1. Introduction
Failure Mode and Effects Analysis (FMEA) has received attention from many researchers [
1,
2,
3,
4,
5,
6,
7], and it can evaluate and analyze various risks in order to reduce these risks to acceptable levels or directly eliminate them. Moreover, FMEA is a very complex system so that information fusion technology is used in evaluation processes, such as evidence theory [
8,
9] and D number [
10]. Since the uncertainty information is inevitable in FMEA, some methods have been widely used, such as Dempster–Shafer evidence theory and so on [
11,
12,
13].
Though FMEA has been used in practice for many years, how to determine the weights of risk factors and team members is still an open issue. In order to define the weights more reasonably, some scholars have proposed many methods. The intuitionistic fuzzy entropy is introduced by Lei and Wang [
14] to determine the weights of risk factors, while, in [
15], the weights of risk factors are calculated by the objective weights. While Boran et al. [
16] determined the subjective weights of risk factors. In the method proposed in [
17], the weights of risk factors are simply determined by the weights calculation proposed by Boran et al. [
16], although the intuitionistic fuzzy set (IFS) model is efficient to deal with FMEA [
18]. However, existing methods do not take the uncertainty into consideration for the relative importance of team members.
In recent years, the relative concept of intelligence has been paid great attention due to the simulation of human intelligence [
19,
20]. As a result, it is reasonable to model experts’ uncertainty in the process of decision-making in FMEA, which is important to improve the intelligent degree of the evaluation system. Thus, the measurement of uncertainty should also be regarded as content worth exploring. The related research of uncertainty metrics has been heavily discussed [
21,
22,
23,
24]. For probability distributions, Shannon entropy is efficient to handle the uncertainty [
25]. However, it can not deal with the uncertainty of basic probability assignment (BPA) in Dempster–Shafer evidence theory [
26]. To address this issue, a new belief entropy, named Deng entropy, is presented [
26]. In recent years, the belief entropy has been widely used in many fields [
27,
28].
In this paper, a hybrid weights determination of team members in the FMEA model is proposed based on the evidence distance [
29] and the belief entropy [
26]. The evidence distance is to measure the degree of conflict for all team members, and the belief entropy is used to model the domain experts’ uncertainty in FMEA. With the combination of evidence distance, the new weights of team members are obtained, which makes the final rank of failure modes be more effective and reasonable.
The rest of this paper is organized as follows. In
Section 2, some basic definitions about the evidence theory, IFS, and belief entropy are briefly introduced. In
Section 3, the new method to determine the weights of team members is proposed. In
Section 4, a numerical example and the computational process are illustrated. Furthermore, the comparisons and discussion have been also mentioned. In
Section 5, some conclusions of the proposed method are drawn.
3. The Proposed Method
In this section, a new method to determine the weights of team members based on the evidence theory, intuitionistic fuzzy sets and belief entropy is proposed to rank the failure modes. The function of Failure Mode and Effects Analysis (FMEA) team members is to assess the risk factors with linguistic variables, such as very low, low, medium, high, very high and so on. Assume that there are
k cross-functional team members
in an FMEA team; after discussing them, the experts prioritize
i potential failure modes
. Each failure mode is evaluated on the
j risk factor
.
is the weight of decision makers which reflects the relative importance of the
kth decision maker with respect to the
jth risk factors for the
ith potential failure modes. In addition, intuitionistic fuzzy numbers [
61], which are represented by the ordered pairs of membership degrees and non-memberships corresponding to the intuitionistic fuzzy sets, is used to simply express the relevant conversion process.
Assume that the IFN
is provided by
on the assessment of
for
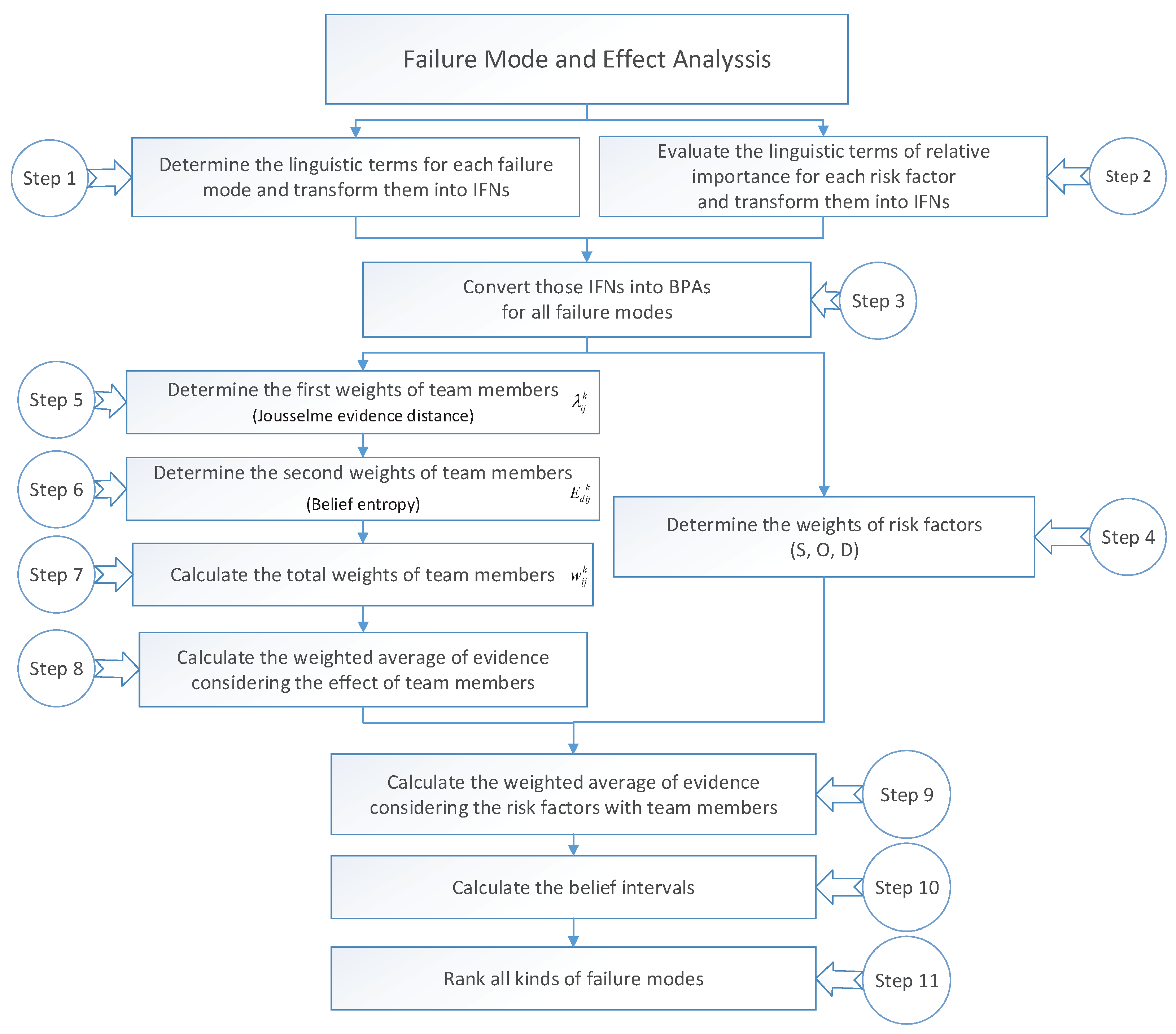
. The proposed method consists of eleven steps. In addition, the flowchart of the proposed approach is shown in
Figure 1.
Step 1: Determine the linguistic terms for each failure mode and transform them into IFNs. The specific judgement levels are divided into ten linguistic parts (see in
Table 1,
Table 2 and
Table 3), which contains Very very low (VVL), Very Low (VL), Low (L), Medium low (ML), Medium (M), Medium high (MH), High (H), Very high (VH), Very very high (VVH) and Extremely high (EH).
Step 2: Evaluate the linguistic terms of relative importance for each risk factor and transform them into IFNs. Similarly, the specific judgement levels are divided into five parts (see in
Table 4), which contains Very important, Important, Medium, Unimportant and Very unimportant.
Step 3: Convert all IFNs into BPAs for all failure modes. In addition, the concrete form can be defined as follows:
Step 4: Determine the weights of risk factors. For the three judgement model S, O and D, each model can be transformed into an IFS to represent the information value. Based on the weight calculation, which is proposed by Boran et al. [
16], the weight
can be obtained. The computational equations are defined as follows:
which satisfy the condition that
Step 5: Determine the weights of team members
by using evidence distance which is introduced by Jousselme et al. [
29].
Assume two groups of BPAs
and
,
are two bodies of evidence (BOE), obtained by two different team members. In this paper, the similarity function, using the evidence distance to define the distance
between
and
, is proposed as follows:
The
is used to represent the degree of
supported by other bodies of evidence. In addition, the reliability degree
are defined as follows:
The
is to define the
Step 6: Determine the weights of team members
by using belief entropy [
26]. Based on the fellow steps, for all team members, their information value has been transformed into IFSs. Then, another weight
is calculated, which expresses the amount of uncertainty for all propositions. The specific equation is defined as follows:
Step 7: Calculate the total weights of team members
by combing
and
. After obtaining the two weights, the total weights of FMEA team members can be calculated as the form of multiplication, which is defined as follows:
where
p is the total number of failure modes for each risk factor.
Step 8: Calculate the weighted average of evidence considering the team members’ effect of FMEA model. For each failure mode
, there exists a group of basic probability assignment functions to express the degree of importance, which can be denoted as
and
. Thus, after obtaining the
weights, the weighted average can be obtained as follows:
Step 9: Calculate the weighted average of evidence considering the risk factors with team members. To consider the impact of different risk factors (S, O, D), the weighted average of evidence which can be denoted as
,
and
is expressed as follows:
Step 10: Calculate the belief intervals. After obtaining the weighted average of evidence in Step 9, the belief interval
which is used to show the degree of support and opposition can be determined as:
Step 11: Rank all kinds of failure modes. Based on the belief intervals, the risk of different failure model can be compared with others by using Equation (
19). After the process of comparison, the list of ranking in FMEA can be obtained.
4. Application
In this section, an example is used to illustrate the complete procedures of the proposed method.
The risk evaluation process has a great impact in many fields, such as multi-criteria decision-making (MCDM) [
62,
63,
64,
65] and other works [
66,
67]. In most situations, the weights for each risk factor may change the final result and lead the decision maker to make the undeserved judgement. To modify the process of products production as an easier and lower-cost method, the Failure mode and Effects Analysis play a growing important role in modern society.
Thus, an FMEA team consisting of five functional team members identifies potential failure modes in the electronics manufacturing project and wants to prioritize them in terms of their risk factors such as S (Severity), O (Occurrence) and D (Detection). In addition, twelve failure modes are identified. For the difficulty of evaluating the risk factors, the FMEA team members in this numerical example are supposed to assess them employing the linguistic terms. The specific transforming process is shown in
Table 1,
Table 2 and
Table 3.
Step 1: The assessment information of the twelve failure modes on each risk factor, which was provided by the five team members, can be illustrated in
Table 5. Each team member comes from different department, such as manufacturing, engineering, design and technique. Considering their deferent specialities and functions, the weights are determined by their degree of importance.
Step 2: Evaluate the linguistic terms of relative importance for each risk factor and transform them into IFNs (see in
Table 6).
Step 3: Convert those IFNs into BPAs for all failure modes. The specific transforming equation is shown in Equations (
12)–(
14).
Step 4: Determine the weights of risk factors. In this paper, the weights calculation of risk factors in this example is shown in Equations (
27) and (
28). In addition, the results are shown in
Table 7.
Step 5: Determine the first weights of team members
by using evidence distance [
29]. The specific value of each mode is shown in
Table 8.
Step 6: Determine the second weights of team members
by using belief entropy. In addition, the results are shown in
Table 9.
Step 7: Calculate the total weights of team members
by combing
and
. After the process of normalization, the specific value of weights is shown in
Table 10.
Step 8: Calculate the weighted average of evidence considering the team members’ effect of FMEA model. The results are shown in
Table 11.
Step 9: Calculate the weighted average of evidence considering the risk factors with team members. By introducing the consideration of risk factors, the weighted average of evidence is calculated. In addition, the results are shown in
Table 12.
Step 10: Calculate the belief intervals. With the Equations (41) and (42), the final results are also shown in
Table 12.
Step 11: Rank all kinds of failure modes. After the process of comparison, the final ranking can be obtained (see in
Table 13).
Here, we present some discussion about the proposed method.
In the previous related research, many scholars have tried to enhance the effectiveness and availability based on intuitionistic fuzzy sets, evidence theory and so on. The ranking comparisons of all the related works are shown in
Table 13. There are some ranking differences among those methods. In general, the higher ranked models are
,
, and the lowest ranked model is
, which is consistent with the previous three methods. For other failure modes, it can be seen that, in the evaluation of the proposed method, the overall ordering of
and
is slightly higher than the previous method, while the remaining rankings are generally consistent. The main reasons are summarized as follows:
The relatively importance of team members are different. In the method proposed by Liu et al. [
15], the relative weights were supposed in advance, which are 0.10, 0.15, 0.20, 0.25 and 0.30. In addition, in the intuitionistic fuzzy TOPSIS method, the impacts of team members are not considered. In addition, the method proposed by Guo [
17] has just considered the conflict of team members simply. In our proposed method, the weights of team members are defined by using both the evidence distance [
29] and the belief entropy [
26]. The evidence distance is to show the degree of conflict for all team members. In addition, the belief entropy is used to reflect the uncertainty of the information of each team member. The combination of them can express the evaluated information completely and effectively. To be specific, since the uncertainty information contained in the results of the expert evaluations in
,
and
is relatively low in this application, the weights obtained by considering the entropy factor has little effect on the final evaluation. Moreover, in
and
, the overall uncertainty of the expert evaluation is relatively high, the second weights obtained by calculating the belief entropy have a relatively large influence on the overall evaluation result, which leads to the final result as shown in
Table 13.
Thus, with the differences mentioned above, the aggregation approaches for all kinds of methods are different. As a comparison, the process of our proposed method to determine the weights of team members is particularly scientific and effective, with strong practical significance and good performance.



{kind=link}