Bayesian Input Design for Linear Dynamical Model Discrimination


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Maximization of Mutual Information between the System Output and Parameter
2.1. Selection between Two Models
2.2. Small Energy Limit
2.3. Large Energy Limit
3. Application to Linear Dynamical Systems
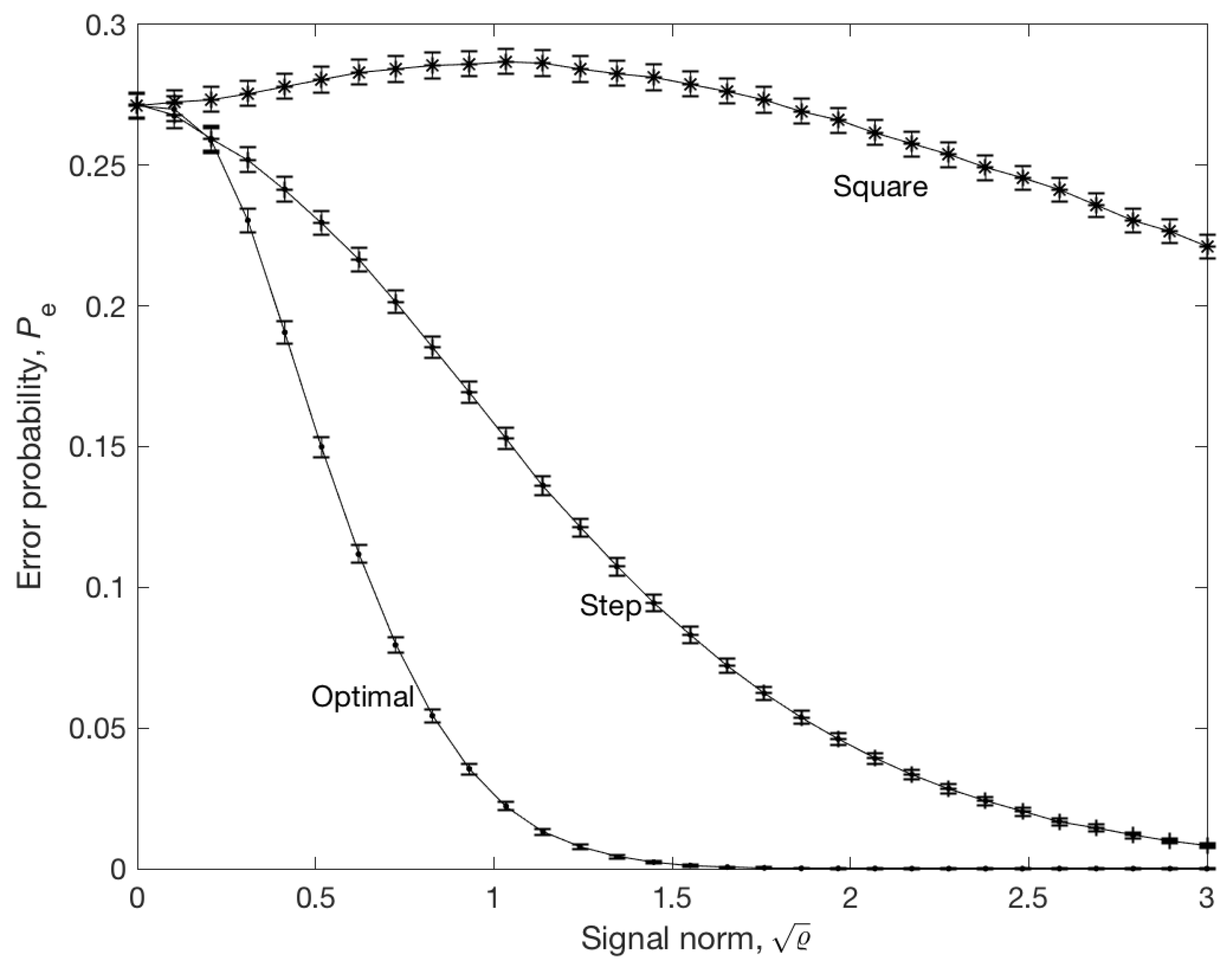
4. Example
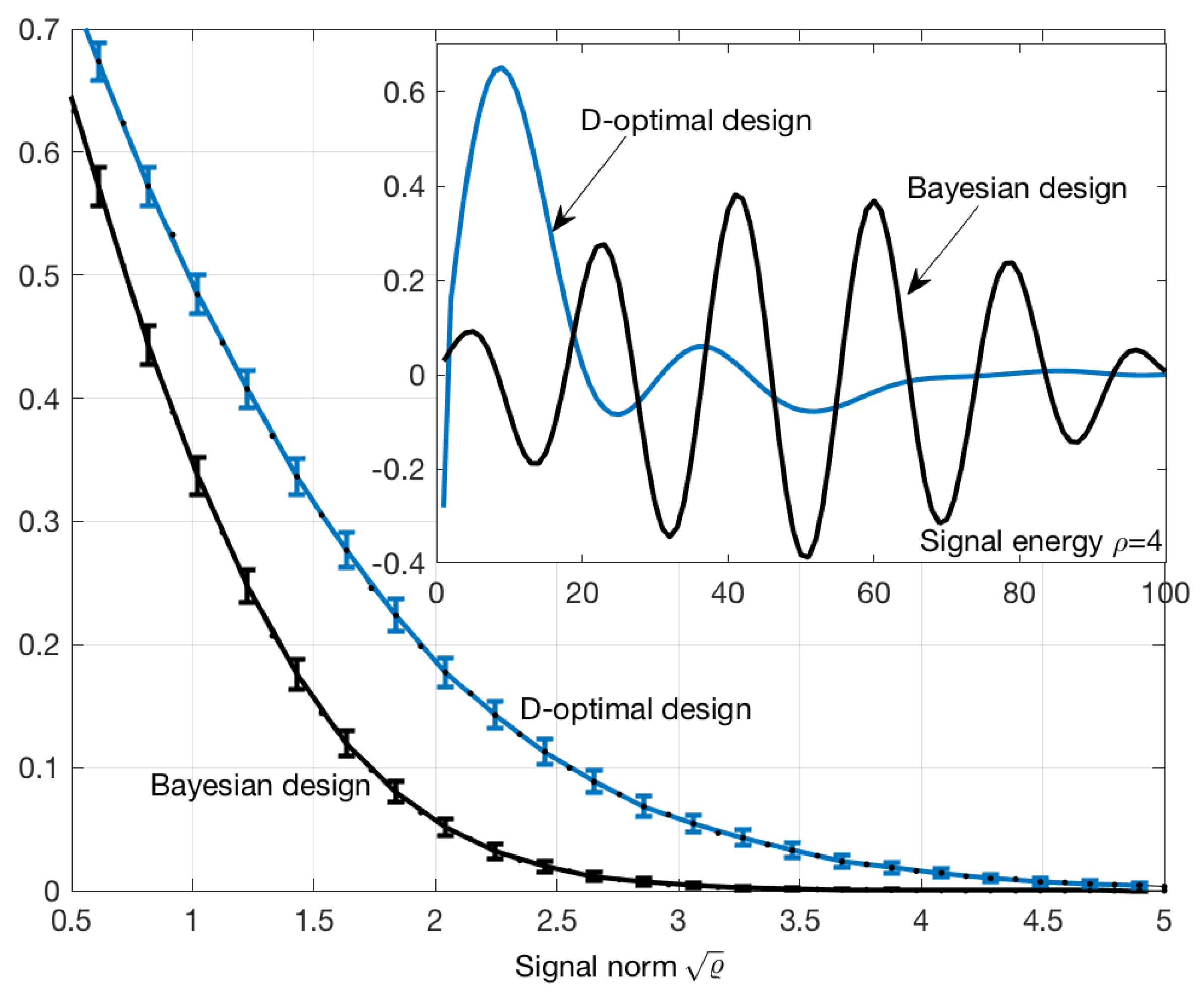
5. Comparison with the Average D-Optimal Design
6. Possible Extensions of the Results
6.1. Non-Linear Models
6.2. Non-Gaussian Models
6.3. Infinite Set of Parameters
7. Discussion and Conclusions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
References
- Bania, P.; Baranowski, J. Bayesian estimator of a faulty state: Logarithmic odds approach. In Proceedings of the 22nd International Conference on Methods and Models in Automation and Robotics (MMAR), Miedzyzdroje, Poland, 28–31 August 2017; pp. 253–257. [Google Scholar]
- Baranowski, J.; Bania, P.; Prasad, I.; Cong, T. Bayesian fault detection and isolation using Field Kalman Filter. EURASIP J. Adv. Signal Process. 2017, 79. [Google Scholar] [CrossRef]
- Blackmore, L.; Williams, B. Finite Horizon Control Design for Optimal Model Discrimination. In Proceedings of the 44th IEEE Conference on Decision and Control, Seville, Spain, 12–15 December 2005. [Google Scholar] [CrossRef]
- Pouliezos, A.; Stavrakakis, G. Real Time Fault Monitoring of Industrial Processes; Kluwer Academic: Boston, MA, USA, 1994. [Google Scholar]
- Bania, P. Example for equivalence of dual and information based optimal control. Int. J. Control 2018. [Google Scholar] [CrossRef]
- Lorenz, S.; Diederichs, E.; Telgmann, R.; Schütte, C. Discrimination of dynamical system models for biological and chemical processes. J. Comput. Chem. 2007, 28, 1384–1399. [Google Scholar] [CrossRef] [PubMed]
- Ucinski, D.; Bogacka, B. T-optimum designs for discrimination between two multiresponse dynamic models. J. R. Stat. Soc. B 2005, 67, 3–18. [Google Scholar] [CrossRef]
- Walter, E.; Pronzato, L. Identification of Parametric Models from Experimental Data. In Series: Communications and Control Engineering; Springer: Berlin/Heidelberg, Germany, 1997. [Google Scholar]
- Pronzato, L. Optimal experimental design and some related control problems. Automatica 2008, 44, 303–325. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Donev, A.N. Optimum Experimental Design; Oxford University Press: Oxford, UK, 1992. [Google Scholar]
- Goodwin, G.C.; Payne, R.L. Dynamic System Identification: Experiment Design and Data Analysis; Academic Press: New York, NY, USA, 1977. [Google Scholar]
- Payne, R.L. Optimal Experiment Design for Dynamic System Identification. Ph.D. Thesis, Department of Computing and Control, Imperial College of Science and Technology, University of London, London, UK, February 1974. [Google Scholar]
- Ryan, E.G.; Drovandi, C.C.; McGree, J.M.; Pettitt, A.N. A Review of Modern Computational Algorithms for Bayesian Optimal Design. Int. Stat. Rev. 2016, 84, 128–154. [Google Scholar] [CrossRef]
- Fedorov, V.V. Convex design theory. Math. Operationsforsch. Stat. Ser. Stat. 1980, 1, 403–413. [Google Scholar]
- Lindley, D.V. Bayesian Statistics—A Review; Society for Industrial and Applied Mathematics (SIAM): Philadelphia, PA, USA, 1972. [Google Scholar]
- Ryan, E.G.; Drovandi, C.C.; Pettitt, A.N. Fully Bayesian Experimental Design for Pharmacokinetic Studies. Entropy 2015, 17, 1063–1089. [Google Scholar] [CrossRef]
- Chaloner, K.; Verdinelli, I. Bayesian Experimental Design: A Review. Stat. Sci. 1995, 10, 273–304. [Google Scholar] [CrossRef]
- DasGupta, A. Review of Optimal Bayes Designs; Technical Report; Purdue University: West Lafayette, IN, USA, 1995. [Google Scholar]
- Routtenberg, T.; Tabrikian, J. A general class of lower bounds on the probability of error in multiple hypothesis testing. In Proceedings of the 25th IEEE Convention of Electrical and Electronics Engineers in Israel, Eilat, Israel, 3–5 December 2008; pp. 750–754. [Google Scholar]
- Feder, M.; Merhav, N. Relations between entropy and error probability. IEEE Trans. Inf. Theory 1994, 40, 259–266. [Google Scholar] [CrossRef]
- Arimoto, S.; Kimura, H. Optimum input test signals for system identification—An information-theoretical approach. Int. J. Syst. Sci. 1971, 1, 279–290. [Google Scholar] [CrossRef]
- Fujimoto, Y.; Sugie, T. Informative input design for Kernel-Based system identification. Procedings of the 2016 IEEE 55th Conference on Decision and Control (CDC), Las Vegas, NV, USA, 12–14 December 2016; pp. 4636–4639. [Google Scholar]
- Hatanaka, T.; Uosaki, K. Optimal Input Design for Discrimination of Linear Stochastic Models Based on Kullback-Leibler Discrimination Information Measure. In Proceedings of the 8th IFAC/IFOORS Symposium on Identification and System Parameter Estimation 1988, Beijing, China, 27–31 August 1988; pp. 571–575. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D. Estimating Mixture Entropy with Pairwise Distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2006. [Google Scholar]
- Atkinson, A.C.; Fedorov, V.V. Optimal design: Experiments for discriminating between several models. Biometrika 1975, 62, 289–303. [Google Scholar]

© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bania, P. Bayesian Input Design for Linear Dynamical Model Discrimination. Entropy 2019, 21, 351. https://doi.org/10.3390/e21040351
Bania P. Bayesian Input Design for Linear Dynamical Model Discrimination. Entropy. 2019; 21(4):351. https://doi.org/10.3390/e21040351
Chicago/Turabian StyleBania, Piotr. 2019. "Bayesian Input Design for Linear Dynamical Model Discrimination" Entropy 21, no. 4: 351. https://doi.org/10.3390/e21040351
APA StyleBania, P. (2019). Bayesian Input Design for Linear Dynamical Model Discrimination. Entropy, 21(4), 351. https://doi.org/10.3390/e21040351