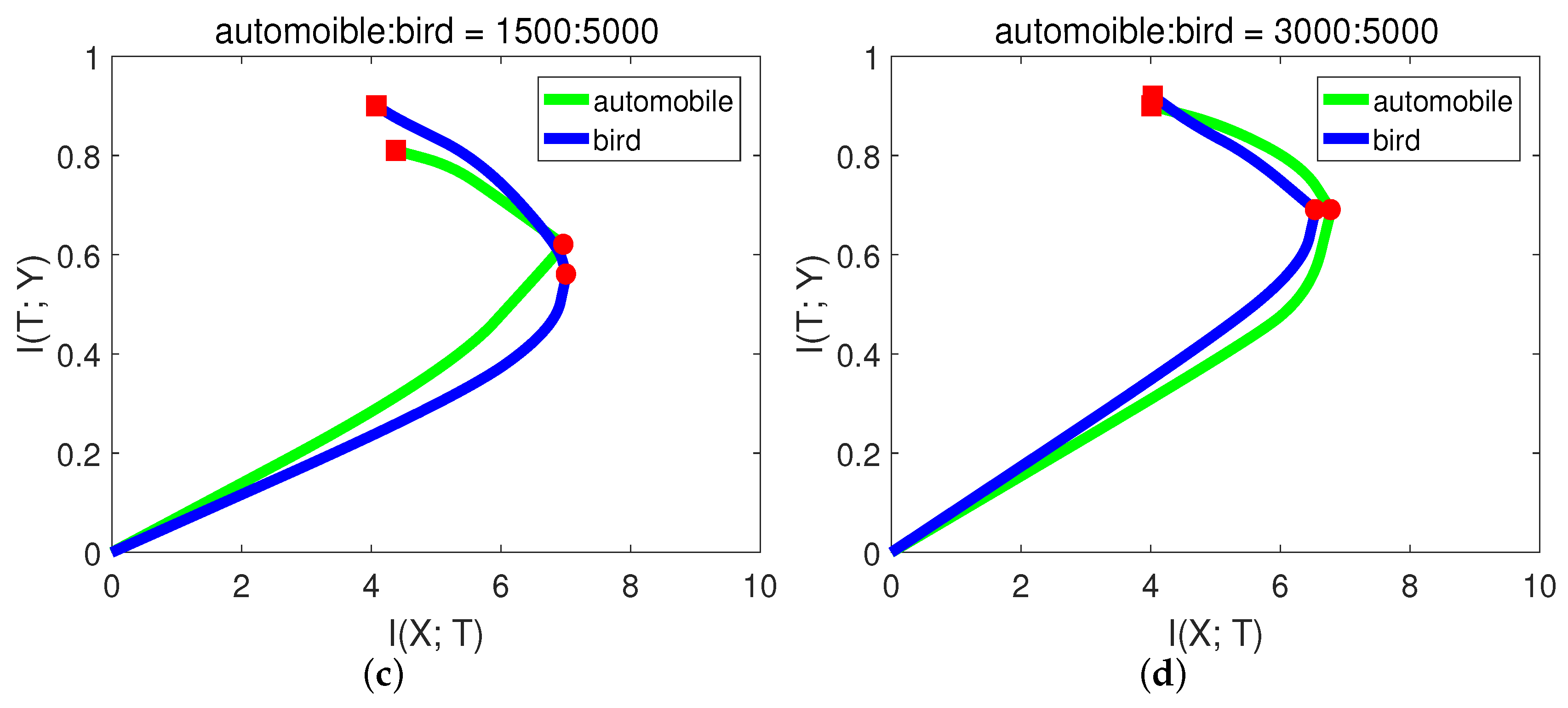
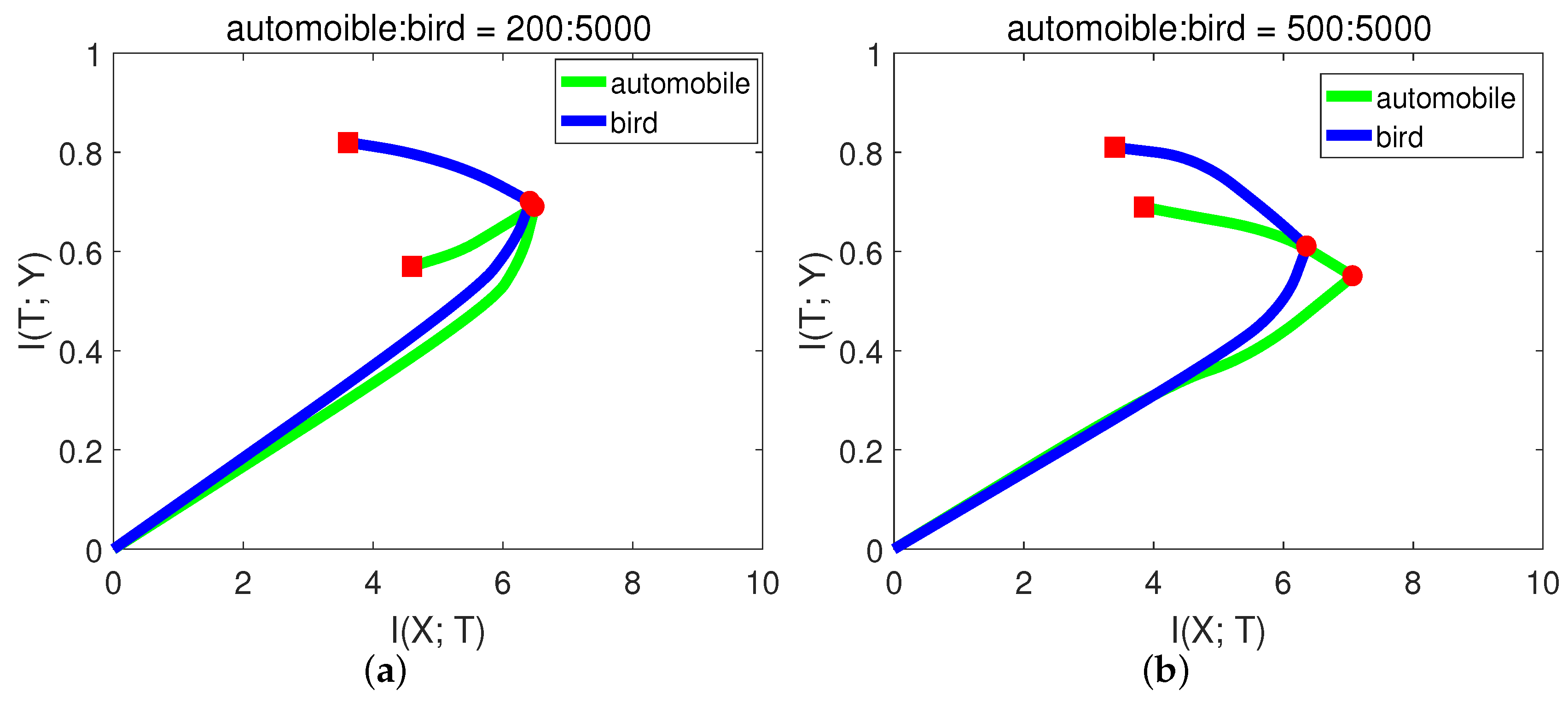
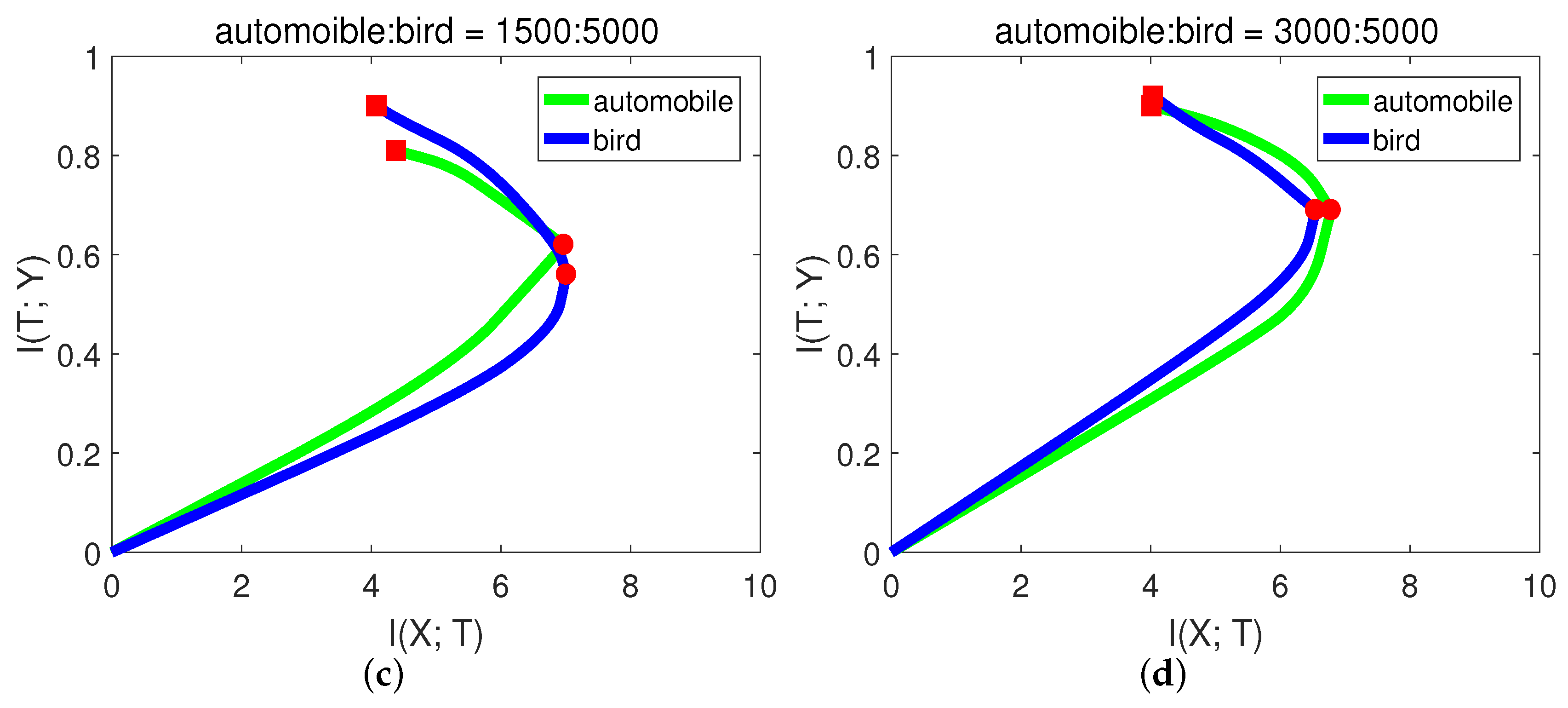
In CIFAR-10, each class has 5000 training samples. For simplicity and better presentation, in this experiment, we chose the classes of “automobile” and “bird”. We hoped that the model had balanced classification capability for these two classes. Let the number of training samples for bird be fixed, and we performed the experiments with variant numbers of samples for automobile. The results are shown in
Figure 10 and
Table 7.
From Figure
Figure 10a, when there were only 200 samples of automobile, the
of automobile even decreased in the second stage. In this case, the network may just over-fit the small sample noise. From (b) and (c), the slope of automobile in the second phase was higher (negative) than bird, indicating low generalization capability. While when automobile:bird = 3:5, from
Figure 10d, the generalization capability of automobile was already comparable to bird. The final validation accuracies from
Table 7 of these two classes are consistent with the generalization capability in
Figure 10. Since the first phase only took a little time, we could decide how many samples were needed by checking the slope in the second phase.
We believe this application has huge potential in some serious areas, such as medical science, especially where people expect computers to automatically classify diseased tissues from samples. For example, at present, cancer classification has two major problems: the healthy and diseased samples are very unbalanced; the AI system lacks interpretability. Since IB explains the network from an informative way and our framework shows we could determine the number of samples for each class in a short time, our framework could be applied to medical science in the future.
3.7. Transfer Learning in the Information Plane
Using the pre-trained model to train data instead of training a neural network from scratch has been common in recent days. It may greatly reduce the training time and make the model easy to learn. In this section, we study why the pre-trained model is better in the language of the information plane.
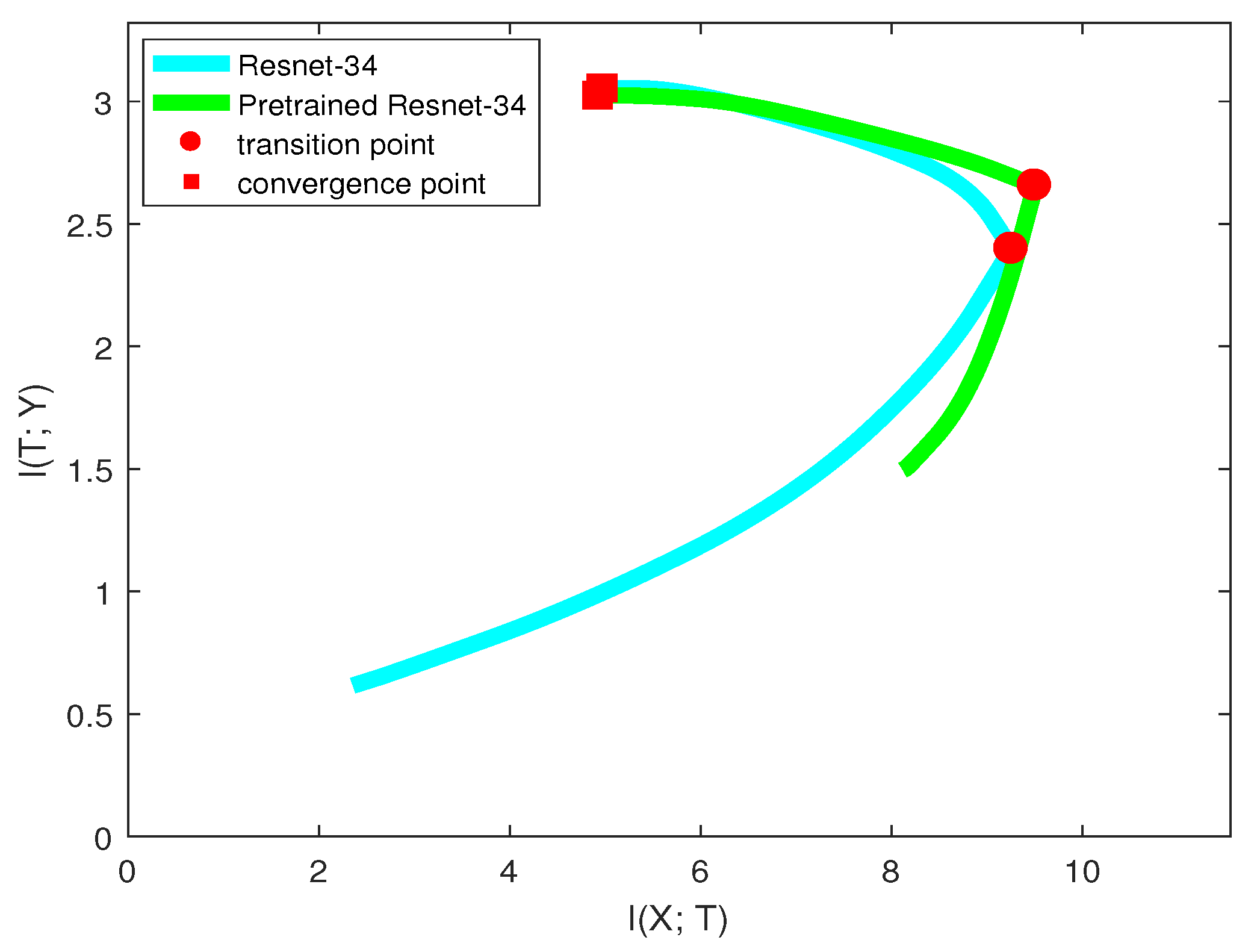
We used the same neural network structure (ResNet-34) as our base model and pre-trained model. The pre-trained model was trained on the ImageNet dataset. We resized the images of CIFAR-10 to
for fitting the network structure.
Figure 11 shows the mutual information paths in the information plane.
We can see for these two models that they had very similar curves in the “compression” phase and ended up with the same convergence point. However, in the “fitting” phase, they acted differently. The pre-trained model had larger and at the initial time, which contributed to the similarity between CIFAR-10 and the ImageNet dataset. Thus, pre-trained model reached the transition point much faster than the base model. After the transition point, since they had the same architecture, the generalization capabilities for these two models were the same.
Therefore, the information plane revealed that pre-trained model improving learning algorithm happened in the “fitting” phase. and it helped the model fit labels efficiently. However, the pre-trained model and the base model without pre-training may have equal generalization capability. Interestingly, our result is consistent with a recent paper [
27], where Kaiming He et al. found that ImageNet pre-training is not necessary. ImageNet can help speed up convergence, but does not necessarily improve accuracy unless the target dataset is too small. Differently, we verified this result by utilizing the information plane.
3.8. SGD versus Adam in the Information Plane
Choosing an appropriate optimization method is essential in the neural network training process. A straightforward way to optimize the loss of DNN is via stochastic gradient descent (SGD). However, the loss function of DNN is highly non-convex, which makes SGD easily stuck in the local minima or saddle points. Thus, several advanced optimization methods were developed in recent years and have become popular. Momentum SGD [
32] is a method that helps accelerate SGD in the relevant direction and dampens oscillations. The work in [
33] adapted the learning rate and performed smaller updates for parameters, which could improve the robustness of SGD. The work in [
34] proposed Adam, an optimization method that has been generally used in deep learning. Adam also keeps an exponentially-decaying average of past gradients, similar to momentum. Whereas momentum can be seen as a ball running down a slope, Adam behaves like a heavy ball with friction, which thus prefers flat minima in the error surface.
However, recently, there have been some criticisms about Adam [
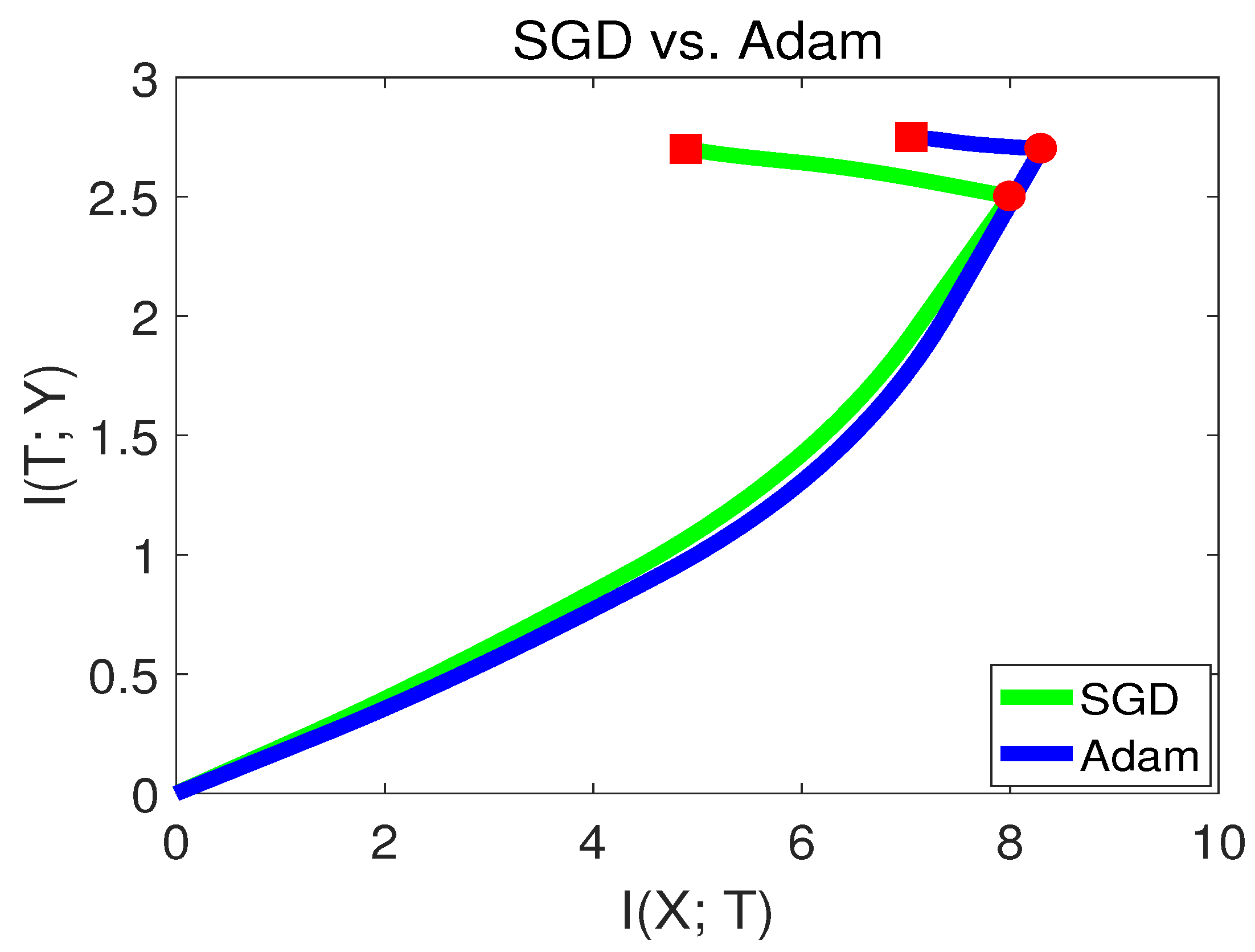
28]. It was stated that Adam may have better performance at the beginning of the training, but may end up with lower accuracy than SGD. To verify this phenomenon, we visualize SGD and the Adam method in the information plane in
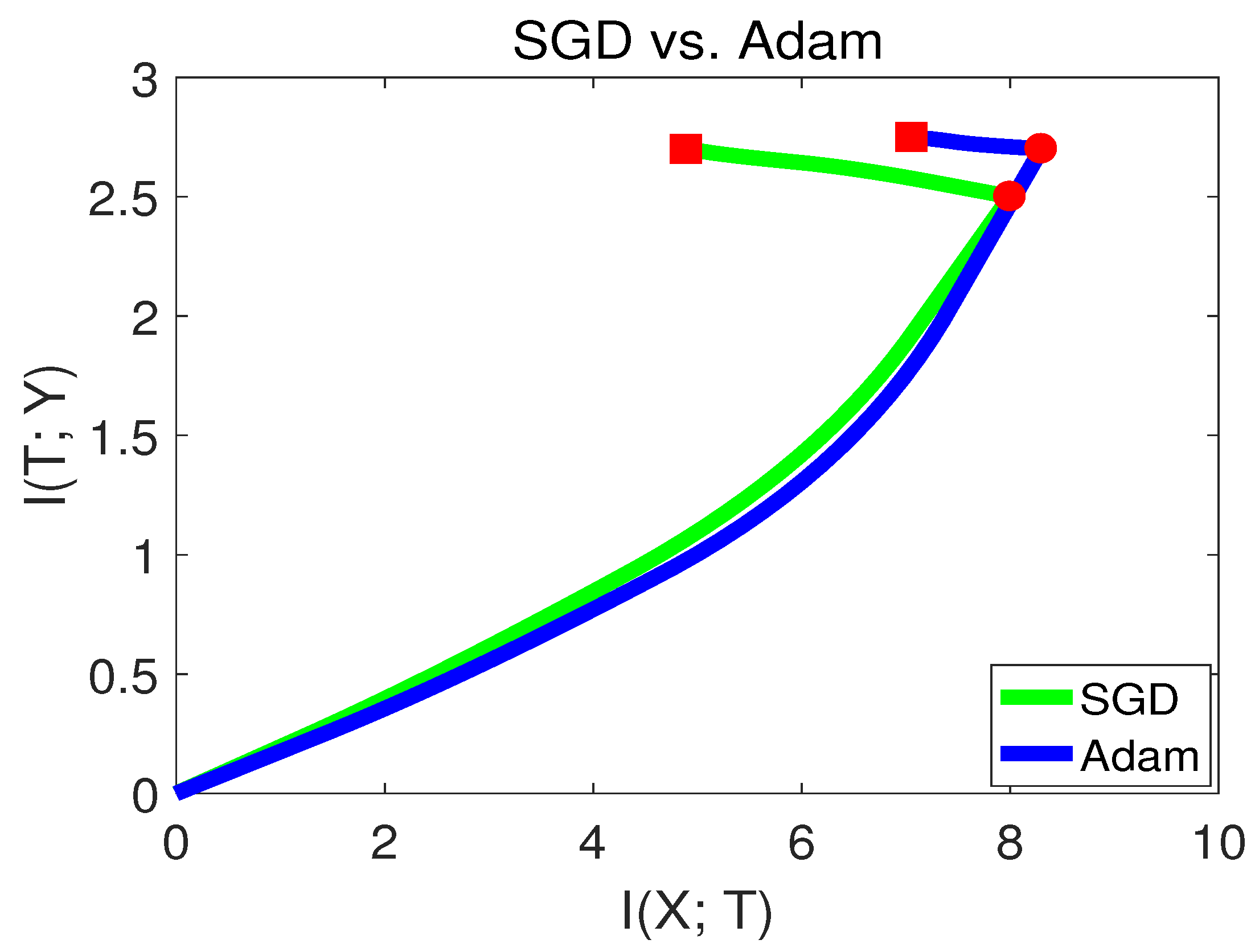
Figure 12.
From
Figure 12, we can see that Adam had a better capability of fitting the labels in the first stage. while in the second stage, SGD behaved better than Adam. Since SGD converged to a point with lower
, this indicates that SGD had better generalization capability than Adam at the end of training. Our finding is consistent with [
28]. The experiments from
Section 3.7 and
Section 3.8 show that the information plane can be used as a tool to analyze variant deep learning algorithms.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}