Nonlinear Information Bottleneck



Abstract
:1. Introduction
- We represent the distribution over X and Y using a finite number of data samples.
- We represent the encoding map and the decoding map as parameterized conditional distributions.
- We use a variational lower bound for the prediction term , and non-parametric upper bound for the compression term , which we developed in earlier work [35].
2. Proposed Approach
3. Relation to Prior Work
3.1. Variational IB
3.2. Neural Networks and Kernel Density Entropy Estimates
3.3. Auto-Encoders
4. Experiments
4.1. Implementation
4.2. Results
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Tishby, N.; Pereira, F.; Bialek, W. The information bottleneck method. In Proceedings of the 37th Annual Allerton Conference on Communication, Control, and Computing, Monticello, IL, USA, 22–24 September 1999. [Google Scholar]
- Dimitrov, A.G.; Miller, J.P. Neural coding and decoding: Communication channels and quantization. Netw. Comput. Neural Syst. 2001, 12, 441–472. [Google Scholar] [CrossRef]
- Samengo, I. Information loss in an optimal maximum likelihood decoding. Neural Comput. 2002, 14, 771–779. [Google Scholar] [CrossRef]
- Witsenhausen, H.; Wyner, A. A conditional entropy bound for a pair of discrete random variables. IEEE Trans. Inf. Theory 1975, 21, 493–501. [Google Scholar] [CrossRef]
- Ahlswede, R.; Körner, J. Source Coding with Side Information and a Converse for Degraded Broadcast Channels. IEEE Trans. Inf. Theory 1975, 21, 629–637. [Google Scholar] [CrossRef]
- Gilad-Bachrach, R.; Navot, A.; Tishby, N. An Information Theoretic Tradeoff between Complexity and Accuracy. In Learning Theory and Kernel Machines; Goos, G., Hartmanis, J., van Leeuwen, J., Schölkopf, B., Warmuth, M.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2777, pp. 595–609. [Google Scholar]
- Slonim, N.; Tishby, N. Document clustering using word clusters via the information bottleneck method. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens, Greece, 24–28 July 2000; pp. 208–215. [Google Scholar]
- Tishby, N.; Slonim, N. Data clustering by markovian relaxation and the information bottleneck method. In Advances in Neural Information Processing Systems 13 (NIPS 2000); MIT Press: Cambridge, MA, USA, 2001; pp. 640–646. [Google Scholar]
- Cardinal, J. Compression of side information. In Proceedings of the 2003 International Conference on Multimedia and Expo, Baltimore, MD, USA, 6–9 July 2003; pp. 569–572. [Google Scholar]
- Zeitler, G.; Koetter, R.; Bauch, G.; Widmer, J. Design of network coding functions in multihop relay networks. In Proceedings of the 2008 5th International Symposium on Turbo Codes and Related Topics, Lausanne, Switzerland, 1–5 September 2008; pp. 249–254. [Google Scholar]
- Courtade, T.A.; Wesel, R.D. Multiterminal source coding with an entropy-based distortion measure. In Proceedings of the 2011 IEEE International Symposium on Information Theory, St. Petersburg, Russia, 31 July–5 August 2011; pp. 2040–2044. [Google Scholar]
- Lazebnik, S.; Raginsky, M. Supervised learning of quantizer codebooks by information loss minimization. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 31, 1294–1309. [Google Scholar] [CrossRef] [PubMed]
- Winn, J.; Criminisi, A.; Minka, T. Object categorization by learned universal visual dictionary. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05) Volume 1, Beijing, China, 17–21 October 2005; Volume 2, pp. 1800–1807. [Google Scholar]
- Hecht, R.M.; Noor, E.; Tishby, N. Speaker recognition by Gaussian information bottleneck. In Proceedings of the 10th Annual Conference of the International Speech Communication Association, Brighton, UK, 6–10 September 2009. [Google Scholar]
- Yaman, S.; Pelecanos, J.; Sarikaya, R. Bottleneck features for speaker recognition. In Proceedings of the Speaker and Language Recognition Workshop, Singapore, 25–28 June 2012. [Google Scholar]
- Van Kuyk, S.; Kleijn, W.B.; Hendriks, R.C. On the information rate of speech communication. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 5625–5629. [Google Scholar]
- Van Kuyk, S. Speech Communication from an Information Theoretical Perspective. Ph.D. Thesis, Victoria University of Wellington, Wellington, New Zealand, 2019. [Google Scholar]
- Zaslavsky, N.; Kemp, C.; Regier, T.; Tishby, N. Efficient compression in color naming and its evolution. Proc. Natl. Acad. Sci. USA 2018, 115, 7937–7942. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez Gálvez, B. The Information Bottleneck: Connections to Other Problems, Learning and Exploration of the IB Curve. Master’s Thesis, KTH Royal Institute of Technology, Stockholm, Sweden, June 2019. [Google Scholar]
- Hafez-Kolahi, H.; Kasaei, S. Information Bottleneck and its Applications in Deep Learning. arXiv 2019, arXiv:1904.03743. [Google Scholar]
- Tishby, N.; Zaslavsky, N. Deep learning and the information bottleneck principle. In Proceedings of the 2015 IEEE Information Theory Workshop (ITW), Jerusalem, Israel, 26 April–1 May 2015; pp. 1–5. [Google Scholar]
- Shamir, O.; Sabato, S.; Tishby, N. Learning and generalization with the information bottleneck. Theor. Comput. Sci. 2010, 411, 2696–2711. [Google Scholar] [CrossRef]
- Vera, M.; Piantanida, P.; Vega, L.R. The Role of the Information Bottleneck in Representation Learning. In Proceedings of the 2018 IEEE International Symposium on Information Theory (ISIT), Vail, CO, USA, 17–22 June 2018; pp. 1580–1584. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep Variational Information Bottleneck. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V. Uncertainty in the variational information bottleneck. arXiv 2018, arXiv:1807.00906. [Google Scholar]
- Amjad, R.A.; Geiger, B.C. Learning Representations for Neural Network-Based Classification Using the Information Bottleneck Principle. arXiv 2018, arXiv:1802.09766. [Google Scholar] [CrossRef]
- Shwartz-Ziv, R.; Tishby, N. Opening the Black Box of Deep Neural Networks via Information. arXiv 2017, arXiv:1703.00810. [Google Scholar]
- Saxe, A.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.; Cox, D. On the information bottleneck theory of deep learning. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Lemaréchal, C. Lagrangian relaxation. In Computational Combinatorial Optimization; Springer: Berlin/Heidelberg, Germany, 2001; pp. 112–156. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Chechik, G.; Globerson, A.; Tishby, N.; Weiss, Y. Information bottleneck for Gaussian variables. J. Mach. Learn. Res. 2005, 6, 165–188. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D.; Van Kuyk, S. Caveats for information bottleneck in deterministic scenarios. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer: Boston, MA, USA, 1998. [Google Scholar] [CrossRef]
- Rodríguez Gálvez, B.; Thobaben, R.; Skoglund, M. The Convex Information Bottleneck Lagrangian. arXiv 2019, arXiv:1911.11000. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D. Estimating Mixture Entropy with Pairwise Distances. Entropy 2017, 19, 361. [Google Scholar] [CrossRef]
- Chalk, M.; Marre, O.; Tkacik, G. Relevant sparse codes with variational information bottleneck. In Proceedings of the 2016 Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 1957–1965. [Google Scholar]
- Achille, A.; Soatto, S. Information Dropout: Learning optimal representations through noise. arXiv 2016, arXiv:1611.01353. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: New York, NY, USA, 2018. [Google Scholar]
- Kolchinsky, A.; Wolpert, D.H. Supervised learning with information penalties. In Proceedings of the 2016 Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Kolchinsky, A.; Tracey, B.D.; Wolpert, D.H. Nonlinear Information Bottleneck. Entropy 2019, 21, 1181. [Google Scholar] [CrossRef]
- Schraudolph, N.N. Optimization of entropy with neural networks. Ph.D. Thesis, University of California, San Diego, CA, USA, 1995. [Google Scholar]
- Schraudolph, N.N. Gradient-based manipulation of nonparametric entropy estimates. IEEE Trans. Neural Netw. 2004, 15, 828–837. [Google Scholar] [CrossRef]
- Shwartz, S.; Zibulevsky, M.; Schechner, Y.Y. Fast kernel entropy estimation and optimization. Signal Process. 2005, 85, 1045–1058. [Google Scholar] [CrossRef]
- Torkkola, K. Feature extraction by non-parametric mutual information maximization. J. Mach. Learn. Res. 2003, 3, 1415–1438. [Google Scholar]
- Hlavávcková-Schindler, K.; Palus, M.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approaches in time series analysis. Phys. Rep. 2007, 441, 1–46. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 2014 Conference on Neural Information Processing Systems (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Hinton, G.E.; Zemel, R.S. Autoencoders, minimum description length, and Helmholtz free energy. In Advances in Neural Information Processing Systems 7 (NIPS 1994); MIT Press: Cambridge, MA, USA, 1994; p. 3. [Google Scholar]
- Hinton, G.E.; Zemel, R.S. Minimizing Description Length in an Unsupervised Neural Network. Available online: https://www.cs.toronto.edu/~fritz/absps/mdlnn.pdf (accessed on 30 November 2019).
- Deco, G.; Finnoff, W.; Zimmermann, H.G. Elimination of Overtraining by a Mutual Information Network. In ICANN’93; Gielen, S., Kappen, B., Eds.; Springer: London, UK, 1993; pp. 744–749. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. In Proceedings of the International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.; Glorot, X.; Botvinick, M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. In Proceedings of the International Conference on Learning Representations (ICLR 2017), Toulon, France, 24–26 April 2017. [Google Scholar]
- Alemi, A.; Poole, B.; Fischer, I.; Dillon, J.; Saurous, R.A.; Murphy, K. Fixing a Broken ELBO. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 159–168. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A novel image dataset for benchmarking machine learning algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]
- Pace, R.K.; Barry, R. Sparse spatial autoregressions. Stat. Probab. Lett. 1997, 33, 291–297. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
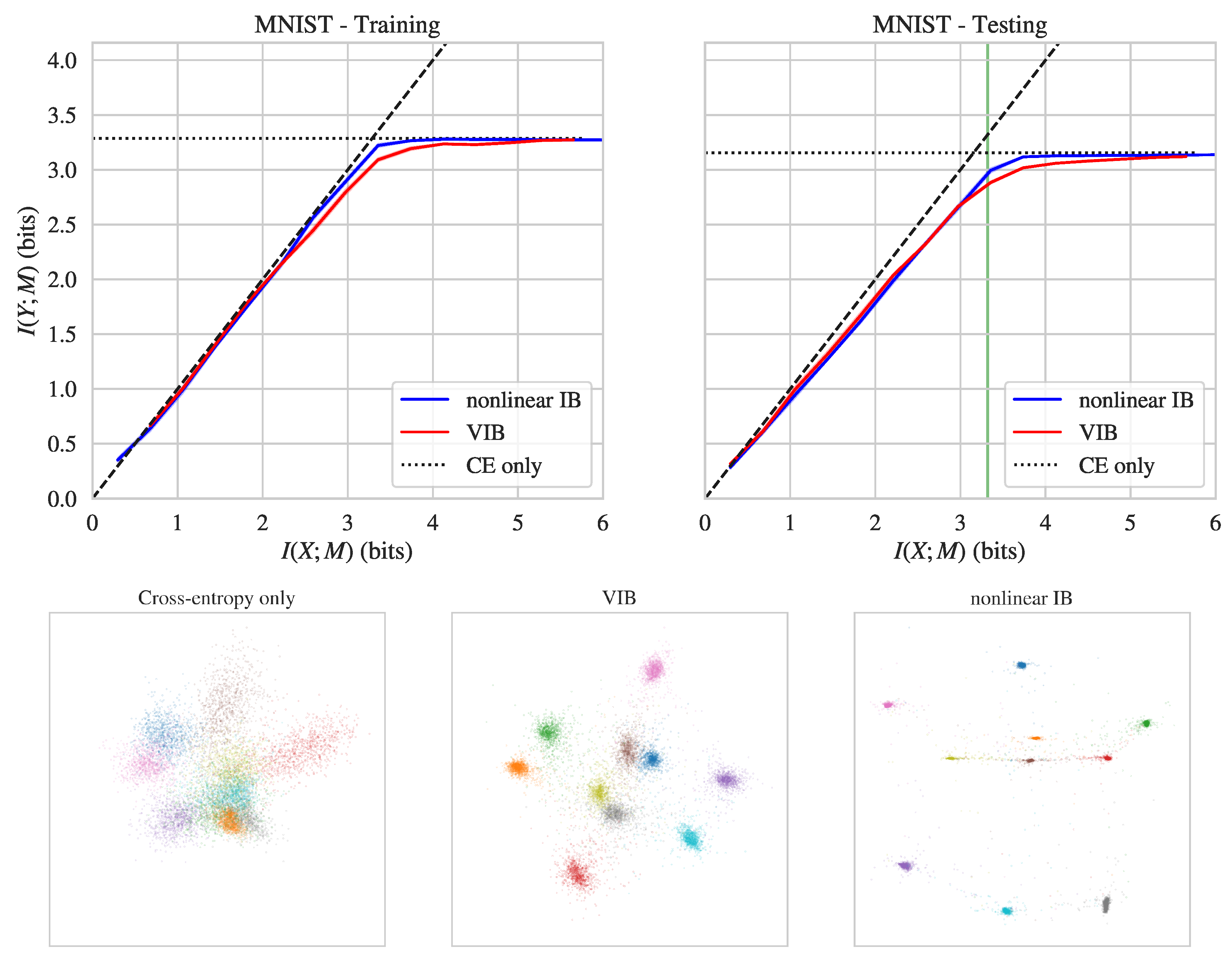
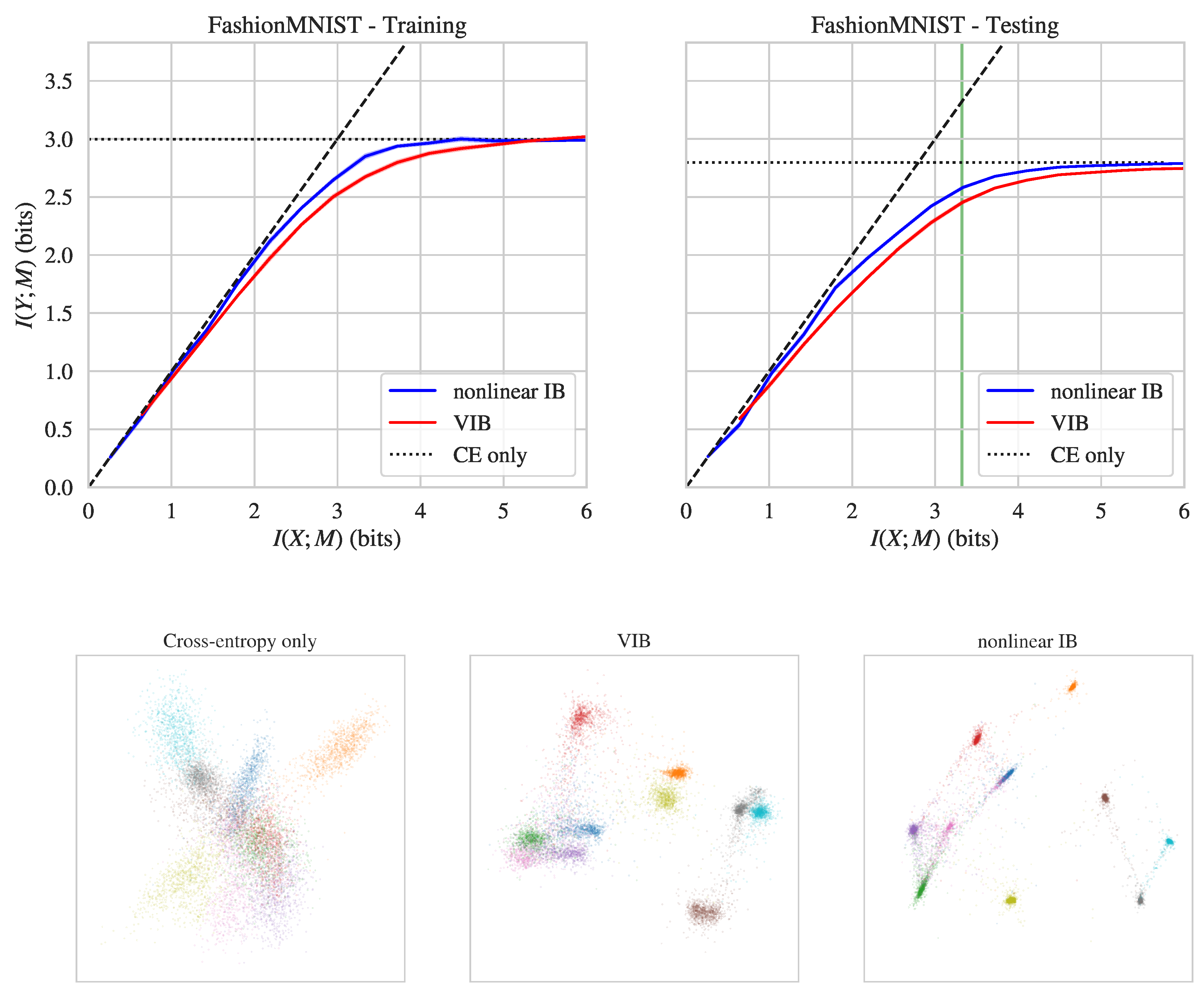
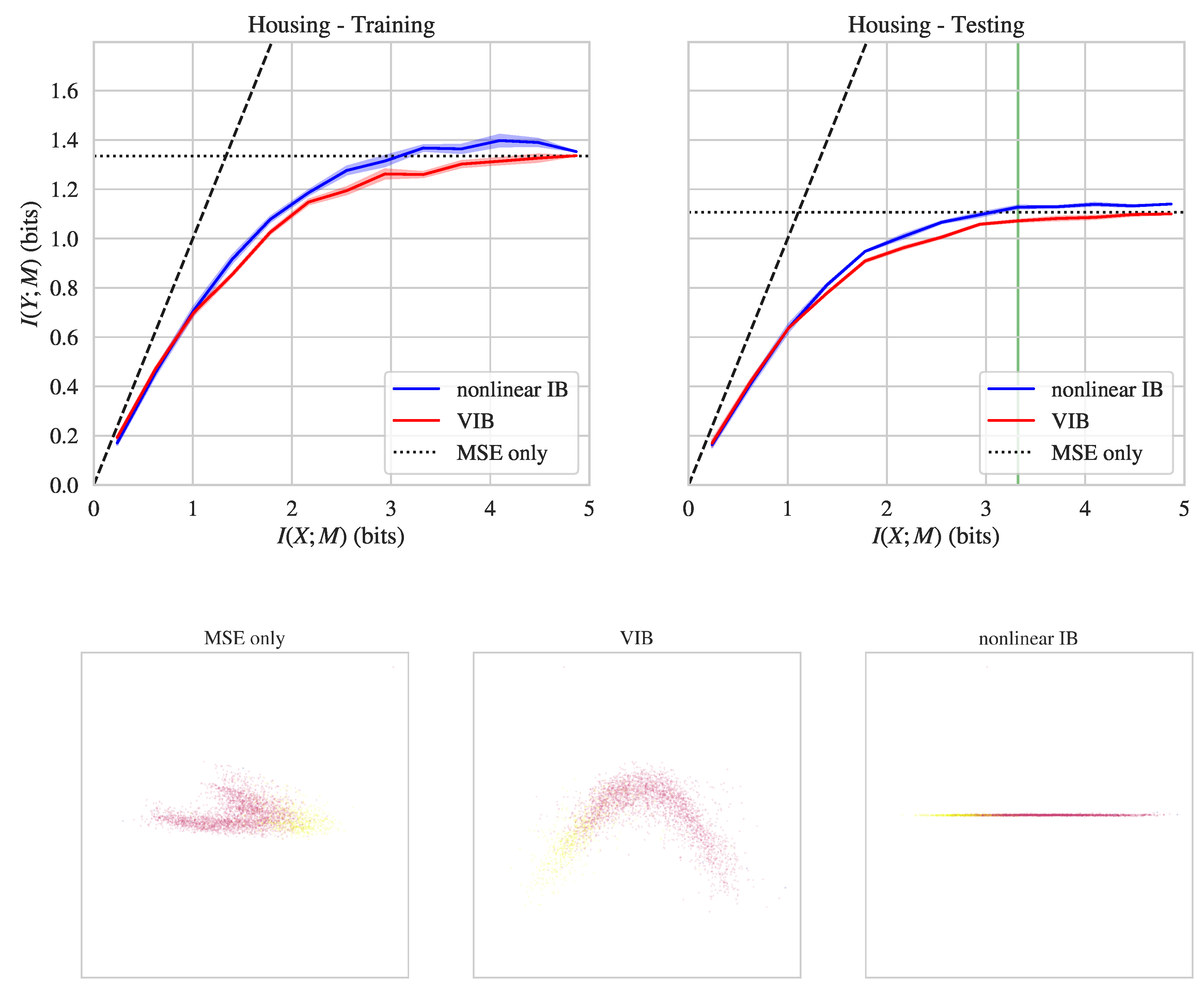

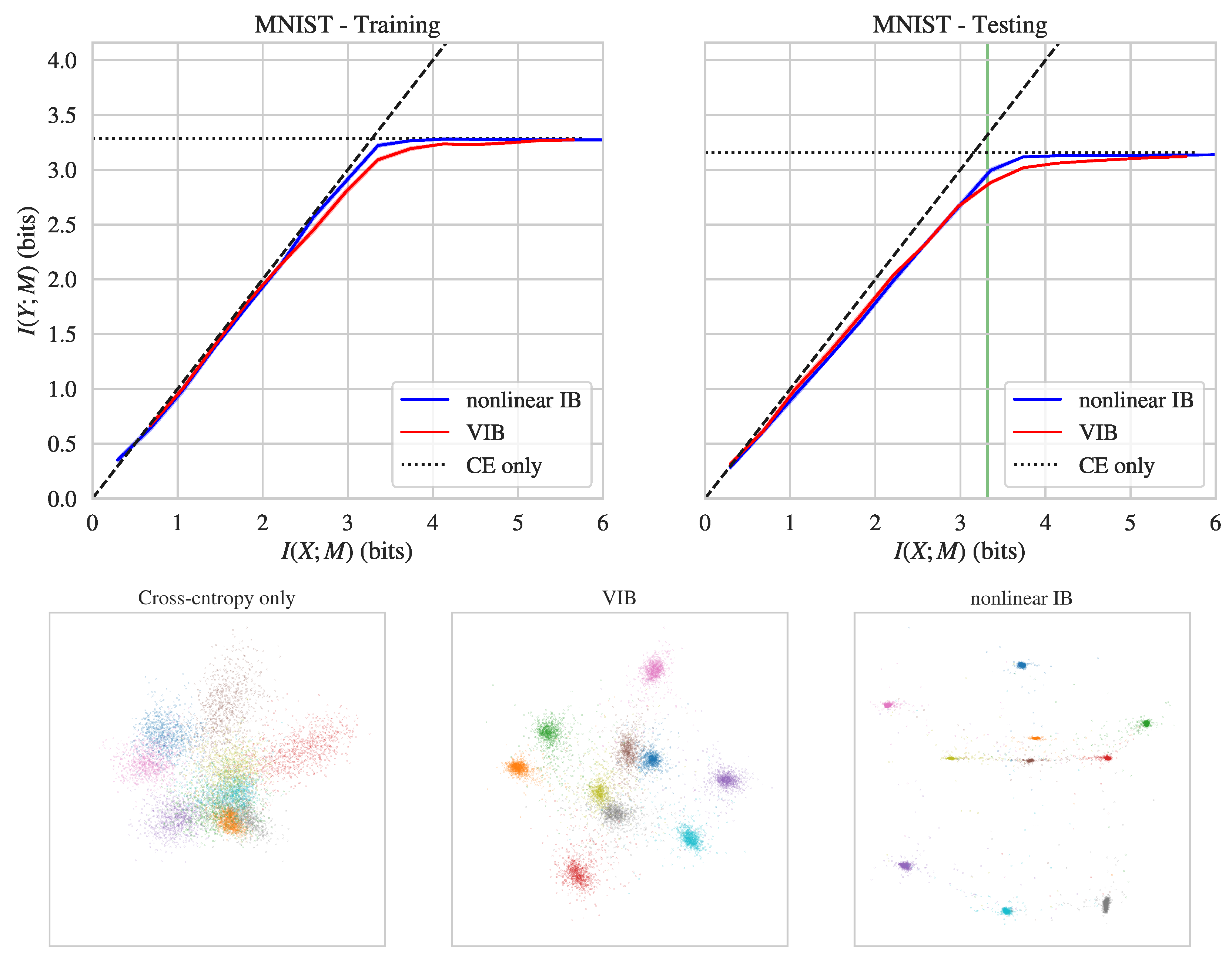{kind=link}
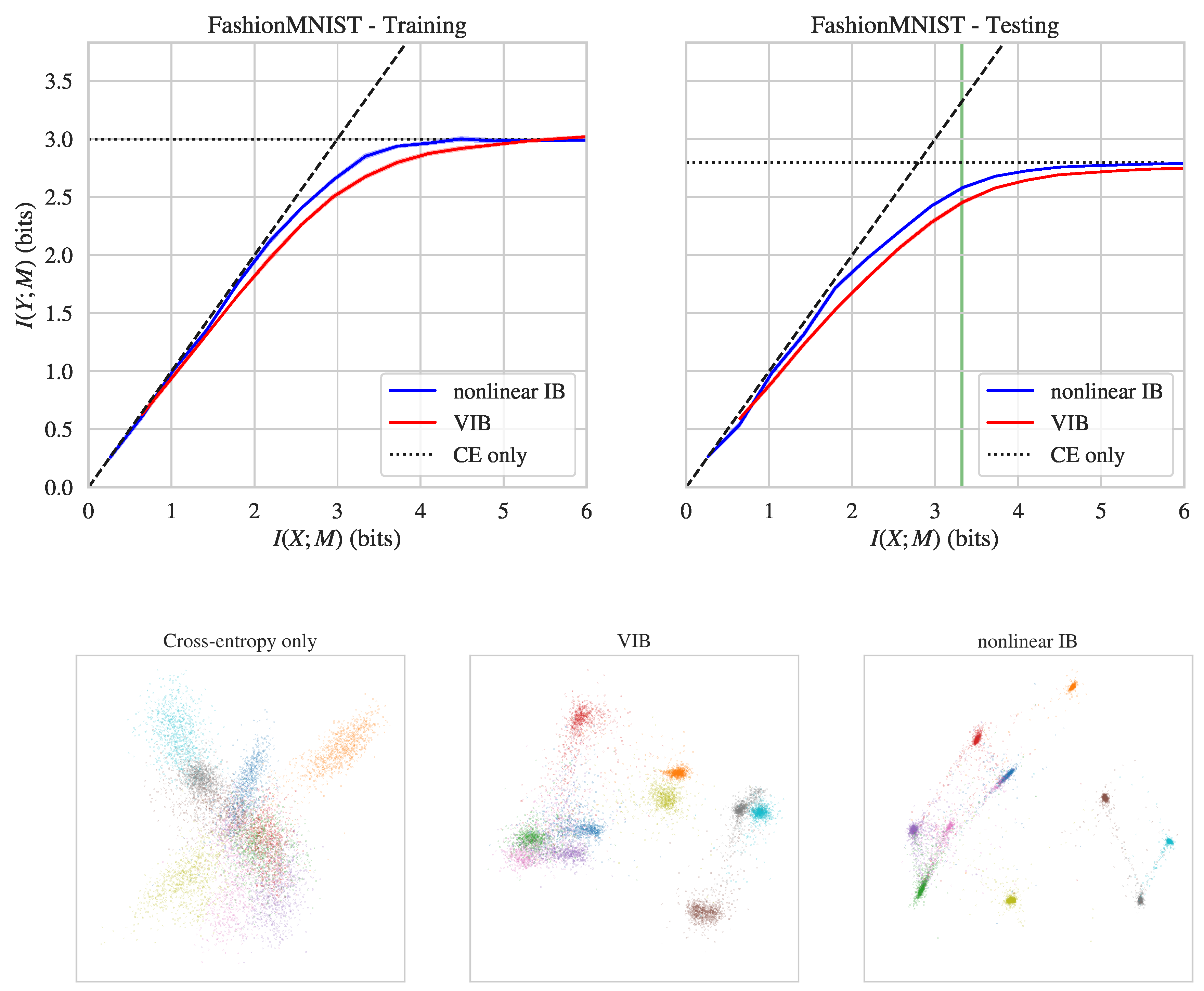{kind=link}
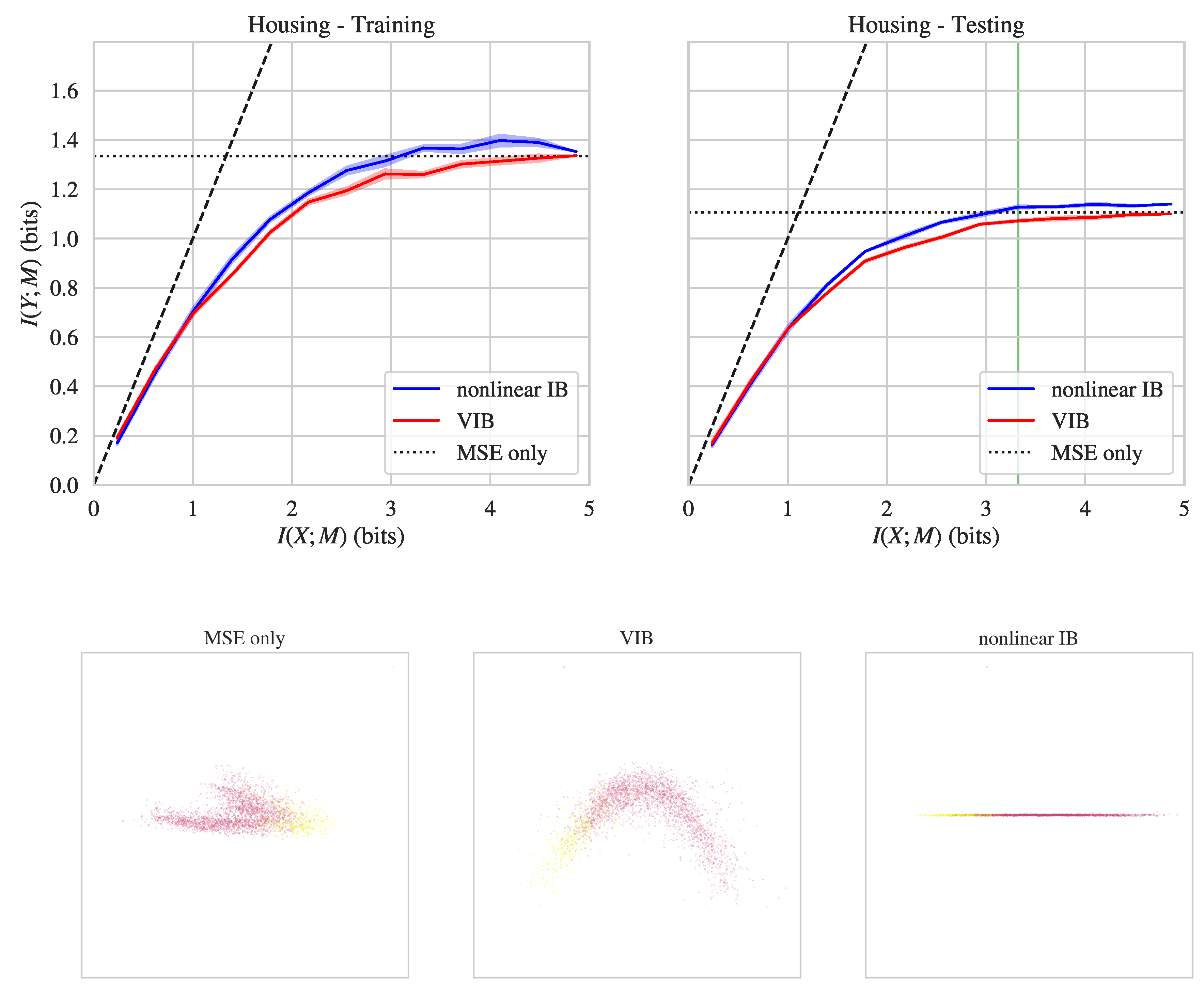{kind=link}
| Dataset | Nonlinear IB | VIB | |
|---|---|---|---|
| MNIST | Training | 3.22 | 3.09 |
| Testing | 2.99 | 2.88 | |
| FashionMNIST | Training | 2.85 | 2.67 |
| Testing | 2.58 | 2.46 | |
| California housing | Training | 1.37 | 1.26 |
| Testing | 1.13 | 1.07 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kolchinsky, A.; Tracey, B.D.; Wolpert, D.H. Nonlinear Information Bottleneck. Entropy 2019, 21, 1181. https://doi.org/10.3390/e21121181
Kolchinsky A, Tracey BD, Wolpert DH. Nonlinear Information Bottleneck. Entropy. 2019; 21(12):1181. https://doi.org/10.3390/e21121181
Chicago/Turabian StyleKolchinsky, Artemy, Brendan D. Tracey, and David H. Wolpert. 2019. "Nonlinear Information Bottleneck" Entropy 21, no. 12: 1181. https://doi.org/10.3390/e21121181
APA StyleKolchinsky, A., Tracey, B. D., & Wolpert, D. H. (2019). Nonlinear Information Bottleneck. Entropy, 21(12), 1181. https://doi.org/10.3390/e21121181