Abstract
We demonstrate that questions of convergence and divergence regarding shapes of distributions can be carried out in a location- and scale-free environment. This environment is the class of probability density quantiles (pdQs), obtained by normalizing the composition of the density with the associated quantile function. It has earlier been shown that the pdQ is representative of a location-scale family and carries essential information regarding shape and tail behavior of the family. The class of pdQs are densities of continuous distributions with common domain, the unit interval, facilitating metric and semi-metric comparisons. The Kullback–Leibler divergences from uniformity of these pdQs are mapped to illustrate their relative positions with respect to uniformity. To gain more insight into the information that is conserved under the pdQ mapping, we repeatedly apply the pdQ mapping and find that further applications of it are quite generally entropy increasing so convergence to the uniform distribution is investigated. New fixed point theorems are established with elementary probabilistic arguments and illustrated by examples.
Keywords:
convergence in Lr norm; fixed point theorem; Kullback–Leibler divergence; relative entropy; semi-metric; uniformity testing MSC:
Primary 62E10; Secondary 62F03
1. Introduction
For each continuous location-scale family of distributions with square-integrable density, there is a probability density quantile (pdQ), which is an absolutely continuous distribution on the unit interval. Members of the class of such pdQs differ only in shape, and the asymmetry of their shapes can be partially ordered by their Hellinger distances or Kullback–Leibler divergences from the class of symmetric distributions on this interval. In addition, the tail behaviour of the original family can be described in terms of the boundary derivatives of its pdQ. Empirical estimators of the pdQs enable one to carry out inference, such as robust fitting of shape parameter families to data; details are in [1].
The Kullback–Leibler directed divergences and symmetrized divergence (KLD) of a pdQ with respect to the uniform distribution on [0,1] is investigated in Section 2, with remarkably simple numerical results, and a map of these divergences for some standard location-scale families is constructed. The ‘shapeless’ uniform distribution is the center of the pdQ universe, as is explained in Section 3, where it is found to be a fixed point. A natural question of interest is to find the invariant information of the pdQ mapping, that is, the conserved information after the pdQ mapping is applied. To this end, it is necessary to repeatedly apply the pdQ mapping to extract the information. Numerical studies indicate that further applications of the pdQ transformation are generally entropy increasing, so we investigate the convergence to uniformity of repeated applications of the pdQ transformation, by means of fixed point theorems for a semi-metric. As the pdQ mapping is not a contraction, the proofs of the fixed point theorems are through elementary probabilistic arguments rather than the classical contraction mapping principle. Our approach may shed light on future research in the fixed point theory. Further ideas are discussed in Section 4.
2. Divergences between Probability Density Quantiles
2.1. Definitions
Let denote the class of cumulative distribution functions (cdfs) on the real line and for each define the associated quantile function of F by , for When the random variable X has cdf F, we write . When the density function exists, we also write . We only discuss F as absolutely continuous with respect to Lebesgue measure, but the results can be extended to the discrete and mixture cases using suitable dominating measures.
Definition 1.
Let . For each , we follow [2] and define the quantile density function . Parzen called its reciprocal function the density quantile function. For , and U uniformly distributed on [0,1], assume is finite; that is, f is square integrable. Then, we can define the continuous pdQ of F by , . Let denote the class of all such F.
Not all f are square-integrable, and this requirement for the mapping means that is a proper subset of The advantages of working with s over fs are that they are free of location and scale parameters; they ignore flat spots in F and have a common bounded support. Moreover, often has a simpler formula than f; see Table 1 for examples.

Table 1.
Quantiles of some distributions, their pdQs and divergences. In general, we denote , but for the normal with density , we use . The logistic quantile function is only defined for , but it is symmetric about Lognormal() represents the lognormal distribution with shape parameter . The quantile function for the Pareto is for the Type II distribution with shape parameter a, and the pdQ is the same for Type I and Type II Pareto models.
Remark 1.
Given that a pdQ exists for a distribution with density f, then so does the cdf and quantile function associated with . Thus, a monotone transformation from to exists; it is simply . For the Power distribution of Table 1, , where , so For the normal distribution with parameters , it is In general, an explicit expression for that depends only on f or F (plus location-scale parameters) need not exist.
2.2. Divergence Map
Next, we evaluate and plot the [3] divergences from uniformity. The [3] divergence of density from density , when both have domain [0,1], is defined as
where U denotes a random variable with the uniform distribution on [0,1]. The divergences from uniformity are easily computed through
and
Kullback ([4], p. 6) interprets as the mean evidence in one observation for over ; it is also known as the relative entropy of with respect to . The terminology directed divergence for is also sometimes used ([4], p. 7) with ‘directed’ explained in ([4], pp. 82, 85); see also [5] in this regard.
Table 1 shows the quantile functions of some standard distributions, along with their pdQs, associated divergences and symmetrized divergence (KLD) defined by . The last measure was earlier introduced in a different form by [6].
Definition 2.
Given pdQs , , let . Then, d is a semi-metric on the space of pdQs; i.e., d satisfies all requirements of a metric except the triangle inequality. Introducing the coordinates , we can define the distance from uniformity of any by the Euclidean distance of from the origin , namely .
Remark 2.
This d does not satisfy the triangle inequality: for example, if and denote the uniform, normal and Cauchy pdQs, then but see Table 1 and Figure 1. However, d can provide an informative measure of distance from uniformity.
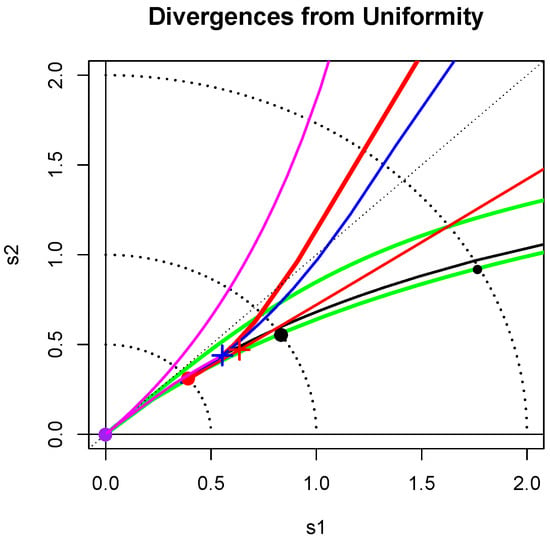
Figure 1.
Divergence from uniformity. The loci of points is shown for various standard families. The large disks correspond respectively to the symmetric families: uniform (purple), normal (red) and Cauchy (black). The crosses correspond to the asymmetric distributions: exponential (blue) and standard lognormal (red). More details are given in Section 2.2.
Figure 1 shows the loci of points for some continuous shape families. The light dotted arcs with radii 1/2, 1 and 2 are a guide to these distances from uniformity. The large discs in purple, red and black correspond to and . The blue cross at distance from the origin corresponds to the exponential distribution. Nearby is the standard lognormal point marked by a red cross. The lower red curve is nearly straight and is the locus of points corresponding to the lognormal shape family.
The chi-squared(), , family also appears as a red curve; it passes through the blue cross when , as expected, and heads toward the normal disc as The Gamma family has the same locus of points as the chi-squared family. The curve for the Weibull() family, for , is shown in blue; it crosses the exponential blue cross when . The Pareto(a) curve is shown in black. As a increases from 0, this line crosses the arcs distant 2 and 1 from the origin for and , respectively, and approaches the exponential blue cross as .
The Power(b) or Beta() for family is represented by the magenta curve of points moving toward the origin as b increases from 1/2 to 1, and then moving out towards the exponential blue cross as . For each choice of the locus of the Beta() pdQ divergences lies above the chi-squared red curve and mostly below the power(b) magenta curve; however, the U-shaped Beta distributions have loci above it.
The lower green line near the Pareto black curve gives the loci of root-divergences from uniformity of the Tukey() with , while the upper green curve corresponds to . It is known that the Tukey() distributions, with , are good approximations to Student’s t-distributions for provided is chosen properly. The same is true for their corresponding pdQs ([1], Section 3.2). For example, the pdQof with degrees of freedom is well approximated by the choice Its location is marked by the small black disk in Figure 1; it is of distance 2 from uniformity. The generalized Tukey distributions of [7] with two shape parameters also fill a large funnel shaped region (not marked on the map) emanating from the origin and just including the region bounded by the green curves of the Tukey symmetric distributions.
2.3. Uniformity Testing
There are numerous tests for uniformity, but as [8] points out, many are undermined by the common practice of estimating location-scale parameters of the null and/or alternative distributions when in fact it is assumed that these distributions are known exactly. In practice, this means that if a test for uniformity is preceded by a probability integral transformation including parameter estimates, then the actual levels of such tests will not be those nominated unless (often complicated and model-specific) adjustments are made. Examples of such adjustments are in [9,10].
Given a random sample of m independent, identically distributed (i.i.d.) variables, each from a distribution with density f, it is feasible to carry out a nonparametric test of uniformity by estimating the pdQ with a kernel density estimator and comparing it with the uniform density on [0,1] using any one of a number of metrics or semi-metrics. Consistent estimators for based on normalized reciprocals of the quantile density estimators derived in [11] are available and described in (Staudte [1], Section 2). Note that such a test compares an arbitrary uniform distribution with an arbitrary member of the location-scale family generated by f; it is a test of shape only. Preliminary work suggests that such a test is feasible. However, an investigation into such omnibus nonparametric testing procedures, including comparison with bootstrap and other kernel density based techniques found in the literature, such as [12,13,14,15,16,17], is beyond the scope of this work.
3. Convergence of Density Shapes to Uniformity via Fixed Point Theorems
The transformation of Definition 1 is quite powerful, removing location and scale and moving the distribution from the support of f to the unit interval. A natural question of interest is to find the information in a density that is invariant after the pdQ mapping is applied. To this end, it is necessary to repeatedly apply the pdQ mapping to extract the information. Examples suggest that another application of the transformation leaves less information about f in and hence it is closer to the uniform density. Furthermore, with n iterations for , it seems that no information can be conserved after repeated *-transformation so we would expect that converges to the uniform density as . An R script [18] for finding repeated *-iterates of a given pdQ is available as Supplementary Material.
3.1. Conditions for Convergence to Uniformity
Definition 3.
Given , we say that f is of *-order n if exist but does not. When the infinite sequence exists, it is said to be of infinite *-order.
For example, the Power() family is of *-order 2, while the Power(2) family is of infinite *-order. The distribution is of finite *-order for and infinite *-order for The normal distribution is of infinite *-order.
We write , , , and . The next proposition characterises the property of infinite *-order.
Proposition 1.
For and , the following statements are equivalent:
- (i)
- ,
- (ii)
- for all ,
- (iii)
- and for all .
In particular, f is of infinite *-order if and only if , .
Proof of Proposition 1.
For each , provided all terms below are finite, we have the following recursive formula
giving
(i) ⇒ (ii) For ,
(ii) ⇒ (iii) Use (2) and proceed with induction for .
(iii) ⇒ (i) By Definition 1, means that . Hence, (i) follows from (2) with . ☐
Next, we investigate the involutionary nature of the *-transformation.
Proposition 2.
Let be a pdQ and assume exists. Then, if and only if .
Proof of Proposition 2.
For , we have
If , then and (3) ensures , so .
Conversely, if , then using (3) again gives . Since a.s., we have a.s. and this can only happen when . Thus, , as required. ☐
Proposition 2 shows that the uniform distribution is a fixed point in the Banach space of integrable functions on [0,1] with the norm for any . It remains to show that has a limit and that the limit is the uniform distribution. It was hoped that the classical machinery for convergence in Banach spaces ([19], Chapter 10) would prove useful in this regard, but the *-mapping is not a contraction. For this reason, although there are many studies of fixed point theory in metric and semi-metric spaces (see, e.g., [20] and references therein), the fixed point Theorems 1, 2 and 3 shown below do not seem to be covered in these general studies. Moreover, our proofs are purely probabilistic and non-standard in this area. For simplicity, we use to stand for the convergence in norm and for convergence in probability as .
Theorem 1.
For with infinite *-order, the following statements are equivalent:
- (i)
- ;
- (ii)
- For all , ;
- (iii)
- as .
Remark 3.
Notice that , , are the moments of the random variable with . Theorem 1 says that the convergence of is purely determined by the moments of . This is rather puzzling because it is well known that the moments do not uniquely determine the distribution ([21], p. 227), meaning that different distributions with the same moments have the same converging behaviour. However, if f is bounded, then is a bounded random variable so its moments uniquely specify its distribution ([21], pp. 225–226), leading to stronger results in Theorem 2.
Proof of Theorem 1
It is clear that (ii) implies (i).
(i) ⇒ (iii): By Proposition 1, . Now,
so (iii) follows immediately.
We write for each bounded function g.
Theorem 2.
If f is bounded, then
- (i)
- for all , and the inequality becomes equality if and only if ;
- (ii)
- for all .
Proof of Theorem 2.
It follows from (4) that and the inequality becomes equality if and only if .
(i) Let be the inverse of the cumulative distribution function of , then , giving . If , then Proposition 2 ensures that , so . Conversely, if , then , so .
(ii) It remains to show that as . In fact, if , since , there exist a and a subsequence such that , which implies
However, , which contradicts (6). ☐
Theorem 3.
For with infinite *-order such that is a bounded sequence, then the following statements are equivalent:
- (i*)
- ;
- (ii)
- For all , ;
- (iii)
- as .
Proof of Theorem 3.
It suffices to show that (i*) implies (iii). Recall that . For each subsequence , there exists a converging sub-subsequence such that as . It remains to show that . To this end, for , we have
(i*) ensures that
as , so applying the bounded convergence theorem to both sides of (7) to get , i.e., . ☐
Remark 4.
We note that not all distributions are of infinite *-order so the fixed point theorems are only applicable to a proper subclass of all distributions.
3.2. Examples of Convergence to Uniformity
The main results in Section 3.1 cover all the standard distributions with infinite *-order in [22,23]. In fact, as observed in the Remark after Theorem 1 that the convergence to uniformity is purely determined by the moments of with , we have failed to construct a density such that does not converge to the uniform distribution. Here, we give a few examples to show that the main results in Section 3.1 are indeed very convenient to use.
Example 1.
Power function family.
From Table 1, the Power family has density , so it is of infinite *-order if and only if . As is bounded for , Theorem 2 ensures that converges to the uniform in for any .
Example 2.
Exponential distribution.
Suppose . f is bounded, so Theorem 2 says that converges to the uniform distribution as By symmetry, the same result holds for .
Example 3.
Pareto distribution.
The Pareto(a) family, with , has for , which is bounded, so an application of Theorem 2 yields that the sequence converges to the uniform distribution as
Example 4.
Cauchy distribution.
The pdQ of the Cauchy density is given by , , see Table 1; it retains the bell shape of f. It follows that for . It seems impossible to obtain an analytical form of for . However, as f is bounded, using Theorem 2, we can conclude that converges to the uniform distribution as .
Example 5.
Skew-normal.
A skew-normal distribution [17,24] has the density of the form
where is a parameter, ϕ and Φ, as before, are the density and cdf of the standard normal distribution. When , f is reduced to the standard normal so it is possible to obtain its by induction and then derive directly that converges to the uniform distribution as . However, the general form of skew-normal densities is a lot harder to handle and one can easily see that the density is bounded and so Theorem 2 can be employed to conclude that converges to the uniform distribution as .
Example 6.
Let , . Then, and as , so we have from Theorem 1 that, for any , converges in norm to constant 1 as .
4. Discussion
The pdQ, transformation from a density function f to extracts the important information of f such as its asymmetry and tail behaviour and ignores the less critical information such as gaps, location and scale, and thus provides a powerful tool in studying the shapes of density functions. We found the directed divergences from uniformity of the pdQs of many standard location-scale families and used them to make a map locating each shape family relative to others and giving its distance from uniformity. It would be of interest to find the pdQs of other shape families, such as the skew-normal of Example 5; however, a simple expression for this pdQ appears unlikely given the complicated nature of its quantile function. Nevertheless, the [25] skew-normal family should be amenable in this regard because there are explicit formulae for both its density and quantile functions. To obtain the information conserved in the pdQ transformation, we repeatedly applied the transformation and found the limiting behaviour of repeated applications of the pdQ mapping. When the density function f is bounded, we showed that each application lowers its modal height and hence the resulting density function is closer to the uniform density than f. Furthermore, we established a necessary and sufficient condition for converging in norm to the uniform density, giving a positive answer to a conjecture raised in [1]. In particular, if f is bounded, we proved that converges in norm to the uniform density for any . The fixed point theorems can be interpreted as follows. As we repeatedly apply the pdQ transformation, we keep losing information about the shape of the original f and will eventually exhaust the information, leaving nothing in the limit, as represented by the uniform density, which means no points carry more information than other points. Thus, the pdQ transformation plays a similar role to the difference operator in time series analysis where repeated applications of the difference operator to a time series with a polynomial component lead to a white noise with a constant power spectral density ([26], p. 19). We conjecture that every almost surely positive density g on is a pdQ of a density function, hence uniquely representing a location-scale family. This is equivalent to saying that there exists a density function f such that . When g satisfies , one can show that the cdf F of f can be uniquely (up to location-scale parameters) represented as , where (Professor A.D. Barbour, personal communication). The condition is equivalent to saying that f has bounded support and it is certainly not necessary, e.g., for and for (see Example 2 in Section 3.2).
5. Conclusions
In summary, the study of shapes of probability densities is facilitated by composing them with their own quantile functions, which puts them on the same finite support where they are absolutely continuous with respect to Lebesgue measure, and thus amenable to metric and semi-metric comparisons. In addition, we showed that further applications of this transformation, which intuitively reduces information and increases the relative entropy, is generally valid but requires a non-standard approach for proof. Similar results are likely to be obtainable in the multivariate case. Further research could investigate the relationship between relative entropy and tail-weight or distance from the class of symmetric pdQs.
Supplementary Materials
An R script entitled StaudteXiaSupp.R, which is available online at http://www.mdpi.com/1099-4300/20/5/317/s1, enables the reader to plot successive iterates of the pdQ transformation on any standard probability distribution available in R.
Author Contributions
Acknowledgments
The authors thank the three reviewers for their critiques and many positive suggestions. The authors also thank Peter J. Brockwell for helpful commentary on an earlier version of this manuscript. The research by Aihua Xia is supported by an Australian Research Council Discovery Grant DP150101459. The authors have not received funds for covering the costs to publish in open access.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Staudte, R. The shapes of things to come: Probability density quantiles. Statistics 2017, 51, 782–800. [Google Scholar] [CrossRef]
- Parzen, E. Nonparametric statistical data modeling. J. Am. Stat. Assoc. 1979, 7, 105–131. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Kullback, S. Information Theory and Statistics; Dover: Mineola, NY, USA, 1968. [Google Scholar]
- Abbas, A.; Cadenbach, A.; Salimi, E. A Kullback–Leibler View of Maximum Entropy and Maximum Log-Probability Methods. Entropy 2017, 19, 232. [Google Scholar] [CrossRef]
- Jeffreys, H. An invariant form for the prior probability in estimation problems. Proc. R. Soc. Lond. A 1946, 186, 453–461. [Google Scholar] [CrossRef]
- Freimer, M.; Kollia, G.; Mudholkar, G.; Lin, C. A study of the generalized Tukey lambda family. Commun. Stat. Theory Methods 1988, 17, 3547–3567. [Google Scholar] [CrossRef]
- Stephens, M. Uniformity, Tests of. In Encyclopedia of Statistical Sciences; John Wiley & Sons: Hoboken, NJ, USA, 2006; Volume 53, pp. 1–8. [Google Scholar] [CrossRef]
- Lockhart, R.; O’Reilly, F.; Stephens, M. Tests of Fit Based on Normalized Spacings. J. R. Stat. Soc. B 1986, 48, 344–352. [Google Scholar]
- Schader, M.; Schmid, F. Power of tests for uniformity when limits are unknown. J. Appl. Stat. 1997, 24, 193–205. [Google Scholar] [CrossRef]
- Prendergast, L.; Staudte, R. Exploiting the quantile optimality ratio in finding confidence Intervals for a quantile. Stat 2016, 5, 70–81. [Google Scholar] [CrossRef]
- Dudewicz, E.; Van Der Meulen, E. Entropy-Based Tests of Uniformity. J. Am. Stat. Assoc. 1981, 76, 967–974. [Google Scholar] [CrossRef]
- Bowman, A. Density based tests for goodness-of-fit. J. Stat. Comput. Simul. 1992, 40, 1–13. [Google Scholar] [CrossRef]
- Fan, Y. Testing the Goodness of Fit of a Parametric Density Function by Kernel Method. Econ. Theory 1994, 10, 316–356. [Google Scholar] [CrossRef]
- Pavia, J. Testing Goodness-of-Fit with the Kernel Density Estimator: GoFKernel. J. Stat. Softw. 2015, 66, 1–27. [Google Scholar] [CrossRef]
- Noughabi, H. Entropy-based tests of uniformity: A Monte Carlo power comparison. Commun. Stat. Simul. Comput. 2017, 46, 1266–1279. [Google Scholar] [CrossRef]
- Arellano-Valle, R.; Contreras-Reyes, J.; Stehlik, M. Generalized Skew-Normal Negentropy and Its Application to Fish Condition Factor Time Series. Entropy 2017, 19, 528. [Google Scholar] [CrossRef]
- R Core Team. R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2008; ISBN 3-900051-07-0. [Google Scholar]
- Luenberger, D. Optimization by Vector Space Methods; Wiley: New York, NY, USA, 1969. [Google Scholar]
- Bessenyei, M.; Páles, Z. A contraction principle in semimetric spaces. J. Nonlinear Convex Anal. 2017, 18, 515–524. [Google Scholar]
- Feller, W. An Introduction to Probability Theory and Its Applications; John Wiley & Sons: New York, NY, USA, 1971; Volume 2. [Google Scholar]
- Johnson, N.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons: New York, NY, USA, 1994; Volume 1. [Google Scholar]
- Johnson, N.; Kotz, S.; Balakrishnan, N. Continuous Univariate Distributions; John Wiley & Sons: New York, NY, USA, 1995; Volume 2, ISBN 0-471-58494-0. [Google Scholar]
- Azzalini, A. A Class of Distributions which Includes the Normal Ones. Scand. J. Stat. 1985, 12, 171–178. [Google Scholar]
- Jones, M.; Pewsey, A. Sinh-arcsinh distributions. Biometrika 2009, 96, 761–780. [Google Scholar] [CrossRef]
- Brockwell, P.; Davis, R. Time Series: Theory and Methods; Springer: New York, NY, USA, 2009. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).