1. Introduction
In financial economics, Sharpe ratio, defined in [
1], provides a measure of a fund’s excess returns relative to its volatility. Let
be an expected return of an asset, and
be the corresponding standard deviation. The Sharpe ratio is defined as
where
is a known risk-free rate of return. Note that the larger the Sharpe ratio is, the more return the investor is getting per unit of risk. It is the standard convention in economics and finance research to report the Sharpe ratio. Therefore, the Sharpe ratio is very well studied as a measure of the mutual fund performance in the financial economic areas such as the portfolio analysis, the pricing of capital asset under conditions of risk and the general behavior of stock market prices. The popularity of the Sharpe ratio in financial economics is not only from its simplicity; the study of the Sharpe ratio will also directly result in deeper understandings in portfolio selections. Assuming that the asset returns are all normally distributed, Sharpe [
1] showed that picking an asset with the largest Sharpe ratio is equivalent to finding a solution of the investor’s expected utility problem.
Under the normality assumption, Jobson and Korkie [
2] proposed a parametric test for the Sharpe ratio, which is a very popular inferential method in economics and finance. However, as shown by many researchers [
3,
4,
5,
6], it is very common for the actual returns of the investments, such as the hedge funds, to have a skewed distribution. When the normality assumption of the investment returns is violated, the commonly used approximate distributions of the Sharpe ratio which are developed under the normality assumption become problematic. Model mis-specification is a big concern for all parametric approaches since a misspecified model may lead to biased results. Since the Sharpe ratio is only involved in the first two moments of the data, one of the themes attempting to resolve the problem is to consider higher order moments. There was abundant literature along this line of research such as [
7,
8,
9,
10] and references therein.
Another line of research to the problem is to use the nonparametric approach. In this article, we adopt the empirical likelihood (EL) method. Empirical likelihood-type method was first used by Thomas and Grunkemeier [
11] to study the survival probabilities estimated by the Kaplan–Meier curve. Owen [
12,
13] formalized the EL as a unified inference method under more general settings. The EL-based confidence region has several beneficial properties: it does not impose prior constraints on region shape, is transformation invariant and Bartlett correctable [
14]. Qin and Lawless [
15] applied the EL to inference on parameters that are generated from estimating equations. When the sample size is small and/or the dimension of the estimating equations is high, the EL approach can be hindered by an empty set problem and under-coverage problem. In order to resolve the empty set problem and improve the coverage probability of the statistical tests of the ordinary EL methods, Chen et al. [
16] proposed the adjusted empirical likelihood (AEL) method by adding one artificial point into the data set. However, only problems without nuisance parameters were considered in [
16]. In this article, we focus on the AEL method with nuisance parameters in addition to the parameter of primary interest. We develop the asymptotic theory of the AEL method when nuisance parameters exist, and demonstrate the use of the AEL method in the application of the Sharpe ratio. Our simulation studies show that the proposed approach provides a beneficial robust alternative to the inference of the Sharpe ratio. The proposed AEL method is comparable to Jobson and Korkie’s method [
2] and outperforms the EL method when the data are from a symmetric distribution, while for data generating from a skewed distribution, the proposed method outperforms all other existing methods, especially for small sample sizes. The AEL method preserves the advantage of the EL method: the shape of confidence region based on the AEL ratio reflects the observed data set, while the confidence region based on other methods (excluding EL) is always symmetric about the point estimator. Therefore, the AEL approach allows the data to speak for themselves, and is robust against model mis-specification.
The rest of the article is organized as follows. A brief introduction to the EL and AEL methodologies is given in
Section 2. In
Section 3, we study the asymptotic property of the AEL method with nuisance parameters. In
Section 4, simulation studies are conducted to investigate the precision of the coverage probabilities in the context of the Sharpe ratio. In
Section 5, a real-data example is analyzed to illustrate the application of the proposed method. Some concluding remarks are given in
Section 6. The technical details are presented in the
Appendix.
2. Review of the Empirical Likelihood and the Adjusted Empirical Likelihood Methods
Let
be the independent and identically distributed random vectors following distribution
F with mean
and a nonsingular covariance matrix. The corresponding observed values are denoted by
. The EL function for the population distribution
F is given by
where
is the probability of observing the value
in a sample from
F. Denote
. The EL function can also be written as
Clearly , we have
and
. Suppose that the goal is to construct a confidence region for the mean
. The profile EL function of
is defined to be
Qin and Lawless [
15] showed that extra information in the form of a set of estimating equations can be used to improve the maximum empirical likelihood estimators (MELE) and the EL ratio confidence intervals. Suppose a
k dimensional parameter
is associated with
F via a vector
of
functionally independent unbiased estimating functions. Then for each
, we have an estimating equation
, which can be written in the vector form as
. The profile EL function of
is
and hence, the profile log-EL function is
The constrained optimization problem in (
3) can be solved by applying the method of Lagrange multipliers. Let
and
be Lagrange multipliers and define
Then maximizing (
3) is equivalent to maximizing
H unconditionally. Setting the first partial derivative of (
4) with respect to
equal to 0, we have
and
where
t can be expressed as a function of
by solving the following equations
Now the profile log-EL function can be written as
Note that (
5) can be rewritten as
Now maximizing (
3) has been transformed into an equivalence of solving (
7) for the Lagrange multiplier
t. In practice, this is achieved by numerical methods. One such algorithm devoted to this end can be found in [
16]. A necessary and sufficient condition for the existence of a solution
in (
7) is that 0 must be an inner point of the convex hull expanded by
.
Qin and Lawless [
15] further showed that under some regularity conditions, the EL ratio statistic
converges to
in distribution as the sample size
n approaches infinity. This result is the foundation for hypothesis test on
and can be used to construct an approximate
confidence region of
,
where
is the
quantile of the
distribution, and
is a pre-specified significance level.
Under mild conditions, the convex hull of
contains 0 as its inner point with probability 1 as
. However, if
is not close to the true parameter
or when the sample size
n is small, the convex hull is not guaranteed to contain 0. Thus, there is a nonzero probability that the solution to (
7) does not exist. It results computational issues when solving the constrained optimization problem in the definition of the EL function. This is known as the empty set problem or the convex hull problem in the EL literature.
In order to resolve the convex hull problem, Chen et al. [
16] proposed the AEL method by adding one artificial point into the data set. Denote
and
Let
be a given positive constant. Define a new point by
Similar to (
2), the profile log-AEL function if defined as
and we have
where
t satisfies
The introduction of
guarantees a solution for
t in (
7). Let the maximum AEL estimator
be the maximizer of
. Under mild regularity conditions, the AEL ratio statistic
converges to
in distribution as the sample size
n approaches infinity. Chen et al. [
16] showed that the statistical tests based on the AEL method give better coverage probabilities than those obtained by the original EL method.
In this article, we propose using the AEL method to conduct inference on the Sharpe ratio. Suppose the data is from a population with mean
and variance
. Without loss of generality, for the rest of this article, define the Sharpe ratio of the population as
In this case, the parameter vector is
, and the parameter of interest is
. The set of estimating functions can either be
or
which has
or
as the nuisance parameter, respectively. Chen et al. [
16] discussed the AEL-based inference without nuisance parameters. Building upon [
15,
16], we develop the convergence theorem for the AEL with nuisance parameters as shown in the next section.
3. The Adjusted Empirical Likelihood Method in the Presence of Nuisance Parameters
Suppose a
k dimensional parameter
consists a
q dimensional parameter of interest
as well as a
dimensional nuisance parameter
. The goal is to test
for some given
. In order to obtain inference for
using the AEL method, the asymptotic results in [
16] need to be reconstructed and extended to the situation with nuisance parameters.
First, we develop a lemma about positive definite matrices. If a matrix M is positive semidefinite, we denote it by ; if M is positive definite, we write . For any matrices G and H, let denote that is positive semidefinite, and let denote that is positive definite.
Lemma 1. Let M be a symmetric positive definite block matrix of the formwhere A is a matrix, B is a matrix, and C is a matrix. Then C is positive definite and The proof of the above lemma is given in
Appendix. In order to prove the main theorem, we also need the following two results about idempotent matrices. The proof of these two results can be found in [
17] (pp. 186–187).
Result 1. A necessary and sufficient condition that has a distribution is that A is idempotent, that is, , in which case the degrees of freedom of is rank A = trace A.
Result 2. If A, B, are matrices of non-negative quadratic forms and A and B are idempotent, then is also idempotent.
Based on Lemma (1) and the above two results, we have the following theorem which gives the asymptotic properties of the AEL ratio test statistic. The theorem is a nonparametric analogue of the theorem in [
18] on the asymptotic distribution of the likelihood ratio. The difference is that Wilks’ theorem is based on parametric likelihood and ours is based on the adjusted empirical likelihood. Moreover, it takes into consideration nuisance parameters. We follow the idea of profiling out nuisance parameters (Corollary 5 in [
15] and Corollary 1 in [
19]) to perform the AEL ratio test. The proof of the theorem is provided in
Appendix.
Theorem 1. Let , where and are and vectors, respectively. For , the profile AEL ratio test statistic iswhere maximizes , and maximizes with respect to . Under , as . It is worth noticing that Theorem 1 holds true as long as
. In application,
with higher orders is usually not recommended, since the AEL ratios are decreasing functions of the adjustment level
[
20]. As suggested by [
16], we set
for all of the simulations and applications if not otherwise specified.
Since in Theorem 1 ,
is the parameter of interest and
is considered as the nuisance parameter. We can apply the theorem to the Sharpe ratio by setting
along with
or
. Therefore, the AEL ratio statistic under the null hypothesis
can be either
or
Our simulation shows that using (
12) or (
13) as the AEL ratio statistic does not make any significant difference in the inference of
.
4. Simulation Study
In order to evaluate the accuracy of the asymptotic chi-square calibration of the AEL method, we choose the coverage probability as an indicator throughout this section. For some fixed sample size n and , suppose we have run the simulation m times and s of the simulated are less than the quantile of for some given . Then the coverage probability is defined to be , which is compared with the nominal value . When m is large, if the coverage probability is close to , then the level test for will tend to give good performance and is considered an acceptable reference distribution for at sample size n.
We compare the coverage probability of the proposed method with other methods for sample sizes
at nominal values
. Each coverage probability is obtained from
simulations. The data are generated from the normal distribution with mean
and standard deviation
,
t-distribution and the chi-square distributions with various degrees of freedom. The methods under comparison are the following: the Jobson and Korkie’s method [
2] (JK), the Mertens’s method [
21] (Mertens), the usual EL inferential method (EL), application of the delta method on the asymptotic distribution of the EL estimator of the mean and standard deviation (Delta), and the proposed method (AEL) with the adjustment level
. Jobson and Korkie [
2] assumed that the data are from a normal distribution. By applying the delta method to approximate the mean and variance of the Sharpe ratio, confidence interval for the Sharpe ratio can then be approximated by the Central Limit Theorem. Mertens [
21] used the skewness and kurtosis to give an adjusted approximation of the variance of the Sharpe ratio derived in Jobson and Korkie [
2] and again obtained the confidence interval of the Sharpe ratio from the Central Limit Theorem. The approach denoted by Delta is similar to JK but based on the EL. For the EL method, whenever the convex hull problem occurs for a set of simulated data, we use the convention to set the value of the profile log-EL function as negative infinity. Results are summarized in
Table 1.
From
Table 1, we can see that the AEL method has the most robust performance for various underlying population distributions. The AEL method always has significantly better performance over the EL method in terms of coverage probability. When the data is normally distributed, the JK method performs the best while when the data comes from a skewed distribution, the JK method performs poorly. For normal data with small sample size, the AEL has slightly less coverage probabilities than the JK method, while for normal data with sample size larger than 50 and data from various
t distributions, the AEL has comparable performance with the JK method. For all other situations, the AEL method significantly outperforms all other methods, especially for cases with small sample sizes.
5. Real Data Analysis
The data we consider is the Nasdaq GS return of the Apple Inc. (Cupertino, CA, USA) from 3 October 2017 to 12 December 2017 (
https://finance.yahoo.com/quote/AAPL/). The return is evaluated from the close price of the current day compared with the close price of the previous day. There are 50 trading days during the period considered. We use the yearly return rate of the 5-year bonds, which is
, as the yearly risk-free return. Therefore, the daily risk-free return rate used in the analysis is
. Based on our data, the Durbin-Watson test statistic is 1.58. Hence, there is no significant evidence of serial correlation. The qqplot of the returns in
Figure 1 reveals some skewness of the data. The confidence intervals of the Sharpe ratio for the Apple Inc. return data produced by different methods are listed in
Table 2. For JK and Mertens methods, the point estimates are the value of
that corresponding to the 50% quantile of the standard normal limiting distribution of their test statistics. The estimates of the Delta, EL and AEL methods are the value of the maximum EL and AEL estimates, respectively.
From
Table 2, we see that since JK and Mertens methods are moment-based methods, both their estimates are the same as the sample Sharpe ratio. The Delta, EL and AEL methods are empirical-likelihood-based methods so the corresponding estimates are different from the previous two approaches. We observe that there is some difference in the confidence intervals for various approaches. Note that the data has some skewness as shown in
Figure 1. Based on the observation from our simulation studies, the skewness will affect the JK method but not the rest of the four methods. The confidence interval based on our proposed AEL method is more robust and trustworthy.



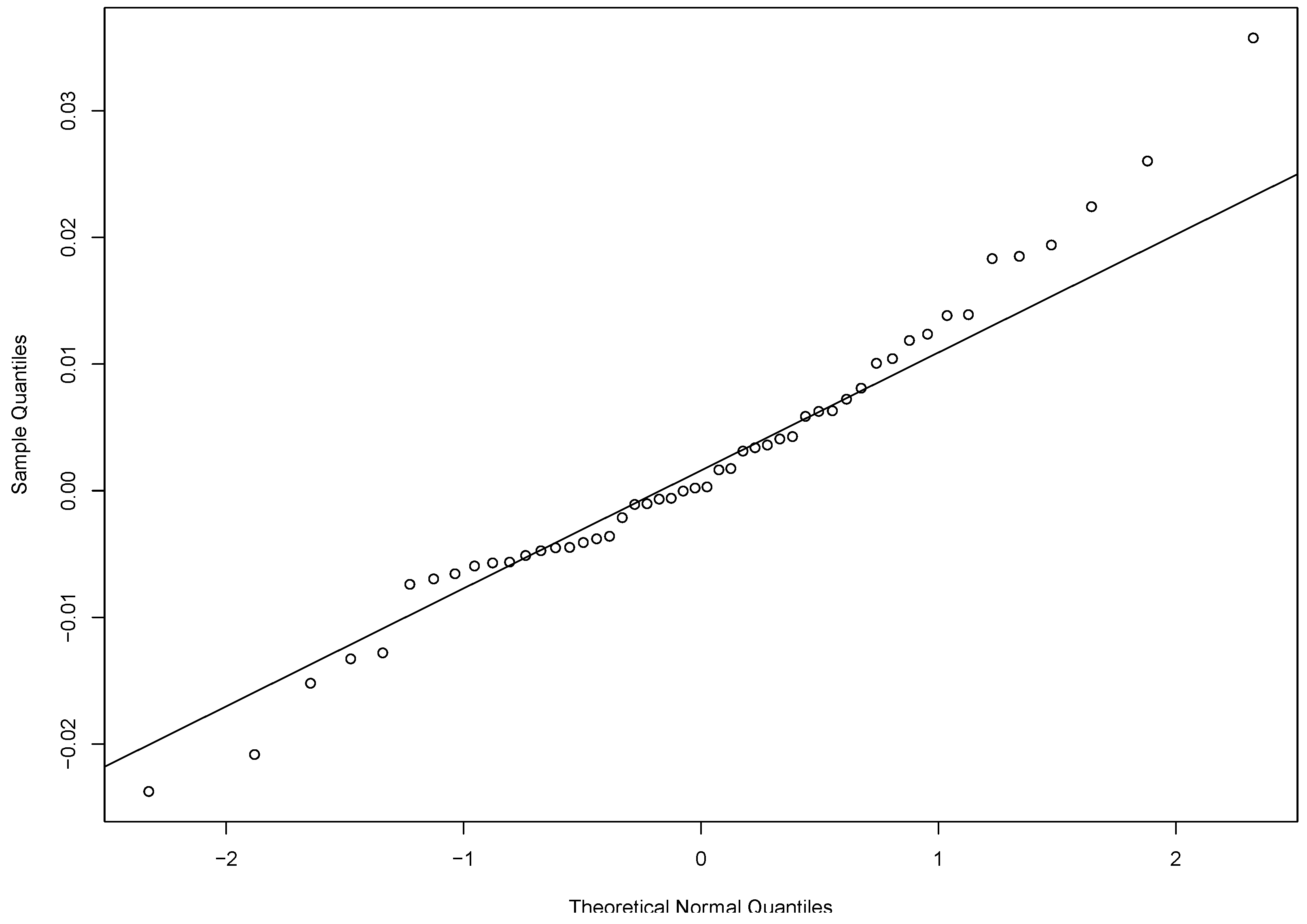

{kind=link}