Compact Belief Rule Base Learning for Classification with Evidential Clustering †



Abstract
1. Introduction
- A supervised version of the ECM algorithm is designed by means of weighted product-space clustering to take into account the class labels, which can obtain credal partitions with both good inter-cluster separability and inner-cluster pureness.
- A systematic method is developed to construct belief rules (composed of the antecedent part, the consequent class, and the rule weight) based on credal partitions of the training set.
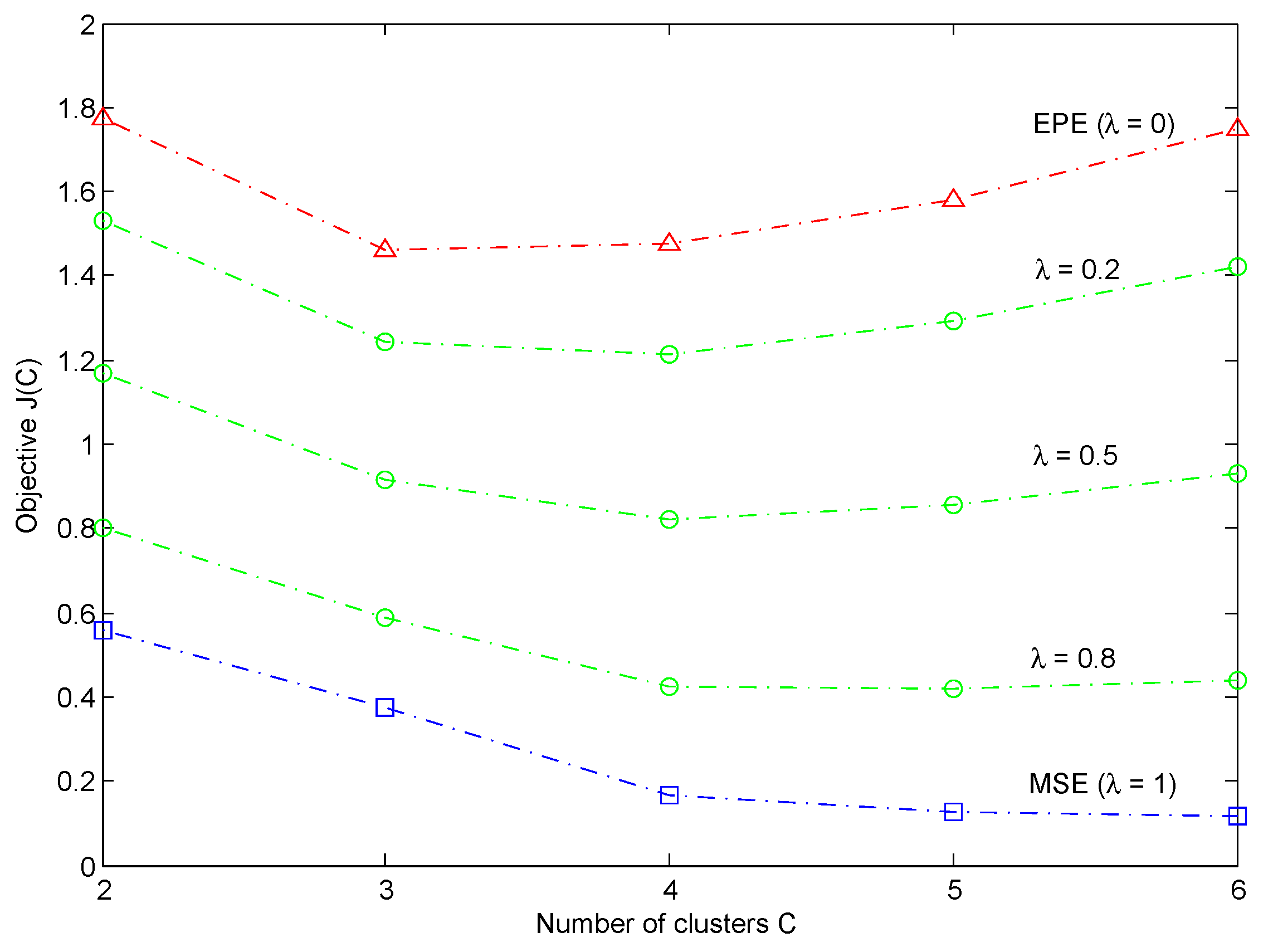
- A two-objective optimization procedure based on both the mean squared error and the evidential partition entropy is designed to get a compact BRB with a better trade-off between accuracy and interpretability.
2. Background
2.1. Basics of the Belief Function Theory
- normal, if . Otherwise, it is subnormal, and is interpreted as a mass of belief given to the hypothesis that might not lie in .
- Bayesian, if all its focal sets are singletons. In this case, the mass function reduces to the precise probability distribution;
- certain, if the whole mass is allocated to a unique singleton. This corresponds to a situation of complete knowledge;
- vacuous, if the whole mass is allocated to . This situation corresponds to complete ignorance.
2.2. Belief Rule-Based Classification System (BRBCS)
- Step 1:
- Partition of the feature space.A fuzzy-grid-based method is used to divide the P-dimensional feature space into fuzzy regions, with being the number of partitions for p-th feature.
- Step 2:
- Generation of the consequent class for each fuzzy region.Each training pattern is assigned to the fuzzy region with the greatest matching degree, and those patterns assigned to the same fuzzy region are fused to get the consequent class.
- Step 3:
- Generation of the rule weights.The rule weights are determined by two measures called confidence and support jointly.
2.3. Evidential C-Means (ECM)
- when each is a certain mass function, then M defines the conventional, crisp partitions of the set of objects;
- when each is a Bayesian mass function, then M specifies the fuzzy partitions, as defined by Bezdek [22].
3. Compact BRB Learning with ECM
3.1. Credal Partition with Supervised ECM
- Limiting the number of credal partitions. By minimizing the objective function displayed as Equation (4), a maximum number of credal partitions can be obtained. However, those credal partitions composed of many classes are quite difficult to interpret and are usually also less important in practice. Therefore, in order to learn a compact BRB, we constrain the focal sets to be either , or to be composed of at most two classes, thereby reducing the maximum number of credal partitions from to .
- Discarding the outlier cluster. In ECM, the training patterns assigned to empty set are considered to be outliers, which are adverse to classification. Thus, we only construct belief rules based on the left credal partitions associated with non-empty focal sets.
3.2. Belief Rule Base Construction
3.2.1. Antecedent Parts Generation
3.2.2. Consequent Classes Generation
3.2.3. Rule Weights Generation
3.3. Parameter Optimization for Trade-Off between Accuracy and Interpretability
4. Experiments
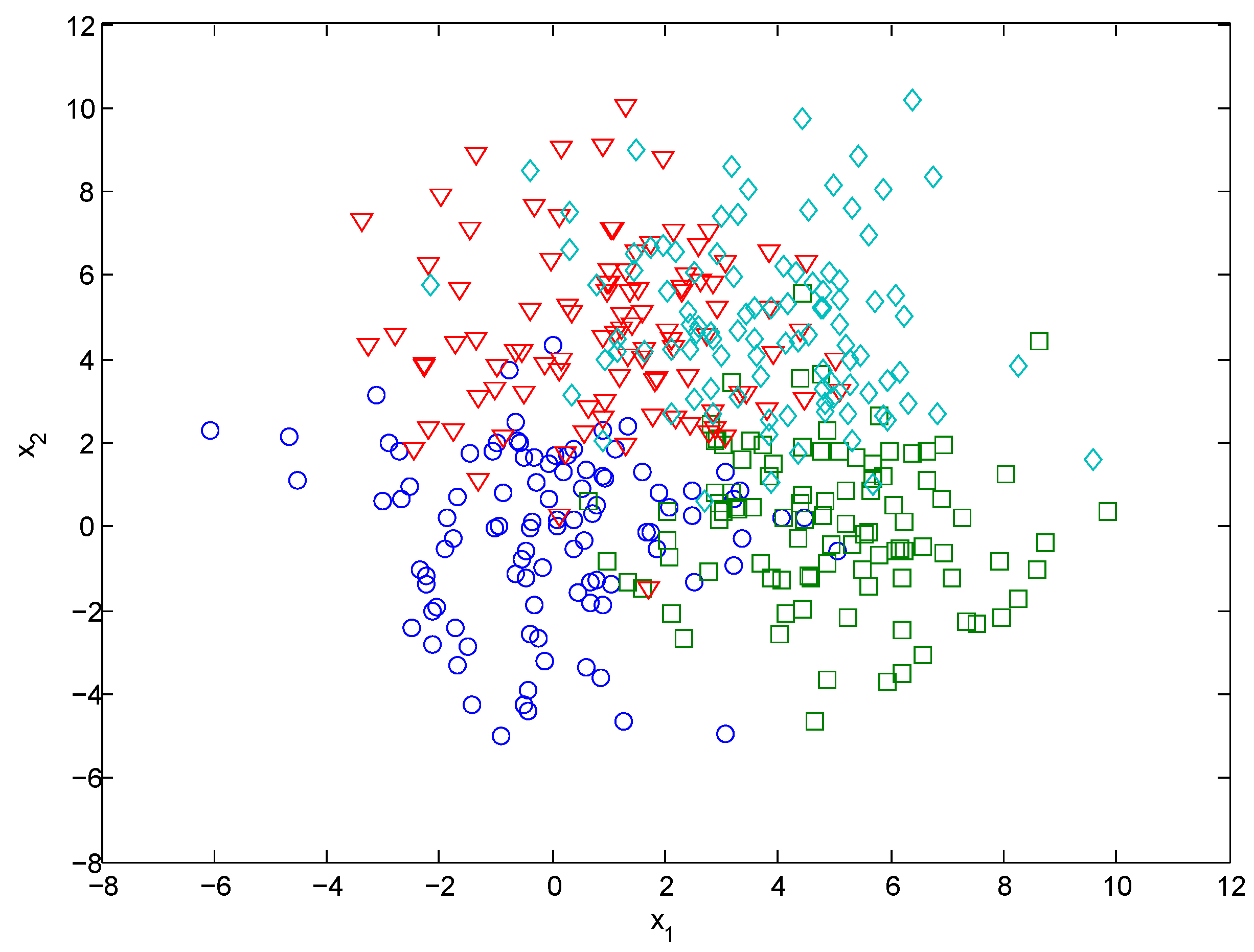
4.1. Synthetic Data Set Test
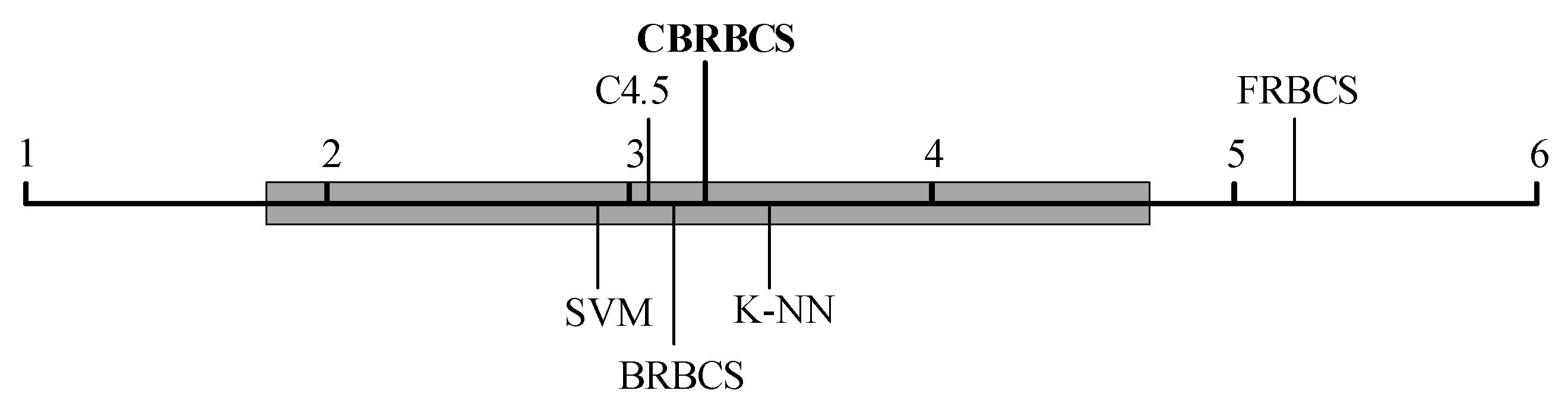
4.2. Real Data Set Test
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aggarwal, C.C. Data Classification: Algorithm and Applications; Chapman & Hall: Boca Raton, FL, USA, 2014. [Google Scholar]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Morgan Kauffman: San Francisco, CA, USA, 1993. [Google Scholar]
- Cortes, C.; Vapnik, V. Support vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chi, Z.; Yan, H.; Pham, T. Fuzzy Algorithms with Applications to Image Processing and Pattern Recognition; World Scientific: Singapore, 1996. [Google Scholar]
- Ishibuchi, H.; Nozaki, K.; Tanaka, H. Distributed representation of fuzzy rules and its application to pattern classification. Fuzzy Sets Syst. 1992, 52, 21–32. [Google Scholar] [CrossRef]
- Zadeh, L.A. Fuzzy sets. Inform. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Stavrakoudis, D.G.; Galidaki, G.N.; Gitas, I.Z.; Theocharis, J.B. A genetic fuzzy-rule-based classifier for land cover classification from hyperspectral imagery. IEEE Trans. Geosci. Remote Sens. 2012, 50, 130–148. [Google Scholar] [CrossRef]
- Samantaray, S.R. Genetic-fuzzy rule mining approach and evaluation of feature selection techniques for anomaly intrusion detection. Appl. Soft Comput. 2013, 13, 928–938. [Google Scholar] [CrossRef]
- Singh, P.; Pal, N.R.; Verma, S.; Vyas, O.P. Fuzzy rule-based approach for software fault prediction. IEEE Trans. Syst. Man Cybern. Syst. 2017, 47, 826–837. [Google Scholar] [CrossRef]
- Paul, A.K.; Shill, P.C.; Rabin, M.R.I.; Murase, K. Adaptive weighted fuzzy rule-based system for the risk level assessment of heart disease. Appl. Intell. 2018, 48, 1739–1756. [Google Scholar] [CrossRef]
- Wu, H.; Mendel, J. Classification of battlefield ground vehicles using acoustic features and fuzzy logic rule-based classifiers. IEEE Trans. Fuzzy Syst. 2007, 15, 56–72. [Google Scholar] [CrossRef]
- Dempster, A. Upper and lower probabilities induced by multivalued mapping. Ann. Math. Stat. 1967, 38, 325–339. [Google Scholar] [CrossRef]
- Shafer, G. A Mathematical Theory of Evidence; Princeton University Press: Princeton, NJ, USA, 1976. [Google Scholar]
- Yager, R.R.; Filev, D.P. Including probabilistic uncertainty in fuzzy logic controller modeling using Dempster-Shafer theory. IEEE Trans. Syst. Man Cybern. 1995, 25, 1221–1230. [Google Scholar] [CrossRef]
- Liu, J.; Yang, J.B.; Wang, J.; Sii, H.S.; Wang, Y.M. Fuzzy rule based evidential reasoning approach for safety analysis. Int. J. Gen. Syst. 2004, 33, 183–204. [Google Scholar] [CrossRef]
- Yang, J.B.; Liu, J.; Wang, J.; Sii, H.S.; Wang, H.W. Belief rule-based inference methodology using the evidential reasoning approach–RIMER. IEEE Trans. Syst. Man Cybern. Part A-Syst. 2006, 36, 266–285. [Google Scholar] [CrossRef]
- Jiao, L.; Pan, Q.; Denœux, T.; Liang, Y.; Feng, X. Belief rule-based classification system: Extension of FRBCS in belief functions framework. Inf. Sci. 2015, 309, 26–49. [Google Scholar] [CrossRef]
- Jiao, L.; Geng, X.; Pan, Q. A compact belief rule-based classification system with interval-constrained clustering. In Proceedings of the 2018 International Conference on Information Fusion, Cambridge, UK, 10–13 July 2018; pp. 2270–2274. [Google Scholar]
- Jiao, L. Classification of Uncertain Data in the Framework of Belief Functions: Nearest-Neighbor-Based and Rule-Based Approaches. Ph.D. Thesis, Université de Technologie de Compiègne, Compiègne, France, 26 October 2015. [Google Scholar]
- Masson, M.H.; Denoeux, T. ECM: An evidential version of the fuzzy c-means algorithm. Pattern Recognit. 2008, 41, 1384–1397. [Google Scholar] [CrossRef]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Plenum Press: New York, NJ, USA, 1981. [Google Scholar]
- Dua, D.; Karra Taniskidou, E. UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 1 July 2017).
- Jiao, L.; Denœux, T.; Pan, Q. A hybrid belief rule-based classification system based on uncertain training data and expert knowledge. IEEE Trans. Syst. Man Cybern. Syst. 2016, 46, 1711–1723. [Google Scholar] [CrossRef]
- Almeida, R.J.; Denoeux, T.; Kaymak, U. Constructing rule-based models using the belief functions framework. In Advances in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 554–563. [Google Scholar]
- Wang, W.; Zhang, Y. On fuzzy cluster validity indices. Fuzzy Sets Syst. 2007, 158, 2095–2117. [Google Scholar] [CrossRef]
- Yang, M.S.; Nataliani, Y. Robust-learning fuzzy c-means clustering algorithm with unknown number of clusters. Pattern Recognit. 2015, 71, 45–59. [Google Scholar] [CrossRef]
- Wu, C.H.; Ouyang, C.S.; Chen, L.W.; Lu, L.W. A new fuzzy clustering validity index with a median factor for centroid-based clustering. IEEE Trans. Fuzzy Syst. 2015, 23, 701–718. [Google Scholar] [CrossRef]
- Lei, Y.; Bezdek, J.C.; Chan, J.; Vinh, N.X.; Romano, S.; Bailey, J. Extending information-theoretic validity indices for fuzzy clustering. IEEE Trans. Fuzzy Syst. 2017, 25, 1013–1018. [Google Scholar] [CrossRef]
- Bezdek, J.C. Cluster validity with fuzzy sets. J. Cybern. 1974, 3, 58–73. [Google Scholar] [CrossRef]
- Jiroušek, R.; Shenoy, P.P. A new definition of entropy of belief functions in the Dempster-Shafer theory. Int. J. Approx. Reason. 2018, 92, 49–65. [Google Scholar] [CrossRef]
- Pan, L.; Deng, Y. A new belief entropy to measure uncertainty of basic probability assignments based on belief function and plausibility function. Entropy 2018, 20, 842. [Google Scholar] [CrossRef]
- Xiao, F. An improved method for combining conflicting evidences based on the similarity measure and belief function entropy. Int. J. Fuzzy Syst. 2018, 20, 1256–1266. [Google Scholar] [CrossRef]
- Pal, N.R.; Bezdek, J.C.; Hemasinha, R. Uncertainty measures for evidential reasoning II: New measure of total uncertainty. Int. J. Approx. Reason. 1993, 8, 1–16. [Google Scholar] [CrossRef]
- Denœux, T.; Masson, M.H. EVCLUS: Evidential clustering of proximity data. IEEE Trans. Syst. Man Cybern. Part B-Cybern. 2004, 34, 95–109. [Google Scholar] [CrossRef]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- García, S.; Fernández, A.; Luengo, J.; Herrera, F. Advanced nonparametric tests for multiple comparisons in the design of experiments in computational intelligence and data mining: Experimental analysis of power. Inf. Sci. 2010, 180, 2044–2064. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definitions |
|---|---|
| AE | aggregated entropy |
| BRB | belief rule base |
| BRBCS | belief rule-based classification system |
| BRM | belief reasoning method |
| CBRBCS | compact belief rule-based classification system |
| ECM | evidential C-means |
| EPE | evidential partition entropy |
| FCM | fuzzy C-means |
| FPE | fuzzy partition entropy |
| FRBCS | fuzzy rule-based classification system |
| K-NN | K-nearest neighbor |
| MSE | mean squared error |
| RBC | rule-based classification |
| SVM | support vector machines |
| antecedent part of belief rule | |
| set of classes | |
| c | class label |
| C | number of clusters |
| distance between object and set | |
| M | credal partition matrix |
| number of partitions for p-th feature | |
| j-th belief rule in the rule base | |
| training data set | |
| V | cluster center matrix |
| W | weight of class labels in clustering process |
| input feature vector | |
| weighting exponent for cardinality in ECM | |
| weighting exponent for fuzziness in ECM | |
| distance to the empty set in ECM | |
| weight of belief rule | |
| weight of classification accuracy | |
| variance of p-th feature values | |
| variance of class values | |
| frame of discernment |
| Data Set | # Instances | # Features | # Classes |
|---|---|---|---|
| Australian | 690 | 14 | 2 |
| Balance | 625 | 4 | 3 |
| Car | 1278 | 6 | 4 |
| Contraceptive | 1473 | 9 | 3 |
| Dermatology | 358 | 34 | 6 |
| Ecoli | 336 | 7 | 8 |
| Glass | 214 | 9 | 6 |
| Hepatitis | 80 | 19 | 2 |
| Ionosphere | 351 | 33 | 2 |
| Iris | 150 | 4 | 3 |
| Lymphography | 148 | 18 | 4 |
| Nursery | 12,690 | 8 | 5 |
| Page-blocks | 5472 | 10 | 5 |
| Sonar | 208 | 60 | 2 |
| Thyroid | 7200 | 21 | 3 |
| Vehicle | 846 | 18 | 4 |
| Vowel | 990 | 13 | 11 |
| Wine | 178 | 13 | 3 |
| Yeast | 1484 | 8 | 10 |
| Zoo | 101 | 16 | 7 |
| Method | Parameter | Value |
|---|---|---|
| K-NN | number of neighbors K | 3 |
| distance metric | Euclidean | |
| C4.5 | pruned? | TRUE |
| confidence level c | 0.25 | |
| minimal instances per leaf i | 2 | |
| SVM | kernel type | RBF |
| penalty coefficient C | 100 | |
| kernel parameter | 0.01 | |
| FRBCS | number of partitions per feature n | 5 |
| membership function type | triangular | |
| reasoning method | single winner | |
| BRBCS | number of partitions per feature n | 5 |
| membership function type | triangular | |
| reasoning method | belief reasoning | |
| CBRBCS | weighting exponent for cardinality | 2 |
| weighting exponent for fuzziness | 2 | |
| accuracy weight | 0.5 |
| Data set | K-NN | C4.5 | SVM | FRBCS | BRBCS | CBRBCS |
|---|---|---|---|---|---|---|
| Australian | 88.78 (1) | 85.22 (2) | 75.51 (6) | 79.86 (5) | 82.74 (4) | 83.90 (3) |
| Balance | 83.37 (5) | 76.80 (6) | 95.51 (1) | 89.60 (4) | 92.66 (3) | 93.20 (2) |
| Car | 92.31 (6) | 92.55 (5) | 94.33 (2) | 92.78 (4) | 95.23 (1) | 93.12 (3) |
| Contraceptive | 44.95 (5) | 52.68 (2) | 55.95 (1) | 39.86 (6) | 49.15 (3) | 48.20 (4) |
| Dermatology | 96.90 (1) | 94.42 (2) | 94.34 (3) | 72.29 (6) | 85.12 (5) | 93.35 (4) |
| Ecoli | 80.67 (3) | 79.47 (4) | 81.96 (2) | 76.02 (6) | 78.34 (5) | 82.62 (1) |
| Glass | 70.11 (1) | 67.44 (5) | 70.00 (2) | 66.04 (6) | 69.04 (3) | 68.15 (4) |
| Hepatitis | 82.51 (3) | 84.00 (1) | 82.18 (4) | 74.41 (6) | 76.28 (5) | 83.68 (2) |
| Ionosphere | 85.18 (6) | 90.90 (3) | 92.60 (1) | 86.55 (5) | 89.11 (4) | 91.66 (2) |
| Iris | 94.00 (4) | 96.00 (3) | 97.33 (1) | 93.67 (5) | 96.67 (2) | 93.33 (6) |
| Lymphography | 77.39 (4) | 74.30 (5) | 81.27 (1) | 72.27 (6) | 79.20 (2) | 77.90 (3) |
| Nursery | 92.54 (6) | 97.30 (1) | 93.18 (5) | 94.02 (4) | 96.05 (2) | 94.65 (3) |
| Page-blocks | 95.91 (2) | 96.97 (1) | 92.36 (5) | 91.92 (6) | 95.10 (4) | 95.28 (3) |
| Sonar | 83.07 (1) | 70.07 (5) | 78.71 (2) | 59.60 (6) | 74.80 (3) | 73.33 (4) |
| Thyroid | 93.89 (5) | 99.63 (1) | 93.49 (6) | 94.03 (4) | 95.04 (2) | 94.39 (3) |
| Vehicle | 71.75 (3) | 74.69 (1) | 52.95 (6) | 60.77 (5) | 71.95 (2) | 70.54 (4) |
| Vowel | 97.78 (1) | 81.52 (5) | 95.76 (2) | 79.90 (6) | 93.28 (3) | 92.10 (4) |
| Wine | 95.49 (3) | 94.90 (4) | 89.74 (6) | 95.82 (2) | 96.14 (1) | 94.48 (5) |
| Yeast | 53.17 (5) | 55.53 (2) | 58.09 (1) | 48.51 (6) | 54.66 (4) | 55.08 (3) |
| Zoo | 92.81 (4) | 93.64 (3) | 96.50 (1) | 85.06 (6) | 90.55 (5) | 95.30 (2) |
| Average rank | 3.45 | 3.05 | 2.90 | 5.20 | 3.15 | 3.25 |
| Data Set | # Train Instances | # Features | # Classes | # Rules | ||
|---|---|---|---|---|---|---|
| BRBCS | CBRBCS | Reduction Rate | ||||
| Australian | 621 | 14 | 2 | 317 | 16 | 94.95% |
| Balance | 552 | 4 | 3 | 66 | 11 | 83.33% |
| Car | 1150 | 6 | 4 | 682 | 22 | 96.77% |
| Contraceptive | 1326 | 9 | 3 | 233 | 22 | 90.56% |
| Dermatology | 322 | 34 | 6 | 315 | 37 | 88.25% |
| Ecoli | 302 | 7 | 8 | 45 | 37 | 17.78% |
| Glass | 192 | 9 | 6 | 40 | 22 | 45.00% |
| Hepatitis | 72 | 19 | 2 | 67 | 7 | 89.55% |
| Ionosphere | 316 | 33 | 2 | 227 | 11 | 95.15% |
| Iris | 135 | 4 | 3 | 14 | 11 | 21.43% |
| Lymphography | 133 | 18 | 4 | 129 | 22 | 82.95% |
| Nursery | 11,421 | 8 | 5 | 4238 | 37 | 99.13% |
| Page-blocks | 4925 | 10 | 5 | 55 | 22 | 60.00% |
| Sonar | 187 | 60 | 2 | 187 | 16 | 91.44% |
| Thyroid | 6480 | 21 | 3 | 460 | 22 | 95.22% |
| Vehicle | 761 | 18 | 4 | 230 | 16 | 93.04% |
| Vowel | 891 | 13 | 11 | 141 | 67 | 52.48% |
| Wine | 160 | 13 | 3 | 122 | 16 | 86.89% |
| Yeast | 1336 | 8 | 10 | 96 | 56 | 41.67% |
| Zoo | 91 | 16 | 7 | 55 | 29 | 47.27% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, L.; Geng, X.; Pan, Q. Compact Belief Rule Base Learning for Classification with Evidential Clustering. Entropy 2019, 21, 443. https://doi.org/10.3390/e21050443
Jiao L, Geng X, Pan Q. Compact Belief Rule Base Learning for Classification with Evidential Clustering. Entropy. 2019; 21(5):443. https://doi.org/10.3390/e21050443
Chicago/Turabian StyleJiao, Lianmeng, Xiaojiao Geng, and Quan Pan. 2019. "Compact Belief Rule Base Learning for Classification with Evidential Clustering" Entropy 21, no. 5: 443. https://doi.org/10.3390/e21050443
APA StyleJiao, L., Geng, X., & Pan, Q. (2019). Compact Belief Rule Base Learning for Classification with Evidential Clustering. Entropy, 21(5), 443. https://doi.org/10.3390/e21050443