1. Introduction
The information bottleneck (IB) principle [
1] extracts relevant information about a target variable
Y from an input variable
X via a
single bottleneck variable
Z. In particular, it constructs a
bottleneck variable
that is a
compressed version of
X but preserves as much
relevant information in
X about
Y as possible. This principle of introducing relevant information under compression finds vast applications in clustering problems [
2], neural network compression [
3], disentanglement learning [
4,
5,
6,
7], and reinforcement learning [
8,
9]. In addition, there have been many variants of the original IB principle, such as multivariate IB [
10], Gaussian IB [
11], meta-Gaussian IB [
12], deterministic IB [
13], and variational IB [
14]. Despite these vast applications and variants of IB, alongside the theoretical analysis of the IB principle in neural networks [
15,
16], the context of stochastic neural networks in which mutual information can be most naturally well-defined [
17] has not been sufficiently studied from the IB insight. In this work, we are particularly interested in this context in which multiple stochastic variables are constructed for representation in the form of a Markov chain.
Stochastic neural networks (SNNs) are a general class of neural networks with stochastic neurons in the computation graph. There has been an active line of research in SNNs, including restricted Boltzmann machines (RBMs) [
18], deep belief networks (DBNs) [
19], sigmoid belief networks (SBNs) [
20], and stochastic feed-forward neural networks (SFFNs) [
21]. One of the advantages of SNNs is that they can induce rich multi-modal distributions in the output space [
20] and enable exploration in reinforcement learning [
22]. For learning SNNs (and deep neural networks in general), the maximum likelihood estimate (MLE) principle (in its various forms, such as maximum log-likelihood or Kullback–Leibler divergence) has generally been a de-facto standard. The MLE principle maximizes the likelihood of the model for observing the entire training data. However, this principle is generic and not specially tailored to the hierarchical structure of neural networks. Particularly, MLE treats the entire neural network as a whole without considering the explicit contribution of its hidden layers to model learning. As a result, the information contained within the hidden structure may not be adequately modified to capture the data regularities reflecting a target variable. Thus, it is reasonable to ask if the MLE principle effectively and sufficiently exploits a neural network’s representative power, and whether there is a better alternative.
Contributions. In this paper, (i) we propose Markov information bottleneck (MIB), a variant of the IB principle for multiple Markov bottlenecks that directly offers an alternative learning principle for SNNs. In MIB, there are multiple bottleneck variables (as opposed to one single bottleneck variable in the original IB) that form a Markov chain. These multiple Markov bottlenecks sequentially extract relevant information for a learning task. From the perspective of MIB, each layer of an SNN is a bottleneck whose information is encoded from the data via the network parameters connecting the layer to the data layer. (ii) We show that in a non-collapse MIB, the information optimality is not simultaneously achievable for all bottlenecks; thus, an optimality compromise is devised. (iii) When applied to SNNs for a learning task, we interpret the inference from a hidden layer to the output layer in SNNs as a variational approximation to that layer’s intractable decoding of relevant information. Consequently, the variational MIB in SNNs generalizes the MLE principle. We demonstrate via a simple analytical argument and synthetic experiment that MLE is unable to learn a good information representation, while the variational MIB can. (iv) We then empirically show that MIB improves the performance in classification, adversarial robust learning, and multi-modal learning in the standard hand-digit recognition data MNIST [
23]. This work is an extended version of our preprint [
24] and the first author’s Master thesis [
25].
2. Related Work
There have been many extensions of the original IB framework [
1]. One natural consideration is to extend it to continuous variables, yet under special settings where the optimal information representation is analytic [
11,
12]. Another direction uses alternative measures for compression and/or relevance in IB [
13]. Since the optimal information representation in IB is tractable only in limited settings such as discrete variables [
1], Gaussian variables [
11], and meta-Gaussian variables [
12], scaling the IB solution using neural networks and variational inference is a very successful extension [
14]. The closest extension to our MIB is multivariate IB [
10], in which they define multi-information to capture the dependence among the elements of a multivariate variable. However, in MIB, we do not focus on capturing such multi-information but rather the optimal information sequentially processed by a Markov chain of (possibly multivariate) bottleneck variables.
The line of work applying the IB principle to learn information representation in neural networks is also relevant to our approach. For example, Reference [
15] proposes the use of the mutual information of a hidden layer with the input layer and the output layer to quantify the performance of neural networks. However, it is not clear as to how the IB information optimality changes in multiple bottlenecks in a neural network and how we can approximate the IB solutions in this high-dimensional context. In addition, MLE is a standard learning principle for neural networks. It has been shown that the IB principle is mathematically equivalent to the MLE principle in the multinomial mixture model for the clustering problem when the input distribution
X is uniform or has a large sample size [
26]. However, it is also not clear how these two principles are related to each other in the context of neural networks. Moreover, regarding the feasibility of the IB principle for representation learning in neural networks, Reference [
17] analyzes two critical issues of mutual information that representation learning might suffer from: indefinite in deterministic encoding, and invariant under bijective transformations. These are inherent properties of mutual information which are also studied in, for example, [
7,
27,
28]. In MIB, we share with [
17] the same insight in these caveats by considering only the scenario where mutual information is well defined. This also explains our rationale in applying MIB to stochastic neural networks.
Deep learning compression schemes [
3,
29] loosely bear some similarity with our work. Both of the directions aim for a more compressed and useful neural networks for given tasks. The critical distinction is that deep learning compression schemes attempt to produce a smaller-sized neural network with similar performance of a larger one so that the network can be efficiently deployed in small devices such as mobile phones. This task therefore involves size-reduction techniques such as neural network pruning, low-rank factorization, transferred convolution filters and knowledge distillation [
29]. On the other hand, our work asks an important representation learning question that given a neural network, what learning principles are the best we can do to improve the information content learned from the data for a given task? In this work, we attempt to address this question via the perspective that a neural network is a set of stochastic variables that sequentially encode information into its layers. We then explicitly improve the information flow (in the sense of more compressed but relevant information) for each layer via our introduced Markov Information Bottleneck framework.
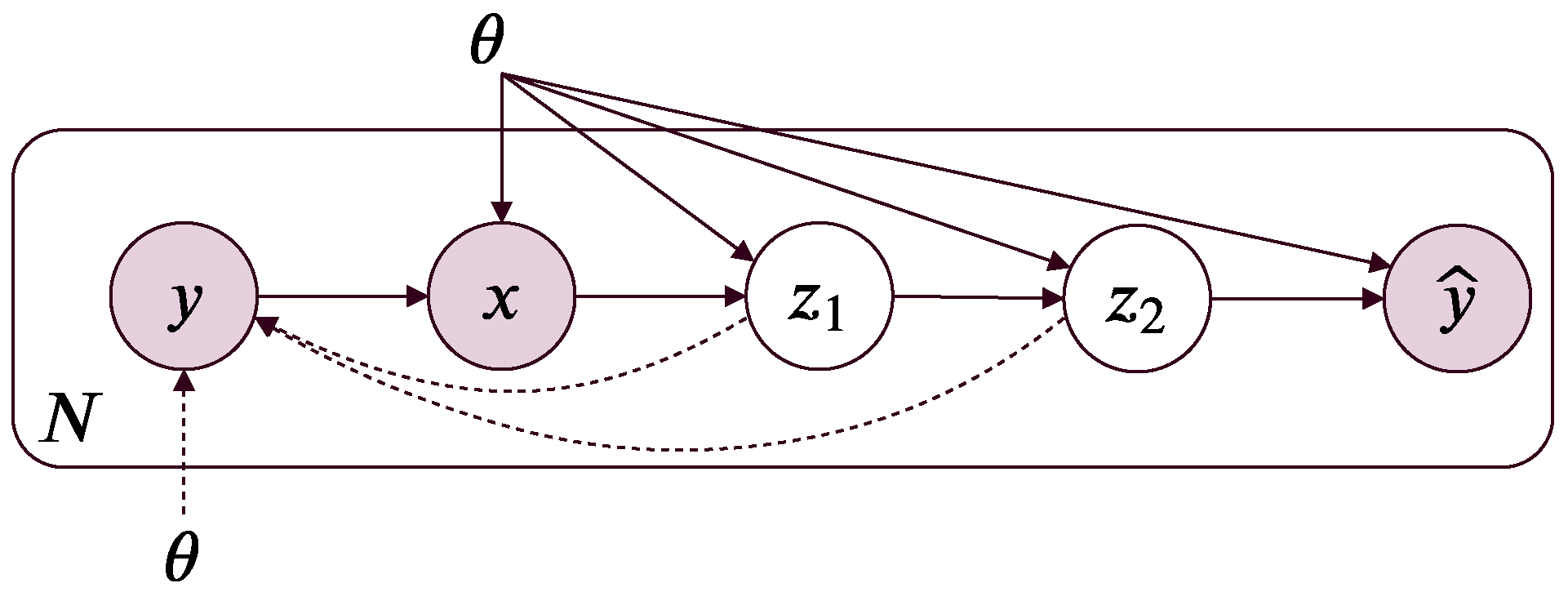
4. Markov Information Bottleneck
Given a data joint distribution
which is possibly only observed via a set of i.i.d. samples
, an information representation
Z for
is said to be good if it encodes sufficient relevant information in
X about
Y in a compressed manner. Ideally,
Z summarizes only the relevant information in
X about
Y and discards all the irrelevant information; more formally,
Z is a minimal sufficient statistic for
Y. Such information representation is desirable because it can capture the regularities in the data and is helpful for generalization in learning problems [
30,
31]. Our main interest is in solving the optimal information representation for a latent variable
Z that has Markov structure, that is,
, where
. The Markov structure is common in deep neural networks whose advantage is the powerful modeling capacity coming from multiple layers. In MIB, each encoder
relates the encoders of the previous bottlenecks in the Markov chain via Bayes’ rule:
where
and
. In addition, each
encoder corresponds to a unique decoder, namely
relevance decoder, that decodes the relevant information in
x about
y from representation
:
In MIB, we further introduce a surrogate target variable
(for the target variable
Y) into the Markov chain:
(
Figure 1). The purpose of the surrogate target variable becomes clear in the section on variational MIB.
A trivial solution to the optimal information representation problem for
Z is to apply the original IB principle for
Z as a whole by computing the optimal IB solution in Equation (
1). However, this solution ignores the Markov structure of
Z. As a principled approach, leveraging the intrinsic structure of a problem can generally provide a new insight that goes beyond the limitation of the perspective that ignores such structure. Thus, in Markov information bottleneck (MIB), we explicitly leverage the Markov structure of
Z to derive a principled and tractable approximate solution to the optimal information representation. We then empirically show that leveraging the intrinsic structure in the case of MIB is indeed beneficial for learning.
In MIB, we reframe the optimal information representation problem as multiple IB problems for each of the bottlenecks
:
for all
.
This extension is a natural approach for multiple bottlenecks because it aims for each bottleneck to achieve its own optimal information, and thus allows more relevant but compressed information to be encoded into
Z. Another advantage is that we can leverage our understanding of the IB solution for each individual IB problem in Equation (
4). Though this approach is promising and has good interpretation, there are two main challenges:
In what follows, we formally establish and present the first challenge, the conflicting property of information optimality in Markov structure, in Theorem 1 followed by a simple compromise to overcome the information conflict. After that, we present variational MIB to address the second challenge.
Without loss of generality, we consider the case when (the result trivially generalizes to ). We first define the collapse mode of the representation Z to be the two extreme cases in which either contains all the information in about X or simply random noise:
Definition 1 (The
collapse mode of MIB).
is said to be in the collapse mode if it satisfies either of the following two conditions:
- (1)
is a sufficient statistic of for X and Y (i.e., );
- (2)
is independent of .
For example, if
where
f is a deterministic bijection,
is a sufficient statistic for
X. We then establish the conflicting property of information optimality in the Markov representation
Z via the following theorem:
Theorem 1 (
Conflicting Markov Information Optimality).
Given and such that and , consider two constrained minimization problems:where , , and . Then, the following two statements are equivalent: Theorem 1 suggests that the Markov information optimality conflicts for most cases of interest (e.g., stochastic neural networks, which we will present in detail in the next section). The values of
and
are important to control the ratio of the relevant information versus the irrelevant one presented in the bottlenecks. These values also determine the conflictability of multiple bottlenecks on the edge cases. Recall by the data processing inequality (DPI) [
27] that for
, we have
and
. If
and
go to infinity, the optimal bottlenecks
and
are both deterministic functions of
X and they do not conflict. When
, the information about
Y in
X is maximally compressed in
and
(i.e.,
), and they do not conflict. The optimal solutions conflict when
and
, as the former leads to a maximally compressed
while the latter prefers an informative
(this contradicts the Markov structure
, which indicates that maximal compression in
leads to maximal compression in
).
We can also easily construct non-conflicting MIBs for
that violate the condition. For example, if
X and
Y are jointly Gaussian, the optimal bottlenecks
and
are linear transforms of
X and jointly Gaussian with
X and
Y [
11]. In this case,
is a sufficient statistic of
for
X. In the case of neural networks, we can also construct a simple but non-trivial neural network that can obtain a non-conflicting Markov information optimality. For example, consider a neural network of two hidden layers
and
, where
is arbitrarily mapped from the input layer
X but
is a sample mean of
n samples i.i.d. drawn from the normal distribution
. This construction guarantees that
is a sufficient statistic of
for
X, and thus there is non-conflicting Markov information optimality.
Theorem 1 is a direct result of DPI if
. In the case that
, we trace down to the Lagrangian multiplier as in the original IB [
1] to complete the proof. Formally, before proving Theorem 1, we first establish the two following lemmas. The first lemma expresses the uncertainty reduction in a Markov chain.
Lemma 1. Given , we have Proof. It follows from [
27] that
, but
since

, hence Equation (
6). The proof for Equation (7) is similar by replacing variable
X with variable
Y. (Q.E.D.) □
Lemma 2. Given and , let us define the conditional information bottleneck objective:If Z is not in the collapse mode, depends on . Proof. Informally, if
in the conditional information bottleneck objective
is not a trivial transform of the bottleneck variable
,
induces a non-trivial topology into the conditional information bottleneck objective. Formally, by the definition of the conditional mutual information
depends on
as long as the presence of
in the conditional information bottleneck objective does not vanish (we will discuss the conditions for
to vanish in the final part of this proof). Note that due to the Markov chain
, we have
.
Thus, depends on as long as does not vanish in the objective. Similarly, the same result also applies to . Hence, depends on (note that prevents the collapse of when summing two mutual informations) if does not vanish in the objective.
Now we discuss the vanishing condition for
in the objective. It follows from Lemma 1 that:
Note that
vanishes in
iff each of the mutual informations in
does not depend on
iff the equality in both (
9) and (10) occur. If
, we have
(i.e.,
is a sufficient statistic for
X and
Y), which also implies that
. Similarly,
implies that
is independent of
, which in turn implies that
. (Q.E.D.) □
We now prove Theorem (1) by using Lemma (
6) and Lemma (7).
Proof of Theorem 1. (⇐) This direction is obvious. When
and
, or
and
, there is effectively only one optimization problem for
, and this reduces into the original information bottleneck (with single bottleneck) [
1].
First we prove that if
Z is not in the collapse mode, the constrained minimization problems are conflicting. Assume, by contradiction, that there exists a solution that minimizes both
and
simultaneously, that is,
s.t.
has a minimum at
and
has a minimum at
. Note that
and
are independent variables for the optimization. By introducing Lagrangian multipliers
and
for the constraint
of
and
, respectively, the stationarity in the Karush–Kuhn–Tucker (KKT) conditions becomes:
where
and
are the Lagrangians:
It follows from Lemma 1 that:
where
(defined in Lemma 2). We take the derivative w.r.t.
both sides of Equation (
15) and use Equations (
11) and (12):
Notice that the left hand side of Equation (
16) strictly depends on
(Lemma 2) while the right hand side is independent of
. This contradiction implies that the initial existence assumption is invalid, and thus implies the conclusion in Theorem 1. (Q.E.D.) □
4.1. Markov Information Optimality Compromise
Due to Theorem 1, we cannot simultaneously achieve the information optimality for all bottlenecks. Thus, we need some compromised approach to instead obtain a compromised optimality. We propose two simple compromise strategies, namely, JointMIB and GreedyMIB. JointMIB is a weighted sum of the IB objectives where . The main idea of JointMIB is to simultaneously optimize all encoders. Even though each bottleneck might not achieve its individual optimality, their joint optimality encourages a joint compromise. On the other hand, GreedyMIB progressively solves the information optimality for each bottleneck given that the encoders for the previous bottlenecks are fixed. In other words, GreedyMIB tries to obtain the conditional optimality of a current bottleneck which is conditioned on the fixed greedy-optimal information of the previous bottlenecks.
4.2. Variational Markov Information Bottleneck
Due to the intractability of encoders in Equation (
2) and relevance decoders in Equation (
3), the resulting mutual information in Equation (
4) is also intractable. In this section, we present variational methods to derive a lower bound on mutual information in MIB.
4.2.1. Approximate Relevance
Note that
, where
, which can be ignored in the minimization of
. It follows from the non-negativity of KL divergence that:
where we specifically use the relevance decoder for surrogate target variable
as a variational distribution to the intractable distribution
:
The variational relevance is a lower bound on . This bound is tightest (i.e., zero gap) when the variational relevance decoder equals the relevance decoder . In what follows, we establish the relationship between the variational relevance and the log likelihood function, thus connecting MIB with the MLE principle:
Proposition 1 (Variational Relevance Inequalities).
Given the definition of variational relevance where is defined in Equation (17), and , we have:for all . where . Proposition 1 suggests that: (i) the log likelihood of (plus the constant output entropy ) is a special case of the variational relevance at bottleneck ; (ii) the log likelihood bound is an upper bound on the variational relevance for all the intermediate bottlenecks and for the composite bottleneck . Therefore, maximizing the log likelihood, as in MLE, does not guarantee to increase the variational relevance for all the the intermediate bottlenecks and the composite bottleneck.
Proof. It follows from Jensen’s inequality and the Markov chain that:
for all
. Thus, we have:
It also follows from the Markov chain that:
Finally, by the definition in Equation (
17), we have:
(Q.E.D.) □
4.2.2. Approximate Compression
In practice (e.g., in SNN presented in the next section), we can model the encoding between consecutive layers
with an analytical form. However, the encoding of non-consecutive layers
for
is generally not analytic as it is a mixture of
. We thus propose to avoid directly estimating
by instead resorting to its upper bound
as its surrogate in the optimization. However,
is still intractable as it involves the intractable marginal distribution
. We then approximate
using a mean-field (factorized) variational distribution
where
:
The mean-field variational inference not only helps derive a tractable approximation but also encourages distributed representation by constraining each neuron to capture an independent factor of variation for the data [
32]; thus, it can potentially represent an exponential number of concepts using independent factors.
5. Case Study: Learning Binary Stochastic Neural Networks
In this section, we officially connect the variational MIB in
Section 4 to stochastic neural networks (SNNs). We consider an SNN with
L hidden layers (without any feedback or skip connection) where the input layer
X, the hidden layers
for
, and the output layer
are considered as random variables. We use the convention that
and
for all
. Without any feedback or skip connection,
and
form a Markov chain in that order. The output layer
is the surrogate target variable presented in
Section 4. The role of SNNs is therefore reduced to transforming from one random variable to another via the Markov chain
such that it achieves the good information representation (i.e., the compression–relevance tradeoff) for each layer. With the MLE principle, the learning in SNNs is performed by maximizing the log likelihood
. However, maximizing the log likelihood does not guarantee to improve the variational relevance for all the intermediate bottlenecks and the composite bottleneck (Proposition 1).
| Algorithm 1:JointMIB |
 |
We here instead combine the variational MIB and the MIB compromise to derive a practical learning principle that encourages compression and relevance for each layer, improving the information flow in SNNs. To make it concrete and simple, we consider a simple network architecture: binary stochastic feed-forward (fully-connected) neural networks (SFNNs). In binary SFNNs, we use a sigmoid as the activation function:
, where
is the (element-wise) sigmoid function,
is the network weights connecting layer
to layer
l,
is a bias vector, and
. Let us define
, where
and
are the approximate relevance and compression defined in Equation (
17) and (
20), respectively. Note that the position of
here is slightly different from its position in Equation (
4). In Equation (
4),
is associated with the relevance term to respect the convention of the original IB, while here it is associated with the compression term for practical reasons. In practice, the contribution of
is higher than
. In computing
and
, any expectation with respect to
is approximated by Monte Carlo simulation in which we sample
M particles
. Regarding the information optimality compromise, we combine the variational MIB objectives into a weighted sum in
JointMIB:
where
. In
GreedyMIB, we greedily minimize
for each
. We also make each
a learnable Bernoulli distribution. The
JointMIB is presented in Algorithm 1. The Monte Carlo sampling operation of Algorithm 1 in stochastic neural networks precludes the backpropagation in a computation graph. It becomes even more challenging with binary stochastic neural networks, as it is not well-defined to compute gradients w.r.t. discrete-valued variables. Fortunately, we can find approximate gradients, which have been proved to be efficient in practice: the REINFORCE estimator [
33,
34], the straight-through estimator [
35], the generalized EM algorithm [
20], and the Raiko (biased) estimator [
21]. Especially, we found that the Raiko gradient estimator works best in our specific setting and thus deployed it in this application. In the Raiko estimator, the gradient of a bottleneck particle
is propagated only through the deterministic term
:
7. Discussion and Future Work
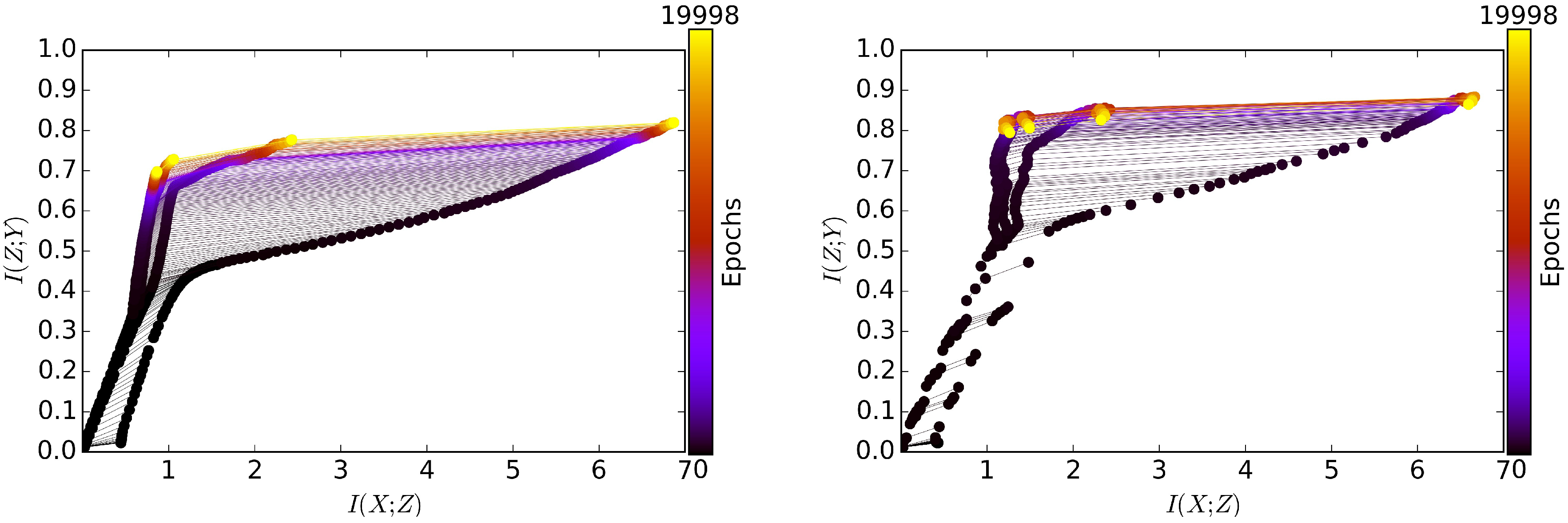
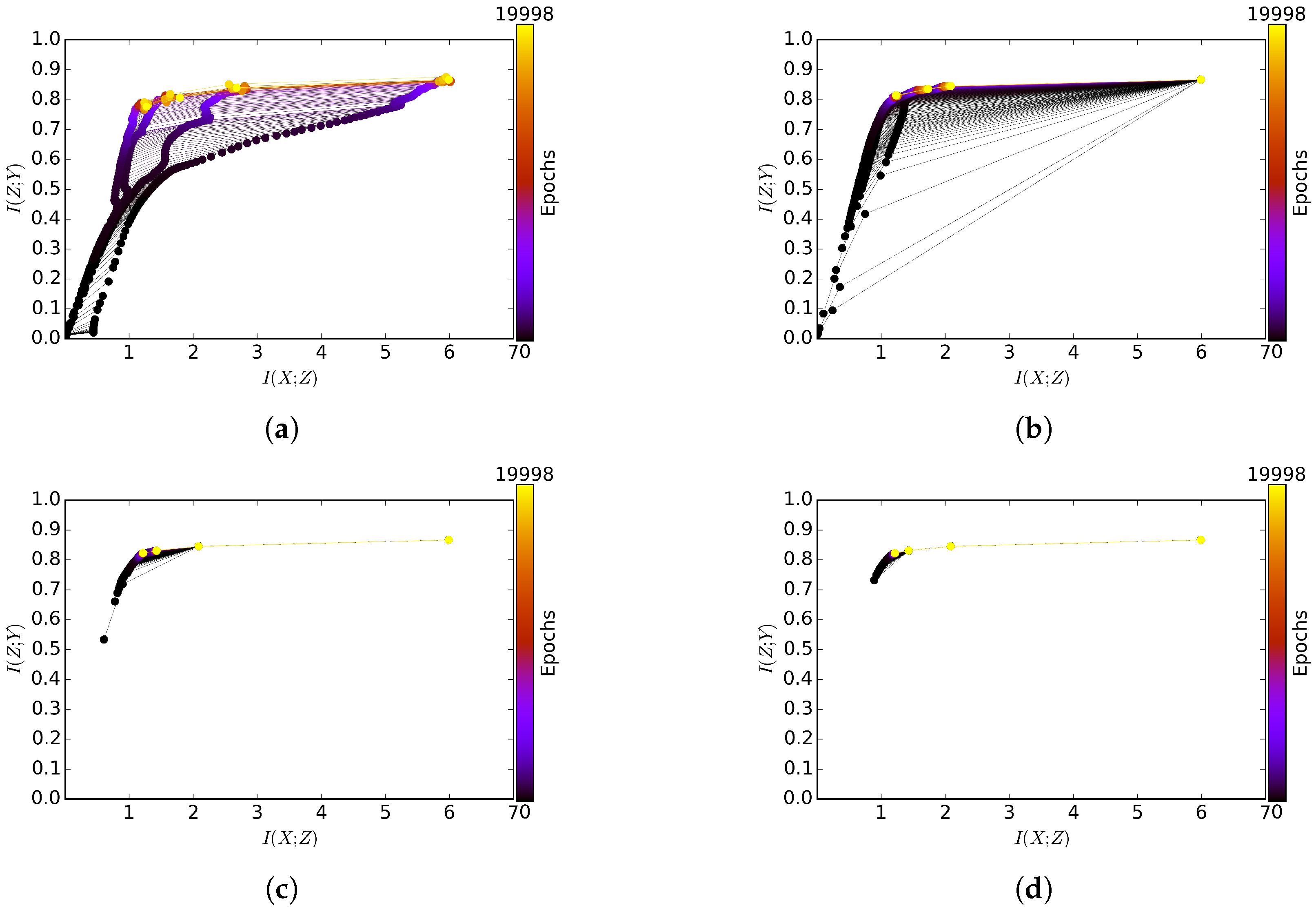
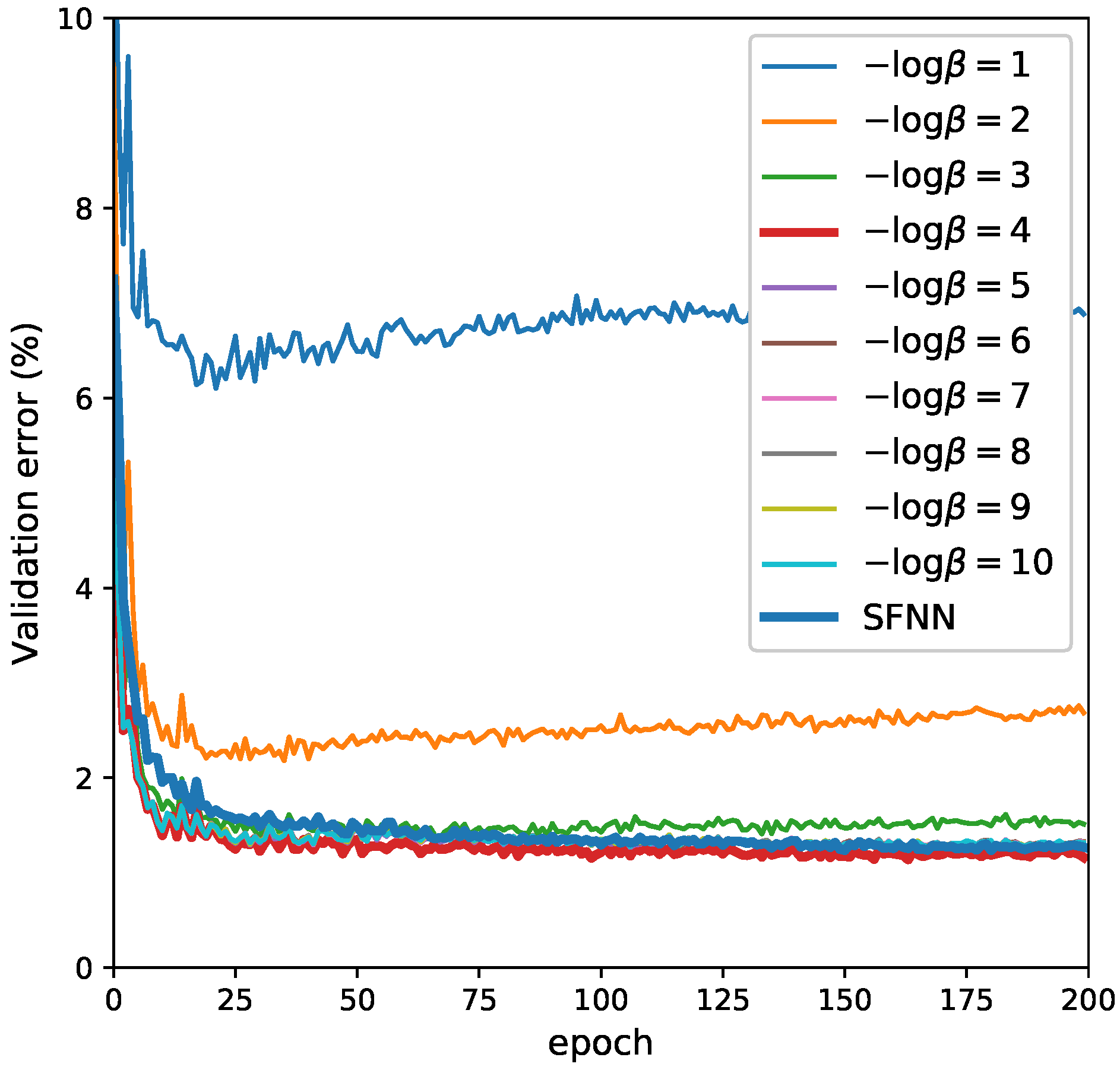
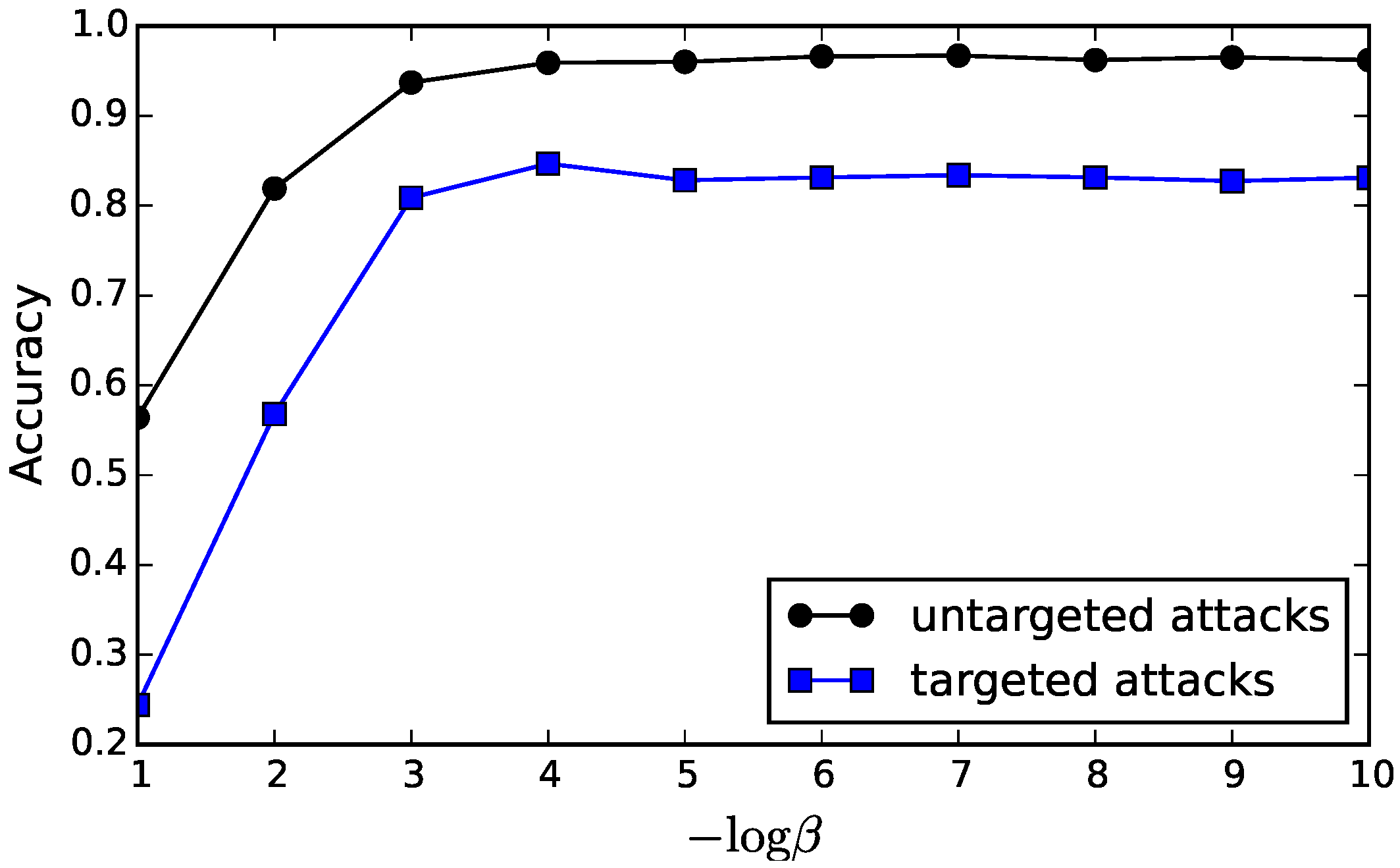
In this work, we introduce Markov Information Bottleneck, an extension of the original Information Bottleneck to the context where a representation is multiple stochastic variables that form a Markov chain. In this context, we show that one cannot simply directly apply the original IB principle to each variable as their information optimality is conflicting for most of the interesting cases. We suggest a simple but efficient fix via a joint compromise. In this scheme, we jointly combine the information trade-offs of each variable into a weighted sum, encouraging the information trade-offs for all the variables better off during the learning. In particular in the context of Stochastic Neural Networks, we present the variational inference to estimate the compression and relevance for each bottleneck. As a result, the variational MIB turns the intractable decoding of each bottleneck approximately into an efficient inference for that bottleneck. This variational approximation turns out to generalize the MLE principle in the context of Stochastic Neural Networks. We empirically demonstrate the effectiveness of MIB by comparing it with the baselines using MLE principle and Variational Information Bottleneck in classification, adversarial robustness and multi-modal learning. The empirical performance supports the potential benefit of explicitly inducing compression and relevance into each layer (e.g., in a jointly manner), presenting a special link between information representation and the performance in classification, adversarial robustness and multi-modal learning.
One limitation of our current approach is the number of samples generated via
used to estimate the variational compression and relevance scales exponentially with the number of layers. This is however a common drawback for performing inference in fully stochastic neural networks. This difficulty can be overcome by using partially stochastic neural networks. In addition, the Monte Carlo sampling to estimate the variational mutual information, though unbiased, is of high variance and sample inefficiency. This sample inefficiency limitation can be overcome by resorting to more advanced methods of estimating mutual information such as [
41,
42]. The MIB framework also admits several possible future extensions including scaling the framework to bigger networks and real-valued stochastic neural networks. The extension to real-valued stochastic neural networks are straightforward by, e.g., constructing a Gaussian layer for modeling
and using reparameterization tricks [
43] to perform back-propagation via sampling. Another dimension of improvement is to study hyperparameter effect of MIB. This current work only considers equal
for
JointMIB and equal
, and tuned
via grid search. We can use, e.g., Bayesian optimization [
44] to efficiently tune
and
with expandable bounds. In addition, we believe that the challenge of applying our methods to more advanced datasets such as Imagenet [
45] is partly associated with that of scaling the stochastic neural network as we tend to need more expressive models for more challenging datasets. Given this perspective, the challenge to scale to large datasets can be partially addressed with the solutions from scaling stochastic neural networks some of which we suggest above. Furthermore, we believe that, as one of the main messages from our work, explicitly inducing compressed and relevant information (e.g., via mutual information as in MIB) into many intermediate layers can be more beneficial to large-scale tasks than simply resorting to the MLE principle. An intuition is to think of this as a way for
information-theoretic regularization for intermediate layers. Finally, a followup important question to ask is whether there is any theoretical and stronger empirical link between an improved information representation (e.g., in the MIB sense) and the generalization of neural networks. This connection might be intuitively correct but a systematically empirical study or a theoretical suggestion are an important future research direction.


 ) to indicate that X and Y are independent (respectively, not independent). We denote a Markov chain by , that is, Y and Z are conditionally independent given X, or . We use the integral notation when taking expectation (e.g., ) over the distribution of a random variable regardless of whether the variable is discrete or continuous. We also adopt the following conventions from [27] for defining entropy (denoted by H), mutual information (denoted by I), and Kullback–Leibler (KL) divergence (denoted by ): .
) to indicate that X and Y are independent (respectively, not independent). We denote a Markov chain by , that is, Y and Z are conditionally independent given X, or . We use the integral notation when taking expectation (e.g., ) over the distribution of a random variable regardless of whether the variable is discrete or continuous. We also adopt the following conventions from [27] for defining entropy (denoted by H), mutual information (denoted by I), and Kullback–Leibler (KL) divergence (denoted by ): .









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}