2.1. Portfolio Selection and Risk Management
In financial contexts, “risk” refers to the likelihood of an investment yielding a different return from the expected one [
5]; thus, in a broad sense, risk does not necessarily only have regard to unfavorable outcomes (downside risk), but rather includes upside risk as well. Any flotation from the expected value of the return of a financial asset is viewed as a source of uncertainty, or “volatility”, as it is more often called in finance.
A rational investor would seek to optimize his interests at all times, which can be expressed in terms of maximization of his expected return and minimization of his risk. Given that future returns are a random variable, there are many possible measures for its volatility; however, the most common measure for risk is the variance operator (second moment), as used in Markowitz [
2]’s Modern Portfolio Theory seminal work, while expected return is measured by the first moment. This is equivalent to assuming that all financial agents follow a mean-variance preference, which is grounded in the microeconomic theory and has implications in the derivation of many important models in finance and asset pricing, such as the CAPM model [
6,
7,
8], for instance.
The assumption of rationality implies that an “efficient” portfolio allocation is a choice of weights
in regard to how much assets you should buy which are available in the market, such that the investor cannot increase his expected return without taking more risk—or, alternatively, how you can decrease his portfolio volatility without taking a lower level of expected return. The curve of the possible efficient portfolio allocations in the risk versus the expected return graph is known as an “efficient frontier”. As shown in Markowitz [
2], in order to achieve an efficient portfolio, the investor should diversify his/her choices, picking the assets with the minimal association (measured by covariances), such that the joint risks of the picked assets tend to cancel each other.
Therefore, for a set of assets with identical values for expected return and variance , choosing a convex combination of many of them will yield a portfolio with a volatility value smaller than , unless all chosen assets have perfect correlation. Such effects of diversification can be seen statistically from the variance of the sum of p random variables: ; since (negative-valued weights represent a short selling), the volatility of a generic portfolio with same-risk assets will always diminish with diversification.
The component of risk which can be diversified, corresponding to the joint volatility between the chosen assets, is known as “idiosyncratic risk”, while the non-diversifiable component of risk, which represents the uncertainties associated to the financial market itself, is known as “systematic risk” or “market risk”. The idiosyncratic risk is specific to a company, industry, market, economy, or country, meaning it can be eliminated by simply investing in different assets (diversification) that will not all be affected in the same way by market events. On the other hand, the market risk is associated with factors that affect all assets’ companies, such as macroeconomic indicators and political scenarios; thus not being specific to a particular company or industry and which cannot be eliminated or reduced through diversification.
Although there are many influential portfolio selection models that arose after Markowitz’s classic work, such as the Treynor-Black model [
9], the Black-Litterman model [
10], as well as advances in the so-called “Post-Modern Portfolio Theory” [
11,
12] and machine-learning techniques [
13,
14,
15], Markowitz [
2] remains as one of the most influential works in finance and is still widely used as a benchmark for alternative portfolio selection models, due to its mathematical simplicity (uses only a vector of expected returns and a covariance matrix as inputs) and easiness of interpretation. Therefore, we used this model as a baseline to explore the potential improvements that arise with the introduction of nonlinear interactions and covariance matrix filtering through the Random Matrix Theory.
2.2. Nonlinearities and Machine Learning in Financial Applications
Buonocore et al. [
16] presents two key elements that define the complexity of financial time-series: the multi-scaling property, which refers to the dynamics of the series over time; and the structure of cross-dependence between time-series, which are reflexes of the interactions among the various financial assets and economic agents. In a financial context, one can view those two complexity elements as systematic risk and idiosyncratic risk, respectively, precisely being the two sources of risk that drive the whole motivation for risk diversification via portfolio allocation, as discussed by the Modern Portfolio Theory.
It is well-known that systematic risk cannot be diversified. So, in terms of risk management and portfolio selection, the main issue is to pick assets with minimal idiosyncratic risk, which in turn, naturally, demands a good estimation for the cross-interaction between the assets available in the market, namely the covariance between them.
The non-stationarity of financial time-series is a stylized fact which is well-known by scholars and market practitioners, and this property has relevant implications in forecasting and identifying patterns in financial analysis. Specifically concerning portfolio selection, the non-stationary behavior of stock prices can induce major drawbacks when using the standard linear Pearson correlation estimator in calculating the covariances matrix. Livan et al. [
17] provides empirical evidence of the limitations of the traditional linear approach established in Markowitz [
2], pointing out that the linear estimator fails to accurately capture the market’s dynamics over time, an issue that is not efficiently solved by simply using a longer historical series. The sensitivity of Markowitz [
2]’s model to its inputs is also discussed in Chen and Zhou [
18], which incorporates the third and fourth moments (skewness and kurtosis) as additional sources of uncertainty over the variance. Using multi-objective particle swarm optimization, robust efficient portfolios were obtained and shown to improve the expected return in comparison to the traditional mean-variance approach. The relative attractiveness of different robust efficient solutions to different market settings (bullish, steady, and bearish) was also discussed.
Concerning the Dynamical Behavior of Financial Systems, Bonanno et al. [
19] proposed a generalization of the Heston model [
20], which is defined by two coupled stochastic differential equations (SDEs) representing the log of the price levels and the volatility of financial stocks, and provided a solution for option pricing that incorporated improvements over the classical Black-Scholes model [
21] regarding financial stylized facts, such as the skewness of the returns and the excess kurtosis. The extension proposed by Bonanno et al. [
19] was the introduction of a random walk with cubic nonlinearity to replace the log-price SDE of Heston’s model. Furthermore, the authors analyzed the statistical properties of escape time as a measure of the stabilizing effect of the noise in the market dynamics. Applying this extended model, Spagnolo and Valenti [
22] tested for daily data of 1071 stocks traded at the New York Stock Exchange between 1987 and 1998, finding out that the nonlinear Heston model approximates the probability density distribution on escape times better than the basic geometric Brownian motion model and two well-known volatility models, namely GARCH [
23] and the original Heston model [
20]. In this way, the introduction of a nonlinear term allowed for a better understanding of a measure of market instability, capturing embedded relationships that linear estimators fail to consider. Similarly, linear estimators for covariance ignore potential associations in higher dimensionality interactions, such that even assets with zero covariance may actually have a very heavy dependence on nonlinear domains.
As discussed in Kühn and Neu [
24], the states of a market can be viewed as attractors resulting from the dynamics of nonlinear interactions between the financial variables, such that the introduction of nonlinearities also has potential implications for financial applications, such as risk management and derivatives pricing. For instance, Valenti et al. [
25] pointed out that volatility is a monotonic indicator of financial risk, while many large oscillations in a financial market (both upwards and downwards) are preceded by long periods of relatively small levels of volatility in the assets’ returns (the so-called “volatility clustering”). In this sense, the authors proposed the mean first hitting time (defined as the average time until a stock return undergoes a large variation—positive or negative—for the first time) as an indicator of price stability. In contrast with volatility, this measure of stability displays nonmonotonic behavior that exhibits a pattern resembling the Noise Enhanced Stability (NES) phenomenon, observed in a broad class of systems [
26,
27,
28]. Therefore, using the conventional volatility as a measure of risk can lead to its underestimation, which in turn can lead to bad allocations of resources or bad financial managerial decisions.
In light of evidence that not all noisy information of the covariance matrix is due to their non-stationarity behavior [
29], many machine-learning methods, such as the Support Vector Machines [
30], Gaussian processes [
31], and deep learning [
32] methods have been discussed in the literature, showing that the introduction of nonlinearities can provide a better display of the complex cross-interactions between the variables and generate better predictions and strategies for the financial markets. Similarly, Almahdi and Yang [
33] proposed a portfolio trading algorithm using recurrent reinforcement learning, using the expected maximum drawdown as a downside risk measure and testing for different sets of transaction costs. The authors also proposed an adaptive rebalancing extension, reported to have a quicker reaction to transaction cost variations and which managed to outperform hedge fund benchmarks.
Paiva et al. [
34] proposed a fusion approach of a Support Vector Machine and the mean-variance optimization for portfolio selection, testing for data from the Brazilian market and analyzing the effects of brokerage and transactions costs. Petropoulos et al. [
35] applied five machine learning algorithms (Support Vector Machine, Random Forest, Deep Artificial Neural Networks, Bayesian Autoregressive Trees, and Naïve Bayes) to build a model for FOREX portfolio management, combining the aforementioned methods in a stacked generalization system. Testing for data from 2001 to 2015 of ten currency pairs, the authors reported the superiority of machine learning models in terms of out-of-sample profitability. Moreover, the paper discussed potential correlations between the individual machine learning models, providing insights concerning their combination to boost the overall predictive power. Chen et al. [
36] generalized the idea of diversifying for individual assets for investment and proposed a framework to construct portfolios of investment strategies instead. The authors used genetic algorithms to find the optimal allocation of capital into different strategies. For an overview of the applications of machine learning techniques in portfolio management contexts, see Pareek and Thakkar [
37].
Regarding portfolio selection, Chicheportiche and Bouchaud [
38] developed a nested factor multivariate model to model the nonlinear interactions in stock returns, as well as the well-known stylized facts and empirically detected copula structures. Testing for the S&P 500 index for three time periods (before, during, and after the financial crisis), the paper showed that the optimal portfolio constructed by the developed model showed a significantly lower out-of-sample risk than the one built using linear Principal Component Analysis, whilst the in-sample risk is practically the same; thus being positive evidence towards the introduction of nonlinearities in portfolio selection and asset allocation models. Montenegro and Albuquerque [
39] applied a local Gaussian correlation to model the nonlinear dependence structure of the dynamic relationship between the assets. Using a subset of companies from the S&P 500 Index between 1992 and 2015, the portfolio generated by the nonlinear approach managed to outperform the Markowitz [
2] model in more than 60% of the validation bootstrap samples. In regard to the effects of dimensionality reduction on the performance of portfolios generated from mean-variance optimization, Tayalı and Tolun [
40] applied Non-negative Matrix Factorization (NMF) and Non-negative Principal Components Analysis (NPCA) for data from three indexes of the Istanbul Stock Market. Optimal portfolios were constructed based on Markowitz [
2]’s mean-variance model. Performing backtesting for 300 tangency portfolios (maximum Sharpe Ratio), the authors showed that the portfolios’ efficiency was improved in both NMF and NPCA approaches over the unreduced covariance matrix.
Musmeci et al. [
41] incorporated a metric of persistence in the correlation structure between financial assets, and argued that such persistence can be useful for the anticipation of market volatility variations and that they could quickly adapt to them. Testing for daily prices of US and UK stocks between 1997 and 2013, the correlation structure persistence model yielded better forecasts than predictors based exclusively on past volatility. Moreover, the paper discusses the effect of the “curse of dimensionality” that arises in financial data when a large number of assets is considered, an issue that traditional econometric methods often fail to deal with. In this regard, Hsu et al. [
4] argues in favor of the use of nonparametric approaches and machine learning methods in traditional financial economics problems, given their better empirical predictive power, as well as providing a broader view of well-established research topics in the finance agenda beyond classic econometrics.
2.3. Regularization, Noise Filtering, and Random Matrix Theory
A major setback in introducing nonlinearities is keeping them under control, as they tend to significantly boost the model’s complexity, both in terms of theoretical implications and computational power needed to actually perform the calculations. Nonlinear interactions, besides often being difficult to interpret and apart from a potentially better explanatory power, may bring alongside them a large amount of noisy information, such as an increase in complexity that is not compensated by better forecasts or theoretical insights, but instead which “pollutes” the model by filling it with potentially useless data.
Bearing in mind this setback, the presence of regularization is essential to cope with the complexity levels that come along with high dimensionality and nonlinear interactions, especially in financial applications in which the data-generating processes tend to be highly chaotic. While it is important to introduce new sources of potentially useful information by boosting the model’s complexity, being able to filter that information, discard the noises, and maintain only the “good” information is a big and relevant challenge. Studies like Massara et al. [
42] discuss the importance of scalability and information filtering in light of the advent of the “Big Data Era”, in which the boost of data availability and abundance led to the need to efficiently use those data and filter out the redundant ones.
Barfuss et al. [
43] emphasized the need for parsimonious models by using information filtering networks, and building sparse-structure models that showed similar predictive performances but much smaller computational processing time in comparison to a state-of-the-art sparse graphical model baseline. Similarly, Torun et al. [
44] discussed the eigenfiltering of measurement noise for hedged portfolios, showing that empirically estimated financial correlation matrices contain high levels of intrinsic noise, and proposed several methods for filtering it in risk engineering applications.
In financial contexts, Ban et al. [
45] discussed the effects of performance-based regularization in portfolio optimization for mean-variance and mean-conditional Value-at-Risk problems, showing evidence for its superiority towards traditional optimization and regularization methods in terms of diminishing the estimation error and shrinking the model’s overall complexity.
Concerning the effects of high dimensionality in finance, Kozak et al. [
46] tested many well-established asset pricing factor models (including CAPM and the Fama-French five-factor model) introducing nonlinear interactions between 50 anomaly characteristics and 80 financial ratios up to the third power (i.e., all cross-interactions between the features of first, second, and third degrees were included as predictors, totaling to models with 1375 and 3400 candidate factors, respectively). In order to shrink the complexity of the model’s high dimensionality, the authors applied dimensionality reduction and regularization techniques considering
and
penalties to increase the model’s sparsity. The results showed that a very small number of principal components were able to capture almost all of the out-of-sample explanatory powers, resulting in a much more parsimonious and easy-to-interpret model; moreover, the introduction of an additional regularized principal component was shown to not hinder the model’s sparsity, but also to not improve predictive performance either.
Depending on the “noisiness” of the data, the estimation of the covariances can be severely hindered, potentially leading to bad portfolio allocation decisions—if the covariances are overestimated, the investor could give up less risky asset combinations, or accept a lesser expected profitability; if the covariances are underestimated, the investor would be bearing a higher risk than the level he was willing to accept, and his portfolio choice could be non-optimal in terms of risk and return. Livan et al. [
17] discussed the impacts of measurement noises on correlation estimates and the desirability of filtering and regularization techniques to diminish the noises in empirically observed correlation matrices.
A popular approach for the noise elimination of financial correlation matrices is the Random Matrix Theory, which studies the properties of matrix-form random variables—in particular, the density and behavior of eigenvalues. Its applications cover many of the fields of knowledge of recent years, such as statistical physics, dynamic systems, optimal control, and multivariate analysis.
Regarding applications in quantitative finance, Laloux et al. [
47] compared the empirical eigenvalues density of major stock market data with their theoretical prediction, assuming that the covariance matrix was random following a Wishart distribution (If a vector of random matrix variables follows a multivariate Gaussian distribution, then its Sample covariance matrix will follow a Wishart distribution [
48]).The results showed that over
of the eigenvalues fell within the theoretical bounds (defined in Edelman [
48]), implying that less than
of the eigenvalues contain actually useful information; moreover, the largest eigenvalue is significantly higher than the theoretical upper bound, which is evidence that the covariance matrix estimated via Markowitz is composed of few very informative principal components and many low-valued eigenvalues dominated by noise. Nobi et al. [
49] tested for the daily data of 20 global financial indexes from 2006 to 2011 and also found out that most eigenvalues fell into the theoretical range, suggesting a high presence of noises and few eigenvectors with very highly relevant information; particularly, this effect was even more prominent during a financial crisis. Although studies like El Alaoui [
50] found a larger percentage of informative eigenvalues, the reported results show that the wide majority of principal components is still dominated by noisy information.
Plerou et al. [
51] found similar results, concluding that the top eigenvalues of the covariance matrices were stable in time and the distribution of their eigenvector components displayed systematic deviations from the Random Matrix Theory predicted thresholds. Furthermore, the paper pointed out that the top eigenvalues corresponded to an influence common to all stocks, representing the market’s systematic risk, and their respective eigenvectors showed a prominent presence of central business sectors.
Sensoy et al. [
52] tested 87 benchmark financial indexes between 2009 and 2012, and also observed that the largest eigenvalue was more than 14 times larger than the Random Matrix Theory theoretical upper bound, while only less than
of the eigenvalues were larger than this threshold. Moreover, the paper identifies “central” elements that define the “global financial market” and analyzes the effects of the 2008 financial crisis in its volatility and correlation levels, concluding that the global market’s dependence level generally increased after the crisis, thus making diversification less effective. Many other studies identified similar patterns in different financial markets and different time periods [
53,
54], evidencing the high levels of noise in correlation matrices and the relevance of filtering such noise for financial analysis. The effects of the covariance matrix cleaning using Random Matrix Theory in an emerging market was discussed in Eterovic and Eterovic [
55], which analyzed 83 stocks from the Chilean financial market between 2000 and 2011 and found out that the efficiency of portfolios generated using Markowitz [
2]’s model were largely improved.
Analogously, Eterovic [
56] analyzed the effects of covariance matrix filtering through the Random Matrix Theory using data from the stocks of the FTSE 100 Index between 2000 and 2012, confirming the distribution pattern of the eigenvalues of the covariance matrix, with the majority of principal components inside the bounds of the Marčenko-Pastur distribution, while the top eigenvalue was much larger than the remaining ones; in particular, the discrepancy of the top eigenvalue was even larger during the Crisis period. Moreover, Eterovic [
56] also found out that the performance improvement of the portfolios generated by a filtered covariance matrix filtering over a non-filtered one was strongly significant, evidencing the ability of the filtered covariance matrix to adapt to sudden volatility peaks.
Bouchaud and Potters [
57] summarized the potential applications of the Random Matrix Theory in financial problems, focusing on the cleaning of financial correlation matrices and the asymptotic behavior of its eigenvalues, whose density was enunciated in Marčenko and Pastur [
58]—and especially the largest one, which was described by the Tracy-Widom distribution [
59]. The paper presents an empirical application using daily data of US stocks between 1993 and 2008, observing the correlation matrix of the 500 most liquid stocks in a sliding window of 1000 days with an interval of 100 days each, yielding 26 sample eigenvalue distributions. On average, the largest eigenvalue represents
of the sum of all eigenvalues. This is a stylized fact regarding the spectral properties of financial correlation matrices, as discussed in Akemann et al. [
60]. Similar results were found in Conlon et al. [
61], which analyzes the effects of “cleaning” the covariance matrix on better predictions of the risk of a portfolio, which may aid the investors to pick the best combination of hedge funds to avoid risk.
In financial applications, the covariance matrix is also important in multi-stage optimization problems, whose dimensionality often grows exponentially as the number of stages, financial assets or risk factor increase, thus demanding approximations using simulated scenarios to circumvent the curse of dimensionality [
62]. In this framework, an important requirement for the simulated scenarios is the absence of arbitrage opportunities, a condition which can be incorporated through resampling or increasing the number of scenarios [
63]. Alternatively, [
64] defined three classes for arbitrage propensity and suggested a transformation on the covariance matrix’s Cholesky decomposition that avoids the possibility of arbitrage in scenarios where it could theoretically exist. In this way, the application of the Random Matrix Theory on this method can improve the simulated scenarios in stochastic optimization problems, and consequently improve the quality of risk measurement and asset allocation decision-making.
Burda et al. [
65] provided a mathematical derivation of the relationship between the sample correlation matrix calculated using the conventional Pearson estimates with its population counterpart, discussing how the dependency structure of the spectral moments can be applied to filter out the noisy eigenvalues of the correlation matrix’s spectrum. In fact, a reasonable choice of a
covariance matrix (like using the S&P 500 data for portfolio selection) induces a very high level of noise in addition to the signal that comes from the eigenvalues of the population covariance matrix; Laloux et al. [
66] used daily data of the S&P 500 between 1991 and 1996, and found out that the covariance matrix estimated by the classical Markowitz model highly underestimates the portfolio risks for a second time period (approximately three times lower than the actual values), a difference that is significantly lower for a cleaned correlation matrix, evidencing the high level of noise and the instability of the market dependency structure over time.
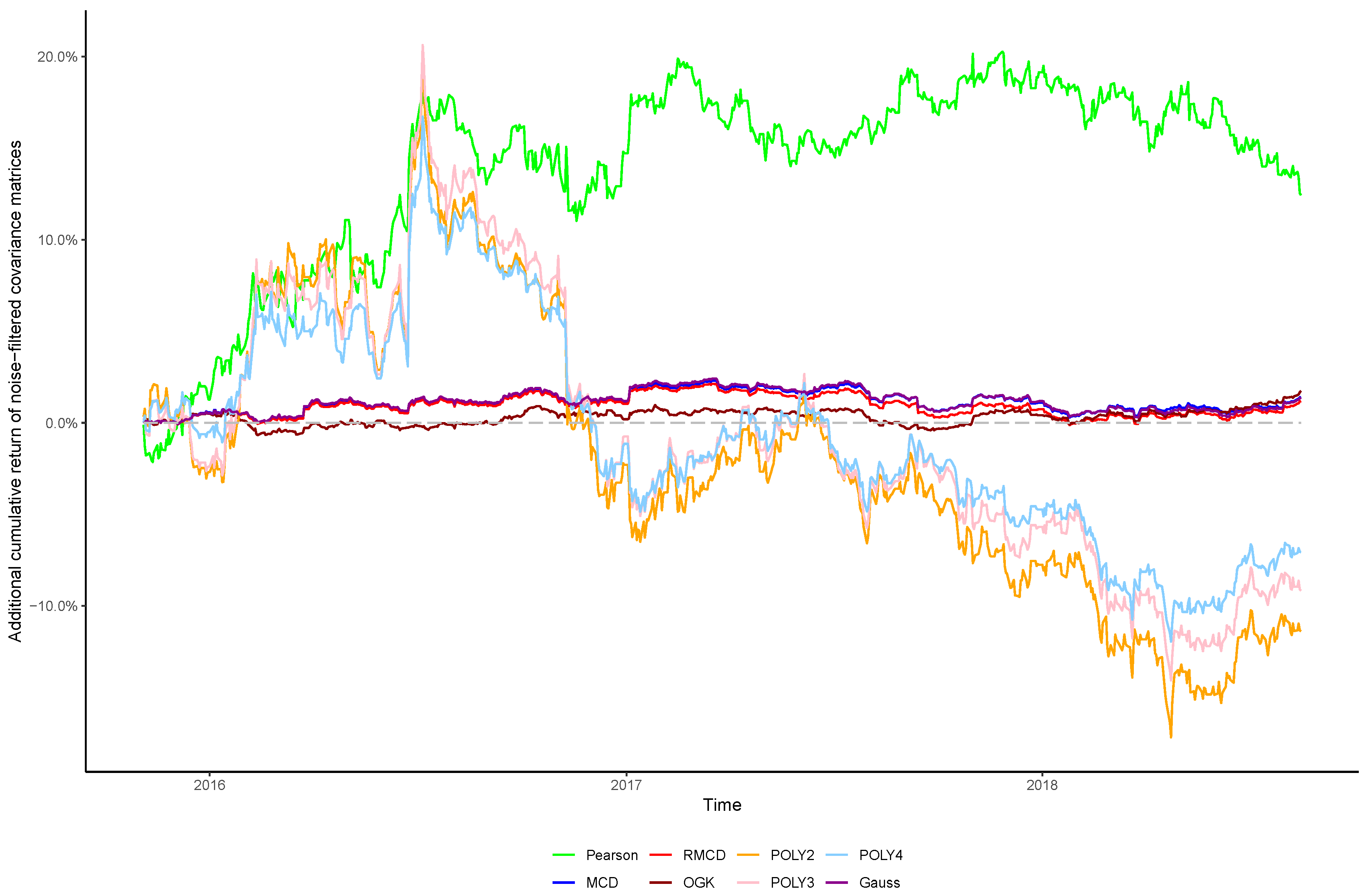
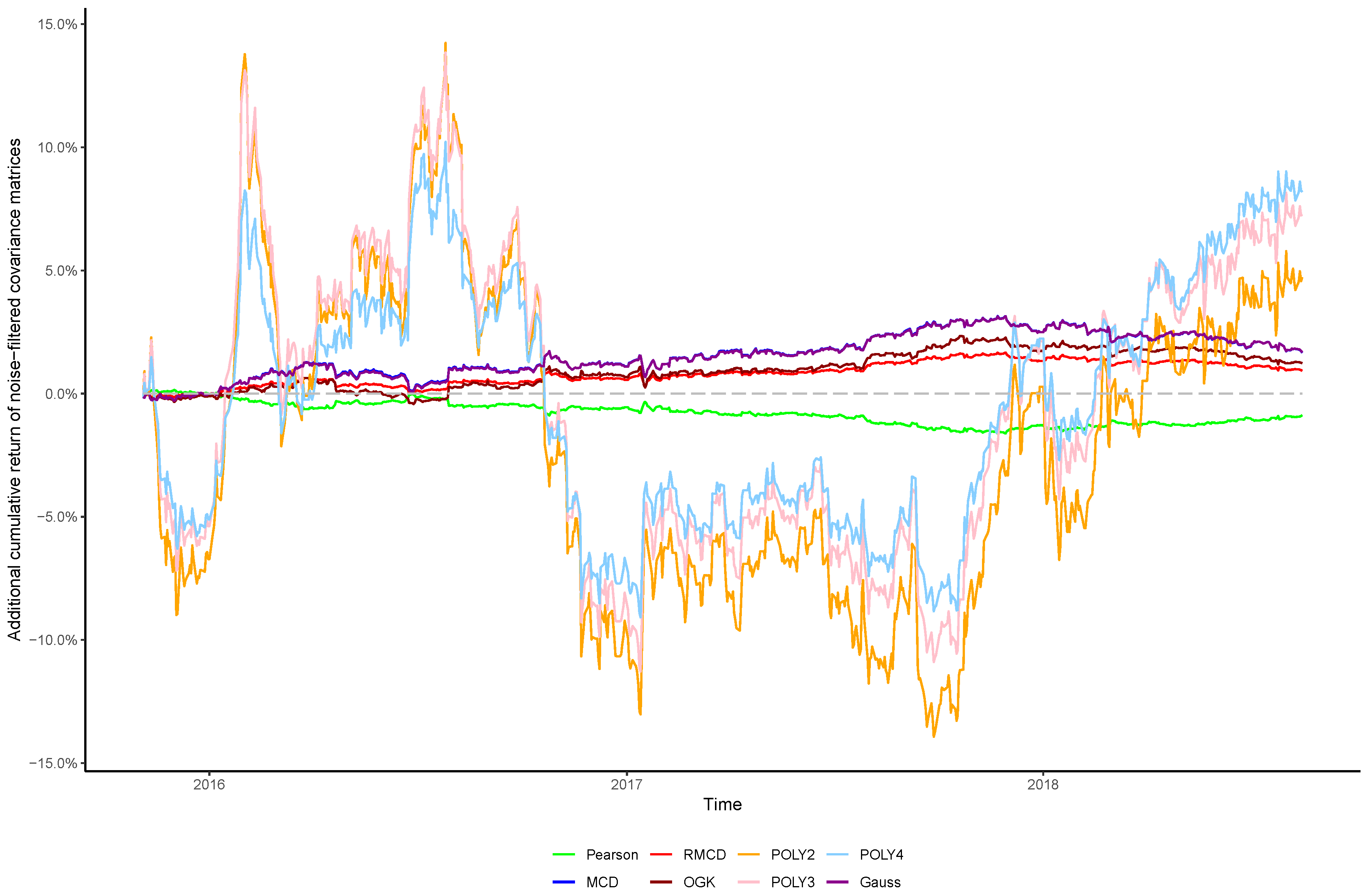
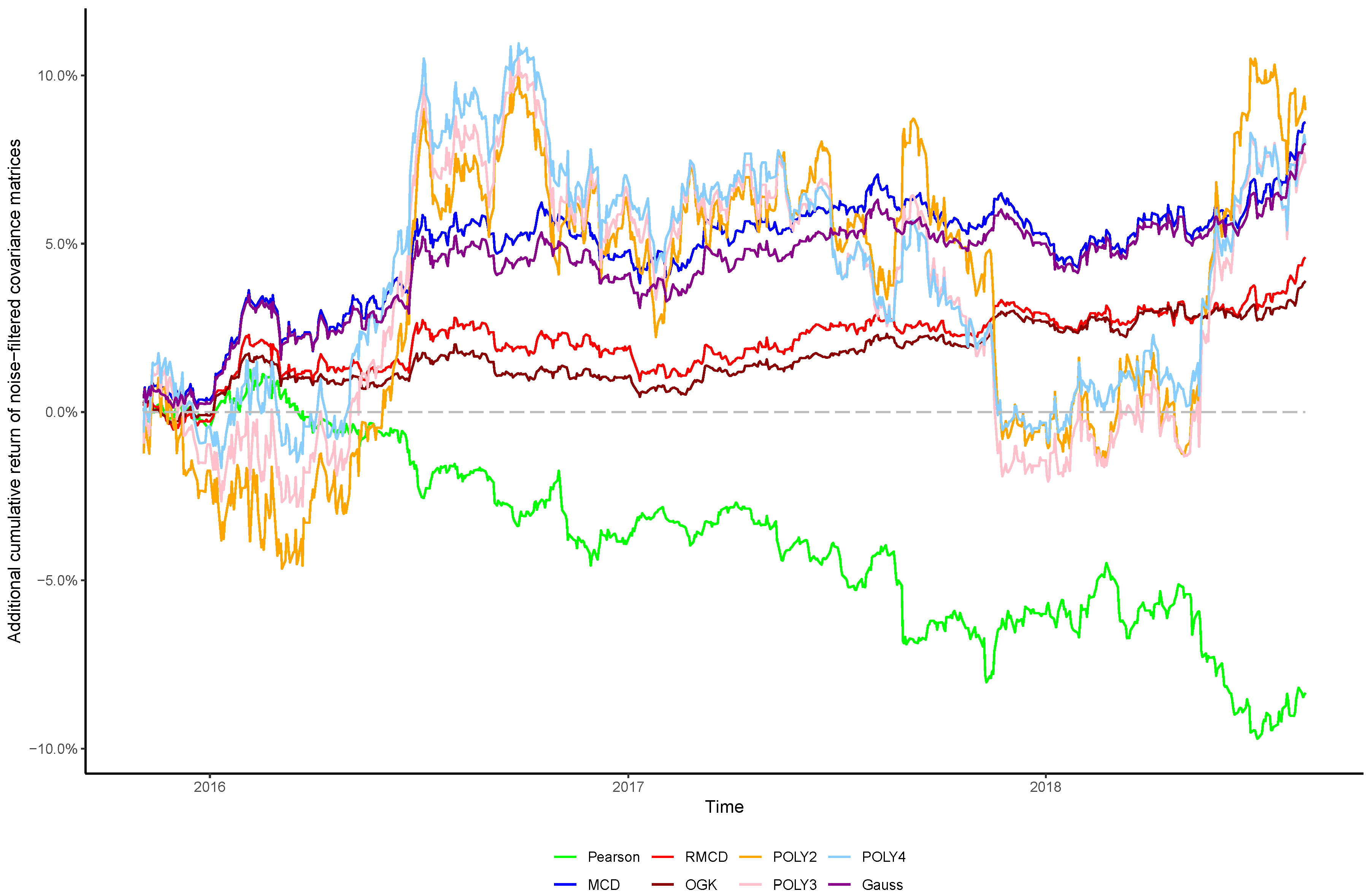
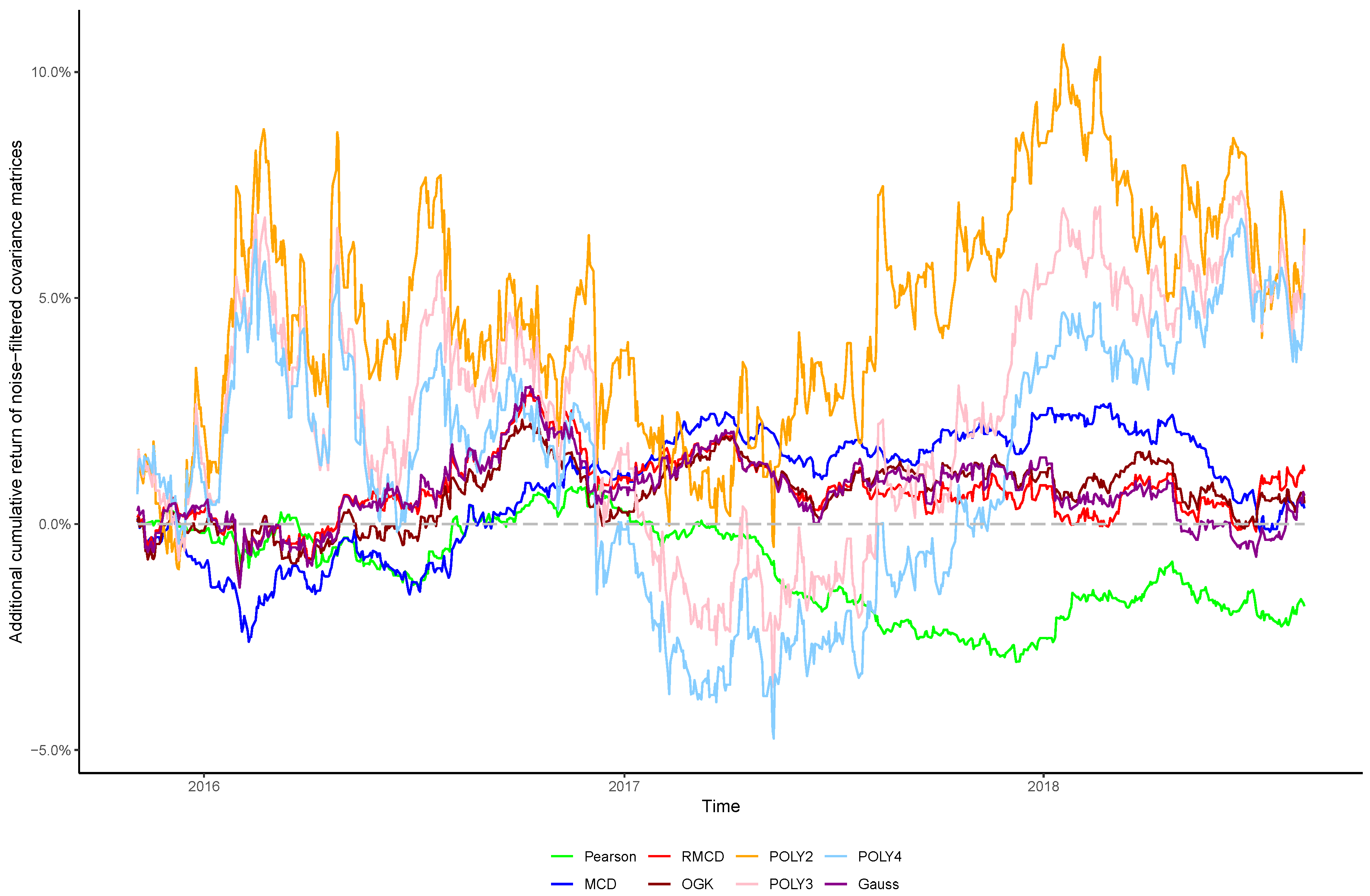
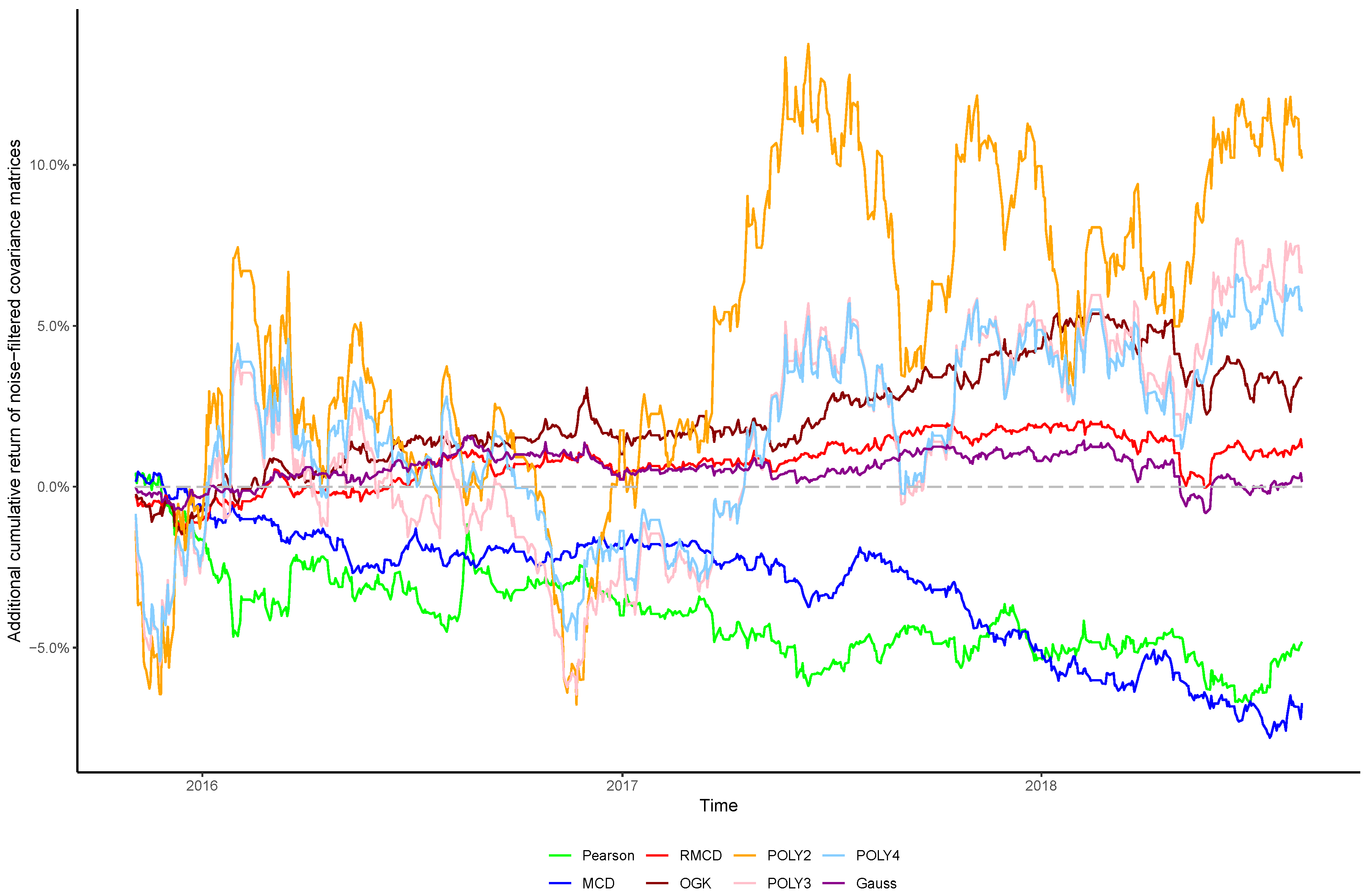
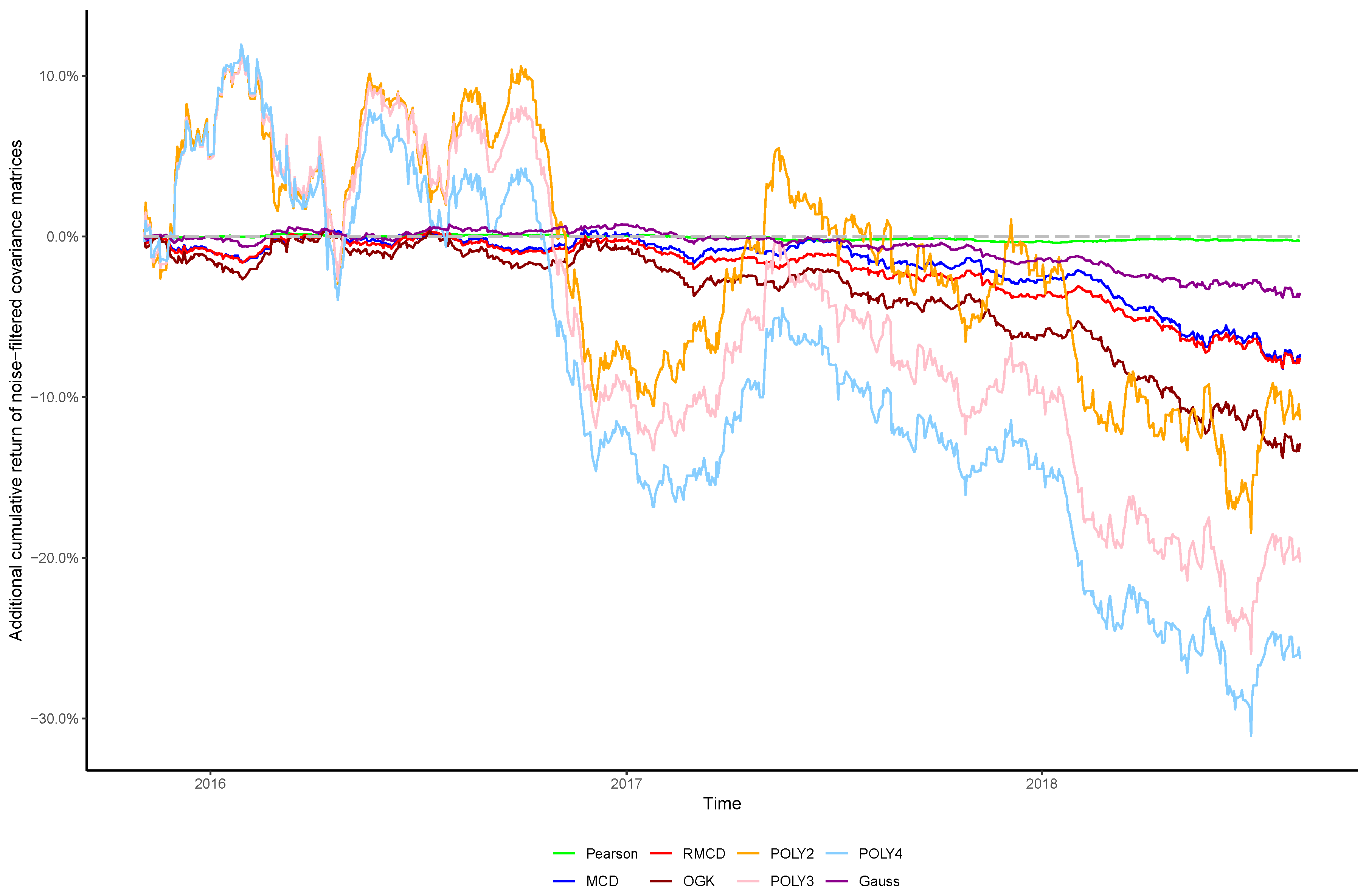
In view of the importance of controlling the complexity introduced alongside nonlinearities, in this paper we sought to verify whether the stylized behavior of the top eigenvalues persists after introducing nonlinearities into the covariance matrix, as well as the effect of cleaning the matrix’s noises in the portfolio profitability and consistency over time, in order to obtain insights regarding the cost–benefit relationship between using higher degrees of nonlinearity to estimate the covariance between financial assets and the out-of-sample performance of the resulting portfolios.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}