A Context Similarity-Based Analysis of Countries’ Technological Performance

Abstract
1. Introduction
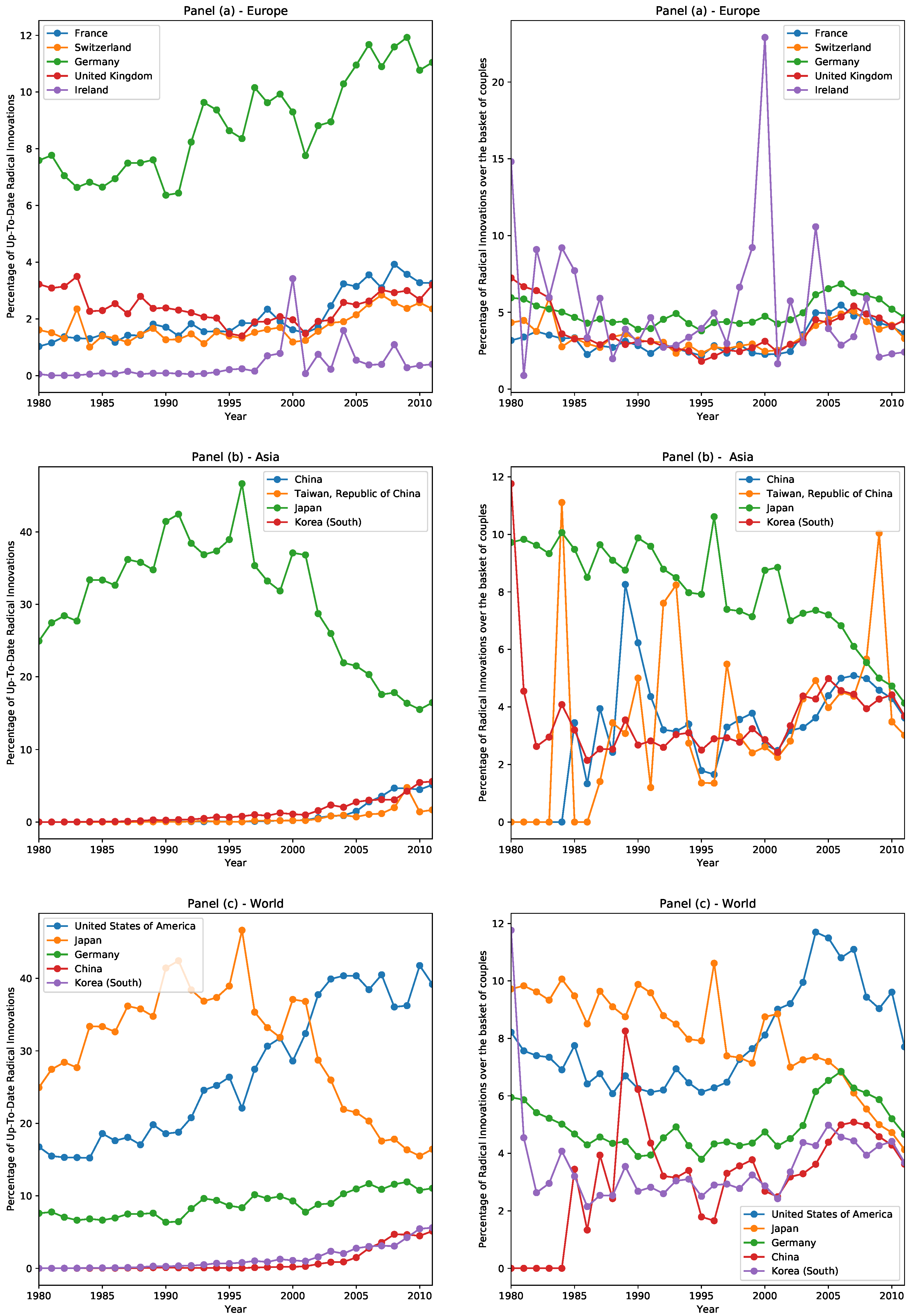
- Europe: The European scene is dominated by Germany, followed by the United Kingdom, France, and Switzerland, which are close to one another in terms of shares of radical innovations. Ireland is in the bottom position among the top European countries. Recall that we assign the nationality of each patent, and, therefore, of each radical innovation, by looking at the nationality of the owner of the patent. It is possible that, due also to easier regulations and lower taxation, Switzerland and Ireland appear among the top innovative countries.
- Asia: Since the 1980s, Japan has been the leading country both in Asia and in the World. In this period of technological dominance, of all radical innovations realized every year in the world, Japan was up-to-date in at least 30% of them, with even a peak of almost 50%. Once it entered the new millennium, however, Japan experienced a decline of its fraction of innovative patents, settling roughly to 20%, while other countries emerged, such as China, Taiwan, and South Korea.
- World: The United States, which was in the second position below Japan until 2000, is since the world leader in technological progress. It is also noteworthy that Germany has always occupied the third position in the time range considered, showing a slightly increasing trend in up-to-date innovations.
2. Results
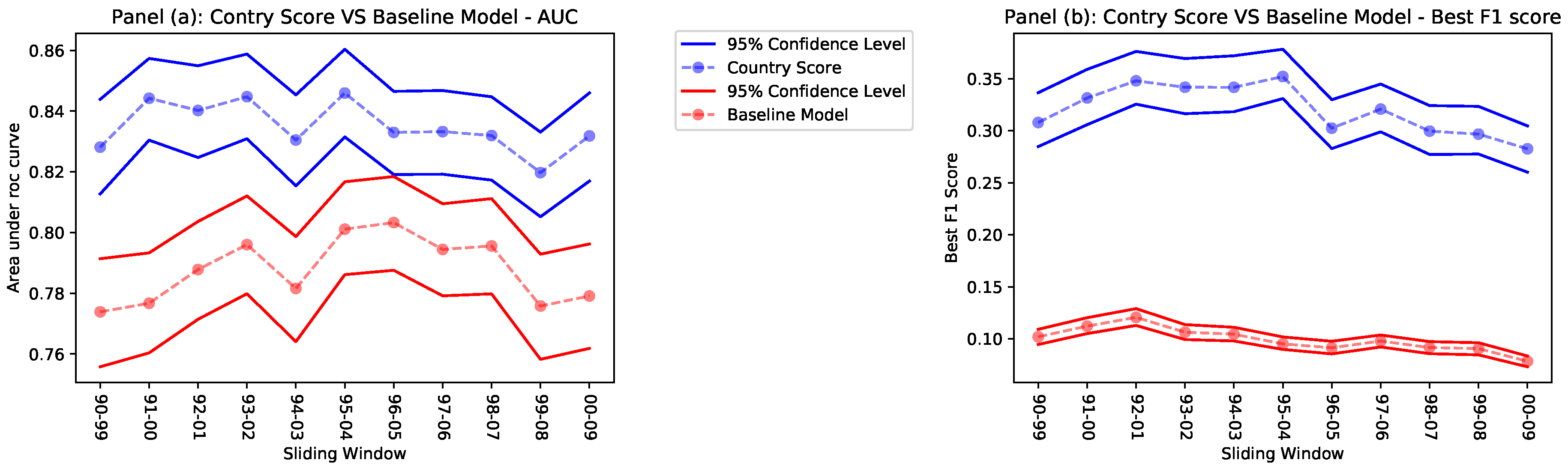
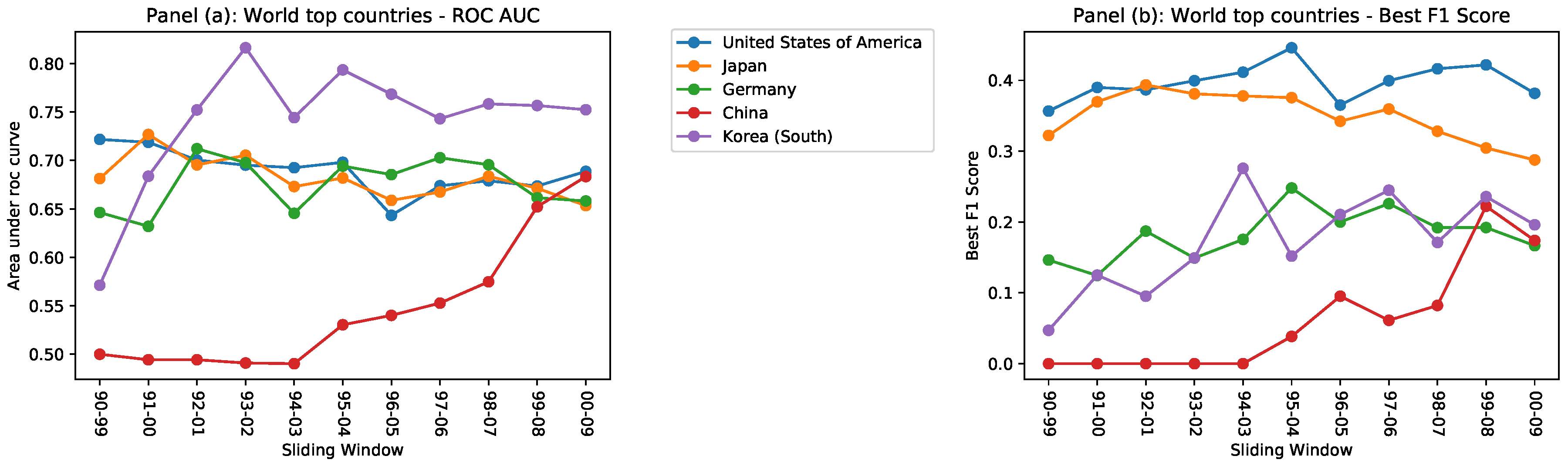
- The AUC, although showing that the CS performs better, is high for both predictors. We argue that having a diversified and florid patenting activity is a fundamental technological capability: countries with a greater patenting activity will more likely be protagonists of the majority of radical innovations.
- However, the best F1 score shows that the CS outperforms the Baseline Model since the latter loses precision and recall (see Methods section) because it fails to take into consideration the coherence of the patenting activity of a country and does not go into the details of each potential innovation.
3. Discussion
4. Materials and Methods
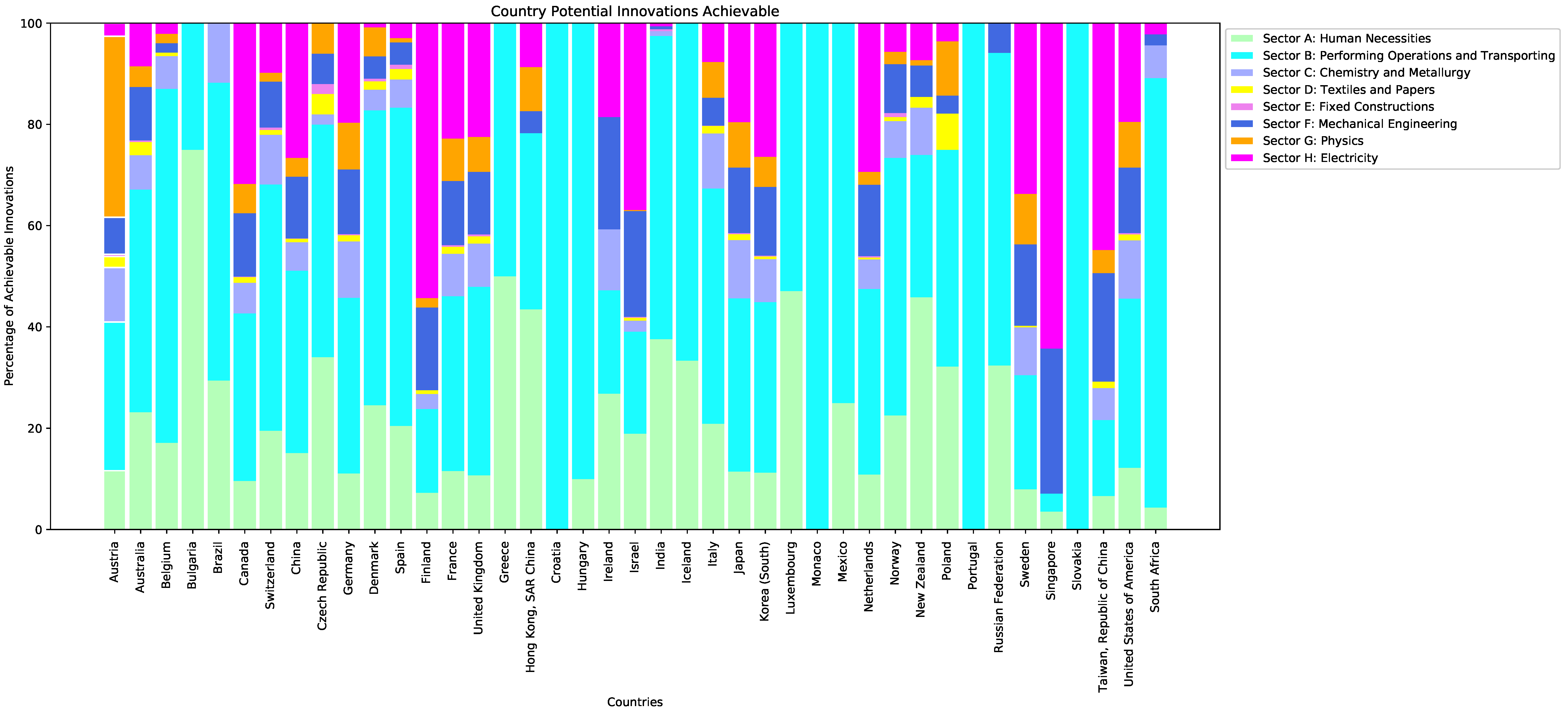
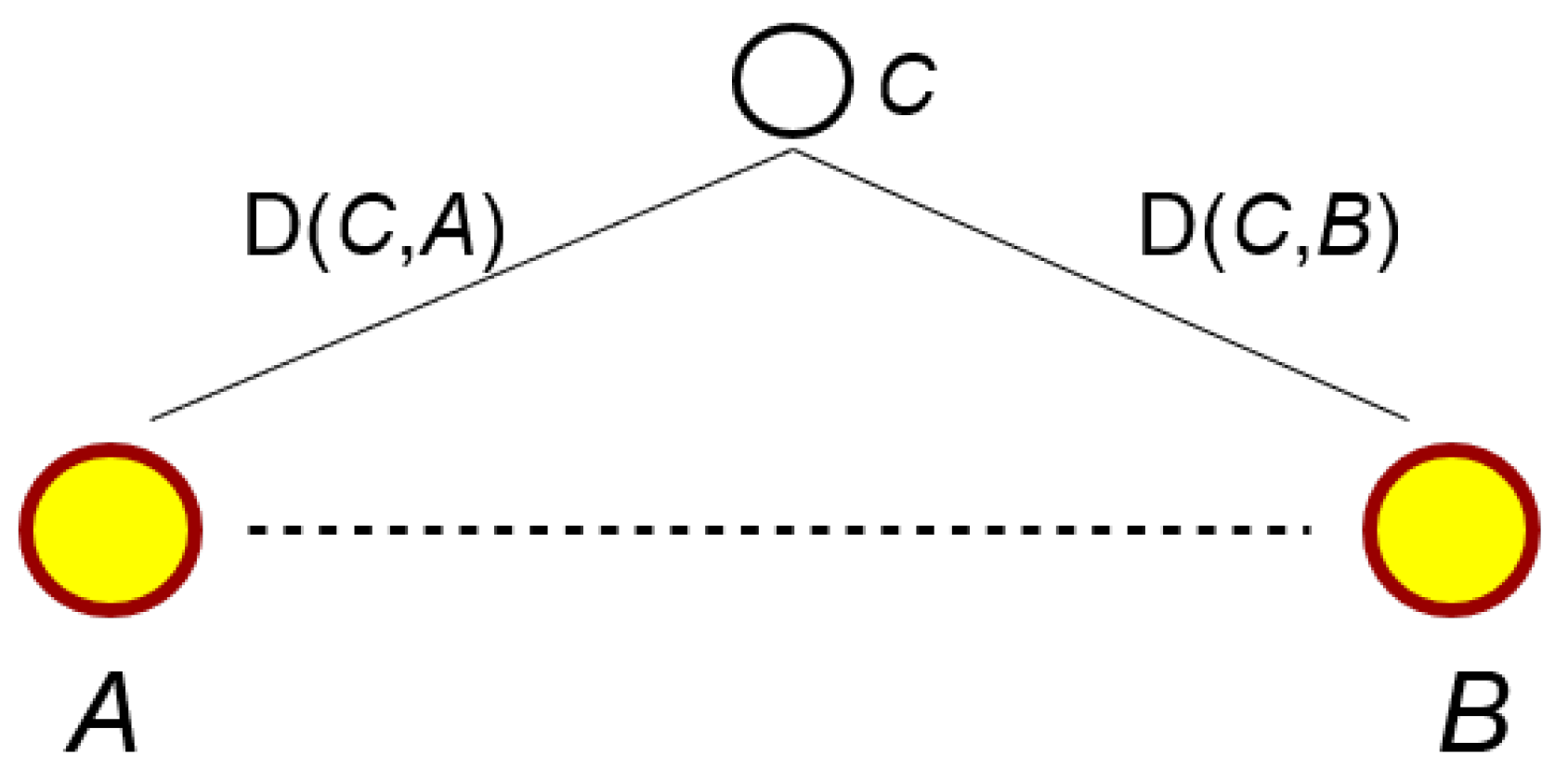
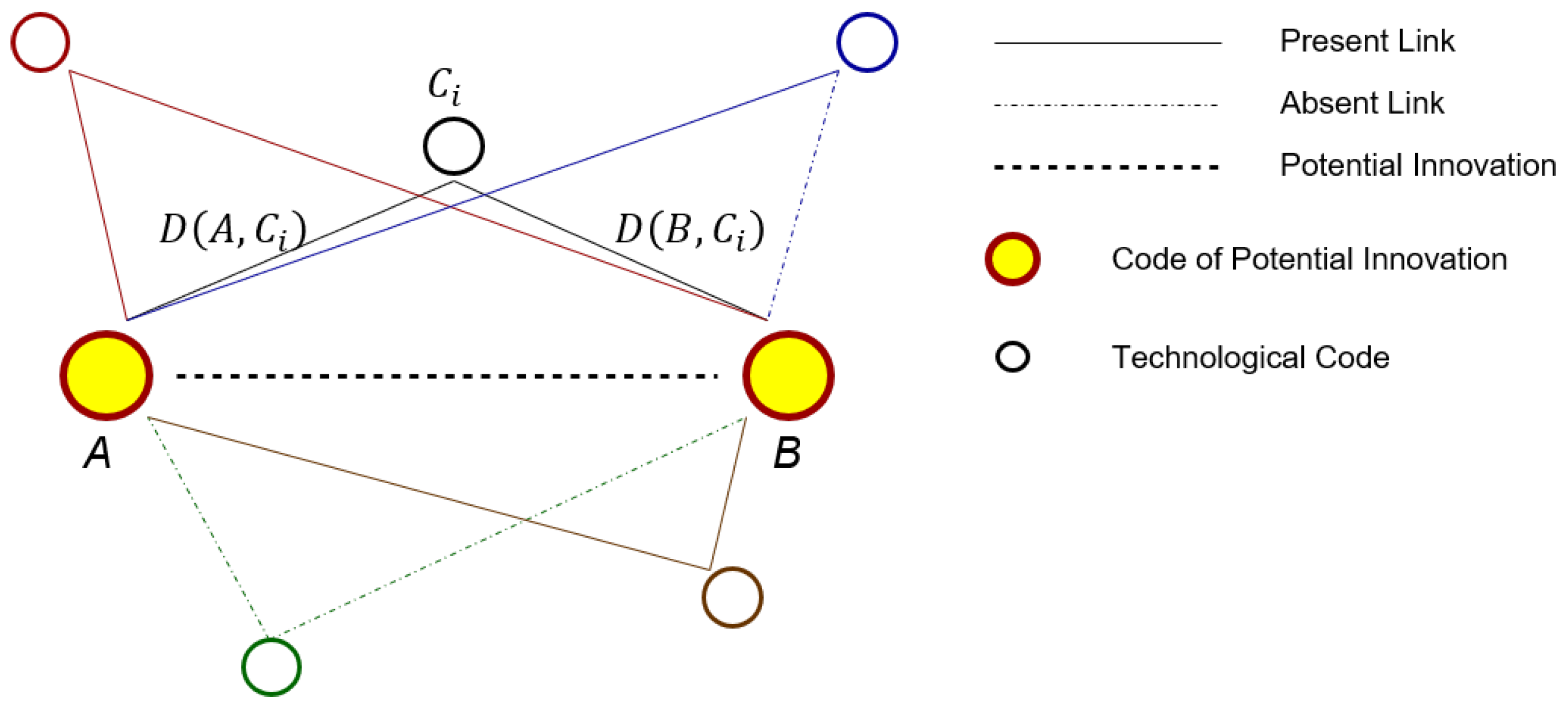
4.1. Context Similarity: A Brief Introduction
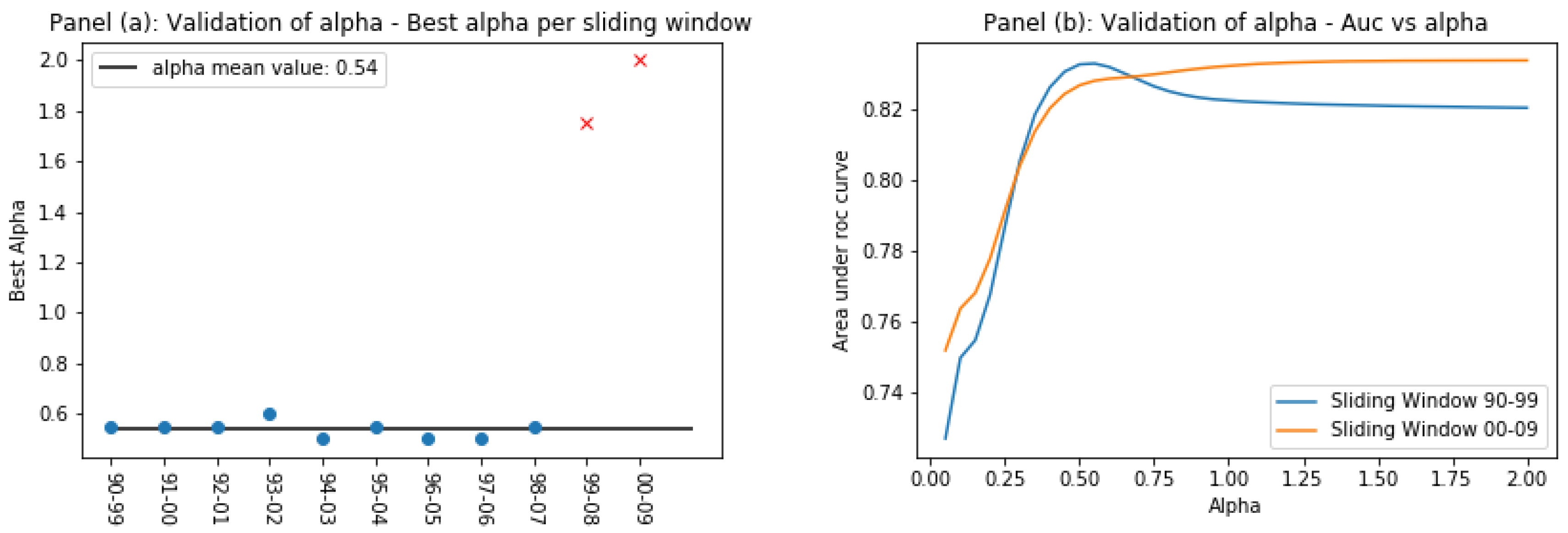
4.2. Country Score: Definition and Tuning
4.3. ROC and F1 Score
- If the outcome from a prediction is class 1, and the actual value is also class 1, then it is called a true positive (TP).
- If the outcome from a prediction is class 1, but the actual value is class 0, then it is said to be a false positive (FP).
- If the outcome from a prediction is class 0, and the actual value is also class 0, then it is called a true negative (TN).
- If the outcome from a prediction is class 0, but the actual value is class 1, then it is said to be a false negative (FN).
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ROC | Receiver Operator Characteristic curve |
| AUC | Area under ROC Curve |
| CS | Country Score |
| NLP | Natural Language Processing |
| TP | True Positive |
| TN | True Negative |
| FP | False Positive |
| FN | False Negative |
| TPR | True Positive Rate |
| FPR | False Positive Rate |
| p | Precision |
| r | Recall |
References
- Baregheh, A.; Rowley, J.; Sambrook, S. Towards multi-disciplinary definition of innovation. Manag. Decis. 2009, 47, 1323–1339. [Google Scholar] [CrossRef]
- Crossan, M.M.; Apaydin, M. A multi-dimensional framework of organizational innovation: A systematic review of the literature. J. Manag. Stud. 2010, 47, 1154–1191. [Google Scholar] [CrossRef]
- Baskara, S.; Mehta, K. What is innovation and why? Your perspective from resource constrained environments. Technovation 2016, 52, 4–17. [Google Scholar] [CrossRef]
- Kauffman, S.A. The Origins of Order: Self-Organization and Selection in Evolution; Oxford University Press: New York, NY, USA, 1993. [Google Scholar]
- Kauffman, S.A. Investigations; Oxford University Press: New York, NY, USA; Oxford, UK, 2000. [Google Scholar]
- Tria, F.; Loreto, V.; Servedio, V.D.P.; Strogatz, S.H. The dynamics of correlated novelties. Nat. Sci. Rep. 2014, 4, 5890. [Google Scholar] [CrossRef] [PubMed]
- Loreto, V.; Servedio, V.D.P.; Strogatz, S.H.; Tria, F. Dynamics on expanding spaces: Modeling the emergence of novelties. arXiv, 2017; arXiv:1701.00994. [Google Scholar]
- Tacchella, A.; di Clemente, R.; Gabrielli, A.; Pietronero, L. The build-up of diversity in complex ecosystems. arXiv, 2016; arXiv:1609.03617. [Google Scholar]
- Zabell, S.L. Predicting the unpredictable. Synthese 1992, 90, 205. [Google Scholar] [CrossRef]
- Sood, V.; Mathieu, M.; Shreim, A.; Grassberger, P.; Paczuski, M. Paczuski, Interacting branching process as a simple model of innovation. Phys. Rev. Lett. 2010, 105, 178701. [Google Scholar] [CrossRef] [PubMed]
- Erwin, D.; Krakauer, D. Insights into innovation. Science 2004, 304, 1117. [Google Scholar] [CrossRef] [PubMed]
- Drucker, P. The discipline of innovation. Harv. Bus. Rev. 2002, 80, 95–104. [Google Scholar] [CrossRef] [PubMed]
- Weiss, C.H.; Poncela-Casasnovas, J.; Glaser, J.I.; Pah, A.R.; Persell, S.D.; Baker, D.W.; Wunderink, R.G.; Amaral, L.A.N. Adoption of a high-impact innovation in a homogeneous population. Phys. Rev. X 2014, 4, 041008. [Google Scholar] [CrossRef] [PubMed]
- McNerney, J.; Farmer, J.D.; Redner, S.; Trancik, J.E. Role of design complexity in technology improvement. Proc. Natl. Acad. Sci. USA 2011, 108, 9008–9013. [Google Scholar] [CrossRef] [PubMed]
- Strumsky, D.; Lobo, J.; Tainter, J. Complexity and the productivity of innovation. Syst. Res. Behav. Sci. 2010, 27, 496–509. [Google Scholar] [CrossRef]
- Youn, H.; Strumsky, D.; Bettencourt, L.M.A.; Lobo, J. Invention as a combinatorial process: Evidence from US patents. J. R. Soc. Interface 2014, 12, 20150272. [Google Scholar] [CrossRef] [PubMed]
- Napoletano, A. The Language of Innovation. Ph.D. Thesis, Sapienza University of Rome, Rome, Italy, 2018. [Google Scholar]
- Tacchella, A.; Napoletano, A.; Pietronero, L. The language of innovation. Awaiting publication. Presented at the CCS2018, Thessaloniki, Greece, 23–29 September 2018. [Google Scholar]
- EPO. Worldwide Patent Statistical Database Data Catalog. 2014. Available online: https://www.epo.org/searching-for-patents/business/patstat.html#tab-1 (accessed on 31 October 2018).
- World Intellectual Property Organization (WIPO). International Patent Classification. In Guide to IPC; WIPO: Geneva, Switzerland, 2016; Volume 10, pp. 142–149. [Google Scholar]
- Fleming, L. Recombinant uncertainty in technological search. Manag. Sci. 2001, 47, 117–132. [Google Scholar] [CrossRef]
- Weitzman, M.L. Recombinant growth. Q. J. Econ. 1998, 113, 331–360. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv, 2013; arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems 26 (NIPS 2013), Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Freeman, C. The ‘National System of Innovation’ in historical perspective. Camb. J. Econ. 1995, 19, 5–24. [Google Scholar] [CrossRef]
- Metcalfe, S. The economic foundations of technology policy: Equilibrium and evolutionary perspectives. In Handbook of the Economics of Innovation and Technological Change; Blackwell Publishers: Oxford, UK; Cambridge, MS, USA, 1995. [Google Scholar]
- Eissebith, M. Bridging scales in innovation policies: How to link regional, national and international innovation systems. Eur. Plan. Stud. 2007, 15, 217–233. [Google Scholar] [CrossRef]
- Hanley, J.A.; McNeil, B.J. The meaning and use of the area under a receiver operating characteristic (ROC) curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [PubMed]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Powers, D.M.W. Evaluation: from precision, recall and f-measure to roc, informedness, markedness and correlation. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- Bertail, P.; Clémençcon, S.J.; Nicolas, V. On bootstrapping the ROC curves. In Advances in Neural Information Processing Systems 21; Curran Associates, Inc.: Red Hook, NY, USA, 2009; pp. 137–144. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Potential Innovation | CS | Label |
|---|---|---|
| Code A–Code B | Score(A B) | 1 |
| Code A–Code D | Score(A D) | 0 |
| Code A–Code F | Score(A F) | 0 |
| Code B–Code C | Score(B C) | 1 |
| Code B–Code D | Score(B D) | 1 |
| Code C–Code D | Score(C D) | 0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Napoletano, A.; Tacchella, A.; Pietronero, L. A Context Similarity-Based Analysis of Countries’ Technological Performance. Entropy 2018, 20, 833. https://doi.org/10.3390/e20110833
Napoletano A, Tacchella A, Pietronero L. A Context Similarity-Based Analysis of Countries’ Technological Performance. Entropy. 2018; 20(11):833. https://doi.org/10.3390/e20110833
Chicago/Turabian StyleNapoletano, Andrea, Andrea Tacchella, and Luciano Pietronero. 2018. "A Context Similarity-Based Analysis of Countries’ Technological Performance" Entropy 20, no. 11: 833. https://doi.org/10.3390/e20110833
APA StyleNapoletano, A., Tacchella, A., & Pietronero, L. (2018). A Context Similarity-Based Analysis of Countries’ Technological Performance. Entropy, 20(11), 833. https://doi.org/10.3390/e20110833