1. Introduction
Using a single classifier has shown limitations in achieving satisfactory recognition performance, and this leads us to use multiple classifiers, which is now a common practice in machine learning. Classifier combination has been studied in many disciplines such as the social sciences, sensor fusion, pattern recognition, etc. Schapire [
1] proved that a strong classifier can be generated by combining weak classifiers. It has been accepted as an effective method to improve classification performances. Many examples of ensemble classifier systems can be found in process engineering or medicine. For a survey of the issues and approaches on classifier combination, readers are referred to Woźniak [
2] and Oza and Turner [
3]. The same type of approach has also been used, for instance, in remote sensing domains (e.g., for land cover mapping with Landsat Multispectral Scanner, elevation) [
4], computer security [
5], financial risks [
6], proteomics [
7].
Classifiers can provide as their final decision only a single class, a ranked list of all the classes, or a score associated with each class as a measure of confidence for the class. In this paper, we focus only on rank-values to perform combination. Rank data are useful when data can not be easily reduced to numbers, such as data that are related to concepts, opinions, feelings, values, and behaviors of people in a social context, genes, characters, etc. Ranking also has the advantage of removing scale effects while permitting ranking patterns to be compared. But rank-ordering has also its disadvantages: it is difficult to combine data from different rankings, and the information contained in the data is limited [
8].
After learning, each classifier of the ensemble has output its own results. Several fusion strategies have been proposed in the literature to combine classifiers at the rank level [
9,
10]. Among them, one of the most common techniques is certainly the linear combination of the classifier outputs [
11,
12]. The voting principle is the simplest method of combination, where the top candidate from each classifier constitutes a single vote. The final decisions can be made by majority rule (over half of the votes) [
13], plurality (maximum number of votes) [
14], weighted sum of significance [
15], or other variants. The method of Borda count [
16], which sums up the rank values of classifiers, can be considered as a generalization of the voting principle. The Bayesian approach estimates the class posterior probabilities conditioned on classifier decisions by approximating various probability densities [
17]. Although decision theory itself does not assume classifiers are independent, this assumption is almost always adopted in practical implementation to reduce the exponential complexity of probability estimation. In summary, classifier combination is an ensemble method that classifies new data by taking a weighted vote of the predictions of a set of classifiers [
18]. This is originally a Bayesian averaging, but more recent algorithms include boosting, bagging, random forests, and variants [
19,
20,
21]. Note that Dempster–Shafer formalism for aggregating beliefs based on uncertainty reasoning lends itself to a more flexible model used to combine multiple pieces of evidence and capable of taking uncertainty and ignorance into account [
22].
Finally, a rank classifier provides an ordered list of classes associating each class with a rank integer that indicates its importance in the list. The output of a classifier is therefore a vector of ranks attributed to the K classes.
An ensemble of classifiers might be a better choice than a single classifier because of the variability of the ensemble errors, which is such that the consensus performance is significantly better than the best individual in the ensemble [
23]. This analysis is certainly true when the classifiers of the ensemble “see” different training patterns, and it can be effective even when the classifiers all share the same training set. In a computerized tomography problem to illustrate how the ensemble consensus outperformed the best individuals, Anthimopoulos observed that the marginal benefit obtained by increasing the ensemble size is usually low due to correlation among errors: most classifiers will get the right answer on easy inputs, while many classifiers will make mistakes on difficult inputs [
24].
In addition, running several searches and combining the solutions produces a better approximation than many learning techniques that use local searches to converge toward a solution, with the risk of staying stacked in local optima (which may not be true in the case of deep learning classifiers, since Kawaguchi has shown that every local minimum is a global minimum [
25]). Thus, we might not be capable of producing the optimal classifier using a training set and a given classifier architecture, compared to a set of several classifiers. Since the number of classifiers can be very high (in the thousands), it is difficult to “understand” the classifier ensemble decision characteristics.
Although general performances are often improved when classifiers are combined, it becomes computationally costly to combine well-trained classifiers [
26]. Most of the time, it is believed that the combination of independent classifiers will provide greater performance improvement [
27], while combiner decisions could be biased toward duplicated outputs. However, this belief stems from the difficulty of using a dependence assumption. In fact, in practical situations, classifier independence is difficult to assess.
How do multiple rank classifiers improve separation performances when individual classification performances are slightly better than random decision making? And what is “classifier independence” ? This term raises several issues that we will address in
Section 4, where we come back to the theory of rank aggregation and propose an algorithm to combine classifiers. The main properties of the classifier are discussed.
Section 2 exposes the general framework and the notations used. A classifier ensemble dependence measure is then proposed to evaluate the conditional mutual information in
Section 5. Experimental results are presented in
Section 6 for the detection of cervical cancer. Finally,
Section 7 gives conclusions on rank classifier combination and further investigations are discussed.
Notations
Set and regions are indicated by double-trace uppercase letters such as , vectors with bold lowercase such as , and matrices with uppercase bold letters such as . The elements of a matrix are indexed by the row index i and the column index j. Lowercase letters refer to individual elements in a vector whose position in the vector is indicated by the last subscript. Therefore, refers to the jth element of vector . is the a priori probability of the random value X belonging to class , K being the number of classes. M is the number of classifiers used for combination. denotes the cardinality of set . denotes the transpose operator.
2. Problem Statement and Model
We consider a classification dataset
with
n observations
obtained from a physical signal, or synonymously, explanatory variables, objects, instances, cases, patterns, t-uples, etc. where each
belongs to class
. The vector
lies in an attribute space
and each component
is a numerical or nominal categorical attribute, also named feature, variable, dimension, component, field, etc.
The output of the
M classifiers
are represented by a
K-dimensional vector
: each component
is a certain value associated with class
given by
. Depending on the nature of the classifier
,
can be a rank value that reflects a complete or partial ordering of all classes, or a value in
corresponding to the predicted class assigned to 1 and the others to zero, or a score, e.g., a discriminant value, associated with each class
, which serves as a confidence measure for the class to be the true class. The latter can easily be converted into the two former. Therefore, each classifier
defines a mapping function from the image domain
to a
K-dimensional vector space defined over a set of values
. The general framework is illustrated in
Figure 1.
In this paper, is a rank value that reflects a complete or partial ordering of the classes. The objective is to design an optimal combination function that takes all the as input and produces as an output the decision vector , where is the rank associated with the decision on class , that is, . Thus, we seek as a discriminant function defined over .
In the following, it is assumed that (i) classifiers have equal individual performance (ii) classifiers are treated as “black boxes”. Hence, the combination operator applies only on the real space vectors .
3. Conditional Independence Properties
The term “classifier independence” has been used in an intuitive manner, but what is classifier independence? Formally, two classifiers
and
are said to be independent if
with
and
being the decision values of
and
. The idea is illustrated in the following example.
Example 1 (Independent classifiers)
. Consider a binary classification problem (with equiprobable classes and ) and two classifiers and with similar performances and whose outputs are and , i.e., their probabilities of correct classification and are equal:Then the total probability rule helps to find the probability of the outputs: The two classifiers are independent if the joint probability factorizes In Equations (5)–(6), and do not appear anymore. The value of should be , independently of the classifier performances. This is possible only if . Thus, the ensemble performance does not depend of the performance of the individuals. In other words, independent classifiers in the sense of definition (2) are random classifiers (recognition rate of 50%)! Suppose now that classifiers are very efficient and that and are almost identical to 1. In this case, the probability that the two answers are correct is also almost equal to 1 andwhich is far from the value of required by the condition of independence. Example (1) suggests that interesting classifiers (non-random!) cannot be independent in the sense of Equation (
2). Making the assumption that decision vectors
are conditionally independent given
, the discriminant function
maximizes the posterior probability
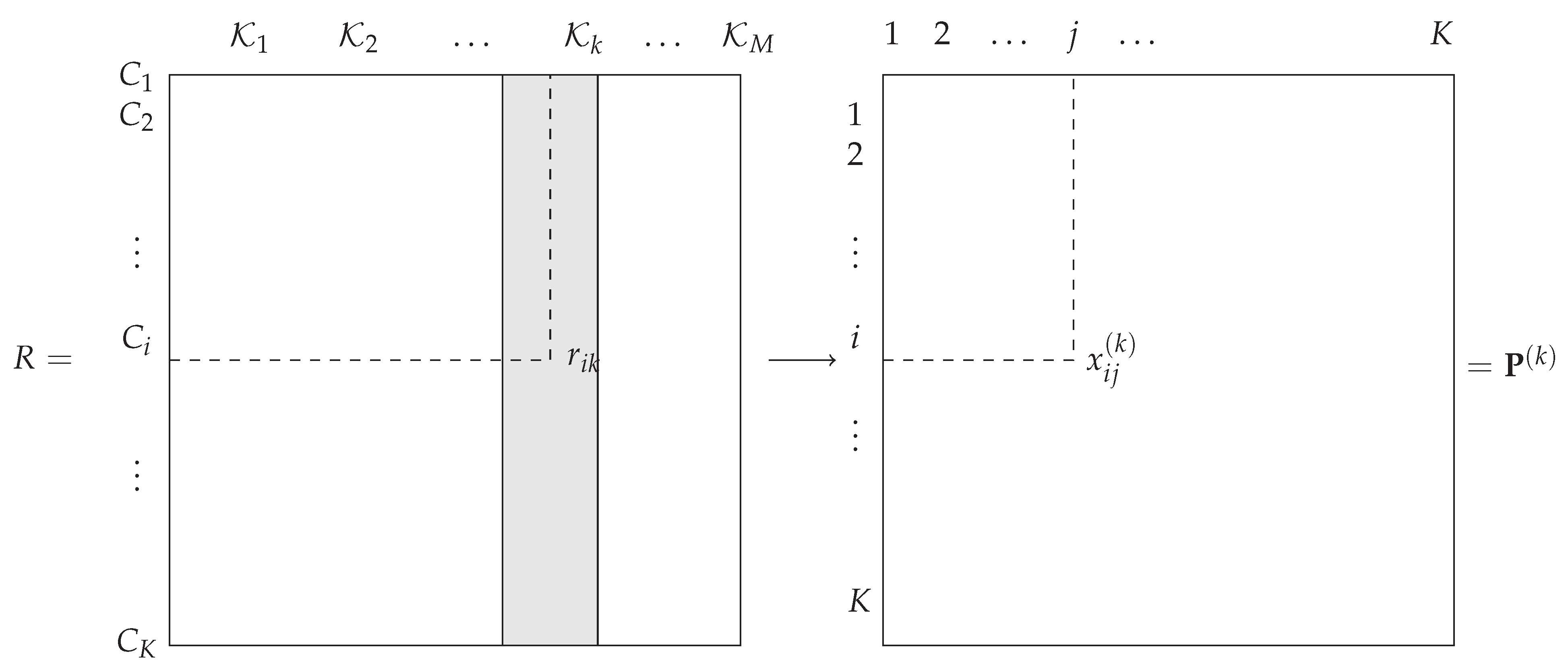
, which can be point estimated from the entries of the
M -confusion matrices, as given, for instance, in
Table 1.
Let
be the indicatrix function for which
if the rank of the class
is less than the alternative class
, and 0 otherwise. Then in
Table 1,
and the line and column marginals are respectively defined by
and
. If class
is the
kth choice for classifier
, then
.
Example 2 (Conditional independent classifiers)
. Consider once again the binary classification case introduced in Example (1) and assume that the classifiers are very efficient: . ThenWe conclude that two classifiers can be conditionally independent even if they are very efficient. Equation (8) does not indicate that the classifiers are independent. It only suggests that they can be conditionally independent or
conditionally dependent. Therefore, conditional independence can be seen as a necessary condition for classifier combination. But the direct use of the confusion matrix as a criterion to derive the optimal combination rule is not feasible since the true classes are unknown.
6. Experiments
6.1. The Detection of Cervical Cancer
Many studies have shown evidence that cervical cancer may be imputed to a subset of DNA viruses called
human papillomavirus (HPV) (referred to as risky patients)that infect cutaneous and mucosal epithelia, and in which acute infection causes benign cutaneous lesions [
34,
35]. Some of these viruses infect the genital tract and cause malignant tumors, which are most commonly located in the cervix. Even though most of these infections are controlled by the immune system, some remain persistent and are ascribed to different types of cancers and particularly, to cervical cancer. In 2016, cervical cancer represented the 12th most lethal female cancer in the European Union, accounting for 13500 deaths a year and 30400 new cases a year. Therefore, cervical cancer screening still continues to play a critical role in the control of cervical cancer. However, the screening of a smear is nowadays mostly made manually: a pathologist inspects each cell of a smear with a microscope to check if it is atypical or not. Consequently, human error is always possible, and in particular, mistakenly diagnosing atypical cells as normal. This situation can occur because of the practitioner’s fatigue or a lack of experience or concentration. In addition, diagnosis is also linked to the preparation of cells, and in some situations, atypical cells can be partially hidden by others, which makes their interpretation or classification difficult. In addition, the presence of atypical cells in the entire studied population is very uncommon (up to 1‰) which makes the detection task even more difficult. Therefore, an error is easily possible. This could have irreversible effects on the evolution of the cancer and can impact treatment. The introduction of an automatic procedure, able to point out the pathological cells, would both help the practitioner in his diagnosis and improve or strengthen it.
Depending on the morphology of the nuclei of the cells, the diagnosis varies: if a nucleus is considered normal and all of the cells removed have the same diagnosis, then the cervix is considered normal. On the other hand, if a nucleus is considered abnormal, the diagnosis is not automatically associated with a risky smear.
We propose to test our classifier combination strategy to cluster cells into three different classes (normal cells, atypical cells, and debris) using a certain number of classifiers.
6.2. The Dataset
The cytological dataset is constituted of smear images from 14 different women. They generally comprise more than one hundred cells characterized by 42 morphological or textural variables. Nine showed a negative hpv test and the other five, a positive test. In addition, few observations were labeled by an expert who pointed out some atypical cells and noisy objects. The dataset is presented in detail in
Table 3. Among the most recurrent patterns of abnormal cells are nucleus regularity or a swollen aspect, nucleus size, important optical density, number of nucleoli, high core/cytoplasm ratio, ratio of minimum/maximum width of the nucleus, etc.
The images were colored with Papanicolaou stain, which is the most widely used reference color for the screening of cervical cancers; it makes it possible to distinguish the different nuclei, which are colored in blue, the mother cells in dark purple to black, and the keratinized and squamous epithelium. The images were then segmented into thumbnail images of pixels which correspond a priori to objects. Most of the time, these objects are nuclei, but they may sometimes be non-identified objects that we call “noise”. Indeed, they can correspond, for example, to a poor segmentation, a superimposed nuclei, etc.
A few observations were labeled by an expert who pointed out some atypical cells and noisy objects. The fact that a nucleus has one of these characteristics does not always imply its malignancy. In fact, a cell can have a singular morphology but not be infected, and others may present abnormalities that correspond to pre-cancerous lesions such as dysplastic cells and in situ carcinomas or to cancerous cells.
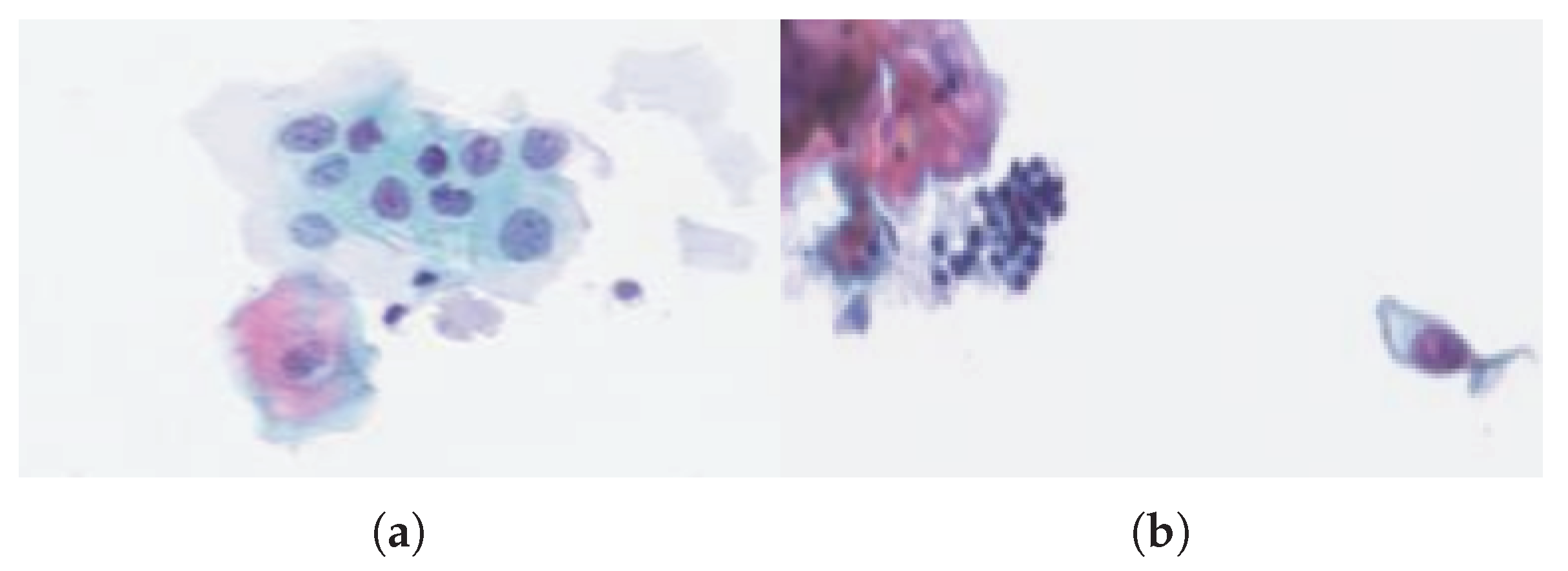
Figure 4a shows a cluster of abnormal cells (with large nuclei) that are not yet cancerous, because of their low density, unlike
Figure 4b, where one can observe a set of abnormal cells with dense nuclei.
Table 4 summarizes the characteristics of the dataset. First, the observed data come from samples of 14 different smears, which supposes the existence of inter-individual variability (confirmed by tests of variance between the hpv negatives, the hpv positives, or between the two types of population; the 5% risk threshold tests rejected the assumption of equality of means for all variables). However, it is possible that this variability is simply relative to the studied dataset, in the sense that the study was done on a small number of smear samples. This assumption remains to be verified on larger databases. It can also be noted in
Table 3 that the known population of “abnormal” cells remains very low in proportion to the other classes, and, in contrast, the recognized “default/waste” class represents more than 15% of the data. The low proportion of the target class and the heterogeneity of the debris present obstacles for clustering. This means that, among the cells belonging to risky patient smears, there exists a non-null risk that some nuclei are atypical. Iin practice, this proportion is usually very low (0.1% to 5%).
From this image segmentation, morphological and photometric features are extracted and computed. In total, the studied dataset has 3857 cell samples belonging to 14 different smears and consists of 42 variables: variables 1 to 19 represent morphological variables, and the rest corresponds to textural and photometric characters. The channel of treatments from the smear image to the dataset is reported in
Figure 5.
Each smear was pre-processed according to a standardized protocol: cell collection, spreading a thin layer on slides, and the staining of these slides. Each slide was then scanned, segmented cell by cell, and finally, underwent an extraction of 42 morphological and textural characteristics.
6.3. Experimental Protocol
Two-layer multilayer perceptrons (MLPs) were chosen as classifiers to produce the desired outputs, which were ordered to produce the ranks. Each multilayer perceptron (MLP) contains 42 input units, 10 hidden units, and 3 output units. Training was achieved using a learning rate of 0.1 and a momentum of 0.9 for two epochs on the training set. We deliberately trained the MLPs without optimization of a validation set. It is important to stress that the training set for the classifier was not the same set as the test set, the ensure that the experiments would be unbiased. The best results obtained for an mlp were a classification error rate of and a false positive rate (FPR) (or false alarm ratio) of . The fpr is the number of false positives divided by the total number of negatives N, i.e., . The false negative rate (FNR) is the number of false negatives divided by the number of real positive cases in the data, i.e., . In practice, this is a test result that indicates that a condition does not hold, while in fact it does.
In order to assess the efficiency of the rank classifier combination algorithms, error rates were computed from a certain percentage of nuclei whose labels were known. This represented 70% of the observations in a subsample, as we took into account the 20 labeled atypical nuclei randomly selected, and we also assumed that those coming from control patients (120) were all normal nuclei. We proceeded in the same manner to compute the fpr which stands for the percentage of actual atypical nuclei mis-classified.
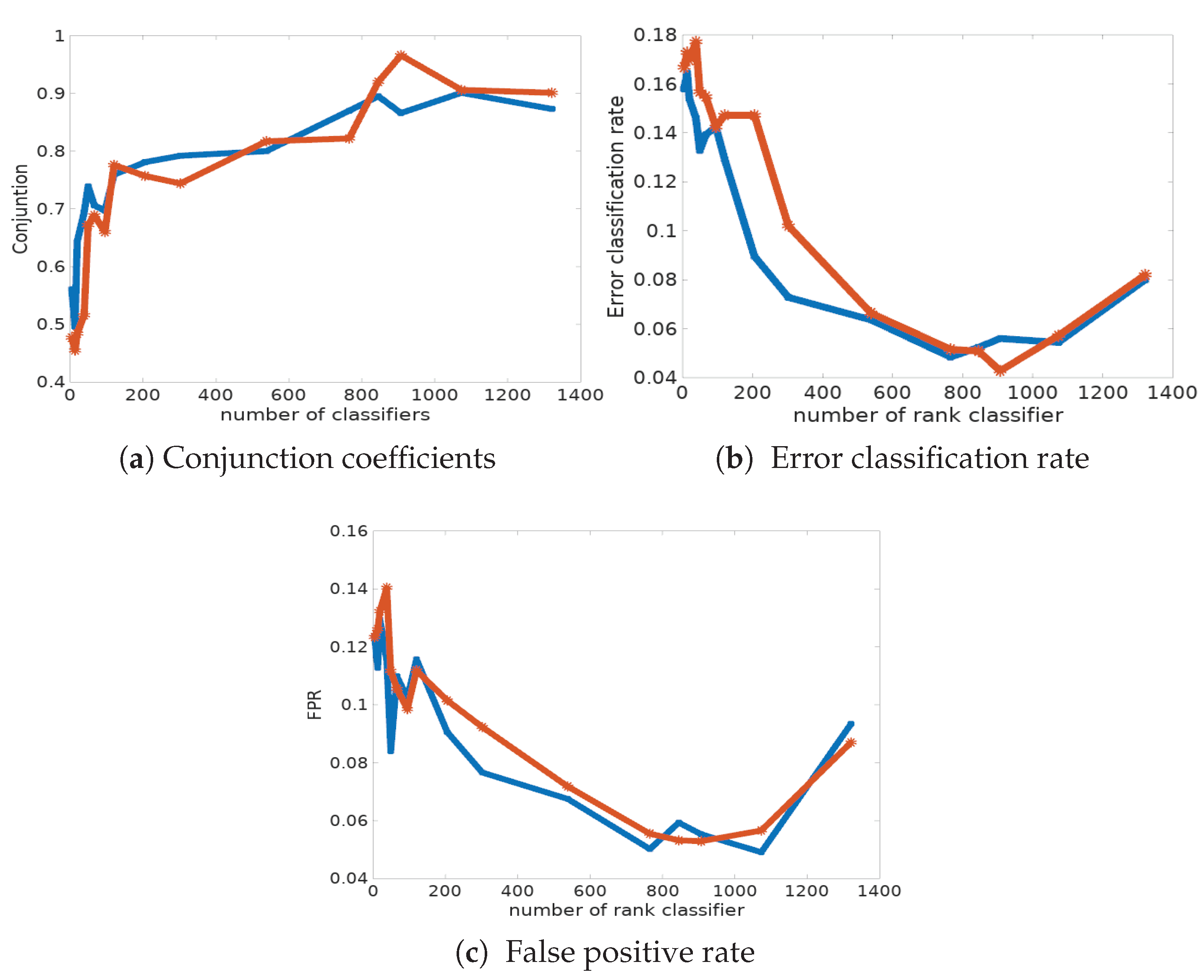
In
Table 5 and in
Figure 6a, we report the classification error rate computed from the data with known labels and its corresponding fpr, for the two procedures. First of all, we can observe that the Condorcet combination rule shows the best performances in terms of classification error rate and fpr (see also
Figure 6c). Indeed, only 4.28% of cells are mis-classified, whereas the disagreement combination rule has a mis-classification rate of 4.84% in the best case, with 765 classifiers. The main conclusion is that the success ratio is strongly improved when combining classifiers. However, it is disappointing to see that the Condorcet algorithm results in a significant number of false negatives (pathological cells classified as normal ones); the fnr also remains relatively high, around 10%, in many simulations. Indeed, the classification risk is not symmetric here: the detection of pathological cells activates the decision for treatment, and their absence implies an absence of treatment.
We compared the clustering partition obtained by the three competitors: sparse
k-means (SkM) proposed by Witten and Tibshirani [
36,
37], general sparse multi-class linear discriminant analysis (GSM-LDA) [
38], and sparse EM (sEM)by Zhong et al. [
39]. First, we can observe that among these algorithms, the sEM shows the best performance in terms of clustering accuracy. Only 9% of observations are mis-classified, on average, whereas the GSM-LDA algorithm has a mis-classification rate of 15.9%, and the SkM algorithm mis-classifies 19.2% of nuclei. However, the sparse approaches provide a better clustering results from a medical point of view since the results can be interpreted conversely to the LDA-type algorithm, for which the fitted discriminative axis is a linear combination of the original variables. Therefore, SkM and sEM provide information which can be interpreted to better understand both the data and the phenomenon.
The rank classifier combination provides the best classification results. We can observe that the global clustering error rates are considerably reduced (
Table 6). Indeed, the best error rate reaches 4.28% with 907 classifiers and a conjunction coefficient of 96.6%.
7. Conclusions and Future Research
In this paper, we show that an exact optimal combination rule for a rank classifier ensemble can be computed as the solution to a binary linear programming problem. This rule can be seen as a total order ranking attributed to K classes by a virtual voter resuming the points of view of M voters. One could also stand the dual problem of the previous one, i.e., is there a distribution of marks or values that could have been attributed to a virtual class C by the m voters? The first problem is related to the idea of aggregating points of view, the second with the idea of summarizing profiles.
We compared disagreement and Condorcet metrics, making it possible to quantify the consensus between the classifiers with a conjunction coefficient. The optimal rankings are not the same, i.e., the solution depends of the metric used. But they have shown their efficiency, in addition to the appealing property of being deterministic algorithms: they improve the classification results and ease the interpretation and the understanding of the results. Another point worth mentioning is the theoretical capability of handling the reject option. A weak point of this technique is that it treats all classifiers equally and does not take into account individual classifier capabilities. This disadvantage can be reduced to a certain degree by applying weights. The weights can be different for every classifier, which in turn requires additional training. This idea deserves to be further explored.
The role of variable selection appears to be significant, as it enables the improvement of both the clustering partition and the modeling of the atypical cells in the cancer detection smear (see
Figure 5). In the future, we propose including a rule to rank the selected features and to investigate how the number and nature of classifiers influence the results of the rank classifier combination.










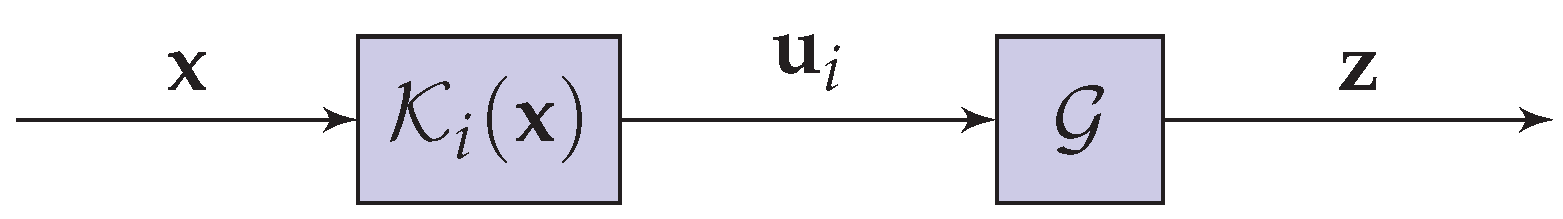{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}