2.1. Convergence of SPSb to a Nadaraya-Watson Kernel Regression
In this section, we prove that the SPSb prediction method converges, for a large number of iterations, to a Nadaraya-Watson kernel regression (NWKR). The idea was originally suggested in [
16], but never developed mathematically. We prove the convergence analytically and numerically so that for all prediction purposes the two methods are interchangeable. The result is significant because it connects SPSb to a well-established, tried and tested technique, and frames the predictions made with this method in a more mathematically rigorous setting. SPSb is a non-deterministic algorithm so, at every run, it will yield slightly different results, while NWKR will always produce the same results up to machine precision. From a computational perspective, NWKR has much smaller time complexity, so our result allows the use of SPSb on much larger datasets than previously explored.
SPSb is fundamentally a nonparametric regression. We describe the algorithm here, and in
Section 3.4. In the original formulation [
18], one is presented with
, the position of a given country
in the Fitness-GDP (FG) plane at time
, and wants to predict the change (displacement) in GDP at the next timestep
, namely
. The method is based on the idea, advanced in [
15], that the growth process of countries is well modeled by a low-dimensional dynamical systems. For many important cases, the best model is argued to be embedded in the two-dimensional Euclidean space given by Fitness and GDPpc. It is not possible to identify the analytical equations of motion, so instead one uses observations of previous positions and displacements of other countries
, which are called
analogues, a term borrowed from [
17]. Because the evolution is argued to be dependent only on two parameters, observed past evolutions of countries nearby
in the FG plane are deemed to be good predictors of
. Threfore SPSb predicts
as a weighted average of past observations. The weights will be proportional to the similarity of country
to its analogues, and the similarity is evaluated by calculating Euclidean distance on the Fitness-GDP plane. A close relative of this approach is the well-known K-nearest neighbours regression [
21]. In order to obtain this weighted average, one samples with repetition a number
B of bootstraps from all
N available analogues. The sample probability density of an analogue
, found at position
is given by a gaussian distribution:
Therefore sampling probability will be inversely proportional to distance, i.e., analogues closer on the FG plane are sampled more often. We will adopt the following notation: each bootstrap will be numbered with
b and each sampled analogue in a bootstrap with
n, so each specific analogue sampled during the prediction of
can be indexed with
. Once the sampling operation is done, one averages the samples per bootstrap, obtaining
. These averaged values constitute the distribution we expect for
. From this distribution we can derive an expectation value and a standard deviation (interpreted as expected prediction error) for
:
NWKR is conceptually very similar to SPSb. We will use the symbol ↔ to establish a correspondence between the two algorithms: in NWKR one is presented with an observation
and wants to predict
from it. Other observations are available
, and the prediction is a weighted average of the
’s.
The weights will be given by
K, a function of the distance on the Euclidean space containing the
values. This function is called
kernel. A more detailed explanation of this technique can be found in
Section 3.5.
2.1.1. Analytical Convergence
SPSb returns both an expected value and a standard deviation for the quantity being measured. We begin by proving convergence of expected value.
Expected values. — Suppose that we execute
B bootstraps of
N samples from all available analogues
, so that each sampled value in a bootstrap can be labelled as
with
and
. Then the SPSb probabilistic forecast
will be:
If we aggregate all
B bootstraps, we can label the frequency with which the analogue
appears overall in the sampled analogues as
where
is intended to be an indicator function. So we can rewrite the forecast as:
where
indicates a sum over all available analogues. But since the analogues are being sampled according to a known probability distribution
, we can expect, by the law of large numbers, that for
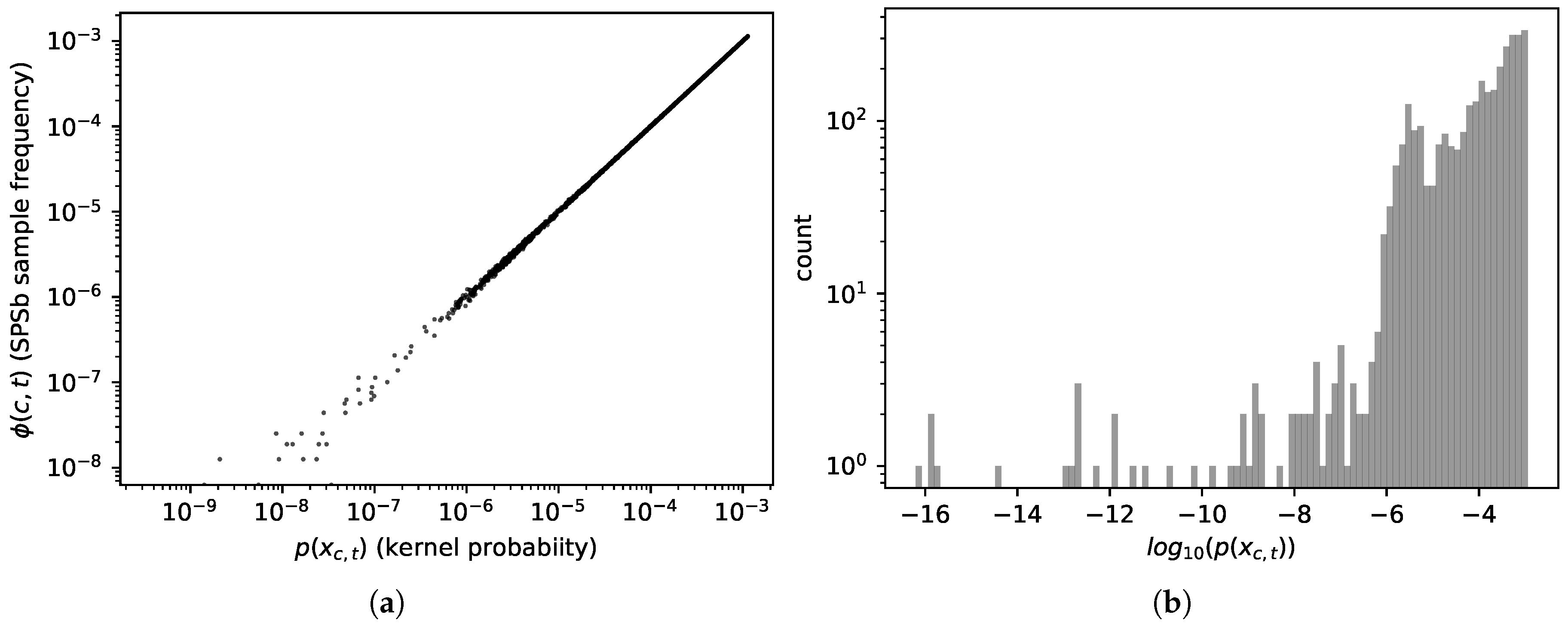
the sample frequency will converge to the probability values (which it does, see
Figure 1a):
Now, SPSb uses a Gaussian probability distribution
(see
Section 3.4) so our forecast will tend to:
but this is exactly the definition of a NWKR with Gaussian kernel that has bandwidth
, see
Section 3.5 (in the machine learning literature it’s usually not called Gaussian, but
radial basis function.). We assumed for brevity that the sum is already normalized, i.e.,
, normalization is needed in Equations (
9) and (
10) if this is not true, but it doesn’t change the result of the proof.
Variances. — The variance of the distribution of samples in SPSb is calculated first by computing
i.e., the average of the samples of each boostrap, and then computing the variance of the
across bootstraps, so (with the same notation as Equation (
6)) it can be written as:
In the second row we considered that , the operation of averaging across all sample analogues, irrespective of which bootstrap they are in, is equivalent to taking the expected value in SPSb. In the third row, because in SPSb we are calculating the variance of the means , and each of the means is done over N samples, for the central limit theorem when we expect a variance that is N times smaller than the population variance of the analogues sampled with probability p, which we called . The approximation in the last row is justified by the fact that in the third and fourth row is an unbiased estimator of the variance, and in the last row is an unbiased estimator of the second moment of the distribution of the samples. In the limit of large B, the relation applies to unbiased estimators too.
Now, we know by the definition of NWKR (
Section 3.5) that
is actually a conditional probability
, i.e., the probability of observing a certain displacement
given the position on the plane
. Therefore we can compute the variance for a NWKR as:
which tranlsates, for SPSb formalism, into:
We again omitted normalization terms in the third and fourth rows. This equation, combined with Equation (
11), means that the standard deviation calculated with NWKR is espected to be proportional to the standard deviation calculated with SPSb multiplied by
. Note that this method makes it possible to estimate any moment of the
distribution, not just the second.
2.1.2. Numerical Convergence
We computed expectations and standard deviations for economic complexity data with both SPSb (
bootstraps) and NWKR. The results here refer to the calculation for GDP prediction, but the same results are obtained with products predictions. It can be clearly seen from
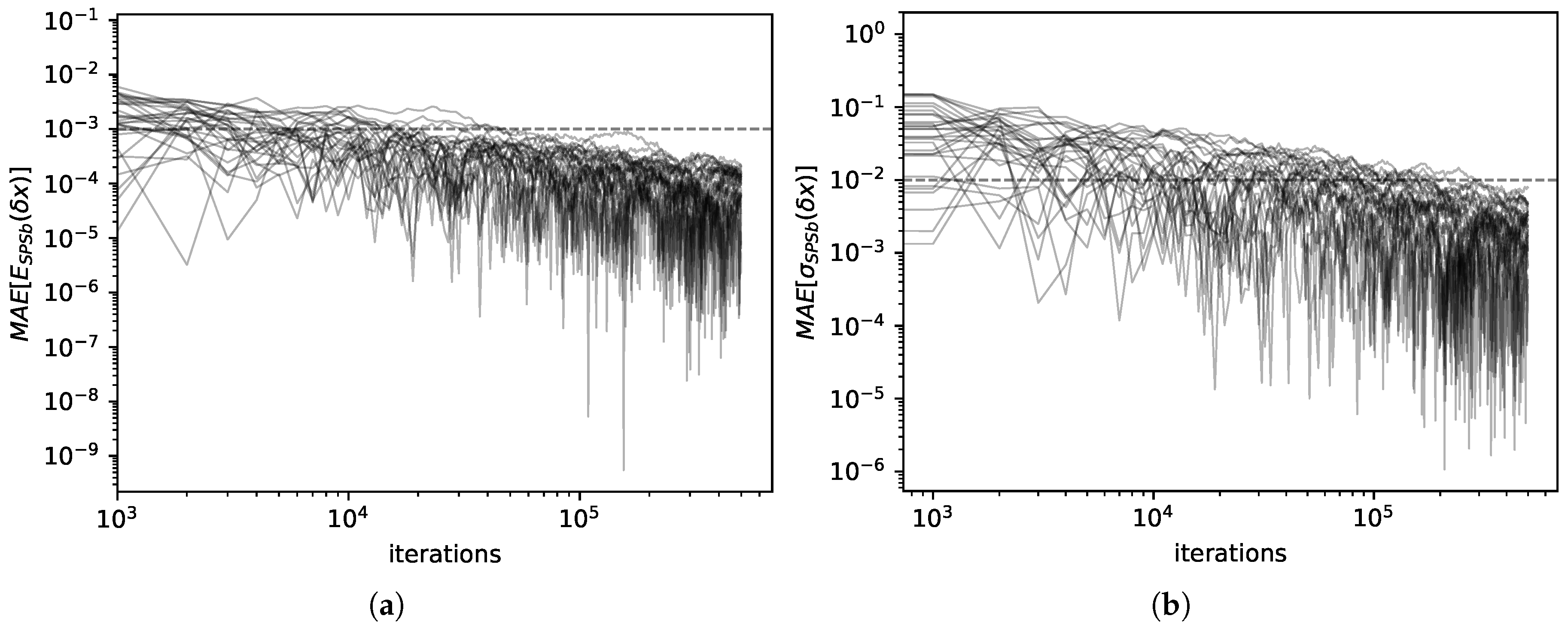
Figure 2a that the expectation values for SPSb converge to NWKR expectation values as the number of bootstraps increases. We show that the mean average error
converges numerically to zero (by
we mean the expectation value of the displacement of
x calculated with method
M). The standard deviations converge as well, as can be seen from
Figure 2b. Here too we calculate
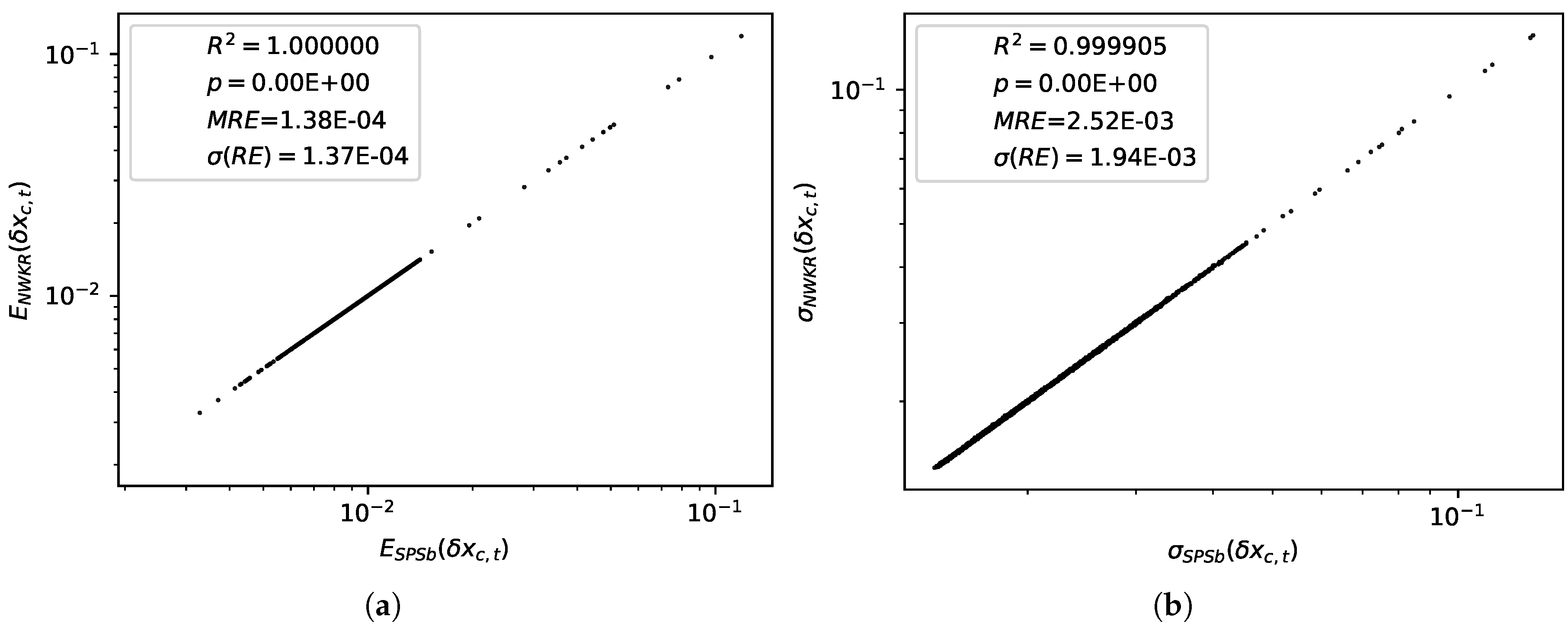
. A comparison of the values obtained for expectations with the two methods is shown in
Figure 3a. The difference between predictions with the two methods is
on average with a standard deviation of
. A comparison of the standard deviations obtained with the two methods is shown in
Figure 3b. The difference between the two methods in this case is
on average with a standard deviation of
. For the purpose of GDP prediction we can therefore say that the two methods are completely interchangeable. The time complexity for SPSb is of the order
, while for NWKR is
, so with
bootstraps (as reccommended by the literature [
18]) NWKR is expected to be
times faster. The same is not true for space complexity, since the original SPSb can be implemented with
memory requirements like NWKR.
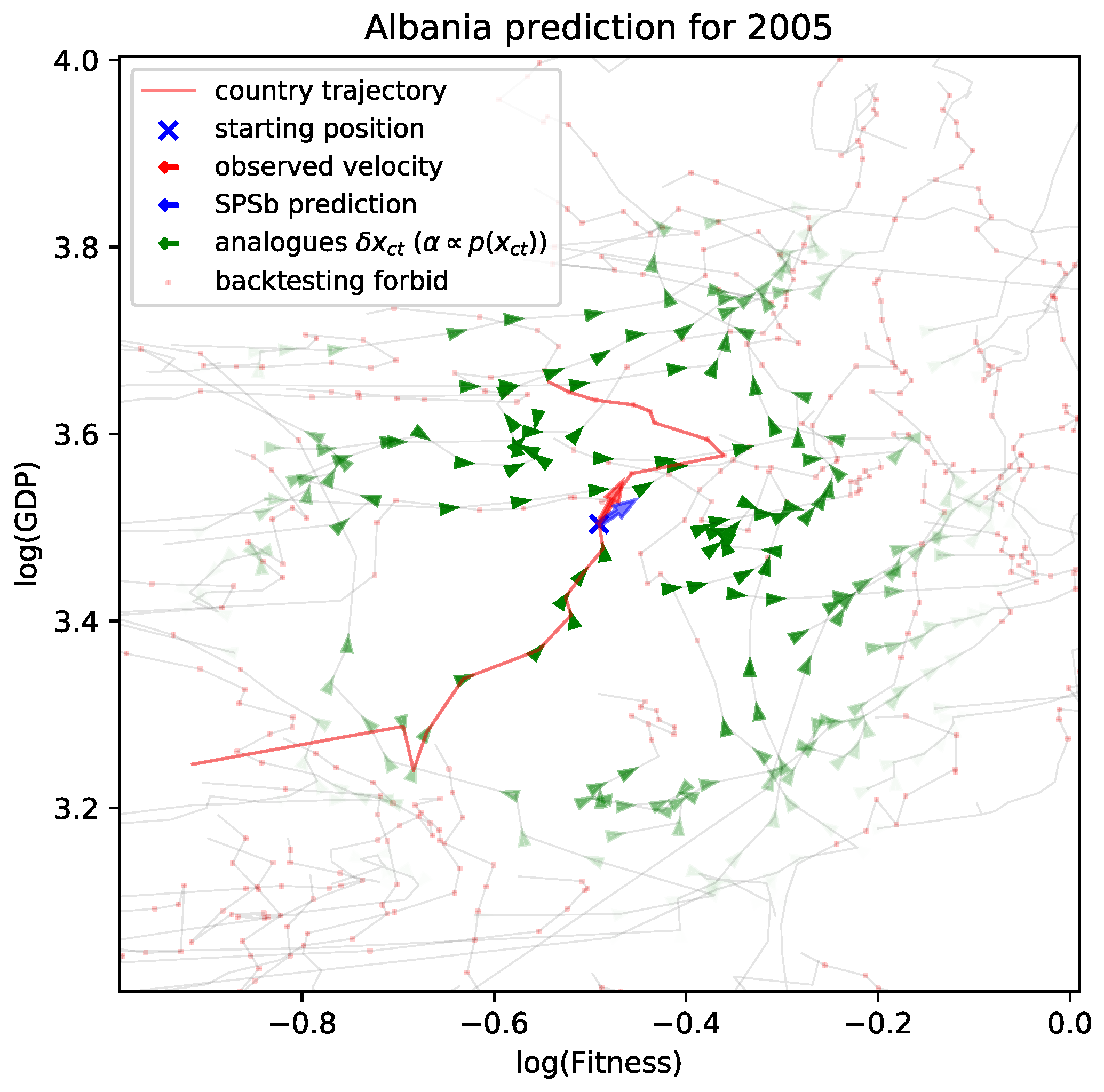
The convergence does not reach machine precision even at
bootstrap cycles of SPSb because many of the analogues have extremely small probabilities to appear in a bootstrap. In
Figure 1b we show the probabilities assigned by the kernel to all analogues of the plane for a typical prediction. In
Figure 1a we compare, for a typical prediction, the sample frequency of each analogue with the sampling probability assigned to it by the kernel. It can be clearly seen from both figures that a sizeable proportion of the analogues has no chance to appear even in a bootstrap of
cycles since about 30 percent of them have probability significantly
(each bootstrap samples
analogues). These analogues are instead included in the NWKR estimate, although with a very small weight. To obtain complete convergence one would have to sample, in total, as many analogues as the inverse of the smallest probability found among the analogues, and this number can go up to
in typical use cases. We expect the discrepancies to decrease with the total number of samples (i.e.,
), as more and more analogues are sampled with the correct frequency. A visual representation of such discrepancies can be seen in
Figure 1a, where we plot the kernel probabilities of each available analogue
against the sampled frequencies
for a bootstrap of
samples. Discrepancies start to show, as expected, at a probability of about
. The code we used to compute NWKR is publicly available [
22].
2.2. HMM Regularization Reduces Noise and Increases Nestedness
In analogy to what happens for countries, product classes too can be represented as points
on the Complexity-logPRODY (CL) plane. Their trajectories over time
t can be then considered, and one can find the average velocity field
by dividing the CL plane into a grid of square cells and averaging the time displacements
of products per cell. The procedure of averaging per cell on a grid can be considered a form of nonparametric regression, but it is by no means the only technique available to treat this problem. All the following results hold independently of the regression technique used to do the spatial averages, as reported in [
20]. The product model described in [
20] and summarised in
Section 3.3 explains the
field in terms of competition maximization. For each product, it is possible to compute the Herfindahl index
(Equation (
20)
Section 3.3), which quantifies the competition on the international market for the export of product
p in year
t. The lower
, the higher the competition. Averaging the values of
per cell on the CL plane gives rise to a scalar field, which we call the Herfindahl field
H. The inverse of the gradient of this field
explains the average velocity field (Equation (
21),
Section 3.3), much like a potential.
The original work where this model was proposed used a dataset of about 1000 products, classified according to the Harmonized System 2007 [
20]. The Harmonized System classifies products hierarchically with a 6-digit code. The first 4 digits specify a certain class of product, and the subsequent two digits a subclass (see
Section 3.7). In [
20], the export flux was aggregated at the 4 digit level, and we will refer to this dataset as noreg4. We recently obtained the full 6-digit database, comprehensive of about 4000 products. We calculated the model on
matrices at 6 digit level (noreg6), to compare it with the noreg4 case. We also obtained the same 6-digit dataset regularized with the aforementioned HMM method [
18] (see
Section 3.6), which we will call hmm6. This method goes beyond the classical definition of the
matrix as a threshold of the RCA matrix (Equations (
14) and (
15), in
Section 3.3). Because the value of RCA fluctuates over time around the threshold, it can lead to elements of the
matrix switching on and off repeatedly, polluting the measurements with noise. The HMM algorithm stabilizes this fluctuation. Because of this, it can significantly increase the accuracy of GDP predictions [
18].
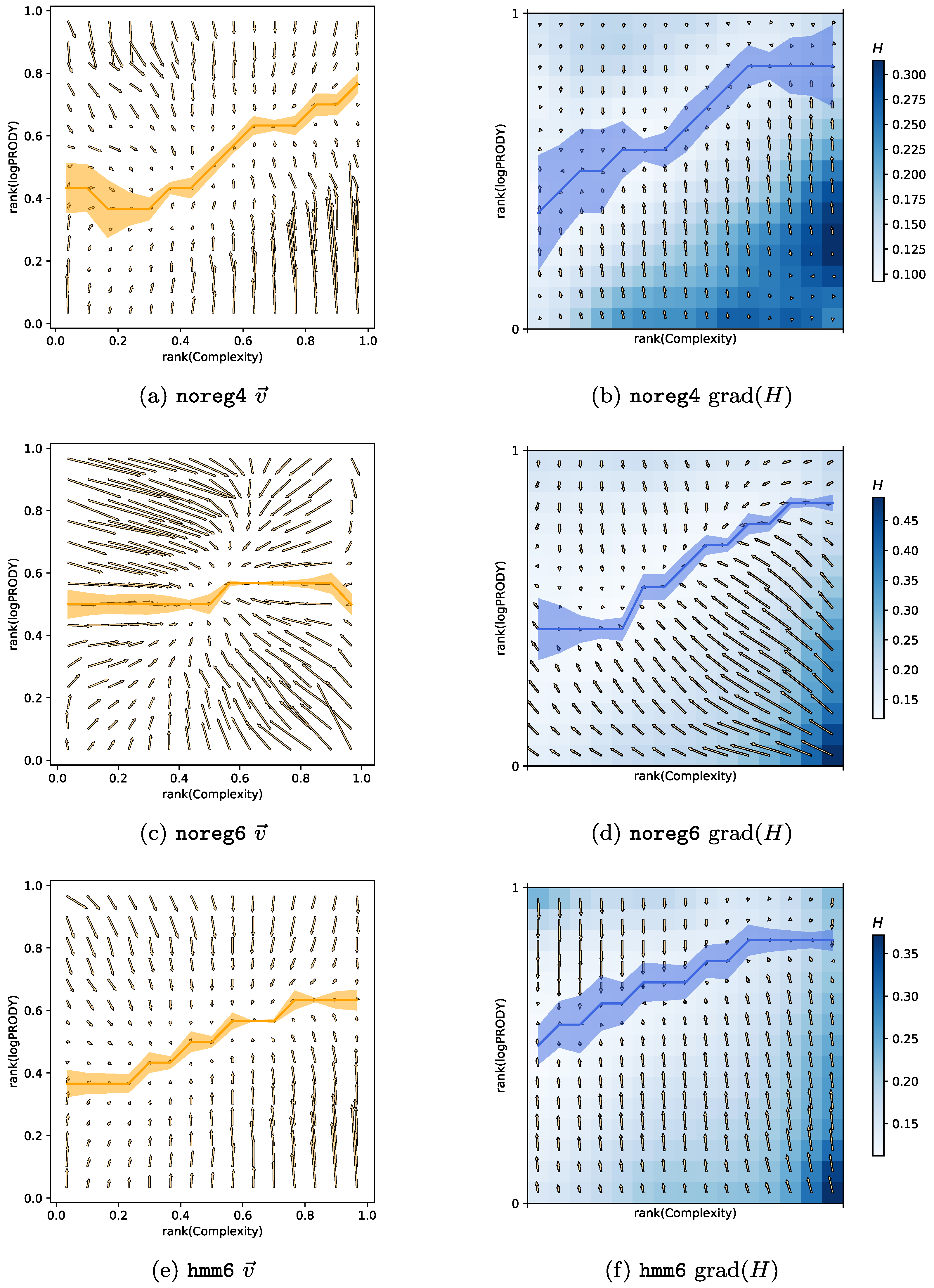
We computed the CL motion model on the three different datasets hitherto described. The results can be compared visually in
Figure 4. Each of the panels in
Figure 4a,c,e show the
for one of the datasets, and the corresponding panels
Figure 4b,d,f plot the
H field in colors, and the gradient
as arrows. The yellow line superimposed on each of the
plots is the minimum of the vertical component of the velocity field along each column of the grid on the plane, together with error bars obtained via bootstrap. The blue line superimposed on each of the
H plots is the minimum of the
H field along each column of the grid together with error bars.
Noise reduction. — Panels in
Figure 4a,b are almost identical to those in [
20], since the noreg4 data set is the same with the addition of one more year of observations (namely 2015).
Figure 4c,d represent the velocity and Herfindahl field obtained with noreg6. The most noticeable change is the strong horizontal component of the velocity field: Complexity changes much faster than in noreg4. We believe this is due to two effects. The first one is the increased noise: when a 4-digit code is disaggregated into many 6-digit codes, there are fewer recorded export trades for each product category. This means that each individual 6-digit product category will be more sensitive to random fluctuations in time, of the kind described in
Section 3.6. The second source of change is due to overly specific product classes. There are some products, such as e.g., products typical of a specific country, for which we would expect generally low Complexity. It typically happens that these products are exported by almost only one, fairly high-Fitness, country, which produces it as a speciality. When the Complexity of such products is computed with Equation (18) (
Section 3.1), it will be assigned a high value, because they have few high-quality exporters. This effect increases the Complexity of the product and is stronger in more granular data. Combined with the stronger fluctuations coming from disaggregation, it contributes to noise in the Complexity measurements.
Another, stronger argument in favour of noise causing fast Complexity change over the years in noreg6 is
Figure 4e,f. These figures show the velocity and Herfindahl field for the regularized hmm6 data. It is clear that the horizontal components of the
field are much smaller compared to noreg6, and that the only change in the data comes from the regularization, which was explicitly developed to reduce the impact of random fluctuations in export measurements. We, therefore, conclude that the HMM regularization is effective in reducing noise and generating smoother Complexity time series. Another interesting observation is that the
obtained from hmm6 is very similar to the noreg4 one. Therefore we would like to conjecture that aggregating data from 6 digits to 4 has an effect similar to that of reducing noise with the HMM algorithm. We will see in the next section that there is a further evidence to this conjecture.
Increase in nestedness. — A yet undocumented effect of HMM regularization is the increase in nestedness of the
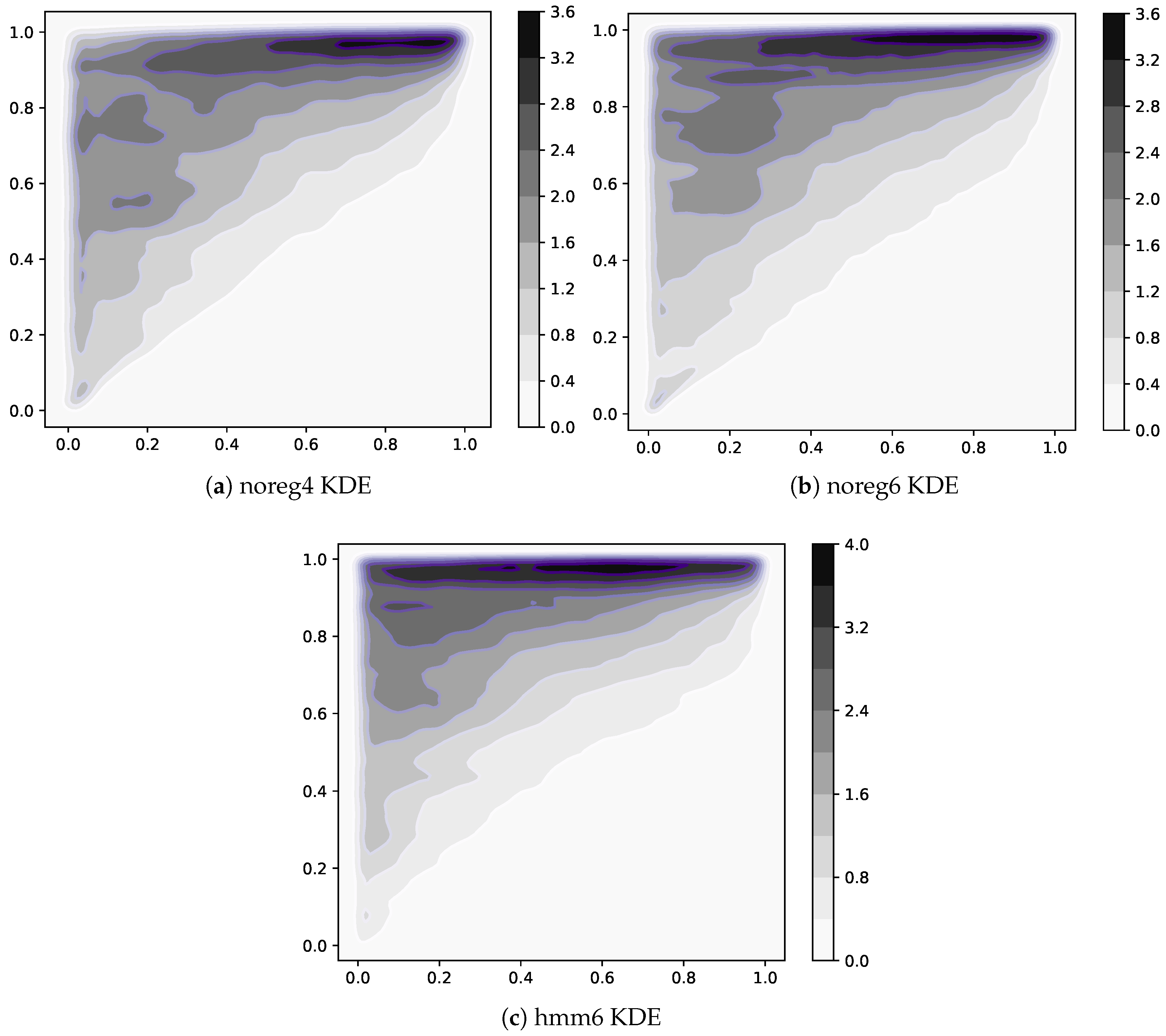
matrices. It can be visualized by looking at
Figure 5a,c,e. Here we show a point for each nonzero element of all
matrices available in each dataset. To be able to resolve the differences in density, we computed a kernel estimate of the density of points on the plane. The horizontal axis is the value of rank(Complexity), while rank(Fitness) is on the vertical axis. All three datasets feature very nested matrices, as expected, but hmm6 has one peculiarity. The top left corner of
Figure 5e exhibits in fact a higher density than the other two. This means that regularization has the effect of activating many low-Complexity exports of high-Fitness countries. This makes sense since we expect the thresholding procedure described in
Section 3.1 to be noisier in this area. Indeed, we know that the high-Complexity products are exported only by high-Fitness countries, so we expect the numerator of the RCA
(proportional to the importance of
p in total world export, see
Section 3.1) in this area to be small. We also know RCA
is proportional to the importance of product
p relative to total exports of
c, so we expect it to be high in the low-Complexity/low-Fitness area since low-Fitness countries export few products. Furthermore, it has been described in [
20] that countries are observed to have similar competitive advantage in low-Complexity products regardless of their level of Fitness. So in the high-Fitness/low-Complexity area, we expect to observe a lower numerator, possibly fluctuating around the thresholding value, due to the high diversification of high-Fitness countries.
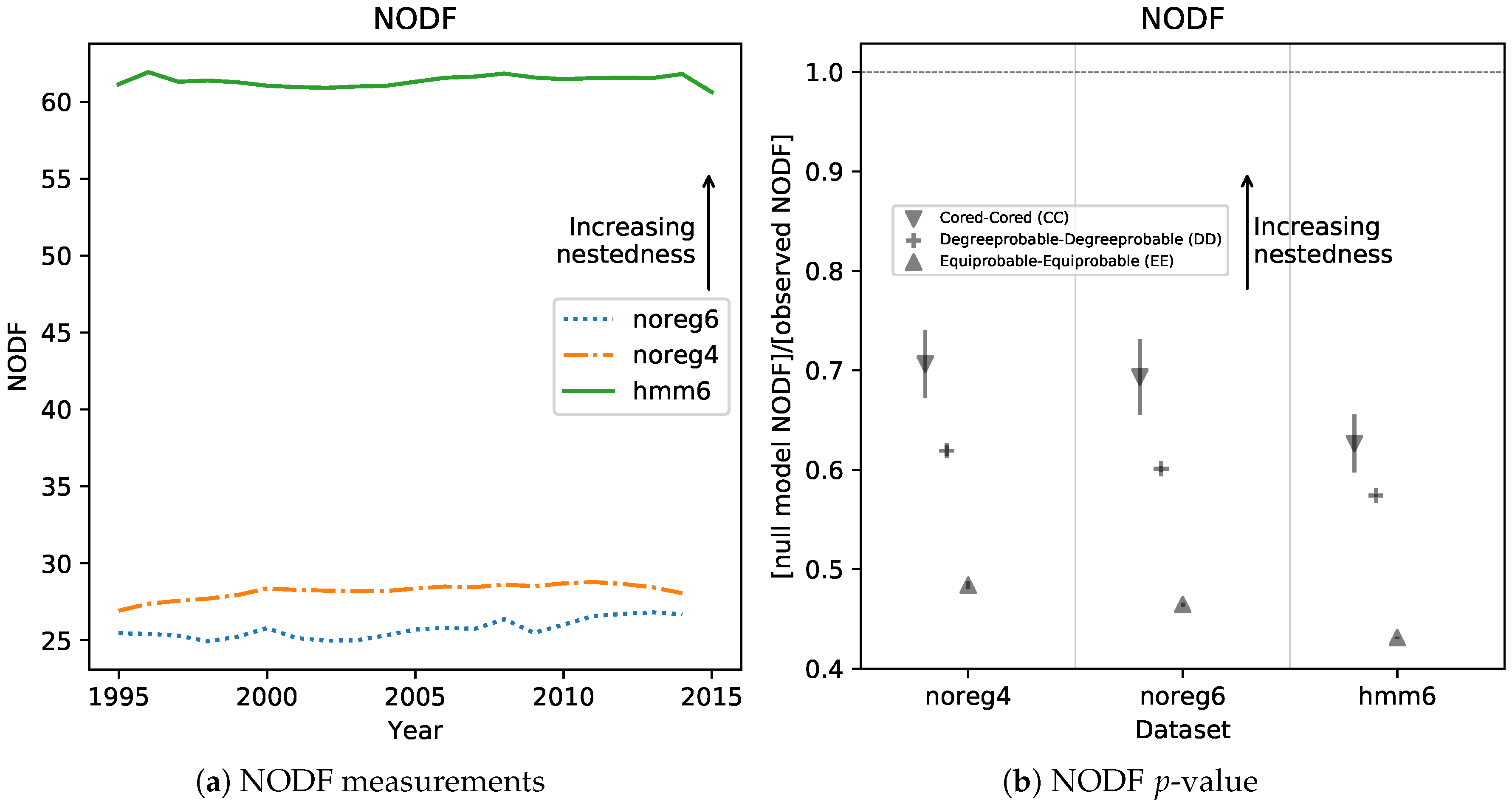
A higher density in the high-Fitness, low-Complexity area naturally results in more nested matrices. To show this, we computed the well-known NODF [
11,
23] measure of nestedness for all
matrices in all datasets. The results can be found in
Figure 6a, and show clearly that hmm6 matrices are much more nested than unregularized ones. Another observed result is that noreg4 matrices are slightly but consistently more nested than the noreg6 ones. This is further support for our conjecture that aggregating from 6 to 4 digit has an effect similar to regularizing with an HMM model.
Figure 6b shows the significance level of the NODF measurements. In order to assess significance, we computed
, the observed value of NODF on the
matrices, and we compared it with
the NODF obtained from null models. The null models usually generate new adjacency matrices at random while holding some of the properties of the observed matrix (such as e.g., total number of nonzero elements) fixed. This is a way to control for the effect of the fixed property on the nestedness. Several runs of a null model generate an empirical probability distribution
. The
p-value of the measurement is assessed by calculating in which quantile of
the observed value
falls. In
Figure 6b we report the ratio between
and the scaled standard deviation of the null distribution
, for three common null models [
23]. The scaling allows to compare very different distributions on the same axis. The ratio of
to
is very small. Thus, the observed measurements’ significance is so high that there is no need to calculate quantiles. NODF was calculated using the FALCON [
23] software package, for which we provide a wrapper in Python [
24].
Model breakdown at 6 digits. — Another observation that can easily be made from
Figure 4 is that, while it works well for 4-digit data, the model of product motion has trouble with reproducing the data at the 6-digit level. Regressing the
components against the derivatives of the
H field, as shown in
Table 1, seems to indicate that the 6-digit models work better (However, the 4-digit BACI dataset hmm4 has one peculiarity that needs explaining. Specifically, the bottom right corner of
Figure 4b does not contain the maximum of
H that is found in all other datasets ever observed (including the Feenstra dataset studied in [
20]). This causes the gradient of
H in that area to produce small values, which do not match the high vertical components of
in the same spot, significantly lowering the
coefficient of a linear regression.). But one key feature of the model disappears when moving from 4 to 6 digits. The yellow and blue lines in
Figure 4 indicate a kernel regression of respectively the minima of the
field and the minima of the
H field across each column of the grid (together with error bars obtained via bootstrap). The model predicts that
will be almost zero where the minima of
H lie, but at 6 digits this feature disappears, and the minima lines become incompatible with each other. We are currently lacking an explanation of this behaviour, that seems independent of regularisation.
2.3. Predictions on Products with SPSb
Dynamics of products on the CL plane appears to be laminar everywhere, in the sense that the average velocity field seems to be smooth [
20], similarly to what happens to countries on the Fitness-GDP plane [
15]. If so, then it’s a reasonable hypothesis that the information contained in the average velocity field can be used to predict the future positions of products on the plane. The idea was originally conceived because it could lead to refined predictions on GDP and Fitness (see
Appendix A). We tried to predict the future displacement of products with SPSb. Because the number of products is about 1 order of magnitude larger than the number of countries used in [
18], the computational demand of the algorithm induced us to develop the proof of convergence reported in
Section 2.1.
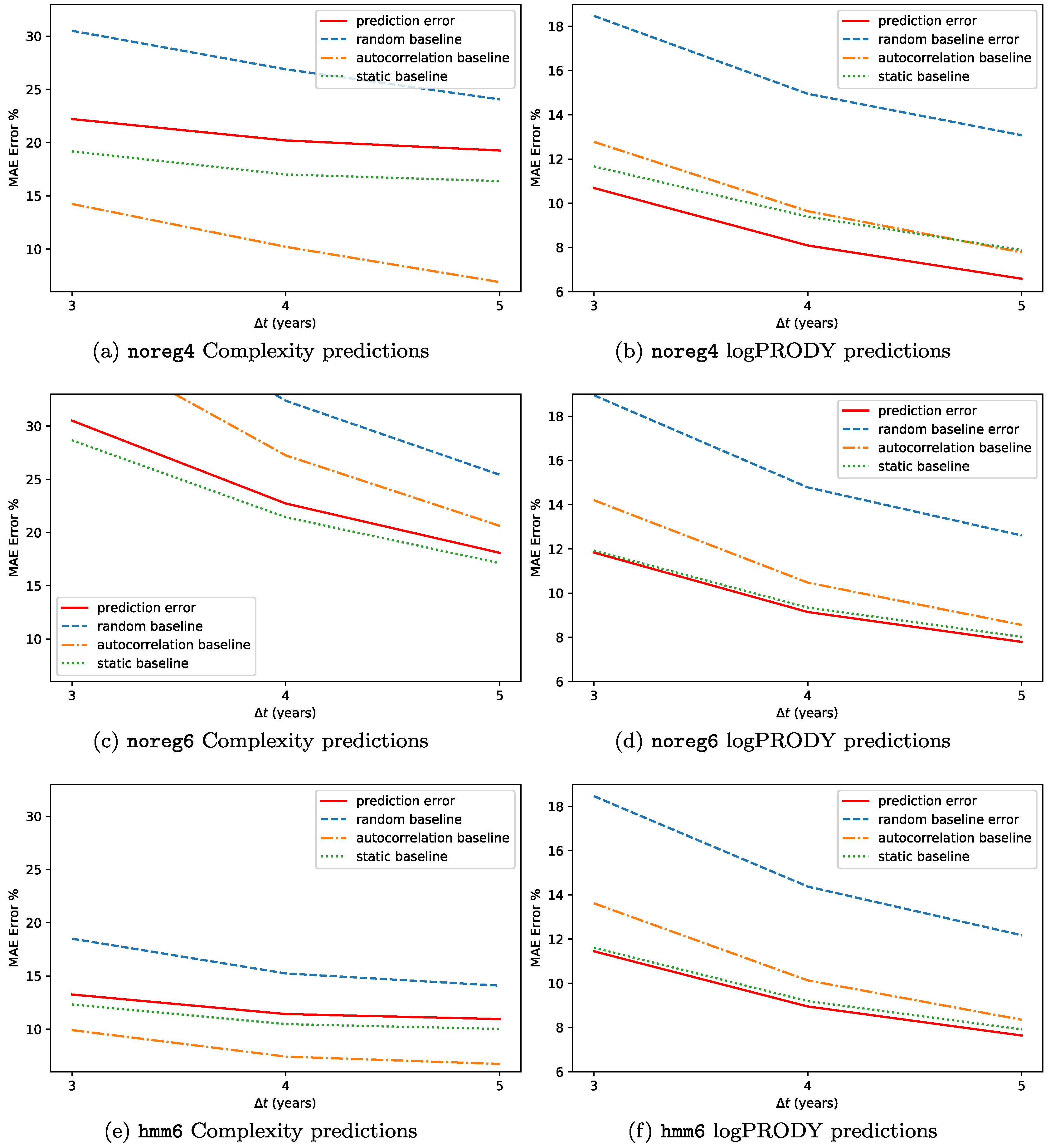
The results for the backtests on this methodology are reported in
Figure 7. We predicted the Percentage Compound Annual Growth Rate (CAGR%) for each of the two metrics, and defined the error as
, so that if e.g., Complexity increases by 2% and we forecast 3%,
. The forecasts are made at timescales
years. We used the three datasets hmm6, noreg6 and noreg4. The predictions are not very accurate, with an error between 12% and 6% for logPRODY and in the 32-13% range for Complexity. We compared the predictions to a
random baseline, i.e., predicting the displacement by selecting an observed displacement at random from all the available analogues. Compared to the random baseline, SPSb is always more accurate. One peculiarity about the predictions, though, is that they are generally much smaller in magnitude than the actual displacements observed. This led us to add another comparison, which we call
static baseline, that consists in predicting zero displacement for all products. Compared to this baseline, SPSb still systematically shows some predictive power for logPRODY, especially in noreg4, but is definitely worse when predicting Complexity. We will clarify our explanation for this behaviour with an analogy. While the average velocity field
exhibits laminar characteristics, in the sense that it is relatively smooth, the actual motion of the underlying products is much more disorderly. In a given neighbourhood of the CL plane, products generally move in every direction, often with large velocities, even though the average of their displacements is nonzero and small. We could tentatively describe this as a Brownian motion with a laminar drift given by
. So trying to predict the future position of a product from their aggregate motion would be similar to trying to predict the position of a molecule in a gas. That’s why the static prediction is better than a random prediction: in general, the last position of a product is a better predictor than a new random position on the plane, since the new one might be farther away. To test this Brownian motion with drift hypothesis, we added a third baseline, which we call
autocorrelation baseline. It consists in forecasting the displacement of a product to be exactly equal to its previous observed displacement. If the hypothesis is true, we expect each product displacement to be uncorrelated with its displacement at previous time steps. For logPRODY the autocorrelation baseline is always worse than the static, which we interpret as a signal that logPRODY changes are not autocorrelated. The reverse is true for Complexity: in fact, for noreg4 and hmm6 the autocorrelation baseline is the best predictor for Complexity change.
As already mentioned, SPSb does still have slightly but systematically more predictive power than the autocorrelation and static prediction, but only for logPRODY. We speculate that this is due to the fact that change in logPRODY is actually a signal of the underlying market structure changing, as explained in [
20] and in
Section 3.3. The fact that this advantage over the baseline is much bigger on noreg4 confirms that the logPRODY model performs significantly better on noreg4, as discussed in
Section 3.3. On the other hand, the autocorrelation prediction (as well as the static one) can be significantly better than SPSb when predicting changes in Complexity. It is not clear whether this implies that changes in Complexity are autocorrelated in time - this effect for example disappears in noreg6, and will require an analysis with different techniques. But the fact that SPSb is always worse than the baseline, combined with the fact that regularization, which is supposed to mitigate noise, significantly reduces changes in Complexity over time raises a doubt over whether changes in Complexity are significant at all, or are drowned by noise in the
. The fact that Complexity predictions are significantly better on the hmm6 dataset suggests confirms the contribution of noise to Complexity changes, although it is not possible to argue that regularization is strengthening the signal coming from these changes over time, since we could not characterize any signal. This might be an important finding because it could shed some light on the nature of the Complexity metric. We suggest that an alternative line of thinking should be explored, in which one treats the Complexity of a product as fixed over time. This resonates with the data structure: product classes are fixed over the timescales considered in our analyses, and new products that might be introduced in the global market during this time are not included. It also might be derived from an interpretation of the theory: Complexity is meant to be a measurement of the number of capabilities required to successfully export a product [
7]. Practically, this means that there is no specific reason to believe that the Complexity of (i.e., the capabilities required for) wheat, or aeroplanes, changes over the course of the 20 years typically considered in this kind of analysis. It is possible that changes in Complexity, defined as a proxy for the number of capabilities required to be competitive in a given product, occur over longer timescales, or maybe that Complexity never changes at all. If this were true, then all observed Complexity changes would be due to noise, and it would be better to consider defining a measure of Complexity that is fixed or slowly changing in time for the model. We remark that these definition problems will probably be insurmountable as long as it is impossible to give an operational definition of capabilities, and they can only be measured indirectly through aggregate proxies, i.e., countries and products. There always is a tradeoff of interpretability to pay in order to give up normative practices in favour of operational definitions, but it affects economics and social sciences more than the physical sciences.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}