Economic Complexity Based Recommendation Enhance the Efficiency of the Belt and Road Initiative


Abstract
1. Introduction
2. Materials and Methods
2.1. International Trade Network
2.2. RCA
2.3. Diffusion Based Recommender Algorithms
2.3.1. Standard
2.3.2. Preferential Diffusion
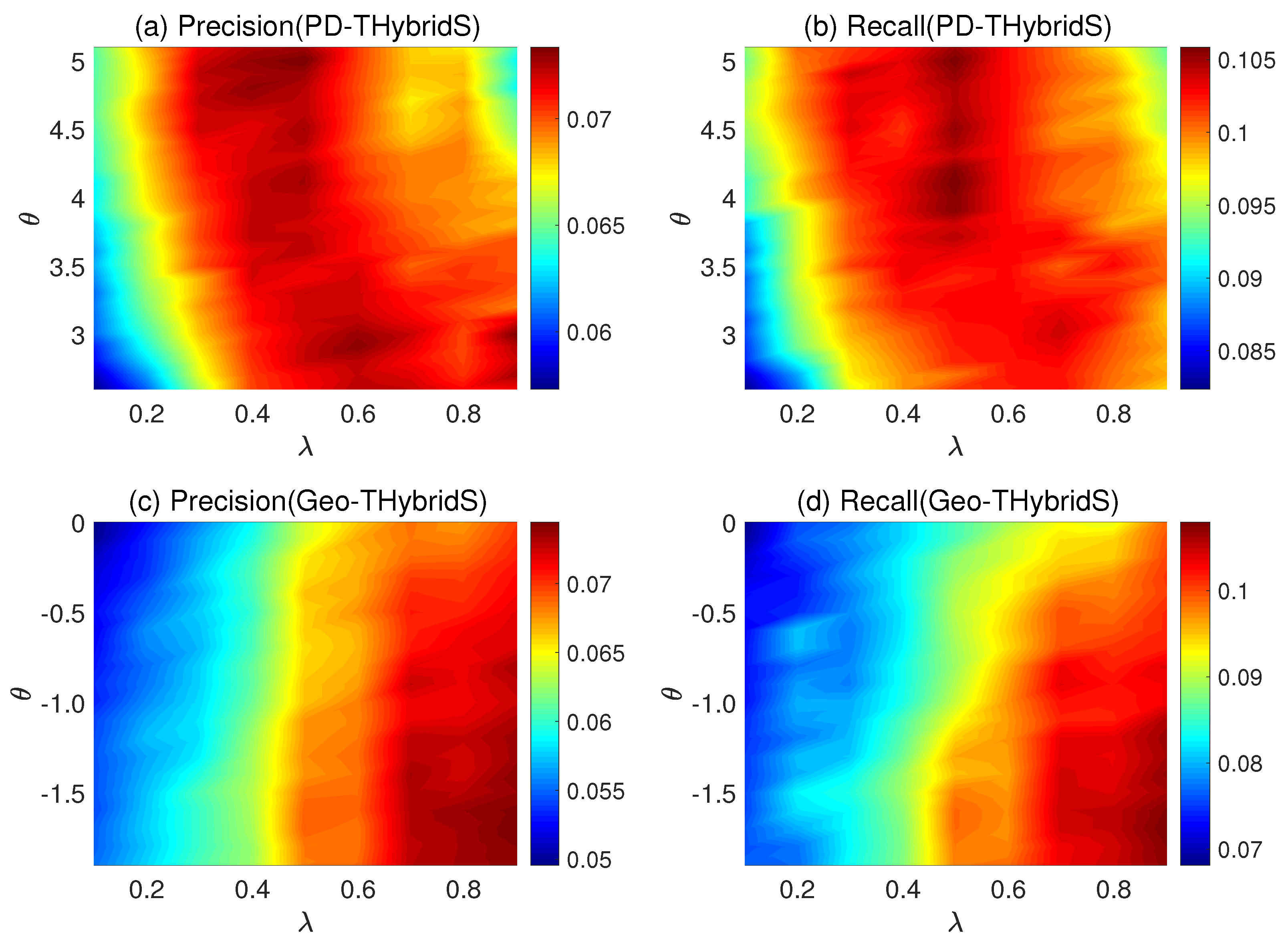
2.3.3. Geography
2.4. Recall
2.5. Fitness and Complexity Metrics
3. Results
3.1. Comparison of Recommendation Algorithms
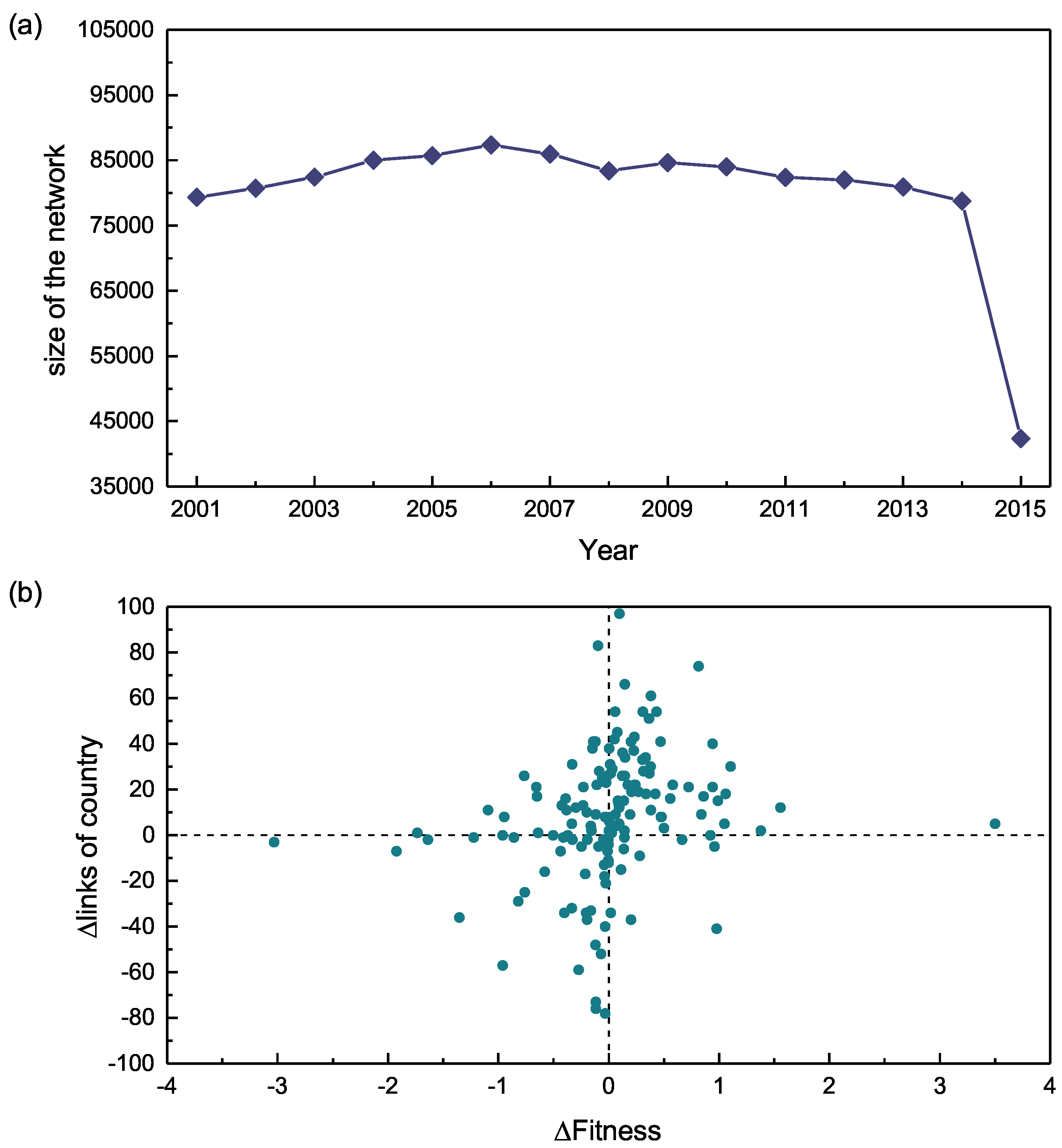
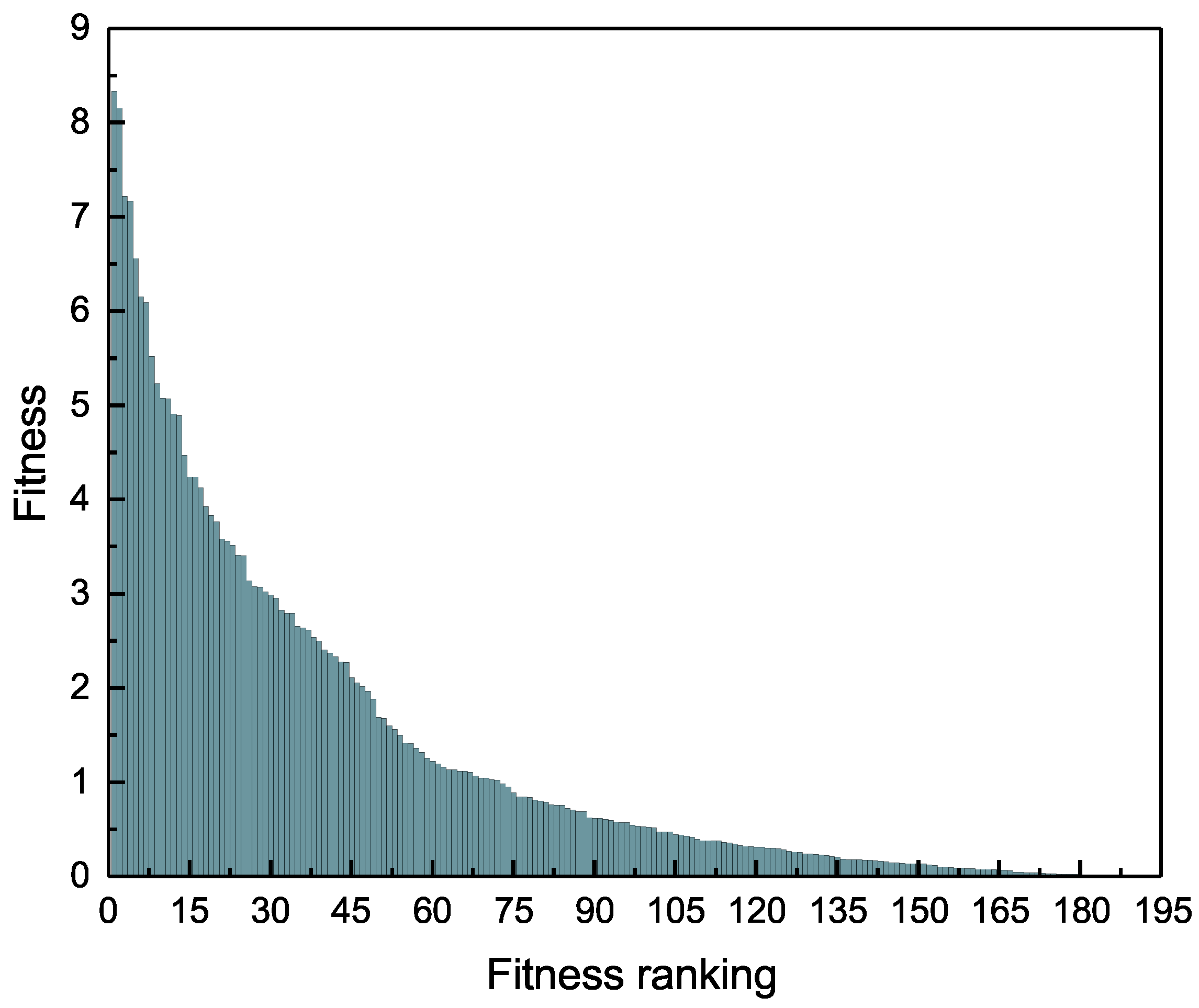
3.2. The Relationship between Fitness and Links
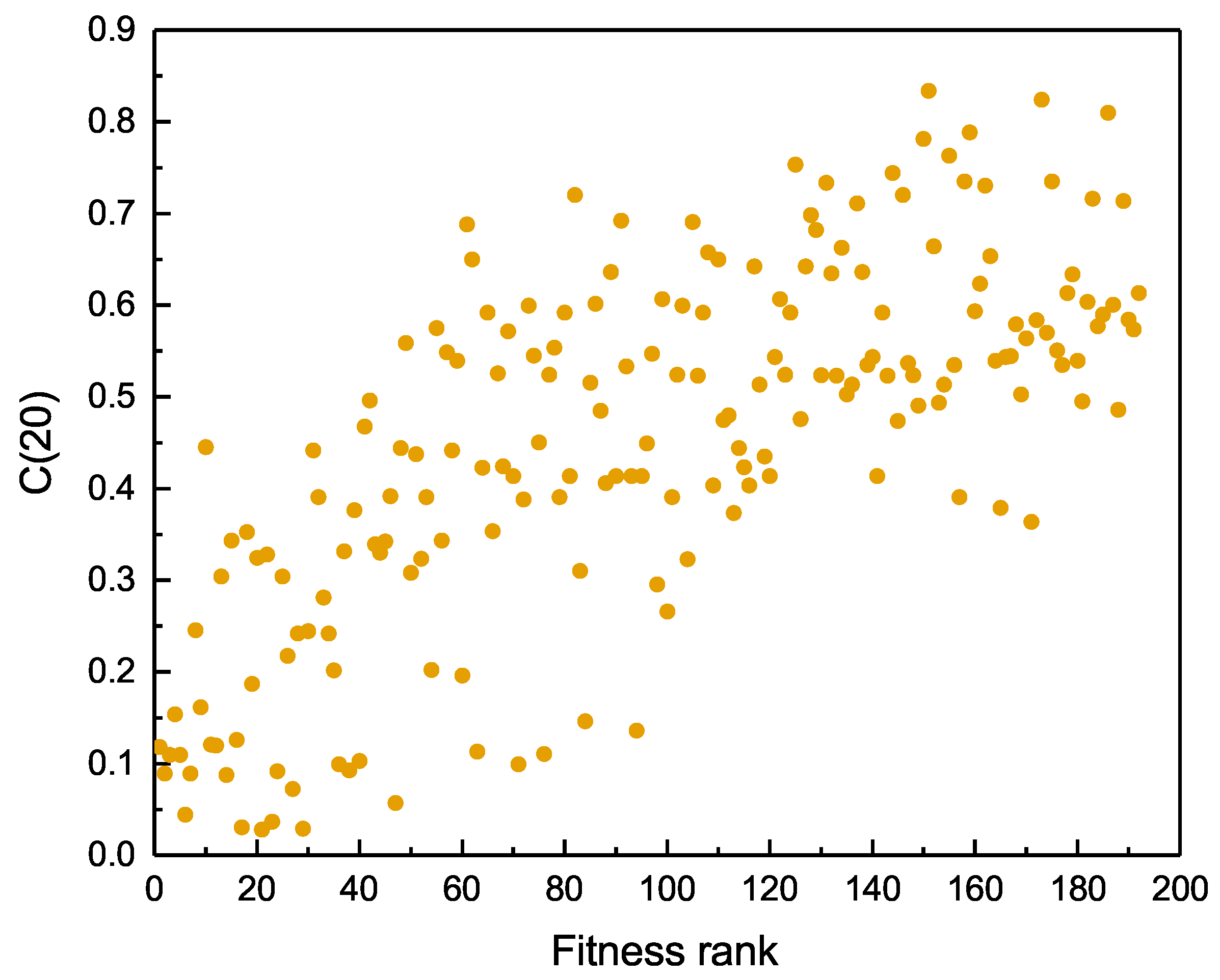
3.3. Complexity Metric
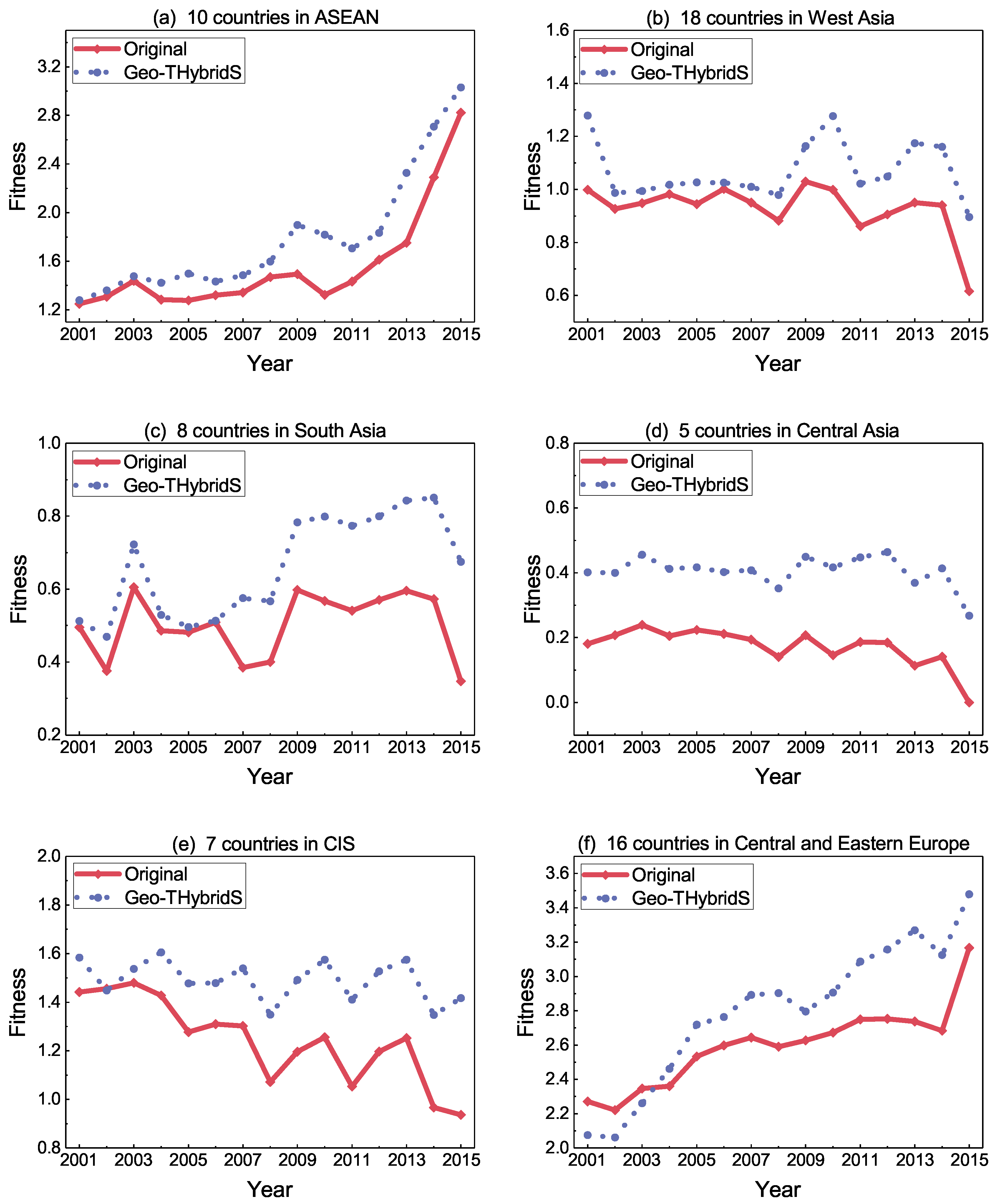
3.4. The Belt and Road Initiative
Fitness Evolution
4. Discussion
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Liu, H.; Wuzhati, Y.; Wang, C. Impacts of the Belt and Road Initiative on the spatial pattern of territory development in China. Prog. Geogr. 2015, 34, 2080–2087. [Google Scholar]
- Fu, X.M.; Chen, H.X.; Xue, Z.K. Construction of the Belt and Road Trade Cooperation Network from the Multi-Distances Perspective. Sustainability 2018, 10, 1439. [Google Scholar] [CrossRef]
- Ferdinand, P. Westward ho—The China dream and ‘one belt, one road’: Chinese foreign policy under Xi Jinping. Int. Aff. 2016, 92, 941–957. [Google Scholar] [CrossRef]
- Sarker, M.N.I.; Hossin, M.A.; Yin, X.; Sarkar, M.K. One Belt One Road Initiative of China: Implication for Future of Global Development. Mod. Econ. 2018, 9, 623–638. [Google Scholar] [CrossRef]
- Zou, J.; Liu, C.; Yin, G.; Tang, Z. Spatial patterns and economic effects of China’s trade with countries along the Belt and Road. Prog. Geogr. 2015, 34, 598–605. [Google Scholar]
- Wang, Y. Offensive for defensive: The belt and road initiative and China’s new grand strategy. Pac. Rev. 2016, 29, 1–9. [Google Scholar] [CrossRef]
- Schmitt-Grohé, S.; Uribe, M. How Important are Terms-Of-Trade Shocks? Int. Econ. Rev. 2018, 59, 85–111. [Google Scholar] [CrossRef]
- Bhattacharya, K.; Mukherjee, G.; Saramäki, J.; Kaski, K.; Manna, S.S. The International Trade Network: Weighted network analysis and modelling. J. Stat. Mech. Theory Exp. 2007, 41, 139–147. [Google Scholar] [CrossRef]
- Waugh, M.E. International Trade and Income Differences. Am. Econ. Rev. 2010, 100, 2093–2124. [Google Scholar] [CrossRef]
- Fagiolo, G. The international-trade network: Gravity equations and topological properties. J. Econ. Interact. Coord. 2010, 5, 1–25. [Google Scholar] [CrossRef]
- Hausmann, R.; Hwang, J.; Rodrik, D. What you export matters. J. Econ. Growth 2007, 12, 1–25. [Google Scholar] [CrossRef]
- Cristelli, M.; Tacchella, A.; Pietronero, L. An overview of the new frontiers of economic complexity. In Econophysics of Agent-Based Models; Springer: Berlin, Germany, 2014; pp. 147–159. [Google Scholar]
- Ellis, M.; Durand, H.; Christofides, P.D. A tutorial review of economic model predictive control methods. J. Process Control 2014, 24, 1156–1178. [Google Scholar] [CrossRef]
- Chaney, T. The network structure of international trade. Am. Econ. Rev. 2014, 104, 3600–3634. [Google Scholar] [CrossRef]
- Almog, A.; Squartini, T.; Garlaschelli, D. A GDP-driven model for the binary and weighted structure of the International Trade Network. New J. Phys. 2015, 17, 013009. [Google Scholar] [CrossRef]
- Hidalgo, C.A.; Klinger, B.; Barabási, A.L.; Hausmann, R. The Product Space Conditions the Development of Nations. Science 2007, 40, 482–487. [Google Scholar] [CrossRef] [PubMed]
- Anidorifón, L.; Santosgago, J.; Caeirorodríguez, M.; Fernándeziglesias, M.; Míguezpérez, R.; Cañasrodríguez, A.; Alonsororís, V.; Garcíaalonso, J.; Pérezrodríguez, R.; Gómezcarballa, M. Recommender Systems. Commun. ACM 2015, 40, 56–58. [Google Scholar]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Rauch, J.E. Networks versus markets in international trade. Nber Work. Pap. 1996, 48, 7–35. [Google Scholar]
- Krugman, P.R. Geography and Trade; MIT Press: Cambridge, CA, USA, 1993; pp. 1–156. [Google Scholar]
- Liu, Y.; Pham, T.A.N.; Cong, G.; Yuan, Q. An experimental evaluation of point-of-interest recommendation in location-based social networks. Proc. VLDB Endow. 2017, 10, 1010–1021. [Google Scholar] [CrossRef]
- Gaulier, G.; Zignago, S. BACI: International Trade Database at the Product-Level. The 1994–2007 Version; Working Papers 2010–2023. CEPII, 2010. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1994500 (accessed on 3 April 2018).
- Balassa, B. Trade liberalisation and “revealed” comparative advantage. Manch. Sch. 1965, 33, 99–123. [Google Scholar] [CrossRef]
- Zhou, T.; Kuscsik, Z.; Liu, J.G.; Medo, M.; Wakeling, J.R.; Zhang, Y.C. Solving the apparent diversity-accuracy dilemma of recommender systems. Proc. Natl. Acad. Sci. USA 2010, 107, 4511–4515. [Google Scholar] [CrossRef] [PubMed]
- Zeng, A.; Gualdi, S.; Medo, M.; Zhang, Y.C. Trend prediction in temporal bipartite networks: The case of movielens, netflix, and digg. Adv. Complex Syst. 2013, 16, 1350024. [Google Scholar] [CrossRef]
- Vidmer, A.; Zeng, A.; Medo, M.; Zhang, Y.C. Prediction in complex systems: The case of the international trade network. Phys. Stat. Mech. Appl. 2015, 436, 188–199. [Google Scholar] [CrossRef]
- Zeng, W.; Zeng, A.; Shang, M.S.; Zhang, Y.C. Information filtering in sparse online systems: Recommendation via semi-local diffusion. PLoS ONE 2013, 8, e79354. [Google Scholar] [CrossRef] [PubMed]
- Caldarelli, G.; Cristelli, M.; Gabrielli, A.; Pietronero, L.; Scala, A.; Tacchella, A. Ranking and clustering countries and their products; a network analysis. arXiv, 2011; arXiv:1108.2590. [Google Scholar]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. A new metrics for countries’ fitness and products’ complexity. Sci. Rep. 2012, 2, 723–730. [Google Scholar] [CrossRef] [PubMed]
- Pietronero, L.; Cristelli, M.; Gabrielli, A.; Mazzilli, D.; Pugliese, E.; Tacchella, A.; Zaccaria, A. Economic Complexity: “Buttarla in caciara” vs a constructive approach. arXiv, 2017; arXiv:1709.05272. [Google Scholar]
- Cristelli, M.; Gabrielli, A.; Tacchella, A.; Caldarelli, G.; Pietronero, L. Measuring the intangibles: A metrics for the economic complexity of countries and products. PLoS ONE 2013, 8, e70726. [Google Scholar] [CrossRef] [PubMed]
- Pugliese, E.; Zaccaria, A.; Pietronero, L. On the convergence of the Fitness-Complexity Algorithm. Eur. Phys. J. Spec. Top. 2016, 225, 1893–1911. [Google Scholar] [CrossRef]
- Liao, H.; Vidmer, A. A Comparative Analysis of the Predictive Abilities of Economic Complexity Metrics Using International Trade Network. Complexity 2018, 2018, 1–12. [Google Scholar] [CrossRef]
- Hidalgo, C.A.; Hausmann, R. The building blocks of economic complexity. Proc. Natl. Acad. Sci. USA 2009, 106, 10570–10575. [Google Scholar] [CrossRef] [PubMed]
- Romer, P.M. Endogenous technological change. J. Polit. Econ. 1990, 98, S71–S102. [Google Scholar] [CrossRef]
- Grossman, G.M.; Helpman, E. Quality ladders in the theory of growth. Rev. Econ. Stud. 1991, 58, 43–61. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | P(20) | R(20) | |
|---|---|---|---|
| ProbS | - | 0.067 | 0.094 |
| HeatS | - | 0.063 | 0.095 |
| TprobS | - | 0.067 | 0.096 |
| THybridS | - | 0.066 | 0.095 |
| PD-ProbS | 2.20 | 0.076 | 0.108 |
| PD-HeatS | 2.10 | 0.065 | 0.099 |
| PD-TprobS | 1.80 | 0.070 | 0.098 |
| PD-THybridS | 3.90 | 0.072 | 0.104 |
| Geo-ProbS | −1.90 | 0.075 | 0.106 |
| Geo-HeatS | −0.50 | 0.067 | 0.100 |
| Geo-TprobS | −2.00 | 0.074 | 0.104 |
| Geo-THybridS | −1.80 | 0.075 | 0.108 |
| Country | Recommended Products |
|---|---|
| 1 country of East Asia | Tugs, special purpose vessels and floating structures |
| Oil seeds and oleaginous fruits | |
| Sheep and lamb skin without the wool, raw | |
| Yarn of regenerated fibres, put up for retail sale | |
| Imitation jewellery | |
| 10 countries of ASEAN | Crystals, and parts of electronic components |
| Base metals and cermets, unwrought | |
| Sheep and lamb skin with the wool on | |
| Ores and concentrates of other non-ferrous base metals | |
| Briquettes, ovoids, from coal, lignite or peat | |
| 18 countries of West Asia | Chemical elements |
| Poultry, live | |
| Groundnut (peanut) oil | |
| Discontinuous synthetic fibres | |
| Refined sugar etc | |
| 8 countries of South Asia | Natural honey |
| Sawlogs and veneer logs, of non-coniferous species | |
| Cotton linters | |
| Distilled alcoholic beverages | |
| cellulosic pulps | |
| 5 countries of Central Asia | Wood packing cases, boxes, cases, crates, etc., complete |
| Builders’ carpentry and joinery (including prefabricated) | |
| Fabrics woven of sheep’s or lambs’ wool or of fine hair | |
| Glass, etc, surface-ground, but no further worked | |
| Railway or tramway sleepers (ties) of wood | |
| 7 countries of CIS | Copper ore and concentrates; copper matte; cement copper |
| Other natural abrasives | |
| Cigarettes | |
| Animals oils, fats and greases | |
| Vegetable textile fibres | |
| 16 countries of Central and Eastern Europe | Tugs, special purpose vessels and floating structures |
| Parts of and accessories for musical instruments; metronomes | |
| Anti-knock preparation, anti-corrosive; viscosity improvers | |
| Batteries and electric accumulators, and parts thereof | |
| Precious and semi-precious stones, not mounted, set or strung |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liao, H.; Huang, X.-M.; Vidmer, A.; Zhang, Y.-C.; Zhou, M.-Y. Economic Complexity Based Recommendation Enhance the Efficiency of the Belt and Road Initiative. Entropy 2018, 20, 718. https://doi.org/10.3390/e20090718
Liao H, Huang X-M, Vidmer A, Zhang Y-C, Zhou M-Y. Economic Complexity Based Recommendation Enhance the Efficiency of the Belt and Road Initiative. Entropy. 2018; 20(9):718. https://doi.org/10.3390/e20090718
Chicago/Turabian StyleLiao, Hao, Xiao-Min Huang, Alexandre Vidmer, Yi-Cheng Zhang, and Ming-Yang Zhou. 2018. "Economic Complexity Based Recommendation Enhance the Efficiency of the Belt and Road Initiative" Entropy 20, no. 9: 718. https://doi.org/10.3390/e20090718
APA StyleLiao, H., Huang, X.-M., Vidmer, A., Zhang, Y.-C., & Zhou, M.-Y. (2018). Economic Complexity Based Recommendation Enhance the Efficiency of the Belt and Road Initiative. Entropy, 20(9), 718. https://doi.org/10.3390/e20090718