Information Theoretic Causal Effect Quantification


Abstract
1. Introduction
1.1. Overview of Relevant Frameworks of Causality Modelling
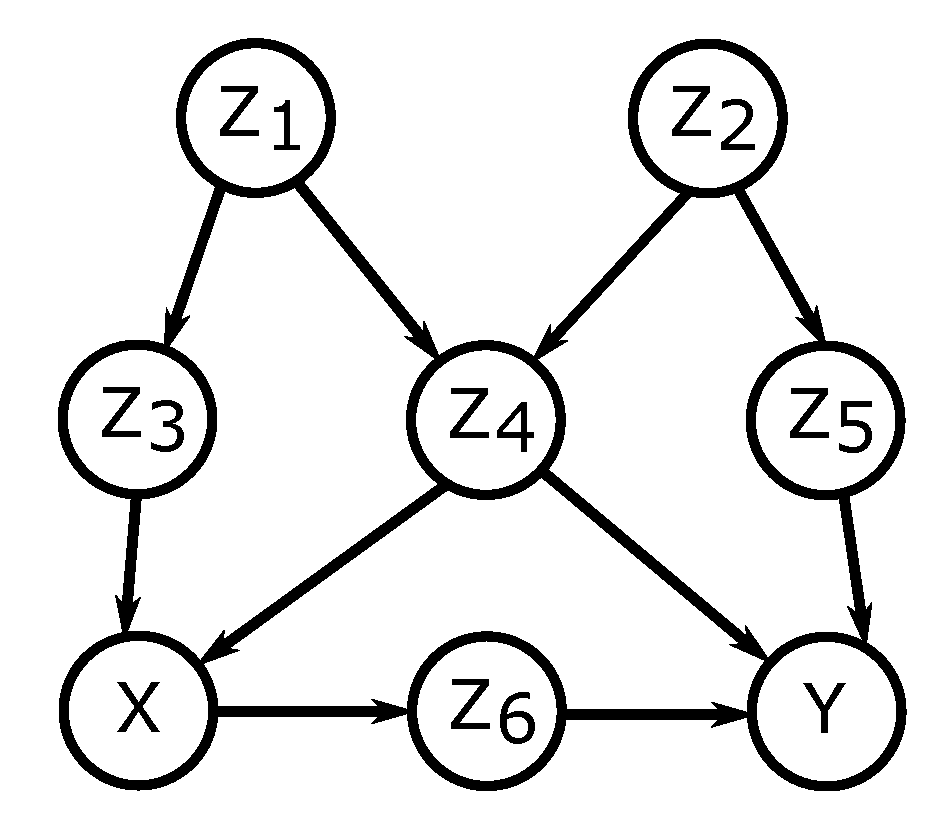
- First, a set of variables confounding the cause and effect variables is found. Confounding of variables X and Y by Z is a notion that formalises the idea of Z causally influencing (directly or not) both X and Y thus impeding the computation of the direct causal influence of X on Y. In a Pearlian graph, a set of confounders Z can be identified with rules of the causal calculus or with graphical criteria called the back-door criterion and front-door criterion. In the Neyman-Rubin potential outcome framework, a cognate criterion for a set Z is called strong ignorability and Z is frequently referred to as a set of sufficient covariates.
- After a set of confounders, or sufficient covariates, Z has been identified, the effect of X on Y is quantified. If such a Z exists, this can be done with only observational data. In the Pearlian setting, this amounts to the computation of the interventional distribution of Y given the intervention on X, which can be shown to be equal to conditioning on or adjusting for Z in the observational distribution of . In the Neyman-Rubin potential outcome framework, the effect of X on Y is frequently measured with the average causal effect of X on Y, that is, the difference between expectations for the two potential outcomes. Even though exactly one potential outcome is observed, one can estimate the distribution of the missing one with observational data if one conditions on Z.
1.2. Causality Modelling and Information Theory
1.3. Related Work on Directed Information and Its History
1.4. Related Work on Graphical Models for Causality
1.5. Paper Contributions
- we formulate a two step procedure for causal deduction in two most widely known frameworks of causality modelling and show that the proposed information theoretic causal effect quantification is equivalent to it,
- we relate to various definitions of directed information and unify them within our approach,
- we clear some of the confusion persistent in previous attempts to information theoretic causality modelling.
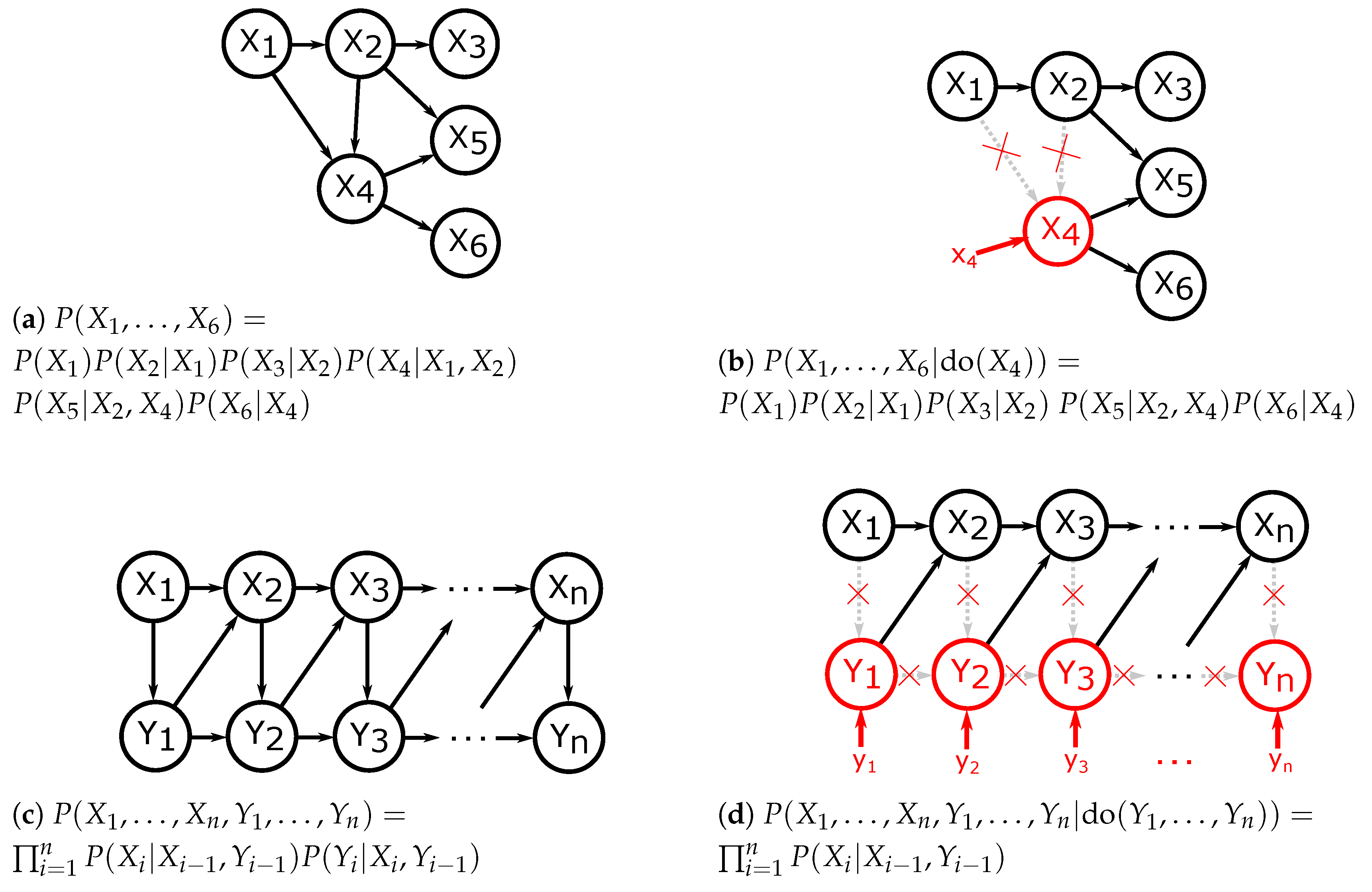
2. Proposed Method for Causal Effect Identification
- S.1
- Make sure that the variables are not confounded or find a set of variables confounding them.
- S.2
- Use the set found in S.1 (if it exists) to quantify the causal effect.
2.1. Notation and Model Set-Up
2.1.1. Controlling Confounding Bias
- no node in Z is a descendant of X and,
- Z blocks (d-separates) all paths between X and Y that contain an arrow into X.
2.1.2. Quantifying Causal Effects
2.1.3. Information Theory and Directed Information
2.2. Causal Deduction with Information Theory
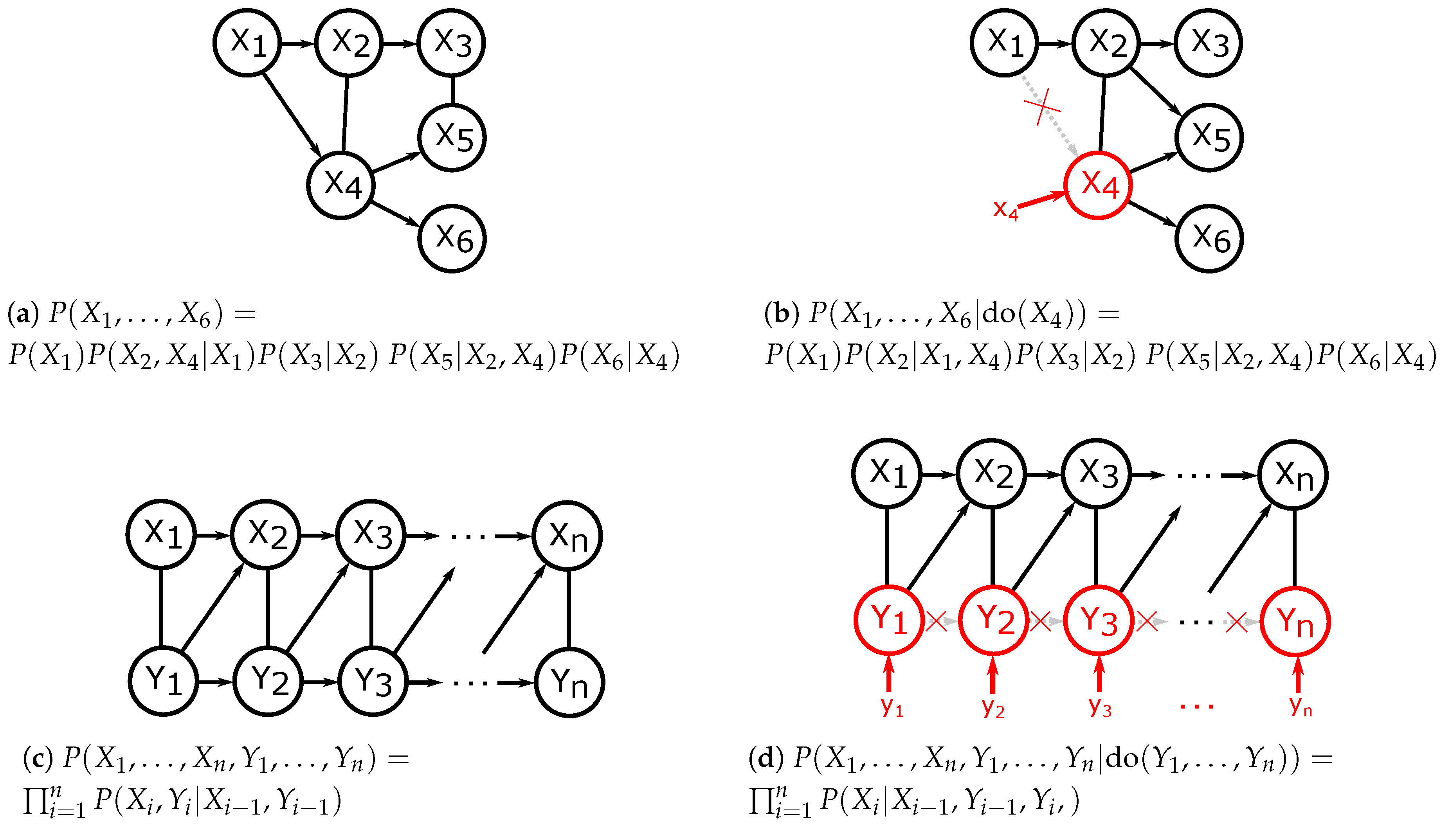
2.2.1. Controlling Confounding Bias with (Conditional) Directed Information
2.2.2. Quantifying the Causal Effect with (Conditional) Mutual Information
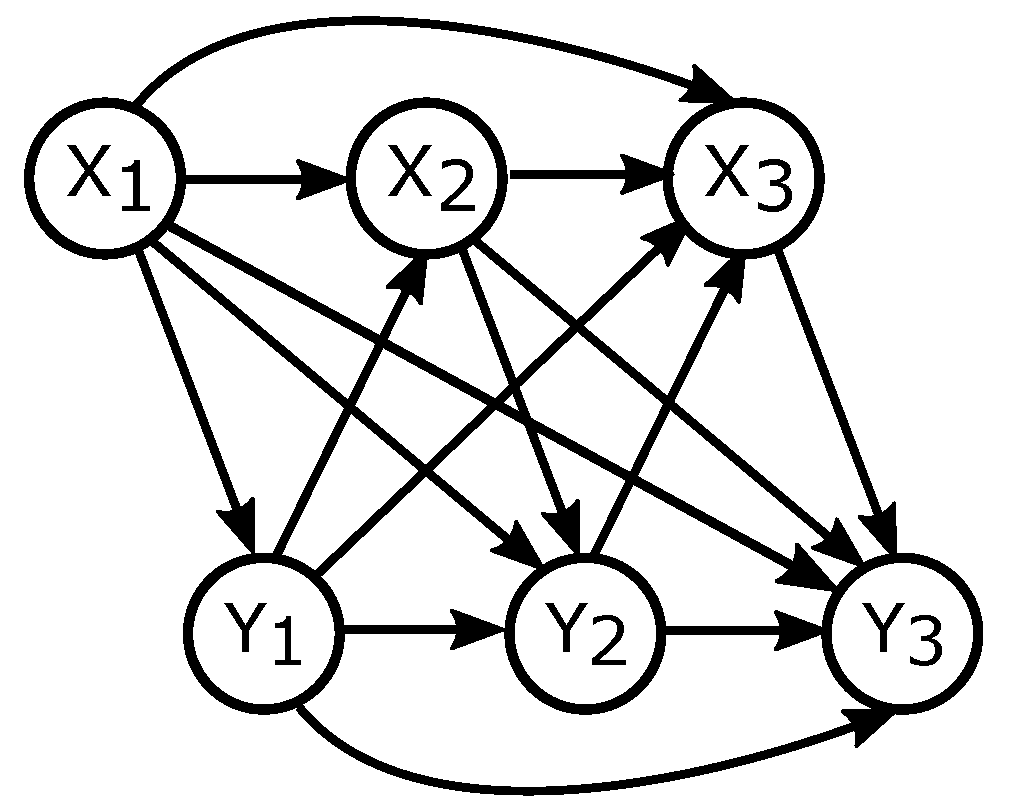
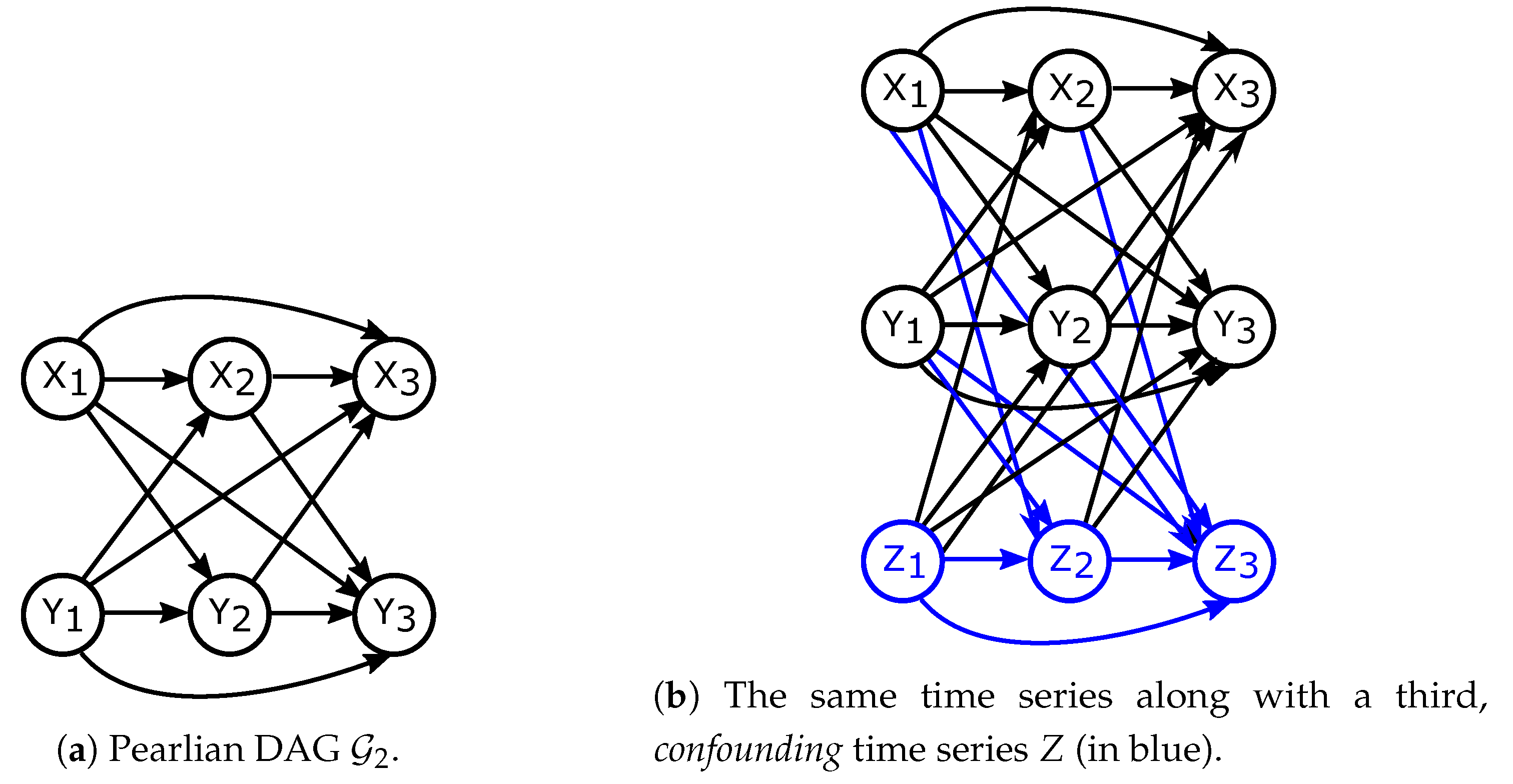
3. Unification of Existing Approaches for Time Series
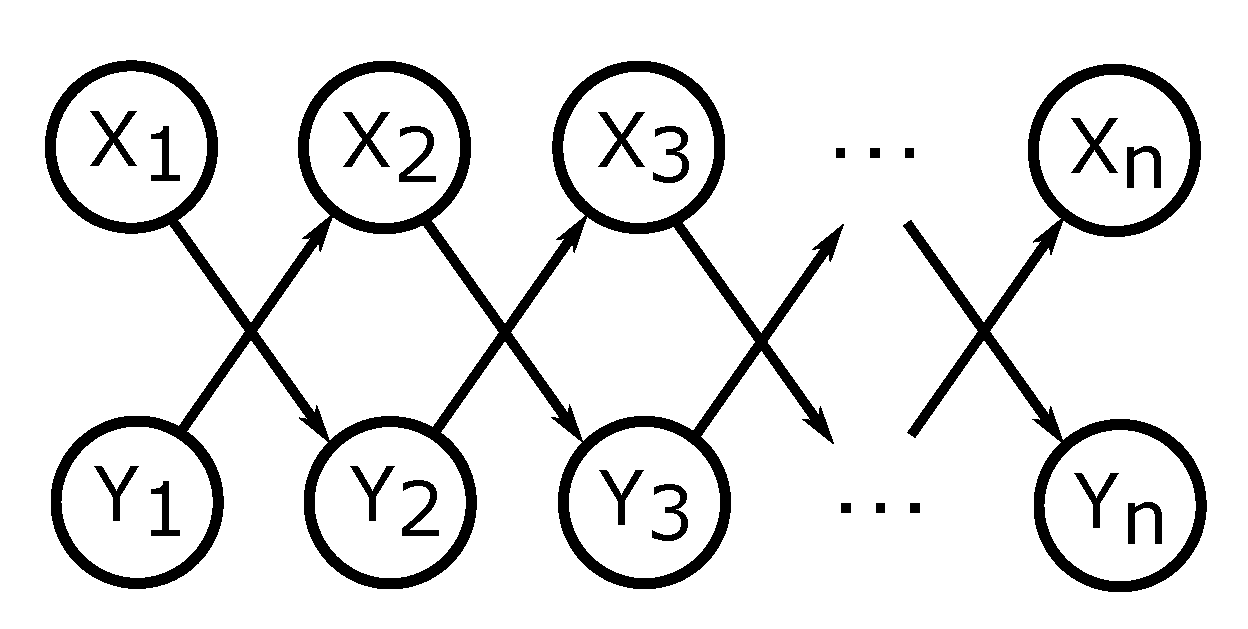
3.1. Directed Information for Time Series Represented with DAGs.
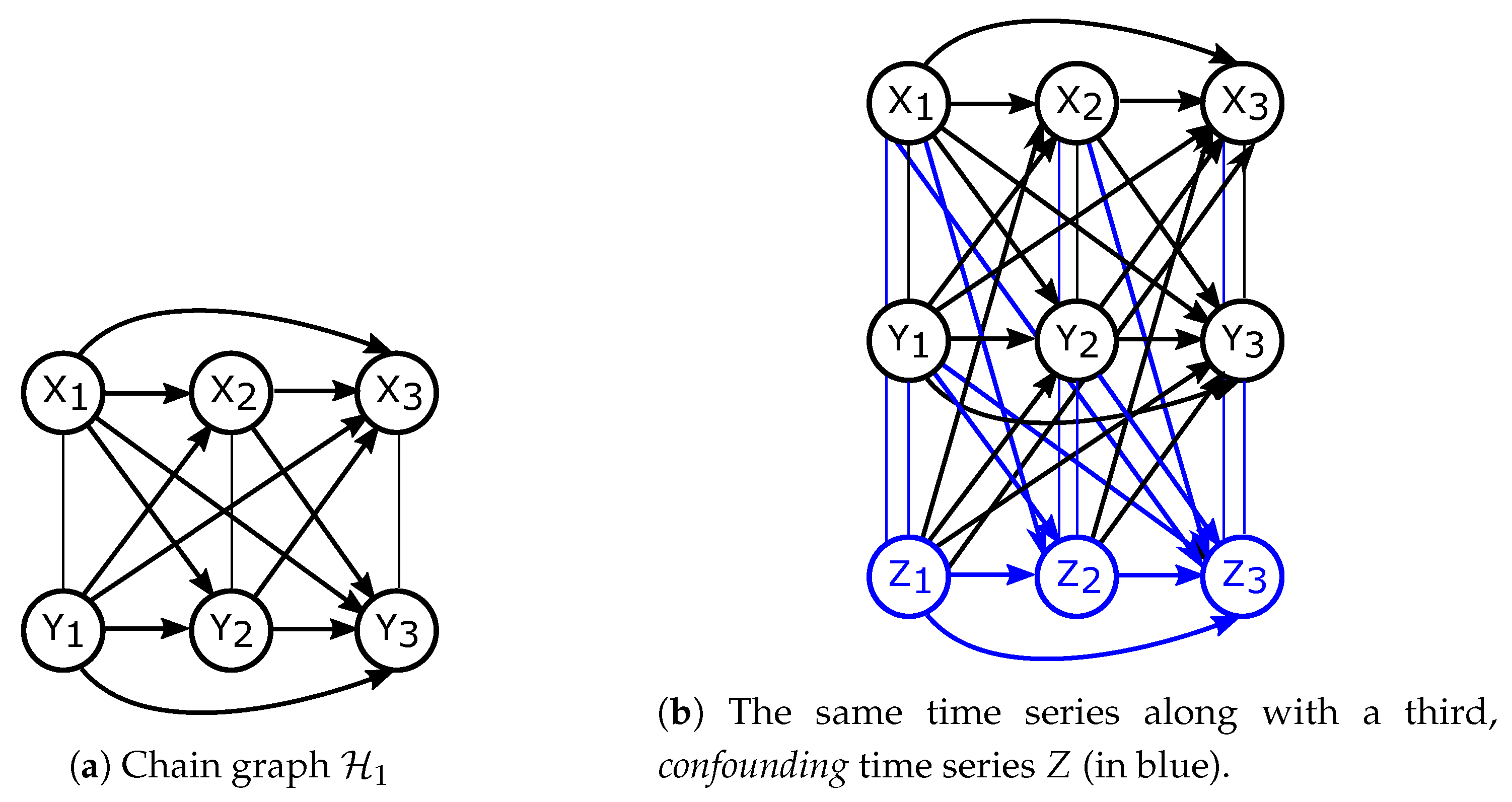
3.2. Factorisations and Interventions in Chain Graphs
3.3. Directed Information for Chain Graphs Representing Aligned Time Series
4. Relation to Critique of Previous Information Theoretic Approaches
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Proofs
References
- Clarke, B. Causality in Medicine with Particular Reference to the Viral Causation of Cancers. Ph.D. Thesis, University College London, London, UK, January 2011. [Google Scholar]
- Rasmussen, S.A.; Jamieson, D.J.; Honein, M.A.; Petersen, L.R. Zika virus and birth defects—Reviewing the evidence for causality. N. Engl. J. Med. 2016, 374, 1981–1987. [Google Scholar] [CrossRef] [PubMed]
- Samarasinghe, S.; McGraw, M.; Barnes, E.; Ebert-Uphoff, I. A study of links between the Arctic and the midlatitude jet stream using Granger and Pearl causality. Environmetrics 2019, 30, e2540. [Google Scholar] [CrossRef]
- Dourado, J.R.; Júnior, J.N.d.O.; Maciel, C.D. Parallelism Strategies for Big Data Delayed Transfer Entropy Evaluation. Algorithms 2019, 12, 190. [Google Scholar] [CrossRef]
- Peia, O.; Roszbach, K. Finance and growth: Time series evidence on causality. J. Financ. Stabil. 2015, 19, 105–118. [Google Scholar] [CrossRef]
- Soytas, U.; Sari, R. Energy consumption and GDP: Causality relationship in G-7 countries and emerging markets. Energy Econ. 2003, 25, 33–37. [Google Scholar] [CrossRef]
- Dippel, C.; Gold, R.; Heblich, S.; Pinto, R. Instrumental Variables and Causal Mechanisms: Unpacking the Effect of Trade on Workers and Voters. Technical Report. National Bureau of Economic Research, 2017. Available online: https://www.nber.org/papers/w23209 (accessed on 2 October 2019).
- Rojas-Carulla, M.; Schölkopf, B.; Turner, R.; Peters, J. Invariant models for causal transfer learning. J. Mach. Learn. Res. 2018, 19, 1309–1342. [Google Scholar]
- Spirtes, P.; Glymour, C.N.; Scheines, R.; Heckerman, D.; Meek, C.; Cooper, G.; Richardson, T. Causation, Prediction, and Search; MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Verma, T.; Pearl, J. Equivalence and Synthesis of Causal Models. In Proceedings of the Sixth Annual Conference on Uncertainty in Artificial Intelligence, Cambridge, MA, USA, 27–29 July 1990; Elsevier Science Inc.: New York, NY, USA, 1991; pp. 255–270. [Google Scholar]
- Massey, J.L. Causality, feedback and directed information. In Proceedings of the International Symposium on Information Theory and Its Applications, Waikiki, HI, USA, 27–30 November 1990. [Google Scholar]
- Eichler, M. Graphical modelling of multivariate time series. Probab. Theory Relat. Fields 2012, 153, 233–268. [Google Scholar] [CrossRef]
- Quinn, C.J.; Kiyavash, N.; Coleman, T.P. Directed information graphs. IEEE Trans. Inf. Theory 2015, 61, 6887–6909. [Google Scholar] [CrossRef]
- Tatikonda, S.; Mitter, S. The capacity of channels with feedback. IEEE Trans. Inf. Theory 2009, 55, 323–349. [Google Scholar] [CrossRef]
- Raginsky, M. Directed information and Pearl’s causal calculus. In Proceedings of the 49th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 28–30 Septemper 2011; pp. 958–965. [Google Scholar]
- Marko, H. The Bidirectional Communication Theory-A Generalization of Information Theory. IEEE Trans. Commun. 1973, 21, 1345–1351. [Google Scholar] [CrossRef]
- Granger, C. Economic processes involving feedback. Inf. Control 1963, 6, 28–48. [Google Scholar] [CrossRef]
- Granger, C. Testing for causality: A personal viewpoint. J. Econ. Dyn. Control 1980, 2, 329–352. [Google Scholar] [CrossRef]
- Kramer, G. Directed Information for Channels with Feedback. Ph.D. Thesis, ETH Zurich, Zürich, Switzerland, 1998. [Google Scholar]
- Amblard, P.O.; Michel, O.J.J. The Relation between Granger Causality and Directed Information Theory: A Review. Entropy 2013, 15, 113–143. [Google Scholar] [CrossRef]
- Amblard, P.O.; Michel, O. Causal Conditioning and Instantaneous Coupling in Causality Graphs. Inf. Sci. 2014, 264, 279–290. [Google Scholar] [CrossRef]
- Quinn, C.J.; Coleman, T.P.; Kiyavash, N. Causal dependence tree approximations of joint distributions for multiple random processes. arXiv 2011, arXiv:1101.5108. [Google Scholar]
- Quinn, C.J.; Kiyavash, N.; Coleman, T.P. Efficient methods to compute optimal tree approximations of directed information graphs. IEEE Trans. Signal Process. 2013, 61, 3173–3182. [Google Scholar] [CrossRef]
- Weissman, T.; Kim, Y.; Permuter, H.H. Directed Information, Causal Estimation, and Communication in Continuous Time. IEEE Trans. Inf. Theory 2013, 59, 1271–1287. [Google Scholar] [CrossRef]
- Pearl, J. Causality; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Eichler, M. Causal inference with multiple time series: principles and problems. Philos. Trans. R. Soc. A 2013, 371, 20110613. [Google Scholar] [CrossRef]
- Jafari-Mamaghani, M.; Tyrcha, J. Transfer entropy expressions for a class of non-Gaussian distributions. Entropy 2014, 16, 1743–1755. [Google Scholar] [CrossRef]
- Ay, N.; Polani, D. Information flows in causal networks. Adv. Complex Syst. 2008, 11, 17–41. [Google Scholar] [CrossRef]
- Peters, J.; Janzing, D.; Schölkopf, B. Elements of Causal Inference: Foundations and Learning Algorithms; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- James, R.G.; Barnett, N.; Crutchfield, J.P. Information flows? A critique of transfer entropies. Phys. Rev. Lett. 2016, 116, 238701. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Sharma, M.; Rhinehart, N.; Kitani, K.M. Directed-Info GAIL: Learning Hierarchical Policies from Unsegmented Demonstrations using Directed Information. arXiv 2018, arXiv:1810.01266. [Google Scholar]
- Tanaka, T.; Skoglund, M.; Sandberg, H.; Johansson, K.H. Directed information and privacy loss in cloud-based control. In Proceedings of the 2017 American Control Conference (ACC), Seattle, WA, USA, 24–26 May 2017; pp. 1666–1672. [Google Scholar]
- Tanaka, T.; Esfahani, P.M.; Mitter, S.K. LQG control with minimum directed information: Semidefinite programming approach. IEEE Trans. Autom. Control 2018, 63, 37–52. [Google Scholar] [CrossRef]
- Etesami, J.; Kiyavash, N.; Coleman, T. Learning Minimal Latent Directed Information Polytrees. Neural Comput. 2016, 28, 1723–1768. [Google Scholar] [CrossRef]
- Zhou, Y.; Spanos, C.J. Causal meets Submodular: Subset Selection with Directed Information. In Advances in Neural Information Processing Systems 29; Lee, D.D., Sugiyama, M., Luxburg, U.V., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2016; pp. 2649–2657. [Google Scholar]
- Mehta, K.; Kliewer, J. Directional and Causal Information Flow in EEG for Assessing Perceived Audio Quality. IEEE Trans. Mol. Biol. Multi-Scale Commun. 2017, 3, 150–165. [Google Scholar] [CrossRef]
- Zaremba, A.; Aste, T. Measures of causality in complex datasets with application to financial data. Entropy 2014, 16, 2309–2349. [Google Scholar] [CrossRef]
- Diks, C.; Fang, H. Transfer Entropy for Nonparametric Granger Causality Detection: An Evaluation of Different Resampling Methods. Entropy 2017, 19, 372. [Google Scholar] [CrossRef]
- Soltani, N.; Goldsmith, A.J. Directed information between connected leaky integrate-and-fire neurons. IEEE Trans. Inf. Theory 2017, 63, 5954–5967. [Google Scholar] [CrossRef]
- Kontoyiannis, I.; Skoularidou, M. Estimating the Directed Information and Testing for Causality. IEEE Trans. Inf. Theory 2016, 62, 6053–6067. [Google Scholar] [CrossRef]
- Charalambous, C.D.; Stavrou, P.A. Directed information on abstract spaces: Properties and variational equalities. IEEE Trans. Inf. Theory 2016, 62, 6019–6052. [Google Scholar] [CrossRef]
- Lauritzen, S.L. Graphical Models; Clarendon Press: Oxford, UK, 1996; Volume 17. [Google Scholar]
- Kalisch, M.; Mächler, M.; Colombo, D.; Maathuis, M.H.; Bühlmann, P. Causal inference using graphical models with the R package pcalg. 2012. [Google Scholar] [CrossRef]
- Richardson, T.; Spirtes, P. Ancestral graph Markov models. Ann. Stat. 2002, 30, 962–1030. [Google Scholar] [CrossRef]
- Zhang, J. On the completeness of orientation rules for causal discovery in the presence of latent confounders and selection bias. Artif. Intell. 2008, 172, 1873–1896. [Google Scholar] [CrossRef]
- Pearl, J. Causal diagrams for empirical research. Biometrika 1995, 82, 669–688. [Google Scholar] [CrossRef]
- Pearl, J. The Causal Foundations of Structural Equation Modeling; Technical Report; DTIC Document; Guilford Press: New York, NY, USA, 2012. [Google Scholar]
- Lauritzen, S.L.; Wermuth, N. Graphical models for associations between variables, some of which are qualitative and some quantitative. Ann. Stat. 1989, 31–57. [Google Scholar] [CrossRef]
- Sonntag, D. A Study of Chain Graph Interpretations. Ph.D. Thesis, Linköping University, Linköping, Sweden, 2014. [Google Scholar]
- Lauritzen, S.L.; Wermuth, N. Mixed Interaction Models; Institut for Elektroniske Systemer, Aalborg Universitetscenter: Aalborg, Denmark, 1984. [Google Scholar]
- Frydenberg, M. The chain graph Markov property. Scand. J. Stat. 1990, 17, 333–353. [Google Scholar]
- Lauritzen, S.L.; Richardson, T.S. Chain graph models and their causal interpretations. J. R. Stat. Soc. B 2002, 64, 321–348. [Google Scholar] [CrossRef]
- Ogburn, E.L.; Shpitser, I.; Lee, Y. Causal inference, social networks, and chain graphs. arXiv 2018, arXiv:1812.04990. [Google Scholar]
- Andersson, S.A.; Madigan, D.; Perlman, M.D. Alternative Markov properties for chain graphs. Scand. J. Stat. 2001, 28, 33–85. [Google Scholar] [CrossRef]
- Cox, D.R.; Wermuth, N. Multivariate Dependencies: Models, Analysis and Interpretation; Chapman and Hall/CRC: London, UK, 2014. [Google Scholar]
- Richardson, T. Markov properties for acyclic directed mixed graphs. Scand. J. Stat. 2003, 30, 145–157. [Google Scholar] [CrossRef]
- Peña, J.M. Alternative Markov and causal properties for Acyclic Directed Mixed Graphs. In Proceedings of the Thirty-Second Conference on Uncertainty in Artificial Intelligence, Jersey City, NJ, USA, 25–29 June 2016; pp. 577–586. [Google Scholar]
- Peña, J.M. Learning acyclic directed mixed graphs from observations and interventions. In Proceedings of the Eighth International Conference on Probabilistic Graphical Models, Lugano, Switzerland, 6–9 September 2016; pp. 392–402. [Google Scholar]
- Studenỳ, M. Bayesian networks from the point of view of chain graphs. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1998; pp. 496–503. [Google Scholar]
- Richardson, T.S. A Factorization Criterion for Acyclic Directed Mixed Graphs. In Proceedings of the Twenty-Fifth Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; AUAI Press: Arlington, VA, USA, 2009; pp. 462–470. [Google Scholar]
- Dawid, A.P. Beware of the DAG! In Proceedings of the Workshop on Causality: Objectives and Assessment, Whistler, BC, Canada, 12 December 2008; MIT Press: Cambridge, MA, USA, 2010; Volume 6, pp. 59–86. [Google Scholar]
- Pearl, J. An introduction to causal inference. Int. J. Biostat. 2010, 6. [Google Scholar] [CrossRef] [PubMed]
- Pearl, J. Causal inference in statistics: An overview. Stat. Surv. 2009, 3, 96–146. [Google Scholar] [CrossRef]
- Rubin, D.B. Bayesian inference for causal effects: The role of randomization. Ann. Stat. 1978, 6, 34–58. [Google Scholar] [CrossRef]
- Spława-Neyman, J. Sur les applications de la théorie des probabilités aux experiences agricoles: Essai des principes. Roczniki Nauk Rolniczych 1923, 10, 1–51. [Google Scholar]
- Spława-Neyman, J.; Dąbrowska, D.M.; Speed, T. On the application of probability theory to agricultural experiments. Essay on principles. Section 9. Stat. Sci. 1990, 5, 465–472. [Google Scholar] [CrossRef]
- Imbens, G.W.; Rubin, D.B. Causal Inference in Statistics, Social, and Biomedical Sciences; Cambridge University Press: Cambridge, UK, 2015. [Google Scholar]
- Dawid, A.P. Statistical causality from a decision-theoretic perspective. Ann. Rev. Stat. Appl. 2015, 2, 273–303. [Google Scholar] [CrossRef]
- Shpitser, I.; VanderWeele, T.; Robins, J.M. On the validity of covariate adjustment for estimating causal effects. In Proceedings of the Twenty-Sixth Conference on Uncertainty in Artificial Intelligence, Catalina Island, CA, USA, 8–11 July 2010; AUAI Press: Arlington, VA, USA, 2010; pp. 527–536. [Google Scholar]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Holland, P.W. Causal inference, path analysis and recursive structural equations models. Sociol. Methodol. 1988, 8, 449–484. [Google Scholar] [CrossRef]
- Dawid, A.P. Fundamentals of Statistical Causality. Research Report No. 279. Available online: https://pdfs.semanticscholar.org/c4bc/ad0bb58091ecf9204ddb5db7dce749b0d461.pdf (accessed on 2 October 2019).
- Guo, H.; Dawid, P. Sufficient covariates and linear propensity analysis. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 3–15 May 2010; Volume 9, pp. 281–288. [Google Scholar]
- Imbens, G.W.; Wooldridge, J.M. Recent developments in the econometrics of program evaluation. J. Econ. Lit. 2009, 47, 5–86. [Google Scholar] [CrossRef]
- Kallus, N.; Mao, X.; Zhou, A. Interval Estimation of Individual-Level Causal Effects Under Unobserved Confounding. In Proceedings of the 22nd International Conference on Artificial Intelligence and Statistics, Okinawa, Japan, 16–18 April 2019; pp. 2281–2290. [Google Scholar]
- Lin, J. Divergence measures based on the Shannon entropy. IEEE Trans. Inf. Theory 1991, 37, 145–151. [Google Scholar] [CrossRef]
- Nielsen, F. On the Jensen–Shannon Symmetrization of Distances Relying on Abstract Means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- DeDeo, S.; Hawkins, R.; Klingenstein, S.; Hitchcock, T. Bootstrap methods for the empirical study of decision-making and information flows in social systems. Entropy 2013, 15, 2246–2276. [Google Scholar] [CrossRef]
- Contreras-Reyes, J.E. Analyzing fish condition factor index through skew-gaussian information theory quantifiers. Fluctuation Noise Lett. 2016, 15, 1650013. [Google Scholar] [CrossRef]
- Zhou, K.; Varadarajan, K.M.; Zillich, M.; Vincze, M. Gaussian-weighted Jensen–Shannon divergence as a robust fitness function for multi-model fitting. Mach. Vis. Appl. 2013, 24, 1107–1119. [Google Scholar] [CrossRef]
- Janzing, D.; Balduzzi, D.; Grosse-Wentrup, M.; Schölkopf, B. Quantifying causal influences. Ann. Stat. 2013, 41, 2324–2358. [Google Scholar] [CrossRef]
- Geiger, P.; Janzing, D.; Schölkopf, B. Estimating Causal Effects by Bounding Confounding. In Proceedings of the Thirtieth Conference on Uncertainty in Artificial Intelligence, Quebec City, QC, Canada, 23–27 July 2014; AUAI Press: Arlington, VA, USA, 2014; pp. 240–249. [Google Scholar]
- Sun, J.; Bollt, E.M. Causation entropy identifies indirect influences, dominance of neighbors and anticipatory couplings. Physica D 2014, 267, 49–57. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. arXiv 2014, arXiv:1401.4082. [Google Scholar]
- Alemi, A.A.; Fischer, I.; Dillon, J.V.; Murphy, K. Deep variational information bottleneck. arXiv 2016, arXiv:1612.00410. [Google Scholar]
- Wieczorek, A.; Wieser, M.; Murezzan, D.; Roth, V. Learning Sparse Latent Representations with the Deep Copula Information Bottleneck. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Bengio, Y.; Deleu, T.; Rahaman, N.; Ke, R.; Lachapelle, S.; Bilaniuk, O.; Goyal, A.; Pal, C. A meta-transfer objective for learning to disentangle causal mechanisms. arXiv 2019, arXiv:1901.10912. [Google Scholar]
- Suter, R.; Miladinovic, D.; Schölkopf, B.; Bauer, S. Robustly Disentangled Causal Mechanisms: Validating Deep Representations for Interventional Robustness. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; pp. 6056–6065. [Google Scholar]
- Besserve, M.; Sun, R.; Schölkopf, B. Counterfactuals uncover the modular structure of deep generative models. arXiv 2018, arXiv:1812.03253. [Google Scholar]
- Chattopadhyay, A.; Manupriya, P.; Sarkar, A.; Balasubramanian, V.N. Neural Network Attributions: A Causal Perspective. arXiv 2019, arXiv:1902.02302. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pearlian Framework | Neyman-Rubin Potential Outcome Framework | Information Theoretic Framework | |
|---|---|---|---|
| Ensuring no confounding | back-door criterion | strong ignorability | conditional directed information |
| Causal effect quantification | interventional distribution | average causal effect | conditional mutual information |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wieczorek, A.; Roth, V. Information Theoretic Causal Effect Quantification. Entropy 2019, 21, 975. https://doi.org/10.3390/e21100975
Wieczorek A, Roth V. Information Theoretic Causal Effect Quantification. Entropy. 2019; 21(10):975. https://doi.org/10.3390/e21100975
Chicago/Turabian StyleWieczorek, Aleksander, and Volker Roth. 2019. "Information Theoretic Causal Effect Quantification" Entropy 21, no. 10: 975. https://doi.org/10.3390/e21100975
APA StyleWieczorek, A., & Roth, V. (2019). Information Theoretic Causal Effect Quantification. Entropy, 21(10), 975. https://doi.org/10.3390/e21100975