1. Introduction
Demand forecasting, a prerequisite for inventory decision-making, plays a vital role in supply chain management. How to improve prediction accuracy has always been the focus of academic circles and enterprises. With the increasingly fierce competition in business, product variety has become an important feature of modern enterprises, which can contribute to meet diverse needs of customers and occupy more market segments [
1]. However, many products, where ‘many’ means hundreds or thousands, bring about a new challenge to demand forecasting. Traditional time series algorithms cannot well adapt to the complex high- or even ultra-high dimensionality, resulting in inferior predictive effectiveness in multi-product scenarios.
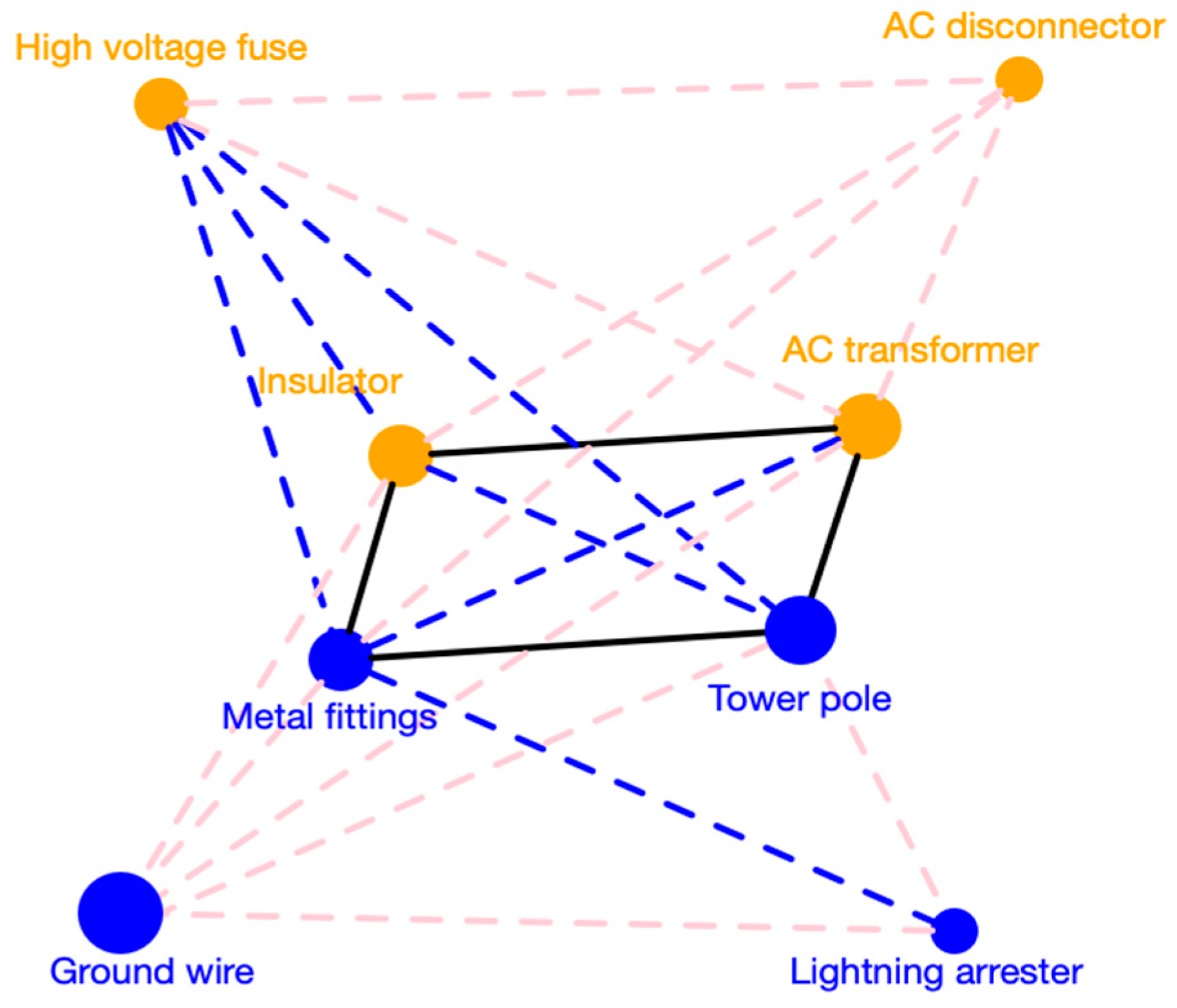
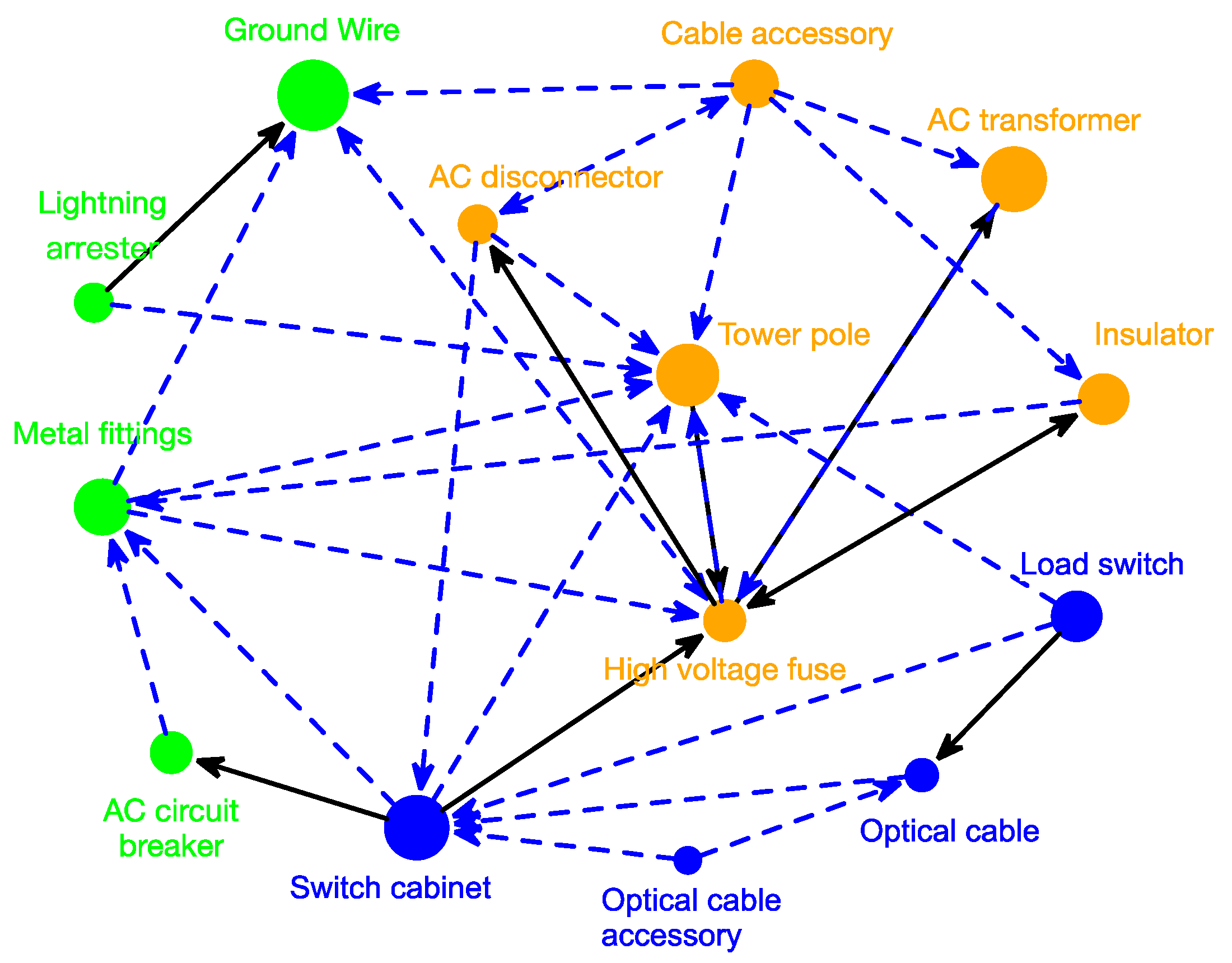
It is worth noting that the demand of multiple products is not completely isolated, but rather complex relationships exist between them. According to the relevant literature, there are two common association relationships between different products: correlation and Granger causality. For example, the demand for complementary products is highly correlated, having contemporaneous influence with each other [
2]. Materials used in engineering projects have a clear sequence, so Granger causality exists in their demand [
3]. Obviously, capturing and making full use of such potential information can be helpful to obtain more accurate prediction results. What’s more, when the time series are short, historic trend cannot provide enough information for future demand. Associated relationships can make up for the defects and reduce the bias of prediction. However, as far as we know, there is currently little research taking into account association relationships between products in demand forecasting. In this paper, we incorporate associated relationships among products into the forecasting framework to construct a more accurate prediction approach.
In previous literature, there are mainly three branches of forecasting models for multi-dimensional time series. The first one is a series of statistical methods, represented by the AIRMA model and its extended versions, including VARMA, VARs, BVAR, etc. [
4,
5,
6,
7,
8,
9,
10,
11,
12,
13]. They treat multi-dimensional time series as an endogenous system. Target variables are regressed by lag items of all series, considering their relations generally. With the development of econometrics, VARs with different settings are widely applied. For example, [
8] proposed five types of VAR and utilized industrial production data from OECD countries to test their forecasting effect. The key defect of VAR is that the number of estimated parameters increases exponentially along with the increase in dimensions. For high-dimensional time series, it is easy to cause overfitting, weakening the prediction ability outside the original sample. Some scholars have assumed that estimated parameters obey a specific prior distribution to reduce their number, i.e., BVAR, applied in macro-economic forecasting [
14,
15,
16,
17], market share forecasting [
12] and business forecasting [
10]. Some other scholars incorporated some unmodeled predictors from exogenous variables to improve original regression models. For example, [
18] integrated intra- and inter-category promotional information to construct multistage LASSO regression to forecast the demand of 3222 products. The results are significantly better than the model only using endogenous variables. Unfortunately, these methods can alleviate but not completely solve the problem of overfitting. Accurate results can be obtained only when the time series is long enough.
The second strand of research concentrates on processing high-dimensional time series through the method of dimension reduction, represented by dynamic factor model (DFM). [
19] holds the belief that a small number of latent factors are able to interpret fluctuations of observed macroeconomic indices. As long as these potential factors can be portrayed accurately, the task of forecasting is simplified substantially and precise results are achievable. There are many algorithms for the estimation of dynamic factors, including maximum likelihood [
19,
20,
21,
22], principle component analysis (PCA) [
23,
24,
25,
26,
27,
28,
29,
30,
31,
32], and data shrinking methods [
33,
34]. As for prediction accuracy, [
35] collected relevant literature and confirmed that DFM performs better than single time series prediction models through a meta-analysis method. Reference [
36] pointed out that a simple AR model may be better than a DFM model when there is a large structural change in the data. Compared with other high-dimensional time series models like shrinkage forecasts, FDM is also superior [
37]. What’s more, [
38] introduced U.S. macroeconomic data to compare two forms of DFM estimation methods [
39,
40]. The results demonstrated that their forecasting precision is not significantly different. However, DFM has the obstacle to tackle sophisticated high-dimensional time series, due to the existence of some isolated series, and the same is true for ultra-high dimensional time series. More specifically, some unique information may be skipped in the process of selecting a limited number of factors, leading to inefficient estimates. If add more dynamic factors, it will fall into the over parameterized problem again.
As the development of artificial intelligence, various machine learning models have been widely used in the area of forecasting, including neural network [
41,
42,
43], support vector machine [
44,
45,
46], nearest neighbor regression [
47,
48], and so on. They are serious contenders to classical statistical models and form a vital research branch. Different from statistical models, these models construct the dependency between historic data and future values through a black-box and nonlinear process. Reference [
49] compared eight types of machine learning models, finding that their rank is unambiguous and does not change much with different features of time series. Reference [
50] tested the accuracy of some popular machine learning models. The results demonstrated that their performances were inferior to eight traditional statistical ones. In addition, [
50] points out that machine learning models need to become more accurate, reduce their computation load, as well as be less of a black box. Therefore, in this paper, we will continue to optimize the statistics models by associated relationships to get higher accuracy, instead of machine learning models.
By summarizing previous literature related to multi-dimensional time series analysis, we find that these methods all fail to deal with the situation where product dimension is large but time dimension is small. Based on this situation, we innovatively construct an improved forecasting model for the target variable based on its precedent values and endogenous predictors selected from associated relationships. In some scenarios, if there are many time series associated with the object, we adopt two feasible schemes to simplify the variable space. Then we conduct an empirical study by using an actual dataset of a Chinese grid company. The results of forecasting errors and inventory simulation show that new approaches are superior to these conventional time series forecasting models, including SES, AR, VAR and FDM. Generally speaking, the proposed methods have three major advantages. Firstly, the number of estimated parameters is simplified significantly, not depending exponentially on the dimensions. Secondly, each variable has a customized forecasting regression, which can describe isolated time series well. Thirdly, it does not necessary to collect extra data to act as exogenous variables. Therefore, one contribution of our work is that the new approaches innovatively incorporate associated relationships into demand forecasting, getting rid of the transitional dependence on historical data, so it can be applied to forecast short time series with large dimensionality, making up for the void of previous algorithms. In addition, we contribute to solving over-fitting problems, providing a new direction for the subsequent research. Besides the above theoretical implications, the study also has important practical significance. Note that life circles of products especially high-tech products are getting shorter and many new products are born due to the acceleration of technological innovation. Demand forecasting in terms of limited time points is very common and necessary in actual business activities. Therefore, our new approaches have a wide range of application scenarios and can provide more accurate decision-making basis for practitioners.
The remainder of this paper is organized as follows: In
Section 2, we give a brief description of two conventional forecasting models for multi-dimensional time series, i.e., VAR and DFM, and then present our new forecasting approaches based on correlation and Granger causality, respectively.
Section 3 describes the procurement dataset and analyzes the relationships between the demands for purchased products. An empirical study and its results are discussed in
Section 4. Finally, we summarize our conclusions in
Section 5.
2. Forecasting Model and Evaluation
In this section, first we review two common models used in multivariable forecasting. Then we detail our new approaches, utilizing correlations and Granger causality among products to improve prediction accuracy respectively. Finally, some indices are introduced to evaluate the forecasting performance.
2.1. VAR and DFM
VAR and DFM are two conventional models used to forecast demand under multi-product scenarios. Both them have specific limitations, struggling with high (or ultra-high) dimensionality and failing to describe evolutions of short time series. Firstly, we introduce the VAR model. Assume that demand of
products at time
is
, t = 1, 2, …, T, where
represents the demand of
th product at time
. The VAR model is as follows:
where
is a matrix polynomial with
lags in total.
is a
parameter matrix of
th lag and
is the lag operator calculated by
.
is a
constant vector, and
is a
vector of white noisy process, without contemporaneous correlation. According to (1), it is obvious that there are total
free parameters need to be estimated in VAR model. With the increase of the number of products (i.e., N), the parameters increase quadratically. Therefore, only time series have moderate dimensionality, i.e., the length of data point is long enough relative to the number of products, can VAR obtain efficient estimates.
As for DFM, it extracts some dynamic factors that can explain the most variation of target variables as predictors, turning the curse of dimensionality into a blessing. However, when the number of products is large, there are some isolated products unavoidably. Common factors cannot explain their demand accurately. Keeping the previous assumptions about
, the general DFM model is as follows:
where
is a
-dimensional column vector, representing values for
unobserved factors at time
. It can supplant the originally large data.
,
, and the meanings of these parameters are similar to
’s in the previous part.
and
are residuals, satisfying some idiosyncratic assumptions. Equation (3) aims to get predictive values of dynamic factors, then applied in Equation (2).
We can see that the quality of factors is the key to determine the accuracy of DFM. As mentioned above, there are many methods to extract factors. Among them, PCA is commonly used in forecasting literature [
28]. In PCA estimation, assume that
, i.e., original time series are only influenced by contemporaneous factors. Because
and
are uncorrelated at all lags, we can decompose the covariance matrix of
into two parts:
where
and
are covariance matrices of
and
respectively. Under the assumptions, the eigenvalues of
is
and
is
, the first
eigenvalues of
are
and the remaining eigenvalues are
. Therefore, the first
principal components of
can act as dynamic factors. If
is known, the estimator of
can be calculated by OLS directly, i.e.,
. However,
is usually unknown for most cases. Similar to regression, the following optimization equation can estimate
and
:
The first order condition for minimizing (5) with respect to
shows that
. By substituting this into the objective function, the results demonstrate that
equals to the first
eigenvectors of
, where
. More detailed derivation process can refer to [
28]. Correspondingly,
is the first
principal components of
. It is the final PCA estimator of dynamic factors in DFM. Finally, let
to get predictive values of the original time series.
2.2. The Forecasting Approach Based on Correlation
Associated relationships between multiple products can provide rich information for demand forecasting. Mining effective predictors from associated time series, instead of all series, will be helpful to eliminate some irrelevant information and reduce the number of parameters significantly. Based on this believe, we propose new approaches based on two typical association relationships, namely correlation and Granger causality, respectively. It is proved that they have higher accuracy and can work well even if a wide range of products only have limited data points in the time dimension.
We start with the forecasting approach based on correlation between products. If two products are highly correlated, their demand has specific interactions in the contemporaneous period. For example, if the demand for a product increases, its complementary products will also see a rise in demand at the same time, while its substitutes will experience a decline. Therefore, we utilize such hidden information to modify forecasting algorithms and get more accurate results. There are mainly three steps in the forecasting approach based on correlation. Firstly, find a proper variable subset for each product in terms of correlated relationships. To be specific, calculate the correlation coefficients between the target one and all other products. Those highly correlated to the targeted one, i.e., whose correlation coefficient is more than a certain threshold, constitute the proper variable subset. If a product does not have highly correlated ones, its proper variable subset is empty. Secondly, run autoregressive model (AR) for each product to get originally predictive values of its demand. AR only depends on past values of a time series to forecast its future evolution, ignoring useful information hidden in other correlated time series. Therefore, the third step is that reconstruct forecasting model for products whose proper variable subset is not empty. We can add these proper variables into AR to get final results. It is worth noting that in some cases one product may have many highly correlated products, i.e., many proper variables. If the time point is not enough, adding too many proper variables results in the over-fitted problem, similar to VAR. For example, in this paper, the training sample only contains 36 time points in total. In terms of the principle that the number of estimated parameters should be less than 1/10 of that of observations, there are no more than 3 parameters in the forecasting model. Since the autoregressive process of original time series occupies at least two parameters, only one predictor based on correlation can be selected. Therefore, we propose two feasible schemes to control the scale of the forecasting model as follows:
Scheme (I): Only select the product having the highest correlation with the object from the proper variable subset as a predictor added in final model.
Scheme (II): Extract the first principle component of all elements in the proper variable subset as a predictor added in the final model.
More formally, Let
represent time series of demand for all products during the T periods, and then the correlation matrix
of
is as follows:
where
is the
th row of
, i.e., the sophistic demand series of
th product. According to
, we can pick up products highly correlated to
, making up for the proper variable subset for
th product. The autoregression
can get originally predictive demand
for
th product in
th period.
is a lag parameter, determined by the Akaike information criterion (AIC). Based on this,
is a matrix, containing original prediction values of all proper variables for
th product. Its rows represent time dimension and columns correspond to products, ranked from left to right in terms of their correlation coefficients with
in descending order. Assume that
is the effective predictor selected from
to improve forecasting. Because it corresponds to prediction values, the first time point is missed. The final model is as follows:
Scheme (I) suggests that , where is the first column of , the product having highest correlation with the th one. According to Scheme (II), is the first principle component of . The procedure of calculating principle components is as follows: (i) computing the covariance matrix of , (ii) determining eigenvalues and eigenvectors , , …, of , where , (iii) getting the first principle component .
2.3. The Forecasting Approach Based on Granger Causality
If Granger causality exists between two products, it means that historic observations of one product can explain the future demand of another product (there is a time lag between them). This situation often occurs when the procurement of products has a stable sequence, such as material procurement in engineering projects. The idea of the forecasting approach based on Granger causality is similar to the former one based on correlation, also consisting of three steps. Firstly, find the proper variable subset for every product by doing Granger causal relation test. When the p-value of Granger test satisfies a critical condition, the corresponding product can join the proper variable subset of the target one. Secondly, run AR for every product to get its originally predictive demand. Finally, select effective predictors from the proper variable subset to reconstruct the forecasting model, if a product’s proper variable subset is not empty. Similarly, there are also two schemes to prevent excessive parameters:
Scheme (I): Only select the product having lowest p-value of Granger test with the object from the proper variable subset as a predictor added in final model.
Scheme (II): Extract the first principle component of all elements in the proper variable subset as a predictor added in the final model.
Assume
is the
p-value matrix of Granger test for
considering
lags, where
is determined by AIC. The rows of
describe Granger results while columns are Granger causes. According to
, we can construct the proper variable subset for the
th product, expressed by a matrix
. The granger cause with the lowest
p-value of the
th product arranges in the first column of
, and so on. Let
represents the effective predictor extracted from
. According to Scheme (I) and Scheme (II),
and
is the first principle component of
respectively. The final forecasting model based on Granger causality is as follows:
2.4. The Forecast Accuracy Measures
According to the previous literature, there are two major methods to evaluate the performance for demand forecasting approaches: forecasting errors and inventory performance, from the perspective of forecasting accuracy and actual inventory management, respectively. It is worth noting that the dataset used in this paper has intermittent demand series: the demand of some products is zero in some periods. Therefore, we adopt absolute scaled error (ASE) to measure forecasting errors. It can overcome the drawback of infinities caused by zero division [
51]. The formula is as follows:
Then mean absolute scaled error is
. A forecasting approach with lower MASE means that it is more accurate during the whole forecasting period in general. Therefore, we can compare different approaches according to their values of MASE. In addition, we also apply relative error (RE) to measure the accuracy of forecasters, i.e., calculating ratios of their ASE to that of a baseline model. In this paper, we set simple exponential smoothing (SES) model as the benchmark, which can refer to [
52]. For multi-period demand forecasting, the overall judgement of RE is usually based on the form of geometric mean instead of arithmetic mean [
51,
53]. Geometric mean relative absolute scaled error is expressed as
, where
is errors of the baseline model.
In fact, optimizing forecasting accuracy aims to provide better guidance for order strategy and inventory management, finally reducing inventory costs and improving managerial efficiency. How forecasting results influence inventory performance is also a concern for scholars and enterprises. A lot of studies assess forecasts by means of inventory simulations [
54,
55,
56,
57,
58]. Therefore, we also introduce inventory performance to evaluate forecasting approaches. The order-up-to-level policy, commonly used in practice, is adopted to control inventory simulation. We set the inventory review period as one month, consistent with the prediction period. The order-up-to level S is
, where
is the predictive demand during the lead time (one month), SS is the safety stock related to the desired service level. At the beginning of each period, check the holding stock H. If H is below S, place an order with the ordering quantity H-S. Otherwise, nothing needs to be done. When face out-of-stocks, the demand will be serviced in the next period. To initialize the simulation system, assume that have full stock at the beginning, i.e., H=S. One index of inventory performance is total inventory costs, consisting of two parts: shortage costs and holding costs, i.e., total inventory costs = unit total cost × (mean inventory per month ×
+ mean stock-out per month ×
) [
52]. The cost parameters
and
reflect the trade-off between stock-holding and out-of-stock.
means that costs of out stocks are more expensive. When
, by contrast, unit stock-holding costs more dollars. In addition, another index is the inventory ratio. A smaller inventory ratio means higher inventory efficiency. It is calculated by the following expression:
5. Conclusions
Along with the trend of technological advance, a rapid increase in product diversity and shortening of product life cycles have become important features for enterprises. This means that practitioners need to use limited historical demand to forecast the future, leading to the failure of traditional forecasting approaches. Fortunately, potential relationships between demand time series of multiple products can provide abundant information to improve forecasting accuracy. Therefore, we proposed an improved approach, whose core idea is utilizing the demand of associated products (including highly correlated ones or ones having significantly causality) as predictors to add in AR model to improve its prediction accuracy. Considering that time series may be short, we introduce two feasible schemes to simplify variables to avoid over-fitting. Then monthly procurement data from a Chinese grid company is used to test the forecasting ability of the proposed approaches, as well as four conventional time series approaches SES, AR, VAR, and FDM.
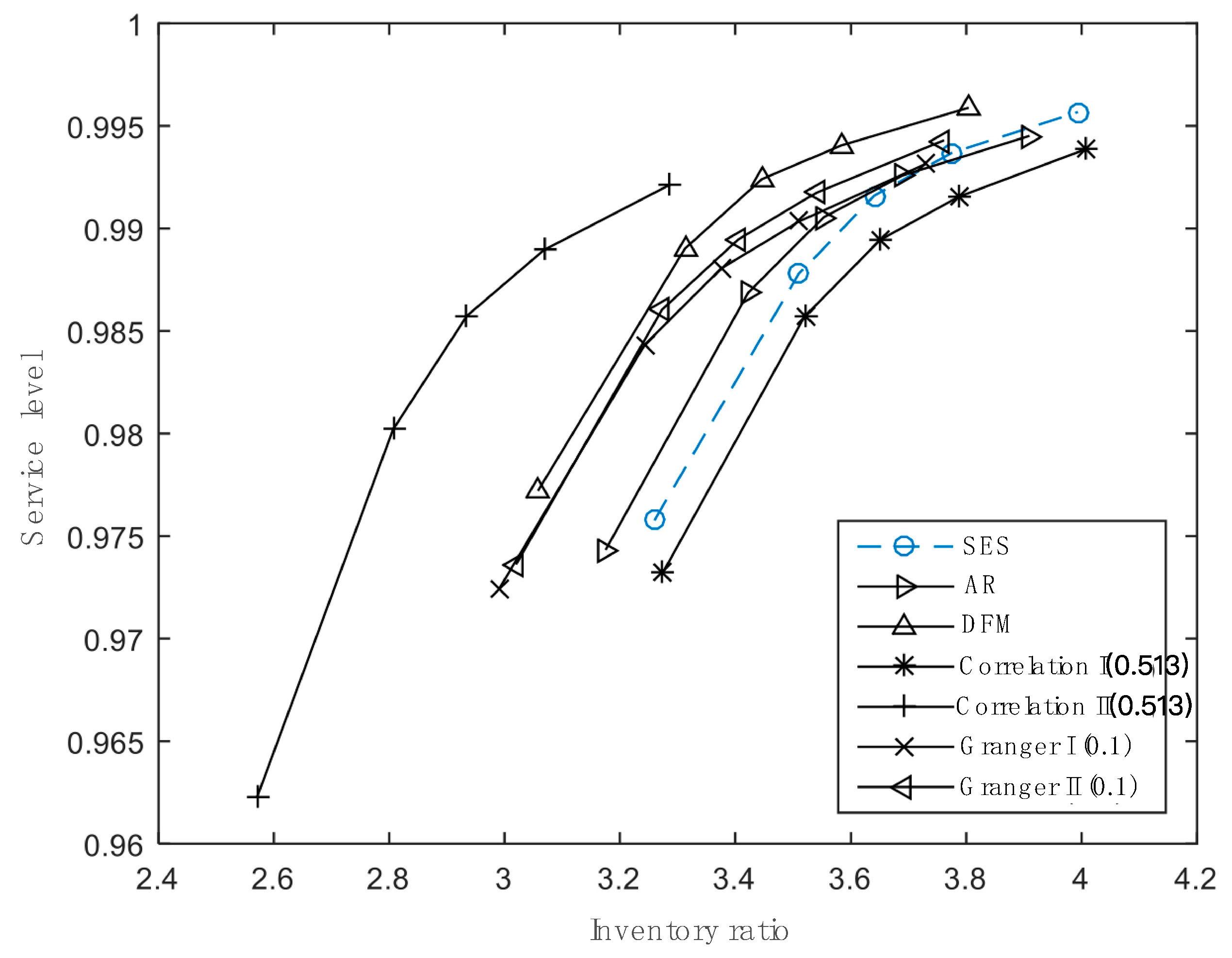
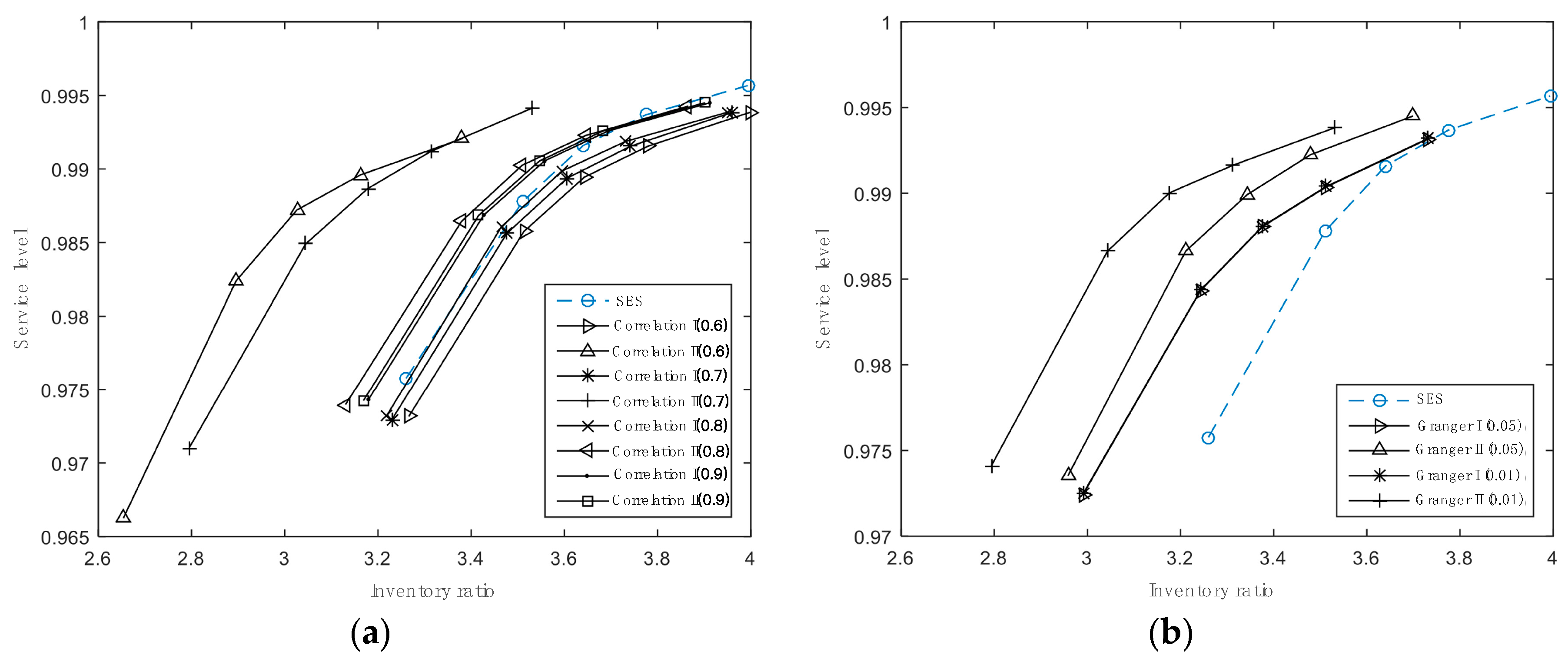
We adopt two types of indicators including forecasting errors and inventory performance to compare these approaches. There are three main findings. Firstly, our new approaches can perform better than those conventional approaches, especially when the product dimensionality is large. Among them, CII with the critical value equal to 0.513 has the best forecasting performance, enjoying the lowest forecasting errors, total inventory costs and inventory ratio, followed by GII with the critical value equal to 0.01. Secondly, Scheme (II) is more effective for the approaches based on associated relationships to achieve higher accuracy, compared with Scheme (I) because it can refine more information and set off the errors of different time series. Finally, it is vital to set a rational threshold condition to select proper variables, which can help to get ideal prediction results. The condition should make sure that most objects have enough proper variables to improve prediction and while the irrelative information is also as less as possible.
However, due to the limitations of the real dataset, we can only pick up one predictor from the associated relationships, so we cannot discuss the influence of the number of selected predictors on the forecasting accuracy. In the future, we can extend our research from the following aspects. Firstly, we can properly test the new approaches through a large wide of diverse datasets, and analyze the most proper number of predictors that should be added in final forecasting models. Secondly, try more methods to dig for predictors from proper variable sets, not limited to PCA. Then compare their prediction performance to find a better one. In addition, “order-up-to level” is the only inventory strategy used to do inventory simulations in this empirical study. Therefore, we can introduce other widely applied strategies into inventory simulations and explore whether the approaches based on associated relationships are appropriate for different inventory strategies.







{kind=link}
{kind=link}
{kind=link}
{kind=link}