Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy



Abstract
1. Introduction
2. Materials and Methods
2.1. Permutation Entropy
2.2. Clustering Algorithm
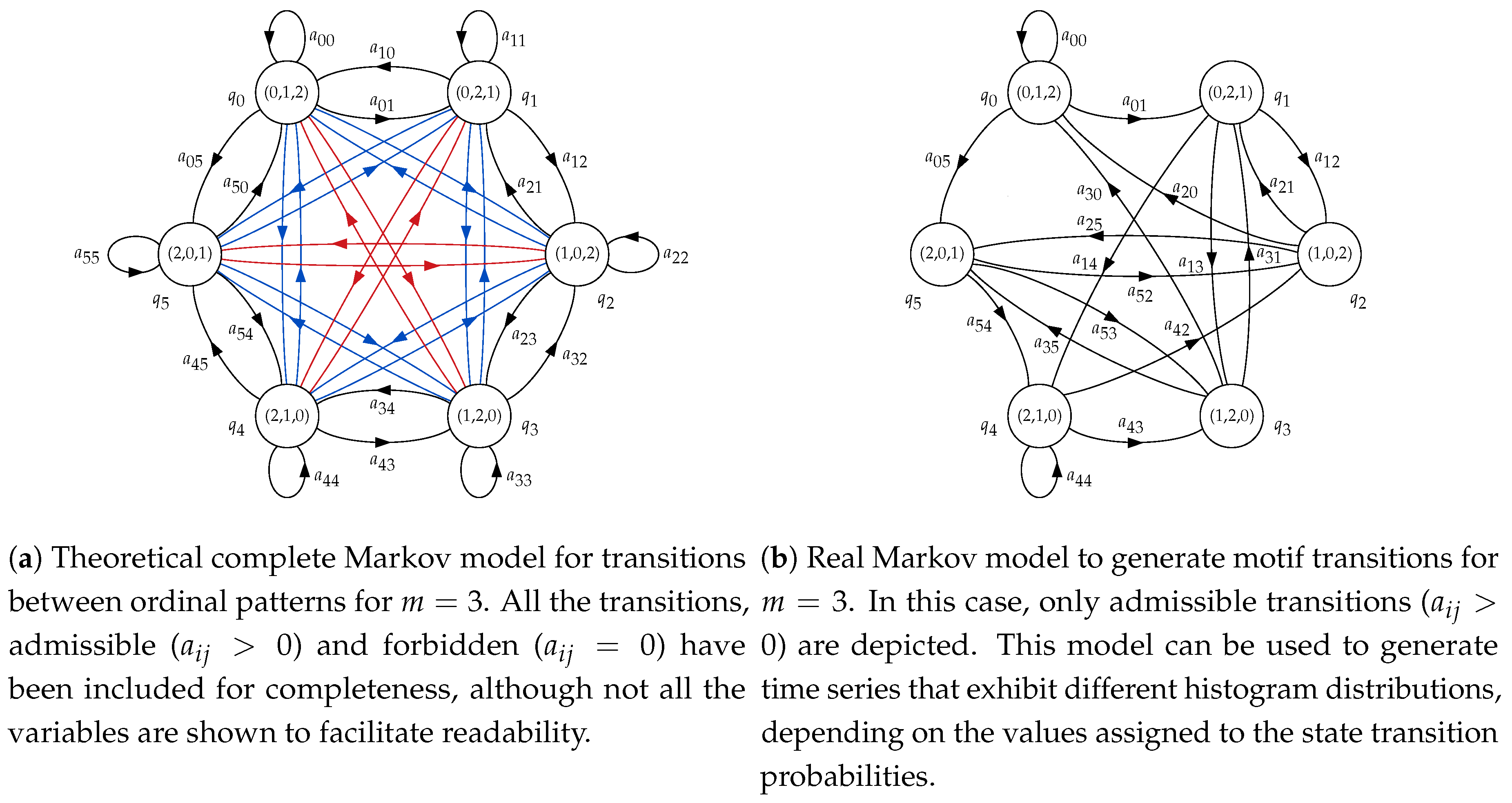
2.3. Hidden Markov Models
- To compute the probability of observing a certain input vector (Evaluation).
- To find a state transition sequence that maximizes the probability of a certain input vector (Generation).
- To induce a model that maximises the probability of a certain input vector (Learning).
2.4. Experimental Dataset
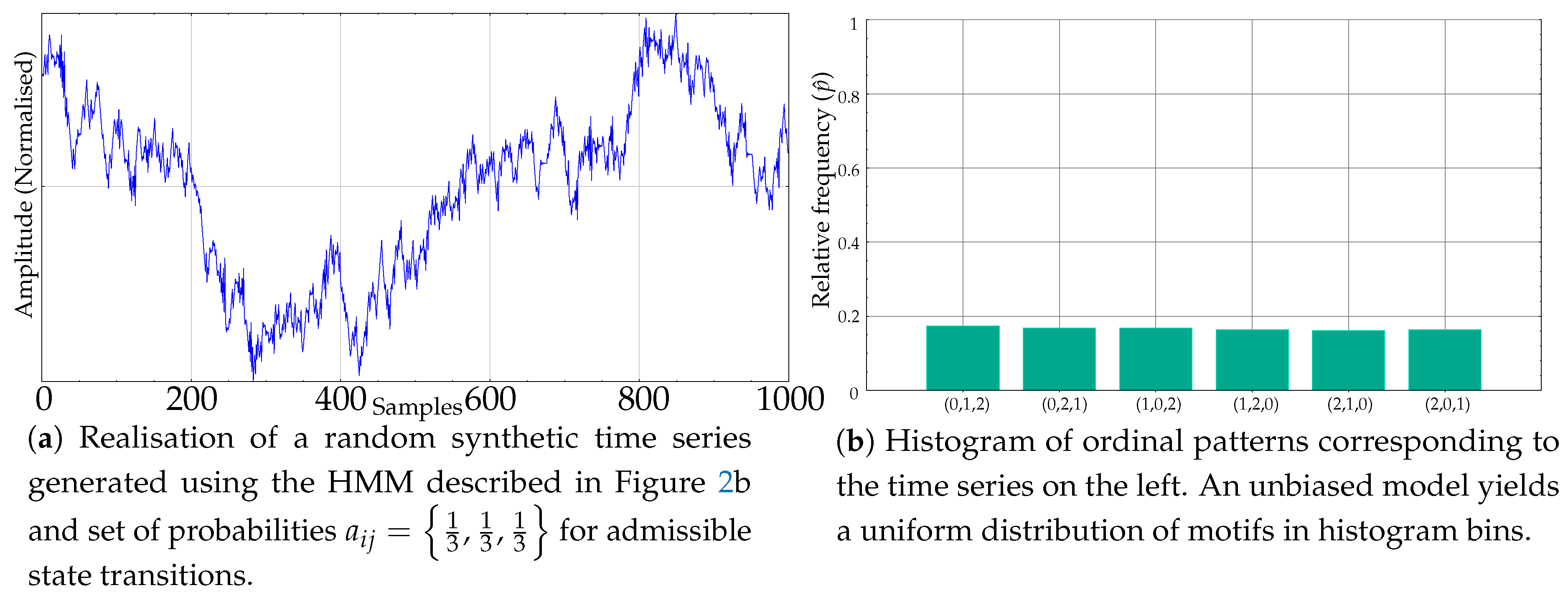
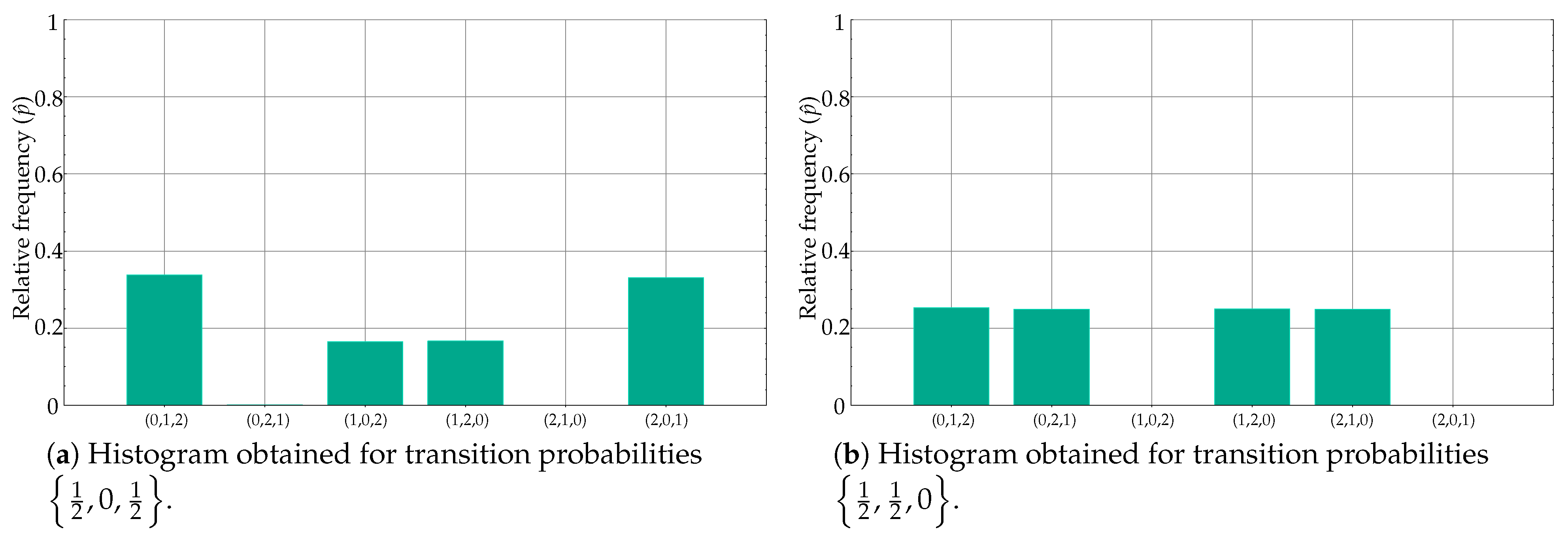
2.4.1. Synthetic Dataset
2.4.2. Real Dataset
3. Experiments and Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Esling, P.; Agon, C. Time-series Data Mining. ACM Comput. Surv. 2012, 45, 12:1–12:34. [Google Scholar] [CrossRef]
- Bagnall, A.; Lines, J.; Bostrom, A.; Large, J.; Keogh, E. The great time series classification bake off: A review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 2017, 31, 606–660. [Google Scholar] [CrossRef]
- Tabar, Y.R.; Halici, U. A novel deep learning approach for classification of EEG motor imagery signals. J. Neural Eng. 2016, 14, 016003. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Biagetti, M.; Quinteiro, R.; Micó, P.; Aboy, M. Unsupervised classification of ventricular extrasystoles using bounded clustering algorithms and morphology matching. Med. Biol. Eng. Comput. 2007, 45, 229–239. [Google Scholar] [CrossRef] [PubMed]
- Dakappa, P.H.; Prasad, K.; Rao, S.B.; Bolumbu, G.; Bhat, G.K.; Mahabala, C. Classification of Infectious and Noninfectious Diseases Using Artificial Neural Networks from 24-Hour Continuous Tympanic Temperature Data of Patients with Undifferentiated Fever. Crit. Rev. Biomed. Eng. 2018, 46, 173–183. [Google Scholar] [CrossRef]
- Wang, C.C.; Kang, Y.; Shen, P.C.; Chang, Y.P.; Chung, Y.L. Applications of fault diagnosis in rotating machinery by using time series analysis with neural network. Expert Syst. Appl. 2010, 37, 1696–1702. [Google Scholar] [CrossRef]
- Fong, S.; Lan, K.; Wong, R. Classifying Human Voices By Using Hybrid SFX Time-series Pre-processing and Ensemble Feature Selection. Biomed Res. Int. 2013, 2013, 1–27. [Google Scholar]
- Lines, J.; Bagnall, A.; Caiger-Smith, P.; Anderson, S. Classification of Household Devices by Electricity Usage Profiles. In Intelligent Data Engineering and Automated Learning-IDEAL; Yin, H., Wang, W., Rayward-Smith, V., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 403–412. [Google Scholar]
- Papaioannou, V.E.; Chouvarda, I.G.; Maglaveras, N.K.; Baltopoulos, G.I.; Pneumatikos, I.A. Temperature multiscale entropy analysis: A promising marker for early prediction of mortality in septic patients. Physiol. Meas. 2013, 34, 1449. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Jordán-Núnez, J.; Oltra-Crespo, S.; Molina-Picó, A. Noisy EEG signals classification based on entropy metrics. Performance assessment using first and second generation statistics. Comput. Biol. Med. 2017, 87, 141–151. [Google Scholar] [CrossRef]
- Li, P.; Karmakar, C.; Yan, C.; Palaniswami, M.; Liu, C. Classification of 5-S Epileptic EEG Recordings Using Distribution Entropy and Sample Entropy. Front. Physiol. 2016, 7, 136. [Google Scholar] [CrossRef]
- Azami, H.; Escudero, J. Amplitude-aware permutation entropy: Illustration in spike detection and signal segmentation. Comput. Meth. Programs Biomed. 2016, 128, 40–51. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Yaan, L.; Liang, H.; Yu, J. Improved Permutation Entropy for Measuring Complexity of Time Series under Noisy Condition. Complexity 2019, 2019, 1403829. [Google Scholar] [CrossRef]
- Manis, G.; Aktaruzzaman, M.; Sassi, R. Bubble Entropy: An Entropy Almost Free of Parameters. IEEE Trans. Biomed. Eng. 2017, 64, 2711–2718. [Google Scholar] [PubMed]
- Simons, S.; Espino, P.; Abásolo, D. Fuzzy Entropy Analysis of the Electroencephalogram in Patients with Alzheimer’s Disease: Is the Method Superior to Sample Entropy? Entropy 2018, 20, 21. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Jordán-Núñez, J.; Vargas, B.; González, P.; Varela-Entrecanales, M. Model Selection for Body Temperature Signal Classification Using Both Amplitude and Ordinality-Based Entropy Measures. Entropy 2018, 20, 853. [Google Scholar] [CrossRef]
- Karmakar, C.; Udhayakumar, R.K.; Li, P.; Venkatesh, S.; Palaniswami, M. Stability, Consistency and Performance of Distribution Entropy in Analysing Short Length Heart Rate Variability (HRV) Signal. Front. Physiol. 2017, 8, 720. [Google Scholar] [CrossRef]
- Amigó, J. Permutation Complexity in Dynamical Systems: Ordinal Patterns, Permutation Entropy and All That; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Greven, A.; Keller, G.; Warnecke, G. Entropy; Princeton University Press: Princeton, NJ, USA, 2014. [Google Scholar]
- Cruces, S.; Martín-Clemente, R.; Samek, W. Information Theory Applications in Signal Processing. Entropy 2019, 21, 653. [Google Scholar] [CrossRef]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; The University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Zunino, L.; Zanin, M.; Tabak, B.M.; Pérez, D.G.; Rosso, O.A. Forbidden patterns, permutation entropy and stock market inefficiency. Physica A 2009, 388, 2854–2864. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Murillo-Escobar, J.P.; Orrego, D.A.; Delgado-Trejos, E. Embedded Dimension and Time Series Length. Practical Influence on Permutation Entropy and Its Applications. Entropy 2019, 21, 385. [Google Scholar] [CrossRef]
- Cuesta–Frau, D. Permutation entropy: Influence of amplitude information on time series classification performance. Math. Biosci. Eng. 2019, 16, 6842. [Google Scholar] [CrossRef]
- Bandt, C.; Pompe, B. Permutation Entropy: A Natural Complexity Measure for Time Series. Phys. Rev. Lett. 2002, 88, 174102. [Google Scholar] [CrossRef] [PubMed]
- Parlitz, U.; Berg, S.; Luther, S.; Schirdewan, A.; Kurths, J.; Wessel, N. Classifying cardiac biosignals using ordinal pattern statistics and symbolic dynamics. Comput. Biol. Med. 2012, 42, 319–327. [Google Scholar] [CrossRef] [PubMed]
- Zanin, M. Forbidden patterns in financial time series. Chaos 2008, 18, 013119. [Google Scholar] [CrossRef] [PubMed]
- Kulp, C.; Chobot, J.; Niskala, B.; Needhammer, C. Using Forbidden Patterns To Detect Determinism in Irregularly Sampled Time Series. Chaos 2016, 26, 023107. [Google Scholar] [CrossRef]
- Tzortzis, G.; Likas, A. The MinMax k–Means clustering algorithm. Pattern Recognit. 2014, 47, 2505–2516. [Google Scholar] [CrossRef]
- Xu, D.; Tian, Y. A Comprehensive Survey of Clustering Algorithms. AODS 2015, 2, 165–193. [Google Scholar] [CrossRef]
- Rodriguez, M.Z.; Comin, C.H.; Casanova, D.; Bruno, O.M.; Amancio, D.R.; Costa, L.d.F.; Rodrigues, F.A. Clustering algorithms: A comparative approach. PLoS ONE 2019, 14, e0210236. [Google Scholar] [CrossRef]
- Yu, S.S.; Chu, S.W.; Wang, C.M.; Chan, Y.K.; Chang, T.C. Two improved k-means algorithms. Appl. Soft. Comput. 2018, 68, 747–755. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Wu, J. Advances in K-means Clustering: A Data Mining Thinking; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Cuesta-Frau, D.; Pérez-Cortes, J.C.; García, G.A. Clustering of electrocardiograph signals in computer-aided Holter analysis. Comput. Meth. Programs Biomed. 2003, 72, 179–196. [Google Scholar] [CrossRef]
- Rodríguez-Sotelo, J.; Peluffo-Ordoñez, D.; Cuesta-Frau, D.; Castellanos-Domínguez, G. Unsupervised feature relevance analysis applied to improve ECG heartbeat clustering. Comput. Meth. Programs Biomed. 2012, 108, 250–261. [Google Scholar] [CrossRef] [PubMed]
- Rodríguez-Sotelo, J.L.; Osorio-Forero, A.; Jiménez-Rodríguez, A.; Cuesta-Frau, D.; Cirugeda-Roldán, E.; Peluffo, D. Automatic Sleep Stages Classification Using EEG Entropy Features and Unsupervised Pattern Analysis Techniques. Entropy 2014, 16, 6573. [Google Scholar]
- Gower, J.C.; Legendre, P. Metric and Euclidean properties of dissimilarity coefficients. J. Classif. 1986, 3, 5–48. [Google Scholar] [CrossRef]
- Pakhira, M.K. Finding Number of Clusters before Finding Clusters. Proc. Tech. 2012, 4, 27–37. [Google Scholar] [CrossRef][Green Version]
- Poomagal, S.; Saranya, P.; Karthik, S. A Novel Method for Selecting Initial Centroids in K-means Clustering Algorithm. Int. J. Intell. Syst. Technol. Appl. 2016, 15, 230–239. [Google Scholar] [CrossRef]
- Kuncheva, L.I.; Vetrov, D.P. Evaluation of Stability of k-Means Cluster Ensembles with Respect to Random Initialization. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1798–1808. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. How much can k-means be improved by using better initialization and repeats? Pattern Recognit. 2019, 93, 95–112. [Google Scholar] [CrossRef]
- Yuan, B.; Zhang, W.; Yuan, Y. A Max-Min clustering method for k-Means algorithm of data clustering. J. Ind. Manag. Optim. 2012, 8, 565. [Google Scholar] [CrossRef]
- Pérez, O.J.; Pazos, R.R.; Cruz, R.L.; Reyes, S.G.; Basave, T.R.; Fraire, H.H. Improving the Efficiency and Efficacy of the K-means Clustering Algorithm Through a New Convergence Condition. In International Conference on Computational Science and Its Applications; Gervasi, O., Gavrilova, M.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 674–682. [Google Scholar]
- Osamor, V.C.; Adebiyi, E.F.; Oyelade, J.O.; Doumbia, S. Reducing the Time Requirement of k-Means Algorithm. PLoS ONE 2012, 7, e49946. [Google Scholar] [CrossRef]
- Har-Peled, S.; Sadri, B. How Fast Is the k-Means Method? Algorithmica 2005, 41, 185–202. [Google Scholar] [CrossRef]
- Lai, J.Z.; Huang, T.J.; Liaw, Y.C. A fast k–means clustering algorithm using cluster center displacement. Pattern Recognit. 2009, 42, 2551–2556. [Google Scholar] [CrossRef]
- Celebi, M.E.; Kingravi, H.A.; Vela, P.A. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Syst. Appl. 2013, 40, 200–210. [Google Scholar] [CrossRef]
- Sun, W.; Wang, J.; Fang, Y. Regularized k-means clustering of high-dimensional data and its asymptotic consistency. Electron. J. Stat. 2012, 6, 148–167. [Google Scholar] [CrossRef]
- Gong, W.; Zhao, R.; Grünewald, S. Structured sparse K-means clustering via Laplacian smoothing. Pattern Recognit. Lett. 2018, 112, 63–69. [Google Scholar] [CrossRef]
- The Probability Distribution of the Sum of Several Dice: Slot Applications. UNLV Gaming Res. Rev. J. 2011, 15, 10.
- Jain, A.K.; Murty, M.N.; Flynn, P.J. Data Clustering: A Review. ACM Comput. Surv. 1999, 31, 264–323. [Google Scholar] [CrossRef]
- Karimov, J.; Ozbayoglu, M. Clustering Quality Improvement of k-means Using a Hybrid Evolutionary Model. Procedia. Comput. Sci. 2015, 61, 38–45. [Google Scholar] [CrossRef]
- Rodriguez-Sotelo, J.L.; Cuesta-Frau, D.; Castellanos-Dominguez, G. An improved method for unsupervised analysis of ECG beats based on WT features and J-means clustering. In 2007 Computers in Cardiology; IEEE: Piscataway, NJ, USA, 2007; pp. 581–584. [Google Scholar]
- Panda, S.; Sahu, S.; Jena, P.; Chattopadhyay, S. Comparing Fuzzy-C Means and K-Means Clustering Techniques: A Comprehensive Study. In Advances in Computer Science, Engineering & Applications; Wyld, D.C., Zizka, J., Nagamalai, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 451–460. [Google Scholar]
- Bahmani, B.; Moseley, B.; Vattani, A.; Kumar, R.; Vassilvitskii, S. Scalable K-means++. Proc. VLDB Endow. 2012, 5, 622–633. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Unakafova, V.; Keller, K. Efficiently Measuring Complexity on the Basis of Real-World Data. Entropy 2013, 15, 4392–4415. [Google Scholar] [CrossRef]
- Zunino, L.; Olivares, F.; Scholkmann, F.; Rosso, O.A. Permutation entropy based time series analysis: Equalities in the input signal can lead to false conclusions. Phys. Lett. A 2017, 381, 1883–1892. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Varela-Entrecanales, M.; Molina-Picó, A.; Vargas, B. Patterns with Equal Values in Permutation Entropy: Do They Really Matter for Biosignal Classification? Complexity 2018, 2018, 1324696. [Google Scholar] [CrossRef]
- Keller, K.; Unakafov, A.M.; Unakafova, V.A. Ordinal Patterns, Entropy, and EEG. Entropy 2014, 16, 6212–6239. [Google Scholar] [CrossRef]
- Cuesta-Frau, D.; Miró-Martínez, P.; Oltra-Crespo, S.; Jordán-Núñez, J.; Vargas, B.; Vigil, L. Classification of glucose records from patients at diabetes risk using a combined permutation entropy algorithm. Comput. Meth. Programs Biomed. 2018, 165, 197–204. [Google Scholar] [CrossRef]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Statist. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Li, D.; Li, X.; Liang, Z.; Voss, L.J.; Sleigh, J.W. Multiscale permutation entropy analysis of EEG recordings during sevoflurane anesthesia. J. Neural Eng. 2010, 7, 046010. [Google Scholar] [CrossRef]
- Liu, T.; Yao, W.; Wu, M.; Shi, Z.; Wang, J.; Ning, X. Multiscale permutation entropy analysis of electrocardiogram. Physica A 2017, 471, 492–498. [Google Scholar] [CrossRef]
- Tao, M.; Poskuviene, K.; Alkayem, N.; Cao, M.; Ragulskis, M. Permutation Entropy Based on Non-Uniform Embedding. Entropy 2018, 20, 612. [Google Scholar] [CrossRef]
- Fadlallah, B.; Chen, B.; Keil, A.; Príncipe, J. Weighted-permutation entropy: A complexity measure for time series incorporating amplitude information. Phys. Rev. E 2013, 87, 022911. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Initial Motif | Admissible Next Motifs | Forbidden Next Motifs |
|---|---|---|
| Class A | Class B | Classification |
|---|---|---|
| Transition Probabilities | Transition Probabilities | Accuracy (%) |
| Class A | Class B | Classification |
|---|---|---|
| Transition Probabilities | Transition Probabilities | Accuracy (%) |
| (Figure 6) | ||
| (Figure 7) |
| Class A | Class B | Classification |
|---|---|---|
| Transition Probabilities | Transition Probabilities | Accuracy (%) |
| Record | (0,1,2) | (0,2,1) | (1,0,2) | (1,2,0) | (2,1,0) | (2,0,1) |
|---|---|---|---|---|---|---|
| Control00 | 0.4058 | 0.0836 | 0.0941 | 0.1255 | 0.1548 | 0.1359 |
| Control01 | 0.5376 | 0.0899 | 0.0836 | 0.0878 | 0.1192 | 0.0815 |
| Control02 | 0.3849 | 0.0753 | 0.0836 | 0.1025 | 0.2426 | 0.1108 |
| Control03 | 0.3870 | 0.0732 | 0.0878 | 0.1129 | 0.2092 | 0.1297 |
| Control04 | 0.3242 | 0.1276 | 0.1255 | 0.1171 | 0.1903 | 0.1150 |
| Control05 | 0.3598 | 0.0962 | 0.0983 | 0.1213 | 0.2008 | 0.1234 |
| Control06 | 0.3912 | 0.0815 | 0.0648 | 0.1401 | 0.1987 | 0.1234 |
| Control07 | 0.3410 | 0.1004 | 0.1317 | 0.0815 | 0.2322 | 0.1129 |
| Control08 | 0.3368 | 0.0941 | 0.0983 | 0.1171 | 0.2301 | 0.1234 |
| Control09 | 0.3159 | 0.1171 | 0.1255 | 0.1234 | 0.1841 | 0.1338 |
| Control10 | 0.4560 | 0.0920 | 0.0962 | 0.1129 | 0.1276 | 0.1150 |
| Control11 | 0.3556 | 0.1004 | 0.1171 | 0.1213 | 0.1694 | 0.1359 |
| Control12 | 0.5334 | 0.0732 | 0.0753 | 0.0899 | 0.1380 | 0.0899 |
| Control13 | 0.2615 | 0.1066 | 0.1234 | 0.1317 | 0.2301 | 0.1464 |
| Control14 | 0.4058 | 0.0836 | 0.0941 | 0.1255 | 0.1548 | 0.1359 |
| Control15 | 0.4518 | 0.0774 | 0.0878 | 0.1276 | 0.1192 | 0.1359 |
| Mean | 0.3905 | 0.0920 | 0.0992 | 0.1149 | 0.1813 | 0.1218 |
| StdDev | 0.0751 | 0.0157 | 0.0198 | 0.0165 | 0.0421 | 0.0174 |
| Record | (0,1,2) | (0,2,1) | (1,0,2) | (1,2,0) | (2,1,0) | (2,0,1) |
|---|---|---|---|---|---|---|
| Pathological00 | 0.4054 | 0.0838 | 0.0920 | 0.1085 | 0.1938 | 0.1161 |
| Pathological01 | 0.3260 | 0.0960 | 0.1036 | 0.1207 | 0.2244 | 0.1290 |
| Pathological02 | 0.4496 | 0.0659 | 0.0683 | 0.1163 | 0.1822 | 0.1175 |
| Pathological03 | 0.3405 | 0.0980 | 0.0926 | 0.1089 | 0.2534 | 0.1062 |
| Pathological04 | 0.2191 | 0.1271 | 0.1348 | 0.1374 | 0.2347 | 0.1465 |
| Pathological05 | 0.2736 | 0.0979 | 0.1083 | 0.1348 | 0.2407 | 0.1444 |
| Pathological06 | 0.3805 | 0.0979 | 0.0992 | 0.1204 | 0.1793 | 0.1224 |
| Pathological07 | 0.3331 | 0.0950 | 0.0950 | 0.1347 | 0.2072 | 0.1347 |
| Pathological08 | 0.4361 | 0.0711 | 0.0660 | 0.1219 | 0.1873 | 0.1174 |
| Pathological09 | 0.3103 | 0.1065 | 0.1019 | 0.1287 | 0.2283 | 0.1241 |
| Pathological10 | 0.4342 | 0.0756 | 0.0919 | 0.0968 | 0.1881 | 0.1131 |
| Pathological11 | 0.3447 | 0.1224 | 0.1155 | 0.1265 | 0.1716 | 0.1190 |
| Pathological12 | 0.3590 | 0.0972 | 0.1072 | 0.1054 | 0.2154 | 0.1154 |
| Pathological13 | 0.4056 | 0.0838 | 0.0943 | 0.0950 | 0.2154 | 0.1056 |
| Mean | 0.3584 | 0.0942 | 0.0979 | 0.1183 | 0.2087 | 0.1222 |
| StdDev | 0.0657 | 0.0174 | 0.0173 | 0.0137 | 0.0255 | 0.0125 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuesta-Frau, D.; Molina-Picó, A.; Vargas, B.; González, P. Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy. Entropy 2019, 21, 1013. https://doi.org/10.3390/e21101013
Cuesta-Frau D, Molina-Picó A, Vargas B, González P. Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy. Entropy. 2019; 21(10):1013. https://doi.org/10.3390/e21101013
Chicago/Turabian StyleCuesta-Frau, David, Antonio Molina-Picó, Borja Vargas, and Paula González. 2019. "Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy" Entropy 21, no. 10: 1013. https://doi.org/10.3390/e21101013
APA StyleCuesta-Frau, D., Molina-Picó, A., Vargas, B., & González, P. (2019). Permutation Entropy: Enhancing Discriminating Power by Using Relative Frequencies Vector of Ordinal Patterns Instead of Their Shannon Entropy. Entropy, 21(10), 1013. https://doi.org/10.3390/e21101013