Causal Composition: Structural Differences among Dynamically Equivalent Systems


Abstract
1. Introduction
2. Theory
2.1. The Compositional Intrinsic Information of an Example System
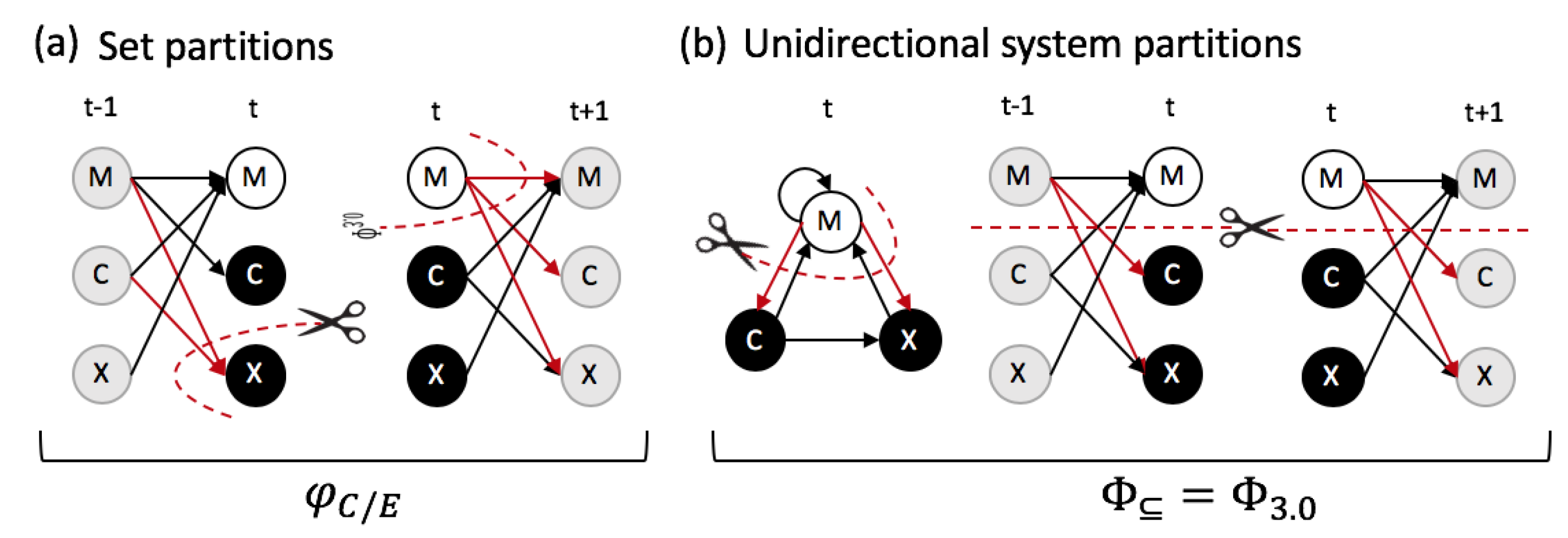
2.2. Causal Composition and System-Level Integration
3. Results
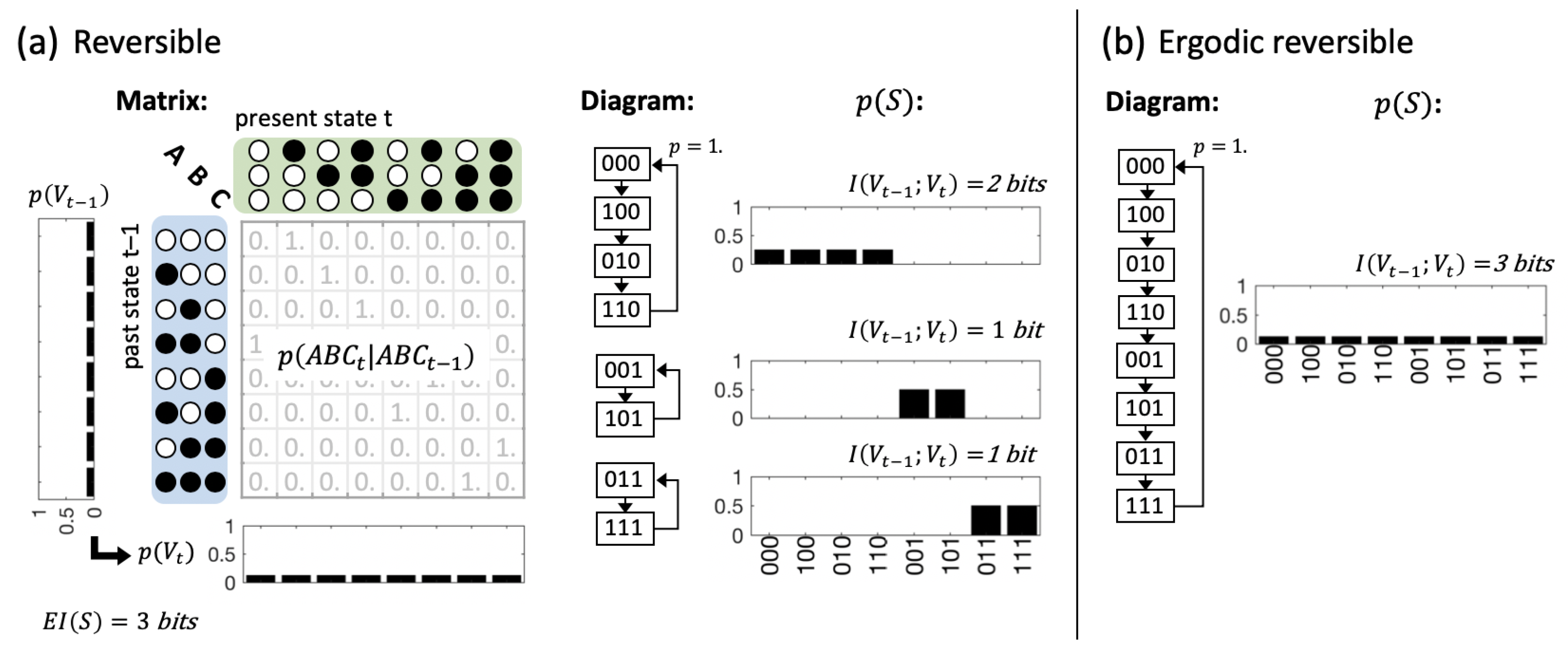
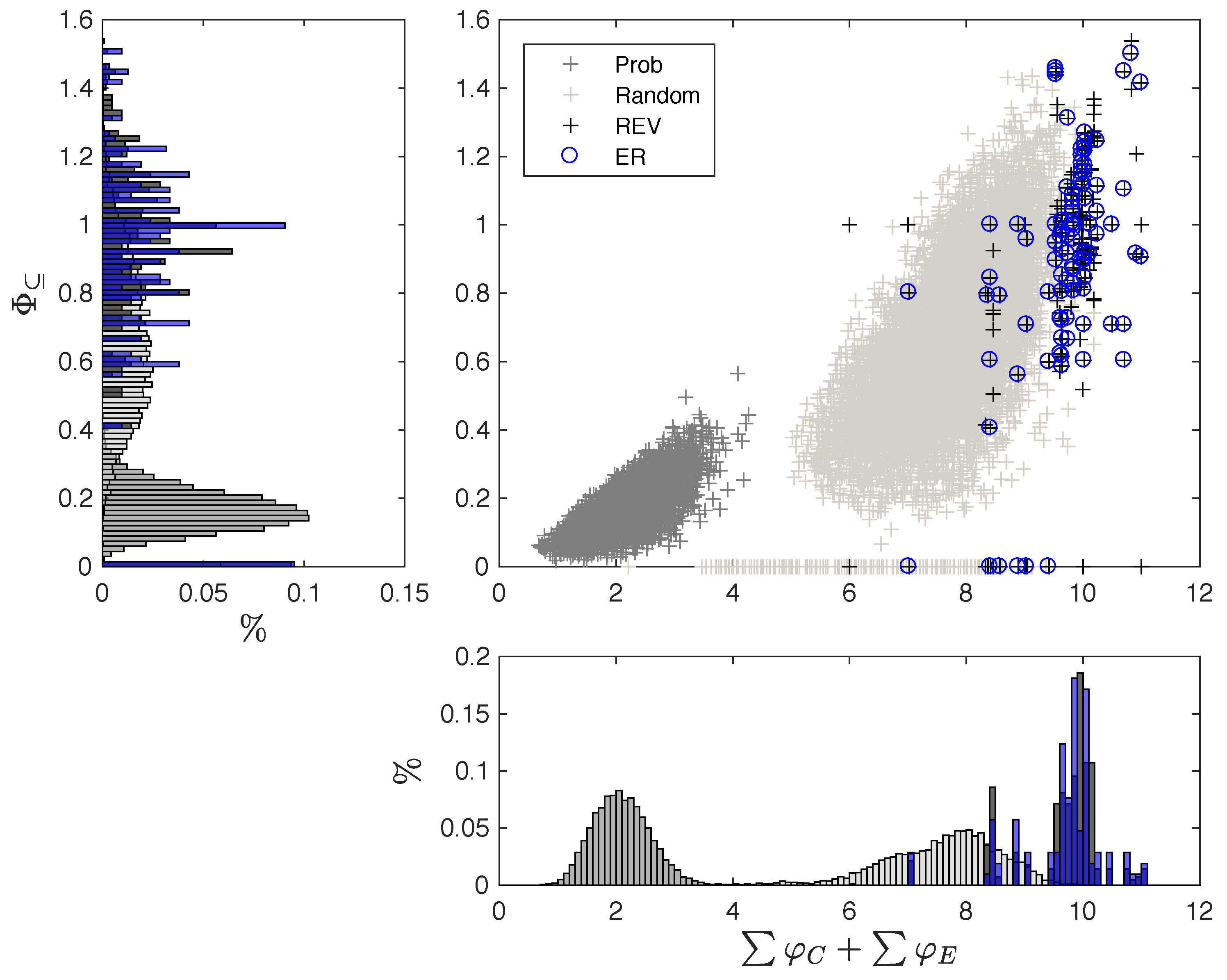
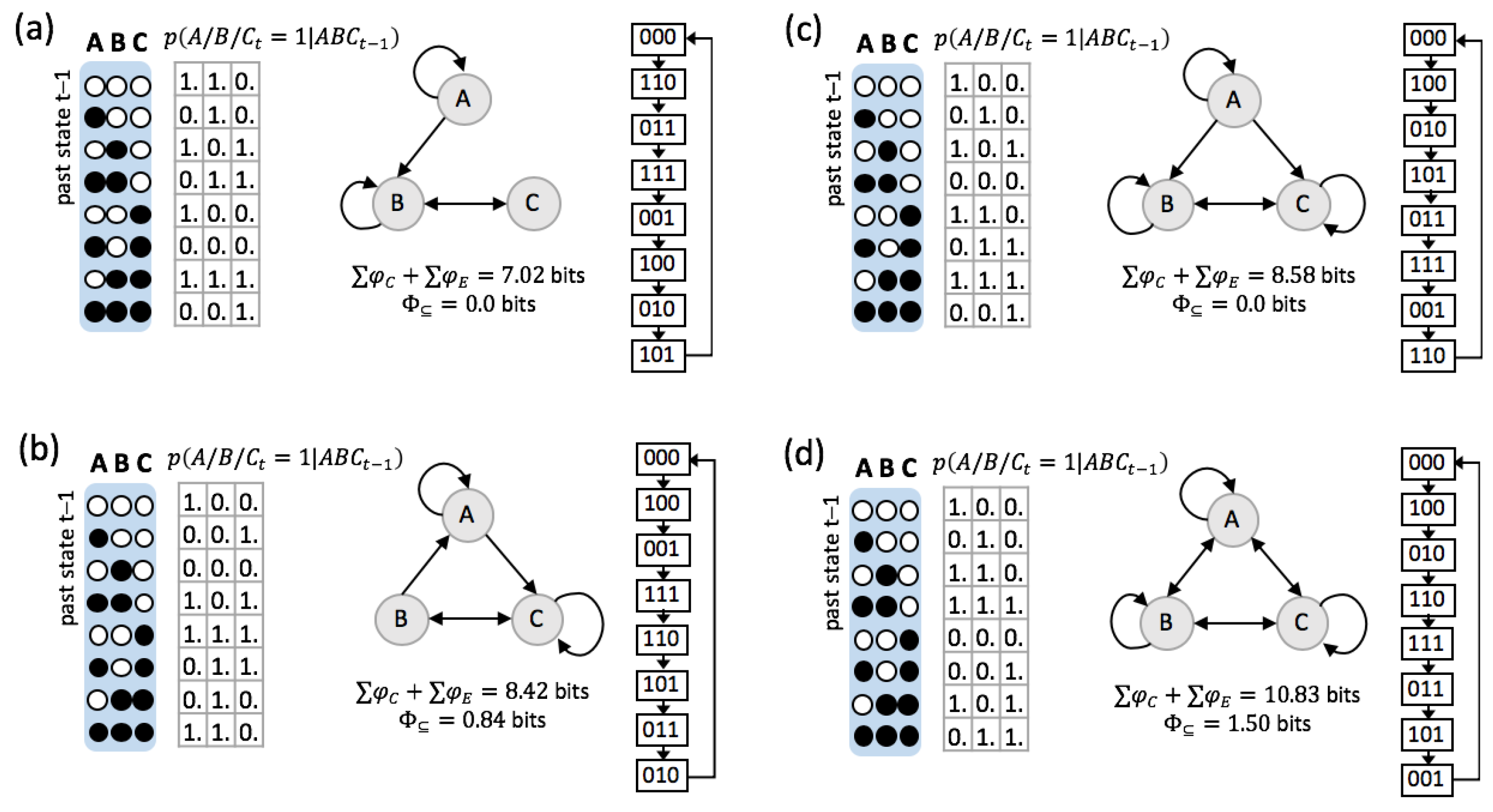
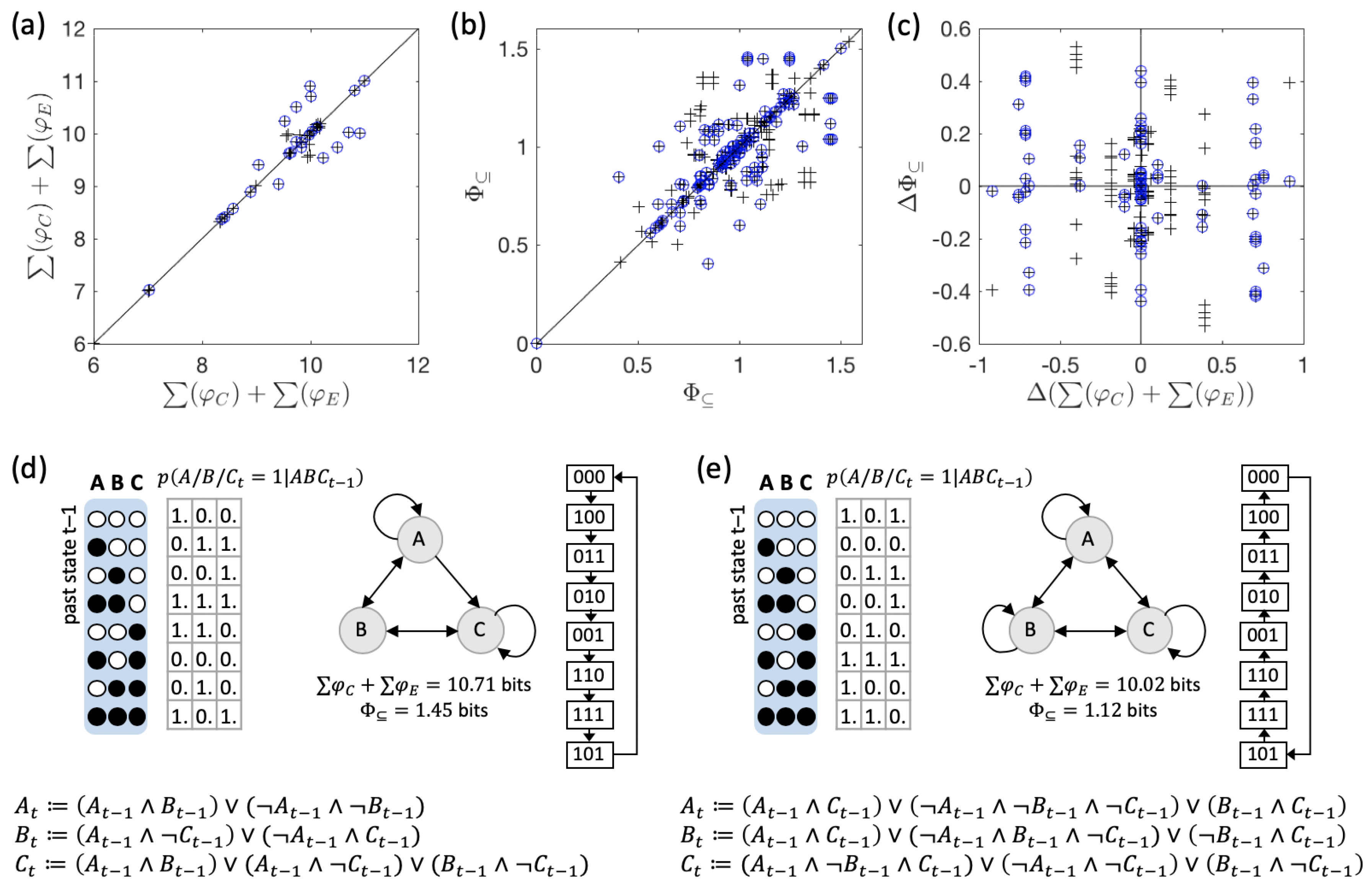
3.1. Same Global Dynamics Different Composition and Integration
3.2. Global vs. Physical Reversibility
4. Discussion
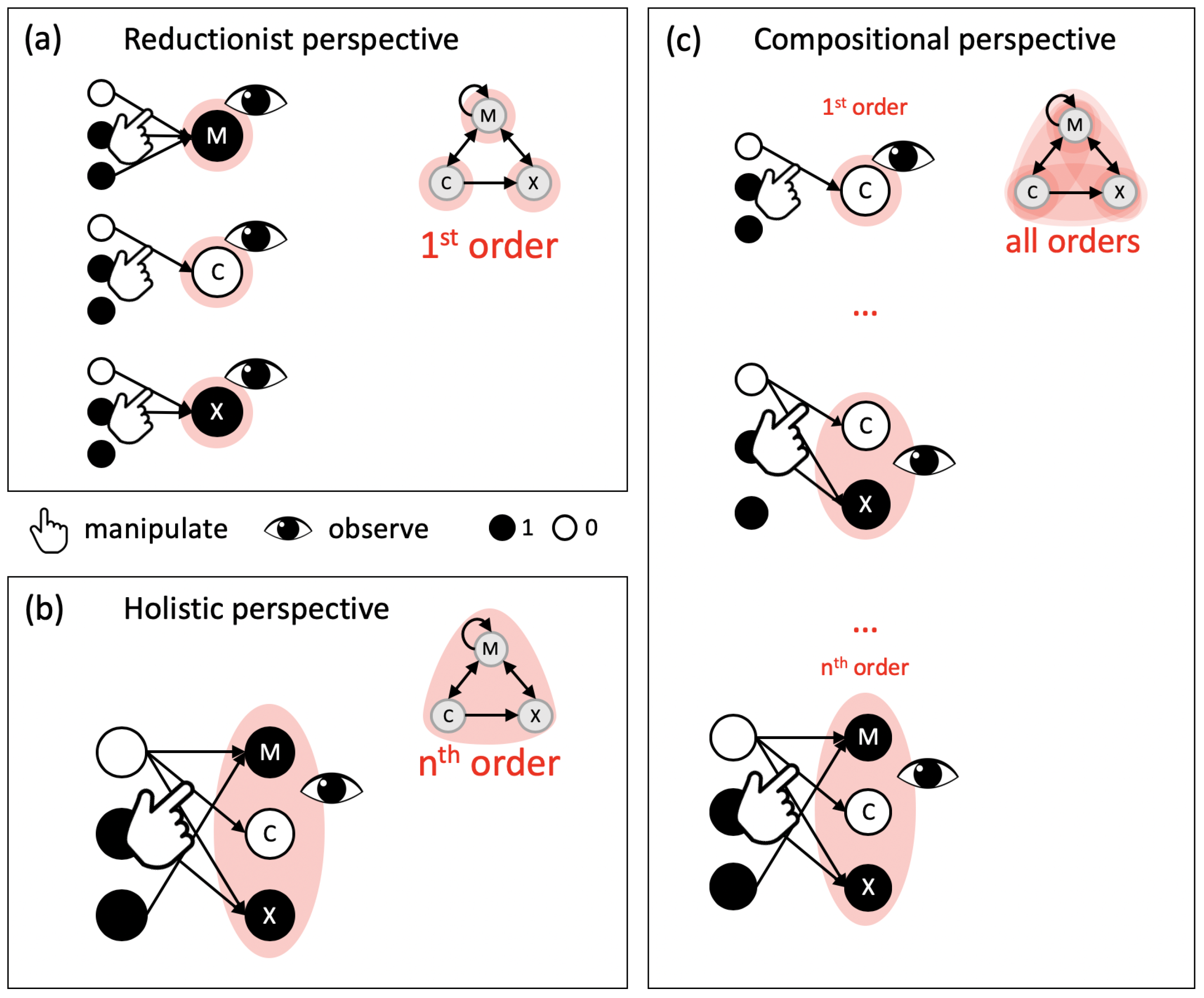
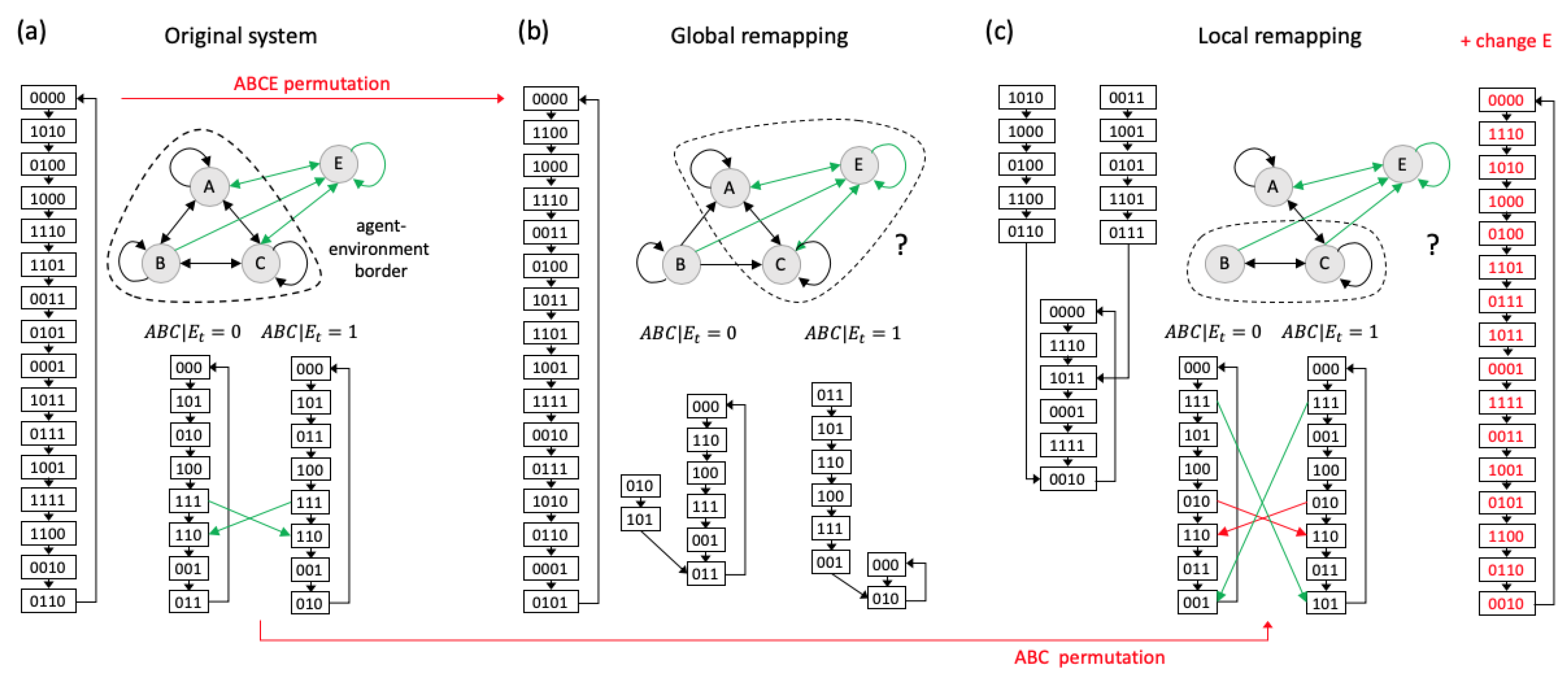
4.1. Composition vs. Decomposition of Information
4.2. Agency and Autonomy
4.3. The Role of Composition in IIT as a Theory of Phenomenal Consciousness
5. Methods
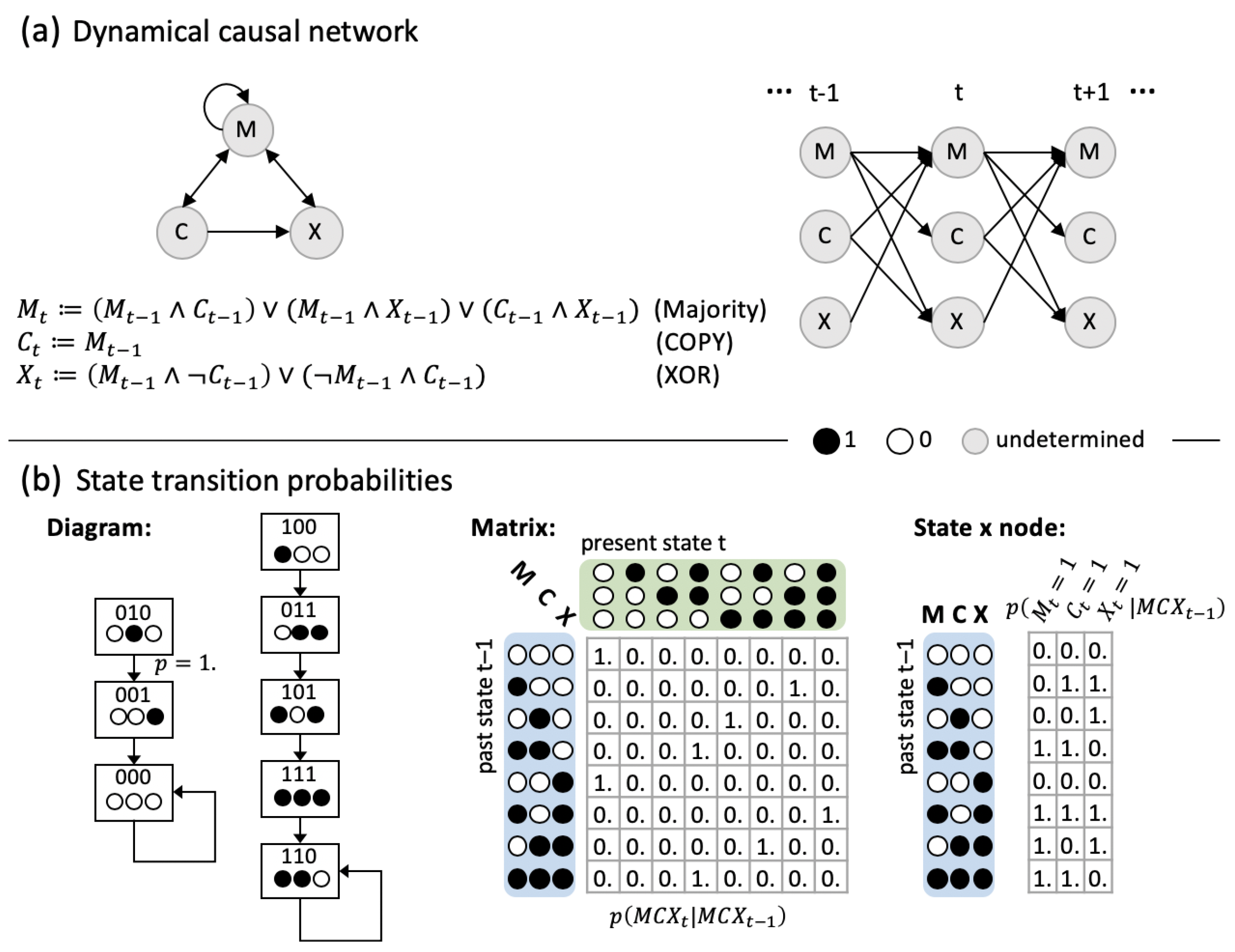
5.1. Dynamical Causal Networks and State Transition Probabilities
5.2. Predictive and Effective Information
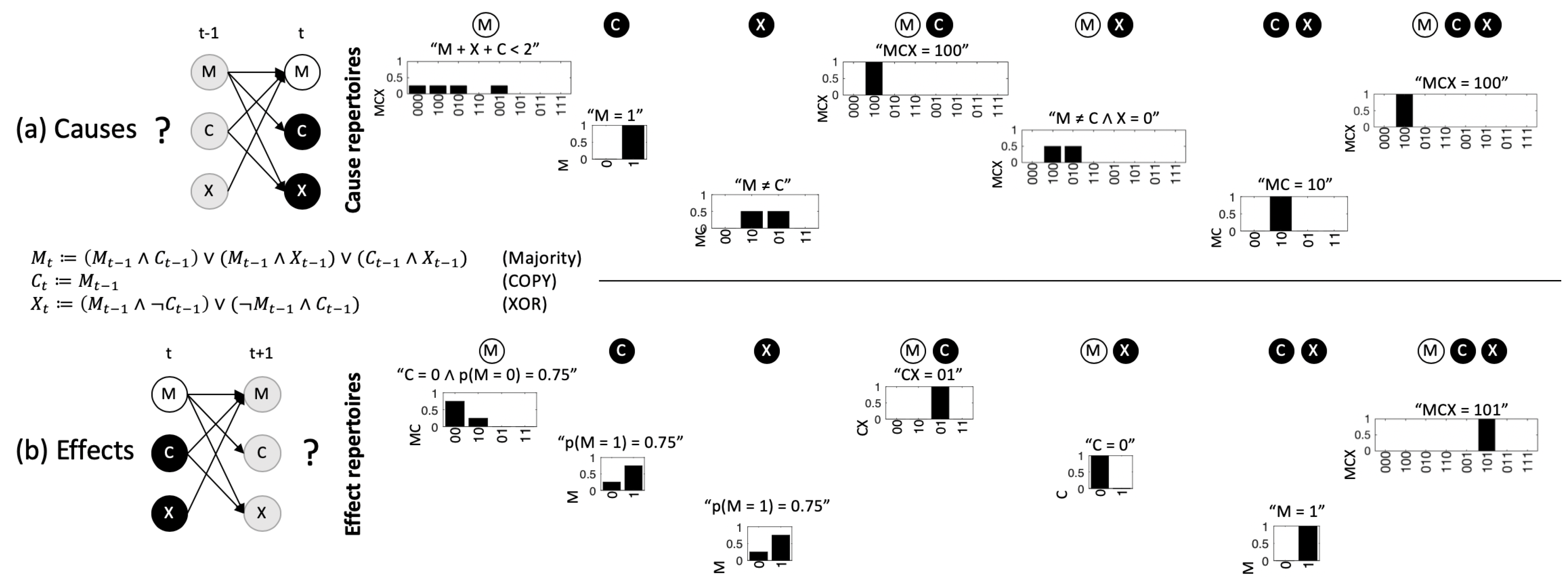
5.3. Cause and Effect Repertoires
5.4. Subset Integration
5.5. System Integration
- We use the KLD to quantify differences between probability distributions in order to facilitate the comparison to standard information-theoretical approaches.
- For simplicity and in line with information-theoretical considerations, and are considered independently instead of only counting for each subset.
- simply evaluates the minimal difference in or under all possible system partitions instead of a more complex difference measure between the intact and partitioned system, such as the extended earth-mover’s distance used in [27].
5.6. Data Sets
- 1.
- , and
- 2.
- .
5.7. Software and Data Analysis
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
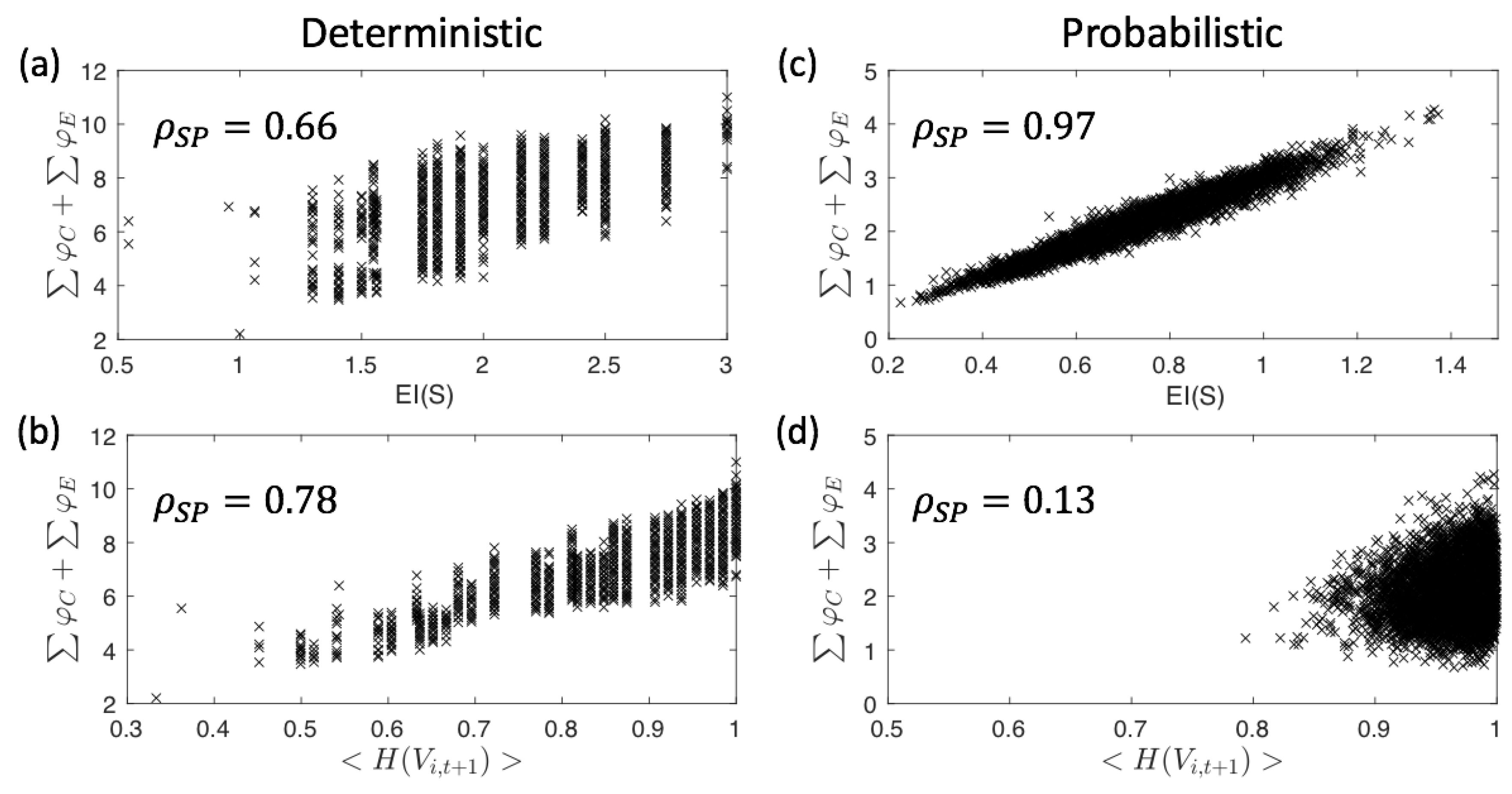
Appendix A. Correlation between EI(S), 〈H(V i,t+1)〉, and ∑φC +∑φE

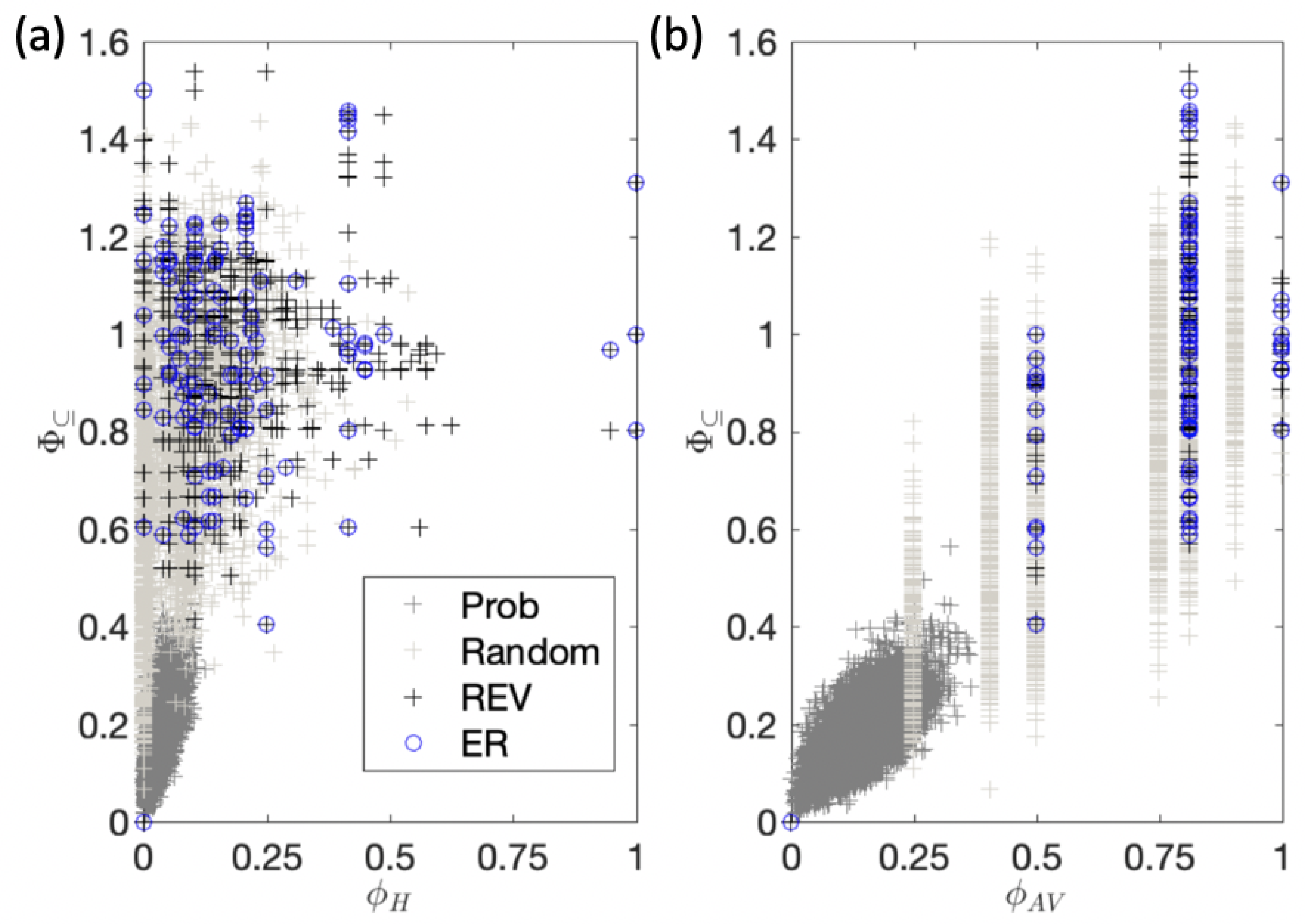
Appendix B. Practical Measures of Integrated Information and Composition

References
- Kubilius, J. Predict, then simplify. NeuroImage 2018, 180, 110–111. [Google Scholar] [CrossRef]
- Hirsch, M.W. The dynamical systems approach to differential equations. Bull. Am. Math. Soc. 1984, 11, 1–65. [Google Scholar] [CrossRef]
- Carlson, T.; Goddard, E.; Kaplan, D.M.; Klein, C.; Ritchie, J.B. Ghosts in machine learning for cognitive neuroscience: Moving from data to theory. NeuroImage 2018, 180, 88–100. [Google Scholar] [CrossRef]
- Kay, K.N. Principles for models of neural information processing. NeuroImage 2018, 180, 101–109. [Google Scholar] [CrossRef]
- Tononi, G.; Sporns, O.; Edelman, G.M. A measure for brain complexity: Relating functional segregation and integration in the nervous system. Proc. Natl. Acad. Sci. USA 1994, 91, 5033–5037. [Google Scholar] [CrossRef]
- Ay, N.; Olbrich, E.; Bertschinger, N.; Jost, J. A geometric approach to complexity. Chaos 2011, 21, 037103. [Google Scholar] [CrossRef]
- Poldrack, R.A.; Farah, M.J. Progress and challenges in probing the human brain. Nature 2015, 526, 371–379. [Google Scholar] [CrossRef]
- Borst, A.; Theunissen, F.E. Information theory and neural coding. Nat. Neurosci. 1999, 2, 947. [Google Scholar] [CrossRef]
- Dayan, P.; Abbott, L.F. Theoretical Neuroscience—Computational and Mathematical Modeling of Neural Systems; MIT Press: Cambridge, MA, USA, 2000; Volume 1, pp. 1689–1699. [Google Scholar] [CrossRef]
- Victor, J.D. Approaches to Information-Theoretic Analysis of Neural Activity. Biol. Theory 2006, 1, 302–316. [Google Scholar] [CrossRef]
- Quian Quiroga, R.; Panzeri, S. Extracting information from neuronal populations: Information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef]
- Timme, N.M.; Lapish, C. A Tutorial for Information Theory in Neuroscience. eNeuro 2018, 5. [Google Scholar] [CrossRef]
- Piasini, E.; Panzeri, S.; Piasini, E.; Panzeri, S. Information Theory in Neuroscience. Entropy 2019, 21, 62. [Google Scholar] [CrossRef]
- Rumelhart, D.; Hinton, G.; Williams, R. Learning Internal Representations by Error Propagation, Parallel Distributed Processing; MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Marstaller, L.; Hintze, A.; Adami, C. The evolution of representation in simple cognitive networks. Neural Comput. 2013, 25, 2079–2107. [Google Scholar] [CrossRef] [PubMed]
- Kriegeskorte, N.; Kievit, R.A. Representational geometry: integrating cognition, computation, and the brain. Trends Cogn. Sci. 2013, 17, 401–412. [Google Scholar] [CrossRef] [PubMed]
- King, J.R.; Dehaene, S. Characterizing the dynamics of mental representations: the temporal generalization method. Trends Cogn. Sci. 2014, 18, 203–210. [Google Scholar] [CrossRef]
- Ritchie, J.B.; Kaplan, D.M.; Klein, C. Decoding the Brain: Neural Representation and the Limits of Multivariate Pattern Analysis in Cognitive Neuroscience. Br. J. Philos. Sci. 2019, 70, 581–607. [Google Scholar] [CrossRef]
- Mitchell, T.M.; Hutchinson, R.; Niculescu, R.S.; Pereira, F.; Wang, X.; Just, M.; Newman, S. Learning to Decode Cognitive States from Brain Images. Mach. Learn. 2004, 57, 145–175. [Google Scholar] [CrossRef]
- Haynes, J.D. Decoding visual consciousness from human brain signals. Trends Cogn. Sci. 2009, 13, 194–202. [Google Scholar] [CrossRef]
- Salti, M.; Monto, S.; Charles, L.; King, J.R.; Parkkonen, L.; Dehaene, S. Distinct cortical codes and temporal dynamics for conscious and unconscious percepts. eLife 2015, 4, e05652. [Google Scholar] [CrossRef]
- Weichwald, S.; Meyer, T.; Özdenizci, O.; Schölkopf, B.; Ball, T.; Grosse-Wentrup, M. Causal interpretation rules for encoding and decoding models in neuroimaging. NeuroImage 2015, 110, 48–59. [Google Scholar] [CrossRef]
- Albantakis, L. A Tale of Two Animats: What Does It Take to Have Goal? Springer: Cham, Switzerland, 2018; pp. 5–15. [Google Scholar] [CrossRef]
- Tononi, G. An information integration theory of consciousness. BMC Neurosci. 2004, 5, 42. [Google Scholar] [CrossRef]
- Tononi, G. Integrated information theory. Scholarpedia 2015, 10, 4164. [Google Scholar] [CrossRef]
- Tononi, G.; Boly, M.; Massimini, M.; Koch, C. Integrated information theory: From consciousness to its physical substrate. Nat. Rev. Neurosci. 2016, 17, 450–461. [Google Scholar] [CrossRef]
- Oizumi, M.; Albantakis, L.; Tononi, G. From the Phenomenology to the Mechanisms of Consciousness: Integrated Information Theory 3.0. PLoS Comput. Biol. 2014, 10, e1003588. [Google Scholar] [CrossRef]
- Lombardi, O.; López, C.; Lombardi, O.; López, C. What Does ‘Information’ Mean in Integrated Information Theory? Entropy 2018, 20, 894. [Google Scholar] [CrossRef]
- Hall, N. Two concepts of causation. In Causation and Counterfactuals; MIT Press: Cambridge, MA, USA, 2004; pp. 225–276. [Google Scholar]
- Halpern, J.Y. Actual Causality; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Albantakis, L.; Marshall, W.; Hoel, E.; Tononi, G. What caused what? A quantitative account of actual causation using dynamical causal networks. Entropy 2019, 21, 459. [Google Scholar] [CrossRef]
- Krakauer, D.; Bertschinger, N.; Olbrich, E.; Ay, N.; Flack, J.C. The Information Theory of Individuality. arXiv 2014, arXiv:1412.2447. [Google Scholar]
- Marshall, W.; Kim, H.; Walker, S.I.; Tononi, G.; Albantakis, L. How causal analysis can reveal autonomy in models of biological systems. Philos. Trans. Ser. A Math. Phys. Eng. Sci. 2017, 375, 20160358. [Google Scholar] [CrossRef]
- Kolchinsky, A.; Wolpert, D.H. Semantic information, autonomous agency and non-equilibrium statistical physics. Interface Focus 2018, 8, 20180041. [Google Scholar] [CrossRef]
- Farnsworth, K.D. How Organisms Gained Causal Independence and How It Might Be Quantified. Biology 2018, 7, 38. [Google Scholar] [CrossRef]
- Tononi, G.; Sporns, O. Measuring information integration. BMC Neurosci. 2003, 4, 1–20. [Google Scholar] [CrossRef]
- Hoel, E.P.; Albantakis, L.; Tononi, G. Quantifying causal emergence shows that macro can beat micro. Proc. Natl. Acad. Sci. USA 2013, 110, 19790–19795. [Google Scholar] [CrossRef]
- Bialek, W.; Nemenman, I.; Tishby, N. Predictability, complexity, and learning. Neural Comput. 2001, 13, 2409–2463. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Nonnegative Decomposition of Multivariate Information. arXiv 2010, arXiv:1004.2515. [Google Scholar]
- Harder, M.; Salge, C.; Polani, D. Bivariate measure of redundant information. Phys. Rev. Stat. Nonlinear Soft Matter Phys. 2013, 87, 012130. [Google Scholar] [CrossRef]
- Bertschinger, N.; Rauh, J.; Olbrich, E.; Jost, J.; Ay, N. Quantifying Unique Information. Entropy 2014, 16, 2161–2183. [Google Scholar] [CrossRef]
- Chicharro, D. Quantifying multivariate redundancy with maximum entropy decompositions of mutual information. arXiv 2017, arXiv:1708.03845. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Ay, N.; Polani, D. Information Flows in Causal Networks. Adv. Complex Syst. 2008, 11, 17–41. [Google Scholar] [CrossRef]
- Kari, J. Reversible Cellular Automata: From Fundamental Classical Results to Recent Developments. New Gener. Comput. 2018, 36, 145–172. [Google Scholar] [CrossRef]
- Esteban, F.J.; Galadí, J.A.; Langa, J.A.; Portillo, J.R.; Soler-Toscano, F. Informational structures: A dynamical system approach for integrated information. PLoS Comput. Biol. 2018, 14, e1006154. [Google Scholar] [CrossRef]
- Kalita, P.; Langa, J.A.; Soler-Toscano, F. Informational Structures and Informational Fields as a Prototype for the Description of Postulates of the Integrated Information Theory. Entropy 2019, 21, 493. [Google Scholar] [CrossRef]
- Hubbard, J.; West, B. Differential Equations: A Dynamical Systems Approach: A Dynamical Systems Approach. Part II: Higher Dimensional Systems; Applications of Mathematics; Springer: New York, NY, USA, 1991. [Google Scholar]
- Griffith, V.; Chong, E.; James, R.; Ellison, C.; Crutchfield, J. Intersection Information Based on Common Randomness. Entropy 2014, 16, 1985–2000. [Google Scholar] [CrossRef]
- Ince, R. Measuring Multivariate Redundant Information with Pointwise Common Change in Surprisal. Entropy 2017, 19, 318. [Google Scholar] [CrossRef]
- Finn, C.; Lizier, J.T. Pointwise Partial Information Decomposition Using the Specificity and Ambiguity Lattices. Entropy 2018, 20, 297. [Google Scholar] [CrossRef]
- Williams, P.L.; Beer, R.D. Generalized Measures of Information Transfer. arXiv 2011, arXiv:1102.1507. [Google Scholar]
- Pearl, J. Causality: Models, Reasoning and Inference; Cambridge University Press: Cambridge, UK, 2000; Volume 29. [Google Scholar]
- Janzing, D.; Balduzzi, D.; Grosse-Wentrup, M.; Schölkopf, B. Quantifying causal influences. Ann. Stat. 2013, 41, 2324–2358. [Google Scholar] [CrossRef]
- Korb, K.B.; Nyberg, E.P.; Hope, L. A new causal power theory. In Causality in the Sciences; Oxford University Press: Oxford, UK, 2011. [Google Scholar] [CrossRef]
- Oizumi, M.; Tsuchiya, N.; Amari, S.I. A unified framework for information integration based on information geometry. Proc. Natl. Acad. Sci. USA 2015, 113, 14817–14822. [Google Scholar] [CrossRef]
- Balduzzi, D.; Tononi, G. Qualia: The geometry of integrated information. PLoS Comput. Biol. 2009, 5, e1000462. [Google Scholar] [CrossRef]
- Balduzzi, D.; Tononi, G. Integrated information in discrete dynamical systems: motivation and theoretical framework. PLoS Comput. Biol. 2008, 4, e1000091. [Google Scholar] [CrossRef]
- Beer, R.D. A dynamical systems perspective on agent-environment interaction. Artif. Intell. 1995, 72, 173–215. [Google Scholar] [CrossRef]
- Maturana, H.R.; Varela, F.J. Autopoiesis and Cognition: The Realization of the Living; Boston Studies in the Philosophy and History of Science; Springer: Dordrecht, The Netherlands, 1980. [Google Scholar]
- Tononi, G. On the Irreducibility of Consciousness and Its Relevance to Free Will; Springer: New York, NY, USA, 2013; pp. 147–176. [Google Scholar] [CrossRef]
- Favela, L.H. Consciousness Is (Probably) still only in the brain, even though cognition is not. Mind Matter 2017, 15, 49–69. [Google Scholar]
- Aguilera, M.; Di Paolo, E. Integrated Information and Autonomy in the Thermodynamic Limit. arXiv 2018, arXiv:1805.00393. [Google Scholar]
- Favela, L. Integrated information theory as a complexity science approach to consciousness. J. Conscious. Stud. 2019, 26, 21–47. [Google Scholar]
- Fekete, T.; van Leeuwen, C.; Edelman, S. System, Subsystem, Hive: Boundary Problems in Computational Theories of Consciousness. Front. Psychol. 2016, 7, 1041. [Google Scholar] [CrossRef] [PubMed]
- Metz, C. How Google’s AI Viewed the Move No Human Could Understand. Available online: https://www.wired.com/2016/03/googles-ai-viewed-move-no-human-understand/ (accessed on 30 May 2018).
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Basic Books: New York, NY, USA, 2018; p. 418. [Google Scholar]
- Albantakis, L.; Hintze, A.; Koch, C.; Adami, C.; Tononi, G. Evolution of Integrated Causal Structures in Animats Exposed to Environments of Increasing Complexity. PLoS Comput. Biol. 2014, 10, e1003966. [Google Scholar] [CrossRef] [PubMed]
- Beer, R.D.; Williams, P.L. Information processing and dynamics in minimally cognitive agents. Cogn. Sci. 2015, 39, 1–38. [Google Scholar] [CrossRef] [PubMed]
- Juel, B.E.; Comolatti, R.; Tononi, G.; Albantakis, L. When is an action caused from within? Quantifying the causal chain leading to actions in simulated agents. arXiv 2019, arXiv:1904.02995. [Google Scholar]
- Haun, A.M.; Tononi, G.; Koch, C.; Tsuchiya, N. Are we underestimating the richness of visual experience? Neurosci. Conscious. 2017, 2017. [Google Scholar] [CrossRef]
- Mayner, W.G.; Marshall, W.; Albantakis, L.; Findlay, G.; Marchman, R.; Tononi, G. PyPhi: A toolbox for integrated information theory. PLoS Comput. Biol. 2018, 14, e1006343. [Google Scholar] [CrossRef]
- Marshall, W.; Gomez-Ramirez, J.; Tononi, G. Integrated Information and State Differentiation. Front. Psychol. 2016, 7, 926. [Google Scholar] [CrossRef]
- Barrett, A.B.; Seth, A.K. Practical measures of integrated information for time-series data. PLoS Comput. Biol. 2011, 7, e1001052. [Google Scholar] [CrossRef] [PubMed]
- Oizumi, M.; Amari, S.i.; Yanagawa, T.; Fujii, N.; Tsuchiya, N. Measuring Integrated Information from the Decoding Perspective. PLoS Comput. Biol. 2016, 12, e1004654. [Google Scholar] [CrossRef] [PubMed]
- Ay, N. Information Geometry on Complexity and Stochastic Interaction. Entropy 2015, 17, 2432–2458. [Google Scholar] [CrossRef]
- Mediano, P.A.M.; Seth, A.K.; Barrett, A.B. Measuring Integrated Information: Comparison of Candidate Measures in Theory and Simulation. Entropy 2018, 21, 17. [Google Scholar] [CrossRef]
- Tegmark, M. Improved Measures of Integrated Information. PLoS Comput. Biol. 2016, 12, e1005123. [Google Scholar] [CrossRef] [PubMed]
- Albantakis, L.; Tononi, G. The Intrinsic Cause-Effect Power of Discrete Dynamical Systems—From Elementary Cellular Automata to Adapting Animats. Entropy 2015, 17, 5472–5502. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset | ||||||||
|---|---|---|---|---|---|---|---|---|
| 1.0 | 1.0 | 1.0 | 1.0 | 0.415 | 1.0 | 0.0 | 5.41 | |
| 1.189 | 0.189 | 0.189 | 1.0 | 0.0 | 0.415 | 0.415 | 3.40 |
| Subset | ||||||||
|---|---|---|---|---|---|---|---|---|
| (a) | (b) | (c) | (d) | (a) | (b) | (c) | (d) | |
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.189 | 1.0 | 0.566 | |
| 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.189 | 0.378 | 0.566 | |
| 1.0 | 1.0 | 1.0 | 1.0 | 0.189 | 1.0 | 0.378 | 0.566 | |
| 0.415 | 0.415 | 1.0 | 1.415 | 0.415 | 0.415 | |||
| 1.0 | 0.415 | 0.83 | 0.415 | 0.415 | ||||
| 0.5 | 0.415 | 0.915 | 0.83 | 0.415 | 0.415 | 0.415 | ||
| 0.415 | 1.0 | 1.0 | 0.415 | 0.83 | ||||
| 3.92 | 4.42 | 5.16 | 6.66 | 3.19 | 3.21 | 3.42 | 3.77 | |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Albantakis, L.; Tononi, G. Causal Composition: Structural Differences among Dynamically Equivalent Systems. Entropy 2019, 21, 989. https://doi.org/10.3390/e21100989
Albantakis L, Tononi G. Causal Composition: Structural Differences among Dynamically Equivalent Systems. Entropy. 2019; 21(10):989. https://doi.org/10.3390/e21100989
Chicago/Turabian StyleAlbantakis, Larissa, and Giulio Tononi. 2019. "Causal Composition: Structural Differences among Dynamically Equivalent Systems" Entropy 21, no. 10: 989. https://doi.org/10.3390/e21100989
APA StyleAlbantakis, L., & Tononi, G. (2019). Causal Composition: Structural Differences among Dynamically Equivalent Systems. Entropy, 21(10), 989. https://doi.org/10.3390/e21100989