1. Introduction
Statistical Process Control (SPC), based on the control chart and other monitoring methods, has been widely used in manufacturing, service, and industrial practices (see [
1]). The conventional Shewhart chart is very popular for monitoring univariate quantity. During the last several decades, the control chart for the mean has been expanded to the well-known Hotelling’s
chart, multivariate cumulative sum (CUSUM) chart and exponentially weighted moving average (EWMA) chart (see [
2,
3]). The Bayesian control chart is also proposed to monitor multivariate quantities (see [
4,
5]). For these control charts, the basic idea is to establish a probability distribution for the monitored quantity at first that can describe its randomness. Actually, this distribution always remains unknown in most practical situations. Then, test the newly monitored sample against the distribution of the monitored quantity. If the newly monitored sample has an obvious difference from the distribution of the monitored quantity, the process can be decided as out-of control. Otherwise, the process is considered as in-control when the newly monitored sample is similar to the distribution of the monitored quantity (see [
6]. For most practical situations, in order to implement SPC easily for practitioners, many conventional SPC techniques take the sample distribution as Normal distribution when the monitored quantity is a continuous variable, e.g., the Shewhart control chart technique, and take the monitored quantity as Poisson or Binomial distribution when it is a discrete variable, e.g., in most situations of sampling inspection in quality control. However, when the quantity being monitored in practical situations is not of the above cases, e.g., for small samples, multivariable and/or auto correlated data (see [
7,
8]), the performances of the conventional SPC techniques tend to be significantly diminished. Because the control limits are inaccurate, the true Type I error which is called false alarm probability will have a large discrepancy comparing to the designated false alarm probability, as well as for the Type II error which is called miss-detection probability in SPC. To provide sufficiently flexible control methods for more complicated problems, many nonparametric control charts have been proposed in recent researches (see [
9]).
The entropy-based techniques have been formalized to detect the randomness of variables. Acharya et al. have discussed the various entropies applied on automated diagnosis of epilepsy using the electroencephalogram (EEG) signal comprehensively (see [
10]). For EEG signal monitoring, there are several entropy features extracted from the EEG signal, and it has found many advantages in applying these entropy features, such as separating the useful signal from redundant information, improving the accuracy for epilepsy diagnosis, etc (see [
10,
11]). In EEG signal diagnosis, the entropy features are calculated as a numerical measure for the chaos of the signal. The entropy-based techniques are also used to detect the shifts of monitored quantities in SPC. Comparing to the EEG signal diagnosis, the entropy is mainly used to determine the probability distributions of monitored quantities. Information-Theoretic Process Control (ITPC) is the signal charting procedures for monitoring the quantity without a need to make distribution assumption (see [
12]). In ITPC, Maximum Entropy (ME) distribution is proposed to approximate the distribution for the monitored quantity. Based on the maximum entropy principle, the ME distribution is estimated by maximizing the Shannon entropy subjected to the specified constraints (see [
13]). Then, the ITPC method takes the Kullback–Leibler (KL) divergence between the ME distribution and the sample distribution as the monitoring statistic. When the KL divergence is larger than the threshold value, the signalling will be generated to mind that the sample is out-of-control. However, for the case of small sample size, the KL divergence might not perform well (see [
6]). Furthermore, when the distribution of the quantity being monitored is multimodal, the in-control region might not be continuous.
Aiming to tackle the weakness of the ITPC method, Das and Zhou (see [
6]) have applied the Maximum Entropy Level Set to design the control chart, which is called the MELS chart. Like the ITPC method, it also uses the ME distribution to fit the distribution of the monitored quantity. However, instead of using the KL divergence as the final monitoring statistic, it proposes a new principle to find the optimal in-control region which is more convenient to use and works well for the small size sample. Generally, it takes the function of quantity
as the monitoring statistic, with the Type I error
; the optimal in-control region is as
where
h denotes the threshold value in the MELS chart.
is a polynomial of
X and it is expressed as the exponential part of the ME distribution function (see
Section 2). For the newly monitored sample, when
, it belongs to the out-of-control region. Otherwise, the newly monitored sample is in-control. The main principle in MELS is: given the Type I error
, it selects the density level set with the minimum volumes to be the optimal in-control region. The MELS chart has been proven to perform better than the ITPC method for the multimodal distributions such as mixture Normal distributions. Because of the multimodal distributions, the acceptance region of
X is probably not a continuous set. Take the multimodal distribution of
from Das and Zhou’s (see [
6]) research as an example. With
, when
h was found to be 2.894, then
X belonging to the acceptance region is
. By using
, it can make the in-control region expression one continuous set, i.e.,
. However, since
always tends to be a high moment polynomial, it is very difficult to calculate
h under the specified
. For the unimodal distribution of quantity
X being monitored, such as the Normal distribution, Gamma distribution, Weibull distribution etc., the maximum entropy density level set for
X must be continuous. Thus, the existing MELS chart is inconvenient and somewhat unnecessary for the unimodal distribution. Since the unimodal distribution of quantity being monitored is very common in practice, we propose a novel method for the unimodal distribution based on the MELS technique in this paper. Instead of taking
as the monitoring statistic, we use
X as the monitoring statistic directly to design the control chart. Because the monitoring statistic
X is simpler than
, the method we propose in this paper is called the simplified MELS chart.
The article is organized as follows. In
Section 2, we introduce the concept of entropy and ME density approximation to the distribution of monitored quantity under the given constraints. The simplified MELS chart for the quantity with unimodal distribution is given in
Section 3, and it also presents the comparison performances between the simplified MELS chart and the other two familiar control charts in this section. Two cases for validating the proposed method are given in
Section 4.
3. Control Chart Based on ME Distribution
After approximating the distribution of monitored quantity by ME distribution density, then we design the control chart based on the ME distribution in this section. Furthermore, we also summarize the design steps and implementation of the control chart.
3.1. Statistic of the Simplified MELS
The basic idea of the control chart we propose in this article is to divide the sample space
S into two regions, the region
I and the region
, which denote the in-control and out-of-control states respectively. The principle to establish the acceptance region is that when the sample is in-control we must accept it with a high probability, otherwise reject it with a high probability. However, there are two risks (Type I error and Type II error) in this process (see
Section 1). Generally, given a specified value
of Type I error rate, the acceptance region must be calculated to meet
. In practice, the value
is usually determined in accordance with the customers’ demands or governments’ rules. In this article, there is a set of acceptance regions formulated by
where
stands for the distribution of monitored quantity
X, and we can take the ME distribution to approximate it.
Theoretically, for a specified value
, there are many sets of
I that satisfy Equation (7), but the corresponding Type II error rates
are different for each
I. According to the principle of control chart design, among these sets, we must find the one with the lower Type II error rate
, and take it as the optimal in-control region
. As for the lower Type II error rate
, the control chart can be signalling with a higher probability when the monitored variable is out-of-control. However, the Type II error rate
is very difficult to calculate, because the real distribution of
X is usually unknown when it is out-of-control. Hence, we cannot predict the exact value of
for an acceptance region beforehand. Park et al. used the Lebesgue measure of set
I to decide the optimal in-control region
, and it has been proven that the upper bound of the Type II error rate will be minimized if the Lebesgue measure of set
I is minimum (see [
23]).Let
denote the distribution of
X when it stays in the out-of-control region and
has the upper bound value of
B. Park et al. (see [
23]) defined the Type II error rate as
where
is the Lebesgue measure of set
I. From Equation (8), the optimal in-control region
can be concluded as
Equations (8) and (9) show that when the Lebesgue measure of acceptance region
I is minimum, there will be a lower upper bound of the Type II error rate. If the distribution
is unimodal, we can prove that, given a specified Type I error rate
, there exists a minimum continuous set for the variable
X with the probability of
. For the symmetric unimodal distribution, the probabilistically symmetric coverage has been proven to contain the minimum volume of
X, e.g., Normal distribution (see [
24]).
Thus, instead of
in MELS, we directly take variable
X as the monitoring statistic in this paper for the unimodal distribution. Because the monitoring statistic
X is simpler than
, the method we propose here is called the simplified MELS chart. Let
be the ME distribution destiny of
X and use it (see Equation (6)) to approximate the distribution
, then the ME cumulative distribution function (c.d.f) is
With a specified
, when the ME density is symmetric, the optimal in-control region
can be calculated as
where
is the inverse ME cumulative distribution function.
When the ME distribution is asymmetric, the optimal in-control region under the Type I error rate
needs to be searched. Letting
r be an appropriate small positive value and
, the optimal in-control region is determined by
such that
Thus, for the asymmetric distribution, the optimal in-control region can be expressed as
When , the optimal in-control region in Equation(13) is equivalent to the case of the symmetric modal distribution. So the symmetric modal distribution is a special case for asymmetric modal distribution.
However, from Equation (6), we can see that the ME distribution density is the high-order exponential distribution. In most cases, it is very difficult to calculate the inverse cumulative distribution function (c.d.f) analytically. Instead of determining the continuous function , given a specified , we always use the numerical approximation method such as dichotomy to calculate the discrete values of . Then, the acceptance regions can be approximately found, as well as the optimal in-control region .
3.2. Comparison Performance of the Three Charts
In order to make the simplified MELS chart easy to understand, we present its comparison performances with the conventional Shewhart chart and nonparameter Quantile chart.
One of the classical control charts in SPC is the conventional Shewhart chart, and it assigns Normal distribution
to the variable
X. Accordingly, with a specified Type I error rate
, we can calculate the optimal in-control region as
, where
k is a constant obtained by
To normal distribution, when , we can find . For the ME distribution estimation, there is a special case that when the only moment constraints in Equation (5) are given as and , then Equation (6) in this case is also formalized as normal distribution . Hence, the optimal in-control regions here obtained by the simplified MELS chart and the conventional Shewhart chart are the same.
The nonparameter Quantile chart is using quantiles of the distribution to decide the in-control acceptance regions, so it must estimate the quantiles first. When the distribution of quantity
X is fitted by ME distribution, given the specified
, the upper quintile and the lower quintile are obtained by
and
respectively. The nonparameter Quantile chart acceptance region is
Comparing the three charts under the same Type I error rate
, we can see that all of the three control charts are somewhat equivalent to finding the acceptance regions when the distribution of the monitored quantity is a symmetric unimodal distribution. Furthermore, for the asymmetric unimodal distribution, the three charts are different to each other. In order to find the better control chart, we have to calculate the Type II error rate
for several control charts. The one with the smallest
is selected as a better control chart (see
Section 4).
3.3. Application Steps for the Proposed Method
To implement the simplified MELS chart, it can be reduced to the following two steps.
Step 1. Estimate the ME destiny of the monitored quantity
X subjected to the constraints of the order moments, and use it as the approximation to the distribution of
X. There is more detailed information in
Section 2.
Step 2. After approximating to the distribution of the monitored quantity, an optimal in-control region for the decision needs to be estimated with a specified Type I error rate . By using the numerical/analytical method, is selected such that .
5. Discussion
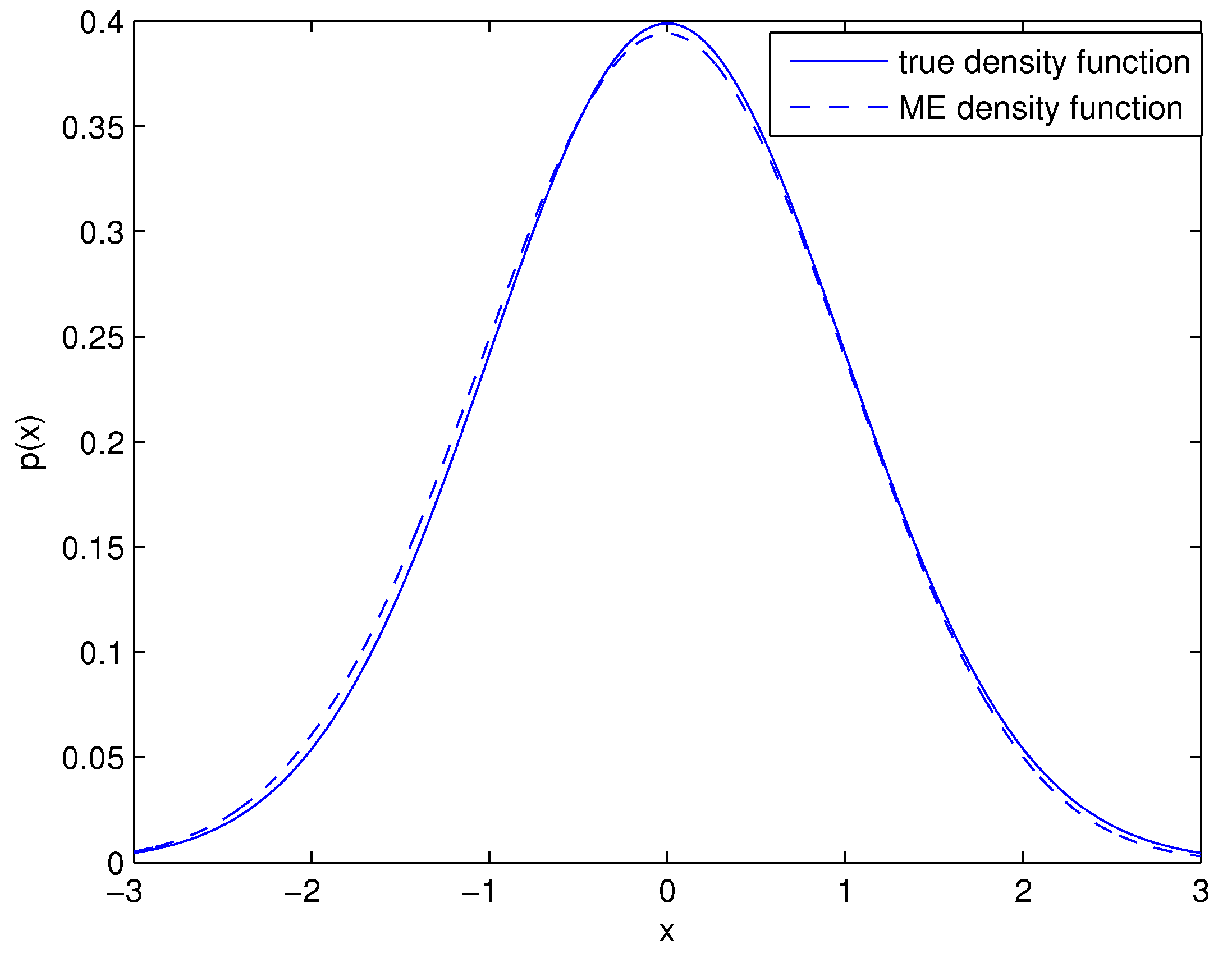
Theoretically, the acceptance regions are supposed to be totally equivalent in the situation of symmetric distribution. The divergences among the three acceptance regions are mainly attributed to the incomplete ME density approximation of the true density (see
Table 1). With the improvement of optimization techniques, the ME distribution and the true distribution tend to overlap (see
Figure 1). Hence, for most symmetric distribution situations, once the sample size for conventional control charts design is required (see [
25]).
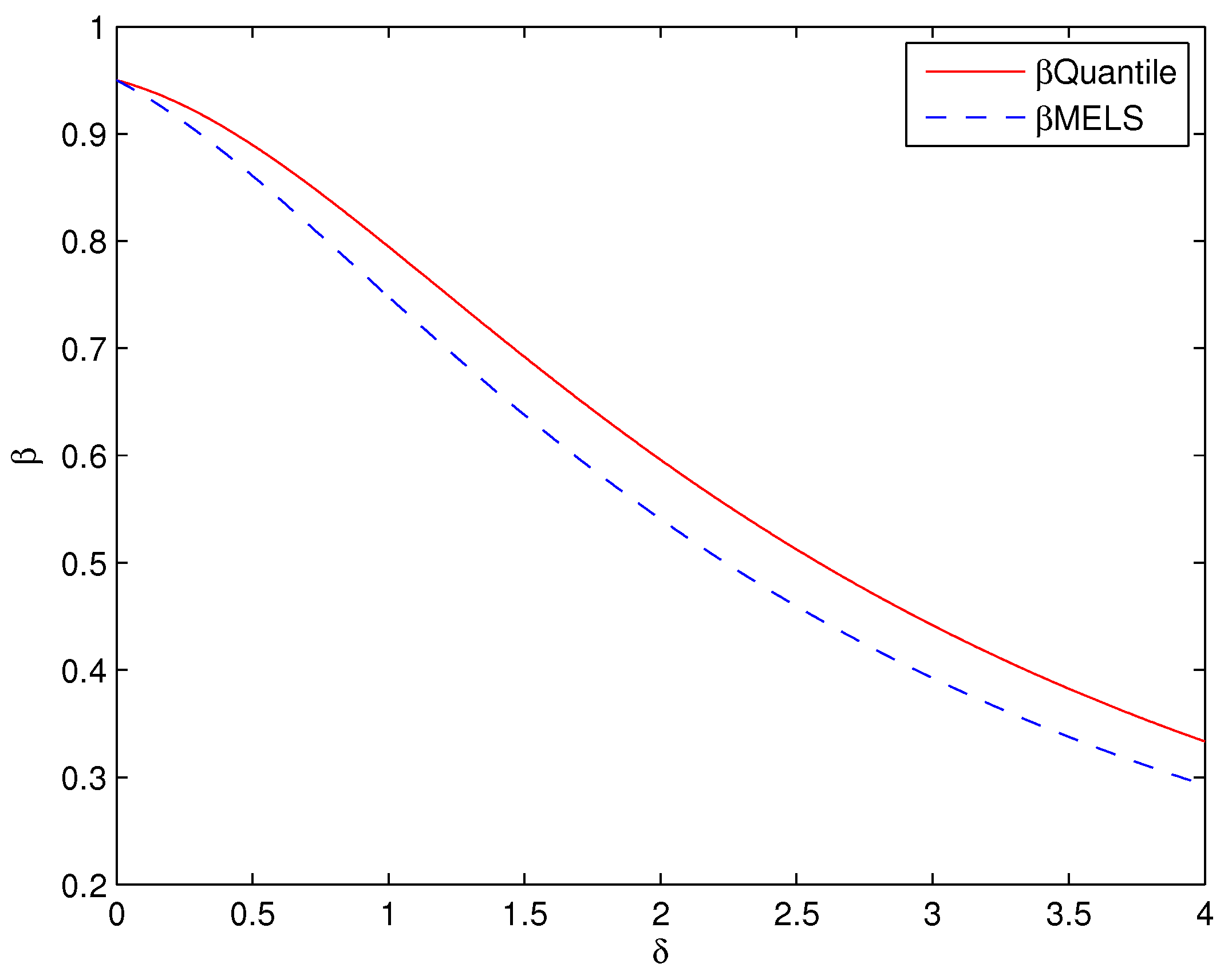
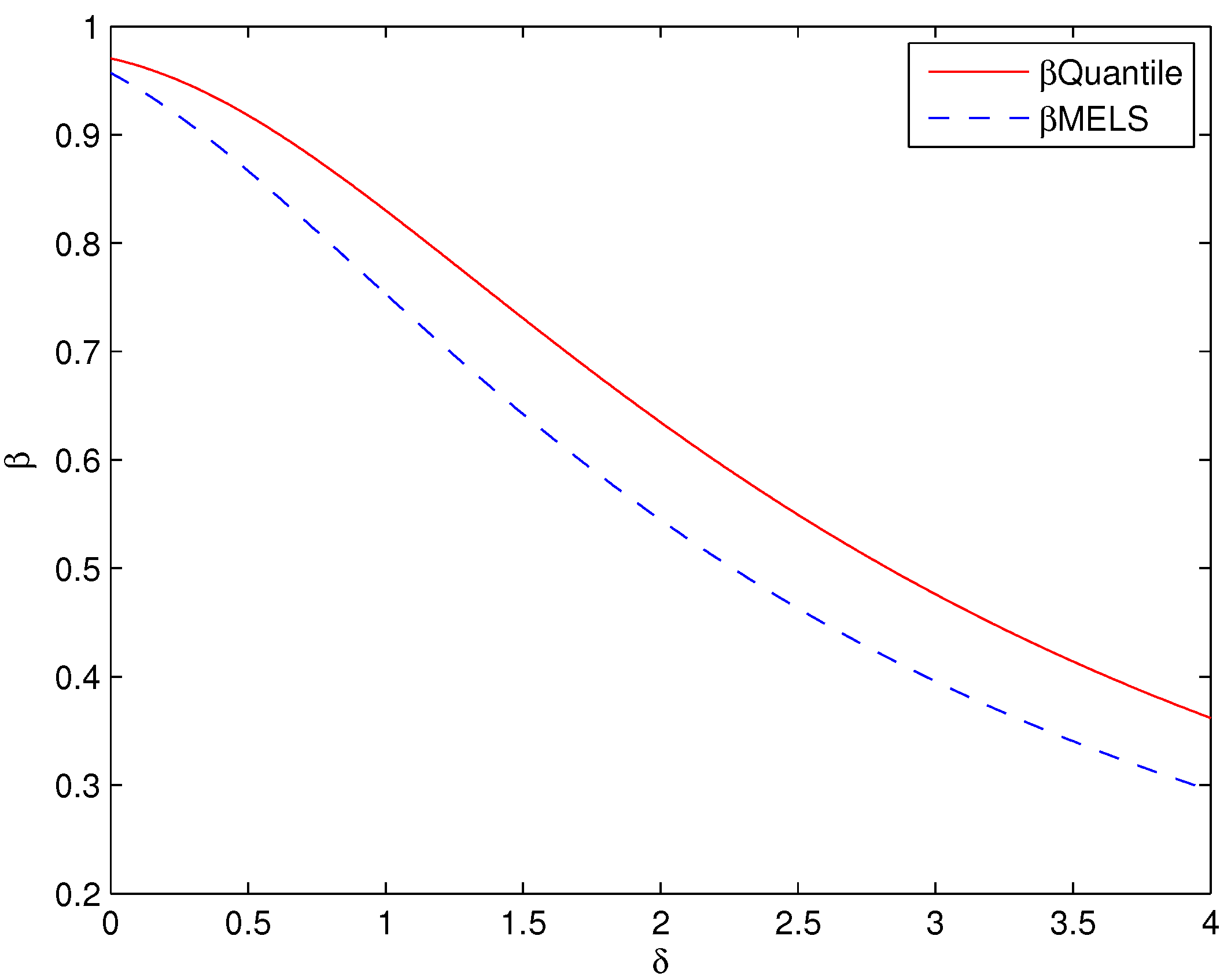
For the asymmetric unimodal distribution, given a specified Type I error rate
, the acceptance regions obtained by the simplified MELS chart have lower Type II error rates
(see
Figure 3 and
Figure 4) whatever the unknown distribution of monitored quantity is approximated by the true distribution or ME distribution. The lower Type II error rate
can improve the higher detection capability for the control chart, thus the simplified MELS chart performs much better than the Shewhart chart and the Quantile chart when the monitored quantity is the asymmetric unimodal distribution.
The advantages of application of the simplified MELS chart are found as follows: (i) For the monitored quantity with unknown distribution in SPC, it can be used to establish the control chart without making an assumption of the distribution of the monitored quantity. (ii) For the monitored quantity with unimodal distribution, it is easier and more convenient for the users to decide the optimal in-control region compared to the existing MELS chart. (iii) It has a higher detection capability than the conventional control charts for the monitored quantity with asymmetric unimodal distribution. (iv) It can be widely used for the nonparametric control chart design in manufacturing, such as the products’ processing control quality attributes such as the length, weight, purity, time, output, etc., even the service quality attributes such as the responsiveness, assurance and reliability.
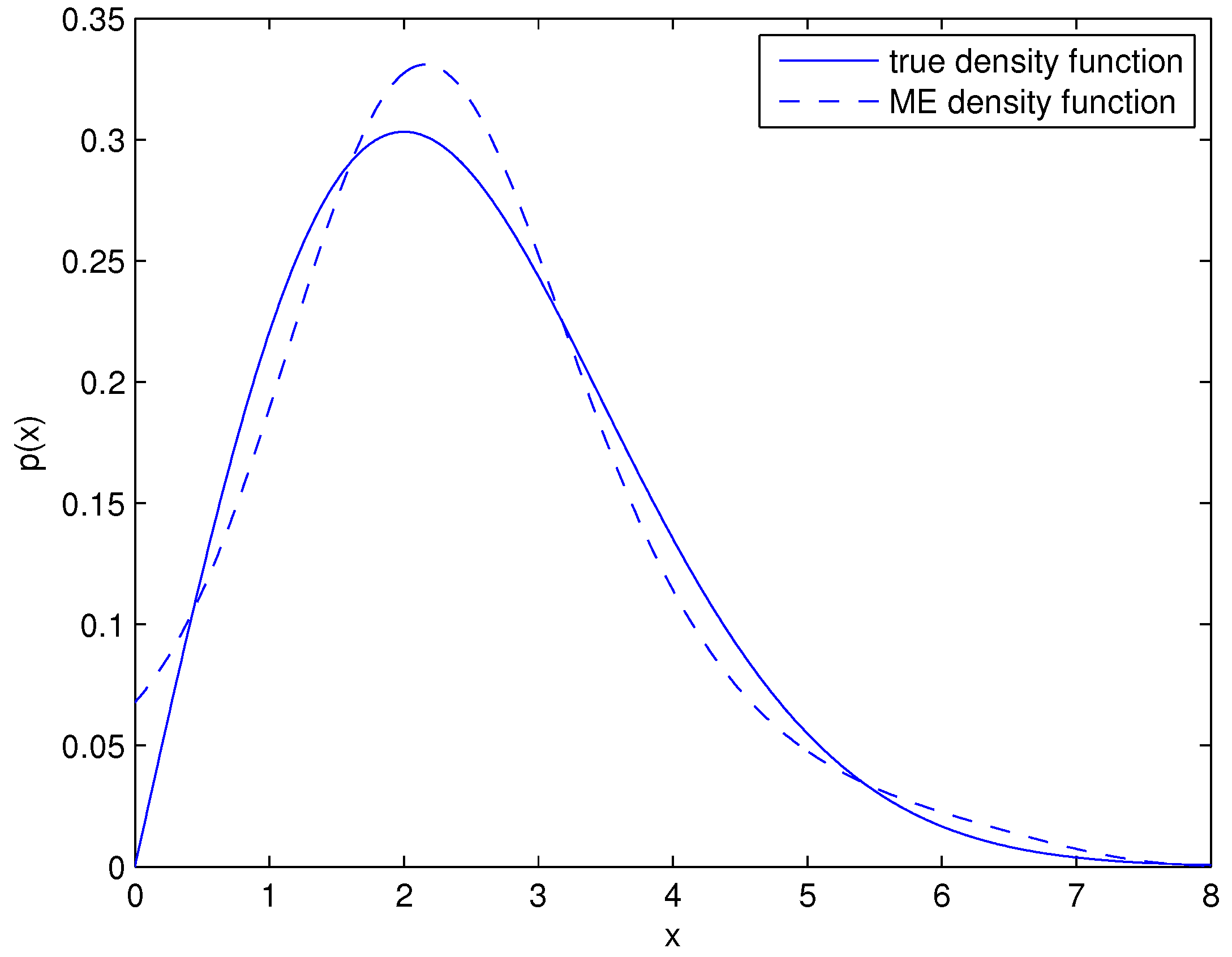
The effectiveness of the simplified MELS method depends a lot on the approximation degree between the ME density and the true density. Thus, the big challenge for the proposed method is the optimization of the Lagrange multipliers
in ME distribution estimation. We can see that the differences between the true density and the ME density in
Figure 2 are larger than that in
Figure 1, because the optimization for
is much more difficult in asymmetric unimodal distribution than in the case of symmetric distribution. In ME density estimation, the higher order moment constraints can help to mine much more information about the monitored quantity, but they also cause a more complicated optimization problem. Thus, in future work, the number of order moments in ME density estimation is a difficult problem that still needs further research. Besides, improving the optimization algorithm in ME density estimation is another way to increase the effectiveness of the MELS/simplified MELS method, and we can try to utilize intelligence algorithms such as the genetic algorithm to improve the optimization results.






{kind=link}
{kind=link}
{kind=link}
{kind=link}