Maximum-Entropy Tools for Economic Fitness and Complexity


Abstract
1. Introduction
1.1. Economic Complexity
1.2. Revealed Comparative Advantage: Current Practice and Flaws
- The RCA as a null model represents a fully connected or very dense network, as by the definition in Equation (6) it has a non-zero value for each i and that have a non-zero total trade. In practice, this is the case for almost all links. In contrast, the world trade network is quite sparse with only 2–4% of all potential links realized throughout the analyzed years.
- The current definition of the RCA only applies to the bipartite network of countries and commodities, while the original world trade network contains another dimension of information, being the receiving importing country. Keeping in mind that a null model should mimic the original network, this importer dimension should also be represented in any appropriate null model—especially so, because the trade weight that the RCA null model would expect does not depend at all on the receiving country, while in reality this is of course of major importance (one would expect more trade to a country with a lot of incoming trade).
- Most importantly, the current methodology does not take into account the statistical significance of the filtered values. An RCA of over 1 could signify an important export product of a country, but could just as well be due to a statistical fluctuation through the years. This flaw is something that Tacchella et al. also partially realized (see supplement of [7]), leading them to develop a hidden Markov model approach to binarize the country-commodity matrix to reduce this noise. We choose a different path, keeping to the original data and performing a statistical analysis to keep noise at bay.
2. Methodology
2.1. The Extended RCA
2.2. Extension to the Multiplex Network
2.3. Link Weight Probability Distribution
- Directed binary configuration model (DBCM),
- Multiplex directed binary configuration model (MDBCM),
- Strength-replaced MDBCM.
2.4. The Directed Binary Configuration Model
2.5. Multiplex Directed Binary Configuration Model
2.6. Strength-Replaced MDBCM
2.7. The Weight Unit Probability
2.8. Statistical Significance
2.9. Practical Implementation
- Calculate for each link using the extended RCA as defined in Equation (7).
- Find the hidden variables—and with that, —applying either the DBCM or the (regular or strength-replaced) MDBCM, by solving Equations (29) or (34), respectively.
- Combine and in Equation (43) to find the variance on each link .
- Use Equation (40) to find the z-score of each country-commodity pair and filter all links in the bipartite network using a threshold on the z-score (typically , or similar).
- Apply the fitness and complexity algorithm as developed Tacchella et al. in [2].
3. Results
3.1. Comparison with Previous Results
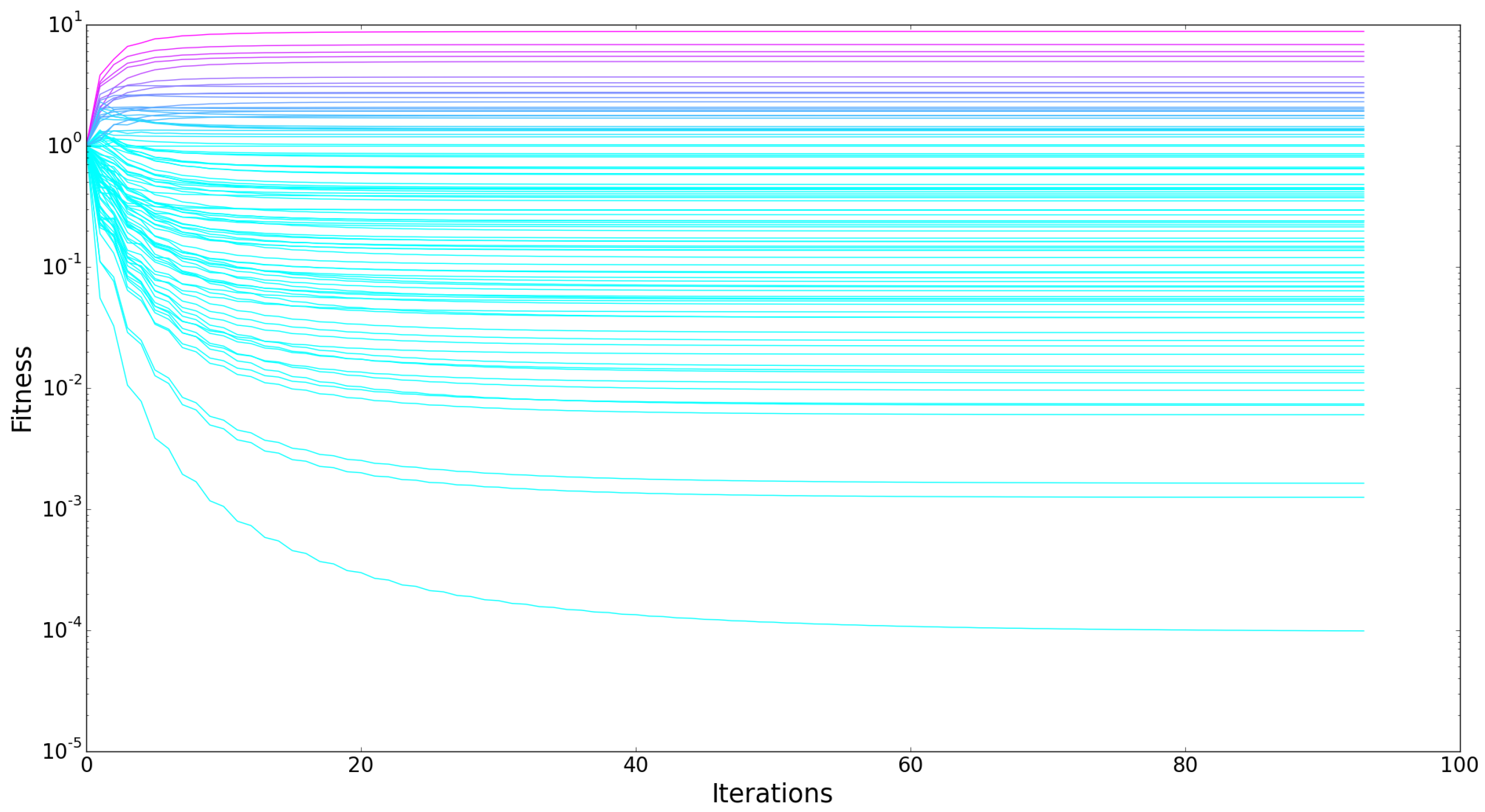
3.1.1. Evolution of Fitness and Complexity
3.1.2. Ranking Countries by Fitness
3.1.3. Correlation with GDP per Capita
3.2. Results with Filtering on Higher Statistical Significance
3.3. Additional Results: z-Score Spectra
4. Discussion
5. Materials and Methods
5.1. Data
5.2. Numerical Methods
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| WTN | World Trade Network |
| RCA | Revealed Comparative Advantage |
| DBCM | Directed Binary Configuration Model |
| MDBCM | Multiplex Directed Binary Configuration Model |
References
- Hidalgo, C.; Hausmann, R. The building blocks of economic complexity. Proc. Natl. Acad. Sci. USA 2009, 26, 10570–10575. [Google Scholar] [CrossRef] [PubMed]
- Tacchella, A.; Cristelli, M.; Caldarelli, G.; Gabrielli, A.; Pietronero, L. A new metrics for countries’ fitness and products’ complexity. Sci. Rep. 2012, 2, 723. [Google Scholar] [CrossRef] [PubMed]
- Cristelli, M.; Gabrielli, A.; Tacchella, A.; Caldarelli, G.; Pietronero, L. Measuring the Intangibles: A metrics for the economic complexity of countries and products. PLoS ONE 2013, 8, e70726. [Google Scholar] [CrossRef] [PubMed]
- Cristelli, M.; Tacchella, A.; Pietronero, L. The heterogeneous dynamics of economic complexity. PLoS ONE 2015, 10, e0117174. [Google Scholar] [CrossRef] [PubMed]
- Morrison, G.; Buldyrev, S.; Imbruno, M.; Doria Arrieta, O.; Rungi, A.; Riccaboni, M.; Pammolli, F. On economic complexity and the fitness of nations. Sci. Rep. 2017, 7, 15332. [Google Scholar] [CrossRef] [PubMed]
- Balassa, B. Trade liberalisation and revealed comparative advantage. Manch. Sch. 1965, 33, 99–123. [Google Scholar] [CrossRef]
- Tacchella, A.; Mazzilli, D.; Pietronero, L. A dynamical systems approach to gross domestic product forecasting. Nat. Phys. 2018, 14, 861–865. [Google Scholar] [CrossRef]
- Squartini, T.; Garlaschelli, D. Analytical maximum-likelihood method to detect patterns in real networks. New J. Phys. 2011, 13, 083001. [Google Scholar] [CrossRef]
- Squartini, T.; Mastrandrea, R.; Garlaschelli, D. Unbiased sampling of network ensembles. New J. Phys. 2015, 17, 023052. [Google Scholar] [CrossRef]
- Napolitano, L.; Evangelou, E.; Pugliese, E.; Zeppini, P.; Room, G. Technology networks: The autocatalytic origins of innovations. R. Soc. Open Sci. 2018, 5. [Google Scholar] [CrossRef] [PubMed]
- Pugliese, E.; Cimini, G.; Patelli, A.; Zaccaria, A.; Pietronero, L.; Gabrielli, A. Unfolding the innovation system for the development of countries: Co-evolution of Science, Technology and Production. arXiv, 2017; arXiv:1707.05146. [Google Scholar]
- Gemmetto, V.; Squartini, T.; Picciolo, F.; Ruzzenenti, F.; Garlaschelli, D. Multiplexity and multireciprocity in directed multiplexes. Phys. Rev. E 2016, 94, 042316. [Google Scholar] [CrossRef] [PubMed]
- Garlaschelli, D.; Loffredo, M. Generalized Bose-Fermi statistics and structural correlations in weighted networks. Phys. Rev. Lett. 2009, 102, 038701. [Google Scholar] [CrossRef] [PubMed]
- Garlaschelli, D.; Loffredo, M. Maximum likelihood: Extracting unbiased information from complex networks. Phys. Rev. E 2008, 78, 015101. [Google Scholar] [CrossRef] [PubMed]
- Caldarelli, G.; Capocci, A.; Rios, P.D.L.; Mun, M.A. Scale-free networks from varying vertex intrinsic fitness. Phys. Rev. Lett. 2002, 89, 258702. [Google Scholar] [CrossRef] [PubMed]
- Garlaschalli, D.; Loffredo, M.I. Fitness-dependent topological properties of the world trade web. Phys. Rev. Lett. 2004, 18, 2–5. [Google Scholar] [CrossRef] [PubMed]
- United Nations Comtrade Database. Available online: http://comtrade.un.org/data/ (accessed on 29 September 2015).
- Feenstra, R.; Lipsey, R. Long Range Comtrade Data. Available online: http://cid.econ.ucdavis.edu/nberus.html (accessed on 29 September 2015).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tacchella et al. (2010) | Replication (2012) |
|---|---|
| Germany | Germany |
| China | China |
| Italy | Italy |
| Japan | Japan |
| USA | USA |
| France | Belgium |
| UK | France |
| Austria | Netherlands |
| Spain | India |
| Belgium | UK |
| Fish (fresh or chilled) |
| Peas |
| Rubber inner tyre tubes |
| Sacks and bags of jute |
| Compacting machinery |
| Resistance welding machines |
| Electric lamps and light fittings |
| z ≥ 0 | z ≥ 1 | z ≥ 2 |
|---|---|---|
| China | China | China |
| Germany | Germany | Germany |
| USA | USA | Italy |
| Japan | Japan | Japan |
| Italy | Italy | USA |
| India | Belgium | Belgium |
| Belgium | India | India |
| France | France | France |
| Netherlands | Netherlands | Netherlands |
| Spain | Spain | UK |
| UK | UK | Spain |
| Hong Kong | Hong Kong | Switzerland |
| Switzerland | Switzerland | Hong Kong |
| Czech Republic | Austria | Austria |
| Austria | Czech Republic | Czech Republic |
| South Korea | South Korea | South Korea |
| Sweden | Sweden | Sweden |
| Poland | Turkey | Thailand |
| Turkey | Thailand | Denmark |
| Denmark | Malaysia | Turkey |
| Thailand | Denmark | Singapore |
| Malaysia | Poland | Malaysia |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krantz, R.; Gemmetto, V.; Garlaschelli, D. Maximum-Entropy Tools for Economic Fitness and Complexity. Entropy 2018, 20, 743. https://doi.org/10.3390/e20100743
Krantz R, Gemmetto V, Garlaschelli D. Maximum-Entropy Tools for Economic Fitness and Complexity. Entropy. 2018; 20(10):743. https://doi.org/10.3390/e20100743
Chicago/Turabian StyleKrantz, Ruben, Valerio Gemmetto, and Diego Garlaschelli. 2018. "Maximum-Entropy Tools for Economic Fitness and Complexity" Entropy 20, no. 10: 743. https://doi.org/10.3390/e20100743
APA StyleKrantz, R., Gemmetto, V., & Garlaschelli, D. (2018). Maximum-Entropy Tools for Economic Fitness and Complexity. Entropy, 20(10), 743. https://doi.org/10.3390/e20100743