
Face Verification with Multi-Task and Multi-Scale Feature Fusion


Abstract
:1. Introduction
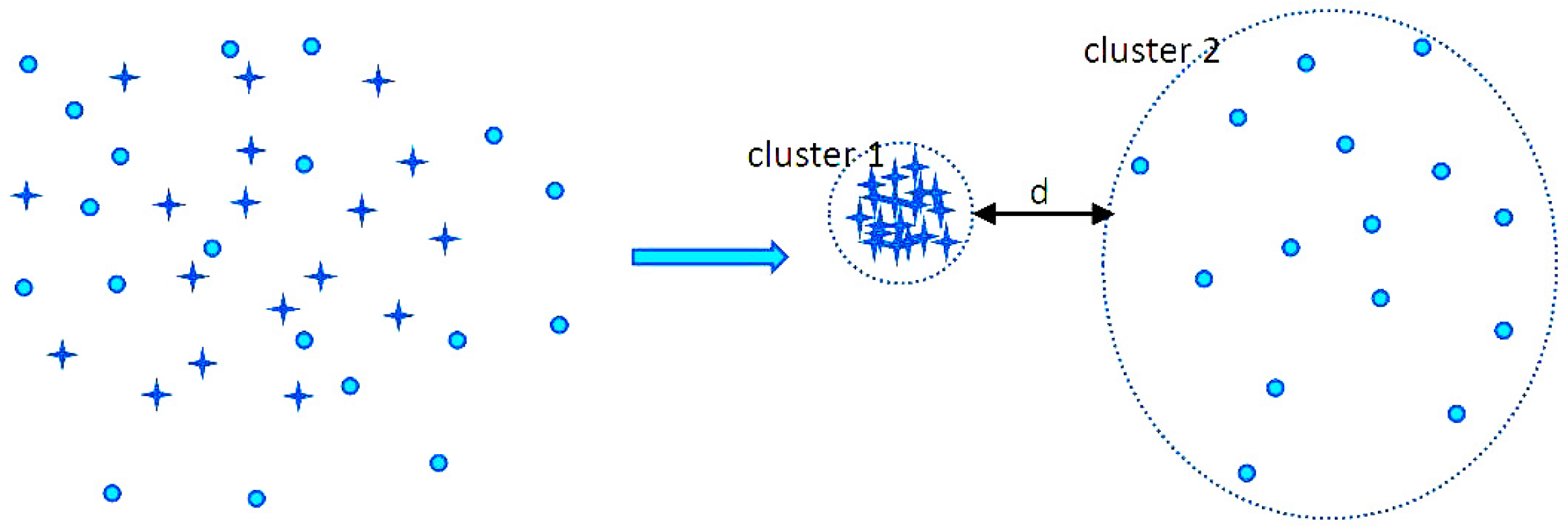
2. The Proposed Loss Function
3. The CNN Architecture and Detailed Parameters
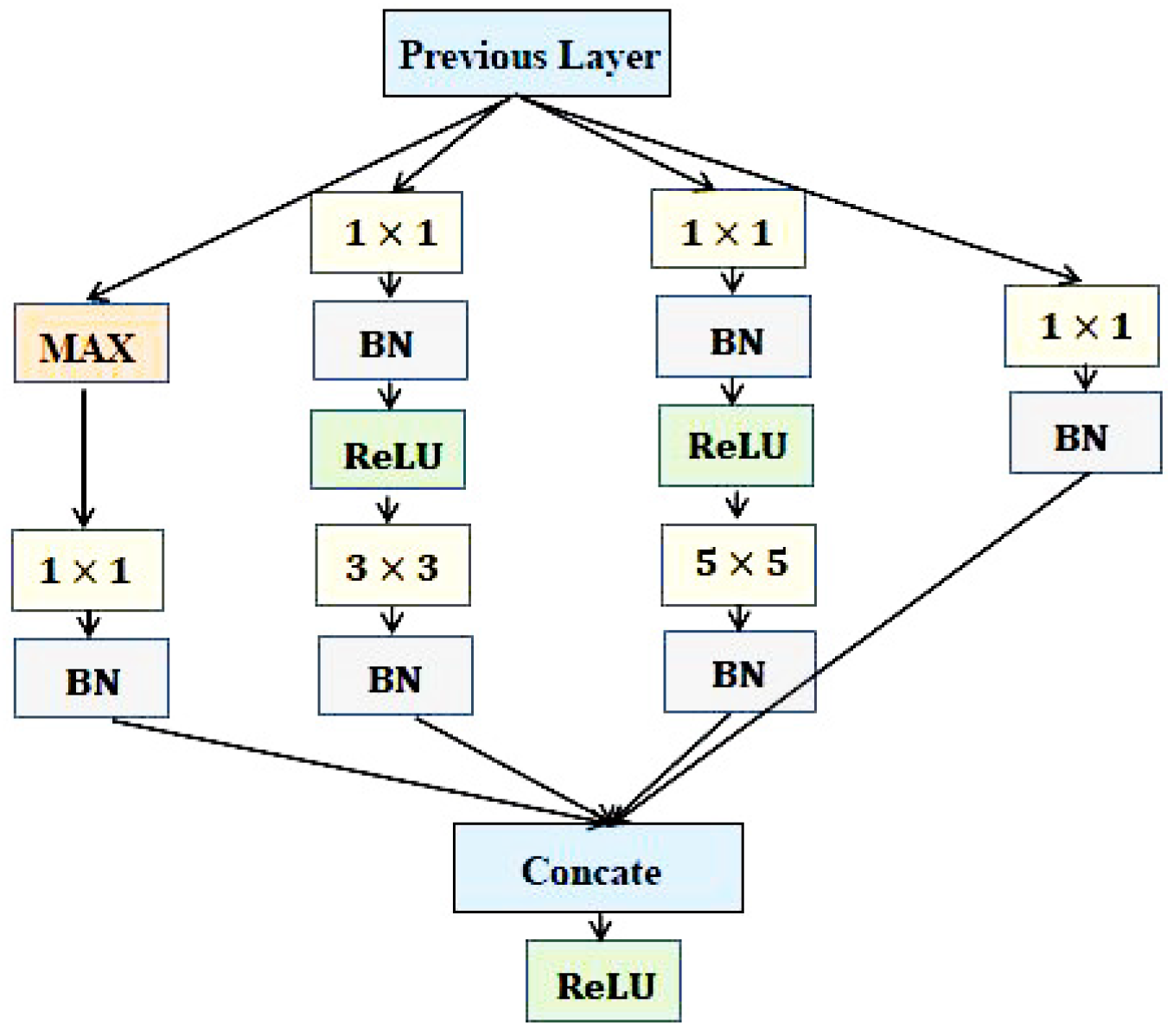
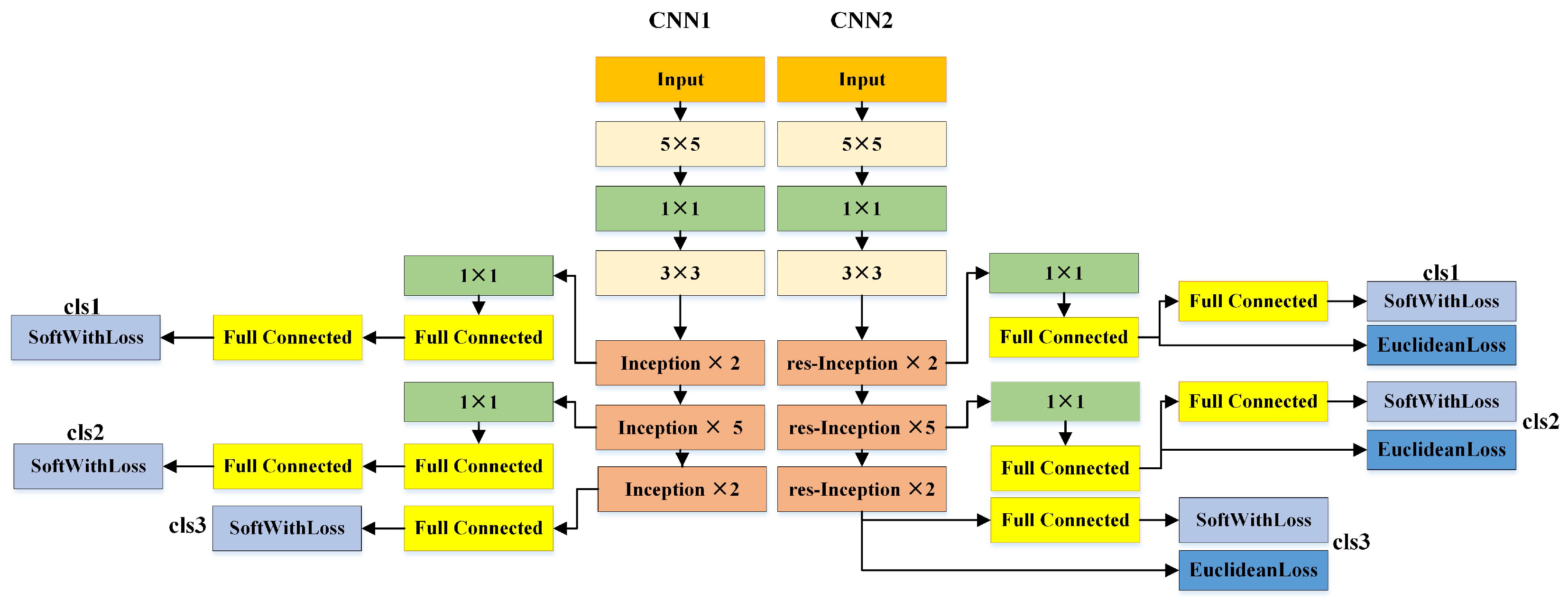
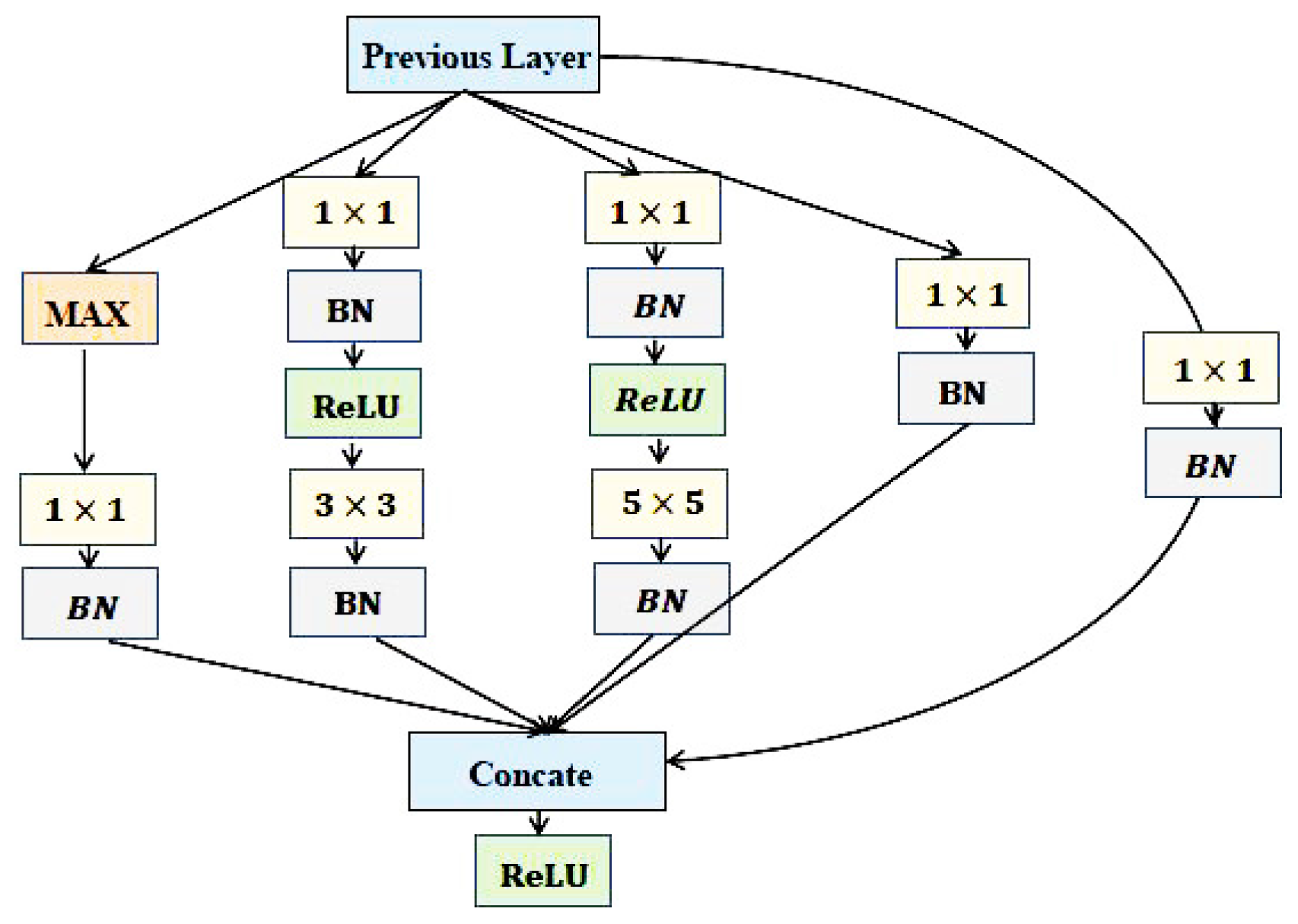
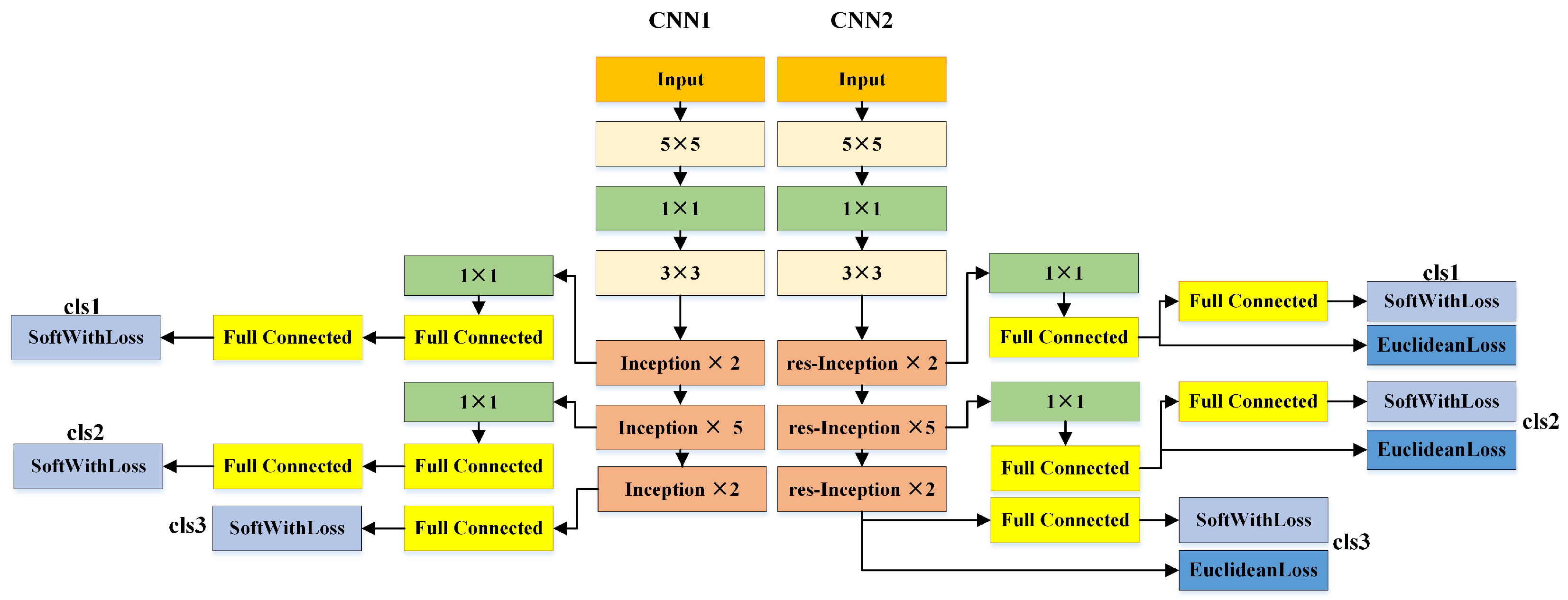
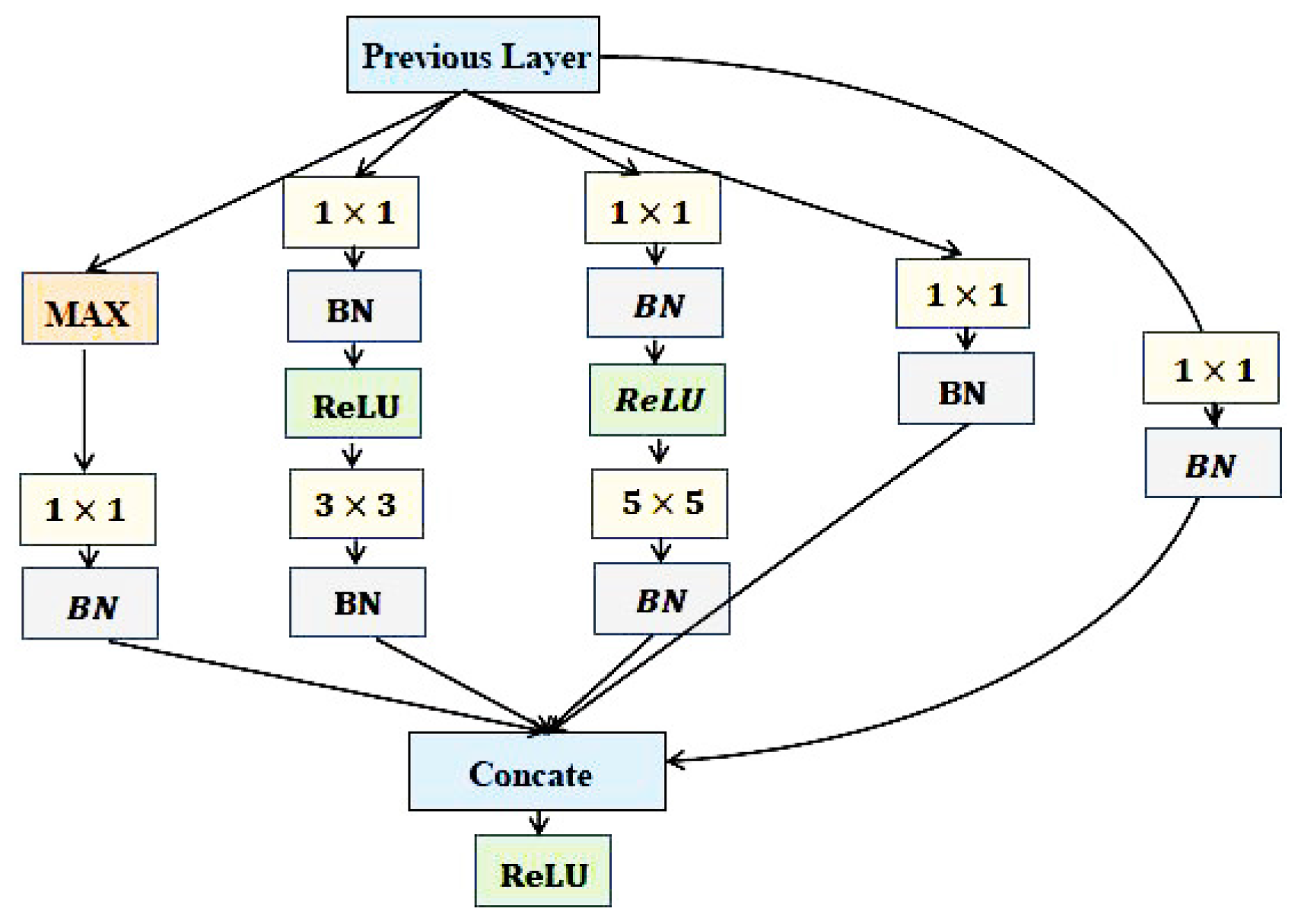
3.1. Deep CNNs for Face Representation
3.2. Detailed Parameters for NNs and the Training Algorithm
| Algorithm 1 The learning algorithm of CNN. | |
| Input: Training database , where denotes face image and is identity label, ; | |
| Output: Weight parameters; | |
| 1: | while not coverage do |
| 2: | , sample training set from training database , the size of each training set is equal to batch size.; |
| 3: | Compute forward process:
|
| 4: | Slice the output of the last convolutional layer at the point . |
| 5: | Compute identification loss and verification loss respectively:
|
| 6: | Compute the value of loss function:
|
| 7: | Compute gradient: |
| 8: | Update network parameters: |
| 9: | end while |
4. Face Verification with Classifier
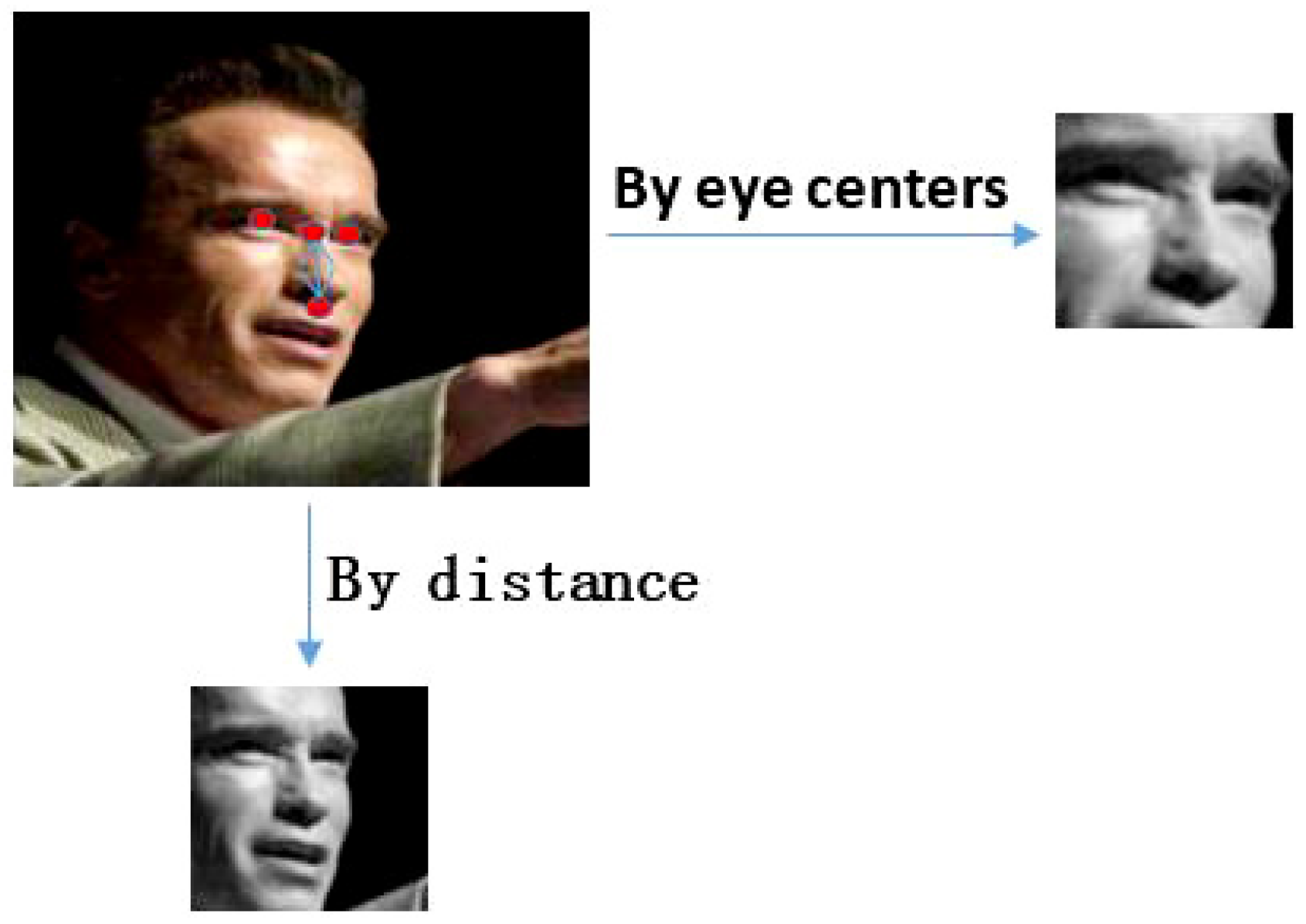
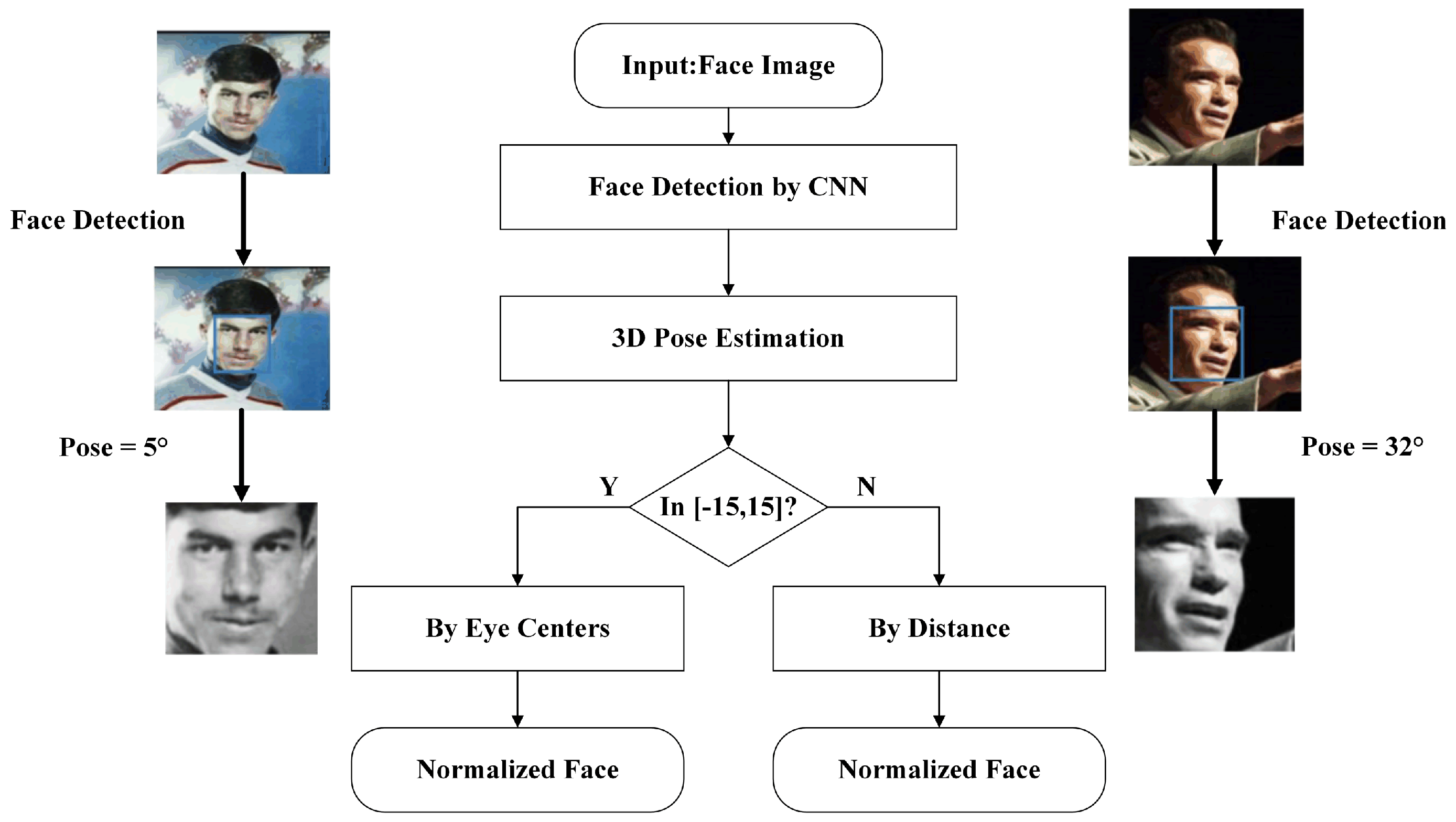
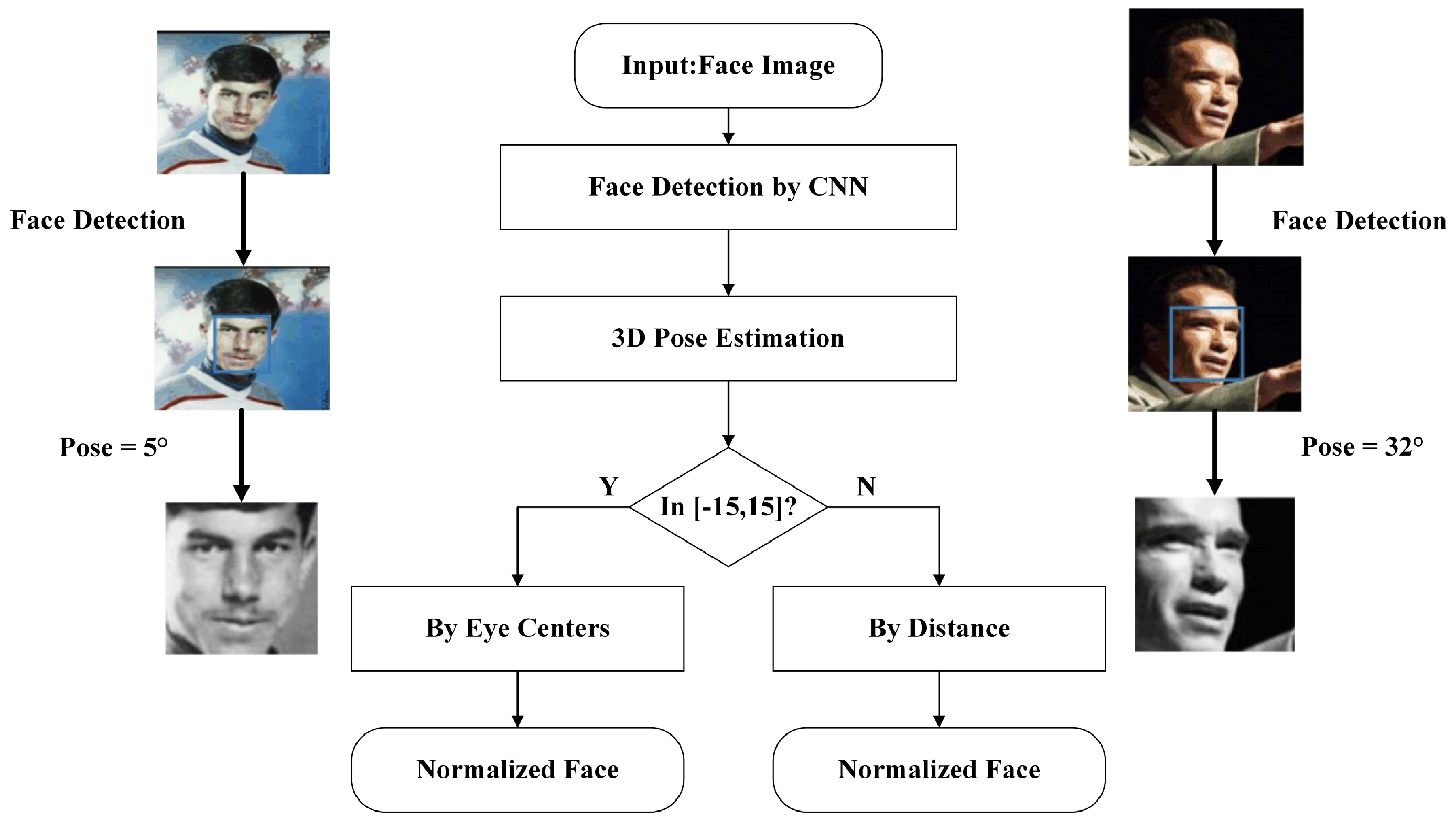
4.1. Face Representation
4.2. Face Verification by Two Classifiers
5. Experiments
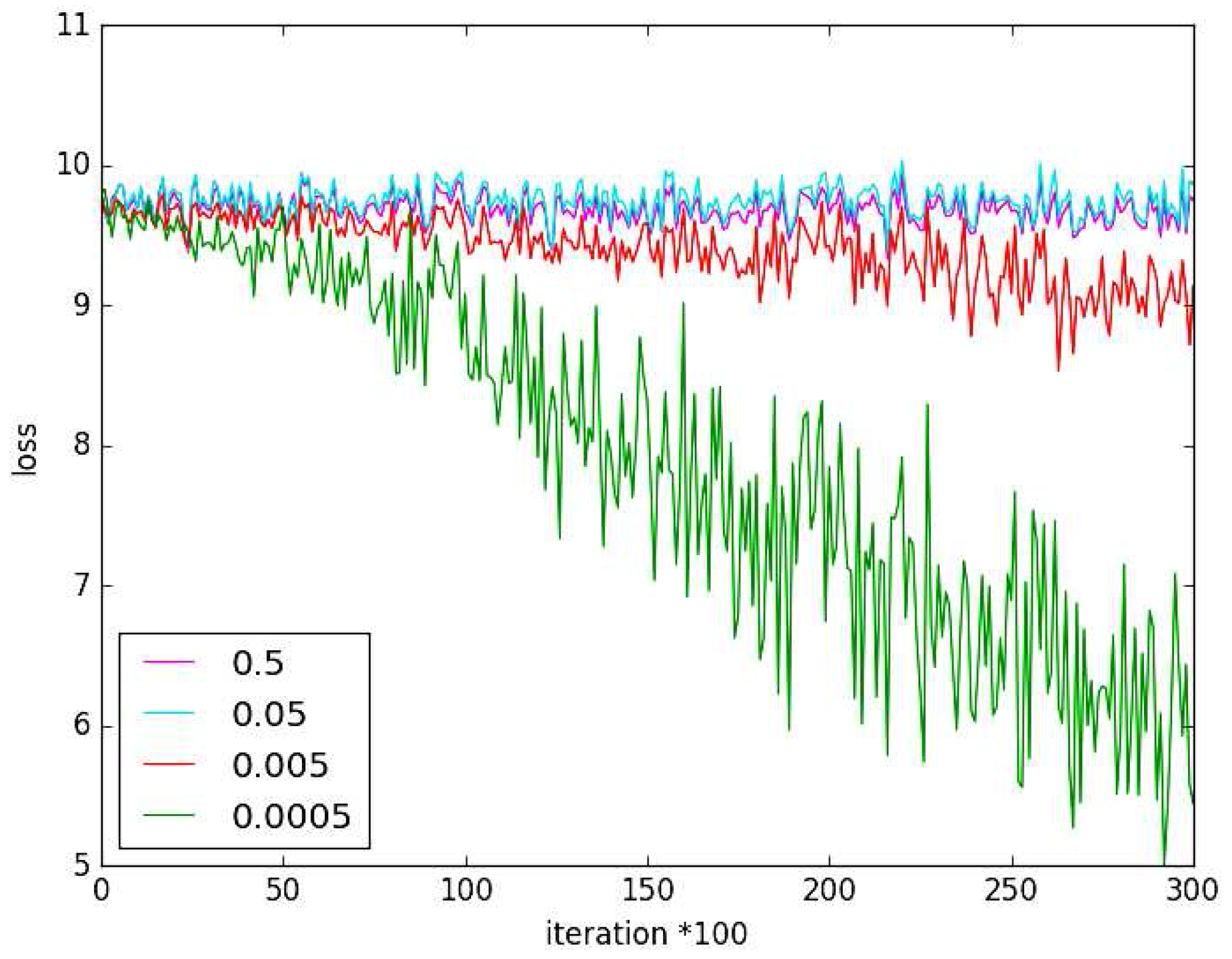
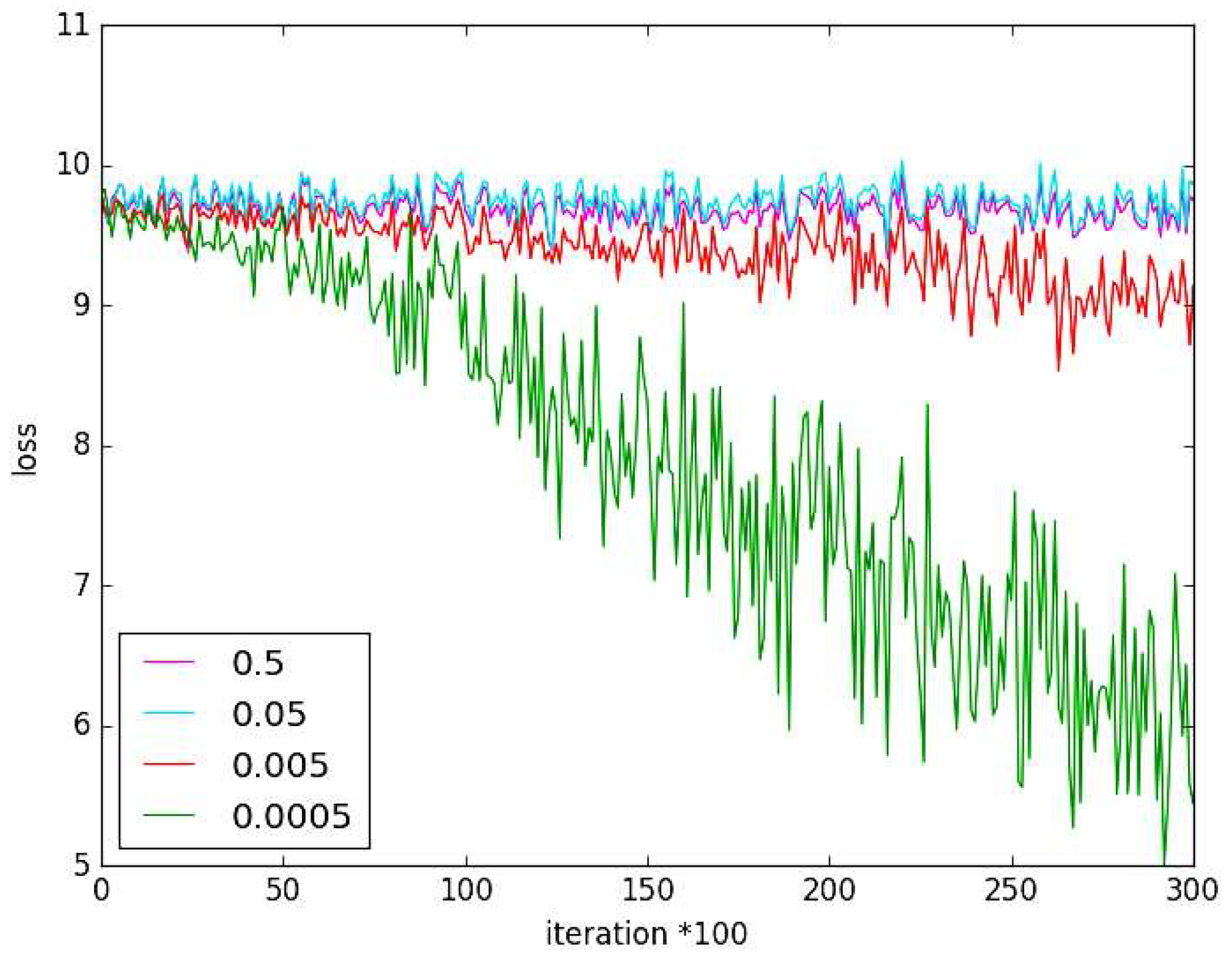
5.1. Experiment on Hyper-Parameter
5.2. Learning Effective Face Representation
5.3. Evaluation on Classifiers
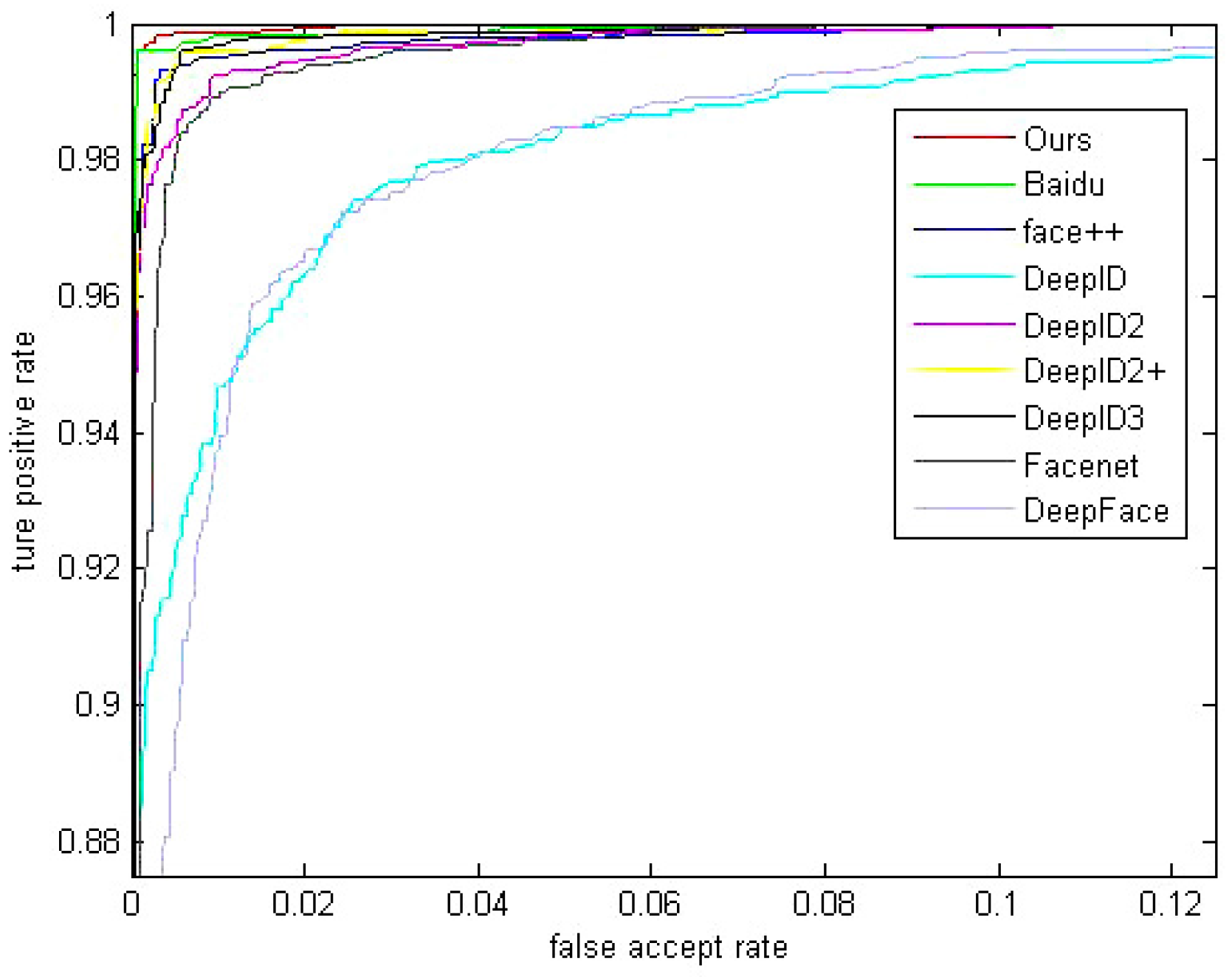
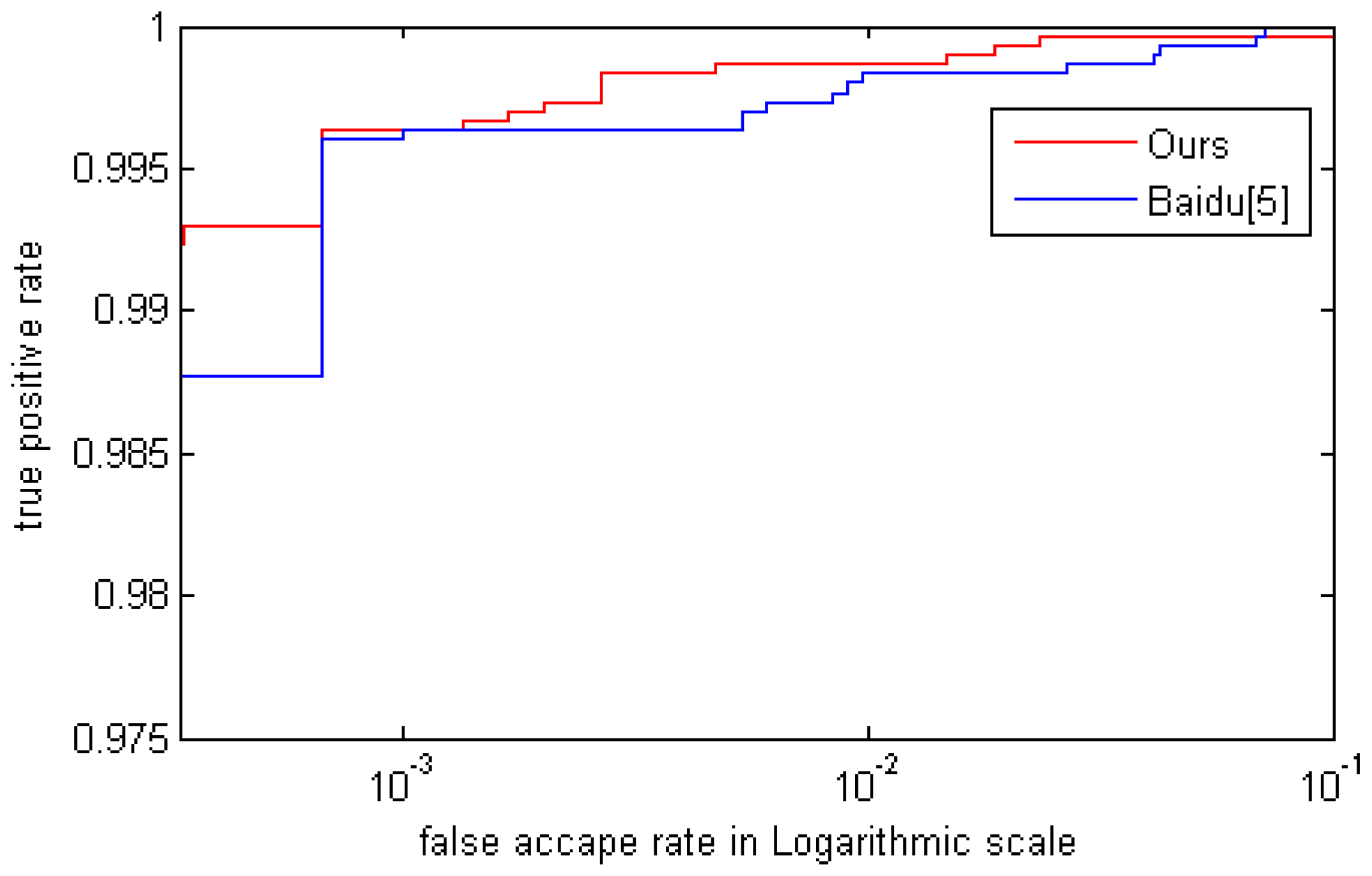
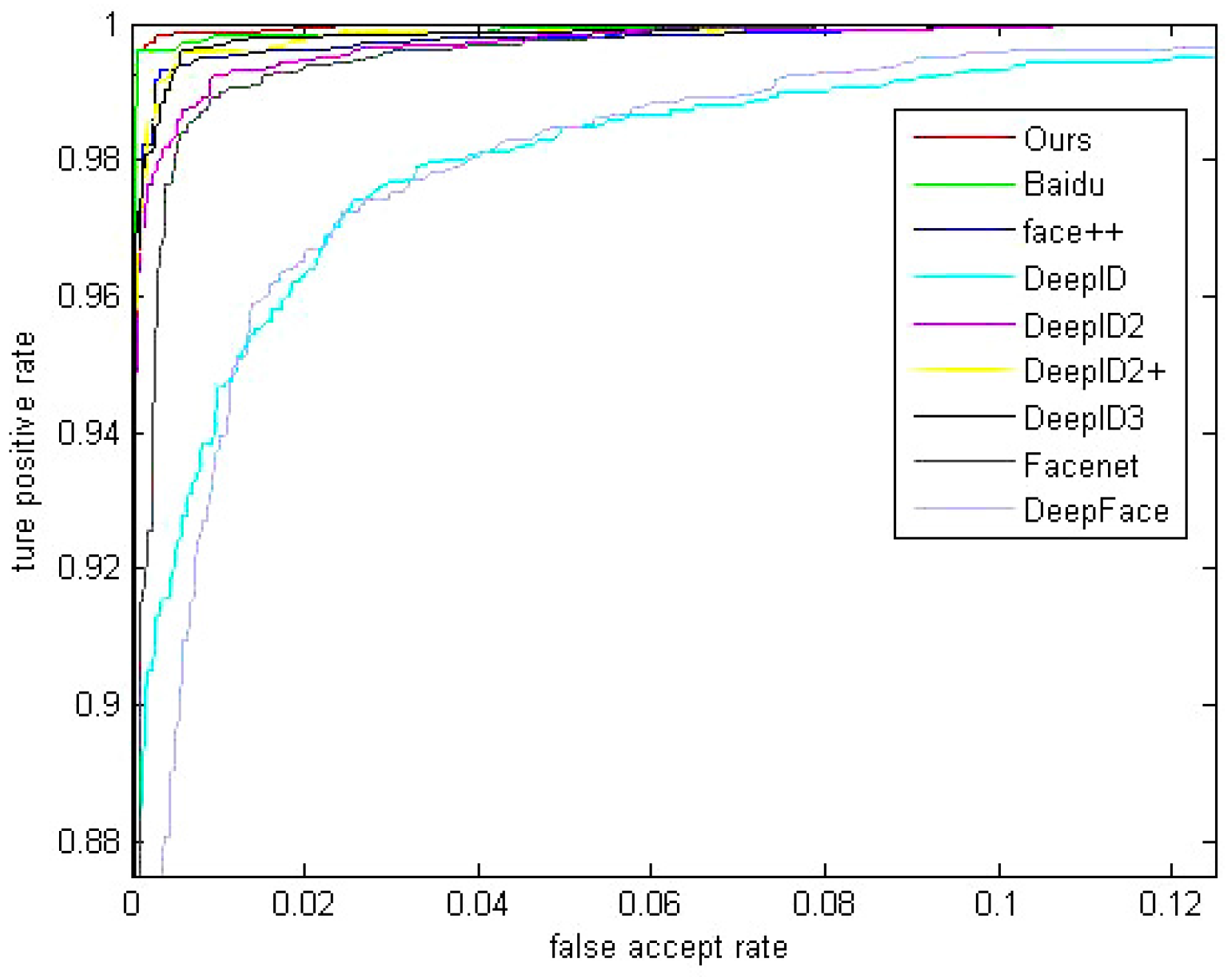
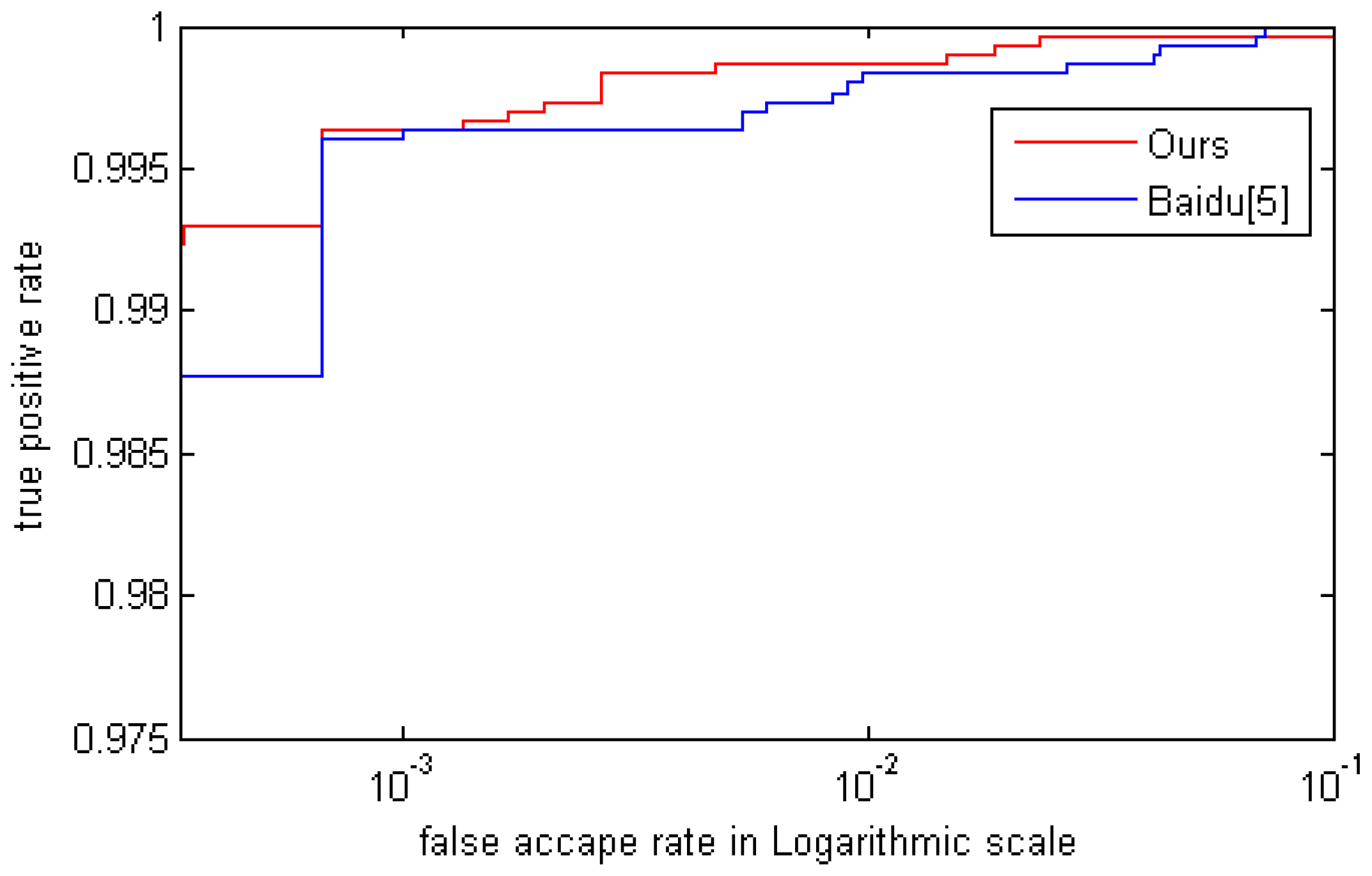
5.4. Comparision with Other Methods
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. arXiv, 2015; arXiv:1506.01497. [Google Scholar] [PubMed]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Twenty-Sixth Annual Conference on Neural Information Processing Systems (NIPS), Stateline, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Liu, J.; Deng, Y.; Bai, T.; Wei, Z.P.; Huang, H. Targeting ultimate accuracy: Face recognition via deep embedding. arXiv, 2015; arXiv:1506.07310. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation by joint identification-verification. arXiv, 2014; arXiv:1406.4773. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deep learning face representation from predicting 10,000 classes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Chopra, S.; Hadsell, R.; Lee, C.Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 539–546. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 11–26. [Google Scholar]
- Yi, D.; Lei, Z.; Liao, S.; Li, S.Z. Learning face representation from scratch. arXiv, 2014; arXiv:1411.7923. [Google Scholar]
- Lee, C.Y.; Xie, S.; Gallagher, P.; Zhang, Z.; Tu, Z. Deeply-Supervised Nets. arXiv, 2014; arXiv:1409.5185. [Google Scholar]
- Song, H.O.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep metric learning via lifted structured feature embedding. arXiv, 2015; arXiv:1511.06452. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization:Accelerating deep network training by reducing internal covariate shift. arXiv, 2015; arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. arXiv, 2016; arXiv:1602.07261. [Google Scholar]
- Yang, S.; Luo, P.; Loy, C.C.; Tang, X. From facial parts responses to face detection: A deep learning approach. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3676–3684. [Google Scholar]
- Ye, M.; Wang, X.; Yang, R.; Ren, L.; Pollefeys, M. Accurate 3d pose estimation from a single depth image. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 731–738. [Google Scholar]
- Chen, D.; Cao, X.; Wang, L.; Wen, F.; Sun, J. Bayesian face revisited: A joint formulation. In Proceedings of the 12th European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; pp. 566–579. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. arXiv, 2014; arXiv:1408.5093. [Google Scholar]
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments; Technical Report; University of Massachusetts: Amherst, MA, USA, 2007; pp. 7–49. [Google Scholar]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. Deepid3: Face recognition with very deep neural networks. arXiv, 2015; arXiv:1502.00873. [Google Scholar]
- Zhou, E.; Cao, Z.; Yin, Q. Naive-deep face recognition: Touching the limit of LFW benchmark or not? arXiv, 2015; arXiv:1501.04690. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deeply learned face representations are sparse, selective, and robust. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. In Proceedings of the British Machine Vision Conference (BMVC), Swansea, UK, 7–10 September 2015; pp. 1–12. [Google Scholar]
- Taigman, Y.; Yang, M.; Ranzato, M.A.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Size/Stride | Channel | Reduction | Reduction | Residual Network | #Pooling Reduction | |||
|---|---|---|---|---|---|---|---|---|---|
| Conv | 64 | - | - | - | - | - | - | - | |
| Pooling | - | - | - | - | - | - | - | - | |
| Conv | 64 | - | - | - | - | - | 92 | - | |
| Conv | 92 | - | - | - | - | - | - | - | |
| Pooling | - | - | - | - | - | - | - | - | |
| res-Incep | - | 256 | 64 | 96 | 128 | 16 | 32 | 256 | 32 |
| res-Incep | - | 480 | 128 | 128 | 192 | 32 | 96 | 480 | 64 |
| cls1 Pooling | - | - | - | - | - | - | - | - | |
| cls1 Conv | 128 | - | - | - | - | - | - | - | |
| cls1 FC | - | 512 | - | - | - | - | - | - | - |
| cls1 FC | - | - | - | - | - | - | - | - | |
| cls1 softmax | - | - | - | - | - | - | - | - | |
| Pooling | - | - | - | - | - | - | - | - | |
| res-Incep | - | 512 | 192 | 96 | 208 | 16 | 48 | 512 | 64 |
| res-Incep | - | 512 | 160 | 112 | 224 | 24 | 64 | 512 | 64 |
| res-Incep | - | 512 | 128 | 128 | 256 | 24 | 64 | 512 | 64 |
| res-Incep | - | 832 | 256 | 160 | 320 | 32 | 128 | 832 | 128 |
| res-Incep | - | 512 | 192 | 96 | 208 | 16 | 48 | 512 | 64 |
| cls2 Pooling | - | - | - | - | - | - | - | - | |
| cls2 Conv | 128 | - | - | - | - | - | - | - | |
| cls2 FC | - | 512 | - | - | - | - | - | - | - |
| cls2 FC | - | - | - | - | - | - | - | - | |
| cls2 softmax | - | - | |||||||
| Pooling | - | - | - | - | - | - | - | - | |
| res-Incep | - | 832 | 256 | 160 | 320 | 32 | 128 | 832 | 128 |
| res-Incep | - | 1024 | 384 | 192 | 384 | 48 | 128 | 1024 | 128 |
| Pooling | - | - | - | - | - | - | - | - | |
| cls3 FC | - | - | - | - | - | - | - | - | |
| cls3 softmax | - | - | - | - | - | - | - | - |
| Signal | Identification () | Identification & Semi-Verification () |
|---|---|---|
| Accuracy | 97.77% | 98.18% |
| CNN1 | CNN2 | ||
|---|---|---|---|
| Combination Manner | Accuracy | Combination Manner | Accuracy |
| cls 1 | 95.73% | cls 1 | 95.92% |
| cls 2 | 96.60% | cls 2 | 96.42% |
| cls 3 | 97.85% | cls 3 | 98.07% |
| cls 1 & cls 2 | 96.78% | cls 1 & cls 2 | 96.68% |
| cls 1 & cls 3 | 98.10% | cls 1 & cls 3 | 97.93% |
| cls 2 & cls 3 | 98.22% | cls 2 & cls 3 | 98.12% |
| cls 1 & cls 2 & cls 3 | 98.25% | cls 1 & cls 2 & cls 3 | 98.18% |
| CNN1 | CNN2 | CNN1 & CNN2 |
|---|---|---|
| 98.25% | 98.18% | 98.50% |
| Classifier | Cosine Distance | Joint Bayesian |
|---|---|---|
| Accuracy | 98.50% | 99.71% |
| Method | Accuracy on LFW | Identities | Face Number | Accuracy on YTF |
|---|---|---|---|---|
| Baidu [5] | 99.77% | 18 k | 1.2 M | NA |
| Ours | 99.71% | 15 k | 0.4 M | 94.6% |
| Centerloss [12] | 99.28% | 17 k | 0.7 M | 94.9% |
| FaceNet [4] | 99.63% | NA | 260 M | 95.1% |
| DeepID3 [25] | 99.53% | 16 k | NA | NA |
| Face++ [26] | 99.50% | 16 k | NA | NA |
| DeepID2+ [27] | 99.47% | NA | NA | 93.2% |
| DeepID2 [3] | 99.15% | 10 k | NA | NA |
| DeepFR [28] | 98.95% | 2.6 k | 2.6 M | 97.3% |
| DeepID [4] | 97.45% | 10 k | NA | NA |
| DeepFace [29] | 97.35% | NA | NA | 91.4% |
| Method | FAR = 0.03% | FAR = 0.1% | FAR = 1% |
|---|---|---|---|
| Baidu [2] | 98.77% | 99.63% | 99.83% |
| Ours | 99.3% | 99.65% | 99.87% |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, X.; Yang, Y.; Zhang, W.; Wang, Q.; Wang, Y. Face Verification with Multi-Task and Multi-Scale Feature Fusion. Entropy 2017, 19, 228. https://doi.org/10.3390/e19050228
Lu X, Yang Y, Zhang W, Wang Q, Wang Y. Face Verification with Multi-Task and Multi-Scale Feature Fusion. Entropy. 2017; 19(5):228. https://doi.org/10.3390/e19050228
Chicago/Turabian StyleLu, Xiaojun, Yue Yang, Weilin Zhang, Qi Wang, and Yang Wang. 2017. "Face Verification with Multi-Task and Multi-Scale Feature Fusion" Entropy 19, no. 5: 228. https://doi.org/10.3390/e19050228
APA StyleLu, X., Yang, Y., Zhang, W., Wang, Q., & Wang, Y. (2017). Face Verification with Multi-Task and Multi-Scale Feature Fusion. Entropy, 19(5), 228. https://doi.org/10.3390/e19050228