
An Entropy-Based Kernel Learning Scheme toward Efficient Data Prediction in Cloud-Assisted Network Environments



Abstract
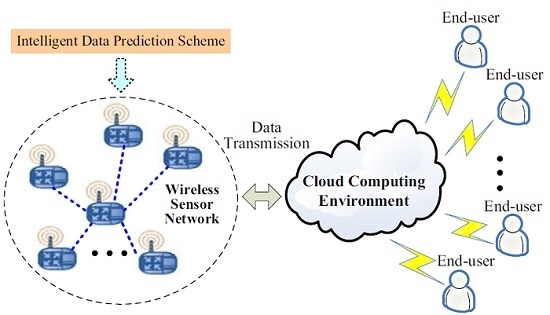
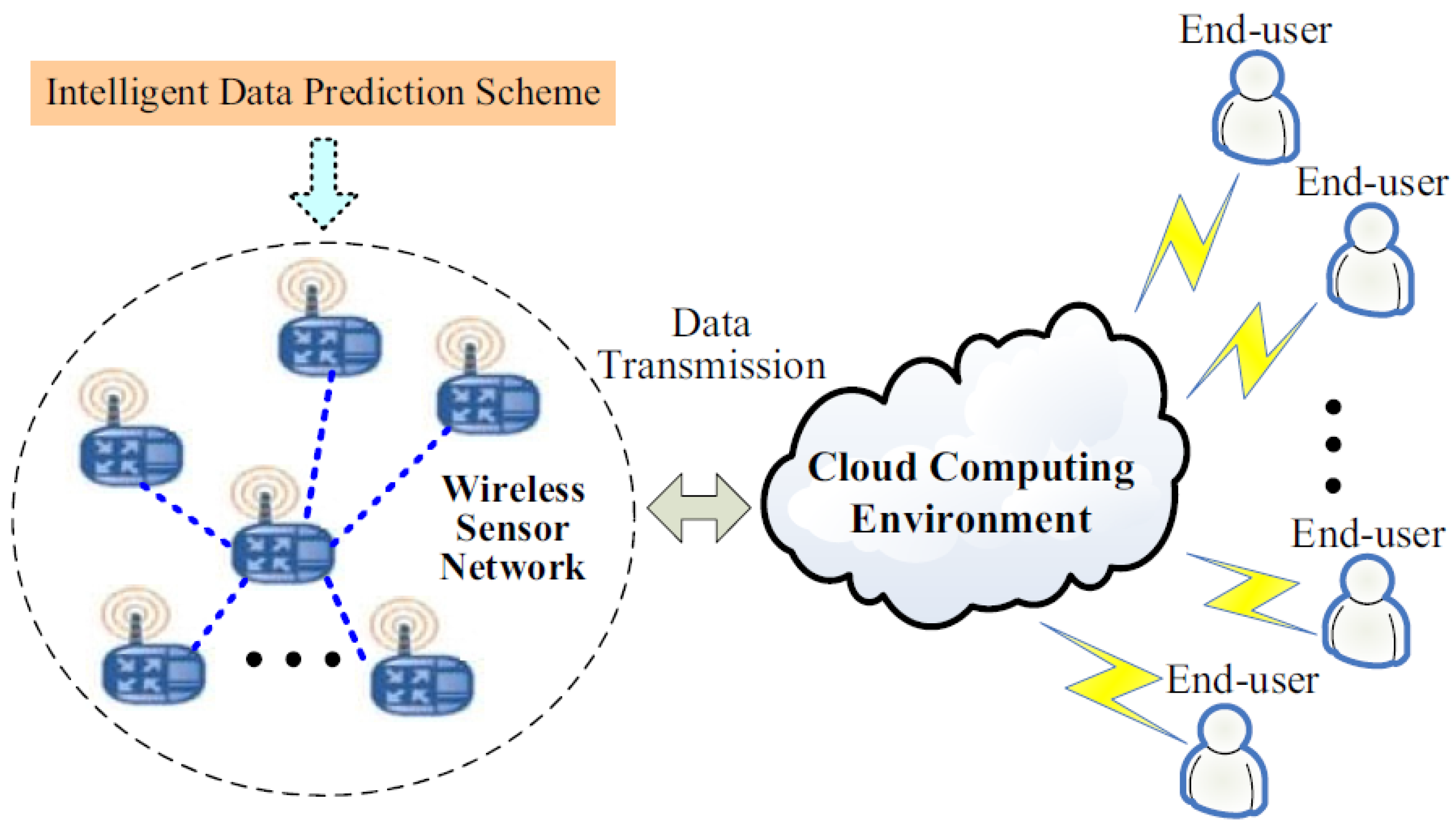
:
1. Introduction
- (1)
- The sensed data are pretreated using entropy technique before data prediction and fusion. In so doing, it will reduce computational errors while decreasing energy consumption since entropy-based optimization can reduce the size of data set.
- (2)
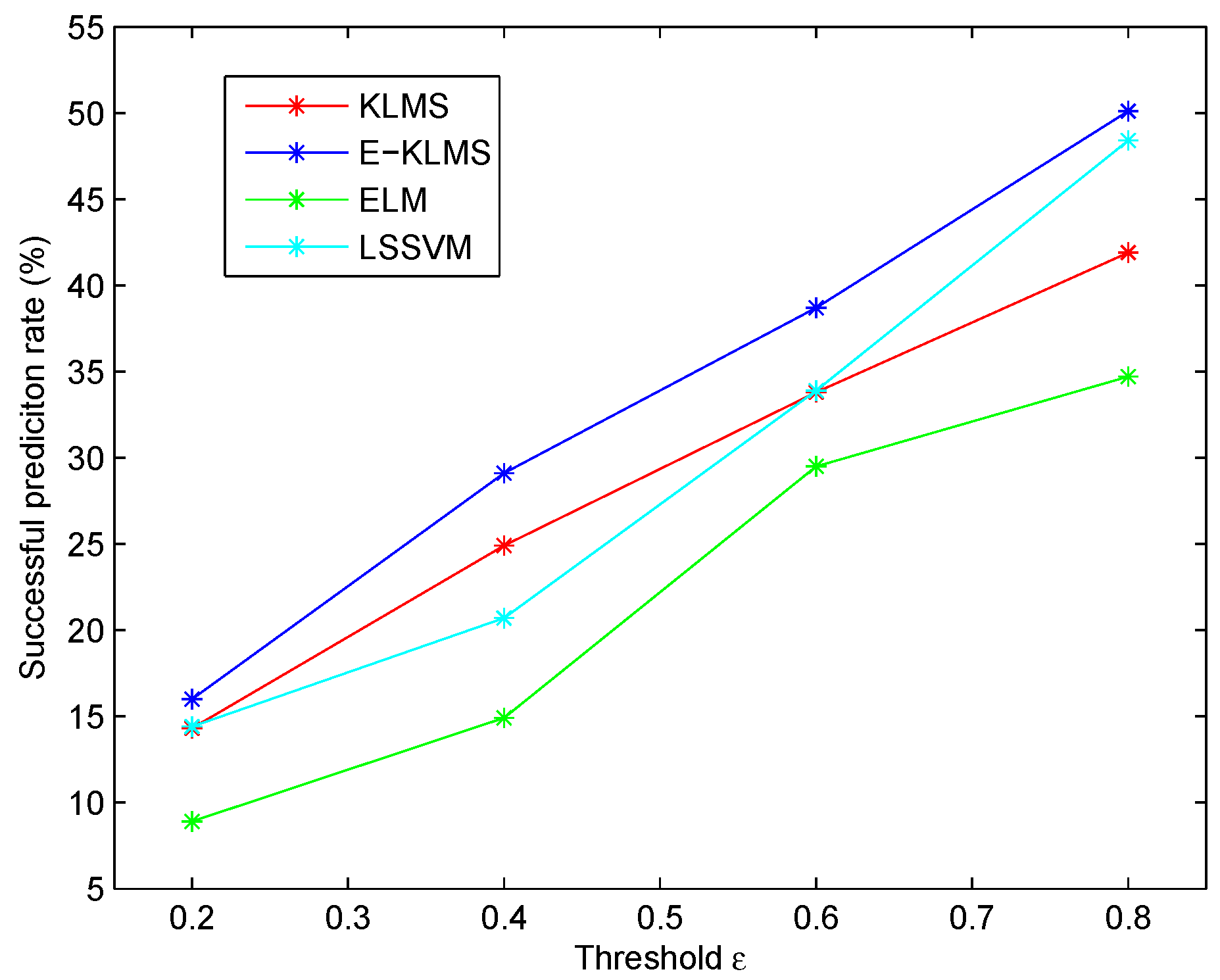
- In the flexible working mechanism of keeping the prediction data synchronous in WSN, E-KLMS can achieve better prediction performance regarding the training time and computational accuracy compared with other machine learning methods such as ELM and LSSVM.
2. Related works
2.1. Data Prediction Approaches
2.2. Prediction Schemes in WSN
3. Backgrounds
3.1. Problem Statement
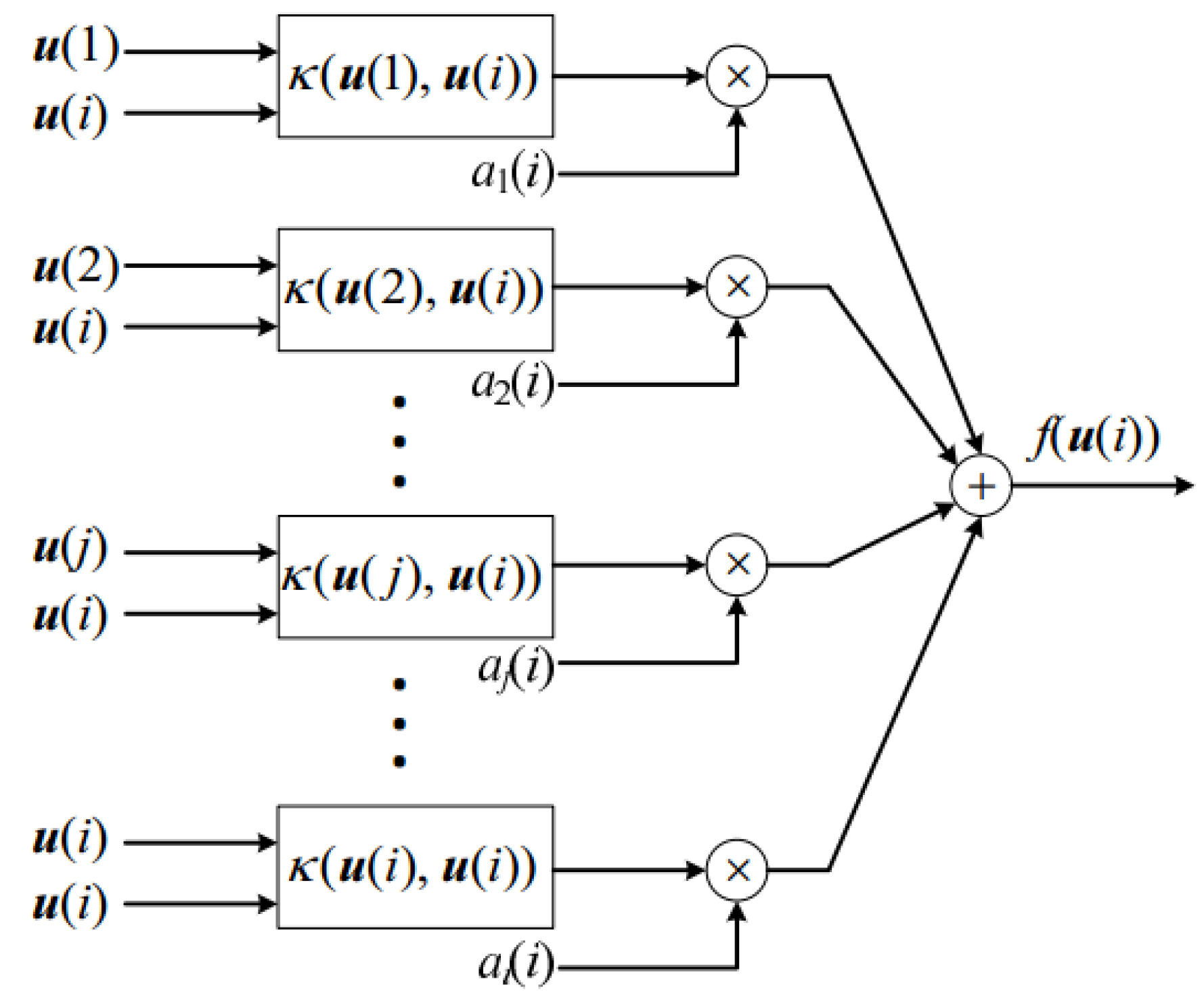
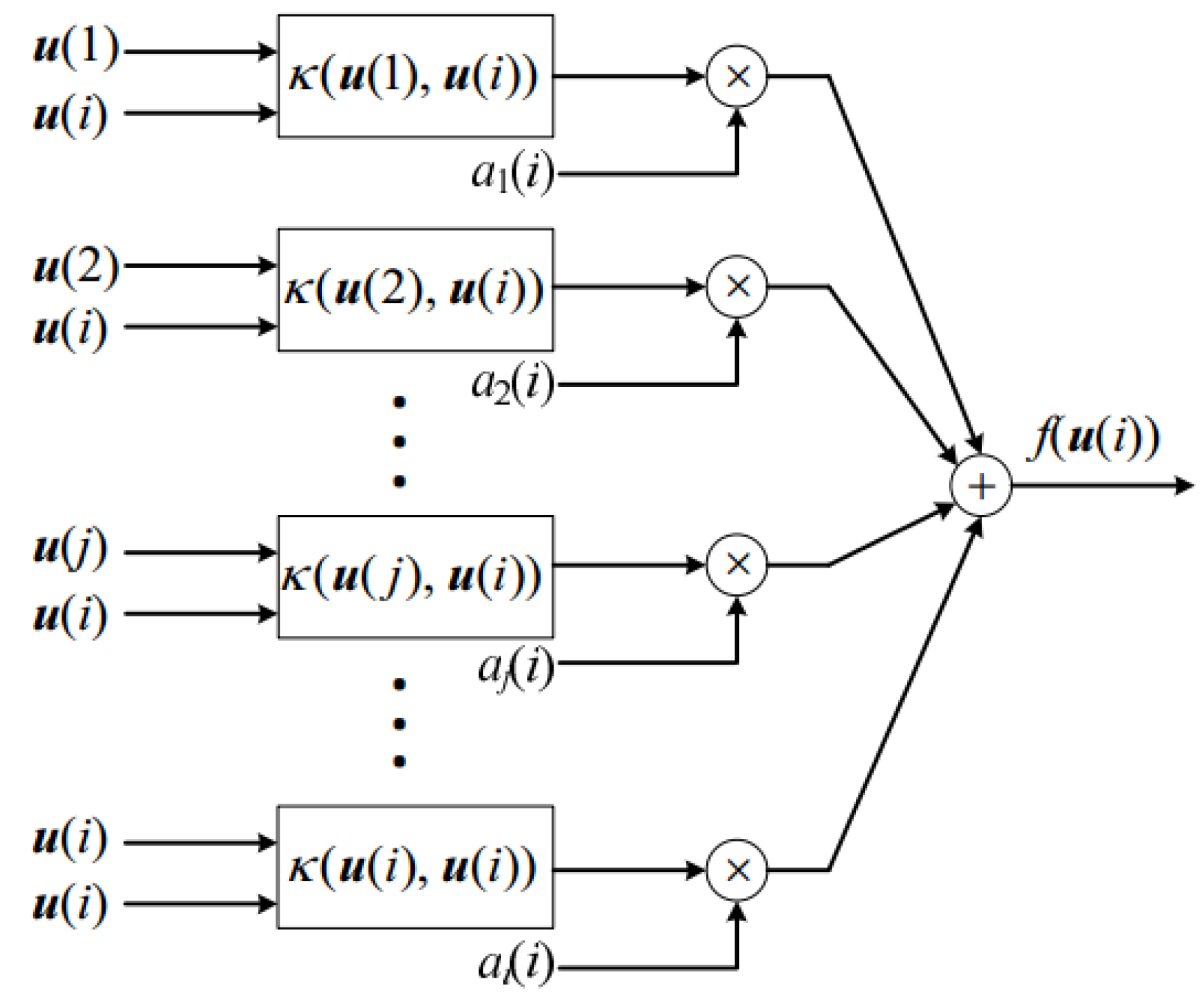
3.2. Kernel Least Mean Square Algorithm
| Algorithm 1 KLMS Algorithm |
| select the kernel κ and a proper step parameter λ, ; |
| ; |
for do
|
| end for |
3.3. Information Entropy
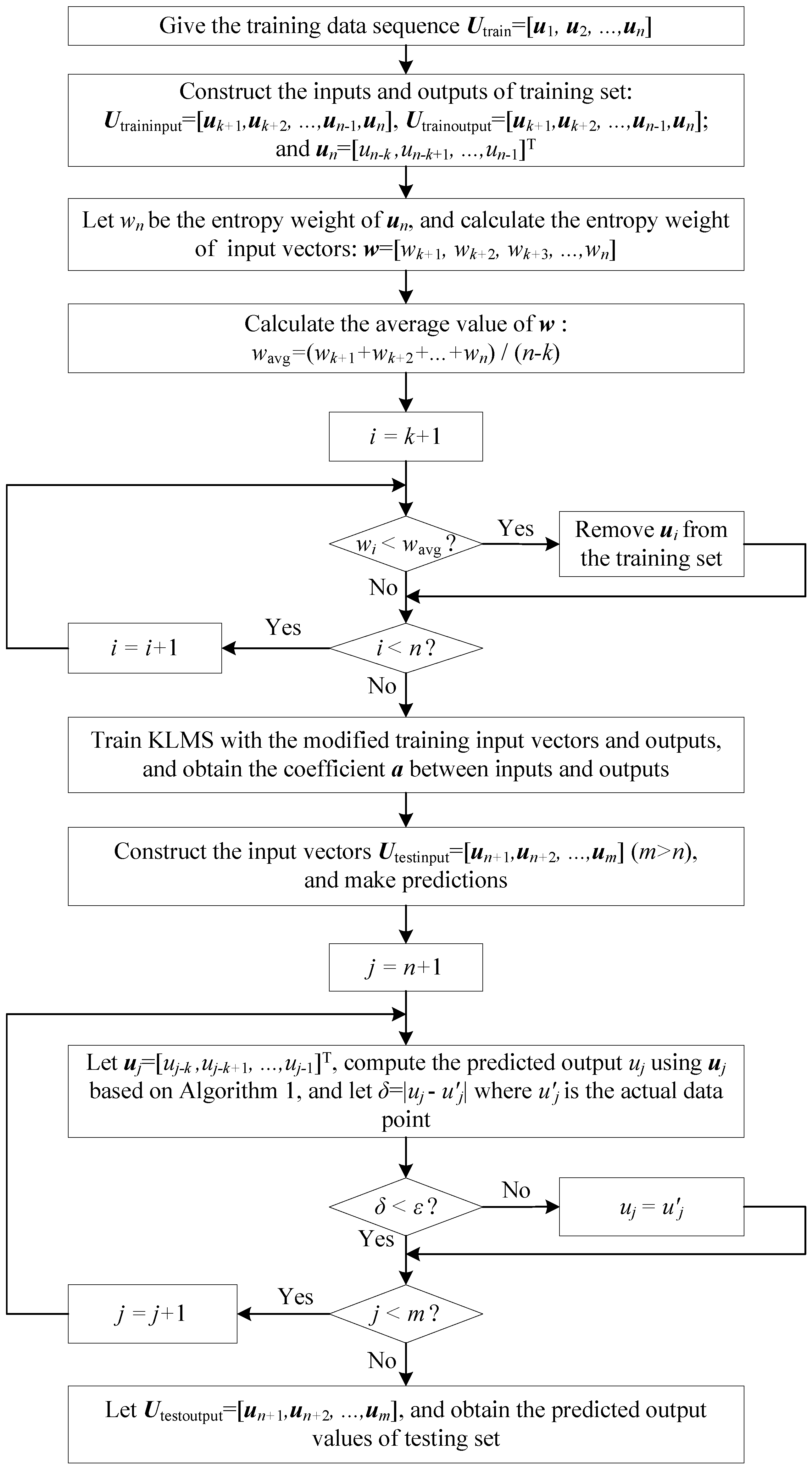
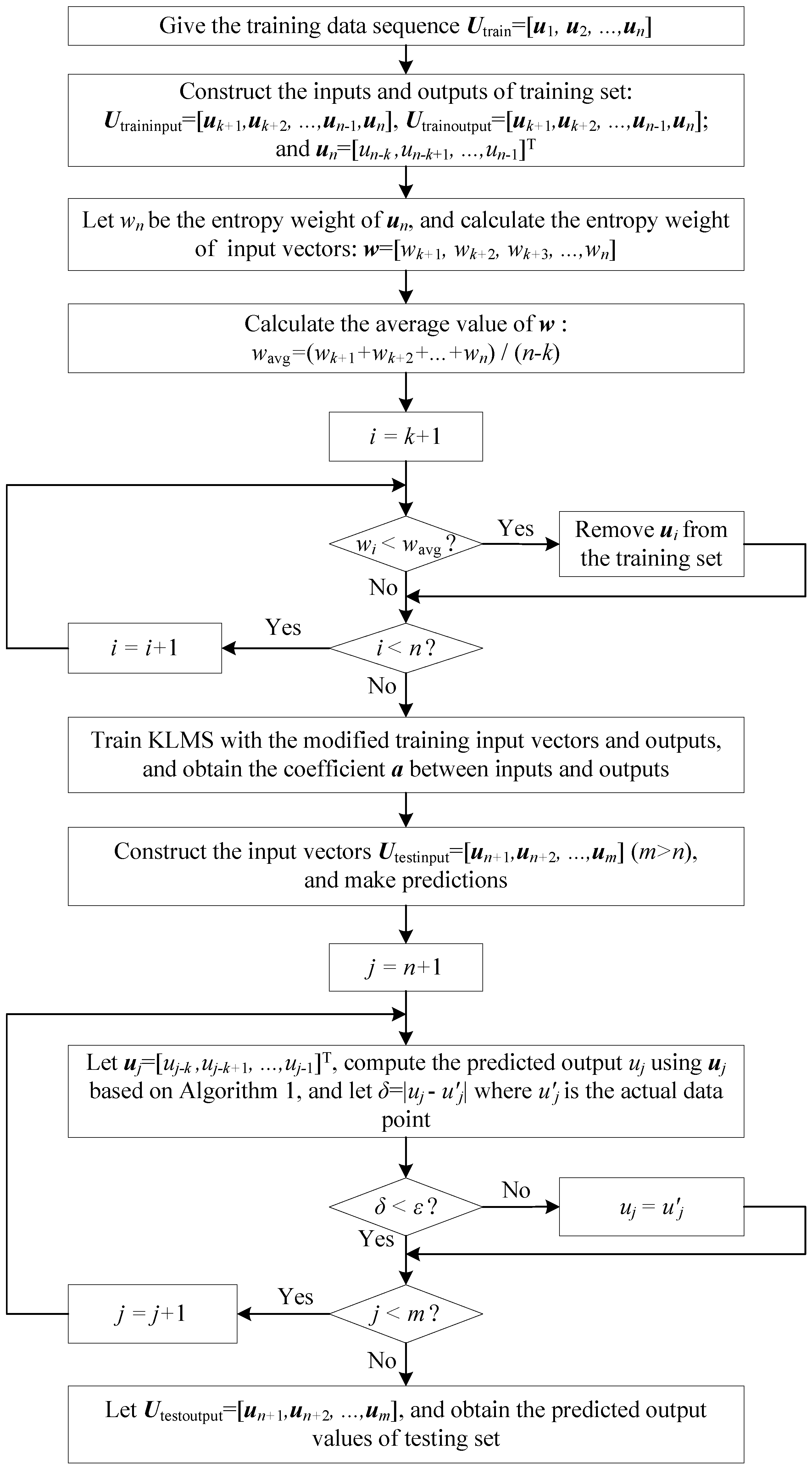
4. E-KLMS Scheme
4.1. Learning and Prediction in the Proposed Scheme
- (1)
- The default predicted error threshold ε will be sent to all working sensor nodes, and all sensor nodes deliver the first n actual values to the sink node which are used as training set data.
- (2)
- These two kinds of nodes implement prediction according to the same prediction strategy and data set. Here is the sequence: where n indicates the size of data points, the inputs and outputs of training set are constructed as followsHere k denotes the dimension of input vectors and .
- (3)
- The entropy weight of each input vectors is calculate on the basis of Equations (14)–(18). Then, we havewhere denotes the entropy weight of .
- (4)
- After comparing entropy weights of all input vectors with the average entropy weight, we remove those input vectors whose entropy weights are less than the average value, and their corresponding outputs are deleted from training set at the same time.
- (5)
- With the modified training set, the KLMS learning model is trained. Then, the coefficient a between inputs and outputs is obtained. And it reveals the hidden relationships between inputs and outputs.
- (6)
- The testing input vector is constructed through the use of its previous k data points. Next, the prediction is conducted by using Algorithm 1. If the prediction error δ is less than ε, the transmission between these two type of nodes will be cancelled and the prediction value will be considered as the real value. Repeat this step until all the outputs are predicted.
4.2. Analysis of Complexity
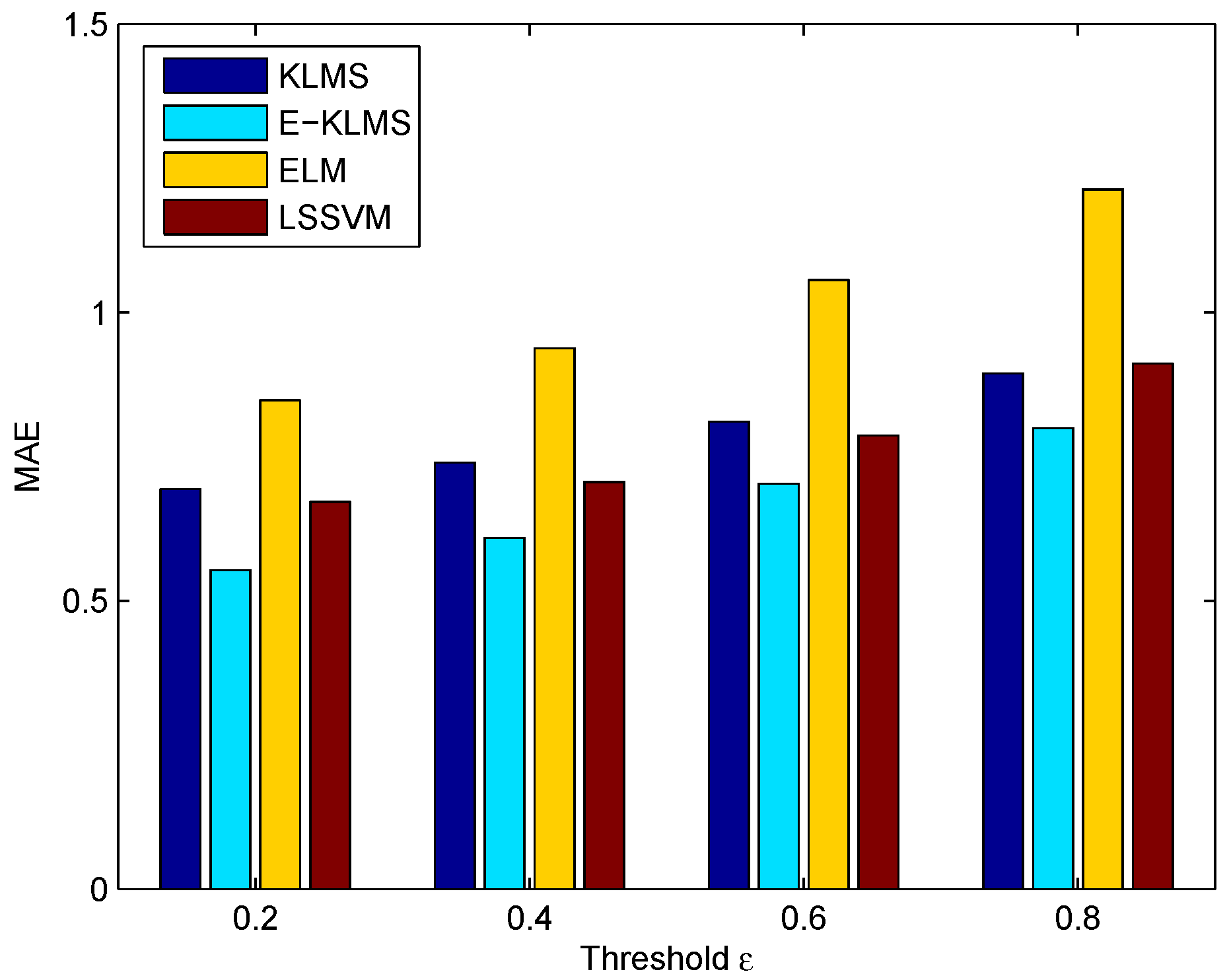
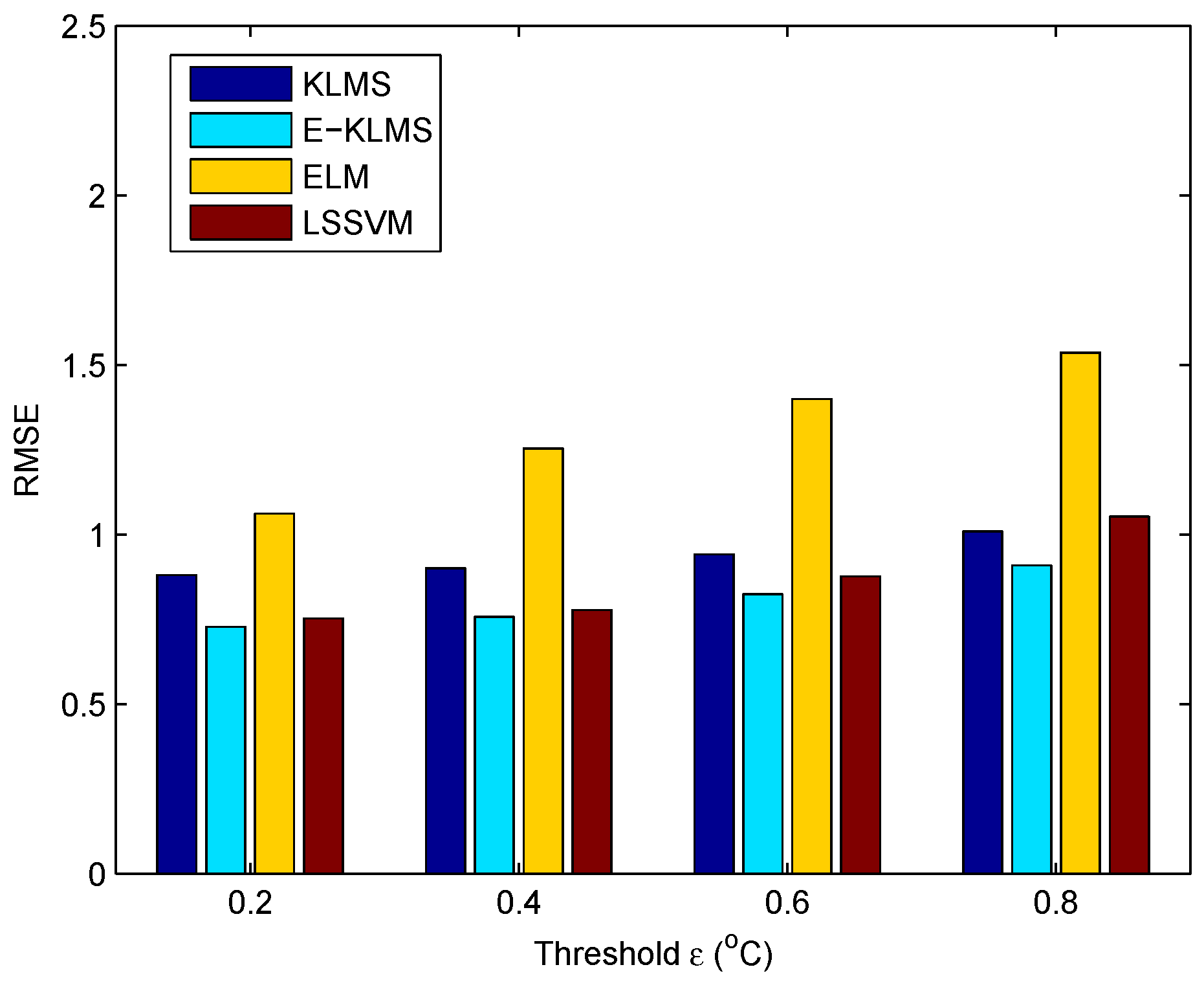
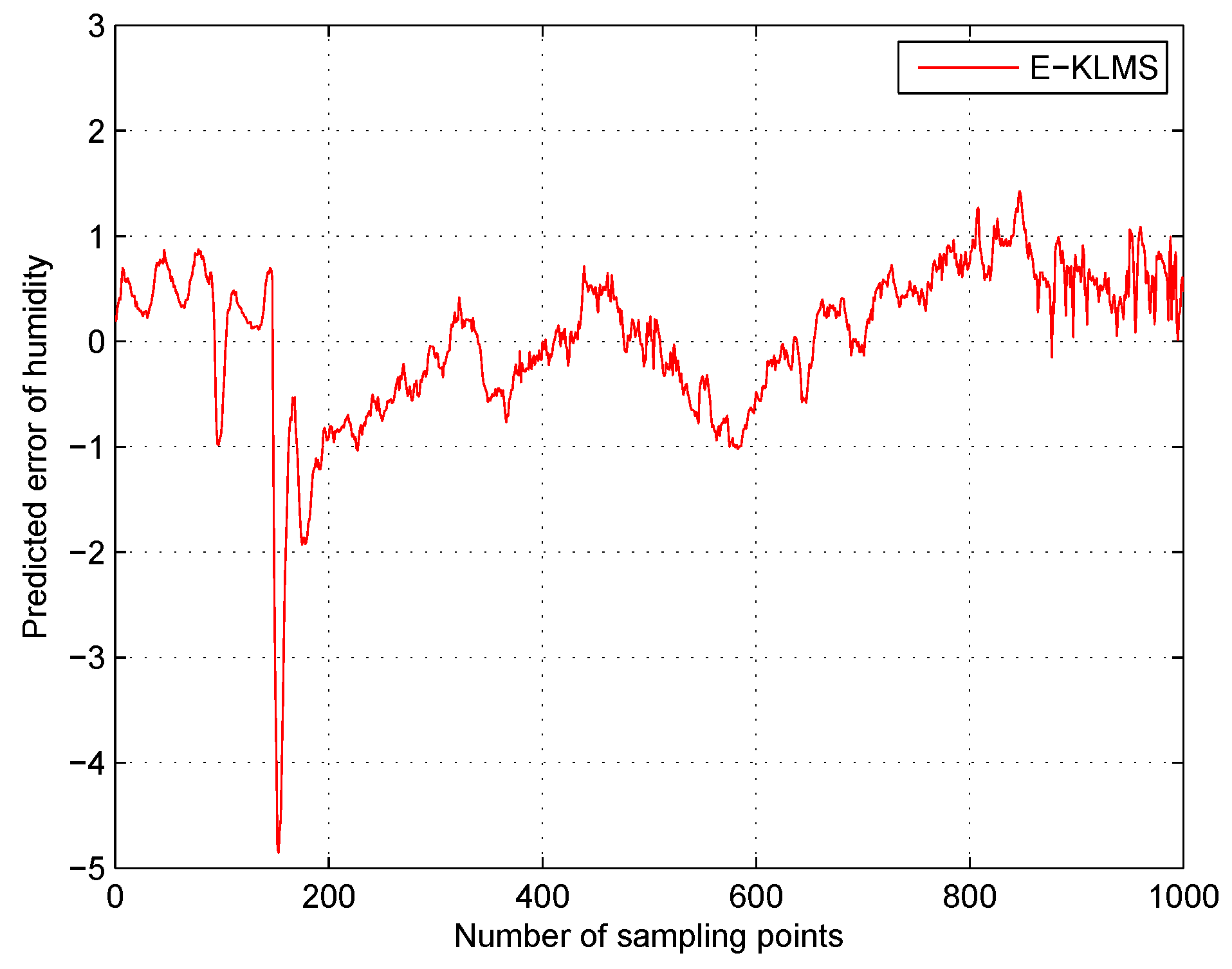
5. Experiments and Discussion
5.1. Experiment Settings
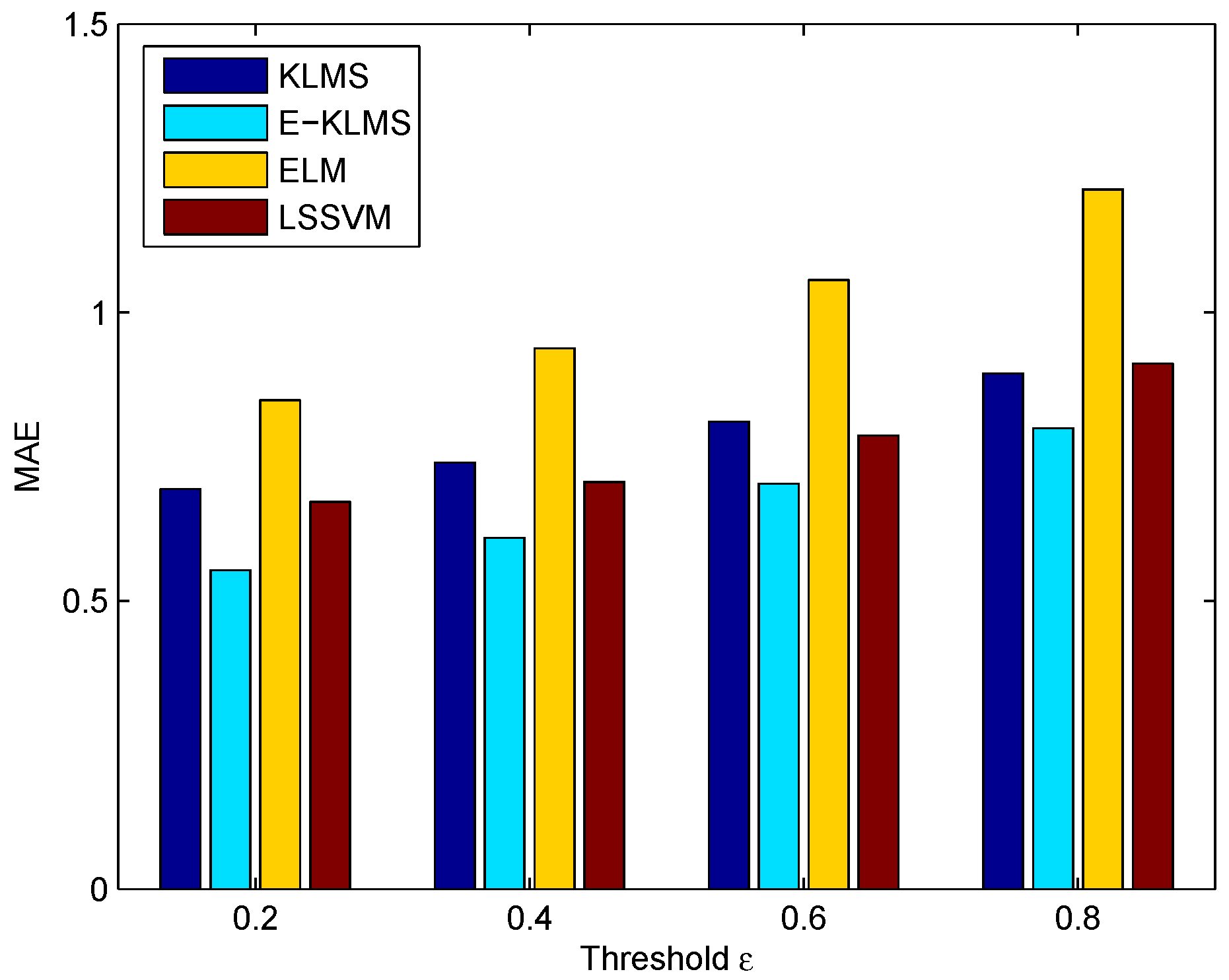
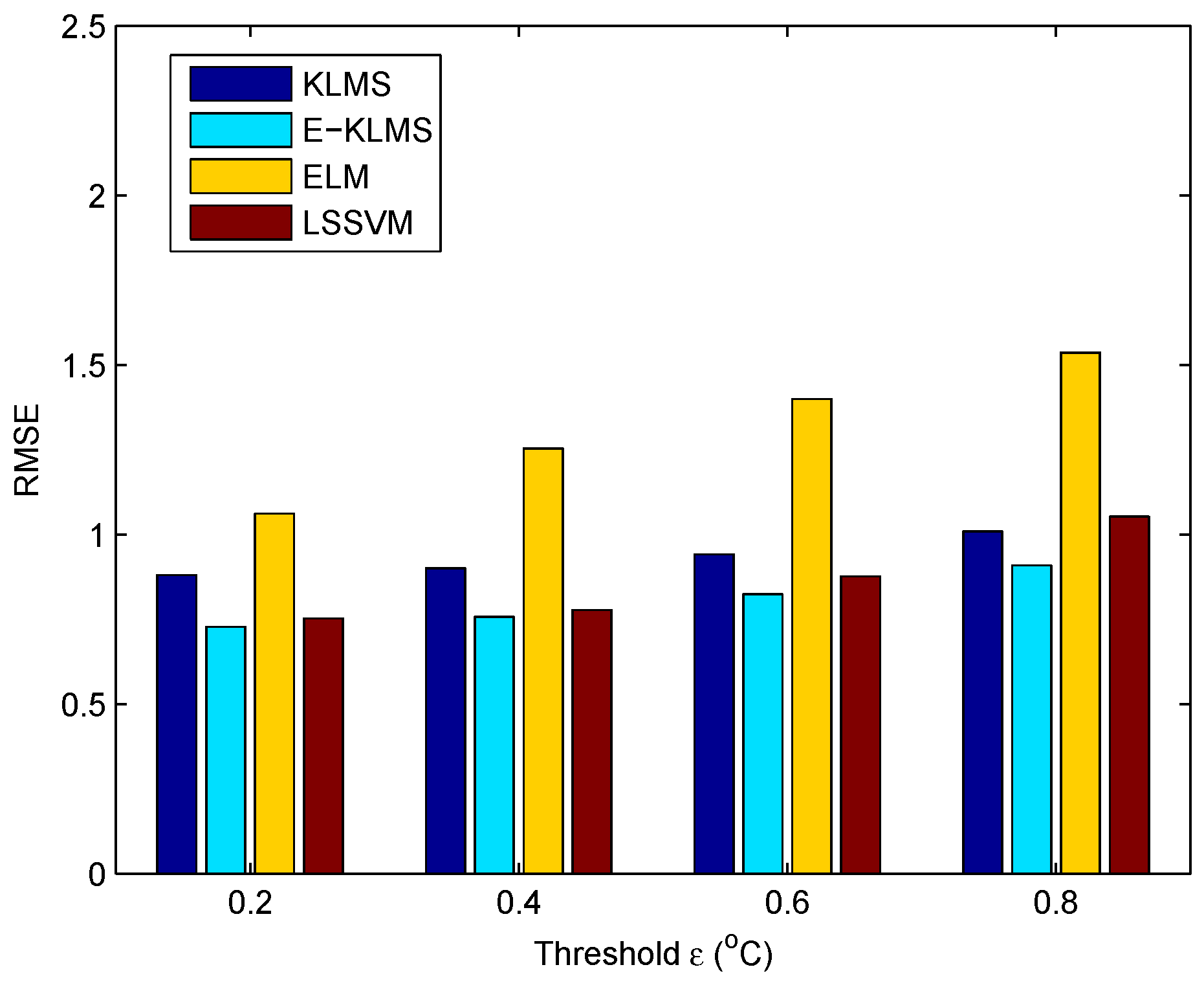
5.2. Metrics
5.3. Analysis for the Implementation of Our Work
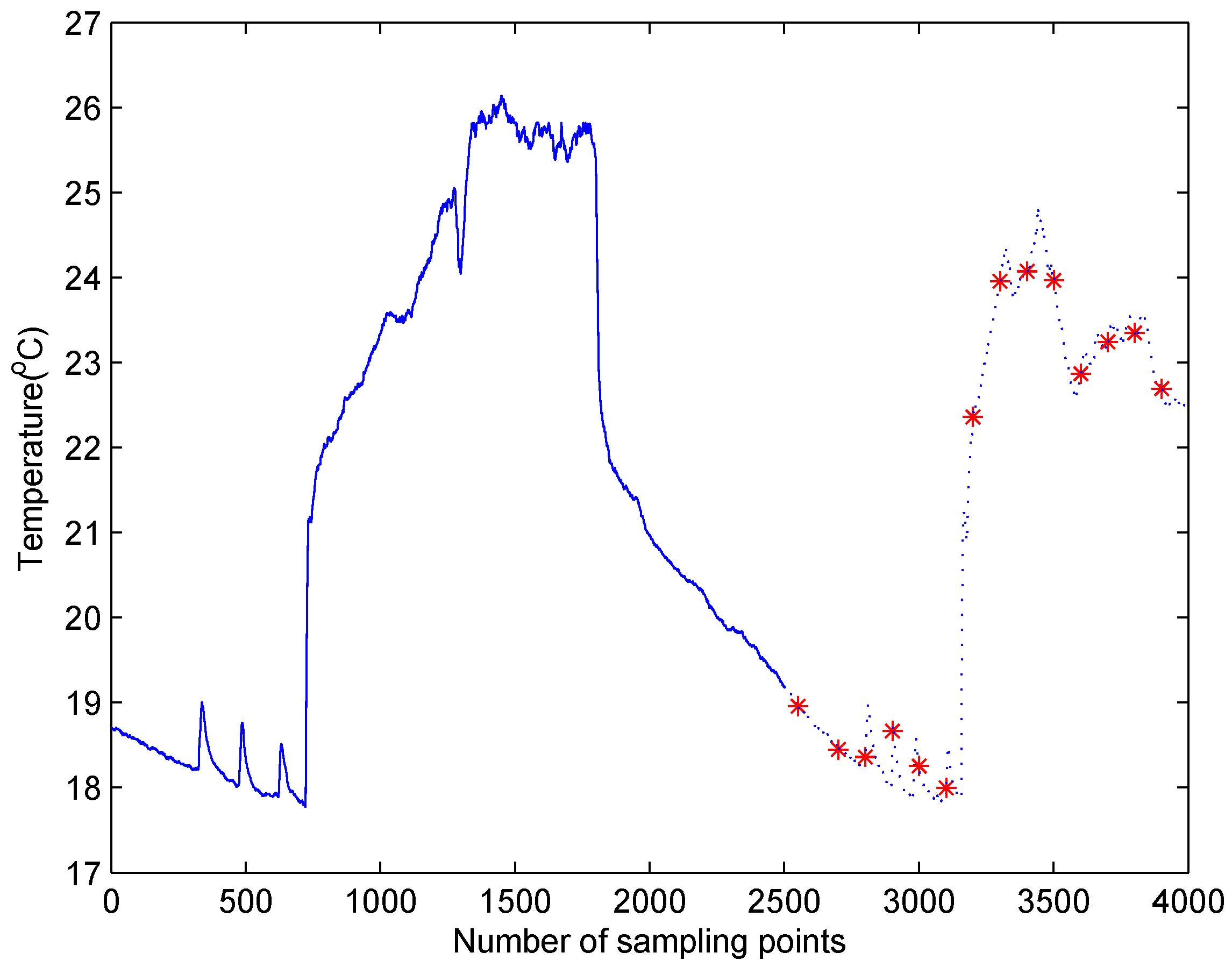
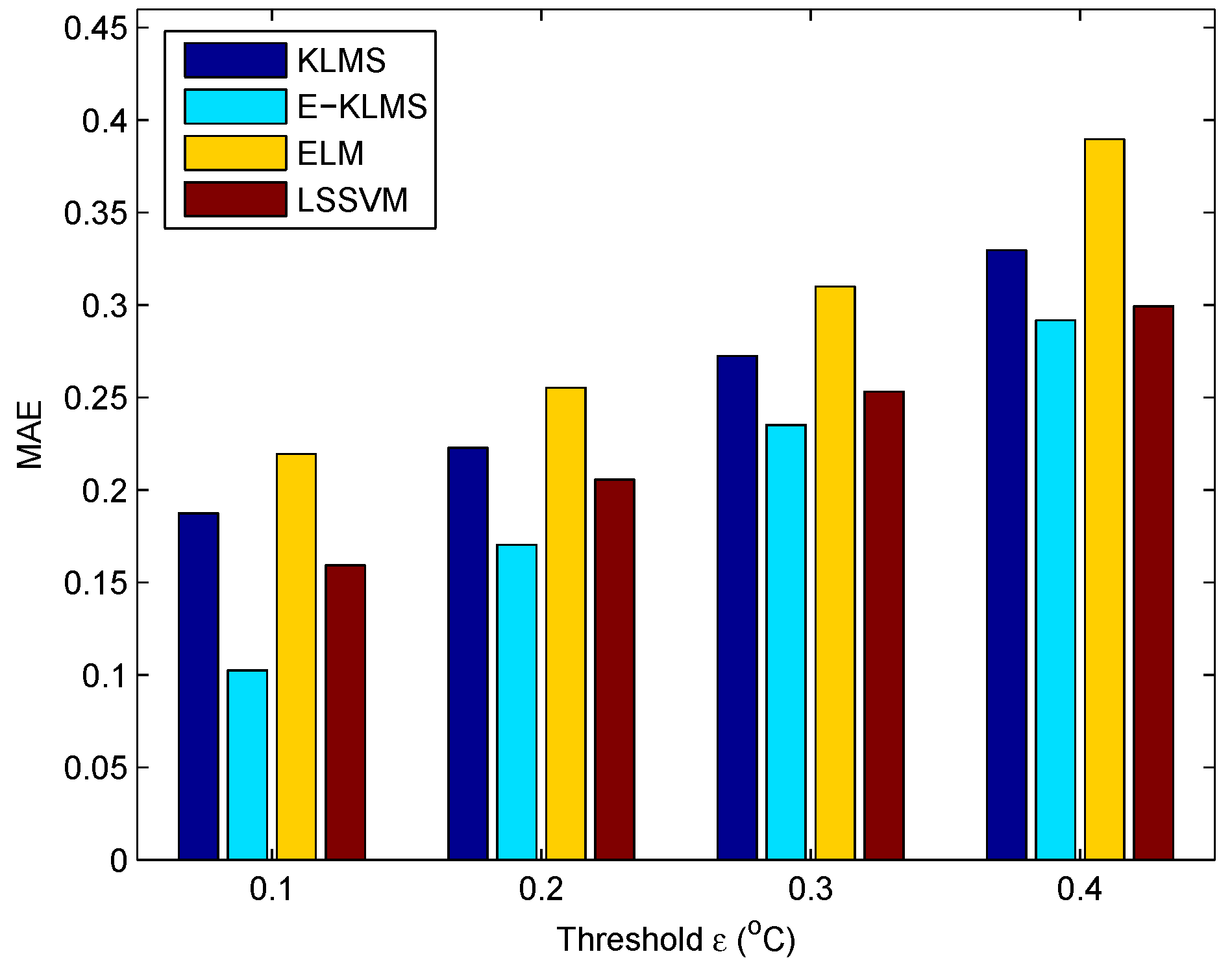
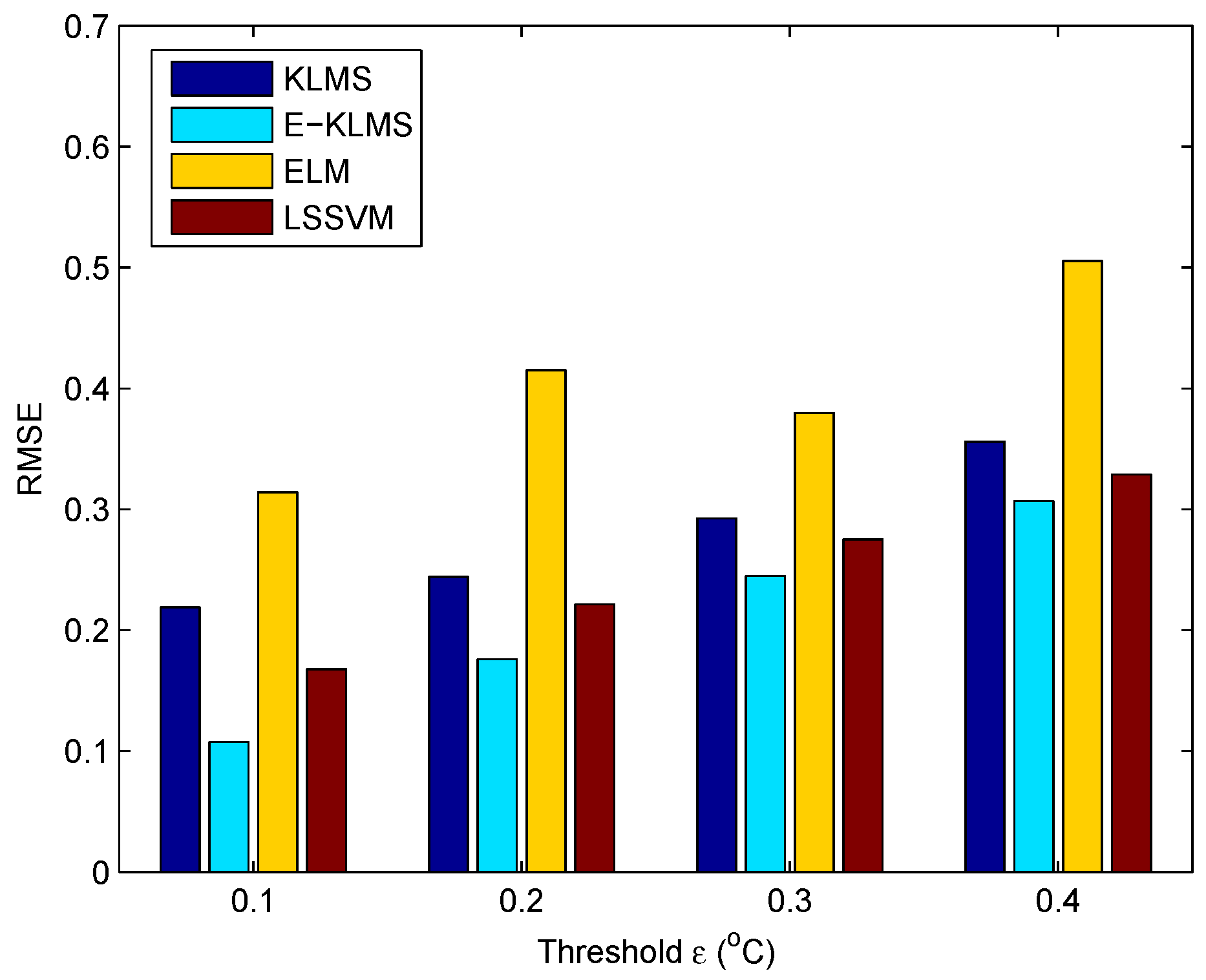
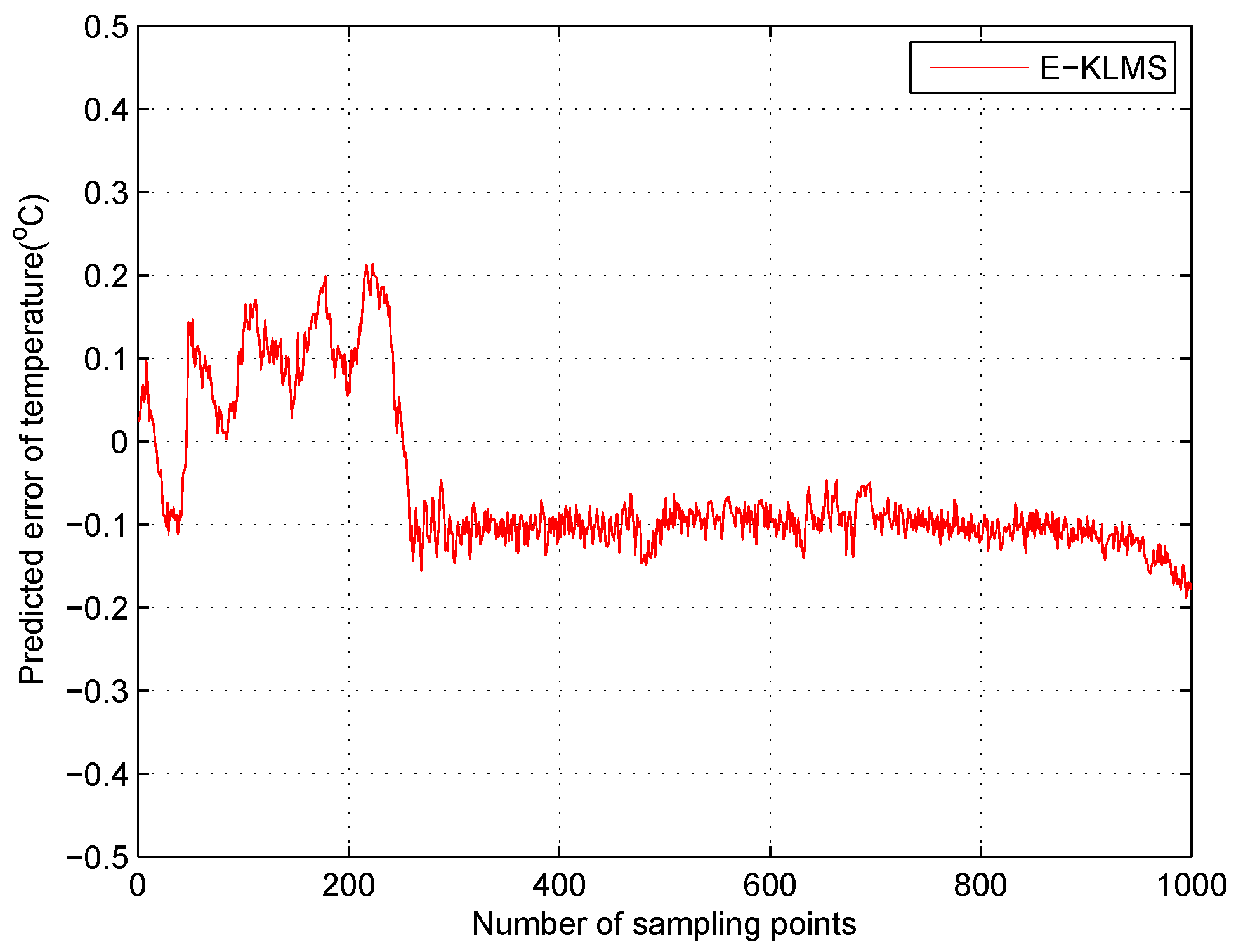
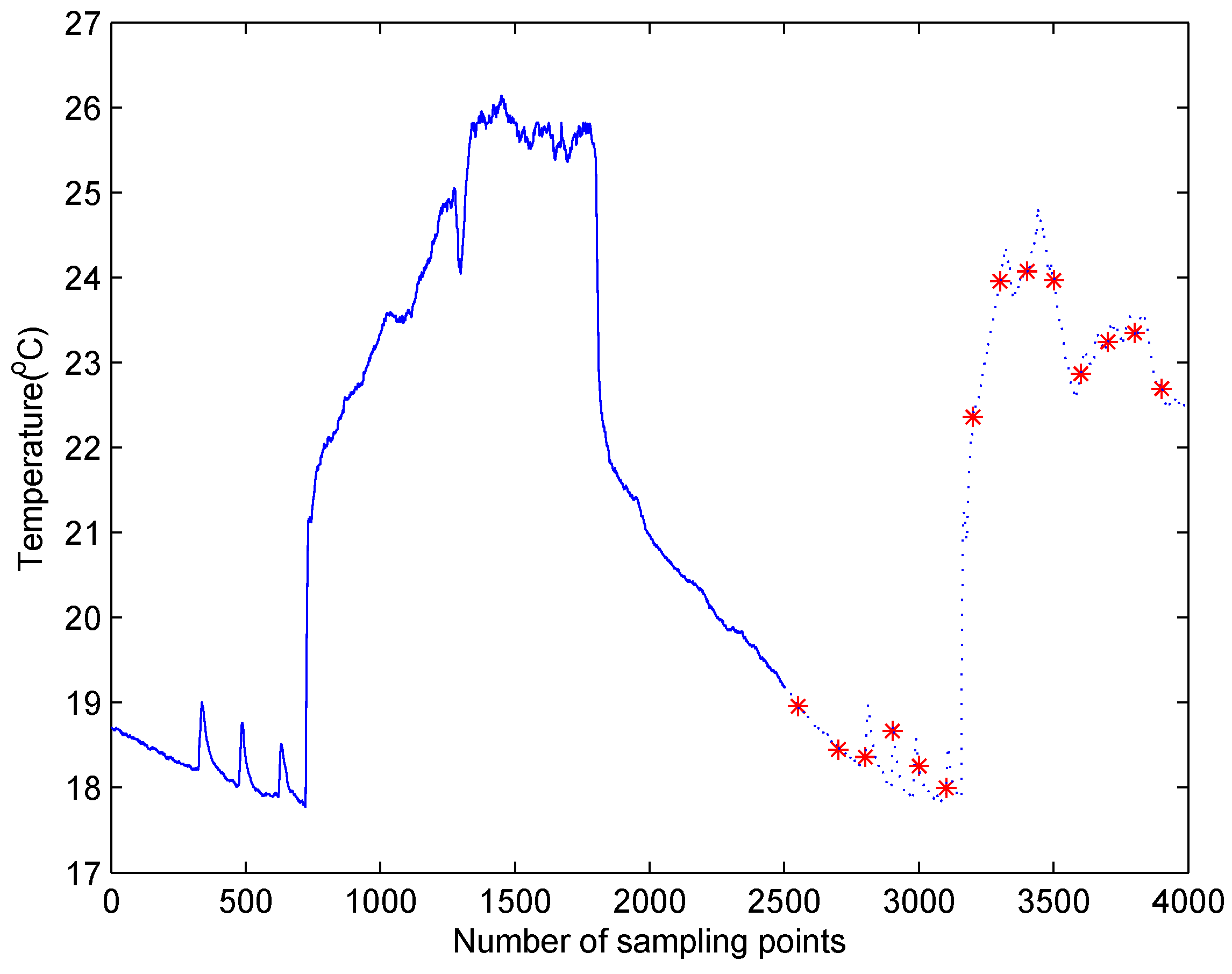
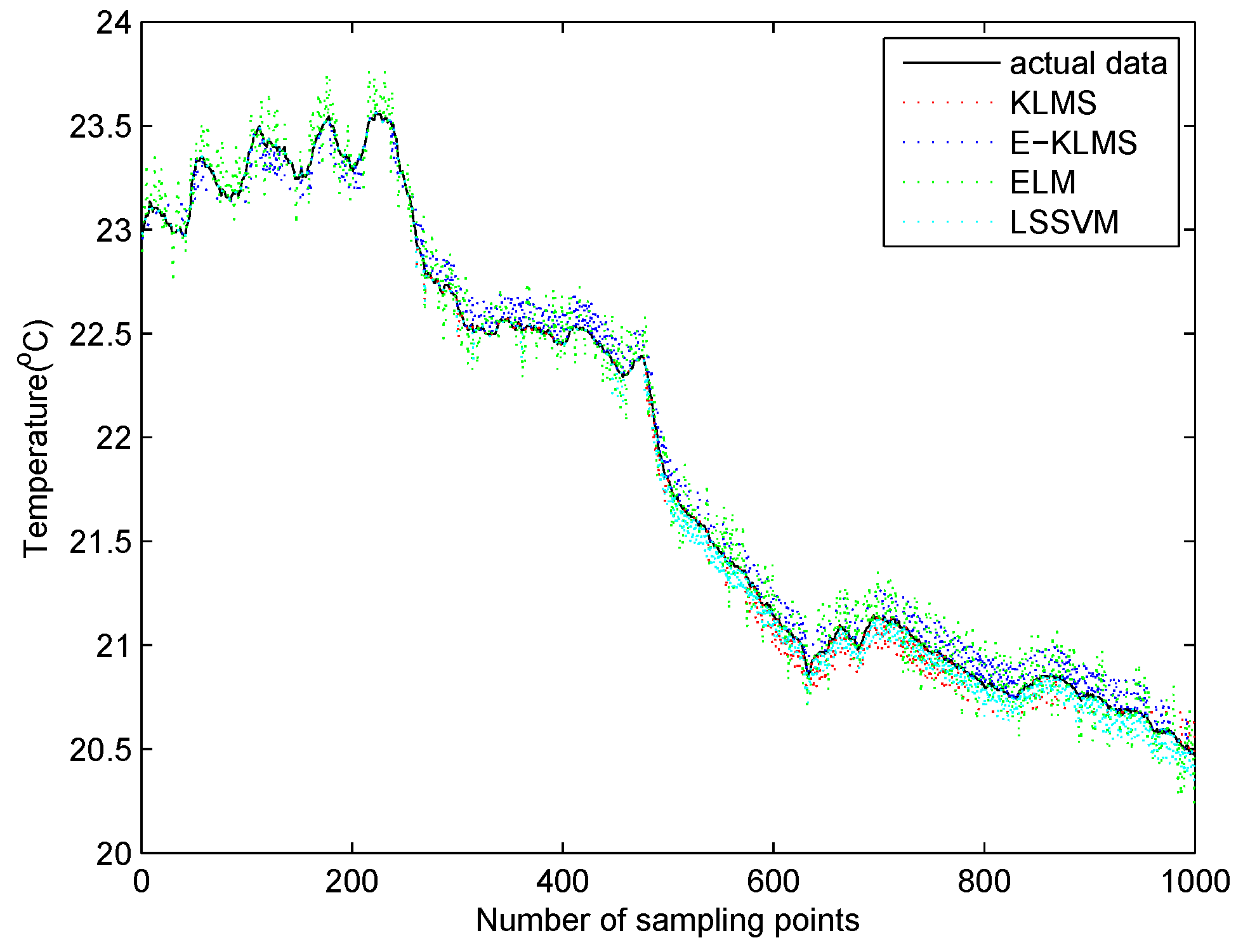
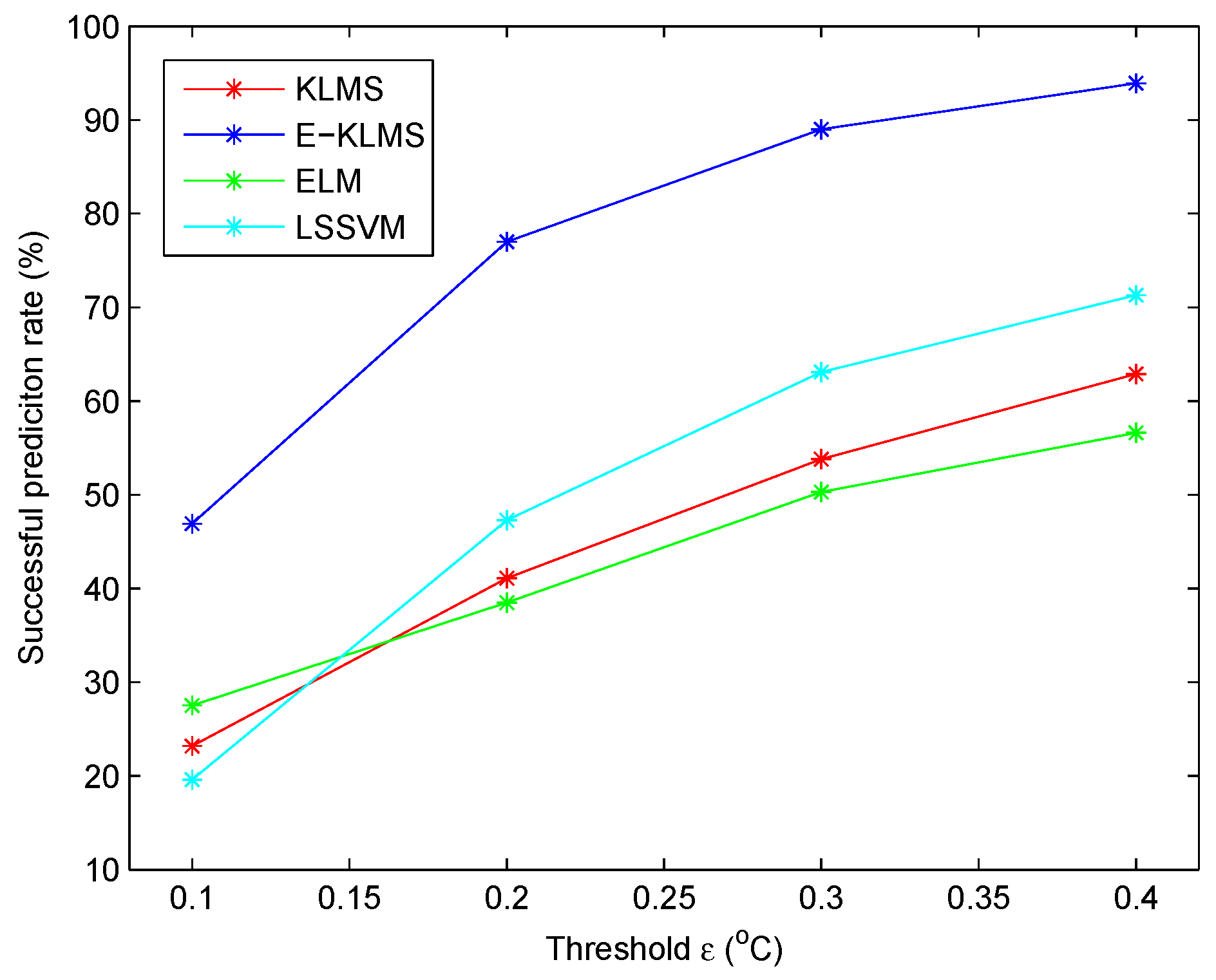
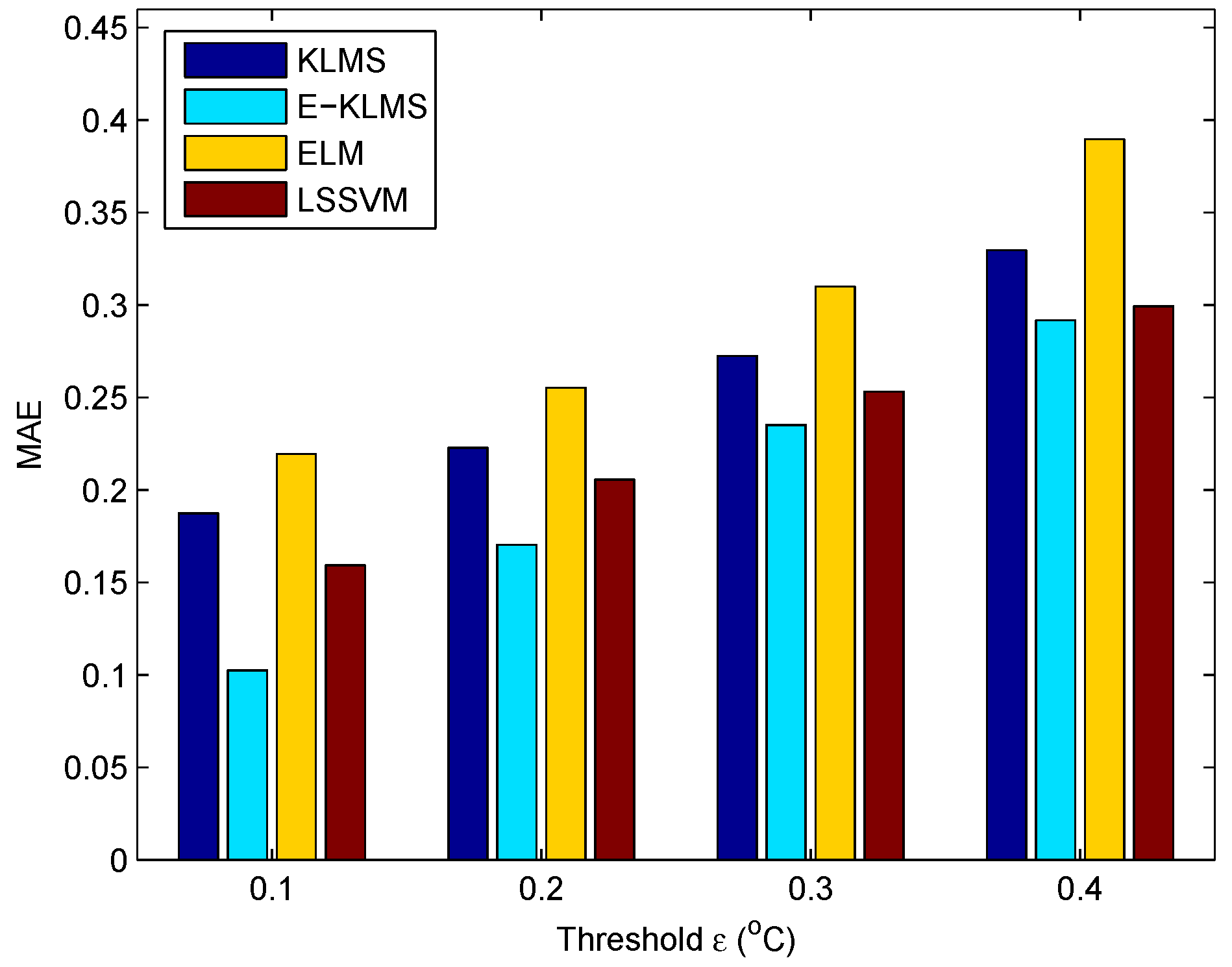
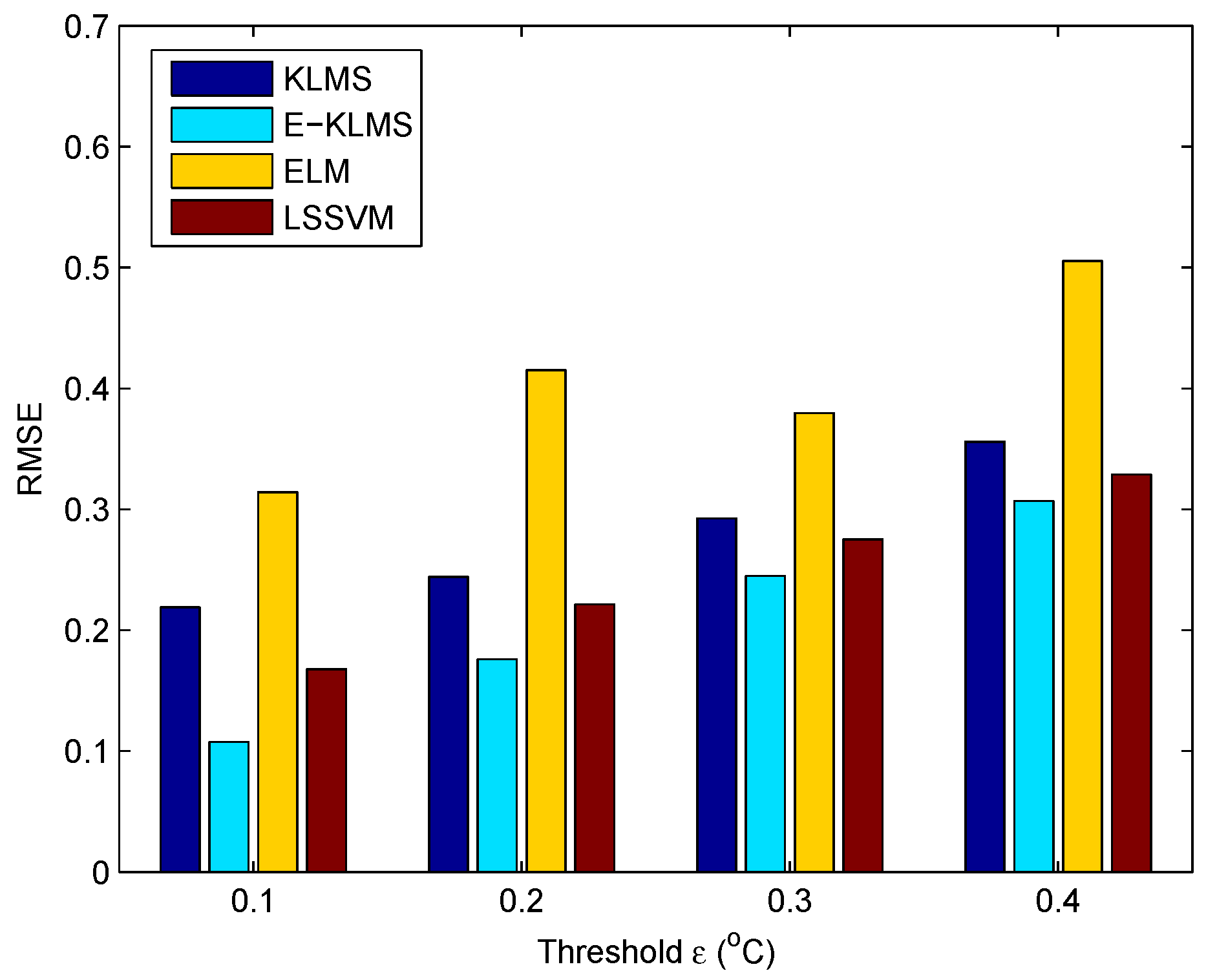
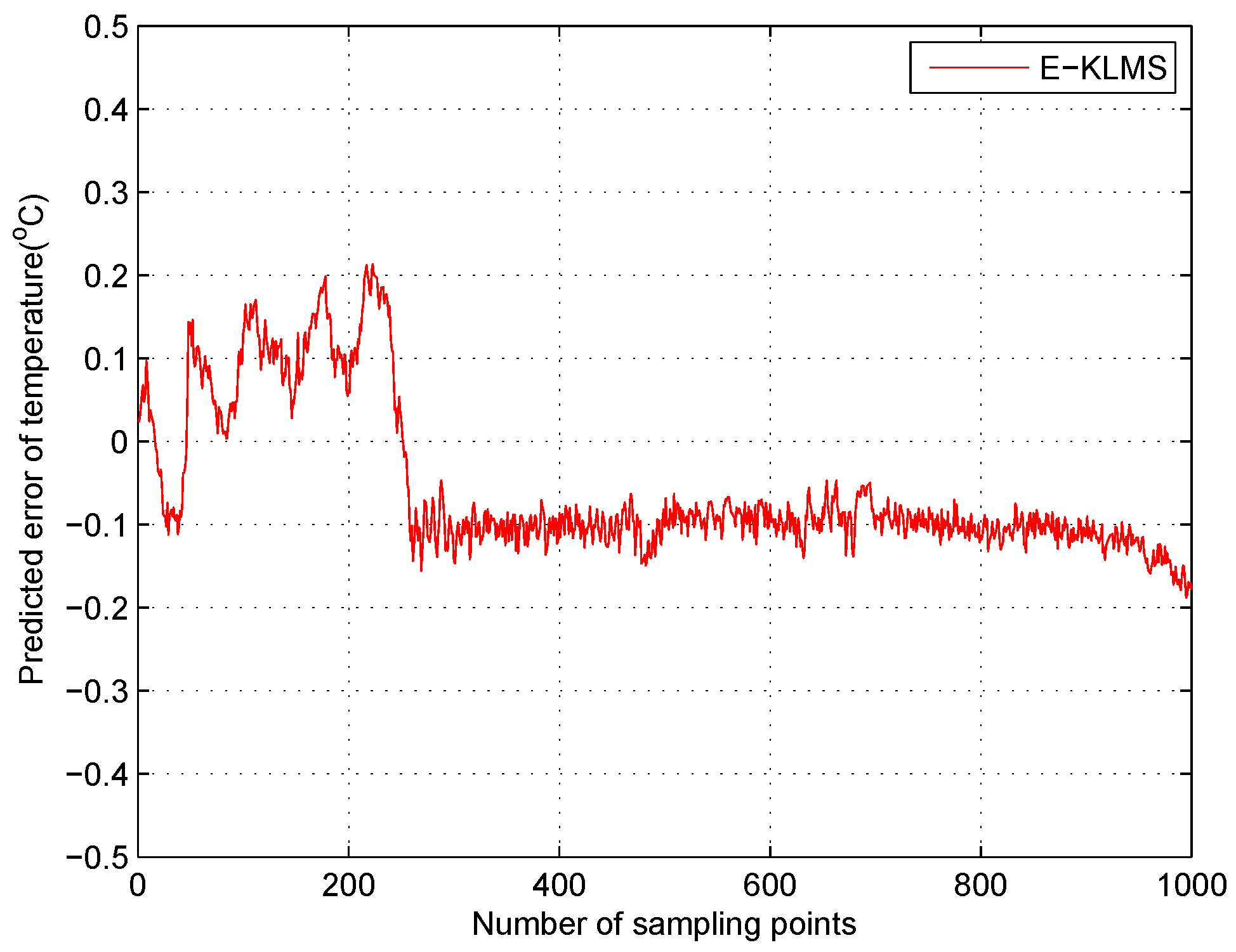
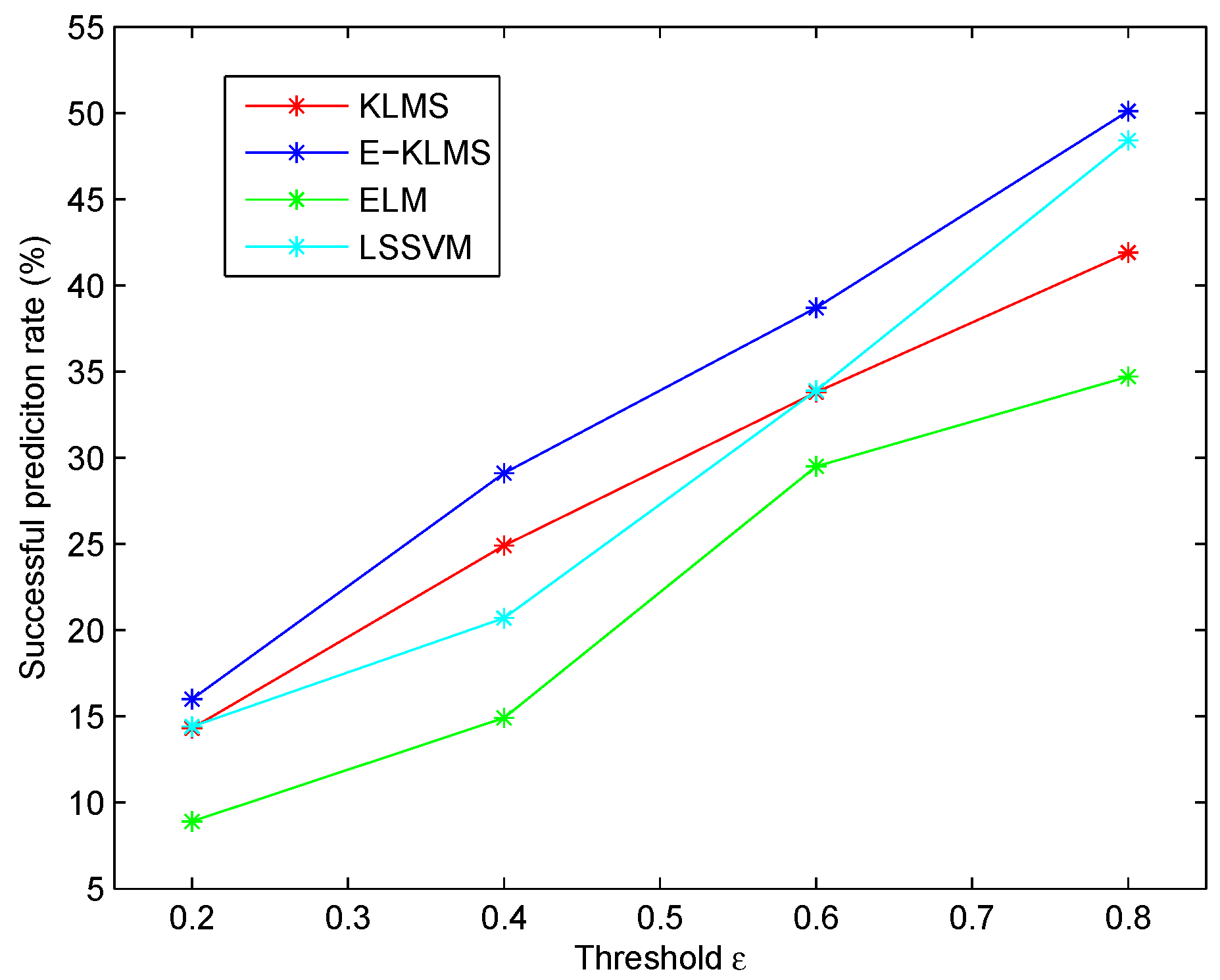
5.4. Test Case in Temperature Data Set
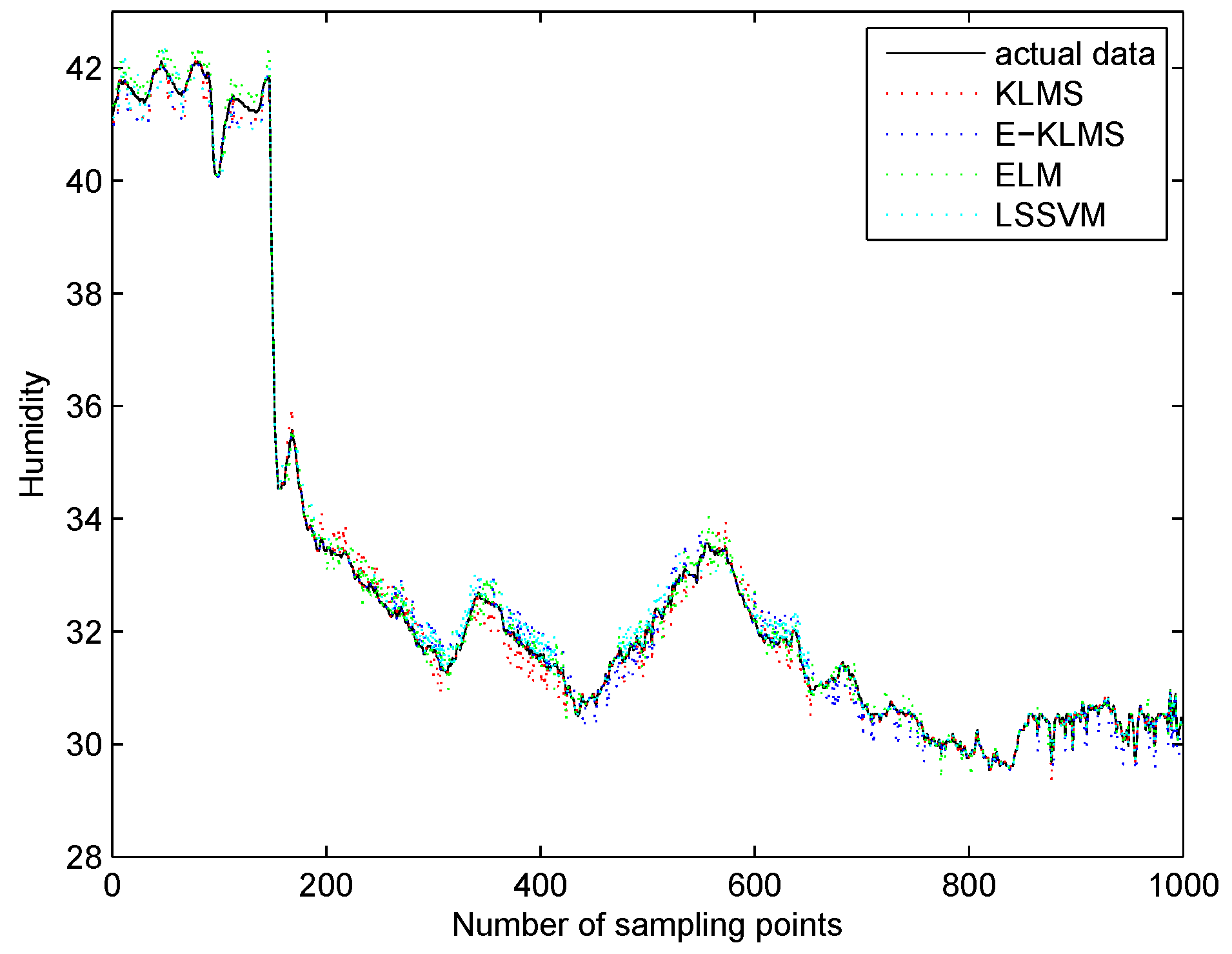
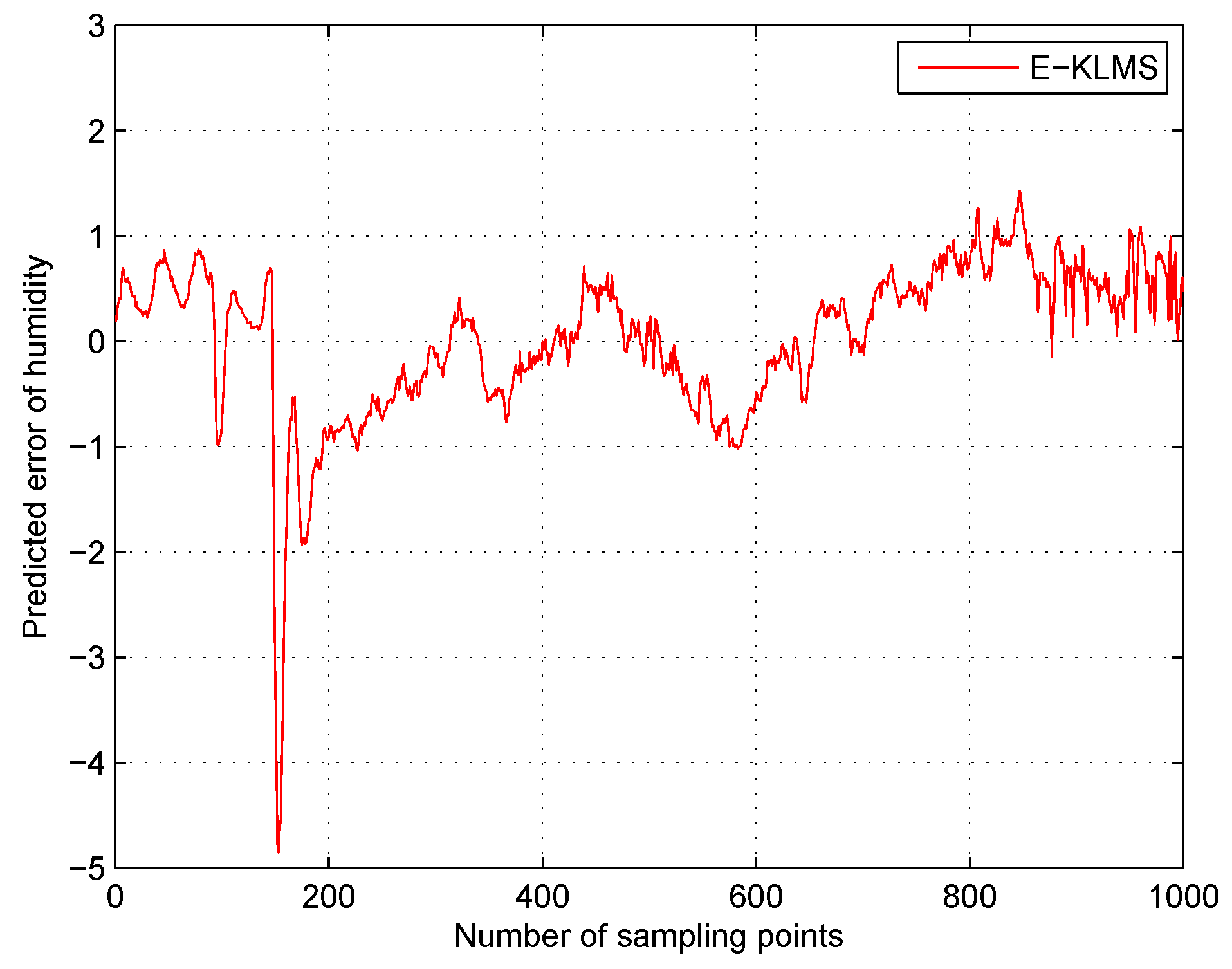
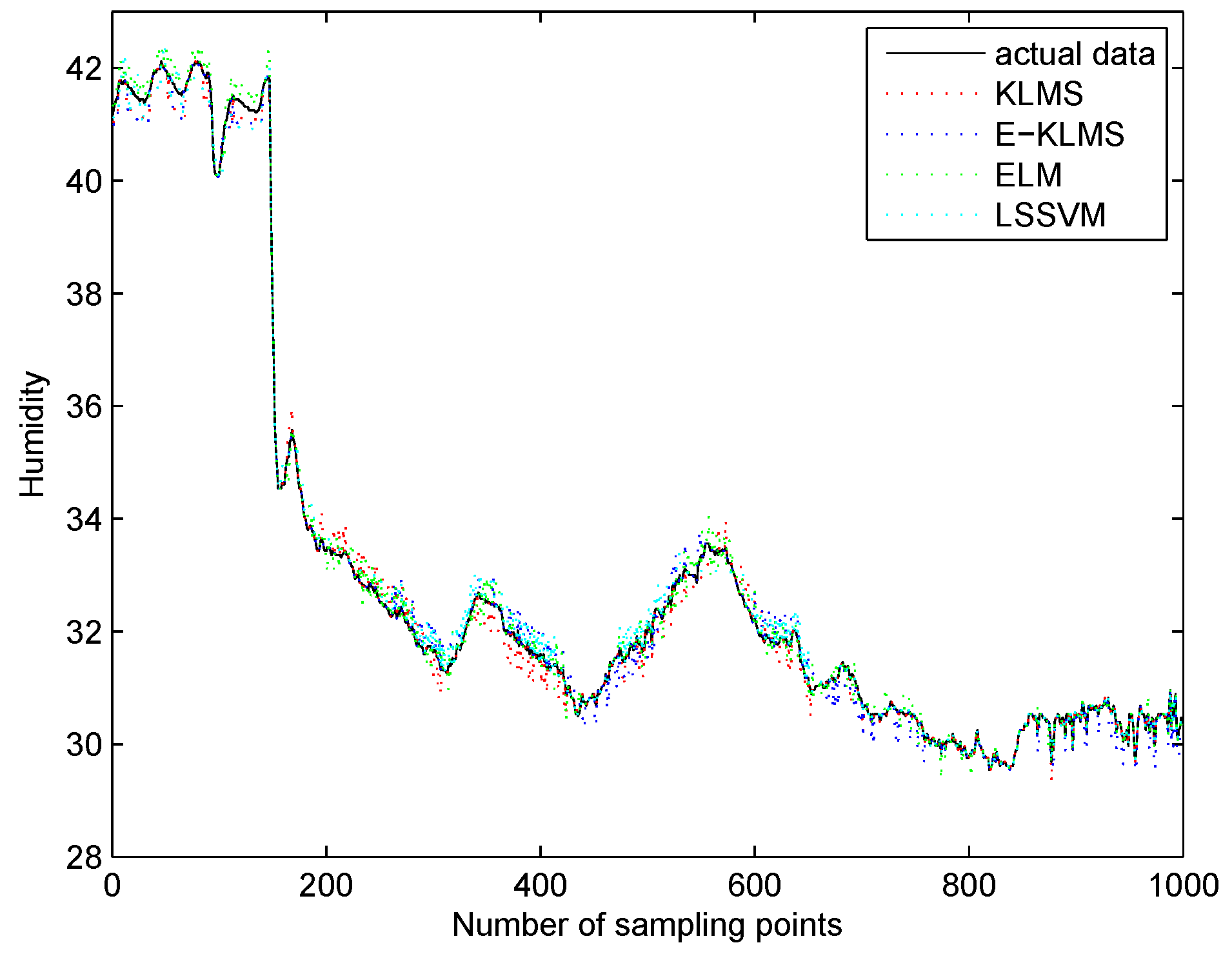
5.5. Test Case in Humidity Data Set
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yick, J.; Mukherjee, B.; Ghosal, D. Wireless sensor network survey. Comput. Netw. 2008, 52, 2292–2330. [Google Scholar] [CrossRef]
- Oliveira, L.M.; Rodrigues, J.J. Wireless sensor networks: A survey on environmental monitoring. J. Commun. 2011, 6, 1796–2021. [Google Scholar] [CrossRef]
- Nam, Y.; Rho, S.; Lee, B.G. Intelligent context-aware energy management using the incremental simultaneous method in future wireless sensor networks and computing systems. EURASIP J. Wirel. Commun. Netw. 2013, 2, 146–155. [Google Scholar] [CrossRef]
- Baccarelli, E.; Cordeschi, N.; Mei, A.; Panella, M.; Shojafar, M.; Stefa, J. Energy-efficient dynamic traffic offloading and reconfiguration of networked data centers for big data stream mobile computing: Review, challenges, and a case study. IEEE Netw. 2016, 30, 54–61. [Google Scholar] [CrossRef]
- Shojafar, M.; Cordeschi, N.; Baccarelli, E. Energy-efficient adaptive resource management for real-time vehicular cloud services. IEEE Trans. Cloud Comput. 2016, PP. [Google Scholar] [CrossRef]
- Ryu, S.; Chen, A.; Choi, K. Solving the stochastic multi-class traffic assignment problem with asymmetric interactions, route overlapping, and vehicle restrictions. J. Adv. Transp. 2016, 50, 255–270. [Google Scholar] [CrossRef]
- Canali, C.; Lancellotti, R. Detecting similarities in virtual machine behavior for cloud monitoring using smoothed histograms. J. Parallel Distrib. Comput. 2014, 74, 2757–2759. [Google Scholar] [CrossRef]
- Yu, C.M.; Chen, C.Y.; Chao, H.C. Verifiable, privacy-assured, and accurate signal collection for cloud-assisted wireless sensor networks. IEEE Commun. Mag. 2015, 53, 48–53. [Google Scholar] [CrossRef]
- Zhu, C.; Leung, V.C.M.; Yang, L.T.; Shu, L. Collaborative location-based sleep scheduling for wireless sensor networks integrated with mobile cloud computing. IEEE Trans. Comput. 2015, 64, 1844–1856. [Google Scholar] [CrossRef]
- Esch, J. A survey on topology control in wireless sensor networks: Taxonomy, comparative study, and open issues. Proc. IEEE 2013, 101, 2534–2537. [Google Scholar] [CrossRef]
- Luo, X.; Chang, X.H. A novel data fusion scheme using grey model and extreme learning machine in wireless sensor networks. Int. J. Control Autom. Syst. 2015, 13, 539–546. [Google Scholar] [CrossRef]
- Yang, F.C.; Yang, L.L. Low-complexity noncoherent fusion rules for wireless sensor networks monitoring multiple events. IEEE Trans. Aerosp. Electron. Syst. 2014, 50, 2343–2353. [Google Scholar] [CrossRef]
- Nakamura, E.F.; Loureiro, A.A.F.; Frery, A.C. Information fusion for wireless sensor networks: Methods, models, and classifications. ACM Comput. Surv. 2007, 39, 415–416. [Google Scholar] [CrossRef]
- Chu, D.; Deshpande, A.; Hellerstein, J.M.; Hong, W. Approximate data collection in sensor networks using probabilistic models. In Proceedings of the 22nd International Conference on Data Engineering, Atlanta, GA, USA, 3–7 April 2006; pp. 48–60.
- Cheng, C.T.; Leung, H.; Maupin, P. A delay-aware network structure for wireless sensor networks with in-network data fusion. IEEE Sens. J. 2013, 13, 1622–1631. [Google Scholar] [CrossRef]
- Hui, A.; Cui, L. Forecast-based temporal data aggregation in wireless sensor networks. Comput. Eng. Appl. 2007, 43, 121–125. [Google Scholar]
- Wang, R.; Tang, J.; Wu, D.; Sun, Q. GM-LSSVM based data aggregation in WSN. Comput. Eng. Des. 2012, 33, 3371–3375. [Google Scholar]
- Liu, W.F.; Pokharel, P.P.; Principe, J.C. The kernel least-mean-square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Chen, B.D.; Zhao, S.L.; Zhu, P.P.; Principe, J.C. Quantized kernel least mean square algorithm. IEEE Trans. Signal Process. 2012, 23, 22–32. [Google Scholar]
- Chen, B.D.; Zhao, S.L.; Zhu, P.P.; Principe, J.C. Quantized kernel recursive least squares algorithm. IEEE Trans. Neural Netw. Learn. Sys. 2013, 24, 1484–1491. [Google Scholar] [CrossRef] [PubMed]
- Luo, X.; Liu, J.; Zhang, D.D.; Chang, X.H. A large-scale web QoS prediction scheme for the industrial Internet of Things based on a kernel machine learning algorithm. Comput. Netw. 2016, 101, 81–89. [Google Scholar] [CrossRef]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- Luo, X.; Zhang, D.D.; Yang, L.T.; Liu, J.; Chang, X.H.; Ning, H.S. A kernel machine-based secure data sensing and fusion scheme in wireless sensor networks for the cyber-physical systems. Future Gener. Comput. Syst. 2016, 61, 85–96. [Google Scholar] [CrossRef]
- Chen, F.Y.; Li, Q.; Liu, J.H.; Zhang, J.Y. Variable smoothing parameter of the double exponential smoothing forecasting model and its application. In Proceedings of the International Conference on Advanced Mechatronic Systems, Tokyo, Japan, 18–21 September 2012; pp. 386–388.
- Contreras, J.; Espinola, R.; Nogales, F.J. ARIMA models to predict next-day electricity prices. IEEE Trans. Power Syst. 2003, 18, 1014–1020. [Google Scholar] [CrossRef]
- Nejad, H.C.; Farshad, M.; Rahatabad, F.N.; Khayat, O. Gradient-based back-propagation dynamical iterative learning scheme for the neuro-fuzzy inference system. Expert Syst. 2016, 33, 70–76. [Google Scholar] [CrossRef]
- Zheng, S.; Shi, W.Z.; Liu, J.; Tian, J. Remote sensing image fusion using multiscale mapped LS-SVM. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1313–1322. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhou, H.; Ding, X.; Zhang, R. Extreme learning machine for regression and multiclass classification. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2012, 42, 513–529. [Google Scholar] [CrossRef] [PubMed]
- Huang, G.B. An insight into extreme learning machines: Random neurons, random features and kernels. Cogn. Comput. 2014, 6, 376–390. [Google Scholar] [CrossRef]
- Liu, W.F.; Principe, J.C.; Haykin, S. Kernel Adaptive Filtering; Wiley: Hoboken, NJ, USA, 2011. [Google Scholar]
- Kreibich, O.; Neuzil, J.; Smid, R. Quality-based multiple-sensor fusion in an industrial wireless sensor network for MCM. IEEE Trans. Ind. Electron. 2014, 61, 4903–4911. [Google Scholar] [CrossRef]
- Chou, C.T.; Ignjatovic, A.; Hu, W. Efficient computation of robust average of compressive sensing data in wireless sensor networks in the presence of sensor faults. IEEE Trans. Parallel Distrib. Syst. 2013, 24, 1525–1534. [Google Scholar] [CrossRef]
- Craciun, S.; Cheney, D.; Gugel, K. Wireless transmission of neural signals using entropy and mutual information compression. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 35–44. [Google Scholar] [CrossRef] [PubMed]
- Principe, J.C.; Chen, B.D. Universal approximation with convex optimization: Gimmick or reality? IEEE Comput. Intell. Mag. 2015, 10, 68–77. [Google Scholar] [CrossRef]
- Chen, B.D.; Zhao, S.L.; Zhu, P.P.; Principe, J.C. Mean square convergence analysis of the kernel least mean square algorithm. Signal Process. 2012, 92, 2624–2632. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Brabanter, J.D.; Lukas, L. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar] [CrossRef]
- LS-SVMlab Toolbox. Available online: http://www.esat.kuleuven.be/sista/lssvmlab (accessed on 14 July 2016).
- Madden, S. Intel Berkeley Research Lab Data. Available online: http://db.csail.mit.edu/labdata/labdata (accessed on 14 July 2016).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X Location | 21.5 | 24.5 | 19.5 | 22.5 | 24.5 | 19.5 | 22.5 | 24.5 | 21.5 | 19.5 | 16.5 | 13.5 |
| Y Location | 23.0 | 20.0 | 19.0 | 15.0 | 12.0 | 12.0 | 08.0 | 04.0 | 02.0 | 05.0 | 03.0 | 01.0 |
| ID | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| X Location | 12.5 | 08.5 | 05.5 | 01.5 | 01.5 | 05.5 | 03.5 | 00.5 | 04.5 | 01.5 | 06.0 | 01.5 |
| Y Location | 05.0 | 06.0 | 03.0 | 02.0 | 08.0 | 10.0 | 13.0 | 17.0 | 18.0 | 23.0 | 24.0 | 30.0 |
| ID | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 | 34 | 35 | 36 |
| X Location | 04.5 | 07.5 | 08.5 | 10.5 | 12.5 | 13.5 | 15.5 | 17.5 | 19.5 | 21.5 | 24.5 | 26.5 |
| Y Location | 30.0 | 31.0 | 26.0 | 31.0 | 26.0 | 31.0 | 28.0 | 31.0 | 26.0 | 30.0 | 27.0 | 31.0 |
| ID | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 | 45 | 46 | 47 | 48 |
| X Location | 27.5 | 30.5 | 30.5 | 33.5 | 36.5 | 39.5 | 35.5 | 40.5 | 37.5 | 34.5 | 39.5 | 35.5 |
| Y Location | 26.0 | 31.0 | 26.0 | 28.0 | 30.0 | 30.0 | 24.0 | 22.0 | 19.0 | 16.0 | 14.0 | 10.0 |
| ID | 49 | 50 | 51 | 52 | 53 | 54 | ||||||
| X Location | 39.5 | 38.5 | 35.5 | 31.5 | 28.5 | 26.5 | ||||||
| Y Location | 06.0 | 01.0 | 04.0 | 06.0 | 05.0 | 02.0 |
| Scheme | Time for Temperature Set (s) | Time for Humidity Set (s) |
|---|---|---|
| KLMS | 214.3298 | 290.4895 |
| E-KLMS | 182.2404 | 261.8789 |
| ELM | 73.7105 | 72.6965 |
| LSSVM | 2133.7000 | 2228.8000 |
| Scheme | Time for Temperature Set (s) | Time for Humidity Set (s) |
|---|---|---|
| KLMS | 0.1715 | 0.2353 |
| E-KLMS | 0.1294 | 0.1807 |
| ELM | 0.0634 | 0.0611 |
| LSSVM | 1.7283 | 1.8276 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Liu, J.; Zhang, D.; Wang, W.; Zhu, Y. An Entropy-Based Kernel Learning Scheme toward Efficient Data Prediction in Cloud-Assisted Network Environments. Entropy 2016, 18, 274. https://doi.org/10.3390/e18070274
Luo X, Liu J, Zhang D, Wang W, Zhu Y. An Entropy-Based Kernel Learning Scheme toward Efficient Data Prediction in Cloud-Assisted Network Environments. Entropy. 2016; 18(7):274. https://doi.org/10.3390/e18070274
Chicago/Turabian StyleLuo, Xiong, Ji Liu, Dandan Zhang, Weiping Wang, and Yueqin Zhu. 2016. "An Entropy-Based Kernel Learning Scheme toward Efficient Data Prediction in Cloud-Assisted Network Environments" Entropy 18, no. 7: 274. https://doi.org/10.3390/e18070274
APA StyleLuo, X., Liu, J., Zhang, D., Wang, W., & Zhu, Y. (2016). An Entropy-Based Kernel Learning Scheme toward Efficient Data Prediction in Cloud-Assisted Network Environments. Entropy, 18(7), 274. https://doi.org/10.3390/e18070274