2. Structure of the State Space
Our knowledge about a system will be represented by a state space. I many applications the state space is given by a set of probability distributions on a sample space. In such cases the state space is a simplex, but it is well-known that the state space is not a simplex in quantum physics. For applications in quantum physics the state space is often represented by a set of density matrices, i.e., positive semidefinite complex matrices with trace 1. In some cases the states are represented as elements of a finite dimensional -algebra, which is a direct sum of matrix algebras. A finite dimensional -algebra that is a sum of matrices has a state space that is a simplex, so the state spaces of finite dimensional -algebras contain the classical probability distributions as special cases.
The extreme points in the set of states are the pure states. The pure states of a
-algebra can be identified with projections of rank 1. Two density matrices
and
are said to be orthogonal if
Any state
s has a decomposition
where
are orthogonal pure states. Such a decomposition is not unique, but for a finite dimensional
-algebra the coefficients
are unique and are called the spectrum of the state.
Sometimes more general state spaces are of interest. In generalized probabilistic theories a state space is a convex set where mixtures are defined by randomly choosing certain states with certain probabilities [
10,
11]. A convex set where all orthogonal decompositions of a state have the same spectrum, is called a spectral state space. Much of the theory in this paper can be generalized to spectral sets. The most important spectral sets are sets of positive elements with trace 1 in Jordan algebras. The study of Jordan algebras and other spectral sets is relevant for the foundation of quantum theory [
12,
13,
14,
15], but in this paper we will restrict our attention to states on finite dimensional
-algebras. Nevertheless some of the theorems and proofs are stated in such a way that they hold for more general state spaces.
3. Optimization
Let
denote a state space of a finite dimensional
-algebra and let
denote a set of self-adjoint operators. Each
is identified with a real valued measurement. The elements of
may represent feasible
actions (decisions) that lead to a payoff like the score of a statistical decision, the energy extracted by a certain interaction with the system, (minus) the length of a codeword of the next encoded input letter using a specific code book, or the revenue of using a certain portfolio. For each
the mean value of the measurement
is given by
In this way the set of actions may be identified with a subset of the dual space of .
Next we define
We note that
F is convex, but
F need not be strictly convex. In principle
may be infinite, but we will assume that
for all states
s. We also note that
F is lower semi-continuous. In this paper we will assume that the function
F is continuous. The assumption that
F is a real valued continuous function is fulfilled for all the applications we consider.
If s is a state and is an action then we say that a is optimal for s if . A sequence of actions is said to be asymptotically optimal for the state s if for
If are actions and is a probability vector then we we may define the mixed action as the action where we do the action with probability We note that We will assume that all such mixtures of feasible actions are also feasible. If almost surely for all states we say that dominates and if almost surely for all states s we say that strictly dominates All actions that are dominated may be removed from without changing the function Let denote the set of self-adjoint operators (observables) a such that Then Therefore we may replace by without changing the optimization problem.
In the definition of regret we follow Servage [
16] but with different notation.
Definition 1. Let F denote a convex function on the state space . If is finite the regret
of the action a is defined by The notion of regret has been discussed in detail in [
17,
18,
19]. In [
20] it was proved that if a regret based decision procedure is transitive then it must be equal to a difference in expected utility as in Equation (
1), which rules out certain non-linear models in [
17,
19].
Proposition 1. The regret of actions has the following properties:
with equality if a is optimal for s.
is a convex function.
If is optimal for the state where is a probability vector then is minimal if a is optimal for .
If the state is
but one acts as if the state were
one may compare what one achieves and what could have been achieved. If the state
has a unique optimal action
a we may simply define the regret of
by
The following definition leads to a regret function that is essentially equivalent to the so-called
generalized Bregman divergences defined by Kiwiel [
21,
22].
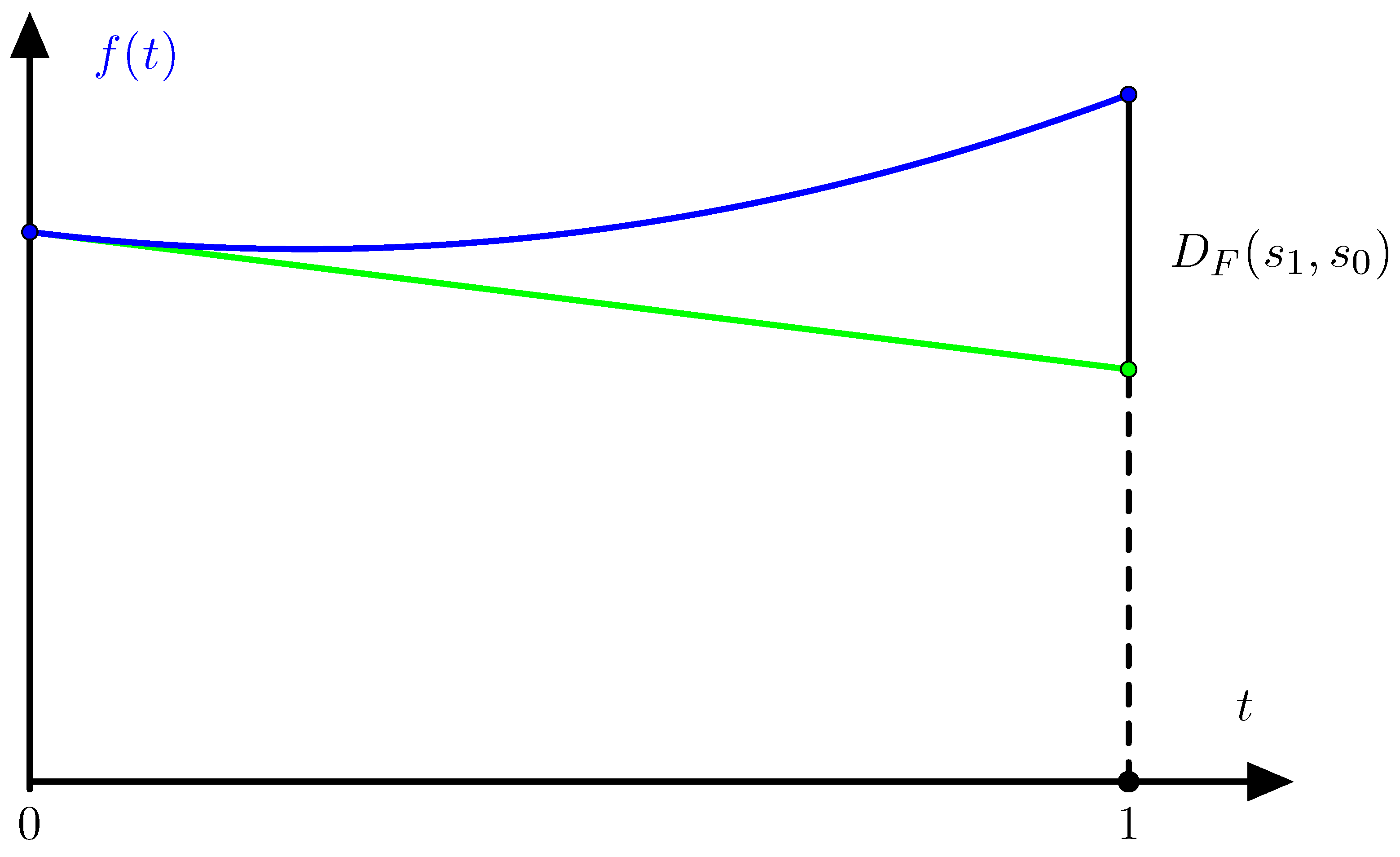
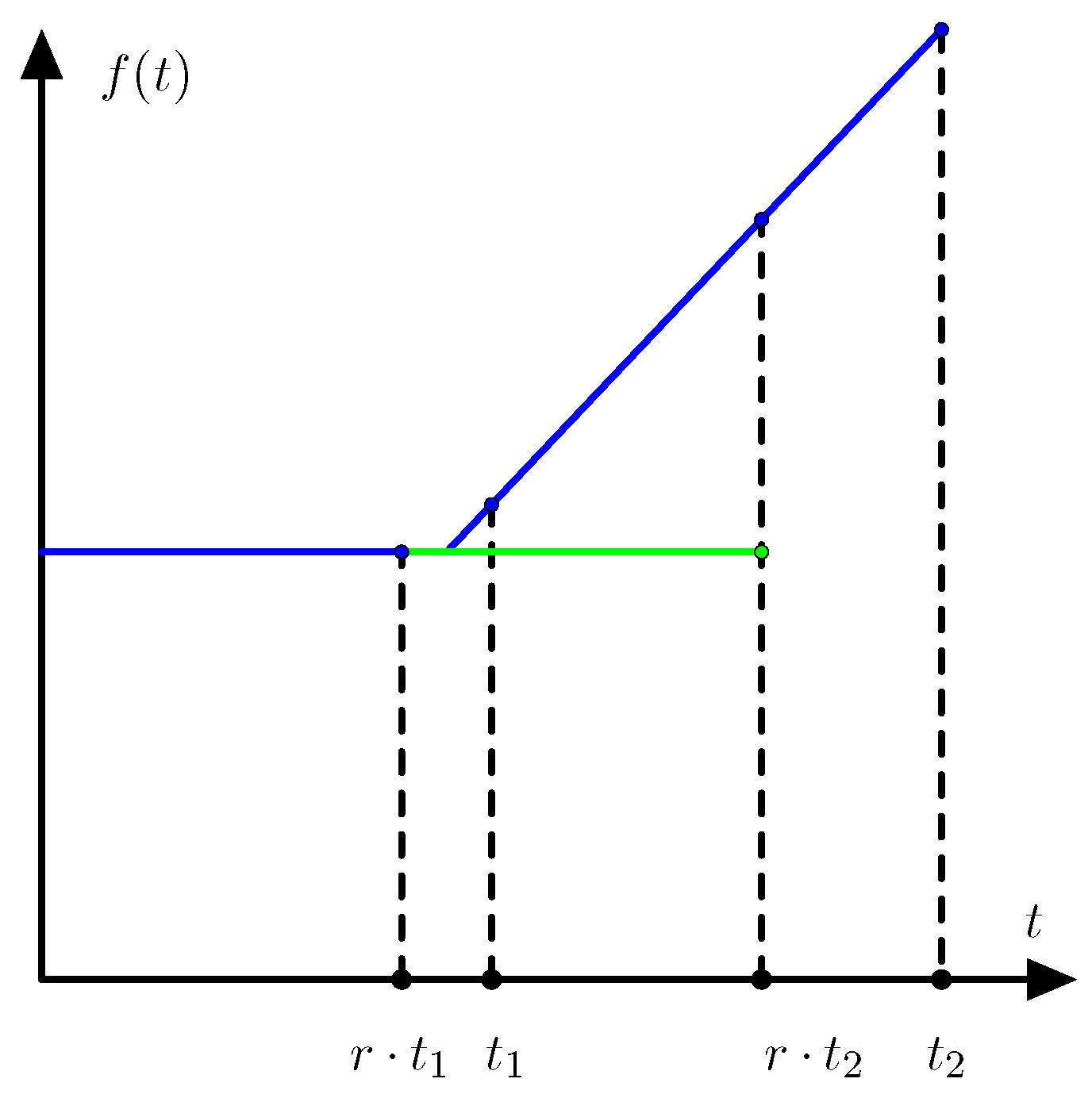
Definition 2. Let F denote a convex function on the state space . If is finite then we define the regret of the state
aswhere the infimum is taken over all sequences of actions that are asymptotically optimal for With this definition the regret is always defined with values in
and the value of the regret
only depends on the restriction of the function
F to the line segment from
to
. Let
f denote the function
where
. As illustrated in
Figure 1 we have
where
denotes the right derivative of
f at
. Equation (
2) is even valid when the regret is infinite if we allow the right derivative to take the value −∞.
If the state
has the unique optimal action
then
so the function
F can be reconstructed from
except for an affine function of
The following proposition follows from Alexandrov’s theorem ([
23], Theorem 25.5).
Proposition 2. A convex function on a finite dimensional convex set is differentiable almost everywhere with respect to the Lebesgue measure.
A state
where
F is differentiable has a unique optimal action. Therefore Equation (
3) holds for almost any state
. In particular the function
F can be reconstructed from
except for an affine function.
Proposition 3. The regret of states has the following properties:
with equality if there exists an action a that is optimal for both and .
is a convex function.
Further, the following two conditions are equivalent:
We say that a regret function
is
strict if
F is strictly convex. The two last properties Proposition 1 do not carry over to regret for states except if the regret is a
Bregman divergence as defined below. The regret is called a
Bregman divergence if it can be written in the following form
where
denotes the (Hilbert-Schmidt) inner product. In the context of forecasting and statistical scoring rules the use of Bregman divergences dates back to [
24]. A similar but less general definition of regret was given by Rao and Nayak [
25] where the name
cross entropy was proposed. Although Bregman divergences have been known for many years they did not gain popularity before the paper [
26] where a systematic study of Bregman divergences was presented.
We note that if
is a Bregman divergence and
minimizes
F then
so that the formula for the Bregman divergence reduces to
Bregman divergences satisfy the
Bregman identity
but if
F is not differentiable this identity can be violated.
Example 1. Let the state space be the interval with two actions and Let and Let further and Then If thenbut Clearly the Bregman identity (5) is violated and will increase if s is replaced by . The following proposition is easily proved.
Proposition 4. For a convex and continuous function F on the state space the following conditions are equivalent:
The function F is differentiable in the interior of any face of .
The regret is a Bregman divergence.
The Bregman identity (5) is always satisfied. For any probability vectors the sum is always minimal when .
4. Examples
In this section we shall see how regret functions are defined in some applications.
4.1. Information Theory
We recall that a code is uniquely decodable if any finite sequence of input symbols give a unique sequence of output symbols. It is well-known that a uniquely decodable code satisfies Kraft’s inequality (see [
27] and ([
28], Theorem 3.8))
where
denotes the length of the codeword corresponding to the input symbol
and
denotes the size of the output alphabet
. Here the length of a codeword is an integer. If
is a probability vector over the input alphabet, then the mean code-length is
Our goal is to minimize the expected code-length. Here the state space consist of probability distributions over the input alphabet and the actions are code-length functions.
Shannon established the inequality
It is a combinatoric problem to find the optimal code-length function. In the simplest case with a binary output alphabet the optimal code-length function is determined by the Huffmann algorithm.
A code-length function dominates another code-length function if all letters have shorter code-length. If a code-length function is not dominated by another code-length function then for all the length is bounded by For fixed alphabets and there exists only a finite number of code-length functions ℓ that satisfy Kraft’s inequality and are not dominated by other code-length functions that satisfying Kraft’s inequality.
4.2. Scoring Rules
The use of scoring rules has a long history in statistics. An early contribution was the idea of minimizing the sum of square deviations that dates back to Gauss and works perfectly for Gaussian distributions. In the 1920s, Ramsay and de Finetti proved versions of the Dutch book theorem where determination of probability distributions were considered as dual problems of maximizing a payoff function [
29]. Later it was proved that any consistent inference procedure corresponds to optimizing with respect to some payoff function. A more systematic study of scoring rules was given by McCarthy [
30].
Consider an experiment with as sample space. A scoring rule f is defined as a function such that the score is when a prediction has been given in terms of a probability distribution Q and has been observed. A scoring rule is proper if for any probability measure the score is minimal when Here the state space consist of probability distributions over and the actions are predictions over , which are also probability distributions over .
There is a correspondence between proper scoring rules and Bregman divergences as explained in [
31,
32]. If
is a Bregman divergence and
g is a function with domain
then
f given by
defines a scoring rule.
Assume that
f is a proper scoring function. Then a function
F can be defined as
This lead to the regret function
Since
f is assumed to be proper
. The Bregman identity (
5) follows by straight forward calculations. With these two results we see that the regret function
is a Bregman divergence and that
Hence a proper scoring rule f has the form where . A strictly proper scoring rule can be defined as a proper scoring rule where the corresponding Bregman divergence is strict.
Example 2. The Brier score is given by The Brier score is generated by the strictly convex function .
4.3. Statistical Mechanics
Thermodynamics is the study of concepts like heat, temperature and energy. A major objective is to extract as much energy from a system as possible. The idea in statistical mechanics is to view the macroscopic behavior of a thermodynamic system as a statistical consequence of the interaction between a lot of microscopic components where the interacting between the components are governed by very simple laws. Here the central limit theorem and large deviation theory play a major role. One of the main achievements is the formula for entropy as a logarithm of a probability.
Here we shall restrict the discussion to the most simple kind of thermodynamic system from which we want to extract energy. We may think of a system of non-interacting spin particles in a magnetic field. For such a system the Hamiltonian is given by
where
is the spin configuration,
is the magnetic moment,
is the strength of an external magnetic field, and
is the spin of the the
j’th particle. If the system is in thermodynamic equilibrium the configuration probability is
where
is the partition function
Here
is the inverse temperature
of the spin system and
is Boltzmann’s constant.
The mean energy is given by
which will be identified with the internal energy
U defined in thermodynamics. The Shannon entropy can be calculated as
The Shannon entropy times k will be identified with the thermodynamic entropy S.
The amount of energy that can be extracted from the system if a heat bath is available, is called the
exergy [
33]. We assume that the heat bath has temperature
and the internal energy and entropy of the system are
and
if the system has been brought in equilibrium with the heat bath. The exergy can be calculated by
The information divergence between the actual state and the corresponding state that is in equilibrium with the environment is
Hence
This equation appeared already in [
34].
4.4. Portfolio Theory
The relation between information theory and gambling was established by J. L. Kelly [
35]. Logarithmic terms appear because we are interested in the exponent in the exponential growth rate of our wealth. Later Kelly’s approach has been generalized to trading of stocks although the relation to information theory is weaker [
36].
Let denote price relatives for a list of k assets. For instance means that 5-th asset increases its value by 4%. Such price relatives are mapped into a price relative vector
Example 3. A special asset is the safe asset where the price relative is 1 for any possible price relative vector. Investing in this asset corresponds to placing the money at a safe place with interest rate equal to 0%.
A portfolio is a probability vector where for instance means that 30% of the money is invested in asset no. 5. We note that a portfolio may be traded just like the original assets. The price relative for the portfolio is The original assets may be considered as extreme points in the set of portfolios. If an asset has the property that the price relative is only positive for one of the possible price relative vectors, then we may call it a gambling asset.
We now consider a situation where the assets are traded once every day. For a sequence of price relative vectors
and
a constant re-balancing portfolio the wealth after
n days is
where the expectation is taken with respect to the empirical distribution of the price relative vectors. Here
is proportional to the
doubling rate and is denoted
where
P indicates the probability distribution of
. Our goal is to maximize
by choosing an appropriate portfolio
The advantage of using constant rebalancing portfolios was demonstrated in [
37].
Definition 3. Let and denote two portfolios. We say that dominates if for any possible price relative vector We say that strictly dominates if for any possible price relative vector A set A of assets is said to dominate the set of assets B if any asset in B is dominated by a portfolio of assets in
The maximal doubling rate does not change if dominated assets are removed. Sometimes assets that are dominated but not strictly dominated may lead to non-uniqueness of the optimal portfolio.
Let
denote a portfolio that is optimal for
P and define
The regret of choosing a portfolio that is optimal for
Q when the distribution is
P is given by the regret function
If is not uniquely determined we take a minimum over all that are optimal for
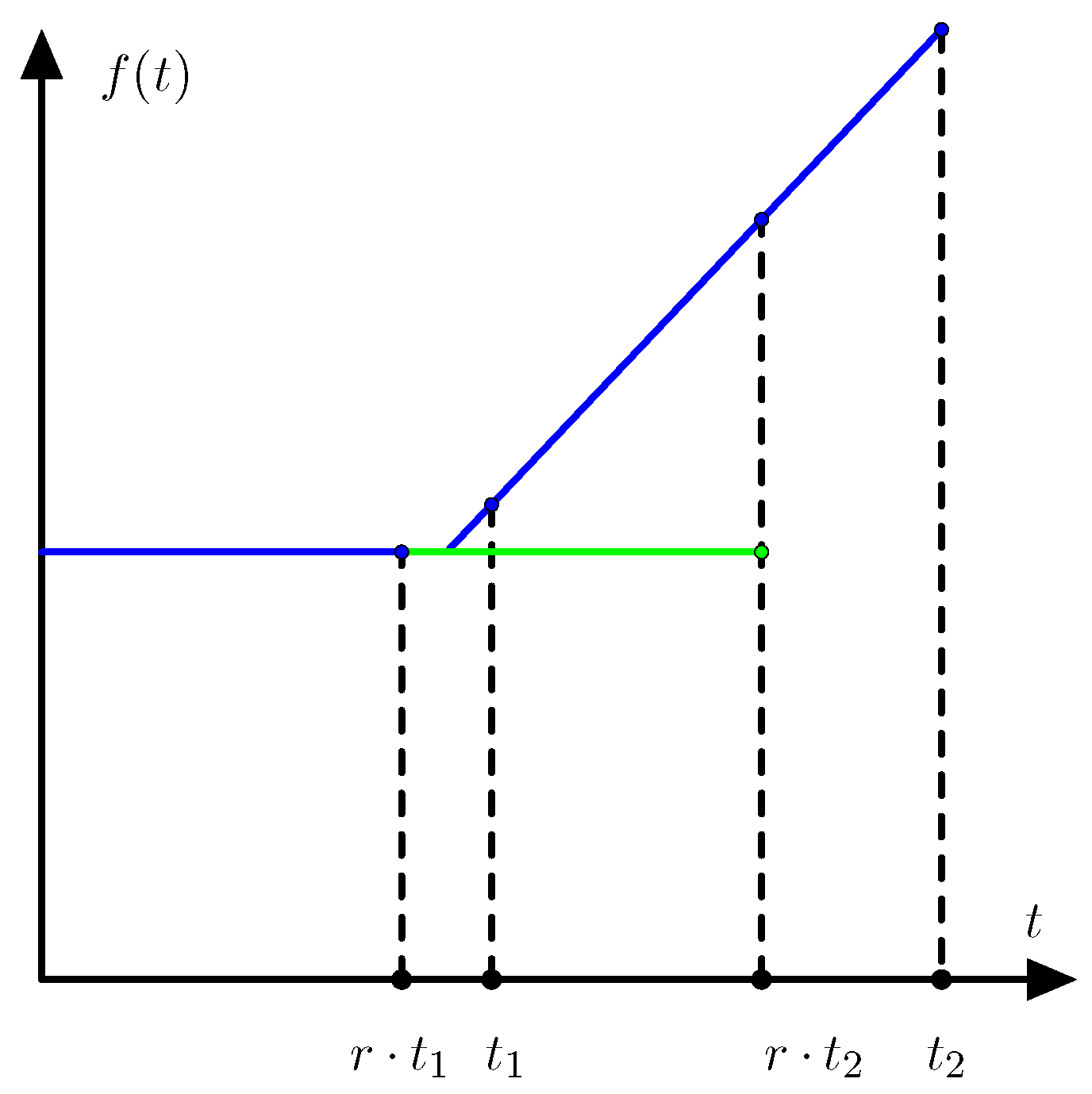
Example 4. Assume that the price relative vector is with probability and with probability t. Then the portfolio concentrated on the first asset is optimal for and the portfolio concentrated on the second asset is optimal for . For values of t between and the optimal portfolio invests money on both assets as illustrated in Figure 2. Lemma 1. If there are only two price relative vectors and the regret function is strict then either one of the assets dominates all other assets or two of the assets are orthogonal gambling assets that dominate all other assets.
Proof. We will assume that no assets are dominated by other assets. Let
denote the two price relative vectors. Without loss of generality we may assume that
If
then
so that if
then
and the asset
i is dominated by the asset
Since we have assumed that no assets are dominated we may assume that
If
is a probability vector over the two price relative vectors then according to [
36] the portfolio
is optimal if and only if
for all
with equality if
Assume that the portfolio
is optimal. Now
is equivalent to
Similarly
is equivalent to
We have to check that
which is equivalent with
The right hand side equals the determinant
which is positive because asset
j is not dominated by a portfolio based on asset
and asset
We see that the portfolio concentrated in asset j is optimal for t in an interval of positive length and the regret between distributions in such an interval will be zero. In particular the regret will not be strict.
Strictness of the regret function is only possible if there are only two assets and if a portfolio concentrated on one of these assets is only optimal for a singular probability measure. According to the formulas for the end points of intervals (
14) and (
15) this is only possible if the assets are gambling assets. ☐
Theorem 1. If the regret function is strict it equals information divergence, i.e., Proof. If the regret function is strict then it is also strict when we restrict to two price relative vectors. Therefore any two price relative vectors are orthogonal gambling assets. If the assets are orthogonal gambling assets we get the type of gambling described by Kelly [
35], for gambling equations can easily be derived [
36]. ☐
7. Concluding Remarks
Convexity of a Bregman divergence is an important property that was first studied systematically in [
56] and extended from probability distributions to matrices in [
57]. In [
58] it was proved that if
f is a function such that the Bregman divergence based on
is monotone on any (simple) C*-algebra then the Bregman divergence is jointly convex. As we have seen monotonicity implies that the Bregman divergence must be proportional to inform divergence, which is jointly convex in both arguments. We also see that in general joint convexity is not a sufficient condition for monotonicity, but in the case where the state space has only two orthogonal states it is not known if joint convexity of a Bregman divergence is sufficient to conclude that the Bregman divergence is monotone.
One should note that the type of optimization presented in this paper is closely related to a game theoretic model developed by F. Topsøe [
59,
60]. In his game theoretic model he needed what he called the
perfect match principle. Using the terminology presented in this paper the perfect match principle states that the regret function is a strict Bregman divergence. As we have seen the perfect match principle is only fulfilled in portfolio theory if all the assets are gambling assets. Therefore, the theory of F. Topsøe can only be used to describe gambling while our optimization model can describe general portfolio theory and our sufficient conditions can explain exactly when our general model equals gambling. The formalism that has been developed in this paper is also closely related to constructor theory [
61], but a discussion will be postponed to another article.
The original paper of Kullback and Leibler [
1] was called “On Information and Sufficiency”. In the present paper, we have made the relation between information divergence and the notion of sufficiency more explicit. The results presented in this paper are closely related to the result that a divergence that is both an
f-divergence and a Bregman divergence is proportional to information divergence (see [
44] or [
62] and references therein). All
f-divergences satisfy a sufficiency condition, which is the reason why this class of divergences has played such a prominent role in the study of the relation between information theory and statistics. One major question has been to find reasons for choosing between the different
f-divergences. For instance
f-divergences of power type (often called Tsallis divergences or Cressie-Read divergences) are popular [
5], but there are surprisingly few papers that can point at a single value of the power
that is optimal for a certain problem except if this value is 1. In this paper we have started with Bregman divergences because each optimization problem comes with a specific Bregman divergence. Often it is possible to specify a Bregman divergence for an optimization problem and only in some of the cases this Bregman divergence is proportional to information divergence.
The idea of sufficiency has different relevance in different applications, but in all cases information divergence prove to be the quantity that convert the general notion of sufficiency into a number. In information theory information divergence appear as a consequence of Kraft’s inequality. For code length functions of integer length we get functions that are piecewise linear. Only if we are interested in extend-able sequences we get a regret function that satisfies a data processing inequality. In this sense information theory is a theory of extend-able sequences. For scoring functions in statistics the notion of locality is important. These applications do not refer to sequences. Similarly the notion of sufficiency that plays a major role in statistics, does not refer to sequences. Both sufficiency and locality imply that regret is proportional to information divergence, but these reasons are different from the reasons why information divergence is used in information theory. Our description of statistical mechanics does not go into technical details, but the main point is that the many symmetries in terms of reversible maps form a set of maps so large that our result on invariance of regret under sufficient maps applies. In this sense statistical mechanics and statistics both apply information divergence for reasons related to sufficiency. For portfolio theory the story is different. In most cases one has to apply the general theory of Bregman divergences because we deal with an optimization problem. The general Bregman divergences only reduce to information divergence when the assets are gambling assets.
Often one talks about applications of information theory in statistics, statistical mechanics and portfolio theory. In this paper we have argued that information theory is mainly a theory of sequences, while some problems in statistics and statistical mechanics are also relevant without reference to sequences. It would be more correct to say that convex optimization has various application such as information theory, statistics, statistical mechanics, and portfolio theory and that certain conditions related to sufficiency lead to the same type of quantities in all these applications.


{kind=link}
{kind=link}
{kind=link}
{kind=link}