The Capacity for Correlated Semantic Memories in the Cortex



Abstract
1. Introduction
1.1. Correlations
1.2. Connectivity
2. Results
2.1. The Potts Network
2.2. Generating Correlated Representations
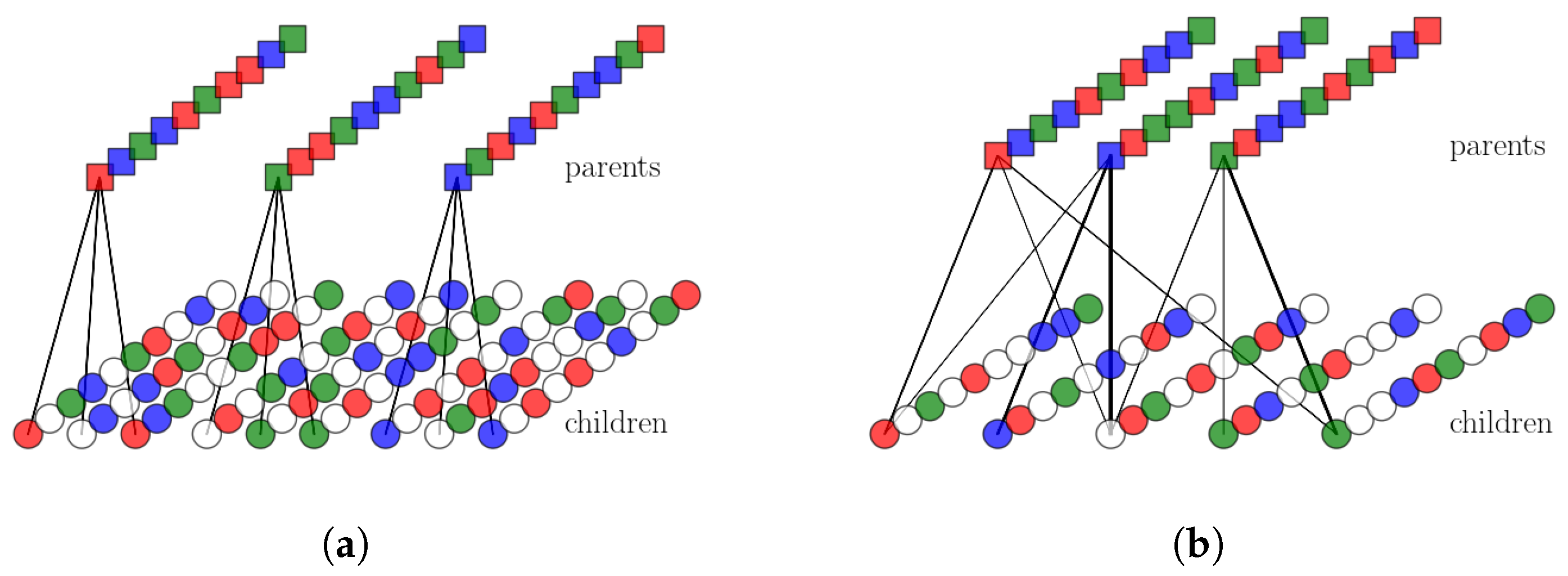
2.2.1. Single Parents and Ultrametrically Correlated Children
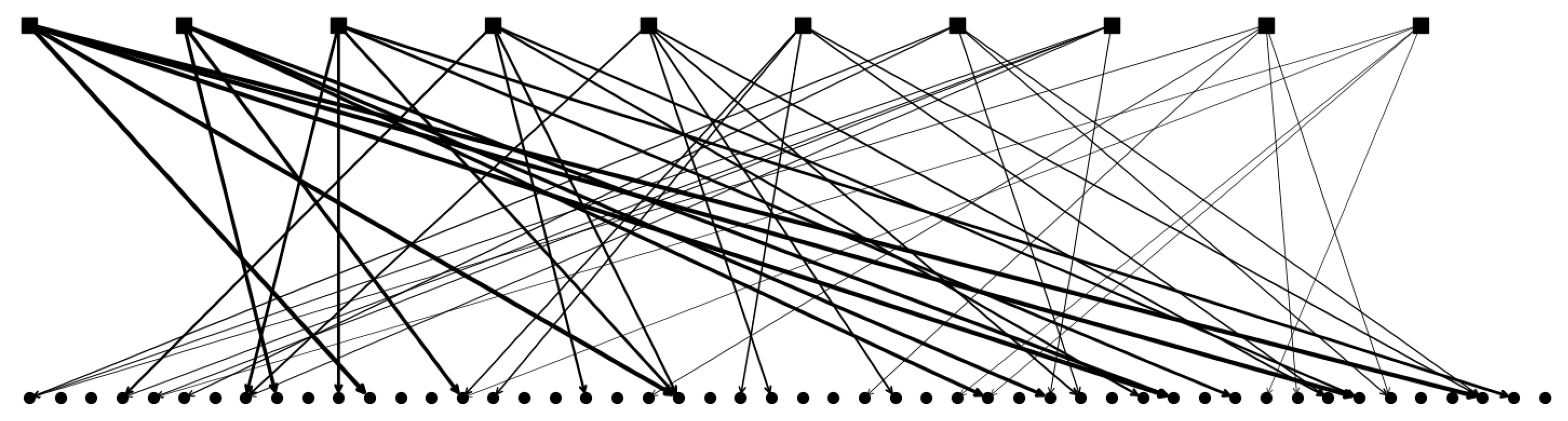
2.2.2. Multiple Parents and Non-Trivially Organized Children
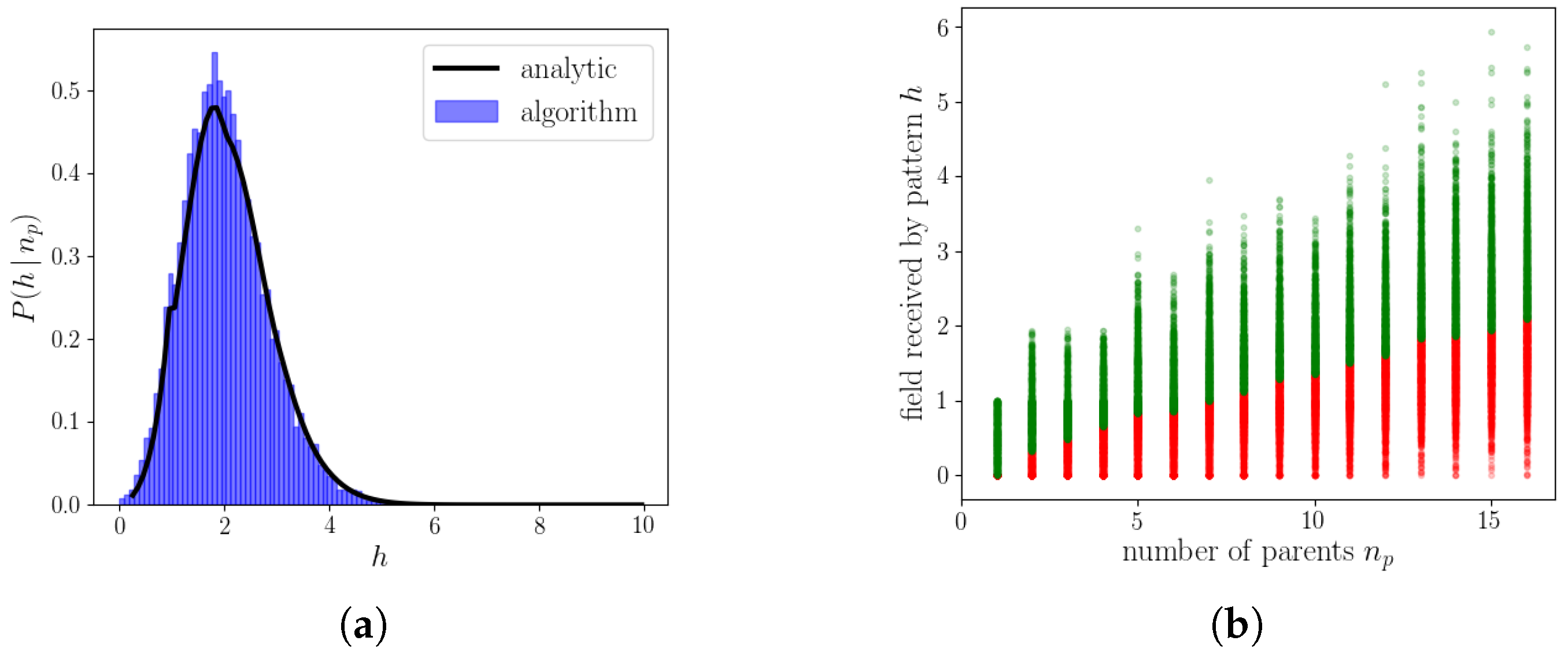
2.2.3. The Algorithm Operating on Simple Binary Units
2.2.4. The Algorithm Operating on Genuine Potts Units
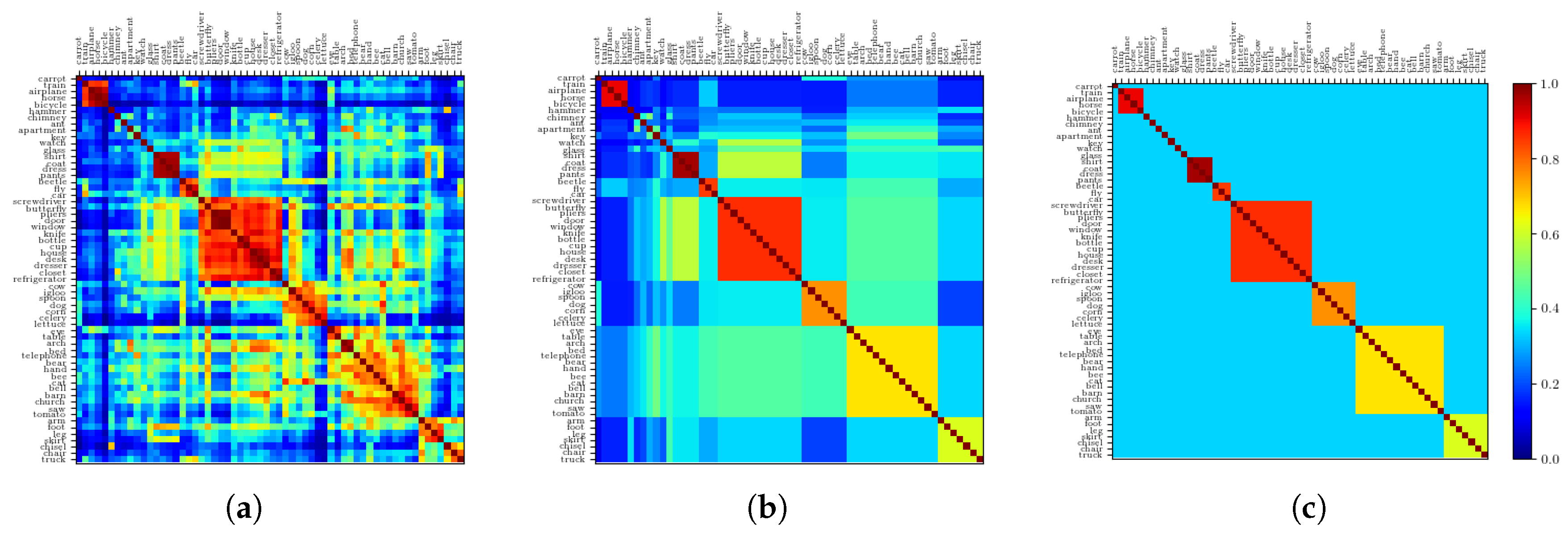
2.2.5. Resulting Patterns and Their Correlations
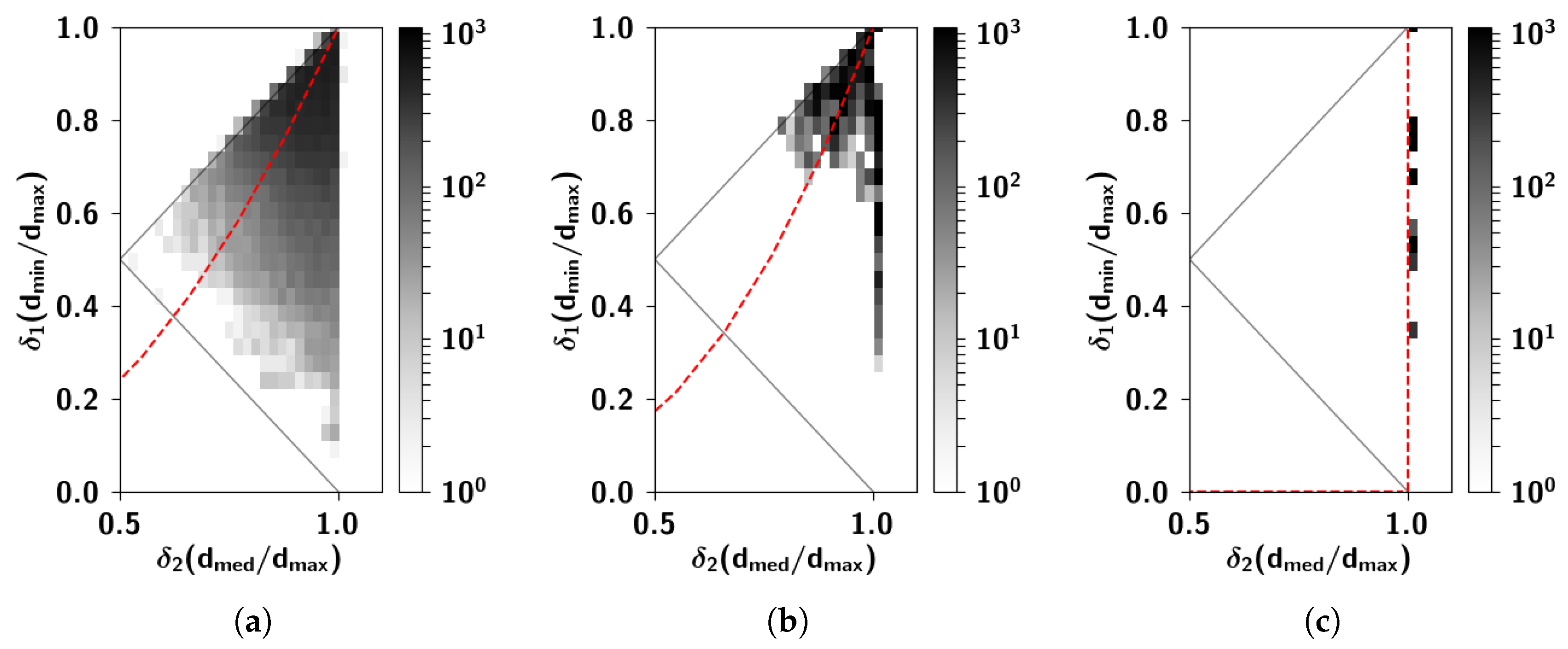
2.2.6. The Ultrametric Limit
2.2.7. The Random Limit
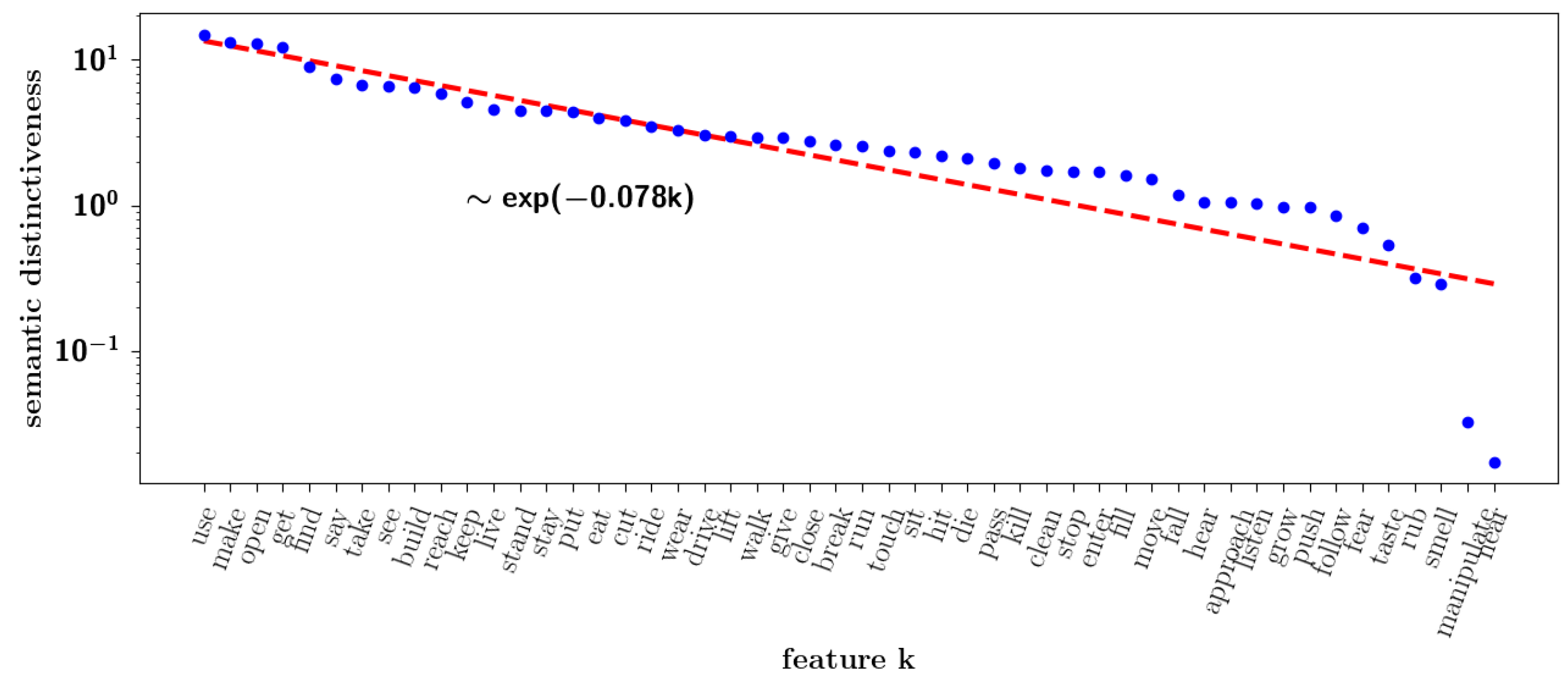
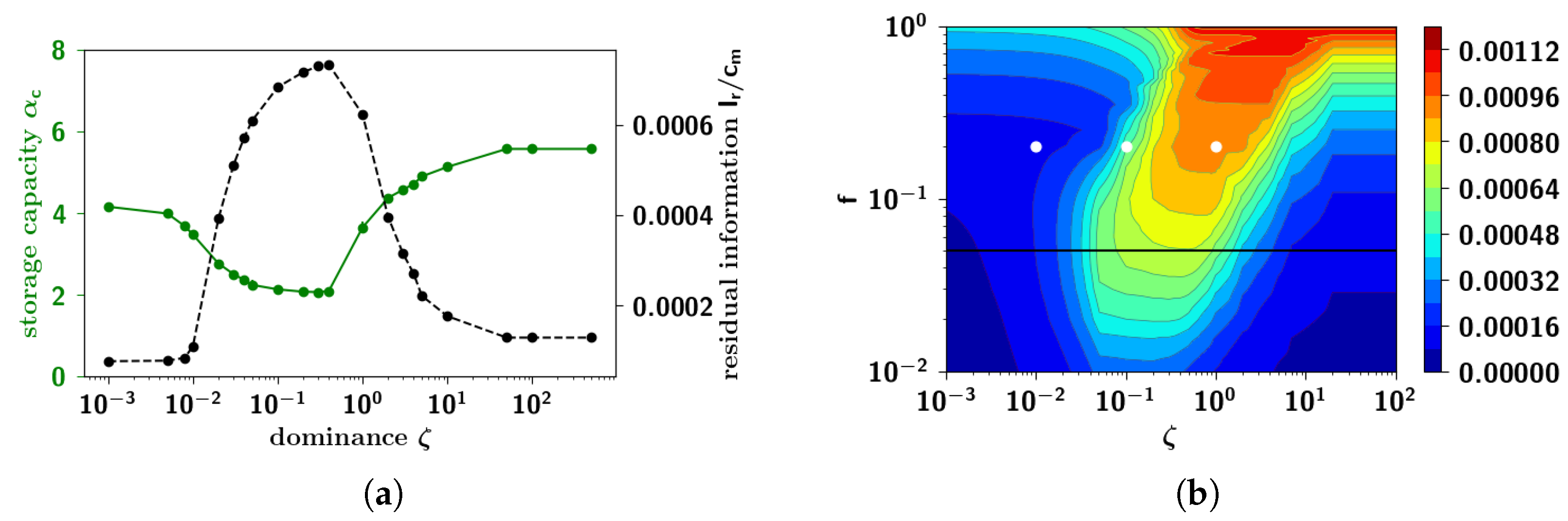
2.2.8. Semantic Dominance
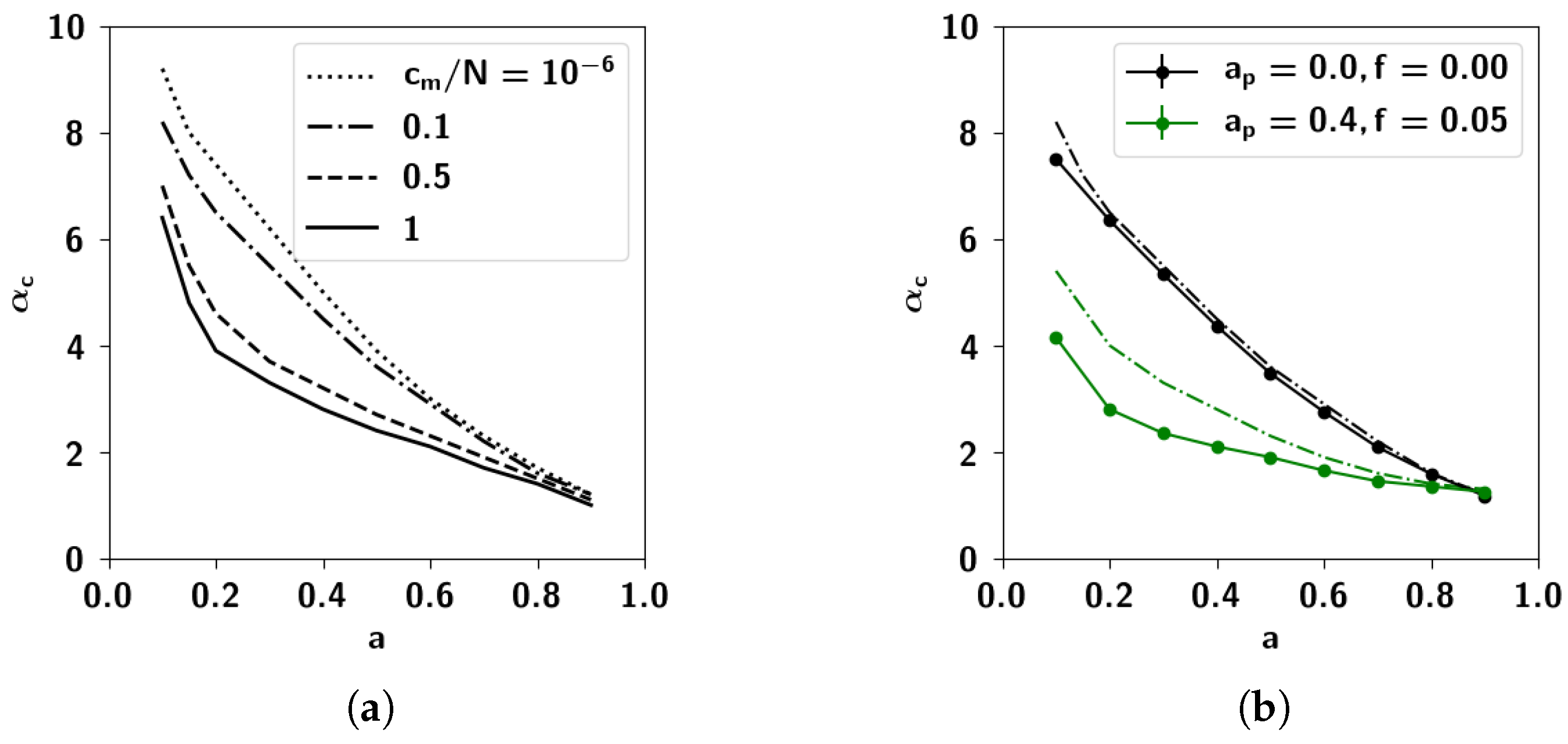
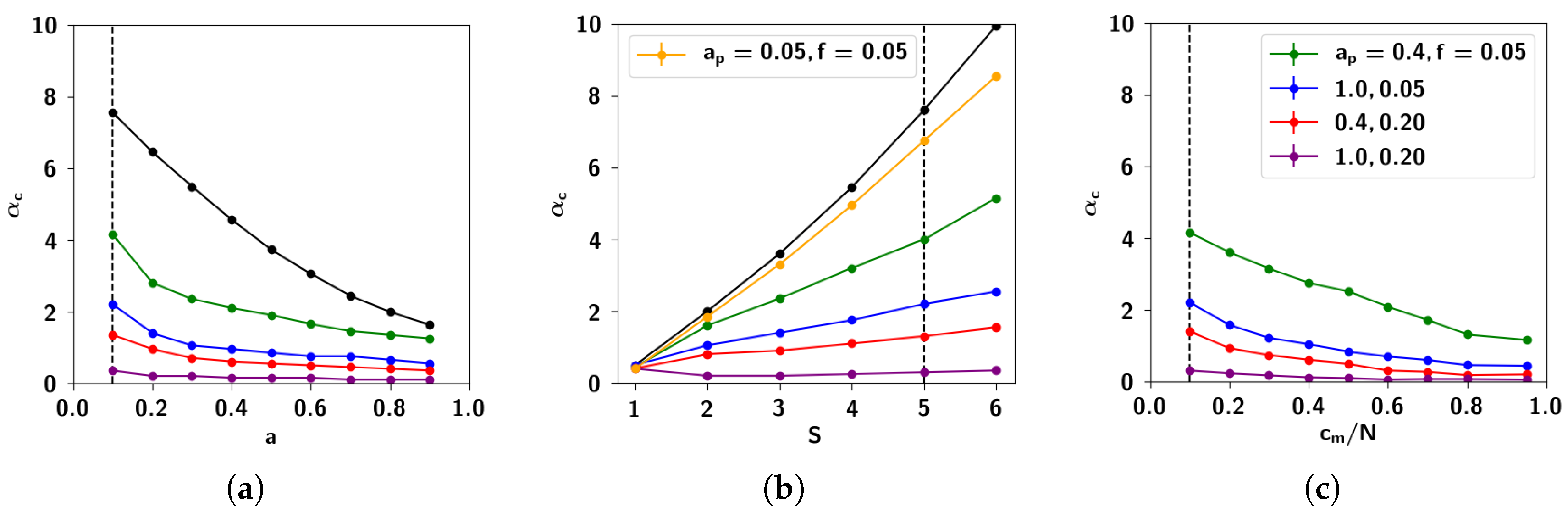
2.3. Storage Capacity of the Potts Network with Correlated Patterns
2.3.1. Self-Consistent Signal to Noise Analysis
2.3.2. Numerical Solutions of Mean-Field Equations and Simulations
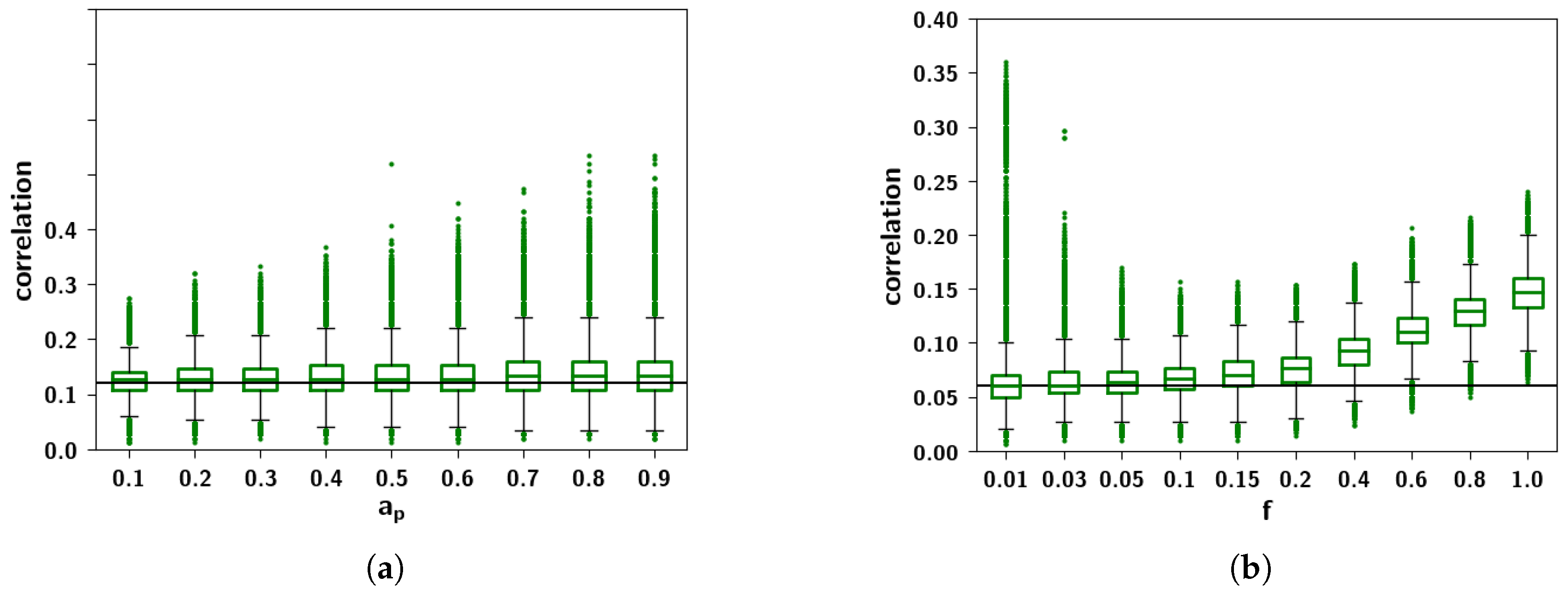
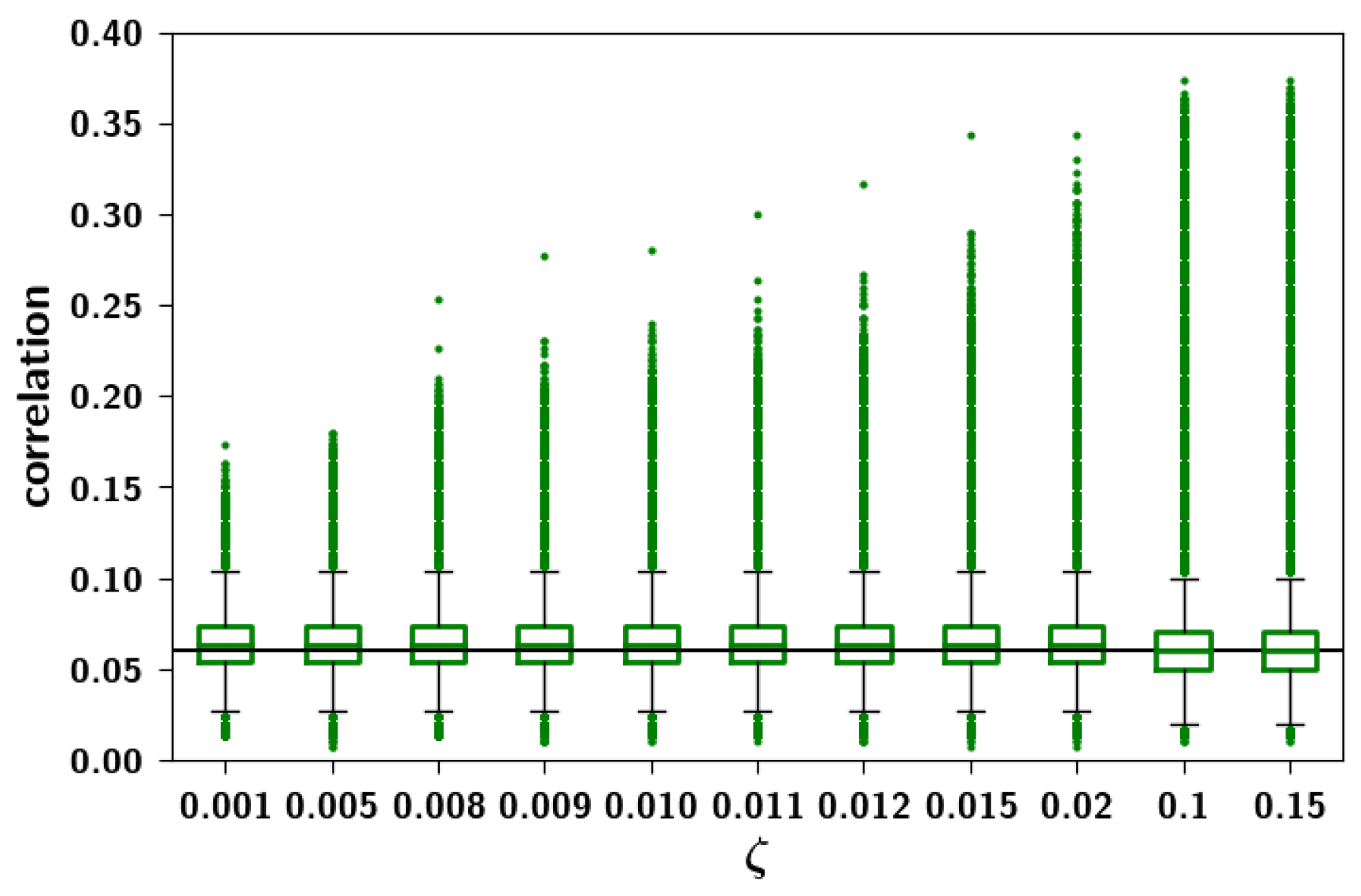
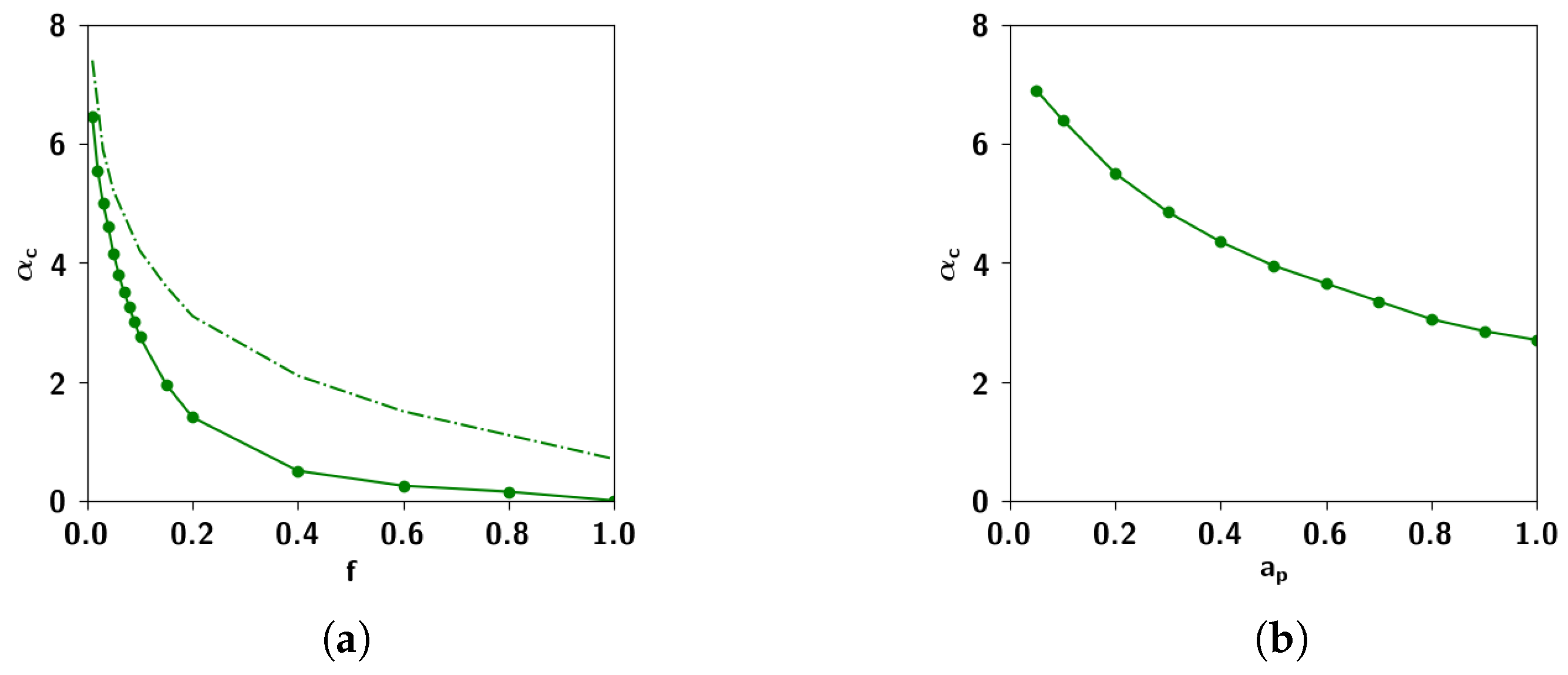
2.3.3. The Effect of Correlation Parameters f and
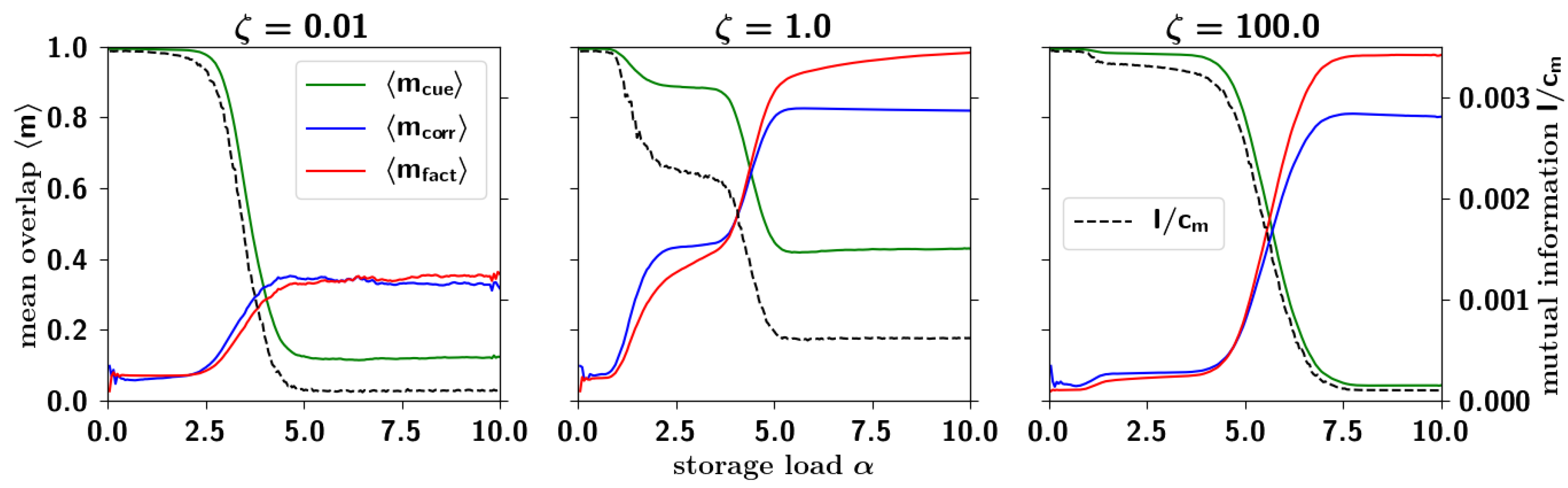
2.3.4. Correlated Retrieval
2.3.5. Residual Information: Memory Beyond Capacity
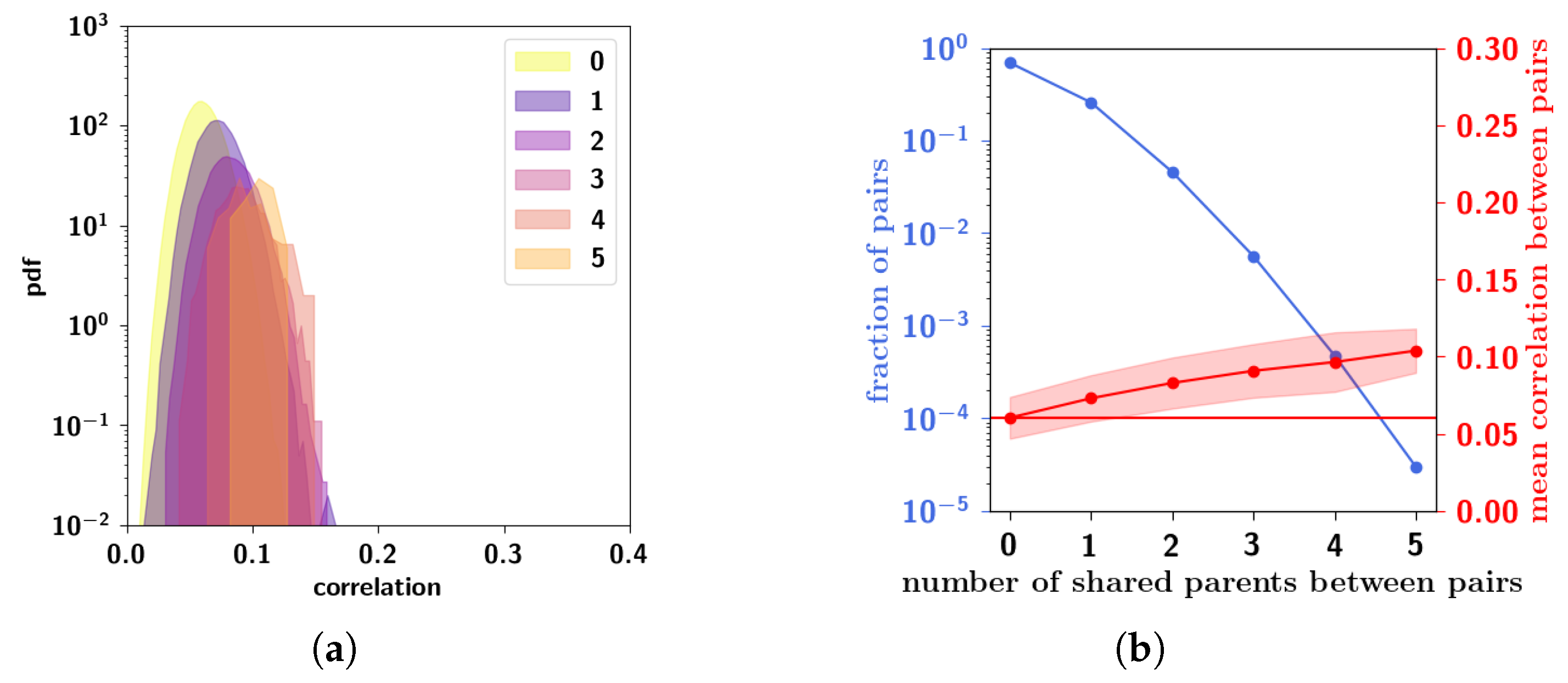
2.3.6. Residual Memory Interpreted through Cluster Analysis
2.3.7. Residual Memory Rides on Fine Differences in Ultrametric Content
3. Discussion: A New Model for the Extraction of Semantic Structure
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
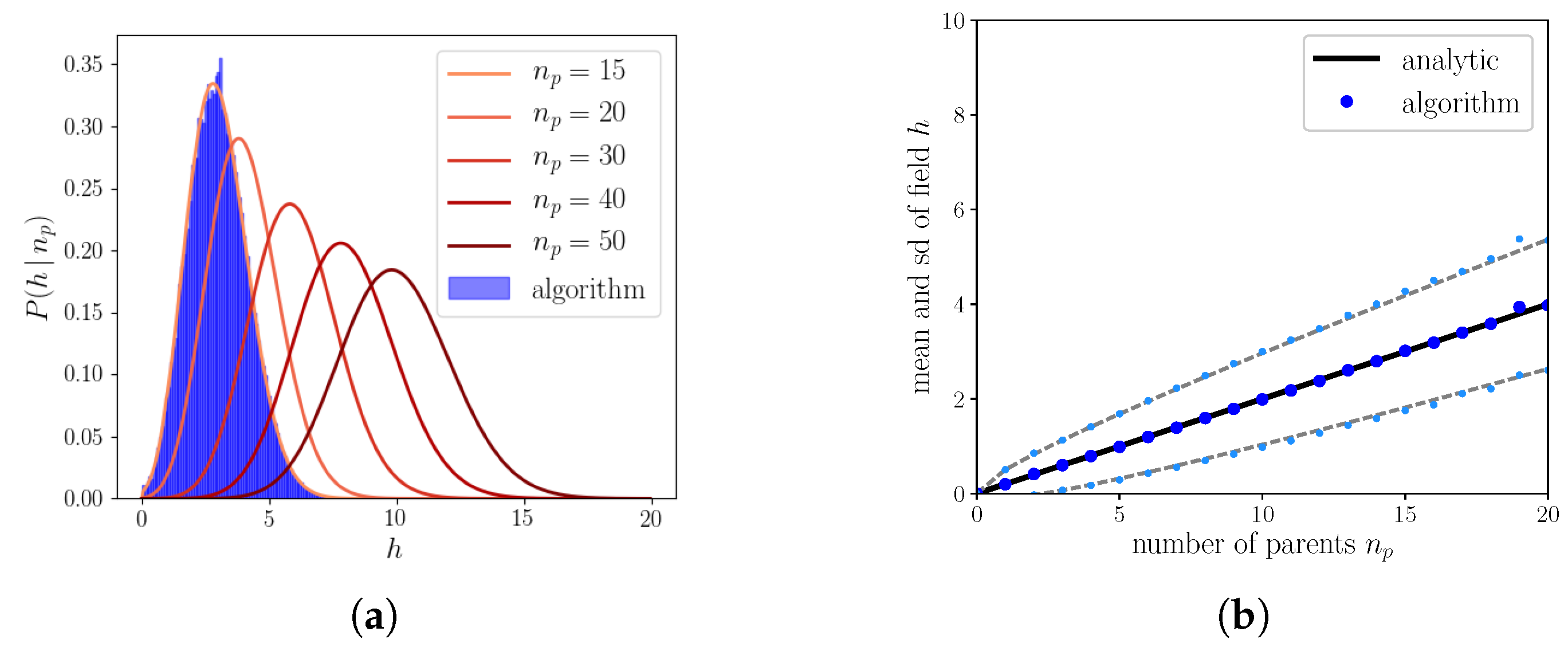
Appendix A. Calculation of the Probability Distribution of the Field for S = 1
Appendix B. Calculation of the Probability Distribution of the Field for S = 2
Appendix C. Ultrametric Content
References
- Yonelinas, A.P. The nature of recollection and familiarity: A review of 30 years of research. J. Mem. Lang. 2002, 46, 441–517. [Google Scholar] [CrossRef]
- Treves, A.; Rolls, E.T. Computational constraints suggest the need for two distinct input systems to the hippocampal CA3 network. Hippocampus 1992, 2, 189–199. [Google Scholar] [CrossRef] [PubMed]
- Alme, C.B.; Miao, C.; Jezek, K.; Treves, A.; Moser, E.I.; Moser, M.B. Place cells in the hippocampus: Eleven maps for eleven rooms. Proc. Natl. Acad. Sci. USA 2014, 111, 18428–18435. [Google Scholar] [CrossRef] [PubMed]
- Lauro-Grotto, R.; Ciaramelli, E.; Piccini, C.; Treves, A. Differential impact of brain damage on the access mode to memory representations: An information theoretic approach. Eur. J. Neurosci. 2007, 26, 2702–2712. [Google Scholar] [CrossRef] [PubMed]
- Huth, A.G.; Nishimoto, S.; Vu, A.T.; Gallant, J.L. A continuous semantic space describes the representation of thousands of object and action categories across the human brain. Neuron 2012, 76, 1210–1224. [Google Scholar] [CrossRef] [PubMed]
- Huth, A.G.; de Heer, W.A.; Griffiths, T.L.; Theunissen, F.E.; Gallant, J.L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 2016, 532, 453–458. [Google Scholar] [CrossRef] [PubMed]
- Mitchell, T.M.; Shinkareva, S.V.; Carlson, A.; Chang, K.M.; Malave, V.L.; Mason, R.A.; Just, M.A. Predicting human brain activity associated with the meanings of nouns. Science 2008, 320, 1191–1195. [Google Scholar] [CrossRef] [PubMed]
- Collins, A.M.; Quillian, M.R. Retrieval time from semantic memory. J. Verbal Learn. Verbal Behav. 1969, 8, 240–247. [Google Scholar] [CrossRef]
- Warrington, E.K. The selective impairment of semantic memory. Q. J. Exp. Psychol. 1975, 27, 635–657. [Google Scholar] [CrossRef] [PubMed]
- Treves, A. On the perceptual structure of face space. BioSystems 1997, 40, 189–196. [Google Scholar] [CrossRef]
- Parga, N.; Virasoro, M.A. The ultrametric organization of memories in a neural network. J. Phys. 1986, 47, 1857–1864. [Google Scholar] [CrossRef]
- Gutfreund, H. Neural networks with hierarchically correlated patterns. Phys. Rev. A 1988, 37, 570–577. [Google Scholar] [CrossRef]
- Franz, S.; Amit, D.J.; Virasoro, M.A. Prosopagnosia in high capacity neural networks storing uncorrelated classes. J. Phys. 1990, 51, 387–408. [Google Scholar] [CrossRef]
- Virasoro, M.A. Categorization in neural networks and prosopagnosia. Phys. Rep. 1989, 184, 301–306. [Google Scholar] [CrossRef]
- Brasselet, R.; Arleo, A. Category Structure and Categorical Perception Jointly Explained by Similarity-Based Information Theory. Entropy 2018, 20, 527. [Google Scholar] [CrossRef]
- Shallice, T.; Cooper, R. The Organisation of Mind; Oxford University Press: Oxford, UK, 2011. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; McClelland, J.L. A general framework for parallel distributed processing. Parallel Distrib. Process. Explor. Microstruct. Cognit. 1986, 1, 45–76. [Google Scholar]
- Farah, M.J.; McClelland, J.L. A computational model of semantic memory impairment: Modality specificity and emergent category specificity. J. Exp. Psychol. Gen. 1991, 120, 339. [Google Scholar] [CrossRef] [PubMed]
- Plaut, D.C. Semantic and associative priming in a distributed attractor network. In Proceedings of the 17th Annual Conference of the Cognitive Science Society, Hillsdale, NJ, USA, 22–25 July 1995; Volume 17, pp. 37–42. [Google Scholar]
- Rogers, T.T.; Lambon Ralph, M.A.; Garrard, P.; Bozeat, S.; McClelland, J.L.; Hodges, J.R.; Patterson, K. Structure and deterioration of semantic memory: A neuropsychological and computational investigation. Psychol. Rev. 2004, 111, 205. [Google Scholar] [CrossRef] [PubMed]
- Hellwig, B. A quantitative analysis of the local connectivity between pyramidal neurons in layers 2/3 of the rat visual cortex. Biol. Cybern. 2000, 82, 111–121. [Google Scholar] [CrossRef] [PubMed]
- Roudi, Y.; Treves, A. An associative network with spatially organized connectivity. J. Stat. Mech. Theory Exp. 2004, 2004, P07010. [Google Scholar] [CrossRef]
- Pucak, M.L.; Levitt, J.B.; Lund, J.S.; Lewis, D.A. Patterns of intrinsic and associational circuitry in monkey prefrontal cortex. J. Comp. Neurol. 1996, 376, 614–630. [Google Scholar] [CrossRef]
- Braitenberg, V.; Schüz, A. Anatomy of the Cortex: Statistics and Geometry; Springer Science & Business Media: Berlin, Germany, 1991; Volume 18. [Google Scholar]
- O’Kane, D.; Treves, A. Short-and long-range connections in autoassociative memory. J. Phys. A Math. Gen. 1992, 25, 5055. [Google Scholar] [CrossRef]
- O’Kane, D.; Treves, A. Why the simplest notion of neocortex as an autoassociative memory would not work. Netw. Comput. Neural Syst. 1992, 3, 379–384. [Google Scholar] [CrossRef]
- Mari, C.F.; Treves, A. Modeling neocortical areas with a modular neural network. Biosystems 1998, 48, 47–55. [Google Scholar] [CrossRef]
- Johansson, C.; Rehn, M.; Lansner, A. Attractor neural networks with patchy connectivity. Neurocomputing 2006, 69, 627–633. [Google Scholar] [CrossRef]
- Dubreuil, A.M.; Brunel, N. Storing structured sparse memories in a multi-modular cortical network model. J. Comput. Neurosci. 2016, 40, 157–175. [Google Scholar] [CrossRef] [PubMed]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic routing between capsules. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 3859–3869. [Google Scholar]
- Naim, M.; Boboeva, V.; Kang, C.J.; Treves, A. Reducing a cortical network to a Potts model yields storage capacity estimates. J. Stat. Mech. Theory Exp. 2018, 2018, 043304. [Google Scholar] [CrossRef]
- Hopfield, J.J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554–2558. [Google Scholar] [CrossRef] [PubMed]
- Tsodyks, M.V.; Feigel’Man, M.V. The enhanced storage capacity in neural networks with low activity level. EPL (Europhys. Lett.) 1988, 6, 101. [Google Scholar] [CrossRef]
- Kropff, E.; Treves, A. The storage capacity of Potts models for semantic memory retrieval. J. Stat. Mech. Theory Exp. 2005, 2005, P08010. [Google Scholar] [CrossRef]
- Mézard, M.; Parisi, G.; Virasoro, M.A. Spin Glass Theory and Beyond: An Introduction to the Replica Method and Its Applications; World Scientific Publishing Co Inc.: Singapore, 1987; Volume 9. [Google Scholar]
- Amit, D.J. Modeling Brain Function: The World of Attractor Neural Networks; Cambridge University Press: Cambridge, UK, 1992. [Google Scholar]
- Treves, A. Frontal latching networks: A possible neural basis for infinite recursion. Cognit. Neuropsychol. 2005, 22, 276–291. [Google Scholar] [CrossRef] [PubMed]
- Sartori, G.; Lombardi, L. Semantic relevance and semantic disorders. J. Cognit. Neurosci. 2004, 16, 439–452. [Google Scholar] [CrossRef] [PubMed]
- Osgood, C.E. Semantic differential technique in the comparative study of cultures. Am. Anthropol. 1964, 66, 171–200. [Google Scholar] [CrossRef]
- Löwe, M. On the storage capacity of Hopfield models with correlated patterns. Ann. Appl. Probab. 1998, 8, 1216–1250. [Google Scholar] [CrossRef]
- Engel, A. Storage capacity for hierarchically correlated patterns. J. Phys. A Math. Gen. 1990, 23, L285. [Google Scholar] [CrossRef]
- Shiino, M.; Fukai, T. Self-consistent signal-to-noise analysis of the statistical behavior of analog neural networks and enhancement of the storage capacity. Phys. Rev. E 1993, 48, 867. [Google Scholar] [CrossRef]
- Kropff, E. Full solution for the storage of correlated memories in an autoassociative memory. Comput. Model. Behav. Neurosci. Closing Gap Neurophysiol. Behav. 2009, 2, 225. [Google Scholar]
- Tamarit, F.A.; Curado, E.M. Pair-correlated patterns in Hopfield model of neural networks. J. Stat. Phys. 1991, 62, 473–480. [Google Scholar] [CrossRef]
- Liberman, A.M.; Harris, K.S.; Hoffman, H.S.; Griffith, B.C. The discrimination of speech sounds within and across phoneme boundaries. J. Exp. Psychol. 1957, 54, 358–368. [Google Scholar] [CrossRef] [PubMed]
- Rips, L.J.; Shoben, E.J.; Smith, E.E. Semantic distance and the verification of semantic relations. J. Verbal Learn. Verbal Behav. 1973, 12, 1–20. [Google Scholar] [CrossRef]
- Rosch, E.H.; Mervis, C.B. Family resemblances: Studies in the internal structure of categories. Cognit. Psychol. 1975, 7, 573–605. [Google Scholar] [CrossRef]
- Kuhl, P.K. Human adults and human infants show a “perceptual magnet effect” for the prototypes of speech categories, monkeys do not. Percept. Psychophys. 1991, 50, 93–107. [Google Scholar] [CrossRef] [PubMed]
- Feldman, N.H.; Griffiths, T.L.; Morgan, J.L. The influence of categories on perception: Explaining the perceptual magnet effect as optimal statistical inference. Psychol. Rev. 2009, 116, 752. [Google Scholar] [CrossRef] [PubMed]
- Haxby, J.V.; Gobbini, M.I.; Furey, M.L.; Ishai, A.; Schouten, J.L.; Pietrini, P. Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science 2001, 293, 2425–2430. [Google Scholar] [CrossRef] [PubMed]
- Norman, K.A.; Polyn, S.M.; Detre, G.J.; Haxby, J.V. Beyond mind-reading: Multi-voxel pattern analysis of fMRI data. Trends Cognit. Sci. 2006, 10, 424–430. [Google Scholar] [CrossRef] [PubMed]
- Preston, A.R.; Eichenbaum, H. Interplay of hippocampus and prefrontal cortex in memory. Curr. Biol. 2013, 23, R764–R773. [Google Scholar] [CrossRef] [PubMed]
- Ciaramelli, E.; Lauro-Grotto, R.; Treves, A. Dissociating episodic from semantic access mode by mutual information measures: Evidence from aging and Alzheimer’s disease. J. Physiol. Paris 2006, 100, 142–153. [Google Scholar] [CrossRef] [PubMed]
- Tulving, E. Episodic memory: From mind to brain. Annu. Rev. Psychol. 2002, 53, 1–25. [Google Scholar] [CrossRef] [PubMed]
- Garrard, P.; Perry, R.; Hodges, J.R. Disorders of semantic memory. J. Neurol. Neurosurg. Psychiatry 1997, 62, 431. [Google Scholar] [CrossRef] [PubMed]
- Conrad, C. Cognitive Economy in Semantic Memory; American Psychological Association: Washington, DC, USA, 1972. [Google Scholar]
- Spivey, M.; Joanisse, M.; McRae, K. The Cambridge Handbook of Psycholinguistics; Cambridge University Press: Cambridge, UK, 2012. [Google Scholar]
- Kitamura, T.; Ogawa, S.K.; Roy, D.S.; Okuyama, T.; Morrissey, M.D.; Smith, L.M.; Redondo, R.L.; Tonegawa, S. Engrams and circuits crucial for systems consolidation of a memory. Science 2017, 356, 73–78. [Google Scholar] [CrossRef] [PubMed]
- McClelland, J.L.; McNaughton, B.L.; O’Reilly, R.C. Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory. Psychol. Rev. 1995, 102, 419. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 0.001 | 0.02 | 0.1 | 1.0 | 10 | ||
| 0.05 | 0.395 | 0.429 | 0.435 | 0.416 | 0.397 | |
| 0.2 | 0.389 | 0.404 | 0.507 | 0.507 | 0.507 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boboeva, V.; Brasselet, R.; Treves, A. The Capacity for Correlated Semantic Memories in the Cortex. Entropy 2018, 20, 824. https://doi.org/10.3390/e20110824
Boboeva V, Brasselet R, Treves A. The Capacity for Correlated Semantic Memories in the Cortex. Entropy. 2018; 20(11):824. https://doi.org/10.3390/e20110824
Chicago/Turabian StyleBoboeva, Vezha, Romain Brasselet, and Alessandro Treves. 2018. "The Capacity for Correlated Semantic Memories in the Cortex" Entropy 20, no. 11: 824. https://doi.org/10.3390/e20110824
APA StyleBoboeva, V., Brasselet, R., & Treves, A. (2018). The Capacity for Correlated Semantic Memories in the Cortex. Entropy, 20(11), 824. https://doi.org/10.3390/e20110824