A Neighborhood Rough Sets-Based Attribute Reduction Method Using Lebesgue and Entropy Measures


Abstract
:1. Introduction
2. Previous Knowledge
2.1. Rough Sets
2.2. Information Entropy Measures
2.3. Neighborhood Rough Sets
3. Attribute Reduction Using Lebesgue and Entropy Measures in Neighborhood Decision Systems
3.1. Lebesgue Measure-Based Neighborhood Uncertainty Measures
3.2. Neighborhood Entropy-Based Uncertainty Measures
3.3. Comparative Analysis with Two Representative Reducts
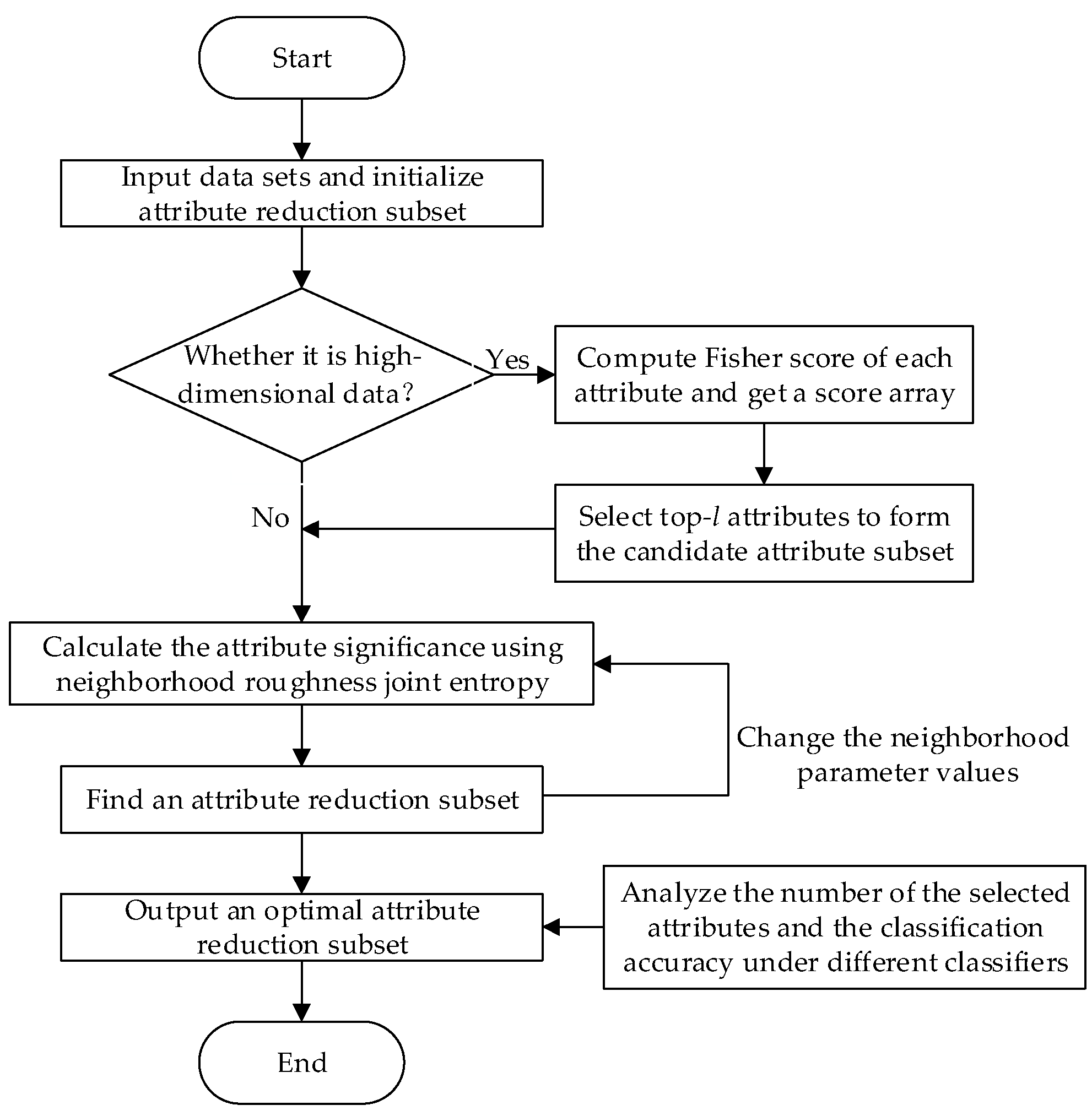
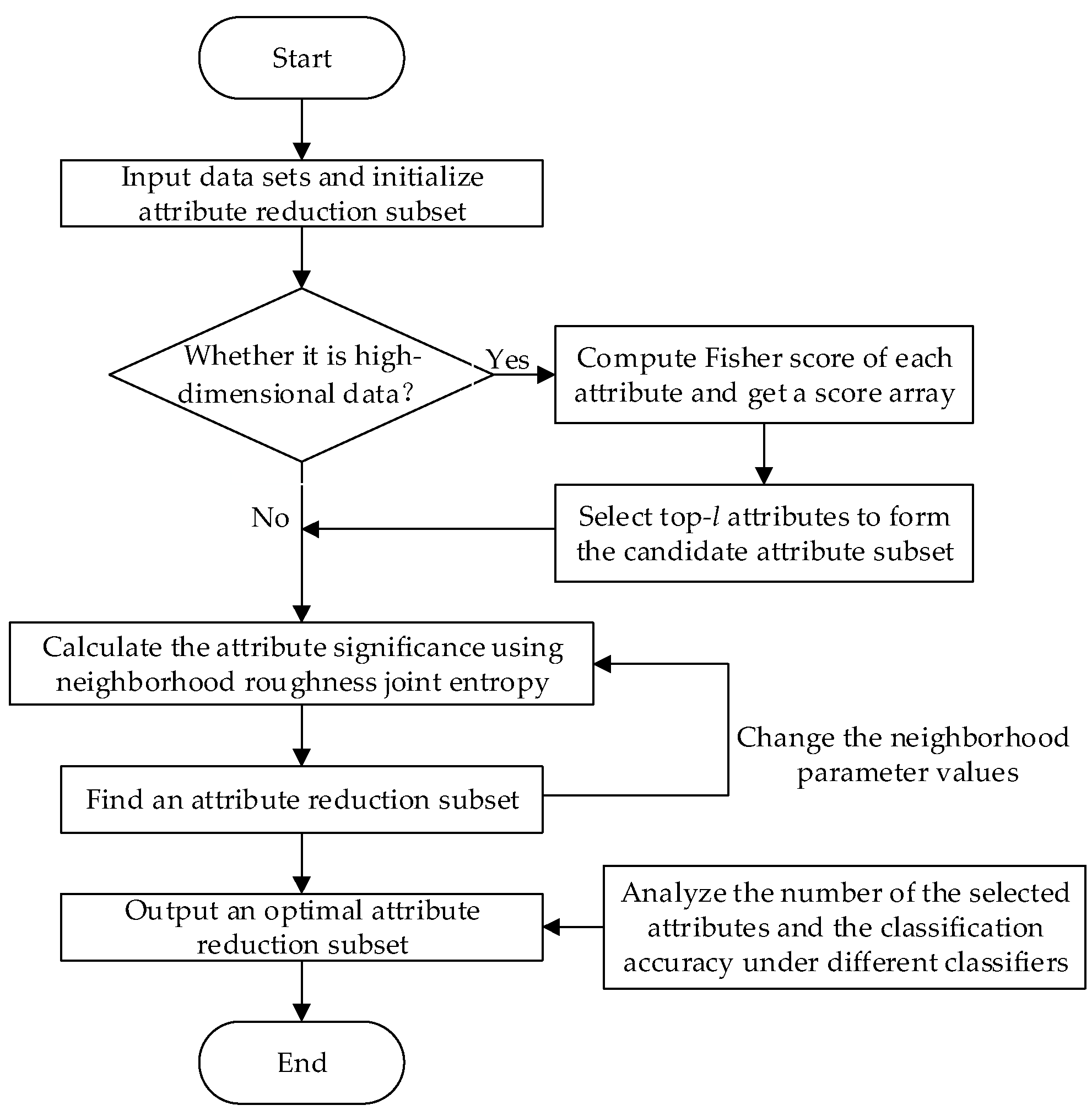
3.4. Description of the Attribute Reduction Algorithm
| Algorithm 1. ARNRJE |
| Input: A neighborhood decision system NDS = <U, C D, δ>, and neighborhood parameter δ. Output: An optimal reduction set B.
|
3.5. Complexity Analysis of ARNRJE
3.6. An Illustrative Example
4. Experimental Results and Analysis
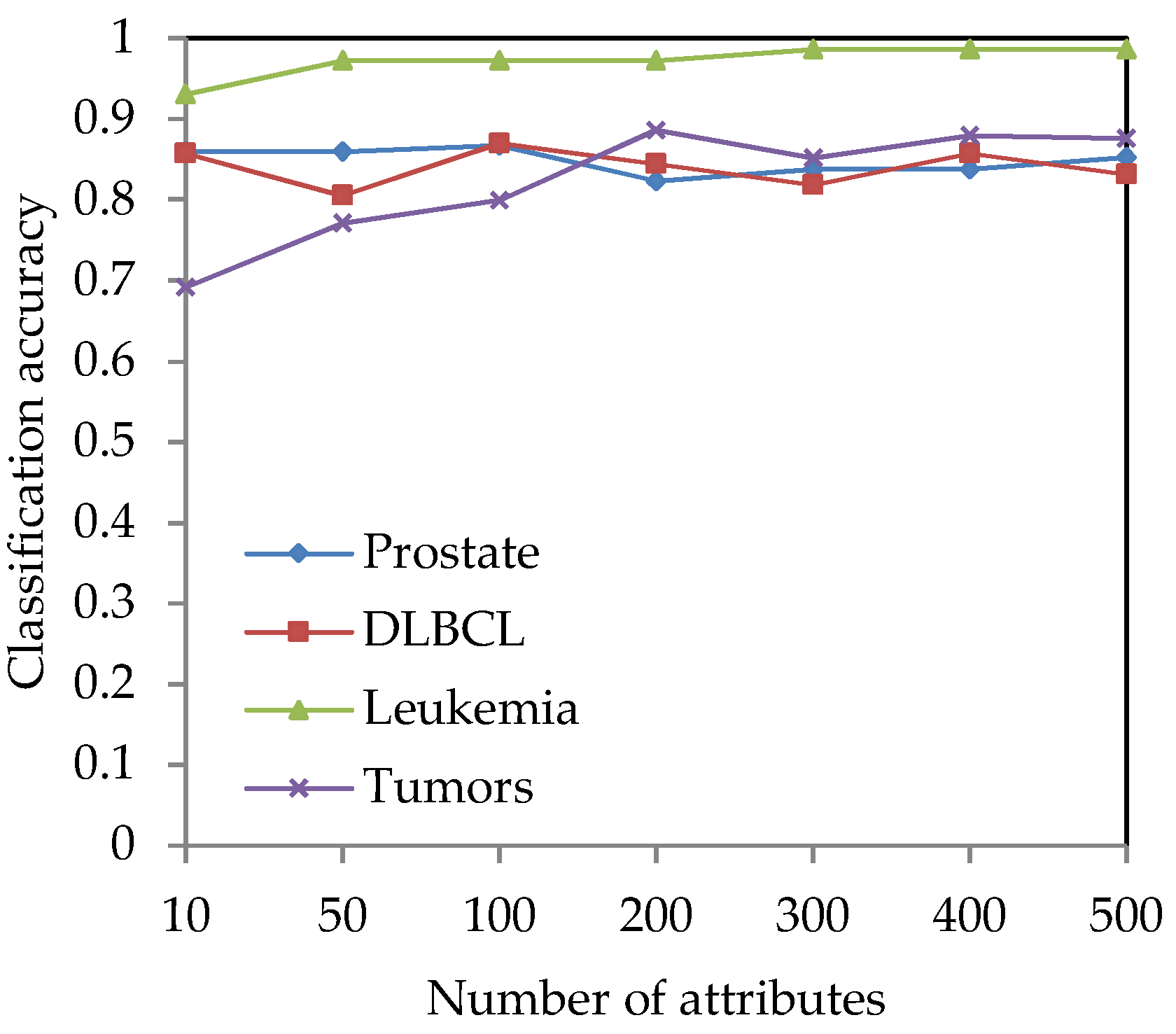
4.1. Experiment Preparation
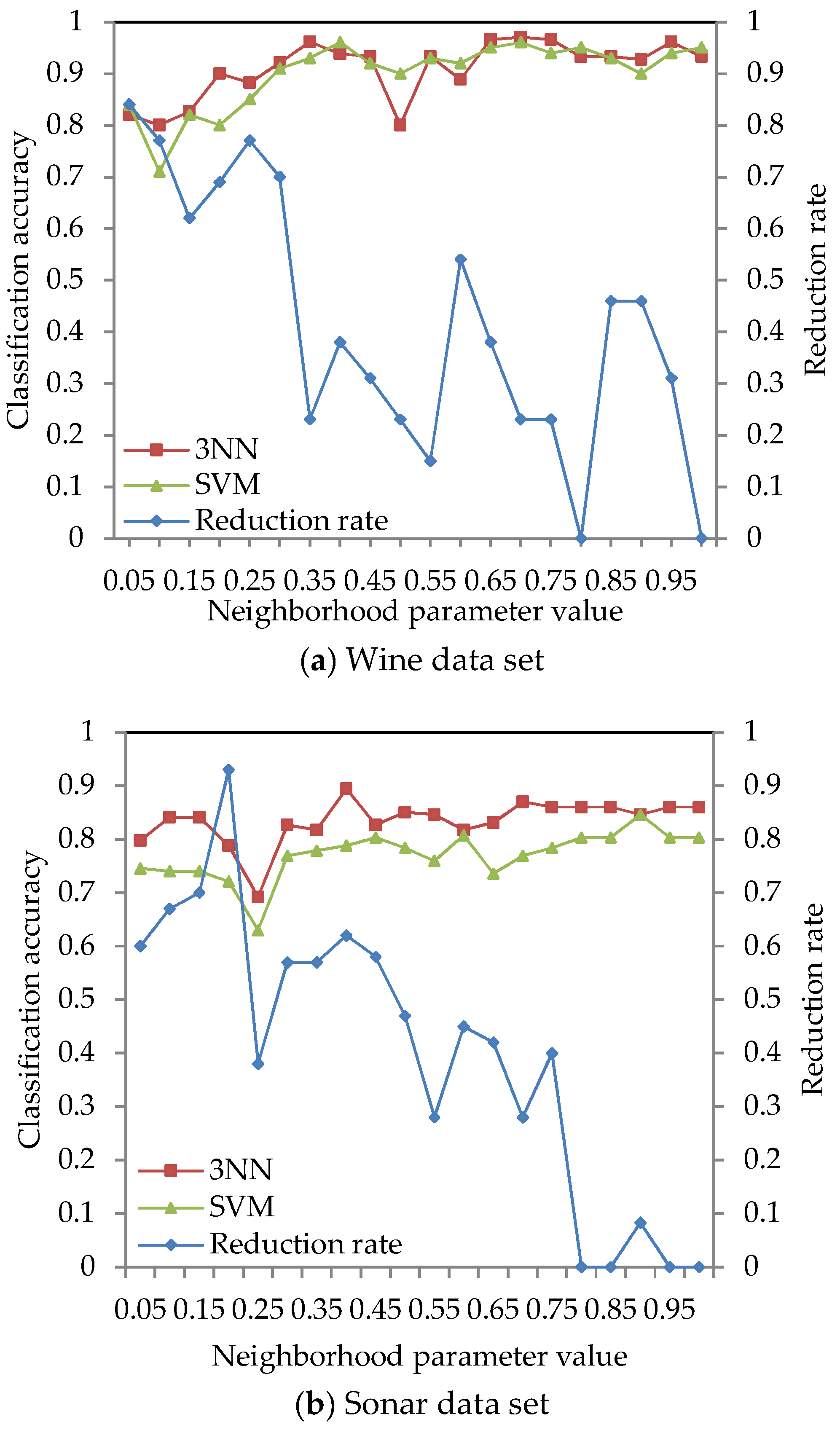
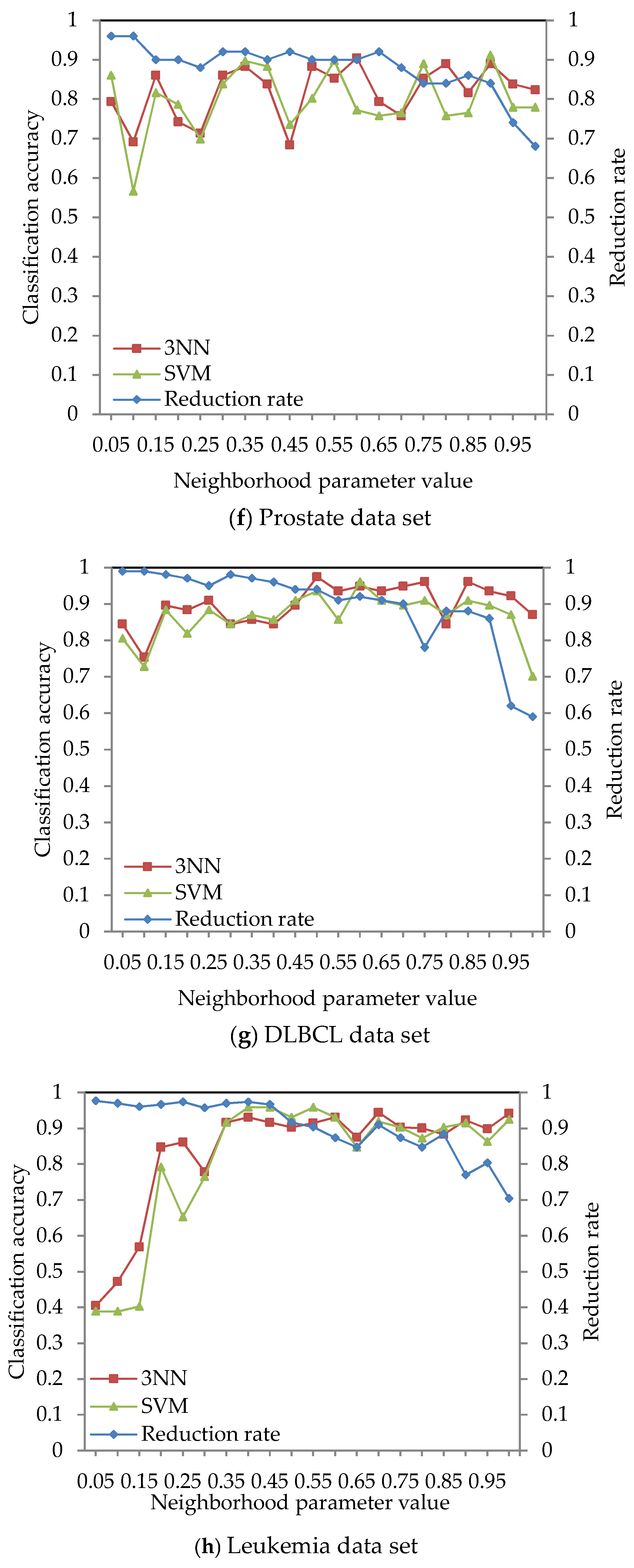
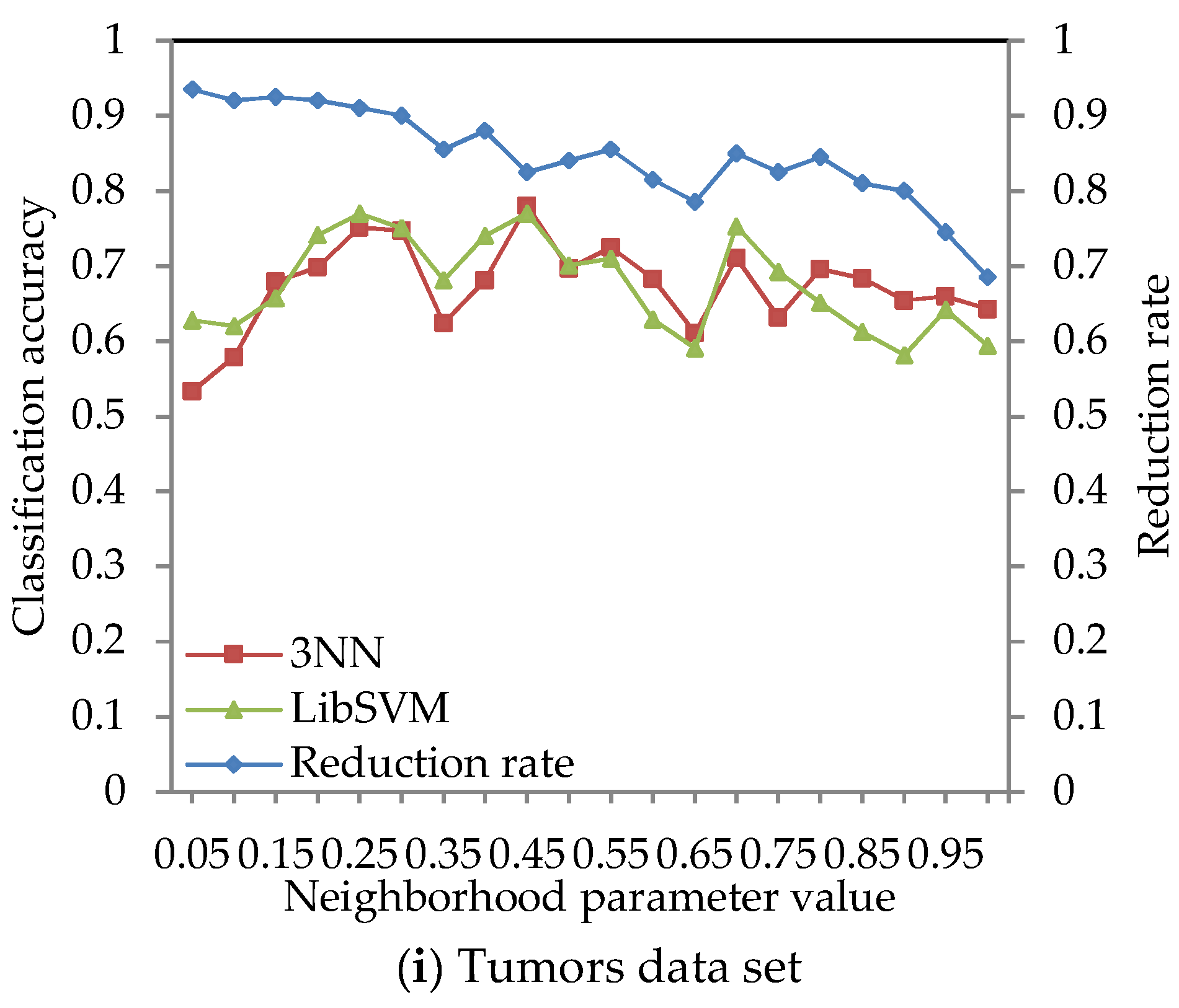
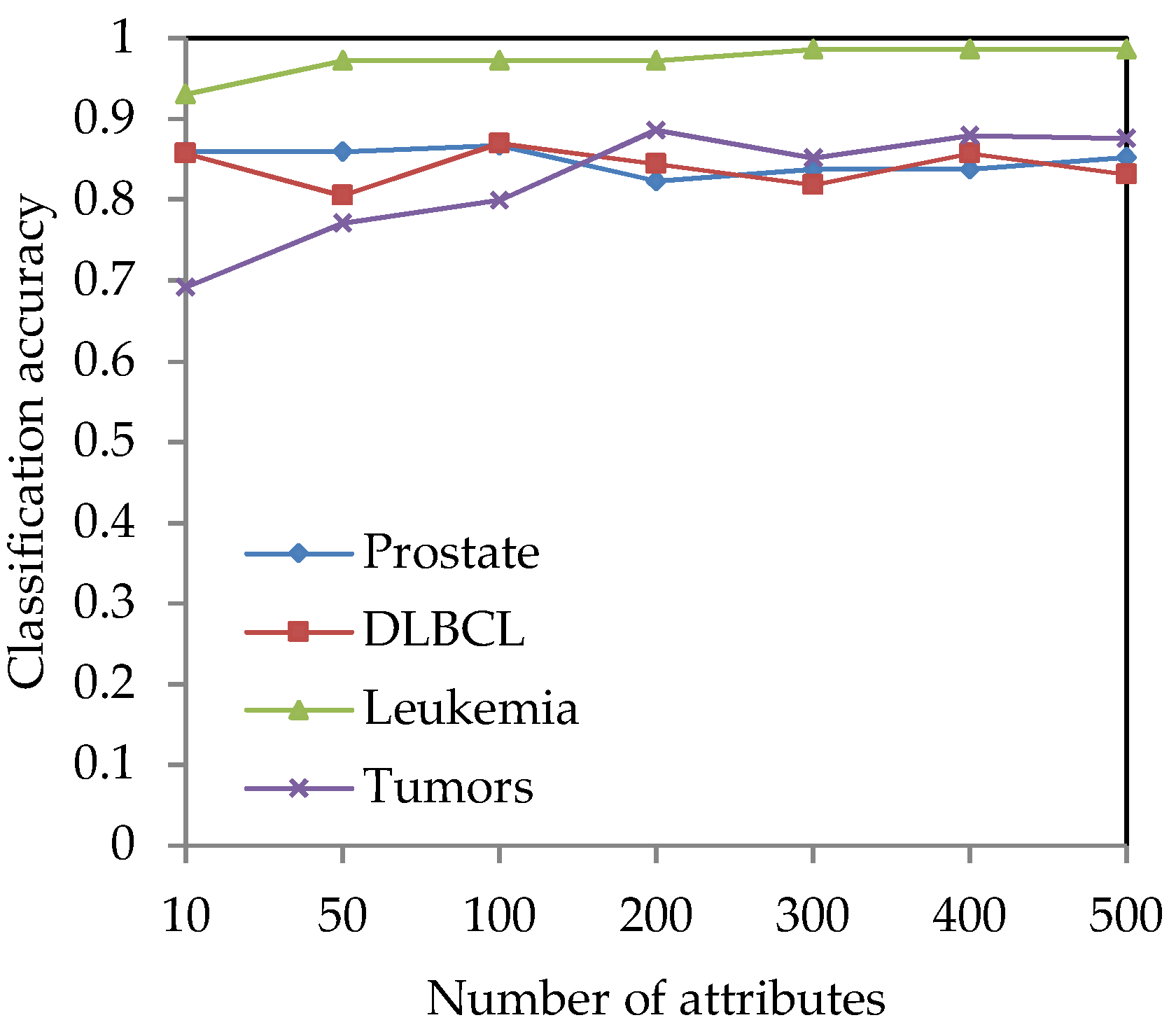
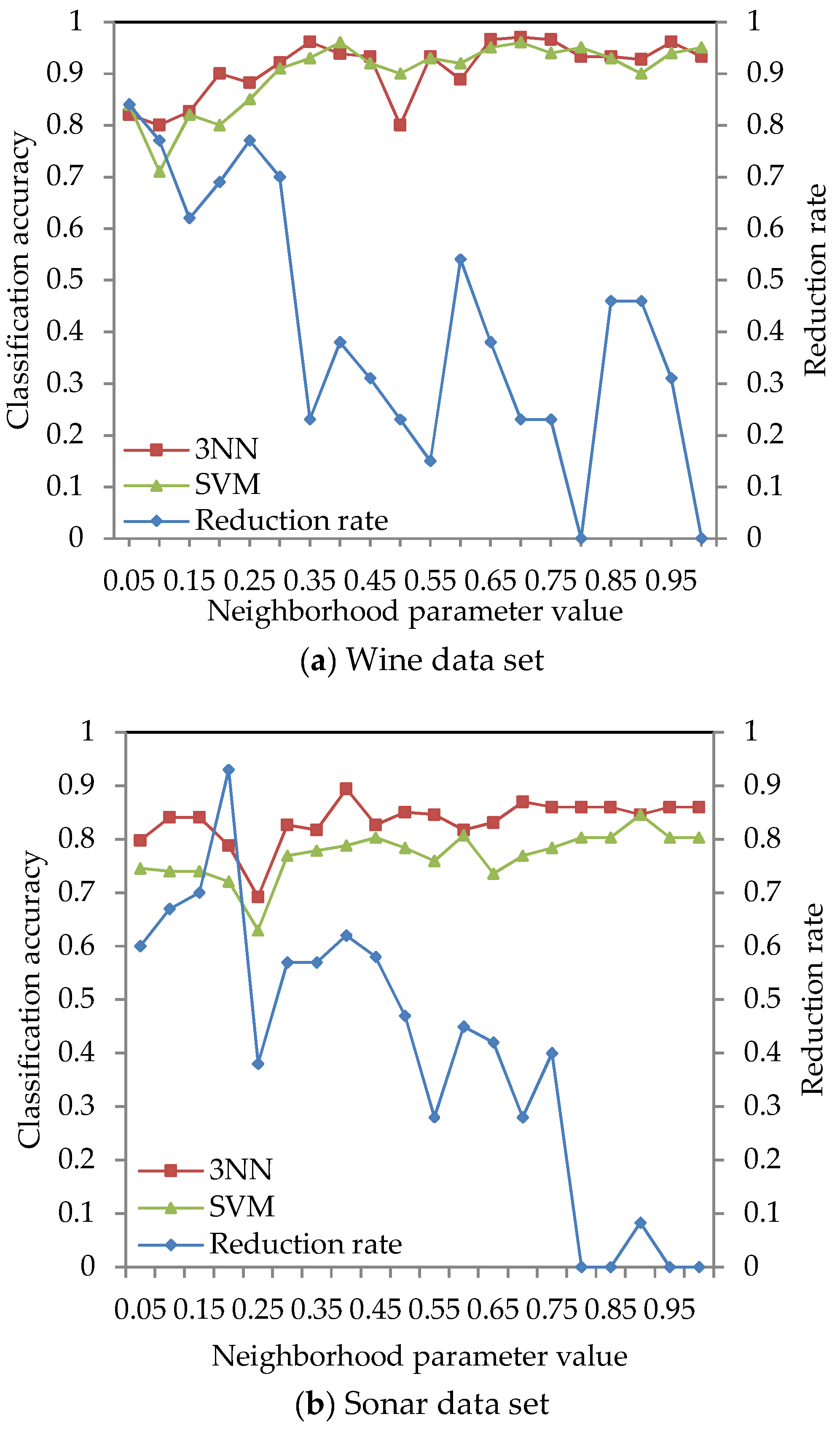
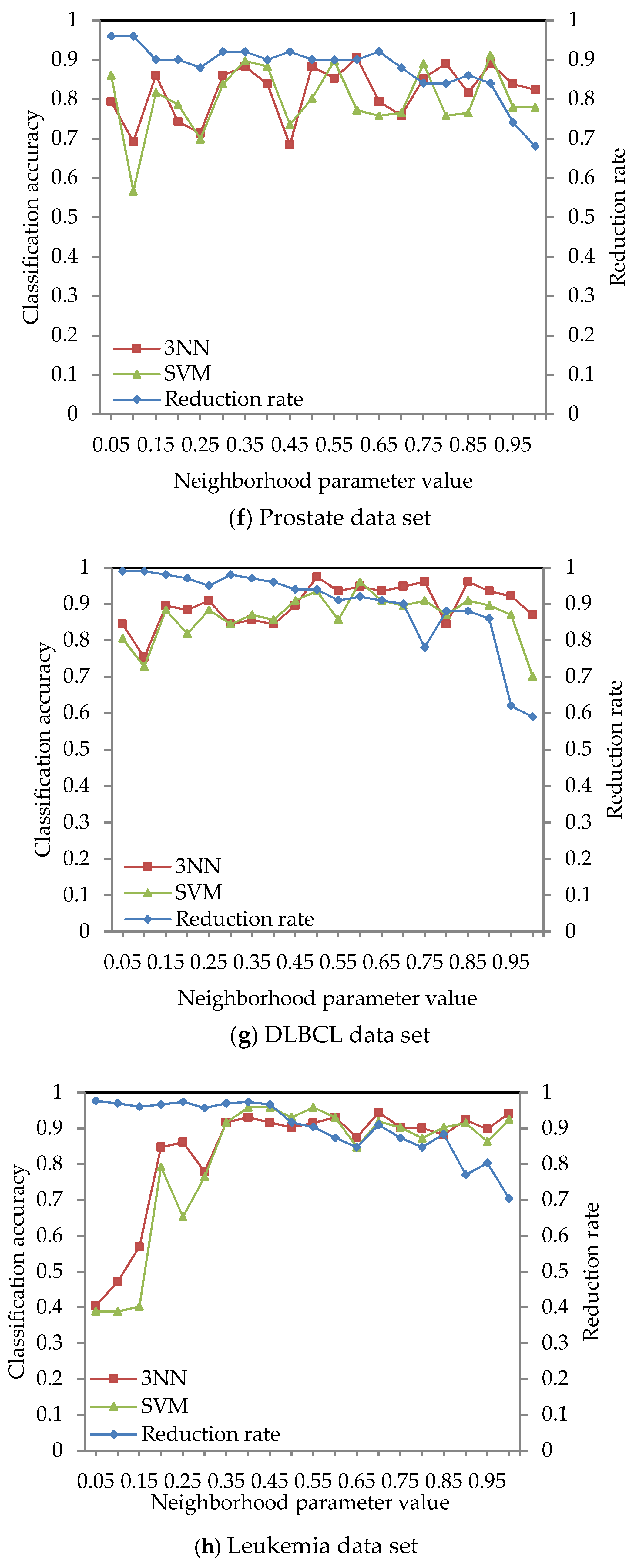
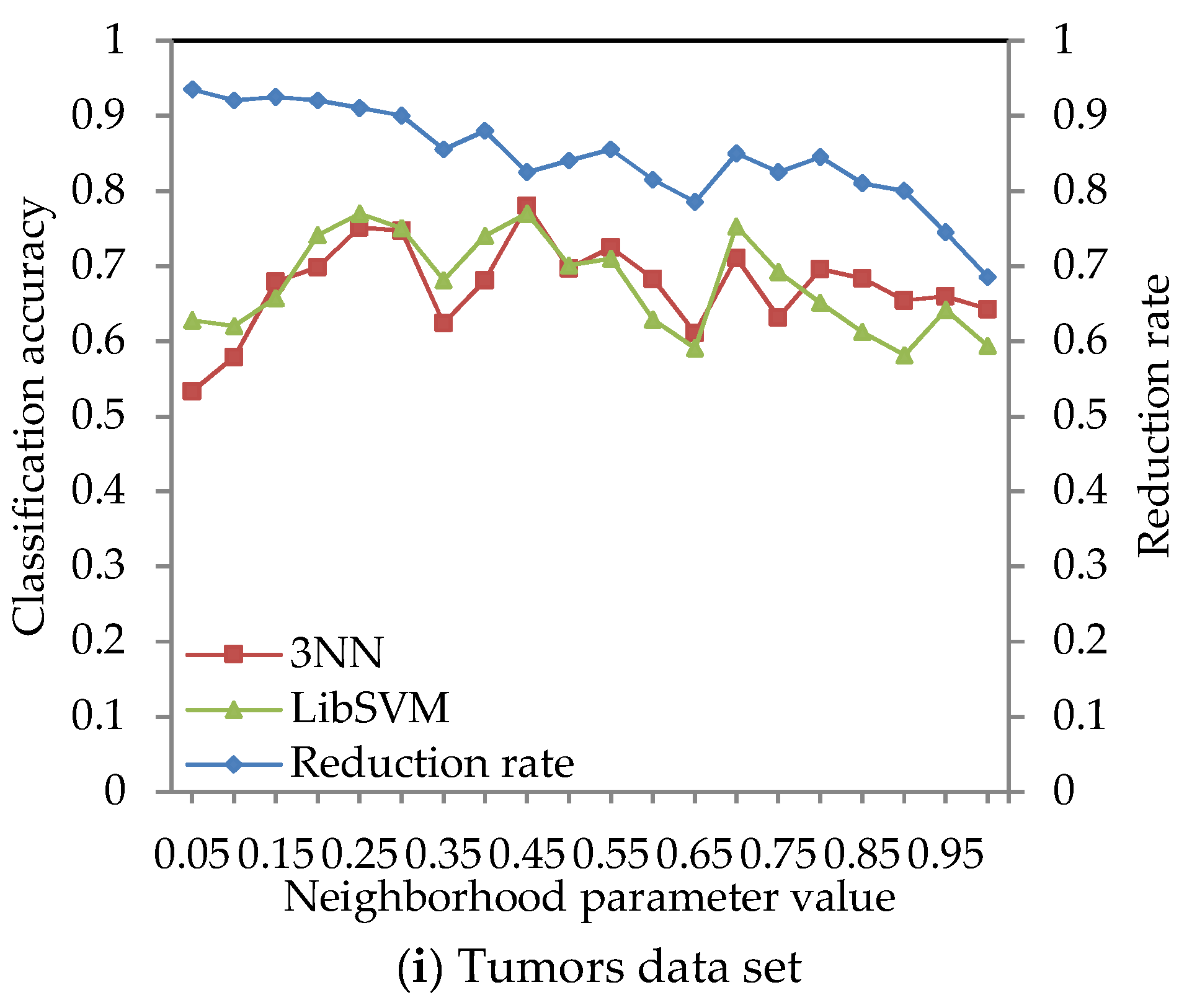
4.2. Effect of Different Neighborhood Parameter Values
4.3. Comparison of Reduction Results with Three Related Reduction Algorithms
4.4. Comparison of Classification Results with Six Reduction Methods on Two Different Classifiers
4.5. Comparison of Recall Rate with Three Reduction Methods on Two Different Classifiers
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Wang, Q.; Qian, Y.H.; Liang, X.Y.; Guo, Q.; Liang, J.Y. Local neighborhood rough set. Knowl.-Based Syst. 2018, 135, 53–64. [Google Scholar] [CrossRef]
- Gao, C.; Lai, Z.H.; Zhou, J.; Zhao, C.R.; Miao, D.Q. Maximum decision entropy-based attribute reduction in decision-theoretic rough set model. Knowl.-Based Syst. 2018, 143, 179–191. [Google Scholar] [CrossRef]
- Zhang, X.Y.; Miao, D.Q. Quantitative/qualitative region-change uncertainty/certainty in attribute reduction: Comparative region-change analyses based on granular computing. Inf. Sci. 2016, 334, 174–204. [Google Scholar] [CrossRef]
- Dong, H.B.; Li, T.; Ding, R.; Sun, J. A novel hybrid genetic algorithm with granular information for feature selection and optimization. Appl. Soft Comput. 2018, 65, 33–46. [Google Scholar] [CrossRef]
- Hu, L.; Gao, W.F.; Zhao, K.; Zhang, P.; Wang, F. Feature selection considering two types of feature relevancy and feature interdependency. Expert Syst. Appl. 2018, 93, 423–434. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, H.; Tan, K.Z.; Chen, Y.H.; Xu, Z.; Wang, L.G. Hyperspectral band selection based on consistency-measure of neighborhood rough set theory. Meas. Sci. Technol. 2016, 27, 055501. [Google Scholar] [CrossRef]
- Lyu, H.Q.; Wan, M.X.; Han, J.Q.; Liu, R.L.; Wang, C. A filter feature selection method based on the Maximal Information Coefficient and Gram-Schmidt Orthogonalization for biomedical data mining. Comput. Biol. Med. 2017, 89, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Zhang, X.Y.; Qian, Y.H.; Xu, J.C.; Zhang, S.G.; Tian, Y. Joint neighborhood entropy-based gene selection method with fisher score for tumor classification. Appl. Intell. 2018. [Google Scholar] [CrossRef]
- Jadhav, S.; He, H.M.; Jenkins, K. Information gain directed genetic algorithm wrapper feature selection for credit rating. Appl. Soft Comput. 2018, 69, 541–553. [Google Scholar] [CrossRef]
- Mariello, A.; Battiti, R. Feature selection based on the neighborhood entropy. IEEE Trans. Neural Netw. Learn. Syst. 2018, 99, 1–10. [Google Scholar] [CrossRef]
- Das, A.K.; Sengupta, S.; Bhattacharyya, S. A group incremental feature selection for classification using rough set theory based genetic algorithm. Appl. Soft Comput. 2018, 65, 400–411. [Google Scholar] [CrossRef]
- Imani, M.B.; Keyvanpour, M.R.; Azmi, R. A novel embedded feature selection method: A comparative study in the application of text categorization. Appl. Artif. Intell. 2013, 27, 408–427. [Google Scholar] [CrossRef]
- Chen, Y.M.; Zeng, Z.Q.; Lu, J.W. Neighborhood rough set reduction with fish swarm algorithm. Soft Comput. 2017, 21, 6907–6918. [Google Scholar] [CrossRef]
- Li, B.Y.; Xiao, J.M.; Wang, X.H. Feature reduction for power system transient stability assessment based on neighborhood rough set and discernibility matrix. Energies 2018, 11, 185. [Google Scholar] [CrossRef]
- Gu, X.P.; Li, Y.; Jia, J.H. Feature selection for transient stability assessment based on kernelized fuzzy rough sets and memetic algorithm. Int. J. Electr. Power Energy Syst. 2015, 64, 664–670. [Google Scholar] [CrossRef]
- Raza, M.S.; Qamar, U. A parallel rough set based dependency calculation method for efficient feature selection. Appl. Soft Comput. 2018, 71, 1020–1034. [Google Scholar] [CrossRef]
- Luan, X.Y.; Li, Z.P.; Liu, T.Z. A novel attribute reduction algorithm based on rough set and improved artificial fish swarm algorithm. Neurocomputing 2015, 174, 522–529. [Google Scholar] [CrossRef]
- Hu, Q.H.; Zhang, L.; Zhang, D.; Pan, W.; An, S.; Pedrycz, W. Measuring relevance between discrete and continuous features based on neighborhood mutual information. Expert Syst. Appl. 2011, 38, 10737–10750. [Google Scholar] [CrossRef]
- Chakraborty, D.B.; Pal, S.K. Neighborhood rough filter and intuitionistic entropy in unsupervised tracking. IEEE Trans. Fuzzy Syst. 2018, 26, 2188–2200. [Google Scholar] [CrossRef]
- Chen, Y.M.; Zhang, Z.J.; Zheng, J.Z.; Ma, Y.; Xue, Y. Gene selection for tumor classification using neighborhood rough sets and entropy measures. J. Biomed. Inf. 2017, 67, 59–68. [Google Scholar] [CrossRef]
- Hu, Q.H.; Pan, W.; An, S.; Ma, P.J.; Wei, J.M. An efficient gene selection technique for cancer recognition based on neighborhood mutual information. Int. J. Mach. Learn. Cybern. 2010, 1, 63–74. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.; Liu, J.F.; Wu, C.X. Neighborhood rough set based heterogeneous feature subset selection. Inf. Sci. 2008, 178, 3577–3594. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, X.Y.; Xu, J.C.; Wang, W.; Liu, R.N. A gene selection approach based on the Fisher linear discriminant and the neighborhood rough set. Bioengineered 2018, 9, 144–151. [Google Scholar] [CrossRef] [PubMed]
- Mu, H.Y.; Xu, J.C.; Wang, Y.; Sun, L. Feature genes selection using Fisher transformation method. J. Intell. Fuzzy Syst. 2018, 34, 4291–4300. [Google Scholar] [CrossRef]
- Halmos, P.R. Measure Theory; Litton Educational Publishing, Inc. and Springer-Verlag New York Inc.: New York, NY, USA, 1970; pp. 100–152. [Google Scholar]
- Song, J.J.; Li, J. Lebesgue theorems in non-additive measure theory. Fuzzy Sets Syst. 2005, 149, 543–548. [Google Scholar] [CrossRef]
- Xu, X.; Lu, Z.Z.; Luo, X.P. A kernel estimate method for characteristic function-based uncertainty importance measure. Appl. Math. Model. 2017, 42, 58–70. [Google Scholar] [CrossRef]
- Halčinová, L.; Hutník, O.; Kiseľák, J.; Šupina, J. Beyond the scope of super level measures. Fuzzy Sets Syst. 2018. [Google Scholar] [CrossRef]
- Park, S.R.; Kolouri, S.; Kundu, S.; Rohde, G.K. The cumulative distribution transform and linear pattern classification. Appl. Comput. Harmon. Anal. 2018, 45, 616–641. [Google Scholar] [CrossRef]
- Marzio, M.D.; Fensore, S.; Panzera, A.; Taylor, C.C. Local binary regression with spherical predictors. Stat. Probab. Lett. 2019, 144, 30–36. [Google Scholar] [CrossRef]
- Khanjani Shiraz, R.K.; Fukuyama, H.; Tavana, M.; Di Caprio, D. An integrated data envelopment analysis and free disposal hull framework for cost-efficiency measurement using rough sets. Appl. Soft Comput. 2016, 46, 204–219. [Google Scholar] [CrossRef]
- Zhang, Z.F.; David, J. An entropy-based approach for assessing the operation of production logistics. Expert Syst. Appl. 2019, 119, 118–127. [Google Scholar] [CrossRef]
- Wang, C.Z.; He, Q.; Shao, M.W.; Xu, Y.Y.; Hu, Q.H. A unified information measure for general binary relations. Knowl.-Based Syst. 2017, 135, 18–28. [Google Scholar] [CrossRef]
- Ge, H.; Yang, C.J.; Li, L.S. Positive region reduct based on relative discernibility and acceleration strategy. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2018, 26, 521–551. [Google Scholar] [CrossRef]
- Sun, L.; Xu, J.C. A granular computing approach to gene selection. Bio-Med. Mater. Eng. 2014, 24, 1307–1314. [Google Scholar]
- Fan, X.D.; Zhao, W.D.; Wang, C.Z.; Huang, Y. Attribute reduction based on max-decision neighborhood rough set model. Knowl.-Based Syst. 2018, 151, 16–23. [Google Scholar] [CrossRef]
- Meng, J.; Zhang, J.; Li, R.; Luan, Y.S. Gene selection using rough set based on neighborhood for the analysis of plant stress response. Appl. Soft Comput. 2014, 25, 51–63. [Google Scholar] [CrossRef]
- Liu, Y.; Huang, W.L.; Jiang, Y.L.; Zeng, Z.Y. Quick attribute reduct algorithm for neighborhood rough set model. Inf. Sci. 2014, 271, 65–81. [Google Scholar] [CrossRef]
- Li, W.W.; Huang, Z.Q.; Jia, X.Y.; Cai, X.Y. Neighborhood based decision-theoretic rough set models. Int. J. Approx. Reason. 2016, 69, 1–17. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Techn. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Chen, Y.M.; Xue, Y.; Ma, Y.; Xu, F.F. Measures of uncertainty for neighborhood rough sets. Knowl.-Based Syst. 2017, 120, 226–235. [Google Scholar] [CrossRef]
- Liang, J.Y.; Shi, Z.Z.; Li, D.Y.; Wierman, M.J. Information entropy, rough entropy and knowledge granulation in incomplete information systems. Int. J. Gen. Syst. 2006, 35, 641–654. [Google Scholar] [CrossRef]
- Sun, L.; Xu, J.C.; Tian, Y. Feature selection using rough entropy-based uncertainty measures in incomplete decision systems. Knowl.-Based Syst. 2012, 36, 206–216. [Google Scholar] [CrossRef]
- Liu, Y.; Xie, H.; Chen, Y.H.; Tan, K.Z.; Wu, X. Neighborhood mutual information and its application on hyperspectral band selection for classification. Chemom. Intell. Lab. Syst. 2016, 157, 140–151. [Google Scholar] [CrossRef]
- Wang, C.Z.; Hu, Q.H.; Wang, X.Z.; Chen, D.G.; Qian, Y.H.; Dong, Z. Feature selection based on neighborhood discrimination index. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2986–2999. [Google Scholar] [CrossRef]
- Wang, G.Y. Rough reduction in algebra view and information view. Int. J. Intell. Syst. 2003, 18, 679–688. [Google Scholar] [CrossRef]
- Teng, S.H.; Lu, M.; Yang, A.F.; Zhang, J.; Nian, Y.J.; He, M. Efficient attribute reduction from the viewpoint of discernibility. Inf. Sci. 2016, 326, 297–314. [Google Scholar] [CrossRef]
- Qian, Y.H.; Liang, J.Y.; Pedryce, W.; Dang, C.Y. Positive approximation: An accelerator for attribute reduction in rough set theory. Artif. Intell. 2010, 174, 597–618. [Google Scholar] [CrossRef]
- Pawlak, Z.; Skowron, A. Rudiments of rough sets. Inf. Sci. 2007, 177, 3–27. [Google Scholar] [CrossRef]
- Sun, L.; Xu, J.C. Information entropy and mutual information-based uncertainty measures in rough set theory. Appl. Math. Inf. Sci. 2014, 8, 1973–1985. [Google Scholar] [CrossRef]
- Chen, Y.M.; Wu, K.S.; Chen, X.H.; Tang, C.H.; Zhu, Q.X. An entropy-based uncertainty measurement approach in neighborhood systems. Inf. Sci. 2014, 279, 239–250. [Google Scholar] [CrossRef]
- Hu, Q.H.; Yu, D.; Xie, Z.X.; Liu, J.F. Fuzzy probabilistic approximation spaces and their information measures. IEEE Trans. Fuzzy Syst. 2006, 14, 191–201. [Google Scholar]
- Jensen, R.; Shen, Q. Semantics-preserving dimensionality reduction: Rough and fuzzy-rough-based approaches. IEEE Trans. Knowl. Data Eng. 2004, 16, 1457–1471. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 15 December 2018).
- BROAD INSTITUTE, Cancer Program Legacy Publication Resources. Available online: http://portals. broadinstitute.org/cgi-bin/cancer/datasets.cgi (accessed on 15 December 2018).
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; Zoubi, A.M.A.; Mirjalili, S.; Fujita, H. An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl.-Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Wang, T.H.; Li, W. Kernel learning and optimization with Hilbert–Schmidt independence criterion. Int. J. Mach. Learn. Cybern. 2018, 9, 1707–1717. [Google Scholar] [CrossRef]
- Yager, R.R. Entropy measures under similarity relations. Int. J. Gen. Syst. 1992, 20, 341–358. [Google Scholar] [CrossRef]
- Sun, L.; Liu, R.N.; Xu, J.C.; Zhang, S.G.; Tian, Y. An affinity propagation clustering method using hybrid kernel function with LLE. IEEE Access 2018, 6, 68892–68909. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| U | a | b | c | d |
|---|---|---|---|---|
| x1 | 0.12 | 0.41 | 0.61 | Y |
| x2 | 0.21 | 0.15 | 0.14 | Y |
| x3 | 0.31 | 0.11 | 0.26 | N |
| x4 | 0.61 | 0.13 | 0.23 | N |
| No. | Data sets | Samples | Attributes | Classes | Author |
|---|---|---|---|---|---|
| 1 | Wine | 178 | 13 | 3 | Faris et al. [56] |
| 2 | Sonar | 208 | 60 | 2 | Wang and Li [57] |
| 3 | Segmentation | 2310 | 19 | 7 | Liu et al. [38] |
| 4 | Wdbc | 569 | 31 | 2 | Li et al. [39] |
| 5 | Wpbc | 198 | 33 | 2 | Chen et al. [13] |
| 6 | Prostate | 136 | 12600 | 2 | Mu et al. [24] |
| 7 | DLBCL | 77 | 5469 | 2 | Sun et al. [8] |
| 8 | Leukemia | 72 | 11225 | 3 | Sun et al. [23] |
| 9 | Tumors | 327 | 12558 | 7 | Wang et al. [45] |
| Data Sets | FINEN | NEIEN | ARNRJE | δ |
|---|---|---|---|---|
| Wine | {1, 2, 3, 4, 6, 7, 8, 9, 10 11, 12, 13}/12 | {1, 2, 3, 4, 5, 7, 10, 11, 12, 13}/10 | {1, 2, 3, 5, 7, 10, 11, 13}/8 | 0.65 |
| Sonar | {1, 5, 9, 10, 11, 12, 18, 19, 22, 26, 27, 28, 29, 32, 35, 36, 37, 40, 45, 46, 48, 53, 57, 58, 59, 60}/26 | {6, 10, 11, 12, 15, 17, 18, 20, 21, 23, 24, 26, 28, 29, 30, 32, 33, 36, 37, 39, 40, 41, 42, 45, 48, 50, 54, 57}/29 | {2, 3, 4, 5, 9, 10, 11, 12, 13, 14, 16, 22, 24, 30, 32, 34, 36, 37, 38, 39, 46, 57, 60}/23 | 0.4 |
| Segmentation | {2, 5, 6, 7, 11, 12, 13, 17, 18}/9 | {2, 5, 6, 7, 11, 12, 13, 17, 18}/9 | {2, 5, 6, 10, 11, 13, 17, 18}/8 | 0.75 |
| Wdbc | {7, 8, 10, 12, 13, 16, 21, 22, 25, 27, 28, 29}/12 | {1, 7, 8, 10, 13, 16, 21, 22, 25, 27, 28, 29}/12 | {6, 8, 9, 11, 12, 14, 16, 19, 20, 25, 27, 28, 29}/13 | 0.35 |
| Wpbc | {1, 12, 13, 16, 24, 32}/6 | {1, 5, 12, 24, 32}/5 | {2, 19, 23, 24, 29, 31}/6 | 0.55 |
| Prostate | {4483, 6185, 8129, 8623, 8850, 9850, 10753, 12067}/8 | {4483, 4847, 6185, 6627, 8623, 8850, 9587, 12067}/8 | {11052, 6185, 8986, 5486, 6392, 5757, 8850, 4483}/8 | 0.9 |
| DLBCL | {453, 1570, 1698, 3127, 3257, 4767}/6 | {453, 2930, 3574, 4767, 5283}/5 | {453, 1479, 1570, 3127, 3257, 4767}/6 | 0.5 |
| Leukemia | {2833, 6720, 5555, 10127, 10038, 4839, 8952, 9053}/8 | {2833, 6720, 5555, 10127, 10038, 3479, 8964, 515}/8 | {461, 1787, 1834, 1962, 2131, 2356, 3821, 5552}/8 | 0.4 |
| Tumors | {2543, 7648, 3264, 6320, 5411, 6671, 8548, 7781, 10126, 6764, 4178, 4448, 8337, 3043, 4831, 3880}/16 | {5411, 6320, 7648, 3264, 3324, 6671, 4300, 6079, 6764, 10126, 8397, 8383, 9046, 7922, 10865, 8687, 2132}/17 | {3880, 843, 1730, 3342, 6151, 2960, 3264, 3596, 5624, 4026, 7648, 8383, 8332, 9788, 5412, 8556, 3324, 10126}/18 | 0.25 |
| Data Sets | ODP | NRS | FRSINT | FINEN | NEIEN | ARNRJE |
|---|---|---|---|---|---|---|
| Wine | 13 | 9.1 | 8.1 | 12.3 | 10.2 | 9.5 |
| Sonar | 60 | 24.8 | 18.7 | 25.8 | 28.9 | 24.6 |
| Segmentation | 19 | 10.7 | 8.4 | 9.5 | 9.2 | 8.9 |
| Wdbc | 30 | 17.3 | 11.9 | 12.1 | 11.8 | 13.3 |
| Wpbc | 32 | 11.6 | 7.8 | 6.4 | 5.3 | 6.2 |
| Prostate | 12600 | 6.5 | 8.9 | 8.4 | 7.7 | 8 |
| DLBCL | 5469 | 8.3 | 8.8 | 6.1 | 5.3 | 7.6 |
| Leukemia | 11225 | 14.7 | 9.8 | 8.5 | 8.2 | 9.1 |
| Tumors | 12558 | 10.6 | 9.5 | 15.8 | 17.1 | 18.2 |
| Average | 4667.3 | 12.6 | 10.2 | 11.7 | 11.5 | 11.7 |
| Data Sets | ODP | NRS | FRSINT | FINEN | NEIEN | ARNRJE |
|---|---|---|---|---|---|---|
| Wine | 0.9192 | 0.9453 | 0.9281 | 0.9577 | 0.9620 | 0.9775 |
| Sonar | 0.8605 | 0.8588 | 0.8504 | 0.8513 | 0.8326 | 0.8942 |
| Segmentation | 0.8714 | 0.8021 | 0.9506 | 0.9504 | 0.9488 | 0.8381 |
| Wdbc | 0.9432 | 0.9553 | 0.9366 | 0.9226 | 0.9385 | 0.9456 |
| Wpbc | 0.6667 | 0.6752 | 0.6312 | 0.6613 | 0.6263 | 0.6919 |
| Prostate | 0.8235 | 0.8329 | 0.8503 | 0.8689 | 0.8431 | 0.8897 |
| DLBCL | 0.8831 | 0.9610 | 0.9635 | 0.9635 | 0.9585 | 0.9740 |
| Leukemia | 0.7339 | 0.9274 | 0.8655 | 0.9246 | 0.886 | 0.9306 |
| Tumors | 0.7074 | 0.725 | 0.7239 | 0.7781 | 0.7372 | 0.7194 |
| Average | 0.8232 | 0.8537 | 0.8556 | 0.8754 | 0.8592 | 0.8734 |
| Data Sets | ODP | NRS | FRSINT | FINEN | NEIEN | ARNRJE |
|---|---|---|---|---|---|---|
| Wine | 0.9210 | 0.9213 | 0.9295 | 0.9503 | 0.9210 | 0.9719 |
| Sonar | 0.6587 | 0.7735 | 0.7909 | 0.8168 | 0.8036 | 0.7885 |
| Segmentation | 0.9048 | 0.8606 | 0.9438 | 0.9317 | 0.9356 | 0.9095 |
| Wdbc | 0.5167 | 0.9453 | 0.9362 | 0.9230 | 0.9449 | 0.9051 |
| Wpbc | 0.7374 | 0.7029 | 0.7002 | 0.6875 | 0.7188 | 0.7374 |
| Prostate | 0.8750 | 0.8353 | 0.8527 | 0.9039 | 0.8691 | 0.9118 |
| DLBCL | 0.8701 | 0.9231 | 0.924 | 0.9051 | 0.8758 | 0.9351 |
| Leukemia | 0.4679 | 0.9165 | 0.9454 | 0.9122 | 0.942 | 0.9583 |
| Tumors | 0.2788 | 0.7516 | 0.7308 | 0.7742 | 0.7712 | 0.7627 |
| Average | 0.6923 | 0.8478 | 0.8615 | 0.8672 | 0.8647 | 0.8756 |
| Data Sets | FINEN | NEIEN | ARNRJE |
|---|---|---|---|
| Wine | 0.961 | 0.978 | 1.000 |
| Sonar | 0.910 | 0.937 | 0.955 |
| Segmentation | 0.833 | 0.833 | 0.838 |
| Wdbc | 0.951 | 0.953 | 0.966 |
| Wpbc | 0.815 | 0.753 | 0.849 |
| Prostate | 0.934 | 0.882 | 0.890 |
| DLBCL | 1.000 | 0.974 | 0.974 |
| Leukemia | 0.917 | 0.958 | 0.979 |
| Tumors | 0.567 | 0.733 | 0.867 |
| Average | 0.876 | 0.889 | 0.924 |
| Data Sets | FINEN | NEIEN | ARNRJE |
|---|---|---|---|
| Wine | 0.958 | 1.000 | 1.000 |
| Sonar | 0.771 | 0.688 | 0.874 |
| Segmentation | 0.567 | 0.567 | 0.667 |
| Wdbc | 0.930 | 0.627 | 0.924 |
| Wpbc | 0.737 | 0.737 | 0.768 |
| Prostate | 0.566 | 0.566 | 0.566 |
| DLBCL | 0.753 | 0.753 | 1.000 |
| Leukemia | 0.389 | 0.389 | 0.653 |
| Tumors | 0.567 | 0.691 | 0.566 |
| Average | 0.693 | 0.669 | 0.780 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, L.; Wang, L.; Xu, J.; Zhang, S. A Neighborhood Rough Sets-Based Attribute Reduction Method Using Lebesgue and Entropy Measures. Entropy 2019, 21, 138. https://doi.org/10.3390/e21020138
Sun L, Wang L, Xu J, Zhang S. A Neighborhood Rough Sets-Based Attribute Reduction Method Using Lebesgue and Entropy Measures. Entropy. 2019; 21(2):138. https://doi.org/10.3390/e21020138
Chicago/Turabian StyleSun, Lin, Lanying Wang, Jiucheng Xu, and Shiguang Zhang. 2019. "A Neighborhood Rough Sets-Based Attribute Reduction Method Using Lebesgue and Entropy Measures" Entropy 21, no. 2: 138. https://doi.org/10.3390/e21020138
APA StyleSun, L., Wang, L., Xu, J., & Zhang, S. (2019). A Neighborhood Rough Sets-Based Attribute Reduction Method Using Lebesgue and Entropy Measures. Entropy, 21(2), 138. https://doi.org/10.3390/e21020138