Computing Entropies with Nested Sampling

Department of Statistics, The University of Auckland, Auckland 1142, New Zealand
Entropy 2017, 19(8), 422; https://doi.org/10.3390/e19080422
Submission received: 12 July 2017
/
Revised: 14 August 2017
/
Accepted: 16 August 2017
/
Published: 18 August 2017
(This article belongs to the Special Issue Maximum Entropy and Bayesian Methods)
{kind=link}
{kind=link}
{kind=link}
Abstract
:The Shannon entropy, and related quantities such as mutual information, can be used to quantify uncertainty and relevance. However, in practice, it can be difficult to compute these quantities for arbitrary probability distributions, particularly if the probability mass functions or densities cannot be evaluated. This paper introduces a computational approach, based on Nested Sampling, to evaluate entropies of probability distributions that can only be sampled. I demonstrate the method on three examples: a simple Gaussian example where the key quantities are available analytically; (ii) an experimental design example about scheduling observations in order to measure the period of an oscillating signal; and (iii) predicting the future from the past in a heavy-tailed scenario.
1. Introduction
If an unknown quantity x has a discrete probability distribution , the Shannon entropy [1,2] is defined as
where the sum is over all of the possible values of x under consideration. The entropy quantifies the degree to which the issue “what is the value of x, precisely?” remains unresolved [3]. More generally, the ‘Kullback–Leibler divergence’ quantifies the degree to which a probability distribution departs from a ‘base’ or ‘prior’ probability distribution [4,5]:
If is taken to be uniform, this is equivalent (up to an additive constant and a change of sign) to the Shannon entropy . With the negative sign reinstated, Kullback–Leibler divergence is sometimes called relative entropy, and is more fundamental than the Shannon entropy [4]. However, this paper focuses on the Shannon entropy for simplicity and because the resulting algorithm calculates the expected value of a log-probability.
The Shannon entropy can be interpreted straightforwardly as a measure of uncertainty. For example, if there is only one possible value that has a probability of one, is zero. Conventionally, is defined to be equal to , which is zero; i.e., ‘possibilities’ with probability zero do not contribute to the sum. If there are N possibilities with equal probabilities each, then the entropy is . If the space of possible x-values is continuous so that is a probability density function, the differential entropy
quantifies uncertainty by generalising the log-volume of the plausible region, where volume is defined with respect to . Crucially, in continuous spaces, the differential entropy is not invariant under changes of coordinates, so any value given for a differential entropy must be understood with respect to the coordinate system that was used. Even in discrete cases, using the Shannon entropy assumes that each possibility contributes equally when counting possibilities—if this is inappropriate, the relative entropy should be used.
Entropies, relative entropies, and related quantities tend to be analytically available only for a few families of probability distributions. On the numerical side, if can be evaluated for any x, then simple Monte Carlo will suffice for approximating . On the other hand, if can only be sampled but not evaluated (for example, if is a marginal or conditional distribution, or the distribution of a quantity derived from x), then this will not work. Kernel density estimation or the like e.g., [6] may be effective in this case, but is unlikely to generalise well to high dimensions.
This paper introduces a computational approach to evaluating the Shannon entropy of probability distributions that can only be sampled using Markov Chain Monte Carlo (MCMC). The key idea is that Nested Sampling can create an unbiased estimate of a log-probability, and entropies are averages of log-probabilities.
Notation and Conventions
Throughout this paper, I use the compact ‘overloaded’ notation for probability distributions favoured by many Bayesian writers [7,8], writing for either a probability mass function or a probability density function, instead of the more cumbersome or . In the compact notation, there is no distinction between the ‘random variable’ itself (X) and a similarly-named dummy variable (x). Probability distributions are implicitly conditional on some prior information, which is omitted from the notation unless necessary. All logarithms are written log and any base can be used, unless otherwise specified (for example by writing ln or ). Any numerical values given for the value of specific entropies are in nats, i.e., the natural logarithm was used.
Even though the entropy is written as , it is imperative that we remember that it is not a property of the value of x itself, but a property of the probability distribution used to describe a state of ignorance about x. Throughout this paper, is used as notation for both Shannon entropies (in discrete cases) and differential entropies (in continuous cases). Which one it is should be clear from the context of the problem at hand. I sometimes write general formulae in terms of sums (i.e., as they would appear in a discrete problem), and sometimes as integrals, as they would appear in a continuous problem.
2. Entropies in Bayesian Inference
Bayesian inference is the use of probability theory to describe uncertainty, often about unknown quantities (‘parameters’) . Some data , initially unknown but thought to be relevant to , is obtained. The prior information leads the user to specify a prior distribution for the unknown parameters, along with a conditional distribution describing prior knowledge of how the data is related to the parameters (i.e., if the parameters were known, what data would likely be observed?). By the product rule, this yields a joint prior
which is the starting point for Bayesian inference [5,9]. In practical applications, the following operations are usually feasible and have a low computational cost:
- Samples can be generated from the prior ;
- Simulated datasets can be generated from for any given value of ;
- The likelihood, , can be evaluated cheaply for any and . Usually, it is the log-likelihood that is actually implemented, for numerical reasons.
Throughout this paper, I assume that these operations are available and inexpensive.
2.1. The Relevance of Data
The entropy of the prior describes the degree to which the question “what is the value of , precisely?” remains unanswered, while the entropy of the joint prior describes the degree to which the question “what is the value of the pair , precisely?” remains unanswered. The degree to which the question “what is the value of ?” would remain unresolved if were resolved is given by the conditional entropy
which is the expected value of the entropy of the posterior, averaged over all possible datasets that might be observed.
One might wish to compute , perhaps to compare it to and quantify how much might be learned about . This would be difficult because the expression for the posterior distribution
contains the marginal likelihood:
also known as the ‘evidence’, which tends to be computable but costly, especially when the summation is replaced by an integration over a high-dimensional parameter space.
It is important to distinguish between and the entropy of given a particular value of , which might be written (‘obs’ for observed). The former measures the degree to which one question answers another ex ante, and is a function of two questions. The latter measures the degree to which a question remains unresolved after conditioning on a specific statement (ex post), and is a function of a question and a statement.
2.2. Mutual Information
The mutual information is another way of describing the relevance of the data to the parameters. Its definition, and relation to other quantities, is
The mutual information can also be written as the expected value (with respect to the prior over datasets ) of the Kullback–Leibler divergence from prior to posterior:
In terms of the prior, likelihood, and evidence, it is
i.e., the mutual information is the prior expected value of the log likelihood minus the log evidence. As with the conditional entropy, the computational difficulty appears in the form of the log evidence, , which must be evaluated or estimated for many possible datasets.
For experimental design purposes, maximising the expected amount of information obtained from the data is a sensible goal. Formally, either maximising or minimising will produce the same result because the prior does not vary with the experimental design. Reference priors [10] also maximise but vary the prior in the maximisation process while keeping the experimental design fixed.
3. Nested Sampling
Nested Sampling (NS), introduced by Skilling [11], is an algorithm whose aim is to calculate the evidence
or, in the simplified notation common when discussing computational matters,
where is the unknown parameter(s), is the prior distribution, and L is the likelihood function. The original NS algorithm, and variations within the same family [12,13,14], have become popular tools in Bayesian data analysis [15,16,17] and have also found use in statistical physics [18,19,20], which was another of its aims. NS also estimates the Kullback–Leibler divergence from the prior to the posterior , which Skilling calls the information. This is a measure of how much was learned about from the specific dataset, and is also useful for defining a termination criterion for NS.
While Z is a simple expectation with respect to , the distribution of L-values implied by tends to be very heavy-tailed, which is why simple Monte Carlo does not work. Equivalently, the integral over is dominated by very small regions where is high.
To overcome this, NS evolves a population of N particles in the parameter space towards higher likelihood regions. The particles are initially initialised from the prior , and the particle with the lowest likelihood, , is found and its details are recorded as output. This worst particle is then discarded and replaced by a new particle drawn from the prior but subject to the constraint that its likelihood must be above . This is usually achieved by cloning a surviving particle and evolving it with MCMC to explore the prior distribution but with a constraint on likelihood value, . This ‘constrained prior’ distribution has probability density proportional to
where is an indicator function that returns one if the argument is true and zero if it is false.
This process is repeated, resulting in an increasing sequence of likelihoods
Defining as the amount of prior mass with likelihood greater than some threshold ℓ,
and each discarded point in the sequence can be assigned an X-value, which transforms Z to a one-dimensional integral. Skilling’s [11] key insight was that the X-values of the discarded points are approximately known from the nature of the algorithm. Specifically, each iteration reduces the prior mass by approximately a factor . More accurately, the conditional distribution of given (and the definition of the algorithm) is obtainable by letting and setting (where ). The quantities are the proportion of the remaining prior mass that is retained at each iteration, after imposing the constraint of the latest value.
The Sequence of X-Values
The sequence of X-values is defined by
and so on, i.e., can be written as
Taking the log and multiplying both sides by –1, we get
Consider , the fraction of the remaining prior mass that is retained in each NS iteration. By a change of variables, the distribution for these compression factors Beta corresponds to an exponential distribution for :
From Equations 23 and 24, we see that the sequence of values produced by a Nested Sampling run can be considered as a Poisson process with a rate equal to N, the number of particles. This is why separate NS runs can be simply merged [11,21]. Walter [22] showed how this view of the NS sequence of points can be used to construct a version of NS that produces unbiased (in the frequentist sense) estimates of the evidence. However, it can also be used to construct an unbiased estimator of a log-probability, which is more relevant to information theoretic quantities discussed in the present paper.
Consider a particular likelihood value ℓ whose corresponding X-value we would like to know. Since the values have the same distribution as the arrival times of a Poisson process with rate N, the probability distribution for the number of points in an interval of length w is Poisson with expected value . Therefore, the expected number of NS discarded points with likelihood below ℓ is :
We can therefore take , the number of points in the sequence with likelihood below ℓ divided by the number of NS particles, as an unbiased estimator of . The standard deviation of the estimator is .
4. The Algorithm
The above insight, that the number of NS discarded points with likelihood below ℓ has expected value , is the basis of the algorithm. If we wish to measure a log-probability , we can use NS to do it. and need not be the prior and likelihood, respectively, but can be any probability distribution (over any space) and any function whose expected value is needed for a particular application.
See Algorithm 1 for a step-by-step description of the algorithm. The algorithm is written in terms of an unknown quantity whose entropy is required. In applications, may be parameters, a subset of the parameters, data, some function of the data, parameters and data jointly, or whatever.
| Algorithm 1 The algorithm which estimates the expected value of the depth: , that is, minus the expected value of the log-probability of a small region near , which can be converted to an estimate of an entropy or differential entropy. The part highlighted in green is standard Nested Sampling with quasi-prior and quasi-likelihood given by minus a distance function . The final result, , is an estimate of the expected depth. | |
| Set the numerical parameters: | |
| ▹ the number of Nested Sampling particles to use | |
| ▹ the tolerance | |
| ▹ Initialise an empty list of results | |
| while more iterations desired do | |
| ▹ Initialise counter | |
| Generate from | ▹ Generate a reference point |
| Generate from | ▹ Generate initial NS particles |
| Calculate for all i | ▹ Calculate distance of each particle from the reference point |
| ▹ Find the worst particle (greatest distance) | |
| ▹ Find the greatest distance | |
| while do | |
| Replace with from | ▹ Replace worst particle |
| Calculate | ▹ Calculate distance of new particle from reference point |
| ▹ Find the worst particle (greatest distance) | |
| ▹ Find the greatest distance | |
| ▹ Increment counter k | |
| ▹ Append latest estimate to results | |
| ▹ Average results | |
The idea is to generate a reference particle from the distribution whose entropy is required. Then, a Nested Sampling run evolves a set of particles , initially representing , towards in order to measure the log-probability near (see Figure 1). Nearness is defined using a distance function , and the number of NS iterations taken to reduce the distance to below some threshold r (for ‘radius’) provides an unbiased estimate of
which I call the ‘depth’. For example, if Nested Sampling particles are used, and it takes 100 iterations to reduce the distance to below r, then the depth is 10 nats.
If we actually want the differential entropy
we can use the fact that density equals mass divided by volume. Assume r is small, so that
where V is the volume of the region where . Then, . It is important to remember that the definition of volume here is in terms of the coordinates , and that a change of coordinates (or a change of the definition of the distance function) would result in a different value of the differential entropy. This is equivalent to counting possibilities or volumes with a different choice of base measure .
Reducing r towards zero ought to lead to a more accurate result because the probability density at a point will be more accurately approximated by the probability of a small region containing the point, divided by the volume of that region. On the other hand, smaller values of r will lead to more Nested Sampling iterations required, and hence less accuracy in the depth estimates. Thus, there is a an awkward trade-off involved in choosing the value of r, which will need to be investigated more thoroughly in the future. However, the algorithm as it currently stands ought to be useful for calculating the entropies of any low-to-moderate dimensional functions of an underlying high-dimensional space.
If the distance function is chosen to be Euclidean, the constraint corresponds to a ball in the space of possible values. The volume of such a ball, of radius r in n dimensions, is
In one dimension, if the threshold r is not small, we might think we are calculating the entropy associated with the question ‘what is , to within a tolerance of ?’. This is not quite correct. See Appendix A for a discussion of this type of question.
In the following sections, I demonstrate the algorithm on three example problems. For each of the examples, I used 1000 repetitions of NS (i.e., 1000 reference particles), and used 10 NS particles and 10,000 MCMC steps per NS iteration.
5. Example 1: Entropy of a Prior for the Data
This example demonstrates how the algorithm may be used to determine the entropy for a quantity whose distribution can only be sampled, in this case, a prior distribution over datasets.
Consider the basic statistics problem of inferring a quantity from 100 observations whose probability distribution (conditional on ) is
I assumed a Normal prior for . Before getting the data, the prior information is described by the joint distribution
The prior over datasets is given by the marginal distribution
This is the distribution whose differential entropy I seek in this section. Its true value is available analytically in this case, by noting that the posterior is available in closed form for any dataset:
which enables the calculation of the mutual information and hence . The true value of is nats. However, in most situations, the entropy of a marginal distribution such as this is not available in closed form.
To use the algorithm, a distance function must be defined, to quantify how far the NS particles are from the reference particle. To calculate the entropy of the data, I applied the algorithm in the joint space of possible parameters and datasets, i.e., distribution of reference particles followed Equation 32. For the distance function, which helps the NS particles approach the reference particle, I used a simple Euclidean metric in the space of datasets:
Since the distance function refers only to the data and not the parameter , the sampling is effectively done in the space of possible datasets only — the parameter can be thought of as merely a latent variable allowing to be explored conveniently.
I ran the algorithm and computed the average depth using a tolerance of , so that the root mean square difference between points in the two datasets was about . From the algorithm, the estimate of the expected depth was
The uncertainty here is the standard error of the mean, i.e., the standard deviation of the depth estimates divided by square root of the number of NS repetitions (the number of reference particles whose depth was evaluated).
The log-volume of a 100-dimensional ball of radius is . Therefore, the differential entropy is estimated to be
which is very close to the true value (perhaps suspiciously close, but this was just a fluke).
To carry out the sampling for this problem, Metropolis–Hastings moves that explore the joint prior distribution had to be implemented. Four basic kinds of proposals were used: (i) those which change while leaving fixed; (ii) those which change and shift correspondingly; (iii) those which resample a subset of the xs from ; and (iv) those which move a single x slightly.
6. Example 2: Measuring the Period of an Oscillating Signal
In physics and astronomy, it is common to measure an oscillating signal at a set of times , in order to infer the amplitude, period, and phase of the signal. Here, I demonstrate the algorithm on a toy version of Bayesian experimental design: at what times should the signal be observed in order to obtain as much information as possible about the period? To answer this, we need to be able to calculate the mutual information between the unknown period and the data.
As the algorithm lets us calculate the entropy of any distribution that can be sampled by MCMC, there are several options. The mutual information can be written in various ways, such as the following:
In a Bayesian problem where is an unknown parameter and is data, the first and second formulas would be costly to compute because the high dimensional probability distribution for the dataset would require a large number of NS iterations to compute and . The fourth involves the Kullback–Leibler divergence from the prior to the posterior, averaged over all possible datasets. This is straightforward to approximate with standard Nested Sampling, but the estimate for a given dataset may be biased. It is quite plausible that the bias is negligible compared to the variance from averaging over many datasets. This is probably true in many situations.
However, more significantly, the above method would not work if we want for a single parameter or a subset of them, rather than for all of the parameters. The prior-to-posterior KL divergence measured by standard NS is the amount learned about all parameters, including nuisance parameters. Therefore, I adopted the third formula as the best way to compute . In the sinusoidal example, the parameter of interest is the period, whereas the model will contain other parameters as well. Since the period will have its prior specified explicitly, will be available analytically. I then use the algorithm to obtain as follows:
This is an expected value over datasets, of the entropy of the posterior given each dataset. I ran the algorithm by generating reference particles from , i.e., generating parameter values from the prior, along with corresponding simulated datasets. Given each simulated dataset, I used NS to compute an unbiased estimate of , by evolving a set of particles (initially from the posterior) towards the reference particle. The role of the “prior” in the NS is actually taken by the posterior, and the “likelihood” was minus a distance function defined in terms of the parameter(s) of interest.
To generate the initial NS particles from the posterior, I used standard MCMC (targeting the posterior), initialised at the -value that produced the simulated dataset , which is a perfect sample from the posterior.
6.1. Assumptions
I consider two possible observing strategies, both involving measurements. The ‘even’ strategy has observations at times
for ; that is, the observation times are —evenly spaced from to , including the endpoints. The second, ‘uneven’ observing strategy schedules the observations according to
which schedules observations close together initially, and further apart as time goes on.
A purely sinusoidal signal has the form
where A is the amplitude, T is the period, and is the phase. Throughout this section, I parameterise the period by its logarithm, . I assumed the following priors:
and the following conditional prior for the data:
That is, the data is just the signal observed at particular times , with Gaussian noise of standard deviation 0.1. The amplitude of the sinusoid is very likely to be around 10 times the noise level, and the period is between 0.1 times and 1 time the duration of the data. An example signal observed with the even and uneven observing schedules is shown in Figure 2.
To carry out the sampling for this problem, Metropolis–Hastings moves that explore the posterior distribution had to be implemented. I used heavy-tailed proposals (as in Section 8.3 of Brewer and Foreman-Mackey [23]), which modified one parameter at a time.
6.2. Results
Letting , and treating A and are nuisance parameters, I calculated the conditional entropy using the algorithm with a tolerance of . The distance function was just the absolute difference between and .
The result was
Converting to a differential entropy by adding , the conditional entropy is
Since the Uniform(0,1) prior for has a differential entropy of zero, the mutual information is nats.
The results for the uneven observing schedule were
The difference in mutual information between the two observation schedules is trivial. The situation may be different if we had allowed for shorter periods to be possible, as irregular observing schedules are known to reduce aliasing and ambiguity in the inferred period [24]. When inferring the period of an oscillating signal, multimodal posterior distributions for the period are common [17,25]. The multimodality of the posterior here raises an interesting issue. Is the question we really want answered “what is the value of T precisely?”, to which the mutual information relates? Most practicing scientists would not feel particularly informed to learn that the vast majority of possibilities had been ruled out, if the posterior still consisted of several widely separated modes! Perhaps, in some applications, a more appropriate question is “what is the value of T to within ± 10%”, or something along these lines. See Appendix A for more about this issue.
In a serious experimental design situation, the relevance is not the only consideration (or the answer to every experimental design problem would be to obtain more data without limit), but it is a very important one.
7. Example 3: Data with Pareto Distribution
Consider a situation where the probability distribution for some data values is a Pareto distribution, conditional on a minimum value and a slope :
where all of the are greater than . If is relatively low (close to zero), then this distribution is very heavy-tailed, and as increases, the probability density for the xs concentrates just above .
With heavy-tailed distributions, it can be difficult to predict future observations from past ones, a notion popularised by Taleb [26]. This occurs for three main reasons. First, the observations may not provide much information about the parameters (in this case, ). Second, even conditional on the parameters, the predictive distribution for future data can be heavy-tailed, implying a lot of uncertainty. Finally, one may always doubt the probability assignment on which such a calculation is based. However, the data clearly provides some nonzero amount of information about the future.
Consider data values, partitioned into two halves, so is the first half of the data and is the second half. Let and be the totals of the two subsets of the data:
In this section, I use the algorithm to answer the questions: (i) How uncertain is ?; (ii) How uncertain is ?; and (iii) How informative is about ? These are quantified by , , and respectively. This can be done despite the fact that is unknown.
The prior for was chosen to be lognormal such that the prior median of is 1 and the prior standard deviation of is also 1. Due to the heavy-tailed nature of the Pareto distribution, I ran the algorithm in terms of and . This affects the differential entropies but not the mutual information (which is invariant under changes of parameterisation). The joint distribution for and , whose properties I aimed to obtain, is shown in Figure 3.
Three types of Metropolis–Hastings proposals were used for this example: (i) a proposal that changes and modifies all of the xs accordingly; (ii) a proposal that resamples a subset of the xs from the Pareto distribution; and (iii) a proposal that moves a single x-value slightly. A fourth proposal that moves while keeping fixed, i.e., a posterior-sampling move, was not implemented.
To compute the entropy of , the distance function was just the absolute value of the distance between the NS particles and the reference particle in terms of . The result, using a tolerance of , was:
Correcting for the volume factor yields a differential entropy estimate of nats. By the symmetry of the problem specification, .
The joint entropy was also estimated by using a Euclidean distance function and a tolerance of . The result was
Applying the log-volume correction yields a differential entropy estimate of nats. Therefore, the mutual information is
The variance of this mutual information estimate was reduced by using a common sequence of reference points for the marginal and joint entropy runs. This is an instance of the ‘common random numbers’ technique (http://demonstrations.wolfram.com/TheMethodOfCommonRandomNumbersAnExample/). In short, for those reference particles with a large depth in terms of the distance function, the depth in terms of the distance function was also large. Since the mutual information involves a difference of the averages of these depths, it is more accurate to compute the average difference (i.e., compute the two depths using the same reference particle, to compute the difference between the two depths) than the difference of the averages.
8. Computational Cost and Limitations
The computational resources needed to compute these quantities was quite large, as Nested Sampling appears in the inner loop of the algorithm. However, it is worth reflecting on the complexity of the calculation that has been done.
In a Bayesian inference problem with parameters and data , the mutual information is
and this measures the dependence between and . A Monte Carlo strategy to evaluate this is to sample from and average the value of the logarithm, which involves computing the log-evidence
for each possible data set. Computing for even a single data set has historically been considered difficult.
However, if we want the mutual information between the data and a subset of the parameters (i.e., there are nuisance parameters we do not care about), things become even more tricky. Suppose we partition the parameters into important parameters and nuisance parameters , such that we want to calculate the mutual information . This is given by
which is equivalent to Equation 63 but with replaced throughout by . However, this is an even more difficult calculation than before, as , the marginal likelihood function with the nuisance parameters integrated out, is typically unavailable in closed form. If we were to marginalise out the nuisance parameters explicitly, this would give us Equation 65 with every probability distribution written as an explicit integral over :
It should not be surprising that this is costly. Indeed, it seems possible to me that any general algorithm for computing entropies will have the property that NS (or a similar algorithm capable of measuring small volumes) appears in an inner loop, since entropies are sums of terms, each of which relates to the downset of a given statement—the downset of a statement S being the set of all statements that imply S [3].
The current implementation of the algorithm (see Appendix B) is in C++ and has not been parallelised. Given the high computational costs, parallelisation should be attempted. This could follow the method of [21], or alternatively, different threads could work on different reference particles simultaneously.
The algorithm as presented will tend to become less accurate on high dimensional problems, as the required depth of the runs will increase correspondingly, since many NS iterations will be required to get a high dimensional vector of quantities to be close to the reference vector. The accuracy of the estimates should degrade in proportion to , due to the Poisson-process nature of the sequence.
Throughout this paper, the question of how to sample from the constrained distributions required by NS has not been discussed in detail. For the examples, I used the original Skilling [11] suggestion of using a short MCMC run initialised at a surviving point. In some problems, this will not be effective, and this will cause the resulting estimates to be incorrect, as in standard Nested Sampling applications. Testing the sensitivity of the results to changes in the number of MCMC steps used is a simple way to increase one’s confidence in the results, but is not a guarantee (no general guarantee can exist, because any algorithm based on sampling a subset of a space might miss a crucial but hard-to-locate dominant spike). Despite this weakness, I hope the algorithm will be useful in a wide range of applications.
Acknowledgments
I would like to thank John Skilling (Maximum Entropy Data Consultants) and the anonymous referee for their comments. It is a pleasure to thank the following people for interesting and helpful conversations about this topic, and/or comments on a draft: Ruth Angus (Flatiron Institute), Ewan Cameron (Oxford), James Curran (Auckland), Tom Elliott (Auckland), David Hogg (NYU), Kevin Knuth (SUNY Albany), Thomas Lumley (Auckland), Iain Murray (Edinburgh), Jared Tobin (jtobin.io). This work was supported by the Centre for eResearch at the University of Auckland.
Conflicts of Interest
The author declares no conflicts of interest.
Appendix A. Precisional Questions
The central issue about the value of a parameter asks “what is the value of , precisely?”. However, in practice, we often don’t need or want to know to arbitrary precision. Using the central issue can lead to counterintuitive results if you don’t keep its specific definition in mind. For example, suppose x could take any integer value from 1 to 1 billion. If we learned the last digit of x, we will have ruled out nine tenths of the possibilities and therefore obtained a lot of information about the central issue. However, this information might be useless for practical purposes. If we learned the final digit was a 9, x could still be 9, or 19, or 29, any number ending in 9 up to 999,999,999.
In practice, we may want to ask a question that is different from the central issue. For example, suppose and we want to know the value of x to within a tolerance of . Any of the following statements would resolve the issue:
- and anything that implies it,
- and anything that implies it,
- and anything that implies it,
- and so on.
According to Knuth [3], the entropy of a question is computed by applying the sum rule over all statements that would answer the question.
We can write the question of interest, Q, as a union of ideal questions (the ideal questions are downsets of statements: the set of all statements that imply S is the downset of S and is denoted ):
The entropy of this question is
where .
Continuous Case
Consider a probability density function , defined on the real line. The probability contained in an interval , which has length r, is
where is the cumulative distribution function (CDF). This probability can be considered as a function of two variables, and r, which I will denote by :
The contribution of such an interval to an entropy expression is , i.e.,
Consider the rate of change of Q as the interval is shifted to the right, but with its width r held constant:
Consider also the rate of change of Q as the interval is expanded to the right, while keeping its left edge fixed:
The entropy of the precisional question is built up from Q terms. The extra entropy from adding the interval and removing the overlap , for small h, is
Therefore, the overall entropy is
Interestingly, calculating the log-probability of an interval to the right of x gives an equivalent result:
This is not quite the same as the expected log-probability calculated by the version of the algorithm proposed in this paper (when the tolerance is not small). However, the algorithm can be made to estimate the entropy of the precisional question, by redefining the distance function. For a one-dimensional quantity of interest, the distance function can be defined such that can only ever be below r if (or alternatively, if ).
Appendix B. Software
A C++ implementation of the algorithm is available in a git repository located at
https://github.com/eggplantbren/InfoNestand can be obtained using the following git command, executed in a terminal:
git clone https://github.com/eggplantbren/InfoNestThe following will compile the code and execute the first example from the paper:
cd InfoNest/cpp make ./mainThe algorithm will run for 1000 ‘reps’, i.e., 1000 samples of , which is time consuming. Output is saved to output.txt. At any time, you can execute the Python script postprocess.py to get an estimate of the depth:
python postprocess.py
By default, postprocess.py estimates the depth with a tolerance of . This value can be changed by calling the postprocess function with a different value of its argument tol. E.g., postprocess.py can be edited so that its last line is postprocess(tol=0.01) instead of postprocess().
The numerical parameters, and the choice of which problem is being solved, are specified in main.cpp. The default problem is the first example from the paper. For Example 2, since it is a conditional entropy that is being estimated (which requires a slight modification to the algorithm), an additional argument InfoNest::Mode::conditional_entropy must be passed to the InfoNest::execute function.
References
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Cover, T.M.; Thomas, J.A. Elements of Information Theory; Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Knuth, K.H. Toward question-asking machines: The logic of questions and the inquiry calculus. In Proceedings of the 10th International Workshop On Artificial Intelligence and Statistics, Barbados, 6–8 January 2005. [Google Scholar]
- Knuth, K.H.; Skilling, J. Foundations of inference. Axioms 2012, 1, 38–73. [Google Scholar] [CrossRef]
- Caticha, A.; Giffin, A. Updating probabilities. AIP Conf. Proc. 2006, 31. [Google Scholar] [CrossRef]
- Szabó, Z. Information theoretical estimators toolbox. J. Mach. Learn. Res. 2014, 15, 283–287. [Google Scholar]
- Jaynes, E.T. Probability theory: The logic of science; Cambridge university press: New York, NY, USA, 2003. [Google Scholar]
- MacKay, D.J. Information Theory, Inference and Learning Algorithms; Cambridge university press: New York, NY, USA, 2003. [Google Scholar]
- Caticha, A. Lectures on probability, entropy, and statistical physics. arXiv 2008, arXiv:0808.0012. [Google Scholar]
- Bernardo, J.M. Reference analysis. Handb. Stat. 2005, 25, 17–90. [Google Scholar]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Feroz, F.; Hobson, M.; Bridges, M. MultiNest: An efficient and robust Bayesian inference tool for cosmology and particle physics. Mon. Not. R. Astron. Soc. 2009, 398, 1601–1614. [Google Scholar] [CrossRef]
- Brewer, B.J.; Pártay, L.B.; Csányi, G. Diffusive nested sampling. Stat. Comput. 2011, 21, 649–656. [Google Scholar] [CrossRef]
- Handley, W.; Hobson, M.; Lasenby, A. PolyChord: Next-generation nested sampling. Mon. Not. R. Astron. Soc. 2015, 453, 4384–4398. [Google Scholar] [CrossRef]
- Knuth, K.H.; Habeck, M.; Malakar, N.K.; Mubeen, A.M.; Placek, B. Bayesian evidence and model selection. Digit. Signal Process. 2015, 47, 50–67. [Google Scholar] [CrossRef]
- Pullen, N.; Morris, R.J. Bayesian model comparison and parameter inference in systems biology using nested sampling. PLoS ONE 2014, 9, e88419. [Google Scholar] [CrossRef] [PubMed]
- Brewer, B.J.; Donovan, C.P. Fast Bayesian inference for exoplanet discovery in radial velocity data. Mon. Not. R. Astron. Soc. 2015, 448, 3206–3214. [Google Scholar] [CrossRef]
- Pártay, L.B.; Bartók, A.P.; Csányi, G. Efficient sampling of atomic configurational spaces. J. Phys. Chem. B 2010, 114, 10502–10512. [Google Scholar] [CrossRef] [PubMed]
- Baldock, R.J.; Pártay, L.B.; Bartók, A.P.; Payne, M.C.; Csányi, G. Determining pressure-temperature phase diagrams of materials. Phys. Rev. B 2016, 93, 174108. [Google Scholar] [CrossRef]
- Martiniani, S.; Stevenson, J.D.; Wales, D.J.; Frenkel, D. Superposition enhanced nested sampling. Phys. Rev. X 2014, 4, 031034. [Google Scholar] [CrossRef]
- Henderson, R.W.; Goggans, P.M.; Cao, L. Combined-chain nested sampling for efficient Bayesian model comparison. Digit. Signal Process. 2017, 70, 84–93. [Google Scholar] [CrossRef]
- Walter, C. Point process-based Monte Carlo estimation. Stat. Comput. 2017, 27, 219–236. [Google Scholar] [CrossRef]
- Brewer, B.J.; Foreman-Mackey, D. DNest4: Diffusive Nested Sampling in C++ and Python. J. Stat. Softw. 2016, in press. [Google Scholar]
- Bretthorst, G.L. Nonuniform sampling: Bandwidth and aliasing. AIP Conf. Proc. 2001, 567. [Google Scholar] [CrossRef]
- Gregory, P.C. A Bayesian Analysis of Extrasolar Planet Data for HD 73526. Astrophys. J. 2005, 631, 1198–1214. [Google Scholar] [CrossRef]
- Taleb, N.N. The Black Swan: The Impact of the Highly Improbable; Random House: New York, NY, USA, 2007. [Google Scholar]
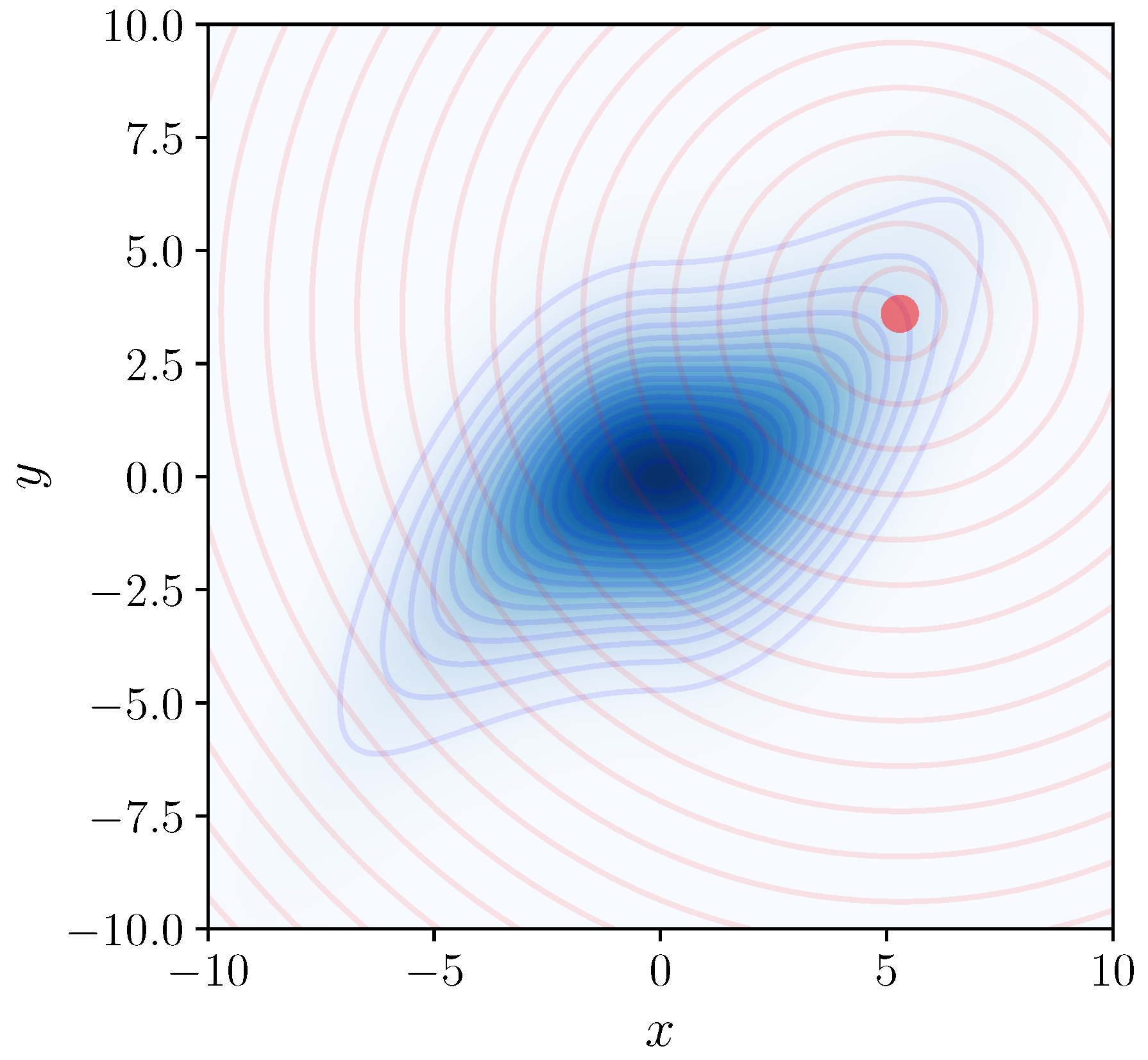
Figure 1.
To evaluate the log-probability (or density) of the blue probability distribution near the red point, Nested Sampling can be used, with the blue distribution playing the role of the “prior” in NS, and the Euclidean distance from the red point (illustrated with red contours) playing the role of the negative log-likelihood. Averaging over selections of the red point gives an estimate of the entropy of the blue distribution.
Figure 1.
To evaluate the log-probability (or density) of the blue probability distribution near the red point, Nested Sampling can be used, with the blue distribution playing the role of the “prior” in NS, and the Euclidean distance from the red point (illustrated with red contours) playing the role of the negative log-likelihood. Averaging over selections of the red point gives an estimate of the entropy of the blue distribution.
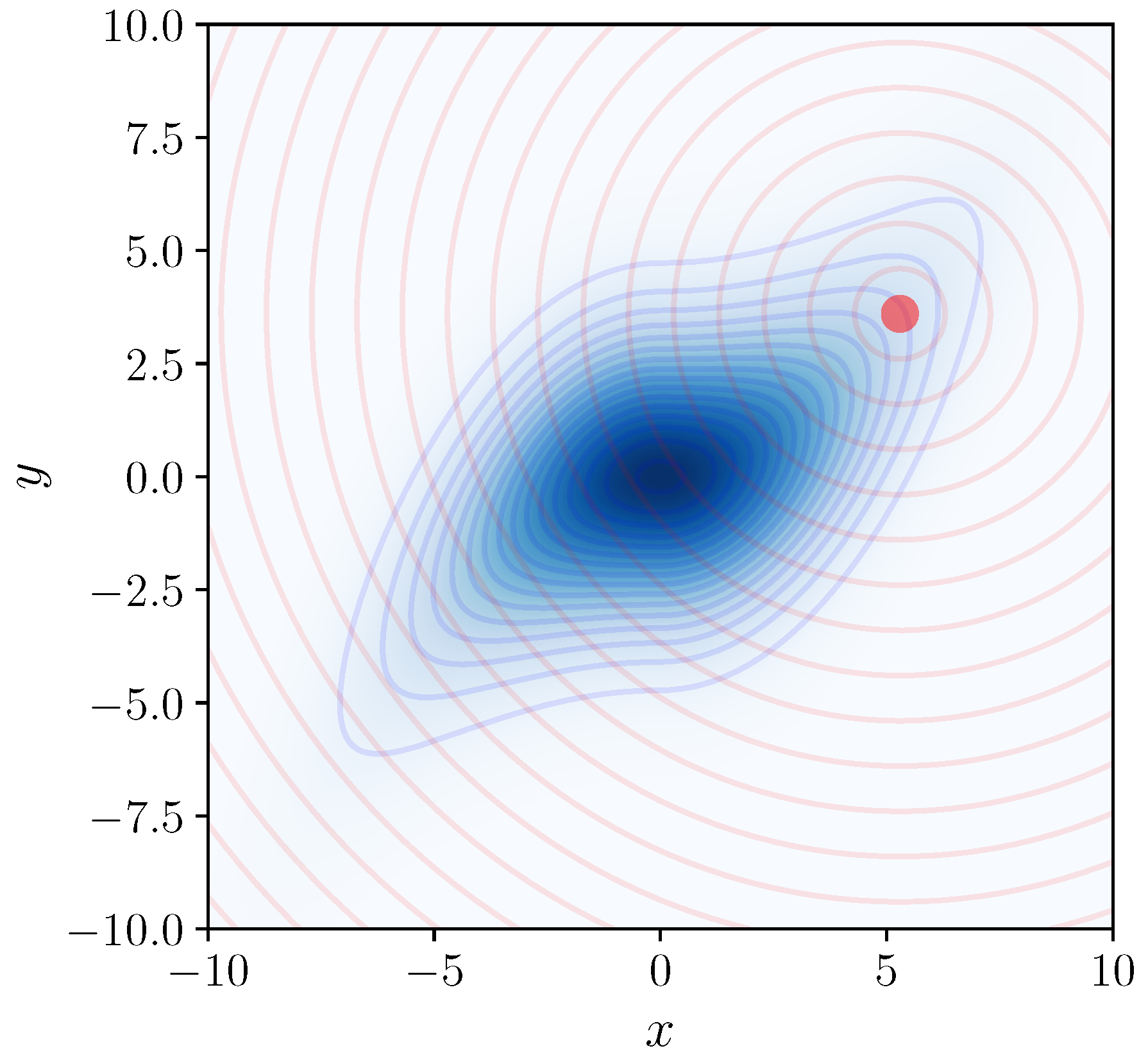
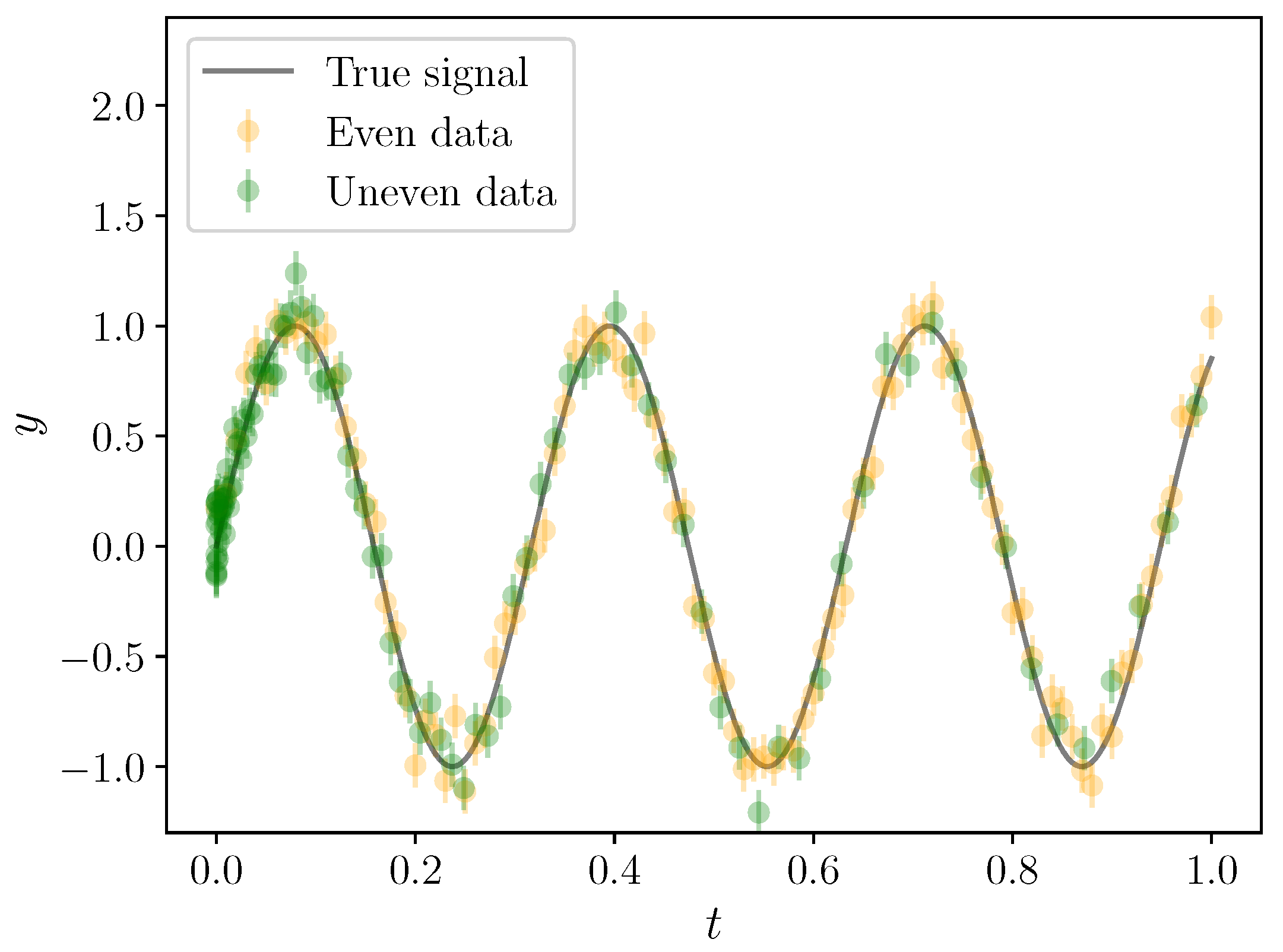
Figure 2.
A signal with true parameters , , and , observed with noise standard deviation 0.1 with the even (gold points) and uneven (green points) observing strategies.
Figure 2.
A signal with true parameters , , and , observed with noise standard deviation 0.1 with the even (gold points) and uneven (green points) observing strategies.

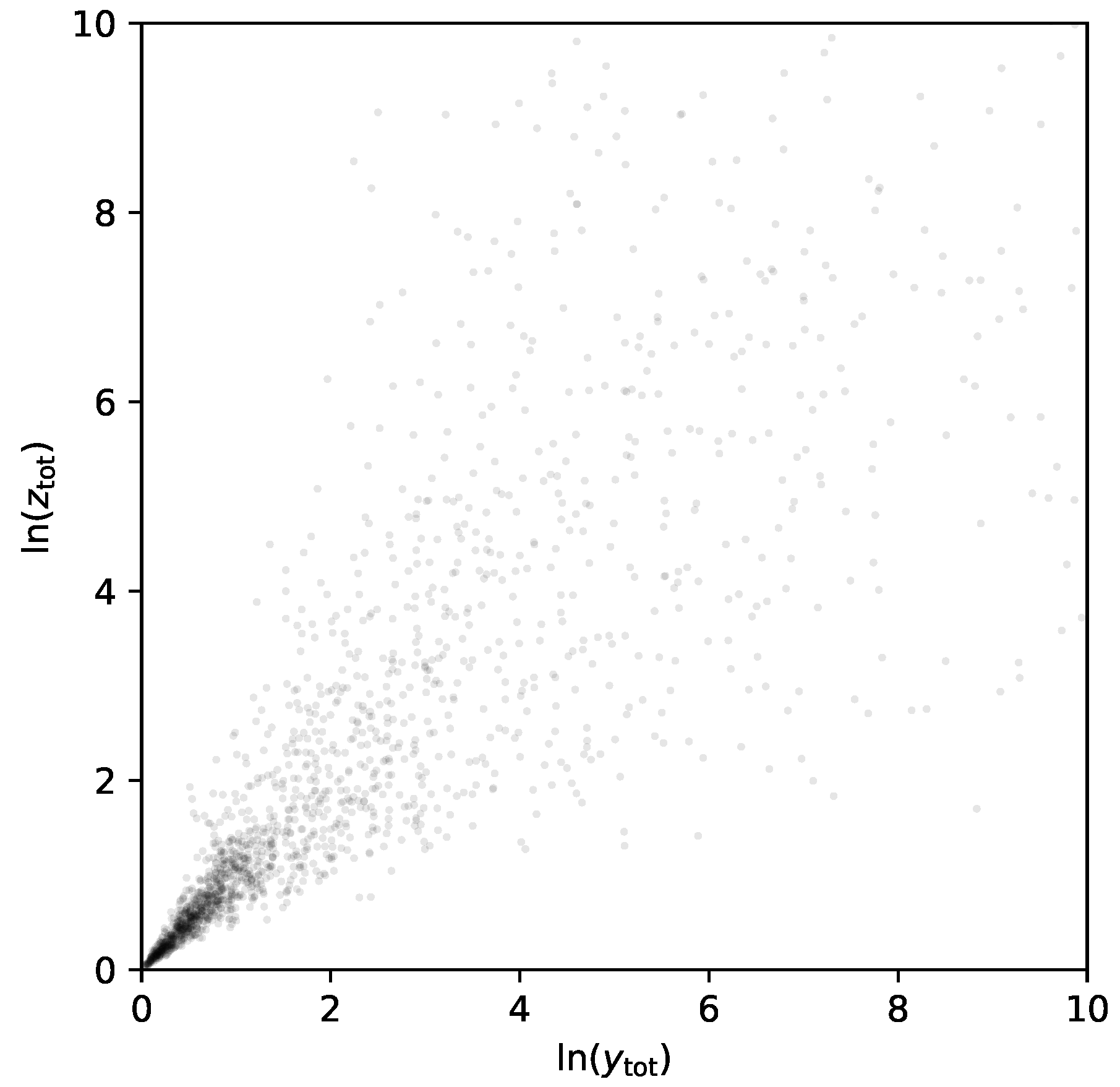
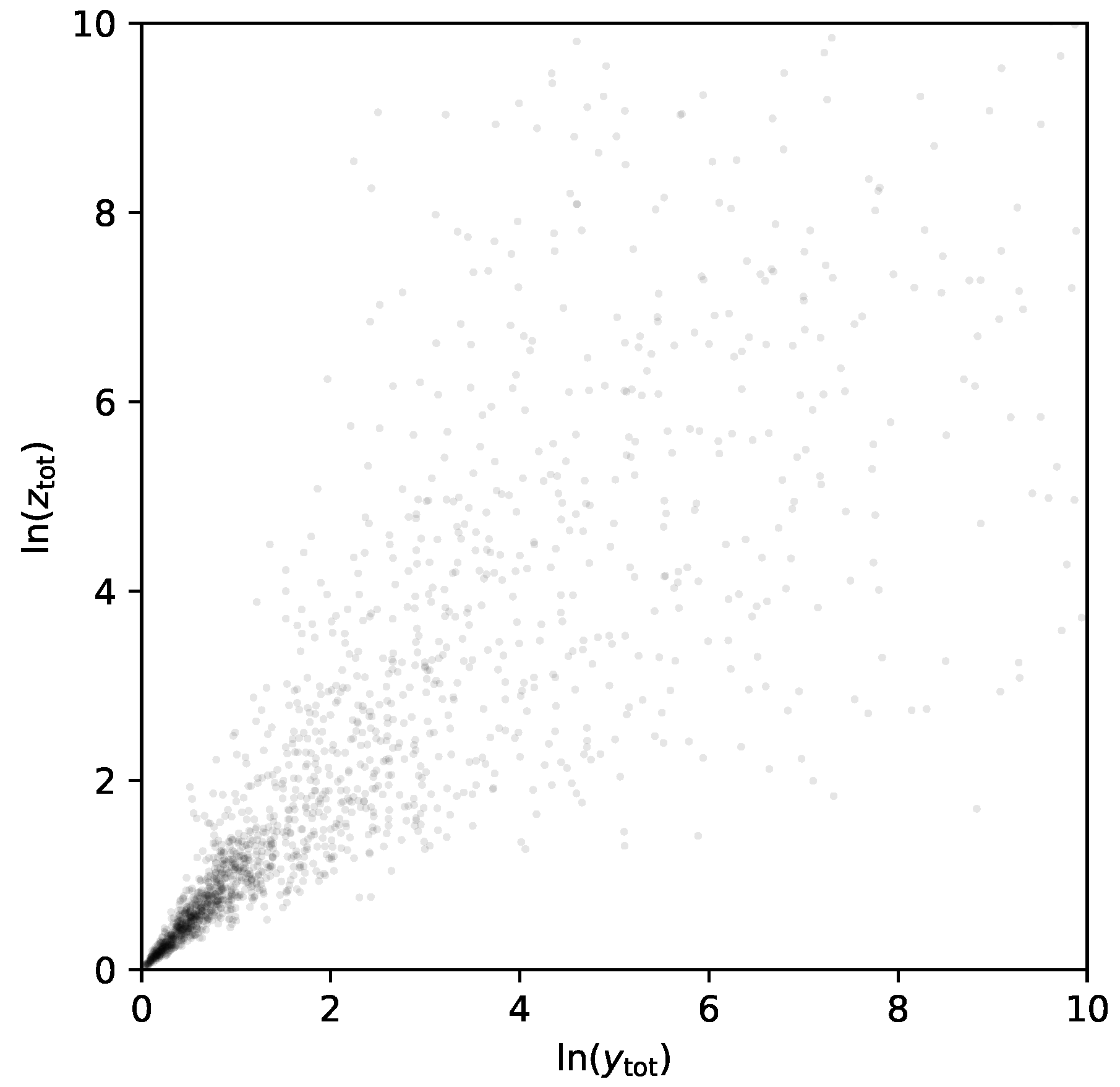
Figure 3.
The joint distribution for the log-sum of the first half of the ‘Pareto data’ and the second half. The goal is to calculate the entropy of the marginal distributions, the entropy of the joint distribution, and hence the mutual information. The distribution is quite heavy tailed despite the logarithms, and extends beyond the domain shown in this plot.
Figure 3.
The joint distribution for the log-sum of the first half of the ‘Pareto data’ and the second half. The goal is to calculate the entropy of the marginal distributions, the entropy of the joint distribution, and hence the mutual information. The distribution is quite heavy tailed despite the logarithms, and extends beyond the domain shown in this plot.
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Brewer, B.J. Computing Entropies with Nested Sampling. Entropy 2017, 19, 422. https://doi.org/10.3390/e19080422
AMA Style
Brewer BJ. Computing Entropies with Nested Sampling. Entropy. 2017; 19(8):422. https://doi.org/10.3390/e19080422
Chicago/Turabian StyleBrewer, Brendon J. 2017. "Computing Entropies with Nested Sampling" Entropy 19, no. 8: 422. https://doi.org/10.3390/e19080422
APA StyleBrewer, B. J. (2017). Computing Entropies with Nested Sampling. Entropy, 19(8), 422. https://doi.org/10.3390/e19080422
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.