Using the Data Agreement Criterion to Rank Experts’ Beliefs


Abstract
1. Introduction
2. Expert-Data (Dis)Agreement
2.1. Data Agreement Criterion
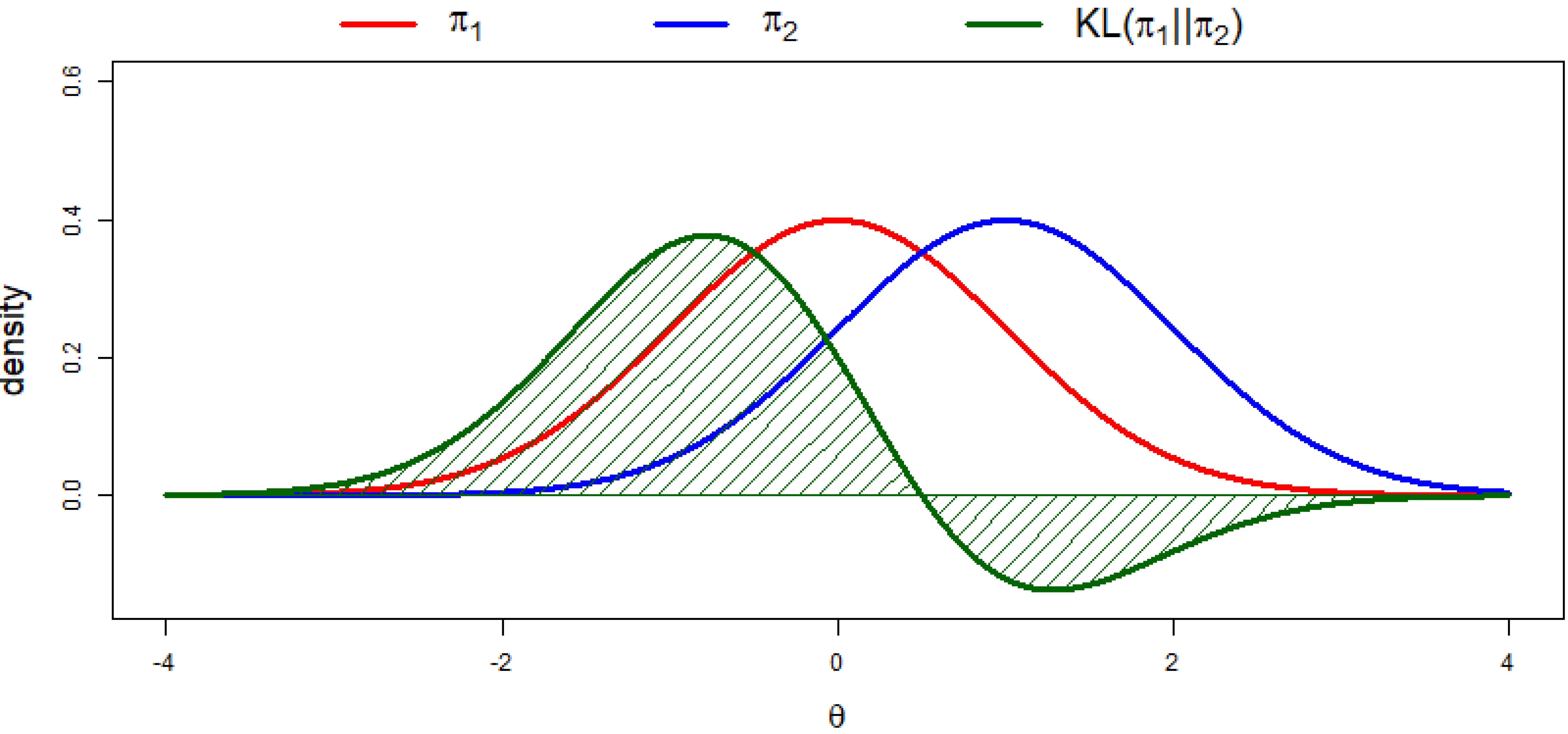
2.1.1. Kullback–Leibler Divergence
2.1.2. DAC
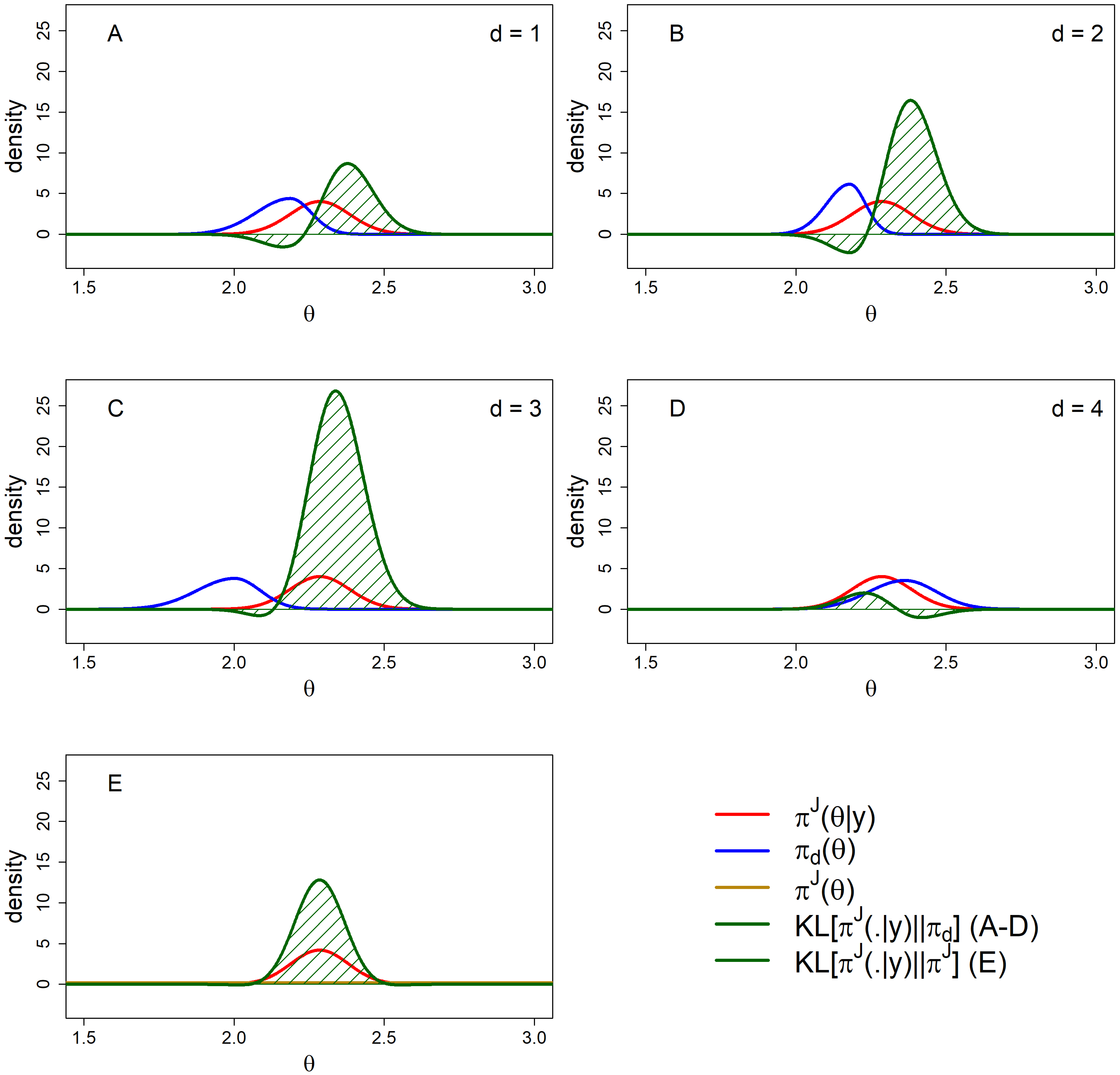
2.1.3. Extension to Multiple Experts
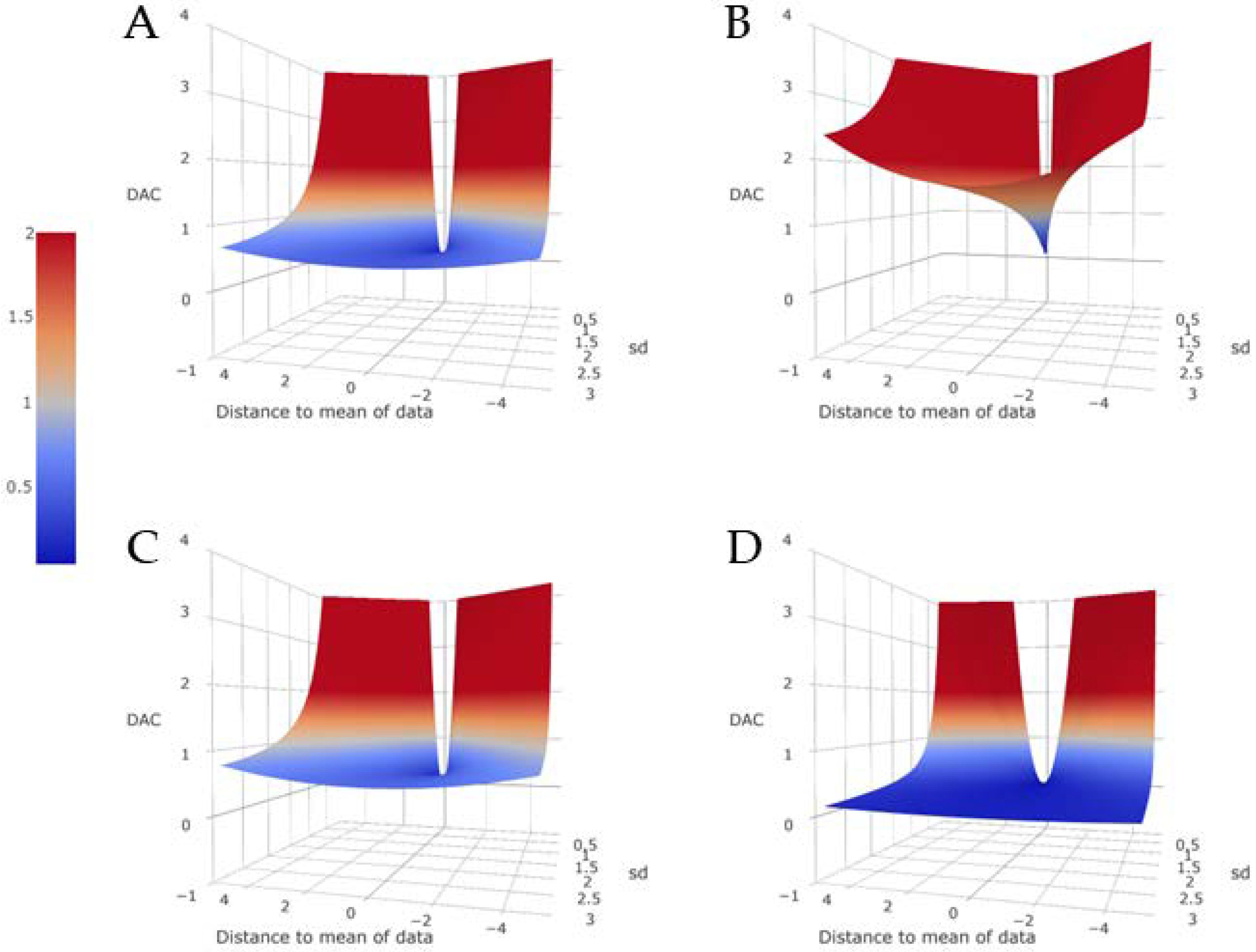
2.1.4. Influence of the Benchmark
2.2. Comparison to Ranking by the Bayes Factor
2.2.1. Marginal Likelihood
2.2.2. Bayes Factor
2.2.3. Benchmark Model
2.3. DAC Versus BF
3. Empirical Example
3.1. Elicitation Procedure
3.2. Ranking the Experts
4. Discussion
- Use instead of BF.
- Specify such that it serves as a reference posterior and drop the association between and .
- Consider whether a meaningful benchmark can be determined. If not, only use and compare experts with each other and not with a benchmark.
- Carrying out a sensitivity analysis is always recommendable, even more so if benchmarks are used.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Gelman, A.; Carlin, J.B.; Stern, H.S.; Dunson, D.B.; Vehtari, A.; Rubin, D.B. Bayesian Data Analysis; CRC Press: Bocaton, FL, USA, 2013; ISBN 1-4398-4095-4. [Google Scholar]
- Lynch, S.M. Introduction to Applied Bayesian Statistics and Estimation for Social Scientists; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2007; ISBN 0-387-71265-8. [Google Scholar]
- Zyphur, M.J.; Oswald, F.L.; Rupp, D.E. Bayesian probability and statistics in management research. J. Manag. 2013, 39, 5–13. [Google Scholar] [CrossRef]
- Bolsinova, M.; Hoijtink, H.; Vermeulen, J.A.; Béguin, A. Using expert knowledge for test linking. Psychol. Methods 2017, 22, 705. [Google Scholar] [CrossRef] [PubMed]
- O’Hagan, A.; Buck, C.E.; Daneshkhah, A.; Eiser, J.R.; Garthwaite, P.H.; Jenkinson, D.J.; Oakley, J.E.; Rakow, T. Uncertain Judgements: Eliciting Experts’ Probabilities; John Wiley & Sons: Hoboken, NJ, USA, 2006; ISBN 0-470-03330-4. [Google Scholar]
- Zondervan-Zwijnenburg, M.; van de Schoot-Hubeek, W.; Lek, K.; Hoijtink, H.; van de Schoot, R. Application and evaluation of an expert judgment elicitation procedure for correlations. Front. Psychol. 2017, 8, 90. [Google Scholar] [CrossRef] [PubMed]
- Bousquet, N. Diagnostics of prior-data agreement in applied Bayesian analysis. J. Appl. Stat. 2008, 35, 1011–1029. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Cooke, R. Experts in Uncertainty: Opinion and Subjective Probability in Science; Oxford University Press: Toronto, ON, Canada, 1991; ISBN 0-19-506465-8. [Google Scholar]
- Quigley, J.; Colson, A.; Aspinall, W.; Cooke, R.M. Elicitation in the classical model. In Elicitation; Dias, L.C., Morton, A., Quigley, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 15–36. [Google Scholar]
- Walley, R.J.; Smith, C.L.; Gale, J.D.; Woodward, P. Advantages of a wholly Bayesian approach to assessing efficacy in early drug development: A case study. Pharm. Stat. 2015, 14, 205–215. [Google Scholar] [CrossRef] [PubMed]
- Fu, S.; Celeux, G.; Bousquet, N.; Couplet, M. Bayesian inference for inverse problems occurring in uncertainty analysis. Int. J. Uncertain. Quantif. 2015, 5, 73–98. [Google Scholar] [CrossRef]
- Fu, S.; Couplet, M.; Bousquet, N. An adaptive kriging method for solving nonlinear inverse statistical problems. Environmetrics 2017, 28, e2439. [Google Scholar] [CrossRef]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Koch, G.G. Intraclass correlation coefficient. Encycl. Stat. Sci. 2004, 6. [Google Scholar] [CrossRef]
- Shrout, P.E.; Fleiss, J.L. Intraclass correlations: Uses in assessing rater reliability. Psychol. Bull. 1979, 86, 420. [Google Scholar] [CrossRef] [PubMed]
- Brier, G.W. Verification of forecasts expressed in terms of probability. Mon. Weather Rev. 1950, 78, 1–3. [Google Scholar] [CrossRef]
- Barons, M.J.; Wright, S.K.; Smith, J.Q. Eliciting probabilistic judgements for integrating decision support systems. In Elicitation; Dias, L.C., Morton, A., Quigley, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2018; pp. 445–478. [Google Scholar]
- Kass, R.E.; Raftery, A.E. Bayes factors. J. Am. Stat. Assoc. 1995, 90, 773–795. [Google Scholar] [CrossRef]
- Liu, C.C.; Aitkin, M. Bayes factors: Prior sensitivity and model generalizability. J. Math. Psychol. 2008, 52, 362–375. [Google Scholar] [CrossRef]
- Wasserman, L. Bayesian model selection and model averaging. J. Math. Psychol. 2000, 44, 92–107. [Google Scholar] [CrossRef] [PubMed]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference. J. R. Stat. Soc. Ser. B Methodol. 1979, 41, 113–147. [Google Scholar]
- Irony, T.; Singpurwalla, N. Noninformative priors do not exist: A discussion with jose m. bernardo. J. Stat. Inference Plan. 1997, 65, 159–189. [Google Scholar] [CrossRef]
- Berger, J.O.; Bernardo, J.M. Estimating a product of means: Bayesian analysis with reference priors. J. Am. Stat. Assoc. 1989, 84, 200–207. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Smith, A.F. Bayesian Theory; John Wiley & Sons: New York, NY, USA, 1994. [Google Scholar]
- Berger, J.O.; Bernardo, J.M.; Sun, D. The formal definition of reference priors. Ann. Stat. 2009, 37, 905–938. [Google Scholar] [CrossRef]
- Gelman, A.; Simpson, D.; Betancourt, M. The prior can often only be understood in the context of the likelihood. Entropy 2017, 19, 555. [Google Scholar] [CrossRef]
- Kass, R.E.; Wasserman, L. The selection of prior distributions by formal rules. J. Am. Stat. Assoc. 1996, 91, 1343–1370. [Google Scholar] [CrossRef]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. Ser. Math. Phys. Sci. 1946, 186, 453–461. [Google Scholar] [CrossRef]
- Jeffreys, S.H. Theory of Probability; Oxford University Press: London, UK, 1961. [Google Scholar]
- Jaynes, E.T. On the rationale of maximum-entropy methods. Proc. IEEE 1982, 70, 939–952. [Google Scholar] [CrossRef]
- Yang, R.; Berger, J.O. A Catalog of Noninformative Priors; Institute of Statistics and Decision Sciences, Duke University: Durham, NC, USA, 1996. [Google Scholar]
- Akaike, H. Information theory as an extension of the maximum likelihood principle. In Second International Symposium on Information Theory; Akademiai Kaido: Budapest, Hungary, 1973; pp. 267–281. [Google Scholar]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2002. [Google Scholar]
- Morey, R.D.; Romeijn, J.-W.; Rouder, J.N. The philosophy of Bayes factors and the quantification of statistical evidence. J. Math. Psychol. 2016, 72, 6–18. [Google Scholar] [CrossRef]
- Raftery, A.E. Approximate Bayes factors and accounting for model uncertainty in generalised linear models. Biometrika 1996, 83, 251–266. [Google Scholar] [CrossRef]
- Dirac, P.A.M. The Principles of Quantum Mechanics; Clarendon Press: Oxford, UK, 1947; ISBN 0-19-852011-5. [Google Scholar]
- Barber, D. Bayesian Reasoning and Machine Learning; Cambridge University Press: Cambridge, UK, 2012; ISBN 0-521-51814-8. [Google Scholar]
- Van de Schoot, R.; Griffioen, E.; Winter, S. Dealing with imperfect elicitation results. In Expert Judgement in Risk and Decision Analysis; Bedford, T., French, S., Hanea, A.M., Nane, G.F., Eds.; DRDC Centre for Security Studies: Ottawa, ON, Canada, 2018. [Google Scholar]
- Veen, D.; Stoel, D.; Zondervan-Zwijnenburg, M.; van de Schoot, R. Proposal for a Five-Step Method to Elicit Expert Judgement. Front. Psychol. 2017, 8, 2110. [Google Scholar] [CrossRef] [PubMed]
- Fernández, C.; Steel, M.F. On Bayesian modeling of fat tails and skewness. J. Am. Stat. Assoc. 1998, 93, 359–371. [Google Scholar]
- Plummer, M. Rjags: Bayesian Graphical Models Using MCMC. In Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC 2003), Vienna, Austria, 20–22 March 2003. [Google Scholar]
- Gelman, A.; Rubin, D.B. Inference from iterative simulation using multiple sequences. Stat. Sci. 1992, 7, 457–472. [Google Scholar] [CrossRef]
- Stan Development Team. RStan: The R Interface to Stan. Available online: https://cran.r-project.org/web/packages/rstan/ (accessed on 8 August 2018).
- Gronau, Q.F.; Singmann, H. Bridgesampling: Bridge Sampling for Marginal Likelihoods and Bayes Factors. Available online: https://cran.r-project.org/web/packages/bridgesampling/ (accessed on 8 August 2018).
- Deza, M.M.; Deza, E. Encyclopedia of distances. In Encyclopedia of Distances; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Expert 1 | 2.15 | 0.09 | 0.78 |
| Expert 2 | 2.16 | 0.07 | 0.82 |
| Expert 3 | 1.97 | 0.11 | 0.82 |
| Expert 4 | 2.35 | 0.11 | 0.94 |
| KL Divergence | DACd | DACd Ranking | ||||
|---|---|---|---|---|---|---|
| Expert 1 | 1.43 | 0.56 | 2 | 5.57 × 10−68 | 0.21 | 3 |
| Expert 2 | 2.86 | 1.12 | 3 | 6.82 × 10−68 | 0.17 | 2 |
| Expert 3 | 5.76 | 2.26 | 4 | 2.19 × 10−69 | 5.31 | 4 |
| Expert 4 | 0.19 | 0.07 | 1 | 1.72 × 10−67 | 0.07 | 1 |
| Benchmark | 2.55 | - | - | 1.16 × 10−68 | - | - |
| 1.43 | 1.42 | 1.37 | 1.42 | 1.42 | |
| 2.86 | 2.84 | 2.75 | 2.85 | 2.85 | |
| 5.76 | 5.75 | 5.67 | 5.76 | 5.77 | |
| 0.19 | 0.19 | 0.20 | 0.19 | 0.19 | |
| 2.55 | 3.93 | 4.18 | 6.46 | 8.76 | |
| 1.16 × 10−68 | 2.91 × 10−69 | 5.65 × 10−69 | 2.26 × 10−69 | 7.33 × 10−70 |
| Expert 1 | Expert 2 | Expert 3 | Expert 4 | |||||
|---|---|---|---|---|---|---|---|---|
| KL Ratio | BF | KL Ratio | BF | KL Ratio | BF | KL Ratio | BF | |
| Expert 1 | 1 | 1 | 0.50 | 0.82 | 0.25 | 25.42 | 7.63 | 0.32 |
| Expert 2 | 2.00 | 1.22 | 1 | 1 | 0.50 | 31.13 | 15.23 | 0.40 |
| Expert 3 | 4.03 | 0.04 | 2.02 | 0.03 | 1 | 1 | 30.75 | 0.01 |
| Expert 4 | 0.13 | 3.09 | 0.07 | 2.52 | 0.03 | 78.54 | 1 | 1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Veen, D.; Stoel, D.; Schalken, N.; Mulder, K.; Van de Schoot, R. Using the Data Agreement Criterion to Rank Experts’ Beliefs. Entropy 2018, 20, 592. https://doi.org/10.3390/e20080592
Veen D, Stoel D, Schalken N, Mulder K, Van de Schoot R. Using the Data Agreement Criterion to Rank Experts’ Beliefs. Entropy. 2018; 20(8):592. https://doi.org/10.3390/e20080592
Chicago/Turabian StyleVeen, Duco, Diederick Stoel, Naomi Schalken, Kees Mulder, and Rens Van de Schoot. 2018. "Using the Data Agreement Criterion to Rank Experts’ Beliefs" Entropy 20, no. 8: 592. https://doi.org/10.3390/e20080592
APA StyleVeen, D., Stoel, D., Schalken, N., Mulder, K., & Van de Schoot, R. (2018). Using the Data Agreement Criterion to Rank Experts’ Beliefs. Entropy, 20(8), 592. https://doi.org/10.3390/e20080592