1. Introduction
Short-term load forecasting (STLF) plays an important role on ensuring power system security and economic operation [
1], and its prediction accuracy is influenced by many interdependent factors. Of all these factors, meteorological factors are the dominant exogenous factors that affects STLF [
2,
3,
4]. More recently, meteorological sensitive load demands such as air conditioning, space heating, agricultural irrigation, etc., increasingly grow, and the influence of weather conditions on electrical demands is further intensified, which makes their relation more complicated. Whether weather factors are properly considered has a significant impact on the prediction accuracy of STLF, while even a small improvement in prediction accuracy means big cost savings and also a great contribution to the environment in which we live [
5]. Meanwhile, with the wide deployment of real-time monitoring devices in several 220- and 110-kV substations across the forecasted area, it becomes possible to gather real-time weather data such as temperature, humidity, rainfall, wind speed, etc. [
6]. In this context, it would be of immense value to develop methods introducing meteorological variables into the forecasting models to improve prediction accuracy and boost prediction speed.
Numerous studies have shown that, of all meteorological factors, temperature has the most remarkable effect on electrical demands [
7,
8]. Humidity also has a major effect on the comfort or discomfort felt, because it affects the amount of heat that the human body rejects through evaporation [
9,
10]. Other factors that have an impact on load demand behavior are the wind speed and cloud cover. Rainfall influences electrical demand rather indirectly by affecting other weather variables [
11]. Meteorological variables could be introduced into the forecasting models in a primitive form or in a derived form created by combining two or few of them, namely, Meteorological Composite Index (MCI), such as Temperature–humidity index (THI), Comfort Index of Human Body (CIHB), etc. [
12]. The MCIs are more popular among conventional models, especially temperature derivatives [
13,
14]. The MCIs created by mixing different variables such as temperature, humidity, and wind speed are also popular among artificial intelligence models. These MCIs include: Heat Index (HI), introduced by USA National Weather Service [
15], tries to represent perception of temperature by a human depending on relative humidity, namely, human-perceived equivalent temperature [
16]. Humidex, proposed by Canadian meteorologists Masterton and Richardson in 1979 [
17], is another parameter calculated using temperature and humidity. It was utilized in similar day-based wavelet neural network (NN) models [
18], and implied models using the MCI performed better than ones using primitives. Temperature–humidity index (THI) is an analysis index used frequently by forecasting models [
19]. Through this, both temperature and humidity are introduced into load prediction, which was employed in some models [
11,
20], and showed its effectiveness. Real sense of temperature is another type of meteorological parameter integrating together temperature, relative humidity and wind speed in an attempt to capture coupling effect of these factors on human perception. A backpropagation based NN model used it as one of its inputs to forecast load demands, and achieved better results [
21]. Comfort Index of Human Body (CIHB) is a measure of synthesized effect combining temperature, relative humidity and wind speed. It is an indicator depicting human body’s comfortable level in atmospheric environment [
22]. An improved Elman neural network model utilized it as one of the inputs, and compared it with another one using temperature only. As a result, better prediction accuracy was acquired with the former solution [
23]. Enthalpy latent days (ELD) is a parameter depicting the influence of humidity on summer load demand for cooling and air-conditioning [
24]. It can be expounded as an amount of energy necessary to decreasing indoor humidity to an acceptable level without reducing the indoor temperature. Wind-chill index (WCI) is an index aiming to capture cooling effect of the wind blowing while temperature is below threshold of 50 °F (10 °C) [
25]. The WCI was selected as an input to wavelet neural network to correct similar-day based forecasting model, and showed an improvement of the accuracy [
18,
26]. Cooling power of the wind (CP) was developed by Taylor and Buizza [
27], which is a nonlinear function of wind speed and average temperature trying to capture chill induced by gusts of wind.
All the aforementioned MCIs have greatly enriched the approaches of introduction of weather factors into STLF and lay a firm foundation for the improvement of prediction accuracy in STLF. All these approaches introducing meteorological variables into STLF models, however, have some intrinsic limitations due to the complexity of the problems involved. Current load demand is affected not only by the temperature of the current moment but also by the previous one because of the accumulative effect of temperature (AET) [
19]. Although Li and Fang et al. [
1,
28] presented their respective corrected models by taking AET into account, a cumulative effect coefficient based on the models must be adjusted frequently over time. Jiang et al. [
29] acquired a quantitative calculation formula for AET by means of curve fitting algorithm, but a proportion coefficient concerning contribution of both continuous number of high temperature days and the highest daily temperature to AET varied over different regions. On the other hand, all the MCIs above involve only the features of daily meteorological factors (Max, Mean, and Min) as their effects on electrical demand. The investigation by Callaway et al. [
30] showed that using a simple daily average temperature cannot provide good representations of weather, therefore, cannot obtain a higher prediction accuracy of STLF. Although Kang et al. [
31] developed a NN model based on real-time meteorological factors for STLF, the number of input variables grows dramatically, which would inevitably lead to an increase in computational costs. Hence, it is more important to investigate pointwise influence of meteorological factors on the load demands to establish load forecasting models point by point under real-time weather information circumstances.
Information theory provides a new way of introducing weather variables into STFL models. The reason is that essentially any type of data or model can be converted to information regardless of disciplinary origin [
32]. Zhu et al. [
33] described STLF as a process of information decision-making, and presented a combined model for STLF based on maximum entropy principle. Sun et al. [
34,
35] regarded STLF as a process of load information movement to tackle uncertainties in STLF, and then developed the minimization of Information Loss Based Hybrid STLF model to improve prediction accuracy, even though weather information is not involved separately, instead it was considered as a whole. It should be noted that, however, rich weather information available throughout various substations provides us a chance to further investigate the impact of meteorological factors on load demands. Thus, the key is to find an appropriate method of introduction of weather variables into STLF to characterize fully its influence on load demands.
Fisher information (FI) is well known for its ability to measure a system’s stability [
32]. Unlike other approaches of system information measures, Fisher information provides a method that can monitor the system states’ changes and shifts by means of measuring the systems’ variables [
36]. In fact, Fisher information has been applied to deriving fundamental equations of physics, thermodynamics, and population genetics [
37,
38]. More recently, Fisher information was widely applied to various areas, such as ecological systems [
36,
39], climate systems [
40], power system fault detection [
41], etc. The objective of this article is to demonstrate our beginning steps in the development of a methodology of introducing climatic factors into STLF models using Fisher information, and examine its effectiveness in practical application using a real data collected from a local utility company.
The remainder of the paper is organized as follows. Fisher information theory and its calculation are presented in
Section 2. The description of introduction of meteorological factors and input variables selection based on FI for STLF models is given in
Section 3. Different forecasting models are constructed with the proposed methodology in
Section 4. Case study and discussion are presented in
Section 5. Finally, the contributions with concluding remarks are reported in
Section 6.
2. Methodology
The statistician Ronald Fisher (Fisher 1922), from a system’s stability point of view, developed a measure of indeterminacy, now called Fisher information. Fisher Information (FI) for a single measurement of one variable is calculated as follows [
42]:
where
P(
s) is the probability density function (PDF), and
s is a state variable.
A system’s stability is conceptually related to the repeatability of observations. Thus, for a system that is perfectly stable, repeated observations of the variables over time acquire the same values within the limits of measurement uncertainty. Hence, for perfect stability, the probability density function (P(s)) becomes a very sharp spike with a derivative dP/ds that is approaching infinity, and a Fisher information (see Equation (1)) is approaching infinity. For a system that is perfectly unstable, the opposite is true. Here, all observations acquire completely different and uncorrelated values for the variables, the likelihood of observing one value is the same as any other value, the probability density function (P(s), i.e., PDF) is flat, and the derivative dP/ds is approaching zero. In addition, when a system flips from a steady state to another, the derivate of the probability density function of the system shows an obvious transition. Real systems, however, exist between these two extremes of perfect stability and perfect instability and infinite and zero Fisher information. Hence, Fisher information is a theoretically sound measure of system stability.
In practical application, to reduce calculation errors due to dividing by small values of
P(
s), we replace the probability density function in Equation (1) with its amplitude, which is defined by
q2(
s) ≡
P(
s). Equation (1) then becomes [
43]:
Note that in specific calculation, we do not know the concrete form of the continuous function
q(
s), but instead we have a finite number of samples
qi. Thus, Fisher information (FI) is usually computed numerically. For that purpose, we shall replace the derivative by the numerical difference Δ
q =
qi −
qi+1 and Δ
s =
si −
si+1, and correspondingly use the sum of finitely many terms to approximate the integral, which then leads to the following formula for calculating Fisher information approximately:
In Equation (3),
si is an index denoting a particular state of the system, i.e.,
s1 is state 1,
s2 is state 2, etc. Accordingly,
si −
si+1 = 1 and the final expression for computing Fisher information is:
The expression in Equation (4) will be used in all our Fisher information calculations afterwards.
2.1. FI Computation for the One-Dimensional Variables
The initial step in computing FI for the one-dimensional variables is to acquire an observed data series that characterize the state of the system over time. Then the time series data are divided into time windows by defining a parameter
w denoting the size of the window. This parameter (
w) is determined based on the amount of data available and the behavior of the system. From empirical studies, the
w should contain at least eight time steps to ensure that one point in the window does not unduly influence the overall computation. A sequence of overlapping windows is then created to measure a system’s stability that may extend beyond the boundary of the window. This is achieved by moving the time window forward by a time increment (
δ). The only rule regarding setting
δ is ensuring that
w >
δ. The parameters
w and
δ denote the integration window size and window increment (in time steps) used to move through the data over time [
43].
Suppose the measured time data serial is
D = {d(1),…, d(
N)}. We then introduce a series of sliding windows
Wm on
D as follows
where
k = 1 +
m ×
δ,
w ∈
N is the window size,
δ ∈
N is the window increment, i.e., sliding factor, and
m = 1, …,
M with
M = (
N −
w)/
δ being the number of windows. Suppose all the elements in a sliding window
Wm can be divided into
I intervals:
where
and
Then, the probability
P(
Zi) that the element d(
k) falls into an interval
Zi is:
Next, the q(Zi) is calculated for each state (), and estimate FI value for each Wm.
We summarize the procedures of calculating FI for the one-dimensional variables as follows: (i) Categorize a time series data into a sequence of time windows, overlapping each other. (ii) Divide each window into intervals with the same length by using the above method, and count the number of elements falling into each interval (iii) Construct a probability distribution function for the window. (iv) Calculate the Fisher information from the PDFs constructed in Step (iii) for each time window.
2.2. FI Computation for the Multidimensional Variables
Given a time series data with length
N in
m-dimensional state space are as follow.
where
X(
ti) = (
x1(
ti),
x2(
ti), …,
xm(
ti)) is a vector with m-dimensional components in the state space. Similarly, a series of overlapping windows each other are constructed on the above data series.
As stated above, the state of the system is defined by its state variables. The behavior of these state variables determines the stability of the system. Support the data points of representing the state variables within each window characterize a series of states for a system, and if
(
is a measurement’s allowed error), then both
X (
ti) and
X(
tj) are deemed as the same state. According to Chebyshev’s theorem [
44], when
takes
(here,
is the standard deviation of all the data points within a window), 75% of data points in this window will be categorized into the same state, no matter what the probability distribution is. Considering that each data point of the above window is an m-dimensional vector, an m-dimensional hyper-rectangle is constructed, and the lengths of the “
m” sides of the hyper rectangles are determined by the uncertainties
in m-dimensional components respectively. (
δ1,
δ2, …,
δM are the standard deviation of data points for corresponding
m-dimensional component within the window). More specifically, the first data point in chronological order within the first time window is taken as the center of the first state and a state hyper rectangle is constructed around it. All the points falling within the boundaries of the first state are counted or binned together, denoted as
Z1, namely:
The next uncounted point within the time window is selected, the second state is built around it, and the points are binned as before. Finally, this procedure is repeated until all the points are binned into states within the current time window, and the process moves to the next time window.
Suppose all the elements in a sliding data window can be put into
L bins. Then, we have
where Length(
W) stands for the total number of data points contained in a window or bin of concern. That is, the total number of elements in a sliding window equals the sum of the subtotals contained in those bins.
We summarize the aforementioned procedures of the binning method: (i) Categorize a multidimensional time series into a sequence of time windows. (ii) In each window, convert data points into states by using the above method. (iii) In each window, construct a probability distribution function for possible states of the system. (iv) Compute the Fisher information from the PDFs constructed in Step (iii).
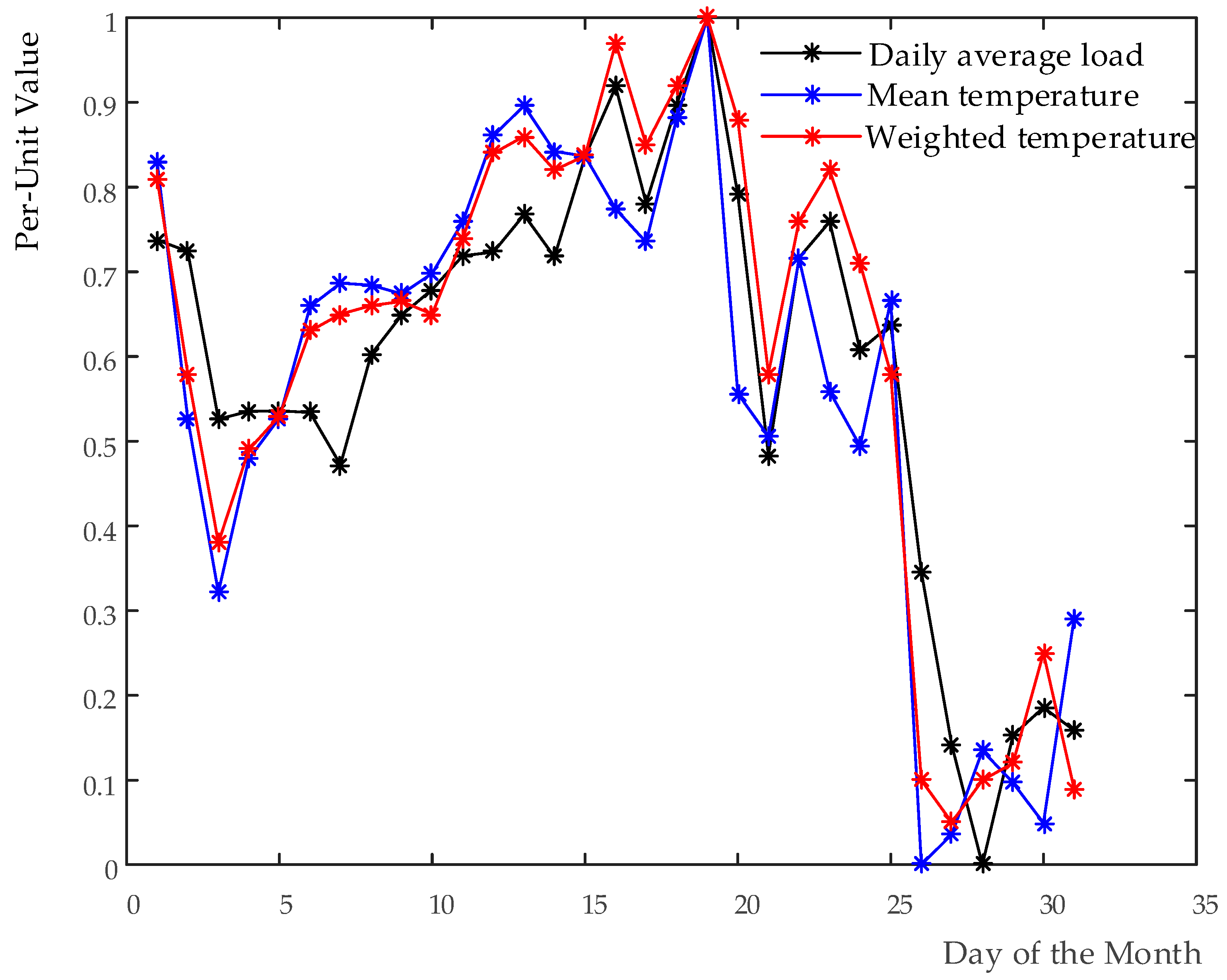
3. Methods of FI-Based Weather Variables Introduction and Feature Selection Process for STLF
Of all the weather factors, temperature is considered to have most influence on electrical demand. During high-temperature seasons, load demands increase sharply when the temperature rises. Particularly, a constantly high temperature has an accumulative effect on it, and a similar situation was found with the other weather variables. Accumulative effect of weather factors has a significant impact on STLF, and hence, it is taken into account in STLF [
29].
FI is a measure of a system’s stability. The degree of the stability of the weather factors in previous period can be described quantitatively by measuring the FI value of past weather variables. In this way, current weather variables value is weighted using the FI value of weather factors in previous period, and then accumulative effect of weather factors on load demands is fully reflected. This approach is well in accordance with one’s general sense of weather variation caused by accumulative effect, that is, “steadily” low or high. It avoids identifying a cumulative effect coefficient regarding weather factors in conventional methods as well.
3.1. Methods of FI-Based Primitive Weather Variables Introduction into STLF Models
Fang et al. [
28] investigated the relation between meteorological sensitive load and real-time temperature to examine accumulative effect of temperature on load demands. The result shows the effect comes from not only currently forecasted day, but previously several days. The former refers that a load demand at forecasted time point on the day was influenced by several previous time points before the time point within the day, especially for one previous time point, two previous time points, and three previous time points (in 1 h sampling time interval), while the latter refers that constantly high temperature within several previous days before the day would lead to grow unusually for the load demand. Specifically, these are one previous day and two previous days. Other weather variables show a similar result. Therefore, the sliding window for FI computation of a single weather variable, considering accumulation effect, consists of three sections as follows (in 15 min sampling time interval).
Note that the first subscript identifies day type, and the second one identifies time point. The subscript d and t represent currently forecasted day and time point, respectively, and the subscript (d − i) and (t − j) represent previous i-th day before the day and previous j-th time point before forecasted time point, respectively. As shown above, the first group is the sampling data points of the weather variables of 12 previous time points prior to the time point within the day. The second group is that of eight previous time points prior to the same time point on one previous day before the day, and the third group is that of four previous time points prior to the same time point on two previous days before the day. That is, the data window used for FI calculation comprises a total of 24 data points, which meets the principle that more sample real data should be selected when the distance regarding time between the sampled data points and the forecasted time point is much nearer and vice versa in handling those issues. This approach makes it more reasonable and comprehensive to depict accumulative impact of the weather factors on load demands.
3.2. Methods of FI-Based MCIs Introduction into STLF Models
MCIs can track more sensitively and describe more effectively load variation compared to the plain weather variables [
19]. This is because one’s feeling of comfort is determined by an integrated effect mixing different weather factors such as temperature, humidity, wind speed, etc., together, while a single weather variable cannot characterize exactly one’s true feeling. In this context, several MCIs were introduced into STLF models, such as HI, THI, CIHB, etc.
Traditionally, the MCIs are defined by two or three weather variables to reflect an effect of interacting and inter coupling between them. One can image the effect is definitely associated with the stability of a system which is defined by corresponding weather variables, and the stability is measured by FI’s value of the multidimensional weather variables. The MCIs, similar to plain weather variables, have an accumulative effect on load demands, which lead to a time lag regarding one’s reaction to outside weather conditions. Accordingly, the effect should be considered when the STLF models are established, which is achieved by the weighted MCIs, namely, the MCIs multiplied by corresponding FI value.
The sliding window data serial for calculation multiple weather variables FI, considering accumulation effect, is constructed as follow.
As displayed above, it consists of three parts similar to the single weather variables in
Section 3.1. It is worth noting that each element in the above window, e.g.,
Xd,t = (
xd,t(1),
xd,t(2),…,
xd,t(M)), is a vector with
m-dimensional components in the weather state space. Data selection for the sliding window and the symbols’ meanings are the same as
Section 3.1.
3.3. FI-Based Feature Selection Process for STLF Models
It is also relevant to notice that the forecasting engine is only a part of an accurate forecasting model and other processes such as feature selection (FS) are very important as well [
45]. FS is commonly applied to identifying the most significant input variables influencing STLF’s prediction accuracy. The variables selection is very crucial for artificial intelligence (AI) models training. Input variables, through selecting reasonably, can improve STLF’s prediction accuracy and reduce models’ training costs. Therefore, how to choose the most important factors impacting on load demands from massive historical data to yield a set of effective and sufficient input variables is a challenging task. Drezga et al. [
46] proposed a phase-space embedding method to identify input variables for NN models, but it is only able to find out historical loads that have the most impact on the future forecasted time point, and has limited effect for the weather variables. Gao et al. [
47] applied orthogonal least square (OLS) approach to select feature for NN models in STLF. It, however, require to identify a measurement’s allowed error in advance. Liu et al. [
48] adopted Relief algorithm to address FS matter for STLF, but computation process is more complicated.
Essentially, Fisher Information is the inverse of the Shannon entropy; Where Shannon entropy measures the degrees of disorder or indeterminacy of the system, while Fisher Information measures the degrees of order or determinacy of the system. For a certain thing, the more deterministic it is, the more it outputs information, the more regular its structure is, and the larger its FI value is. By means of this property, the importance degree of all the input variables in STLF can be identified. The concrete implementation process is as follow.
Suppose a historical daily average load consumption dataset with length
m is used to analyze the impact of
n factors on load, and the following matrix for the analysis is then constructed:
To avoid the effect of different dimension, each element in the matrix is normalized to [0, 1] to acquire a normalized matrix
. FI value regarding per column corresponding to a factor is calculated, then is normalized to [0, 1] once again. The weight of the
j-th influencing factor is computed as follow.
As can be seen in Equation (14), when the j-th factor all takes the same value in the j-th column, the factor’s FI value takes the maximum 1, while its weight Wj takes the minimum 0, which signifies the factor cannot provide any useful information for STLF. The factor should be ignored or deleted from the above influencing factors. Conversely, when the j-th factor takes completely different and uncorrelated values in the j-th column, the factor’s FI value takes the minimum, while its weight Wj takes the maximum, which signifies the factor can provide useful information and much attention should be paid to the factor in STLF. As a result, the j-th factor’s value is weighted using its weight wj above to acquire a final value as the j-th input variable of STLF models. All the rest of the input variables are determined in the same way. FI-based feature selection process (FSP) can reduce the redundant information and improve the prediction accuracy and speed.
4. Load Forecasting Models
Over the past few decades, using weather variables as an integral part of forecasting process has been the most populous. It is common approach among neural network (NN) ones. Of all these methods using weather variables, backpropagation (BP) NN is one of the most widely applied means. The reason for this is that it can approximate numerically any continuous function to the desired accuracy. In addition, it is data-driven methods, in the sense, it is not necessary for the researchers to postulate tentative models and then estimate their parameters [
49]. The most common BP structure has three layers with a sigmoid transfer function for the activation function in the hidden layer and a linear transfer function in the output layer. The possible drawbacks for the method are, first, no theoretical approach can be applied to calculating the appropriate number of hidden layer nodes [
50]. Secondly, it is prone to overfit sample data because of the large number of parameters that must be estimated [
49]. In consideration of this, it is adopted to demonstrate the effectiveness of FI-based weather variables introduction and feature selection process for STLF, although it should be noted that the choice of modeling technique is not central to this paper.
4.1. Forecasting Model with Primitive Weather Variables
Previous load forecasting methods mainly consider characteristics of daily meteorological factors, yet out of consideration is the influence of meteorological factors on load at different time points over a day. For depicting pointwise influence of meteorological factors on the load by means of primitive weather variables, a BP NN-based STLF model with 19 inputs variables is built [
31]. The model consists of three layers, namely the input layer, the hidden layer, and the output layer, and the output layer has only one variable, i.e., the forecasted load at this point. Temperature, humidity, and load, both at different points in the same day and at the same point in different days, and others, are defined as input variables for the model. All the input variables are shown in
Table 1.
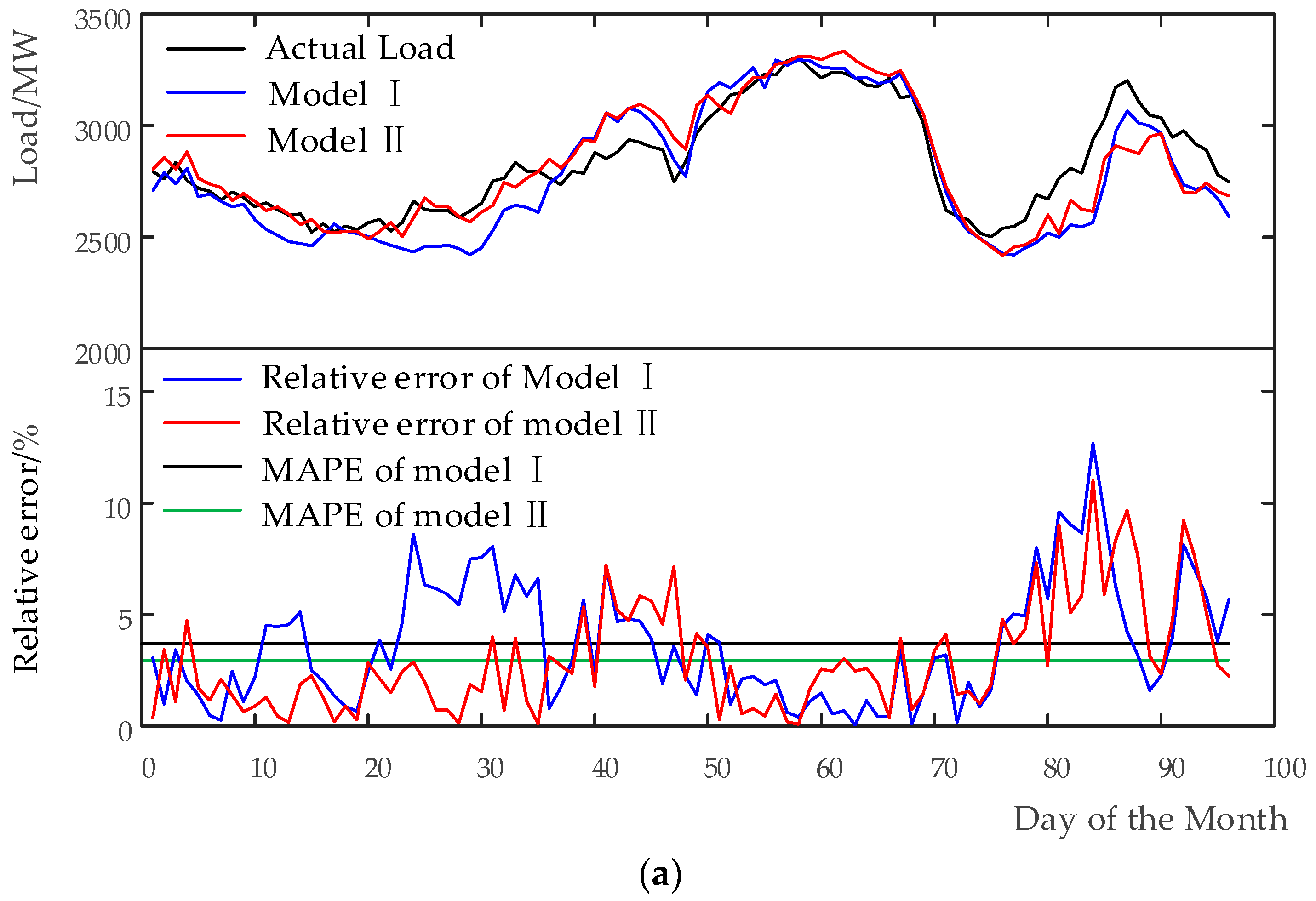
Nineteen variables are applied to the input neurons of BP neural network algorithm to examine the impact of real-time weather factors on load. This model is adopted as the benchmark method and denoted as Model I, for comparing with the following methods based on FI, in this paper.
4.2. Forecasting Model with Primitive MCIs
For a long time, MCIs have played a significant role in introducing weather variables into STLF models, and tey exhibit a comprehensive effect for outside weather conditions compared to the primitive weather variables. Therefore, it is imperative to construct a BP NN-based STLF model with primitive MCIs in terms of real-time MCI influence on load, which is achieved by using an MCI (specifically, THI) instead of both temperature and humidity in Model I. The model is presented in
Table 2.
This model with 13 input variables is denoted as Model II to demonstrate the impact of real-time MCI on load, and also to compare it with Model I above.
4.3. Forecasting Model with Weighted Weather Variables Based on FI
Using the aforementioned Model I as a basis, temperature and humidity are renewably introduced the model by means of FI-based approach, and then, the input variables are reduced to 11. They are displayed in
Table 3.
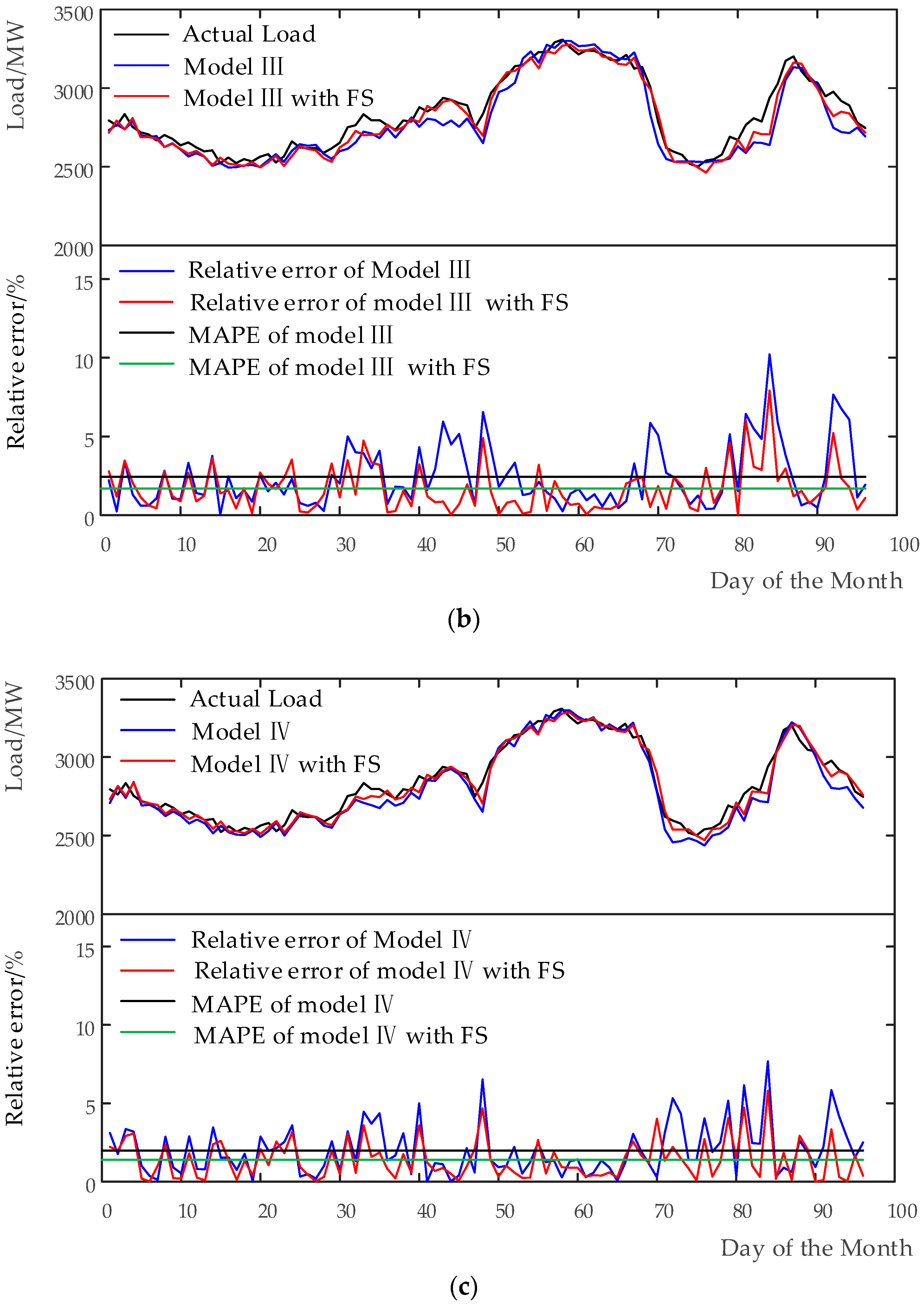
This model with 11 input variables is denoted as Model III. The model can describe well accumulative effect of both temperature and humidity on load demands by means of the proposed method. In addition, it offsets the time differences between load variation and weather conditions, which makes the variation of load with weather conditions to exhibit a real-timely effect.
4.4. Forecasting Model with Weighted MCIs Based on FI
THI is one of the most widely applied MCIs because of its practicability. As a result, the THI is utilized for demonstrating the performance of the method of weighted MCIs introduction into STLF models. The THI is the temperature and humidity index, which can be calculated with the following formula [
19]:
where
T and
R are temperature (in degrees Celsius) and relative humidity (integer percentage), respectively. The THI value computed multiplies by two-dimensional FI value of both temperature and relative humidity as a weighted THI (WTHI), as stated in
Section 3.2, and is introduced BP NN model. In this manner, the input variables are reduced to nine. They are described in
Table 4.
This model with nine input variables is denoted as Model IV. The model is established, using the proposed method, to characterize the accumulation impact of the MCIs on load point by point. It is supposed to be capable of further improving the accuracy and speed of STLF.
6. Conclusions
The principal contributions in this paper are to propose a robust methodology as a practical means of both introducing weather factors into STLF models and selecting its input variables, and comparing it with traditional methods.
Weather information is an important factor in load forecasting models. How to effectively introduce meteorological variables and reasonably select feature for STLF models has always been a topic of interest in this area. When looked at from an information point of view, FI can be interpreted as the amount of information that can be extracted from a set of measurements. From this point, the amount of weather information in previous period can be measured from past weather variables by FI. In this way, current weather variables value is weighted using the FI value of weather information in previous period, and then accumulative effect of weather factors on load demands is fully reflected. The same applies to FS in STLF models.
The advantages of the proposed method are easy to understand and convenient to apply in practical load forecasting. As demonstrated above, the method overcomes the main drawback of traditional method in term of considering accumulative effect of both the plain weather variables and the MCIs on load, and displaying a real-time effect on the load demands. In addition, the proposed FS approach reduces the redundant information, saves model training time and improves STLF’s prediction speed. Different forecasting models with the proposed approach are established and implemented, based on the case study of Zhenjiang City in southeast China, to assess the performance of the methodology. The simulation results obtained show the usefulness of the proposed methodology, which can be used as a unified method for weather variables introduction and feature selection for STLF models.







{kind=link}
{kind=link}
{kind=link}
{kind=link}