
Using Generalized Entropies and OC-SVM with Mahalanobis Kernel for Detection and Classification of Anomalies in Network Traffic


Abstract
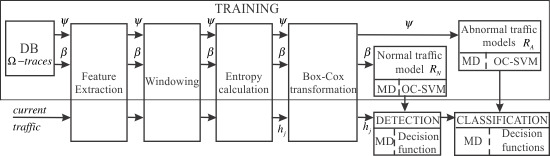
:
1. Introduction
2. Related Work
- the use of Mahalanobis distance for construction of decision regions,
- the novel inclusion of the MK in OC-SVM for classification improvement respect to RBF kernel,
- the refinement of classification via the k-nn algorithm in the temporal sense.
3. Mathematical Background
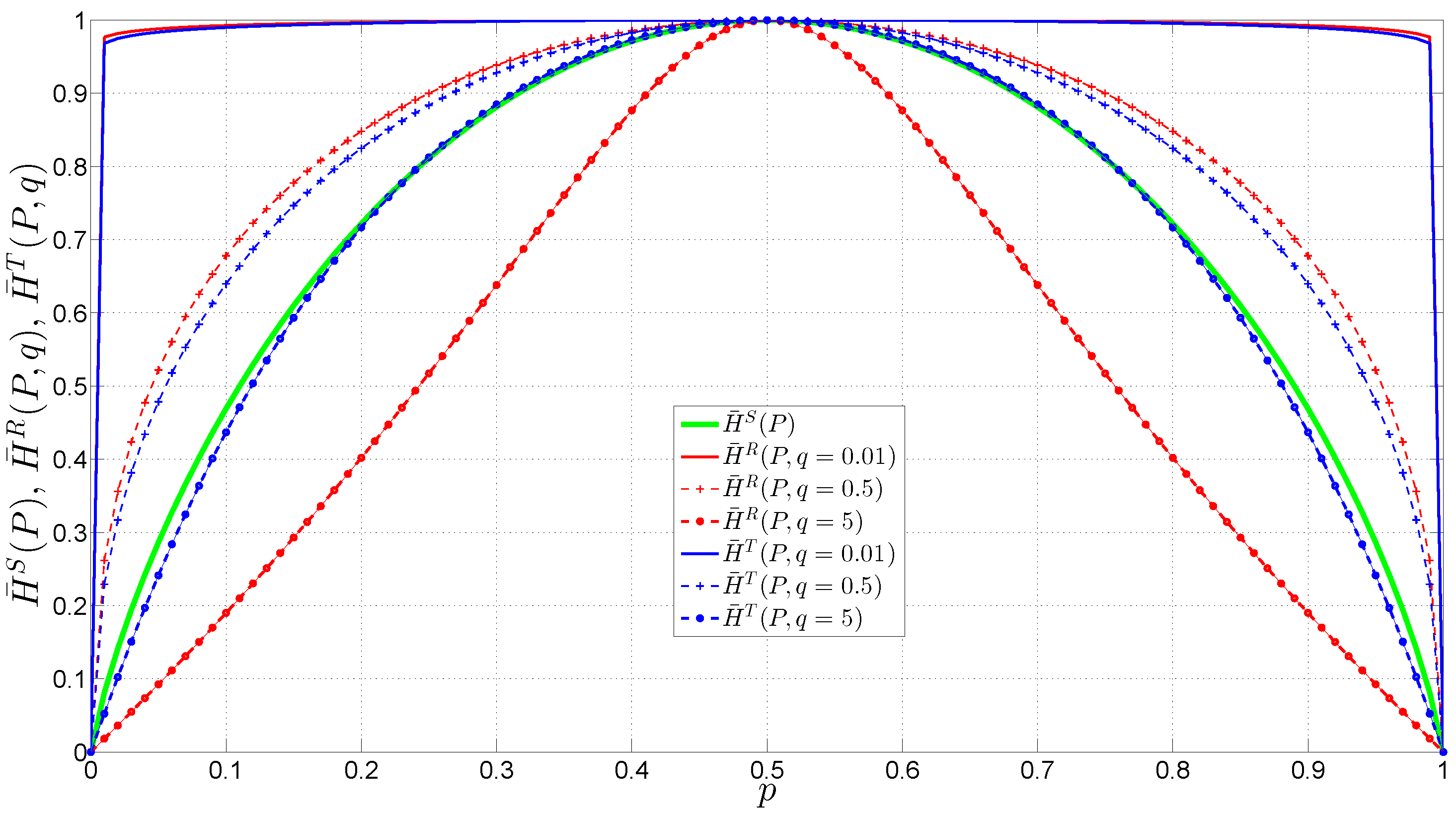
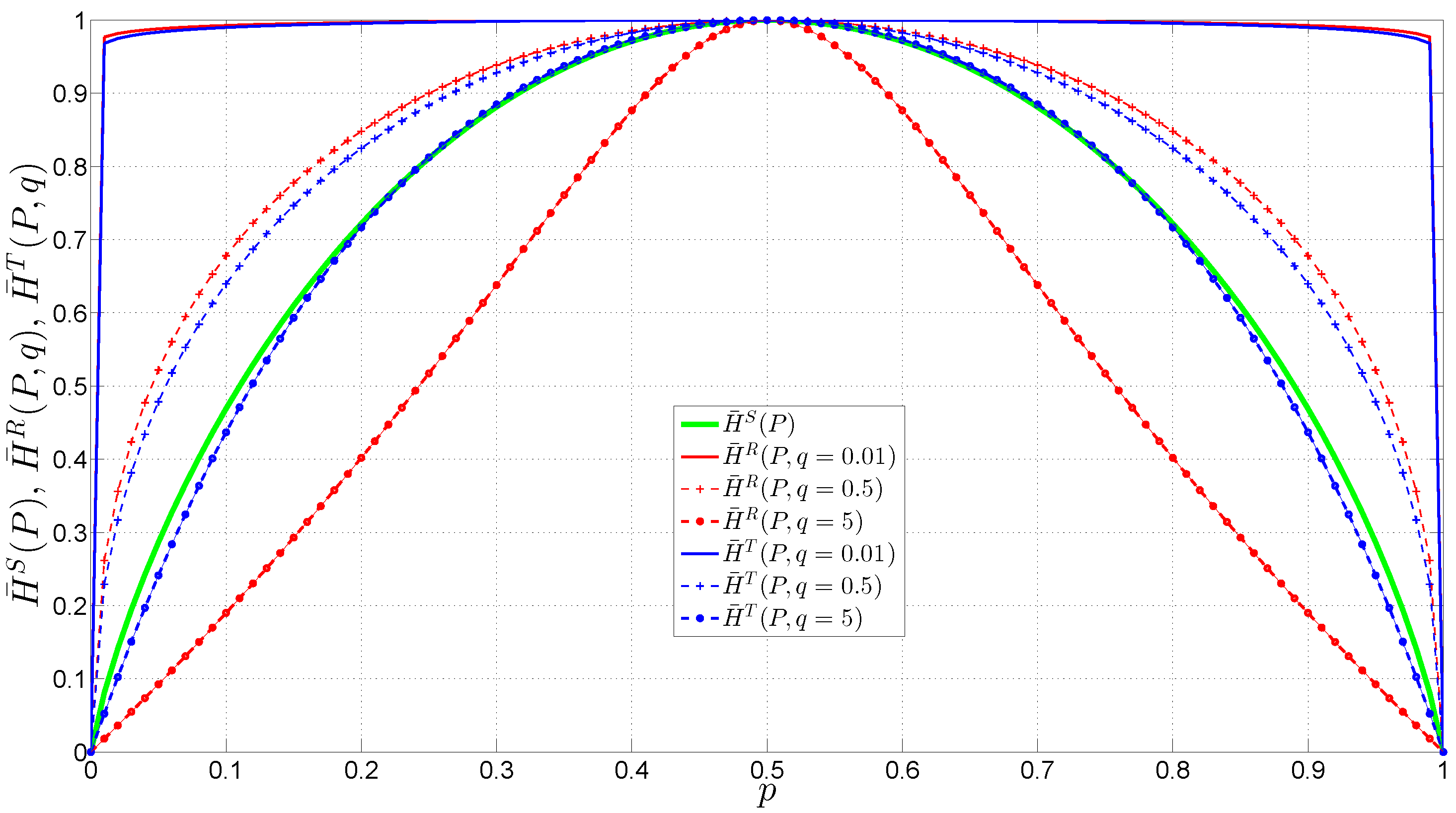
3.1. Entropy Estimators
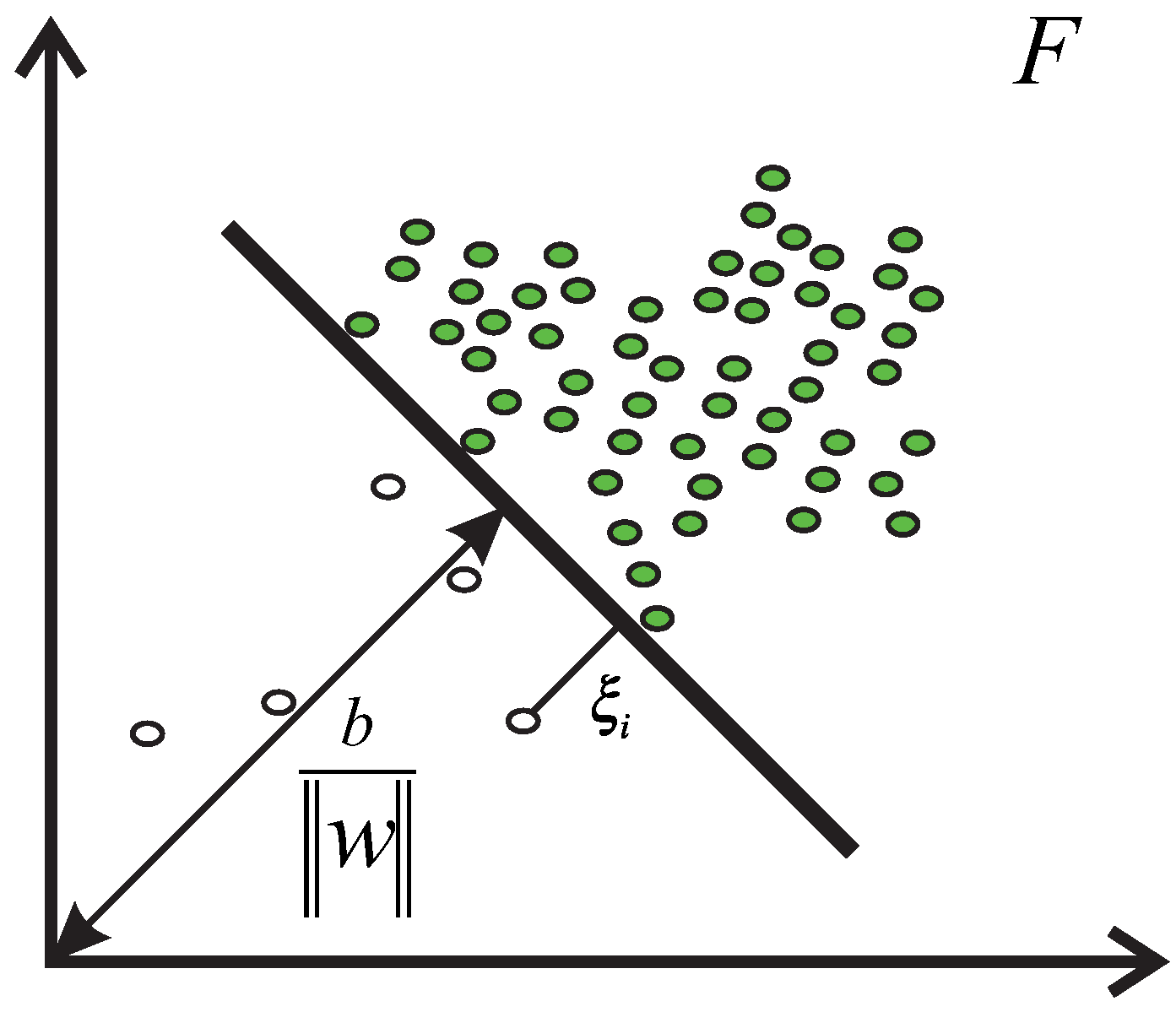
3.2. Feature Space
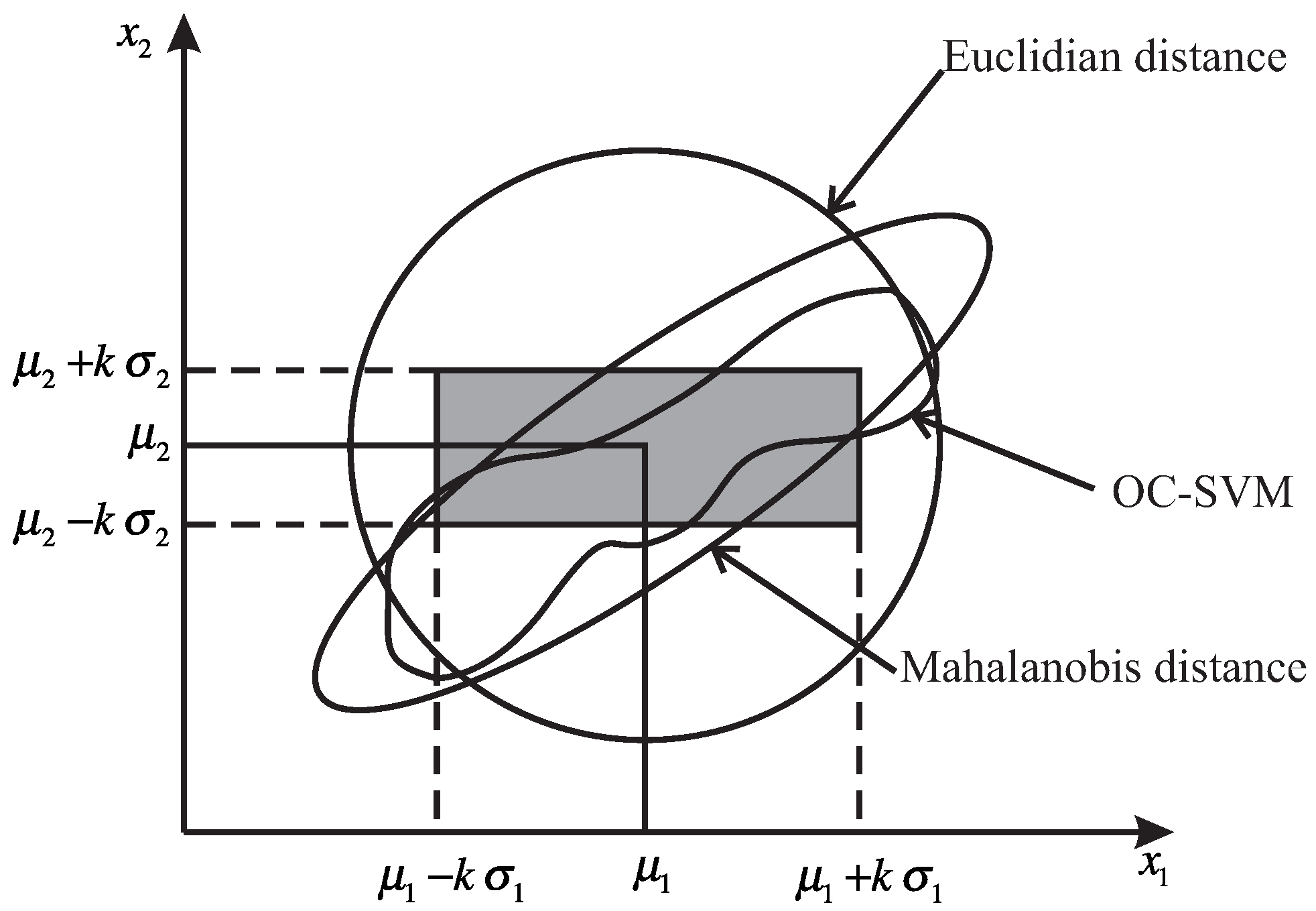
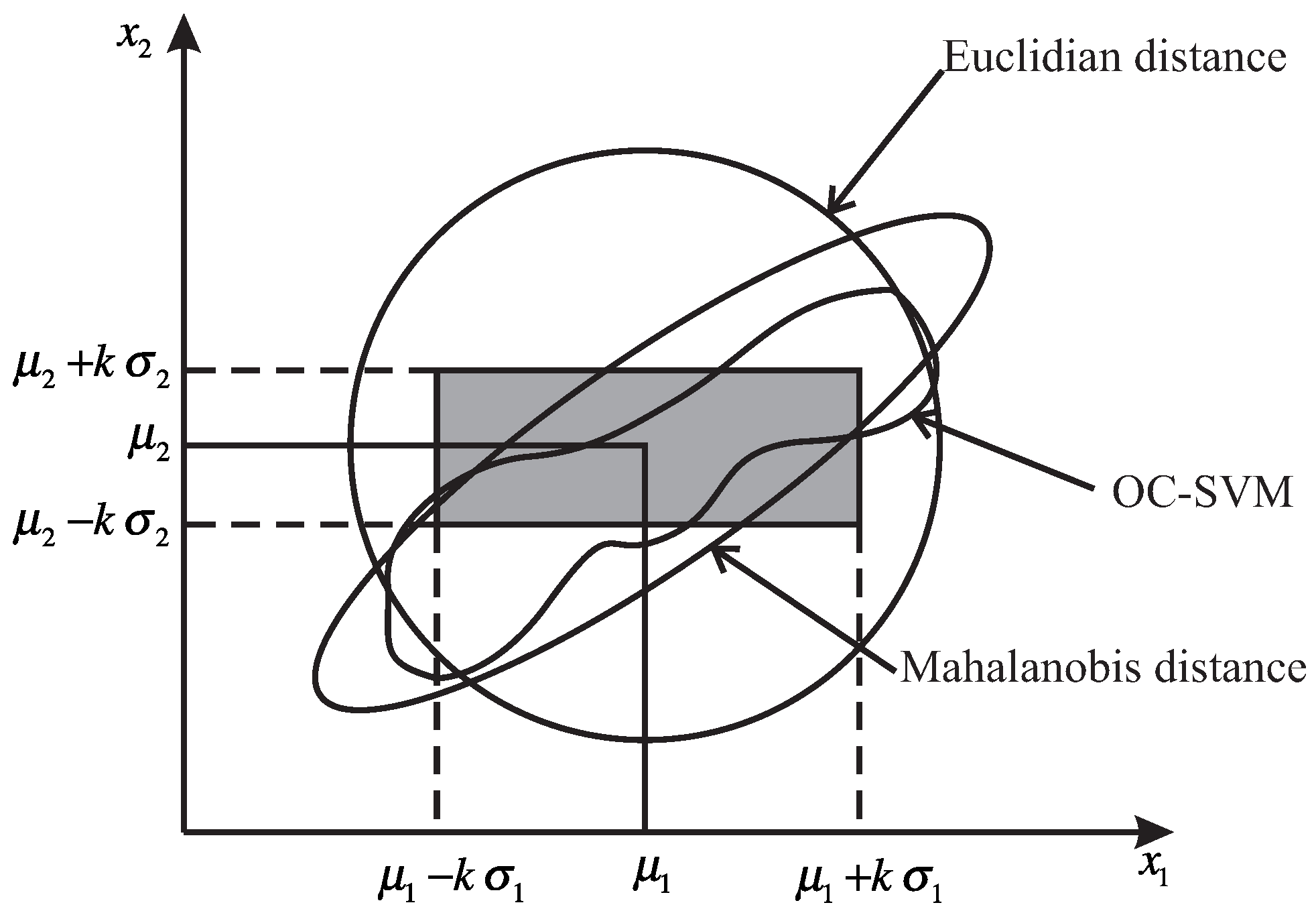
3.3. Mahalanobis Distance
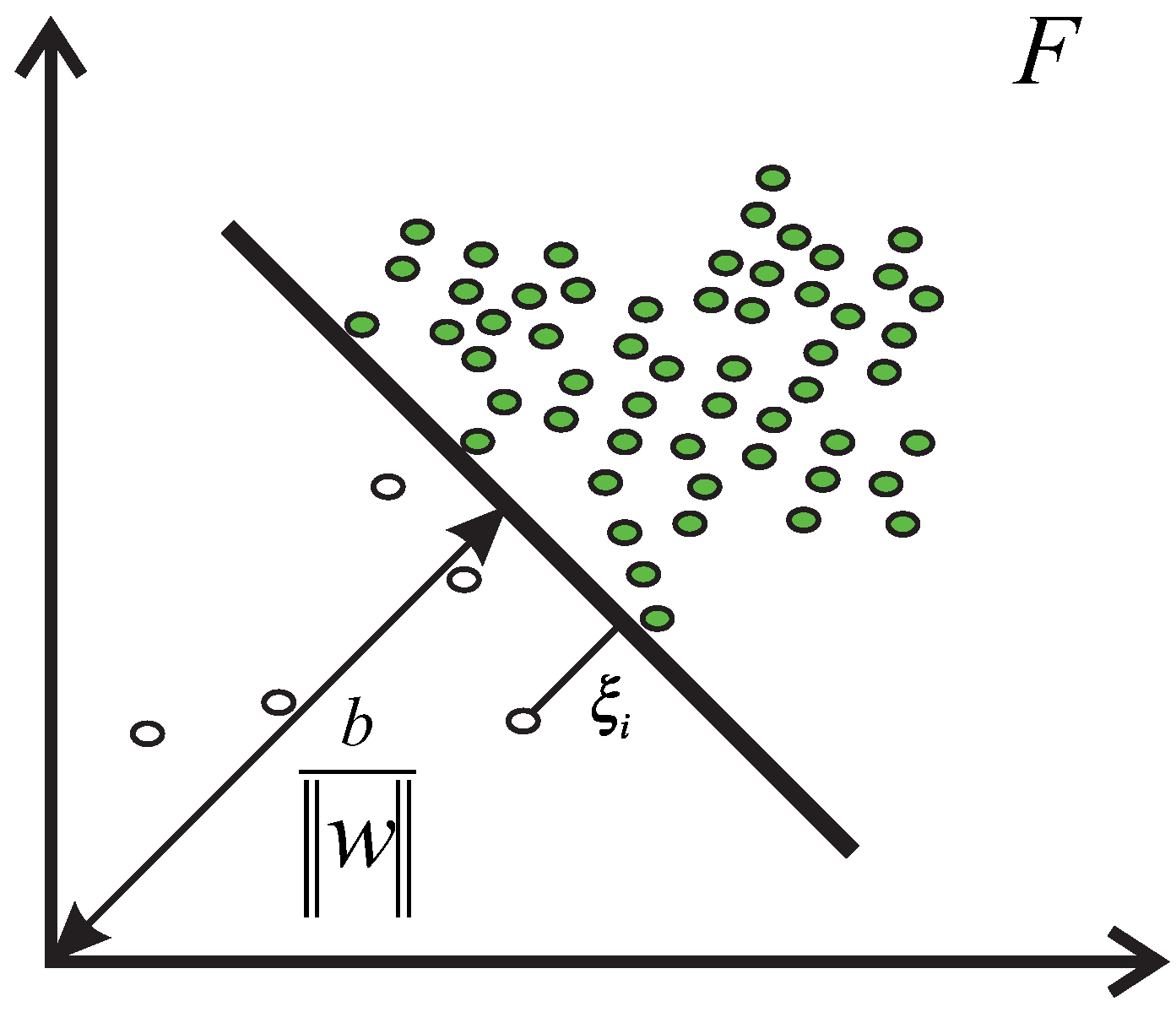
3.4. One Class Support Vector Machine and Mahalanobis Kernel
4. Problem Statement
- if Ω-trace was obtained during “normal” network traffic and the outlier exclusion was performed, it will be called β-trace,
- if Ω-trace was obtained during a period containing “normal” traffic plus one or more attacks, it will be called ψ-trace.
- if Ω-trace is β-trace, then a region (“normal” traffic) can be constructed and it will serve to detect the anomalies,
- if Ω-trace is ψ-trace, then a region (abnormal traffic) can be constructed and will serve to classify the anomalies of this class.
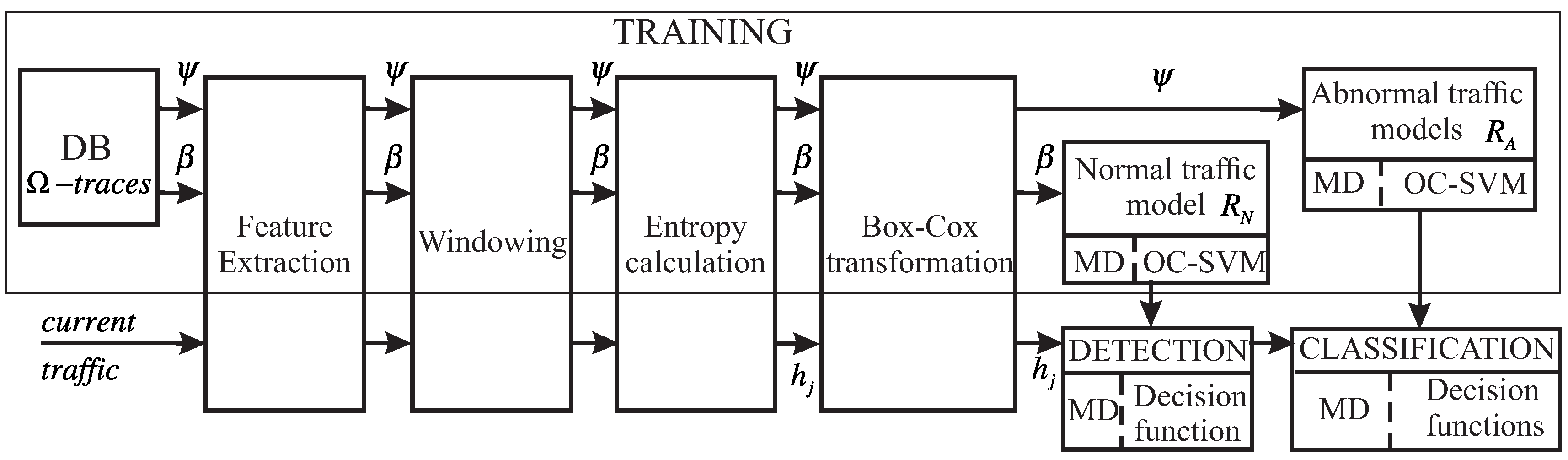
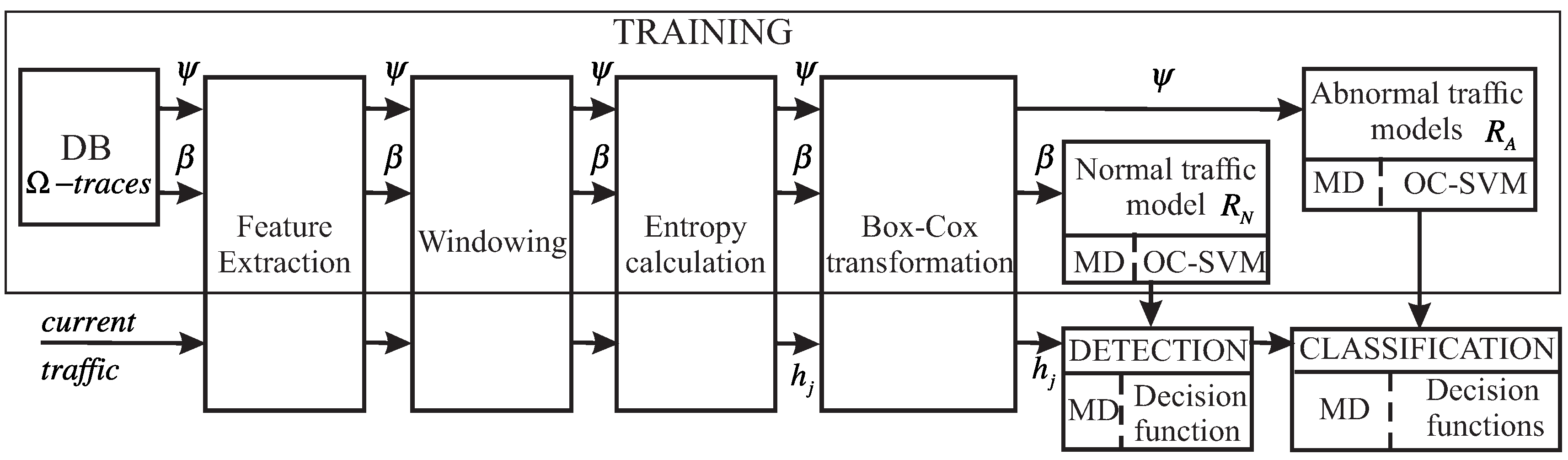
4.1. Algorithm for the Construction of Decision Regions
4.1.1. Training Stage
- Verify that the columns of the H matrix follow a Gaussian distribution. If the data are non-Gaussian, then a transformation is performed so that the new data approximately follow a distribution of this type. In this paper, the Box-Cox transformation was employed.
- Perform the exclusion of outliers of the H matrix. The limit for Mahalanobis distance is calculated through Equation (11).
- Calculate the mean vector where the i-element is the mean of the i-column of the H matrix, see Equation (9).
- Calculate the covariance matrix of the H matrix. As the matrix is positive definite and Hermitian, all its eigenvalues are real and positive, and its eigenvectors form a set of orthogonal basis vectors that span the p-dimensional vector space.
- Solve the matrix equation according to a specific algorithm in order to obtain the eigenvalues and eigenvectors of
- Finally, define a hyper-ellipsoidal region obtained from the H matrix by means of
- Verify that the columns of the H matrix follow a Gaussian distribution. If the data are non-Gaussian, then a transformation is performed so that the new data approximately follow a distribution of this type.
- Perform the exclusion of outliers of the H matrix. The limit for Mahalanobis distance is calculated through Equation (11).
4.1.2. Detection Stage
- In the current traffic, a j-slot of size L packets is captured, the p features or variables associated to each packet are extracted, and their entropies estimated. With these values, the input vector is built as follows:
- The decision function for the MD region is given by Equation (10). If then the j-slot is considered “normal”; otherwise, it is an anomaly.
- The decision function for OC-SVM is expressed by Equation (13). If the decision function maps to then is considered “normal”; otherwise, it is an anomaly.
4.1.3. Anomaly Classification Stage

5. Experiments and Results
5.1. Our Data Sets
5.2. Traffic Features
5.3. The Classifier Metrics
- The accuracy (AC) is the proportion of the total number of predictions that were correct:
- The sensitivity, detection rate, or true positive rate (TPR) is the proportion of positive cases that were correctly identified:
- The specificity or true negative rate (TNR) is defined as the proportion of negative cases that were classified correctly:
- The false negative rate (FNR) is the proportion of positive cases that were incorrectly classified as negative:
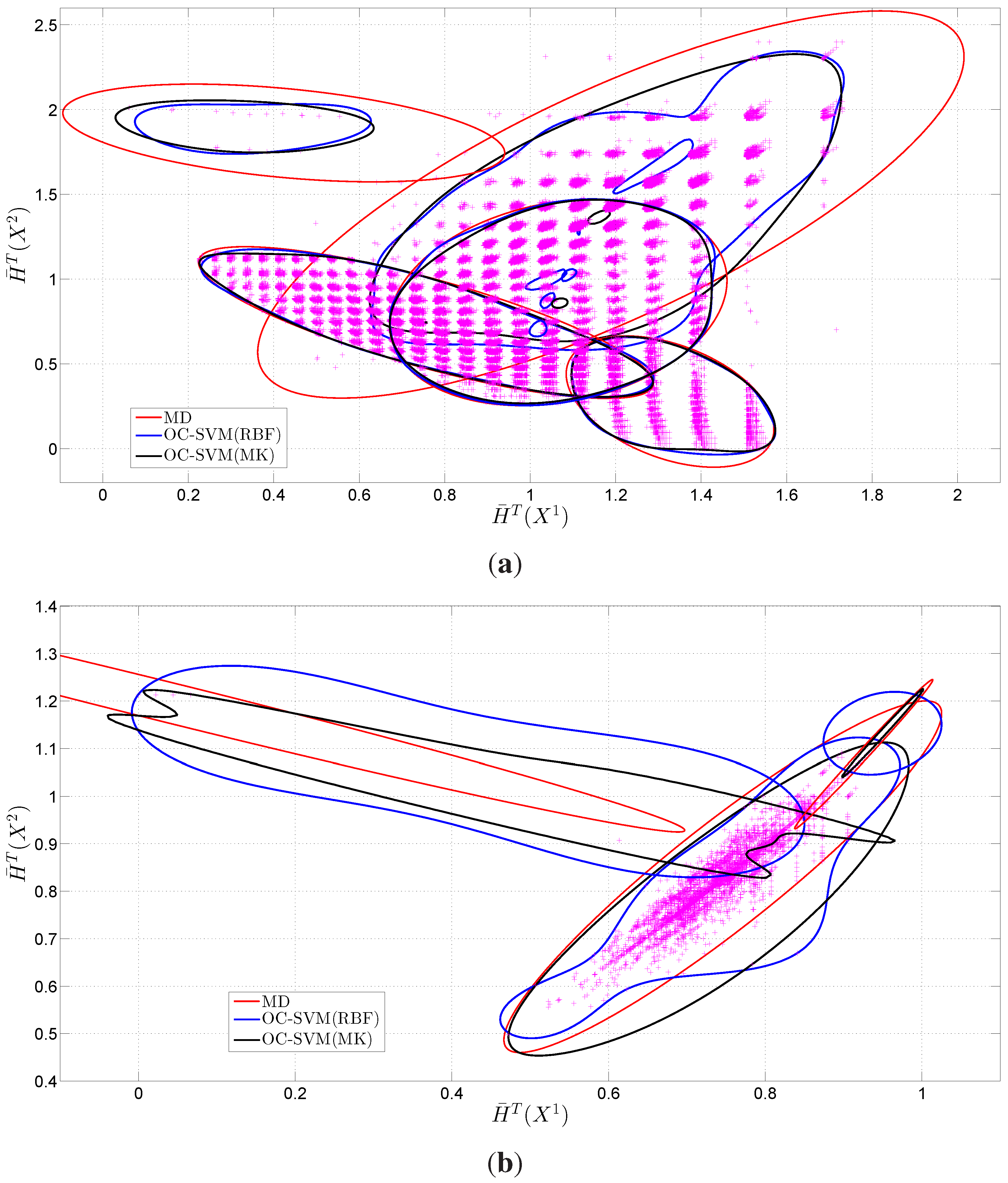
5.4. Detection of Anomalies in Network Traffic

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
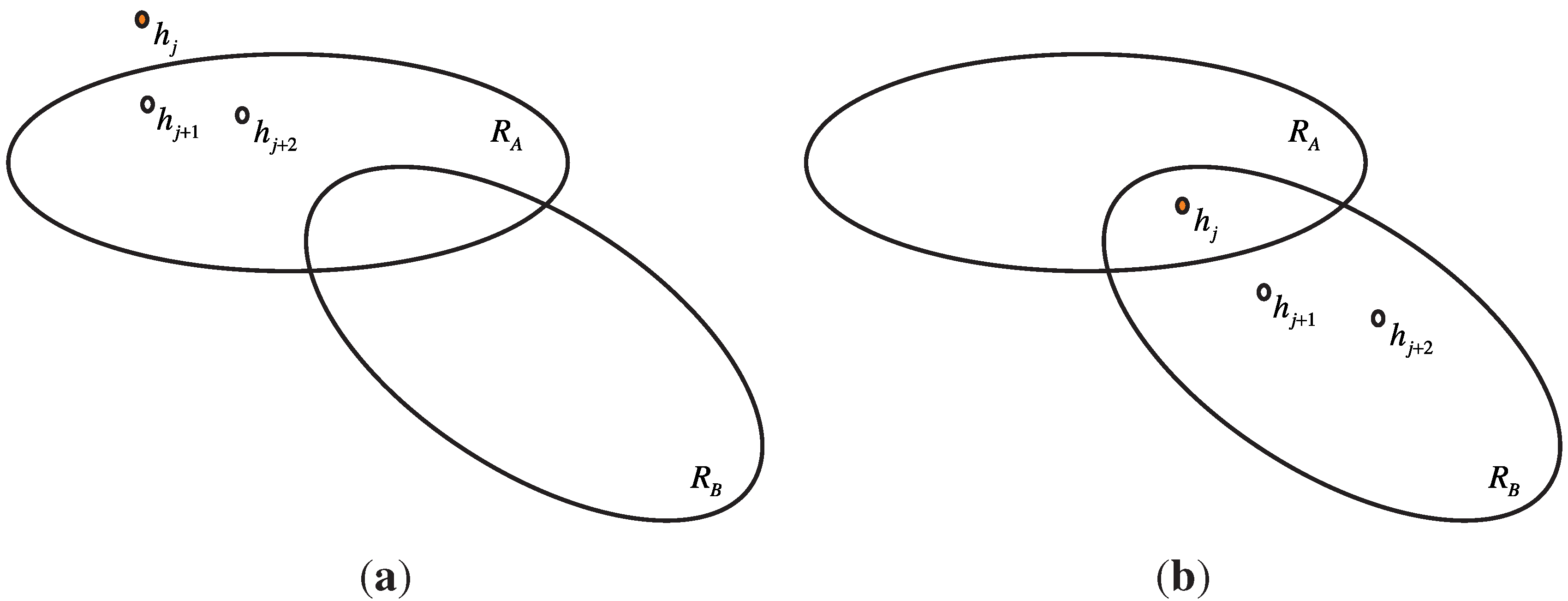{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Region | LAN | MIT-DARPA | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ν | η | # SV | ν | η | # SV | |||||||||||
| MK | 0.1 | 0.01 | 167 | 91.29 | 100 | 99.37 | 81.64 | 85.97 | 0.03 | 0.001 | 6 | 99.98 | 99.91 | 0.0 | 92.85 | 22.22 |
| RBF | 9.4 | 0.01 | 178 | 95.78 | 100 | 99.24 | 75.56 | 85.46 | 25 | 0.001 | 12 | 99.96 | 99.91 | 0.0 | 92.85 | 22.22 |
| MD | 98.32 | 100 | 99.43 | 66.43 | 57.58 | 99.98 | 99.91 | 0.0 | 92.85 | 22.22 | ||||||
| MK | 0.2 | 0.01 | 172 | 92.61 | 88.88 | 84.57 | 61.18 | 94.09 | 0.03 | 0.001 | 9 | 99.76 | 99.39 | 100 | 92.85 | 88.88 |
| RBF | 9.4 | 0.01 | 194 | 92.36 | 88.88 | 83.34 | 61.14 | 91.07 | 25 | 0.001 | 17 | 99.76 | 99.82 | 100 | 92.85 | 88.88 |
| MD | 98.36 | 77.77 | 75.92 | 60.66 | 69.02 | 99.58 | 99.39 | 100 | 92.85 | 100 | ||||||
| MK | 0.12 | 0.01 | 196 | 94.96 | 100 | 99.59 | 73.73 | 98.91 | 0.05 | 0.001 | 10 | 99.89 | 99.91 | 100 | 92.85 | 44.44 |
| RBF | 9.4 | 0.01 | 226 | 96.77 | 100 | 99.73 | 48.85 | 99.66 | 25 | 0.001 | 34 | 99.82 | 99.91 | 100 | 92.85 | 66.66 |
| MD | 98.13 | 100 | 99.52 | 65.89 | 97.98 | 99.82 | 99.91 | 100 | 92.85 | 66.66 | ||||||
| MK | 0.2 | 0.01 | 206 | 93.62 | 100 | 99.47 | 87.12 | 99.59 | 0.05 | 0.001 | 12 | 99.87 | 99.91 | 0.0 | 92.85 | 88.88 |
| RBF | 10.6 | 0.01 | 232 | 96.74 | 100 | 99.48 | 87.93 | 99.39 | 25 | 0.001 | 30 | 99.84 | 99.91 | 0.0 | 92.85 | 100 |
| MD | 98.23 | 100 | 99.55 | 69.54 | 99.25 | 99.81 | 99.91 | 0.0 | 92.85 | 100 | ||||||
| MK | 0.12 | 0.01 | 206 | 95.23 | 100 | 99.65 | 79.75 | 99.59 | 0.05 | 0.001 | 14 | 99.82 | 99.91 | 100 | 92.85 | 88.88 |
| RBF | 10.4 | 0.01 | 291 | 96.23 | 100 | 99.76 | 86.38 | 99.75 | 25 | 0.001 | 58 | 99.56 | 99.91 | 100 | 92.85 | 100 |
| MD | 97.94 | 100 | 99.62 | 69.01 | 99.23 | 99.61 | 99.91 | 100 | 92.85 | 100 | ||||||
5.5. Classification of Worm Attacks
| Kernel | LAN | MIT-DARPA | ||||||||||||||||
| ν | η | # SV | ν | η | # SV | ν | η | # SV | ν | η | # SV | ν | η | # SV | ν | η | # SV | |
| MK | 0.01 | 0.6 | 3 | 0.01 | 0.7 | 28 | 0.01 | 0.9 | 163 | 0.01 | 0.9 | 115 | 0.0001 | 0.1 | 2 | 0.01 | 0.08 | 2 |
| RBF | 0.001 | 8 | 3 | 0.01 | 13 | 29 | 0.01 | 10 | 162 | 0.001 | 15 | 33 | 0.0005 | 3 | 2 | 0.01 | 25 | 2 |
| MK | 0.01 | 0.6 | 5 | 0.01 | 0.7 | 25 | 0.01 | 0.9 | 35 | 0.01 | 0.9 | 59 | 0.0001 | 0.1 | 3 | 0.01 | 0.08 | 3 |
| RBF | 0.001 | 8 | 6 | 0.01 | 13 | 48 | 0.01 | 10 | 42 | 0.001 | 15 | 21 | 0.0005 | 3 | 2 | 0.01 | 25 | 3 |
| MK | 0.01 | 0.6 | 6 | 0.01 | 0.7 | 42 | 0.01 | 0.9 | 189 | 0.01 | 0.9 | 133 | 0.0001 | 0.1 | 2 | 0.01 | 0.08 | 2 |
| RBF | 0.001 | 8 | 6 | 0.01 | 13 | 66 | 0.01 | 10 | 195 | 0.001 | 15 | 173 | 0.0005 | 3 | 2 | 0.01 | 25 | 3 |
| MK | 0.01 | 0.6 | 8 | 0.01 | 0.7 | 34 | 0.01 | 0.9 | 173 | 0.01 | 0.9 | 136 | 0.0001 | 0.1 | 2 | 0.01 | 0.08 | 2 |
| RBF | 0.001 | 8 | 6 | 0.01 | 13 | 49 | 0.01 | 10 | 179 | 0.001 | 15 | 85 | 0.0005 | 3 | 2 | 0.01 | 25 | 5 |
| MK | 0.01 | 0.6 | 8 | 0.01 | 0.7 | 47 | 0.01 | 0.9 | 193 | 0.01 | 0.9 | 148 | 0.0001 | 0.1 | 2 | 0.01 | 0.08 | 4 |
| RBF | 0.001 | 8 | 5 | 0.01 | 13 | 115 | 0.01 | 10 | 217 | 0.001 | 15 | 283 | 0.0005 | 3 | 2 | 0.01 | 25 | 9 |
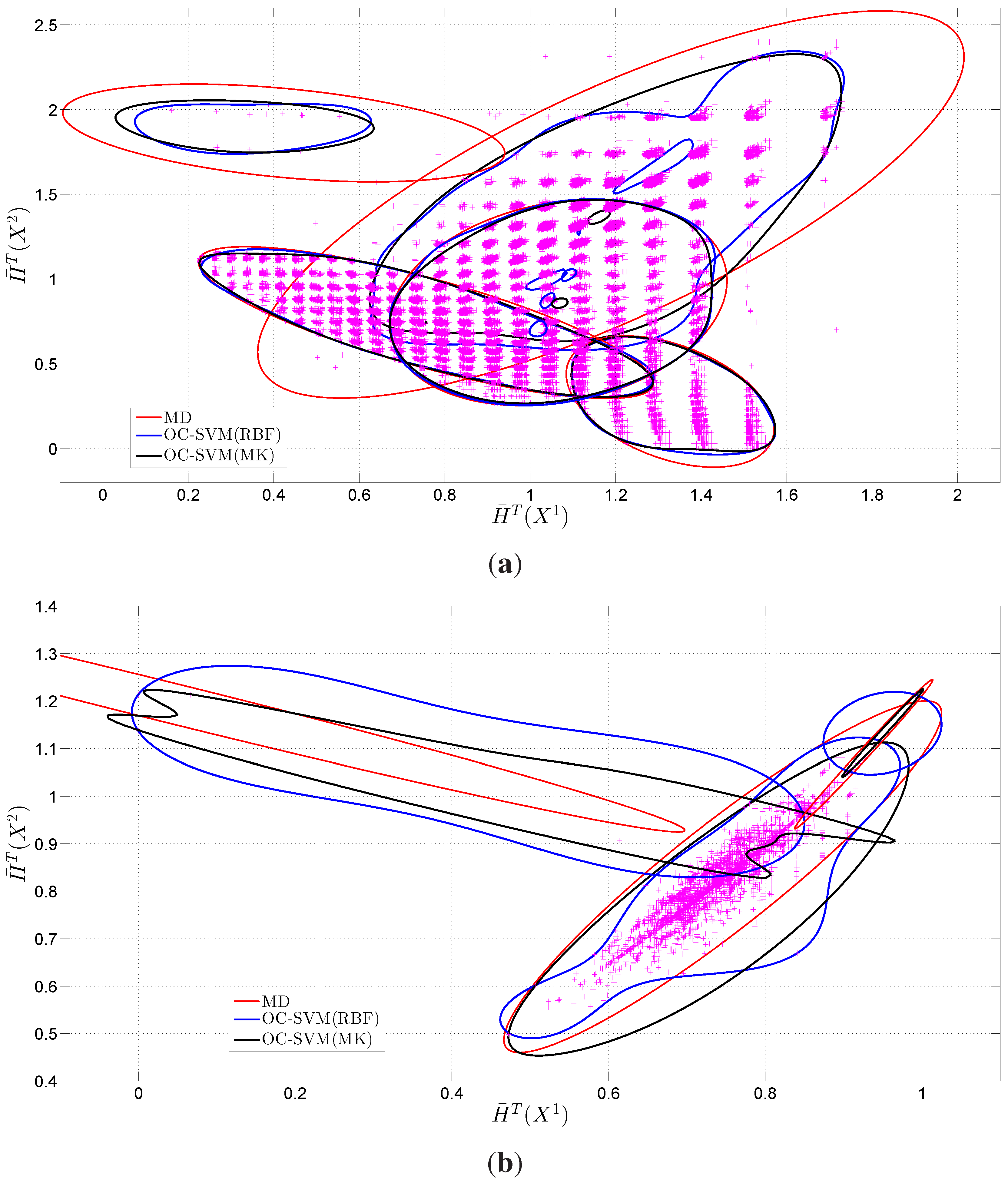
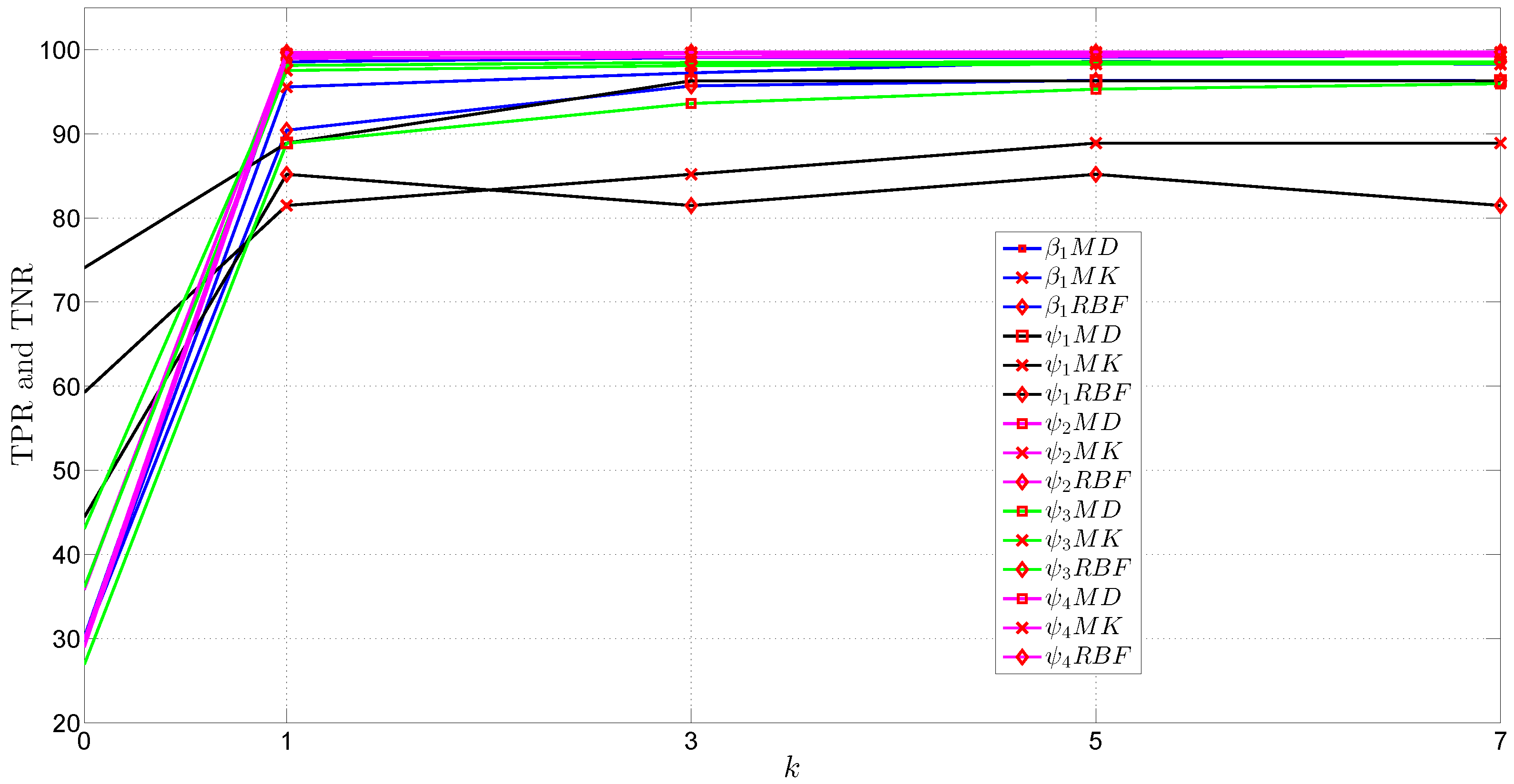
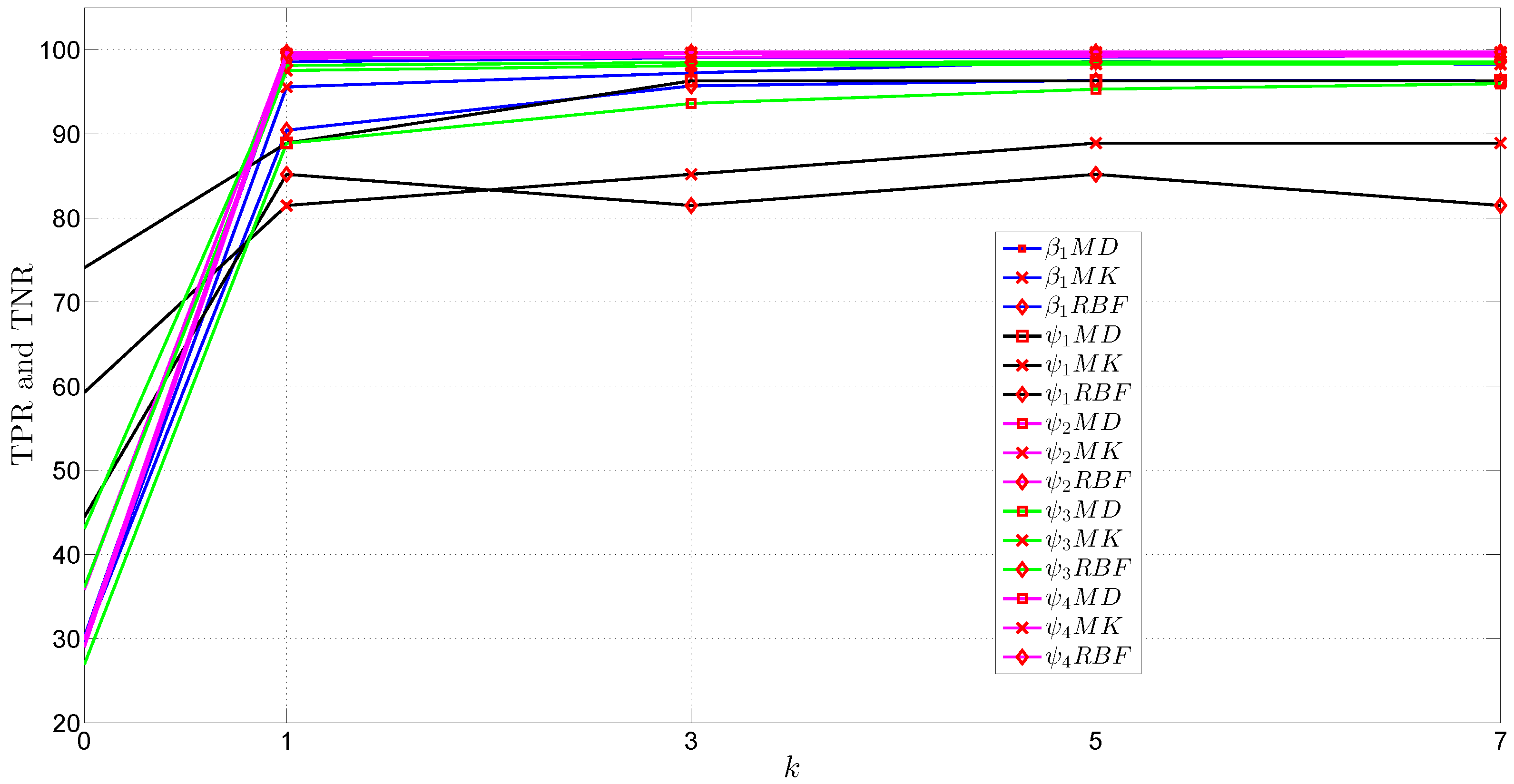
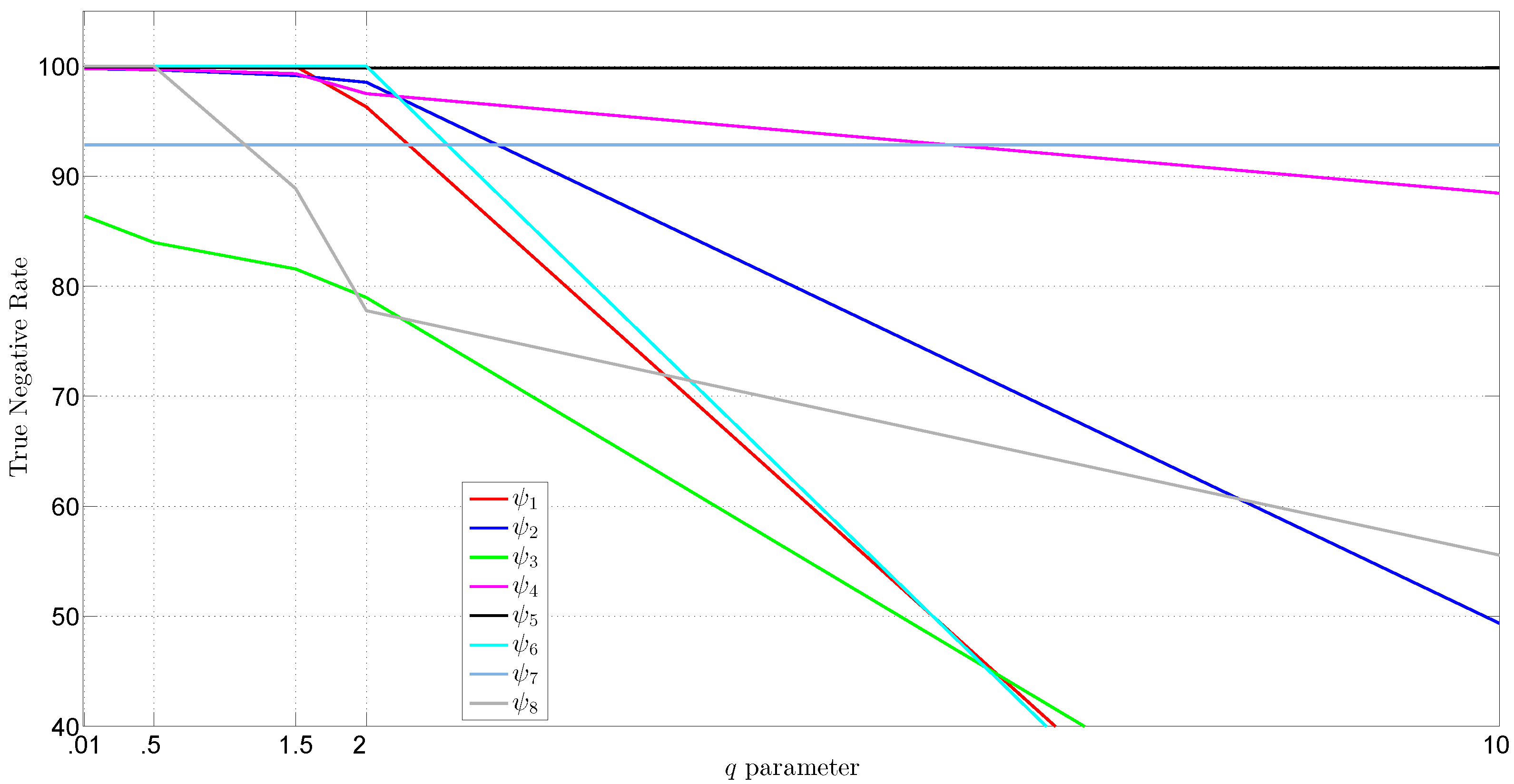
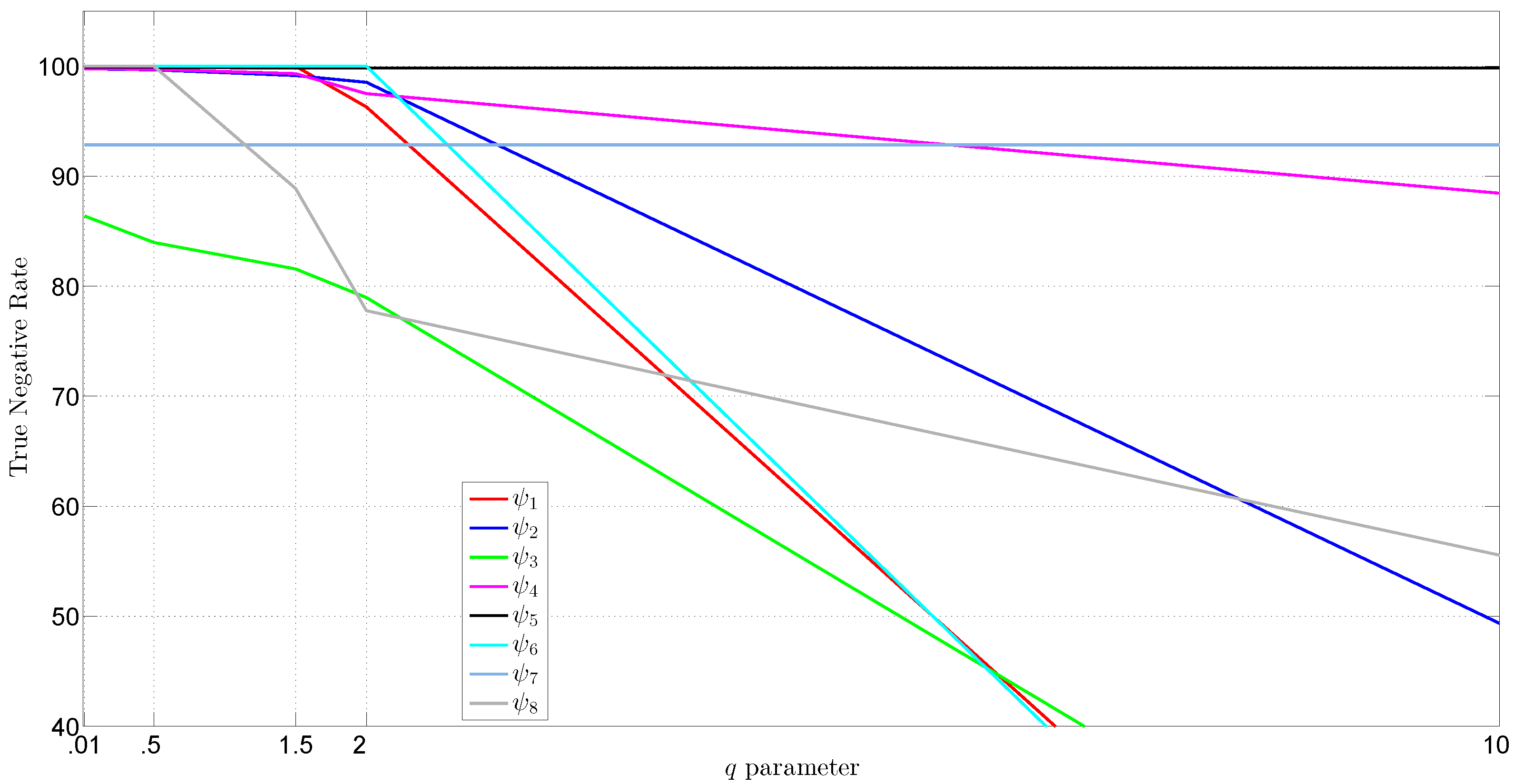
6. Discussion of the Experimental Results
- the classification of an entropy vector as normal or abnormal, and
- the classification of an abnormal entropy vector based on known attacks.
| k | OC-SVM MK | OC-SVM RBF | MD | ||||||
|---|---|---|---|---|---|---|---|---|---|
| LAN | |||||||||
| 0 | 32.4027 | 61.3592 | 38.9434 | 33.8506 | 66.0973 | 40.3794 | 30.1646 | 55.5757 | 33.7279 |
| 1 | 98.7503 | 98.8099 | 97.9229 | 98.7698 | 98.6869 | 98.9292 | 96.9534 | 96.1043 | 95.4036 |
| 3 | 99.1611 | 99.1210 | 98.2794 | 99.1871 | 99.0668 | 99.0142 | 98.0583 | 97.3197 | 96.3232 |
| 5 | 99.3079 | 99.2017 | 98.3141 | 99.2695 | 99.1844 | 99.0906 | 98.4566 | 97.7738 | 96.6380 |
| 7 | 99.2917 | 99.2695 | 98.3856 | 99.2716 | 99.2066 | 99.0771 | 98.6311 | 98.1488 | 96.8542 |
| MIT-DARPA | |||||||||
| 0 | 24.2665 | 25.6156 | 23.8716 | 14.1701 | 8.7415 | 9.9645 | 86.7067 | 92.3433 | 93.2046 |
| 1 | 99.9595 | 98.6699 | 99.9167 | 99.2338 | 99.9690 | 99.7382 | 99.9952 | 99.9976 | 99.9976 |
| 3 | 99.7430 | 99.6359 | 99.9357 | 99.8025 | 99.7596 | 99.7644 | 99.9952 | 99.9976 | 99.9976 |
| 5 | 99.6573 | 99.6097 | 99.9310 | 99.8524 | 99.6264 | 99.6811 | 99.9928 | 99.9952 | 99.9952 |
| 7 | 99.4670 | 99.6407 | 99.9286 | 99.8477 | 99.3908 | 99.4694 | 99.9904 | 99.9928 | 99.9928 |
7. Conclusions
- For Academic LAN traces, using Tsallis entropy with , OC-SVM with Mahalanobis kernel, and considering for the k-temporal nearest neighbor algorithm the highest results of accuracy (99.30%) were obtained.
- For MIT-DARPA traces, using the MD method, Rényi entropy with and for the k-temporal nearest neighbor algorithm the highest results of accuracy (99.99%) were obtained.
Open Issues
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Chandola, V.; Banerjee, A.; Kumar, V. Anomaly Detection: A Survey. ACM Comput. Surv. 2009, 41. [Google Scholar] [CrossRef]
- Lakhina, A.; Crovella, M.; Diot, C. Mining Anomalies Using Traffic Feature Distributions. In Proceedings of the 2005 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; Volume 35, pp. 217–228.
- Wagner, A.; Plattner, B. Entropy Based Worm and Anomaly Detection in Fast IP Networks. In Proceedings of the 14th IEEE International Workshops on Enabling Technologies: Infrastructure for Collaborative Enterprise, Linköping, Sweden, 13–15 June 2005; pp. 172–177.
- Xu, K.; Zhang, Z.L.; Bhattacharyya, S. Profiling Internet Backbone Traffic: Behavior Models and Applications. In Proceedings of the 2005 conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, Philadelphia, PA, USA, 22–26 August 2005; Volume 35, pp. 169–180.
- Santiago-Paz, J.; Torres-Roman, D.; Velarde-Alvarado, P. Detecting anomalies in network traffic using Entropy and Mahalanobis distance. In Proceedings of the 2012 22nd International Conference on Electrical Communications and Computers (CONIELECOMP), Cholula, Mexico, 27–29 February 2012; pp. 86–91.
- Santiago-Paz, J.; Torres-Roman, D. Characterization of worm attacks using entropy, Mahalanobis distance and K-nearest neighbors. In Proceedings of the 2014 International Conference on Electronics, Communications and Computers (CONIELECOMP), Cholula, Mexico, 26–28 February 2014; pp. 200–205.
- Mason, R.L.; Young, J.C. Multivariate Statistical Process Control with Industrial Applications; Siam: Philadelphia, PA, USA, 2002; Volume 9. [Google Scholar]
- Li, K.L.; Huang, H.K.; Tian, S.F.; Xu, W. Improving one-class SVM for anomaly detection. In Proceedings of the 2003 International Conference on Machine Learning and Cybernetics, Xi’an, China, 2–5 November 2003; Volume 5, pp. 3077–3081.
- Zhang, R.; Zhang, S.; Lan, Y.; Jiang, J. Network anomaly detection using one class support vector machine. In Proceedings of the International MultiConference of Engineers and Computer Scientists (IMECS), Hong Kong, China, 19–21 March 2008.
- Nychis, G.; Sekar, V.; Andersen, D.G.; Kim, H.; Zhang, H. An Empirical Evaluation of Entropy-based Traffic Anomaly Detection. In Proceedings of the 8th ACM SIGCOMM Conference on Internet Measurement, Vouliagmeni, Greece, 20–22 October 2008; ACM: New York, NY, USA, 2008; pp. 151–156. [Google Scholar]
- Ziviani, A.; Gomes, A.T.A.; Monsores, M.L.; Rodrigues, P.S. Network anomaly detection using nonextensive entropy. IEEE Commun. Lett. 2007, 11, 1034–1036. [Google Scholar] [CrossRef]
- Tellenbach, B.; Burkhart, M.; Schatzmann, D.; Gugelmann, D.; Sornette, D. Accurate Network Anomaly Classification with Generalized Entropy Metrics. Comput. Netw. 2011, 55, 3485–3502. [Google Scholar] [CrossRef]
- Ma, X.; Chen, Y. DDoS Detection method based on chaos analysis of network traffic entropy. Commun. Lett. IEEE 2014, 18, 114–117. [Google Scholar] [CrossRef]
- Bhuyan, M.H.; Bhattacharyya, D.; Kalita, J. An empirical evaluation of information metrics for low-rate and high-rate DDoS attack detection. Pattern Recognit. Lett. 2015, 51, 1–7. [Google Scholar] [CrossRef]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Rényi, A. Probability Theory; North-Holland Series in Applied Mathematics and Mechanics; Elsevier: Amsterdam, The Netherlands, 1970. [Google Scholar]
- Tsallis, C. Possible generalization of Boltzmann-Gibbs statistics. J. Stat. Phys. 1988, 52, 479–487. [Google Scholar] [CrossRef]
- Mahalanobis, P.C. On the Generalised Distance in Statistics; Proceedings of the National Institute of Science: Calcutta, India, 1936; Volume 2, pp. 49–55. [Google Scholar]
- Tracy, N.D. Multivariate control charts for individual observations. J. Qual. Technol. 1992, 24, 88–95. [Google Scholar]
- Box, G.E.P.; Cox, D.R. An Analysis of Transformations. J. R. Stat. Soc. B Stat. Methodol. 1964, 26, 211–252. [Google Scholar]
- Schölkopf, B.; Platt, J.C.; Shawe-Taylor, J.C.; Smola, A.J.; Williamson, R.C. Estimating the Support of a High-Dimensional Distribution. Neural Comput. 2001, 13, 1443–1471. [Google Scholar] [CrossRef] [PubMed]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A Training Algorithm for Optimal Margin Classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; ACM: New York, NY, USA, 1992; pp. 144–152. [Google Scholar]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: New York, NY, USA, 1995. [Google Scholar]
- Schölkopf, B.; Burges, C.J.C.; Smola, A.J. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Abe, S. Training of Support Vector Machines with Mahalanobis Kernels. In Artificial Neural Networks: Formal Models and Their Applications—ICANN 2005; Lecture Notes in Computer Science; Duch, W., Kacprzyk, J., Oja, E., Zadrożny, S., Eds.; Springer: Berlin, Germany, 2005; Volume 3697, pp. 571–576. [Google Scholar]
- Platt, J. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines; Technical Report MSR-TR-98-14; Microsoft Research: Redmond, WA, USA, 1998. [Google Scholar]
- Velarde-Alvarado, P.; Vargas-Rosales, C.; Torres-Román, D.; Martinez-Herrera, A. Entropy-based profiles for intrusion detection in LAN traffic. Adv. Artif. Intell. 2008, 40, 119–130. [Google Scholar]
- Kendall, K. A Database of Computer Attacks for the Evaluation of Intrusion Detection Systems; Technical Report, DTIC Document; Massachusetts Institute of Technology: Cambridge, MA, USA, 1999. [Google Scholar]
- Fawcett, T. An Introduction to ROC Analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Kohavi, R.; Provost, F. Glossary of Terms. J. Mach. Learn. 1998, 30, 271–274. [Google Scholar]
- Chang, C.C.; Lin, C.J. LIBSVM: A Library for Support Vector Machines. ACM Trans. Intell. Syst. Technol. 2011, 2. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Santiago-Paz, J.; Torres-Roman, D.; Figueroa-Ypiña, A.; Argaez-Xool, J. Using Generalized Entropies and OC-SVM with Mahalanobis Kernel for Detection and Classification of Anomalies in Network Traffic. Entropy 2015, 17, 6239-6257. https://doi.org/10.3390/e17096239
Santiago-Paz J, Torres-Roman D, Figueroa-Ypiña A, Argaez-Xool J. Using Generalized Entropies and OC-SVM with Mahalanobis Kernel for Detection and Classification of Anomalies in Network Traffic. Entropy. 2015; 17(9):6239-6257. https://doi.org/10.3390/e17096239
Chicago/Turabian StyleSantiago-Paz, Jayro, Deni Torres-Roman, Angel Figueroa-Ypiña, and Jesus Argaez-Xool. 2015. "Using Generalized Entropies and OC-SVM with Mahalanobis Kernel for Detection and Classification of Anomalies in Network Traffic" Entropy 17, no. 9: 6239-6257. https://doi.org/10.3390/e17096239
APA StyleSantiago-Paz, J., Torres-Roman, D., Figueroa-Ypiña, A., & Argaez-Xool, J. (2015). Using Generalized Entropies and OC-SVM with Mahalanobis Kernel for Detection and Classification of Anomalies in Network Traffic. Entropy, 17(9), 6239-6257. https://doi.org/10.3390/e17096239